基于Matlab编写的语音端点检测
基于Matlab编写的语音端点检测

基于Matlab编写的语音端点检测专业:班级:姓名:指导教师:2011 年6月18 日一、实验目的1.学会MATLAB的使用,掌握MATLAB的程序设计方法;3.掌握语音处理的基本概念、基本理论和基本方法;4.掌握基于MATLAB编程实现带噪语音信号端点检测;5.学会用MATLAB对信号进行分析和处理。
二、实验内容简介:(1)采集一段语音信号,采样率为8KHZ,量化精度为16比特线性码;(2)分析帧长30ms(或10ms~50ms);(3)利用公式分别计算这段语音信号的短时能量、短时平均幅度、短时过零率曲线;(4)利用(3)中的结果画出短时零能比曲线;(零能比: 即同一时间段内的过零率和能量的比值)(5)根据上述结果判断找出其中的一帧浊音信号和一帧清音信号,分别计算他们的短时自相关函数和平均幅度差函数;(6)调整能量门限,设置参数。
实现语音端点的检测。
三,实验心得这次的实验,,给我最大的收获就是培养了独立思考和动手的能力,还有就是实验的灵活性,总得来说就是在独立与创新这二个环节,我更加掌握MATLAB 的程序设计方法,进一步的了解了掌握基于MATLAB编程实现带噪语音信号端点检测的原理,这充分锻炼了我们独立的动手能力和独立的解决所遇到的问题,让我对这门课程又有了新的理解。
四.课程设计原理端点检测是语音信号处理过程中非常重要的一步,它的准确性直接影响到语音信号处理的速度和结果,因此端点检测方法的研究一直是语音信号处理中的热点。
本设计使用传统的短时能量和过零率相结合的语音端点检测算法利用短时过零率来检测清音.用短时能量来检测浊音,两者相配合便实现了信号信噪比较大情况下的端点检测。
算法对于输入信号的检测过程可分为短时能量检测和短时过零率检测两个部分。
算法以短时能量检测为主,短时过零率检测为辅。
根据语音的统计特性,可以把语音段分为清音、浊音以及静音(包括背景噪声)三种。
在本算法中,短时能量检测可以较好地区分出浊音和静音。
基于MATLAB的语音端点检测
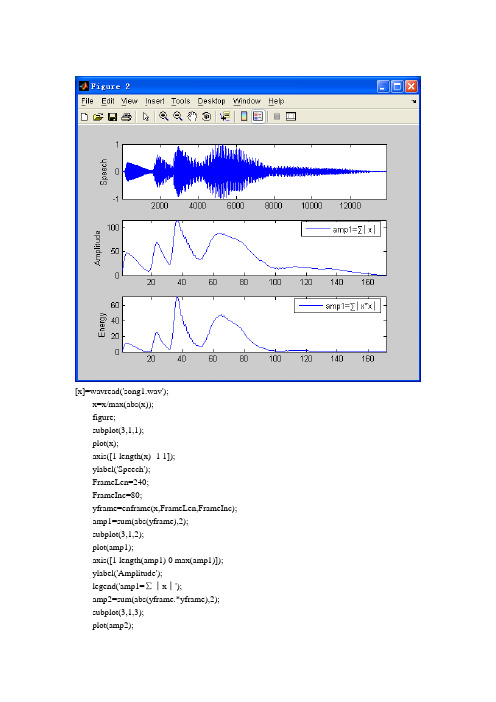
[x]=wavread('song1.wav');x=x/max(abs(x));figure;subplot(3,1,1);plot(x);axis([1 length(x) -1 1]);ylabel('Speech');FrameLen=240;FrameInc=80;yframe=enframe(x,FrameLen,FrameInc);amp1=sum(abs(yframe),2);subplot(3,1,2);plot(amp1);axis([1 length(amp1) 0 max(amp1)]);ylabel('Amplitude');legend('amp1=∑│x│');amp2=sum(abs(yframe.*yframe),2);subplot(3,1,3);plot(amp2);axis([1 length(amp2) 0 max(amp2)]);ylabel('Energy');legend('amp1=∑│x*x│');[x]=wavread('song1.wav');figure;subplot(3,1,1);plot(x);axis([1 length(x) -1 1]);ylabel('Speech');FrameLen = 240;FrameInc = 80;amp = sum(abs(enframe(filter([1 -0.9375], 1, x), FrameLen, FrameInc)), 2); subplot(312)plot(amp);axis([1 length(amp) 0 max(amp)])ylabel('Energy');tmp1 = enframe(x(1:end-1), FrameLen, FrameInc);tmp2 = enframe(x(2:end) , FrameLen, FrameInc);signs = (tmp1.*tmp2)<0;diffs = (tmp1 -tmp2)>0.02;zcr = sum(signs.*diffs, 2);subplot(3,1,3);plot(zcr);axis([1 length(zcr) 0 max(zcr)])ylabel('ZCR');[x,fs,nbits]=wavread('song1.wav');x = x / max(abs(x));%幅度归一化到[-1,1]%参数设置FrameLen = 256; %帧长inc = 90; %未重叠部分amp1 = 10; %短时能量阈值amp2 = 2;zcr1 = 10; %过零率阈值zcr2 = 5;minsilence = 6; %用无声的长度来判断语音是否结束minlen = 15; %判断是语音的最小长度status = 0; %记录语音段的状态count = 0; %语音序列的长度silence = 0; %无声的长度%计算过零率tmp1 = enframe(x(1:end-1), FrameLen,inc);tmp2 = enframe(x(2:end) , FrameLen,inc);signs = (tmp1.*tmp2)<0;diffs = (tmp1 -tmp2)>0.02;zcr = sum(signs.*diffs,2);%计算短时能量amp = sum((abs(enframe(filter([1 -0.9375], 1, x), FrameLen, inc))).^2, 2);%调整能量门限amp1 = min(amp1, max(amp)/4);amp2 = min(amp2, max(amp)/8);%开始端点检测for n=1:length(zcr)goto = 0;switch statuscase {0,1} % 0 = 静音, 1 = 可能开始if amp(n) > amp1 % 确信进入语音段x1 = max(n-count-1,1); % 记录语音段的起始点status = 2;silence = 0;count = count + 1;elseif amp(n) > amp2 || zcr(n) > zcr2 % 可能处于语音段status = 1;count = count + 1;else % 静音状态status = 0;count = 0;endcase 2, % 2 = 语音段if amp(n) > amp2 ||zcr(n) > zcr2 % 保持在语音段count = count + 1;else % 语音将结束silence = silence+1;if silence < minsilence % 静音还不够长,尚未结束count = count + 1;elseif count < minlen % 语音长度太短,认为是噪声status = 0;silence = 0;count = 0;else % 语音结束status = 3;endendcase 3,break;endendcount = count-silence/2;x2 = x1 + count -1; %记录语音段结束点subplot(3,1,1)plot(x)axis([1 length(x) -1 1])ylabel('Speech');line([x1*inc x1*inc], [-1 1], 'Color', 'red');line([x2*inc x2*inc], [-1 1], 'Color', 'red');subplot(3,1,2)plot(amp);axis([1 length(amp) 0 max(amp)])ylabel('Energy');line([x1 x1], [min(amp),max(amp)], 'Color', 'red');line([x2 x2], [min(amp),max(amp)], 'Color', 'red');subplot(3,1,3)plot(zcr);axis([1 length(zcr) 0 max(zcr)])ylabel('ZCR');line([x1 x1], [min(zcr),max(zcr)], 'Color', 'red');line([x2 x2], [min(zcr),max(zcr)], 'Color', 'red');。
基于MATLAB语音信号检测分析及处理

基于MATLAB语音信号检测分析及处理目录一、内容概述 (2)1. 研究背景与意义 (3)2. MATLAB在语音信号处理中的应用 (4)3. 论文研究内容及结构 (5)二、语音信号基础 (6)1. 语音信号概述 (8)2. 语音信号的特性 (9)3. 语音信号的表示方法 (10)三、MATLAB语音信号处理工具 (11)1. MATLAB语音工具箱介绍 (12)2. 常用函数及其功能介绍 (13)四、语音信号检测与分析 (15)1. 语音信号检测原理及方法 (16)2. 语音信号的频谱分析 (18)3. 语音信号的时频分析 (19)4. 语音信号的端点检测 (20)五、语音信号处理算法研究 (21)1. 预加重处理算法 (22)2. 分帧与加窗处理算法 (23)3. 预处理算法 (24)4. 特征提取算法 (25)5. 模式识别与分类算法 (26)六、语音信号处理实验设计与实现 (27)1. 实验目的与要求 (28)2. 实验环境与工具配置 (29)3. 实验内容与步骤 (30)4. 实验结果分析与讨论 (31)七、语音信号处理应用案例 (32)1. 语音识别系统应用案例 (33)2. 语音合成系统应用案例 (34)3. 语音情感识别应用案例 (35)4. 其他领域应用案例 (36)八、总结与展望 (38)1. 研究成果总结 (39)2. 研究不足与问题剖析 (40)3. 未来研究方向与展望 (41)一、内容概述语音信号捕捉与预处理:介绍如何使用MATLAB捕捉语音信号,包括从麦克风等输入设备获取原始语音数据,并对信号进行预处理,如去除噪声、增强语音质量等。
特征提取:详述如何从预处理后的语音信号中提取关键特征,如梅尔频率倒谱系数(MFCC)、线性预测编码(LPC)等,以便进行后续的模型训练或识别。
语音信号检测分析:探讨基于MATLAB的语音信号检测分析方法,包括端点检测、语音活动等检测算法的实现,以及基于统计模型、机器学习模型的语音信号分析。
如何使用MATLAB进行语音信号处理与识别

如何使用MATLAB进行语音信号处理与识别引言:语音信号处理与识别是一项应用广泛的领域,它在语音通信、语音识别、音频压缩等方面发挥着重要作用。
在本文中,我们将介绍如何使用MATLAB进行语音信号处理与识别。
首先,我们将讨论语音信号的特征提取,然后介绍常用的语音信号处理方法,最后简要概述语音信号的识别技术。
一、语音信号的特征提取语音信号的特征提取是语音信号处理与识别的重要一环。
在MATLAB中,我们可以通过计算音频信号的频谱特征、时域特征以及声学特征等方式来进行特征提取。
其中,最常见的特征提取方法是基于傅里叶变换的频谱分析方法,比如短时傅里叶变换(STFT)和梅尔频谱倒谱系数(MFCC)。
1. 频谱特征:频谱特征主要包括功率谱密度(PSD)、频谱包络、谱熵等。
在MATLAB中,我们可以使用fft函数来计算信号的频谱,使用pwelch函数来计算功率谱密度,使用spectrogram函数来绘制语谱图等。
2. 时域特征:时域特征主要包括幅度特征、能量特征、过零率等。
在MATLAB中,我们可以使用abs函数来计算信号的幅度谱,使用energy函数来计算信号的能量,使用zcr函数来计算信号的过零率等。
3. 声学特征:声学特征主要包括基频、共振频率等。
在MATLAB中,我们可以通过自相关函数和Cepstral分析等方法来计算声学特征。
二、语音信号处理方法语音信号处理方法主要包括降噪、去除回声、语音增强等。
在MATLAB中,我们可以通过滤波器设计、自适应噪声抑制和频谱减法等方法来实现这些功能。
1. 降噪:降噪通常包括噪声估计和降噪滤波两个步骤。
在MATLAB中,我们可以使用统计模型来估计噪声,然后使用Wiener滤波器或者小波阈值法来降噪。
2. 去除回声:回声是语音通信中的常见问题,我们可以使用自适应滤波器来抑制回声。
在MATLAB中,我们可以使用LMS算法或者NLMS算法来实现自适应滤波。
3. 语音增强:语音增强通常包括增加语音信号的声音清晰度和提高语音的信噪比。
一种基于Matlab的语音信号端点检测方法

( .C l g f l t ncE gn e ig He o gin i ri , r i 5 0 0。 h n ;2 e at n f c a i l n lcr a E gn e 1 o l eo e r i n ie r , i n j gUn v s y Ha bn 1 0 8 C i a .D p rme t h nc dE e ti l n ie r e E co n l a e t o Me aa c
0 引
言
1 检 测原 理
语 音端点 检测 ( n on tcin 是从 包 含 E dp it et ) De o
语音信 号一般 可分为 无声段 、 清音段 和浊音段 。 无 声段是 背景噪声 段 , 平均 能量最 低 ; 浊音 段为声带 振 动发 出对应 的语 音信号 段 , 平均 能量最 高 ; 清音段 为 空气在 口腔 中的摩 擦 、 冲击 或 爆 破 而发 出的语音 信 号段 , 均能 量居 于 两 者之 间 。采用 基 于 幅度 的 平
i ,Qiia ct nl olg , qh r1 10 , i nj n , hn ) n g qhrVoai a C l eQiia 6 0 5 Hel gi g C ia o e o a
Ab t a t Th s p p rf s l t o u e o ea e o c p so p e h e d p i t e e t n n h n ma e s r c : i a e i t i r d c ss mer l t d c n e t fs e c n — o n t c i ,a d t e k s r y n d o e d— o n e e t n b h o b n to fs o tt ea e a e ma n t d n h r i ea e a e z r — r s n — i td t c i y t e c m i a i n o h r i v r g g i e a d s o tt v r g e o c o s p o m u m — — i g r t .Fo u i g o u l h e h l l o i m e i n a d i lm e t t n o h r c s ,t e M a lb p o n ae c sn n d a— r s o d a g r h d sg n mp e n a i f ep o e s h t r — t t o t a
语音信号处理14

3.5 基于能量和过零率的语音端点检测
语音端点检测就是指从包含语音的一段信号中确定出 语音的起始点和结束点。
正确的端点检测对于语音识别和语音编码系统都有 重要的意义。
本节介绍基于能量和过零率的语音端点检测方法—— 两级判决法及程序实现。
13.5 基于能量和过零率的语来自端点检测两级判决法示意图
样点数
图3.5-1 利用能量和过零率进行语音端点检测的两级判决法示意图
2
3.5基于能量和过零率的语音端点检测 基于MATLAB程序实现能量与过零率的端点检测算法步 骤如下: (1)语音信号x(n)进行分帧处理。 (2)得到语音的短时帧能量。 (3)计算每一帧语音的过零率,得到短时帧过零率。 (4)确定T1,T2,T3,完成两级判决。
基于matlab的语音识别技术

项目题目:基于Matlab的语音识别一、引言语音识别技术是让计算机识别一些语音信号,并把语音信号转换成相应的文本或者命令的一种高科技技术。
语音识别技术所涉及的领域非常广泛,包括信号处理、模式识别、人工智能等技术。
近年来已经从实验室开始走向市场,渗透到家电、通信、医疗、消费电子产品等各个领域,让人们的生活更加方便。
语音识别系统的分类有三种依据:词汇量大小,对说话人说话方式的要求和对说话人的依赖程度。
(1)根据词汇量大小,可以分为小词汇量、中等词汇量、大词汇量及无限词汇量识别系统。
(2)根据对说话人说话方式的要求,可以分为孤立字(词)语音识别系统、连接字语音识别系统及连续语音识别系统。
(3)根据对说话人的依赖程度可以分为特定人和非特定人语音识别系统。
二、语音识别系统框架设计2.1语音识别系统的基本结构语音识别系统本质上是一种模式识别系统,其基本结构原理框图如图l所示,主要包括语音信号预处理、特征提取、特征建模(建立参考模式库)、相似性度量(模式匹配)和后处理等几个功能模块,其中后处理模块为可选部分。
三、语音识别设计步骤3.1语音信号的特征及其端点检测图2 数字‘7’开始部分波形图2是数字”7”的波形进行局部放大后的情况,可以看到,在6800之前的部分信号幅度很低,明显属于静音。
而在6800以后,信号幅度开始增强,并呈现明显的周期性。
在波形的上半部分可以观察到有规律的尖峰,两个尖峰之间的距离就是所谓的基音周期,实际上也就是说话人的声带振动的周期。
这样可以很直观的用信号的幅度作为特征,区分静音和语音。
只要设定一个门限,当信号的幅度超过该门限的时候,就认为语音开始,当幅度降低到门限以下就认为语音结束。
3.2 语音识别系统3.2.1语音识别系统的分类语音识别按说话人的讲话方式可分为3类:(1)即孤立词识别(isolated word recognition),孤立词识别的任务是识别事先已知的孤立的词,如“开机”、“关机”等。
基于MATLAB的语音识别DTW算法设计

目录1概述 (2)1.1研究的目的和意义 (2)1.2国内外发展状况 (2)1.2.1国外研究历史及现状 (3)1.2.3国内研究历史及现状 (4)2语音识别系统的概述 (4)3 MA TLAB中的语音信号的采集 (4)3.1 wavrecord函数 (4)3.2 wavplay函数 (6)4语音信号的端点检测 (6)4.1语音信号端点检测的流程 (6)4.1.1短时能量 (8)4.1.2过零率的计算 (9)4.1.3双门限端点检测 (11)5语音识别参数提取 (12)5.1 MFCC的基本原理 (12)6特定人语音识别算法-DTW算法 (13)6.1DTW算法原理 (13)6.2DTW算法流程及实验结果 (15)7 GUI界面的设计 (16)7.1图形用户界面设计工具的启动 (16)7.3测试与分析 (18)总结 (20)致谢 (21)参考文献 (22)附件 (23)基于MATLAB的特定人语音识别算法设计摘要在高度发达的社会,语言是一种人类交流最方便的,最速度的信息,在高度发达的社会中,用数字化的方式举行语音的保存、传递、判别、加强和合成等是全部数字化通信过程中最基础、最重要的组成的一部分。
由于人类进入信息社会节奏加快, 语音信号处理方面的知识被越来越多的地方需要。
本设计主要在MATLAB平台下先语音信号的端点检测、预处理,然后提取特征参数,建立两个模块,一个为参考模块,一个为测试模块,然后通过动态时间归整技术(DTW)算法进行匹配,算出匹配结果。
最后在用户开发界面(GUI界面)直观地呈现出来。
本次设计录制0~10的数字做为参考库(model),测试库(test)中为需要测试及识别的语音,0的序号为11,1~9的数字以相应数字做为文件名的命名。
关键词:端点检测; MFCC特征提取;语音识别;DTW算法1概述1.1研究的目的和意义随着计算机技术和科技成果的的飞速发展,人们早已不再满足于让计算机做一些简单的科学计算和运算,而是向它提出了更高的要求,即要求我们的计算机向智能化方向发展,于是人们便开始了第五代计算机(即智能计算机)的研究。
语音端点检测及其在Matlab中的实现

描述它们的定义和检测方法。
2.1短时能量
N
N
1—1.1
E=艺Ix(n)I或E=乞xZ(n)
n=l
n=1
式中x(n)为信号幅度,N为语音帧长。
检测过程:将短时能量与给定能量门限Gl相比,若大于它 并能在一定时问内达到门限G2并维持给定帧数(防止把短时 脉冲误判为语音),则认为是语音起点,否则继续向下找。判定 起点后,继续将短时能量与给定门限G3比较,当小于它并能在 一定时间内降到门限G4并维持给定帧数(防止将语音中的小 停顿误判为语音结束),认为是终点,否则继续向下找。 2.2过零率
英文刊名: 年,卷(期): 被引用次数:
刘羽 桂林工学院科技处,广西,桂林,541004
计算机时代 COMPUTER ERA 2005(8) 8次
参考文献(4条) 1.李强;赵伟 MATLAB数据处理与应用 2001
2.果永振;何遵文 一种多特征语音端点检测算法及实现[期刊论文]-通讯技术 2003(1)
出版社,1983.
【2】何强,何英.Matlab扩展编程.清华大学出版社,2002.
【3】果采振,何遵文.一种多特征语音端点枪测算法反实现.通讯技术,
2003.1.
[41李强,赵伟·M妣文据处理与应用·国防工业出版社,2001· 豳
万方数据
语音端点检测及其在Matlab中的实现
作者: 作者单位: 刊名:
以方便地进行一些语音的处理工作。例如:
一
(1)语音采样可以用以下命令实现:
x=wavrecord(k+fs,fs,‘dtype’):
其中x为语音采样信号,fs为采样率,k为采样秒数,。dtype’为
采样数据类型。
(2)语音数据也可以用以下命令从语音文件中读取:
基于MATLAB语音信号检测分析及处理

第一章绪论Matlab是矩阵实验室(Matrix Laboratory)的简称,是美国MathWorks公司出品的商业数学软件,用于算法开发、数据可视化、数据分析以及数值计算的高级技术计算语言和交互式环境,主要包括Matlab和Simulink两大部分。
1.1 Matlab简介MATLAB是英文MATrix LABoratory(矩阵实验室)的缩写。
早期的MATLAB 是用FORTRAN语言编写的,尽管功能十分简单,但作为免费软件,还是吸引了大批使用者。
经过几年的校际流传,在John Little。
Cleve Moler和Steve Banger 合作,于1984年成立MathWorks公司,并正式推出MATLAB第一版版。
从这时起,MATLAB的核心采用C语言编写,功能越来越强大,除原有的数值计算功能外,还新增了图形处理功能。
MathWorks公司于1992年推出了具有划时代意义的4.0版;1994年推出了4.2版扩充了4.0版的功能,尤其在图形界面设计方面提供了新方法;1997年春5.0版问世,5.0版支持了更多的数据结构,使其成为一种更方便、更完善的编程语言;1999年初推出的MATLAB5.3版在很多方面又进一步改进了MATLAB语言的功能,随之推出的全新版本的最优化工具箱和Simulink3.0达到了很高水平;2000年10月,MATLAB6.0版问世,在操作页面上有了很大改观,为用户的使用提供了很大方便,在计算机性能方面,速度变的更快,性能也更好,在图形界面设计上更趋合理,与C语言接口及转换的兼容性更强,与之配套的Simulink4.0版的新功能也特别引人注目;2001年6月推出的MATLAB6.1版及Simulink4.1版,功能已经十分强大;2002年6月推出的MATLAB6.5版及Simulink5.0版,在计算方法、图形功能、用户界面设计、编程手段和工具等方面都有了重大改进;2004年,MathWorks公司推出了最新的MA TLAB7.0版,其中集成了最新的MATLAB7编译器、Simumlink6.0仿真软件以及很多工具箱。
基于MATLAB的语音信号的端点检测

基于MATLAB的语音信号的端点检测摘要:语音端点检测是指从一段语音信号中准确的找出语音信号的起始点和结束点,它的目的是为了使有效的语音信号和无用的噪声信号得以分离,因此在语音识别、语音增强、语音编码、回声抵消等系统中得到广泛应用。
目前端点检测方法大体上可以分成两类,一类是基于阈值的方法,另一类方法是基于模式识别的方法,本文主要对基于阀值的方法进行研究。
端点检测在语音识别中占有十分重要的地位,直接影响着系统的性能。
本文首先对语音信号进行简单的时域和频域分析及预处理,其次利用基于短时能量和短时过零率的双门限算法进行语音端点检测,并对这几种用这种算法进行端点检测,进行实验分析,分析此方法的优缺点。
关键词:语音信号处理;语音端点检测;双门限;短时能量;短时过零率Voice signal endpoint detection based on MATLABAbstract:Endpoint detection is a voice signal from the accurate speech signal to the identify start and the end points, the purpose is to enable to separated the effective voice signals and un-useful noise. So, in the speech recognition system, speech enhancement, speech coding, echo cancellation and other systems are widely used.In Current the endpoint detection can be roughly divided into two categories, one is based on the threshold method, another method is based on the method of pattern recognition , the main in this paper is based on the method of threshold method. The Endpoint detection is take a very important position in the speech recognition, it directly affects the performance of the system. In this article first domain analysis in simple speech signal time, than dual threshold algorithm, cepstrum algorithm, spectral entropy algorithm for endpoint detection, and these types of endpoint detection algorithms, and experimental analysis points and analysis the advantages and disadvantages of this method.Key word:Signal processing; voice activity detection; double threshold; Short-time energy ;The rate of short-time zero-passing1.绪论语音,即语言的声音,是语言符号系统的载体。
基于Matlab语音识别系统的设计与实现

随着全球化的发展,多语言支持成为语音识别系统的一个重要需求, 如何实现多语言的语音识别是一个研究方向。
深度学习与神经网络的应用
深度学习和神经网络在语音识别领域的应用是一个研究热点,如何将 深度学习技术应用于现有的语音识别系统也是一个挑战。
THANKS FOR WATCHING
感谢您的观看
实时性能
评估模型的实时性能,确保系统能够满足实 际应用的需求。
结果分析
结果展示
将测试结果以图表的形式展示出来,便于分 析和比较。
误差分析
分析模型在测试数据集上的误差来源,找出 可能存在的问题和改进方向。
性能对比
将本系统的性能与其他同类系统进行对比, 评估本系统的优劣。
应用前景
探讨本系统在实际应用中的前景和潜在价值, 为后续的研究和应用提供参考。
基于Matlab的语音识别系统界面友好,操作简单,方便用户使 用。
未来研究方向与挑战
提高识别精度
随着语音技术的不断发展,需要不断优化现有的语音识别算法,提高 系统的识别精度。
处理复杂环境下的语音
在实际应用中,复杂环境下的语音识别是一个重要的研究方向,如何 提高系统在噪声、口音、语速等方面的鲁棒性是一个挑战。
特征提取模块设计
预加重
分帧
通过一个一阶差分滤波器对语音信号进行 预加重,增强高频部分。
将语音信号分成若干短时帧,每帧长度通 常为20-40ms。
加窗
快速傅里叶变换(FFT)
对每帧信号加窗,常用的窗函数有汉明窗 、汉宁窗等。
将每帧信号从时域转换到频域,得到频谱 。
分类器设计
基于规则的分类器
根据语音特性制定规则进行分类,如基于DTW(动态时间 规整)的分类器。
基于Matlab的语音识别端点检测算法研究与实现

测后面的样点值分布。 验 中.往往假设通过线性预测分析得到的声道模型系统 为:
( : ) :— 1 + a k z - 女
’
t t
( 7)
图2 采用 双 门限检 测 法进 行 端点 检测 结 果 图
冲击响应 ( ) 的倒谱表示为 . i ; ( , , ),有 :
示 ,则其 计算 公式 为” :
=
图 1 双 门 限 端 点 检 测 流 程 图
双 门限 检 测 法 中 ,将 平 均 过 零 率 和 短 时能 量 结 合 起 来 ,在
∑s : ( , , 1 )
m =O
( 1 )
开 始进行端点检测之前,需要对短时能量以及过零率分别没置
两个 门 限 ,即一 个 高门 限 ( T )和一 个 低 门限 ( T 。 )。当 语音 信 号 的低 门限 T . 被 超过 时 ,则 表 示 语音 信 号 有 可 能进 入 语 音段 ,
( 1 ) L P C 倒 谱 系数 。线 性 预 测 l 的 基 本思 路 是 :充 分 考 虑
一
I L 山 . 【 | L 一 ¨
T 丫 T 下 1 一
段语音信号中可能存在的联系性 ,根据过去样点的分布情况预 L P C 系数可以用来表示整 ̄ ' L P C 系统冲击响应的倒谱 ,在实
就 称 之 为过 零 。其 定 义如 下 :
=
二 m=O
∑I s g n 脚 ) 卜s g n [ s . 一 1 ) 】 l
( 2 )
语音信号的倒谱分析就是求取语音倒谱特征参数的过程 。 ,
它 可 以 通过 同 态处 理 ( 同态 滤 波 ) 来 实现 ,同 态 滤 波成 功 地 将
《语音信号处理》实验1-端点检测

华南理工大学《语音信号处理》实验报告实验名称:端点检测姓名:学号:班级:10级电信5班日期:2013年5 月9日1.实验目的1.语音信号端点检测技术其目的就是从包含语音的一段信号中准确地确定语音的起始点和终止点,区分语音和非语音信号,它是语音处理技术中的一个重要方面。
本实验的目的就是要掌握基于MATLAB编程实现带噪语音信号端点检测,利用MATLAB对信号进行分析和处理,学会利用短时过零率和短时能量,对语音信号的端点进行检测。
2. 实验原理1、短时能量语音和噪声的区别可以体现在它们的能量上,语音段的能量比噪声段能量大,语音段的能量是噪声段能量叠加语音声波能量的和。
在信噪比很高时,那么只要计算输入信号的短时能量或短时平均幅度就能够把语音段和噪声背景区分开。
这是仅基于短时能量的端点检测方法。
信号{x(n)}的短时能量定义为:语音信号的短时平均幅度定义为:其中w(n)为窗函数。
2、短时平均过零率短时过零表示一帧语音信号波形穿过横轴(零电平)的次数。
过零分析是语音时域分析中最简单的一种。
对于连续语音信号,过零意味着时域波形通过时间轴;而对于离散信号,如果相邻的取样值的改变符号称为过零。
过零率就是样本改变符号次数。
信号{x(n)}的短时平均过零率定义为:式中,sgn为符号函数,即:过零率有两类重要的应用:第一,用于粗略地描述信号的频谱特性;第二,用于判别清音和浊音、有话和无话。
从上面提到的定义出发计算过零率容易受低频干扰,特别是50Hz交流干扰的影响。
解决这个问题的办法,一个是做高通滤波器或带通滤波,减小随机噪声的影响;另一个有效方法是对上述定义做一点修改,设一个门限T,将过零率的含义修改为跨过正负门限。
于是,有定义:3、检测方法利用过零率检测清音,用短时能量检测浊音,两者配合。
首先为短时能量和过零率分别确定两个门限,一个是较低的门限数值较小,对信号的变化比较敏感,很容易超过;另一个是比较高的门限,数值较大。
基于MATLAB的音频信号处理与语音识别系统设计

基于MATLAB的音频信号处理与语音识别系统设计一、引言音频信号处理与语音识别是数字信号处理领域的重要研究方向,随着人工智能技术的不断发展,语音识别系统在日常生活中得到了广泛应用。
本文将介绍如何利用MATLAB软件进行音频信号处理与语音识别系统的设计,包括信号预处理、特征提取、模式识别等关键步骤。
二、音频信号处理在进行语音识别之前,首先需要对音频信号进行处理。
MATLAB提供了丰富的信号处理工具,可以对音频信号进行滤波、降噪、增益等操作,以提高后续语音识别的准确性和稳定性。
三、特征提取特征提取是语音识别中至关重要的一步,它能够从复杂的音频信号中提取出最具代表性的信息。
常用的特征包括梅尔频率倒谱系数(MFCC)、线性预测编码(LPC)等。
MATLAB提供了丰富的工具箱,可以方便地实现这些特征提取算法。
四、模式识别模式识别是语音识别系统的核心部分,它通过对提取出的特征进行分类和识别,从而实现对不同语音信号的区分。
在MATLAB中,可以利用支持向量机(SVM)、人工神经网络(ANN)等算法来构建模式识别模型,并对语音信号进行分类。
五、系统集成将音频信号处理、特征提取和模式识别整合到一个系统中是设计语音识别系统的关键。
MATLAB提供了强大的工具和函数,可以帮助我们将各个部分有机地结合起来,构建一个完整的语音识别系统。
六、实验与结果分析通过实际案例和数据集,我们可以验证所设计的基于MATLAB的音频信号处理与语音识别系统的性能和准确性。
通过对实验结果的分析,可以进一步优化系统设计,并提高语音识别系统的性能。
七、结论基于MATLAB的音频信号处理与语音识别系统设计是一个复杂而又具有挑战性的任务,但是借助MATLAB强大的功能和工具,我们可以更加高效地完成这一任务。
未来随着人工智能技术的不断发展,基于MATLAB的语音识别系统将会得到更广泛的应用和进一步的优化。
通过本文对基于MATLAB的音频信号处理与语音识别系统设计进行介绍和讨论,相信读者对该领域会有更深入的了解,并能够在实际应用中灵活运用所学知识。
语音端点检测算法的研究及matla程序仿真与实现毕业设计 精品

摘要摘要语音端点检测是指从一段语音信号中准确的找出语音信号的起始点和结束点,它的目的是为了使有效的语音信号和无用的噪声信号得以分离,因此在语音识别、语音增强、语音编码、回声抵消等系统中得到广泛应用。
目前端点检测方法大体上可以分成两类,一类是基于阈值的方法,该方法根据语音信号和噪声信号的不同特征,提取每一段语音信号的特征,然后把这些特征值与设定的阈值进行比较,从而达到语音端点检测的目的,该方法原理简单,运算方便,所以被人们广泛使用,本文主要对基于阀值的方法进行研究。
另一类方法是基于模式识别的方法,需要估计语音信号和噪声信号的模型参数来进行检测。
由于基于模式识别的方法自身复杂度高,运算量大,因此很难被人们应用到实时语音信号系统中去。
端点检测在语音信号处理中占有十分重要的地位,直接影响着系统的性能。
本文首先对语音信号进行简单的时域分析,其次利用短时能量和过零率算法、倒谱算法、谱熵算法进行语音端点检测,并对这几种算法进行端点检测,并进行实验分析。
本文首先分别用各算法对原始语音信号进行端点检测,并对各算法检测结果进行分析和比较。
其次再对语音信号加噪,对不同信噪比值进行端点检测,分析比较各算法在不同信噪比下的端点检测结果,实验结果表明谱熵算法语音端点检测结果比其他两种方法好。
关键词语音端点检测;语音信号处理;短时能量和过零率;倒谱;谱熵IAbstractEndpoint detection is a voice signal from the accurate speech signal to the identify start and the end points, the purpose is to enable to separated the effective voice signals and un-useful noise. So, in the speech recognition system, speech enhancement, speech coding, echo cancellation and other systems are widely used.In Current the endpoint detection can be roughly divided into two categories, one is based on the threshold method based on the different characteristics of speech signal and the noise signals, a voice signal for each extracted feature, and then set the values of these thresholds compare with the values to achieve the endpoint detection purposes, This method is simple, it convenient operation, it is widely used, the main in this paper is based on the method of threshold method. Another method is based on the method of pattern recognition , it needs to estimate the speech signal and the noise signal model parameters were detected. Because is based on the method of pattern recognition and high self-complexity, a large amount of computation, so it is difficult to be use in real-time voice signal system for people.The Endpoint detection is take a very important position in the speech recognition, it directly affects the performance of the system. In this article first domain analysis in simple speech signal time, than dual threshold algorithm, cepstrum algorithm, spectral entropy algorithm for endpoint detection, and these types of endpoint detection algorithms, and experimental analysis points. Firstly, the algorithm were used to the original speech signal detection, and the algorithm to analyze and compare results. Secondly, the speech signal and then adding noise, SNR values for different endpoint detection, analysis and comparison of various algorithms under different SNR endpoint detection results, experimental results show that the spectral entropy of speech endpoint detectionIIalgorithm results better than the other two methods.Keywords voice activity detection;Signal processing; Average energy use of short-term and short-time average zero-crossing rat; cepstrum; spectral entropyIII毕业设计(论文)原创性声明和使用授权说明原创性声明本人郑重承诺:所呈交的毕业设计(论文),是我个人在指导教师的指导下进行的研究工作及取得的成果。
Matlab在语音识别中的应用
1.基于GUI的音频采集处理系统注:本实验是对“东、北、大、学、中、荷、学、院”孤立文字的识别!首先是GUI的建立,拖动所需控件,双击控件,修改控件的参数;主要有string T ag(这个是回调函数的依据),其中还有些参数如value style 也是需要注意的,这个在实际操作中不能忽视。
这里需要给说明一下:图中所示按钮都是在一个按钮组里面,都属于按钮组的子控件。
所以在添加回调函数时,是在按钮组里面添加的,也就是说右击三个按钮外面的边框,选择View Callback——SelectionChange,则在主函数中显示该按钮的回调函数:function uipanel1_SelectionChangeFcn(hObject, eventdata, handles)以第一个按钮“录音”为例讲解代码;下面是“播放”和“保存”的代码:以上就是语音采集的全部代码。
程序运行后就会出现这样的界面:点击录音按钮,录音结束后就会出现相应波形:点击保存,完成声音的保存,保存格式为.wav。
这就完成了声音的采集。
2.声音的处理与识别2.1打开文件语音处理首先要先打开一个后缀为.wav的文件,这里用到的不是按钮组,而是独立的按钮,按钮“打开”的回调函数如下:function pushbutton1_Callback(hObject, eventdata, handles)其中pushbutton1是“打开”按钮的Tag.在回调函数下添加如下代码:运行结果如图:2.2预处理回调函数如下:function pushbutton2_Callback(hObject, eventdata, handles)运行结果如图:2.3短时能量短时能量下的回调函数:function pushbutton3_Callback(hObject, eventdata, handles)其回调函数下的代码是:2.4端点检测这里要先声明一点,为了避免在以后的函数调用中,不能使用前面的变量,所以其实后面的函数都包含了前面的部分。
Matlab在语音端点检测系统中的应用

很 快 地 起 伏 。 此 , 常 认 为 一 个 语 音 帧 以 避 免 这 种 情 况 。 因 通 判 定 起 点 后 , 续 将 短 时 能 量 与 给 定 继 内 , 含 有 1 个 基 音 周 期 , 采 样 率 为 应 ~7 在 3 当 1k 的情 况下 , 选择 在 i0 0 量级 是 门 限 G 比较 , 小 于 它并 能 在 一 定 时 间 内 0 Hz N 0 -2 0 合 适 的 。 帧 可 以 是 连 续 的 , 可 以是 交 叠 降 到 门 限 G4 维 持 给 定 帧 数 ( 分 也 并 防止 将语 音 的 。 了使 特 征 参 数 的 平 滑 过 渡 , 为 保证 其 连 中 的 小 停 顿 误 判 为 语 音 结 束 ) 认 为 是 终 , 续性 , 帧常采用交叠 的。 分 点, 则继续向下找 。 否 1 3短 时能量【 . 。 1
对于语音信号{ }短时能量的定义 2用 MA L B ), ( T A 实现语音端点检测[ 1 ( 】 X ” 2 ( )
语音 数据 用wa r a 函数 直接 从语 音文 v ed 件 中读 取 : I, bt] 【 sn is x, =wa ra (fe a v e d ’ ln me’ i )
语 音 信 号 进 行 预 处 理 , 于 语 音 信 号 由
的 高 频 端 大 约 在 8 0 Hz 0 O 以上 , 因此 需 要 提 如图1 示 。 所 滤 尤 表示 在 信 号 的 第 1个 点 开 始加 窗 时 升 高 频 部 分 , 除 低 频 干 扰 , 其 是 消 除 " 1 0 或6 Hz 可 的短 时 能 量 , 时 能 量 可 以 看 作 语 音 信 号 5 Hz 0 的工 频干 扰 。 通 过将 语 音 信 短 号 通 过 一 个 一 阶 的 高 通 滤 波 器来 实 现 , 滤 的平 方 经 过 一 个 线 性 滤 波 器 的 输 出 。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
基于Matlab编写的语音端点检测专业:班级:姓名:指导教师:2011 年6月18 日一、实验目的1.学会MATLAB的使用,掌握MATLAB的程序设计方法;3.掌握语音处理的基本概念、基本理论和基本方法;4.掌握基于MATLAB编程实现带噪语音信号端点检测;5.学会用MATLAB对信号进行分析和处理。
二、实验内容简介:可利用时域分析(短时能量、短时过零率、短时自相关)方法的某一个特征或某几个特征的结合,判定某一语音信号的端点,尤其在有噪声干扰时,如何准确检测语音信号的端点,这在语音处理中是富有挑战性的一个课题。
要求:(1)录制语音,读入文件,绘制波形(2)分帧,绘制能量曲线和短时过零率曲线(3)根据上述端点检测原理,实现端点检测(4)界面三.课程设计原理端点检测是语音信号处理过程中非常重要的一步,它的准确性直接影响到语音信号处理的速度和结果,因此端点检测方法的研究一直是语音信号处理中的热点。
本设计使用传统的短时能量和过零率相结合的语音端点检测算法利用短时过零率来检测清音.用短时能量来检测浊音,两者相配合便实现了信号信噪比较大情况下的端点检测。
算法对于输入信号的检测过程可分为短时能量检测和短时过零率检测两个部分。
算法以短时能量检测为主,短时过零率检测为辅。
根据语音的统计特性,可以把语音段分为清音、浊音以及静音(包括背景噪声)三种。
在本算法中,短时能量检测可以较好地区分出浊音和静音。
对于清音,由于其能量较小,在短时能量检测中会因为低于能量门限而被误判为静音;短时过零率则可以从语音中区分出静音和清音。
将两种检测结合起来,就可以检测出语音段(清音和浊音)及静音段1、短时能量计算定义n 时刻某语音信号的短时平均能量n E 为:∑∑--=+∞-∞=-=-=n N n m m n m n w m x m n w m x E )1(22)]()([)]()([式中N 为窗长,可见短时平均能量为为一帧样点值的甲醛平方和。
特殊地,当窗函数为矩形窗时,有∑--==n N n m n m x E )1(2)(2、短时过零率过零就是指信号通过零值。
过零率就是每秒内信号值通过零值的次数。
对于离散时间序列,过零则是指序列取样值改变符号,过零率则是每个样本的改变符号的次数。
对于语音信号,则是指在一帧语音中语音信号波形穿过横轴(零电平)的次数。
可以用相邻两个取样改变符号的次数来计算。
如果窗的起点是n=0,短时过零率Z 为波形穿过横轴(零电平)的次数短时过零可以看作信号频率的简单度量浊音的短时平均幅度最大,无声的短时平均幅度最小,清音的短时过零率最大,无声居中,浊音的短时过零率最小。
3、短时自相关函数1、是偶函数;2、s(n)是周期的,那么R(k)也是周期的;3、可用于基音周期估计和线性预测分析4、判断语音信号的起点和终点利用短时平均幅度和短时过零率可以判断语音信号的起点和终点。
语音端点检测方法可采用测试信号的短时能量或短时对数能量、联合过零率等特征参数,并采用双门限判定法来检测语音端点,即利用过零率检测清音,用短时能量检测浊音,两者 配合。
首先为短时能量和过零率分别确定两个门∑-=--=100))1(())((21N n w w n S Sgn n S Sgn Z ∑--=+=10)()()(k N n w w w k n s n s k R ⎩⎨⎧<-≥=0,10,1)sgn(x x x限,一个是较低的门限数值较小,对信号的变化比较敏感,很容易超过;另一个是比较高的门限,数值较大。
低门限被超过未必是语音的开始,有可能是很短的噪声引起的,高门限被超过并且接下来的自定义时间段内的语音超首先,可根据浊语音情况下短时平均幅度M的概率密度函数P(M/V)确定一个阈值参数MH, MH的值定得比较高。
当一帧输入信号的M值超过MH 时,就可以十分肯定该帧语音信号不是无声,而有相当大的可能性是浊音由N1’向前和N2’向后继续用短时过零率Z进行搜索。
根据无声情况下短时过零率Z的均值,设置一个参数Z0,如果由N1’向前搜索时Z始终大于Z0的3倍,则认为这些信号仍属于语音段,直至Z突然下降到低于3Z0值时,这时可以确定语音的精确起点(为了保证可靠,由N1’向前搜索时间不超过25ms)。
对终点做同样的处理。
采取这一算法的原因在于,N1’以前可能是一段清辅音段(如f,s),它的能量相当弱,依靠能量不可能把他们与无声段区别开,而他们的过零率明显高于无声,因而能用这个参数来精确的判断二者的分割点,也就是语音真正的起点。
四、实验步骤及分步结果1.界面设计2.程序设计(1).①打开语音文件function openbutton_Callback(hObject, eventdata, handles) clc;axes(handles.wavaxes);cla reset;boxon;set(gca,'XTickLabel',[],'YTickLabel',[]);axes(handles.Energeaxes);cla reset;boxon;set(gca,'XTickLabel',[],'YTickLabel',[]);axes(handles.Zerorateaxes);cla reset;boxon;set(gca,'XTickLabel',[],'YTickLabel',[]);set(handles.T1edit,'string',0);set(handles.T2edit,'string',0);set(handles.T3edit,'string',0);%´ò¿ª´ý´¦ÀíµÄÓïÒôÎļþ[filename,pathname]=uigetfile({'*.wav','All WavFiles'},'Ñ¡ÔñÓïÒôÎļþ');if filename == 0return;%Èç¹ûûÓÐÑ¡ÔñеÄÎļþ£¬Ôò·µ»Øendfile=fullfile(pathname,filename);%ÎļþÃû[signal,fs,bit]=wavread(file);%¶ÁÈ¡Ñ¡ÔñµÄÓïÒôÊý¾Ýaxes(handles.wavaxes)plot(signal)%ÏÔʾ²¨ÐÎhandles.wavsignal=signal;%update handles structureguidata(hObject,handles);②预处理预处理程序function prebutton_Callback(hObject, eventdata, handles)% hObject handle to prebutton (see GCBO)% eventdata reserved - to be defined in a future version of MATLAB% handles structure with handles and user data (see GUIDATA)signal=handles.wavsignal;signal=filter([1,-0.9375],1,signal);%Ô¤¼ÓÖØÂ˲¨axes(handles.wavaxes)plot(signal)%ÏÔʾԤ¼ÓÖغó²¨ÐÎtitle('Ô¤¼ÓÖØÂ˲¨ºóÓïÒô²¨ÐÎ');handles.wavsignal=signal;framelength=256;%´°³¤£»framenumber=fix(length(signal)/framelength);%×ÜÖ¡Êýfor i=1:framenumber;framesignal(i,1:framelength)=signal((i-1)*framelength+1:i*framelength);%·ÖÖ¡´¦Àíendhandles.framesignal=framesignal;%Update handles structureguidata(hObject,handles);③短时能量短时能量function Energebutton_Callback(hObject, eventdata, handles)% hObject handle to Energebutton (see GCBO)% eventdata reserved - to be defined in a future version of MATLAB % handles structure with handles and user data (see GUIDATA) framesignal=handles.framesignal;framenumber=size(framesignal,1);%»ñµÃÊý¾ÝèåÊýfor i=1:framenumber;E(i)=0;E(i)=sum(framesignal(i,:).^2);%¼ÆËã¶ÌʱÄÜÁ¿endaxes(handles.Energeaxes)%c=[1 2 3 4 5 6 4 3 3 3 3];plot(E);%½«ÄÜÁ¿Ö»ÏÔʾÔÚÄÜÁ¿´°¿Úhandles.E=E;%Update handles structureguidata(hObject,handles);% --- Executes on button press in Zeroratebutton.function Zeroratebutton_Callback(hObject, eventdata, handles)% hObject handle to Zeroratebutton (see GCBO)% eventdata reserved - to be defined in a future version of MATLAB% handles structure with handles and user data (see GUIDATA) framesignal=handles.framesignal;framenumber=size(framesignal,1);%ÓïÒôÊý¾ÝÖ¡Êýframelength=size(framesignal,2);%»ñÈ¡ÓïÒôÖ¡³¤for i=1:framenumber;Z(i)=0;for j=2:framelength-1;Z(i)=Z(i)+abs(sign(framesignal(i,j))-sign(framesignal(i,j-1)));%¼ÆËã¶Ìʱ¹ýÁãÂÊendendaxes(handles.Zerorateaxes)%ÏÔʾ֡¹ýÁãÂÊÇúÏßplot(Z)handles.Z=Z;handles.framelength=framelength;%Update handles structureguidata(hObject,handles);④短时过零率短时过零率function Zeroratebutton_Callback(hObject, eventdata, handles)% hObject handle to Zeroratebutton (see GCBO)% eventdata reserved - to be defined in a future version of MATLAB% handles structure with handles and user data (see GUIDATA) framesignal=handles.framesignal;framenumber=size(framesignal,1);%ÓïÒôÊý¾ÝÖ¡Êýframelength=size(framesignal,2);%»ñÈ¡ÓïÒôÖ¡³¤for i=1:framenumber;Z(i)=0;for j=2:framelength-1;Z(i)=Z(i)+abs(sign(framesignal(i,j))-sign(framesignal(i,j-1)));%¼ÆËã¶Ìʱ¹ýÁãÂÊendendaxes(handles.Zerorateaxes)%ÏÔʾ֡¹ýÁãÂÊÇúÏßplot(Z)handles.Z=Z;handles.framelength=framelength;%Update handles structureguidata(hObject,handles);⑤设定门限1.2阈值设置门限1.2(编辑框2)function T2edit_Callback(hObject, eventdata, handles)% hObject handle to T2edit (see GCBO)% eventdata reserved - to be defined in a future version of MATLAB% handles structure with handles and user data (see GUIDATA)clcaxes(handles.Energeaxes);cla reset;box on;set(gca,'XTicklabel',[],'YTicklabel',[]);%ÔÚÊäÈëеÄa,bֵʱ£¬ÒªÇå¿ÕEn ergeaxesÀïµÄͼÏñTL=get(handles.T1edit,'string');%»ñµÃTLÖµTH=get(handles.T2edit,'string');%»ñµÃTHÖµTL=str2num(TL);%½«×Ö·ûÀàÐÍת»¯³ÉÊýÖµÀàÐÍTH=str2num(TH);E=handles.E;MeanE=mean(E(1:10));%ÇóÇ°10Ö¡µÄÄÜÁ¿¾ùÖµaxes(handles.Energeaxes)plot(E)hold online([1 length(E)],[TL TL],'Color','r');%ÓúìÏß»-³öTLÖµhold online([1 length(E)],[TH,TH],'Color','b');%ÓÃÀ¶Ïß»-³öTHÖµhandles.TL=TL;handles.TH=TH;%Update handles structureguidata(hObject,handles);⑥编辑框3门限3function T3edit_Callback(hObject, eventdata, handles)% hObject handle to T3edit (see GCBO)% eventdata reserved - to be defined in a future version of MATLAB % handles structure with handles and user data (see GUIDATA)clcaxes(handles.Zerorateaxes);cla reset;box on;set(gca,'XTickLabel',[],'YtickLabel',[]);v=get(handles.T3edit,'string');v=1*str2num(v);Z=handles.Z;MeanZ=mean(Z(1:10));VarZ=std(Z(1:10));ZT=min(v,MeanZ+VarZ);axes(handles.Zerorateaxes)plot(Z)hold online([1,length(Z)],[ZT,ZT],'Color','b'); handles.ZT=ZT;guidata(hObject,handles);⑦端点检测端点检测function Detectpointbutton_Callback(hObject, eventdata, handles) TL=handles.TL;%¼ÓÔØÊý¾ÝTH=handles.TH;ZT=handles.ZT;Z=handles.Z;E=handles.E;startflag=1;startframe=11;mins=min(handles.wavsignal);maxs=max(handles.wavsignal);axes(handles.wavaxes);plot(handles.wavsignal);accustartflag=1;accustartframe=startframe-15;i=accustartframe;k=0;i=11;while(startflag)%ÓöÌʱÄÜÁ¿³õ²½¼ÆËãÆðʼµãif((E(i)>TL)&(E(i+1)>TH))startframe=i;startflag=0;%±ê־λÇåÁãÍ˳öÑ-»·while(accustartflag)%ÓöÌʱ¹ýÁãÂʽøÒ»²½¼ÆËãÆðʼµãif(Z(i)>ZT);k=k+1;if(k==3)accustartflag=0;accustartframe=i-3startframe=accustartframe;endelsek=0;endi=i+1;endelsei=i+1;endendendflag=1;endframe=length(E);i=endframe;accuendflag=1;accuendframe=endframe+15;i=accuendframe;k=0;j=size(E);for i=11:j-1;%ÓɶÌʱÄÜÁ¿´ÖÅÐÖÕÖ¹µãif(i==1)break;endif((E(i)>TL)&(E(i-1)>TH))endframe=i;while(accuendflag)%ÓɶÌʱ¹ýÁãÂʽøÒ»²½¼ÆËãÖÕÖ¹µãif(i>length(Z))break;endif(Z(i)>ZT)k=k+1;if(k==3)accuendflag=0;accuendframe=i;endframe=accuendframe;endflag=0;endelsek=0;endi=i+1;endelse i=i-1;endendhold online([startframe*256 startframe*256],[-0.50.5],'Color','b');%»-³öÆðʼµãhold online([endframe*256 endframe*256],[-0.5 0.5],'Color','r');%»-³öÖÕÖ¹µã五、实验结论分析:(1)从图中明显可以看出,浊音信号的具有明显的周期性,其自相关函数和平均幅度差函数也表现出周期性。