R语言练习
R语言课程模拟题

(1)查看其类型,同时提取前十行数据;
(2)提取出速度大于10小于20的所有子数据集;
(3)添加新的一列,其数据集为刹车距离与速度的商qut.
(4)对cars数据集进行从小到大排序。
8.计算如下问题:
(1)模拟生成100个自由度为2的卡方随机变量,再求其中位数。
(2)计算自由度2的卡方分布的95%分位数。
11.使用cat()函数输出下列内容
(1)12 3 abc de
(2)123abcde
(3)1/2/3/abc/de
12. 对下列数列 7.3, 6.8, 0.005, 9, 12, 2.4, 18.9, 0.9
(a) 计算数列的均值;
(b) 将均值从数列中减去;
(c) 找出数列中本身大于其平方根的所有元素;
7.矩阵与数据框的区别与联系。
8.数据框在缺失值处理的三种方法。
9.因子的常用函数tapply()、split()以及by()函数的区别与联系。
10.简述函数tapply(x,f,g)执行操作。
11. 举例描述R语言排序相关的的三个函数:sort(),rank(),order()。
12. 简述apply系列函数在R语言中的应用。
6. 编写符合下列要求循环函数:
(1)使用三种循环,输出向量1:100中所有数据。
(2)使用repeat循环求1至100之间的奇数和
r语言二项分布例题

r语言二项分布例题二项分布是统计学中一种常见的离散概率分布,适用于研究在固定次数的独立实验中,成功的次数。
在R语言中,我们可以使用一系列内置函数来计算二项分布相关的概率或生成对应的随机数,这些函数包括dbinom, pbinom, qbinom,和rbinom。
首先,让我们通过一个简单的例子来理解如何在R语言中操作二项分布。
例题:假设一个硬币正面朝上的概率为0.5,现在我们抛10次硬币,我们希望计算恰好有5次正面朝上的概率。
1. dbinom函数用于计算特定成功次数的概率密度。
```R dbinom(5, size = 10, prob = 0.5) ``` 这里的`size`参数代表试验的总次数,`prob`参数代表单次试验的成功概率。
2. pbinom函数可以计算累积概率,即计算成功次数小于等于某个值的概率。
```R pbinom(5, size = 10, prob = 0.5) ```3. qbinom函数用于计算分位数,即找到累积概率为给定值的成功次数。
```R qbinom(0.5, size = 10, prob = 0.5) ```4. rbinom函数可以生成符合二项分布的随机数。
```R rbinom(n = 1, size = 10, prob = 0.5) ``` 这里的`n`参数代表需要生成的随机数的数量。
以上就是使用R语言处理二项分布问题的一个基础例子。
在实际应用中,二项分布可以帮助我们处理很多现实生活中涉及到的统计问题。
例如,在市场研究、质量控制和生物信息学等领域,二项分布都有广泛的应用。
本文重点介绍了R语言中关于二项分布的几个核心函数的用法,希望能够帮助读者在处理相关统计问题时,更加得心应手。
此外,不断实践和探索不同参数对结果的影响,将有助于读者深入理解和掌握二项分布的性质和应用。
总结:本文介绍了在R语言中处理二项分布的核心方法和例题,包括了计算概率密度、累积概率、找分位数以及生成随机数等四个方面的函数应用。
R语言习题
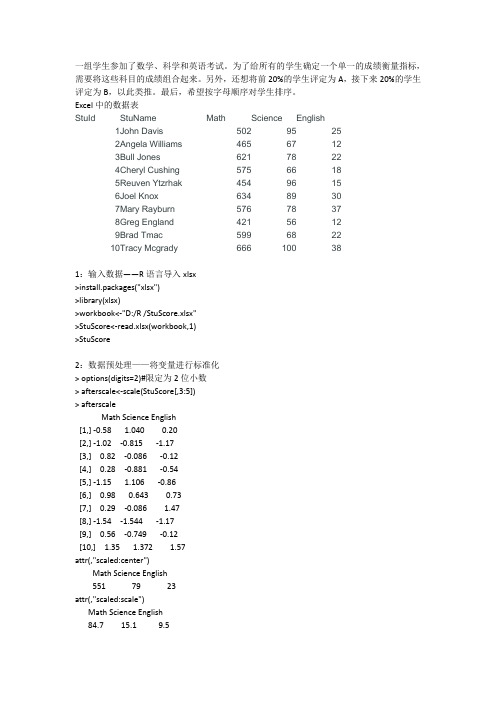
7:把name分成Firstname和LastName,加入到StuScore中
> FirstName<-sapply(name,"[",1)
> LastName<-sapply(name,"[",2)
> StuScore<-cbind(FirstName,LastName,StuScore[,-1])
一组学生参加了数学、科学和英语考试。为了给所有的学生确定一个单一的成绩衡量指标,需要将这些科目的成绩组合起来。另外,还想将前20%的学生评定为A,接下来20%的学生评定为B,以此类推。最后,希望按字母顺序对学生排序。
Excel中的数据表
StuId
StuName
Math
Science
English
1
John Davis
1 1 John Davis 502 95 25 0.22
2 2 Angela Williams 465 67 12 -1.00
3 3 Bull Jones 621 78 22 0.21
4 4 Cheryl Cushing 575 66 18 -0.38
5 5 Reuven Ytzrhak 454 96 15 -0.30
10 Tracy Mcgrady Mcgrady Tracy Mcgrady 666 100 38 1.43 B
8:order排序
> StuScore[order(LastName,FirstName),]
FirstName LastName LastNameStuName Math Science English score grade
r语言编程试题

r语言编程试题
以下是一些R语言的编程试题,这些试题考察的是基础的编程技能和对R语言
的掌握情况。
1.题目:假设有一个数据框(data.frame),其名称是"mydata",请你创建一个新的变量(列),
其名为"newvar",值为原变量"oldvar"的两倍。
r
mydata$newvar <- 2 * mydata$oldvar
2.题目:在R语言中,假设我们有一个向量v = c(1, 2, 3, 4, 5),我们想要创建一个新向
量v_squared,其中包含v中每个元素的平方。
r
v <- c(1, 2, 3, 4, 5)
v_squared <- v^2
3.题目:假设我们有一个数据框df,其中包含两列:一列是日期(date),一列是温度(temp)。
我们想要按日期对df进行排序,并且使得温度列的值显示为正数。
r
df <- df[order(df$date), ]
df$temp <- abs(df$temp)
4.题目:假设我们有一个向量x = c(1, 2, 3, 4, 5),我们想要计算x中所有元素的和。
r
x <- c(1, 2, 3, 4, 5)
sum <- sum(x)
5.题目:假设我们有一个数据框df,其中包含两列:一列是姓名(name),一列是年龄
(age)。
我们想要筛选出年龄大于等于20岁的人,并查看他们的姓名。
r
df <- df[df$age >= 20, ]
print(df$name)。
最新R语言自主练习题

1,某⼯⼚⽣产⼀批滚珠,其直径服从正态分布N(µ,σ2),现从某天的产品中随机抽出六件,测得直径为:15.1,14.8,15.2,14.9,14.6,15.1,。
若σ2 =0.06,求µ的置信区间。
(置信度为0.95)解:x<-c(15.1,14.8,15.2,14.9,14.6,15.1)sigema<-sqrt(0.06)alpha<-0.05xbar<-mean(x)n<-length(x)t1<-xbar-qnorm(1-alpha/2)*sigema/sqrt(n)t2<-xbar+qnorm(1-alpha/2)*sigema/sqrt(n)list(t1,t2),2,某某⾃动包装机包装洗⾐粉,其重量ζ~N(µ,σ2),其中µ,σ未知。
今随机抽取⼗⼆袋测得其重量,经计算得样本均值为xbar=1000.25,修正样本标准差s*=2.6329,试求总体标准差σ的置信⽔平为0.95的置信区间。
解:alpha<-0.05Xbar<-1000.25Sdx<-2.6329T1<-sqrt(11)*Sdx/sqrt(qchisq(1-alpha/2,11))T2<-sqrt(11)*Sdx/sqrt(qchisq(alpha/2,11))list(T1,T2)使⽤t.text函数进⾏⽅差未知的均值假设检验t检验t.test():调⽤格式:(数统P138,例6-3)x <- c(11.6,11.5,11.3,11.2,11.4,11.7,11.5,11.6,11.4,11.3)α<- 0.05solution <- t.test(x,mu=11.4,alternative="two.sided",conf.level = 1-α)#x是⼀个服从正态分布的总体,mu是均值µ#alternative是指备择假设,“two.sided”(缺省)指双侧(H1:µ≠µ0),less表⽰单边检验(H1:µ<µ1),greater表⽰单边检验(H1:µ>µ1) #conf.level指置信度即1-αsolutionif(solution$p.value>α){print("接受H0")}else{print("拒绝H0,接受H1")x <- c(49.6,49.3,50.1,50.0,49.2,49.9,49.8,51.0,50.2)α<- 0.05solution <- t.test(x,mu=50,alternative="two.sided",conf.level = 1-α)solutionif(solution$p.value>α){print("接受H0")}else{print("拒绝H0,接受H1")}p-value>α,接受H0认为包装机⼯作正常。
r语言入门100道题

r语言入门100道题以下是100个R语言入门的问题,供您参考:1. 如何在R中创建一个向量?2. 如何在R中创建一个矩阵?3. 如何在R中创建一个数据框?4. 如何在R中创建一个列表?5. 如何在R中创建一个因子?6. 如何在R中创建一个日期对象?7. 如何在R中读取一个CSV文件?8. 如何在R中写入一个CSV文件?9. 如何在R中读取一个Excel文件?10. 如何在R中写入一个Excel文件?11. 如何在R中读取一个文本文件?12. 如何在R中写入一个文本文件?13. 如何在R中计算一个向量的平均值?14. 如何在R中计算一个向量的标准差?15. 如何在R中计算一个向量的中位数?16. 如何在R中计算一个向量的最大值?17. 如何在R中计算一个向量的最小值?18. 如何在R中计算一个向量的总和?19. 如何在R中计算一个向量的排序列表?20. 如何在R中计算一个矩阵的行数和列数?21. 如何在R中计算一个矩阵的转置矩阵?22. 如何在R中计算一个矩阵的行列式?23. 如何在R中计算一个矩阵的逆矩阵?24. 如何在R中计算一个矩阵的特征值和特征向量?25. 如何在R中计算一个矩阵的行和列的总和?26. 如何在R中计算一个数据框的行数和列数?27. 如何在R中计算一个数据框的列的平均值?28. 如何在R中计算一个数据框的列的标准差?29. 如何在R中计算一个数据框的列的中位数?30. 如何在R中计算一个数据框的列的最大值?31. 如何在R中计算一个数据框的列的最小值?32. 如何在R中计算一个数据框的列的总和?33. 如何在R中从一个向量中选择指定的元素?34. 如何在R中从一个向量中删除指定的元素?35. 如何在R中从一个向量中查找指定的元素?36. 如何在R中从一个向量中替换指定的元素?37. 如何在R中从一个向量中添加元素?38. 如何在R中从一个向量中提取唯一的元素?39. 如何在R中从一个矩阵中选择指定的行和列?40. 如何在R中从一个矩阵中删除指定的行和列?41. 如何在R中从一个矩阵中查找指定的行和列?42. 如何在R中从一个矩阵中替换指定的行和列?43. 如何在R中从一个矩阵中添加行和列?44. 如何在R中从一个数据框中选择指定的行和列?45. 如何在R中从一个数据框中删除指定的行和列?46. 如何在R中从一个数据框中查找指定的行和列?47. 如何在R中从一个数据框中替换指定的行和列?48. 如何在R中从一个数据框中添加行和列?49. 如何在R中对一个向量进行排序?50. 如何在R中对一个矩阵的行和列进行排序?51. 如何在R中对一个数据框的列进行排序?52. 如何在R中对一个数据框的多个列进行排序?53. 如何在R中对一个向量进行分组求和?54. 如何在R中对一个数据框的列进行分组求和?55. 如何在R中对一个向量进行分组统计?56. 如何在R中对一个数据框的列进行分组统计?57. 如何在R中对一个向量进行条件筛选?58. 如何在R中对一个数据框的列进行条件筛选?59. 如何在R中对一个向量进行条件替换?60. 如何在R中对一个数据框的列进行条件替换?61. 如何在R中对一个数据框的列进行合并去重?62. 如何在R中对一个数据框的列进行合并求和?63. 如何在R中对一个数据框的列进行合并求平均值?64. 如何在R中计算一个向量的累计和?65. 如何在R中计算一个向量的累计乘积?66. 如何在R中计算一个向量的累计均值?67. 如何在R中计算一个矩阵的累计和?68. 如何在R中计算一个矩阵的累计乘积?69. 如何在R中计算一个矩阵的累计均值?70. 如何在R中计算一个数据框的累计和?71. 如何在R中计算一个数据框的累计乘积?72. 如何在R中计算一个数据框的累计均值?73. 如何在R中计算两个向量的点积?74. 如何在R中计算两个向量的叉积?75. 如何在R中计算两个向量的欧几里得距离?76. 如何在R中计算两个矩阵的乘积?77. 如何在R中计算两个矩阵的点积?78. 如何在R中计算两个矩阵的叉积?79. 如何在R中将一个向量转换为矩阵?80. 如何在R中将一个向量转换为数据框?81. 如何在R中将一个向量转换为列表?82. 如何在R中将一个向量转换为因子?83. 如何在R中将一个矩阵转换为向量?84. 如何在R中将一个矩阵转换为数据框?85. 如何在R中将一个矩阵转换为列表?86. 如何在R中将一个矩阵转换为因子?87. 如何在R中将一个数据框转换为向量?88. 如何在R中将一个数据框转换为矩阵?89. 如何在R中将一个数据框转换为列表?90. 如何在R中将一个数据框转换为因子?91. 如何在R中将一个列表转换为向量?92. 如何在R中将一个列表转换为矩阵?93. 如何在R中将一个列表转换为数据框?94. 如何在R中将一个列表转换为因子?95. 如何在R中将一个因子转换为向量?96. 如何在R中将一个因子转换为矩阵?97. 如何在R中将一个因子转换为数据框?98. 如何在R中将一个因子转换为列表?99. 如何在R中将一个日期对象转换为字符对象?100. 如何在R中将一个字符对象转换为日期对象?这些问题涵盖了R语言中一些基本操作的方方面面,希望对您入门R语言有所帮助。
森林图-R语言代码-(含备注-附练习数据)

森林图R语言代码(含备注,附练习数据)#代码install.packages("forestplot")library(forestplot)library(readr)#从本地导入forest.csv数据,命名成mydatamydata<-read_csv("csv格式的文件路径")#例如:mydata<-read_csv("C:/Users/Lenovo/Desktop/data.csv")#定义表头row_name<-cbind(c("Subgroups",mydata$Subgroups),c("No. of. patients",mydata$`No. of patients`),c("OR 95%CI.",mydata$`OR(95% CI)`))#增加一行mydata<-rbind(rep(NA,3),mydata)#查看数据View(mydata)forestplot(labeltext=row_name,#设置用于文本展示的列,此处我们用数据的前三列作为文本,在图中展示mydata[,c("OR","LL","UL")],zero=1,#设置参照值,此处我们展示的是OR值,故参照值是1xlog=T,#对数x轴xticks=c(0.5,1.0,2.0,4.0),#x轴刻度boxsize=0.1,#设置点估计的方形大小lineheight=unit(10,'mm'),#设置图形中的行距colgap=unit(3,'mm'),#设置图形中的列间距lwd.zero=2,#设置参考线的粗细lwd.ci=1.5,#设置区间估计线的粗细col=fpColors(box='black',summary="black",lines='black',zero='red'),#使用fpColors()函数定义图形元素的颜色,从左至右分别对应点估计方形,汇总值,区间估计线,参考线xlab="Odd Ratios",#设置x轴标签lwd.xaxis=2,#设置x轴粗细graph.pos=3,#设置森林图的位置,此处设置为3,则出现在第三列is.summary=c(T,F,T,F,F,T,F,F,T,F,F))#该参数接受一个逻辑向量,用于定义数据中的每一行是否汇总值,若是,则在对应位置设置TRUE,若否,则设置为FALSE,设置为TRUE的行则以粗体出现library(ggplot2)forestplot(labeltext=row_name,mydata[,c("OR","LL","UL")],zero=1,xlog=F,xticks=c(0.5,1.0,2.0,4.0),boxsize=0.1,lineheight=unit(10,'mm'),colgap=unit(3,'mm'),lwd.zero=2,lwd.ci=1.5,col=fpColors(box='black',summary="black",lines='black',zero='red'),xlab="Odd Ratios",lwd.xaxis=2,graph.pos=3,axis.text.x = element_text(size =20,family="TNM"),#–x坐标轴axis.text.y = element_text(size=20,family="TNM"),#–y轴legend.title = element_text(size=20,family="TNM"),legend.text = element_text(size =20,family="TNM"),is.summary=c(T,F,T,F,F,T,F,F,T,F,F))附件:练习数据。
R语言与统计分析第四章答案

#第四章习题#4.1x<-rbinom(1000,100,0.3)hist(x z main=c("1000个参数为0.3的伯努利分布随机数”))#4.2x<-rnorm(1000,10z4) hist(x/probability=Xxlim=c(min(x)/max(x)),nclass=max(x)-min(x)+l z coh'lightblue^main^cf'lOOO 个正态分布随机数"))lines(density(x/bw=l)/col='blue,,lwd=3)#43x^samplefcfrtflOALrtflO^Jjtf 10,10)),1000,replace=T) hist(x/xlim=c(min(x)/max(x)),probability=l;n class=max(x)-min(x)+l/col=,lightblue,/ main=c("3个t分布混合样本直方图")) lines(density(x/bw=l)/col='blue,,lwd=2)#方法二k<-matrix(,3,100)k[lJ=rt(100z l)k[2j=rt(100z2) k[3j=rt(100,10) x=c(k[l,],k[2,],k[3,]) #3个t分布混合成一个样本hist(x/xlim=c(min(x)/max(x)),probability=l;n class=max(x)-min(x)+l/col=,lightblue,/ main=c("3个t分布混合样本直方图")) lines(density(x/bw=l),col=,blue,,lwd=2)#4.4install.packages(n DAAG H) library(DAAG) data(possum)par(mfrow=c(2,2))hist(possum$age,breaks=l+(0:8)*l)hist(possum$age,breaks=0+(0:9)*l)hist(possum$age,breaks=l+(0:5)*2) hist(possum$age,breaks=0+(0:5)*2) summary(possum$age) age<-possum$age[!is.na(possum$age)] summary(age)sd(age)#4.5install.packages(n DAAG H)library(DAAG)data(tinti ng)ts<-table(tinting$sex,tinting$tint) # 列联表barplot(ts) #联合柱状图windows() # 新图op<-par()layout(matrix(c(2/l z0,3)/2/2/byrow=T)/c(l/6)/c(4,l)) par(mar=c(l/l,5/l)) plot(tinting$age,tinting$it) lines(lowess(tinting$age,tinting$it)Jwd=2) #拟合线rug(side=2,jitter(tinting$age,5)) #细小刻度rug(side=l/jitter(tinting$it/5)) par(mar=c(l/2,5/l))boxplot(tinting$age,axes=F)par(mar=c(5/l,l/2))boxplot(ti ntin g$it,horizontal=Taxes=F) windows()#因子为tintcoplot(ti nting$age~tinting$it | tintin g$ti nt)windows()#因子为tint与sexcoplot(ti nting$age~tinti ng$it| tintin g$ti nt*tinti ng$sex)windows()#等高线图library(MASS)z<-kde2d(tinti ng$it,ti nt in g$csoa) contour(z/col="red,,,drawlabels=FALSE)windows() #matplot 图d<-data.frame(yl=tinting$age/y2=ti ntin g$it,y3=ti ntin g$csoa) matplot(d,type=T,mai n="matplot11) #4.6data(l nsectSprays)cs<-table(l nsectSprays$count」nsectSprays$spray) #歹ij 联表barplot(cs)windows ()mys<・c( 123,4,5,6 川nsectSprays$spray] # 分类图plot(lnsectSprays$count/col=mys,pch=mys)legend(x=40/y=26Jegend=c(,,A,I;,B,,;,C,I;,D,,;,E,,;,F,,)/col=c(l/2/3A5,6),pch=c(l/2,3A5/6)) c.s<-data.frame(A=l nsectSprays$count[l:12],#分类归纳B=lnsectSprays$count[13:24],C=ln sectSprays$co un t[25:36],D=lnsectSprays$count[37:48],E=lnsectSprays$count[49:60],F=lnsectSprays$count[61:72])summary(c.s)#4.7options(didits=4)db<-rnorm(100/75,9)print("均值“)mean(db)print("方差”)sd(db)print(“标准差”)sqrt(sd(db))print(“极差”)max(db)-min(db)print(“四分位极值”)mad(db)printf'变异系数”)sd(db)/mean(db)in stall.packages(,,fBasics H)library(fBasics)print(“偏度”)skew ness(db)print(“峰度”)kurtosis(db)print(”五数概括“)fivenum(db)hist(db,xlim=c(mi n(db),max(db)),probability=rn class=max(db)・min(db)+l,col='lightblue:main="直方图”)lines(density(db)/col=,red,Jwd=3)windows()qqnorm(db z main=,,QQ 图”)qqline(db,col=,red,)windows()x<-sort(db)n<-length(x)y<-(l:n)/nm<-mean(db)s<-sd(db)plot(x,y,type='s',main="经验分布图")curve(p norm(x,rTbs),col—recf」wd=2,add=T)print(”茎叶图“)stem(db)windows()boxplot(db,mai n="框须图”) #4.8install.packages(n RODBC n) #从Excel 读入数据library(RODBC) z<-odbcConnectExcel(,,C:/Users/Tang/Desktop/R/第四章数据・xls") data<-sqlFetch(z/,,Sheetl H) close(z)plot(data$体重~data$身高,main=“体重对身高散点图”)windows()coplot(data$ 体重~data$ 身高 | data$ 性别)windows()coplot(data$ 体重~data$ 身高 | data$ 年龄)windows()coplot(data$ 体重~data$ 身高 | data$ 性别*data$ 年龄)。
R语言数据分析与挖掘(谢佳标微课版) 习题及答案chapter08

一、多选题1.常用聚类分析技术有(ABCDE)A.K-均值聚类(K-MeanS)B.K•中心点聚类(K-MedOidS)C.密度聚类(DenSit-basedSpatia1C1usteringofApp1icationwithNoise z DBSCAN)D.层次聚类(系谱聚类Hierarchica1C1ustering,HC)E.期望最大化聚类(EXPeCtationMaximization z EM)2.常用划分(分类)方法的聚类算法有(AB)A.K-均值聚类(K-MeanS)B.K•中心点聚类(K-MedoidS)C.密度聚类(DenSit-basedSpatia1C1usteringofApp1icationwithNoise z DBSCAN)D.聚类高维空间算法(OJOUE)3.层次聚类分析常用的函数有(ABC)A.hc1ust()B.cutree()C.rect.hc1ust()D.ctree()4. K.均值聚类方法效率高,结果易于理解,但也有(ABCD)缺点A.需要事先指定簇个数kB.只能对数值数据进行处理C.只能保证是局部最优,而不一定是全局最优D.对噪声和孤立点数据敏感二、上机题1.数据集(1A.Neighborhoodsisv)是美国普查局2000年的洛杉矶街区数据,一共有I1O个参考答案:>u<-w[,c(1,2,5,6,11,16)]>rownames(u)<-u[,1]>#标准化数据,聚类方法="comp1ete">hh<-hc1ust(dist(sca1e(u[z-1])1"comp1ete") >#画树状图(分成五类)>Iibraryffactoextra)>fviz-dend(hh,k=5,rect=TRUE)OuΛ∙rD∙oαogr∙fr。
大学r语言考试题及答案

大学r语言考试题及答案一、选择题(每题2分,共20分)1. R语言是一种()。
A. 编程语言B. 数据分析工具C. 操作系统D. 网页浏览器答案:A2. 在R语言中,用于生成随机数的函数是()。
A. seq()B. rep()C. sample()D. random()答案:C3. 下列哪个函数可以用来计算R语言中的向量元素的总和?()A. sum()B. mean()C. median()D. max()答案:A4. R语言中,用于创建数据框(data frame)的函数是()。
A. data.frame()B. matrix()C. list()D. vector()答案:A5. 在R语言中,如何引用一个名为“x”的变量的第一个元素?()A. x[1]B. x(1)C. x{1}D. x->1答案:A6. R语言中,用于绘制直方图的函数是()。
A. plot()B. hist()C. bar()D. pie()答案:B7. 下列哪个选项是R语言中的数据类型?()A. 数字(numeric)B. 文本(text)C. 日期(date)D. 所有选项都是答案:D8. 在R语言中,如何将一个向量反向?()A. rev()B. reverse()C. flip()D. invert()答案:A9. R语言中,用于执行逻辑“与”操作的函数是()。
A. &B. &&C. &D. and()答案:A10. 下列哪个命令可以用来安装R语言的包?()A. install.packages()B. load.packages()C. get.packages()D. fetch.packages()答案:A二、简答题(每题5分,共30分)11. 简述R语言中向量和矩阵的区别。
答:R语言中的向量是一维的数据结构,可以包含相同类型的数据元素。
矩阵是二维的,由行和列组成,且矩阵中的所有元素必须是相同类型的。
r语言期末考试题及答案

r语言期末考试题及答案# R语言期末考试题及答案一、选择题(每题2分,共20分)1. 在R语言中,以下哪个是正确的向量创建方式?A. vector(1, 2, 3)B. c(1, 2, 3)C. vector(1, 2, 3, mode = "numeric")D. list(1, 2, 3)答案:B2. 下列哪个函数可以用来计算数据集的均值?A. mean()B. median()C. sum()D. range()答案:A3. 如果要对数据进行排序,应该使用哪个函数?A. sort()B. order()C. arrange()D. rank()答案:A4. R语言中,以下哪个是正确的数据框(data frame)创建方式?A. data_frame(a = 1:5, b = letters[1:5])B. data_frame(a = 1:5, b = letters[1:5], s = 1:5)C. data.frame(a = 1:5, b = letters[1:5])D. dataframe(a = 1:5, b = letters[1:5])答案:C5. 下列哪个选项是R语言中读取CSV文件的正确方法?A. read.csv()B. read.table()C. read.data()D. load.csv()答案:A...(此处省略其他选择题,共10题)二、简答题(每题10分,共20分)1. 简述R语言中列表(list)和向量(vector)的区别。
答案:向量是R语言中最基本的数据结构,它是一个一维数组,可以包含相同类型的元素。
向量的操作通常是向量化的,即对向量中的每个元素应用函数。
而列表是一种更复杂的数据结构,可以包含不同类型的元素,并且可以是多维的。
列表中的每个元素可以是一个向量、矩阵或其他列表,甚至可以是函数。
2. 解释R语言中条件语句if-else的用法。
R语言数据分析练习题参考答案

R语言数据分析练习题参考答案一、问题描述在这个练习中,我们将进行R语言数据分析的练习,并给出相应的参考答案。
以下是各个问题的具体描述:1. 统计数据给定一个包含10个正整数的向量x,求出以下统计数据:(1)向量x的均值;(2)向量x的中位数;(3)向量x的最大值;(4)向量x的最小值;(5)向量x的标准差。
2. 数据可视化使用R语言绘制以下数据的散点图:(1)给定一个包含50个数据点的数据集,x轴为变量x,y轴为变量y;(2)给定一个包含100个数据点的数据集,x轴为变量x,y轴为变量y,并对数据点进行颜色编码。
3. 数据处理给定一个包含100个数据点的数据集,其中的数据存在缺失值。
请使用R语言进行数据处理,具体要求如下:(1)删除包含缺失值的数据点;(2)计算数据集的均值并输出;(3)使用均值填充缺失值,并重新计算数据集的均值并输出。
二、问题解答下面给出以上问题的详细解答。
1. 统计数据(1)向量x的均值:mean(x)(2)向量x的中位数:median(x)(3)向量x的最大值:max(x)(4)向量x的最小值:min(x)(5)向量x的标准差:sd(x)2. 数据可视化(1)散点图1:plot(x, y)(2)散点图2:plot(x, y, col = colors)3. 数据处理(1)删除包含缺失值的数据点:complete_data <- na.omit(data)(2)计算数据集的均值并输出:mean(data)(3)使用均值填充缺失值,并重新计算数据集的均值并输出:data_filled <- datadata_filled[is.na(data_filled)] <- mean(data_filled, na.rm = TRUE)mean(data_filled)以上就是R语言数据分析练习题的参考答案。
通过这些练习,希望能够帮助你熟悉R语言的数据分析操作,并掌握常用的统计和可视化技巧。
多元统计分析及R语言建模(第五版)——第3章多元数据的直观表示课后习题
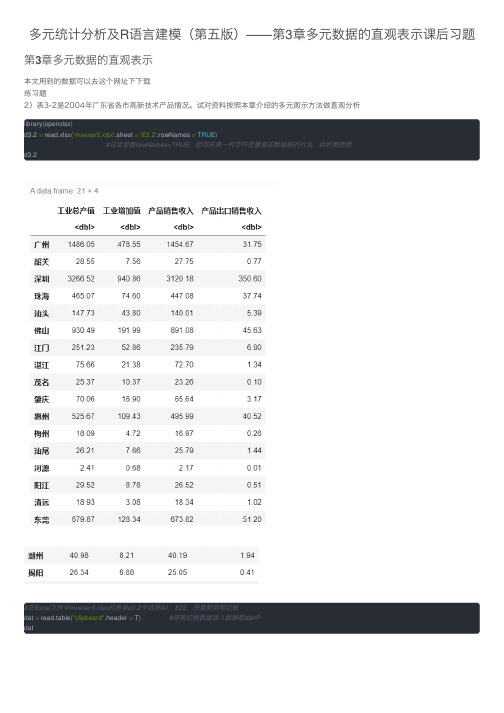
多元统计分析及R语⾔建模(第五版)——第3章多元数据的直观表⽰课后习题第3章多元数据的直观表⽰本⽂⽤到的数据可以去这个⽹址下下载练习题2)表3-2是2004年⼴东省各市⾼新技术产品情况。
试对资料按照本章介绍的多元图⽰⽅法做直观分析library(openxlsx)d3.2= read.xlsx('mvexer5.xlsx',sheet ='E3.2',rowNames =TRUE)#设定参数rowNames=TRUE,即可将第⼀列字符变量变成数据框的⾏名,供后期使⽤d3.2#在Excel⽂件中mvexer5.xlsx的表单d3.2中选择A1:E22,并复制到剪切板dat = read.table("clipboard",header = T)#将剪切板数据读⼊数据框dat中dat#数据框标记转换函数msa.X <-function(df){#将数据框第⼀列设置为数据框⾏名 X = df[,-1]#删除数据框df的第⼀列并赋给Xrownames(X)= df[,1]#将df的第⼀列值赋给X的⾏名X #返回新的数值数据框=return(X)}d3.2= msa.X(dat)d3.2barplot(apply(d3.2,2,mean))#按⾏作均值条形图barplot(apply(d3.2,1,mean),las =3)#修改横坐标标记barplot(apply(d3.2,2,mean))#按列作均值条图barplot(apply(d3.2,2,median))#按列作中位数条图barplot(apply(d3.2,2,median),col =1:8)#按列取⾊boxplot(d3.2)#按列作箱尾图boxplot(d3.2,horizontal = T)#箱尾图中图形按⽔平放置install.packages('aplpack',repos="https:///CRAN/") library(aplpack)faces(d3.2,ncol.plot =7)#按每⾏7个作脸谱图install.packages('TeachingDemos',repos="https:///CRAN/") library(TeachingDemos)faces2(d3.2,ncols =7)#作⿊⽩脸谱图install.packages('andrews',repos="https:///CRAN/") library(andrews)andrews(d3.2,clr =2,ymax =5)#⼀般调和曲线source('msaR.R')msa.andrews(d3.2)#改进调和曲线msa.andrews(d3.2[c(1,3,5,7,9,11,13,15,17),])#作第1,3,5,7,9,11,13,15,17个观测的调和曲线图。
R语言时间序列作业

2016年第二学期时间序列分析及应用R 语言课后作业 第三章 趋势3.4(a) data(hours);plot(hours,ylab='Monthly Hours',type='o') 画出时间序列图(b) data(hours);plot(hours,ylab='Monthly Hours',type='l')type='o' 表示每个数据点都叠加在曲线上;type='b' 表示在曲线上叠加数据点,但是该数据点附近是断开的;type='l' 表示只显示各数据点之间的连接线段;type='p' 只想显示数据点。
points(y=hours,x=time(hours),pch=as.vector(season(hours)))3.10(a)TimeM o n t h l y H o u r s1983198419851986198739.039.540.040.541.041.5TimeM o n t h l y H o u r s1983198419851986198739.039.540.040.541.041.5TimeM o n t h l y H o u r s1983198419851986198739.039.540.040.541.041.5J A SO N D J FM A M J J AS O N DJ F M AM J J A S O N DJ F MA M JJA S ON DJ FM AMJ JA S ONDJ F M AM Jdata(hours);hours.lm=lm(hours~time(hours)+I(time(hours)^2));summary(hours.lm) 用最小二乘法拟合二次趋势,结果显示如下: Call:lm(formula = hours ~ time(hours) + I(time(hours)^2))Residuals:Min 1Q Median 3Q Max -1.00603 -0.25431 -0.02267 0.22884 0.98358Coefficients:Estimate Std. Error t value Pr(>|t|) (Intercept) -5.122e+05 1.155e+05 -4.433 4.28e-05 *** time(hours) 5.159e+02 1.164e+02 4.431 4.31e-05 *** I(time(hours)^2) -1.299e-01 2.933e-02 -4.428 4.35e-05 *** ---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1Residual standard error: 0.423 on 57 degrees of freedomMultiple R-squared: 0.5921, Adjusted R-squared: 0.5778 F-statistic: 41.37 on 2 and 57 DF, p-value: 7.97e-12(b)plot(y=rstudent(hours.lm),x=as.vector(time(hours)),type='l',ylab='Standardized Residuals')points(y=rstudent(hours.lm),x=as.vector(time(hours)),pch=as.vector(season(hour s)))标准残差的时间序列,应用月度绘图标志。
r语言简答题

1. R语言是什么?
R语言是一种用于统计分析和数据可视化的编程语言,它广泛应用于数据挖掘、机器学习、生物信息学等领域。
2. R语言的特点有哪些?
R语言具有以下特点:
- 免费开源;
- 功能强大,支持多种统计分析方法;
- 丰富的数据处理和可视化工具;
- 支持并行计算和分布式计算;
- 社区活跃,有大量的扩展包可供使用。
3. R语言的数据类型有哪些?
R语言的主要数据类型包括:数值型(numeric)、字符型(character)、因子型(factor)、逻辑型(logical)、复数型(complex)等。
4. R语言的基本语法规则有哪些?
R语言的基本语法规则包括:
- 使用#号表示注释;
- 使用双引号或单引号表示字符串;
- 使用$符号访问对象的属性和方法;
- 使用<-符号进行赋值操作;
- 使用cat()函数输出文本,使用print()函数输出变量值;
- 使用ifelse()、switch()等函数进行条件判断;
- 使用for循环、while循环等结构进行循环操作。
R语言菜鸟练习笔记8

选择题1、产量(X ,台)与单位产品成本(Y ,元/台)之间的回归方程为ˆ356 1.5YX =-,这说明( D )。
A.产量每增加一台,单位产品成本增加356元B.产量每增加一台,单位产品成本减少1.5元C.产量每增加一台,单位产品成本平均增加356元D.产量每增加一台,单位产品成本平均减少1.5元根据上表找出回归方程,并据此模型预报广告费用为6万元时销售额为B A .63.6万元 B .65.5万元 C .67.7万元 D .72.0万元3、某项存款利率为6%,每半年复利一次,其实际利率为(B ) A3% B6.09% C6% D6.6%4、有一种债券面值2000元,票面利率为6%,每年支付一次利率,5年到期,同等风险投资的必要报酬率为10%,则该债券的价格在( D )元以下时才可以投资A 1600.57B 696.75C 1966.75D 1696.755、6年分期付款购物,每年年初付款500元,设银行利率为10%,该项分期付款相当于现在一次现金支付的购价是(A )。
A.2395.50元 B.1895.50元 C.1934.50元 D.2177.50元6、学校准备设立科研基金,现在存入一笔现金,预计以后无期限地在每年年末支取利息40000元。
在存款年利率为8%的条件下,现在应存款(A )元。
A .500000 B .40000 C .432000 D .4500007、企业采用融资租赁方式租入一台设备,价值100万元,租期5年,折现率为10%,则每年年初支付的等额租金是(C )万元。
A .20 B .26.98 C .23.98 D .16.38判断题1、在利率和计息期数相同的条件下,复利现值系数与复利终值系数互为倒数;年金现值系数与年金终值系数互为倒数。
(F )2、在本金和利率相同的情况下,若只有一个计息期,单利终值与复利终值是相同的。
(T )3、复利现值就是为在未来一定时期获得一定的本利和而现在所需的年金。
R语言5—函数

>sqr<-function(x) {1/2*a*b*sin(c)} >a<-1;b<-3;c<-1;x<-c(a,b,c) > sqr(x) [1] 1.262206 • >function(a,b,C){s<-a*b*sin(C)*(1/2) } • > s(2,3,pi/2) • > s<-function(a,b,C){ a*b*sin(C) } • > a<-2 • > b<-3 • > C<-pi/2 • > s(a,b,C) • [1] 6
R语言5—函数
生物统计学系 2010春
练习: 1.将标准目录中的data1.txt数据读入R中,名为 dd。并在df中加入新的变量ID,ID为1到20。 2.将上题结果保存为datadd.txt和datadd.R到指定 目录文件,并将dd数据保存为Excel文件格式。 3.查看在R的(base)中可用的数据库,并调用BOD 数据,最后在R中显示出BOD数据。 4.已知三角形的两个边长a、b,及他们的夹角C 编辑一个求此三角形面积的程序。
T=
2 (X −Y ) (n − 1) S12 + (n2 − 1) S 2 , S2 = 1 n1 + n2 − 2 1 1 S + n1 n2
X,Y为两组数据的样本均值,S12,S22为样本方差,n1,n2 为个数。
11
twosam<-function(y1,y2){ n1<-length(y1);n2<-length(y2) yb1<-mean(y1);yb2<-mean(y2) s1<-var(y1);s2<-var(y2) s<-((n1-1)*s1+(n2-1)*s2)/(n1+n2-2) (yb1-yb2)/sqrt(s*(1/n1+1/n2)) } > A<-c(79.98, 80.04, 80.02, 80.04, 80.03, 80.03, 80.04, 79.97, 80.05, 80.03, 80.02, 80.00, 80.02) >B<-c(80.02, , 79.95, 79.97) >twosam(A,B) [1] 3.472245
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一、填空
1.下列变量名中的 是合法变量
(A)char_1,data_2,x_j (B)x*y ,a.1 (C)x\y ,a1234 (D)end ,2bcx 2.已知x 为一个向量,计算其正弦函数的运算为 (A)SEC(X) (B)SIN(x) (C)sin(x) (D)secx 3.已知x =2^(0:3),则命令2*x 返回的结果为 4.命令rep(c(1,3),each=3)返回结果为 5.命令matrix(2:7,nrow=2,byrow=F)返回的结果为
6.已知矩阵⎥
⎥
⎥⎥⎦
⎤⎢⎢⎢
⎢⎣⎡=161284151173141062
13951A ,则命令A%*%A 返回的结果为 7.已知矩阵⎥⎥
⎥⎦
⎤
⎢⎢⎢⎣⎡=129631185210741B ,则命令dim(B)返回的结果为 8.已知矩阵⎥
⎦⎤
⎢⎣⎡=43214321A ,则命令rowSums(A)返回的结果为 9.已知矩阵⎥⎦⎤
⎢⎣⎡=54324321A ,则命令apply(A,2,sum)返回的结果为 10.命令rbind(1:3,1:4)返回的结果为
11.执行命令b=list(name="Fred",wife="Mary",no.children=3,child.ages=c(4,7,9))后,则命令length(b)返回的结果为
12.执行命令xx=array(1:24,c(3,4,2))后,则命令xx[2,1:3,2]返回的结果为 13.已知变量x=c(2,3),则执行命令x[5]<-5后变量x 的结果为 14.命令paste("x",1:5,sep="")返回的结果为 15.已知变量x=(1:10)+2,则命令x[1:5]返回的结果为
二、写出相应的命令和程序:
1、用函数rep()构造一个向量x,它由5个3,10个2,98个1构成
2、10位同学的姓名、性别、年龄、身高、体重数据如下:
Name Sex Age Height Weight
Alice F 13 56.5 84.0
Sandy F 11 51.3 50.5
Sharon F 15 62.5 112.5
Tammy F 14 62.8 102.5
Alfred M 14 69.0 112.5
Duke M 14 63.5 102.5
Guido M 15 67.0 133.0
Robert M 12 64.8 128.0
Thomas M 11 57.5 85.0
William M 15 66.5 112.0
(1)用数据框的形式读入数据,数据框的名称为my.class
(2)将上述数据写成一个纯文本的文件(文件名为class.txt),并用函数read.table()读取文件中的身高和体重数据
(3)按性别分组绘制学生身高的直方图
3、新建一个脚本文件,名为vector,,完成如下功能
(1)创建一个2到50的向量vector1
(2)选取vector1中的第10,15,20个元素
(3)选取vector1中第10到20个元素
(4)选取vector1中值大于40的元素
(5)将向量中的数据降序排列
4、新建一个脚本文件,名为plot,完成如下功能:
(1)生成0到2之间的50个随机数,分别命名为x,y
(2)绘制散点图,要求:
主标题为:“散点图”,横轴命名为“横坐标”,纵轴命名为“纵坐标”
设置文本颜色为红色
(3)在散点图的坐标为(0.6,0.6)的位置写入文本“text at (0.6,0.6)”
(4)在h=0.6,v=0.6处分别添加参考线
5、编写一个函数sqtest,给出两个数之后,直接给出这两个数的平方和,并调用该函数,实现计算20^2+15^2。