数据库中表之间的关系
数据库表关系模型解析6——多对多

数据库表关系模型解析6——多对多狼奔代码生成器是一款为程序员设计的前期开发辅助工具,是一个软件项目智能开发的平台,它可以自动生成页面及后台代码。
实践开发过程中,我们使用PowerDesigner设计数据库模型。
狼奔代码生成器就是读取PowerDesigner设计的数据库模型,分析其中的表与表之间的关系模型,分析其中的表和字段的说明信息中的关键字,自动生成不同的页面。
表与表之间的关系模型包括1.单表数据模型2.自连接数据模型3.一对一数据模型4.一对多数据模型5.一对多数据模型中的一张表是自连接6.多对多数据模型7.多对多数据模型中的一张表是自连接关键字包括1.查询2.状态3.上传4.工作流架构图数据访问层(DAL)数据实体Entity Framework业务实体和校验元数据业务逻辑层(BLL)业务处理工作流事务接口层(IBLL)服务契约展示层(App )View (视图)Controller (控制器)Models (页面实体)对其他系统暴露服务Service (服务)公共组件安全组件日志记录异常捕获公共类库(Common)组件说明图表1项目组件说明图1)App——页面展示层采用MVC框架,使用Jquery脚本库,控件选用Easyui。
2)WcfHost——服务宿主(后期扩展)为对外的服务提供宿主,使用WCF技术,HTTPS通讯协议。
3)IBLL——业务接口层业务逻辑层的方法对外暴露的接口和服务契约。
4)BLL——业务逻辑层业务逻辑的操作,包括业务处理,事务,日志。
5)DAL——数据访问层数据库访问的操作,数据实体,业务实体,数据校验,使用Entity Framework。
6)Common——公共组件层整个应用程序使用的公共辅助方法。
7)WFActivitys——工作流活动层(后期扩展)定义了工作流需要的活动,使用微软WF技术。
8)WFDesigner——工作流设计器(后期扩展)可以让实施人员自由配置工作流的设计器,使用微软WPF技术。
数据库中表的关联设计

数据库中表的关联设计数据库中表的关联设计是数据库设计的核心环节之一,它关系到数据的完整性、查询效率以及系统的可扩展性。
在进行数据库表关联设计时,需要遵循一定的原则和方法,以确保数据库结构的合理性和高效性。
本文将深入探讨数据库中表的关联设计,包括关联类型、设计原则、实施步骤以及优化策略等方面。
一、关联类型数据库中的表关联主要分为三种类型:一对一关联(1:1)、一对多关联(1:N)和多对多关联(M:N)。
1. 一对一关联(1:1):指两个表中的记录之间存在一一对应的关系。
例如,一个用户表和一个用户详情表,每个用户都有唯一的详情信息。
在这种关联中,通常将两个表合并为一个表,或者在主表中添加一个唯一的外键列来引用另一个表。
2. 一对多关联(1:N):指一个表中的记录可以与另一个表中的多个记录相关联。
例如,一个部门表可以有多个员工表记录与之关联。
在这种关联中,通常在多的一方添加一个外键列,用于引用一的一方的主键。
3. 多对多关联(M:N):指两个表中的记录都可以与对方表中的多个记录相关联。
例如,学生和课程之间的关系,一个学生可以选修多门课程,一门课程也可以被多个学生选修。
在这种关联中,通常需要引入一个中间表来表示两个表之间的关联关系,中间表包含两个外键列,分别引用两个表的主键。
二、设计原则在进行数据库表关联设计时,需要遵循以下原则:1. 规范化原则:通过数据规范化来消除数据冗余和依赖,确保数据的完整性和一致性。
规范化过程中,将数据分解到多个表中,并定义表之间的关系,以减少数据的重复存储。
2. 完整性原则:确保数据的完整性和准确性。
通过设置主键、外键、唯一约束等数据库对象,来维护数据的完整性。
同时,还需要考虑业务规则和数据校验等方面的需求。
3. 可扩展性原则:数据库设计应具有良好的可扩展性,能够适应未来业务的发展和变化。
在设计过程中,需要预留一定的扩展空间,避免过多的硬编码和固定配置。
4. 性能原则:数据库设计应充分考虑查询性能和数据处理能力。
Access 2003 课后练习题

一、填空题:1.Access 2003中,一个数据库对于操作系统中的1个文件,其文件的扩展名是。
2.Access 2003中最基本的数据单位是。
3.Access 2003数据库中的表以行和列来组织数据,每一行称为,每一列称为。
4.Access 2003数据库中表之间的关系有、和关系。
5.任何一个数据库管理系统都是基于某种数据模型的,数据库管理系统支持的数据模型有、、和三种。
6.数据库系统由5部分组成,分别是、、、用户和。
7.报表是把数据库中的数据的特有形式。
8.在Access 2003中表有两种视图,即视图和视图。
9.如果一张数据表中含有“照片”字段,那么“照片”字段的数据类型应定义为。
10.如果字段的取值只有两种可能,字段的数据类型应选用类型。
11.是数据表中其值能唯一标识一条记录的一个字段或多个字段组成的一个组合。
12.如果字段的值只能是4位数字,则该字段的输入掩码的定义应为。
13.字段的属性用于检查错误的输入或不符合要求的数据输入。
14.对表的修改分为对的修改和对的修改。
15.在“查找和替换”对话框中,“查找范围”列表用来确定在哪个字段中查找数据,“匹配”列表框用来匹配方式,包括、和三种方式。
16.在查找时,如果确定了查找内容的范围,可以通过设置来减小查找的范围。
17.数据类型为、或的字段不能排序。
18.设置表的数据视图列宽时,当拖动字段列右边边界的分隔线超过左边界时,将会该列。
19.当冻结某个或某些字段,无论怎么样水平滚动窗口,这些被冻结的字段列总是固定可见的并且显示在窗口的。
20.Access 2003提供了、、、、和5种筛选方式。
21.在Access 2003中,查询的运行一定会导致数据表中数据发生变化。
22.在“商品”表中,查出数量大于等于50且小于100的商品,可输入和条件表达式是。
23.在交叉表查询中,只能有一个和值,但可以有一个或多个。
24.在创建查询时,有些实际需要的内容在数据源的字段中并不存在,但可以通过在查询中增加来完成。
数据库之表与表之间建关系

数据库之表与表之间建关系⼀、⼀对多关系定义⼀张部门员⼯表我们就会发现把所有数据存放于⼀张表的弊端:1.组织结构不清晰2.浪费硬盘空间3.扩展性极差这样的弊端是不是看着很眼熟,没错!这就类似于我们代码全部写在⼀个py⽂件中,那么当我们发现⼀个py⽂件中的代码冗余度很⾼会怎么做呢?当然就是要进⾏解耦合!那么我再来分析这张表数据之间的关系:多个⽤户对应⼀个部门,⼀个部门就对应了多个⽤户,那么他们之间的关系就应该是⼀对多的关系,我们可以将上⾯的表拆开成两张表,⼀张是记录⽤户信息,另⼀张记录部门信息,再⽤某种⽅法使者两张表关联起来,这个⽅法就是:使⽤Foreign Key确⽴表与表之间的关系⼀定要换位思考(必须两⽅⾯都考虑周全之后才能得出结论)Foreign Key:外键约束1.在创建表的时候,必须先创建被关联表2.插⼊数据的时候,也必须先插⼊被关联表的数据创建表:1#在创建表的时候,⼀定要先建被关联的表,才能创建关联表2create table dep(3id int primary key auto_increment,4 dep_name varchar(64),5 dep_desc varchar(64)6);78create table emp(9id int primary key auto_increment,10 name varchar(16),11 gender enum('male','female','others')not null default 'male',12age int,13emp_id int,14foreign key(emp_id) references dep(id)15 );插⼊记录:1#插⼊记录时,必须先插被关联的表dep,才能插关联表emp2insert into dep(dep_name,dep_desc) values3 ('⽂娱部','⽂艺熏陶'),4 ('体育部','强⾝健体'),5 ('⼩卖部','好吃好喝');67insert into emp(name,gender,age,emp_id) values8 ('jason','female',18,1),9 ('egon','male',90,2),10 ('tank','male',38,2),11 ('kevien','female',20,3),12 ('jerry','male',40,3);这样我们就把表都创建好了,并且表与表之间也建⽴了联系,但是问题也接踵⽽来,当我想修改emp⾥的dep_id或dep⾥⾯的id(修改成两张表都没有id)或者删除dep表⾥的记录时都会报错,如下图:解决⽅式有两种:⽅式1:先删除部门对应的所有的员⼯,在删除这个部门★⽅式2:先把之前创的表删除,先删除员⼯表,再删除部门表,最后按照下⾯的⽅式重新创建表关系更新与删除都需要考虑到关系与被关联的关系,也就是做到同步更新,同步删除1create table dep(2 id int primary key auto_increment,3 dep_name varchar(64),4 dep_desc varchar(64)5 );6 create table emp(7 id int primary key auto_increment,8 name varchar(16),9 gender enum('male','female','others')not null default 'male',10 age int,11 emp_id int,12 foreign key(emp_id) references dep(id)13 on update cascade14 on delete cascade15 );插⼊记录:1insert into dep(dep_name,dep_desc) values2 ('⽂娱部','⽂艺熏陶'),3 ('体育部','强⾝健体'),4 ('⼩卖部','好吃好喝');56insert into emp(name,gender,age,emp_id) values7 ('jason','female',18,1),8 ('egon','male',90,2),9 ('tank','male',38,2),10 ('kevien','female',20,3),11 ('jerry','male',40,3);删除部门后,对应的部门⾥⾯的员⼯表数据同步对应删除更新部门后,对应员⼯表中的标识部门的字段同步更新⼆、多对多例:图书表与作者表之间的关系我们仍然站在两张表的⾓度来分析:1.站在图书表:⼀本书可不可以有多个作者,可以的!那么就是书籍多对⼀了作者2.站在作者表:⼀个作者可不可以写多本书,也可以!那么就是作者多对⼀了书籍双⽅都能⼀条数据对应对⽅多条记录,这种关系就是多对多!那么我们应该如何创建表呢?图书表需要有⼀个外键关联作者,作者也需要有⼀个外键来关联书籍,然后问题来了,那我到底先创建谁呢?怎么解决这个问题呢?解决⽅案:创建第三张表,该表中应该有⼀个foreign key字段关联图书表中的id,还应该有⼀个foreign key字段来关联作者表中的id,这样这两张表就通过⼀个中间者,建⽴起了联系。
数据库之表与表之间的关系

数据库之表与表之间的关系表1 foreign key 表2则表1的多条记录对应表2的⼀条记录,即多对⼀利⽤foreign key的原理我们可以制作两张表的多对多,⼀对⼀关系多对多:表1的多条记录可以对应表2的⼀条记录表2的多条记录也可以对应表1的⼀条记录⼀对⼀:表1的⼀条记录唯⼀对应表2的⼀条记录,反之亦然分析时,我们先从按照上⾯的基本原理去套,然后再翻译成真实的意义,就很好理解了1、先确⽴关系2、找到多的⼀⽅,吧关联字段写在多的⼀⽅⼀、多对⼀或者⼀对多(左边表的多条记录对应右边表的唯⼀⼀条记录)需要注意的:1.先建被关联的表,保证被关联表的字段必须唯⼀。
2.在创建关联表,关联字段⼀定保证是要有重复的。
其实上⼀篇博客已经举了⼀个多对⼀关系的⼩例⼦了,那我们在⽤另⼀个⼩例⼦来回顾⼀下。
这是⼀个书和出版社的⼀个例⼦,书要关联出版社(多个书可以是⼀个出版社,⼀个出版社也可以有好多书)。
谁关联谁就是谁要按照谁的标准。
书要关联出版社被关联的表create table press(id int primary key auto_increment,name char(20));关联的表create table book(book_id int primary key auto_increment,book_name varchar(20),book_price int,press_id int,constraint Fk_pressid_id foreign key(press_id) references press(id)on delete cascadeon update cascade);插记录insert into press(name) values('新华出版社'),('海燕出版社'),('摆渡出版社'),('⼤众出版社');insert into book(book_name,book_price,press_id) values('Python爬⾍',100,1),('Linux',80,1),('操作系统',70,2),('数学',50,2),('英语',103,3),('⽹页设计',22,3);运⾏结果截图:⼆、⼀对⼀例⼦⼀:⽤户和管理员(只有管理员才可以登录,⼀个管理员对应⼀个⽤户)管理员关联⽤户===========例⼦⼀:⽤户表和管理员表=========先建被关联的表create table user(id int primary key auto_increment, #主键⾃增name char(10));在建关联表create table admin(id int primary key auto_increment,user_id int unique,password varchar(16),foreign key(user_id) references user(id)on delete cascadeon update cascade);insert into user(name) values('susan1'),('susan2'),('susan3'),('susan4'),('susan5'),('susan6');insert into admin(user_id,password) values(4,'sds156'),(2,'531561'),(6,'f3swe');运⾏结果截图:例⼦⼆:学⽣表和客户表========例⼦⼆:学⽣表和客户表=========create table customer(id int primary key auto_increment,name varchar(10),qq int unique,phone int unique);create table student1(sid int primary key auto_increment,course char(20),class_time time,cid int unique,foreign key(cid) references customer(id)on delete cascadeon update cascade);insert into customer(name,qq,phone) values('⼩⼩',13564521,11111111),('嘻哈',14758254,22222222),('王维',44545522,33333333),('胡军',545875212,4444444),('李希',145578543,5555555),('李迪',754254653,8888888),('艾哈',74545145,8712547),('啧啧',11147752,7777777);insert into student1(course,class_time,cid) values('python','08:30:00',3),('python','08:30:00',4),('linux','08:30:00',1),('linux','08:30:00',7);运⾏结果截图:三、多对多(多条记录对应多条记录)书和作者(我们可以再创建⼀张表,⽤来存book和author两张表的关系)要把book_id和author_id设置成联合唯⼀联合唯⼀:unique(book_id,author_id)联合主键:alter table t1 add primary key(id,avg)多对多:⼀个作者可以写多本书,⼀本书也可以有多个作者,双向的⼀对多,即多对多 关联⽅式:foreign key+⼀张新的表========书和作者,另外在建⼀张表来存书和作者的关系#被关联的create table book1(id int primary key auto_increment,name varchar(10),price float(3,2));#========被关联的create table author(id int primary key auto_increment,name char(5));#========关联的create table author2book(id int primary key auto_increment,book_id int not null,author_id int not null,unique(book_id,author_id),foreign key(book_id) references book1(id)on delete cascadeon update cascade,foreign key(author_id) references author(id)on delete cascadeon update cascade);#========插⼊记录insert into book1(name,price) values('九阳神功',9.9),('葵花宝典',9.5),('辟邪剑谱',5),insert into author(name) values('egon'),('e1'),('e2'),('e3'),('e4'); insert into author2book(book_id,author_id) values(1,1),(1,4),(2,1),(2,5),(3,2),(3,3),(3,4),(4,5);多对多关系举例⽤户表,⽤户组,主机表-- ⽤户组create table user (id int primary key auto_increment,username varchar(20) not null,password varchar(50) not null);insert into user(username,password) values('egon','123'),('root',147),('alex',123),('haiyan',123),('yan',123);-- ⽤户组表create table usergroup(id int primary key auto_increment,groupname varchar(20) not null unique);insert into usergroup(groupname) values('IT'),('Sale'),('Finance'),('boss');-- 建⽴user和usergroup的关系表create table user2usergroup(id int not NULL UNIQUE au to_increment,user_id int not null,group_id int not NULL,PRIMARY KEY(user_id,group_id),foreign key(user_id) references user(id)ON DELETE CASCADEon UPDATE CASCADE ,foreign key(group_id) references usergroup(id)ON DELETE CASCADEon UPDATE CASCADE);insert into user2usergroup(user_id,group_id) values(1,1), (1,2),(1,3),(1,4),(2,4),(3,4);-- 主机表CREATE TABLE host(id int primary key auto_increment,ip CHAR(15) not NULL UNIQUE DEFAULT '127.0.0.1' );insert into host(ip) values('172.16.45.2'),('172.16.31.10'),('172.16.45.3'),('172.16.31.11'),('172.10.45.3'),('172.10.45.4'),('172.10.45.5'),('192.168.1.20'),('192.168.1.21'),('192.168.1.22'),('192.168.2.23'),('192.168.2.223'),('192.168.2.24'),('192.168.3.22'),('192.168.3.23'),('192.168.3.24');-- 业务线表create table business(id int primary key auto_increment,business varchar(20) not null unique);insert into business(business) values('轻松贷'),('随便花'),('⼤富翁'),('穷⼀⽣');-- 建⽴host和business关系表CREATE TABLE host2business(id int not null unique auto_increment,host_id int not null ,business_id int not NULL ,PRIMARY KEY(host_id,business_id),foreign key(host_id) references host(id),FOREIGN KEY(business_id) REFERENCES business(id));insert into host2business(host_id,business_id) values (1,1),(1,2),(1,3),(2,2),(2,3),(3,4);-- 建⽴user和host的关系create table user2host(id int not null unique auto_increment,user_id int not null,host_id int not null,primary key(user_id,host_id),foreign key(user_id) references user(id),foreign key(host_id) references host(id));insert into user2host(user_id,host_id) values(1,1), (1,2),(1,3),(1,4),(1,5),(1,6),(1,7),(1,8),(1,9),(1,10),(1,11),(1,12),(1,13),(1,14),(1,15),(1,16),(2,2),(2,3), (2,4), (2,5), (3,10), (3,11), (3,12);练习。
access总结建立表间关系、举例说明级联更新、级联删除总结

access总结建立表间关系、举例说明级联更新、级联删除总结1.表间关系的建立在A cc es s数据库中,我们可以通过建立表间关系来连接不同的表,实现数据的关联和查询。
常见的表间关系有一对一关系、一对多关系和多对多关系。
1.1一对一关系一对一关系指的是两个表之间的每条记录在关联字段上都是唯一的。
举个例子,我们有两个表:学生表和身份证信息表,其中学生和身份证之间是一对一关系。
每个学生都对应着一个唯一的身份证号码。
在A cc es s中建立一对一关系,可以通过以下步骤:1.打开Ac ce ss数据库,并打开表设计视图。
2.在两个表的关联字段上创建索引。
3.在数据库工具中选择“关系”选项,然后将两个表拖动到“关系”窗口中。
4.在关联字段上建立关系。
1.2一对多关系一对多关系指的是一个表的记录在关联字段上可以与另一个表的多个记录相关联。
比如,我们有一个学生表和一个课程表,一个学生可以选择多门课程,而一门课程只能被一个学生选择。
在A cc es s中建立一对多关系,可以通过以下步骤:1.打开Ac ce ss数据库,并打开表设计视图。
2.在两个表的关联字段上创建索引。
3.在数据库工具中选择“关系”选项,然后将两个表拖动到“关系”窗口中。
4.在关联字段上建立关系。
1.3多对多关系多对多关系指的是两个表之间的每个记录在关联字段上可以与另一个表的多个记录相关联。
举个例子,我们有一个学生表和一个课程表,一个学生可以选择多门课程,而一门课程也可以被多个学生选择。
在A cc es s中建立多对多关系,通常需要借助第三张关系表来实现。
以下是建立多对多关系的步骤:1.创建第三张关系表,该表包含两个表的主键作为外键,并成为这两个表之间的中间表。
2.在数据库工具中选择“关系”选项,然后将三张表拖动到“关系”窗口中。
3.在关联字段上建立关系。
2.级联更新的举例说明在A cc es s数据库中,我们可以通过级联更新来确保数据库中关联的记录在更新时保持一致。
简述表与表之间的关系、表与表之间的连接方式以及特点

简述表与表之间的关系、表与表之间的连接方式以及特点【原创实用版4篇】目录(篇1)1.表的定义与作用2.表之间的关系3.表之间的连接方式4.表之间的特点正文(篇1)在数据库中,表是一种用于存储数据的基本结构,它可以看作是一个二维数组,由行(记录)和列(字段)组成。
表之间的关系、连接方式以及特点对于数据库的设计和优化至关重要。
一、表的定义与作用表是一种用于存储相关数据的结构,通常由行和列组成。
在数据库中,表用于存储具有相同属性的数据,这些数据可以按照行或列进行组织。
表是数据库中最基本的数据组织单位,其作用在于将数据以结构化的形式存储,以便进行高效的查询和分析。
二、表之间的关系在数据库中,表之间的关系主要分为以下几种:1.主外键关系:主键是用于唯一标识一条记录的字段,外键是用于连接两个表的字段。
主外键关系可以建立在两个表之间,使得一个表中的记录与另一个表中的记录相互关联。
2.一对多关系:这种关系指的是一个表中的记录可以对应另一个表中的多条记录。
例如,一个学生表和一个课程表之间就存在一对多关系,因为一个学生可以选择多门课程,而一门课程只能被多个学生选择。
3.多对多关系:多对多关系指的是一个表中的记录可以对应另一个表中的多条记录,同时另一个表中的记录也可以对应多个表中的记录。
例如,一个作者表和一个书籍表之间就存在多对多关系,因为一个作者可以写多本书,而一本书也可以由多个作者共同完成。
三、表之间的连接方式表之间的连接方式主要有以下几种:1.内连接:内连接是数据库中最常用的连接方式,它指的是根据两个表之间的关联字段,将两个表中具有相同关联字段的记录进行连接。
内连接可以分为等值连接、非等值连接和自连接等。
2.外连接:外连接是指根据两个表之间的关联字段,将一个表中的所有记录与另一个表中具有相同关联字段的记录进行连接。
外连接可以分为左外连接、右外连接和全外连接等。
3.交叉连接:交叉连接是指将两个表中的所有记录进行组合,生成一个新的表。
数据库数据表数据库管理系统之间的关系

数据库数据表数据库管理系统之间的关系数据库数据表和数据库管理系统是密不可分的,因为后者是通过前者来管理和维护数据的。
数据库数据表是数据库中数据存储的基本单位,它是由一系列包含特定数据的行和列组成的,每一列都定义了一个特定的数据类型,而每一行则包含了各自对应的数据。
在数据库中,数据被以表的形式组织存储,每个表都有一个唯一的名称。
而数据库管理系统(DBMS)的主要作用就是管理和维护数据,它是一种为管理大量数据而设计的软件程序,它提供了一些基本的操作功能,例如添加、删除、查询、更新等,同时它也提供了数据安全和数据完整性方面的保障。
数据库管理系统通过它内部的管理系统来调用和维护表,也就是说,数据表是数据库管理系统中的核心功能之一。
在数据库管理系统中,数十万、数百万乃至上亿的数据可以被分散储存在数十个表中。
因此,在建立数据库和数据处理过程中,需要相当复杂的处理方法和模型来协助管理各个表格之间的关系。
而关系型数据库就是为了解决这一问题而设计的,它可以通过多个表之间的连接来组合和整合数据。
最常见的关系型数据库模型是通过标准化数据存储来设计的,因此,这种数据库是具有符合ACID(原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability))的事务处理标准的,提供了强有力的数据保护和完整性检查机制。
在关系型数据库中,数据可以按需求在多个表格之间进行连接和共享,从而提供了灵活性更高的数据管理和操作方式。
总之,数据库数据表和数据库管理系统的关系是紧密相连的,后者是通过前者来管理和维护数据的。
只有将数据库管理系统和数据库数据表结合使用,才能构建起高效、可靠、稳定的数据存储和管理系统。
同时,关系型数据库的出现,使得不同的表之间可以协调管理数据,实现数据共享、数据调用、数据整合等操作,为数据处理带来了更高的效率和更广泛的应用场合。
数据库中的三种关系模式

数据库中的三种关系模式数据库是一种用于存储和管理数据的软件。
数据库中的关系模式定义了数据在数据库中的组织方式。
数据库中的三种关系模式分别是关系型、层次型和网状型。
1. 关系型模式关系型数据库最为常见,它是基于表格的模式。
每一个表格代表着一个实体,每一行代表着一个实例。
关系型数据库在存储数据时将数据分解为多个表格,并利用多个表格之间的关系保证数据的完整性和一致性。
关系型数据库的特点:(1)表格之间存在明确的关系,比如一对多、多对多。
(2)表格中存储的数据具有一定的关联性。
(3)表格中每一列的数据类型都是预定义好的,保证了数据的一致性。
(4)数据在表格中以行的形式存储,方便进行查询、更新、插入和删除操作。
(5)可以通过使用SQL语言来查询和操作关系型数据库。
2. 层次型模式层次型模式中的数据是以树状结构来组织的,一个节点可以有多个子节点,但只能有一个父节点。
这种模式适合存储有层次关系的数据,比如组织机构、文件系统等。
层次型数据库的特点:(1)数据以树状结构来组织,父节点和子节点之间存在明确的层次关系。
(2)在查询子节点时,需要沿数组逐级向下查询,比较麻烦。
(3)不适合存储数据之间存在多对多关系的数据。
(4)层次型数据库由于数据的层次性使得它适合存储树状数据结构。
3. 网状型模式网状型模式中的数据是以网络结构来组织的。
一个节点可以有多个父节点和多个子节点,这种模式适合存储数据之间存在复杂的关系,比如生物介绍中的食物链、人员之间的关系等。
网状型数据库的特点:(1)数据之间的关系非常复杂,可以用网状结构来建模。
(2)节点之间没有严格的层次关系,查询起来比较方便。
(3)数据的完整性和一致性需要人工进行维护。
(4)网状型数据库管理系统性能好,但不够普及。
总结数据库中的三种关系模式各有特点,适合存储不同类型的数据。
关系型模式以表格为基础,并在表格之间建立明确的关系,适合存储数据之间有一定关联的数据。
层次型模式以树状结构为基础,适合存储树状数据结构。
数据库表中的三种关系

数据库表中的三种关系
在数据库表中,存在三种基本的关系:一对一(One-to-One)、一对多(One-to-Many)和多对多(Many-to-Many)。
这些关系描述了表与表之间的连接方式。
1. 一对一关系(One-to-One):这种关系意味着,表中的每一行都与另一个表中的一行相关联。
例如,一个员工有一个唯一的员工ID,这个ID也可以唯一地确定一个员工。
这种关系通常通过在两个表中都使用主键和外键来实现。
2. 一对多关系(One-to-Many):这种关系意味着,表中的每一行都可以与另一个表中的多行相关联,但另一表中的每一行只能与这一表中的一行相关联。
例如,一个班级有多个学生,但每个学生只属于一个班级。
这种关系通常通过在“多”的一方设置一个外键来实现。
3. 多对多关系(Many-to-Many):这种关系意味着,表中的每一行都可以与另一个表中的多行相关联,并且另一表中的每一行也可以与这一表中的多行相关联。
这种关系需要一个单独的关联表来处理。
例如,一个学生可以选多门课程,一门课程也可以有多个学生选。
这种关系通常通过在两个表中都设置外键,并使用关联表来连接两个表来实现。
在设计数据库时,理解并正确使用这些关系是非常重要的,因为它们决定了数据如何在不同的表中存储和检索。
数据库表关联关系、继承关系、聚合关系

数据库表关联关系、继承关系、聚合关系一、数据库表关联关系1.数据库表关联关系是指在关系数据库中,不同表之间存在的一种关系。
这种关系可以通过在表中添加外键来实现。
2.数据库表的关联关系分为一对一关系、一对多关系和多对多关系。
其中,一对一关系是指一个表的每一条记录只能对应另一个表中的一条记录,而另一个表中的每一条记录也只能对应一个记录;一对多关系是指一个表的每一条记录可以对应另一个表中的多条记录,而另一个表中的每一条记录只能对应一个记录;多对多关系是指一个表中的多条记录可以对应另一个表中的多条记录。
3.在实际应用中,数据库表的关联关系被广泛应用于数据的查询和管理。
通过关联表,可以实现数据的多表查询和联合查询,从而满足不同业务需求。
二、数据库表继承关系1.数据库表继承关系是指在关系数据库中,一个表可以从另一个表中继承属性。
这种关系可以通过实现表的继承来实现。
2.数据库表继承关系可以分为单表继承和多表继承。
单表继承是指一个表从另一个表中继承属性,而多表继承是指一个表可以从多个表中继承属性。
3.利用数据库表继承关系,可以实现数据的抽象和组织,提高了数据的可维护性和扩展性。
也可以简化数据的操作和管理。
三、数据库表聚合关系1.数据库表聚合关系是指在关系数据库中,一个表可以包含另一个表。
这种关系可以通过在表中添加外部表的引用来实现。
2.数据库表聚合关系可以分为简单聚合和复杂聚合。
简单聚合是指一个表包含另一个表,而复杂聚合是指一个表可以包含多个表。
3.适当的使用数据库表聚合关系,可以提高数据的组织和管理效率,同时也可以减少数据冗余和提高数据的一致性。
四、总结通过以上分析可以看出,数据库表的关联关系、继承关系和聚合关系在关系数据库中都发挥着重要的作用。
这些关系可以帮助实现数据之间的信息和组织,提高数据的查询和管理效率,从而满足不同的业务需求。
在设计数据库表结构时,应充分考虑不同关系之间的应用场景,合理运用这些关系,从而更好地组织和管理数据。
Access-数据库应用编辑数据表之间的关系

【任务实施】
(1)关闭与已经有关系有关旳数据表,打开 【关系】窗口。
(2)在【关系】窗口中单击选中关系旳连接线, 然后在关系旳【设计】上下文命令选项卡中【工具】 组中单击选择【编辑关系】按钮,打开如图4-55旳 【编辑关系】对话框。
图4-55 【编辑关系】对话框
4
(3)在【编辑关系】对话框中单击选择【联 接类型】按钮会打开如图4-57所示旳【联接属性】 对话框,在该对话框中设置好联接属性后,单击 【拟定】即可。
图4-57 【联接属性》
单元4 维护与使用Access数据表
《Access2010数据库应用》
单元4 维护与使用Access数据表
4.3 建立与编辑数据表之间旳关系
4.3.2 编辑数据表旳关系
2
《Access2010数据库应用》
【任务4-14】编辑数据表之间旳关系
【任务描述】
编辑“图书类型”数据表和“图 书信息”数据表之间旳关系。
Access 2010数据库应用:数据表之间的关系

004
人民邮电出版社
人邮
北京市崇文区夕照寺街14号 (010)67170985
005
机械工业出版社
机工
北京市西城区百万庄大街22号 (010)68993821
006
西安电子科技大学出 版社
西电
西安市太白南路2号
(010)88242885
007
科学出版社
科学
北京东黄城根北街16号
(010)62136131
17
TP3/2605
UML与Rosc软件建模案 例教程
17
陈承欢
002
陈承欢
004
2015/8/1 38.5 2015/3/1 25
TP3/2701
跨平台的移动Web开发 实战
17
陈承欢
004
2015/3/1 29
TP3/2706
C#网络应用开发例学与 实践
17
TP3/2714 数据结构
17
TP3/2715
8
② 一对多关系
主表的每条记录可与相关表中的多条记录相 关联,也就是说主表中一条记录与相关表中的多 条记录相匹配,而相关表中的一条记录只与主表 中的一条记录相匹配。
在一对多关系中,主表必须根据相关联的字 段建立主键。例如“图书类型”表与“图书信息” 表就是一对多关系,“出版社”表与“图书信息” 表也是一对多关系。
Access2010数据库应用
《Access2010数据库应用》
单元4 维护与使用Access数据表
数据表之间的关系
2
《Access2010数据库应用》
Access是一个关系型数据库,数据表建立后, 还要建立数据表之间的关系,Access根据数据表之 间的关系来连接数据表或查询数据表中的数据。由 于每个数据表都有一个主题,存储同一个主题的数 据。例如“图书信息”数据表存储有关“图书”主 题数据,包括图书编号、图书名称、图书类型编号、 作者、出版社编号、出版日期、价格等信息,如表 4-2所示。
oracle表关联方式

oracle表关联方式在Oracle数据库中,表关联是一种将两个或多个表之间建立关系的方法,以便在查询数据时可以更方便地检索和组合数据。
本文将介绍Oracle表关联的常用方式,包括一对一关联、一对多关联和多对多关联,并通过实战案例讲解如何使用关联查询,最后给出关联查询的优化建议。
1.Oracle表关联简介Oracle表关联是基于表之间的主键和外键关系实现的。
通过关联,可以在查询结果中返回多个表的相关数据,从而简化查询语句和提高查询效率。
2.一对一关联一对一关联是指两个表之间存在唯一的关系,其中一个表的主键列与另一个表的外键列相对应。
在这种情况下,可以通过关联查询实现表之间的数据组合和筛选。
例如,设有两个表:用户表(user)和订单表(order)。
用户表中有主键user_id,订单表中有外键order_id。
通过一对一关联,可以查询用户及其对应的订单信息。
3.一对多关联一对多关联是指一个表的主键列与另一个表的外键列相对应,但一个主键值对应多个外键值。
在这种情况下,可以通过关联查询实现对多个相关数据的查询。
例如,设有三个表:产品表(product)、订单表(order)和订单详情表(order_detail)。
产品表中有主键product_id,订单表中有外键order_id,订单详情表中有外键order_detail_id。
通过一对多关联,可以查询某个产品对应的多个订单和订单详情。
4.多对多关联多对多关联是指两个表之间存在多个主键和外键对应关系,即一个主键值对应多个外键值,且多个主键值对应多个外键值。
在这种情况下,可以通过关联查询实现对多个相关数据的查询。
例如,设有两个表:用户表(user)和角色表(role)。
用户表中有主键user_id,角色表中有主键role_id。
用户与角色之间存在多对多关联,可以通过关联查询实现用户及其对应角色的查询。
5.关联查询实战案例以下是一个简单的关联查询实战案例:设有三个表:用户表(user)、订单表(order)和订单详情表(order_detail)。
数据库定义表之间关系(带图)

如何定义数据库表之间的关系特别说明数据库的正规化是关系型数据库理论的基础。
随着数据库的正规化工作的完成,数据库中的各个数据表中的数据关系也就建立起来了。
在设计关系型数据库时,最主要的一部分工作是将数据元素如何分配到各个关系数据表中。
一旦完成了对这些数据元素的分类,对于数据的操作将依赖于这些数据表之间的关系,通过这些数据表之间的关系,就可以将这些数据通过某种有意义的方式联系在一起。
例如,如果你不知道哪个用户下了订单,那么单独的订单信息是没有任何用处的。
但是,你没有必要在同一个数据表中同时存储顾客和订单信息。
你可以在两个关系数据表中分别存储顾客信息和订单信息,然后使用两个数据表之间的关系,可以同时查看数据表中每个订单以及其相关的客户信息。
如果正规化的数据表是关系型数据库的基础的话,那么这些数据表之间的关系则是建立这些基础的基石。
出发点下面的数据将要用在本文的例子中,用他们来说明如何定义数据库表之间的关系。
通过Boyce-Codd Normal Form(BCNF)对数据进行正规化后,产生了七个关系表:Books: {Title*, ISBN, Price}Authors: {FirstName*, LastName*}ZIPCodes: {ZIPCode*}Categories: {Category*, Description}Publishers: {Publisher*}States: {State*}Cities: {City*}现在所需要做的工作就是说明如何在这些表之间建立关系。
关系类型在家中,你与其他的成员一起存在着许多关系。
例如,你和你的母亲是有关系的,你只有一位母亲,但是你母亲可能会有好几个孩子。
你和你的兄弟姐妹是有关系的——你可能有很多兄弟和姐妹,同样,他们也有很多兄弟和姐妹。
如果你已经结婚了,你和你的配偶都有一个配偶——这是相互的——但是一次只能有一个。
在数据表这一级,数据库关系和上面所描述现象中的联系非常相似。
数据库中表的一对多、多对多、一对一关系等
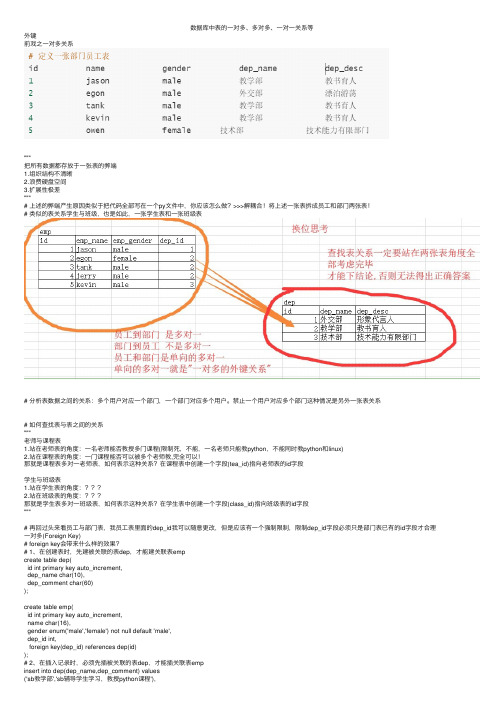
数据库中表的⼀对多、多对多、⼀对⼀关系等外键前戏之⼀对多关系"""把所有数据都存放于⼀张表的弊端1.组织结构不清晰2.浪费硬盘空间3.扩展性极差"""# 上述的弊端产⽣原因类似于把代码全部写在⼀个py⽂件中,你应该怎么做?>>>解耦合!将上述⼀张表拆成员⼯和部门两张表!# 类似的表关系学⽣与班级,也是如此,⼀张学⽣表和⼀张班级表# 分析表数据之间的关系:多个⽤户对应⼀个部门,⼀个部门对应多个⽤户。
禁⽌⼀个⽤户对应多个部门这种情况是另外⼀张表关系# 如何查找表与表之间的关系"""⽼师与课程表1.站在⽼师表的⾓度:⼀名⽼师能否教授多门课程(限制死,不能,⼀名⽼师只能教python,不能同时教python和linux)2.站在课程表的⾓度:⼀门课程能否可以被多个⽼师教,完全可以!那就是课程表多对⼀⽼师表,如何表⽰这种关系?在课程表中创建⼀个字段(tea_id)指向⽼师表的id字段学⽣与班级表1.站在学⽣表的⾓度:2.站在班级表的⾓度:那就是学⽣表多对⼀班级表,如何表⽰这种关系?在学⽣表中创建⼀个字段(class_id)指向班级表的id字段"""# 再回过头来看员⼯与部门表,我员⼯表⾥⾯的dep_id我可以随意更改,但是应该有⼀个强制限制,限制dep_id字段必须只是部门表已有的id字段才合理⼀对多(Foreign Key)# foreign key会带来什么样的效果?# 1、在创建表时,先建被关联的表dep,才能建关联表empcreate table dep(id int primary key auto_increment,dep_name char(10),dep_comment char(60));create table emp(id int primary key auto_increment,name char(16),gender enum('male','female') not null default 'male',dep_id int,foreign key(dep_id) references dep(id));# 2、在插⼊记录时,必须先插被关联的表dep,才能插关联表empinsert into dep(dep_name,dep_comment) values('sb教学部','sb辅导学⽣学习,教授python课程'),('外交部','⽼男孩上海校区驻张江形象⼤使'),('nb技术部','nb技术能⼒有限部门');insert into emp(name,gender,dep_id) values('alex','male',1),('egon','male',2),('lxx','male',1),('wxx','male',1),('wenzhou','female',3);# 当我想修改emp⾥的dep_id或dep⾥⾯的id时返现都⽆法成功# 当我想删除dep表的教学部的时候,也⽆法删除# ⽅式1:先删除教学部对应的所有的员⼯,再删除教学部# ⽅式2:受限于外键约束,导致操作数据变得⾮常复杂,能否有⼀张简单的⽅式,让我不需要考虑在操作⽬标表的时候还需要考虑关联表的情况,⽐如我删除部门,那么这个部门对应的员⼯就应该跟着⽴即清空# 先把之前创建的表删除,先删员⼯表,再删部门表,最后按章下⾯的⽅式重新创建表关系# 3.更新于删除都需要考虑到关联与被关联的关系>>>同步更新与同步删除create table dep(id int primary key auto_increment,dep_name char(10),dep_comment char(60));create table emp(id int primary key auto_increment,name char(16),gender enum('male','female') not null default 'male',dep_id int,foreign key(dep_id) references dep(id)on update cascadeon delete cascade);insert into dep(dep_name,dep_comment) values('sb教学部','sb辅导学⽣学习,教授python课程'),('外交部','⽼男孩上海校区驻张江形象⼤使'),('nb技术部','nb技术能⼒有限部门');insert into emp(name,gender,dep_id) values('alex','male',1),('egon','male',2),('lxx','male',1),('wxx','male',1),('wenzhou','female',3);# 删除部门后,对应的部门⾥⾯的员⼯表数据对应删除# 更新部门后,对应员⼯表中的标⽰部门的字段同步更新多对多# 图书表与作者表之间的关系"""仍然站在两张表的⾓度:1.站在图书表:⼀本书可不可以有多个作者,可以!那就是书多对⼀作者2.站在作者表:⼀个作者可不可以写多本书,可以!那就是作者多对⼀书双⽅都能⼀条数据对应对⽅多条记录,这种关系就是多对多!"""# 先来想如何创建表?图书表需要有⼀个外键关联作者,作者也需要有⼀个外键字段关联图书。
数据库表关系详解

数据库表关系是指数据库中各种表之间的连接和对应关系。
在数据库中,表是用于存储数据的基本单位,每个表都包含一组相关的数据字段。
表之间的关系可以通过建立关联字段来实现,这些关联字段在多个表中具有相同的值,从而将它们连接在一起。
数据库中的表关系通常可以分为三种类型:一对一关系、一对多关系和多对多关系。
一对一关系是指两个表之间存在一端对一端的关系,即一个表中的一条记录只能与另一个表中的一条记录相关联。
这种关系通常用于表示两个实体之间的唯一对应关系。
例如,一个客户表和一个订单表之间可能存在一对一关系,因为每个客户只能对应一个订单,而每个订单只能对应一个客户。
一对多关系是指一个表中的记录可以与另一个表中的多条记录相关联。
这种关系通常用于表示一个实体的一组相关属性与另一个实体的单一属性之间的关系。
例如,一个员工表可以与一个工资表建立一对多关系,因为每个员工可以有多个工资记录,而每个工资记录只与一个员工相关联。
多对多关系是指两个表之间存在两个端点之间的多对多的关系。
这种关系通常用于表示两个实体之间的多个属性之间的交叉关系。
例如,一个学生表和一个课程表之间可能存在多对多关系,因为一个学生可以选修多门课程,同时一门课程也可以被多个学生选修。
在这种情况下,可以使用中间表来存储这种关系。
除了上述三种基本的关系类型,数据库中还可能存在其他的关系类型,如共享字段关系、父-子关系等。
这些关系类型的具体应用取决于数据的特性和需求。
理解数据库表之间的关系对于数据库设计和查询非常重要。
通过了解表之间的关系,可以更好地组织数据,提高查询效率,并确保数据的一致性和完整性。
在设计和维护数据库时,需要仔细考虑表之间的关系,并使用适当的索引和关联技术来优化数据访问和检索性能。
总之,数据库表关系是数据库中数据组织和存储的核心概念之一。
通过理解不同类型的表关系,可以更好地管理数据并提高数据库的性能和可靠性。
数据库表与表之间的关系

数据库表与表之间的关系
表与表之间的关系有三种:⼀对⼀、⼀对多、多对多
1. ⼀对⼀
⼀张表的⼀条记录⼀定只能与另外⼀张表的⼀条记录进⾏对应;反之亦然。
⼀个常⽤表中的⼀条记录,永远只能在⼀张不常⽤表中匹配⼀条记录;反过来,⼀个不常⽤表中的⼀条记录在常⽤表中也只能匹配⼀条记录:⼀对⼀关系。
在实际的开发中应⽤不多,因为⼀对⼀可以创建成⼀张表。
建表原则:
外键唯⼀:主表的主键和从表的外键(唯⼀),形成主外键关系,外键唯⼀。
外键是主键:主表的主键和从表的外键,形成主外键关系。
2. ⼀对多
⼀张表中有⼀条记录可以对应另外⼀张表中的多条记录;但是反过来,另外⼀张表的⼀条记录只能对应第⼀张表的⼀条记录。
建表原则:
在“多”的⼀⽅创建⼀个字段,字段作为外键指向“⼀”的⼀⽅的主键。
3. 多对多
第⼀张表中的⼀条记录能够对应第⼆张表中的多条记录;同时第⼆张表中的⼀条记录也能对应第⼀张表中的多条记录。
中间表与⽼师表形成⼀对多的关系,⽽且中间表是“多”的⼀⽅,维护了能够唯⼀找到“⼀”表的关系;同样的,学⽣表与中间表也形成了⼀对多的关系。
⽼师找学⽣:⽼师表-中间表-学⽣表
学⽣赵⽼师:学⽣表-中间表-⽼师表
建表原则:
创建第三张表,中间表⾄少两个字段,分别作为外键指向各⾃⼀⽅的主键。
access数据表之间的关系

复习:
教材表 教材Id,教材名,作者,出版社Id
1.创建表
出版社表 出版社Id,出版社名称,地址.....
2.维护表
3.创建教材表和出版社表
任务六 表间关联关系的建立
表间 关系
一对一
• 左表中的一条记录最多只能匹配于右表中的一条 记录,反之亦然。
• 如果相关字段都是主键或都具有唯一约束,则可 以创建一对一关系。
任务六 表间关联关系的建立
(二) 查看关系
任务六 表间关联关系的建立
(三) 编辑关系
任务四中的字段有效性规则是 对表内字段的限制规则,而本任务 涉及到的参照完整性规则属于表间 规则,用于在编辑记录时维持已定 义的表间关系。
任务六 表间关联关系的建立
(四) 创建子表
在创建子数据表之前,必须确 保父表和子表之间已经建立了关系。
订单编号,图书ID,订购册数,享受折扣
实训一
• 创建“选课管理”中的学生、课程和
选课表
表
字段
课程
课程ID,课程名称,课程性质,学 时,学分,开课学期,开课专业
学生 学号,姓名,专业,入学年份
选课 选课ID,学号,课程IDห้องสมุดไป่ตู้成绩
[实训要求] 按照给定的字段,使用“表向导”创建“学生”
表;通过输入数据创建“课程”表;使用“表设计
器”创建“设选置课学”生表姓和名“字学生段”的表长。度时, 一定要考虑到少数民族姓名等字段 较多的情况。
• 这种关系并不常见,因为以这种方式相关的大多 数数据一般都可以设计在一个表中。
一对多
• 左表中的每条记录和右表中的多条记录相 关联,而右表中的每条记录和左表中的记 录只能有一条相匹配。
简述记录、字段、表与数据库之间的关系。。

简述记录、字段、表与数据库之间的关系本文将介绍记录、字段、表和数据库之间的基本关系,帮助读者更好地理解数据库的基本概念。
下面是本店铺为大家精心编写的5篇《简述记录、字段、表与数据库之间的关系》,供大家借鉴与参考,希望对大家有所帮助。
《简述记录、字段、表与数据库之间的关系》篇1记录、字段、表和数据库是数据库系统中的四个基本概念。
它们之间的关系如下:1. 记录记录是数据库中最基本的数据单元,它是数据库中的一行数据。
每个记录都包含一定数量的字段,字段是记录中的数据属性。
记录是数据库中的实体,可以用来描述某个事物或对象。
例如,一个人可以用一个记录来描述,其中包含姓名、年龄、性别等字段。
2. 字段字段是记录中的数据属性,用于描述记录中的某个特定信息。
例如,在描述一个人的记录中,姓名、年龄、性别等都是字段。
字段是数据库中的基本构成单元,可以用来描述记录中的数据。
3. 表表是数据库中的数据容器,用于存储记录。
表由一个或多个字段组成,每个表都有一个唯一的名称。
表中的记录可以通过索引或主键来访问。
例如,一个包含多个学生信息的表可以包含学生姓名、年龄、性别等字段。
4. 数据库数据库是存储在计算机存储设备中的结构化数据的集合。
数据库包含一个或多个表,每个表包含一个或多个字段。
数据库是一个统一的管理数据的系统,可以用来存储、管理和访问数据。
例如,一个学校可以使用一个数据库来存储学生的信息,其中包含多个表,每个表包含不同的字段,用于描述学生的不同信息。
总之,记录、字段、表和数据库是数据库系统中的四个基本概念,它们之间的关系是:记录包含字段,字段属于表,表属于数据库。
数据库是一个统一的管理数据的系统,可以用来存储、管理和访问数据。
《简述记录、字段、表与数据库之间的关系》篇2记录、字段、表和数据库是计算机数据管理中的基本概念,之间的关系如下所述:1. 记录 (Record):记录是数据的基本单位,包含了一组相关联的数据项,通常是一个实体或者对象的属性值。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
数据库中表之间的关系
表关系(一对一,一对多,多对多) 收藏
可以在数据库图表中的表之间创建关系,以显示一个表中的列与另一个表中的列是如何相链接的。
在一个关系型数据库中,利用关系可以避免多余的数据。
例如,如果设计一个可以跟踪图书信息的数据库,您需要创建一个名为 titles 的表,它用来存储有关每本书的信息,例如书名、出版日期和出版社。
您也可能保存有关出版社的信息,诸如出版社的电话、地址和邮政编码。
如果您打算在 titles 表中保存所有这些信息,那么对于某出版社出版的每本书都会重复该出版社的电话号码。
更好的方法是将有关出版社的信息在单独的表,publishers,中只保存一次。
然后可以在 titles 表中放置一个引用出版社表中某项的指针。
为了确保您的数据同步,可以实施 titles 和 publishers 之间的参照完整性。
参照完整性关系可以帮助确保一个表中的信息与另一个表中的信息相匹配。
例如,titles 表中的每个书名必须与 publishers 表中的一个特定出版社相关。
如果在数据库中没有一个出版社的信息,那么该出版社的书名也不能添加到这个数据库中。
为了更好地理解表关系,请参阅:
定义表关系
实施参照完整性
定义表关系
关系的确立需要通过匹配键列中的数据(通常是两表中同名的列)。
在大多数情况下,该关系会将一个表中的主键(它为每行提供了唯一标识)与另一个表的外部键中的某项相匹配。
例如,通过创建 titles 表中的 title_id(主键)与 sales 表中的 title_id 列(外部键)之间的关系,则销售额就与售出的特定书名相关联了。
表之间有三种关系。
所创建关系的类型取决于相关列是如何定义的。
一对多关系
多对多关系
一对一关系
一对多关系
一对多关系是最普通的一种关系。
在这种关系中,A 表中的一行可以匹配 B 表
中的多行,但是 B 表中的一行只能匹配 A 表中的一行。
例如,publishers 和titles 表之间具有一对多关系:每个出版社出版很多书,但是每本书名只能出自一个出版社。
只有当一个相关列是一个主键或具有唯一约束时,才能创建一对多关系。
多对多关系
在多对多关系中,A 表中的一行可以匹配 B 表中的多行,反之亦然。
要创建这种关系,需要定义第三个表,称为结合表,它的主键由 A 表和 B 表的外部键组成。
例如,authors 和 titles 表具有多对多关系,这是由于这些表都与titleauthors 表具有一对多关系。
titleauthors 表的主键是 au_id 列(authors 表的主键)和 title_id 列(titles 表的主键)的组合。
一对一关系
在一对一关系中,A 表中的一行最多只能匹配于 B 表中的一行,反之亦然。
如果相关列都是主键或都具有唯一约束,则可以创建一对一关系。
这种关系并不常见,因为一般来说,按照这种方式相关的信息都在一个表中。
可以利用一对一关系来:
分割具有多列的表。
由于安全原因而隔离表的一部分。
保存临时的数据,并且可以毫不费力地通过删除该表而删除这些数据。
保存只适用于主表的子集的信息。
实施参照完整性
参照完整性是一个规则系统,能确保相关表行之间关系的有效性,并且确保不会在无意之中删除或更改相关数据。
当实施参照完整性时,必须遵守以下规则:
如果在相关表的主键中没有某个值,则不能在相关表的外部键列中输入该值。
但是,可以在外部键列中输入一个 null 值。
例如,不能将一项工作分配给一位没有包含在 employee 表中的雇员,但是可以在 employee 表的 job_id 列中输入一个 null 值,表明一位雇员没有分配工作。
如果某行在相关表中存在相匹配的行,则不能从一个主键表中删除该行。
例如,如果在 employee 表中表明某些雇员分配了某项工作,则不能在 jobs 表中删除该工作所对应的行。
如果主键表的行具有相关行,则不能更改主键表中的某个键的值。
例如,如果一位雇员分配了 jobs 表中的某项工作,则不能从 employee 表中删除该雇员。
当符合下列所有条件时,才可以设置参照完整性:
主表中的匹配列是一个主键或者具有唯一约束。
相关列具有相同的数据类型和大小。
两个表属于相同的数据库。