基于K-means聚类算法的客户价值分析研究概要
matlab k-means聚类结果还原-概述说明以及解释

matlab k-means聚类结果还原-概述说明以及解释1.引言在概述部分,您可以介绍k-means聚类算法的背景和作用,以及本篇文章的研究重点和目的。
以下是一个示例:1.1 概述在数据挖掘与机器学习领域,聚类是一种常用的数据分析技术,用于将相似的数据对象划分为不同的组别或簇。
其中,k-means聚类算法被广泛应用于众多领域,例如图像处理、生物信息学和市场分析等。
k-means聚类算法将数据集分成k个不重叠的簇,其中每个簇代表一种相似的数据集合。
算法通过计算每个数据点与k个聚类中心的距离,并将数据点分配到距离最近的聚类中心,从而实现数据的聚类。
然而,尽管k-means聚类算法在实际应用中表现出色,但在某些情况下,聚类结果可能会失真或难以解释。
因此,本文的重点是探讨分析k-means聚类结果的问题,并提出一种方法来还原k-means聚类结果,以改进算法的准确性和可解释性。
通过还原k-means聚类结果,我们可以更好地理解聚类分析的结果,从而更精确地解释数据的结构和模式。
同时,本文将讨论该方法的局限性,并展望未来在k-means聚类结果还原方面的研究方向。
通过本文的研究,我们期望能够提高k-means聚类算法的应用效果,并为数据挖掘与机器学习领域的研究者和实践者提供有价值的思路和方法。
1.2 文章结构文章结构部分的内容可以包括以下内容:文章结构部分旨在介绍整篇文章的组织结构,以帮助读者更好地理解文章的内容和逻辑。
文章在此部分将简要概述各个章节的内容,为读者提供预览和导引。
2. 正文部分将围绕matlab k-means聚类算法展开,主要分为三个章节。
首先,在第2.1节中,我们将对matlab中的k-means聚类算法进行简要介绍。
我们将介绍k-means聚类算法的基本原理和应用领域,并探讨算法的优势和不足之处。
此节将帮助读者对k-means聚类算法有一个整体的认识。
接下来,在第2.2节中,我们将分析k-means聚类结果的问题。
基于K-means算法的税务客户分类研究与应用

中图分类号 : T P 3 l 1 . 1 3
文献标识码 : B
文章编号: 1 0 0 2 — 2 2 7 9 ( 2 0 1 3 ) 0 5— 0 0 6 3 — 0 3
t e c h n o l o y i g n t h e t a x a t i o n ma n a g e me n t s y s t e m i s b e c o mi ng a f o c u s o f a t t e n t i o n. T h e t a x c u s t o me r
Z HU J i a n , YU Xi a o—h a n 。 , L U B i n g—l i a n g 4 ( 1 . S h e n y a n g A i r c r a t f C o r p o r a t i o n , A V I C, S h e n y a n g 1 1 0 0 3 4 , C h i n a ; 2 . S h e n y a n g A e r o au n t i c a l V o c a t i o n a l C o l l e g e , S h e n y a n g 1 1 0 0 3 4 , C h i a; n 3 . L i a o n i n g E Q I A O F i s c a l &T a x S c i e n c e a n d T e c h n o l o g y C o . , L T D, S h e n y a n g 1 1 0 0 0 1 , C h i n a ; 4 . ch S o o l o fC o m p u t e r S c i e ce n a n d E n g i n e e r i n g , S h e n y a n g A e r o s p a c e U n i v e  ̄ i t y , S h e n y a n g 1 1 0 1 3 6 , C h i a) n
基于K-means算法的亚洲足球聚类研究
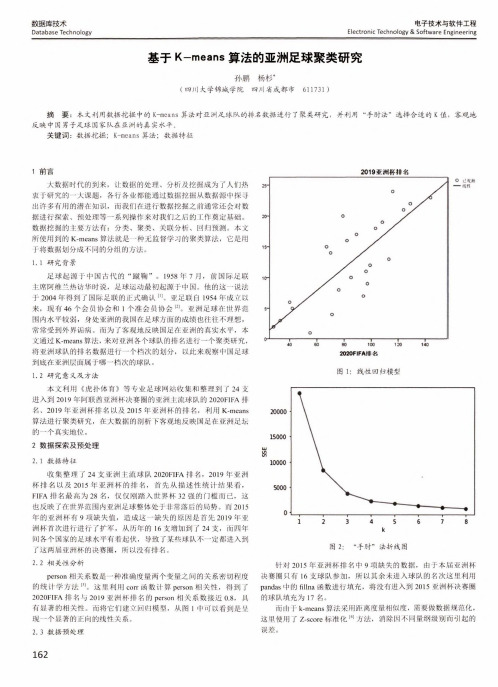
电子技术与软件工程Electronic Technology & Software Engineering数据库技术Database Technology 基于K-means 算法的亚洲足球聚类研究孙鹏杨杉*(四川大学锦城学院 四川省成都市 611731 )摘 要:本文利用数据挖掘中的K-means 算法对亚洲足球队的排名数据进行了聚类研究,并利用“手肘法”选择合适的K 值,客观地 反映中国男子足球国家队在亚洲的真实水平。
关键词:数据挖掘;K-means 算法;数据特征1前言大数据时代的到来,让数据的处理、分析及挖掘成为了人们热 衷于研究的一大课题,各行各业都能通过数据挖掘从数据源中探寻 出许多有用的潜在知识,而我们在进行数据挖掘之前通常还会对数 据进行探索、预处理等一系列操作来对我们之后的工作奠定基础。
数据挖掘的主要方法有:分类、聚类、关联分析、回归预测。
本文 所使用到的K-means 算法就是一种无监督学习的聚类算法,它是用 于将数据划分成不同的分组的方法。
1. 1研究背景足球起源于中国古代的“蹴鞠”。
1958年7月,前国际足联 主席阿维兰热访华时说,足球运动最初起源于中国。
他的这一说法 于2004年得到了国际足联的正式确认⑴。
亚足联自1954年成立以 来,现有46个会员协会和1个准会员协会⑵。
亚洲足球在世界范 围内水平较弱,身处亚洲的我国在足球方面的成绩也往往不理想, 常常受到外界诟病。
而为了客观地反映国足在亚洲的真实水平,本 文通过K-means 算法,来对亚洲各个球队的排名进行一个聚类研究, 将亚洲球队的排名数据进行一个档次的划分,以此来观察中国足球 到底在亚洲层面属于哪一档次的球队。
1. 2研究意义及方法本文利用《虎扑体育》等专业足球网站收集和整理到了 24支 进入到2019年阿联酋亚洲杯决赛圈的亚洲主流球队的2020FIFA 排 名、2019年亚洲杯排名以及2015年亚洲杯的排名,利用K-means 算法进行聚类研究,在大数据的剖析下客观地反映国足在亚洲足坛 的一个真实地位。
基于某百货商场销售数据的K-means聚类分析
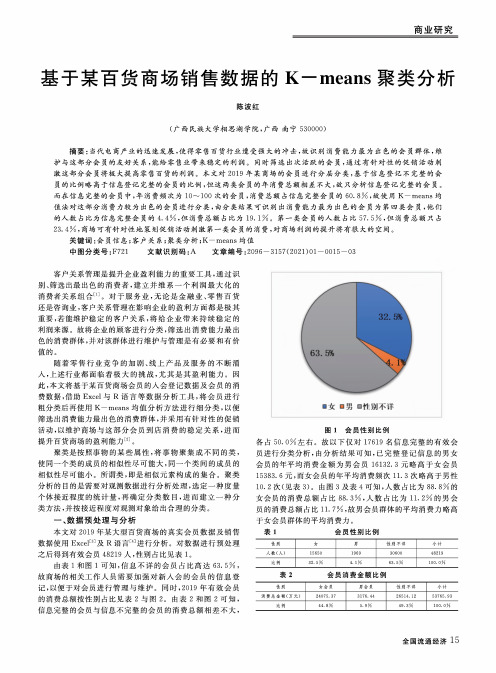
基于某百货商场销售数据的K—means聚类分析陈波红(广西民族大学相思湖学院,广西南宁530000)摘要:当代电商产业的迅速发展,使得零售百货行业遭受强大的冲击,故识别消费能力最为出色的会员群体,维护与这部分会员的友好关系,能给零售业带来稳定的利润。
同时筛选出次活跃的会员,通过有针对性的促销活动刺激这部分会员将极大提高零售百货的利润。
本文对2019年某商场的会员进行分层分类,基于信息登记不完整的会员的比例略高于信息登记完整的会员的比例,但这两类会员的年消费总额相差不大,故只分析信息登记完整的会员。
而在信息完整的会员中,年消费频次为10〜100次的会员,消费总额占信息完整会员的60.8%,故使用K-means均值法对这部分消费力较为出色的会员进行分类,由分类结果可识别出消费能力最为出色的会员为第四类会员,他们的人数占比为信息完整会员的4.4%,但消费总额占比为19.1%。
第一类会员的人数占比57.5%,但消费总额只占23.4%,商场可有针对性地策划促销活动刺激第一类会员的消费,对商场利润的提升将有很大的空间。
关键词:会员信息;客户关系;聚类分析;K-means均值中图分类号:F721文献识别码:A文章编号:2096-3157(2021)01-0015-03客户关系管理是提升企业盈利能力的重要工具,通过识别、筛选出最出色的消费者,建立并维系一个利润最大化的消费者关系组合旳。
对于服务业,无论是金融业、零售百货还是咨询业,客户关系管理在影响企业的盈利方面都是极其重要,若能维护稳定的客户关系,将给企业带来持续稳定的利润来源。
故将企业的顾客进行分类,筛选出消费能力最出色的消费群体,并对该群体进行维护与管理是有必要和有价值的。
随着零售行业竞争的加剧、线上产品及服务的不断涌入,上述行业都面临着极大的挑战,尤其是其盈利能力。
因此,本文将基于某百货商场会员的入会登记数据及会员的消费数据,借助Excel与R语言等数据分析工具,将会员进行粗分类后再使用K-means均值分析方法进行细分类,以便筛选出消费能力最出色的消费群体,并采用有针对性的促销活动,以维护商场与这部分会员到店消费的稳定关系,进而提升百货商场的盈利能力⑵。
一种基于遗传算法的Kmeans聚类算法

一种基于遗传算法的K-means聚类算法一种基于遗传算法的K-means聚类算法摘要:传统K-means算法对初始聚类中心的选取和样本的输入顺序非常敏感,容易陷入局部最优。
针对上述问题,提出了一种基于遗传算法的K-means聚类算法GKA,将K-means算法的局部寻优能力与遗传算法的全局寻优能力相结合,通过多次选择、交叉、变异的遗传操作,最终得到最优的聚类数和初始质心集,克服了传统K-means 算法的局部性和对初始聚类中心的敏感性。
关键词:遗传算法;K-means;聚类聚类分析是一个无监督的学习过程,是指按照事物的某些属性将其聚集成类,使得簇间相似性尽量小,簇内相似性尽量大,实现对数据的分类[1]。
聚类分析是数据挖掘技术的重要组成部分,它既可以作为独立的数据挖掘工具来获取数据库中数据的分布情况,也可以作为其他数据挖掘算法的预处理步骤。
聚类分析已成为数据挖掘主要的研究领域,目前已被广泛应用于模式识别、图像处理、数据分析和客户关系管理等领域中。
K-means算法是聚类分析中一种基本的划分方法,因其算法简单、理论可靠、收敛速度快、能有效处理较大数据而被广泛应用,但传统的K-means算法对初始聚类中心敏感,容易受初始选定的聚类中心的影响而过早地收敛于局部最优解,因此亟需一种能克服上述缺点的全局优化算法。
遗传算法是模拟生物在自然环境中的遗传和进化过程而形成的一种自适应全局优化搜索算法。
在进化过程中进行的遗传操作包括编码、选择、交叉、变异和适者生存选择。
它以适应度函数为依据,通过对种群个体不断进行遗传操作实现种群个体一代代地优化并逐渐逼近最优解。
鉴于遗传算法的全局优化性,本文针对应用最为广泛的K-means方法的缺点,提出了一种基于遗传算法的K-means聚类算法GKA(Genetic K-means Algorithm),以克服传统K-means算法的局部性和对初始聚类中心的敏感性。
用遗传算法求解聚类问题,首先要解决三个问题:(1)如何将聚类问题的解编码到个体中;(2)如何构造适应度函数来度量每个个体对聚类问题的适应程度,即如果某个个体的编码代表良好的聚类结果,则其适应度就高;反之,其适应度就低。
利用KMeans聚类进行航空公司客户价值分析

利⽤KMeans聚类进⾏航空公司客户价值分析准确的客户分类的结果是企业优化营销资源的重要依据,本⽂利⽤了航空公司的部分数据,利⽤Kmeans聚类⽅法,对航空公司的客户进⾏了分类,来识别出不同的客户群体,从来发现有⽤的客户,从⽽对不同价值的客户类别提供个性化服务,指定相应的营销策略。
⼀、分析⽅法和过程1.数据抽取——>2.数据探索与预处理——>3。
建模与应⽤传统的识别客户价值应⽤最⼴泛的模型主要通过3个指标(最近消费时间间隔(Recency)、消费频率(Frequency)和消费⾦额(Monetary))来进⾏客户细分,识别出价值⾼的客户,简称RFC模型。
点击查看在RFC模型中,消费⾦额表⽰在⼀段时间内,客户购买产品的总⾦额。
但是不适⽤于航空公司的数据处理。
因此我们⽤客户在⼀段时间内的累计飞⾏⾥程M和客户在⼀定时间内乘坐舱位的折扣系数C代表消费⾦额。
再在模型中增加客户关系长度L,所以我们⽤LRFMC模型。
因此本次数据挖掘的主要步骤:1).从航空公司的数据源中进⾏选择性抽取与新增数据抽取分别形成历史数据和增量数据2).对步骤1)中形成的两个数据集进⾏数据探索分析和预处理,包括数据缺失值和异常值分析。
即数据属性的规约、清洗和变换3).利⽤步骤2)中的处理的数据进⾏建模,利⽤Python下Sklearn库中提供的KMeans⽅法,进⾏聚类4)。
针对模型的结果进⾏分析。
⼆。
数据处理1.下⾯是本次试验数据集的⼀部分截图,数据集抽取2012-4-1到2014-3-31内乘客的数据,⼀个62988条数据。
包括了会员卡号、⼊会时间、性别、年龄等44个属性。
2.数据探索分析:主要是对数据进⾏缺失值分析与异常值的分析。
通过发现原始数据中存在票价为空值,票价最⼩值为0,折扣率最⼩值为0、总飞⾏公⾥数⼤于0的记录。
其Python代码如下:def explore(datafile,exploreoutfile):"""进⾏数据的探索@Dylan:param data: 原始数据⽬录:return: 探索后的结果"""data=pd.read_csv(datafile,encoding='utf-8')explore=data.describe(percentiles=[],include='all').T####包含了对数据的基本描述,percentiles参数是指定计算多少分位数explore['null']=len(data)-explore['count'] ##⼿动计算空值数explore=explore[['null','max','min']]####选取其中的重要列explore.columns=['空值数','最⼤值','最⼩值']"""describe()函数⾃动计算的字段包括:count、unique、top、max、min、std、mean。
基于Kmeans的专利文本聚类分析

5、解读和应用:对可视化的专利地图进行解读,以获取技术趋势、竞争对 手以及潜在的市场机会等信息。
参考内容二
随着专利制度的不断发展,专利文本数据日益丰富,这为文本分析提供了丰 富的素材。专利文本聚类分析作为文本分析的一种重要方法,有助于从大量专利 数据中提取有用的信息,进而为企业、政府等决策提供有力支持。本次演示将探 讨专利文本聚类分析的方法和可视化研究。
2、特征提取:我们使用词袋模型(Bag of Words)从专利文本中提取特征。 具体来说,我们首先对文本进行分词处理,然后统计每个单词出现的频率,并将 这些频率作为文本的特征。
3、K-means聚类:我们使用K-means算法对提取的特征进行聚类。在算法中, 我们首先随机选择K个初始聚类中心,然后根据每个数据点到聚类中心的距离将 其分配到相应的聚类中。接着,算法重新计算每个聚类的中心点,重复这个过程 直到达到预设的迭代次数或收敛条件。
一、专利文本聚类分析
1.预处理
专利文本涉及大量专业术语,且文本表达可能存在不规范之处,因此需要进 行预处理,包括去除停用词、标点符号,统一专业术语等。通过预处理,使得文 本数据更加规范,为后续的聚类分析提供基础。
2.特征提取
特征提取型、词嵌入模型等。这些方法能够从文本数据中提取出有用的特征,为 后续的聚类算法提供输入。
4、结果评估:我们使用一些常用的评估指标来评估聚类结果的质量,如轮 廓系数(Silhouette Coefficient)、调整兰德系数(Adjusted Rand Index) 和调整互信息(Adjusted Mutual Information)。
四、结果与讨论
在实验中,我们将数据分成训练集和测试集,并使用训练集进行K-means聚 类。然后,我们使用测试集对聚类结果进行评估。评估结果表明,我们的方法可 以有效地将相似的专利文本分组在一起。例如,在最佳的聚类结果中,同组内的 专利文本之间的相似度平均达到了0.8以上。
K-Means聚类算法的研究

K-Means聚类算法的研究周爱武;于亚飞【摘要】The algorithm of K-means is one kind of classical clustering algorithm, including both many points and also shortages.For example must choose the initial clustering number.The choose of initial clustering centre has randomness.The algorithm receives locally optimal solution easily, the effect of isolated point is serious.Mainly improved the choice of initial clustering centre and the problem of isolated point.First of all ,the algorithm calculated distance between all data and eliminated the effect of isolated point.Then proposed one new method for choosing the initial clustering centre and compared the algorithm having improved and the original algorithm using the experiment.The experiments indicate that the effect of isolated point for algorithm having improved reduces obviously, the results of clustering approach the actual distribution of the data.%K-Means算法是一种经典的聚类算法,有很多优点,也存在许多不足.比如初始聚类数K要事先指定,初始聚类中心选择存在随机性,算法容易生成局部最优解,受孤立点的影响很大等.文中主要针对K-Means算法初始聚类中心的选择以及孤立点问题加以改进,首先计算所有数据对象之间的距离,根据距离和的思想排除孤立点的影响,然后提出了一种新的初始聚类中心选择方法,并通过实验比较了改进算法与原算法的优劣.实验表明,改进算法受孤立点的影响明显降低,而且聚类结果更接近实际数据分布.【期刊名称】《计算机技术与发展》【年(卷),期】2011(021)002【总页数】4页(P62-65)【关键词】K-Means算法;初始聚类中心;孤立点【作者】周爱武;于亚飞【作者单位】安徽大学,计算机科学与技术学院,安徽,合肥,230039;安徽大学,计算机科学与技术学院,安徽,合肥,230039【正文语种】中文【中图分类】TP301.6聚类分析是数据挖掘领域中重要的研究课题,用于发现大规模数据集中未知的对象类。
《基于改进K-means聚类和WKNN算法的WiFi室内定位方法研究》范文

《基于改进K-means聚类和WKNN算法的WiFi室内定位方法研究》篇一一、引言随着无线通信技术的快速发展,室内定位技术在诸多领域如智能建筑、物流管理、智慧城市等扮演着日益重要的角色。
其中,WiFi因其覆盖面广、布网方便和低成本等优势,已成为室内定位的主流技术之一。
然而,传统的WiFi室内定位方法在面对复杂多变的室内环境时,仍存在定位精度不高、稳定性差等问题。
因此,本文提出了一种基于改进K-means聚类和WKNN(加权k近邻)算法的WiFi室内定位方法,旨在提高定位精度和稳定性。
二、K-means聚类算法的改进K-means聚类算法是一种常用的无监督学习方法,通过迭代优化将数据划分为K个聚类,使得每个聚类内部的样本具有较高的相似性。
在WiFi室内定位中,我们可以将WiFi信号强度作为数据特征,利用K-means算法对不同位置点的WiFi信号强度进行聚类。
然而,传统的K-means算法在处理大规模数据时存在计算复杂度高、易陷入局部最优等问题。
因此,本文提出了一种改进的K-means算法。
该算法通过引入密度峰值检测技术,能够在迭代过程中自动识别并剔除噪声数据和异常值,从而提高聚类的准确性和稳定性。
此外,我们还采用了一种基于质心的初始化方法,以减少算法陷入局部最优的可能性。
三、WKNN算法的引入WKNN算法是一种基于距离度量的分类与回归方法,通过计算待测样本与已知样本之间的距离,并赋予不同的权重,以实现对未知样本的分类或预测。
在WiFi室内定位中,我们可以将WKNN算法应用于计算用户设备(UE)与各个接入点(AP)之间的距离,进而确定UE的位置。
相比传统的KNN算法,WKNN算法通过引入权重因子,能够更好地处理不同特征之间的差异性,提高定位精度。
此外,WKNN算法还可以通过调整权重的计算方式,灵活地适应不同的应用场景和需求。
四、基于改进K-means和WKNN的WiFi室内定位方法本文将改进的K-means聚类算法和WKNN算法相结合,提出了一种新的WiFi室内定位方法。
基于无监督Kmeans聚类方法的移动公司客户细分研究

2019年2月基于无监督K-means聚类方法的移动公司客户细分研究李明杨(山东省临清市第一中学,山东聊城252600)【摘要】伴随互联网技术全球化进程的加快,数据的爆炸式增长推动了大数据时代的到来。
如何有效地从这些复杂的多元数据中挖掘出其中的有价值信息,成为当今时代急需解决的难题之一。
本文利用数据挖掘领域经典的K-means聚类算法,对某移动通讯运营商的客户通话行为数据进行分析,将所有客户按照其显著特点细分为五种典型的客户群体。
针对每一类客户群,运营商可以制定具有针对性的营销策略,推行个性化的服务,将有限的资源集中于高价值商用客户,发展、保持中端客户以及普通客户,保持良好稳定的客户公司关系,提升自身竞争力,最终实现企业自身利益的长远增长。
【关键词】数据挖掘;聚类分析;客户细分;K-means【中图分类号】F626【文献标识码】A【文章编号】1006-4222(2019)02-0008-031前言计算机技术在我们的日常生活中扮演了越来越重要的角色,成为我们工作、生活,学习,休闲娱乐中不可分割的一部分[1]。
与此同时,各行各业产生、积累了不计其数的原始数据,海量的数据已经渗透到了金融,教育,医学,艺术,航空航天,生物等领域[2]。
然而,人们利用计算机技术从中提取有效信息的能力远远不能满足实际需求。
人工智能技术给人们的生活带来了极大地变化,特别是近年来伴随包括机器学习、数据挖掘以及模式识别等理论的迅速发展,人工智能由传统的理论研发进入到了全新的应用阶段,成为了信息时代不可或缺的组成推动因素。
特别地,作为人工智能领域实际应用最为广泛的方向之一,数据挖掘(data mining)以其稳健高效地知识发现能力,受到当今社会的青睐。
他所解决的问题就是从海量的有噪声实际应用数据中,利用科学有效地方法提取出隐含在其中的具有潜在应用价值的信息[3]。
目前,数据挖掘已经在诸多领域取得了令人瞩目的成果。
例如,人脸识别系统,通过对人脸图像进行比对分析,可以识别目标个体的身份,并被成功的应用于考勤,支付宝人脸支付,监控系统犯罪嫌疑人检测等许多场景;用户行为分析,通过建立顾客历史消费浏览记录与未来消费行为之间的潜在关系,个性化为消费者进行具有针对性的商品推荐,实现消费者与供应商的互利共赢[4];航空公司客户价值分析,通过分析乘客的历史消费特点及相关属性特征,将其划分为高价值客户及低价值客户等具体群组类型,针对每一种客户细分人群的特点,航空公司可以提供具有针对性的个性化客户定制服务,将有限的资源集中于关键人群[5]。
基于聚类算法的客户细分研究──以零售企业为例

基于聚类算法的客户细分研究──以零售企业为例随着市场竞争的加剧,企业越来越意识到客户细分的重要性。
如何更好地了解顾客的需求和行为,针对不同客户提供个性化的营销服务,已经成为零售企业的重要课题。
而聚类算法作为数据挖掘领域的一个重要算法,它可以对客户进行细致的划分和分析,为企业的营销决策提供有效的支持和依据。
本文将基于聚类算法的客户细分研究,并以零售企业为例进行分析。
一、聚类算法概述聚类算法是指将大量的数据集合,根据它们之间的相似性分成若干个簇的过程。
在聚类过程中,同一簇内的数据对象相似度高,不同簇间的数据对象相似度低。
聚类算法广泛应用于各种领域,如数据分析、图像处理、机器学习等。
根据数据的类型和特征不同,聚类算法可以分为多种,如K-Means聚类、层次聚类、密度聚类等。
其中,K-Means聚类算法是最为常用的一种算法。
K-Means聚类是根据数据点之间的欧式距离求解数据簇划分的一种算法。
它的基本思想是通过随机选择初始簇中心点,将数据点逐个分配到最近的簇中心中,然后重新计算每一簇的中心点,再次将所有数据点分配到最近的簇中,这个过程一直重复直至达到收敛条件为止,最终得到簇划分结果。
K-Means聚类算法的优点在于计算速度快、容易实现、易于解释等。
二、客户细分的应用客户细分是指将客户按照其特定的属性或者行为进行分类,以便于企业更好地针对客户的需求和行为进行营销活动。
客户细分的目的在于实现个性化营销,让不同的客户得到不同的服务和关爱,从而提高客户满意度和忠诚度。
客户细分的应用非常广泛,如零售业、银行业、保险业等。
其中,零售企业在客户细分方面的应用最为广泛,它通过对客户购买行为、消费习惯等进行分析,将客户划分为高价值客户、中等价值客户、低价值客户等不同层次的客户,并给予相应的服务和关怀。
三、零售企业的客户细分实践以某家超市为例,对不同类型的客户进行聚类分析。
1. 数据采集和处理针对某家超市的顾客,使用线下营销与线上活动的数据进行收集。
k-means聚类法_标准化数值_概述及解释说明

k-means聚类法标准化数值概述及解释说明1. 引言1.1 概述在数据分析和机器学习领域中,聚类算法是一种常用的无监督学习方法,它可以将具有相似特征的数据点划分为不同的组或簇。
其中,k-means聚类法是一种经典且广泛使用的聚类算法。
它通过迭代计算数据点与各个簇中心之间的距离,并将数据点划分到距离最近的簇中心。
k-means聚类法在数据挖掘、图像处理、模式识别等领域有着广泛的应用。
1.2 文章结构本文主要围绕着k-means聚类法以及标准化数值展开讨论。
首先介绍了k-means聚类法的原理和应用场景,详细解释了其算法步骤和常用的聚类质量评估指标。
接下来对标准化数值进行概述,并阐述了常见的标准化方法以及标准化所具有的优缺点。
随后,文章从影响因素分析角度探讨了k-means聚类算法与标准化数值之间的关系,并深入剖析了标准化在k-means中的作用及优势。
最后,通过实例解释和说明,对文中所述的理论和观点进行了验证与分析。
1.3 目的本文旨在向读者介绍k-means聚类法及其在数据分析中的应用,并深入探讨标准化数值在k-means聚类算法中扮演的重要角色。
通过本文的阐述,希望读者能够理解k-means聚类法的基本原理、运行步骤以及质量评估指标,并认识到标准化数值对于提高聚类算法性能以及结果准确性的重要性。
最终,通过结论与展望部分,给出对未来研究方向和应用领域的展望和建议,为相关领域研究者提供参考和启示。
2. k-means聚类法:2.1 原理及应用场景:k-means聚类算法是一种常用的无监督学习方法,主要用于将数据集划分为k 个不同的簇(cluster)。
该算法基于距离度量来确定样本之间的相似性,其中每个样本被划分到距离最近的簇。
它的主要应用场景包括图像分割、文本分类、市场细分等。
2.2 算法步骤:k-means聚类算法具有以下几个步骤:1. 初始化: 选择k个随机点作为初始质心。
2. 分配: 对于每个数据点,计算其与各个质心之间的距离,并将其分配到最近的质心所属的簇中。
基于SPSS和KNIME的K_means聚类结果研究

1 K-means 算 法
K - means [2] 算 法 是 一 种 著 名 的 并 且 常 用 的 聚 类 方 法 。
K -means 以 k 为 参 数 , 把 n 个 对 象 分 为 k 个 簇 (cluster),
以使簇内具有较高的相似度,而簇间的相似度较低。 相
似度的计算是根据一个簇中对象的平均值(被看作簇的
5
表 5 SPSS 中 K-means 运 算 的 结 果 (k=3)
Cluster 组织文化 组织氛围 领导角色 员工发展 包含数目
1 89 . 50 88 . 75 82 . 25 83 . 25
8
2 68 . 33 69 . 83 90 . 17 86 . 67
6
3 79 . 00 87 . 00 50 . 00 51 . 00
《微型机与应用》 2010 年第 12 期
综述与评论 Review and Comment
表 4 SPSS 中 K-means 运 算 的 结 果 (k=2)
Cluster 组织文化 组织氛围 领导角色 员工发展 包含数目
1 75 . 20 75 . 60 87 . 60 87 . 20
10
2 90 . 60 92 . 00 74 . 60 73 . 00
一种优化的K—means聚类中心算法研究

基 于 密度方 法 的改进 中主 要考虑 高 密度 、远 距 离初
始点 的选择 而忽 略簇 内相似 度 以及迭 代波 动性 结果
的分析 。在 实际 应用 中考虑 样本 密度 特点 与聚 类 点的 有效结 合找 到合适 的 初始聚 类 中心 ,降低传 统
第3 卷 第4 4 期
2 1 — ( ) [9 02 4下 11
务l l 出 I 5
质 ,在文 献 【, , , 】 出的选择 高 密度点作 为初 5689 提 始 聚 类 中心 方法 的基 础 上 进 行 改 进 ,提 出 以簇 内 相似 度 最 高 的具 有 高 密 度分 布 的点 为 聚 类 中 心选 择 算 法 ,通 过 评 价 函数 即 聚 类 问 距 、聚 类 内 距和 簇 内个数 分布 差异 度得 到聚类 最优 解。
密度 、 网格 、模 型和 约 束聚 类 算法 。K men 是 基 — as
于划分 的 聚类算 法 ,它以平 方误 差作 为衡 量聚 类质 量 的 目标 准则 函数 。通 过 随机选 择 k个 初 始聚 类 中
f ∑( 脚 P ) 2
=
1 P∈ c,
心 ,计 算每 个数 据对 象与 聚类 中心 的距离 ,将数 据 对象划 分到 距离 中心 最近 的簇 ,再计 算 、调整 聚类
21 改进 的初 始聚类 中心 选择步 骤 . 以 样 本 数 据 表 ( i 为 例 ,k 3时 ,其 初 始 表 ) =
聚 类 中心选择 方法 步骤 如表 I 所示 。
表 1 样本数据表
序号 属性 1 属性2 序号 属性 I 属性2 序号 属性I 属性2
1 2 l 1 1 2 6 7 4 5 5 4 l 1 1 2 I O 9 3 3
K-Means聚类算法

K—means聚类算法综述摘要:空间数据挖掘是当今计算机及GIS研究的热点之一。
空间聚类是空间数据挖掘的一个重要功能.K—means聚类算法是空间聚类的重要算法。
本综述在介绍了空间聚类规则的基础上,叙述了经典的K-means算法,并总结了一些针对K-means算法的改进。
关键词:空间数据挖掘,空间聚类,K—means,K值1、引言现代社会是一个信息社会,空间信息已经与人们的生活已经密不可分。
日益丰富的空间和非空间数据收集存储于空间数据库中,随着空间数据的不断膨胀,海量的空间数据的大小、复杂性都在快速增长,远远超出了人们的解译能力,从这些空间数据中发现邻域知识迫切需求产生一个多学科、多邻域综合交叉的新兴研究邻域,空间数据挖掘技术应运而生.空间聚类分析方法是空间数据挖掘理论中一个重要的领域,是从海量数据中发现知识的一个重要手段。
K—means算法是空间聚类算法中应用广泛的算法,在聚类分析中起着重要作用。
2、空间聚类空间聚类是空间数据挖掘的一个重要组成部分.作为数据挖掘的一个功能,空间聚类可以作为一个单独的工具用于获取数据的分布情况,观察每个聚类的特征,关注一个特定的聚类集合以深入分析。
空间聚类也可以作为其它算法的预处理步骤,比如分类和特征描述,这些算法将在已发现的聚类上运行。
空间聚类规则是把特征相近的空间实体数据划分到不同的组中,组间的差别尽可能大,组内的差别尽可能小。
空间聚类规则与分类规则不同,它不顾及已知的类标记,在聚类前并不知道将要划分成几类和什么样的类别,也不知道根据哪些空间区分规则来定义类。
(1)因而,在聚类中没有训练或测试数据的概念,这就是将聚类称为是无指导学习(unsupervised learning)的原因。
(2)在多维空间属性中,框定聚类问题是很方便的。
给定m个变量描述的n个数据对象,每个对象可以表示为m维空间中的一个点,这时聚类可以简化为从一组非均匀分布点中确定高密度的点群.在多维空间中搜索潜在的群组则需要首先选择合理的相似性标准.(2)已经提出的空间聚类的方法很多,目前,主要分为以下4种主要的聚类分析方法(3):①基于划分的方法包括K—平均法、K—中心点法和EM聚类法。
Python数据分析与应用_第7章_航空公司客户价值分析报告

特征名称 最小值 最大值
L 12.17 114.57
R 0.03 24.37
F
M
C
2
368
0.14
213
580717
1.5
大数据挖掘专家
17
标准化LRFMC五个特征
L、R、F、M和C五个特征的数据示例,上图为原始数据,下图为标准差标准化处理后的数据。
LOAD_TIME
FFP_DATE
LAST_ TO_END
1.34
大数据挖掘专家
18
目录
1
了解航空公司现状与客户价值分析
2
预处理航空客户数据
3
使用K-Means算法进行客户分群
4
小结
大数据挖掘专家
19
了解K-Means聚类算法
1. 基本概念
K-Means聚类算法是一种基于质心的划分方法,输入聚类个数k,以及包含n个数据对象的数据库,输出满足 误差平方和最小标准的k个聚类。算法步骤如下。 ➢ 从n个样本数据中随机选取k个对象作为初始的聚类中心。 ➢ 分别计算每个样本到各个聚类质心的距离,将样本分配到距离最近的那个聚类中心类别中。 ➢ 所有样本分配完成后,重新计算k个聚类的中心。 ➢ 与前一次计算得到的k个聚类中心比较,如果聚类中心发生变化,转(2),否则转(5)。 ➢ 当质心不发生变化时停止并输出聚类结果。
最大乘机间隔 积分兑换次数 总精英积分
促销积分 合作伙伴积分 总累计积分 非乘机的积分变动次数 总基本积分
6
思考
原始数据中包含40多个特征,利用这些特征做些什么呢?我们又该 从哪些角度出发呢?
大数据挖掘专家
7
项目目标
结合目前航空公司的数据情况,可以实现以下目标。
python_一维数据的k-means算法_概述及解释说明

python 一维数据的k-means算法概述及解释说明1. 引言1.1 概述本文将介绍K-means算法在处理一维数据上的应用。
K-means算法是一种常用的聚类分析方法,可帮助我们将数据集划分为不同的簇。
聚类分析是一种无监督学习方法,通过找到数据中的相似性来对其进行分类,从而提取出隐藏在数据背后的模式和特征。
1.2 文章结构本文共包含以下几个部分:引言、K-means算法概述、一维数据的K-means 算法解释、示例与实现讲解以及结论与展望。
在引言部分,我们将提供一个简要介绍并概括本文所要讨论的主题。
接下来,在K-means算法概述中,我们将详细解释该算法的原理、步骤说明以及适用的场景。
然后,我们会详细探讨如何在一维数据上应用K-means算法,并对其中涉及到的数据预处理、聚类中心计算与更新以及聚类结果评估与迭代调整进行解释。
紧接着,在示例与实现讲解部分,我们将通过具体示例来演示如何使用Python 编写代码实现一维数据的K-means算法,并给出结果可视化和分析解读。
最后,在结论与展望部分,我们将总结本文的主要观点和发现,并展望未来关于K-means算法在一维数据上的研究方向和应用场景的拓展。
1.3 目的本文的目标是为读者提供对K-means算法在处理一维数据时的全面了解和应用指导。
通过阅读本文,读者将了解K-means算法的基本原理、步骤说明以及适用场景,并能够根据具体需求编写代码实现该算法并进行结果分析和解释。
同时,我们还希望通过本文对一维数据的K-means算法进行详细讲解,加深读者对该算法在实际问题中的应用理解和掌握能力。
2. K-means算法概述:2.1 算法原理:K-means算法是一种基于聚类的机器学习算法,主要用于将一组数据分成k 个不同的簇。
该算法通过计算数据点与各个簇中心之间的距离来确定每个数据点所属的簇,并且不断迭代更新簇中心以优化聚类结果。
其核心思想是最小化数据点到其所属簇中心的欧氏距离平方和。
基于K-means聚类算法的青岛房屋分布及价格分析

2021年2月基于聚类算法的青岛房屋分布及价格分析吴正哲(山东科技大学计算机科学与工程学院,山东青岛266590)【摘要】随着大数据时代的到来,互联网已经深深地改变了我们的生活模式。
本文使用Python爬虫技术从青岛链家网二手房网站中抓取招聘信息并清洗;然后利用Python中的matplotlib库,对清洗后的数据进行可视化分析,分析不同类型房屋情况的分布;最后,通过K-means算法和线性回归算法分析青岛房屋的分布与价格,准确得出多个方面的分析数据,起到购房决策辅助作用。
【关键词】K-means;线性回归;数据可视化;机器学习;Python语言;Beautiful Soup技术【中图分类号】G350【文献标识码】A【文章编号】1006-4222(2021)02-0297-020引言“互联网+”时代的到来,增强了房地产经纪业务适应线上、线下场景的产品和服务能力,目前我国房地产经纪业务已经形成O2O的发展格局,未来线上线下渠道将继续加速融合发展。
因此,无论是从带动国民经济发展的角度,还是从满足人民群众基本需求以及开发商投资决策的角度,掌握了解商品住宅价格的变动发展趋势都显得尤为重要。
1相关工作Beautiful Soup是一个可以从HTML或XML文件中提取数据的Python库,简单来说,它能将HTML的标签文件解析成树形结构,然后方便地获取到指定标签的对应属性。
爬取网页的内容其实就是先把页面的信息先通过Urllib库抓取到本地,然后再通过Beautiful Soup库精细划分抓取得到的页面内容数据。
K表示聚类个数,读取全部数据之后,随机选取K个数据作为初始聚类中心,然后将剩余数据计算到聚类中心距离并分配到最近的中心簇,并且相应的删除每个聚类中的个数,更新聚类中心。
Means也就是均值,就是每次“选举大会”每个组内由X和Y的平均值组成新的老大,往往是虚拟的。
形成的新簇并不一定是最好的划分,因此生成的新簇中,重新计算每个簇的中心点,然后在重新进行划分,直到每次划分的结果保持不变。
基于k-means算法改进的短文本聚类研究与实现

文章编号:1009 - 2552(2019)12 - 0076 - 05 DOI:10 13274 / j cnki hdzj 2019 12 016
基于 K ̄means 算法改进的短文本聚类研究与实现
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
基于K-means聚类算法的客户价值分析研究
摘要本文重点讨论了聚类分析方法中K-means聚类算法在客户价值分析中的作用,通过对客户的现有价值和潜在价值进行分析,对客户进行细分。
在此基础上,企业可结合行业的特征找出各类客户的特点,实行差异化服务策略,让更好的资源和服务提供给最有价值客户,从而达到顾客满意、企业盈利的目的。
关键词聚类分析 K-means聚类算法客户价值
1 引言
市场分析理论认为,20%的客户带来约80%的利润,即帕累托所谓“关键的少数与次要的多数”的关于市场分布的一般规律[1]。
通常情况下,只有少部分高价值的客户才能够为企业带来大部分利润。
进行客户细分后,企业可以为高价值客户提供足够的技术和人力试粗С郑猿浞致闫涠云笠悼突Х竦钠谕O喾矗俨糠值图壑档目突в惺焙蛏踔粱岣笠荡锤豪蟆6蠖嗍突г虼τ诟呒壑涤氲图壑抵屑洌瞧笠抵匾目突海;岫云笠档牟莆褚导ú艽蟮挠跋臁R环矫妫腔岽锤嗟目突Х⒄够幔涣硪环矫妫且不嵬贝春芨叩脑擞缦铡6云笠道唇玻呒壑悼突峁┯胖实姆窈苤匾煌忝娴目突峁┫嘤Φ挠姓攵孕缘姆褚餐匾?lt;/DIV>
作为数据挖掘技术中的一种重要的方法,聚类分析可以用于大量客户群细分。
按不同特征将客户分群后,就可以为每一群开发独立的预测模型,并根据每一群的不同特点进行分析,从而提供差异化服务或产品。
常见的聚类分析算法主要有以下三类:
(1)划分法:给定一个有N个(K<N)元组或者记录的数据集,构造K个分组,每一个分组就代表一个聚类。
对于给定的K,算法首先给出一个初始的分组方法,以后通过反复迭代的方法改变分组,使得每一次改进之后的分组方案都较前一次好。
使用该基本思想的算法有K-means算法、K-medoids 算法和CLARANS算法。
(2)层次法:对给定的数据集进行层次似的分解,直到某种条件满足为止。
具体又可分为“自底向上”和“自顶向下”两种方案。
代表算法有BIRCH算法、CURE算法以及CHAMELEON算法等。
(3)基于密度的方法:基本思想就是:只要一个区域中的点的密度大过某个阀值,就把它加到与之相近的聚类中去,以克服基于距离的算法只能发现“类圆形”聚类的缺点。
客户价值作为客户细分的关键变量,传统的市场营销或CRM方案
通常按客户过去或现在对企业的利润水平细分客户,把客户划分为高赢利客户、一般赢利客户和不赢利客户,以此为基础为不同类型的客户设计相应的产品或营销方案。
在客户需求瞬息万变的今天,这种战略容易忽视对潜在客户和成长性客户之间关系的构建和管理,从而影响企业长期的发展。
客户价值研究给企业的启示是,客户细分不仅要考虑客户当前的利润贡献,更要考虑客户的生命周期价值;也就是说既要考虑到客户的现有价值,也要考虑到客户的潜在价值。
本文将应用K-means聚类算法对客户的现有价值和潜在价值进行客户的分类。
2 K-means聚类算法思想及基本步骤
K-means聚类的核心思想如下:算法把n个向量x
j
(j=1,2…,n)
分为c个组G
i
(i=1,2,…,c),并求每组的聚类中心,使得非相似性(或距离)指标的价值函数(或目标函数)达到最小。
当选择欧几里德距离为组j中
向量x
k 与相应聚类中心c
i
下面给出数据集x
i
(1n)的K-means算法的基本步骤。
该算法重复使用下列步骤,确定聚类中心c
i
和隶属矩阵U:
步骤1:初始化聚类中心c
i
,i=1,…,c。
典型的做法是从所有数据点中任取c个点。
步骤2:用式(3)确定隶属矩阵U。
步骤3:根据式(1)计算价值函数。
如果它小于某个确定的阀值,或它相对上次价值函数值的改变量小于某个阀值,则算法停止。
步骤4:根据式(4)修正聚类中心。
返回步骤2。
该算法本身是迭代的,且不能确保它收敛于最优解。
K-means算法的性能依赖于聚类中心的初始位置。
所以,为了使它可取,要么用一些前端方法求好的初始聚类中心;要么每次用不同的初始聚类中心,将该算法运行多次。
此外,上述算法仅仅是一种具有代表性的方法;还可以先初始化一个任意的隶属矩阵,然后再执行迭代过程。
3 K-means聚类算法在客户价值分析中的应用
3.1 算法描述
本文所用的K-means算法,其聚类的数量k是在算法运行前确定的(这是很多聚类算法的典型情况),先从样本中随机捡取k个聚类中心,再根据欧氏距离把每个点分配到最接近其均值的聚类中,然后计算被分配到每个聚类的点的均值向量,并作为新的中心进行递归。
具体的算法是这样的:假定数据点D={X1…….Xn},任务是找到k个聚类{C1……Ck}:
伪代码如下:
for k=1,…n,令R(k)为从D中随机选取的一个点;
while在聚类Ck中有变化发生 do
形成聚类;
for k=1,….,n do
Ck={X属于D|D(Rk,x)≤D(Rj,x) 对所有j=1…..k,j≠k};
end;
计算新的聚类中心;
for k=1,….,n do
Rk =Ck内点的均值向量;
end;
end;
3.2 测试数据及运行结果分析
K-means算法在本文中主要是对客户的现有价值和潜在价值进行聚类分析,从而对客户进行分类,最后根据行业的特定规律和方法分析聚类的结果,产生最终的分析报告。
该算法所使用的测试数据格式如表1所示。
其中,sort为每组数据最终所归属的类别,id为每个客户的代码,sco1为客户的现有价值,sco2为客户的潜在价值。