Linux中文乱码解决
astah,linux下中文输入乱码有关问题解决方案_1

astah,linux下中文输入乱码有关问题解决方案_1竭诚为您提供优质文档/双击可除astah,linux下中文输入乱码有关问题解决方案篇一:关于linux下中文乱码的完整解决方案关于linux下中文显示为乱码的完整解决方案linux,作为一款免费的操作系统,相对于高额费用的windows系列操作系统,有着更强的优势,所以,许多人也都开始学习linux操作系统的知识。
但是,由于windows系列操作系统还是当今社会的主流,所以,人们少不了在windows和linux系统之间进行文件的传输。
但是一个新问题出现了,那就是中文乱码问题,这个问题困扰着无数的linux用户,尤其是linux的初学者,对于这个问题相当的头疼。
主要问题如下:1、ssh中,中文显示为乱码:在windows 系统下,用ssh远程连接linux系统,对于在linux下显示正常的中文,在ssh中却显示为完全无法识别的乱码字符。
2、中文传输乱码:把windows中的中文文件传输到linux 操作系统中,原本在windows下显示正常的文件,到了linux 系统下,成了无法识别的乱码。
分析其原因,是因为linux和windows系统下,所用户的字符集不同,linux系统使用的是unicode字符集,而windows使用的是gb 字符集。
所以,在网上出现了两种解决方案:方法一:使用putty代替secureshellclient(ssh):在putty终端设置中,修改window-〉translation中的Receiveddataassumedtobeinwhichcharacterset值为linux 中的字符集utF-8,再连接linux,发现这时,linux中的中文可以正常显示了。
但是一个新问题出现了,把windows中的文件上传了linux中,原本在windows下显示正常的中文文件,现在却成了乱码。
所以,这个方法无法彻底解决乱码问题。
linux使用源码安装unzip,解决中文乱码问题

使用源码安装unzip,解决中文乱码问题1.下载unzip-5.52:/RAYSLX/pool/main/u/unzip/2.卸载linux系统自带的unzip:#rpm -e unzip3.解压文件:#tar zxvf unzip_5.52.orig.tar.gz4.进入unzip目录#cd unzip-5.525.找到文件unzpriv.h (修改内容大概在文件末尾),修改以下内容:/* Convert filename (and file comment string) into "internal" charset.* This macro assumes that Zip entry filenames are coded in OEM (IBM DOS) * codepage when made on* -> DOS (this includes 16-bit Windows 3.1) (FS_FAT_)* -> OS/2 (FS_HPFS_)* -> Win95/WinNT with Nico Mak's WinZip (FS_NTFS_ && hostver == "5.0") * EXCEPTIONS:* PKZIP for Windows 2.5 and 2.6 flag their entries as "FS_FAT_", but the* filename stored in the local header is coded in Windows ANSI (ISO 8859-1). * Likewise, PKZIP for UNIX 2.51 flags its entries as "FS_FAT_", but the* filenames stored in BOTH the local and the central header are coded* in the local system's codepage (usually ANSI codings like ISO 8859-1).** All other ports are assumed to code zip entry filenames in ISO 8859-1.*/#ifndef Ext_ASCII_TO_Native# define Ext_ASCII_TO_Native(string, hostnum, hostver, isuxatt, islochdr) \if (((hostnum) == FS_FAT_ && \!(((islochdr) || (isuxatt)) && \(hostver) >= 25 && (hostver) <= 26)) || \(hostnum) == FS_HPFS_ || \((hostnum) == FS_NTFS_ && (hostver) == 50)) { \_OEM_INTERN((string)); \} else { \_ISO_INTERN((string)); \}#endif注释其他语句,只留_ISO_INTERN((string)),修改如下:#ifndef Ext_ASCII_TO_Native# define Ext_ASCII_TO_Native(string, hostnum, hostver, isuxatt, islochdr) \ /* if (((hostnum) == FS_FAT_ && \* !(((islochdr) || (isuxatt)) && \* (hostver) >= 25 && (hostver) <= 26)) || \* (hostnum) == FS_HPFS_ || \* ((hostnum) == FS_NTFS_ && (hostver) == 50)) { \* _OEM_INTERN((string)); \* } else { \ */_ISO_INTERN((string)); \/* } */#endif6.复制unix编译文件到当前目录下#cp unix/Makefile .7.安装#make prefix=/usr linux#make prefix=/usr install。
linux中显示中文乱码的问题

linux中显示中文乱码的问题/seuxiaoqi/article/details/5577195分类:linux 2010-05-11 09:154586人阅读评论(0)收藏举报由于在windows下默认是gb编码,而我的vim默认是utf-8(gedit默认也是utf-8),所以打开会成乱码。
修改了一下配置文件,使vi支持gb编码就好了。
$vi ~/.vimrclet &termencoding=&encodingset fileencodings=utf-8,gbk$:wq再次打开vi,显示就正常了。
如果你需要在linux下面用到windows下的文件,拷贝上去后经常发现中文显示乱码。
原因是Windows中默认的文件格式是 GBK(gb2312),而Linux一般都是UTF-8。
比较繁琐的方法是在windows下用程序把内容转换为utf-8编码格式的,但是相当麻烦,而且遇到一个文件转一回。
下面介绍一下,在Linux中如何一劳永逸的解决这个问题,查看文件的编码及如何进行对文件进行编码转换。
查看文件编码在Linux中查看文件编码可以通过以下几种方式:1.在Vim中可以直接查看文件编码:set fileencoding即可显示文件编码格式。
文件编码转换1.如果你只是想查看其它编码格式的文件或者想解决用Vim查看文件乱码的问题,那么你可以在~/.vimrc(在/etc目录下面)文件中添加以下内容:set encoding=utf-8 fileencodings=ucs-bom,utf-8,cp936其中encoding是vim的默认显示编码格式,fileencodings是vim打开文件时检测的编码格式,存在这种类型的编码即转换为utf-8 编码。
这样,就可以让vim自动识别文件编码(可以自动识别UTF-8或者GBK编码的文件),其实就是依照fileencodings提供的编码列表尝试,如果没有找到合适的编码,就用latin-1(ASCII)编码打开。
详解Linux中文乱码问题终极解决方法

详解Linux中⽂乱码问题终极解决⽅法初⼊linux的程序员们,经常会受到乱码的问候。
可谓“始乱终弃”。
因为乱码,并且最终放弃了linux的不在少数。
好吧,⾔归正传,下⾯来看⼀下linux乱码的具体解决办法吧。
⽅法⼀:修改/root/.bash_profile⽂件,增加export LANG=zh_CN.GB18030该⽂件在⽤户⽬录下,对于其他⽤户,也必须相应修改该⽂件。
使⽤该⽅法时putty能显⽰中⽂,但桌⾯系统是英⽂,⽽且所有的⽹页中⽂显⽰还是乱码⽅法⼆:修改/etc/sysconfig/i18n⽂件#LANG="en_US.UTF-8"#SUPPORTED="en_US.UTF-8:en_US:en"#SYSFONT="latarcyrheb-sun16"修改为:LANG="zh_CN.GB18030"LANGUAGE="zh_CN.GB18030:zh_CN.GB2312:zh_CN"SUPPORTED="zh_CN.GB18030:zh_CN:zh"SYSFONT="lat0-sun16"SYSFONTACM="8859-15"参考:Linux中⽂乱码问题最近,公司在XP系统于LINUX之间传数据时出现了中⽂乱码问题!⾸先,字符集:汉字编码:* GB2312字集是简体字集,全称为GB2312(80)字集,共包括国标简体汉字6763个。
* BIG5字集是台湾繁体字集,共包括国标繁体汉字13053个。
* GBK字集是简繁字集,包括了GB字集、BIG5字集和⼀些符号,共包括21003个字符。
* GB18030是国家制定的⼀个强制性⼤字集标准,全称为GB18030-2000,它的推出使汉字集有了⼀个“⼤⼀统”的标准。
ASCII:American Standard Code for Information Interchange,美国信息交换标准码。
linux文件乱码解决方案

Linux文件乱码解决方案一、引言在使用L in ux系统时,我们可能会遇到文件乱码的情况,这给我们的工作和学习带来了不便。
本文将为您介绍一些常见的L in ux文件乱码解决方案,帮助您解决文件乱码问题,提高您在Li nu x系统下的使用体验。
二、检查文件编码文件编码是导致文件乱码的主要原因之一。
首先我们需要检查文件的编码方式,以确定是否是编码导致了文件乱码的问题。
我们可以使用一些工具来检查文件的编码方式,例如使用`fil e`命令或者`e nc a`工具。
这些工具可以自动判断文件的编码方式,并给出相应的结果。
根据结果,我们可以采取相应的解决方案。
三、使用合适的文本编辑器使用合适的文本编辑器也是解决文件乱码问题的重要一环。
不同的文本编辑器对于文件编码的支持程度不同,选择合适的文本编辑器可以减少文件乱码的可能性。
在L in ux系统中,有很多文本编辑器可以选择,例如`V i`、`Vi m`、`E ma cs`、`S ub li me T ex t`等。
这些编辑器具有不同的特点和优势,可以根据自己的需要选择合适的编辑器来编辑文本文件。
同时,我们还需要确保文本编辑器的编码设置与文件的编码方式一致,避免出现编码不匹配的问题。
四、转换文件编码如果确定文件的编码方式与文本编辑器设置的编码方式不一致导致了文件乱码,我们可以考虑将文件的编码方式转换为与文本编辑器设置的编码方式一致。
在L in ux系统中,我们可以使用一些工具来进行文件编码转换,例如`i co nv`命令。
该命令可以将文件从一种编码方式转换为另一种编码方式,解决文件乱码的问题。
使用`i co nv`命令时,需要指定源文件的编码方式和目标文件的编码方式,通过该命令进行文件编码的转换。
五、使用合适的字体有时,文件的乱码可能是由于系统缺少相应的字体文件导致的。
我们可以尝试安装合适的字体文件来解决文件乱码问题。
L i nu x系统中,我们可以通过包管理器来安装字体文件。
Linux操作系统下linux命令乱码的终极解决方案

英文字符linux命令乱码
一般该字符linux命令乱码多出现在cat了二进制的文件时,因为二进制文件中多有控制码,会导致终端界面linux命令乱码,通常解决方法是用reset终端复位命令解决问题
其他伪终端linux命令乱码
有时是通过SSH进入远程LINUX服务器时,cat一个core文件,并且用reset命令都不能成功,怎么办?很简单,看以下试验,首先cat一个python的编译文件
以上是Linux操作系统下linux命令乱码的终极解决方案,希望对您有所acle@linux-suse:~> VT102VT102
\-bash: VT102VT102: command not found
oracle@linux-suse:~>
在SSH终端上看到是的linux命令乱码,提示符都是乱的,可以用以下命令恢复
oracle@linux-suse:~> tput sgr0
linux命令乱码问题产生的原因是SSH的问题,因为在其他终端下,cat用样一个文件,不会产生乱码,于是试验linux命令乱码产生的原因
oracle@linux-suse:~> ^N
只要用ctrl+v,ctrl+n就使用屏幕linux命令乱码,当然恢复后再试验
oracle@linux-suse:~> cat fibo.pyc
m?
{?鯡c@sd
Zd
ZdS(cCs:d\}}x'jo G }}qWdS(Nii(ii(tatbtn(RRR((tfibo.pytfibs
cCsIg}d\}}x0jo" i}}qW S(Nii(ii(tresultRRRtappend(RRRR((Rtfib2 s
linux 乱码的解决方法

linux 乱码的解决方法嘿,朋友们!咱今天来聊聊 Linux 乱码这档子事儿。
你说这乱码就像调皮的小精灵,时不时就蹦出来捣乱,让人头疼得很呐!咱先来说说为啥会出现乱码。
就好比你去一个陌生的地方,人家说的话你听不懂,那可不就懵了嘛!Linux 系统也一样,有时候它遇到一些它不太熟悉的字符编码格式,就搞不明白了,然后乱码就出现了。
那咋解决呢?嘿,这办法还不少嘞!首先啊,咱得看看系统的语言环境设置对不对。
就像你出门得先选对要穿的衣服一样,得合适才行呀!如果设置错了,那不乱码才怪呢!咱得把它调整到正确的编码格式,比如 UTF-8 啥的,这可是个常用的好东西呢!然后呢,再检查一下那些文件的编码。
哎呀,就好比你看书,要是书的印刷有问题,那你能看清内容才怪嘞!要是文件本身的编码就不对,那显示出来可不就乱套啦!得把它们转换成合适的编码。
还有啊,有些软件也可能会导致乱码哦!这就像一个团队里有个捣蛋鬼,得把它揪出来才行。
看看是不是软件的设置有问题,或者是不是该更新一下啦。
你想想看,要是你电脑上老是出现乱码,你看着不心烦呀?那感觉就像你走路老是被石头绊脚一样,多闹心呐!所以啊,咱得把这些乱码问题给解决咯,让咱的 Linux 系统顺顺畅畅的。
比如说,你正在处理一个很重要的文档,结果打开一看,全是乱码,那你不得抓狂呀!这时候你就得赶紧用咱说的这些方法去试试,把乱码赶跑。
再比如,你在看一些外文资料,结果因为乱码啥都看不清,那不就白费劲了嘛!所以说呀,学会解决 Linux 乱码问题可太重要啦!总之呢,Linux 乱码并不可怕,只要咱找对方法,就能轻松搞定。
就像打怪兽一样,找到它的弱点,一下就把它打败啦!可别让这些乱码影响了咱使用 Linux 的好心情哟!大家加油吧!让咱的 Linux 系统一直清清爽爽,没有乱码的困扰!。
Linux中文显示乱码问题解决方法(编码查看及转换)

Linux中⽂显⽰乱码问题解决⽅法(编码查看及转换)Linux中⽂显⽰乱码问题解决⽅法(编码查看及转换)1,⽰例图中名为⼀个.sql⽂件的⼀段内容,是⼀个数据库⽂件。
其在windows中打开显⽰正常,在Linux中,中⽂部分显⽰为乱码。
注意:这个与数据库乱码的情况不同,属于⽂件内容的乱码。
2,分析Linux系统与windows系统在编码上有显著的差别。
Windows中的⽂件的格式默认是GBK(gb2312),⽽Linux系统中⽂件的格式默认是UTF-8。
这两个系统就好⽐是中国和⽇本。
⽂件就好⽐是⼀个⼈,如果要在另外的国家居住就要办理居住许可证,使⽤他国的证件(编码和字符集),否则是不被允许的⿊户。
因此,解决中⽂乱码问题要从编码和字符集着⼿。
⽂件出现编码错误的原因:当前系统的字符集有问题某个⽂件的编码有问题3,解决⽅案3.1⽅案⼀:从系统的字符集处理当系统中多个⽂件的内容出现乱码问题,或者中⽂⽂件名显⽰乱码时,就先从系统的字符集处理。
常⽤字符集:中⽂LANG=“zh_CN.UTF-8”英⽂LANG=“en_US.UTF-8”或LANG=C1,查看字符集<1>查看当前系统默认采⽤的字符集locale<2>查看系统当前字符集echo $LANG<3>查看系统是否安装中⽂字符集出现zh开头的,即为安装了中⽂字符集如未安装,需执⾏: yum -y groupinstall chinese-supportlocale -a |grep zh2,修改系统字符集<1>修改系统字符集为中⽂如果前⾯查看到的系统当前的字符集是英⽂,通常修改系统字符集为中⽂即可成功。
临时修改(当前终端⽣效):export LANG="zh_CN.UTF-8"永久修改:echo"export LANG="zh_CN.UTF-8" >> /etc/proflilesource /etc/profile<2>查看echo $LANG3.2 解决⽅法⼆:从⽂件的编码处理当系统的字符集为中⽂,⽂件的中⽂部分仍然显⽰乱码,就从⽂件的编码格式处理。
解决linux乱码 linux中文 linux字库 Red Hat乱码 Red Hat中文 Red Hat字库

解决虚拟机中Red Hat Enterprise Linux 5中文乱码问题最近在虚拟机中安装了红帽linux,可能是装的时候点错了,无法显示中文,研究了一下网上提供的方法,大都是用命令#vi i18n,或者更改language,可改了之后,系统中却出现了乱码,乱码的出现表示系统中没有中文支持,就是没有在字体库中没有字体,这意味着系统中任何地方都无法显示中文,系统没有中文倒是无所谓,对付着能看懂些,可是浏览器没有中文就很悲剧了,研究了一下,以下是解决乱码的发方法,其实就是把字库弄进系统里。
启动虚拟机,找到你的linux系统,但先不要启动linux,这时点编辑虚拟机设置,如下图。
找到CD/DVD(IDE) ,在右侧勾择Use ISO image file 并在Browse...中找到你的红帽安装映像ISO文件,点OK完成,结果如下图。
Server文件夹。
打开Server 找到fonts-chinexe-3.02-.12.el5.noarch.rpm这个压缩包,如下图。
右键选择Open with "Archive Manager",打开该压缩包,如下图。
在压缩包中找到/usr/share/fonts/chinese/TrueType/中的两个字体文件,并选中,如下图。
单击Extract后,如下图,选择你的文件夹,单击Extract,解压这两个字体文件。
这时在你的文件夹中会有这两个字体文件,如下图。
这时我们有了中文的字库文件,将这两个字体文件拷贝到/usr/share/fonts/default下的文件夹ghostscript和文件夹Type1("1"而不是"L")中。
因为这两个文件夹是只读文件夹,要先用su root 命令取得root权限,之后用命令cp拷贝文件,如下图。
拷贝结束,到系统管理中找到"language",如下图。
远程linuxxshell下输出中文乱码解决方法

远程linuxxshell下输出中⽂乱码解决⽅法
使⽤xshell登录中⽂版CentOS或者redhat时,在xshell下如果输出的是中⽂的话可能会显⽰乱码,通过如下办法可以有效的解决乱码问题
:
复制代码代码如下:
[root@localhost ~]# cd /etc/sysconfig/
[root@localhost sysconfig]# cp i18n i18n.bak #备份i18n⽂件
[root@localhost sysconfig]# echo "" >i18n
[root@localhost sysconfig]# vi i18n #加⼊以下内容
LANG="zh_CN.GB18030"
LANGUAGE="zh_CN.GB18030:zh_CN.GB2312:zh_CN"
SUPPORTED="zh_CN.GB18030:zh_CN:zh:en_US.UTF-8:en_US:en"
SYSFONT="lat0-sun16"
但是这样修改过以后,linux物理机上使⽤终端命令⾏时显⽰的汉字为乱码,如果不在本地登录的话,可以⽤这种⽅法
:
通过修改远程⼯具的编码来正常的显⽰中⽂,把远程⼯具中的编码格式显⽰为utf8格式即可解决linux中⽂乱码的问题!有的⼯具可能没有修改编码的功能,建议⼤家使⽤xhell,功能强⼤!。
linux python中文乱码解决方法-概述说明以及解释

linux python中文乱码解决方法-概述说明以及解释1.引言1.1 概述概述部分是文章引言的一部分,它的目的是提供一个简要的介绍,概括文章的主题和内容。
在“Linux Python中文乱码解决方法”这篇长文中,概述部分可以包括以下内容:概述:随着Linux和Python的广泛应用,中文乱码问题也逐渐成为了许多开发者和用户的关注焦点。
在日常的Linux和Python编程过程中,我们经常会遇到中文乱码的情况,这不仅给我们的工作带来了不便,还可能影响程序的正确执行。
因此,解决Linux和Python中文乱码问题成为了一个重要的任务。
本文将从两个方面详细介绍Linux 和Python 中文乱码问题的原因和解决方法。
首先,我们将探讨Linux 系统中的中文乱码问题,分析其产生的原因和对应的解决方法。
其次,我们将深入探讨Python 编程语言中出现的中文乱码问题,解释其中的原因,并提供相应的解决方案。
通过本文的阐述,读者将能够更好地理解和解决在Linux 和Python 中遇到的中文乱码问题。
总结:在本文的结论部分,我们将总结我们在解决Linux 和Python 中文乱码问题的过程中所采用的方法和技巧。
我们将讨论这些方法的有效性和适用性,并提供一些建议,帮助读者在实际的工作和学习中更好地解决中文乱码问题。
通过本文提供的解决方案,读者将能够提高工作效率,避免中文乱码带来的困扰,并更好地利用Linux 和Python 进行程序开发和日常使用。
通过本文的阅读和理解,读者将对Linux 和Python 中文乱码问题有更清晰的认识,并能够运用相应的解决方法,提高工作效率和代码质量。
同时,本文还为解决其他编程语言或操作系统中出现的中文乱码问题提供了一个思路和参考。
文章结构部分的内容:1.2 文章结构本文将分为三个主要部分:引言、正文和结论。
- 引言部分将概述整篇文章的主要内容和目的,以便读者能够了解文章的背景和意义。
Linux中unzip解压时中文乱码的解决办法

Linux中unzip解压时中⽂乱码的解决办法
Linux 中unzip解压时中⽂乱码的解决办法
当我们在linux中解压⼀个含有中⽂名字的压缩包如“资料.zip”时,如果直接使⽤如下的命令,将会出现中⽂乱码。
unzip 资料.zip
主要的原因是因为unzip在解压的时候会将编码转化为其内部默认的编码,⽽默认的编码根本不⽀持中⽂CP936编码。
因此我们需要在解压的时候明确的指定需要使⽤的编码。
⽬前可以采⽤如下两种⽅式解决
⽅法⼀在解压的时候直接指定编码格式
#指定GBK GB18030编码也是可以的
unzip -O CP936 资料.zip
⽅法⼆配置环境变量,指定unzip的参数
在环境变量中,指定unzip参数,总是以指定的字符集显⽰和解压⽂件
⽐如,需要在/etc/environment中加⼊2⾏:
UNZIP="-O CP936"
ZIPINFO="-O CP936"
如有疑问请留⾔或者到本站社区交流讨论,感谢阅读,希望能帮助到⼤家,谢谢⼤家对本站的⽀持!。
linux中ssh客户端显示中文乱码修改解决办法

linux中ssh客户端显示中文乱码修改解决办法linux中ssh客户端显示中文乱码修改解决办法切换root用户Su root方法一:修改配置文件原因在于文件/etc/sysconfig/i18n这个文件是系统的区域语言设置,i18n是国际化internationalization的缩写i和n之间正好18个字母解释:LANG=”zh_CN.gb2312″//表明你当前系统的语言环境变量设置SUPPORTED=”zh_CN.gb2312:zh_CN:zh:en_US.UTF-8:en_US:en”//表明系统预置了那些语言支持,不在项目中的语言不能正常显示SYSFONT=”latarcyrheb-sun16″//定义控制台终端字体,你文本登录的时候显示的字体就是这个latarcyrheb-sun16 如果你看到你的i18n文件里面与上面的文件里的gb2312不同,比如是UTF-8,那么你的ssh 客户端就会显示乱码.要么你修改你的ssh客户端中文使用UTF-8,或者修改成和我上面的一样,乱码就可以解决.(1)修改配置文件如下:#vi /etc/sysconfig/i18nLANG="zh_CN.GB18030"LANGUAGE="zh_CN.GB18030:zh_CN.GB2312:zh_CN"SUPPORTED="zh_CN.GB18030:zh_CN:zh:en_US.UTF-8:en_US:en"SYSFONT="lat0-sun16"这样中文在SSH,telnet终端就可以正常显示了。
方法二:安装LINUX的时候选择的是中文字,但是使用的时候出现了乱码解决方法是在命令提示下输入# export LANG=C# export LC_ALL=zh_CN.GBK# export LANG=zh_CN.GBK方法三:在客户端设置字符编码模式(1)解决securecrt连接linux,出现的中文乱码问题在使用SecureCRT软件用SSH连接LINUX时,经常会出现乱码的情况,有的时候是汉字无法显示,也有时是英文无法显示。
Linux系统修改默认语言环境为zh_CN.UTF-8字符集,解决中文乱码问题

Linux系统修改默认语⾔环境为zh_CN.UTF-8字符集,解决中⽂乱码问题原因:简单的说是因为服务器没有安装zh_CN.UTF-8 字符集,导致不⽀持中⽂!解决办法环境:CentOS7. ⽆GUI安装。
默认安装英⽂。
⾸先查询语⾔环境:# locale# locale -a 可以查看⽀持的字符集。
# locale -a |grep -i cn1.临时修改:# export LANG=zh_CN.UTF-82.永久修改:# vim /etc/locale.confor# localectl set-locale LANG=zh_CN.UTF8更改为zh_CN.UTF-8,重启。
# reboot---------------------下⾯可忽略:3.发现重启之后 .locale 和 locale.conf 都是 en_US.UTF-8.4.centos7 在开机初始化时,locale.conf 来⾃ /etc/profile.d/lang.sh 的加载。
5.打开 lang.sh脚本。
即使修改成zh_CN.UTF-8之后,加载脚本时仍然会初始化为en_US.UTF-8.6.修改之后,重启。
更改时区:ln -sf localtime /usr/share/zoneinfo/Asia/Shanghai参考:环境:Ubuntu 141.安装基本的软件包(第2步安装 zh_CN 中⽂字符集时要⽤到)sudo apt-get update //系统更新软件包列表sudo apt-get install -y language-pack-zh-hanssudo apt-get install -y language-pack-zh-hant (安装zh_HK和zh_TW)2. 在/etc/profile或/etc/bash.bashrc⽂件添加如下内容# cat /etc/profile |grep -i cnexport LANG="zh_CN.UTF-8"export LANGUAGE="zh_CN.UTF-8"export LC_ALL="zh_CN.UTF-8"3.source /etc/profile 查看是否⽣效# localeLANG=zh_CN.UTF-8LANGUAGE=zh_CN.UTF-8LC_CTYPE="zh_CN.UTF-8"LC_NUMERIC="zh_CN.UTF-8"LC_TIME="zh_CN.UTF-8"LC_COLLATE="zh_CN.UTF-8"LC_MONETARY="zh_CN.UTF-8"LC_MESSAGES="zh_CN.UTF-8"LC_PAPER="zh_CN.UTF-8"LC_NAME="zh_CN.UTF-8"LC_ADDRESS="zh_CN.UTF-8"LC_TELEPHONE="zh_CN.UTF-8"LC_MEASUREMENT="zh_CN.UTF-8"LC_IDENTIFICATION="zh_CN.UTF-8"LC_ALL=zh_CN.UTF-8。
debiangunlinux中文乱码解决办法securecrt中文乱码

debian GUNlinux 中文乱码解决办法,secureCRT中文乱码问题描述:通过secureCRT通过ls命令查看目录下中文文件命及中文内容时乱码系统:通过# cat /etc/issue查看版本Debian GNU/Linux 6.0 \n \l说明:我的所有操作均在终端下操作#su root首先安装locales#apt-get install locales然后重新选择字符编码#dpkg-reconfigure locales把所有zh开头的用空格选择,用tab键切换到OK。
debian里没有~/.bash_profile 所以需要在~/.bashrc里面最下面加入exportLC_ALL=zh_CN.UTF-8#reboot重启后通过#locale 就可以查看到所有的LC*都是中文编码了。
如果在secureCRT依然是乱码那么就在菜单上选择选项---会话选项--外观--字符编码选择(UTF-8)选项---会话选项--外观--字体(新宋体)通过以上对linux及secureCRT 的设置,就可以解决中文乱码问题,至少我是这么解决的。
最后放入我所查阅过的资料备份,如果上面已解决可以无视。
下载安装字符apt-get install xfonts-wqy ttf-wqy-zenhei ttf-wqy-microheilocale的设定及其LANG、LC_ALL、LANGUAGE环境变量的区别(很有用)例如zh_CN.GB2312、zh_CN.GB18030或者zh_CN.UTF-8。
很多人都不明白这些古里古怪的表达方式。
这个外星表达式规定了什么东西呢?这个问题稍后详述,现在只需要知道,这是locale的表达方式就可以了。
locale这个单词中文翻译成地区或者地域,其实这个单词包含的意义要宽泛很多。
Locale是根据计算机用户所使用的语言,所在国家或者地区,以及当地的文化传统所定义的一个软件运行时的语言环境。
关于Linux连接工具mobaxterm显示中文乱码问题
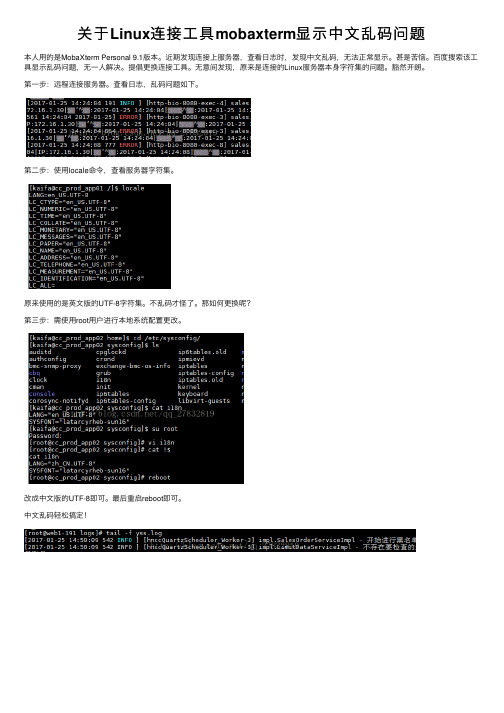
关于 Linux连接工具 mobaxterm显示中文乱码问题
本人用的是MobaXterm Personal 9.1版本。近期发现连接上服务器,查看日志时倡更换连接工具。无意间发现,原来是连接的Linux服务器本身字符集的问题。豁然开朗。 第一步:远程连接服务器。查看日志,乱码问题如下。
第二步:使用locale命令,查看服务器字符集。
原来使用的是英文版的UTF-8字符集。不Байду номын сангаас码才怪了。那如何更换呢? 第三步:需使用root用户进行本地系统配置更改。
改成中文版的UTF-8即可。最后重启reboot即可。 中文乱码轻松搞定!
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
这些变量中LANG变量是在字符模式和图形界面下都用到的,在你登录系统后就被读取并生效,相信很多人在字符界面下输入Linux命令的时候经常会遇到显示出来的出错信息是乱码的情况,必需安装zhcon或者cce等字符模式下的中文软件才能正常显示中文的出错信息。如果我不要他显示中文乱码,我也不要为了看个很简单的出错信息而特意起用zhcon那我该怎么办呢?一个简单的零时解决的办法就是设置一下LANG变量:
/etc/X11/xinit/xinput.d/${lang_region} \
/etc/X11/xinit/xinput.d/default ; do
[ -r $f ] && source $f && break
done
代码:
4;en_US.UTF-8"
即把系统的语言临时设置成英文,或者更简单一点,可以直接这样:
代码:
[root@gucuiwen ~]# LANG=""
即把LANG变量清空,由于英语是无论什么情况都支持的,LANG变量被清空后,系统就默认用英语。这样设置后,在字符模式下输出的出错信息等就是全英文的了。但这种设置是临时的,只是临时改变了LANG这个bash变量而已。当退出重新登录或者切换到其他字符终端后就无效了。到现在,读者应该想到了,只要把i18n文件中的LANG变量设置成英文的”en_US.UTF-8”,就可以永久解决这个问题了。修改后的文件如下:
代码:
LANG="zh_CN.UTF-8"
SYSFONT="latarcyrheb-sun16"
SUPPORTED="zh_CN.UTF-8:zh_CN:zh"
其中LANG变量是language的简称,稍微有英语基础的用户一看就看出来这个变量是决定系统的默认语言的,即系统的菜单、程序的工具栏语言、输入法默认语言等。SYSFONT是system font的简称,决定系统默认用哪一种字体。SUPPORTED变量决定系统支持的语言,即系统能够显示的语言。需要说明的是,由于计算机起源于英语国家,因此,不管你把这些变量设置成什么,英语总是默认支持的,而且不管用什么字体,英文字体总包含在其中。
发现startx是一个shell 脚本,于是我打开它分析并阅读,看看能不能找到一些关于输入法起动过程和相关变量的线索:
代码:
[root@gucuiwen ~]# vi /usr/X11R6/bin/startx
我找到了该脚本在运行过程中调用的其他脚本和配置文件的信息:
代码:
那么,如果我在系统中安装了不同的语言包和不同的字体,系统是如何判断我所要的语言界面并调用相关的字体的呢?系统中那些文件和变量在控制这些呢?
在redHat和FC系列Linux系统下,记录系统默认使用语言的文件是/etc/sysconfig/i18n,如果默认安装的是中文的系统,i18n的内容如下:
/etc/X11/xinit/目录下,阅读并分析该目录下的脚本,这些脚本有些是startx直接调用的,有些是被startx调用的脚本再调用的,存在着多级嵌套的关系,没有一点耐心还真是搞不清楚。最终我在/etc/X11/xinit/xinitrc.d目录中的xinput.sh脚本中找到了和输入法相关的代码:
通过分析脚本,我知道,图形界面启动的时候脚本是根据LANG变量来决定是否启用输入法,以及启用哪种语言的输入法等。问题在于:我们还没有把LANG变量改成英语之前,系统得到的LANG变量是中文的,因此,它知道需要在图形界面启动过程中启用中文输入法,但把LANG变量改成英文后,系统根据LANG变量知道系统是英文的,它便不再启动中文输入法,也不再设置和导出相关的变量,导致中文输入法不可用。因此,只要在这个脚本中,“骗”过系统,让输入法脚本“以为”系统是中文的,它不就运行中文输入法,并导出相关变量了吗? 于是,通过分析脚本,我在xinput.sh中的:
上面提了一下我解决问题的思路。我是顺着这个思路开始的:
中文输入法是在图形界面下使用的,是图形界面下运行的一个程序。而图形界面中的一切,都是由startx程序开启运行的。这就是问题的根源。
找出startx的位置:
代码:
[root@gucuiwen ~]# which startx
好了,一切由startx开始。当你需要在Linux系统中设置某个东西,或者配置某个服务的时候,最关键的是要知道,这一切是怎么开始的。知其然必需知其所以然。如果你有空把/etc/rc.d目录下的系统起动时运行的脚本通读一遍,就完全知道了/etc下的各种配置文件是用来干什么的、如何修改、修改后有什么效果等等。玩起系统来也能随心所欲想怎么改就怎么改。这就是我一直强调的,知其然一定要知其所以然。一定要深入系统,读脚本,学会用命令和手工修改系统配置文件。这样对系统才会有透彻的了解,整天用图形界面的工具是不能帮助你对系统有教为透彻深入的了解的,不同的linux系统提供的图形界面配置程序会不同,但命令和配置文件都是相同的,越是底层的东西越具有通用性。所以,应当先学会手动配置和修改系统配置文件,等熟悉了以后,再用图形界面的工具修改,以便减少工作量。
现在的linux安装完成后,默认就运行在第5个系统运行级别。在SYSTEM V 风格的UNIX系统中,系统被分为不同的运行级别,这和BSD分支的UNIX有所不同,常用的为0~6七个级别:
0 关机
1 单用户
2 不带网络的多用户
3 带网络的多用户
4 保留,用户可以自给定义
5 图形界面的多用户
userclientrc=$HOME/.xinitrc
userserverrc=$HOME/.xserverrc
sysclientrc=/etc/X11/xinit/xinitrc
sysserverrc=/etc/X11/xinit/xserverrc
并且知道,startx的目的是寻找系统中可用的桌面系统X服务器系统、以及用户自定义的参数,最终调用xinit来初始化X图形界面。我没有在startx脚本中找到直接和起动输入法相关的代码,于是就可以肯定,输入法相关的代码在startx调用的脚本中。于是我来到
本文主要通过修改系统配置的过程来展现修改linux系统配置的一般思路和过程,如果你不太有耐心看完,请跳过文章的1—4节,直接看第五节快速设置部分。
一,相关变量介绍
我们知道大部分Linux系统是无所谓中文版和英文版的,以FC4 Linux为例,系统发行的时候全世界都一样,系统是中文的还是英文的完全取决于你选择的语言包。不同国家的人在安装使用的时候选择属于自己国家的语言包,应用程序中的语言也不是写死的,它根据系统的设置来调用相关的语言,所以,一个应用程序写出来不经过修改,全世界不同国家的用户都可以以母语界面使用它,这就事所谓的internationalization(国际化),简称i18n。这也是未来软件的发展趋势。
代码:
id:5:initdefault:
这一行,修改成
代码:
id:3:initdefault:
保存后就重起,系统就默认起动到字符界面。不同运行级别之间的差别的在于系统默认起动的服务的不同,如运行级别3默认不启动X图形界面服务,而运行级别5却默认起动。本质上是没有区别的,更无所谓不同级别间功能强弱的问题。用户完全可自给定义不同级别的默认服务。在任何运行级别,用户都可用init 命令来切换到其他运行级别。
/usr/X11R6/bin/startx
看startx是一个脚本还是二进制文件:
代码:
[root@gucuiwen ~]# file /usr/X11R6/bin/startx
/usr/X11R6/bin/startx: Bourne shell script text executable
也许你不相信,直接图形登录到系统确实会有很多问题,因此,作为一个有6年Linux使用经验的Linux和Solaris 系统管理员,我强烈建议在系统安装完成后把系统的默认运行等级设置在第3级,在字符终端登录后,再手工输入startx 命令起动图形界面。可以用如下的方法修改:
用文本编辑器修改 /etc/inittab文件 ,把
三,调出中文输入法:
我之所以要在上面费那么多笔墨来讲系统运行级别,是因为对系统的认识是从底部向上开始的。
先把默认运行级别修改成3级别,当然,如果你实在不想修改,就临时用init 3命令切换到第3级。
这样你就可以用startx起动图形界面,然后用ctrl+alt+backspace退出图形界面。请注意我说的是“退出”图形界面,而不是按ctrl+alt+F2切到一个字符终端。
代码:
#LANG="zh_CN.UTF-8"
LANG="en_US.UTF-8"
SYSFONT="latarcyrheb-sun16"
SUPPORTED="zh_CN.UTF-8:zh_CN:zh"
请不要把LANG变量简单的清空,因为这个变量不仅在字符模式下用到,在图形界面下也用到,简单清空在字符模式下确实不会有问题,但在图形界面下,却会造成中文无法正常显示的情况,在过去Re d ha t 系列的版本中i18n文件中还有一个叫LANGUAGE的变量,专门控制图形界面下的语言设置,现在的FC系列中已经把这两个变量整合成一个变量了。
代码:
lang_region=$(echo $tmplang | sed -e 's/\..*//')
lang_region="zh_CN" #这一行是修改后加上去的
for f in $HOME/.xinput.d/${lang_region} \