相关系数的检验方法
怎样对数据做相关性检验?

怎样对数据做相关性检验?最简单直观的方法就是做相关系数矩阵了,另外就是Pearson 相关系数或者Spearman 相关系数用SPSS软件或者SAS软件都可以分析。
用SPSS更简单。
如果你用SPSS软件,分析的步骤如下:1.点击“分析(Analyze)”2. 选中“相关(Correlate)”3. 选中“双变量(Bivariate)”4 选择你想要分析的变量5 选择Pearson 相关系数(或者Spearman 相关系数)6 选择恰当的统计检验(单边或双边)7 点击“OK”即可SPSS中pearson(皮尔逊相关系数)确定相关性,数据分析如下图,请问1与2的相关性是什么。
急。
图片0-1为什么显著相关,请分析一下。
不是相关系数越接近于1或-1,相关度越强,相关系数越接近于0,相关度越弱么。
回答<0.4显著弱相关,0.4-0.75中等相关,大于0.75强相关追问可我的pearson相关系数是-0.39。
是负数,怎么是显著负相关呢。
回答你好像一点都不会啊。
看sig的,小于0.05提问者评价原来是这样,感谢!相关性分析的表格输出是一个矩阵你只需要看横向或者纵向的1和2的交叉系数都可以pearson相关性表示的是两者相关系数的大小,-0.397 表示两者是负相关,相关性大小为0.397显著性的0.000也就是p值,用来判断相关性是否显著如何使用SPSS进行皮尔森相关系数分析??Pearson’s correlation coefficients1.单击“Analyze”,展开下拉菜单2.下拉菜单中寻找“Correlate”弹出小菜单,从小菜单上寻找“Bivariate...”,单击之,则弹出相关分析“Bivariate Correlations”对话框3.把左边的源变量中要分析相关的变量调入右边的“Va riables:”下的矩形框内4.勾选“Correlation Coelficients”中的“Pearson”选项5.点击“OK”即可求问了:因子分析明明是基于相关系数矩阵的,但为什么大家都直接把数据导进去就分析呢?= =!因子分析是有一定条件需求的,变量之间要存在一定的相关性,而因子分析时也会有一个检验,从过程上将必须先做了这些之后才做因子分析的,所以说很多人都是在想当然的用,很多发表的论文上都存在用法不当的问题利用SPSS,相关系数矩阵怎么算analyze-correlate-bivariate-选择变量OK输出的是相关系数矩阵相关系数下面的Sig.是显著性检验结果的P值,越接近0越显著。
相关分析的实验原理和方法

相关分析的实验原理和方法相关分析是一种统计方法,用于研究变量之间的关系。
它可以帮助我们理解不同变量之间的相互关联性,揭示隐藏的模式和趋势,并评估它们之间的强度和方向。
在实验设计中,相关分析可以用来确定两个或多个变量之间的关系,以及它们之间的因果关系。
本文将介绍相关分析的原理和方法。
首先,我们需要了解相关系数的定义和计算方法。
相关系数是衡量两个变量之间关联程度的统计量。
常用的相关系数有皮尔逊相关系数、斯皮尔曼等级相关系数和切比雪夫相关系数。
皮尔逊相关系数适用于连续变量,斯皮尔曼等级相关系数适用于有序变量,切比雪夫相关系数适用于定性变量。
这些相关系数的取值范围在-1和1之间,其中-1表示完全负相关,1表示完全正相关,0表示无相关。
进行相关分析的第一步是收集数据。
我们需要收集多个观测值对于所研究的变量,并记录下来。
数据可以通过实际观察、调查问卷、实验测量等方式获取。
收集的数据应该具有代表性,并且样本的大小足够大,以确保结果的可靠性。
在数据收集之后,我们可以计算相关系数。
以皮尔逊相关系数为例,它可以通过以下公式计算:r = (Σ((X - X̄)(Y - Ȳ))) / (n * σX * σY)其中,r是相关系数,X和Y分别是两个变量的观测值,X̄和Ȳ是它们的平均值,n是样本大小,σX和σY是它们的标准差。
计算相关系数之后,我们可以进行统计检验,以确定相关系数是否显著不等于零。
常用的检验方法有t检验和F检验。
t检验适用于小样本,F检验适用于大样本。
通过检验,我们可以得出关于相关系数是否具有统计显著性的结论,如果相关系数显著不等于零,则我们可以认为两个变量之间存在相关性。
此外,相关分析还可以进行回归分析。
回归分析是一种用于预测和解释因变量变化的方法。
在回归分析中,我们可以使用相关系数作为自变量和因变量之间关系的衡量指标,从而建立预测模型。
回归分析可以帮助我们预测因变量的未来变化,并确定哪些自变量对于因变量的影响最大。
相关系数检验法步骤

相关系数检验法步骤一、相关系数检验法步骤相关系数检验法是一种用于检验两个变量之间关系强度的统计方法。
它可以衡量两个变量之间的相关性,并判断这种相关性是否显著。
以下是相关系数检验法的步骤:1. 收集数据:首先,需要收集相关的数据,包括两个变量的观测值。
这些数据可以通过实地调查、实验或其他可靠的数据源获得。
2. 计算相关系数:接下来,需要计算两个变量之间的相关系数。
常用的相关系数包括皮尔逊相关系数和斯皮尔曼相关系数。
皮尔逊相关系数适用于连续变量,而斯皮尔曼相关系数适用于等级变量或非线性关系。
3. 假设检验:在进行相关系数检验前,需要先建立假设。
通常,零假设为两个变量之间不存在相关关系,备择假设为两个变量之间存在相关关系。
4. 计算检验统计量:根据所选的相关系数和样本大小,计算相关系数的检验统计量。
检验统计量的计算方式与所选的相关系数有关。
5. 确定显著性水平:确定显著性水平,通常将其设定为0.05或0.01。
显著性水平表示拒绝零假设的临界值。
6. 判断是否拒绝零假设:将计算得到的检验统计量与显著性水平进行比较。
如果检验统计量的值小于显著性水平对应的临界值,则拒绝零假设,认为两个变量之间存在相关关系;如果检验统计量的值大于临界值,则接受零假设,认为两个变量之间不存在相关关系。
7. 解释结果:最后,根据检验结果对两个变量之间的相关性进行解释。
如果拒绝了零假设,可以说明两个变量之间存在相关关系,并根据相关系数的值来判断相关关系的强度和方向。
二、相关系数检验法的应用相关系数检验法广泛应用于各个领域的研究中。
以下是一些常见的应用场景:1. 经济学研究:在经济学中,相关系数检验法常用于分析不同变量之间的关系,如GDP与失业率、通货膨胀与利率等。
通过相关系数检验,可以了解变量之间的关系强度,为经济政策的制定提供依据。
2. 市场营销研究:在市场营销领域,相关系数检验法可以用来分析产品销售与广告投入、价格变动等因素之间的关系。
两条时间序列相关系数检验

两条时间序列相关系数检验
时间序列相关系数检验是用于判断两个时间序列之间的相关关系的统计方法。
常见的时间序列相关系数检验方法包括皮尔逊相关系数检验和斯皮尔曼相关系数检验。
1. 皮尔逊相关系数检验:皮尔逊相关系数检验用于判断两个连续变量之间的线性相关关系,可以用于检验两条时间序列之间的线性相关性。
相关系数的取值范围在-1到1之间,接近-1表示负相关,接近1表示正相关,接近0表示无相关。
在进行皮尔逊相关系数检验时,可以使用相关系数的显著性水平进行判断,如果相关系数显著不为0,则可以判断两个时间序列之间存在相关关系。
2. 斯皮尔曼相关系数检验:斯皮尔曼相关系数检验用于判断两个变量之间的单调相关关系,可以用于检验两条时间序列之间的单调相关性。
斯皮尔曼相关系数的取值范围在-1到1之间,接近-1表示负相关,接近1表示正相关,接近0表示无相关。
在进行斯皮尔曼相关系数检验时,可以使用相关系数的显著性水平进行判断,如果相关系数显著不为0,则可以判断两个时间序列之间存在单调相关关系。
需要注意的是,时间序列相关系数检验只能判断两个时间序列之间的相关关系,不能确定因果关系。
此外,相关系数检验还有其他变体和扩展方法,如滞后相关系数检验和小波相关系数检验等,可以根据具体问题和数据特点选择合适的方法进行分析。
相关系数显著

相关系数显著1. 引言相关系数是用于衡量两个变量之间关系强度和方向的统计量。
它是统计学中常用的工具,可以帮助我们理解变量之间的相关性,并通过显著性检验确定相关系数的可信度。
本文将介绍相关系数的概念、计算方法以及相关系数的显著性检验。
2. 相关系数的概念和计算相关系数衡量了两个变量之间的线性关系的强度和方向。
常用的相关系数有皮尔逊相关系数、斯皮尔曼相关系数和切比雪夫距离等。
其中,皮尔逊相关系数是最常用的相关系数之一,它适用于连续变量且满足正态分布的情况。
皮尔逊相关系数的计算公式如下:r=∑(X i−X‾)(Y i−Y‾)n s−1⋅1s X s Y其中,X i和Y i分别表示第i个样本的两个变量的取值,X‾和Y‾分别表示两个变量的均值,n s表示样本的数量,s X和s Y分别表示两个变量的标准差。
3. 相关系数的显著性检验在实际应用中,我们不仅关心两个变量之间是否存在相关关系,还关心这个相关关系是否是显著的。
为了进行相关系数的显著性检验,我们需要进行假设检验。
假设检验的零假设(H0)为两个变量之间不存在线性关系,即相关系数为0。
备择假设(H1)为两个变量之间存在线性关系,即相关系数不为0。
在统计学中,我们通常使用t检验或者F检验进行相关系数的显著性检验。
对于小样本情况,可以使用t检验;对于大样本情况,可以使用F检验。
在进行t检验时,我们需要计算t统计量的值,并与t分布的临界值进行比较。
计算t 统计量的公式如下:t=r√n−2√1−r2其中,r表示计算得到的相关系数,n s表示样本的数量。
在进行F检验时,我们需要计算F统计量的值,并与F分布的临界值进行比较。
F统计量的计算公式如下:F=r21−r2⋅n s−21其中,r表示计算得到的相关系数,n s表示样本的数量。
t检验和F检验的临界值可以在统计表中查找,也可以使用统计软件进行计算。
4. 示例为了更好地理解相关系数的显著性检验,我们来看一个实际的例子。
16 方差、相关系数及比率的显著性检验

方差、相关系数及比率的显著性检验
一 方差的差异性检验
二 相关系数的显著性检验
仅仅根据计算得到的相关系数还不足以确定变量之间是否存在相关。只有通过对相关系数显著性的检验,才能确定相关关系是否存在。 对相关系数进行显著性检验包括三种情况(即三种零假设):一是ρ=0;二是ρ=ρ0;三是ρ1=ρ2。本讲主要介绍前两种情况。
1.积差相关系数的显著性检验
相关系数的显著性检验即样本相关系数与总体相关系数的差异检验。 包括两种情况: ρ=0和ρ=ρ0 对ρ=0的检验是确认相关系数是否显著; 对ρ=ρ0的检验是确认样本所代表的总体的相关系数是否为ρ0 。
根据样本相关系数 r 对总体相关系数ρ进行推断,是以 r 的抽样分布正态性为前提的,只有当总体相关系数为零,或者接近于零,样本容量 n 相当大(n>50或n>30)时,r 的抽样分布才接近于正态分布。
⑴.H0:ρ=0条件下, 相关系数的显著性检验
检验形式:双侧检验 统计量为t,检验计算公式为:
(19.4)
例:经计算,10个学生初一和初二数学成绩的相关系数为0.780,能否说学生初一和初二的数学成绩之间存在显著相关?
解: 提出假设 H0:ρ=0,H1: ρ≠0 选择检验统计量并计算 对积差相关系数进行ρ=0的显著性检验,检验统计量为t
计 算
统计决断 根据df=10-2=8,查t值表P⑵,得t(8)0.01=3.355, |t|>t(8)0.01,则P<0.01,差异极其显著 应在0.01显著性水平拒绝零假设,接受研究假设 结论:学生初一和初二的数学成绩之间存在极其显著的相关。
另一种方法:查积差相关系数临界值表
根据df=8,查附表7,从α=0.01一列中找到对应的积差相关系数临界值为0.765。 计算得到的r=0.780,大于表中查到的临界值。因此应接受该相关关系极其显著的结论,而拒绝相关关系不显著的零假设。
线性回归中的相关系数

线性回归中的相关系数山东 胡大波线性回归问题在生活中应用广泛,求解回归直线方程时,应该先判断两个变量就是否就是线性相关,若相关再求其直线方程,判断两个变量有无相关关系的一种常用的简便方法就是绘制散点图;另外一种方法就是量化的检验法,即相关系数法.下面为同学们介绍相关系数法. 一、关于相关系数法统计中常用相关系数r 来衡量两个变量之间的线性相关的强弱,当i x 不全为零,y i 也不全为零时,则两个变量的相关系数的计算公式就是:()()nnii i ixx y y x ynx yr ---==∑∑r 就叫做变量y 与x 的相关系数(简称相关系数).说明:(1)对于相关系数r ,首先值得注意的就是它的符号,当r 为正数时,表示变量x ,y 正相关;当r 为负数时,表示两个变量x ,y 负相关;(2)另外注意r 的大小,如果[]0.751r ∈,,那么正相关很强;如果[]10.75r ∈--,,那么负相关很强;如果(]0.750.30r ∈--,或[)0.300.75r ∈,,那么相关性一般;如果[]0.250.25r ∈-,,那么相关性较弱.下面我们就用相关系数法来分析身边的问题,确定两个变量就是否相关,并且求出两个变量间的回归直线. 二、典型例题剖析(1)对变量y 与x 进行相关性检验;(2)如果y 与x 之间具有线性相关关系,求回归直线方程; (3)如果父亲的身高为73英寸,估计儿子身高.解:(1)66.8x =,67y =,102144794i i x ==∑,102144929.22i i y ==∑,4475.6x y =,24462.24x =,24489y =,10144836.4i i i x y ==∑,所以10i ix ynx yr -∑44836.4104475.6(4479444622.4)(44929.2244890)-⨯=--80.40.9882.04≈≈, 所以y 与x 之间具有线性相关关系. (2)设回归直线方程为y a bx =+,则101102211010i ii i i x yxyb x x==-=-∑∑44836.4447560.46854479444622.4-=≈-,670.468566.835.7042a y bx =-=-⨯=.故所求的回归直线方程为0.468535.7042y x =+. (3)当73x =英寸时,0.46857335.704269.9047y =⨯+=, 所以当父亲身高为73英寸时,估计儿子的身高约为69、9英寸.点评:回归直线就是对两个变量线性相关关系的定量描述,利用回归直线,可以对一些实际问题进行分析、预测,由一个变量的变化可以推测出另一个变量的变化.这就是此类问题常见题型.例2 10其中x 为高一数学成绩,y 为高二数学成绩. (1)y 与x 就是否具有相关关系;(2)如果y 与x 就是相关关系,求回归直线方程. 解:(1)由已知表格中的数据,利用计算器进行计算得 101710ii x==∑,101723i i y ==∑,71x =,72.3y =,10151467i i i x y ==∑.102150520ii x==∑,102152541i i y ==∑.1010i ix yx yr -=∑0.78=≈.由于0.78r ≈,由0.780.75>知,有很大的把握认为x 与y 之间具有线性相关关系. (2)y 与x 具有线性相关关系,设回归直线方程为y a bx =+,则1011022211051467107172.31.2250520107110i ii i i x yx yb x x==--⨯⨯==≈-⨯-∑∑,72.3 1.227114.32a y bx =-=-⨯=-.所以y 关于x 的回归直线方程为 1.2214.32y x =-.点评:通过以上两例可以瞧出,回归方程在生活中应用广泛,要明确这类问题的计算公式、解题步骤,并会通过计算确定两个变量就是否具有相关关系.。
相关系数检验_相关系数的显著性检验
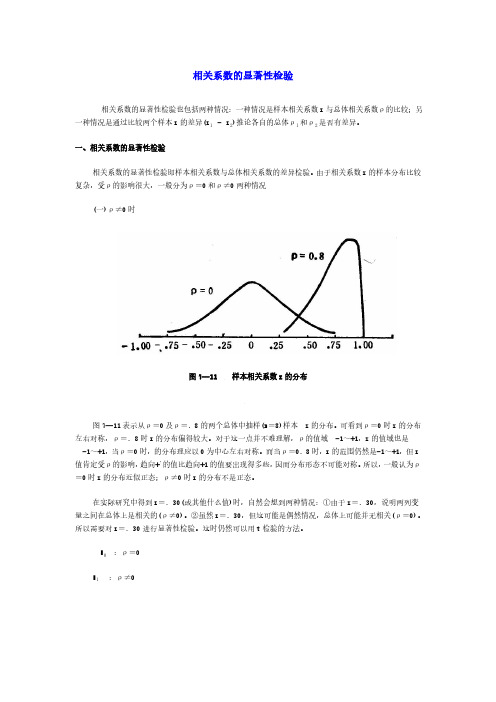
相关系数的显著性检验相关系数的显著性检验也包括两种情况:一种情况是样本相关系数r与总体相关系数ρ的比较;另一种情况是通过比较两个样本r的差异(r1 -r2)推论各自的总体ρ1和ρ2是否有差异。
一、相关系数的显著性检验相关系数的显著性检验即样本相关系数与总体相关系数的差异检验。
由于相关系数r的样本分布比较复杂,受ρ的影响很大,一般分为ρ=0和ρ≠0两种情况(一)ρ≠0时图7—11 样本相关系数r的分布图7—11表示从ρ=0及ρ=.8的两个总体中抽样(n=8)样本r的分布。
可看到ρ=0时r的分布左右对称,ρ=.8时r的分布偏得较大。
对于这一点并不难理解,ρ的值域-1~+1,r的值域也是-1~+1,当ρ=0时,的分布理应以0为中心左右对称。
而当ρ=0.8时,r的范围仍然是-1~+1,但r 值肯定受ρ的影响,趋向+'的值比趋向+1的值要出现得多些,因而分布形态不可能对称。
所以,一般认为ρ=0时r的分布近似正态;ρ≠0时r的分布不是正态。
在实际研究中得到r=.30(或其他什么值)时,自然会想到两种情况:①由于r=.30,说明两列变量之间在总体上是相关的(ρ≠0)。
②虽然r=.30,但这可能是偶然情况,总体上可能并无相关(ρ=0)。
所以需要对r=.30进行显著性检验。
这时仍然可以用t检验的方法。
H0:ρ=0H1 :ρ≠0(df=n-2) (2-27) 如果t>t.05/2,则拒绝H0,说明所得到的r不是来自ρ=0的总体,或者说r是显著的。
若t< t.05/2,则说明所得到的r值具有偶然性,从r值还不能断定总体具有相关关系。
或者说r 不显著。
[例1] 18名被试进行了两种能力测验,结果r=.40,试问这两种能力是否存在相关解:H0:ρ=0H1 :ρ≠0查附表2,t.05/2=2.12t=1.798<2.12不能拒绝H0所以r=.40并不显著,即不能推翻ρ=0的假设。
在实际应用中,更多地是直接查表来断定r是否显著。
相关性分析方法

相关性分析方法相关性分析是一种用于研究变量之间关系的统计方法,它可以帮助我们理解变量之间的相互影响和关联程度。
在实际应用中,相关性分析方法被广泛运用于市场营销、金融风险管理、医学研究等领域。
本文将介绍几种常见的相关性分析方法,并对它们的应用进行简要说明。
首先,最常见的相关性分析方法之一是皮尔逊相关系数。
皮尔逊相关系数是衡量两个连续变量之间线性关系强度和方向的统计量。
它的取值范围在-1到1之间,-1表示完全负相关,1表示完全正相关,0表示无相关。
通过计算皮尔逊相关系数,我们可以了解两个变量之间的线性相关程度,从而进行进一步的分析和预测。
其次,斯皮尔曼相关系数是一种非参数的相关性分析方法,它用于衡量两个变量之间的单调关系。
与皮尔逊相关系数不同,斯皮尔曼相关系数不要求变量呈现线性关系,因此更适用于实际数据中存在异常值或者不符合正态分布的情况。
通过计算斯皮尔曼相关系数,我们可以更全面地了解变量之间的相关性,从而准确地评估它们之间的关系。
另外,判定系数(R^2)是用于衡量线性回归模型拟合程度的统计量,它可以帮助我们评估自变量对因变量变化的解释能力。
判定系数的取值范围在0到1之间,越接近1表示模型拟合得越好。
通过计算判定系数,我们可以确定回归模型的拟合程度,从而进行模型选择和预测分析。
最后,信息熵是一种用于衡量两个变量之间非线性关系的统计量,它可以帮助我们发现变量之间的复杂关联。
信息熵的计算基于信息论,它可以帮助我们发现变量之间的潜在模式和规律,从而进行更深入的分析和预测。
综上所述,相关性分析方法是一种重要的统计工具,它可以帮助我们理解变量之间的关系,从而进行进一步的分析和预测。
在实际应用中,我们可以根据数据的特点选择合适的相关性分析方法,从而更准确地理解变量之间的关联程度。
希望本文介绍的相关性分析方法对您有所帮助。
相关性分析方法(Pearson、Spearman)

相关性分析⽅法(Pearson、Spearman)
有时候我们根据需要要研究数据集中某些属性和指定属性的相关性,显然我们可以使⽤⼀般的统计学⽅法解决这个问题,下⾯简单介绍两种相关性分析⽅法,不细说具体的⽅法的过程和原理,只是简单的做个介绍,由于理解可能不是很深刻,望⼤家谅解。
1、Pearson相关系数
最常⽤的相关系数,⼜称积差相关系数,取值-1到1,绝对值越⼤,说明相关性越强。
该系数的计算和检验为参数⽅法,适⽤条件如下:(适合做连续变量的相关性分析)
(1)两变量呈直线相关关系,如果是曲线相关可能不准确。
(2)极端值会对结果造成较⼤的影响
(3)两变量符合双变量联合正态分布。
2、Spearman秩相关系数
对原始变量的分布不做要求,适⽤范围较Pearson相关系数⼴,即使是等级资料,也可适⽤。
但其属于⾮参数⽅法,检验效能较Pearson系数低。
(适合含有等级
变量或者全部是等级变量的相关性分析)
3、⽆序分类变量相关性
最常⽤的为卡⽅检验,⽤于评价两个⽆序分类变量的相关性。
根据卡⽅值衍⽣出来的指标还有列联系数、Phi、Cramer的V、Lambda系数、不确定系数等。
OR、RR也是衡量两变量之间的相关程度的指标。
卡⽅检验⽤于检验两组数据是否具有统计学差异,从⽽分析因素之间的相关性。
卡⽅检验有pearson卡⽅检验,校正检验等,不同的条件下使⽤不同的卡⽅检验⽅
法,⽐如说满⾜双⼤于(40,5)条件的情况下要使⽤pearson卡⽅检验⽅法,另外的情况下要使⽤校正卡⽅检验⽅法。
说的不多,只是想在⼤家使⽤相关⽅法的时候清楚他们之间的差别,以及不同⽅法的适⽤条件是什么。
如何进行有效的相关性分析

如何进行有效的相关性分析相关性分析是一种常用的统计方法,用于探索变量之间的关系。
它帮助我们理解不同变量之间的相关程度,以及它们之间的因果关系。
在本文中,我们将介绍如何进行有效的相关性分析,以及一些常见的工具和技术。
一、相关性分析的基本概念在开始进行相关性分析之前,我们首先需要了解一些基本概念。
1. 相关系数:相关系数是衡量两个变量之间关系强度的统计量。
常见的相关系数有皮尔逊相关系数、斯皮尔曼相关系数和切比雪夫距离等。
选择适当的相关系数取决于变量类型和数据特点。
2. 正相关与负相关:当两个变量的值朝相同方向变化时,它们之间存在正相关关系;当两个变量的值朝相反方向变化时,它们之间存在负相关关系。
3. 相关矩阵:相关矩阵是一个矩阵,用于展示多个变量之间的相关性。
矩阵中的每个元素代表两个变量之间的相关系数。
二、相关性分析的步骤进行有效的相关性分析,需要按照以下步骤进行:1. 收集数据:首先,需要收集相关的数据。
确保数据质量好,准确性高,并且涵盖了所有要分析的变量。
2. 数据预处理:在进行相关性分析之前,需要对数据进行预处理。
这包括数据清洗、缺失值处理、异常值处理等。
通过预处理,确保数据的准确性和完整性。
3. 确定相关系数:根据变量类型和数据特点,选择合适的相关系数。
常用的皮尔逊相关系数适用于连续变量之间的线性关系;斯皮尔曼相关系数适用于有序变量或非线性关系;切比雪夫距离适用于分类变量之间的关系。
4. 计算相关系数:使用选定的相关系数公式,计算各个变量之间的相关系数。
可以使用统计软件或编程语言来实现计算。
5. 相关性可视化:相关性可视化有助于更好地理解变量之间的关系。
常用的可视化方法包括散点图、热力图和线性回归图。
选择适当的可视化方法,将相关系数结果呈现出来。
6. 分析结果解读:根据相关系数的数值和可视化结果,进行结果解读。
判断变量之间的相关性强度、方向以及是否存在显著性差异。
注意结果解读时需谨慎,应结合具体情境和领域知识进行分析。
因子分析中的数据相关性检验方法(十)

因子分析是一种常用的统计方法,用于确定一组观察变量之间的内在关系。
在因子分析中,数据相关性检验是一个非常重要的步骤,它可以帮助确定哪些变量之间存在显著的相关性,以及这些相关性是否对因子分析的结果产生影响。
在进行因子分析之前,首先需要对数据进行相关性检验。
通常情况下,这涉及到计算变量之间的相关系数,以及进行显著性检验。
常用的相关系数包括皮尔逊相关系数和斯皮尔曼相关系数,它们分别适用于不同类型的数据。
而显著性检验则可以帮助确定相关系数是否显著不等于零,从而判断变量之间是否存在显著的相关性。
在进行相关性检验时,需要注意一些常见问题。
首先,需要考虑样本量是否足够大,以确保相关系数的估计是可靠的。
其次,需要考虑变量之间可能存在的非线性关系,以及可能存在的异常值和离群点。
针对这些问题,可以使用非参数方法或者鲁棒方法来进行相关性检验,以减少对数据分布的假设。
除了计算相关系数和进行显著性检验之外,还可以使用图形方法来进行数据相关性检验。
散点图和相关矩阵图是常用的图形方法,它们可以直观地展示变量之间的关系,帮助检查是否存在明显的相关性模式。
此外,还可以使用聚类分析和因子分析等方法,来进行变量之间的模式识别和关系挖掘,从而更全面地了解数据的相关性结构。
在进行因子分析时,数据相关性检验的结果将直接影响因子提取和旋转的结果。
如果变量之间存在显著的相关性,那么在进行因子提取时需要考虑共线性的问题,以避免因子间存在多重共线性。
此外,如果相关系数太高,可能会导致因子解释困难,甚至无法解释的情况。
因此,在因子分析的结果解释时,需要综合考虑因子载荷、共线性和解释力度等方面的信息,以确保因子分析结果的可靠性和解释性。
总之,数据相关性检验是因子分析中的重要一环,它可以帮助确定变量之间的关系,指导因子提取和旋转的过程,以及解释因子分析的结果。
通过合理选择相关性检验方法,综合考虑不同类型的信息,可以更好地理解数据的内在结构,提高因子分析结果的可信度和有效性。
公式计算相关性检验

公式计算相关性检验为了研究不同变量之间的关系,统计学提供了相关性检验的方法。
相关性检验可以用来判断两个变量之间是否存在线性相关性,并且可以通过计算相关系数来描述它们之间的关系强度和方向。
相关性检验常用的方法有皮尔逊相关系数、斯皮尔曼等级相关系数和判定系数等。
这些方法都有相应的计算公式,通过计算可以得到相关系数的数值。
1. 皮尔逊相关系数皮尔逊相关系数是用来描述两个连续型变量之间线性关系的强度和方向的常用方法。
计算皮尔逊相关系数的公式如下:r = (Σ((X_i - X)(Y_i - Ȳ))) / (n * S_X * S_Y)其中,r代表皮尔逊相关系数,Σ表示求和,X_i和Y_i分别表示第i个观测值,X和Ȳ分别表示X和Y的均值,n表示样本量,S_X和S_Y分别表示X和Y的标准差。
皮尔逊相关系数的取值范围为-1到1,值为-1表示完全负相关,值为1表示完全正相关,值为0表示无相关性。
2. 斯皮尔曼等级相关系数斯皮尔曼等级相关系数是用来描述两个顺序变量之间的相关性的统计方法。
计算斯皮尔曼等级相关系数的公式如下:rs = 1 - ((6 * Σ(D_i^2)) / (n * (n^2 - 1)))其中,rs表示斯皮尔曼等级相关系数,Σ表示求和,D_i表示每对顺序变量的差距,n表示样本量。
斯皮尔曼等级相关系数的取值范围也是-1到1,具有相同的解释方式。
3. 判定系数判定系数是用来衡量一个回归模型的拟合程度的指标。
计算判定系数的公式如下:R^2 = SSR / SST其中,R^2表示判定系数,SSR表示模型的回归平方和,SST表示总平方和。
判定系数的取值范围为0到1,值越接近1表示模型拟合程度越好。
综上所述,公式计算相关性检验是进行统计分析中重要的一步。
通过计算相关系数,我们可以了解变量之间的关系,进一步推断出潜在的影响因素。
不同的公式适用于不同类型的变量,选择合适的相关性检验方法可以提高研究的准确性和可信度。
相关分析及检验相关系数

相关分析及检验相关系数
相关分析是统计学中一种基本的研究方法,它可以帮助我们了解变量
之间的关系,即在一定范围内,当一个变量变化时,另一个变量的变化趋势。
它可以用来发现变量之间的线性或非线性相关关系,它也可以用来评
估因变量的变化是否受自变量影响时的统计显著性。
相关分析可以采用多种不同的方法,包括协方差分析,假定检验,特
征向量,统计点相关和统计方差分析等。
相关系数
相关系数是一种统计因子,它是用来度量变量之间的线性相关性的数字。
它可以用来衡量连续变量之间的任何相关性,例如,它可以用来衡量
收入和教育水平之间的关系,当两个变量的变化趋势朝着一个方向变化时,它们之间的相关系数就会高,也就是说,它们有较强的正相关性。
在实际应用中,相关系数的值被一般认为是一个介于-1到+1的值。
相关性检验的知识要点

相关性检验的知识要点(1)相关系数r 的定义对于变量x 与y 随机抽取到的n 对数据11(,)x y ,22(,)x y ,……,(,)n n x y ,称()()nn i ii i x x y y x y nx y r ---==∑∑x 与y 的样本相关系数。
(2)相关系数r 的作用样本相关系数r 用于衡量两个变量之间是否具有线性相关关系,描述线性相关关系的强弱:①||1r ≤越接近1,表明两个变量之间的线性相关程度越强;越接近0,表明两个变量之间的线性相关程度越弱。
②当r >0时,表明两个变量正相关, 即x 增加,y 随之相应地增加,若x 减少,y 随之相应地减少.当r <0时,表明两个变量负相关, 即x 增加,y 随之相应地减少;若x 减少,y 随之相应地增加.若r=0,则称x 与y 不相关。
③当||0.75r >,认为x 与y 之间具有很强的线性相关关系。
④当大于时,表明有95%的把握认为x 与y 之间具有线性相关关系,这时求回归直线方程有必要也有意义,当0.05||r r ≤时,寻找回归直线方程就没有意义。
(3)利用相关系数r 检验的一般步骤:法一:①作统计假设:x 与y 不具有线性相关关系。
②根据样本相关系数计算公式算出r 的值。
③比较与的大小关系,得出统计结论。
如果||0.75r >,认为x 与y 之间具有很强的线性相关关系。
法二:①作统计假设:x 与y 不具有线性相关关系。
②根据样本相关系数计算公式算出r 的值。
③根据小概率与n-2在相关性检验的临界值表中查出r 的一个临界值(n 未数据的对数)。
④比较与,作统计推断,如果0.05||r r >,表明有95%的把握认为x 与y 之间具有线性相关关系。
如果0.05||r r ≤,我们没有理由拒绝原来的假设,即不认为x 与y 之间具有线性相关关系。
这时寻找回归直线方程是毫无意义的。
相关性分析方法

相关性分析方法相关性分析是一种常见的数据分析方法,用于确定变量之间的关系或相关程度。
通过相关性分析,我们可以了解变量之间的关联性,从而对数据进行更深入的研究和预测。
本文将简要介绍相关性分析的概念、常用的相关系数和相关性检验方法,并探讨相关性分析在不同领域的应用。
一、相关性分析的概念相关性指的是两个或多个变量之间存在的关联关系。
当一个变量的取值发生变化时,另一个或多个变量的取值也会有相应的变化。
例如,当温度上升时,冰淇淋的销售量也会随之增加。
相关性分析就是通过统计方法来确定变量之间的相关关系的强度和方向。
相关性分析的目的是找出变量之间的相互关系。
如果两个变量之间存在强相关性,那么我们可以使用一个变量来预测另一个变量。
相关性分析还可以帮助我们理解多个变量之间的相互作用,从而为决策提供有力的支持。
二、相关系数相关系数是衡量两个变量之间关联程度的统计指标。
常用的相关系数包括皮尔逊相关系数、斯皮尔曼相关系数和切比雪夫相关系数等。
1. 皮尔逊相关系数(Pearson correlation coefficient)是一种线性相关性的度量,用于衡量两个连续变量之间的关联程度。
计算公式如下:其中,r为皮尔逊相关系数,rr和rr分别为第r个数据点的x、y值,r¯和r¯分别为x和y的均值。
2. 斯皮尔曼相关系数(Spearman's rank correlation coefficient)是一种非线性相关性的度量,用于衡量两个变量之间的关联程度,不考虑变量的具体取值,而是根据变量的排名进行计算。
检验自变量因变量关系的方法

检验自变量因变量关系的方法在科学研究中,为了确定自变量和因变量之间的关系,可以采用多种方法进行检验。
本文将介绍几种常用的方法,包括相关分析、回归分析和实验设计。
一、相关分析相关分析是用来检验两个变量之间的相关关系的一种统计方法。
它可以通过计算相关系数来衡量两个变量之间的线性相关程度。
常用的相关系数有皮尔逊相关系数和斯皮尔曼相关系数。
1.皮尔逊相关系数:适用于两个变量都是连续变量的情况。
它的取值范围在-1到1之间,当相关系数接近1时,表示两个变量呈正相关,接近-1时表示呈负相关,接近0时表示没有线性相关。
2.斯皮尔曼相关系数:适用于两个变量中至少有一个是有序分类变量或者是偏态分布的连续变量的情况。
它的取值范围也在-1到1之间,但是它不要求变量之间的关系是线性的。
相关分析的优点是简单易行,可以帮助研究者快速了解两个变量之间的关系。
但是它只能检验两个变量之间是否存在相关关系,不能判断因果关系,可能存在其他变量的干扰。
二、回归分析回归分析是用来确定自变量和因变量之间关系的一种统计方法。
通过建立一个数学模型,来描述自变量对因变量的影响程度。
常见的回归分析方法有简单线性回归和多元线性回归。
1. 简单线性回归:适用于只有一个自变量和一个因变量的情况。
它的模型为Y=a+bx,其中Y表示因变量,X表示自变量,a和b是回归系数。
简单线性回归可以用来分析两个变量之间的线性关系,通过计算回归系数b来判断自变量对因变量的影响程度。
2. 多元线性回归:适用于有多个自变量和一个因变量的情况。
它的模型为Y=a+b1x1+b2x2+...+bnxn,其中Y表示因变量,x1、x2、..、xn表示自变量,a、b1、b2、..、bn是回归系数。
多元线性回归可以用来分析多个自变量对因变量的影响程度,并且可以控制其他变量的影响。
回归分析的优点是可以确定自变量和因变量之间的量化关系,并且可以通过计算回归系数来判断影响程度。
但是需要满足一些假设前提,如误差项服从正态分布、自变量和因变量之间是线性关系等。
相关系数检验

相关系数检验一、相关系数简介相关系数是用以衡量两个变量之间的关联程度的统计学指标。
在实际数据分析中,相关系数检验是一种常用方法,用来验证变量之间的相关性是否显著。
二、Pearson相关系数Pearson相关系数是衡量两个连续变量之间线性关联程度的指标,范围在-1到1之间。
当相关系数接近1时,表示两个变量呈正相关;当相关系数接近-1时,表示两个变量呈负相关;相关系数接近0时,表示两个变量之间没有线性关系。
三、相关系数检验步骤1.提出假设:零假设为“两个变量之间不存在相关性”,备择假设为“两个变量之间存在相关性”。
2.计算相关系数:使用统计软件计算得到两个变量的Pearson相关系数。
3.确定显著性水平:选择适当的显著性水平α,一般取0.05。
4.计算临界值:根据显著性水平和样本容量自由度,查找相关系数的临界值。
5.判断显著性:比较计算得到的相关系数和临界值,若计算得到的相关系数显著大于临界值,则拒绝零假设,否则接受零假设。
四、案例分析以两种肥胖度评价方法为例,比较其与BMI指数之间的相关系数。
假设零假设为两种肥胖度评价方法与BMI指数之间不存在相关性,备择假设为存在相关性。
通过数据收集和计算得到相关系数后,进行相关系数检验,判断两种评价方法与BMI指数之间的关联程度是否显著。
五、结论相关系数检验是一种常用的统计方法,用来验证两个变量之间的相关性是否显著。
在实际数据分析中,通过计算相关系数并进行显著性检验,可以帮助我们理解变量之间的关联程度,从而做出合理的推断和决策。
以上是关于相关系数检验的简要介绍和步骤说明,希望能对您有所帮助。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Correlations
进食量
Kendall's tau_b 进食量 Correlation Coefficient
1.000
Sig. (2-tailed)
.
N
10
体重增量 Correlation Coefficient
.750**
Sig. (2-tailed)
.003
N
10
**.Correlation is significant at the 0.01 level (2-tailed).
Price Mileage (mpg)
Weight (lbs.) Price
Correlation
1.000
-.068
Significance (2-tailed)
.
.567
df
0
71
Mileage (mpg) Correlation
-.068
1.000
Significance (2-tailed)
分析 → 相关分析 → 相关分析 相关系数复选框:Spearman
Correlations
进食量 体重增量
Spearman's rho 进食量 Correlation Coefficient 1.000
.899**
Sig. (2-tailed)
.
.000
N
10
10
体重增量 Correlation Coefficient .899**
相关系数的检验方法
样本相关系数r 是总体相关系数ρ 的估计值, 需进行假设检验。 H0:ρ=0,两变量间无直线相关关系 H1:ρ≠0,两变量间有直线相关关系
在SPSS中,直接给出最终的P值。
积差相关系数的适用条件
积差相关系数适用于线性相关的情形,且各自 均服从正态分布。
样本中存在的极端值对积差相关系数的计算影 响极大,要慎重考虑和处理,必要时可以对其 进行剔除,或者加以变量变换。
.000
.000
N
74
74
74
**.Correlation is significant at the 0.01 level (2-tailed).
分析实例
SPSS分析过程
分析 →相关分析 → 偏相关分析 变量框:price、mpg 控制框:weight
Correlations
Control Variables
分析:汽车的自重可影响每加仑汽油可行驶公 里数。
利用相关分析得到3个变量两两之间的相关关系:
Correlations
Price
Price Mileage (mpg) Weight (lbs.)
Pearson Correlation
1
-.46*9*
.539**
Sig. (2-tailed)
.000
进食量 1
体重增量 .940**
Sig. (2-tailed)
.000
N
10
10
体重增量
Pearson Correlation Sig. (2-tailed)
.940**
1
.000
N
10Βιβλιοθήκη 10**. Correlation is significant at the 0.01 level (2-tailed).
1.000
Sig. (2-tailed)
.000
.
N
10
10
**.Correlation is significant at the 0.01 level (2-tailed).
结论
进食量和体重增量的Spearman相关系数为0.899, P<0.01,有统计学意义。
Kendall’s 等级相关系数
.000
N
74
74
74
Mileage (mpg) Pearson Correlation
-.46*9*
1
-.80*7*
Sig. (2-tailed)
.000
.000
N
74
74
74
Weight (lbs.) Pearson Correlation
.539**
-.80*7*
1
Sig. (2-tailed)
实习15 相关分析与回归分析
学习目标
能用SPSS做简单相关分析 能用SPSS做简单回归分析
主要内容
15.1 相关分析简介 15.2 简单相关分析 15.3 偏相关分析 15.4 简单回归分析
15.1 相关分析简介
一些基本概念
直线相关:研究两个变量是否存在直线相关关 系,以及关系的密切程度
系数)的计算
lxx
1 n 1
n i 1
( xi
x)2
l yy
1 n 1
n i 1
( yi
y)2
lxy
1 n 1
n i 1
( xi
x)( yi
y)
r lxy l xx l yy
l xx、l yy 和l xy 都是离均差积和
所以r又称为积差相关系数
注:积差相关系数严格上仅适用于两变量呈线性相关时。
分析结论
进食量和体重增量的相关系数为0.940,P<0.01, 有统计学意义。
2. 秩相关系数
适用情况:不服从双变量正态分布、分布未知、 等级资料。
Spearman等级相关用rs表示两变量的相关关 系的密切程度及相关方向。
基本思想:将两变量分别从小到大编秩,对秩 次进行前述的相关分析。
SPSS分析过程
工具:散点图、直方图、K-S检验等。
散点图可以用来发现异常值!
分析实例
数据文件是corr.sav
分析实例
相关分析用于进行两个/多个变量间的相关分析 SPSS分析过程
图形 →散点图 → 简单散点图 分析 → 相关分析 → 双变量相关分析
分析实例
Correlations
进食量
Pearson Correlation
正相关、负相关、完全相关 相关系数:表示相关的密切程度与相关方向的
指标,取值范围:[-1, 1]。
SPSS中的相关分析过程
双变量相关分:变量之间的两两相关 偏相关分析:对其他变量控制后的两两相关 距离:同一变量内部观测值或不同变量间的相
似性和不相似性
15.2 简单相关分析
1. 积差相关系数(Pearson相关
体重增量 .750** .003 10 1.000 . 10
适用于两个变量均为有序分类的情况!
15.3 偏相关分析
方法原理
控制其它变量影响的情况下,分析两个变量之 间的关系。
偏相关系数:揭示两变量之间的真实联系。
分析实例
例15.2:分析汽车价格和每加仑汽油可行驶公 里数的相关关系。教材中的auto.sav。
.567
.
df
71
0
结论
控制了汽车自重的影响后汽车价格和每加仑汽油可 行驶公里数的相关系数r=-0.068,p=0.539,无统 计学意义,即汽车价格和每加仑汽油可行驶公里数 无相关性,汽车自重为混杂因素。