ggplot例子整理
R语言ggplot初级入门教程

library(maps)library(maptools)library(rgdal)library(plyr)library(MASS)library(dplyr)library(ggplot2)set.seed(123)# 从整个数据集取出100行进行分析dsmall <- diamonds[sample(nrow(diamonds), 100), ]dim(dsmall)# 1.1.1根据x和y和数据集自动作图qplot(carat, price, data = diamonds)# 1.1.2根据log x和log y和数据集,自动作图qplot(log(carat), log(price), data = diamonds)# 1.1.3根据x和y和数据集按照color进行分类,自动作图qplot(carat, price, data = dsmall, colour = color)# 1.1.4根据x和y和数据集按照shape进行分类,自动作图qplot(carat, price, data = dsmall, shape = cut)# 1.1.5根据x和y和数据集,指定作图的类型,自动作图qplot(carat, price, data = dsmall, geom = c("point", "smooth"))# 1.1.6根据x和y和数据集,做箱线图qplot(cut, price / carat, data = diamonds, geom = "boxplot")# 1.1.7根据x和y和数据集,做条形图qplot(color, data = diamonds, geom = "bar")# 1.1.8根据x和y和数据集,做直方图qplot(carat, data = diamonds, geom = "histogram")# 1.1.9根据x和y和数据集,做核密度图qplot(carat, data = diamonds, geom = "density") 图 1.1.1 图 1.1.2 图 1.1.3 图 1.1.4 图1.1.5 图 1.1.6# 1.1.10 使用facets对需要分组的字段进行分组qplot(carat, data = diamonds, facets = color ~ .,geom = "histogram", binwidth = 0.1, xlim = c(0, 3))# 1.1.11 给图形添加信息qplot(carat, price, data = dsmall,xlab = "Price ($)", ylab = "Weight (carats)",main = "Price-weight relationship") 图 1.1.10 按照不同的颜色对重量进行统计 图1.1.11 添加和标题,X轴,Y轴解释案例2:地图(不包含中国) ggplot是基于图层进行作图的df <- data.frame(x = rnorm(2000), y = rnorm(2000))norm <- ggplot(df, aes(x, y))norm # 图层1norm + geom_point() # 图层2# 改变点的大小和形状norm + geom_point(shape = 1)norm + geom_point(shape = ".") 图层 1 图层2 图层3 采用ggplot2自带的美国城市数据集us.city 数据集变量简介## name 城市名称## country.etc 简称## pop 人口数量## lat 纬度## lon 经度## capital 是否是首府 2.1找出美国人口大于500000的城市big_cities <- subset(us.cities, pop > 500000)qplot(long, lat, data = big_cities) + borders("state", size = 0.5) 图 2.1 2.2 做出德州地图tx_cities <- subset(us.cities, country.etc == "TX")# 在使用map做地图的时候,记住x和y一定指的是经纬度ggplot(tx_cities, aes(long, lat)) +borders("county", "texas", colour = "grey70") +geom_point(colour = alpha("black", 0.5)) 图 2.2 德州地图 2.3结合USAssert来做出美国各个州的犯罪率# 从map中获取洲数据states <- map_data("state")# 获取犯罪数据arrests <- USArrests# 将犯罪的数据列名转换为小写names(arrests) <- tolower(names(arrests))# 获取根据行名获取区域数据arrests$region <- tolower(rownames(USArrests))# 将两个数据集进行合并choro <- merge(states, arrests, by = "region")# 按犯罪率升序排列choro <- choro[order(choro$order), ]# 2.3.1 犯罪率的分布qplot(long, lat, data = choro, group = group,fill = assault, geom = "polygon") # 2.3.2 谋杀率的分布qplot(long, lat, data = choro, group = group,fill = assault / murder, geom = "polygon") 图 2.3.1 结论:越往东北犯罪率越低 图 2.3.2 结论:越往西北谋杀率越低案例3:中国地图 3.1 做出各个省份人口的数量# 载入中国地图数据集china=readShapePoly('E:\\Udacity\\Data Analysis High\\R\\R_Study\\第一天数据\\bou2_4p.shp')# 获取数据x<-china@data# 转换为datafarmexs<-data.frame(x,id=seq(0:924)-1)# 将china转换为datafarmeshapefile_df <- fortify(china)# 组合成完整的dataframechina_mapdata<-join(shapefile_df, xs, type = "full")# 省份名称NAME<-c("北京市","天津市","河北省","山西省","内蒙古自治区","辽宁省","吉林省","黑龙江省","上海市","江苏省","浙江省","安徽省","福建省", "江西省","山东省","河南省","湖北省", "湖南省","广东省", "广西壮族自治区","海南省", "重庆市","四川省", "贵州省","云南省","西藏自治区","陕西省","甘肃省","青海省","宁夏回族自治区","新疆维吾尔自治区","台湾省","香港特别行政区")# 各个省份的人口pop<-c(7355291,3963604,20813492,10654162,8470472,15334912,9162183,13192935,8893483,25635291,2006 17253385,19029894,32222752,13467663,2451819,10272559,26383458,10745630,12695396,689521,11084516,7113833,1586635,1945064,6902850,23193638,7026400)# 组合成完整的d人口-省份的dataframepop<-data.frame(NAME,pop)# 和中国的地图信息相结合,组合成datdaframechina_pop<-join(china_mapdata, pop, type = "full")ggplot(china_pop, aes(x = long, y = lat, group = group,fill=pop))+geom_polygon( )+geom_path(colour = "grey40")# 使用subset来取出上海市的信息SH<-subset(china_mapdata,NAME=="上海市")ggplot(SH, aes(x = long, y = lat, group = group,fill=NAME))+ geom_polygon(fill="lightblue" )+geom_path(colour = "grey40")+ggtitle("中华人民共和国上海市")+annotate("text",x=121.4,y=31.15,label="上海市") 图 3.2案例4:时间数据 采用ggplot2自带的economics数据集 数据集变量简介## date 时间## pop 人口## uempmed 失业率## unemploy 失业人数 4.1 通过时间查看失业率ggplot(aes(x=date,y=uempmed),data=economics)+geom_line() 图4.1 图层1 4.2查看不同政党执政时期的失业率# 获取失业率的折线图图层1(unemp <- qplot(date, unemploy, data=economics, geom="line",xlab = "", ylab = "No. unemployed (1# 由于是1970年开始,所以去掉前三行,从尼克松开始统计presidential1 <- presidential[-(1:3), ]#确定x和y的边界yrng <- range(economics$unemploy)xrng <- range(economics$date)# 图层2unemp + geom_vline(aes(xintercept = start), data = presidential)# 图层3unemp + geom_rect(aes(NULL, NULL, xmin = start, xmax = end,fill = party), ymin = yrng[1], ymax = yrng[2],data = presidential1) + scale_fill_manual(values =alpha(c("blue", "red"), 0.2)) 4.2 图层2 图层 3 5.作图其他设置 5.1 叠加多个图形# 美国5大湖之一的休伦湖数据集huron <- data.frame(year = 1875:1972, level = LakeHuron)ggplot(huron, aes(year)) +geom_line(aes(y = level - 5), colour = "blue") +geom_line(aes(y = level ), colour = "black") +geom_line(aes(y = level + 5), colour = "red") 图5.1 5.2 颜色设置# 使用mtcars数据集# 制定乐填充色red和边框色blackggplot(birthwt, aes(x=bwt)) + geom_histogram(fill="red", colour="black") # 将cyl转变为因子mtcars$cyl <- factor(mtcars$cyl)# 对不同的ctl进行绘图ggplot(mtcars, aes(x=wt, y=mpg, colour=cyl)) + geom_point() 图5.2.1 图 5.2.2 5.3 图例# 采用的是植物数据集p <- ggplot(PlantGrowth, aes(x=group, y=weight, fill=group)) + geom_boxplot()# 5.3.1 默认的图例放在右边p# 5.3.2 不使用图例p + guides(fill=FALSE)# 5.3.3 将图例放在顶部p + theme(legend.position="top")# 5.3.4 指定图例的位置p + theme(legend.position=c(1,0), legend.justification=c(1,0)) 图 5.3.1 图 5.3.2 图 5.3.3 图5.4.4。
ggplot 坐标轴 截断符号

ggplot 坐标轴截断符号ggplot是一种用于数据可视化的R语言包,它提供了强大而灵活的功能来绘制各种类型的图表。
在ggplot中,坐标轴是图表中一个非常重要的组成部分,它们可以通过截断符号来进行调整和定制。
在本文中,我们将详细介绍ggplot坐标轴截断符号的功能及其应用。
ggplot的坐标轴截断符号用于调整坐标轴上的刻度范围,以显示特定范围内的数据。
这在处理一些具有极端值或离群值的数据时非常有用,因为它可以避免这些离散数据对整体数据分布的影响,同时仍然能够准确显示其他数据点的变化。
在ggplot中,可以使用scale_x_continuous()和scale_y_continuous()函数来调整x和y轴的刻度范围。
这两个函数提供了一系列参数来控制坐标轴的截断符号。
下面是一些常用的参数:- limits:通过设置limits参数,可以指定坐标轴的上限和下限值。
所有超过这个范围的数据点都会被截断显示。
例如,limits=c(0, 100)将限制坐标轴的范围在0到100之间。
- expand:expand参数用于控制截断数据后坐标轴的扩展比例。
例如,expand=c(0, 0)表示不进行任何扩展,而expand=c(0.1, 0.1)表示在截断的范围上方和下方都增加10%的空间。
- oob:oob参数用于设置超出限制范围的数据点的显示方式。
默认值为"censor",表示将超过范围的数据点截断显示。
还可以使用"squish"将超过范围的数据点拉伸到限制范围的边界上,或者使用"warning"在超出范围时显示警告信息。
- breaks:使用breaks参数可以指定坐标轴上的刻度值。
当截断数据时,ggplot会自动计算刻度值,并保证刻度范围内有合适的刻度点。
但是,设置breaks参数可以手动指定刻度点的位置,以更好地展示数据。
下面我们将通过一个示例来说明如何使用ggplot中的坐标轴截断符号。
ggplot2用法

ggplot2是R语言中一个非常强大的可视化包,可以创建各种精美的统计图形。
它的基本使用方法如下:
首先,确保已经安装了ggplot2包。
如果没有安装,可以使用以下命令进行安装:
```r
install.packages("ggplot2")
```
然后,你可以通过以下命令导入ggplot2包:
```r
library(ggplot2)
```
下面是一个简单的例子,说明如何使用ggplot2创建一个散点图。
在这个例子中,我们将使用ggplot2包中的mpg数据框(这个数据框包含了美国环保协会收集的38种车型的观测数据),并绘制一个散点图,以展示每辆车的马力与重量之间的关系:
```r
#导入数据
data(mpg)
#绘制散点图
ggplot(mpg, aes(x=hp, y=wt)) +
geom_point() +
labs(title="Scatter plot of mpg data", x="Horsepower", y="Weight")
```
在这个例子中,`ggplot()`函数用于创建一个绘图对象,`aes()`函数用于映射数据到视觉属性,`geom_point()`函数用于指定要绘制的图形类型(这里是散点图),`labs()`函数用于设置图形的标题和坐标轴标签。
这只是ggplot2的一小部分功能,它还可以创建各种其他类型的图形,如线图、条形图、饼图等等。
你可以查看ggplot2的官方文档,了解更多关于它的使用方法和示例。
r语言ggplot函数

R语言ggplot函数引言R语言是一种用于数据分析和绘图的编程语言,广泛应用于统计学、数据科学和机器学习等领域。
ggplot函数是R语言中一款强大的绘图工具,通过使用ggplot函数,我们可以简单而灵活地创建各种复杂的统计图形。
ggplot函数的基本用法使用ggplot函数进行绘图的基本步骤如下:1.安装和加载ggplot包install.packages("ggplot2") # 安装ggplot2包library(ggplot2) # 加载ggplot2包2.创建一个绘图对象p <- ggplot(data = dataset, aes(x = x_variable, y = y_variable))在上述代码中,dataset是一个包含待绘制数据的数据框,x_variable和y_variable分别是数据框中指定的自变量和因变量。
通过这些参数,我们可以定义出一幅空的图形。
3.添加图层和美化图形p + geom_point() # 添加散点图层p + geom_line() # 添加折线图层p + geom_bar() # 添加条形图层我们可以根据需求选择不同的图层来完成绘图任务。
此外,我们还可以通过添加标签、调整颜色、设置标题等方式对图形进行美化。
4.输出图形print(p) # 在R控制台中输出图形ggsave(file = "output.png", plot = p) # 保存图形为png格式可以通过print(p)函数在R控制台中输出图形,也可以使用ggsave函数将图形保存为png/jpeg/pdf等格式。
ggplot函数的进阶用法设置坐标轴和刻度通过使用scale_x_continuous和scale_y_continuous函数,我们可以设置x和y轴的刻度范围、名称、刻度标签等。
例如:p + scale_x_continuous(name = "x轴名称", limits = c(0, 10), breaks = seq(0, 10, 2))上述代码中,name参数用于设置x轴的名称,limits参数用于设置x轴的刻度范围,breaks参数用于设置x轴的刻度标签。
菜鸟学绘图——手把手教你学ggplot2(含代码和案例)
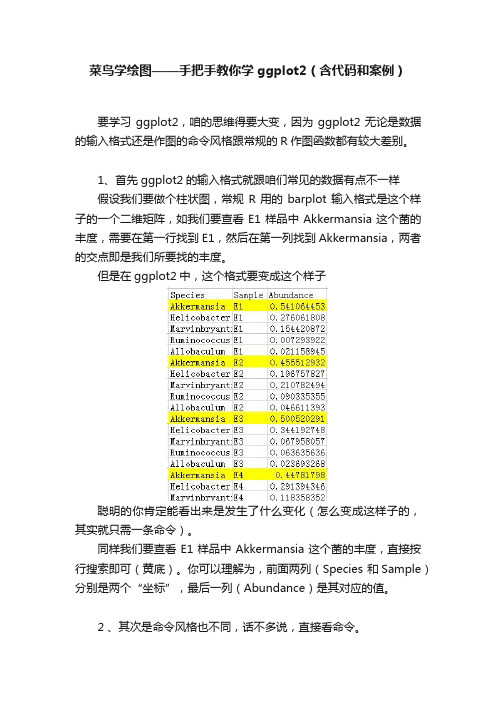
菜鸟学绘图——手把手教你学ggplot2(含代码和案例)要学习ggplot2,咱的思维得要大变,因为ggplot2无论是数据的输入格式还是作图的命令风格跟常规的R作图函数都有较大差别。
1、首先ggplot2的输入格式就跟咱们常见的数据有点不一样假设我们要做个柱状图,常规R用的barplot输入格式是这个样子的一个二维矩阵,如我们要查看E1样品中Akkermansia这个菌的丰度,需要在第一行找到E1,然后在第一列找到Akkermansia,两者的交点即是我们所要找的丰度。
但是在ggplot2中,这个格式要变成这个样子聪明的你肯定能看出来是发生了什么变化(怎么变成这样子的,其实就只需一条命令)。
同样我们要查看E1样品中Akkermansia这个菌的丰度,直接按行搜索即可(黄底)。
你可以理解为,前面两列(Species 和Sample)分别是两个“坐标”,最后一列(Abundance)是其对应的值。
2 、其次是命令风格也不同,话不多说,直接看命令。
首先从百度云盘下载我们提供的示例数据(链接: https:///s/1c2WbLRU 密码: w3gt),将它放到你的R的当前工作目录,可通过在命令行输入getwd()查看你的工作目录,也可以通过下面的命令修改工作目录。
setwd('E:/R-work/ggplot2') ###修改R的工作目录,因为Spe_matrix.txt文件在此目录下spe<>spe<>spe ###查看spe###常规的barplot作图命令par(mar=c(5,4,4,10))barplot(spe,width=0.7,beside = TRUE,col=c('#0000ee','#9933cc','#009999','#ff0000','#ff9933'),le gend=rownames(spe),args.legend = list(x='right',bty='n',inset=-0.4,cex=1))####ggplot2作图命令library(ggplot2)library(reshape2)data-melt(spe)>colnames(data)-c('species','sample','abundance')>data ####查看转化后的数据ggplot(data,aes(x=Sample,y=Abundance,fill=Species))+geo m_bar(stat='identity',position='dodge')+ggtitle('Example')+the me() # ####ggplot()中包含的是作图的数据以及数据的映射,所谓映射简单理解就是,x、y轴分别对应哪一列数据,哪一列用来区分填充的颜色等;geom_bar()则指明作图形式,你是作要柱图还是点图;通过theme()可修改图中字体、坐标轴等元素的显示形式,此处采用默认形式。
使用ggplot2进行高级绘图--介绍(小案例)
使⽤ggplot2进⾏⾼级绘图--介绍(⼩案例)使⽤ggplot2进⾏⾼级绘图除了基础图形,grid、lattice和ggplot2软件包也提供了图形系统,它们克服了R基础图形系统的低效性,⼤⼤扩展了R的绘图能⼒。
grid图形系统可以很容易地控制图形基础单元,给予编程者创作图形的极⼤灵活性。
lattice包通过⼀维、⼆维或三维条件绘图,即所谓的⽹格图形(trellis graph)来对多元变量关系进⾏直观展⽰。
ggplot2包则基于⼀种全⾯的图形“语法”,提供了⼀种全新的图形创建⽅法。
1 R 中的四种图形系统R中有四种主要的图形系统。
基础图形系统由Ross Ihaka编写,每个R都默认安装,之前的⼤部分图形都是依赖于基础图形函数创建的。
grid图形提供了⼀种⽐标准图形系统更低⽔平的⽅法。
⽤户可以在图形设备上随意创建矩形区域,在该区域定义坐标系统,然后使⽤⼀系列丰富的绘图基础单元来控制图形元素的摆放和外观。
grid图形的灵活性对于软件开发者是⾮常有价值的,但是grid包没有提供⽣成统计图形以及完整绘图的函数。
因此,数据分析师很少直接采⽤grid包来分析数据。
lattice包由Deepayan Sarkar(2008)编写,可绘制Cleveland(1985,1993)所描述的⽹格图形。
总的来说,⽹格图形显⽰⼀个变量的分布或是变量之间的关系,分别显⽰⼀个或多个变量的各个⽔平。
lattice包基于grid包创建,在多元数据的可视化功能⽅⾯已经远超Cleveland的原始⽅法。
它为R提供了⼀种全⾯的、创建统计图形的备选系统。
ggplot2包的⽬标是提供⼀个全⾯的、基于语法的、连贯⼀致的图形⽣成系统,允许⽤户创建新颖的、有创新性的数据可视化图形。
该⽅法的⼒量已经使得ggplot2成为使⽤R进⾏数据可视化的重要⼯具。
2 ggplot2 包介绍ggplot2包实现了⼀个在R中基于全⾯⼀致的语法创建图形时的系统。
使用ggplot2绘制分面图形

使⽤ggplot2绘制分⾯图形在之前的⼀系列ggplot2绘图中都没有涉及到关于分⾯的操作,分⾯是数据可视化最实⽤的技术之⼀,通过facet_grid()和facet_wrap()函数将分组数据横向或纵向或横纵向排列,这样更有助于图形之间的⽐较。
上⾯提到facet_grid()和facet_wrap()函数可以实现可视化的分⾯,具体两种之间有什么区别呢?先上⼏幅图,通过形象的对⽐,就能记住两者之间的差异和⽤法。
⼀、绘制分⾯图```{r}library(ggplot2)#创建模拟数据集set.seed(1234)M <- c('⼀⽉','⼆⽉','三⽉','四⽉','五⽉','六⽉','七⽉','⼋⽉','九⽉','⼗⽉','⼗⼀⽉','⼗⼆⽉')Month <- rep(M, each = 5)Region <- rep(c('East','South','West','North','Center'), times = 12)Amount <- round(runif(n = 60, min = 500, max = 5000))df <- data.frame(Month = Month, Region = Region, Amount = Amount)```⾸先⽤facet_grid()函数绘制横向或纵向分⾯图:```{r}#绘制横向的分⾯图ggplot(data = df, mapping = aes(x = Region, y = Amount, fill = Region)) + geom_bar(stat ='identity') + facet_grid(. ~ Month) + theme(axis.text.x = element_blank(), axis.ticks.x = element_blank())```这样⼀幅横向分⾯的条形图就绘制成功了,下⾯在看看纵向分⾯图该如何绘制?```{r}#绘制纵向的分⾯图ggplot(data = df, mapping = aes(x = Region, y = Amount, fill = Region)) + geom_bar(stat ='identity') + facet_grid(Month ~ .) + theme(axis.text.x = element_blank(), axis.ticks.x = element_blank())```图形很难看,我们从新构建⼀组数据以绘制纵向的分⾯图:```{r}set.seed(1234)Year <- rep(seq(from = 2001, to = 2015),times = 4)Type <- rep(c('A','B','C','D'), each = 15)Value <- round(runif(60, min = 10, max = 100))df2 <- data.frame(Year = Year, Type = Type, Value = Value)#绘制纵向的分⾯图ggplot(data = df2, mapping = aes(x = factor(Year), y = Value, group = 1)) + geom_line(colour = 'blue') + xlab('Year') + facet_grid(Type ~ .)我们按照facet_grid()函数的语法,使⽤facet_wrap()函数绘制分⾯图:```{r}#绘制横向的分⾯图ggplot(data = df, mapping = aes(x = Region, y = Amount, fill = Region)) + geom_bar(stat ='identity') + facet_wrap(.~ Month) + theme(axis.text.x = element_blank(), axis.ticks.x = element_blank())```报错了!显⽰错误内容为:分⾯中⾄少包含⼀个分层变量。
ggplot 数据平滑函数

在ggplot中,可以使用geom_smooth()函数来对数据进行平滑处理。
geom_smooth()函数可以使用不同的平滑方法,如loess(局部加权回归)、gam(广义可加模型)等。
下面是一个简单的示例,使用geom_smooth()函数对数据进行平滑处理:
r
# 示例数据
<-(
=1:10,
=1:10+(10,0,1))
# 创建 ggplot 对象
(,(,))+
# 添加数据点
()+
# 添加平滑曲线
(="loess")
在上述示例中,首先创建了一个包含x 和y 列的数据框。
然后,使
用ggplot()函数创建一个ggplot对象,并使用aes()函数指定x 和y 列作为坐标轴。
接下来,使用geom_point()函数添加数据点。
最后,使用geom_smooth()函数对数据进行平滑处理,其中method = "loess"表示使用局部加权回归进行平滑。
你可以根据实际需要调整平滑方法和其他参数,以得到最合适的平滑效果。
ggtitle用法

ggtitle用法ggtitle是一个R语言中的函数,主要用于设置ggplot2绘图包创建的图形对象的标题。
ggplot2是一个广泛使用的数据可视化包,提供了一种简洁而强大的绘图语法。
通过ggtitle函数,我们可以自定义图形的标题,以便更好地传达图形的主题或信息。
使用ggtitle函数,可以将任何字符串作为标题添加到ggplot2绘图对象中。
以下是一个示例代码,展示了如何使用ggtitle函数:```Rlibrary(ggplot2)# 创建一个简单的散点图plot <- ggplot(mtcars, aes(x = mpg, y = disp)) +geom_point()# 设置标题plot <- plot + ggtitle("Miles per Gallon vs. Displacement")# 打印图形对象print(plot)```在上述示例中,我们首先加载了ggplot2包,并使用`ggplot`函数创建了一个简单的散点图,其中x轴表示每加仑汽油行驶的英里数,y轴表示汽车发动机的排量。
然后,我们使用`ggtitle`函数将标题设置为"Miles per Gallon vs. Displacement"。
最后,我们通过`print`函数打印了图形对象。
使用`ggtitle`函数还可以在标题中包含变量值。
例如,假设我们想要在标题中显示散点图中的最大汽车排量。
我们可以使用R语言的字符串插值功能,如下所示:```Rlibrary(ggplot2)# 创建一个简单的散点图plot <- ggplot(mtcars, aes(x = mpg, y = disp)) +geom_point()# 计算最大排量值max_disp <- max(mtcars$disp)# 设置动态标题plot <- plot + ggtitle(sprintf("Miles per Gallon vs. Displacement (Max Disp = %.2f)", max_disp))# 打印图形对象print(plot)```在这个例子中,我们首先使用`max`函数计算出最大排量值,并将其存储在`max_disp`变量中。
ggplot shape 种类

今天我要和大家共享的主题是ggplot shape种类。
ggplot是一个用来可视化数据的R语言包,它提供了丰富的图形绘制功能,其中包括shape参数,可以用来对数据点的形状进行定制。
在本文中,我将从简单到复杂,由浅入深地探讨ggplot shape种类及其用法。
1. 基础概念在ggplot中,shape参数用来指定数据点的形状,可以用整数或字符来表示不同的形状。
ggplot中内置了一些常见的形状,如圆圈、三角形、正方形等。
通过指定shape参数,我们可以让数据点以不同的形状展现在图表中,从而增加数据的可读性和美感。
2. 常见形状ggplot中常见的形状包括圆圈(1)、三角形(2)、正方形(3)、菱形(4)、十字(5)等。
这些形状可以通过设置shape参数来实现,使得我们可以根据不同的数据特征来选择合适的形状进行展示。
3. 自定义形状除了内置的常见形状外,ggplot还支持自定义形状,我们可以通过提供自定义形状的坐标点,来实现更加个性化的数据点展示。
这种方式可以让我们根据具体的需求,选择更加符合数据特征的形状,从而提高图表的表现力和信息传递能力。
4. 应用场景在实际的数据可视化中,shape参数的应用非常广泛。
比如在分类数据的散点图中,通过设置不同的形状来表示不同的类别;在多分类数据的箱线图中,通过设置不同的形状来区分不同的分组;在时间序列数据的折线图中,通过设置不同形状来标识不同的时间节点等等。
通过灵活运用shape参数,我们可以在图表中更加清晰地展现数据的特征和规律。
总结回顾通过本文的介绍,我们了解了ggplot shape种类的基础概念、常见形状、自定义形状以及应用场景。
ggplot shape种类是一个非常实用的数据可视化工具,通过灵活运用shape参数,我们可以设计出更加美观、清晰和富有信息的图表。
在实际应用中,我们应该根据数据的特点和展现需求,合理选择合适的形状,并结合其他参数进行综合设计,从而达到最佳的可视化效果。
r语言数据处理实例 -回复

r语言数据处理实例-回复[R语言数据处理实例],以中括号内的内容为主题,写一篇1500-2000字文章,一步一步回答在数据科学和统计学领域中,R语言是一种广泛使用的编程语言。
它提供了丰富的数据处理和分析功能,方便数据科学家和统计学家进行数据挖掘、可视化和分析。
在本文中,我们将介绍一个实例,以帮助读者了解如何使用R语言进行数据处理。
假设我们有一个关于销售业绩的数据集。
数据集由三列组成,分别是销售员的姓名、销售额和销售时间。
我们想要对这个数据集进行一些处理,例如计算每个销售员的平均销售额和每个月的总销售额。
下面将按照以下步骤进行数据处理。
首先,我们需要导入所需的R包。
在R中,包是一组功能相关的函数的集合。
为了处理数据,我们将使用dplyr包和ggplot2包。
dplyr包提供了丰富的数据处理函数,而ggplot2包用于可视化数据。
Rlibrary(dplyr)library(ggplot2)接下来,我们需要读取我们的数据集。
假设我们的数据集保存在一个名为sales.csv的文件中。
我们可以使用read.csv函数将其读入到一个名为sales的数据框中。
Rsales <- read.csv("sales.csv")数据读取完成后,我们可以使用head函数来查看前几行数据,以确保数据已正确加载。
Rhead(sales)然后,我们可以开始进行数据处理。
首先,我们要计算每个销售员的平均销售额。
我们可以使用dplyr包提供的group_by和summarize函数来实现。
Rsales_summary <- sales >group_by(姓名) >summarize(平均销售额= mean(销售额))在上面的代码中,我们调用group_by函数将数据按照姓名分组,然后使用summarize函数计算每个组的销售额均值,并将结果保存到一个名为sales_summary的新数据框中。
使用ggplot2进行数据可视化--案例

使⽤ggplot2进⾏数据可视化--案例使⽤ggplot2进⾏数据可视化1 mpg数据框mpg 包含了由美国环境保护协会收集的 38 种车型的观测数据。
mpg 中包括如下变量。
• displ:引擎⼤⼩,单位为升。
• hwy:汽车在⾼速公路上⾏驶时的燃油效率,单位为英⾥ / 加仑(mpg)。
与燃油效率⾼的汽车相⽐,燃油效率低的汽车在⾏驶相同距离时要消耗更多燃油。
1.1 创建ggplot图形为了绘制 mpg 的图形,运⾏以下代码将 displ 放在 x 轴,hwy 放在 y 轴:ggplot(data = mpg) +geom_point(mapping = aes(x = displ, y = hwy))#函数 geom_point() 向图中添加⼀个点层,这样就可以创建⼀张散点图。
ggplot2 中的每个⼏何对象函数都有⼀个 mapping 参数。
这个参数定义了如何将数据集中的变量映射为图形属性。
mapping 参数总是与 aes() 函数成对出现,aes() 函数的 x 参数和 y参数分别指定了映射到 x 轴的变量与映射到 y 轴的变量。
结果分析:上图显⽰出引擎⼤⼩(displ)和燃油效率(hwy)之间是负相关关系。
换句话说,⼤引擎汽车更耗油。
1.2 图形属性映射可以向⼆维散点图中添加第三个变量,⽐如 class,⽅式是将它映射为图形属性。
图形属性是图中对象的可视化属性,其中包括数据点的⼤⼩、形状和颜⾊。
通过改变图形属性的值,可以⽤不同的⽅式来显⽰数据点。
ggplot(data = mpg) +geom_point(mapping = aes(x = displ, y = hwy, color = class))#mpg 数据集中的 class 变量对汽车进⾏了分类,⽐如⼩型、中型和 SUV结果分析:右侧橙红⾊那些离群点多数是双座汽车,因为这些车不会是混合动⼒的,因为它们具有⼤引擎。
当然,class可以⽤同样的⽅式将其映射为点的⼤⼩size,也可以将 class 映射为控制数据点透明度的 alpha 图形属性,还可以将其映射为点的形状shape[ggplot2 只能同时使⽤ 6 种形状。
R_ggplot2基础(三)

R_ggplot2基础(三)7 scale_xxx()标度调整标度用于控制变量映射到视觉对象的具体细节,如坐标轴标签和图例视觉对象分为:坐标轴,alpha透明度,color/fill颜色,date/time时间轴, hue色相, grey灰度,shape点形, size尺寸, linetype线型, radius半径, area面积它们都有相应的标度函数分为简单函数和复合函数,复合函数内包含简单函数,简单函数如下:(点击放大)复合标度函数:除去默认的8个系统默认的标度scale_xxx_identity(),软件默认的一般用不上,用得上就不需要改了,这8个分别是:scale_color_identity(), scale_fill_identity(), scale_shape_identity(), scale_linetype_identity(),scale_alpha_identity(), scale_size_identity(), scale_discrete_identity(), scale_continuous_identity()还有一个手动处理任意离散变量的标度函数scale_discrete_manual(),其增加了1个映射参数,如aesthetics = c('color', 'fill')现在还剩下11组标度函数,分类如下:(点击放大)7.1 坐标轴标度与scales包(点击放大)参数解释:* name 表示指定坐标轴名称,也将作为对应的图例名称* breaks 表示指定坐标轴刻度位置,即粗网格线位置* labels 表示指定坐标轴刻度标签内容* limits 表示指定坐标轴显示范围,支持反区间* expand 表示扩展坐标轴显示范围,不能缩小* trans 表示指定坐标轴变换函数,自带有“asn”,“atanh”,“boxcox”,“exp”,“identity”,“log”,“log10”,“log1p”,“log2”,“logit”,“probability”,“probit”,“reciprocal”。
R语言与医学统计图形-【20】ggplot2图例

R语⾔与医学统计图形-【20】ggplot2图例ggplot2绘图系统——图例:guide函数、标度函数、overrides.aes参数图例调整函数guide_legend也属于标度函数,但不能单独作为对象使⽤,即不能如p+guide_legend()使⽤。
1. guides及guides_legend函数guide_legend函数参数:guide_legend(title = , #图例标题title.position = ,#top/bottom/right/lefttitle.theme = , #图例风格title.hjust = , #标题⽔平调整title.vjust = ,label = TRUE, #是否显⽰标签label.position = , #标签位置,同上titlelabel.theme = ,label.hjust = ,label.vjust = ,keywidth = , #图标宽度keyheight = ,direction = , #图标⽅向,horizontal/veticaldefault.unit = 'line',override.aes = list(), #忽略aes中设置nrow = , #⼏⾏ncol = , #⼏列byrow = FALSE, #是否按⾏reverse = FALSE, #图例是否翻转order = 0,...)guide_legend结合guides函数调整图例。
图例的四种形式:fill, color, shape, size,使⽤guides函数时,使⽤相应参数即可。
df <- data.frame(x=1:20,y=1:20,color=letters[1:20])p <- ggplot(df,aes(x,y))+geom_point(aes(color=color))p+guide_legend(title='legend',nrow = 4,ncol = 5) #errorp+guides(color=guide_legend('legend',nrow=4,ncol=5,label.position='left'))不同的图例可以同时调整。
R语言ggplot2简介

R语⾔ggplot2简介ggplot2是⼀个绘制可视化图形的R包,汲取了R语⾔基础绘图系统(graphics) 和l attice包的优点,摒弃了相关的缺点,创造出来的⼀套独⽴的绘图系统;ggplot2 有以下⼏个特点:1)图形映射,⾃动化的将数据映射到图形上;2)图层叠加,将不同形状的图表视为图层(layer), 可以⽅便的进⾏叠加3)提供了范围控制(scale),坐标系转换(coord), 分⾯(facet)等特性;先看⼀个最简单的例⼦,⽤ggplot2 绘制⼀副散点图:代码⽰例:library(ggplot2)data <- data.frame(x = 1:3, y = rep(3,3), group = c("A", "B", "C"))ggplot(data, aes(x = x , y = y)) + geom_point()效果图如下:⾸先,我们准备绘图使⽤的数据, data 是⼀个数据框对象,有三列,第⼀列为x , 对应散点图中的 x 轴;第⼆列为y, 对应散点图中的y轴,第三列为group, 代表每个点的分类信息在使⽤ggplot2 绘图时,⾸先调⽤ ggplot 这个函数,声明绘图使⽤的数据,aes 参数指定的是绘图使⽤的变量,x代表x轴的变量,y代表y轴的变量然后使⽤ ‘+’ 添加⼀个图层,⽤来展⽰数据,这⾥我们选择的图层是散点图 geom_point通过上⾯的例⼦我们可以看到,ggplot2 绘图时使⽤的是⼀个数据框对象,图中的属性对应数据框中的某⼀列下⾯看⼀个映射的例⼦,将group 分组信息映射到颜⾊上代码⽰例;ggplot(data, aes(x = x , y = y, color = group)) + geom_point()效果图如下:从图中可以看出,只需要在aes 参数中,添加⼀个color = group, 就可以将group 信息映射到颜⾊上,⽽且ggplot2会⾃动化的给出对应的图例2)接下来看⼀个图层叠加的例⼦代码⽰例:ggplot(data, aes(x = x , y = y)) + geom_point() + geom_line()效果图如下:从图中我们可以看到,只需要⽤ ‘+’ 在后⾯添加对应的图层,就可以⽅便的在⼀张图中展⽰多种类型的图表。
关于ggplot2的几个例子

关于ggplot2包的几个例子library(ggplot2)# ggplot2例子1:图层控制与直方图# 建立数据层p <- ggplot(mpg, aes(x = hwy))# 建立直方图图层p <- p + geom_histogram(position = 'identity', # 分布类型:单独的,非累积 alpha = 0.5, # 透明度# 按照年份填充颜色,density为使用密度函数aes(y = ..density..,fill = factor(year)))# 建立密度函数分布图层p <- p + stat_density(geom = 'line', # 曲线类型position = 'identity', # 分布类型:单独的,非累积aes(colour = factor(year))) # 颜色按年份# 根据某个变量分开绘制p <- p + facet_grid(drv ~ year) # drv为行变量,year为列变量# ggplot2例子2:位置调整与条形图# 条形图各种形式with(mpg,table(class,year))p <- ggplot(data = mpg, aes(x = class,fill = factor(year)))p + geom_bar(position = 'dodge') # 将不同年份的数据并列放置p + geom_bar(position = 'stack') # 将不同年份数据推叠放置p + geom_bar(position = 'fill') # 和stack类似,但是以百分比的形式出现p + geom_bar(position = 'identity',alpha = 0.5) # 直接显示,要显示成透明才能看到# 美国GDP增长率例子y = c(1.1,1.8,2.5,3.6,3.1,2.7,1.9,-0.1,-3.5,3.0)x = 2001:2010data = data.frame(x,y) # ggplot2一定要是数据框的形式p <- ggplot(data, aes(x,y,fill = y)) # 建立数据层,颜色以y变量实现渐变p <- p + geom_bar(stat = "identity") # 图形类型为独立显示p <- p + geom_abline(intercept = 0, slope = 0,size=1,colour='gray')p <- p + geom_text(aes(label=y),hjust=0.5, vjust=-0.5 ) # 添加标签,设置偏移系数p <- p + scale_y_continuous(limits=c(-3.8,4.2)) # 设置y坐标的范围p <- p + labs(x='年份', y='GDP增长率%') # 设置坐标标签p <- p + opts(title = "美国GDP增长率") # 设置标题# 课间佐料:同一个窗口画多个图layout(matrix(c(2,0,1,3),2,2,byrow=TRUE), c(1,1), c(1,1), TRUE)plot(x1, y1)plot(x2, y2)plot(x3, y3)# ggplo2例子3:散点图p <- ggplot(mpg, aes(cty, hwy))# 对色彩的形状的控制p1 <- p + geom_point(aes(colour = factor(year), # 颜色按年区分shape = factor(year), # 点状按年区分size = displ), # 点的大小以变量displ控制alpha = 0.6, # 控制透明度position = 'jitter') # 在点太过集中的时候,错开print(p1)# 对坐标的控制cty.mean=with(mpg,mean(cty))cty.sd=with(mpg,sd(cty))p1 + scale_x_continuous(trans='log', # 对x轴进行对数变换# 只需要在x轴显示坐标breaks=c(cty.mean-cty.sd,cty.mean,cty.mean+cty.sd),# 只需要在x轴显示坐标对应的命名labels=c("high", "mean", "low"))+ scale_y_continuous(trans='log') # 对y轴进行对数变换# 添加文字说明p <- ggplot(mpg, aes(x=cty, y=hwy,colour=factor(year),label=year))p <- p + geom_text(hjust=0,vjust=-1,alpha=0.8)p <- p + geom_point(size=3,aes(shape=factor(year)))# 矩阵散点图plotmatrix(USArrests) + geom_smooth() # ggplot2包自带的矩阵散点图函数pairs(USArrests) # 基础包自带的矩阵散点图# ggplo2例子4:时间序列library(quantmod)getSymbols('^SSEC',src='yahoo',from = '1997-01-01')close <- (Cl(SSEC))time <- index(close)value <- as.vector(close)p <- ggplot(data.frame(time,value),aes(time,value))p <- p + geom_line()yrng <- range(value)xrng <- range(time)data <- data.frame(start=as.Date(c('1997-01-01','2003-01-01')),end=as.Date(c('2002-12-30','2012-01-20')),core=c('jiang','hu'))timepoint <- as.Date(c('1999-07-02','2001-07-26','2005-04-29','2008-01-10','2010-03-31'))events <- c('证券法实施','国有股持减','股权分置改革','次贷危机爆发','融资融券试点')data2 <- data.frame(timepoint,events,stock=value[time %in% timepoint])p <- p + geom_line()if (F) {p <- p + geom_rect(aes(NULL,NULL,xmin = start, xmax = end, fill = core), ymin = yrng[1],ymax=yrng[2],data = data)p <- p + scale_fill_manual(values = alpha(c('blue','red'),0.2))}# 添加文本说明p <- p + geom_text(aes(timepoint, stock, label = events),data = data2,vjust = -2,size = 5)# 添加标记点p <- p + geom_point(aes(timepoint, stock),data = data2,size = 5,colour = 'red',alpha = 0.5)。
ggplot2笔记2:图层的使用——基础、怎样加标签、注释

ggplot2笔记2:图层的使⽤——基础、怎样加标签、注释⼀点碎碎念:今天开始看第三章Toolbox,主要讲的是图层的⽤法,在图像的基础上,图层可以让plot的信息更加丰富和完整,于是就有了怎样加标签,加注释等等。
这些内容虽然不难但是很琐碎,由于R基础薄弱,有些代码理解起来需要时间。
所以,在这⾥我想先以读书笔记和翻译的形式,记录为主,尽量去逐字逐句理解。
除了添加注释、标签等之外,使⽤图层还可以完成箱线图、多边形等等多种群组⼏何对象类型的图,还可以绘制曲⾯图等。
下⾯是第三章的主要内容:使⽤图层的三个主要⽬的:1. 展⽰数据:绘制原始数据时唯⼀的⼀层(数据层)2. 展⽰数据的统计摘要:在数据背景下展⽰模型的统计预测效果,模型层通常绘制在数据层之上3. 添加额外的元数据(metadata)、上下⽂信息和注释:也称背景层,了解数据的背景信息或强调数据中的某些特征,⼀般在最后绘制。
1. 基本图形类型⼏何对象是ggplot2的基本组成部分,可以独⽴构建图形。
他们都是⼆维的,主要函数有geom_area(),geom_bar(),geom_line,geom_point(),geom_polygon(),geom_tile()等等。
这些函数包括x,y两个主要属性,另外也可以接受color和size两个图形属性,他们构成了基本的数据层。
我们可以通过使⽤+来添加图层。
1. df <> data.frame(2. x = c(3, 1, 5),3. y = c(2, 4, 6),4. label = c('a','b','c')5. )6. df7. p <> ggplot(df, aes(x, y, label = label)) +8. labs(x = NULL, y = NULL) + # Hide axis label9. theme(plot.title = element_text(size = 12)) # Shrink plot title10.11. p + geom_point() + ggtitle('point')12. p + geom_text() + ggtitle('text')13. p + geom_bar(stat = 'identity') + ggtitle('bar')14. p + geom_tile() + ggtitle('raster')15. p + geom_line() + ggtitle('line')16. p + geom_area() + ggtitle('area')17. p + geom_path() + ggtitle('path')18. p + geom_polygon() + ggtitle('polygon')以上命令运⾏后可依次⽣成散点图、含标签的散点图、条形图、⾊深图、线条图、⾯积图、路径图和多边形图等⼋个图,其中ggtitle()是给各个图⽚添加注释/命名2. 添加标签(label)主要函数geom_text():和散点类似,就是将point换成了⽂字。
geom_boxplot参数

geom_boxplot参数geom_boxplot参数是在数据可视化中常用的一个参数。
它可以用来展示数据的分布情况以及异常值的存在。
在本文中,我们将详细介绍geom_boxplot参数的用法,并通过实际例子来说明其作用。
我们需要了解一下geom_boxplot参数的基本含义。
geom_boxplot 是ggplot2包中的一个函数,用于绘制箱线图。
箱线图是一种常用的统计图形,可以用来展示数据的分布情况。
它由五个统计量组成,分别是最小值、下四分位数、中位数、上四分位数和最大值。
通过箱线图,我们可以直观地了解数据的中心位置、离散程度以及异常值的存在。
接下来,我们来看一个具体的例子,以更好地理解geom_boxplot参数的使用。
假设我们有一份关于某公司员工薪资的数据集,其中包含了员工的姓名、部门和薪资信息。
我们想要通过箱线图来展示各个部门的薪资分布情况。
我们需要加载所需的包,并读取数据集。
```library(ggplot2)data <- read.csv("employee_salary.csv")```接下来,我们可以使用geom_boxplot函数来绘制箱线图。
我们将x轴设置为部门,y轴设置为薪资,并用不同的颜色表示不同的部门。
```ggplot(data, aes(x = department, y = salary, fill = department)) +geom_boxplot() +labs(title = "各部门薪资分布情况") +theme_minimal()```通过上述代码,我们可以得到一张展示各个部门薪资分布情况的箱线图。
图中每个箱子表示一个部门,箱子的上边界和下边界分别表示上四分位数和下四分位数,箱子中间的线表示中位数,箱子上方的线表示最大值,箱子下方的线表示最小值。
通过观察箱线图,我们可以发现各个部门的薪资分布情况。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
28 position=position_dodge(0.7)) 调整柱形图相对位置 ggplot(cabbage_exp, aes(x=Date, y=Weight, fill=Cultivar)) +
geom_bar(stat="identity", width=0.5, position=position_dodge(0.7))
sp1 <- ggplot(ChickWeight, aes(x=Time, y=weight)) sp1 + geom_point() sp1 + geom_point(position="jitter") head(ChickWeight)
13Geom_boxplot的几何对象
sp1 + geom_boxplot(aes(group=Time))
7scale_fill_gradient设置break的大小
ggplot(heightweight, aes(x=weightLb, y=heightIn, fill=ageYear)) + geom_point(shape=21, size=2.5) + scale_fill_gradient(low="black", high="red", breaks=12:17, guide=guide_legend())
method=loess sp + geom_point() + stat_smooth(method=lm, level=0.99)
sp + geom_point() + stat_smooth(method=lm, se=FALSE,colour=“black”)
16 Annotate添加文本
9Alpha参数修改透明度
sp <- ggplot(diamonds, aes(x=carat, y=price)) sp + geom_point() sp + geom_point(alpha=.1) sp + geom_point(alpha=.01)
10使用bin方法显示高密度散点图
sp + stat_bin2d()
26 position图形的位置关系
ggplot(cabbage_exp, aes(x=Date, y=Weight, fill=Cultivar)) + geom_bar(position=“dodge”) #去掉position则柱形图堆起来
27 width调整柱形图的宽
ggplot(cabbage_exp, aes(x=Date, y=Weight, fill=Cultivar)) + geom_bar(stat="identity", width=0.5)
22Element_blank()表示清空
ggplot(tophit, aes(x=reorder(name, avg), y=avg)) + geom_point(size=3)+theme_bw() + theme(axis.text.x = element_text(angle=60, hjust=1), panel.grid.major.y = element_blank(), panel.grid.minor.y = element_blank(), panel.grid.major.x = element_line(colour="grey60", linetype="dashed"))
sp + stat_bin2d() + scale_fill_gradient(low="lightblue", high="red", breaks=c(0, 250, 500, 1000, 2000, 4000, 6000), limits=c(0, 6000))
12Position=“jetter ”画扰动图
Using ggplot2
zting整理 2.7
Hadley Wickham 是 RStudio 的首席科学家以及 Rice University 统计系的助理教授。他是著名图形可视化软件 包 ggplot2 的开发者,以及其他许多被广泛使用的软件包 的作者,代表作品如 ply手势
ggplot(mtcars, aes(x=wt, y=mpg)) + geom_point()
Mtcars数据格式
2shape参数修改图形的形状
ggplot(mtcars, aes(x=wt, y=mpg)) + geom_point(shape=21)
3size参数修改图形的大小
5 scale_shape_manual 设置想要shape
ggplot(heightweight, aes(x=ageYear, y=heightIn, shape=sex, colour=sex)) + geom_point() + scale_shape_manual(values=c(1,2)) + scale_colour_brewer(palette="Set1")
ggplot(mtcars, aes(x=wt, y=mpg)) + geom_point(size=1.5) ggplot(mtcars, aes(x=wt, y=mpg)) + geom_point(size=5)
4 多因素作图
heightweight[, c("sex", "ageYear", "heightIn")] ggplot(heightweight, aes(x=ageYear, y=heightIn, colour=sex)) + geom_point() ggplot(heightweight, aes(x=ageYear, y=heightIn, shape=sex,color=sex)) + geom_point()
ggplot(tophit, aes(x=avg, y=name)) + geom_segment(aes(yend=name), xend=0, colour="grey50") + geom_point(size=3, aes(colour=lg)) + scale_colour_brewer(palette="Set1", limits=c("NL","AL"), guide=FALSE) + theme_bw() + theme(panel.grid.major.y = element_blank()) + facet_grid(lg ~ ., scales="free_y", space="free_y")
8scale_size_area()使图形比例恰当
ggplot(heightweight, aes(x=ageYear, y=heightIn, size=weightLb, colour=sex)) + geom_point(alpha=.5) + scale_size_area() +scale_colour_brewer(palette="Set1")
sp + annotate("text", label="r^2=0.42", x=16.5, y=52)
17 Annotate添加标签
sp <- ggplot(subset(countries, Year==2009 & healthexp>2000), aes(x=healthexp, y=infmortality)) +geom_point() sp + annotate("text", x=4350, y=5.4, label="Canada") + annotate("text", x=7400, y=6.8, label="USA")
18 Geom_text(aes(lable=))批量添加标 签
sp + geom_text(aes(label=Name), size=4)
19Geom_text通过设置x=确定标签位置
sp + geom_text(aes(x=healthexp+100, label=Name), size=4, hjust=0)
20stat_density2d()画二维散点图
p <- ggplot(faithful, aes(x=eruptions, y=waiting)) p + geom_point() + stat_density2d()
21 scale_colour_brewer(palette="Set1") 对调色板进行选择
6scale_fill_gradient设置legend的颜色
ggplot(heightweight, aes(x=weightLb, y=heightIn, fill=ageYear)) + geom_point(shape=21, size=2.5) + scale_fill_gradient(low="black", high="red")
14stat_smooth(method=lm)对散点图增 加线性回归
sp <- ggplot(heightweight, aes(x=ageYear, y=heightIn)) sp + geom_point() + stat_smooth(method=lm) # 默认95%置信