用python实现mapreduce的web访问日志统计分析
使用Python进行大数据分析和处理

使用Python进行大数据分析和处理一、引言随着大数据时代的到来,数据分析和处理技术愈发重要。
Python作为一种简单易学、功能强大的编程语言,被广泛应用于数据科学领域。
本文将介绍如何使用Python进行大数据分析和处理,并分为以下几个部分:数据获取、数据清洗、数据分析、数据可视化和模型建立。
二、数据获取在进行大数据分析和处理之前,我们需要从各种数据源中获取数据。
Python提供了丰富的库和工具,可以轻松地从数据库、API、Web页面以及本地文件中获取数据。
比如,我们可以使用pandas库中的read_sql()函数从数据库中读取数据,使用requests库从API获取数据,使用beautifulsoup库从Web页面获取数据,使用csv库从本地CSV文件中获取数据。
三、数据清洗获取到原始数据之后,通常需要进行数据清洗。
数据清洗是指对数据进行预处理,包括处理缺失值、处理异常值、处理重复值、数据格式转换等。
Python提供了丰富的库和函数来帮助我们进行数据清洗,如pandas库中的dropna()函数用于处理缺失值,使用numpy库中的where()函数用于处理异常值,使用pandas库中的duplicated()函数用于处理重复值。
四、数据分析数据分析是大数据处理的核心环节之一。
Python提供了强大的库和工具来进行数据分析,如pandas库和numpy库。
使用这些库,我们可以进行数据聚合、数据筛选、数据排序、数据计算等。
例如,我们可以使用pandas库中的groupby()函数进行数据聚合,使用pandas库中的query()函数进行数据筛选,使用pandas库中的sort_values()函数进行数据排序,使用numpy库中的mean()函数进行数据计算。
五、数据可视化数据可视化是将数据以图形化的方式展现出来,帮助我们更好地理解数据的分布和趋势。
Python提供了多种库和工具来进行数据可视化,如matplotlib库和seaborn库。
mapreduce编程实验报告心得

mapreduce编程实验报告心得【实验报告心得】总结:本次mapreduce编程实验通过实际操作,使我对mapreduce编程框架有了更深入的理解。
在实验过程中,我学会了如何编写map和reduce函数,并利用这些函数从大数据集中进行数据提取和聚合分析。
通过这个实验,我还掌握了如何调试和优化mapreduce任务,以提高数据处理效率和性能。
一、实验目的:本次实验的目的是掌握mapreduce编程框架的使用方法,理解其实现原理,并在实际编程中熟练运用map和reduce函数进行数据处理和分析。
二、实验环境和工具:本次实验使用Hadoop分布式计算框架进行mapreduce编程。
使用的工具包括Hadoop集群、HDFS分布式文件系统以及Java编程语言。
三、实验过程:1. 实验准备:在开始实验前,我首先了解了mapreduce的基本概念和特点,以及Hadoop集群的配置和使用方法。
2. 实验设计:根据实验要求,我选择了一个适当的数据集,并根据具体需求设计了相应的map和reduce函数。
在设计过程中,我充分考虑了数据的结构和处理逻辑,以保证mapreduce任务的高效完成。
3. 实验编码:在实验编码过程中,我使用Java编程语言来实现map 和reduce函数。
我按照mapreduce编程模型,利用输入键值对和中间结果键值对来进行数据处理。
在编码过程中,我注意了代码的规范性和可读性,并进行了适当的优化。
4. 实验测试:完成编码后,我在Hadoop集群上部署和运行了我的mapreduce任务。
通过对数据集进行分析和处理,我验证了自己编写的map和reduce函数的正确性和性能。
5. 实验总结:在实验结束后,我对本次实验进行了总结。
我分析了实验中遇到的问题和挑战,并提出了相应的解决方法。
我还对mapreduce编程框架的优缺点进行了评估,并给出了自己的观点和建议。
四、实验结果和观点:通过本次实验,我成功实现了对选定数据集的mapreduce处理。
Spark实践——基于SparkStreaming的实时日志分析系统

Spark实践——基于SparkStreaming的实时⽇志分析系统本⽂基于《Spark 最佳实践》第6章 Spark 流式计算。
我们知道⽹站⽤户访问流量是不间断的,基于⽹站的访问⽇志,即 Web log 分析是典型的流式实时计算应⽤场景。
⽐如百度统计,它可以做流量分析、来源分析、⽹站分析、转化分析。
另外还有特定场景分析,⽐如安全分析,⽤来识别 CC 攻击、 SQL 注⼊分析、脱库等。
这⾥我们简单实现⼀个类似于百度分析的系统。
1.模拟⽣成 web log 记录在⽇志中,每⾏代表⼀条访问记录,典型格式如下:分别代表:访问 ip,时间戳,访问页⾯,响应状态,搜索引擎索引,访问 Agent。
简单模拟⼀下数据收集和发送的环节,⽤⼀个 Python 脚本随机⽣成 Nginx 访问⽇志,为了⽅便起见,不使⽤ HDFS,使⽤单机⽂件系统。
⾸先,新建⽂件夹⽤于存放⽇志⽂件然后,使⽤ Python 脚本随机⽣成 Nginx 访问⽇志,并为脚本设置执⾏权限, 代码见设置可执⾏权限的⽅法如下之后,编写 bash 脚本,⾃动⽣成⽇志记录,并赋予可执⾏权限,代码见赋予权限执⾏ genLog.sh 查看效果,输⼊ ctrl+c 终⽌。
2.流式分析创建 Scala 脚本,代码见3.执⾏同时开启两个终端,分别执⾏ genLog.sh ⽣成⽇志⽂件和执⾏ WebLogAnalyse.scala 脚本进⾏流式分析。
执⾏ genLog.sh执⾏ WebLogAnalyse.scala, 使⽤ spark-shell 执⾏ scala 脚本效果如下,左边是 WebLogAnalyse.scala,右边是 genLog.sh。
一起学Hadoop——使用IDEA编写第一个MapReduce程序(Java和Python)

⼀起学Hadoop——使⽤IDEA编写第⼀个MapReduce程序(Java和Python)上⼀篇我们学习了MapReduce的原理,今天我们使⽤代码来加深对MapReduce原理的理解。
wordcount是Hadoop⼊门的经典例⼦,我们也不能免俗,也使⽤这个例⼦作为学习Hadoop的第⼀个程序。
本⽂将介绍使⽤java和python编写第⼀个MapReduce程序。
本⽂使⽤Idea2018开发⼯具开发第⼀个Hadoop程序。
使⽤的编程语⾔是Java。
打开idea,新建⼀个⼯程,如下图所⽰:在弹出新建⼯程的界⾯选择Java,接着选择SDK,⼀般默认即可,点击“Next”按钮,如下图:在弹出的选择创建项⽬的模板页⾯,不做任何操作,直接点击“Next”按钮。
输⼊项⽬名称,点击Finish,就完成了创建新项⽬的⼯作,我们的项⽬名称为:WordCount。
如下图所⽰:添加依赖jar包,和Eclipse⼀样,要给项⽬添加相关依赖包,否则会出错。
点击Idea的File菜单,然后点击“Project Structure”菜单,如下图所⽰:依次点击Modules和Dependencies,然后选择“+”的符号,如下图所⽰:选择hadoop的包,我⽤得是hadoop2.6.1。
把下⾯的依赖包都加⼊到⼯程中,否则会出现某个类找不到的错误。
(1)”/usr/local/hadoop/share/hadoop/common”⽬录下的hadoop-common-2.6.1.jar和haoop-nfs-2.6.1.jar;(2)/usr/local/hadoop/share/hadoop/common/lib”⽬录下的所有JAR包;(3)“/usr/local/hadoop/share/hadoop/hdfs”⽬录下的haoop-hdfs-2.6.1.jar和haoop-hdfs-nfs-2.7.1.jar;(4)“/usr/local/hadoop/share/hadoop/hdfs/lib”⽬录下的所有JAR包。
mapreduce词频统计实验过程

mapreduce词频统计实验过程mapreduce是一种分布式计算框架,被广泛应用于大数据处理中。
其核心思想是将任务分为两个阶段,分别为map和reduce阶段。
其中,map 阶段将输入数据切分为一个个的小块,并由多个workers并行处理;而reduce阶段则汇总并合并map阶段的输出结果,生成最终的统计结果。
在本文中,我将介绍使用mapreduce进行词频统计的实验过程。
首先,我们需要准备实验环境。
在介绍实验环境之前,我们需要先了解一下mapreduce的基本组成部分。
mapreduce由一个master节点和多个worker节点组成。
每个worker节点都有自己的计算资源和存储空间。
在实验中,我将使用三台虚拟机作为worker节点,另一台虚拟机作为master 节点。
接下来,我们需要编写并运行map和reduce函数。
在本次实验中,我们将使用Python编写这两个函数。
map函数的作用是将输入数据切分为若干个小块,并对每个小块进行词频统计。
具体的代码如下所示:pythondef map_function(data):words = data.split()word_count = {}for word in words:if word in word_count:word_count[word] += 1else:word_count[word] = 1return word_count在这段代码中,我们首先将输入数据按空格切分成一个个的单词。
然后,我们使用一个字典来统计每个单词出现的次数。
最终,我们将这个字典作为map函数的输出。
接下来,我们需要编写reduce函数。
reduce函数的作用是将map阶段输出的结果进行合并,并生成最终的词频统计结果。
具体的代码如下所示:pythondef reduce_function(word_counts):result = {}for word_count in word_counts:for word, count in word_count.items():if word in result:result[word] += countelse:result[word] = countreturn result在这段代码中,我们首先定义了一个空字典result,用于保存最终的统计结果。
mapreduce实验报告总结

mapreduce实验报告总结一、引言MapReduce是一种用于处理和生成大数据集的编程模型和模型化工具,它由Google提出并广泛应用于各种大数据处理场景。
通过MapReduce,我们可以将大规模数据集分解为多个小任务,并分配给多个计算节点并行处理,从而大大提高了数据处理效率。
在本实验中,我们通过实践操作,深入了解了MapReduce的工作原理,并尝试解决了一些实际的大数据处理问题。
二、实验原理MapReduce是一种编程模型,它通过两个核心阶段——Map阶段和Reduce阶段,实现了对大规模数据的处理。
Map阶段负责处理输入数据集中的每个元素,生成一组中间结果;Reduce阶段则对Map阶段的输出进行汇总和聚合,生成最终结果。
通过并行处理和分布式计算,MapReduce可以在大量计算节点上高效地处理大规模数据集。
在本实验中,我们使用了Hadoop平台来实现MapReduce模型。
Hadoop是一个开源的分布式计算框架,它提供了包括MapReduce在内的一系列数据处理功能。
通过Hadoop,我们可以方便地搭建分布式计算环境,实现大规模数据处理。
三、实验操作过程1.数据准备:首先,我们需要准备一个大规模的数据集,可以是结构化数据或非结构化数据。
在本实验中,我们使用了一个包含大量文本数据的CSV文件。
2.编写Map任务:根据数据处理的需求,我们编写了一个Map任务,该任务从输入数据集中读取文本数据,提取出关键词并进行分类。
3.编写Reduce任务:根据Map任务的输出,我们编写了一个Reduce任务,该任务将相同关键词的文本数据进行汇总,生成最终结果。
4.运行MapReduce作业:将Map和Reduce任务编译成可执行脚本,并通过Hadoop作业调度器提交作业,实现并行处理。
5.数据分析:获取处理后的结果,并进行数据分析,以验证数据处理的有效性。
四、实验结果与分析实验结束后,我们得到了处理后的数据结果。
如何在Hadoop中使用MapReduce进行数据分析

如何在Hadoop中使用MapReduce进行数据分析在当今信息爆炸的时代,数据分析已经成为了企业和组织决策的重要工具。
而Hadoop作为一个开源的分布式计算框架,提供了强大的数据处理和分析能力,其中的MapReduce就是其核心组件之一。
本文将介绍如何在Hadoop中使用MapReduce进行数据分析。
首先,我们需要了解MapReduce的基本原理。
MapReduce是一种分布式计算模型,它将大规模的数据集划分成若干个小的数据块,然后通过Map和Reduce两个阶段进行并行处理。
在Map阶段,数据集会被分割成若干个键值对,每个键值对由一个键和一个值组成。
然后,Map函数会对每个键值对进行处理,生成一个新的键值对。
在Reduce阶段,相同键的值会被分组在一起,然后Reduce函数会对每个键的值进行聚合和处理,最终生成最终的结果。
在Hadoop中使用MapReduce进行数据分析的第一步是编写Map和Reduce函数。
在编写Map函数时,我们需要根据具体的数据分析任务来定义键值对的格式和生成方式。
例如,如果我们要统计某个网站的访问量,那么键可以是网站的URL,值可以是1,表示一次访问。
在Reduce函数中,我们需要根据具体的需求来定义对键的值进行聚合和处理的方式。
例如,如果我们要统计每个网站的总访问量,那么Reduce函数可以将所有的值相加得到最终的结果。
编写好Map和Reduce函数后,我们需要将数据加载到Hadoop中进行分析。
在Hadoop中,数据通常以HDFS(Hadoop Distributed File System)的形式存储。
我们可以使用Hadoop提供的命令行工具或者编写Java程序来将数据加载到HDFS 中。
加载完成后,我们就可以使用Hadoop提供的MapReduce框架来进行数据分析了。
在运行MapReduce任务之前,我们需要编写一个驱动程序来配置和提交任务。
在驱动程序中,我们需要指定Map和Reduce函数的类名、输入数据的路径、输出数据的路径等信息。
Python数据分析实战之大数据分析案例

Python数据分析实战之大数据分析案例Python已经成为了数据分析领域中的佼佼者,它凭借其高度的灵活性和流畅的语法,成为了数据分析项目的首选语言。
在我们的工作和生活中,使用Python进行数据分析已经成为了一种常见的方法。
而大数据作为当今最重要的技术之一,也随着数据分析不断发展进入到了我们的视野。
本篇文章将介绍Python数据分析实战中的大数据分析案例。
一、数据分析准备工作要进行数据分析,首先需要了解数据来源和处理方式。
在实际的大数据分析场景中,我们需要使用分布式计算技术来完成数据处理。
在这里,我们选择使用Hadoop和Spark作为我们的分布式计算框架。
使用Python可以方便地访问Hadoop和Spark中存储的数据,并进行数据预处理和分析。
二、数据清洗和预处理在进行数据分析之前,我们需要进行数据清洗和预处理。
在实践中,数据分析人员往往需要处理大量杂乱无章的数据,并将其转化为可分析的数据集。
因此,数据清洗和预处理是大数据分析的重要组成部分。
在Python中,可以使用Pandas库进行数据清洗和预处理。
Pandas库提供了一组数据结构,可以轻松地进行数据读取、处理、过滤和转换。
在进行大数据分析时,Pandas库还可以与Apache Spark集成,以进行大规模数据处理和分析。
三、数据可视化数据可视化是数据分析的一个重要方面。
通过数据可视化,我们可以更直观地了解数据中包含的信息。
在Python中,Matplotlib和Seaborn是两个流行的数据可视化库。
这两个库提供了各种绘图函数和选项,可以使你轻松地创建各种数据可视化效果。
四、机器学习机器学习是大数据分析的另一个重要方面。
在Python中,Scikit-learn和TensorFlow是两个流行的机器学习库。
Scikit-learn提供了各种常见的机器学习算法,例如回归、分类和聚类。
TensorFlow是一个面向深度学习的库,可以用于构建和训练神经网络模型。
mapreduce编程实验报告心得

mapreduce编程实验报告心得一、实验背景MapReduce是一种分布式计算框架,主要用于大规模数据处理。
它可以将一个大型数据集分成许多小的数据块,并在多台计算机上并行处理这些数据块。
MapReduce框架由Google公司提出,被广泛应用于搜索引擎、社交网络等领域。
二、实验目的本次实验的目的是掌握MapReduce编程模型及其应用。
通过实现一个简单的WordCount程序,学习MapReduce编程的基本流程和技巧。
三、实验环境本次实验使用Hadoop作为分布式计算框架,Java作为编程语言。
四、实验步骤1. 编写Mapper类Mapper类负责将输入文件中的每一行文本转换成(key,value)对,并输出给Reducer进行处理。
在WordCount程序中,我们需要将每个单词作为key,出现次数作为value输出。
下面是Mapper类代码:```javapublic class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {private final static IntWritable one = new IntWritable(1);private Text word = new Text();public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {String line = value.toString();StringTokenizer tokenizer = new StringTokenizer(line);while (tokenizer.hasMoreTokens()) {word.set(tokenizer.nextToken());context.write(word, one);}}}2. 编写Reducer类Reducer类负责将Mapper输出的(key,value)对进行归并,统计每个单词出现的次数。
python分析慢查询日志生成报告
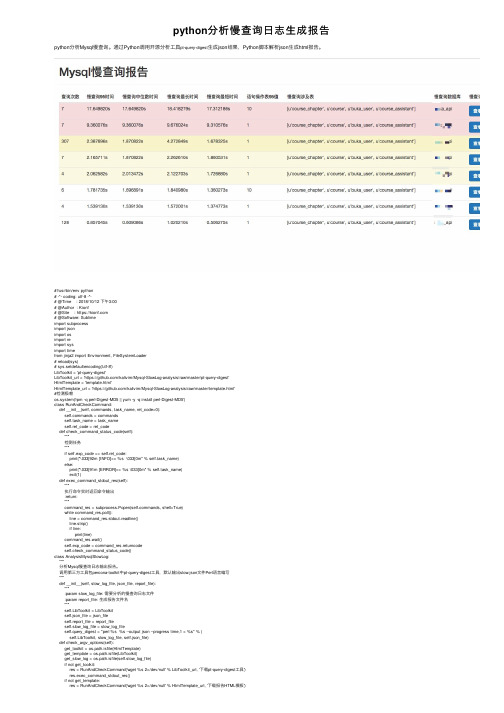
python分析慢查询⽇志⽣成报告python分析Mysql慢查询。
通过Python调⽤开源分析⼯具pt-query-digest⽣成json结果,Python脚本解析json⽣成html报告。
#!/usr/bin/env python# -*- coding: utf-8 -*-# @Time : 2018/10/12 下午3:00# @Author : Kionf# @Site : https://# @Software: Sublimeimport subprocessimport jsonimport osimport reimport sysimport timefrom jinja2 import Environment, FileSystemLoader# reload(sys)# sys.setdefaultencoding('utf-8')LibToolkit = 'pt-query-digest'LibToolkit_url = 'https:///kalivim/Mysql-SlowLog-analysis/raw/master/pt-query-digest'HtmlTemplate = 'template.html'HtmlTemplate_url = 'https:///kalivim/Mysql-SlowLog-analysis/raw/master/template.html'#检测极赖os.system('rpm -q perl-Digest-MD5 || yum -y -q install perl-Digest-MD5')class RunAndCheckCommand:def __init__(self, commands, task_name, ret_code=0):mands = commandsself.task_name = task_nameself.ret_code = ret_codedef check_command_status_code(self):"""检测任务"""if self.exp_code == self.ret_code:print("\033[92m [INFO]>> %s \033[0m" % self.task_name)else:print("\033[91m [ERROR]>> %s \033[0m" % self.task_name)exit(1)def exec_command_stdout_res(self):"""执⾏命令实时返回命令输出:return:"""command_res = subprocess.Popen(mands, shell=True)while command_res.poll():line = command_res.stdout.readline()line.strip()if line:print(line)command_res.wait()self.exp_code = command_res.returncodeself.check_command_status_code()class AnalysisMysqlSlowLog:"""分析Mysql慢查询⽇志输出报告。
Python中的数据分析和统计方法

Python中的数据分析和统计方法Python是一门功能强大的编程语言,广泛应用于数据分析和统计方法。
本文将详细介绍Python中常用的数据分析和统计方法,并按类进行章节划分,深入探讨每个章节的具体内容。
第一章:数据预处理在进行数据分析之前,通常需要对原始数据进行清洗和预处理。
Python提供了很多用于数据预处理的库和方法。
其中,pandas是最常用的库之一。
pandas可以用于数据的读取、清洗、转换和合并等操作。
另外,NumPy库也提供了许多用于数组操作和数值运算的函数,可用于数据预处理过程中的一些计算。
第二章:数据可视化数据可视化是数据分析的重要环节,它可以使得数据更加直观和易于理解。
Python中有多个可视化库可以使用,如Matplotlib、Seaborn和Plotly等。
这些库可以生成各种类型的图表,如线图、散点图、柱状图和饼图等。
通过合理选择和使用可视化方法,可以更好地展示数据的分布和趋势。
第三章:统计描述统计描述是对数据进行摘要和概括的过程。
在Python中,可以使用pandas库的describe()函数来计算数据的基本统计量,如均值、标准差、最大值和最小值等。
此外,还可以使用scipy库中的一些函数来计算概率分布、置信区间和假设检验等统计指标。
第四章:回归分析回归分析是数据分析中常用的一种方法,用于探究变量之间的关系和预测未来趋势。
Python中的statsmodels库提供了许多回归分析的方法,如线性回归、逻辑回归和多元回归等。
通过回归分析,可以得到模型的参数估计和拟合优度等指标,进而对未知数据进行预测和推测。
第五章:聚类分析聚类分析是将数据按照相似性进行分组的一种方法。
在Python 中,可以使用scikit-learn库中的KMeans算法来进行聚类分析。
KMeans算法通过迭代计算将数据划分为K个簇,使得同一簇内的数据相似度最高,不同簇之间的相似度最低。
聚类分析可以帮助我们发现数据中潜在的模式和规律。
Python实现MapReduce,wordcount实例,MapReduce实现两表的Join

Python实现MapReduce,wordcount实例,MapReduce实现两表的Join Python实现MapReduce下⾯使⽤mapreduce模式实现了⼀个简单的统计⽇志中单词出现次数的程序:from functools import reducefrom multiprocessing import Poolfrom collections import Counterdef read_inputs(file):for line in file:line = line.strip()yield line.split()def count(file_name):file = open(file_name)lines = read_inputs(file)c = Counter()for words in lines:for word in words:c[word] += 1return cdef do_task():job_list = ['log.txt'] * 10000pool = Pool(8)return reduce(lambda x, y: x+y, pool.map(count, job_list))if __name__ == "__main__":rv = do_task()⼀个python实现的mapreduce程序2017年05⽉13⽇ 21:42:12 阅读数:814 标签:更多个⼈分类:版权声明:本⽂为博主原创⽂章,未经博主允许不得转载。
https:///weijianpeng2013_2015/article/details/71908340map:# !/usr/bin/env pythonimport sysfor line in sys.stdin:line = line.strip()words = line.split()for word in words:print ("%s\t%s") % (word, 1)1234567891011reduce:#!/usr/bin/env pythonimport operatorimport syscurrent_word = Nonecurent_count = 0word = Nonefor line in sys.stdin:line = line.strip()word, count = line.split('\t', 1)try:count = int(count)except ValueError:continueif current_word == word:curent_count += countelse:if current_word:print '%s\t%s' % (current_word,curent_count)current_word=wordcurent_count=countif current_word==word:print '%s\t%s' % (current_word,curent_count)1234567891011121314151617181920212223测试:[root@node1 input]# echo "foo foo quux labs foo bar zoo zoo hying" | /home/hadoop/input/max_map.py | sort | /home/hadoop/input/max_reduce.py1执⾏:可将其写⼊脚本⽂件//注意\-file之间⼀定不能空格hadoop jar /hadoop64/hadoop-2.7.1/share/hadoop/tools/lib/hadoop-*streaming*.jar -D stream.non.zero.exit.is.failure=false \-file /home/hadoop/input/max_map.py -mapper /home/hadoop/input/max_map.py \-file /home/hadoop/input/max_reduce 12使⽤python语⾔进⾏MapReduce程序开发主要分为两个步骤,⼀是编写程序,⼆是⽤Hadoop Streaming命令提交任务。
Python在统计分析中的应用

Python在统计分析中的应用Python作为一种高级编程语言,广泛应用于各个领域,其中包括统计分析。
统计分析作为数据处理和决策支持的关键方法之一,在现代社会发挥着重要的作用。
本文将探讨Python在统计分析中的应用,包括数据收集、数据清洗、数据可视化、统计模型建立和分析等方面。
一、数据收集在进行统计分析之前,首先需要收集相关的数据。
Python提供了许多强大的库,用于数据的获取和读取。
例如,可以使用requests库获取网络上的数据,使用pandas库读取CSV或Excel格式的数据,使用BeautifulSoup库从网页中提取数据等。
这些库提供了便捷的方法,使得数据的收集工作变得更加高效。
二、数据清洗在得到原始数据后,往往需要对其进行清洗和预处理,以提高数据的质量和准确性。
Python在数据清洗方面提供了丰富的工具和库,例如pandas库提供了各种数据清洗和处理函数,如缺失值填充、异常值处理、重复值删除等。
此外,还可以利用正则表达式等方法对文本数据进行清洗和提取。
通过Python的强大功能,可以将原始数据转化为干净、规范的数据,为后续的分析工作打下坚实的基础。
三、数据可视化数据可视化是统计分析的重要环节,能够将庞大的数据转化为直观的图表,帮助人们更好地理解和分析数据。
Python中的matplotlib和seaborn库提供了丰富的绘图功能,能够绘制各种类型的图表,如折线图、柱状图、散点图等。
此外,还可以利用plotly库创建交互式图表,增加用户的参与度。
通过Python可视化工具的使用,可以将分析结果以直观的形式呈现,提升分析的可解释性和可视性。
四、统计模型建立与分析Python作为一种通用编程语言,提供了多种统计模型的建立和分析方法。
statsmodels是Python中常用的统计分析库,提供了各类统计模型的建立和分析函数。
例如,可以利用statsmodels进行线性回归、逻辑回归、时间序列分析等。
用Python实现数据分析和机器学习

用Python实现数据分析和机器学习在本文中,我们将探讨Python在数据分析和机器学习方面的应用,并介绍如何在Python中使用这些库。
我们将学习如何处理数据和应用机器学习算法来解决一些实际问题。
一、Python在数据分析方面的应用Python可用于数据的获取、处理、转换、统计和可视化等方面的应用,例如获取网络数据、处理CSV、Excel和数据库等格式的数据文件。
1. 获取数据当我们从互联网上获取数据时,可以使用Python的requests和BeautifulSoup来爬取网页内容。
requests 库用于HTTP协议的网络数据获取,而 BeautifulSoup 库则用于HTML和XML文件内容的解析。
requests 和 BeautifulSoup的优秀组合可以帮助我们获取互联网上的数据并将其转换为Python中的数据对象。
2. 数据处理在Python中, Pandas 库是一个非常强大的数据处理库。
Pandas 可以将Excel、CSV和数据库等各种数据格式转换为Python的数据帧(DataFrames),从而方便地进行数据处理和操作。
Pandas的数据帧具有类似于Excel中的工作表的结构。
数据帧有多种功能,例如数据筛选,数据排序以及数据汇总等等。
3. 数据可视化Matplotlib 是Python的一个重要的数据可视化工具。
这个库可以用来生成各种图表和图形,例如散点图、折线图、柱状图等等。
Matplotlib 对于数据分析师或机器学习人员来说非常有用,因为它可以让你更直观的了解所获得的数据。
二、Python在机器学习方面的应用Python在机器学习方面的应用同样是非常广泛的,特别是Scikit-learn 和TensorFlow。
Scikit-learn是一个开源的机器学习库,提供了包括分类、回归、聚类、降维等多种算法。
TensorFlow是Google开发的深度学习库,是目前最受欢迎的深度学习框架之一。
Python中的日志记录和调试技巧

Python中的日志记录和调试技巧在Python编程领域中,日志记录和调试技巧是非常重要的一部分。
尽管这两个概念看上去非常不同,但实际上它们之间有密切的联系。
在本文中,我们将深入探讨Python编程中的日志记录和调试技巧,以及如何将它们应用于实际项目中。
1.日志记录技巧在Python编程中,日志记录技巧旨在帮助开发人员更好地跟踪和诊断代码中发生的事件。
具体而言,以下是一些日志记录技巧,开发人员可以采用来最好地记录其代码的运行:1.1 级别在Python的日志中,级别(level)是指事件的重要性或者是严重程度。
Python的logging模块定义了5个级别,分别为:debug、info、warning、error和critical。
当记录级别设置为某个特定的级别时,比该级别重要的所有记录都将被记录。
可根据实际需要来选择不同的日志级别,以便更好地组织和调试代码中的事件。
1.2 格式化日志记录中的格式化是指在记录的输出中,如果需要添加更多信息,可通过格式化获取变量的值。
Python logging中,可使用格式和占位符将变量格式化并输出到记录中。
因此,格式化对于日志记录来说是一个不可缺少的部分,它可帮助开发人员更清晰地了解和跟踪代码发生的事件。
1.3 模块Python中的logging模块提供模块级别的日志记录,这将自动继承父模块的日志记录器配置,因而在模块代码中在使用 logging 时,不必再定义日志器。
这样,代码结构也更加合理。
2.调试技巧Python调试是指诊断和纠正代码中的错误。
虽然Python是一门相对容易学习的语言,但是即使是资深开发者,仍然会有代码出现问题的情况。
以下是一些调试技巧,可帮助开发人员快速解决问题:2.1 print语句print语句是Python调试的最基本方式。
插入print语句到代码中,可用于输出变量和文本消息,便于跟踪代码执行过程。
2.2 logging语句与日志记录技巧类似,logging语句也可用于调试。
mapreduce简单例子

mapreduce简单例子
1. 嘿,你知道吗?就像把一堆杂乱的拼图碎片整理清楚一样,MapReduce 可以用来统计一个大文档里某个单词出现的次数呢!比如说统计《哈利·波特》里“魔法”这个词出现了多少次。
2. 哇塞,想象一下把一个巨大的任务拆分给很多小能手去做,这就是MapReduce 呀!像计算一个庞大的数据库中不同类别数据的数量,这多厉害呀!
3. 嘿呀,MapReduce 就像是一支高效的团队!比如统计一个城市里各种宠物的数量,能快速又准确地得出结果。
4. 哎呀呀,用 MapReduce 来处理大量的数据,这简直就像是一群勤劳的小蜜蜂在共同完成一项大工程!比如分析一个月的网络流量数据。
5. 你瞧,MapReduce 能轻松搞定复杂的任务,这不就跟我们一起合作打扫一间大房子一样嘛!像处理海量的图片数据。
6. 哇哦,MapReduce 真的好神奇!可以像变魔术一样把一个巨大的计算任务变得简单。
例如统计全国人口的年龄分布。
7. 嘿嘿,它就像是一个神奇的魔法棒!用 MapReduce 来计算一个大型工厂里各种产品的产量,是不是超简单。
8. 哎呀,MapReduce 真是太有用啦!就好像有无数双手帮我们一起做事一样。
举个例子,分析一个大型网站的用户行为数据。
9. 总之啊,MapReduce 真的是数据处理的一把好手,能搞定很多看似不可能的任务,就像一个超级英雄!它能在各种场景大显身手,帮助我们更高效地处理数据呀!。
统计学导论,基于python应用

统计学导论,基于python应用统计学是一门研究数据收集、分析、解释和应用的学科。
它在各个领域都有重要的应用价值,包括科学研究、商业决策、社会调查等。
而Python作为一种强大的编程语言,具有丰富的数据处理和分析库,被广泛应用于统计学的研究和实践中。
在统计学导论中,我们首先需要了解统计学的基本概念和原理。
统计学主要关注数据的收集和分析,通过对数据的整理、描述和推断,揭示数据背后的规律和趋势。
而Python作为一种高效的编程语言,提供了丰富的数据处理和分析库,如NumPy、Pandas、Matplotlib 等,可以帮助我们进行数据的整理、可视化和分析。
数据的整理是统计学中非常重要的一步。
在Python中,我们可以使用Pandas库来读取和处理数据。
Pandas提供了DataFrame这个数据结构,可以方便地处理各种类型的数据。
我们可以通过读取CSV 文件、Excel文件或者数据库,将数据导入到DataFrame中,并进行各种操作,如数据清洗、缺失值处理等。
数据的描述是统计学中另一个重要的内容。
Python中的描述统计学主要通过计算数据的基本统计量来实现,如均值、中位数、标准差等。
我们可以使用NumPy库来进行这些计算。
NumPy提供了各种统计函数,可以方便地计算数据的基本统计量。
此外,我们还可以使用Matplotlib库来绘制各种图表,如直方图、折线图等,以便更直观地描述数据的分布和趋势。
数据的推断是统计学中最为重要的一环。
通过对样本数据的分析,我们可以对总体数据进行推断。
在Python中,我们可以使用Scipy 库来进行统计推断。
Scipy提供了各种统计推断函数,如t检验、方差分析等,可以帮助我们对样本数据进行假设检验和置信区间估计。
除了基本的数据处理和分析,Python还提供了一些高级的统计学方法和模型。
例如,我们可以使用Statsmodels库来进行线性回归分析,可以使用Scikit-learn库来进行机器学习和数据挖掘。
了解并利用日志分析与可视化工具

了解并利用日志分析与可视化工具日志分析与可视化工具是一种用于处理和分析日志数据的工具,它可以帮助我们深入了解系统的运行情况、识别潜在的问题和优化系统性能。
本文将介绍几种常用的日志分析与可视化工具,并探讨如何在实际应用中最大程度地利用这些工具。
1. ELK StackELK Stack是由Elastic公司推出的一套日志管理工具,包括Elasticsearch、Logstash和Kibana三个组件。
Elasticsearch是一款强大的搜索和分析引擎,用于存储和查询大量的日志数据;Logstash是用于数据收集、过滤和转换的工具;Kibana则是一个用于可视化数据并构建交互式仪表板的工具。
使用ELK Stack进行日志分析与可视化,首先需要将日志数据通过Logstash收集并转换成适合存储在Elasticsearch中的格式,然后通过Kibana实时地对这些数据进行可视化分析。
Kibana提供了丰富的图表和仪表板工具,可以帮助我们直观地了解系统的运行情况,比如日志产生的频率、异常发生的位置和趋势等。
2. SplunkSplunk是一款功能强大的日志分析和监控工具,它可以帮助用户实时收集、索引、搜索和分析大量的日志数据。
Splunk支持多种数据源和数据格式,包括日志文件、数据库、消息队列等,也可以通过API 集成第三方应用程序。
通过Splunk,用户可以创建自定义的搜索查询,快速定位问题和异常,并进行可视化分析。
Splunk还提供了丰富的报表和仪表板功能,可以轻松构建个性化的分析和监控界面。
此外,Splunk还支持机器学习和智能告警功能,可以帮助用户更好地了解系统的性能和行为。
3. GrafanaGrafana是一款开源的数据可视化工具,最初用于监控指标的可视化,但现在也可以用于分析和可视化日志数据。
Grafana支持多种数据源,包括Elasticsearch、InfluxDB、Prometheus等,可以将这些数据源中的数据进行处理和可视化。
大数据分析师如何进行数据挖掘工具和技术的应用案例

大数据分析师如何进行数据挖掘工具和技术的应用案例在当今的大数据时代,数据挖掘成为了一种重要的技术手段,帮助企业和组织从庞大的数据中发现隐藏的模式和知识。
作为大数据分析师,掌握数据挖掘工具和技术的应用是至关重要的。
本文将介绍一些常用的数据挖掘工具和技术,并通过实际案例展示它们的应用。
1. Python与Scikit-learnPython作为一种流行的编程语言,具备丰富的数据分析和挖掘库,其中最受欢迎的就是Scikit-learn。
Scikit-learn提供了各种机器学习算法和数据处理工具,可以进行数据预处理、特征选择、聚类、分类和回归等任务。
举个例子,一个大型电商公司想要通过用户行为数据推荐相关产品,数据分析师可以使用Scikit-learn中的聚类算法对用户进行分群,然后根据用户所在的群体进行个性化推荐。
2. SQL和关系数据库SQL是结构化查询语言的缩写,是一种管理关系型数据库的语言。
数据分析师在工作中通常需要处理大量的结构化数据,并从中提取有价值的信息。
通过编写SQL查询语句,可以方便地对数据库中的数据进行筛选、排序和汇总。
例如,一家银行想要分析客户的消费习惯,数据分析师可以使用SQL查询语句从交易记录中挖掘客户的消费偏好,进而制定个性化的推广策略。
3. Hadoop和MapReduceHadoop是一个用于分布式计算的开源框架,而MapReduce是其核心编程模型。
数据分析师可以利用Hadoop和MapReduce技术处理大规模的非结构化数据,如日志文件、社交媒体数据等。
比如,一家电信公司想要通过分析用户的通话记录预测用户的流失风险,数据分析师可以使用Hadoop和MapReduce将大量的通话数据进行处理,提取出有关用户通话时长、通话次数等特征,并利用机器学习算法进行流失风险预测。
4. Tableau和Power BITableau和Power BI是两个常用的数据可视化工具,它们能够将复杂的数据转化为易于理解和分析的可视化图表。
python数据分析案例

python数据分析案例在数据分析领域,Python 凭借其强大的库和简洁的语法,成为了最受欢迎的编程语言之一。
本文将通过一个案例来展示如何使用 Python进行数据分析。
首先,我们需要安装 Python 以及一些数据分析相关的库,如 Pandas、NumPy、Matplotlib 和 Seaborn。
这些库可以帮助我们读取、处理、分析和可视化数据。
接下来,我们以一个实际的数据分析案例来展开。
假设我们有一个包含用户购物数据的 CSV 文件,我们的目标是分析用户的购买行为。
1. 数据加载与初步查看使用 Pandas 库,我们可以轻松地读取 CSV 文件中的数据。
首先,我们导入必要的库并加载数据:```pythonimport pandas as pd# 加载数据data = pd.read_csv('shopping_data.csv')```然后,我们可以使用 `head()` 方法来查看数据的前几行,以确保数据加载正确。
```pythonprint(data.head())```2. 数据清洗在数据分析之前,数据清洗是一个必不可少的步骤。
我们需要处理缺失值、重复数据以及异常值。
例如,我们可以使用以下代码来处理缺失值:```python# 检查缺失值print(data.isnull().sum())# 填充或删除缺失值data.fillna(method='ffill', inplace=True)```3. 数据探索在数据清洗之后,我们进行数据探索,以了解数据的分布和特征。
我们可以使用 Pandas 的描述性统计方法来获取数据的概览:```pythonprint(data.describe())```此外,我们还可以绘制一些图表来可视化数据,例如使用Matplotlib 和 Seaborn 绘制直方图和箱线图:```pythonimport matplotlib.pyplot as pltimport seaborn as sns# 绘制直方图plt.figure(figsize=(10, 6))sns.histplot(data['purchase_amount'], bins=20, kde=True) plt.title('Purchase Amount Distribution')plt.xlabel('Purchase Amount')plt.ylabel('Frequency')plt.show()# 绘制箱线图plt.figure(figsize=(10, 6))sns.boxplot(x='category', y='purchase_amount', data=data) plt.title('Purchase Amount by Category')plt.xlabel('Category')plt.ylabel('Purchase Amount')plt.show()```4. 数据分析在数据探索的基础上,我们可以进行更深入的数据分析。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
pass
sorted_word2count = sorted(word2count.items(),key=itemgetter(0))
for word,count in sorted_word2count:
print'%s\t%s'%(word,count)
112.111.183.57 - - [29/Sep/2013:00:10:58 +0800] "POST /wp-comments-post.php HTTP/1.1" 302 513
5.63.145.70 - - [29/Sep/2013:00:11:03 +0800] "HEAD / HTTP/1.1" 200 221 "-" ""
for word in words:
print'%s\@%s'%(word,1)
reduce实现
#!/usr/bin/python
#_*_ coding:utf-8 _*_
#Filename:reduce.py
from operator import itemgetter
import sys
for line in sys.stdin:
line = line.strip()
if line.find('GET')!=-1:
words=line[:line.find(' ')]+'\t'+line[line.find('GET')+3:line.find('HTTP')]
用python实现mapreduce的web访问日志统计分析
注意:1、需给py脚本执行权限 chmod +x XXX.py。2、在执行前在系统用管道命令进行调试 cat test|map.py|reduce.py
日志类型:
175.44.19.36 - - [29/Sep/2013:00:10:57 +0800] "GET /mapreduce-nextgen/client-codes/ HTTP/1.1" 200 25470
words = filter(lambda word: word, words.split('\n'))
for word in words:
print'%s\t%s'%(word,1)
mapper实现--元组打印 (遇2 - 统计目录访问次数(/mapreduce-nextgen/client-codes/)
mapper实现--filter(lambda)打印
#!/usr/bin/python
# _*_ coding:utf-8 _*_
#Filename:mapper_3_2.py
import sys
elif line.find('HEAD')!=-1:
words=line[line.find('HEAD')+4:line.find('HTTP')]
else:
words=line[line.find('POST')+4:line.find('HTTP')]
words=line[:line.find(' ')]+'\t'+line[line.find('POST')+4:line.find('HTTP')]
else:
words=''
words = filter(lambda word:word, words.split('\n'))
import sys
word2count = {}
for line in sys.stdin:
line = line.strip()
word,count = line.split('\@',1)
try:
count = int(count)
word2count[word] = word2count.get(word,0)+count
words=re.match('(\d{1,3}\.){3}\d{1,3}',line).group()
words = words.split('\n')
for i in range(0,len(words)):
print'%s\t%s'%(words[i],1)
# if line.find('POST')!=-1:
elif line.find('HEAD')!=-1:
words=line[:line.find(' ')]+'\t'+line[line.find('HEAD')+4:line.find('HTTP')]
elif line.find('POST')!=-1:
for line in sys.stdin:
line = line.strip()
if line.find('GET')!=-1:
words=line[line.find('GET')+3:line.find('HTTP')]
# if line.find('POST')!=-1:
words=line[:line.find(' ')]
words = words.split('\n')
for i in range(0,len(words)):
print'%s\t%s'%(words[i],1)
reduce与之前一样
取IP 和路径 1
如果一样 +1
思路:IP和目录用\t来做分隔符,然后使用特殊符号\@来做为和1的分隔符,在reduce中进行分割,然后比对IP和目录,进行累加
mapper实现
#!/usr/bin/python
# _*_ coding:utf-8 _*_
#Filename:mapper_3_3.py
# _*_ coding:utf-8 _*_
#Filename:mapper_3_2.py
import sys
for line in sys.stdin:
line = line.strip()
if line.find('GET')!=-1:
words=line[line.find('GET')+3:line.find('HTTP')]
# if line.find('POST')!=-1:
elif line.find('HEAD')!=-1:
words=line[line.find('HEAD')+4:line.find('HTTP')]
else:
words=line[line.find('POST')+4:line.find('HTTP')]
mapper实现--字符串
#!/usr/bin/python
# _*_ coding:utf-8 _*_
#Filename:mapper_3_1_1.py
import sys
for line in sys.stdin:
line = line.strip()
words = filter(lambda word: word, words.split('\n'))
for word in words:
print'%s\t%s'%(word,1)
reduce与之前一样
3.3 - 统计每个 ip,访问的子目录次数,输出如:175.44.30.93 /structure/heap/ 8
3.1 - 统计访问ip地址数目
mapper实现--正则表达式
#!/usr/bin/python
# _*_ coding:utf-8 _*_
#Filename:mapper_3_1.py
import re
import sys
for line in sys.stdin:
line = line.strip()