医学统计学重点
医学统计学重点概要

第一章 绪论总体:根据研究目的确定的同质的所有观察单位某种变量值的集合。
总体包括有限总体和无限总体。
样本:从总体中随机抽取的部分观察单位,其实测值的集合。
获取样本仅仅是手段,通过样本信息来推断总体特性才是研究的目的。
资料的类型计量资料、计数资料和等级资料。
误差包括随机误差、系统误差和非系统误差。
抽样误差:由抽样造成的样本统计量和总体参数之间的差异或者是各个样本统计量之间的差异称为抽样误差。
概率:是描述随机事件发生可能性大小的一个度量。
取值范围0≤P ≤1。
小概率事件:表示在一次实验或观察中该事件发生的可能性很小,可以认为很可能不发生。
P ≤0.05或P ≤0.01。
医学统计学的步骤:设计、收集资料、整理资料和分析资料。
统计分析包括:统计描述和统计推断。
统计推断包括:参数估计和假设检验。
第二章计量资料的统计描述频数表和频数分布图的用途:(1)描述频数分布的类型,以便选择相应的统计指标和分析方法。
对称分布:集中位置在中间,左右两侧頻数基本对称。
偏态分布:正、负偏态分布正偏态集中位置偏向值小一侧,负偏态反之。
(2)描述頻数分布的特征;(3)便于发现资料中的可疑值;(4)便于进一步计算统计指标和进行统计分析。
计量资料集中趋势包括算术均数、几何均数和中位数。
算术均数:直接法(样本小):n x x ∑=;頻数表法(样本大)x =nfx ∑ 几何均数:直接法:)lg (lg 1n x G ∑-=;頻数表法)lg (lg )lg (lg 11n x f fx f G ∑∑∑--==(常用于等比资料或对数正态分布资料)中位数:直接法:n 为奇数2/)1(+=n x M ,n 为偶数2/)(12/2/++=n n x x M ;頻数表法:∑-⨯+=)%50(L M M f n f iL M 。
中位数的应用注意事项:可用于各种分布资料,不受极端值的影响,主要用于(1)偏态分布资料(2)端点无确切值的资料(3)分布不明确的资料。
新版医学统计学知识点归纳总结

新版医学统计学知识点归纳总结医学统计学是医学研究中不可或缺的一部分,它涉及到数据的收集、分析和解释,帮助医学工作者从大量数据中提取有价值的信息。
以下是新版医学统计学的知识点归纳总结:1. 研究设计:研究设计是统计分析的前提,包括观察性研究和实验性研究。
观察性研究如队列研究、病例对照研究,而实验性研究如随机对照试验(RCT)。
2. 数据类型:医学统计学中的数据可分为定性数据和定量数据。
定性数据如性别、血型,定量数据如血压、体重。
3. 描述性统计:描述性统计用于描述数据集的特征,包括集中趋势(均值、中位数、众数)和离散程度(方差、标准差、极差)。
4. 概率分布:在统计学中,概率分布描述了随机变量取值的概率。
常见的分布有正态分布、二项分布和泊松分布。
5. 假设检验:假设检验是统计推断的核心,用于判断样本数据是否支持某个假设。
常见的检验方法有t检验、卡方检验和F检验。
6. 置信区间:置信区间提供了一个范围,用以估计总体参数的可能值。
95%的置信区间意味着有95%的把握认为总体参数落在这个区间内。
7. 回归分析:回归分析用于研究一个或多个自变量对因变量的影响。
简单线性回归和多元线性回归是常见的回归分析方法。
8. 生存分析:生存分析关注个体生存时间的分布和相关因素,常用于肿瘤学和流行病学研究。
Kaplan-Meier估计和Cox比例风险模型是生存分析中的重要工具。
9. 诊断试验评价:诊断试验评价涉及敏感性、特异性、阳性预测值和阴性预测值等指标,用于评估诊断方法的准确性。
10. 样本量计算:样本量计算是研究设计的重要环节,它决定了研究的可行性和结果的可靠性。
样本量计算需要考虑效应大小、显著性水平和检验力。
11. 多变量分析:多变量分析用于同时考虑多个变量对结果的影响,如多元回归分析和判别分析。
12. 统计软件的应用:统计软件如SPSS、SAS和R在医学统计分析中扮演着重要角色,它们提供了数据处理和统计分析的功能。
医学统计学重点

医学统计学重点说明:本重点仅供参考:不能包括所有选择题考题,名词和简答可信度高,计算题熟练运算过程;同时自己要清楚各种检验方法的基本思想,重点程度与星号数量相关)一、名词解释1、★★★医学统计学:用概率论和数理统计方法研究医学事件的群体特征的一门方法。
2、★总体:根据研究目的确定的同质的研究对象的全体(集合)。
3、样本:从总体中随机抽取的部分研究对象。
4、随机:总体中每个个体有同等的机会进入样本。
5、系统误差:指数据搜集和测量过程中由于仪器不准确、标准不规范等原因,造成观察结果呈倾向性的偏大或偏小,这种误差称为系统误差。
6、随机误差:由于一些非人为的偶然因素使得结果或大或小,是不确定、不可预知的。
7、★★抽样误差:由于抽样原因造成的样本指标与总体指标之间的差,或者是样本指标与样本指标之间的差。
8、准确度(accuracy)或真实性(validity):观察值与真值的接近程度,受系统误差的影响(9、可靠度(reliabiliy)——也称精密度(precision)或重复性(repeatability):重复观察时观察值与其均值的接近程度,受随机误差的影响。
10、★★★小概率事件:一般常将p ≤ 0.05或p ≤ 0.01称为小概率事件,表示某事件发生的可能性很小。
通俗讲一次抽样是不可能发生的事件。
11、★★正态分布定:又称高斯分布,是一条中间高,两头低,左右完全对称地下降,但永远不与横轴相交的钟形曲线。
12、★★医学参考值范围:指绝大多数正常人的解剖、生理、生化、免疫及组织代谢产物的含量等各种数据的波动范围。
最常用的是95%参考值范围。
13、★★标准误:用于反映均数抽样误差大小的指标,也叫样本均数的标准差,它反映了样本均数之间的离散程度。
14、★95%的可信区间:如果从同一总体中重复抽取100个独立样本,将可能有95个可信区间包括总体均数,有5个可信区间未包括总体均数。
二、填空题1、★医学统计学工作基本步骤:统计设计;收集资料.;整理资料;分析资料2、★统计分析包括:统计描述、统计推断3、频数分布的两个重要特征:集中趋势和离散趋势4、正态分布的两个参数:均数;标准差。
医学统计学重点

医学统计学重点第一章 绪论1.基本概念:总体:根据研究目的确定的性质相同或相近的研究对象的某个变量值的全体。
样本:从总体中随机抽取部分个体的某个变量值的集合。
总体参数:刻画总体特征的指标,简称参数。
是固定不变的常数,一般未知。
统计量:刻画样本特征的指标,由样本观察值计算得到,不包含任何未知参数。
抽样误差:由随机抽样造成的样本统计量与相应的总体参数之间的差异。
频率:若事件A在n次独立重复试验中发生了m次,则称m为频数。
称m/n为事件A在n次试验中出现的频率或相对频率。
概率:频率所稳定的常数称为概率。
统计描述:选用合适统计指标(样本统计量)、统计图、统计表对数据的数量特征及其分布规律进行刻画和描述。
统计推断:包括参数估计和假设检验。
用样本统计指标(统计量)来推断总体相应指标(参数),称为参数估计。
用样本差别或样本与总体差别推断总体之间是否可能存在差别,称为假设检验2.样本特点:足够的样本含量、可靠性、代表性。
3.资料类型:(1)定量资料:又称计量资料、数值变量或尺度资料。
是对观察对象测量指标的数值大小所 得的资料,观察指标是定量的,表现为数值大小。
每个个体都能观察到一个观察指标的 数值,有度量衡单位。
(2)分类资料:包括无序分类资料(计数资料)和有序分类资料(等级资料)①计数资料:是将观察单位按某种属性或类别分组,清点各组观察单位的个数(频数),由 各分组标志及其频数构成。
包括二分类资料和多分类资料。
二分类:将观察对象按两种对立的属性分类,两类间相互对立,互不相容。
多分类:将观察对象按多种互斥的属性分类②等级资料:将观察单位按某种属性的不同程度、档次或等级顺序分组,清点各组观察单 位的个数所得的资料。
4.统计工作基本步骤:统计设计、资料收集、资料整理、统计分析。
第二章 实验研究的三要素1.实验设计三要素:被试因素、受试对象、实验效应2.误差分类:随机误差(抽样误差、随机测量误差)、系统误差、过失误差。
2024年度-医学统计学重点笔记一复习必备

即标准正态分布,当样本量足够大时(n>30),t分布近似u分布。
14
总体均数置信区间估计
置信区间的概念
按一定的置信水平(1-α),根据样 本统计量估计总体参数所在的范围。
置信区间的计算
根据样本均数、标准差和样本量计算 置信区间。常用的置信水平为95%和
99%。
置信区间的意义
表示总体参数有100(1-α)%的可能性 落在此区间内。
适用条件
01
R×C列联表资料,即多行多列列联表,用于分析两个多分类变
量之间的关联。
检验统计量
02
卡方值,计算公式为χ2=∑(O-E)2/E,其中O为观察频数,E为
理论频数。
拒绝域
03
根据自由度和显著性水平确定拒绝域,自由度为(R-1)(C-1)。
29
配对设计四格表资料卡方检验
01
适用条件
配对设计四格表资料,即两个相 关样本的二分类变量之间的关联 分析。
26
06
卡方检验
27
四格表资料卡方检验
适用条件
四格表资料,即2×2列联表,用于分析两个二分类变量之间的关联。
检验统计量
卡方值,计算公式为χ2=(ad-bc)2N/(a+b)(c+d)(a+c)(b+d),其 中N为样本总量。
拒绝域
根据自由度和显著性水平确定拒绝域,自由度为1。
28
R×C列联表资料卡方检验
正态分布在医学中的应用 许多医学指标如身高、体重、血压等服从或近似服从正态 分布;在估计医学参考值范围、质量控制等方面有广泛应 用。
正态性检验方法 图形法(直方图、P-P图、Q-Q图)、计算法(偏度系数 和峰度系数检验、Shapiro-Wilk检验、KolmogorovSmirnov检验等)。
医学统计学重点

1.变异:同质事物之间的差别。
2.频数分布的两个特征:集中位置,离散趋势3.数据分布的类型:对称分布和非对称分布。
非对称分布又称偏态分布,包括正偏态和负偏态。
单峰分布,双峰分布,多峰分布。
4.统计描述:用统计表、统计图和统计指标等方法对资料的数量特征与分布规律进行描述。
5.集中位置的描述,集中位置指标又称平均数指标。
有哪些及适用条件?(1)算数平均数:最适用于单峰对称分布资料的平均水平的描述,特别是正态分布资料(2)几何平均数:适用于①等比资料②对数正态分布资料(3)中位数和百分位数:适用于①偏态分布的资料②开口资料③资料分布不明等6.离散趋势的描述(1)全距亦称极差,适用于单峰小样本资料(2)四分位数间距,适用于单峰小样本资料(3)方差和标准差,适用于对称分布尤其是正态分布资料(4)变异系数,常用于①比较度量衡单位不同的两组或多种资料的变异度②比较均数相差悬殊的两组或多组资料的变异度7.常用相对数(1)率,是二分类指标(2)构成比(3)比8.正确应用相对数应注意几个问题:(1)计算相对数的分母不宜过小(2)分析时不能以构成比代替率(3)对观察单位数不等的几个率,不能直接相加求其总率(4)计算率时要注意资料的同质性,对比分析时应注意资料的可比性(5)也有抽样误差,需要假设检验。
9.率的标准法(1)基本思想:采用统一的标准,以消除病情构成不同对治愈率比较的影响,使算得的标准化治愈率有可比性。
(2)目的:控制混杂因素对研究结果的影响。
10.正态分布(1)概念P16(2)标准正态分布,u变换:u=σμ-X,u是标准正态离差,μ是均数,σ是标准差。
u~N(0,1)(3)正态分布的特征:①是单峰分布,高峰位置在均数X=μ处。
②以均数为中心,左右完全对称。
③取决于两个参数,均数μ和标准差σ。
μ为位置参数,μ越大,则曲线沿横轴向右移动;μ越小,则曲线沿横轴向左移动。
σ为形态参数,表示数据的离散程度,若σ小,则曲线形态“瘦高”;σ大,则曲线形态“矮胖”。
医学统计学重点官方版

一:基本概念:1.参数:反映总体的统计指标。
2. 统计量:反映样本的统计指标称为统计量。
3. 概率:描述随机事件发生的可能性的大小的一个量度4.小概率事件:把p小于等于0.05或小于等于0.01的随机事件。
资料类型:计量资料,计数资料,等级资料。
医学统计的基本步骤:研究设计,收集资料,整理资料,分析资料,结果报告与结论表达。
二:变量分布:1.正态分布:指变量的频数或频率呈中间最多,两端逐渐对称地减少,表现为钟形的一种概率分布。
特征:(1)正态分布曲线是单峰,对称,钟形曲线,X=μ时曲线达到最高峰。
(2)正态曲线有两个参数,总体均数μ和总体标准差σ,μ越大曲线右移,越小左移,故称位置参数,σ越小曲线越瘦高,越大曲线越矮胖,故称形状参数。
(3)正态分布曲线下的面积分布具有一定的规律。
P80页。
应用:(1)质量控制(2)是统计学的理论基础(3)制定医学参考值范围制定医学参考值范围:包括绝大多数正常人的人体形态功能和代谢反应等各种生理生化指标的波动范围,是作为判定某项指标正常与否的参考标准。
方法:确定正常人对象的范围,统一测量标准,确定分组,样本含量确定,确定参考值范围的但双侧,确定百分界值,医学参考值范围的估计。
2.二项分布特征:(1)二项分布的图形:当π=0.5时图形对称,π≠0.5时,图形呈偏态,且当n的含量增大时,图形趋于对称。
(2)二项分布的均数与标准差:μ=n π;σ²=nπ(1-π);σ=根号下nπ(1-π)(3)二项分布的正态近似:当n无限增大时越趋近于正态分布。
应用:对立性,独立性,重复性三:统计分析:㈠1.统计描述:图表和指标(1)图表:频数分布图分为正偏态和负偏态,长尾向右侧延伸为正偏态,向左侧延伸为负偏态。
频数分布的特点:集中趋势和离散趋势。
(2)指标:分为计数指标和计量指标。
计数指标:相对数。
应用相对数的注意事项:①计算相对数时分母不宜太小②观测单位数不等的几个率不能直接想加求其合计率③资料对比时注意可比性④资料分析时不能以构成比代替率⑤考虑存在抽样误差计量指标:1.集中趋势:①算数均数χ:适用于对称分布资料,特别是正态或近似正态分布的计量资料。
医学统计学 必过重点

1.总体:是根据研究目的确定的同质的观察单位的全体,更确切的说,是同质的所有观察单位某种观察值(变量值)的集合。
总体可分为有限总体和无限总体。
总体中的所有单位都能够标识者为有限总体,反之为无限总体。
样本:从总体中随机抽取部分观察单位,其测量结果的集合称为样本。
样本应具有代表性。
所谓有代表性的样本,是指用随机抽样方法获得的样本。
2.随机抽样:随机抽样是指按照随机化的原则(总体中每一个观察单位都有同等的机会被选入到样本中),从总体中抽取部分观察单位的过程。
随机抽样是样本具有代表性的保证。
3.变异:在自然状态下,个体间测量结果的差异称为变异。
变异是生物医学研究领域普遍存在的现象。
严格的说,在自然状态下,任何两个患者或研究群体间都存在差异,其表现为各种生理测量值的参差不齐。
4.计量资料:对每个观察单位用定量的方法测定某项指标量的大小,所得的资料称为计量资料。
计量资料亦称定量资料、测量资料。
.其变量值是定量的,表现为数值大小,一般有度量衡单位。
如某一患者的身高(cm)、体重(kg)、红细胞计数(1012/L)、脉搏(次/分)、血压(KPa)等计数资料:将观察单位按某种属性或类别分组,所得的观察单位数称为计数资料(。
计数资料亦称定性资料或分类资料。
其观察值是定性的,表现为互不相容的类别或属性。
如调查某地某时的男、女性人口数;治疗一批患者,其治疗效果为有效、无效的人数;调查一批少数民族居民的A、B、AB、O 四种血型的人数等。
等级资料:将观察单位按测量结果的某种属性的不同程度分组,所得各组的观察单位数,称为等级资料(ordinal data)。
等级资料又称有序变量。
如患者的治疗结果可分为治愈、好转、有效、无效或死亡,各种结果既是分类结果,又有顺序和等级差别,但这种差别却不能准确测量;一批肾病患者尿蛋白含量的测定结果分为+、++、+++等。
等级资料与计数资料不同:属性分组有程度差别,各组按大小顺序排列。
等级资料与计量资料不同:每个观察单位未确切定量,故亦称为半计量资料。
医学统计学重点

医学统计学重点医学统计学是医学领域中不可或缺的一门学科,它借助数理统计方法研究医学数据和临床试验的结果,为医学决策提供可靠的依据。
以下是医学统计学的几个重点内容。
一、描述统计学描述统计学是医学统计学的基础,主要研究如何分类、整理和描述医学数据。
其主要方法包括测量尺度、频率分布表、中心趋势测量和变异程度测量。
1. 测量尺度在医学统计学中,常见的测量尺度包括名目尺度、有序尺度和数值尺度。
名目尺度适用于无序分类的变量,有序尺度适用于有序分类的变量,而数值尺度适用于具有度量意义的变量。
2. 频率分布表频率分布表用来展示变量的分布情况,主要包括类别、频数和频率等内容。
通过频率分布表,可以直观地了解变量的分布状况。
3. 中心趋势测量中心趋势测量主要包括平均数、中位数和众数。
平均数是所有观测值的总和除以观测值的个数,中位数是将观测值按大小排列后的中间值,众数是出现次数最多的观测值。
4. 变异程度测量变异程度测量用来描述数据的分散程度,主要包括极差、方差和标准差。
极差是最大观测值与最小观测值之间的差异,方差是观测值与均值之间的差异的平方的平均数,标准差是方差的平方根。
二、推断统计学推断统计学是医学统计学的核心内容,主要研究如何通过样本数据推断总体参数,并对假设进行检验。
其中包括参数估计、假设检验和置信区间等方法。
1. 参数估计参数估计是利用样本数据估计总体参数,常用的方法有点估计和区间估计。
点估计是通过样本数据得到一个单一的数值作为总体参数的估计值,区间估计是通过样本数据得到一个范围作为总体参数的估计区间。
2. 假设检验假设检验是用来检验某个陈述是否与观察数据相符的方法。
在医学研究中,研究者常常根据实验数据对研究假设进行检验,以确定是否有统计显著性。
3. 置信区间置信区间是对总体参数的一个范围估计。
置信区间的计算方法与区间估计相似,通过对样本数据进行分析计算得到。
三、生存分析生存分析是医学统计学中的一个重要分支,主要研究疾病患者的生存时间和生存率等问题。
医学统计学重点
一、名词解释:1、总体: 所有同质观察单位某种观察值(即变量值)的全体。
2、样本:是总体中抽取部分观察单位的观察值的集合。
3、小概率事件:当某事件发生的概率小于或等于0.05时,统计学习惯上称该事件为小概率事件,其含义是该事件发生的可能性很小,进而认为它在一次抽样中不可能发生,这就是所谓小概率事件原理,它是进行统计推断的重要基础。
4、抽样误差: 由个体变异产生的、随机抽样引起的样本统计量与总体参数间的差异称抽样误差,描述抽样误差大小的定量指标是标准误。
5、队列研究: 是将一个范围明确的人群按是否暴露于某可疑因素及其暴露程度分为不同的亚组,追踪其各自的结局,比较不同亚组之间结局的差异,从而判定暴露因子与结局之间有无因果关联大小的一种观察性研究方法。
6、内对照:即先选择一组研究人群,将其中暴露于所研究因素的对象作为暴露组,其余非暴露者即为非暴露组。
也就是说在选定的一群研究因素的对象内部既包含了暴露组,又包含了对照组,不需到另外的人群中去找。
这样的好处是,选取对照比较省事,并可以无误地从总体上了解研究对象的发病率情况。
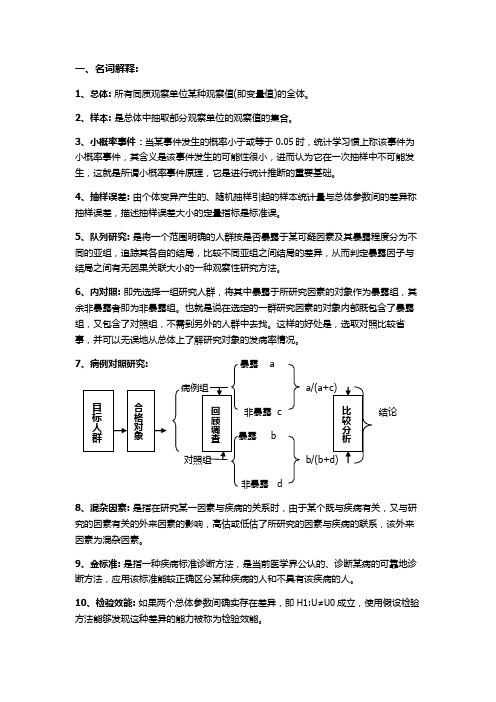
7、病例对照研究:暴露 aa/(a+c)非暴露 c 结论bb/(b+d)非暴露 d8、混杂因素:是指在研究某一因素与疾病的关系时,由于某个既与疾病有关,又与研究的因素有关的外来因素的影响,高估或低估了所研究的因素与疾病的联系,该外来因素为混杂因素。
9、金标准: 是指一种疾病标准诊断方法,是当前医学界公认的、诊断某病的可靠地诊断方法,应用该标准能较正确区分某种疾病的人和不具有该疾病的人。
10、检验效能: 如果两个总体参数间确实存在差异,即H1:U≠U0成立,使用假设检验方法能够发现这种差异的能力被称为检验效能。
二、填空题1、t检验的应用条件: 小样本、正态分布、方差相等。
2、变量变换的目的:使资料转换为正态分布、使资料达到方差齐性、使曲线直线化。
3、根据误差产生的来源,在医学科研设计时必须遵守四个基本原则: 对照原则、重复原则、随机化原则、盲法设计原则。
医学统计学知识点

医学统计学知识点医学统计学是一门应用统计学方法和原理,研究医学领域中数据的收集、整理、分析和解释的科学。
它为医学研究、临床实践和公共卫生决策提供了重要的工具和方法。
下面让我们来了解一些关键的医学统计学知识点。
一、数据类型在医学研究中,我们会遇到不同类型的数据。
主要包括:1、定量数据:也称为数值数据,是可以用数字进行测量和记录的数据,如身高、体重、血压等。
定量数据又可分为连续型数据(可以在一定区间内取任意值,如身高)和离散型数据(只能取整数,如白细胞计数)。
2、定性数据:也称分类数据,是按照某种属性或类别进行划分的数据,如性别(男、女)、疾病的诊断(是、否)等。
定性数据又分为无序分类数据(各类别之间没有顺序关系,如血型)和有序分类数据(各类别之间有顺序关系,如疾病的严重程度分为轻、中、重)。
二、数据的收集为了获得准确和有用的数据,我们需要遵循科学的方法进行收集。
1、抽样方法:包括简单随机抽样、系统抽样、分层抽样和整群抽样等。
简单随机抽样是从总体中随机抽取个体;系统抽样是按照一定的间隔抽取样本;分层抽样是将总体按照某些特征分层,然后从各层中抽样;整群抽样则是以群体为单位进行抽样。
2、样本量的确定:样本量的大小取决于研究的目的、总体的变异程度、研究的精度和检验效能等因素。
一般来说,样本量越大,结果的准确性越高,但研究成本也会增加。
三、数据的整理收集到数据后,需要对其进行整理,以便后续的分析。
1、频数分布:将数据按照不同的类别或区间进行分组,计算每组的频数(出现的次数)和频率(频数与总例数的比值),可以了解数据的分布特征。
2、统计图表:常用的图表有直方图、折线图、饼图等,用于直观地展示数据的分布和趋势。
四、描述性统计描述性统计是对数据的基本特征进行概括和描述。
1、集中趋势的描述:包括算术均数、中位数和众数。
算术均数适用于正态分布的数据;中位数适用于偏态分布或分布不明的数据;众数是出现次数最多的数据值。
2、离散程度的描述:常用的指标有标准差、方差和极差。
医学统计学重点

<<医学统计学>>重点1. 总体:根据研究的目的确定的同质研究对象中所有的观察单位变量值的集合。
2. 样本:按随机化原则从同质总体中随机抽取的部分观察单位某变量值的集合。
3. 同质:影响究指研标的主要因素易控制的因素基本上相同。
4. 抽样误差:在抽样研究中,由于变异的存在,即使在同一总体中抽取的几个样本,各样本统计量往往不等。
样本统计量与总体参数也不等,这种由于抽样研究所至样本之间和样本与总体之间的差异称为。
5. 变量:观察指标在统计学上统称为指标变量,它反应的是生物个体间的变异情况,根据其性质可分为定性变量(分类)和定量变量(连续)。
6. 截尾数据:生存时间观察过程被人为的截止称为截尾,又称删失或终检。
原因:失访/退出/终止(研究时限已到而终止观察)。
7. 卡方基本思想:X2分布是一种连续型分布,可用于检验资料的实际频数和按检验假设计算的理论频数是否相等等问题。
X2反应实现了实际频数与理论频数的吻合程度。
如果检验假设成立,则A-T一般不大,X2应很小,即出现大X2值概率很小。
即X2越大,P越小,若P≤a时,就怀疑假设的成立,拒绝H0。
若P>a则没有理由拒绝H0。
8. X2用途:(1)实际频数与拟合频数拟合优度:A推断两个或两个以上总体率或构成比有无差别(四格表/行x列表)。
B两变量之间有无相互关系。
C频数分布的拟合优度检验(判断次样本是否来自某种分布)。
(2)某些分布可用X2近似。
(3)间接应用:如t分布和F分布就是在X2分布基础上推导出来的。
9. 方差分析的基本思想:根据研究目的和设计类型,把总体变异中离均差平方和分解成两部分或更多部分,也把总变异中的自由度相应分成两部分或更多部分,然后再进行比较,评价由某种因素引起的变异是否具有统计学意义。
10. 假设检验中P,a,b(倍他)的关系及统计学意义:a:检验水准,即显著性检验,在此概率之下的认为是小概率事件,统计学上以为此事件“不可能发生”,以此判断是否不拒绝H0无效假设,在假设检验中,按a检验水准,拒绝了原来正确的H0,即犯了第1类错误,犯此错误的概率为a。
医学统计学 重点知识总结

名词解释1、一类错误:拒绝了实际上成立的H。
,这类“弃真”的错误称为I型错误或第一类错误。
2、参数和统计量:这些总体的统计指标或特征值称为参数。
由样本所算出的统计指标或特征值称为统计量。
3、变异系数:亦称离散系数,为标准差与均数之比,常用百分数表示。
4、P值:即概率,反映某一事件发生的可能性大小。
5、检验效能:B称为检验效能或把握度,即两总体却有差别,按α水准能发现它们有差别的能力。
简答题1、描述数值变量资料(统计资料)的集中程度有哪些指标,有何运用条件?算数均数:单峰对称分布的资料几何均数:对数变换后的单峰对称的资料中位数:偏态分布,分布不明资料,有不确定值的资料。
百分位数:当样本含量较少时不宜用靠近俩端的百分位数来估计频数分布范围。
2、实验研究的基本要素和基本原则是什么?基本要素:处理因素、受试对象和实验效应。
基本原则:对照原则、随机化原则和重狂原则大题1、(1)变量资料(2)成组t检验对立性正态性方差齐性(3)H0ιμ1=μ2,新药与常规药物的疗效相同H1rμ1≠μ2,新药与常规药物的疗效不同α=0.05T=1.0195V=n1+n2-2=18(2)t<t0.05z18,p>0.05,按a=0.05水准,不拒绝H0,差别无统计学意义。
结论:t检验结果表明,故尚不能认为新药与常规药物的疗效相同。
2、(1)T=13×17/47=4.7(2)x2检验(3)X2>X2(0.05,1),p<0.05,按a=0.05水准,拒绝H0,接受HQ差别有统计学意义。
结论:x2检验结果表明,乙疗法比甲疗法好。
3、(1)成组设计两样本比较的秩和检验(2)实验组秩次:13、I15、8.5、14、15.5、15.5、17、18对照组秩次:1、2、4、3、5、6、8.5、7、10、11.5(3)H0:两组局部温热的疗效总体分布相同H1:两组局部温热的疗效总体分布不同4(1)Ho:P=O,即母体内时间与体重无线性相关关系H1:P≠0,即母体内时间与体重有线性相关关系a=0.05F>5.23,拒绝HO,接受HI,相关系数有统计学意义。
医学统计学重点总结

1.简述总体和样本的定义;并且举例说明..总体是研究目的确定的所有同质观察单位的全体..样品是从研究总体中抽取部分有代表性的观察单位..2.简述参数和统计量的定义;并且举例说明..描述总体特征的指标称为参数;描述样本特征的指标称为统计量..3.变量的类型有哪几种举例说明各种类型变量有什么特点..①定量数据:计量资料;定量的观测值是定量的;其特点是能够用数值的大小衡量其水平的高低..②定性数据:计数资料;变量的观测值是定性的;表现为互不相容的类别或属性..③有序数据:半定量数据/等级资料;变量的观测值是定性的;但各类别属性有程度或顺序上的差异..4.请举例说明一种类型的变量如何变换为另一种类型的变量..定量数据>有序数据>定性数据--------------->5.请简述什么是小概率事件概率是描述事件发生可能性大小的度量;P≤0.05事件称为小概率事件..6.举例说明什么是配对设计..配对设计是将受试对象按某些重要特征相近的原则配成对子;每对中的两个个体随机地给予两种处理..①同源配对:同一受试对象或同一标本的两个部分;随机分配接受两种不同处理;②异源配对:为消除混杂因素的影响;将两个同质受试对象配对分别接受两种处理..7.非参数假设检验适合什么类型数据进行分析①总体分布类型未知或非正态分布数据;②定量或半定量数据;③数据两端无确定的数值..8.简述P25 P50P75的统计学意义..条件:明显偏态且不能转化为正态或近似对称;一端或两端无确定数值;分布情况未知用来描述资料的观测值序列在某百分位置的水平;四分位数间距可以作为说明个体差异的指标说明个体在不同位置的变异情况..9.直条图、直方图、圆饼图的使用条件是什么直条图:各自独立的统计指标的数值大小和他们之间的对比;直方图:连续变量频数分布情况;圆饼图:全体中各部分所占的比例..10.统计分析包括哪两个方面的内容为什么要进行统计推断统计描述和统计分析;统计描述用来描述及总结一组数据的重要特征;其目的是使实验或观察得到的数据表达清楚并便于分析..统计推断指由样本数据的特征推断总体特征的方法;包括参数估计点估计和区间估计和假设检验判断随机波动引起差别的概率大小..统计推断是通过样本推断总体的统计方法/根据样本提供的信息和抽样分布的规律;以一定的概率推断总体的特征..总体是通过总体分布的数量特征即参数如方差来反映的..很多时候并不知道总体的参数;只能由样本统计量推断获得..11.定量数据如何进行统计描述请举例说明..通过具体数值反应高低水平..12.定性数据如何进行统计描述请举例说明..根据类别或属性的不同分类..13.简述均数的抽样误差及率的抽样误差..由抽样造成的样本统计量与总体参数的差异称为抽样误差;样本均数X̅̅̅不等于总体均数μ;总体率参数π不等于样本率p..14.简述正态分布和标准正态分布的关系..z=X−Xμ=0;σ=1关系:标准正态分布是正态分布的一种;具有正态分布的所有特征..所X有正态分布都可以通过Z分数公式转换成标准正态分布..区别:正态分布的平均数为μ;标准差为σ;不同的正态分布可能有不同的μ值和d值;正态分布曲线形态因此不同..标准正态分布平均数μ=0;标准差σ=1;μ和σ都是固定值;标准正态分布曲线形态固定..X(X)=X√2X X−12(X−XX)2(−∞<X<+∞)概率密度函数F(X)=1X√2XX−12(X−X X)2XXX−∞(−∞<X<+∞)概率分布函数15简述正态分布的特点..1.正态分布是单峰分布;以X=X为中心;左右完全对称;正态曲线以X轴为渐近线;两端与X轴不相交..2.正态曲线在X=μ处有最大值;其值为X(X)=X√XX;X越远离X;X(X)值越小;在X=X±X处有拐点;呈现为钟形..3.正态分布完全由两个参数X和X决定;X是位置参数;描述正态分布的平均水平;决定着正态曲线在x轴上的位置;X是形状参数;描述正态分布的变异程度;决定着正态曲线的分布形状..若X固定而改变X;曲线沿着X轴平行移动;其形状不变;改变的只是位置;若X固定而改变X;X越大曲线越“矮胖”;表示数据越分散即变异越大;X越小曲线越“瘦高”;表示数据越集中即变异越小..因此;不同的X与不同的X对应不同的正态分布..4.正态曲线下的面积分布有一定的规律..①曲线下的面积即为概率;服从正态分布的随机变量在某区间上的曲线下面积与该随机变量在同区间上的概率相等;②曲线下的总面积为1;以X为中心左右两侧面积各占50%;越靠近μ处曲线下面积越大;两边逐渐减少;③所有正态曲线;在μ左右的任意个标准差范围内面积相同:区间X±X范围内的面积约为68.27%;区间X±X.XXX范围内的面积约为90.00%;区间X±X.XXX范围内的面积约为95.00%;区间X±X.XXX范围内的面积约为积约为99.00%16.什么是医学参考值范围..医学参考值范围的作用..满足正态分布的双侧医学参考值范围怎么计算..医学参考值范围是指“正常”人的解剖、生理、生化指标等数据大多数个体值的波动范围..确切含义是:从选择的参考总体中获得的所有个体观察值;用统计学方法建立百分位数界限;由此得到个体观察值的波动区间..作用:①基于临床实践;从个体角度;作为临床上判定正常与异常的参考标准;用于划分界限或分类;②基于预防医学实践;从人群角度;可用来评价儿童发育水平..步骤:1.确定参考值范围百分比;2.查表得到Z值;3.x∈(μ−zσ,μ+zσ)..17.总体均数的95%可信区间的计算方法及其意义..意义:该区间包括总体均数X的概率为95%①X已知:z分布:−X<X̅̅̅−XX X̅̅̅<X?−X<X̅̅̅−XX√X<X?X∈(X̅̅̅−√X X̅̅̅+√X) 1.96②X未知;n较小<=50:自由度为v=n-1的t分布:−X XX ,X<X̅̅̅−XX X̅̅̅<X XX,X?−X XX ,X<X̅̅̅−XX√X<X XX,X?X∈(X̅̅̅−X XX,XX√XX̅̅̅+X XX,XX√X)③X未知;n较大n>50:z分布:−X<X̅̅̅−XX X̅̅̅<X?−X<X̅̅̅−XX√X<X?X∈(X̅̅̅−XX√XX̅̅̅+XX√X)18.三种t检验的适用条件..1.单样本t检验:适用于样本均数X̅̅̅与已知总体均数X X的比较;目的是检验样本均数X̅̅̅所代表的总体均数μ是否与已知总体均数X X有差别..2.配对样本t检验:适用于配对设计计量资料均数的比较;目的是检验两相关样本均数所代表的未知总体均数是否有差别..3.两独立样本t检验:适用于完全随机设计的两样本均数的比较;目的是检验两样本所来自总体的均数是否相等..19.完全随机设计的方差分析适用条件..是一种将实验对象随机分配到不同处理组的单因素设计方法..正态性;独立性样本总体间相互独立;方差齐性..20.三种卡方检验的适用条件..1.四表格资料的X X检验:两独立样本的两个分类个体数排列成四表格资料;目的是推断两个或多个总体率或构成比之间有无差别..2.配对四表格资料的X X检验:常用于两种检测方法、两种诊断方法或两种细菌培养方法的比较;适用于样本量不是很大的资料;特点是对样本中个观察单位分别用两种方法检测或处理;然后按两分类变量计数结果..3.X×X列联表资料的X X检验:用于多个样本率或多个构成比的比较..21.线性相关系数r的意义..是说明具有直线相关关系的两个数值变量间相关的密切程度和相关方向的统计量..相关系数r没有度量衡单位;其取值范围为−X≤X≤X..r>0表示正相关;r<0表示负相关;r=0表示无相关;即无直线关系;当|X|=X时为完全相关..相关系数的绝对值意接近1;相关愈密切;相关系数愈接近0;相关愈不密切..22.t分布的特点..①t分布是以0为中心;左右两侧对称的单峰分布;②t分布曲线是一簇曲线;其形态变化与自由度v的大小有关..自由度v越小;则t值越分散;曲线越低平;自由度v逐渐增大时;t分布逐渐逼近标准正态分布..当v=∞时;t分布就完全成为标准正态分布了..23.卡方检验的基本思想..成立;基于此前提计算出X X值;它表示观察值与理论值之该检验的基本思想是:首先假设H间的偏离程度..根据X X分布及自由度可以确定在H0假设成立的情况下获得当前统计量及更极端情况的P..如果当前统计量大于P值;说明观察值与理论值偏离程度太大;应当拒绝无效假设;表示比较资料之间有;否则就不能拒绝无效假设;尚不能认为所代表的实际情况和理论假设有差别..主要是比较两个及两个以上样本率构成比以及两个的关联性分析..建立检验假设并确定检验水准;计算统计检验量;确定P值;做出推断结论..24.假设检验的基本思想..目的是比较总体参数之间有无差别..的基本思想是小概率思想..小概率思想是指小概率事件P<0.01或P<0.05在一次试验中基本上不会发生..思想是先提出假设检验假设H0;再用适当的统计方法确定假设成立的可能性大小;如可能性小;则认为假设不成立;若可能性大;则还不能认为不假设成立..具体作法是:根据问题的需要对所研究的总体作某种假设;记作H0;选取合适的统计量;这个统计量的选取要使得在假设H0成立时;其分布为已知;由实测的样本;计算出统计量的值;并根据预先给定的进行检验;作出拒绝或接受假设H0的判断..25.简述一类错误、二类错误..当Ho为真时;假设检验结论拒绝Ho;接受H;这类错误称为I类错误; 在医学中亦称假阳性错误..检验水准a是预先规定的允许犯I类错误的概率;当a=0.05时;表示在Ho为真的条件下重复100次试验;理论上会有5次拒绝Ho..当真实情况为Ho不成立时;假设检验结论不拒绝Ho;这类错误称为II类错误;在医学中亦称假阴性错误..其概率大小用B表示..B只取单侧;其值的大小一般未知;对于计量资料必须在知道两总体的标准差、均数的实际差值和样本含量时才能算出..。
医学统计学重点重点知识总结

医学统计学重点一.选择1.几何均数:平均血清抗体滴度(如P9例2.4)2.正态分布:横轴为µ1.962.5%单侧双侧90%: 1.6495%: 1.64 1.9699%: 2.583.P值与ɑ的关系,ɑ是人为规定的,它们之间没有关系; P值↑,ɑ↑(×)4.方差分析自由度v的计算,v总=n-1;v组间=组数(k)-1;v组间=v总-v组间5.理论秩和(n(n+1)/2),实际秩和(通过平均秩次算)6.可信区间的正确应用:总体参数有95%的可能落在该区间内(×);有95%的总体参数在该区间内(×);该区间包含95%的总体参数(x);该区间有95%的可能包含总体参数。
(x);这个区间的可信度为95%(√);总体参数只有一个,要么在区间内,要么不在7.相关系数与回归系数:相关系数为0,两个变量之间没有相关关系(×);回归系数↑,相关系数↑(×);(要做假设检验)二、名解1.参考值范围:根据正常人的数据估计绝大多数的正常人所在的范围2.区间估计(可信区间):按一定的概率或可信度(1-α)用一个区间估计总体参数所在范围。
这个范围称作可信度为1-α的可信区间,又称置信区间。
3.P值:拒绝H0时所冒的风险(或“作出拒绝H0 而接受H1 ”结论时冒了P风险)4.ɑ(第一类错误):H0真实时被拒绝(或H0真实时,拒绝H0,接受H1)5.β(第二类错误):H0不真实时不拒绝(或H0不真实时,不拒绝H0)1-β检验效能:对真实的H1做肯定结论之概率6.秩次:是指全部观察值按某种顺序排列的位序;7.秩和:同组秩次之和8.剩余标准差:扣除了X的影响后,Y方面的变异; 引进回归方程后, Y方面的变异。
三、简答1.假设检验与可信区间的联系与区别分辨多个样本是否分别属于不同的总体,并对总体作出适当的结论。
分辨一个样本是否属于某特定总体等。
区间估计(可信区间):按一定的概率或可信度(1-α)用一个区间估计总体参数所在范围。
医学统计学重点总结

样本统计量的标准差称为标准误。
2
都表示变异的大小;
3
样本含量一定时,标准差越大,标准误越大。
1
联系:
标准误与标准差(1)
标准差
01
含义:
02
一组变量值离散程度;
03
标准差越小,均数的代表性越好;
04
应用: 估计参考值范围;
05
与n的关系:样本含量越大,标准差越稳定,n 很大时,标准差趋向于总体标准差。
7. X±2.58s包括变量值的 A. 68.3% B. 90.0% C. 95.0% D. 99.0% 8. 均数与标准差之间的关系是 A.标准差越小,均数代表性越好 B. 标准差越小,均数代表性越差 C. 均数越大,标准差越小 D. 均数越大,标准差越大 9.分析定性资料时,最常用的显著性检验方法是 A.t检验 B.正态检验 C.U检验 D.χ2检验 10.四格表如有一个实际数为0 A.就不能做χ2检验; B.就不能用校正χ2检验; C.还不能决定是否可做χ2检验; D.肯定可做校正χ2检验。
43
10
53
40
16
56
83
26
109
40.36
12.64
42.64
11.36
T11=53× 83/109=40.36 T12=53× 26/109=12.64 T21=56× 83/109=42.64 T22=56× 26/109=13.36
既非呈连续分布的定量资料,也非仅按性质归属于独立的若干类的定性资料;
线性相关
01
列联相关
03
等级相关
02
线性回归
04
相关与回归
1 ≤ r ≤ 1
r<0为负相关
医学统计知识点总结

医学统计知识点总结在医学领域中,统计学的应用非常广泛,它可以帮助医生和研究人员分析和解释医学数据,研究疾病的发病机制以及评估治疗方法的有效性。
本文将重点总结医学统计学中的重要知识点,包括描述统计学和推论统计学。
描述统计学描述统计学是研究数据集中各变量的集中趋势和离散程度的方法。
主要包括以下几个方面的内容。
1. 数据的整理和呈现在医学研究中,首先需要对收集到的数据进行整理和呈现。
常用的方法包括频数分布表、直方图、饼图、条形图等,这些方法可以直观地展示各变量的分布情况。
2. 中心趋势的度量中心趋势代表着数据集中值的位置,主要包括均值、中位数和众数。
均值是各观测值之和除以观测次数,中位数是按数值大小排列后位于中间位置的值,众数是出现次数最多的值。
3. 离散程度的度量离散程度描述了数据集中值的分散程度,通过方差和标准差进行度量。
方差是各观测值与均值之差的平方和的平均值,标准差是方差的平方根。
推论统计学推论统计学可以根据样本数据推断总体的特征,包括参数估计和假设检验两个方面。
1. 参数估计参数估计是根据样本数据估计总体特征的值,主要包括点估计和区间估计。
点估计是用样本数据求得总体参数的估计值,例如用样本均值估计总体均值。
区间估计是用样本数据求得总体参数的估计区间,例如用置信区间估计总体均值。
2. 假设检验假设检验是通过样本数据推断总体参数是否符合某种假设,主要包括参数检验和非参数检验。
参数检验是对总体参数进行检验,例如对总体均值或总体比例进行检验。
非参数检验是不对总体参数进行具体假设的检验,例如对数据分布进行检验。
医学研究设计医学研究设计是医学统计学中非常重要的一部分,它关系到研究的可靠性和准确性。
主要包括以下几种设计。
1. 随机化对照试验随机化对照试验是医学研究设计中最可靠的一种设计,它可以有效地减少随机误差和系统误差。
研究对象被随机分配到不同的处理组中,其中一个组作为对照组,另一个组接受实验处理。
2. 横断面研究横断面研究是在特定时间点对研究对象进行一次观察,了解其疾病或特征的分布情况。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
医学统计学重点第一章绪论1.基本概念:总体:根据研究目的确定的性质相同或相近的研究对象的某个变量值的全体。
样本:从总体中随机抽取部分个体的某个变量值的集合。
总体参数:刻画总体特征的指标,简称参数。
是固定不变的常数,一般未知。
统计量:刻画样本特征的指标,由样本观察值计算得到,不包含任何未知参数。
抽样误差:由随机抽样造成的样本统计量与相应的总体参数之间的差异。
频率:若事件A在n次独立重复试验中发生了m次,则称m为频数。
称m/n为事件A在n次试验中出现的频率或相对频率。
概率:频率所稳定的常数称为概率。
统计描述:选用合适统计指标(样本统计量)、统计图、统计表对数据的数量特征及其分布规律进行刻画和描述。
统计推断:包括参数估计和假设检验。
用样本统计指标(统计量)来推断总体相应指标(参数),称为参数估计。
用样本差别或样本与总体差别推断总体之间是否可能存在差别,称为假设检验。
2.样本特点:足够的样本含量、可靠性、代表性。
3.资料类型:(1)定量资料:又称计量资料、数值变量或尺度资料。
是对观察对象测量指标的数值大小所得的资料,观察指标是定量的,表现为数值大小。
每个个体都能观察到一个观察指标的数值,有度量衡单位。
(2)分类资料:包括无序分类资料(计数资料)和有序分类资料(等级资料)①计数资料:是将观察单位按某种属性或类别分组,清点各组观察单位的个数(频数),由各分组标志及其频数构成。
包括二分类资料和多分类资料。
二分类:将观察对象按两种对立的属性分类,两类间相互对立,互不相容。
多分类:将观察对象按多种互斥的属性分类②等级资料:将观察单位按某种属性的不同程度、档次或等级顺序分组,清点各组观察单位的个数所得的资料。
4.统计工作基本步骤:统计设计、资料收集、资料整理、统计分析。
第二章实验研究的三要素1.实验设计三要素:被试因素、受试对象、实验效应2.误差分类:随机误差(抽样误差、随机测量误差)、系统误差、过失误差。
3.实验设计的三个基本原则:对照原则、随机化分组原则、重复原则。
4.实验设计方法有析因设计正交试验设计均匀试验设计交互作用两组:异体配对设计同体配对设计交叉设计无随机同期对照实验设计(单因素两水平)扩展多组:单因素多水平配伍组设计拉丁方设计(两因素多水平)(三因素多水平)配伍组设计:也称随机区组设计,将条件相近的受试对象配伍,每个配伍组中的对象随机分配到各处理组中。
析因设计:考察两个或两个以上的处理因素,将各个因素的水平进行全面组合,每个组合下至少有两个以上的观察对象重复测量。
一般来讲,应尽可能安排等重复试验,以简化计算,2-3个水平数。
优点是全面性和均衡性较好,可同时分析处理因素的效应及因素间的交互作用。
拉丁方设计:用于三因素等水平无交互。
第三章定量资料的统计描述、参考值范围1.频数表编制过程(了解)(1)找出样本数据的最大值和最小值,计算极差 R;(2)分组:确定分组的组距 d 和组数 k;一般n<50,5-6组;n在100左右,7-10组;n>100,10-15组(3)求频率密度:统计频数,算出频率、频率密度和累积频率;(4)画出直方图。
2.频数表和直方图的作用:用于观察个数较多资料的统计描述,可以直观提示资料的分布特征和分布类型。
3.集中趋势、离散趋势的指标及适用范围(1)集中趋势:x,G,M,Px ,M算术均数:适用于对称分布;不适用于偏态分布和资料中出现极值的资料。
几何均数:适用于呈倍数关系的资料或对数正态分布的资料,尤其是正偏态分布。
不适用与观察值中有0或正负数值同时出现的资料。
中位数:适用于大样本偏态分布或分布情况不明的资料或资料中有不确定数值的资料。
百分位数的作用:多个百分位数结合使用,全面描述数据分布的特征;用于确定医学参考值范围(偏态或分布不明的资料)。
众数:适用于大样本,较粗糙。
(2)离散趋势:极差:优点:简单明了、容易使用。
缺点:①只反映最大值和最小值间的差异,不能反映其他观察值的变异程度。
②样本容量越大,极差可能越大。
③极差的抽样误差大,不稳定。
四分位数间距:适用于确定医学参考值范围,与中位数一起描述偏态分布资料变异程度。
缺点:类似于极差,利用度低。
方差与标准差:与均数一起描述对称分布,特别是正态分布的分布特征。
变异系数:适用于:①适用于比较度量衡单位不同资料的变异度。
②比较均数相差悬殊的资料的变异度。
③衡量实验精密度和稳定性的常用指标。
(3)频数分布特征高峰在中间,左右大致对称,称为对称分布。
平均数=中位数=众数高峰偏向小值的一侧(左侧),称正偏态分布(亦称右偏态)。
平均数>中位数>众数高峰偏向大值的一侧(左侧),称负偏态分布(亦称左偏态)。
平均数<中位数<众数对称分布正(右)偏态分布负(左)偏态分布4.正态分布图形的特点及意义(1)特点:①f (x )关于x=μ对称 ②x=μ时取得最大值③在x=μ±σ处为拐点,且以 x 轴为水平渐近线 ④f (x )大于0⑤P (x=a )=0⑥若 f (x) 在点 x 处连续,则F ´(x )=f (x) (2)意义:⎰+∞∞-)(x f =1,f (x )在负无穷到正无穷的积分值为1,即曲线下方面积为1。
5.μ和σ2的意义μ:位置参数,当σ固定时,μ增大,曲线沿横轴向右移动;μ减小,曲线沿横轴向左移动。
σ2:形状参数,当μ固定时,σ越大,曲线越矮胖;σ越小,曲线越高瘦。
6.标准化变换z=σμ-x x ~N (μ,σ2) z ~N (0,1) F (x)=Ф(σμ-x )=Ф(z) 即P (X ≤x)=Ф(σμ-x )=P (Z ≤z)P (a<x<b)=F (b)-F (a)=Ф(σμ-b )-Ф(σμ-a P (σμ-a <σμ-x <σμ-b )=P (σμ-a < Z <σμ-b )7.标准正态分布界值规定:界值右侧曲线下方面积等于它的下角标。
下角标一致,x 轴上方中间面积一致。
双侧界值:P (|z|≤z 2α)=1-α P (z<z 2α)=1-2αP (|z|≥z 2α)=α P (z>z 2α)=2α单侧界值:上限: 下限:P (z>z α)=α P (z>z 1-α)=1-α P (z<z α)=1-α P (z<z 1-α)=α8.正常值范围及意义概念:医学临床中,常将就诊者的某些生理、生化、免疫学指标的测定结果,与排除了对研 究指标有影响的疾病和有关因素的大多数“正常人”的相应数值进行比较,以就诊者 的测定值是否超出了大多数“正常人”相应指标的波动范围,作为临床诊断的重要参 考,又称医学参考值范围。
意义:95%的参考值范围含义是指:样本中有95%的个体测定值在所求范围之内。
以95%的置信区间来说,意义是:该区间以95%的概率包含了待估计的参数,这种 估计的可信度是95%,会冒5%的风险。
公式: 双侧95%的界限值:x ±1.96s 单侧95%的上限值:x +1.645s 单侧95%的上限值:x -1.645s第四章 总体均数的估计、假设检验1.标准误(1)概念:每次样本计算出的x 不同,这些x 的标准差称为均数的标准误。
(2)意义:是衡量样本统计量抽样误差大小的统计指标。
(3)与标准差的区别:二者都是描述变异程度的指标,标准差描述个体值的变异,标准误描 述统计量的变异。
(4)均数标准误的公式:S x =ns 2.置信区间(1)定义:设θ为总体的未知参数,若由样本确定的两个统计量θ1(x 1、x 2、…、xn)和θ2(x 1、 x 2、…、x n ),且θ1<θ2,对于预先给定的值α(0<α<1),若满足P(^θ1<^θ2)=1-α, 则称随机区间(^θ1,^θ2)为θ的1-α置信区间,其中称为^θ1置信下限,称为^θ2 置信上限,1-α称置信度。
(2)意义:区间(^θ1,^θ2)包含有参数θ的概率为1-α,不能说θ在(^θ1,^θ2)的概率为 1-α。
例:可以说(a ,b )包含均数μ的概率为95%,不能说μ在(a ,b )的概率为95%。
(3)公式:单个正态总体均数μ的区间估计①σ已知:双侧:nz x σα2± 即 x z x σα2±z 分布单侧:nz x σα± 即 x z x σα±②σ未知:双侧:n st x 2α± 即 x s t x 2α± 小样本(n ≤50) t 分布单侧:nst x α± 即 x s t x α±双侧:n sz x 2α± 即 x s z x 2α± 大样本(n>50) z 分布单侧:nsz x α± 即 x s z x α± (4)两要素:准确度:由1-α 决定,1-α 越大,准确度越高。
精确度:由区间长度决定。
99%置信区间准确度高于95%置信区间。
95%置信区间精确度更高。
3.抽样分布(1)t 分布①定义: 来自正态总体的一组样本,x 和s 分别是样本的均数和标准差。
则t=ns x /μ-~t 分布,自由度 df=n-1,极限分布是标准正态分布。
②图形分布特征:以0为中心,左右对称的单峰分布。
自由度越大,越高瘦③界值: 双侧:P (|t|≤t 2α)=1-α P (t<t 2α)=1-2αP (|t|≥t 2α)=α P (t>t 2α)=2α单侧:上限: 下限:P (t<t α)=1-α P (t<t 1-α)=α P (t>t α)=α P (t>t 1-α)=1-α (2)χ2分布①定义:若从均数为μ,标准差σ的正态总体中,每次抽取样本含量为n 的样本,计算 样本标准差s ,则χ2=(n-1)s 2/σ2服从自由度df=n-1的χ2分布。
②图形分布特征: 曲线偏向左边 自由度越小曲线越偏 ③界值: 双侧:P (x 2>x 22α)=2α P (x 2>212α-x )=1-2α P (x 2<x 22α)=1-2α P (x 2<212α-x )=2α 单侧:上限: 下限:P (x 2>x 2α)=α P (x 2>x 21-α)=1-α P (x 2<x 2α)=1-α P (x 2<x 21-α)=α (3)F 分布①定义:如果分别从两个正态总体N (μ1,σ1)和N (μ1,σ1)中随机抽取样本含量 n 1、n 2的两个样本,算出样本均数和方差分别为x 1,s 21和x 2,s 22,则σσ22222121//s s F =服从df 1=n 1-1,df 2=n 2-1的F 分布。