linux tcpip协议栈分析
linux协议栈

linux协议栈Linux协议栈是Linux操作系统中网络通信的核心组件,也是实现网络通信的关键。
它基于TCP/IP协议栈,提供了一系列的网络协议和接口,负责数据在网络中的传输和接收。
Linux协议栈由多层协议组成,每层都有不同的功能和责任。
从底层到高层依次是链路层(Ethernet)、网络层(IP)、传输层(TCP/UDP)和应用层(HTTP/FTP等)。
每一层都有专门的协议来处理各自的任务,并通过各层之间的接口来传递数据。
在链路层,Linux协议栈使用网络接口卡(NIC)来将数据从计算机发送到网络,并从网络接收数据。
它负责将数据以数据帧的形式封装成网络包,并通过以太网协议(Ethernet)发送出去。
同时,它还负责接收数据帧,并将其解析成网络包交给上层协议处理。
在网络层,Linux协议栈使用IP协议来实现网络寻址和路由功能。
它负责将数据包从源地址发送到目标地址,同时还提供了一些其他的功能,如分片、重组和数据包的生存周期控制等等。
IP协议是整个互联网通信的基石,可以实现跨网络的通信。
在传输层,Linux协议栈提供了TCP和UDP两种协议来实现可靠传输和无连接传输。
TCP协议提供了可靠的、面向连接的数据传输,它通过采用滑动窗口、序号和确认机制来保证数据的可靠性。
而UDP协议则是一种无连接的传输协议,它只提供了数据传输的基本功能,不保证可靠性。
在应用层,Linux协议栈支持各种应用层协议,如HTTP、FTP、SMTP等,以满足不同的应用需求。
这些协议定义了应用程序与网络之间的通信规则和数据格式,让应用程序能够进行网络通信。
除了以上的四层协议,Linux协议栈还包括了其他的功能模块,如网络设备驱动、socket接口和网络管理等,它们共同协同工作,完成网络通信的任务。
总之,Linux协议栈是Linux操作系统中网络通信的核心组件,它提供了一系列的网络协议和接口,负责数据在网络中的传输和接收。
它基于TCP/IP协议栈,包括链路层、网络层、传输层和应用层等多层协议,以及其他的功能模块。
linux 协议栈

linux 协议栈Linux协议栈,又称网络协议栈,是指在Linux操作系统中负责处理网络通信传输的一系列协议和软件集合。
它是实现网络通信的核心组件,负责在应用层和网络硬件之间进行数据传输和信息处理。
Linux协议栈由多个协议层组成,包括物理层、数据链路层、网络层、传输层和应用层。
物理层负责将数据从高层转化为物理信号进行传送,而数据链路层负责将数据在网络间的传递过程中进行帧的封装和解封装,以及网卡的驱动程序。
网络层则负责寻址和路由功能,传输层实现了可靠的端到端通信,应用层提供了各种网络服务。
在物理层的硬件设备中,网络接口卡(NIC)是协议栈与外部网络通信的接口。
协议栈通过驱动程序与NIC进行交互,将数据封装成数据包,并通过数据链路层将数据发往目的地。
在数据链路层,协议栈通过各种链路层协议(如以太网协议)进行数据帧的封装和解封装。
网络层则根据不同的网络协议(如IP协议)进行寻址和路由,将数据从源主机传送到目的主机。
传输层通过传输协议(如TCP或UDP)实现端到端的可靠数据传输。
而应用层则提供了各种网络服务,如HTTP、FTP、DNS等。
Linux协议栈的优点在于其开放源代码的特性和丰富的功能。
由于其开源的特性,用户可以自由地进行定制和修改。
并且,Linux协议栈支持多种网络协议和服务,如IP、TCP、UDP、FTP等。
这使得Linux操作系统具有很高的灵活性和可扩展性,能够满足不同的用户需求。
另外,由于众多开发者的贡献和不断的更新迭代,Linux协议栈也具有较高的稳定性和安全性。
然而,Linux协议栈也存在一些挑战和问题。
对于一些特殊的应用场景和网络需求,Linux协议栈可能无法提供最佳的性能和效果。
此外,在网络安全方面,由于Linux协议栈的复杂性和开放性,也面临着一些潜在的安全风险和漏洞。
总的来说,Linux协议栈是Linux操作系统中的重要组件,负责处理网络通信传输。
它由多个协议层组成,实现了从物理层到应用层的数据传输和处理。
计算机网络:TCPIP协议栈概述

计算机⽹络:TCPIP协议栈概述⽬录参考模型在⽹络刚刚被搞出来的年代,通常只有同⼀个⼚家⽣产的设备才能彼此通信,不同的⼚家的设备不能兼容。
这是因为没有统⼀的标准去要求不同的⼚家按照相同的⽅式进⾏通信,所以不同的⼚家都闭门造车。
为了解决这个问题,后来就产⽣出参考模型的概念。
参考模型是描述如何完成通信的概念模型,它指出了完成⾼效通信所需要的全部步骤,并将这些步骤划分为称之为“层”的逻辑组。
分层最⼤的优点是为上层隐藏下层的细节,即对于开发者来说,如果他们要开发或实现某⼀层的协议,则他们只需要考虑这⼀层的功能即可。
其它层都⽆需考虑,因为其它层的功能有其它层的协议来完成,上层只需要调⽤下层的接⼝即可。
参考模型的优点如下:1. 将⽹络通信过程划分为更⼩、更简单的组件,使得组件的开发、设计和排错更为⽅便;2. 通过标准化⽹络组件,让不同的⼚商能够协作开发;3. 定义了模型每层执⾏的功能,从⽽⿎励了⾏业标准化;4. 让不同类型的⽹络硬件和软件能够彼此通信;5. 避免让对⼀层的修改影响其它层,从⽽避免妨碍开发⼯作。
协议计算机⽹络中的数据交换必须遵守事先约定好的规则,这些规则明确规定了所交换的数据的格式以及有关的同步问题,⽹络协议 (network protocol)是为进⾏⽹络中的数据交换⽽建⽴的规则、标准或约定。
⽹络协议有 3 个要素:1. 语法:数据与控制信息的结构或格式;2. 语义:需要发出何种控制信息,完成何种动作以及做出何种响应;3. 同步:事件实现顺序的详细说明。
OSI 模型OSI 模型旨在以协议的形式帮助⼚商⽣产兼容的⽹络设备和软件,让不同⼚商的⽹络能够协同⼯作。
同时对于⽤户⽽⾔,OSI 能帮助不同的主机之间传输数据。
OSI 并⾮是具体的模型,⽽是⼀组指导原则,开发者以此为依据开发⽹络应⽤。
同时它也提供了框架,指导如何制定和实施⽹络标准、制造设备,以及制定⽹络互联的⽅案。
OSI 模型包含 7 层,上三层指定了终端中应⽤程序如何彼此通信,以及如何与⽤户交互,下四层指定了如何进⾏端到端数据传输。
eth协议数据结构

竭诚为您提供优质文档/双击可除eth协议数据结构篇一:linuxtcpip协议栈的关键数据结构socketbuffer linuxtcp/ip协议栈的关键数据结构socketbuffersk_buff结构可能是linux网络代码中最重要的数据结构,它表示接收或发送数据包的包头信息。
它在中定义,并包含很多成员变量供网络代码中的各子系统使用。
这个结构在linux内核的发展过程中改动过很多次,或者是增加新的选项,或者是重新组织已存在的成员变量以使得成员变量的布局更加清晰。
它的成员变量可以大致分为以下几类:layout布局general通用Feature-specific功能相关managementfunctions管理函数这个结构被不同的网络层(mac或者其他二层链路协议,三层的ip,四层的tcp或udp等)使用,并且其中的成员变量在结构从一层向另一层传递时改变。
l4向l3传递前会添加一个l4的头部,同样,l3向l2传递前,会添加一个l3的头部。
添加头部比在不同层之间拷贝数据的效率更高。
由于在缓冲区的头部添加数据意味着要修改指向缓冲区的指针,这是个复杂的操作,所以内核提供了一个函数skb_reserve(在后面的章节中描述)来完成这个功能。
协议栈中的每一层在往下一层传递缓冲区前,第一件事就是调用skb_reserve在缓冲区的头部给协议头预留一定的空间。
skb_reserve同样被设备驱动使用来对齐接收到包的包头。
如果缓冲区向上层协议传递,旧的协议层的头部信息就没什么用了。
例如,l2的头部只有在网络驱动处理l2的协议时有用,l3是不会关心它的信息的。
但是,内核并没有把l2的头部从缓冲区中删除,而是把有效荷载的指针指向l3的头部,这样做,可以节省cpu时间。
1.网络参数和内核数据结构就像你在浏览tcp/ip规范或者配置内核时所看到的一样,网络代码提供了很多有用的功能,但是这些功能并不是必须的,比如说,防火墙,多播,还有其他一些功能。
TCPIP协议知识科普

TCPIP协议知识科普简介本⽂主要介绍了⼯作中常⽤的TCP/IP对应协议栈相关基础知识,科普⽂。
本博客所有⽂章:TCP/IP⽹络协议栈TCP/IP⽹络协议栈分为四层, 从下⾄上依次是:1. 链路层其实在链路层下⾯还有物理层, 指的是电信号的传输⽅式, ⽐如常见的双绞线⽹线, 光纤, 以及早期的同轴电缆等, 物理层的设计决定了电信号传输的带宽, 速率, 传输距离, 抗⼲扰性等等。
在链路层本⾝, 主要负责将数据跟物理层交互, 常见⼯作包括⽹卡设备的驱动, 帧同步(检测什么信号算是⼀个新帧), 冲突检测(如果有冲突就⾃动重发), 数据差错校验等⼯作。
链路层常见的有以太⽹, 令牌环⽹的标准。
2. ⽹络层⽹络层的IP协议是构成Internet的基础。
该层次负责将数据发送到对应的⽬标地址, ⽹络中有⼤量的路由器来负责做这个事情, 路由器往往会拆掉链路层和⽹络层对应的数据头部并重新封装。
IP层不负责数据传输的可靠性, 传输的过程中数据可能会丢失, 需要由上层协议来保证这个事情。
3. 传输层⽹络层负责的是点到点的协议, 即只到某台主机, 传输层要负责端到端的协议, 即要到达某个进程。
典型的协议有TCP/UDP两种协议, 其中TCP协议是⼀种⾯向连接的, 稳定可靠的协议, 会负责做数据的检测, 分拆和重新按照顺序组装,⾃动重发等。
⽽UDP就只负责将数据送到对应进程, ⼏乎没有任何逻辑, 也就是说需要应⽤层⾃⼰来保证数据传输的可靠性。
4. 应⽤层即我们常见的HTTP, FTP协议等。
这四层协议对应的数据包封装如下图:四层协议对应的通信过程如下图:链路层以太⽹数据帧以太⽹数据帧格式如下:说明如下:1. ⽬的地址和源地址是指⽹卡的硬件地址(即MAC地址), 长度是48位, 出⼚的时候固化的。
2. 类型字段即上层协议类型, ⽬前有三种值: IP, ARP, RARP。
3. 数据对应了上层协议传输的数据, 以太⽹规定数据⼤⼩是46~1500字节, 最⼤值1500即以太⽹的最⼤传输单元(MTU), 不同⽹络类型有不同MTU, 如果需要跨不同类型链路传输的话, 就需要对数据进⾏重新分⽚。
详解TCPIP协议栈面临的五大网络安全问题

详解TCP/IP协议栈面临的五大网络安全问题TCP/IP协议栈面临的五大网络安全问题,也介绍到企业网络安全管理人员在面临问题时所能采取的应对措施。
下面是店铺收集整理的详解TCP/IP协议栈面临的五大网络安全问题,希望对大家有帮助~~ 详解TCP/IP协议栈面临的五大网络安全问题1. IP欺骗IP Spoof即IP 电子欺骗,可以理解为一台主机设备冒充另外一台主机的IP地址与其他设备通信,从而达到某种目的技术。
早在1985年,贝尔实验室的一名工程师Robbert Morris在他的一篇文章“A weakness in the 4.2bsd UNIX TCP/IP software”中提出了IP Spoof 的概念,有兴趣的读者可参见原文:/~emv/tubed/archives/Morris_weakness_in _ TCPIP.txt 。
但要注意:单纯凭借IP Spoof技术不可能很好地完成一次完整的攻击,因为现有IP Spoof技术是属于一种“盲人”式的入侵手段。
一般来说,IP欺骗攻击有6个步骤:(1)首先使被信任主机的网络暂时瘫痪,以免对攻击造成干扰;(2)然后连接到目标机的某个端口来猜测ISN基值和增加规律;(3)接下来把源地址伪装成被信任主机,发送带有SYN标志的数据段请求连接;(4)然后等待目标机发送SYN+ACK包给已经瘫痪的主机;(5)最后再次伪装成被信任主机向目标机发送的ACK,此时发送的数据段带有预测的目标机的ISN+1;(6)连接建立,发送命令请求。
下面是它的两个关键步骤:(1)使被信任主机失去工作能力为了伪装成被信任主机而不露馅,需要使其完全失去工作能力。
由于攻击者将要代替真正的被信任主机,他必须确保真正的被信任主机不能收到任何有效的网络数据,否则将会被揭穿。
有许多方法可以达到这个目的(如SYN洪水攻击、Land等攻击)。
(2)序列号取样和猜测对目标主机进行攻击,必须知道目标主机的数据包序列号。
linux,ip协议栈源代码分析,pdf

竭诚为您提供优质文档/双击可除linux,ip协议栈源代码分析,pdf篇一:netfilter源代码分析详解一、概述filter/iptables框架简介netfilter/iptables是继2.0.x的ipfwadm、2.2.x的ipchains之后,新一代的linux防火墙机制。
netfilter采用模块化设计,具有良好的可扩充性。
其重要工具模块iptables连接到netfilter的架构中,并允许使用者对数据报进行过滤、地址转换、处理等操作。
netfilter提供了一个框架,将对网络代码的直接干涉降到最低,并允许用规定的接口将其他包处理代码以模块的形式添加到内核中,具有极强的灵活性。
2.主要源代码文件linux内核版本:2.4.21netfilter主文件:net/core/netfilter.cnetfilter主头文件:include/linux/netfilter.hipv4相关:c文件:net/ipv4/netfilter/*.c头文件:include/linux/netfilter_ipv4.hinclude/linux/netfilter_ipv4/*.hipv4协议栈主体的部分c文件,特别是与数据报传送过程有关的部分:ip_input.c,ip_forward.c,ip_output.c,ip_fragment.c等二、netfilter/iptables-ipv4总体架构netfilter主要通过表、链实现规则,可以这么说,netfilter是表的容器,表是链的容器,链是规则的容器,最终形成对数据报处理规则的实现。
详细地说,netfilter/iptables的体系结构可以分为三个大部分:filter的hook机制netfilter的通用框架不依赖于具体的协议,而是为每种网络协议定义一套hook函数。
这些hook函数在数据报经过协议栈的几个关键点时被调用,在这几个点中,协议栈将数据报及hook函数标号作为参数,传递给netfilter框架。
LINUX内核网络协议栈

LINUX内核网络协议栈Linux内核网络协议栈是一个关键的软件组件,它实现了Linux操作系统的网络功能。
网络协议栈位于操作系统内核中,负责处理网络传输的各个层级。
Linux内核网络协议栈包括多个层级,从物理层到应用层。
每个层级都有特定的功能和协议。
下面是对每个层级的详细介绍:1.物理层:物理层是网络协议栈的最低层,负责传输数据的物理介质,如电缆、光纤等。
物理层由硬件设备支持,并通过设备驱动程序与内核进行通信。
2.数据链路层:数据链路层负责将数据转换为数据帧,并通过物理介质进行传输。
它包括两个子层:逻辑链路控制层和介质访问控制层。
逻辑链路控制层处理数据的流控制和错误检测,介质访问控制层则管理多个设备的访问冲突。
3.网络层:网络层处理数据包的路由和分组。
它使用IP协议进行路由和寻址,并通过路由表决定数据包的最佳路径。
网络层还可以处理一些附加功能,如分片和重新组装。
4.传输层:传输层负责在不同主机之间的进程之间提供可靠的数据传输。
它使用TCP协议和UDP协议来实现,TCP协议提供可靠的数据传输,而UDP协议提供不可靠但高效的传输。
5.会话层:会话层负责建立、管理和终止网络会话。
它处理会话标识符的生成和管理,并提供可靠的会话传输。
6.表示层:表示层负责数据的编码和解码,以确保数据在不同系统之间的互通。
它处理数据的格式、加密和压缩。
7.应用层:应用层是网络协议栈的最高层,提供用户与网络之间的接口。
它包括多个协议,如HTTP、FTP和SMTP,用于实现各种应用程序的网络功能。
Linux内核网络协议栈的功能包括数据传输、路由、安全、流量控制和错误检测。
内核通过各个层级的协议来实现这些功能。
内核还提供各种工具和接口,使用户可以配置网络设置、监控网络流量和诊断网络问题。
除了基本功能,Linux内核网络协议栈还支持各种高级功能,如多路复用、多队列和嵌入式系统。
它还可以通过加载额外的模块来支持特定的网络协议或功能。
linux网络知识点总结

linux网络知识点总结Linux是一种开放源代码的操作系统,其网络功能十分强大。
本文将从网络基础知识、网络配置、网络命令和网络安全等方面对Linux网络进行详细介绍和总结。
一、网络基础知识1. OSI模型OSI模型是计算机网络体系结构的标准模型,它将网络通信分为七层,每一层都有特定的功能和协议。
从上到下分别为应用层、表示层、会话层、传输层、网络层、数据链路层和物理层。
2. TCP/IP协议TCP/IP协议是Internet上通信的基础协议,它包括TCP、UDP、IP、ICMP等协议。
其中TCP协议提供可靠的数据传输,UDP协议提供不可靠的数据传输,IP协议提供网络层的路由和寻址,ICMP协议用于网络状态的管理和诊断。
3. IP地址IP地址是计算机在Internet上的唯一标识,它分为IPv4和IPv6两种类型。
IPv4地址由32位二进制数表示,通常以四个十进制数表示,例如192.168.1.1;IPv6地址由128位二进制数表示,通常以8组16进制数表示,例如2001:0db8:85a3:0000:0000:8a2e:0370:7334。
4. 子网和子网掩码为了更好地管理IP地址,Internet上的IP地址被划分为多个子网,每个子网有自己的子网掩码。
子网掩码用于将IP地址分割成网络部分和主机部分,例如255.255.255.0表示前三段为网络部分,最后一段为主机部分。
5. 路由和路由表路由是决定数据包从源地址到目的地址的路径的过程,而路由表是保存着路由信息的表格。
当数据包到达路由器时,路由器会根据路由表来选择下一跳路由器或者直接交付目的主机。
二、网络配置1. ifconfig命令ifconfig命令用于配置和显示网络接口的信息,可以使用ifconfig来设置IP地址、子网掩码、默认网关等网络参数。
2. route命令route命令用于配置和显示路由表信息,可以使用route来添加、删除、显示路由表项等操作。
Linux服务器丢包故障的解决思路及引申的TCPIP协议栈理论

我们使用Linux作为服务器操作系统时,为了达到高并发处理能力,充分利用机器性能,经常会进行一些内核参数的调整优化,但不合理的调整常常也会引起意想不到的其他问题,本文就一次Linux服务器丢包故障的处理过程,结合Linux 内核参数说明和TCP/IP协议栈相关的理论,介绍一些常见的丢包故障定位方法和解决思路。
问题现象本次故障的反馈现象是:从办公网访问公网服务器不稳定,服务器某些端口访问经常超时,但Ping测试显示客户端与服务器的链路始终是稳定低延迟的。
通过在服务器端抓包,发现还有几个特点:∙从办公网访问服务器有多个客户端,是同一个出口IP,有少部分是始终能够稳定连接的,另一部分间歇访问超时或延迟很高∙同一时刻的访问,无论哪个客户端的数据包先到达,服务端会及时处理部分客户端的SYN请求,对另一部分客户端的SYN包“视而不见”,如tcpdump数据所示,源端口为56909的SYN请求没有得到响应,同一时间源端口为50212的另一客户端SYN请求马上得到响应。
Shell1 2 3 4 5 6 7 8 $ sudo tcpdump -i eth0 port 22 and "tcp[tcpflags] & (tcp-syn) != 0"18:56:37.404603 IP CLIENT.56909 > SERVER.22: Flags [S], seq 1190606850, win 29200, options [mss 1448,sackOK,TS val 198321481 ecr 0,nop,wscale 7], length 018:56:38.404582 IP CLIENT.56909 > SERVER.22: Flags [S], seq 1190606850, win 29200, options [mss 1448,sackOK,TS val 198321731 ecr 0,nop,wscale 7], length 018:56:40.407289 IP CLIENT.56909 > SERVER.22: Flags [S], seq 1190606850, win 29200, options [mss 1448,sackOK,TS val 198322232 ecr 0,nop,wscale 7], length 018:56:44.416108 IP CLIENT.56909 > SERVER.22: Flags [S], seq 1190606850, win 29200, options [mss 1448,sackOK,TS val 198323234 ecr 0,nop,wscale 7], length 018:56:45.100033 IP CLIENT.50212 > SERVER.22: Flags [S], seq 4207350463, win 65535, options91011 [mss 1366,nop,wscale 5,nop,nop,TS val 821068631 ecr 0,sackOK,eol], length 018:56:45.100110 IP SERVER.22 > CLIENT.50212: Flags [S.], seq 1281140899, ack 4207350464, win 27960, options [mss 1410,sackOK,TS val 1709997543 ecr 821068631,nop,wscale 7], length 018:56:52.439086 IP CLIENT.56909 > SERVER.22: Flags [S], seq 1190606850, win 29200, options [mss 1448,sackOK,TS val 198325240 ecr 0,nop,wscale 7], length 018:57:08.472825 IP CLIENT.56909 > SERVER.22: Flags [S], seq 1190606850, win 29200, options [mss 1448,sackOK,TS val 198329248 ecr 0,nop,wscale 7], length 018:57:40.535621 IP CLIENT.56909 > SERVER.22: Flags [S], seq 1190606850, win 29200, options [mss 1448,sackOK,TS val 198337264 ecr 0,nop,wscale 7], length 018:57:40.535698 IP SERVER.22 > CLIENT.56909: Flags [S.], seq 3621462255, ack 1190606851, win 27960, options [mss 1410,sackOK,TS val 1710011402ecr 198337264,nop,wscale 7], length 0排查过程服务器能正常接收到数据包,问题可以限定在两种可能:部分客户端发出的数据包本身异常;服务器处理部分客户端的数据包时触发了某种机制丢弃了数据包。
linuxOSI七层模型、TCPIP协议栈及每层结构大揭秘
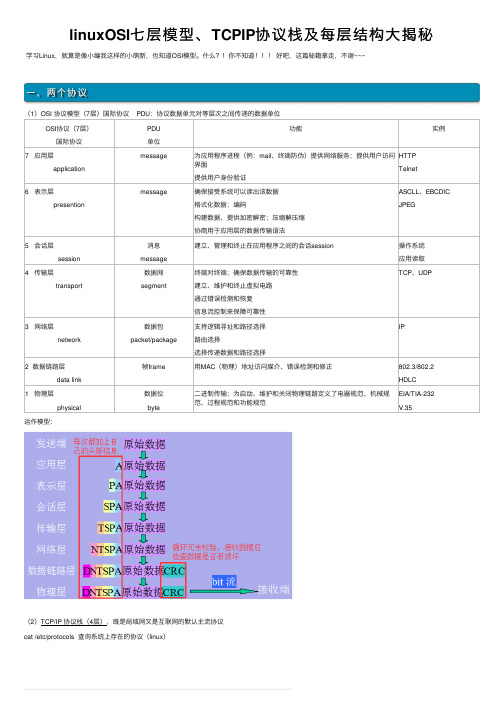
linuxOSI 七层模型、TCPIP 协议栈及每层结构⼤揭秘学习Linux ,就算是像⼩编我这样的⼩萌新,也知道OSI 模型。
什么?!你不知道!!! 好吧,这篇秘籍拿⾛,不谢~~~⼀、两个协议(1)OSI 协议模型(7层)国际协议 PDU :协议数据单元对等层次之间传递的数据单位OSI 协议(7层)国际协议PDU 单位功能实例7 应⽤层applicationmessage为应⽤程序进程(例:mail 、终端防伪)提供⽹络服务;提供⽤户访问界⾯提供⽤户⾝份验证HTTP Telnet6 表⽰层presentionmessage 确保接受系统可以读出该数据格式化数据;编码构建数据、提供加密解密;压缩解压缩协商⽤于应⽤层的数据传输语法ASCLL 、EBCDIC JPEG5 会话层session消息message 建⽴、管理和终⽌在应⽤程序之间的会话session操作系统应⽤读取4 传输层transport数据⽹segment终端对终端;确保数据传输的可靠性建⽴、维护和终⽌虚拟电路通过错误检测和恢复信息流控制来保障可靠性TCP 、UDP 3 ⽹络层network数据包packet/package⽀持逻辑寻址和路径选择路由选择选择传递数据和路径选择IP2 数据链路层data link帧frame⽤MAC (物理)地址访问媒介、错误检测和修正802.3/802.2HDLC 1 物理层physical数据位byte⼆进制传输;为启动、维护和关闭物理链路定义了电器规范、机械规范、过程规范和功能规范EIA/TIA-232V.35运作模型:(2)TCP/IP 协议栈(4层),既是局域⽹⼜是互联⽹的默认主流协议cat /etc/protocols 查询系统上存在的协议(linux )(3)相同点 两者都是以协议栈的概念为基础 协议栈中的协议彼此相互独⽴ 下层对上层提供服务,每层都有区分上层类型的标签不同点 OSI是先有模型;TCP/IP是先有协议,后有模型 OSI适⽤于各种协议栈;TCP/IP只适⽤于TCP/IP⽹络 层次数量不同(4)每层有⾃⼰的结构,下⾯会详解,下表是个简例数据链路层帧Internet IP协议传输层 TCP协议应⽤层⽬标mac 地址源 mac地址源IP地址⽬标IP地址源端⼝⽬标端⼝app数据date⼆、数据链路层帧(1)Ethernet Frame以太⽹帧,IEEE定了国际标准(2)Ethernet Frame 以太⽹帧结构(EthernetII 和 802.3的区别)(数据链路层)以太⽹长度:72-1526(抓包为60-1514除去前8最后4字节) EthernetII866246-15004序⾔Preamble⽬标物理(mac)地址源mac地址Type上层类型Data (包含上层协议头部信息)FCS 检查数据包故障 IEEE 802.37166246-15004序⾔Preamble SOF⽬标物理(mac)地址源mac地址Length长度Data (包含上层协议头部信息)FCS 检查数据包故障EthernetII 有标识Type上层⽂件类型,IEEE 802.3没有(存在问题)(3)抓包实例(4)mac地址(48位)不同地⽅不同的意思,媒体访问控制media access control MAC 48全为1(12个F):⼴播三、传输层,TCP和UDP协议(1)TCP可靠性和 UDP⾼效性区别区别TCP可靠性UDP⾼效性Connection Type⾯向连接connection-oriented ⾮⾯向连接connectionless序列化Sequencingyes noUses E-mailFile sharingDownloading...voice streamingvideo streaming(2)TCP1.特性 ⼯作在传输层⾯向连接协议 全双⼯协议 半关闭(分⼿的时候) 错误检查 将数据打包成段,排序,序列号 确认机制 数据恢复,重传 流量控制,滑动窗⼝ 拥塞控制,慢启动和拥塞避免算法(慢启动)2.TCP包头(20固定[+40可选项])①源端⼝、⽬标端⼝:计算机上的进程要和其他进程通信是要通过计算机端⼝的,⽽⼀个计算机端⼝某个时刻只能被⼀个进程占⽤,所以通过指定源端⼝和⽬标端⼝,就可以知道是哪两个进程需要通信。
几个主流TCPIP协议栈介绍

⼏个主流TCPIP协议栈介绍我们知道协议栈内包括了诸多协议。
那么对于这当中的协议的功能以及作⽤,我们来具体了解⼀下吧。
现在让我们做⼀个盘点,帮助⼤家总结⼀下,还望对⼤家能够有所帮助。
1、BSD TCP IP协议栈BSD栈历史上是其他商业栈的起点,⼤多数专业TCP/IP栈(VxWorks内嵌的TCP/IP栈)是BSD栈派⽣的.这是因为BSD栈在BSD许可协议下提供了这些专业栈的雏形,BSD许⽤证允许BSD栈以修改或未修改的形式结合这些专业栈的代码⽽⽆须向创建者付版税.同时,BSD也是许多TCP/IP协议中的创新(如⼴域⽹中饿拥塞控制和避免)的开始点.2、uC/IPuC/IP是由Guy Lancaster编写的⼀套基于uC/OS且开放源码的TCP IP协议栈,亦可移植到其它操作系统,是⼀套完全免费的、可供研究的TCP IP协议栈,uC/IP⼤部分源码是从公开源码BSD发布站点和KA9Q(⼀个基于DOS单任务环境运⾏的TCP IP协议栈)移植过来.uC/IP具有如下⼀些特点:带⾝份验证和报头压缩⽀持的PPP协议,优化的单⼀请求/回复交互过程,⽀持IP/TCP/UDP协议,可实现的⽹络功能较为强⼤,并可裁减.UCIP协议栈被设计为⼀个带最⼩化⽤户接⼝及可应⽤串⾏链路⽹络模块.根据采⽤CPU、编译器和系统所需实现协议的多少,协议栈需要的代码容量空间在30-60KB之间.3、LwIPLwIP是瑞⼠计算机科学院(Swedish Institute of Computer Science)的Adam Dunkels等开发的⼀套⽤于嵌⼊式系统的开放源代码TCP IP协议栈.LwIP的含义是Light Weight(轻型)IP协议,相对于uip.LwIP可以移植到操作系统上,也可以在⽆操作系统的情况下独⽴运⾏.LwIP TCP/IP实现的重点是在保持TCP协议主要功能的基础上减少对RAM的占⽤,⼀般它只需要⼏⼗K的RAM和40K左右的ROM就可以运⾏,这使LwIP协议栈适合在低端嵌⼊式系统中使⽤.LwIP的特性如下:⽀持多⽹络接⼝下的IP转发,⽀持ICMP协议 ,包括实验性扩展的的UDP(⽤户数据报协议),包括阻塞控制,RTT估算和快速恢复和快速转发的TCP(传输控制协议),提供专门的内部回调接⼝(Raw API)⽤于提⾼应⽤程序性能,并提供了可选择的Berkeley接⼝API。
linux协议栈

Init_call_start以及init_call_end
Link script会把特定类型的段放在了特定位 置,vmlinxu_32_lds.S是内核的ld script, 在这个文件中定义了init_call_start以及 init_call_end 当编译内核的时候,它会把所有定义为 __init的函数放在以init_call_start开始, 以init_call_end结束的节中,这样 do_initcalls()就可以挨个调用实现定义好 的函数了 可以通过objdump –t vmlinux | grep install 查看
Link script
连接器有自己的一套语言规范,其目的是描述输入文件中 的section是如何被映射到输出文件中,并控制输出文件的 内存排列。 编译生成用户态执行的程序使用ld -verbose查看默认 script,它是内置在连接器中,ld就是使用这个缺省的 script去输出应用程序 而编译内核的时候,使用的是内核提供的script--arch/xxx/kernel/vmlinux_32.lds.S
IP Stack在Linux中的位置
由IP Stack所处的位置上看,它牵扯到内核中大部分模块,如果对其中没一 部分没有一定的了解的话,那么对IP Stack工作行为理解就会出现一些问题, 这个也是协议栈的难点
网络协议发展介绍
1 网络协议的优胜劣汰----无数的私有协议逐渐的消 失 2 IP协议的出现----被学校和军方发展壮大,形成协 议族TCP/IP 3 TCP/IP协议族----健壮、简单 4 蚕食其他网络市场份额--IPX
挂接ISR
ISR挂接过程: 1 驱动程序要首先正确的初始化 2 调用request_irq() 3 然后调用set_irq(),把申请的中断挂入相应的 中断链 4 handle_IRQ_event()就可以根据irq直接找到 handle
TCPIP协议分析_实验4_分析ARP缓冲区、IPv4和IPv6的路由表和路由协议

《TCP/IP协议分析》实验报告实验序号:4 实验项目名称:分析ARP缓冲区、IPv4和IPv6的路由表和路由协议20网工学号姓名专业、班实验地点指导教师实验时间2022-09-28 一、实验目的、步骤和结果动手项目4-1:管理本地ARP缓冲区项目目标:学习如何管理本地ARP的内容。
(1)单击Start(开始)按钮,单击Run(运行),在Open(打开)文本框中输入cmd,单击OK(确定)按钮。
屏幕上显示一个命令提示符窗口。
(2)在命令提示符下,输入arp -a命令,按Enter 键,浏览本地ARP缓冲区的内容。
记录出现在ARP缓冲区中的任何项。
(3)输入arp -d命令,按Enter键,删除本地ARP缓冲区的内容。
(4)输入arp -a命令,按Enter键,再次浏览ARP缓冲区。
记录出现在你的ARP缓冲区中的新项。
此时缓冲区应该为空。
(5)输入ping ip_address命令,其中ip_address 本地网络中的一台IP主机,然后按Enter键。
(6)在ping命令运行结束后,输入arp -a命令并按Enter 键,再次查看ARP缓冲区的内容,记录出现的新项。
此时的ARP缓冲区应只有ping之后的项了,如图所示。
动手项目4-2:读取本地IPv4路由表项目描述:学习如何查看本地计算机IPv4网卡路由表。
(1)单击Start(开始)按钮,单击Run(运行)按钮,在Open(打开)文本框中输入cmd,单击OK(确定)按钮。
屏幕上显示一个命令提示符窗口。
(2)在命令提示符下,输入netsh命令,并按Enter键。
(3)在netsh提示符后面,输入interface ipv4命令,然后按Enter 键。
(4)在命令提示符下,输入show route 命令,并按Enter键,查看本地IPv4路由表,如图所示。
(5)输入exit命令并按Enter 键,然后再输入exit命令并按Enter键,关闭命令提示符窗口。
TCPIP协议栈及OSI参考模型详解(2021年整理)

TCPIP协议栈及OSI参考模型详解(word版可编辑修改)编辑整理:尊敬的读者朋友们:这里是精品文档编辑中心,本文档内容是由我和我的同事精心编辑整理后发布的,发布之前我们对文中内容进行仔细校对,但是难免会有疏漏的地方,但是任然希望(TCPIP协议栈及OSI参考模型详解(word版可编辑修改))的内容能够给您的工作和学习带来便利。
同时也真诚的希望收到您的建议和反馈,这将是我们进步的源泉,前进的动力。
本文可编辑可修改,如果觉得对您有帮助请收藏以便随时查阅,最后祝您生活愉快业绩进步,以下为TCPIP协议栈及OSI参考模型详解(word版可编辑修改)的全部内容。
OSI参考模型OSI RM:开放系统互连参考模型(open systeminterconnection reference model)OSI参考模型具有以下优点:•简化了相关的网络操作;•提供设备间的兼容性和标准接口;•促进标准化工作;•结构上可以分隔;•易于实现和维护。
20世纪60年代以来,计算机网络得到了飞速增长.各大厂商为了在数据通信网络领域占据主导地位,纷纷推出了各自的网络架构体系和标准,如IBM公司的SNA,Novell IPX/SPX协议,Apple公司的AppleTalk协议,DEC公司的DECnet,以及广泛流行的TCP/IP协议。
同时,各大厂商针对自己的协议生产出了不同的硬件和软件。
各个厂商的共同努力促进了网络技术的快速发展和网络设备种类的迅速增长。
但由于多种协议的并存,也使网络变得越来越复杂;而且,厂商之间的网络设备大部分不能兼容,很难进行通信。
为了解决网络之间的兼容性问题,帮助各个厂商生产出可兼容的网络设备,国际标准化组织ISO于1984年提出了OSI RM(OpenSystem Interconnection Reference Model,开放系统互连参考模型)。
OSI 参考模型很快成为计算机网络通信的基础模型。
在设计OSI 参考模型时,遵循了以下原则:各个层之间有清晰的边界,实现特定的功能;层次的划分有利于国际标准协议的制定;层的数目应该足够多,以避免各个层功能重复.OSI分层通常OSI参考模型第一层到第三层称为底层(lower layer),又叫介质层(media layer),底层负责数据在网络中的传送,网络互连设备往往位于下三层,以硬件和软件的方式来实现.OSI参考模型的第五层到第七层称为高层(upper layer),又叫住几层(host layer),高层用于保障数据的正确传输,以软件方式来实现。
LINUX网络篇课件

FTP服务器配置
FTP通过客户端和服务器之间的交互,实现 文件的上传和下载。
FTP安全问题
FTP面临的安全问题包括文件泄露、密码破 解和恶意软件传播等,需要采取相应的安全 措施来保护FTP服务器的安全。
HTTP服务
01
HTTP服务概述
HTTP(Hypertext Transfer Protocol)是一种用于传输超 文本的协议,是互联网上应用 最广泛的一种网络协议。
工作原理
firewalld通过监听系统事件和网络状态,动态地调整防火墙规则,以 适应不同的网络环境和安全需求。
优点
firewalld具有动态管理的能力,可以快速响应网络环境和安全需求的 变化。
缺点
firewalld的功能较为复杂,需要一定的技术背景和经验才能熟练使用 。
05
Linux网络编程
socket编程基础
01
TCP/IP协议栈是互联网的基础, 它由多个协议组成,包括TCP、 IP、UDP等。
02
03
IP是网络层协议,负责将数据从 一个网络节点传送到另一个网络 节点。
04
IP地址和子网掩码
01
IP地址是网络中每个主机的唯一标识,由32位二进制数组成, 通常以十进制形式表示。
02
IP地址分为五类,分别是A、B、C、D和E类,其中常用的是A
02
HTTP工作原理
HTTP通过客户端和服务器之 间的请求和响应交互,实现网 页的浏览和数据的传输。
03
HTTP服务器配置
配置HTTP服务器需要设置网 页目录、MIME类型和访问权 限等,以确保网页的正常显示 和数据的安全传输。
04
HTTP安全问题
HTTP面临的安全问题包括跨 站脚本攻击(XSS)、SQL注 入和跨站请求伪造(CSRF) 等,需要采取相应的安全措施 来保护HTTP服务器的安全。
Linux协议栈实现分析完整版

sys_socketcall()
sys_socketcall()
sys_socketcall()
sys_socketcall()
sys_socket()
sys_bind()
sys_listen()
sys_accept()
sock_create()
sockfd_lookup()
sockfd_lookup()
ip_route_connect()
sock_close()
tcp_connect()
sock->ops->release()
tcp_transmit_skb()
tcp_close()、udp_close()
read调用
read() sys_read() sock_readv() sock_readv_writev()
如果定义了NETFILTER,则先进入 IP_FORWARD
Iq
lter
ip_options_compile ip_forward_finish ip_route_input_slow 在缓存中找到
ip_output.c:367
ip
进行路由,并把skb->dst->input函数 指针指向ip_local_deliver或ip_error 或ip_forward或ip Route.c:1658-1675行,在路由时 会先在路由缓存中查找,没找到则 由ip_route_input_slow函数从路 由表中查,并加入到缓存中
sockfd_lookup()
__sock_create()
security_socket_bind()
security_socket_listen()
TCPIP详解

TCPIP详解TCP/IP不是⼀个协议,⽽是⼀个协议族的统称。
⾥⾯包括了IP协议,IMCP协议,TCP协议,以及我们更加熟悉的http、ftp、pop3协议等等。
TCP/IP协议分层提到协议分层,我们很容易联想到ISO-OSI的七层协议经典架构,但是TCP/IP协议族的结构则稍有不同。
如图所⽰TCP/IP协议族按照层次由上到下,层层包装。
最上⾯的就是应⽤层了,这⾥⾯有http,ftp,等等我们熟悉的协议。
第⼆层则是传输层,著名的TCP和UDP(User Datagram Protocol)协议就在这个层次。
第三层是⽹络层,IP协议就在这⾥,它负责对数据加上IP地址和其他的数据以确定传输的⽬标。
第四层是叫数据链路层,这个层次为待传送的数据加⼊⼀个以太⽹协议头,并进⾏CRC编码,为最后的数据传输做准备。
再往下则是硬件层次了,负责⽹络的传输,这个层次的定义包括⽹线的制式,⽹卡的定义等等发送协议的主机从上⾃下将数据按照协议封装,⽽接收数据的主机则按照协议从得到的数据包解开,最后拿到需要的数据。
这种结构⾮常有栈的味道,所以某些⽂章也把tcp/ip协议族称为tcp/ip协议栈。
⼀些基本的常识互联⽹地址(ip地址):⽹络上每⼀个节点都必须有⼀个独⽴的Internet地址(也叫做IP地址)。
现在,通常使⽤的IP地址是⼀个32bit的数字,也就是我们常说的IPv4标准,这32bit的数字分成四组,也就是常见的255.255.255.255的样式。
IPv4标准上,地址被分为五类,我们常⽤的是B类地址。
具体的分类请参考其他⽂档。
需要注意的是IP地址是⽹络号+主机号的组合,这⾮常重要。
域名系统:域名系统是⼀个分布的数据库,它提供将主机名(就是⽹址啦)转换成IP地址的服务。
RFC:RFC是什么?RFC就是tcp/ip协议的标准⽂档,它⼀共有4000多个协议的定义,当然,我们所要学习的,也就是那么⼗⼏个协议⽽已。
端⼝号(port):这个端⼝号是⽤在TCP,UDP上的⼀个逻辑号码,并不是⼀个硬件端⼝,我们平时说把某某端⼝封掉了,也只是在IP层次把带有这个号码的IP包给过滤掉了⽽已。
net_device

Linux TCP/IP 协议栈的关键数据结构 net_device2008-07-16 14:39:13| 分类:学习日记 | 标签:|字号大中小订阅net_device结构保存与网络设备相关的所有信息。
每一个网络设备都对应一个这样的结构,包括真实设备(例如以太网卡)和虚拟设备(比如bonding或VLAN)。
Bonding,也被称作EtherChannel(Cisco的术语)和 trunking(Sun的术语),允许把一定数量的接口组合起来当作一个新的设备。
这个特性在系统需要把多个点对点设备组合起来以获取更高带宽时有用。
新设备的速度可以成倍增加,一般来说,新设备的吞吐量是单个设备吞吐量的总和。
VLAN代表虚拟局域网。
VLAN的作用是在二层交换机上划分不同的广播域,从而把不同广播域的流量隔离开。
它通过在链路层上增加一个标记来实现这个功能。
你可以在/article /7268找到VLAN的简介以及它在LINUX中的使用方法。
所有设备的net_device结构都放在一个全局链表中,链表的头指针是dev_base。
net_device 结构的定义在include/linux/netdevice.h中。
与sk_buff类似,net_device结构比较大,而且包含了很多特性相关的参数,这些参数在不同的协议层中使用。
出于这个原因,net_device结构的组织会有一些改变,用于优化协议栈的性能。
网络设备可以分为不同的类型,比如以太网卡和令牌环网卡。
net_device结构中的某些变量对同一类型的设备来说,取值是相同的;而某些变量在同一设备的不同工作模式下,取值必须不同。
因此,对几乎所有类型的设备,linux内核提供了一个通用的函数用于初始化那些在所有模式下取值相同的变量。
每一个设备驱动在调用这个函数的同时,还初始化那些在当前模式下取值不同的变量。
设备驱动同样可以覆盖那些由内核初始化的变量(例如,在优化设备性能时)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
sk_buff结构可能是linux网络代码中最重要的数据结构,它表示接收或发送数据包的包头信息。
它在<include/linux/skbuff.h>中定义,并包含很多成员变量供网络代码中的各子系统使用。
这个结构在linux内核的发展过程中改动过很多次,或者是增加新的选项,或者是重新组织已存在的成员变量以使得成员变量的布局更加清晰。
它的成员变量可以大致分为以下几类:∙Layout 布局∙General 通用∙Feature-specific功能相关∙Management functions管理函数这个结构被不同的网络层(MAC或者其他二层链路协议,三层的IP,四层的TCP或UDP等)使用,并且其中的成员变量在结构从一层向另一层传递时改变。
L4向L3传递前会添加一个L4的头部,同样,L3向L2传递前,会添加一个L3的头部。
添加头部比在不同层之间拷贝数据的效率更高。
由于在缓冲区的头部添加数据意味着要修改指向缓冲区的指针,这是个复杂的操作,所以内核提供了一个函数skb_reserve (在后面的章节中描述)来完成这个功能。
协议栈中的每一层在往下一层传递缓冲区前,第一件事就是调用skb_reserve在缓冲区的头部给协议头预留一定的空间。
skb_reserve同样被设备驱动使用来对齐接收到包的包头。
如果缓冲区向上层协议传递,旧的协议层的头部信息就没什么用了。
例如,L2的头部只有在网络驱动处理L2的协议时有用,L3是不会关心它的信息的。
但是,内核并没有把L2的头部从缓冲区中删除,而是把有效荷载的指针指向L3的头部,这样做,可以节省CPU时间。
1. 网络参数和内核数据结构就像你在浏览TCP/IP规范或者配置内核时所看到的一样,网络代码提供了很多有用的功能,但是这些功能并不是必须的,比如说,防火墙,多播,还有其他一些功能。
大部分的功能都需要在内核数据结构中添加自己的成员变量。
因此,sk_buff里面包含了很多像#ifdef这样的预编译指令。
例如,在sk_buff结构的最后,你可以找到:struct sk_buff {... ... ...#ifdef CONFIG_NET_SCHED_ _u32 tc_index;#ifdef CONFIG_NET_CLS_ACT_ _u32 tc_verd;_ _u32 tc_classid;#endif#endif}它表明,tc_index只有在编译时定义了CONFIG_NET_SCHED符号才有效。
这个符号可以通过选择特定的编译选项来定义(例如:"Device Drivers Networking supportNetworking options QoS and/orfair queueing")。
这些编译选项可以由管理员通过make config来选择,或者通过一些自动安装工具来选择。
前面的例子有两个嵌套的选项:CONFIG_NET_CLS_ACT(包分类器)只有在选择支持“QoS and/or fair queueing”时才能生效。
顺便提一下,QoS选项不能被编译成内核模块。
原因就是,内核编译之后,由某个选项所控制的数据结构是不能动态变化的。
一般来说,如果某个选项会修改内核数据结构(比如说,在sk_buff里面增加一个项tc_index),那么,包含这个选项的组件就不能被编译成内核模块。
你可能经常需要查找是哪个make config编译选项或者变种定义了某个#ifdef标记,以便理解内核中包含的某段代码。
在2.6内核中,最快的,查找它们之间关联关系的方法,就是查找分布在内核源代码树中的kconfig文件中是否定义了相应的符号(每个目录都有一个这样的文件)。
在2.4内核中,你需要查看Documentation/Configure.help文件。
2. Layout Fields有些sk_buff成员变量的作用是方便查找或者是连接数据结构本身。
内核可以把sk_buff组织成一个双向链表。
当然,这个链表的结构要比常见的双向链表的结构复杂一点。
就像任何一个双向链表一样,sk_buff中有两个指针next和prev,其中,next指向下一个节点,而prev指向上一个节点。
但是,这个链表还有另一个需求:每个sk_buff结构都必须能够很快找到链表头节点。
为了满足这个需求,在第一个节点前面会插入另一个结构sk_buff_head,这是一个辅助节点,它的定义如下:struct sk_buff_head {/* These two members must be first. */ struct sk_buff * next;struct sk_buff * prev;_ _u32 qlen;spinlock_t lock;};qlen代表链表元素的个数。
lock用于防止对链表的并发访问。
sk_buff和sk_buff_head的前两个元素是一样的:next和prev指针。
这使得它们可以放到同一个链表中,尽管sk_buff_head要比sk_buff小得多。
另外,相同的函数可以同样应用于sk_buff和sk_buff_head。
为了使这个数据结构更灵活,每个sk_buff结构都包含一个指向sk_buff_head的指针。
这个指针的名字是list。
图1会帮助你理解它们之间的关系。
Figure 1. List of sk_buff elements其他有趣的成员变量如下:struct sock *sk这是一个指向拥有这个sk_buff的sock结构的指针。
这个指针在网络包由本机发出或者由本机进程接收时有效,因为插口相关的信息被L4(TCP或UDP)或者用户空间程序使用。
如果sk_buff只在转发中使用(这意味着,源地址和目的地址都不是本机地址),这个指针是NULL。
unsigned int len这是缓冲区中数据部分的长度。
它包括主缓冲区中的数据长度(data指针指向它)和分片中的数据长度。
它的值在缓冲区从一个层向另一个层传递时改变,因为往上层传递,旧的头部就没有用了,而往下层传递,需要添加本层的头部。
len同样包含了协议头的长度。
unsigned int data_len和len不同,data_len只计算分片中数据的长度。
unsigned int mac_len这是mac头的长度。
atomic_t users这是一个引用计数,用于计算有多少实体引用了这个sk_buff缓冲区。
它的主要用途是防止释放sk_buff 后,还有其他实体引用这个sk_buff。
因此,每个引用这个缓冲区的实体都必须在适当的时候增加或减小这个变量。
这个计数器只保护sk_buff结构本身,而缓冲区的数据部分由类似的计数器(dataref)来保护. 有时可以用atomic_inc和atomic_dec函数来直接增加或减小users,但是,通常还是使用函数skb_get 和kfree_skb来操作这个变量。
unsigned int truesize这是缓冲区的总长度,包括sk_buff结构和数据部分。
如果申请一个len字节的缓冲区,alloc_skb函数会把它初始化成len+sizeof(sk_buff)。
struct sk_buff *alloc_skb(unsigned int size,int gfp_mask){... ... ...skb->truesize = size + sizeof(struct sk_buff);... ... ...}当skb->len变化时,这个变量也会变化。
unsigned char *headunsigned char *endunsigned char *dataunsigned char *tail它们表示缓冲区和数据部分的边界。
在每一层申请缓冲区时,它会分配比协议头或协议数据大的空间。
head 和end指向缓冲区的头部和尾部,而data和tail指向实际数据的头部和尾部,参见图2。
每一层会在head 和data之间填充协议头,或者在tail和end之间添加新的协议数据。
图2中右边数据部分会在尾部包含一个附加的头部。
Figure 2. head/end versus data/tail pointersvoid (*destructor)(...)这个函数指针可以初始化成一个在缓冲区释放时完成某些动作的函数。
如果缓冲区不属于一个socket,这个函数指针通常是不会被赋值的。
如果缓冲区属于一个socket,这个函数指针会被赋值为sock_rfree 或sock_wfree(分别由skb_set_owner_r或skb_set_owner_w函数初始化)。
这两个sock_xxx函数用于更新socket的队列中的内存容量。
3. General Fields本节描述sk_buff的主要成员变量,这些成员变量与特定的内核功能无关:struct timeval stamp这个变量只对接收到的包有意义。
它代表包接收时的时间戳,或者有时代表包准备发出时的时间戳。
它在netif_rx里面由函数net_timestamp设置,而netif_rx是设备驱动收到一个包后调用的函数。
struct net_device *dev这个变量的类型是net_device,net_device它代表一个网络设备。
dev的作用与这个包是准备发出的包还是刚接收的包有关。
当收到一个包时,设备驱动会把sk_buff的dev指针指向收到这个包的设备的数据结构,就像下面的vortex_rx里的一段代码所做的一样,这个函数属于3c59x系列以太网卡驱动,用于接收一个帧。
(drivers/net/3c59x.c):static int vortex_rx(struct net_device *dev){... ... ...skb->dev = dev;... ... ...skb->protocol = eth_type_trans(skb, dev);netif_rx(skb); /* Pass the packet to the higher layer*/... ... ...}当一个包被发送时,这个变量代表将要发送这个包的设备。
在发送网络包时设置这个值的代码要比接收网络包时设置这个值的代码复杂。
有些网络功能可以把多个网络设备组成一个虚拟的网络设备(也就是说,这些设备没有和物理设备直接关联),并由一个虚拟网络设备驱动管理。
当虚拟设备被使用时,dev指针指向虚拟设备的net_device结构。
而虚拟设备驱动会在一组设备中选择一个设备并把dev指针修改为这个设备的net_device结构。
因此,在某些情况下,指向传输设备的指针会在包处理过程中被改变。