3G移动终端的BER统计测试算法

3G 移动终端的BER 统计测试算法
李昊,刘岚
武汉理工大学信息工程学院(430070)
E-mail::lihao_0228@https://www.360docs.net/doc/901526489.html,
摘 要:在3GPP 测试规范中,定义了一种新的BER 统计测试算法。本文首先介绍了该算法的理论依据,然后提出了实际3G 移动终端BER 测试中的应用方案,并使用LabVIEW 软件实现其统计判决部分,最后通过与传统测试算法的比较,验证该算法的特性。
关键词:3G BER 测试算法
1.引言
误比特率(BER ,Bit Error ratio )是重要的移动设备测试项目,而BER 测试算法的好坏将直接决定BER 测试的质量。良好的测试算法应满足四点:
1)在每个独立的测试中,保证适度的低风险通过一个坏设备;
2)在每个独立的测试中,具有高概率通过一个好设备;
3)测试具有高度的统计意义;
4)保证测试时间尽可能短。
在3GPP 测试规范中,定义了一种新的BER 统计测试算法,较以往的测试算法具有许多优点。
2.3G 的BER 统计测试理论
2.1 泊松分布与置信区间
如果指定一个采样数ns ,然后累计在ns 个样本内出现的错误数ne ,那么ne/ns=ber 。但是这种简单测试缺乏统计意义。
如果将这种简单测试重复无穷次,我们会看到在一定ns 内出现的ne 的概率符合泊松分布:
(,)(/!)ne NE dpois ne NE NE ne e ?=
NE 为ne 的平均值,NE/ns 才是最终的BER 。
参数NE 决定了变量为ne 的泊松分布的特征。用不同的参数NE 可以描述不同的分布。 在一个简单的测试里,我们应用某一采样数ns 测量到错误数ne ,这个测量结果可能是不同分布里的一部分。下面我们来寻找其中两种特殊的分布:
(1)最坏概率分布NE high :包含我们测量到的ne 、概率D=0.0085%,
00.000085(,)ne high dpois ni NE dni =∫
反累加操作的结果是:NE high 。
(2)最好概率分布NE low :包含我们测量到的ne 、概率D=0.0085%,
0.000085(,)high ne dpois ni NE dni ∞=∫
反累加操作的结果是:NE low 。
- 1 -
NE low 和NE high 构成的区间就称为置信区间[1]。
2.2 置信区间在测试中的应用
我们不可能将简单测试重复无穷次来获取NE ,但是通过一个简单的测试得到的ne ,我们可以计算出一个置信区间,最终的NE 将会以很高的概率出现在这个区间内。
在测试过程中,对每个新样本,我们实时计算此刻的置信区间,并与判决门限比较: 如果发现整个置信区间在门限好的一边,我们说:最终的NE 会以1-D 的高概率比门限好,允许提早通过(Early Pass );
如果发现整个置信区间在门限坏的一边,我们说:最终的NE 会以1-D 的高概率比门限坏,允许提早失败(Early Fail );
如果发现置信区间包括了门限的两边,不作任何提早判决。
根据这个定义,我们得到了两条判决门限:
提早通过的门限Early Pass Limit 为:
2(,)(1,2)ne bernormpass ne D qchisq D ne =
?
提早失败的门限Early Fail Limit 为: 2(,)(,2)ne
bernormfail ne D qchisq D ne =
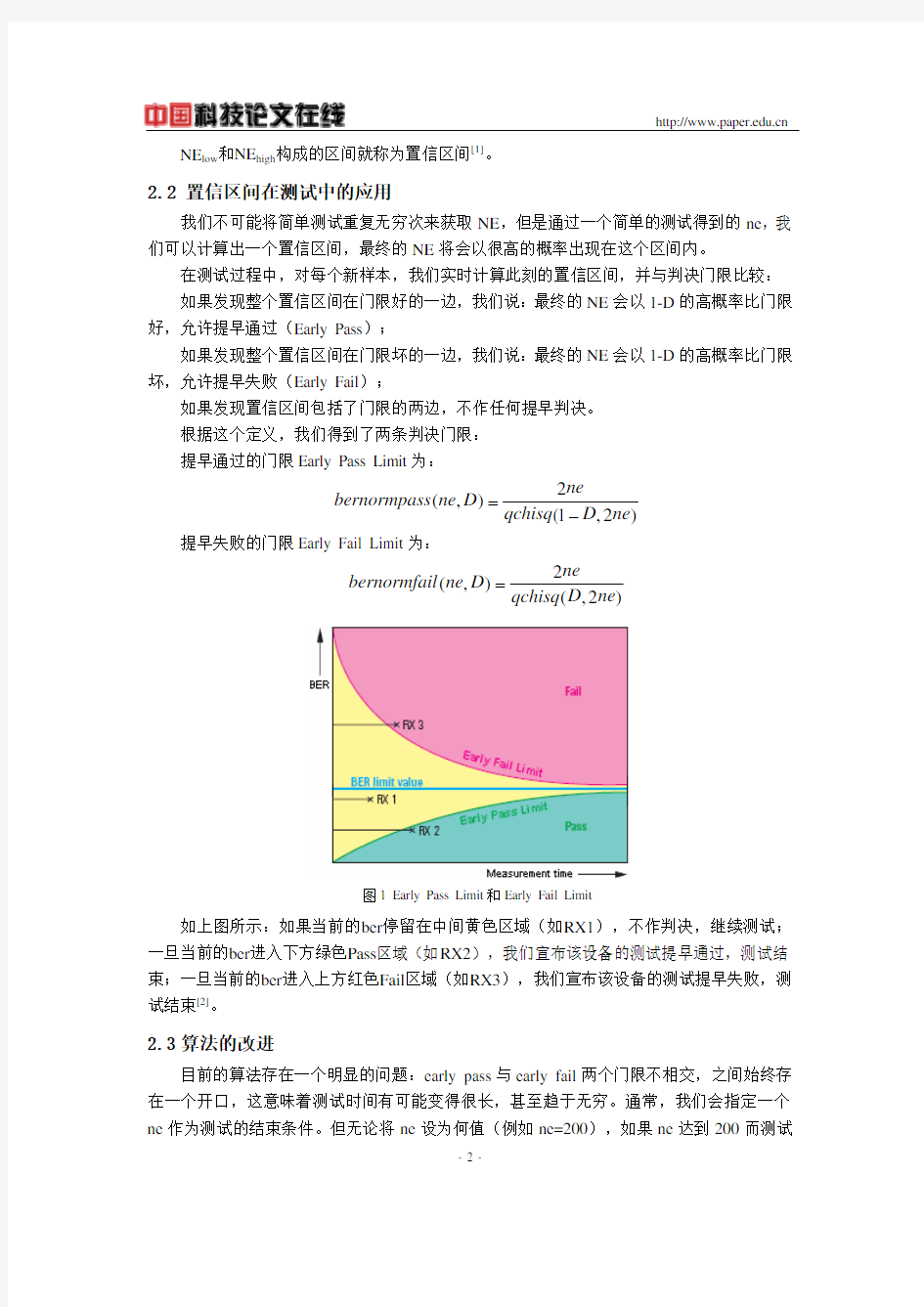
图1 Early Pass Limit 和Early Fail Limit
如上图所示:如果当前的ber 停留在中间黄色区域(如RX1),不作判决,继续测试;一旦当前的ber 进入下方绿色Pass 区域(如RX2),我们宣布该设备的测试提早通过,测试结束;一旦当前的ber 进入上方红色Fail 区域(如RX3),我们宣布该设备的测试提早失败,测试结束[2]。
2.3算法的改进
目前的算法存在一个明显的问题:early pass 与early fail 两个门限不相交,之间始终存在一个开口,这意味着测试时间有可能变得很长,甚至趋于无穷。通常,我们会指定一个ne 作为测试的结束条件。但无论将ne 设为何值(例如ne=200),如果ne 达到200而测试 - 2 -
曲线未越过两个门限,此时必须做出强制判决。这种情形的弊端在于使得测试具有两种不同的质量,严重损害了原有的高度统计意义。
于是,我们对算法做如下改进。
保留early fail limit 的定义不变:我们判决一个DUT 测试失败,而它实际上比门限要好,该误判概率为D 可以接受。
重新定义一个有意义的early pass limit :我们判决一个DUT 测试通过,而它实际上比门限的M 倍要差,该误判概率为D 可以接受。(M 称为Bad DUT factor ,M >1)
这样处理的结果是:early pass limit 上升了M 倍,与early fail limit 相交。
提早通过门限Early Pass Limit :
2**lim (,)(1,2*)pass ne M ber bad D ne qchisq D ne =
?
相对于bad DUT 门限。
提早失败门限Early Fail Limit : 2*lim (,)(,2*)fail ne ber D ne qchisq D ne =
相对于指定的门限。 若取D=0.000085,则最终的标准化门限=1.234。
图2 重新定义的Early Pass Limit 和Early Fail Limit
3.实际移动终端BER 测试的应用方案
以3GPP 测试规范为基础,参考国内外各通信测量仪器厂商的测试方法,我们可以采用如下的移动终端BER 测试方案:
目前,利用系统模拟器SS 实现终端一致性测试是较为通用的方式。它要求将待测用户设备UE 与SS 相连接,建立起RRC 连接,建立无线承载,并将UE 设置为Loopback 类型1(UE 的一种工作状态,UE 会将接收到的解CRC 校验后的数据原封不动地发还给SS )。
3GPP 测试规范定义BER 为接收到的错误比特与所有发送的数据比特之比,这里的比特 - 3 -
[3]
是指卷积/Turbo解码器之上的信息比特。SS在每个传输时间间隔(TTI)内将一组数据编码调制后发射给UE,然后在上行链路上等待UE发还,再将解调解码后的数据与原数据对比,累计误码个数。
测试过程中可能出现的问题有三个:
一是上行链路上出错。BER测试主要用于UE的接收机性能测试,因此,我们要求所有的误码都来自下行链路,而上行链路必须是完全无误的。这就要求SS对接收的数据作CRC 校验,一旦CRC校验出误码,我们认为该数据块无效并抛弃。
二是数据块丢失。SS还需要检测传输格式组合指示(TFCI),以确定某个TTI内是否有数据发送或有数据块丢失。实际测试中,为了缩短测试时间,SS通常会在每个TTI内都发送数据,而利用CRC校验就可以检验出是否有数据块丢失,无需额外检测TFCI[4]。
三是超时。Loopback存在一定的延时,3GPP测试规范定义,Loopback的延时不能超过相当于10倍TTI的无线帧的个数。实际测试中,如果仪器性能允许,可以适当地超出[4],但是必须有超时设置,在UE长时间没有响应时中止测试。
SS在每个TTI内获得的样本数和误码数实时送交统计判决模块分析。
3G的BER统计测试使用到的参数有:测试要求=0.001;标准化门限=[1.24];最大错误事件数=200;错误判决概率D=0.2%(或者说置信等级=99.8%);Bad DUT factor=[1.5]。同时注意:early fail limit曲线的有效范围是5<ne≤200;early pass limit曲线的有效范围是1<ne ≤200[3]。
在测试开始时,需要人为地引入一个错误事件,以确保实验的有效性。
测试过程中,在每个TTI累计从测试开始至该时刻的所有样本数和错误事件数,包括开始时引入的那个人为错误,计算相应的BER,并绘制BER轨迹曲线。期间要随时关注绘制的BER轨迹是否越过early fail limit和early pass limit曲线:
如果BER超出或相交于early fail limit曲线,则认为BER测试提早失败,测试结束;
如果BER低于或相交于early pass limit曲线,则认为BER测试提早通过,测试结束。
若已经达到指定的最大错误事件数200,仍然不能做出判决(这几乎是不可能的),则直接与标准化门限[1.24]比较。
4.3G的BER统计测试算法的实现与验证
在TD-SCDMA移动终端测试的研究过程中,我们使用LabVIEW 7.1实现了3G的BER 测试的统计判决部分。下图是BER=0.0008时某次统计分析的运行结果图。
- 4 -
图3 BER=0.0008时某次统计分析的运行结果
为了验证3G统计算法的特性,我们设计如下实验:
比较三种测试算法:算法一是3G统计算法;算法二是检测200个误比特,累计采样数,误比特总数与采样总数的比值即为ber(这是2G的一种BER算法,具有一定的统计意义);算法三是检测20000个比特样本,累计误比特数,误比特总数与采样总数的比值即为ber(这是目前很多终端测试仪器常采用的一种简单的BER算法)。
选用12.2kbps的参考测量信道,TTI=20ms,(即每个TTI内发送244bit数据块),并假定没有CRC校验错误、数据块丢失和Loopback超时。
实验中,每次产生244个01数据以对应一个TTI,即ns=244,根据指定的BER值随机产生若干个错误,得到该TTI内的ne值,再分别采用三种测试算法分析数据,记录各种算法消耗的TTI个数(即测试的时间)和判决结果。我们在0.0001-0.01范围内选取81个BER 值,每个BER值测试1000次。
图4 三种算法的测试时间比较图5 三种算法的判决准确性比较实验结果如图所示。可以看到,当BER值高于门限时,3G统计算法仅做出了极少数的Pass判决,可以“保证适度的低风险通过一个坏设备”;当BER值低于门限时,3G的算法判决绝大多数的设备Pass,说明“能够以高概率通过一个好设备”;虽然误判的风险略高于算法二,但是以此为代价,换来的是测试时间的大幅缩减。这正是3G统计算法的优势所在。至于算法三,属于独立的简单测试,统计意义很差,而且误判风险相对较高,明显劣于3G
- 5 -
统计算法。
5.结语
试规范中定义的这种新的BER 统计测试算法,是一种良好的测试算法,是BER 测试为一个独立的测试项目,而
是作参考文献
[1] 3GPP Test Specification TR34.901 V3.0.0.Te ication Group Terminals; Test Time Optimization
BER statistical testing arithmetic for 3G mobile terminal
School of information engineering, W nology, Wuhan, PRC (430070)
There is a new BER statistical testing arithme in 3GPP technical specification. Firstly, this 3GPP 测算法长期研究的成果,将应用于3G 移动设备的性能测试中。而且,该算法的理论同样适用于BLER (Block error ratio )测试以及RRM delay 测试。
但是,不同于2G ,3GPP 测试规范并没有将BER 测试设置为各接收机测试项目的中间环节出现,
由此产生的测试算法旨在以尽可能短的时间,以尽可能低的误判风险通知测试者待测设备是否符合门限要求,而无法提供一个精确的BER 计算结果。另外,该测试算法基于一种假定,即比特之间是相互独立的。然而,由于卷积/Turbo 编码等过程的存在,比特之间不可能完全独立,这必将影响到计算的准确性。这两点是该测试算法有待改进的地方。
chnical Specif based on statistical approaches; Statistical theory applied and evaluation of statistical significance [S].
[2] Rudolf Schindlmeier .Reducing measurement times by means of statistical BER measurements
[EB/OL].https://www.360docs.net/doc/901526489.html,/www/publicat.nsf/article/n179_cmu200-ber.pdf ,2003.
[3] 3GPP Test Specification TS34.122 V5.1.0.Technical Specification Group Terminal; Terminal conformance (T specification; Radio transmission and reception DD) [S].
[4] Agilent Technologies .Loopback Bit Error Ratio Measurement Description
://https://www.360docs.net/doc/901526489.html,/rfc [EB/OL].http wireless.agile omms/refdocs/wcdma/wcdma_meas_loopber_desc.php ,2005.
Li Hao ,Liu Lan
uhan university of Tech Abstract
tic defined paper introduced the theory of this arithmetic and supplied an application rule in the actual test. Then simulated its statistical testing arithmetic with LabVIEW, and compared it with traditional testing arithmetic to prove its characteristic.
Keywords: 3G; BER; testing arithmetic
- 6 -
产业集聚度的测算
一 产业集聚度概念和测度方法 产业集中度的概念:产业集中度也叫市场集中度,是指市场上的某种行业内少数企业的生产量、销售量、资产总额等方面对某一行业的支配程度,它一般是用这几家企业的某一指标(大多数情况下用销售额指标)占该行业总量的百分比来表示。 产业集聚测度方法 1、 集中度(Concentrion ration of industry ) 行业集中度是用规模最大的几个地区有关数值(销售额、就业人数、生产额等) 占整个行业的份额来度量。计算公式为: 11n i i n N i i X CR X ===∑∑ 其中n CR 代表X 产业的集聚度,1n i i X =∑代表规模最大几个地区X 产业的销售额 或者生产额、就业人数等,1N i i X =∑代表全部地区X 产业的销售额或者生产额、 就业人数等。 优点:计算方法简单,采用最常用的指标,能够形象的反应产业集聚水平。 缺点:一是集聚度的测算季节容易受到n 值选取的影响,二是忽略了规模最大地区之外其它地区的规模分布情况, 三是不能反映规模最大地区内部之间产业结构与分布的差别。 2、 区位熵(Entropy index ) 所谓熵, 就是比率的比率,它由哈盖特(P ·Haggett )首先提出并用于区位分析中。区位熵, 又称专门化率,用以衡量某一区域要素的空间分布情况,反映某一产业部门的专业化程度,以及某一区域在高层次区域的地位和作用等方面。在产业结构研究中,通常用于分析区域主导专业化部门的状况。计算公式为: 11E /i i ij n n i i i i q Q q Q === ∑∑ 其中E ij 表示某区域i 部门对于高层次区域的区域熵;i q 为某区域部门的有关
《数值计算方法》试题集及答案
《数值计算方法》复习试题 一、填空题: 1、????? ?????----=410141014A ,则A 的LU 分解为 A ??? ?????????=? ?????????? ?。 答案: ?? ????????--??????????--=1556141501 4115401411A 2、已知3.1)3(,2.1)2(,0.1)1(===f f f ,则用辛普生(辛卜生)公式计算求得 ?≈3 1 _________ )(dx x f ,用三点式求得≈')1(f 。 答案:, 3、1)3(,2)2(,1)1(==-=f f f ,则过这三点的二次插值多项式中2 x 的系数为 , 拉格朗日插值多项式为 。 答案:-1, )2)(1(21 )3)(1(2)3)(2(21)(2--------= x x x x x x x L 4、近似值*0.231x =关于真值229.0=x 有( 2 )位有效数字; 5、设)(x f 可微,求方程)(x f x =的牛顿迭代格式是( ); ( 答案 )(1)(1n n n n n x f x f x x x '--- =+ 6、对1)(3 ++=x x x f ,差商=]3,2,1,0[f ( 1 ),=]4,3,2,1,0[f ( 0 ); 7、计算方法主要研究( 截断 )误差和( 舍入 )误差; 8、用二分法求非线性方程 f (x )=0在区间(a ,b )内的根时,二分n 次后的误差限为 ( 1 2+-n a b ); 9、求解一阶常微分方程初值问题y '= f (x ,y ),y (x 0)=y 0的改进的欧拉公式为
( )] ,(),([2111+++++=n n n n n n y x f y x f h y y ); 10、已知f (1)=2,f (2)=3,f (4)=,则二次Newton 插值多项式中x 2系数为( ); 11、 两点式高斯型求积公式?1 d )(x x f ≈( ?++-≈1 )] 321 3()3213([21d )(f f x x f ),代数精 度为( 5 ); 12、 解线性方程组A x =b 的高斯顺序消元法满足的充要条件为(A 的各阶顺序主子式均 不为零)。 13、 为了使计算 32)1(6 )1(41310-- -+-+ =x x x y 的乘除法次数尽量地少,应将该表 达式改写为 11 ,))64(3(10-= -++=x t t t t y ,为了减少舍入误差,应将表达式 19992001-改写为 199920012 + 。 14、 用二分法求方程01)(3 =-+=x x x f 在区间[0,1]内的根,进行一步后根的所在区间 为 ,1 ,进行两步后根的所在区间为 , 。 15、 、 16、 计算积分?1 5 .0d x x ,取4位有效数字。用梯形公式计算求得的近似值为 ,用辛卜 生公式计算求得的近似值为 ,梯形公式的代数精度为 1 ,辛卜生公式的代数精度为 3 。 17、 求解方程组?? ?=+=+042.01532121x x x x 的高斯—塞德尔迭代格式为 ?????-=-=+++20/3/)51()1(1)1(2)(2)1(1 k k k k x x x x ,该迭 代格式的迭代矩阵的谱半径)(M ρ= 121 。 18、 设46)2(,16)1(,0)0(===f f f ,则=)(1x l )2()(1--=x x x l ,)(x f 的二次牛顿 插值多项式为 )1(716)(2-+=x x x x N 。 19、 求积公式 ?∑=≈b a k n k k x f A x x f )(d )(0 的代数精度以( 高斯型 )求积公式为最高,具 有( 12+n )次代数精度。
(完整版)产业集聚测量方法
摘要:本文介绍了目前常用的产业集聚测量方法,主要包括:行业集中度、赫芬达尔指数、熵指数、空间基尼系数、E-G指数。通过对比分析,阐述了各种测量方法的优缺点。分析认为,E-G指数是测量产业集聚比较适合的方法,但受制于数据的可获取性。 关键词:产业集聚测量 一、前言 区域经济理论认为,产业集聚对一个地区整体产业竞争力及区域经济增长具有重要影响。因此推动产业集聚成为了许多地方政府发展区域经济的重要手段。制定产业集聚相关政策必须以实证研究为基本前提,而对于产业集聚的实证研究,一个最根本的问题是如何测度产业的集聚度水平,因为无论是单纯进行产业集聚的研究还是探讨产业集聚对经济增长、经济稳定以及其他方面的影响,它都直接影响到最终研究结论的可信程度。 二、产业集聚常用的测量方法 目前比较常用的产业集聚测量方法主要有:行业集中度、赫芬达尔指数、熵指数、空间基尼系数、E-G集聚指数。 1、行业集中度 行业集中度是一种比较简单的指标,用来衡量某产业规模最大的前几个地区在全国所占的份额。其计算公式如下: 其中IC代表行业集中度;A i代表产业A中排名第i位区域的产值或者销售额、从业人员等;N代表产业A中的地区数目。上式表明行业集中度等于产业A中规模排名前n位 (n一般取4或8)的区域企业规模之和占产业A 全国总规模的比例。由于IC主要反映行业在几个区域的集中程度,没有涉及到行业的企业数目与行业总规模之间的差异,行业集中系数就是为了弥补这个缺陷。以P表示计算的企业占行业企业总数的比例:
那么,行业集中系数 CC可表示为: 行业集中度与集中系数能够形象地反映产业区域集中水平以及行业中企业数量的影响,测算方法便捷直观。 然而,行业集中度指标存在一些缺点:第一,仅说明了产业分布规模最大的几个地区的情况,而忽略了其余地区 的规模分布情况;第二,不能反映最大几个地区的个别情况;第三,存在选取规模最大的区域数目不同集中度 结果不同的问题。因此,一般较少单独用来测度产业集聚的情况,更多的是把它作为一个辅助指标。 2、赫芬达尔指数 赫芬达尔指数 (HHI)是产业经济学中衡量市场结构的一个主要指标,也可以用来衡量产业集聚程度,其计算公 式为: 其中A代表产业总规模,A i代表区域i的产业规模,N代表产业中的地区数目。HHI实质上是给产业中每个地区的市场份额赋予一个权重,此权重又以市场份额来代替。HHI的取值范围是[1/N,l],取值越大表示产业地理 集聚程度越高。极端情况下,如果一个产业所有的经济活动都集中在一个地区,那么该产业的HHI为最大值l; 而如果该产业的经济活动均匀分布在N个地区,那么这时HHI为最小值1/N。 赫芬达尔的优点是能够比较准确地反映产业地区集中程度,因为它考虑了地区数目和地区产业规模两个因素 的影响;计算上比较简便,容易理解。但是赫芬达尔指数的不足在于它没有考虑其他产业的空间分布,使得不 同产业之间难以进行比较。此外,这一指数没有考虑不同地区的地域面积差异,因此难以反映产业分布的实际 情况。 3、熵指数 熵指数的计算公式为:
线损理论计算方法
线损理论计算方法 线损理论计算是降损节能,加强线损管理的一项重要的技术管理手段。通过理论计算可发现电能损失在电网中分布规律,通过计算分析能够暴露出管理和技术上的问题,对降损工作提供理论和技术依据,能够使降损工作抓住重点,提高节能降损的效益,使线损管理更加科学。所以在电网的建设改造过程以及正常管理中要经常进行线损理论计算。 线损理论计算是项繁琐复杂的工作,特别是配电线路和低压线路由于分支线多、负荷量大、数据多、情况复杂,这项工作难度更大。线损理论计算的方法很多,各有特点,精度也不同。这里介绍计算比较简单、精度比较高的方法。 理论线损计算的概念 1.输电线路损耗 当负荷电流通过线路时,在线路电阻上会产生功率损耗。 (1)单一线路有功功率损失计算公式为 △P=I2R 式中△P--损失功率,W; I--负荷电流,A; R--导线电阻,Ω (2)三相电力线路 线路有功损失为 △P=△PA十△PB十△PC=3I2R (3)温度对导线电阻的影响: 导线电阻R不是恒定的,在电源频率一定的情况下,其阻值 随导线温度的变化而变化。 铜铝导线电阻温度系数为a=。 在有关的技术手册中给出的是20℃时的导线单位长度电阻值。但实际运行的电力线路周围的环境温度是变化的;另外;负载电流通过导线电阻时发热又使导线温度升高,所以导线中的实际电阻值,随环境、温度和负荷电流的变化而变化。为了减化计算,通常把导线电阴分为三个分量考虑: 1)基本电阻20℃时的导线电阻值R20为 R20=RL 式中R--电线电阻率,Ω/km,; L--导线长度,km。 2)温度附加电阻Rt为 Rt=a(tP-20)R20 式中a--导线温度系数,铜、铝导线a=0.004; tP--平均环境温度,℃。 3)负载电流附加电阻Rl为 Rl= R20 4)线路实际电阻为 R=R20+Rt+Rl (4)线路电压降△U为 △U=U1-U2=LZ 2.配电变压器损耗(简称变损)功率△PB
计算方法试题
计算方法考试题(一) 满分70分 一、选择题:(共3道小题,第1小题4分,第2、3小题3分,共10分) 1、将A 分解为U L D A --=,其中),,(2211nn a a a diag D =,若对角阵D 非奇异(即),1,0n i a ii =≠,则b Ax =化为b D x U L D x 1 1)(--++=(1) 若记b D f U L D B 111 1),(--=+= (2) 则方程组(1)的迭代形式可写作 ) 2,1,0(1 )(1)1( =+=+k f x B x k k (3) 则(2)、(3)称 【 】 (A)、雅可比迭代。(B)、高斯—塞德尔迭代 (C)、LU 分解 (D)、Cholesky 分解。 2、记*x x e k k -=,若0lim 1≠=+∞→c e e p k k k (其中p 为一正数)称序列}{k x 是 【 】 (A)、p 阶收敛; (B)、1阶收敛; (C)、矩阵的算子范数; (D)、p 阶条件数。 3、牛顿切线法的迭代公式为 【 】 (A)、 ) () (1k x f x f x x k k k '- =+ (B)、 )()())((111--+--- =k k k k k k k x f x f x x x f x x 1 )() ()1()()()(x x f x f x f k i k i k i ??+=+ (D)、 )() ()()1(k k k x f x x -=+ 二、填空题:(共2道小题,每个空格2分,共10分) 1、设0)0(f =,16)1(f =,46)2(f =,则一阶差商 ,二阶差商=]1,2,0[f ,)x (f 的二次牛顿 插值多项式为 2、 用二分法求方程 01x x )x (f 3 =-+=在区间]1,0[内的根,进行第一步后根所在的区间为 ,进行第二步后根所在的区间 为 。 三、计算题:(共7道小题,第1小题8分,其余每小题7分,共50分) 1、表中各*x 都是对准确值x 进行四舍五入得到的近似值。试分别指出试用抛物插值计算115的近似值,并估计截断误差。 3、确定系数101,,A A A -,使求积公式 ) ()0()()(101h f A f A h f A dx x f h h ++-≈? -- (1) 具有尽可能高的代数精度,并指出所得求积公式的代数精度。
地方时计算方法及试题精选(DOC)
关于地方时的计算 一.地方时计算的一般步骤: 1.找两地的经度差: (1)如果已知地和要求地同在东经或同在西经,则: 经度差=经度大的度数—经度小的度数 (2)如果已知地和要求地不同是东经或西经,则: 经度差=两经度和(和小于180°时) 或经度差=(180°—两经度和)。(在两经度和大于180°时) 2.把经度差转化为地方时差,即: 地方时差=经度差÷15°/H 3.根据要求地在已知地的东西位置关系,加减地方时差,即:要求点在已知点的东方,加地方时差;如要求点在已知点西方,则减地方时差。 二.东西位置关系的判断: (1)同是东经,度数越大越靠东。即:度数大的在东。 (2)是西经,度数越大越靠西。即:度数大的在西。 (3)一个东经一个西经,如果和小180°,东经在东西经在西;如果和大于180°,则经度差=(360°—和),东经在西,西经在东;如果和等于180,则亦东亦西。 三.应用举例: 1、固定点计算 【例1】两地同在东经或西经 已知:A点120°E,地方时为10:00,求B点60°E的地方时。 分析:因为A、B两点同是东经,所以,A、B两点的经度差=120°-60°=60° 地方时差=60°÷15°/H=4小时 因为A、B两点同是东经,度数越大越靠东,要求B点60°E比A点120°E小,所以,B点在A点的西方,应减地方时差。 所以,B点地方时为10:00—4小时=6:00 【例2】两地分属东西经 A、已知:A点110°E的地方时为10:00,求B点30°W的地方时. 分析:A在东经,B在西经,110°+30°=140°<180°,所以经度差=140°,且A点东经在东,B 点西经在西,A、B两点的地方时差=140°÷15°/H=9小时20分,B点在西方, 所以,B点的地方时为10:00—9小时20分=00:40。 B、已知A点100°E的地方时为8:00,求B点90°W的地方时。 分析:A点为东经,B点为西经,100°+90°=190°>180°, 则A、,B两点的经度差=360°—190°=170°,且A点东经在西,B点西经在东。 所以,A、B两点的地方时差=170°÷15°/H=11小时20分,B点在A点的东方, 所以B点的地方时为8:00+11小时20分=19:20。 C、已知A点100°E的地方8:00,求B点80°W的地方时。 分析:A点为100°E,B点为80°W,则100°+80°=180°,亦东亦西,即:可以说B点在A 点的东方,也可以说B点在A点的西方,A,B两点的地方时差为180÷15/H=12小时。 所以B点的地方时为8:00+12小时=20:00或8:00—12小时,不够减,在日期中借一天24小时来,即24小时+8:00—12小时=20:00。 2、变化点计算 【例1】一架飞机于10月1日17时从我国上海(东八区)飞往美国旧金山(西八区),需飞行14小时。到达目的地时,当地时间是() A. 10月2日15时 B. 10月2日3时 C. 10月1日15时 D. 10月1日3时
产业集聚测度方法的研究综述
2008/11 总第379期 商业研究 COMM ERC I AL R ES EARCH 文章编号:1001-148X (2008)11-0064-03 产业集聚测度方法的研究综述 刘斯敖 (河海大学商学院,江苏南京210098) 摘要:产业集聚测度方法是产业集聚研究重要的工具,一直倍受经济学家关注。随着产业集聚理论的 演变与发展,其测度方法也在不断演变与发展。对产业集聚测度方法进行输理与比较分析,以供更好地选择与运用。 关键词:产业集聚;测度方法;研究中图分类号:F22419 文献标识码:B 收稿日期:2007-12-13 作者简介:刘斯敖(1975-),男,河海大学商学院博士研究生,浙江工业大学之江学院讲师,研究方向: 区域经济与产业。 产业集聚作为一种重要的产业空间分布,一直以来备受经济学家的关注。从早期马歇尔的外部性和韦伯的区域经济理论开始,产业集聚的外部规模经济、溢出效应得到了广泛的研究和探讨(胡佛,1990; Fujita&Thisse,2004);以克鲁格曼、藤田昌久等为代 表的新经济地理理论(Krug man,1991;Fujita etal, 1999)又提出了集聚经济的内部规模经济。中间投入 品和劳动力的共享、知识的溢出(马歇尔,1890)、运输费用的节约(韦伯,1909)以及专业化分工与协作所带来的各种交易成本的降低,使产业集群成为许多国家和地区获取竞争优势的源泉(M ichael Por 2 ter,1990)。 早期的研究侧重于对产业集聚定性的观察与描述,随着研究地深入,产业集聚程度与影响集聚的关键因素的定量测度开始成为区域经济学家们关注的课题。随着产业集聚理论的发展,有关产业集聚程度的测度方法不断发展与完善,经历了有集中率、区位熵、赫芬达尔指数、空间基尼系数、EG 指数等的发展过程。 一、集中度(Concentri on ration of industry )行业集中度是用规模最大的几个地区有关数值 (销售额、就业人数、生产额等)占整个行业的份额 来度量。计算公式为:CR n = ∑n i =1X i ∑N i =1 X i 其中,CR n 代表X 产业的市场集中度, ∑n i =1 X i 代表 规模最大的几个地区X 产业的销售额或生产额、就业 人数等, ∑N i =1 X i 代表全部地区X 产业的销售额或生产 额、就业人数等。徐康宁、冯春虎(2003)运用指标计算了中国制造业28个行业1997年的地理集中度。在研究产业地理集聚中,CR n 也经常作为一个辅助的指标加以使用,如罗勇、曹丽莉(2005)和王子龙等 (2006)在测算制造业集聚程度和中国高科技产业集 聚程度时使用了集中度作为集聚程度测算一个辅助指标进行分析。 在各种测度产业集聚水平的方法中,集中度是最简单、最常用的计算指标,能够形象地反映产业市场集中水平。但是,集中度也存在不少缺陷:一是CR n 的值易受n 的影响,n 越大即选择地区越多,CR n 就会越大,二是忽略了规模最大地区之外其它地区的规模分布情况,三是不能反映规模最大地区内部之间产业结构与分布的差别。 二、区位熵(Entr opy index ) 所谓熵,就是比率的比率,它由哈盖特(P ? Haggett )首先提出并用于区位分析中。区位熵,又称 专门化率,用以衡量某一区域要素的空间分布情况,反映某一产业部门的专业化程度,以及某一区域在高层次区域的地位和作用等方面。在产业结构研究中,通常用于分析区域主导专业化部门的状况(崔功豪等,2003)。 区位熵的计算公式为:E ij = q i ∑n i =1 q i / Q i ∑n i =1 Q i 式中,E ij 表示某区域i 部门对于高层次区域的区域熵;q i 为某区域部门的有关指标(通常可用产值、产
《计算方法》期末考试试题
《计算方法》期末考试试题 一 选 择(每题3分,合计42分) 1. x* = 1.732050808,取x =1.7320,则x 具有 位有效数字。 A 、3 B 、4 C 、5 D 、6 2. 取7 3.13≈(三位有效数字),则 ≤-73.13 。 A 、30.510-? B 、20.510-? C 、10.510-? D 、0.5 3. 下面_ _不是数值计算应注意的问题。 A 、注意简化计算步骤,减少运算次数 B 、要避免相近两数相减 C 、要防止大数吃掉小数 D 、要尽量消灭误差 4. 对任意初始向量)0(x ?及常向量g ?,迭代过程g x B x k k ? ??+=+)() 1(收敛的充分必要条件是_ _。 A 、11< B B 、1<∞ B C 、1)(计算方法2006-2007试卷
计算方法2006-2007第一学期 1 填空 1). 近似数253.1*=x 关于真值249.1=x 有几位有效数字 ; 2). 设有插值公式)()(1 1 1 k n k k x f A dx x f ?∑-=≈,则∑=n k k A 1 =______ 3) 设近似数0235.0*1=x ,5160.2*2 =x 都是有效数,则相对误差≤)(*2 *1 x x e r ____ 4) 求方程x x cos =的根的牛顿迭代格式为 5) 矛盾方程组?????-=+=-=+1211212121x x x x x x 与??? ??-=+=-=+1 2122221 2121x x x x x x 得最小二乘解是否相同。 2 用迭代法(方法不限)求方程1=x xe 在区间(0,1)内根的近似值,要求先论证收敛性,误差小于210-时迭代结束。 3 用最小二乘法x be ax y +=2中的常数a 和b ,使该函数曲线拟合与下面四个点 (1,-0.72)(1.5, 0.02),(2.0, 0.61),(2.5, 0.32) (结果保留到小数点后第四位) 4.(10分)用矩阵的直接三角分解法求解线性方程组 ???? ? ? ? ??=??????? ????????? ??717353010342110100201 4321x x x x 5.(10分)设要给出()x x f cos =的如下函数表 用二次插值多项式求)(x f 得近似值,问 步长不超过多少时,误差小于3 10- 6. 设有微分方程初值问题 ?? ?=≤<-='2 )0(2 .00,42y x x y y - )
南通市现代服务业集聚水平测度实证研究
南通市现代服务业集聚水平测度实证研究 服务业集群化发展已经成为现代城市发展的重要现象。南通应致力于打造现代服务业产业集聚区,更好的发挥集聚效应,促进经济快速健康发展。运用改进的区位熵和空间基尼系数对南通2013年现代服务业的集聚程度进行测度,得出南通现代服务业产业间集聚水平极不均衡,行业内部各指标间协调性较差等结论,由此提出优化布局、健全机制、创新驱动以及建设服务平台等产业集聚措施。 标签:南通市;现代服务业;集聚测度;空间基尼系数;改进区位熵 1研究背景 现代服务业是依托信息技术和现代管理理念而发展起来的知识密集型服务业。我国经济正由“服务经济”主导进入向“现代服务业”为主导转变。现代服务业相比较传统服务业、制造业等产业有着更低的资源消耗和更高的产业关联带动性,发展现代服务业已经成为各地产业调整、提升经济发展质量的重要战略任务。参照中华人民共和国国民经济行业分类标准及经济合作与发展组织的分类标准,本文将交通运输、仓储和邮政业、信息传输、计算机服务和软件业、金融业、房地产业、租赁和商务服务业、科学研究、技术服务和地址勘查业以及文化、体育和娱乐业划归为现代服务业范畴。 近年来,服务业集群化发展已经成为城市发展的重要现象。集群化,是指某个特定产业中相互关联的若干企业和机构,在地理位置上的相对集中。产业集聚能够提高生产效率、降低交易和信息成本、增强企业竞争力,促进区域经济的发展。为了追求规模经济和外部效应,更有效的满足需求,现代服务业需要更接近生产企业和消费者的需求地,另外现代服务业对信息和知识的依赖性较高,信息和知识往往形成一定空间范围的集聚,从而导致服务业相关资源、要素和企业在地理空间上的集中化。 我国学者对现代服务业集聚的研究相对比较晚,随着现代服务业的不断发展,学者的研究成果日渐丰富。研究领域主要涉及形成机制、动力机制、功能作用、发展演变机制、影響因素以及集聚水平测量等。笔者通过中国知网的中国全文期刊数据库,对产业聚集度研究进行检索。以“篇名=服务业+集聚+测度(测量)”为检索词进行精确搜索,我国学者对服务业集聚水平测量的研究始于“九五”末期,利用测度模型对相关地区及产业的产业集聚度、影响因素、动力机制、区域差异分析以及与制造业集聚比较等问题进行研究。 南通在“十二五”规划中明确提出建设“长三角北翼经济中心”的城市战略发展定位。南通应致力于加快发展现代服务业,推动区域协调发展,打造现代服务业产业集聚区,更好的发挥集聚效应,促进经济快速健康发展。因此有必要对南通目前服务业产业集聚水平和发展途径进行研究。 2南通服务业聚集水平测度实证研究
波浪理论的计算方法
波浪理论的计算方法 1)第一浪只是推动浪开始 2)第二浪调整不能超过第一波浪起点 比率: 2浪=1浪0.5或0.618 3)第三浪通常是最长波浪,但绝不能是最短(相对1浪和5浪长度) 比率: 3浪=1浪1.618, 2或2.618倍 4)第四浪的调整不能与第一浪重迭(楔形除外) 比率: 4浪=3浪0.382倍。 5)第五浪在少数情况下未能超第三浪终点,即以失败形态告终 比率: 5浪=1浪或5浪=(1浪-3浪)0.382、0.5、0.618倍。 6)A浪比率: A浪=5浪0.5或0.618倍。 7)B浪比率: B浪=A浪0.382、0.5、0.618倍。 8)C浪比率: C浪=A浪1倍或0.618、1.382、1.618倍。 1、波浪理论基础 1) 波浪理论由8浪组成、1、3、5浪影响真正的走势,无论是下跌行情还是上升行情, 都在这三个浪中赚钱; 2) 2、4浪属于逆势发展(回调浪) 3) 6、7、8浪属于修正浪(汇价短期没有创新低或新高) 2、波浪理论相关法则 1) 第3永远不是最短的浪 2) 第4浪不能跌破第2浪的低点,或不能超过第2浪的高点 3) 数浪要点:你看到的任何一浪都是第1浪,第2浪永远和你真正的趋势相反; 4) 数浪规则:看到多少浪就是多少浪,倒回去数浪; 3、相关交易法则 1) 第3浪是最赚钱的一浪,我们应该在1、3、5浪进行交易,避免在2、4浪进场以 及避免在2、4浪的低点或者高点挂单,因为一旦上破或者下坡前期高点或者低点,则会出现发转,具体还要配合RSI和MACD指标进行分析;
4、波浪理论精华部分 1) 波浪理论中最简单的一个循环,或者说最小的一个循环为两浪循环,即上升浪或下跌浪+回调浪 2) 每一波上升浪或下跌浪由5个浪组成,这5浪中有两次2T确认进场; 3) 每一波回调浪由3个浪组成,这3浪中只有一次2T确认进场; 4) 波浪和移动均线共振时,得出进场做多、做空选择,同时要结合4R法则以及123法则进行分析 波浪理论图解 2011-10-21 19:14 每位投资者都希望能预测未来,波浪理论正是这样一种价格趋势分析工具,它根据周期循环的波动规律来分析和预测价格的未来走势。波浪理论的创始人——美国技术分析大师R.N.艾略特(1871~1948)正是在长期研究道琼斯工业平均指数的走势图后,于二十世纪三十年代创立了波浪理论。投资者一走进证券部就会看到记录着股价波动信息的K线图,它们有节奏、有规律地起伏涨落、周而复始,好像大海的波浪一样,我们也可以感受到其中蕴涵的韵律与协调。我们特别邀请到了研究波浪理论的资深专家杨青老师来与读者们一起“冲浪”。 1、基础课波浪理论在技术分析中被广泛采用波浪理论最主要特征就是它的通用性。人类社会经济活动的许多领域都遵循着波浪理论的基本规律,即在相似和不断再现的波浪推动下重复着自己。因为股票、债券的价格运动是在公众广泛参与的自由市场之中,市场交易记录完整,与市场相关的信息全面丰富,因此特别适于检验和论证波浪理论,所以它是诸多股票技术分析理论中被运用最多的,但不可否认,它也是最难于被真正理解和掌握的。专家导读:被事实验证的传奇波浪波浪理论的初次亮相极富传奇色彩。1929年开始的全球经济危机引发了经济大萧条,美国股市在1929年10月创下386点的高点后开始大崩盘,到 1932年仲夏时节,整个市场弥漫着一片绝望的气氛。这时,波浪理论的始作俑者艾略特给《美国投资周刊》主编格林斯发电报,明确指出长期下跌的走势已经结束,未来将会出现一个大牛市。当格林斯收到电报时,道琼斯30种工业指数已经大幅飙升,从邮戳上的时间看,电报就在道琼斯30种工业指数见底前两个小时发出。此后道琼斯指数在9周内上涨了100%,而且从此开始一路上扬。 但是波浪理论在艾略特生前却长期被人们忽视,直到1978年,他的理论继承者帕彻特出版了《波浪理论》一书,并在期货投资竞赛中运用波浪理论取得了四个月获利400%以上的骄人成绩后,这一理论才被世人广泛关注,并开始迅速传播。 2、波浪周期及实例解读 0 && image.height>0){if(image.width>=700){this.width=700;this.height=image .height*700/image.width;}}> 专家解读:五浪上升三浪下降组成完整周期一个完整的波动周期,即完成所谓从牛市到熊市的全过程,包括一个上升周期和一个下跌周期。上升周期由五浪构成,用1、2、3、4、5表示,其中1、3、 5浪上涨,2、4浪下跌;下跌周期由三浪构成,用a、b、c表示,其中a、c浪下跌,b 浪上升。与主趋势方向(即所在周期指明的大方向)相同的波浪我们称为推动浪,
数值计算方法》试题集及答案
《计算方法》期中复习试题 一、填空题: 1、已知3.1)3(,2.1)2(,0.1)1(===f f f ,则用辛普生(辛卜生)公式计算求得 ?≈3 1 _________ )(dx x f ,用三点式求得≈')1(f 。 答案:2.367,0.25 2、1)3(,2)2(,1)1(==-=f f f ,则过这三点的二次插值多项式中2 x 的系数为 ,拉 格朗日插值多项式为 。 答案:-1, )2)(1(21 )3)(1(2)3)(2(21)(2--------= x x x x x x x L 3、近似值*0.231x =关于真值229.0=x 有( 2 )位有效数字; 4、设)(x f 可微,求方程)(x f x =的牛顿迭代格式是( ); 答案 )(1)(1n n n n n x f x f x x x '--- =+ 5、对1)(3 ++=x x x f ,差商=]3,2,1,0[f ( 1 ),=]4,3,2,1,0[f ( 0 ); 6、计算方法主要研究( 截断 )误差和( 舍入 )误差; 7、用二分法求非线性方程 f (x )=0在区间(a ,b )内的根时,二分n 次后的误差限为 ( 1 2+-n a b ); 8、已知f (1)=2,f (2)=3,f (4)=5.9,则二次Newton 插值多项式中x 2系数为( 0.15 ); 11、 两点式高斯型求积公式?1 d )(x x f ≈( ?++-≈1 )] 321 3()3213([21d )(f f x x f ),代数精度 为( 5 ); 12、 为了使计算 32)1(6 )1(41310-- -+-+ =x x x y 的乘除法次数尽量地少,应将该表达 式改写为 11 ,))64(3(10-= -++=x t t t t y ,为了减少舍入误差,应将表达式1999 2001-
第一性原理计算原理和方法
第二章 计算方法及其基本原理介绍 化学反应的本质是旧键的断裂和新建的形成,参与成键原子的电子壳层重新组合是导致生成稳定多原子化学键的明显特征。因此阐述化学键的理论应当描写电子壳层的相互作用与重排,借助求解满足适当的Schrodinger 方程的波函数描写分子中电子分布的量子力学,为解决这一问题提供了一般的方法,然而,对于一些实际的体系,不引入一些近似,就不可能求解其Schrodinger 方程。这些近似使一般量子力学方程简化为现代电子计算机可以求解的方程。这些近似和关于分子波函数的方程形成计算量子化学的数学基础。 2.1 SCF-MO 方法的基本原理 分子轨道的自洽场计算方法 (SCF-MO)是各种计算方法的理论基础和 核心部分,因此在介绍本文计算工作所用 方法之前,有必要对其关键的部分作一简 要阐述。 2.1.1 Schrodinger 方程及一些基本近似 为了后面介绍各种具体在自洽场分子轨道(SCF MO)方法方便,这里将主要阐明用于本文量子化学计算的一些重要的基本近似,给出SCF MO 方法的一些基本方程,并对这些方程作简略说明,因为在大量的文献和教材中对这些方程已有系统的推导和阐述[1-5]。 确定任何一个分子的可能稳定状态的电子结构和性质,在非相对论近似下,须求解定态Schrodinger 方程 ''12121212122ψψT p B A q p A p pA A pq AB B A p A A A E R Z r R Z Z M =??????? ?-++?-?-∑∑∑∑∑∑≠≠ (2.1) R AB =R 图2-1分子体系的坐标
其中分子波函数依赖于电子和原子核的坐标,Hamilton 算符包含了电子p 的动能和电子p 与q 的静电排斥算符, ∑∑≠+?-=p q p pq p e r H 12121?2 (2.2) 以及原子核的动能 ∑?-=A A A N M H 2121? (2.3) 和电子与核的相互作用及核排斥能 ∑∑≠+-=p A B A AB B A pA A eN R Z Z r Z H ,21? (2.4) 式中Z A 和M A 是原子核A 的电荷和质量,r pq =|r p -r q |,r pA =|r p -R A |和R A B =|R A -R B |分别是电子p 和q 、核A 和电子p 及核A 和B 间的距离(均以原子单位表示之)。上述分子坐标系如图2.1所示。可以用V(R,r)代表(2.2)-(2.4)式中所有位能项之和 ∑∑∑-+= ≠≠p A pA A B A q p pq AB B A r Z r R Z Z r R V ,12121),( (2.5) ● 原子单位 上述的Schrodinger 方程和Hamilton 算符是以原子单位表示的,这样表示的优点在于简化书写型式和避免不必要的常数重复计算。在原子单位的表示中,长度的原子单位是Bohr 半径 A == 52917725.042220e m h a e π 能量是以Hartree 为单位,它定义为相距1Bohr 的两个电子间的库仑排斥作用能 2 1a e Hartree = 质量则以电子制单位表示之,即定义m e =1 。 ● Born-Oppenheimer 近似 可以把分子的Schrodinger 方程(2.1)改写为如下形式
《数值计算方法》试题集及答案
《数值计算方法》复习试题 一、填空题: 1、????? ?????----=410141014A ,则A 的LU 分解为 A ??? ?????????=? ?????????? ?。 答案: ?? ????????--??????????--=1556141501 4115401411A 3、1)3(,2)2(,1)1(==-=f f f ,则过这三点的二次插值多项式中2 x 的系数 为 ,拉格朗日插值多项式为 。 答案:-1, )2)(1(21 )3)(1(2)3)(2(21)(2--------= x x x x x x x L 4、近似值*0.231x =关于真值229.0=x 有( 2 )位有效数字; 5、设)(x f 可微,求方程)(x f x =的牛顿迭代格式是( ); 答案 )(1)(1n n n n n x f x f x x x '--- =+ 6、对1)(3 ++=x x x f ,差商=]3,2,1,0[f ( 1 ),=]4,3,2,1,0[f ( 0 ); 7、计算方法主要研究( 截断 )误差和( 舍入 )误差; 8、用二分法求非线性方程 f (x )=0在区间(a ,b )内的根时,二分n 次后的误差限为 ( 1 2+-n a b ); 10、已知f (1)=2,f (2)=3,f(4)=5.9,则二次Ne wton 插值多项式中x 2系数为 ( 0.15 ); 11、 解线性方程组A x =b 的高斯顺序消元法满足的充要条件为(A 的各阶顺序主子式均 不为零)。 12、 为了使计算 32)1(6 )1(41310-- -+-+ =x x x y 的乘除法次数尽量地少,应将该
城市化水平测度方法研究综述
基金项目石河子大学校级项目:新疆城市化水平综合评价研究(RWSK 2006-Y22)。 作者简介徐秋艳(1972-),女,河南省兰考人,硕士,讲师,从事统计学 及经济学的教学与研究。 收稿日期2007-07-30 城市化,是当今世界上重要的社会、经济现象之一。在其各种各样的定义中,较为主要的提法是“人口向城市集中的过程”,这一过程包含了社会、人口、空间及经济转换等多方面的内容。城市化水平即指城市化发展的程度,对它的测度一般采用城市地区人口占地区人口的比重。目前国内外学者对城市化水平的测度方法主要有两种:单一指标法和复合指标法。笔者对目前国内外学者城市化水平的测定作一回顾与总结,并简要地对各种方法作一评论,使读者对这一方面的研究情况有所了解,以便明确进一步深入研究的方向。1 国外研究综述 对单一指标法研究具有代表性学者如诺瑟姆把一个国家或地区的城镇人口占总人口的比重作为衡量一国或一个地区的城镇化水平。 国外对于复合指标法来衡量城市化水平的系统研究的著述并不多见,大多分散于各种社会、经济发展理论中。由于发达国家已经基本完成城市化的过程,近年来甚至出现了逆城市化现象,因此对于复合指标法的研究,比较成熟的有以下几种:第一,联合国和社会事务部统计处建立的指标系统采用19个社会经济指标来考察各发达国家和发展中国家与经济、社会、人口统计变化之间的关系。第二,英国地理学家克劳克从人口、职业、居住及距离城市中心距离远近等16个指标进行分析,建立城市化的指标系统。第三,美国斯坦福大学社会学教授因克尔斯提出的现代化指标体系。该标准作为现代化的标准体系在国际上较为通行。尽管该指标体系并非直接描述城市化,但是它可以反映城市化中相当大的一部分内涵。此外,1980年经济合作与发展组织提出的社会指标体系15项,1982年英国制定的社会指标体系10项,1982年印度提出的社会指标体系7项,1986年欧洲的33个世界卫生组织成员国联合发起建立“健康城市”,提出38项目标等,也是对现代化评价指标体系的有益探索,可供借鉴。 2国内研究综述 单一指标法最常用的是人口指标法,即城市人口占总人口的比重。但这种方法却存在以下问题:一是市镇的建制标准多次发生变动。由于市镇人口的多少与市镇的设置标准密切相关,不断地调整市镇的设制标准必然会导致同一地区设市(镇)前后城镇人口的统计出现差异,从而不能如实地反映出该地区城市化水平的变化。二是城镇人口统计的地域范围与城镇实体的地理界线不一致。我国城镇人口的统计是按市镇的辖区范围为单元进行的,而中国市镇的行政辖区要远比城镇的实体范围大。1980年实行的撤县建市、撤乡建镇以及市带县的体制,使统计出的城镇人口中包含了大量的农业人口,导致测出的城市化水平不真实。另外国民经济统计资料及人口普查都是以各级行政区为基本单元统计的,一旦行政区划改变,本来在实体上并没有很大变化的城市人口,在统计资料上却有了很大的变化。三是城镇人口的统计对象没有形成统一的标准。1963年以前,我国把市镇辖区内的全部常住人口都统计为城镇人口。1964年以后,规定只限于市镇辖区内的非农业人口为城镇人口。1982年以后,又把区内农业人口统计在内。1980年以后,有大量流动人口涌入城市,对城市的发展起很大作用,但是他 们却不被公安部门登记为城镇非农业人口,而这部分人口无论是从事的职业上,还是在生活和集聚性上,都具有相当大程度的城市特性。有的学者曾对城市人口占总人口的比重这一指标的计算方法做出相应的修正,用以消除与实际的偏离,试图能反映一个地区比较真实的城市化水平。李文博等利用国民经济中从业人员的就业比重推算总人口中城市化人口比重。还有采用非农业人口比重指标,即某一地区的非农业人口占总人口的比重作为城市化水平评价指标。这一指标体现了人口在经济活动上的结构关系,较准确把握了城市化的经济意义和内在动因。但由于存在大量在城市从事各种各样工作的非农业人口,使该指标与实际也有很大偏离。此外,还有采用城市用地指标等进行衡量。赵燕菁将城市化看作对社会分工水平和规模的度量。在这个新的理论看来,将职业和居住的空间位置作为分析的基础本身就是不牢靠的。真正的城市化指标应当建立在分工的基础上,这种分工无论发生在什么地方都一定会推动城市化的进程。他在参与一项关于中国城市化道路的中美合作研 城市化水平测度方法研究综述 徐秋艳 (石河子大学商学院商务信息系,新疆五家渠831300) 摘要对国内外学者有关城市化水平的测定作了回顾与总结,并简要地对各种方法作一评论,使读者对目前在这一方面的研究情况有所了解,以便明确进一步深入研究的方向。关键词城市化;城市化水平;测度法中图分类号F291文献标识码A 文章编号0517-6611(2007)29-09407-02Summarization of Researches on Measuring Method of Urbanization Level XU Qiu 蛳yan (College of Business,Shihezi University,Wujiaqu,Xingjiang 831300) Abstract Measuring methods of urbanization level of some scholars at home and abroad were reviewed and https://www.360docs.net/doc/901526489.html,mentary on each method was briefly conducted,which helped readers to understand the current research situation in this aspect and nail down the direction of further study. Key words Urbanization;Urbanization level;Measuring method 安徽农业科学,Journal of Anhui Agri.Sci.2007,35(29):9407-9408责任编辑曹淑华责任校对王淼