语音识别-矢量量化
简述语音信号处理的关键技术

简述语音信号处理的关键技术语音信号处理是一门研究如何对语音信号进行分析、合成、增强、压缩等处理的学科。
在语音通信、语音识别、语音合成等领域都有广泛的应用。
本文将以简述语音信号处理的关键技术为标题,介绍语音信号处理的几个关键技术。
一、语音信号的数字化语音信号是一种连续的模拟信号,为了进行数字化处理,首先需要对其进行采样和量化。
采样是指在一定时间间隔内对语音信号进行测量,将其离散化;量化是指将采样得到的连续幅值值域离散化为一组有限的幅值级别。
通过采样和量化,将语音信号转换为离散的数字信号,为后续的数字信号处理提供了基础。
二、语音信号的预处理语音信号中可能存在噪声、回声等干扰,需要对其进行预处理。
常用的预处理方法有滤波和语音增强。
滤波是通过滤波器对语音信号进行去噪处理,常用的滤波器有陷波滤波器、带通滤波器等。
语音增强是通过增强语音信号中的有用信息,提高语音信号的质量。
常用的语音增强方法有谱减法、波束形成等。
三、语音信号的特征提取语音信号中包含了大量的特征信息,如频率、能量等。
为了方便后续的分析和处理,需要对语音信号进行特征提取。
常用的特征提取方法有短时能量、过零率、倒谱系数等。
这些特征可以用来描述语音信号的时域和频域特性,为语音识别等任务提供基础。
四、语音信号的压缩与编码语音信号具有较高的数据量,为了减少存储和传输的开销,需要对语音信号进行压缩与编码。
语音信号压缩是指通过一系列的算法和技术,将语音信号的冗余信息去除或减少,从而减小信号的数据量。
常用的语音信号压缩算法有线性预测编码(LPC)、矢量量化、自适应差分编码等。
五、语音信号的识别与合成语音识别是指将语音信号转换为对应的文字或命令,是语音信号处理的一个重要应用。
语音识别技术可以分为基于模型的方法和基于统计的方法。
基于模型的方法是指通过建立声学模型和语言模型,利用模型的匹配程度来进行识别。
基于统计的方法是指通过统计分析语音信号和文本之间的关系,利用统计模型进行识别。
语音识别技术简介

语音识别技术简介我想大家都听过阿里巴巴与四十大盗的故事,阿里巴巴的“芝麻开门”就是一个语音识别的例子,可见语音识别是很早就启蒙了。
今天我就和大家一起来学习一下语音识别技术。
让机器听懂人类的语音,这是人们长期以来梦寐以求的事情。
伴随计算机技术发展,语音识别己成为信息产业领域的标志性技术,在人机交互应用中逐渐进入我们日常的生活,并迅速发展成为“改变未来人类生活方式厅的关键技术之一”。
语音识别技术以语音信号为研究对象,是语音信号处理的一个重要研究方向。
其最终目标是实现人与机器进行自然语言通信。
语音识别技术就是让机器通过识别和理解过程把语音信号转变为相应的文本或命令的高技术。
主要包括特征提取技术、模式匹配准则及模型训练技术三个方面,所涉及的领域包括:信号处理、模式识别、概率论和信息论、发声机理和听觉机理、人工智能等。
今天主要讲的内容有:语音识别的发展历史、系统分类、基本方法、系统结构、面临问题以及前景展望。
语音识别发展历史1952年贝尔研究所Davis等人研究成功了世界上第一个能识别10个英文数字发音的实验系统。
1960年英国的Denes等人研究成功了第一个计算机语音识别系统。
大规模的语音识别[3]研究是在进入了70年代以后,在小词汇量、孤立词的识别方面取得了实质性的进展。
进入80年代以后,研究的重点逐渐转向大词汇量、非特定人连续语音识别。
在研究思路上也发生了重大变化,即由传统的基于标准模板匹配的技术思路开始转向基于统计模型(HMM)的技术思路。
此外,再次提出了将神经网络技术引入语音识别问题的技术思路。
进入90年代以后,在语音识别的系统框架方面并没有什么重大突破。
但是,在语音识别技术的应用及产品化方面出现了很大的进展。
我国语音识别研究工作起步于五十年代,但近年来发展很快。
研究水平也从实验室逐步走向实用。
我国语音识别技术的研究水平已经基本上与国外同步,在汉语语音识别技术上还有自己的特点与优势,并达到国际先进水平。
带你了解语音识别技术
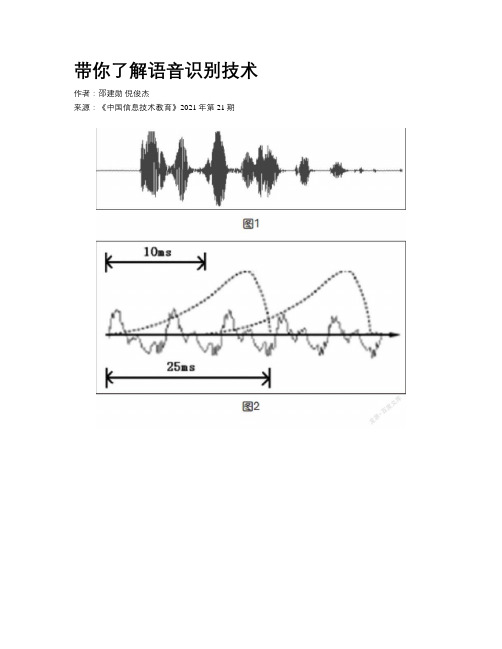
带你了解语音识别技术作者:邵建勋倪俊杰来源:《中国信息技术教育》2021年第21期编者按:语音识别技术在生活中的应用已经非常广泛,如在车载导航、智能家居、日常办公等领域都有涉及,给人们生活带来了很多便利。
由于语音交互是一种更便利、更自然、更高效的沟通形式,所以它必定成为未来最主要的人机交互接口之一。
那么,你真的了解语音识别技术吗?它的发展历程和技术原理又是怎样的?我们一起来了解。
语音识别技术又称ASR技术(Automatic Speech Recognition),指机器自动将语音转成文字。
语音识别技术属于人工智能方向的一个重要分支,涉及许多学科,如信号处理、计算机科学、语言学、声学、生理学、心理学等,是人机自然交互技术中的关键环节。
语音识别技术诞生半个多世纪以来,由于缺乏突破性进展,在技术上存在较大缺陷,一直处在实验室研究阶段,没有在实际应用中得到认可。
2009年是一个转折点,深度学习和人工神经网络的兴起,使得语音识别技术在常见词汇场景下识别率超过了95%,这意味着语音识别技术具备了与人类相仿的语言识别能力。
但不可否认的是,即使到现在,语音识别技术还是存在着很多不足,如对强噪声、超远场、强干扰、多语种、大词汇等场景下的语音识别还有很大的提升空间。
国内某机构发布的《2018—2022年中国智能语音行业深度调研及投资前景预测报告》显示,我国智能语音市场整体处于启动期,智能车载、智能家居、智能可穿戴等垂直领域处于爆发前夜。
因此,我们有必要深入了解一下它的发展历程和技术原理。
语音识别技术的发展历程最早在1952年,著名的贝尔实验室首次实现Aurdrey英文数字识别实验系统(6英尺高),该系统有两个特点:①可以识别0~9单个数字的发音;②对熟人的发音识别准确度高达90%以上。
同时期,美国麻省理工学院的林肯实验室开发了针对十个元音的非特定人语音识别系统,普林斯顿大学的RCA实验室也开发了单音节识别系统,能够识别特定人的十个单音节词中所包含的不同音节。
语音识别技术是什么_语音识别技术应用领域介绍

语音识别技术是什么_语音识别技术应用领域介绍语音识别技术,也被称为自动语音识别AutomaTIc Speech RecogniTIon,(ASR),其目标是将人类的语音中的词汇内容转换为计算机可读的输入,例如按键、二进制编码或者字符序列。
与说话人识别及说话人确认不同,后者尝试识别或确认发出语音的说话人而非其中所包含的词汇内容。
语音识别系统提示客户在新的场合使用新的口令密码,这样使用者不需要记住固定的口令,系统也不会被录音欺骗。
文本相关的声音识别方法可以分为动态时间伸缩或隐马尔可夫模型方法。
文本无关声音识别已经被研究很长时间了,不一致环境造成的性能下降是应用中的一个很大的障碍。
其工作原理:动态时间伸缩方法使用瞬间的、变动倒频。
1963年Bogert et al出版了《回声的时序倒频分析》。
通过交换字母顺序,他们用一个含义广泛的词汇定义了一个新的信号处理技术,倒频谱的计算通常使用快速傅立叶变换。
从1975年起,隐马尔可夫模型变得很流行。
运用隐马尔可夫模型的方法,频谱特征的统计变差得以测量。
文本无关语音识别方法的例子有平均频谱法、矢量量化法和多变量自回归法。
平均频谱法使用有利的倒频距离,语音频谱中的音位影响被平均频谱去除。
使用矢量量化法,语者的一套短期训练的特征向量可以直接用来描绘语者的本质特征。
但是,当训练向量的数量很大时,这种直接的描绘是不切实际的,因为存储和计算的量变得离奇的大。
所以尝试用矢量量化法去寻找有效的方法来压缩训练数据。
Montacie et al在倒频向量的时序中应用多变量自回归模式来确定语者特征,取得了很好的效果。
想骗过语音识别系统要有高质量的录音机,那不是很容易买到的。
一般的录音机不能记录声音的完整频谱,录音系统的质量损失也必须是非常低的。
对于大多数的语音识别系统,模仿的声音都不会成功。
用语音识别来辨认身份是非常复杂的,所以语音识别系统会结合个人身份号码识别或芯片卡。
用改进的遗传算法实现语音特征矢量的矢量量化

M =
( q( 一 一 ) 1 2 )
(一 6 q) , () 2
其 中 , 分 别 为 X 的 最 大 值 和 最 小 值 , 为 二 进 制 位 串编 码 l 对 应 的 十 进 制 数 。 实 验 中 采 用 部 分 随 机 生 成 种 群 个 体 与 L G聚 类 生 成 的一 个 码 本 所 构成 的种 群 作 为初 始种 群 , 传 统 B 对
的设 定 。
m
, j 】
为种 群 中个 体 的 平 均
失真测度 。两矢量 间的失真测度 越小,表示个体 对应的码
本 就 越 好 ,越 容 易 被选 入 作 为 新 种 群 中的 个 体 。式 ( )即 3 为 训 练 语 音 矢 量 集 对 该 个 体 ( 本 ) 的平 均 量 化 失 真 测 度 的 码
21 0 1年 第 4期 ( 第 1 0期 ) 总 4
大 众 科 技
DA ZHONG KE J
矢量量化与语音信号处理

x
码字c2
4 34 1
212 3 码字c3
码书
4
d ( X , C) (xi ci )2 i 1
d(x,c0)=5 d(x,c1)=11 d(x,c2)=8 d(x,c3)=8
✓ 图像编码例子: 原图象块(4灰度级,矢量维数 k=4×4=16)
x
0
1
2
3
码书C ={y0, y1 , y2, y3}
Xi
矢量
Yj
量化器
4.判断规则
当给矢量量化器输入一种任意矢量Xi进行矢 量量化时,矢量量化器首先判断它属于那个子空 间,怎样判断就是要根据一定旳规则,选择一种 合适旳失真测度,分别计算每个码字替代Xi所带 来旳失真,当拟定产生最小失真旳那个码字Yj时, 就将Xi量化成Yj, Yj就是Xi旳重构矢量(和恢复 矢量)。
码本
Y1 Y2
码本
Y1 Y2
语音
YJ
信号
帧
特征 矢量
Xi
VQ 编码
V
形成
器
传播 或
V
存储
YJ
VQ Yj 译码
器
矢量量化在语音通信中旳应用
✓矢量量化编码与解码构造图:
编码 器
解码 器
信 输入 源 矢量
索引 近来邻 搜索
信道
索引
查表
输出 信 矢量 宿
码书
码书
用LBG(GLA)算 法生成
N个特征矢量 wen {X1 , X2 , … , XN}
xL
xa1
xak
xak+1
xaL
xaL+1
1-dimensional VQ is shown below:
语言辨识的矢量量化方法(VQ)

子包 括旅游信息 、 急服务 、 应 以及 购物 和 银 行 、 票 股
交 易 。例 如 A & T T向 处 理 9 l紧 急 呼 救 的 社 会 机 1 构 和 警 察 局 推 出 语 言 热 线 服 务 ¨ 。 图 l 明 了 两 说 个 讲 不 同语 言 的 人 是 如 何 通 过 一 个 多 语 言 话 音 系 统 进 行 交 流 。 自动 语 言辨 识 技 术 还 能 够 用 于 多 语 言 机 器 翻译 系统 的 前 端 处 理 , 当对 大 量 录 音 资 料 进 行 翻译 分 配 时 , 要 预 先 判 定 每 一 段 语 音 的 语 言 。 需 此 外 军 事 上 还 可 以 用 来 对 说 话 人 身 份 和 国 籍 进 行 监 听 或 判 别 _ 。 随 着 信 息 时 代 的 到 来 以及 国 际 因 2
( nlh 、 语 ( na n 、 斯 语 ( a i、 语 E gi ) 汉 s Ma d r ) 波 i Fr ) 法 s
( rnh 、 语 ( ema ) 北 印 度 语 ( id ) Fe c ) 德 Gr n 、 H n i 、日语 (a a ee 、 鲜 语 ( oen 、 班 牙 语 ( pns ) 泰 Jp n s) 朝 K ra ) 西 Sai 、 h
一
每 种 语 言 的 10个 持 母 语 的 人 在 实 际 的 电 话 线 路 0 上 产 生 。发 音 的 时 长 从 1秒 到 5 O秒 长 短 不 等 , 平 均 为 l. 3 4秒 。语 言 的 选 取 考 虑 了 各 种 因 素 , 时 同
个 相 对 较 新 的 领 域 。尽 管 在 某 些 方 面 , 类 似 于 其 自动 语 音识 别 、 话 人 识 别 和 声 调 检 测 ,但 所 有 这 说
人机论文

目录摘要 (1)正文 (1)1、语音识别技术概述 (1)2、发展历史 (1)3、语音识别原理 (2)4、语音识别系统简介 (3)5、语音识别的系统类型 (4)5.1、限制用户的说话方式 (4)5.2、限制用户的用词范围 (5)5.3、限制系统的用户对象 (5)6、语音识别的几种主要研究方法 (5)6.1、动态时间规整(DTW) (5)6.2、矢量量化(VQ) (5)6.3、隐马尔可夫模型(HMM) (6)6.5、支持向量机(SVM) (6)7、语音识别的发展趋势 (6)7.1、提高可靠性。
(7)7.2、增加词汇量。
(7)7.3、应用拓展。
(8)7.4、降低成本减小体积。
(8)8、语音识别所面临的问题 (9)9、值得研究方向 (9)10、语音识别技术的前景展望 (10)参考文献 (11)浅谈语音识别技术摘要:语音识别是一门交叉学科。
近二十年来,语音识别技术取得显著进步,开始从实验室走向市场。
人们预计,未来10年内,语音识别技术将进入工业、家电、通信、汽车电子、医疗、家庭服务、消费电子产品等各个领域。
语音识别听写机在一些领域的应用被美国新闻界评为1997年计算机发展十件大事之一。
很多专家都认为语音识别技术是2000年至2010年间信息技术领域十大重要的科技发展技术之一。
语音识别技术所涉及的领域包括:信号处理、模式识别、概率论和信息论、发声机理和听觉机理、人工智能等等。
关键词:语音识别,矢量化,人工神经元网络,动态时间规整正文1、语音识别技术概述语音识别是解决机器“听懂”人类语言的一项技术。
作为智能计算机研究的主导方向和人机语音通信的关键技术,语音识别技术一直受到各国科学界的广泛关注。
如今,随着语音识别技术研究的突破,其对计算机发展和社会生活的重要性日益凸现出来。
以语音识别技术开发出的产品应用领域非常广泛,如声控电话交换、信息网络查询、家庭服务、宾馆服务、医疗服务、银行服务、工业控制、语音通信系统等,几乎深入到社会的每个行业和每个方面。
语音识别

语音识别技术概述语音识别技术,也被称为自动语音识别Automatic Speech Recognition,(ASR),其目标是将人类的语音中的词汇内容转换为计算机可读的输入,例如按键、二进制编码或者字符序列。
与说话人识别及说话人确认不同,后者尝试识别或确认发出语音的说话人而非其中所包含的词汇内容。
语音识别技术的应用包括语音拨号、语音导航、室内设备控制、语音文档检索、简单的听写数据录入等。
语音识别技术与其他自然语言处理技术如机器翻译及语音合成技术相结合,可以构建出更加复杂的应用,例如语音到语音的翻译。
语音识别技术所涉及的领域包括:信号处理、模式识别、概率论和信息论、发声机理和听觉机理、人工智能等等。
历史早在计算机发明之前,自动语音识别的设想就已经被提上了议事日程,早期的声码器可被视作语音识别及合成的雏形。
而1920年代生产的"Radio Rex"玩具狗可能是最早的语音识别器,当这只狗的名字被呼唤的时候,它能够从底座上弹出来。
最早的基于电子计算机的语音识别系统是由A T&T贝尔实验室开发的Audrey语音识别系统,它能够识别10个英文数字。
其识别方法是跟踪语音中的共振峰。
该系统得到了98%的正确率。
到1950年代末,伦敦学院(Colledge of London)的Denes已经将语法概率加入语音识别中。
1960年代,人工神经网络被引入了语音识别。
这一时代的两大突破是线性预测编码Linear Predictive Coding (LPC),及动态时间弯折Dynamic Time Warp技术。
语音识别技术的最重大突破是隐含马尔科夫模型Hidden Markov Model的应用。
从Baum提出相关数学推理,经过Labiner等人的研究,卡内基梅隆大学的李开复最终实现了第一个基于隐马尔科夫模型的大词汇量语音识别系统Sphinx。
[1]。
此后严格来说语音识别技术并没有脱离HMM框架。
语音识别技术综述

语音辨别技术综述语音辨别技术综述电子信息工程2010 级 1 班郭珊珊【纲要】跟着计算机办理能力的快速提升,语音辨别技术获得了飞快发展,该技术的发展和应用改变了人们的生产和生活方式,正逐渐成为计算机办理技术中的要点技术。
语音技术的应用已经成为一个拥有竞争性的新兴高技术家产。
【要点词】语音辨别;语音辨别原理;语音辨别发展;产品语音辨别是以语音为研究对象,经过语音信号办理和模式辨别让机器人自动辨别和理解人类口述的语言。
语音辨别技术就是让机器经过辨别和理解过程把语音信号转变成相应的命令或文本的高新技术。
1语音识其余原理语音辨别系统本质是一种模式辨别系统,包含特色提取、模式般配、参照模式库等三个基本单位元。
未知语音经过话筒变换成电信号后加载识别系统的输入端,第一经过预办理,再依据人的语音特色成立语音模型,对输入的语音信号进行剖析,并抽取所需特色,在此基础上成立语音辨别所需的模板。
计算机在辨别过程中要依据语音识其余模型,将计算机中寄存的语音模板与输入的语音信号的特色进行比较,依据必定的搜寻和般配策略,找出一系列最优的与输入语音般配的模板。
而后依据此模板的定义,经过查表可给出计算机的辨别结果。
这类最优的结果与特色的选择、语音模型的利害、模板能否正确都有直接的关系。
2语音辨别系统的分类语音辨别系统能够依据对输入语音的限制加以分类。
2.1 从说话者与辨别系统的有关性考虑能够将辨别系统分为 3 类: (1) 特定人语音辨别系统:仅考虑关于专人的话音进行识别; (2) 非特定人语音系统:识其余语音与人没关,往常要用大批不一样人的语音数据库对识别系统进行学习; (3) 多人的辨别系统:往常能辨别一组人的语音,或许成为特定组语音辨别系统,该系统仅要求对要识其余那组人的语音进行训练。
2.2 从说话的方式考虑也能够将辨别系统分为 3 类: (1) 孤立词语音辨别系统:孤立词辨别系统要求输入每个词后要停留; (2) 连结词语音辨别系统:连结词输入系统要求对每个词都清楚发音,一些连音现象开始出现; (3) 连续语音辨别系统:连续语音输入是自然流畅的连续语音输入,大批连音和变音会出现。
应用动态时间规整与矢量量化的语音识别算法

徐 相 华 , 伯 庆 徐
( 上海理工大学 光电信息 与计算机工程学 院, 上海 20 9 ) 0 0 3
摘 要 : 出了一种基 于动 态 时间规 整 ( TW ) 改进 平均 最小距 离识 别 算 法 , 提 D 的 改善 了孤 立 词识 别 的鲁棒 性 并提 高 了识 别 率 。同 时对 矢量 量 化 ( VQ) 法分 析 了不 同码 本 大 小 下 的识 别 率 , 比 算 并 较 了各种 算 法 的运 算 时 间。通 过在 MaL b上 实现 特 定人 孤 立词 小 词 汇量 语 音识 别 , ta 实验 的 结 果表 明 : 于 D 基 TW 算 法的 改进 平均 最 小距 离法识 别 率显 著提 高 ; 本较 大 时 VQ 算 法 的识别 率 码 最 高 ; 算 法 的识 别 率一般 高于 D VQ Tw 算 法且运 行 时 间短 。
引 言
在语音 识 别 系 统 中 , 法 的 选 择 很 大 程 度 上 决 定 了 识 别 的 性 能 。动 态 时 间 规 整 ( y a c t 算 d n mi i me wapn , TW ) 矢量 量化 ( etrq a t ain VQ) 目前 语 音 识 别 系 统 中广 泛使 用 的两 种 技术 。动 r ig D 和 v co u ni t , z o 是 态 时 间规 整采用 动态 规 划思想 很 好地 解 决 了语 音模 式 匹 配 过程 中 的时 间 对 准难 题 。矢 量 量 化 技 术 通过
t e c m p t g tme o a h a g rt m . By r a ia i n o p cfcp r o s lt d wo d s l h o u i i f e c l o ih n e l to f s e ii- e s n io a e - r ma l z — v c b l r p e h r c g ii n o a La ,t e r s a c h ws t a h a e o p o e e n o a u a y s e c e o n to n M t b h e e r h s o h t t e r t f i r v d m a m
语音识别基本知识及单元模块方案设计

语音识别基本知识及单元模块方案设计Last revision on 21 December 2020语音识别是以语音为研究对象,通过语音信号处理和模式识别让机器自动识别和理解人类口述的语言。
语音识别技术就是让机器通过识别和理解过程把语音信号转变为相应的文本或命令的高技术。
语音识别是一门涉及面很广的交叉学科,它与声学、语音学、语言学、信息理论、模式识别理论以及神经生物学等学科都有非常密切的关系。
语音识别技术正逐步成为计算机信息处理技术中的关键技术,语音技术的应用已经成为一个具有竞争性的新兴高技术产业。
1语音识别的基本原理语音识别系统本质上是一种模式识别系统,包括特征提取、模式匹配、参考模式库等三个基本单元,它的基本结构如下图所示:未知语音经过话筒变换成电信号后加在识别系统的输入端,首先经过预处理,再根据人的语音特点建立语音模型,对输入的语音信号进行分析,并抽取所需的特征,在此基础上建立语音识别所需的模板。
而计算机在识别过程中要根据语音识别的模型,将计算机中存放的语音模板与输入的语音信号的特征进行比较,根据一定的搜索和匹配策略,找出一系列最优的与输入语音匹配的模板。
然后根据此模板的定义,通过查表就可以给出计算机的识别结果。
显然,这种最优的结果与特征的选择、语音模型的好坏、模板是否准确都有直接的关系。
2语音识别的方法目前具有代表性的语音识别方法主要有动态时间规整技术(DTW)、隐马尔可夫模型(HMM)、矢量量化(VQ)、人工神经网络(ANN)、支持向量机(SVM)等方法。
动态时间规整算法(Dynamic Time Warping,DTW)是在非特定人语音识别中一种简单有效的方法,该算法基于动态规划的思想,解决了发音长短不一的模板匹配问题,是语音识别技术中出现较早、较常用的一种算法。
在应用DTW算法进行语音识别时,就是将已经预处理和分帧过的语音测试信号和参考语音模板进行比较以获取他们之间的相似度,按照某种距离测度得出两模板间的相似程度并选择最佳路径。
第四章 矢量量化.

第四章矢量量化1、矢量量化?(VQ)是1956年由steinhaus首次提出的,1970年代后期发展起来的数据压缩和编码技术。
它主要应用于:语音编码、语音合成、语音识别和说话人识别。
矢量量化在语音信号处理中占有重要地位。
2、标量量化和矢量量化?✓标量量化:是对标量进行量化,即一维的矢量量化。
将动态范围分成若干个小区间,每小区间有一个代表值。
当输入信号落入某区间时,量化成该代表值。
✓矢量量化:是对矢量进行量化。
将矢量空间分成若干个小区域,每小区域有一个代表矢量。
当输入矢量落入某区域时,量化成该代表矢量。
矢量量化是标量量化的发展。
矢量量化总是优于标量量化,维数越高,性能越优越。
矢量量化有效利用各分量间的互相关性。
1970年代末,Linde,Buzo,Gray和Markel等人首次解决了矢量量化码书生成的方法,并首先将矢量量化用于语音编码获得巨大成功。
如,在语音通信方面,将在原来编码速率为2.4kbit/s的线性预测声码器基础上,将每帧的10个反射系数加以10维的矢量量化,就可使编码速率降低到800bit/s,而声音质量基本未下降。
又如分段声码器,由于采用矢量量化,可以使数码率降低到150bit/s。
3、矢量量化的基本原理?标量量化是对信号的单个样本或参数的幅度进行量化;标量是指被量化的变量,为一维变量。
矢量量化的过程是将语音信号波形的K个样点的每一帧,或有K个参数的每一参数帧构成K维空间的一个矢量,然后对这个矢量进行量化。
标量量化可以说是K=1的矢量量化。
矢量量化的过程和标量量化过程相似。
在标量量化时,在一维的零至无穷大值之间设置若干个量化阶梯,当某输入信号的幅度值落在某相邻的两个量化阶梯之间时,就被量化成两阶梯的中心值。
而在矢量量化时,则将K维无限空间划分为M 个区域边界,然后将输入矢量与这些边界进行比较,并被量化为“距离”最小的区域边界的中心矢量值。
矢量量化的定义将信号序列{}i y 的每K 个连续样点分成一组,形成K 维欧氏空间中的一个矢量,矢量量化就是把这个K 维输入矢量X 映射成另一个K 维量化矢量。
语音信号矢量量化设计与实现算法的matlab仿真设计说明书

引言21世纪是信息的社会,各种科技领域的信息大爆炸。
数字信号的数据量通常很巨大,对存储器的存储容量,通信信道的带宽及计算机的处理速度带来压力,因此必须对其进行量化压缩来紧缩数据存储容量,较快地传输各种信号,并使发信机功率降低。
矢量量化(VQ)是一种极其重要的信号压缩方法,其在语音信号处理中占有十分重要的地位,广泛应用于语音编码,语音识别,语音合成等领域。
在许多重要的课题中,VQ都起着非常重要的作用。
采用矢量量化技术对信号波形或参数进行压缩处理,可以获得非常高的效益。
VQ不仅可以压缩表示语音参数所需的数码率,而且在减少运算量方面也是非常高效的,它还能直接用于构成语音识别和说话人识别系统。
语音数字通信的两个关键部分是语音质量和传输数码率。
但这两者是矛盾的:要获得较高的语音质量,就必须使用较高的传输码率;相反,为了实现高效地压缩传输数码率,就很难得到良好的语音质量。
但是矢量量化却是一种既能得到高效压缩的数码率,又能保证语音质量的方法。
量化可以分为两大类:一类是标量量化,一类是矢量量化VQ。
标量量化是把抽样后的信号值逐个进行量化,而矢量量化是先将k个抽样值组成k 维空间中的一个矢量,然后将此矢量进行量化,它可以极大的降低数码率,优于标量量化。
各种数据都可以用矢量表示,直接对矢量进行量化,可以方便的对数据进行压缩。
矢量量化属于不可逆压缩方法,具备比特率低,解码简单,失真较小的优点。
矢量量化的发展大致可以分为两各阶段:第一阶段约为1956至1977年。
1956年steinhaus第一次系统的阐述了最佳矢量量化的问题。
1957年,在loyd的“PCM中的最小平方化”一文中给出了如何划分量化区间和如何求量化值问题的结论。
约于此同时MAX也得出同样的结果。
虽然他们谈论的都是标量量化问题,但他们的算法对后面的矢量量化的发展有着深刻的影响。
1964年,NEWMAN研究了正六边形原理。
1977年,berger的‘率失真理论’一书出版。
语音识别 PPT课件

1. 原理描述 DTW 是把时间规整和距离测度计算结合起来的一种 非线性规整技术。
测试语音参数共有I 帧矢量,而参考模板共有J 帧矢量,
I 和J 不等,寻找一个时间规整函数 j=w(i),它将测试矢量 的时间轴i 非线性地映射到模板的时间轴 j上,并使该函数
代价函数。
j
j
时间规整函数 j=w(i)
A
i
i
B
图13.4 动态时间规整
为了使T(测试)的第i 个样本与R(参考)的第 j 个样本 对正,其对应的点不在直线对角线上,得到一条弯曲的曲 线j=w(i)。j=w(i) 称为规整函数。
2. 时间规整解决的问题
设 T={a1 , a2 , …… , ai , …… , aI} i=1~I,
矢量量化识别时,将输入语音的K维帧矢量与已有的 码本中M个区域边界比较,按失真测度最小准则找到与该 输入矢量距离最小的码字标号来代替此输入的K维矢量, 这个对应的码字即为识别结果,再对它进行K维重建就得 到被识别的信号。
模型1 码本1
语音 信号 预 处 理
参 数 提 取
模型2 码本2
· · ·
识别输 判决逻辑 出结果
由此来判别出未知语音。
特征提取的基本思想:将信号通过一次变换,去除 冗余部分,将代表语音本质的特征参数抽取出来。 与特征提取相关的内容是特征间的距离测度。 特征的选择对识别效果至关重要。同时,还要考虑特征
参数的计算量。
语音信号的特征主要有时域和频域两种。
时域特征:短时平均能量、短时平均过零率、共 振峰、基音周期等; 频 域 特 征 : 线 性 预 测 系 数 (LPC) 、 LP 倒 谱 系 数 (LPCC)、线谱对参数(LSP) 、短时频谱、 Mel频率倒谱 系数(MFCC)等。 目前已有结合时间和频率的特征,即时频谱,充
语音识别的主要过程

2.语音信号预处理 预滤波 (1)抑制输入信号各频域分量中频率超出采样频率的
一半的所有分量,以防止混叠干扰。 (2)抑制50Hz的电源工频干扰。
1
10.4.2 语音识别的主要过程
语音信号预处理 采样:对信号进行量化,量化不可避免地会产生误 差。量化后的信号值与原信号值之间的差值为量化误 差,又称为量化噪声。 预加重:是提升高频部分,使信号的频谱变得平坦, 保持在低频到高频的整个频带中,能用同样的信噪比 求频谱,以便于频谱分析或声道参数分析。 端点检测:包含语音的一段信号中确定出语音的起点 以及终点。
4
10.4.2 语音识别的主要过程
4.向量量化
矢量量化(vector quantization,VQ)技术是七十 年代后期发展起来的一种数据压缩和编码技术。
在标量量化中整个动态范围被分成若干个小区间, 每个小区间有一个代表值,对于一个输入的标题信 号,量化时落入小区间的值就用这个代表值代替。 矢量量化的基本原理:将若干个标量数据组成一个 矢量在多维空间给予整体量化,从而可以在信息量 损失较小的情况下压缩数据量。
6
5
10.4.2 语音识别的主要过程
5.识别。识别系统的输入是从语音信号中提出的特征参数
语音识别所采用的方法一般有:
(1)模板匹配法。在训练阶段,用户将词汇表中的每一个词 依次说一遍,将其特征矢量作为模板存入模板库。在识别 阶段,将输入语音的特征矢量序列依次与模板库中的每个 模板进行相似度比较,将相似度最高者作为识别结果输出。
()随机模型法。如隐马尔可夫模型(HMM)。用HMM的概 率参数来对似然函数进行估计与判决,从而得到识别结果。
(3)概率语法分析法。不同的人说同一些语音时,相应的语 谱总有一些共同的特点以区分于其他语音。将区别性特征 与来自构词、句法、语义等语用约束相互结合,构成由底 向上或自顶向下的交互作用知识系统。
(语音与音频编码)第四章矢量量化

多级矢量量化是一种灵活的量化方法。它将输入的矢量空间划分为多个级别,每个级别对应 不同的精度和码本大小。在量化过程中,可以根据需要选择合适的级别进行量化,以满足不
同的应用需求。这种方法具有较好的灵活性和适应性,但需要更多的计算和存储资源。
04
矢量量化的优化技术
码本压缩技术
码本压缩
通过减少码本中存储的向量数量或降低码本中向 量的精度,来实现码本的压缩。
矢量量化的应用场景
语音编码
在语音编码中,矢量量化被广泛 应用于对语音信号的压缩,以提 高语音传输的效率和存储空间利
用率。
音频处理
在音频处理中,矢量量化可用于实 现音频信号的降噪、增强和特征提 取等任务。
数据压缩
在数据压缩领域,矢量量化可以用 于图像、视频等数据的压缩,以减 小数据存储和传输的开销。
05
矢量量化的应用实例
语音信号的矢量量化
语音压缩
矢量量化技术可以用于语音信号的压缩,通过将语音信号 的样点聚类成矢量,并使用少量的参数来表示这些矢量, 从而实现高效的语音压缩。
语音识别
在语音识别中,矢量量化技术可以用于特征提取,将原始 语音信号转换为具有代表性的矢量序列,从而便于后续的 分类和识别。
详细描述
嵌入式矢量量化是一种逐一构建码本的算法。它从初始的简单码本开始,逐步将码字替换为更复杂的 码字,同时记录下替换过程中的信息。在反量化时,根据记录的信息可以逐步恢复到原始数据。这种 方法能够有效地压缩数据,但需要更多的存储空间来记录替换过程中的信息。
多级矢量量化
总结词
将输入的矢量空间划分为多个级别,每个级别对应不同的精度和码本大小,以适应不同 的应用需求。
动态码本
根据输入数据的特性,动态地选择码本中的向量 进行量化,以减少存储空间和计算复杂度。
语音信号的提取与识别

语音识别(Speech Recognition)是让机器通过识别和理解过程把语音信号转变为相应的文本或命令的技术。
说话人识别是语音识别的一种特殊方式。
本论文中,将主要介绍说话人识别系统。
通过采用VQ(Vector Quantization,矢量量化)算法,对说话人的识别进行了初步探讨和研究,实现了在MATLAB软件环境下说话人的语音识别,并针对VQ的主要特点及不足做出了总结,并提出了改进。
VQ算法基于LBG算法的思想,首先解决了矢量量化码书生成的问题,设计一个好的码本;其次是解决了未知矢量量化的问题。
最后是判决逻辑,识别结果输出。
关键词:语音识别,说话人识别,VQ,MATLAB,LBG算法Speech Recognition is a kind of technology that is using computer to transfer the voice signal to an associated text or command by identification and understand. speaker recognition is a kind of special way of V oice-identifications .The paper is going to introduce speaker recognition..In this paper,VQ arithmetic is adapted to study and research the implement.the identification of speaker,and Speech recognition for speaker is realized by using MATLAB.In the end,this paper gets a conclusion on the feature and the shortage of VQ and put forward the improvement.VQ arithmetic based on the method of LBG has solved the problems that set up good codebook of vector Quantization and quantization unknown vector.After compared ,the output of recognition is putout.Key words:V oice-Identification ,Speaker-recognition,VQ,MATLAB,LBG- arithmetic目录1 引言 (1)2 语音识别技术的基础 (2)2.1 语音识别技术的发展历史 (2)2.2 语音识别技术的应用 (3)2.3 语音识别的概述 (5)2.4 语音识别的原理 (5)2.5 语音识别系统分类 (10)3 说话人语音识别技术的基本方法 (11)3.1 说话人语音识别的一般方法 (11)3.2 模板匹配法 (13)4 基于VQ的远程说话人识别系统 (15)4.1识别系统总体框图 (15)4.2 组成部分模块介绍 (15)4.3 systerview实现介质中传输模块的仿真 (15)5 MATLAB软件简介 (18)6 系统中VQ算法实现 (19)6.1 VQ算法原理 (19)6.2 VQ算法实现 (23)6.2.1 VQ算法简介 (23)6.2.2 程序运行流程 (25)6.2.3 运行结果 (26)7 VQ算法的不足和改进措施 (28)总结 (29)附录A:源主程序 (30)附录B:对信号s1和s2经过各种变换后的图形 (31)致谢 (35)参考文献 (36)1.引言语音识别的研究工作可以追溯到20世纪50年代AT&T贝尔实验室的Audry 系统,它是第一个可以识别十个英文数字的语音识别系统。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
① 随机选取法
② 分裂法
分裂法
0.01~0.05
D' D
Find centroid
m=1 Yes
yn yn (1 ) yn yn (1 ) D' 0
m=2*m
Classify vectors
Find Cnetroid
m<M
No Stop
Nearest - Neighbor search K - means chestering
数的初始化为m=1
第二步:迭代
1)根据最近邻准则将S分成N个子集 S1(m) ,
S
(m 2
)
,┅,S N(m,)
即当
X S1(m时) ,下式成
立: d ( X ,Yl(m1) d ( X ,Yi(m1) ), i, j l
2)计算失真:
N
D(m)
d( X ,Yl(m1) )
i 1 XSl( m )
2. 树形搜索的矢量量化系统
• 树形搜索是减少矢量量化计算量的一种重要方法。
• 它又分为二叉树和多叉树两种:
码字不象普通的码字那样随意放置, 而是排列在一棵树的接点上,如图所 示,码本尺寸为M=8的二叉树,它的 码本中共包含14个码字。输入矢量X 先与Y0和Y1比较,计算出失真d(X,Y0) 和d(X,Y1)。如果后者较小,则走下面 支路,同时送出“1”,同理,如果 最后达到Y101,则送出的输出角标 101。这就是矢量量化的过程。
矢量量化研究的目的?
针对特定的信息源和矢量维数,设计 出一种最优化的量化器,在R(量化速率) 一定的情况下,给出的量化失真尽可能 接近D(R)(最小量化失真)。
术语
❖ 码本 Codebook ❖ 码字 CodeWord ❖ 码本大小 Codebook Size ❖ Voronoi Cell 胞腔
F
( x xd ) (x x xd )
(x xF )
当两矢量的能量接近时(即 E E xd),忽略能量差异引起的影响;当 两矢量能量相差很大时,即进行线性加权;而当能量差超过门限 xF 时,则 为固定值
4 .4 最佳矢量量化器和码本的设计
一、矢量量化器最佳设计的两个条件 最佳设计就是使失真最小 1、最佳划分 2、最佳码书
这种失真测度是针对线性预测模型、用最 大似然准则推导出来,所以特别适用于LPC参 数,描述语音信号的情况,常用于LPC编码中。 我们由此又推导出两种线性预测色失真测度, 他们比上述具有更好的性能,即
①对比似然比失真测度
d LLR(
f
,
f
)
ln
p2
2
aT Ra ln( aT Ra )
②模型失真测度
2 预测误差能量
A(e j ) 2
信号的功率谱 预测逆滤波器的频率响应
相应的,设码书中某重构矢量的功率谱为
f ( )
X (e j ) 2
p2
A(e j ) 2
则定义Itakura-Saito距a离T 为
d IS (
f
,
f
)
aT Ra
2
ln
1
p
aT Ra r(0)ra(0) 2 r(i)ra(i) i 1
多级矢量量化不仅可以减少计算量还可以减少存储量。 多级矢量量化器由若干个小码书构成。
先采用一个小的码书, 其长度为M1,用它来 逼近输入信号矢量; 然后再用第二个小码 书,其长度为M2,用 它来对第一次的误差 进行编码;输入矢量 与第一级匹配,得到 其地址编号i,然后在 第二级码书中搜索与 这个误差矢量最佳匹 配的矢量,得到其地
❖ 模糊矢量量化的步骤如下:
1)对于待矢量量化的输入矢量 Xi,模糊矢量量化不是通过矢量 量化把输入矢量 X i量化成为某个码字 Yk ,而是把输入矢量 X i
量化成由隶属度函数组成的矢量U(Xi ) u1(Xi ),u2(Xi),...,uJ (Xi) ,它 表示 X i分别属于码字Yk (k 1, 2,..., J ) 的程度是多少;其中uk (Xi )由 下式给定:
dr ( X ,Y )
1 K
K i 1
xi
yi
r
2. r平均误差
d
' r
(
X
,
Y
)
[
1
K
K i 1
xi
yi
1
r ]r
3.绝对值平均误差
1 K
d1( X ,Y ) K i1 xi yi
4.最大平均误差
1
d
M
(
X
,Y
)
lim[d
r
r
(
X
,
Y
)]r
max
1i K
xi
yi
二、线性预测失真测度
3)计算新码字 Y1(m) ,Y2(m) , ,YN(m) :
Yi(m)
1 Ni
X
X Si( m)
4)计算相对失真改进量 (m):
(m)
D( m ) D(m)
D(m失真门限值 进行比较。若 (m)
则转入 6)否则转入5);
5)若 m L 则转至6),否则m加1,转至1)
失真测度是矢量量化和模式识别中一个十分重 要的问题,选择合适与否直接影响系统的性能。
失真度选择必须具备的特性
必须在主观评价上有意义,即小的失真应该对应于 好的主观语音质量;
必须是易于处理的,即在数学上易于实现,这样可 以用于实际的矢量量化器的设计;
平均失真存在并且可以计算;
易于硬件实现
失真测度主要有均方误差失真测度(即欧氏距 离)、加权的均方误差失真测度、板仓-斋藤 (Itakura-Saito)距离,似然比失真测度等,还 有人提出的所谓的“主观的”失真测度。
第三步:结束
6)得到最终的训练码书 Y1(m) ,Y2(m) , ,YN(m) ,
并输出总失真 D(m)
为了避免迭代算法无限制循环下去,这里设 置了两个阈值参数:最大迭代次数L和失真控制
门限 。 的值设得远小于1,当 (m) 时,
表明再进行迭代运算失真得减小是有限的、可
以停止运算。L是限制迭代次数的参数,防止
N
ukm ( X i )gXi
Yk
i 1 N
ukm ( X i )
i 1
,1 k J
uk ( Xi )
J
d
(
X i ,Yk
2
) m1
2
,1
k
J
,1
i
N
j1 d ( X i ,Yj )m1
式 4-34
❖ 模糊矢量量化码本估计的步骤如下:
1)设定初始码本和每个码字的初始隶属度函数u,k 为了方便可
用全极模型表示的线性预测方法,广泛应用于语音 信号处理中。它在分析时得到的是模型的预测系数.仅 由预测系数的差值,不能完全表征这两个语音信息的 差别。应该直接由这些系数所描述的信号模型的功率 谱来进行比较。
当预测器的阶数 p ,信号与模型
完全匹配时,信号功率谱为:
f ( )
X (e j ) 2
uk ( Xi )
J
2
d ( X i ,Yk ) m1
2
1
,1
最佳矢量量化器满足的两个必要条件
1)Voronoi分割条件(最近邻准则) 对信号空间的分割应满足
Sl {X RK : d ( X ,Yl ) d ( X ,Yi ); i l}
根据该条件可以对信号空间进行最佳划分, 得到的 Sl 称为一个胞腔
2)Centroid质心条件
子空间分割固定后,Voronoi胞元 的质心就是量化器的码字
dm(
f
,
f
)
p2 2
1
aT aT
Ra Ra
1
注:这两种失真测度都仅仅比较两矢量的 功率谱,而没有考虑其他能量信息。
三、识别失真测度 失真测度的定义
输入信号矢量的归一化能量
d( f , E) dLLR( f , f ) g( E E )
加权因子 码书重构矢量的归一化能量
0
g(
x
)
x
x
自适应矢量量化
自适应矢量量化 (Adaptive VQ)是采用 多个码书,量化时根据 输入矢量的不同特征采 用不同的码书。
实际例子:语音参数的矢量量化
语音参数的矢量量化 —— 将语音信号经过分析,得到各 种参数,然后再将这些按帧分析所得的参数构成矢量, 进行矢量量化。
线性预测系数的矢量量化是人们最关心的问题。 例:线性预测编码的矢量量化器(VQ LPC)声码器。
回顾 失真测度 最佳矢量量化器和码本设计 降低复杂度的矢量量化系统 语音参数的矢量量化
回顾
❖ 矢量量化(VQ,Vector Quantization)是 一种极其重要的信号压缩方法。VQ在语音信 号处理中占十分重要的地位。广泛应用于语 音编码、语音识别和语音合成等领域。
❖ 凡是要用量化的地方都可以采用矢量量化。
Yl E[X X Sl ]
对于一般的失真测度和信源分布,很难找到
质心的计算方法,但对于一般的分布和常用的
均方失真测度,可以证明
1
Yl
Nl
X
XSl
是 S l中包含的矢量个数
二、LBG算法 K-means clustering algorithm
1980年由Linde,Buzo和Gray提出, 它是标量量化器中Lloyd算法的推广,在矢 量量化中是一个基本算法。
Compute Distortion D
D D'
No
Yes
降低复杂度的矢量量化系统 ()知识 扩展)