Linux内核中工作队列(work_queue)的操作
linux内核Documents

linux内核文档名词解释并发管理工作队列Concurrency Managed Workqueue1.介绍CMW适用于异步执行的程序有很多实例的情况。
一个异步程序对应到一个CMW,而程序中的实例放入CMW的队列中,依次执行。
一个独立的进程会处理这个异步程序。
存放异步程序实例的队列就叫“工作队列(workqueue)”,而后台执行这些实例的进程叫“工作者(worker)”。
2.为什么选择CWMQ在最开始的工作队列的实现中,一个多线程的工作队列(MTWQ)在每个CPU上都有一个“工作者”,工作者数量等同CPU数量;一个单线程的工作队列在系统上只有一个“工作者”。
现在内核增加了很多MTWQ的用户。
尽管MTWQ耗用了大量资源,但是其提供的并发能力并不能满足需求。
无论是单线程工作队列,还是多线程工作队列,其中的任务都需要竞争有限的执行上下文,这会导致一系列问题,如死锁等。
并发能力和资源的紧缺,使得用户不得不做一些额外的权衡。
比如在async和fscache中,需要实现自己的线程池。
CWMQ致力于完成以下目标,而重新实现了工作队列:●兼容原有WQ的API●使用所有工作队列共享的per-cpu统一工作者池(Worker Pool),提供更灵活的并发级别,使用更少的资源●自动调整工作者池和并发级别,API用户不用关注这些细节3.CWMQ的设计为了简化程序的异步执行,引入一个新的抽象:工作项目(work item),简称项目。
一个项目是一个持有异步执行函数指针的结构体。
如果一个子系统或者驱动希望一个函数被异步的执行,那就要初始化一个工作项目,并将项目放到工作队列里排队。
而工作者线程负责一个个的执行队列中的函数。
如果工作队列为空,那工作者线程空闲。
工作者线程在工作者池中进行管理。
由两个工作者线程池,一个池用于高优先级工作项,另一个用于普通工作项。
子系统和驱动通过WQ的API来创建工作项,并入列。
可以通过设置入列工作项的WQ的flags来影响工作项执行的行为。
workqueue的初始化及工作流程

workqueue的初始化及工作流程
工作队列(workqueue)的初始化及工作流程如下:
在初始化阶段,系统首先会调用workqueue_init_early函数进行早期初始化,这个过程主要包括分配内存、创建wq数据结构等。
这个阶段的工作会在基本的内存分配、cpumasks和idr完成后立即进行。
之后会进行workqueue_init函数,使工作队列子系统完全online。
当用户调用workqueue的初始化接口create_workqueue或者
create_singlethread_workqueue对workqueue队列进行初始化时,内
核就开始为用户分配一个workqueue对象,并且将其链到一个全局的workqueue队列中。
然后Linux根据当前CPU的情况,为workqueue对象分配与CPU个数相同的cpu_workqueue_struct对象,每个cpu_workqueue_struct对象都
会存在一条任务队列。
紧接着,Linux为每个cpu_workqueue_struct对象分配一个内核thread,即内核daemon去处理每个队列中的任务。
至此,用户调用初始化接口将workqueue初始化完毕,返回workqueue的指针。
然后可以将work_struct加入到任务队列中,Linux会唤醒daemon去处理任务。
以上内容仅供参考,如需更多信息,建议查阅Linux内核源码或相关文档。
linux工作队列

linux 工作队列INIT_DELAYED_WORK()是一个宏,我们给它传递了两个参数.&hub->leds和led_work.对设备驱动熟悉的人不会觉得INIT_DELAYED_WORK()很陌生,其实鸦片战争那会儿就有这个宏了,只不过从2.6.20的内核开始这个宏做了改变,原来这个宏是三个参数,后来改成了两个参数,所以经常在网上看见一些同志抱怨说最近某个模块编译失败了,说什么make的时候遇见这么一个错误:error: macro "INIT_DELAYED_WORK" passed 3 arguments, but takes just 2当然更为普遍的看到下面这个错误:error: macro "INIT_WORK" passed 3 arguments, but takes just 2于是就让我们来仔细看看INIT_WORK和INIT_DELAYED_WORK.其实前者是后者的一个特例,它们涉及到的就是传说中的工作队列.这两个宏都定义于include/linux/workqueue.h中:79 #define INIT_WORK(_work, _func) /80 do { /81 (_work)->data = (atomic_long_t) WORK_DATA_INIT(); /82 INIT_LIST_HEAD(&(_work)->entry); /83 PREPARE_WORK((_work), (_func)); /84 } while (0)8586 #define INIT_DELAYED_WORK(_work, _func) /87 do { /88 INIT_WORK(&(_work)->work, (_func)); /89 init_timer(&(_work)->timer); /90 } while (0)有时候特怀念谭浩强那本书里的那些例子程序,因为那些程序都特简单,不像现在看到的这些,动不动就是些复杂的函数复杂的数据结构复杂的宏,严重挫伤了我这样的有志青年的自信心.就比如眼下这几个宏吧,宏里边还是宏,一个套一个,不是说看不懂,因为要看懂也不难,一层一层展开,只不过确实没必要非得都看懂,现在这样一种朦胧美也许更美,有那功夫把这些都展开我还不如去认认真真学习三个代表呢.总之,关于工作队列,就这么说吧,Linux内核实现了一个内核线程,直观一点,ps命令看一下您的进程,localhost:/usr/src/linux-2.6.22.1/drivers/usb/core # ps -elF S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD4 S 0 1 0 0 76 0 - 195 - ? 00:00:02 init1 S 02 1 0 -40 - - 0 migrat ? 00:00:00 migration/01 S 0 3 1 0 94 19 - 0 ksofti ? 00:00:00 ksoftirqd/01 S 0 4 1 0 -40 - - 0 migrat ? 00:00:00 migration/11 S 0 5 1 0 94 19 - 0 ksofti ? 00:00:00 ksoftirqd/11 S 0 6 1 0 -40 - - 0 migrat ? 00:00:00 migration/21 S 0 7 1 0 94 19 - 0 ksofti ? 00:00:00 ksoftirqd/21 S 0 8 1 0 -40 - - 0 migrat ? 00:00:00 migration/31 S 0 9 1 0 94 19 - 0 ksofti ? 00:00:00 ksoftirqd/31 S 0 10 1 0 -40 - - 0 migrat ? 00:00:00 migration/41 S 0 11 1 0 94 19 - 0 ksofti ? 00:00:00 ksoftirqd/41 S 0 12 1 0 -40 - - 0 migrat ? 00:00:00 migration/51 S 0 13 1 0 94 19 - 0 ksofti ? 00:00:00 ksoftirqd/51 S 0 14 1 0 -40 - - 0 migrat ? 00:00:00 migration/61 S 0 15 1 0 94 19 - 0 ksofti ? 00:00:00 ksoftirqd/61 S 0 16 1 0 -40 - - 0 migrat ? 00:00:00 migration/71 S 0 17 1 0 94 19 - 0 ksofti ? 00:00:00 ksoftirqd/75 S 0 18 1 0 70 -5 - 0 worker ? 00:00:00 events/01 S 0 19 1 0 70 -5 - 0 worker ? 00:00:00 events/15 S 0 20 1 0 70 -5 - 0 worker ? 00:00:00 events/25 S 0 21 1 0 70 -5 - 0 worker ? 00:00:00 events/35 S 0 22 1 0 70 -5 - 0 worker ? 00:00:00 events/41 S 0 23 1 0 70 -5 - 0 worker ? 00:00:00 events/55 S 0 24 1 0 70 -5 - 0 worker ? 00:00:00 events/65 S 0 25 1 0 70 -5 - 0 worker ? 00:00:00 events/7瞅见最后这几行了吗,events/0到events/7,0啊7啊这些都是处理器的编号,每个处理器对应其中的一个线程.要是您的计算机只有一个处理器,那么您只能看到一个这样的线程,events/0,您要是双处理器那您就会看到多出一个events/1的线程.哥们儿这里Dell PowerEdge 2950的机器,8个处理器,所以就是events/0到events/7了.那么究竟这些events代表什么意思呢?或者说它们具体干嘛用的?这些events被叫做工作者线程,或者说worker threads,更确切的说,这些应该是缺省的工作者线程.而与工作者线程相关的一个概念就是工作队列,或者叫work queue.工作队列的作用就是把工作推后,交由一个内核线程去执行,更直接的说就是如果您写了一个函数,而您现在不想马上执行它,您想在将来某个时刻去执行它,那您用工作队列准没错.您大概会想到中断也是这样,提供一个中断服务函数,在发生中断的时候去执行,没错,和中断相比,工作队列最大的好处就是可以调度可以睡眠,灵活性更好.就比如这里,如果我们将来某个时刻希望能够调用led_work()这么一个我们自己写的函数,那么我们所要做的就是利用工作队列.如何利用呢?第一步就是使用INIT_WORK()或者INIT_DELAYED_WORK()来初始化这么一个工作,或者叫任务,初始化了之后,将来如果咱们希望调用这个led_work()函数,那么咱们只要用一句schedule_work()或者schedule_delayed_work()就可以了,特别的,咱们这里使用的是INIT_DELAYED_WORK(),那么之后我们就会调用schedule_delayed_work(),这俩是一对.它表示,您希望经过一段延时然后再执行某个函数,所以,咱们今后会见到schedule_delayed_work()这个函数的,而它所需要的参数,一个就是咱们这里的&hub->leds,另一个就是具体自己需要的延时.&hub->leds是什么呢?structusb_hub中的成员,struct delayed_work leds,专门用于延时工作的,再看struct delayed_work,这个结构体定义于include/linux/workqueue.h:35 struct delayed_work {36 struct work_struct work;37 struct timer_list timer;38 };其实就是一个struct work_struct和一个timer_list,前者是为了往工作队列里加入自己的工作,后者是为了能够实现延时执行,咱们把话说得更明白一点,您看那些events线程,它们对应一个结构体,struct workqueue_struct,也就是说它们维护着一个队列,完了您要是想利用工作队列这么一个机制呢,您可以自己创建一个队列,也可以直接使用events对应的这个队列,对于大多数情况来说,都是选择了events对应的这个队列,也就是说大家都共用这么一个队列,怎么用呢?先初始化,比如调用INIT_DELAYED_WORK(),这么一初始化吧,实际上就是为一个struct work_struct结构体绑定一个函数,就比如咱们这里的两个参数,&hub->leds和led_work()的关系,就最终让hub_leds这个struct work_struct结构体和函数led_work()相绑定了起来,您问怎么绑定的?您瞧,struct work_struct也是定义于include/linux/workqueue.h:24 struct work_struct {25 atomic_long_t data;26 #define WORK_STRUCT_PENDING 027 #define WORK_STRUCT_FLAG_MASK (3UL)28 #define WORK_STRUCT_WQ_DATA_MASK (~WORK_STRUCT_FLAG_MASK)29 struct list_head entry;30 work_func_t func;31 };瞅见最后这个成员func了吗,初始化的目的就是让func指向led_work(),这就是绑定,所以以后咱们调用schedule_delayed_work()的时候,咱们只要传递struct work_struct的结构体参数即可,不用再每次都把led_work()这个函数名也给传递一次,一旦绑定,人家就知道了,对于led_work(),那她就嫁鸡随鸡,嫁狗随狗,嫁混蛋随混蛋了.您大概还有一个疑问,为什么只要这里初始化好了,到时候调用schedule_delayed_work()就可以了呢?事实上,events这么一个线程吧,它其实和hub的内核线程一样,有事情就处理,没事情就睡眠,也是一个死循环,而schedule_delayed_work()的作用就是唤醒这个线程,确切的说,是先把自己的这个struct work_struct插入workqueue_struct这个队列里,然后唤醒昏睡中的events.然后events就会去处理,您要是有延时,那么它就给您安排延时以后执行,您要是没有延时,或者您设了延时为0,那好,那就赶紧给您执行.咱这里不是讲了两个宏吗,一个INIT_WORK(),一个INIT_DELAYED_WORK(),后者就是专门用于可以有延时的,而前者就是没有延时的,这里咱们调用的是INIT_DELAYED_WORK(),不过您别美,过一会您会看见INIT_WORK()也被使用了,因为咱们hub驱动中还有另一个地方也想利用工作队列这么一个机制,而它不需要延时,所以就使用INIT_WORK()进行初始化,然后在需要调用相关函数的时候调用schedule_work()即可.此乃后话,暂且不表.基本上这一节咱们就是介绍了Linux内核中工作队列机制提供的接口,两对函数INIT_DELAYED_WORK()对schedule_delayed_work(),INIT_WORK()对schedule_work().关于工作队列机制,咱们还会用到另外两个函数,它们是cancel_delayed_work(struct delayed_work *work)和flush_scheduled_work().其中cancel_delayed_work()的意思不言自明,对一个延迟执行的工作来说,这个函数的作用是在这个工作还未执行的时候就把它给取消掉.而flush_scheduled_work()的作用,是为了防止有竞争条件的出现,虽说哥们儿也不是很清楚如何防止竞争,可是好歹大二那年学过一门专业课,数字电子线路,尽管没学到什么有用的东西,怎么说也还是记住了两个专业名词,竞争与冒险.您要是对竞争条件不是很明白,那也不要紧,反正基本上每次cancel_delayed_work之后您都得调用flush_scheduled_work()这个函数,特别是对于内核模块,如果一个模块使用了工作队列机制,并且利用了events这个缺省队列,那么在卸载这个模块之前,您必须得调用这个函数,这叫做刷新一个工作队列,也就是说,函数会一直等待,直到队列中所有对象都被执行以后才返回.当然,在等待的过程中,这个函数可以进入睡眠.反正刷新完了之后,这个函数会被唤醒,然后它就返回了.关于这里这个竞争,可以这样理解,events对应的这个队列,人家本来是按部就班的执行,一个一个来,您要是突然把您的模块给卸载了,或者说你把你的那个工作从工作队列里取出来了,那events作为队列管理者,它可能根本就不知道,比如说它先想好了,下午3点执行队列里的第N个成员,可是您突然把第N-1个成员给取走了,那您说这是不是得出错?所以,为了防止您这种唯恐天下不乱的人做出冒天下之大不韪的事情来,提供了一个函数,flush_scheduled_work(),给您调用,以消除所谓的竞争条件,其实说竞争太专业了点,说白了就是防止混乱吧.Ok,关于这些接口就讲到这里,日后咱们自然会在hub驱动里见到这些接口函数是如何被使用的.到那时候再来看.这就是蝴蝶效应.当我们看到INIT_WORK/INIT_DELAYED_WORK()的时候,我们是没法预测未来会发生什么的.所以我们只能拭目以待.又想起了那句老话,大学生活就像被强奸,如果不能反抗,那就只能静静的去享受它.工作队列(work queue)是另外一种将工作推后执行的形式,它和前面讨论的tasklet有所不同。
linux 的内核任务队列

驱动程序需要将任务延迟到以后处理,但又不想借助中断。
Linux 为此提供了三种方法:任务队列、tasklet(从内核 2.3.43 开始)和内核定时器。
任务队列和tasklet 的使用很灵活,可以或长或短地延迟任务到以后处理,在编写中断处理程序时非常有用,我们还将在第9章“Tasklet和底半部处理”一节中继续讨论。
内核定时器则用来调度任务在未来某个指定时间执行,将在本章的“内核定时器”一节中讨论。
使用任务队列或tasklet的一个典型情形是,硬件不产生中断,但仍希望提供阻塞型的读取。
此时需要对设备进行轮询,同时要小心地不使CPU 负担过多无谓的操作。
将读进程以固定的时间间隔唤醒(例如,使用current->timeout 变量)并不是个很好的方法,因为每次轮询需要两次上下文切换(一次是切换到读进程中运行轮询代码,另一次是返回执行实际工作的某个进程),而且通常来讲,恰当的轮询机制应该在进程上下文之外实现。
类似的情形还有象不时地给简单的硬件设备提供输入。
例如,有一个直接连接到并口的步进马达,要求该马达能一步步地移动,但马达每次只能移动一步。
在这种情况下,由控制进程通知设备驱动程序进行移动,但实际上,移动是在write 返回后,才在周期性的时间间隔内一步一步进行的。
快速完成这类不定操作的恰当方法是注册任务在未来执行。
内核提供了对“任务队列”的支持,任务可以累积,而在运行队列时被“消耗”。
我们可以声明自己的任务队列,并且在任意时刻触发它,或者也可以将任务注册到预定义的任务队列中去,由内核来运行(触发)它。
任务队列的本质任务队列其实是一个任务链表,每个任务用一个函数指针和一个参数表示。
任务运行时,它接受一个void * 类型的参数,返回值类型为void,而指针参数可用来将一个数据结构传入函数,或者可以被忽略。
队列本身是一个结构(即任务)链表,并由声明和操纵它们的内核模块所拥有。
模块要全权负责这些数据结构的分配和释放,为此一般使用静态的数据结构。
linux kernel workqueue

分成两大部分,第一部分是用来执行work queue中每个节点上挂载的函数的内核线程,第二部分是从驱动程序的角度看work queue的使用。
第一部分worker_thread内核线程Linux系统启动期间会创建一名为worker_thread线程,该线程创建之后就处于sleep状态。
这里所谓的内核线程,从调度器的角度就是一可以调度的进程,从代码的表现形式看,就是一函数。
系统创建的这个worker_thread线程基于一workqueue_struct结构变量上(该结构体变量的成员name为"events").第二部分work queue的使用1.只考虑使用系统的keventd管理的工作队列驱动程序调用schedule_work向工作队列递交新的工作节点,schedule_work内部会唤醒worker_thread内核线程(使之进程状态为可调度)。
在下一次进程调度时刻,worker_thread 被调度执行,其主要任务便是调用它所管理工作队列中每个工作节点上挂载的函数,调用完毕该工作节点会从任务队列中被删除。
当所有节点上的函数调用完毕,worker_thread继续sleep,直到schedule_work再次被某个驱动程序调用。
与使用驱动程序自己创建的工作对列的区别是:schedule_work内部是调用queue_work(keventd_wq, work),而使用驱动程序自己创建的工作队列在调用queue_work 时的第一个参数是驱动程序自己创建的工作队列。
2.驱动程序使用自己创建的工作队列这种情况驱动程序调用create_workqueue。
该函数的原理跟1中基本是一样的,只不过再会创建一个内核进程,该内核进程的内核函数名字依然为worker_thread,只不过这个worker_thread工作在新的属于驱动程序自己的工作队列。
使用方法是:a. 调用create_workqueue生成属于驱动程序自己的work queue. struct workqueue_struct *my_workqueue = create_workqueue("my_workqueue");b.调用queue_work象a中生成的my_workqueue中注册工作节点,queue_work(my_workqueue, work)这两种情况下的内核线程其实都是利用了一个名为kthreadd的内核线程来创建工作队列的worker_thread,其本质是向全局列表kthread_create_list中加入相应的内核线程函数节点,由kthreadd来负责创建进程框架,然后运行kthread_create_list中加入的节点上的内核线程函数。
Linux工作队列
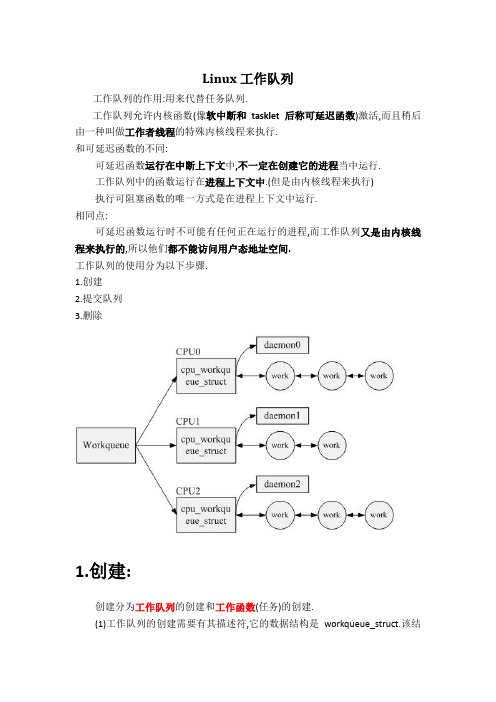
Linux工作队列工作队列的作用:用来代替任务队列.工作队列允许内核函数(像软中断和tasklet后称可延迟函数)激活,而且稍后由一种叫做工作者线程的特殊内核线程来执行.和可延迟函数的不同:可延迟函数运行在中断上下文中,不一定在创建它的进程当中运行.工作队列中的函数运行在进程上下文中.(但是由内核线程来执行)执行可阻塞函数的唯一方式是在进程上下文中运行.相同点:可延迟函数运行时不可能有任何正在运行的进程,而工作队列又是由内核线程来执行的,所以他们都不能访问用户态地址空间.工作队列的使用分为以下步骤.1.创建2.提交队列3.删除1.创建:创建分为工作队列的创建和工作函数(任务)的创建.(1)工作队列的创建需要有其描述符,它的数据结构是workqueue_struct.该结构定义在<linux/workqueue.h>中.这里我们不需要关心它的具体组成,内核已经写他们的区别在于实际处理器的多少,如果是单核处理器的话,他们毫无区别.因为每个工作队列都有一个或多个(多核处理器)专用的进程(内核线程),这些进程运行提交到该工作队列函数.create_workqueue内核会在系统中的每个处理器上为该工作队列创建专用的线程.这样,如果工作队列足够多的话,可能对系统的性能有所杀伤,而create_singlethread_workqueue则只会创建一个专用的线程.所以,如果单个工作线程足够使用,推荐使用第二个函数来创建工作队列.同样的,工作任务的创建也需要有其描述符,它的数据结构是work_struct.内核同样为我们创建好了几个宏来方便的创建它.PREPARE_WORK没有INIT_WORK初始化彻底,因为它不会初始化用来将work_struct结构连接到工作队列的指针.如果结构已经被提交到工作队列,而只是需要修改该结构,则应该使用PREPARE_WORK而不是INIT_WORK.2.提交:如果要将工作提交到工作队列,则可使用如下两个函数之一:int queue_work(struct workqueue_struct *queue,struct work_struct *work);int queue_delayed_work(struct workqueue_struct *queue,struct work_struct *work,unsigned long delay);它们都会将work添加到给定的queue.但是如果使用queue_delayed_work,则实际工作至少会在经过指定的jiffies(由delay指定)之后才会执行.如果工作被成功添加到队列,则上述函数的返回值为1,返回值为非零意味着给定的work_struct 结构已经等待在该队列中,从而不能两次加入该队列.3.删除:结束对工作队列的使用后,可调用下面的函数释放相关资源.void destroy_workqueue(struct workqueue_struct *queue);4.编程接口概念性注释SMP, shared memory processor. daemo ,守护进程。
Linux学习之Workqueue

struct global_cwq {} 每个CPU都有一个gcwq,主要完成除了内存回收的紧急工作队列任务,
和在CPU下线过程中的工作任务这两个任务外的所有任务。
这两个任务是极高优先级和极紧迫任务,他们将会被worker直接执行,避免被管理。
struct cpu_workqueue_struct {} 特定CPU上的工作队列
struct wq_flusher {} 刷新清空结构体,不重要。
struct workqueue_struct {} 工作队列结构体,直接由work_struct结构体构成,如果是多个CPU,
将工作项加入到工作队列中:
extern int queue_work(struct workqueue_struct *wq, struct work_struct *work);
任务进到自定义的队列中。其实质也是调用了一个queue_work_on。
则先由work_struct构成cpu_workqueue_struct,然后再构成该workqueue_struct。
系统在启动是,启动了六个公共的默认共享工作队列。
-> 执行核心process_one_work()。
PS,根据标志位优先执行高优先级任务所开辟的thread,也通过process_one_work()。
用该宏创建一个队列。 --> alloc_workqueue() --> __alloc_workqueue_key() 位置:workqueue.h
#define create_freezable_workqueue(name) alloc_workqueue((name), WQ_FREEZABLE | WQ_UNBOUND | WQ_MEM_RECLAIM, 1)
栈和队列的基本操作方法

栈和队列的基本操作方法栈和队列是常见的数据结构,它们在计算机科学中有着广泛的应用。
栈和队列都是一种线性数据结构,但它们在插入和删除元素的方式上有所不同。
接下来,将介绍栈和队列的基本操作方法,包括定义、插入、删除和查询等。
一、栈(Stack)的基本操作方法:1. 定义:栈是一种先进后出(Last-In-First-Out,LIFO)的数据结构。
类似于现实生活中的一叠盘子,只能在栈顶进行操作。
2.创建栈:可以使用数组或链表作为栈的底层数据结构。
通过创建一个空数组或链表,称之为栈顶指针或栈顶节点,初始时指向空,表示栈为空。
3. 入栈(Push):将一个元素添加到栈顶。
需要将新增元素放在栈顶指针或栈顶节点之后,更新栈顶指针或栈顶节点的指向。
4. 出栈(Pop):删除栈顶元素,并返回删除的元素值。
需要将栈顶指针或栈顶节点向下移动一个位置,指向下一个元素。
5. 获取栈顶元素(Top):返回栈顶元素的值,但不删除该元素。
只需访问栈顶指针或栈顶节点所指向的元素即可。
6. 判断栈是否为空(isEmpty):通过检查栈顶指针或栈顶节点是否为空来判断栈是否为空。
二、队列(Queue)的基本操作方法:1. 定义:队列是一种先进先出(First-In-First-Out,FIFO)的数据结构。
类似于现实生活中的排队,按照先后顺序依次进入队列,先进入队列的元素首先被删除。
2.创建队列:可以使用数组或链表作为队列的底层数据结构。
通过创建一个空数组或链表,分别设置一个队首指针和一个队尾指针,初始时指向空,表示队列为空。
3. 入队(Enqueue):将一个元素添加到队尾。
需要将新增元素放在队尾指针或队尾节点之后,更新队尾指针或队尾节点的指向。
4. 出队(Dequeue):删除队首元素,并返回删除的元素值。
需要将队首指针或队首节点向下移动一个位置,指向下一个元素。
5. 获取队首元素(Front):返回队首元素的值,但不删除该元素。
Linux工作队列实现机制

Linux工作队列实现机制工作项、工作队列和工作者线程把推后执行的任务叫做工作(work),描述它的数据结构为work_struct ,这些工作以队列结构组织成工作队列(workqueue),其数据结构为workqueue_struct ,而工作线程就是负责执行工作队列中的工作。
系统默认的工作者线程为events。
工作队列(work queue)是另外一种将工作推后执行的形式。
工作队列可以把工作推后,交由一个内核线程去执行—这个下半部分总是会在进程上下文执行,但由于是内核线程,其不能访问用户空间。
最重要特点的就是工作队列允许重新调度甚至是睡眠。
通常,在工作队列和软中断/tasklet中作出选择非常容易。
可使用以下规则:如果推后执行的任务需要睡眠,那么只能选择工作队列;如果推后执行的任务需要延时指定的时间再触发,那么使用工作队列,因为其可以利用timer延时;如果推后执行的任务需要在一个tick之内处理,则使用软中断或tasklet,因为其可以抢占普通进程和内核线程;如果推后执行的任务对延迟的时间没有任何要求,则使用工作队列,此时通常为无关紧要的任务。
实际上,工作队列的本质就是将工作交给内核线程处理,因此其可以用内核线程替换。
但是内核线程的创建和销毁对编程者的要求较高,而工作队列实现了内核线程的封装,不易出错,所以我们也推荐使用工作队列。
工作队列使用相关文件:kernel/include/linux/workqueue.hKernel/kernel/workqueue.c工作队列的创建要使用工作队列,需要先创建工作项,有两种方式:1)静态创建:DECLARE_WORK(name,function);定义正常执行的工作项DECLARE_DELAYED_WORK(name,function);定义延后执行的工作项2)动态创建,运行时创建:通常在probe()函数中执行下面的操作来初始化工作项:INIT_WORK(&work,new_ts_work);INIT_DELAYED_WORK(&led_work,s0340_ledtime_sca nf);工作队列待执行的函数原型是:typedefvoid(*work_func_t)(structwork_struct *work);这个函数会由一个工作者线程执行,因此,函数会运行在进程上下文中。
linux?内核work工作队列实现

linux 内核work工作队列实现写这篇blog的缘由是因为最近调试模块代码的时候,出现了kernel crash,堆栈如下:PID: 0 TASK: ffffffff81a8d020 CPU: 0 COMMAND: "swapper"#0 [ffff8800282038b0] machine_kexec at ffffffff81035c0b#1 [ffff880028203910] crash_kexec at ffffffff810c0dd2#2 [ffff8800282039e0] oops_end at ffffffff81511680#3 [ffff880028203a10] die at ffffffff8100f19b#4 [ffff880028203a40] do_trap at ffffffff81510ee4#5 [ffff880028203aa0] do_invalid_op at ffffffff8100cdb5#6 [ffff880028203b40] invalid_op at ffffffff8100be5b[exception RIP: queue_work_on+73]RIP: ffffffff81091379 RSP: ffff880028203bf0 RFLAGS: 00010206RAX: ffffc90005dea068 RBX: ffff8801f496e8c8 RCX: 0000000000000000RDX: ffffc90005dea060 RSI: ffff88021b230740 RDI: 0000000000000000RBP: ffff880028203bf0 R8: ffffc90005dea038 R9: 0000000000000001R10: ffff8802163a1900 R11: 0000000000000001 R12: 0000000000000000R13: ffff8801f496e8c8 R14: 0000000000003600 R15: 0000000000000000ORIG_RAX: ffffffffffffffff CS: 0010 SS: 0018#7 [ffff880028203bf8] queue_work at ffffffff810913cf最后的log日志则如下:------------[ cut here ]------------kernel BUG at kernel/workqueue.c:191!invalid opcode: 0000 [#1] SMPlast sysfs file: /sys/kernel/mm/ksm/runCPU 0Modules linked in: ext3 jbd binlogdev(U) ip6table_filter ip6_tables iptable_filter ip_tables ebtable_nat ebtables bnx2fc fcoe libfcoe libfc scsi_transport_fc scsi_tgt 8021q garp sunrpc bridge stp llc vhost_net macvtap macvlan tun kvm_intel kvm sg serio_raw i2c_i801 i2c_core iTCO_wdt iTCO_vendor_support shpchp memdisk(U) memcon(U) ext4 mbcache jbd2 sd_mod crc_t10dif megaraid_sas e1000e video output ahci dm_mirror dm_region_hash dm_log dm_mod be2iscsi bnx2i cnic uio ipv6 cxgb4i cxgb4 cxgb3i libcxgbi cxgb3 mdio libiscsi_tcp qla4xxx iscsi_boot_sysfs libiscsi scsi_transport_iscsi [last unloaded: scsi_wait_scan]Pid: 0, comm: swapper Not tainted 2.6.32-358.6.1.el6.x86_64 #1 Supermicro X9SCI/X9SCA/X9SCI/X9SCARIP: 0010:[] [] queue_work_on+0x49/0x60RSP: 0018:ffff880028203be0 EFLAGS: 00010006RAX: ffffc9000578d068 RBX: 0000000000000286 RCX: 0000000000000000RDX: ffffc9000578d060 RSI: ffff88021acddc00 RDI: 0000000000000000RBP: ffff880028203be0 R08: ffffc9000578d038 R09: 0000000000000001R10: ffff8802159bee80 R11: 0000000000000001 R12: 0000000000000000R13: ffff8800c4702558 R14: 0000000000002400 R15: 0000000000000000FS: 0000000000000000(0000) GS:ffff880028200000(0000) knlGS:0000000000000000CS: 0010 DS: 0018 ES: 0018 CR0: 000000008005003bCR2: 000000000246d000 CR3: 00000001f1db3000 CR4: 00000000000427e0DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000DR3: 0000000000000000 DR6: 00000000ffff0ff0 DR7: 0000000000000400Process swapper (pid: 0, threadinfo ffffffff81a00000, task ffffffff81a8d020)Stack:ffff880028203bf0 ffffffff810913cf ffff880028203c10 ffffffffa033b642ffff8800c4702558 ffff8800c4702558 ffff880028203c30 ffffffffa0342b3cffffffffa0342b00 ffffffffa0342b00 ffff880028203c60 ffffffffa01b5d7fCall Trace:[] queue_work+0x1f/0x30省去了调用queue_work的流程。
workqueue

导论慢工作机制为什么说是“提供过内核中还曾短暂出现过慢工作机制(slow work mechanism)”,原因是在mainline内核中,曾经出现过慢工作机制(slow work mechanism),但随着并发管理工作队列(cmwq) 的出现,它已经全部被cmwq所替换,淡出了mainline在内核代码中,经常希望延缓部分工作到将来某个时间执行,这样做的原因很多,比如:在持有锁时做大量(或者说费时的)工作不合适;或希望将工作聚集以获取批处理的性能;或调用了一个可能导致睡眠的函数使得在此时执行新调度非常不合适等。
内核中提供了许多机制来提供延迟执行,如中断的下半部处理可延迟中断上下文中的部分工作;定时器可指定延迟一定时间后执行某工作;工作队列则允许在进程上下文环境下延迟执行等。
除此之外,内核中还曾短暂出现过慢工作机制(slow work mechanism),还有异步函数调用(asynchronous function calls)以及各种私有实现的线程池等。
在上面列出的如此多的内核基础组件中,使用最多则是工作队列。
几个术语在讨论之前,先定义几个内核中使用工作队列时用到的术语方便后面描述。
∙workqueues:所有工作项被( 需要被执行的工作) 排列于该队列,因此称作工作队列(workqueues) 。
∙worker thread:工作者线程(worker thread) 是一个用于执行工作队列中各个工作项的内核线程,当工作队列中没有工作项时,该线程将变为idle 状态。
∙single threaded(ST)::工作者线程的表现形式之一,在系统范围内,只有一个工作者线程为工作队列服务∙multi threaded(MT):工作者线程的表现形式之一,在多CPU 系统上每个CPU 上都有一个工作者线程为工作队列服务工作队列的优点工作队列之所以成为使用最多的延迟执行机制,得益于它的实现中的一些有意思的地方:∙使用的接口简单明了对于使用者,基本上只需要做3 件事情,依次为:o创建工作队列( 如果使用内核默认的工作队列,连这一步都可以省略掉)o创建工作项o向工作队列中提交工作项∙执行在进程上下文中,这样使得它可以睡眠,被调度及被抢占执行在进程上下文中是一个非常大的优势,其他的下半部工作机制,基本上都运行于中断上下文中,我们知道在中断上下文里,不能睡眠,不能阻塞;原因是中断上下文并不与任何进程关联,如在中断上下文睡眠,调度器将不能将其唤醒,所以在中断上下文中不能有导致内核进入睡眠的行为,如持有信号量,执行非原子的内存分配等。
workqueue 参数传递

workqueue 参数传递1.引言概述部分的内容可以描述以下内容:1.1 概述工作队列(workqueue)是一个用于以异步方式执行任务的机制。
在计算机系统中,任务是指一项需要在后台执行的工作,例如处理用户请求、计算复杂的算法、执行耗时的操作等。
工作队列的概念最早出现在操作系统中,用于管理后台任务的执行。
随着计算机系统的发展,工作队列也被引入到了其他领域,例如多线程编程、网络编程等。
工作队列的主要特点是能够实现任务的延迟执行和异步执行。
通过将任务放入工作队列中,可以避免在任务需要执行时阻塞主线程或其他线程,从而提升系统的响应速度和性能。
在工作队列中,任务是以"工作项"的形式存在的。
每个工作项包含了需要执行的具体任务和相关的参数。
参数传递是工作队列中一个重要的概念,它允许将任务执行所需的参数传递给工作项,在任务执行时可以使用这些参数进行相应的操作。
本文将重点介绍工作队列中的参数传递问题。
我们将探讨参数传递的含义以及常用的方法,以帮助读者更好地理解工作队列的使用和优化。
总之,工作队列是一种用于管理异步任务执行的机制,通过参数传递可以实现任务执行所需的数据传递。
本文将详细介绍工作队列中参数传递的概念和方法,以帮助读者更好地理解和应用工作队列。
文章结构文章的结构遵循以下大纲:1. 引言1.1 概述1.2 文章结构1.3 目的2. 正文2.1 workqueue2.1.1 定义2.1.2 作用2.2 参数传递2.2.1 含义2.2.2 方法3. 结论3.1 总结3.2 展望在本文中,将首先介绍该文章的引言部分,包括对工作队列(workqueue)和参数传递的概述。
随后,文章将会详细探讨workqueue 的定义和作用。
然后,文章将转向参数传递部分,解释参数传递的含义以及常用的方法。
最后,文章将给出结论,对整篇文章进行总结,并展望未来的研究方向。
通过以上结构,本文旨在全面讨论workqueue和参数传递的相关内容,帮助读者深入了解这些概念和技术,并为进一步的研究提供指导。
linux内核中的workqueue_和work_使用方法__示例及解释说明

linux内核中的workqueue 和work 使用方法示例及解释说明1. 引言1.1 概述Linux内核是操作系统的核心,工作队列(workqueue)和work是其重要的组成部分。
工作队列提供了一种异步机制,用于处理长时间运行的任务或者需要在后台执行的任务。
而work则是具体的任务对象,通过将任务封装为work对象,可以方便地在工作队列中进行调度和管理。
1.2 文章结构本文将详细介绍Linux内核中的工作队列(workqueue)和work的使用方法,并通过示例和解释说明来展示其具体应用。
文章分为五个部分:引言、Workqueue和Work基础知识、Workqueue使用方法、Work使用方法和示例说明以及结论与展望。
1.3 目的本文旨在帮助读者全面了解Linux内核中工作队列和work的概念以及它们的使用方法。
通过深入解析其原理和实践案例,读者可以掌握如何利用工作队列和work来进行高效地后台任务处理,并为未来的研究和应用提供思路和参考。
2. Workqueue和Work基础知识:2.1 Workqueue介绍:Workqueue是Linux内核中的一种机制,用于管理和执行工作任务。
它是一种异步处理的机制,可以在后台处理一些耗时的操作,而不会阻塞系统或其他任务的执行。
2.2 Work介绍:Work是由Workqueue管理的工作任务。
每个Work代表一个需要在后台执行的具体工作。
一个Work可以被认为是一段代码,在特定条件或事件发生时被调用执行。
2.3 Work之间的关系:Workqueue可以创建和管理多个Work任务。
当某个条件满足时,例如硬件中断发生或定时器超时,Workqueue会从任务队列中选择一个可用的Work,并将其分配给空闲的内核线程来运行,以完成相应的工作。
在这个过程中,多个Work之间不存在直接依赖关系。
每个Work都是独立地被分配、执行和管理。
它们并行运行,并且不需要等待其他Work的完成。
linux 等待队列用法 -回复

linux 等待队列用法-回复Linux 等待队列用法在Linux 操作系统中,等待队列(Wait Queue)是一种常用的数据结构,用于实现进程间的同步和通信。
当一个进程需要等待某个事件发生或者某个资源可用时,它可以将自己加入等待队列,并进入睡眠状态,直到满足等待条件后被唤醒。
本文将详细介绍Linux 等待队列的用法和实现原理,让读者更好地理解和应用这一重要的操作系统概念。
1. 等待队列的基本概念和作用等待队列是一种链表结构,用于存放需要等待同一个事件或资源的进程。
当一个进程需要等待某个条件满足时,它会把自己放入等待队列,并进入睡眠状态,等待被唤醒。
等待队列的作用在于帮助进程实现阻塞、睡眠和唤醒操作,使得进程能够在需要等待某个条件满足时能够有效地等待,避免了占用CPU 资源。
2. Linux 等待队列的数据结构和设计Linux 等待队列的主要数据结构包括等待队列头(wait_queue_head_t)和等待队列项(wait_queue_t)。
2.1 等待队列头(wait_queue_head_t)等待队列头是一个结构体,用于表示一个等待队列,它包含两部分数据:等待队列中的等待项列表和唤醒函数指针。
等待队列头的定义如下:typedef struct __wait_queue_head {spinlock_t lock;struct list_head task_list;wait_queue_proc_t procs;} wait_queue_head_t;其中,lock 是一个自旋锁,用于保护等待队列的访问;task_list 是一个链表结构,用于保存等待队列中的等待项;procs 是一个指向唤醒函数的指针,用于在唤醒等待队列中的进程时执行相应的操作。
2.2 等待队列项(wait_queue_t)等待队列项用于表示等待队列中的一个等待项,它包含了等待的条件和等待的进程。
等待队列项的定义如下:struct __wait_queue {unsigned int flags;void *private;wait_queue_func_t func;struct list_head task_list;};typedef __wait_queue wait_queue_t;其中,flags 用于表示等待的条件;private 是一个指针,用于保存等待过程中的私有数据;func 是唤醒函数,用于在满足等待条件时唤醒相应的进程;task_list 是链表结构,用于保存等待队列中的所有等待项。
应用程序和内核模块的区别及中断

驱动编程学习----内核模块与应用程序区别只有现实上是内核的一部分的函数才可以在内核模块里使用. 内核相干的不论什么东西都在头文件里声明, 这些个头文件在你已成立和配置的内核源码树里; 大多相干的头文件位于 include/linux和 include/asm, 但是别的 include 的子目录已新增到联系瓜葛特别指定内核子系统的质料里了别的一个在内核编程和应用步伐编程之间的重要差别是每一个情况是如何措置惩罚错误: 在应用步伐开发中段错误是无害的, 一个调试器每每用来追踪错误到源码中的问题, 而一个内核错误如果不终止全般系统至少会杀当进步程内核模块比拟于应用步伐每个内核模块只注册本身以便来服务未来的哀求, 而且它的初始化函数立刻终止. 换言之, 模块初始化函数的使命是为往后调用模块的函数做筹办; 仿佛是模块说, " 我在这搭, 这是我能做的."模块的退出函数( 例子里是你好_exit )就在模块被卸载时兴小调用. 它仿佛告诉内核, "我再也不在那里了, 不要要求我做不论什么事了."这类编程的方法类似于事务驱动的编程, 但是虽然不是所有的应用步伐都是事务驱动的, 每个内核模块都是. 别的一个首要的差别, 在事务驱动的应用步伐和内核代码之间, 是退出函数: 一个终止的应用步伐可以在释放资源方面懒惰, 或者纯粹不做清算事情, 但是模块的退出函数必需小心恢复每个由初始化函数成立的东西, 否则会保留一些东西直至系统重启.卸载模块的能力是你将最赏识的模块化的此中一个特色, 由于它有助于减少开发时间; 你可试验你的新驱动的连续的版本, 而不消每次履历漫长的关机/重启周期.应用可以调用分外的库,所以有些函数不需要去定义就能够直接调用,而内核不可以,只能是本身定义才使用,而且缺少浮点的撑持中断的下半部1.中断处理局限性中断处理程序以异步方式执行,可能会打断其他重要代码.这个屏蔽时间短.中断处理程序会引起其他中断屏蔽.这个时间必须短.中断处理程序需要对硬件操作.通常对时间要求很高.需要尽快响应.中断处理程序不在进程的上下文中运行,所以不能阻塞.把那些中断处理中对时间要求不严格的部分,应该推后到中断被激活后运行.因此整个中断处理程序被分成两部分,前部分就是通过request_irq注册的函数.2.下半部下半部的任务就是执行与中断处理密切相关,但中断处理程序本身不执行的工作.1.如何划分上下部分如果一个任务对时间敏感,则放在中断处理程序中.如果一个任务和硬件相关,则放在中断处理程序中执行.如果一个任务要保证不被其他中断打断,则放在中断处理程序中执行.其他所有任务,考虑放到下半部执行.2.为什么要用下半部通常下半部在中断处理程序一返回就会运行,采用了下半部的关键在于他们运行的时候,允许响应所有的中断.2.6中支持的下半部方法:软中断(softirq): 不能睡眠Tasklet: 基于软中断实现,不能睡眠工作队列(work queue):基于内核线程,可以睡眠,可以调度,但不能访问用户空间.3.软中断的实现软中断是在编译期间静态分配的.共有32个.对性能要求很高的情况下才使用软中断.软中断在cpu上可以同时进行.一个软中断不会去强占另一个软中断.只有中断处理程序才会强占软中断.软中断的实现方式对任何共享数据要求严格的锁保护.1.软中断的处理程序在kernel/softirq.c中实现,用softirq_action结构表示:定义在<linux/interrupt.h>中: Struct softirq_action {Void (*action)(struct softirq_action);Void *data;}在kernel/softirq.c中定义了一个包含32个结构体的数组:Static struct softirq-action softirq_vec[32];每个软中断都占据该数组的一项,当前内核只用了6个.待处理中断会被检查和执行:1.从一个硬件中断代码返回时2.在ksoftirqd内核线程中.3.在显式检查和执行待处理的软中断的代码中.所有软中断都通过do_softirq()执行,内容如下:U32 pending = softirq_pending(cpu);If(pending) {Struct softirq_action *h = softirq_vec;Softirq_pending(cpu) = 0;Do {If(pending & 1)H->action(h);H++;Pending >> 1;}while (pending);}4.如何加入自己的软中断1.添加声明在编译期间,通过<linux/interrupt.h>中的定义的枚举类型来静态地声明软中断. HI_SOFTIRQ 0:优先级高的taskletTIMER_SOFTIRQ 1 ;定时器的下半部NET_TX_SOFTIRQ 2 ;发送网络数据包.NET_RX_SOFTIRQ 3; 接受网络数据包SCSI_SOFTIRQ 4;scsi的下半部TASKLET_SOFTIRQ 5: tasklet如:open_softirq(NET_TX_SOFTIRQ,net_tx,action,NULL)3.触发软中断Raise_softirq(NET_TX_SOFTIRQ5.tasklet的实现Tasklet是通过软中断实现的,它跟软中断不同是他是动态创建的.不同的tasklet 可以在不同的处理器上使用.但相同的不可以.tasklet结构体在<linux/interrupt.h>Struct tasklet_struct {Struct tasklet_struct *next;Unsigned long state;Atomic_t count;Void (*func)(unsigned long );Unsigned long data;}State : 0 or TASKLET_STATE_SCHEDCount :不为0则tasklet被禁止,为0时,tasklet激活.调度tasklet已调度(schdule)的tasklet(等同与被触发raise的软中断)存放在两个单处理器数据结构中.tasklet_vec and tasklet_hi_vec.这两个结构体是由tasklet 构成的链表.通过tasklet_schedule() and tasklet_hi_schedule()进行调度.6.如何创建我们的tasklet1.声明 <linux/interrupt.h>静态声明DECLARE_TASKLET(name,func,data);DECLARE_TASKLED(name,func,data);动态声明Sturct tasklet_struct *t = kmalloc(sizeof(tasklet_struct ),GFP_KENEL);Tasklet_init(t,tasklet_handler,dev);2.编写自己的tasklet处理程序Void tasklet_handler(unsigned long data ) {....};Tasklet 不能睡眠,且在运行在开中断时.3.调度自己的tasklet通常在中断处理函数结束前进行调度.Tasklet_schedule(&my_tasklet);Tasklet 只运行一次.4.其他tasklet处理函数Tasklet_disable()Tasklet_disable_nosync()Tasklet_enable();Tasklet_kell();7.工作队列work_queue的实现Work_queue是下半部的另一种实现方式.他可以把工作推后,交给内核线程执行.work_queue将在进程上下文中运行,从而允许重新调度甚至睡眠.如果推后的任务要睡眠,选择work_queue,如果不睡眠,那么就选者中断或tasklet.内核中为每个cpu建立了一个默认的工作线程.单cpu只有enets/0这样一个线程.8.使用默认的工作队列#include <linux/workqueue.h>1.创建我们完成的工作结构静态DECLARE_WORK(name,voie (*func)(void *),void *data);动态Struct work_struct *mywork = kmalloc(....);INIT_WORK(struct work_struct *mywork,void (*func)(void *),void *data);2.处理函数Void work_handle(void *data)该函数会由一个工作者线程执行,运行在进程的上下文.默认情况下,可以响应中断,并且不持有任何锁.函数可以睡眠.3.对工作进行调度我们的工作被提交个默认的evens 工作线程,调用:Schedule_work(&mywork) ;mywork 马上会被调度,一旦线程被唤醒,它就回被执行.Schedule_delayed_work(&work,delay); 延迟delay个时钟节拍执行工作.4.刷新工作队列Void flush_scheduled_work(void);函数会一直等待,直到队列中所有的对象都被执行以后才返回.5.取消延迟的操作Int cancel_delayed_work(struct work_struct *work)9.创建我们的工作队列参见<linux/workqueue.h>创建新的工作队列Struct workqueue_struct *create_workqueue(const char *name);在每个 cpu 上创建一个名为name/n的线程Struct workqueue_struct *create_singlethread_workqueue(const char *name);只在当前cpu上创建线程.2,创建要完成的工作和工作队列的处理函数和使用events队列是一样的.3.对工作进行调度Int queue_work(struct workqueue_struct *wq,struct work_struct *work);或Int queue_delayed_work(struct workqueue_struct *wq,struct work_struct *work,unsigned long delay);4,刷新指定的工作队列Flush_work_queue(stuct workqueue_strcut *wq);在编写设备驱动时, tasklet 机制是一种比较常见的机制,通常用于减少中断处理的时间,将本应该是在中断服务程序中完成的任务转化成软中断完成。
【原创】Linux中断子系统(四)-Workqueue
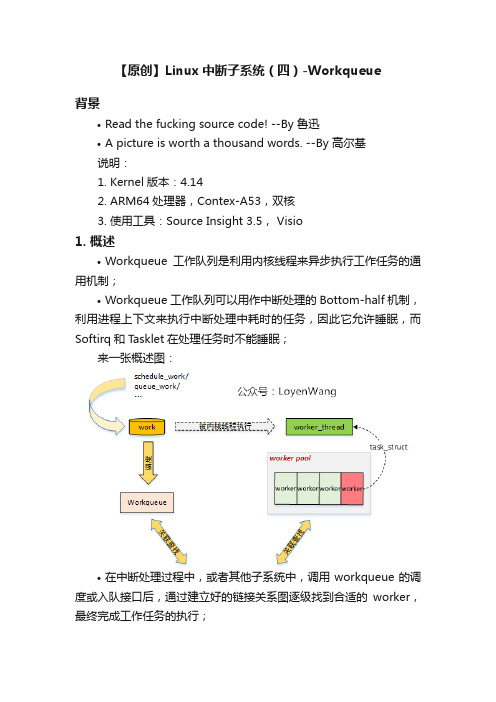
【原创】Linux中断子系统(四)-Workqueue背景•Read the fucking source code! --By 鲁迅•A picture is worth a thousand words. --By 高尔基说明:1.Kernel版本:4.142.ARM64处理器,Contex-A53,双核3.使用工具:Source Insight 3.5, Visio1. 概述•Workqueue工作队列是利用内核线程来异步执行工作任务的通用机制;•Workqueue工作队列可以用作中断处理的Bottom-half机制,利用进程上下文来执行中断处理中耗时的任务,因此它允许睡眠,而Softirq和Tasklet在处理任务时不能睡眠;来一张概述图:•在中断处理过程中,或者其他子系统中,调用workqueue的调度或入队接口后,通过建立好的链接关系图逐级找到合适的worker,最终完成工作任务的执行;2. 数据结构2.1 总览此处应有图:•先看看关键的数据结构:1.<>e>work_struct:工作队列调度的最小单位,work item;2.workqueue_struct:工作队列,work item都挂入到工作队列中;3.worker:work item的处理者,每个worker对应一个内核线程;4.worker_pool:worker池(内核线程池),是一个共享资源池,提供不同的worker来对work item进行处理;5.pool_workqueue:充当桥梁纽带的作用,用于连接workqueue和worker_pool,建立链接关系;下边看看细节吧:2.2 workstruct work_struct用来描述work,初始化一个work并添加到工作队列后,将会将其传递到合适的内核线程来进行处理,它是用于调度的最小单位。
关键字段描述如下:struct work_struct {atomic_long_t data; //低比特存放状态位,高比特存放worker_pool的ID或者pool_workqueue的指针struct list_head entry; //用于添加到其他队列上work_func_t func; //工作任务的处理函数,在内核线程中回调#ifdef CONFIG_LOCKDEPstruct lockdep_map lockdep_map;#endif};图片说明下data字段:2.3 workqueue•内核中工作队列分为两种:1.bound:绑定处理器的工作队列,每个worker创建的内核线程绑定到特定的CPU上运行;2.unbound:不绑定处理器的工作队列,创建的时候需要指定WQ_UNBOUND标志,内核线程可以在处理器间迁移;•内核默认创建了一些工作队列(用户也可以创建):1.system_mq:如果work item执行时间较短,使用本队列,调用schedule[_delayed]_work[_on]()接口就是添加到本队列中;2.system_highpri_mq:高优先级工作队列,以nice值-20来运行;3.system_long_wq:如果work item执行时间较长,使用本队列;4.system_unbound_wq:该工作队列的内核线程不绑定到特定的处理器上;5.system_freezable_wq:该工作队列用于在Suspend时可冻结的work item;6.system_power_efficient_wq:该工作队列用于节能目的而选择牺牲性能的work item;7.system_freezable_power_efficient_wq:该工作队列用于节能或Suspend时可冻结目的的work item;struct workqueue_struct关键字段介绍如下:struct workqueue_struct {struct list_head pwqs; /* WR: all pwqs of this wq */ //所有的pool_workqueue都添加到本链表中struct list_head list; /* PR: list of all workqueues */ //用于将工作队列添加到全局链表workqueues中struct list_head maydays; /* MD: pwqs requesting rescue */ //rescue状态下的pool_workqueue添加到本链表中struct worker *rescuer; /* I: rescue worker */ //rescuer内核线程,用于处理内存紧张时创建工作线程失败的情况struct pool_workqueue *dfl_pwq; /* PW: only for unbound wqs */char name[WQ_NAME_LEN]; /* I:workqueue name *//* hot fields used during command issue, aligned to cacheline */unsigned int flags ____cacheline_aligned; /* WQ: WQ_* flags */struct pool_workqueue __percpu *cpu_pwqs; /* I: per-cpu pwqs */ //Per-CPU都创建pool_workqueuestruct pool_workqueue __rcu *numa_pwq_tbl[]; /* PWR: unbound pwqs indexed by node */ //Per-Node创建pool_workqueue...};2.4 worker•每个worker对应一个内核线程,用于对work item的处理;•worker根据工作状态,可以添加到worker_pool的空闲链表或忙碌列表中;•worker处于空闲状态时并接收到工作处理请求,将唤醒内核线程来处理;•内核线程是在每个worker_pool中由一个初始的空闲工作线程创建的,并根据需要动态创建和销毁;关键字段描述如下:struct worker {/* on idle list while idle, on busy hash table while busy */union {struct list_head entry; /* L: while idle */ //用于添加到worker_pool的空闲链表中struct hlist_node hentry; /* L: while busy */ //用于添加到worker_pool的忙碌列表中};struct work_struct *current_work; /* L: work being processed */ //当前正在处理的workwork_func_t current_func; /* L: current_work's fn */ //当前正在执行的work回调函数struct pool_workqueue *current_pwq; /* L: current_work's pwq */ //指向当前work所属的pool_workqueuestruct list_head scheduled; /* L: scheduled works */ //所有被调度执行的work都将添加到该链表中/* 64 bytes boundary on 64bit, 32 on 32bit */struct task_struct *task; /* I: worker task */ //指向内核线程struct worker_pool *pool; /* I: the associated pool */ //该worker所属的worker_pool/* L: for rescuers */struct list_head node; /* A: anchored at pool->workers */ //添加到worker_pool->workers链表中/* A: runs through worker->node */...};2.5 worker_pool•worker_pool是一个资源池,管理多个worker,也就是管理多个内核线程;•针对绑定类型的工作队列,worker_pool是Per-CPU创建,每个CPU都有两个worker_pool,对应不同的优先级,nice值分别为0和-20;•针对非绑定类型的工作队列,worker_pool创建后会添加到unbound_pool_hash哈希表中;•worker_pool管理一个空闲链表和一个忙碌列表,其中忙碌列表由哈希管理;关键字段描述如下:struct worker_pool {spinlock_t lock; /* the pool lock */int cpu; /* I: the associated cpu */ //绑定到CPU的workqueue,代表CPU IDint node; /* I: the associated node ID */ //非绑定类型的workqueue,代表内存Node IDint id; /* I: pool ID */unsigned int flags; /* X: flags */unsigned long watchdog_ts; /* L: watchdog timestamp */struct list_head worklist; /* L: list of pending works */ //pending状态的work添加到本链表int nr_workers; /* L: total number of workers */ //worker的数量/* nr_idle includes the ones off idle_list for rebinding */int nr_idle; /* L: currently idle ones */struct list_head idle_list; /* X: list of idle workers */ //处于IDLE状态的worker添加到本链表struct timer_list idle_timer; /* L: worker idle timeout */struct timer_list mayday_timer; /* L: SOS timer for workers *//* a workers is either on busy_hash or idle_list, or the manager */DECLARE_HASHTABLE(busy_hash,BUSY_WORKER_HASH_ORDER); //工作状态的worker添加到本哈希表中/* L: hash of busy workers *//* see manage_workers() for details on the two manager mutexes */struct worker *manager; /* L: purely informational */struct mutex attach_mutex; /* attach/detach exclusion */struct list_head workers; /* A: attached workers */ //worker_pool管理的worker添加到本链表中struct completion *detach_completion; /* all workers detached */struct ida worker_ida; /* worker IDs for task name */struct workqueue_attrs *attrs; /* I: worker attributes */struct hlist_node hash_node; /* PL: unbound_pool_hash node */ //用于添加到unbound_pool_hash中...} ____cacheline_aligned_in_smp;2.6 pool_workqueue•pool_workqueue充当纽带的作用,用于将workqueue和worker_pool关联起来;关键字段描述如下:struct pool_workqueue {struct worker_pool *pool; /* I: the associated pool */ //指向worker_poolstruct workqueue_struct *wq; /* I: the owning workqueue */ //指向所属的workqueueint nr_active; /* L: nr of active works */ //活跃的work数量int max_active; /* L: max active works */ //活跃的最大work数量struct list_head delayed_works; /* L: delayed works */ //延迟执行的work挂入本链表struct list_head pwqs_node; /* WR: node on wq->pwqs */ //用于添加到workqueue链表中struct list_head mayday_node; /* MD: node on wq->maydays */ //用于添加到workqueue链表中...} __aligned(1 << WORK_STRUCT_FLAG_BITS);2.7 小结再来张图,首尾呼应一下:3. 流程分析3.1 workqueue子系统初始化•workqueue子系统的初始化分成两步来完成的:workqueue_init_early和workqueue_init。
linux工作队列机制

linux工作队列机制Linux工作队列机制是Linux内核中的一项重要功能,用于处理延迟执行的任务。
本文将详细介绍Linux工作队列机制的原理和使用方法。
一、什么是工作队列机制工作队列机制是Linux内核中的一种任务调度机制,用于处理那些不需要立即执行的任务。
在Linux内核中,许多任务需要延迟执行,例如延迟写入磁盘、定时器处理等。
为了避免阻塞其它关键任务,Linux内核采用了工作队列机制。
二、工作队列的类型Linux内核中的工作队列分为两种类型:即时工作队列和延迟工作队列。
1. 即时工作队列即时工作队列用于处理一些需要立即执行的任务。
当一个任务需要立即执行时,可以将其添加到即时工作队列中。
即时工作队列中的任务会尽快被执行,不会有太大的延迟。
2. 延迟工作队列延迟工作队列用于处理一些可以延迟执行的任务。
当一个任务需要延迟执行时,可以将其添加到延迟工作队列中。
延迟工作队列中的任务会在一定的延迟时间后被执行,这样可以避免影响关键任务的执行。
三、工作队列的实现原理Linux内核中的工作队列是通过task_struct结构体来表示的。
每个工作队列都包含一个task_struct结构体,用于记录队列的状态和任务的执行情况。
在Linux内核中,工作队列的实现主要依赖于两个重要的数据结构:workqueue_struct和work_struct。
1. workqueue_structworkqueue_struct是工作队列的管理结构,用于管理工作队列中的任务。
每个工作队列都有一个唯一的workqueue_struct结构体,用于表示该工作队列的状态和属性。
2. work_structwork_struct是工作队列中的任务结构,用于表示一个待执行的任务。
每个工作队列都包含一个或多个work_struct结构体,用于保存待执行的任务。
四、工作队列的使用方法在Linux内核中,使用工作队列机制非常简单。
只需要按照以下步骤进行操作:1. 定义工作队列需要定义一个工作队列,即初始化一个workqueue_struct结构体。
【IT专家】[Linux API]linux 工作队列workqueue
![【IT专家】[Linux API]linux 工作队列workqueue](https://img.taocdn.com/s3/m/65c73ae180eb6294dc886c02.png)
本文由我司收集整编,推荐下载,如有疑问,请与我司联系[Linux API]linux 工作队列workqueue2017/07/13 2 1,功能描述:Linux中的Workqueue机制就是为了简化内核线程的创建。
通过调用workqueue的接口就能创建内核线程。
并且可以根据当前系统CPU的个数创建线程的数量,使得线程处理的事务能够并行化。
workqueue是内核中实现简单而有效的机制,他显然简化了内核daemon的创建,方便了用户的编程。
工作队列(workqueue)是另外一种将工作推后执行的形式.工作队列可以把工作推后,交由一个内核线程去执行,也就是说,这个下半部分可以在进程上下文中执行。
最重要的就是工作队列允许被重新调度甚至是睡眠。
2,结构体/源码相关推后执行的任务叫做工作,对应的结构体 //参考文件kernel/include/linux/workqueue.hstruct work_struct { atomic_long_t data; //paramters of work func 宏做函数的参数struct list_head entry; //work node point链接结构提指针,一个链表节点work_func_t func; //deal with work func 处理工作的函数,typedef void (*work_func_t)(struct work_struct *work);#ifdef CONFIG_LOCKDEP struct lockdep_map lockdep_map;#endif};//参考文件kernel/include/linux/workqueue.hstruct delayed_work { struct work_struct work; struct timer_list timer; /* target workqueue and CPU - timer uses to queue - work */ struct workqueue_struct *wq; int cpu;};创建类型: 静态地创建工作项: DECLARE_WORK(n, f) DECLARE_DELAYED_WORK(n, f) 动态地创建工作项: INIT_WORK(struct work_struct work, work_func_t func); PREPARE_WORK(struct work_struct work, work_func_t func); INIT_DELAYED_WORK(struct delayed_work work, work_func_t func); PREPARE_DELAYED_WORK(struct delayed_work work, work_func_t func); 3相关术语workqueue: 所有工作项(需要被执行的工作)被排列于该队列. worker thread: 是一个用于执行workqueue 中各个工作项的内核线程, 当。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
cwq->thread = p;
return p;
}
static int worker_thread(void *__cwq)
{
struct cpu_workqueue_struct *cwq = __cwq;
// 声明一个等待队列
DECLARE_WAITQUEUE(wait, current);
// 参数初始化定义, 而该宏用在程式之中对工作结构赋值
#define INIT_WORK(_work, _func, _data) \
do { \
INIT_LIST_HEAD(&(_work)->entry); \
(_work)->pending = 0; \
/*
* The externally visible workqueue abstraction is an array of
* per-CPU workqueues:
*/
// 工作队列结构
struct workqueue_struct {
struct cpu_workqueue_struct *cpu_wq;
int cpu)
{
// 每个CPU的工作队列
struct cpu_workqueue_struct *cwq = per_cpu_ptr(wq->cpu_wq, cpu);
struct task_struct *p;
spin_lock_init(&cwq->lock);
{
...
keventd_wq = create_workqueue("events");
...
}
核心创建函数是__reate_workqueue:
struct workqueue_struct *__create_workqueue(const char *name,
int singlethread)
// 工作队列节点
struct workqueue_struct *wq;
// 进程指针
struct task_struct *thread;
int run_depth; /* Detect run_workqueue() recursion depth */
} ____cacheline_aligned;
// 下一个要插入节点的序号
long insert_sequence; /* Next to add */
// 工作机构链表节点
struct list_head worklist;
// 要进行处理的等待队列
wait_queue_head_t more_work;
// 处理完的等待队列
wait_queue_head_t work_done;
destroy = 1;
}
}
mutex_unlock(&workqueue_mutex);
/*
* Was there any error during startup? If yes then clean up:
*/
if (destroy) {
// 建立线程失败, 释放工作队列
3. 一些宏定义
/* include/linux/workqueue.h */
// 初始化工作队列
#define __WORK_INITIALIZER(n, f, d) { \
// 初始化list
.entry = { &(n).entry, &(n).entry }, \
// 为每个CPU分配单独的工作队列空间
wq->cpu_wq = alloc_percpu(struct cpu_workqueue_struct);
if (!wq->cpu_wq) {
kfree(wq);
return NULL;
}
wq->name = name;
mutex_lock(&workqueue_mutex);
// 回调函数
.func = (f), \
// 回调函数参数
.data = (d), \
// 初始化定时器
.timer = TIMER_INITIALIZER(NULL, 0, 0), \
}
// 声明工作队列并初始化
#define DECLARE_WORK(n, f, d) \
const char *name;
struct list_head list; /* Empty if single thread */
};
kernel/workqueue.c中定义了一个工作队列链表, 任何工作队列能够挂接到这个链表中:
static LIST_HEAD(workqueues);
destroy_workqueue(wq);
wq = NULL;
}
return wq;
}
EXPORT_SYMBOL_GPL(__create_workqueue);
// 创建工作队列线程
static struct task_struct *create_workqueue_thread(struct workqueue_struct *wq,
for_each_online_cpu(cpu) {
p = create_workqueue_thread(wq, cpu);
if (p) {
// 绑定CPU
kthread_bind(p, cpu);
// 唤醒线程
wake_up_process(p);
} else
* flush_scheduled_work() was called.
*/
// 这个结构是针对每个CPU的
struct cpu_workqueue_struct {
// 结构锁
spinlock_t lock;
// 下一个要执行的节点序号
long remove_sequence; /* Least-recently added (next to run) */
* until all currently-scheduled works are completed, but it doesn't
* want to be livelocked by new, incoming ones. So it waits until
* remove_sequence is >= the insert_sequence which pertained when
struct work_struct n = __WORK_INITIALIZER(n, f, d)
/*
* initialize a work-struct's func and data pointers:
*/
// 重新定义工作结构参数
#define PREPARE_WORK(_work, _func, _data) \
/*
* The per-CPU workqueue (if single thread, we always use the first
* possible cpu).
*
* The sequence counters are for flush_scheduled_work(). It wants to wait
init_waitqueue_head(&cwq->more_work);
// 初始化等待队列work_done, 该队列处理执行完的工作结构
init_waitqueue_head(&cwq->work_done);
// 建立内核线程work_thread
if (is_single_threaded(wq))
struct work_struct {
// 等待时间
unsigned long pending;
// 链表节点
struct list_head entry;
// workqueue回调函数
void (*func)(void *);
// 回调函数func的数据
void *data;
{
int cpu, destroy = 0;
struct workqueue_struct *wq;
struct task_struct *p;
// 分配工作队列结构空间
wq = kzalloc(sizeof(*wq), GFP_KERNEL);
if (!wq)
return NULL;
1. 前言
工作队列(workqueue)的Linux内核中的定义的用来处理不是很紧急事件的回调方式处理方法.
以下代码的linux内核版本为2.6.19.2, 源代码文档主要为kernel/workqueue.c.
2. 数据结构
/* include/linux/workqueue.h */
// 工作节点结构
PREPARE_WORK((_work), (_func), (_data)); \
init_timer(&(_work)->timer); \
} while (0)
4. 操作函数
4.1 创建工作队列
一般的创建函数是create_workqueue, 但这其实只是个宏: