oracle绝密培训 11.分区表(章节)
ORACLE数据库分区表

tengyc@
五.分区表的修改:
分区数据的移动:
将分区的数据移动到另一个表空间上。 用于将分区移动到其它磁盘上。 减少分区碎片。 产生新的数据段、 清除旧的数据段。
SQL>Alter Table Employee Move Partition P1 Tablespace Sales_data;
TABLESPACE。
tengyc@
创建分区表举例:
SQL>Create table Employee( name varchar2(20), identification number(11), birth_date date, salary number(7,2), location char(50)) PARTITION BY RANGE(salary) (PARTITION p1 VALUES THAN (500) TABLESPACE ts1, PARTITION p2 VALUES THAN (800) TABLESPACE ts2, PARTITION p3 VALUES THAN (1000) TABLESPACE ts3, PARTITION p4 VALUES THAN (MAXVALUE) TABLESPACE ts4 );
tengyc@
五.分区表的修改:
删除分区:
SQL>Alter Table Employee Drop Partition p4;
SQL>Alter Table Employee Truncate Partition p4;
tengyc@
五.分区表的修改:
Oracle 11g培训课程资料

• • • • • • • • • • • • • •
2--表t_student的创建 create table t_student( stuno varchar2(20), name varchar2(20), age number(3), gender varchar2(4) );
SELECT * FROM T_STUDENT; DESC T_STUDENT; --增加字段 ALTER TABLE T_STUDENT ADD(CLASSID NUMBER(4)); --修改字段 ALTER TABLE T_STUDENT MODIFY (GENDER VARCHAR2(4) DEFAULT '男'); • ALTER TABLE T_STUDENT MODIFY (NAME VARCHAR2(10)); • ALTER TABLE T_STUDENT MODIFY (GENDER VARCHAR2(4)
数据库用户
11.系统全局区(SGA)
SGA有几个内存结构组成: – 共享池 – 数据库高速缓存 – 重做日志缓存 – 其它结构(例如锁和闩锁,数 据状态) 在SGA中有两个可选的内存结构: – 大池 – JAVA池
共享缓冲区 库缓冲区 数据字典
SGA
数据缓冲区 日志缓冲区
Java池
大池
12.SQL查询语句的步骤 编译(parse) 首先在共享池中搜索是否有相同的SQL语句,如果没有就进行后续操作 检查SQL语句的语法是否正确 通过查看数据字典来检查表和列的定义 对所操作的对象加编译锁,以便在编译语句期间对象的定义不能被改变 检查所引用对象的用户权限 生产执行该SQL语句所需的优化执行计划 将SQL语句的执行计划装入共享的SQL区 执行(execute) 提取数据(fetch)
Oracle中分区表

Oracle中分区表 分区表就是通过使⽤分区技术,将⼀张⼤表,拆分成多个表分区(独⽴的segment),从⽽提升数据访问的性能,以及⽇常的可维护性。
分区表分为 : 范围分区(range),列表分区(list),散列分区(hash),复合分区,交换分区 数据库的逻辑结构 : 表空间tablspace,段segment,区extent,块block 可以对分区表进⾏ : insert , update ,delete 需要注意:虽然各个分区可以存放在不同的表空间中,但这些表空间所使⽤的块⼤⼩必须⼀致。
分区表是建表之初建⽴的,不能后期添加1.RANGE(范围分区) 范围分区 : 按照范围进⾏分区,通常是按照字段分区,⽐如申请时间,⼊职时间等...创建语法:CREATE TABLE 表名( 列名数据类型,....)PARTITION BY RANGE (字段)( PARTITION 分区名1 VALUES LESS THAN (值1或⽇期1),PARTITION 分区名2 VALUES LESS THAN (值2或⽇期2),PARTITION 分区名3 VALUES LESS THAN (值3或⽇期3),PARTITION 分区名4 VALUES LESS THAN (MAXVALUE));/* VALUSE LESS THAN 特点 :VALUES < 值1VALUES >= 值1 AND VALUES < 值2VALUES >= 值2 AND VALUES < 值3VALUES >= 值3 AND VALUES < 值4....*/--新增分区 : ⾸先表⼀定要是分区表才可以新增--新增分区⾼于最后⼀个分区界限新增语法:ALTER TABLE 表名 ADD PSRTITION 分区名VALUES LESS THAN (值或⽇期);删除语法:ALTER TABLE 表名 GROP PARTITION 分区名;查询语法:SELECT <SELECT_LIST> FROM 表名 PARTITION(分区名);注意 : 除明确要求,尽量不要使⽤"MAXVALUE"2.LIST(列表分区)列表分区 : 按照列表分区,例如⾝份证号最后⼀位等创建语法:CREATE TABLE 表名( 列名数据类型,....)PARTITION BY LIST (字段)( PARTITION 分区名1 VALUES (值1),PARTITION 分区名2 VALUES (值2),PARTITION 分区名3 VALUES (值3));新增语法:ALTER TABLE 表名 ADD PSRTITION 分区名 VALUES (值);删除语法:ALTER TABLE 表名 GROP PARTITION 分区名;查询语法:SELECT <SELECT_LIST> FROM 表名 PARTITION(分区名);3.HESH(散列分区或哈希分区)实际结论见下:1. 数据随机插⼊Hash分区⼀般是在分区键值⽆法确定的情况下,使⽤的⼀种分区策略,Oracle按照hash 算法把数据插⼊⽤户指定的分区键中,它是随机的插⼊到某个区中,不受⼈为的⼲预。
Oracle分区表(partitioned table)

Oracle分区表(partitioned table)管理分区表和索引一、什么是分区表现在的数据库,单个表的数据量可能很大,达到几百个G和几T的程度,这时侯,你需要使用分区表和分区索引来管理数据,它将一个大的多分为块,称为分区(patitions),甚至子分区(subpartition)。
每一个分区都保存在自已的段中,可以单独的管理。
分区可以结合并行执行和合理的数据分布来提高系统的可用性和性能。
●减少数据中断的可能性●可以单独备份或恢复每一个分区●控制分区的分布(平衡I/O负荷)●提高可管理性,可用性和性能二、表分区的方法1. range 使用表的字段的值的范围来进行分区,它特别适用于数据有逻辑范围的表。
如一年中的月。
当数据在范围内均匀分布时性能最好。
create table salse ( invoice_no number, sale year int not null, sale month int not null, sale_day int not null) partion by range(sale yea,sale_month,sale_day) (partition sale_q1 value less than (1999,04,01) tablespace tsa partition sale_q2 value less than (2000,04,01) tablespace tsb partition sale_q2 value less than (maxvalue) tablespace tsc);--最大值maxvalue 可以指定 enable row movement来设置当分区列的值被修改时,将行移动到不同的分区。
2. hash 当数据不容易使用range分区,但你又需要使用分区来提高性能和可管理性,hash分区方法,根据分区值(partitioning key)的hash值来确定分区。
ORACLE分区表、分区索引详解

ORACLE分区表、分区索引详解ORACLE分区表、分区索引ORACLE对于分区表⽅式其实就是将表分段存储,⼀般普通表格是⼀个段存储,⽽分区表会分成多个段,所以查找数据过程都是先定位根据查询条件定位分区范围,即数据在那个分区或那⼏个内部,然后在分区内部去查找数据,⼀个分区⼀般保证四⼗多万条数据就⽐较正常了,但是分区表并⾮乱建⽴,⽽其维护性也相对较为复杂⼀点,⽽索引的创建也是有点讲究的,这些以下尽量阐述详细即可。
1、类型说明:range分区⽅式,也算是最常⽤的分区⽅式,其通过某字段或⼏个字段的组合的值,从⼩到⼤,按照指定的范围说明进⾏分区,我们在INSERT数据的时候就会存储到指定的分区中。
List分区⽅式,⼀般是在range基础上做的⼆级分区较多,是⼀种列举⽅式进⾏分区,⼀般讲某些地区、状态或指定规则的编码等进⾏划分。
Hash分区⽅式,它没有固定的规则,由ORACLE管理,只需要将值INSERT进去,ORACLE会⾃动去根据⼀套HASH算法去划分分区,只需要告诉ORACLE要分⼏个区即可。
分区可以进⾏两两组合,ORACLE 11G以前两两组合都必须以range作为⼀级分区的开头,ORACLE⽬前最多⽀持2级别分区,但这个级别已经够我们使⽤了。
我这只以最简单的分区⽅式创建分区来说明问题,就拿range分区来说明问题吧(基本创建语句如下):CREATE [url=]TABLE[/url] TABLE_PARTITION(COL1 NUMBER,COL2 VARCHAR2(10))partition by range(COL1)(partition TAB_PARTOTION_01 values less than (450000),partition TAB_PARTOTION_02 values less than (900000),partition TAB_PARTOTION_03 values less than (1350000),partition TAB_PARTOTION_04 values less than (1800000),partition TAB_PARTOTION_OTHER values less THAN (MAXVALUE));这个分区表创建了四个定长分区,理想情况下,存储450000条数据,扩展分区是超过这个数额的分区,当发现扩展分区有数据的时候,可以进⾏将扩展分区做SPLIT操作,这个后⾯说明,这⾥先说⼀下⼀些常⽤的分区表查询功能,我们先插⼊⼀些数据进去。
多做知识的积累 详解ORACLE数据库的分区表

多做知识的积累详解ORACLE数据库的分区表此文从以下几个方面来整理关于分区表的概念及操作: 1.表空间及分区表的概念2.表分区的具体作用3.表分区的优缺点4.表分区的几种类型及操作方法5.对表分区的维护性操作.(1.) 表空间及分区表的概念表空间:是一个或多个数据文件的集合,所有的数据对象都存放在指定的表空间中,但主要存放的是表,所以称作表空间。
分区表:当表中的数据量不断增大,查询数据的速度就会变慢,应用程序的性能就会下降,这时就应该考虑对表进行分区。
表进行分区后,逻辑上表仍然是一张完整的表,只是将表中的数据在物理上存放到多个表空间(物理文件上),这样查询数据时,不至于每次都扫描整张表。
( 2).表分区的具体作用Oracle的表分区功能通过改善可管理性、性能和可用性,从而为各式应用程序带来了极大的好处。
通常,分区可以使某些查询以及维护操作的性能大大提高。
此外,分区还可以极大简化常见的管理任务,分区是构建千兆字节数据系统或超高可用性系统的关键工具。
分区功能能够将表、索引或索引组织表进一步细分为段,这些数据库对象的段叫做分区。
每个分区有自己的名称,还可以选择自己的存储特性。
从数据库管理员的角度来看,一个分区后的对象具有多个段,这些段既可进行集体管理,也可单独管理,这就使数据库管理员在管理分区后的对象时有相当大的灵活性。
但是,从应用程序的角度来看,分区后的表与非分区表完全相同,使用 SQL DML 命令访问分区后的表时,无需任何修改。
什么时候使用分区表:1、表的大小超过2GB。
2、表中包含历史数据,新的数据被增加都新的分区中。
(3).表分区的优缺点表分区有以下优点:1、改善查询性能:对分区对象的查询可以仅搜索自己关心的分区,提高检索速度。
2、增强可用性:如果表的某个分区出现故障,表在其他分区的数据仍然可用;3、维护方便:如果表的某个分区出现故障,需要修复数据,只修复该分区即可;4、均衡I/O:可以把不同的分区映射到磁盘以平衡I/O,改善整个系统性能。
oracle分区表详解

oracle分区表详解⼀、分区表的概述:Oracle的表分区功能通过改善可管理性、性能和可⽤性,从⽽为各式应⽤程序带来了极⼤的好处。
通常,分区可以使某些查询以及维护操作的性能⼤⼤提⾼。
此外,分区还可以极⼤简化常见的管理任务,分区是构建千兆字节数据系统或超⾼可⽤性系统的关键⼯具。
分区功能能够将表、索引或索引组织表进⼀步细分为段,这些数据库对象的段叫做分区。
每个分区有⾃⼰的名称,还可以选择⾃⼰的存储特性。
从数据库管理员的⾓度来看,⼀个分区后的对象具有多个段,这些段既可进⾏集体管理,也可单独管理,这就使数据库管理员在管理分区后的对象时有相当⼤的灵活性。
1、分区表的优点:(1)由于将数据分散到各个分区中,减少了数据损坏的可能性;(2)可以对单独的分区进⾏备份和恢复;(3)可以将分区映射到不同的物理磁盘上,来分散IO;(4)提⾼可管理性、可⽤性和性能。
2、什么时候⽤分区表(1) 单表过⼤,超过⼀定范围,建议以g计算表,均可考虑⽤分区(2)历史数据据需要剥离的(3)查询特征⾮常明显,⽐如是按整年、整⽉或者按某个范围!3、分区表的类型1、range分区,按范围2、list分区,列举分区3、hash分区,根据hash值进⾏的散列分区4、复合分区,9i开始,Oracle就包括了2种复合分区,RANGE-HASH和RANGE-LIST。
在11g,Oracle⼀下就提供了4种复合分区:RANGE-RANGE、LIST-RANGE、LIST-HASH和LIST-LIST。
⼆、创建分区的举例1、range分区create table p_table(obj_id number(10),object_id number(10),object_name varchar2(128),owner varchar2(30),object_type varchar2(19),created date)partition by range (obj_id)(partition obj_id1 values less than (20000),partition obj_id2 values less than (40000),partition obj_id3 values less than (60000),partition obj_id4 values less than (80000),partition obj_id5 values less than (99999));2、list分区create table l_table(obj_id number(10),object_id number(10),object_name varchar2(128),owner varchar2(30),segment_type varchar2(19),created date)partition by LIST(segment_type)(partition l_type1 values ('LOBINDEX') tablespace my_space1,partition l_type2 values ('VIEW') tablespace my_space2,partition l_type3 values ('TABLE') tablespace my_space2);3、hash分区create table h_table(obj_id number(10),object_id number(10),object_name varchar2(128),owner varchar2(30),object_type varchar2(19),partition by hash(object_id)( partition h_objid1,partition h_objid2,partition h_objid3,partition h_objid4);4、复合分区Oracle11g⼀下就提供了4种复合分区:RANGE-RANGE、LIST-RANGE、LIST-HASH和LIST-LIST。
Oracle分区表详解

Oracle分区全解一、Oracle分区简介ORACLE的分区是一种处理超大型表、索引等的技术。
分区是一种“分而治之”的技术,通过将大表和索引分成可以管理的小块,从而避免了对每个表作为一个大的、单独的对象进行管理,为大量数据提供了可伸缩的性能。
分区通过将操作分配给更小的存储单元,减少了需要进行管理操作的时间,并通过增强的并行处理提高了性能,通过屏蔽故障数据的分区,还增加了可用性。
二、Oracle分区优缺点优点:增强可用性:如果表的某个分区出现故障,表在其他分区的数据仍然可用;维护方便:如果表的某个分区出现故障,需要修复数据,只修复该分区即可;均衡I/O:可以把不同的分区映射到磁盘以平衡I/O,改善整个系统性能;改善查询性能:对分区对象的查询可以仅搜索自己关心的分区,提高检索速度。
缺点:分区表相关:已经存在的表没有方法可以直接转化为分区表。
不过Oracle 提供了在线重定义表的功能。
三、Oracle分区方法范围分区:范围分区就是对数据表中的某个值的范围进行分区,根据某个值的范围,决定将该数据存储在哪个分区上。
如根据序号分区,根据业务记录的创建日期进行分区等。
Hash分区(散列分区):散列分区为通过指定分区编号来均匀分布数据的一种分区类型,因为通过在I/O设备上进行散列分区,使得这些分区大小一致。
List分区(列表分区):当你需要明确地控制如何将行映射到分区时,就使用列表分区方法。
与范围分区和散列分区所不同,列表分区不支持多列分区。
如果要将表按列分区,那么分区键就只能由表的一个单独的列组成,然而可以用范围分区或散列分区方法进行分区的所有的列,都可以用列表分区方法进行分区。
范围-散列分区(复合分区):有时候我们需要根据范围分区后,每个分区内的数据再散列地分布在几个表空间中,这样我们就要使用复合分区。
复合分区是先使用范围分区,然后在每个分区内再使用散列分区的一种分区方法(注意:先一定要进行范围分区)范围-列表分区(复合分区):范围和列表技术的组合,首先对表进行范围分区,然后用列表技术对每个范围分区再次分区。
ORACLE分区表

ORACLE分区表一什么是分区表分区表就是将一张“大表”按照一定的条件分成多个区,各个区建议存放在不同的表空间中,这样可以提高可用性。
二分区类型分区表共有四种类型分别为:Range Partitioning–区间分区Hash Partitioning-散列分区List Partitioning-列表分区Composite Partitioning-组合分区三分区类型举例:3.1Range Partitioning–区间分区区间分区示例创建语句如下:CREATE TABLE sales_range(salesman_id NUMBER(5),salesman_name VARCHAR2(30),sales_amount NUMBER(10),sales_date DATE)COMPRESSPARTITION BY RANGE(sales_date)(PARTITION sales_jan2000 VALUES LESS THAN(TO_DATE('02/01/2000','DD/MM/YYYY')) tablespace p1,PARTITION sales_feb2000 VALUES LESS THAN(TO_DATE('03/01/2000','DD/MM/YYYY'))tablespacep2,PARTITION sales_mar2000 VALUES LESS THAN(TO_DATE('04/01/2000','DD/MM/YYYY')) tablespace p3,PARTITION sales_apr2000 VALUES LESS THAN(TO_DATE('05/01/2000','DD/MM/YYYY')) tablespace p4,PARTITION SALES_MAX VALUES LESS THAN (MAXVALUE) TABLESPACE P4);分区键:分区表引入了分区键以便于根据某个区间值将表进行分区,上边示例中的sales_date就是区间分区的分区键。
oracle表分区详解

一、Oracle分区简介ORACLE的分区是一种处理超大型表、索引等的技术。
分区是一种“分而治之”的技术,通过将大表和索引分成可以管理的小块,从而避免了对每个表作为一个大的、单独的对象进行管理,为大量数据提供了可伸缩的性能。
分区通过将操作分配给更小的存储单元,减少了需要进行管理操作的时间,并通过增强的并行处理提高了性能,通过屏蔽故障数据的分区,还增加了可用性。
二、Oracle分区优缺点优点:增强可用性:如果表的某个分区出现故障,表在其他分区的数据仍然可用;维护方便:如果表的某个分区出现故障,需要修复数据,只修复该分区即可;均衡I/O:可以把不同的分区映射到磁盘以平衡I/O,改善整个系统性能;改善查询性能:对分区对象的查询可以仅搜索自己关心的分区,提高检索速度。
缺点:分区表相关:已经存在的表没有方法可以直接转化为分区表。
不过Oracle 提供了在线重定义表的功能。
三、Oracle分区方法范围分区:范围分区就是对数据表中的某个值的范围进行分区,根据某个值的范围,决定将该数据存储在哪个分区上。
如根据序号分区,根据业务记录的创建日期进行分区等。
Ha sh分区(散列分区):散列分区为通过指定分区编号来均匀分布数据的一种分区类型,因为通过在I/O设备上进行散列分区,使得这些分区大小一致。
List分区(列表分区):当你需要明确地控制如何将行映射到分区时,就使用列表分区方法。
与范围分区和散列分区所不同,列表分区不支持多列分区。
如果要将表按列分区,那么分区键就只能由表的一个单独的列组成,然而可以用范围分区或散列分区方法进行分区的所有的列,都可以用列表分区方法进行分区。
范围-散列分区(复合分区):有时候我们需要根据范围分区后,每个分区内的数据再散列地分布在几个表空间中,这样我们就要使用复合分区。
复合分区是先使用范围分区,然后在每个分区内再使用散列分区的一种分区方法(注意:先一定要进行范围分区)范围-列表分区(复合分区):范围和列表技术的组合,首先对表进行范围分区,然后用列表技术对每个范围分区再次分区。
oracle表空间表分区详解

oracle表空间表分区详解及oracle表分区查询使用方法此文从以下几个方面来整理关于分区表的概念及操作:1.表空间及分区表的概念2.表分区的具体作用3.表分区的优缺点4.表分区的几种类型及操作方法5.对表分区的维护性操作.(1.) 表空间及分区表的概念表空间:是一个或多个数据文件的集合,所有的数据对象都存放在指定的表空间中,但主要存放的是表,所以称作表空间。
分区表:当表中的数据量不断增大,查询数据的速度就会变慢,应用程序的性能就会下降,这时就应该考虑对表进行分区。
表进行分区后,逻辑上表仍然是一张完整的表,只是将表中的数据在物理上存放到多个表空间(物理文件上),这样查询数据时,不至于每次都扫描整张表。
( 2).表分区的具体作用Oracle的表分区功能通过改善可管理性、性能和可用性,从而为各式应用程序带来了极大的好处。
通常,分区可以使某些查询以及维护操作的性能大大提高。
此外,分区还可以极大简化常见的管理任务,分区是构建千兆字节数据系统或超高可用性系统的关键工具。
分区功能能够将表、索引或索引组织表进一步细分为段,这些数据库对象的段叫做分区。
每个分区有自己的名称,还可以选择自己的存储特性。
从数据库管理员的角度来看,一个分区后的对象具有多个段,这些段既可进行集体管理,也可单独管理,这就使数据库管理员在管理分区后的对象时有相当大的灵活性。
但是,从应用程序的角度来看,分区后的表与非分区表完全相同,使用 SQL DML 命令访问分区后的表时,无需任何修改。
什么时候使用分区表:1、表的大小超过2GB。
2、表中包含历史数据,新的数据被增加都新的分区中。
(3).表分区的优缺点表分区有以下优点:1、改善查询性能:对分区对象的查询可以仅搜索自己关心的分区,提高检索速度。
2、增强可用性:如果表的某个分区出现故障,表在其他分区的数据仍然可用;3、维护方便:如果表的某个分区出现故障,需要修复数据,只修复该分区即可;4、均衡I/O:可以把不同的分区映射到磁盘以平衡I/O,改善整个系统性能。
oracle分区表

Oracle 分区表2011-11-03 11:30Oracle 分区表Oracle提供了分区技术以支持VLDB(Very Large DataBase)。
分区表通过对分区列的判断,把分区列不同的记录,放到不同的分区中。
分区完全对应用透明。
Oracle的分区表可以包括多个分区,每个分区都是一个独立的段(SEGMENT),可以存放到不同的表空间中。
查询时可以通过查询表来访问各个分区中的数据,也可以通过在查询时直接指定分区的方法来进行查询。
分区提供以下优点:由于将数据分散到各个分区中,减少了数据损坏的可能性;可以对单独的分区进行备份和恢复;可以将分区映射到不同的物理磁盘上,来分散IO;提高可管理性、可用性和性能。
Oracle提供了以下几种分区类型:范围分区(range);哈希分区(hash);列表分区(list);范围-哈希复合分区(range-hash);范围-列表复合分区(range-list)。
Range分区:Range分区呢是应用范围比较广的表分区方式,它是以列的值的范围来做为分区的划分条件,将记录存放到列值所在的range分区中,比如按照时间划分,2008年1季度的数据放到a分区,08年2季度的数据放到b分区,因此在创建的时候呢,需要你指定基于的列,以及分区的范围值,如果某些记录暂无法预测范围,可以创建maxvalue分区,所有不在指定范围内的记录都会被存储到maxvalue所在分区中,并且支持指定多列做为依赖列,后面在讲how的时候会详细谈到。
Hash分区:通常呢,对于那些无法有效划分范围的表,可以使用hash分区,这样对于提高性能还是会有一定的帮助。
hash分区会将表中的数据平均分配到你指定的几个分区中,列所在分区是依据分区列的hash值自动分配,因此你并不能控制也不知道哪条记录会被放到哪个分区中,hash分区也可以支持多个依赖列。
List分区:List分区与range分区和hash分区都有类似之处,该分区与range分区类似的是也需要你指定列的值,但这又不同与range分区的范围式列值---其分区值必须明确指定,也不同与hash分区---通过明确指定分区值,你能控制记录存储在哪个分区。
深入Oracle11g分区功能

深入Oracle 11g分区功能深入Oracle 11g分区功能∙摘要:Oracle 11g分区功能可以减轻DBA的工作负担,简化Oracle数据库的日常管理维护工作。
本文向您详细介绍Oracle 11g分区功能。
∙标签:Oracle 11g分区数据库分区是每种数据库都需具备的关键功能之一。
几乎所有的Oracle数据库都使用分区功能来提高查询的性能,Oracle 11g分区功能可以简化数据库的日常管理维护工作,大大减轻了DBA(数据库设计和管理工程师)的工作负担。
Oracle 11g中提供的新功能增添了更多的数据库分区功能选择,使分区功能在使用和维护上变得更加灵活;同时,Oracle 11g也提供更多的分区功能选择。
Oracle 8.0版最早推出了表格的分区功能,使Oracle成为了第一个支持物理分区的RDBMS供应商。
SQL Server(2000)和DB2都只支持逻辑分区(使用UNION ALL视图),而SQL Server 2005并不直接支持物理分区(需通过分区功能)。
Oracle的分区功能选择很受用户群的欢迎,因为分区功能能够改善应用程序的性能、可管理性和可用性,其中最重要的是DSS应用程序。
由于该功能受到广泛的喜爱,因此每次发布新版本都会有功能上的不断提高。
下面的表格列举了随版本更新而不断提高的分区功能(高级):分区功能类型现在让我们简单的讨论一下以上每个分区功能的特性:范围分区:数据根据分区键值范围指定进行分布。
比如,如果我们选择一个日期列作为分区键,分区“JAN-2007”就会包括所有包含从01-JAN-2007到31-JAN-2007之间的分区键值(假设分区的范围是从这个月的第一天到这个月的最后一天)。
散列分区:将散列算法用于分区键来确定指定行所在的分区。
这个分区方法能够保持I/O平衡,但是不可用于范围查询或不等式查询。
列表分区:数据根据分区键值列表指定进行分布。
这个分区方法对于离散的列表非常有用,如地区、国家等。
oracle表分区详解

oracle表分区详解Oracle表分区详解Oracle表分区是指将一张表(table)拆分为多个部分(partition),每个部分相互独立,根据不同的属性进行存储。
通过表分区,可以大幅提高查询效率和降低维护成本,也有助于加快数据库备份和恢复。
下面我们来详细了解一下Oracle表分区。
一、表分区的概念表分区是将一张大表(table)拆分为多个小表(partition)。
每个小表可以拥有自己独立的数据存储形式,这些小表可以根据一些共同的属性进行划分。
例如按时间,按地区进行划分。
通过表分区,可以实现多个子表之间的相互独立,从而降低维护成本,提高查询效率。
二、表分区的类型表分区可以分为水平分区和垂直分区两种类型。
1. 水平分区水平分区是将一张表根据某一属性分成多个分区,每个分区存储不同的数据。
常见的分区属性有时间、地区、业务范围等。
水平分区可以减少查询的数据量,提高查询效率,同时也可以降低备份和恢复的难度。
2. 垂直分区垂直分区是将一张表拆分成多个表,每个表存储不同的属性。
在垂直分区中,每张小表都包含唯一一些行数据,但是这些小表通过某些公共的列或者键连接起来。
垂直分区比较适合需要存储大型的或者变量长度的字段的表,可以有效的提高查询效率。
三、表分区的策略表分区的策略是根据表的特点选择分区方式。
表的分区策略可以采用以下几种方式:基于时间:按照时间划分,例如按天、按周、按月、按季度等。
基于列:按照列的属性划分,例如根据地区、类型、状态等进行划分。
基于范围:按照数值的范围划分,例如按价格、数量、面积等进行划分。
基于哈希:采用哈希算法划分,可以保证数据均衡,但是不适用于区间查询。
基于列表:根据给定的列值列表来定义分区。
四、表分区的优点表分区的优点包括以下几个方面:1. 提高查询效率:表分区可以减少查询的数据量,提高查询效率。
2. 便于备份和恢复:表分区可以将数据拆分开来,便于备份和恢复。
3. 分区维护简单:分区之间相互独立,可以进行单独的维护。
oracle分区表原理学习
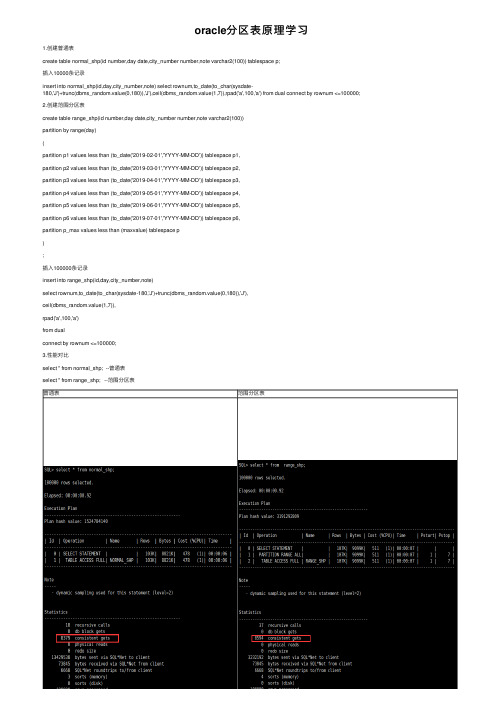
oracle分区表原理学习1.创建普通表create table normal_shp(id number,day date,city_number number,note varchar2(100)) tablespace p;插⼊10000条记录insert into normal_shp(id,day,city_number,note) select rownum,to_date(to_char(sysdate-180,'J')+trunc(dbms_random.value(0,180)),'J'),ceil(dbms_random.value(1,7)),rpad('a',100,'a') from dual connect by rownum <=100000;2.创建范围分区表create table range_shp(id number,day date,city_number number,note varchar2(100))partition by range(day)(partition p1 values less than (to_date('2019-02-01','YYYY-MM-DD')) tablespace p1,partition p2 values less than (to_date('2019-03-01','YYYY-MM-DD')) tablespace p2,partition p3 values less than (to_date('2019-04-01','YYYY-MM-DD')) tablespace p3,partition p4 values less than (to_date('2019-05-01','YYYY-MM-DD')) tablespace p4,partition p5 values less than (to_date('2019-06-01','YYYY-MM-DD')) tablespace p5,partition p6 values less than (to_date('2019-07-01','YYYY-MM-DD')) tablespace p6,partition p_max values less than (maxvalue) tablespace p);插⼊100000条记录insert into range_shp(id,day,city_number,note)select rownum,to_date(to_char(sysdate-180,'J')+trunc(dbms_random.value(0,180)),'J'),ceil(dbms_random.value(1,7)),rpad('a',100,'a')from dualconnect by rownum <=100000;3.性能对⽐select * from normal_shp; --普通表select * from range_shp; --范围分区表普通表范围分区表在不加任何条件时,进⾏查询发现,两者的逻辑读数量⼤致相同,花费⼤致相同;其中范围分区表的逻辑读和花费甚⾄略⾼于范围分区表。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第十一章:分区表 (1)概述 (2)范围分区 (2)HASH分区(散列分区) (3)列表分区 (3)复合分区 (4)分区表操作 (4)分区表的管理 (5)第十一章:分区表学习目标⏹了解分区表的基本概念⏹操作分区表概述在大型的企业应用或企业级的数据库应用中,要处理的数据量通常可以达到几十到几百GB,有的甚至可以到TB级。
虽然存储介质和数据处理技术的发展也很快,但是仍然不能满足用户的需求,为了使用户的大量的数据在读写操作和查询中速度更快,Oracle提供了对表和索引进行分区的技术,以改善大型应用系统的性能使用分区表有如下优点:1.增强可用性:如果表的某个分区出现故障,表在其他分区的数据仍然可用;2.维护方便:如果表的某个分区出现故障,需要修复数据,只修复该分区即可;3.均衡I/O:可以把不同的分区映射到磁盘以平衡I/O,改善整个系统性能;4.改善查询性能:对分区对象的查询可以仅搜索自己关心的分区,提高检索速度分区的方法有如下几种:1.范围分区2.HASH分区(散列分区)3.列表分区4.复合分区(范围+HASH)(范围+列表)下面我们创建表空间,以备课程练习使用:CREATE TABLESPACE TEST1 DATAFILE 'C:\TEMP\TEST1.DBF' SIZE 10MCREATE TABLESPACE TEST2 DATAFILE 'C:\TEMP\TEST2.DBF' SIZE 10MCREATE TABLESPACE TEST3 DATAFILE 'C:\TEMP\TEST3.DBF' SIZE 10M范围分区范围分区就是对数据表中的某个值的范围进行分区,根据某个值的范围,决定将该数据存储在哪个分区上。
如根据序号分区,根据业务记录的创建日期进行分区等。
如:物料交易表,表名:material_transactions,将来该表可能有千万条数据记录,要求使用分区表。
可以使用序号分区分到3个区上,每个区中预计存储三千万条数据,也可以使用日期分区,如每5年的数据存储在一个分区上。
我们下面创建这个表:Create table material_test(transaction_id number primary key,Item_id number(8) not null,Item_description varchar2(300),Transaction_date date not null)Partition by range(transaction_id)2第 2 页共8 页(partition part_01 values less than(30000000) tablespace test1,partition part_02 values less than(60000000) tablespace test2,partition part_03 values less than(maxvalue) tablespace test3)当然我们也可以通过时间来进行分区,语法如下:Create table material_test1(transaction_id number primary key,Item_id number(8) not null,Item_description varchar2(300),Transaction_date date not null)Partition by range(transaction_date)(partition part_01 values less than(to_date('2006-01-01','yyyy-mm-dd')) tablespace test1, partition part_02 values less than(to_date('2010-01-01','yyyy-mm-dd')) tablespace test2, partition part_03 values less than(maxvalue) tablespace test3)HASH分区(散列分区)在列的取值不容易确定时可以采用此方法。
如按照身份证进行分区,就很难确定身份证分区范围。
HASH实际上是一种算法,当向表插入数据时,系统会自动根据当前分区列的值计算出HASH值之后确定应该将该行存放在哪个表空间。
创建散列分区表如下:Create table material_test2(transaction_id number primary key,Item_id number(8) not null,Item_description varchar2(300),Transaction_date date not null)Partition by hash(transaction_id)(partition part_01 tablespace test1,partition part_02 tablespace test2,partition part_03 tablespace test3)列表分区此功能是ORACLE10G增加的功能,对表的某个列的可列举的值进行分区,如果分区的字段的值并不能划分范围,同时分区的值的取值有一个范围,则在分区条件中可以只用枚举的方式列出分区字段的所有选项,从而达到分区的目的。
创建列表分区语法如下:Create table material_test3(transaction_id number primary key,Item_id number(8) not null,Item_description varchar2(300),第 3 页共8 页 3Transaction_date date not null,city varchar2(100))Partition by list(city)(partition part_01 values('北京') tablespace test1,partition part_02 values('上海') tablespace test2,partition part_03 values(default) tablespace test3)复合分区复合分区是一种组合。
如:将物料交易的记录按时间分区,然后每个分区中的数据分3个子分区,将数据散列的存储在3个指定的表空间中。
创建复合分区的语法如下:Create table material_test4(transaction_id number primary key,Item_id number(8) not null,Item_description varchar2(300),Transaction_date date not null)Partition by range(transaction_date) subpartition by hash(transaction_id)subpartitions 3 store in (test1,test2,test3)(partition part_01 values lessthan(to_date('2006-01-01','yyyy-mm-dd')),partition part_02 values lessthan(to_date('2010-01-01','yyyy-mm-dd')),partition part_03 values less than(maxvalue));分区表操作下面我们对建立的分区表进行操作,我们以material_test1表为例子,如下:insert into material_test1 values(1,12,'BOOKS',sysdate);insert into material_test1 values(2,12,'BOOKS',sysdate+30);insert into material_test1 values(3,12,'BOOKS',to_date('2006-05-30','yyyy-mm-dd'));insert into material_test1 values(4,12,'BOOKS',to_date('2007-06-23','yyyy-mm-dd'));insert into material_test1 values(5,12,'BOOKS',to_date('2011-02-26','yyyy-mm-dd'));insert into material_test1 values(6,12,'BOOKS',to_date('2011-04-30','yyyy-mm-dd'));commit;--查询分区表select * from material_test1 partition(part_01);select * from material_test1 partition(part_02);4第 4 页共8 页select * from material_test1 partition(part_03);--分区表与一般的表一样,也支持直接查询select * from material_test1;--更新分区数据update material_test1 partition(part_01) t sett.item_description='DESK'where t.transaction_id=1;commit;注意:这里将第一个分区中的交易ID=1的记录中的item_description 字段更新为“DESK”,可以看到已经成功更新了一条记录。
但是当更新的时候指定了分区,而根据查询的记录不在该分区中时,将不会更新数据。
--再次更新分区数据update material_test1 partition(part_01) t sett.item_description='DESK' wheret.transaction_id=6;commit;注意:指定了在第一个分区中更新记录,但是条件中限制交易ID为6,而查询全表,交易ID为6的记录在第三个分区中,这样该条语句将不会更新记录。