第五章 LL文法及其分析程序
实验原理ll1分析法

实验原理ll1分析法
LL(1)分析法是一种语法分析方法,是从上到下递归分析的一种方式。
LL指的是“Left to right, leftmost derivation”,表示从左到右、最左派生。
1表示在当前读入符号下,只需要向前看一个符号即可确定使用哪个产生式进行推导。
其核心思想是通过预测分析表来进行语法分析,预测分析表是一个二维数组,横坐标是非终结符号,纵坐标是终结符号。
在分析过程中,根据当前读入的终结符号和栈顶的非终结符号,查找分析表中对应的表项,判断使用哪个产生式进行推导。
如果表项为空,则表示当前输入串不符合语法规则。
LL(1)分析法的优点是实现简单、可自动化,同时可以处理大部分常见的上下文无关文法,且分析的速度较快,适合在语法分析器中应用。
缺点是只能处理LL(1)文法,对于LL(k)文法或其他类型的文法稍显局限。
如何判断一个文法是ll课件文法

03
LL(k)文法的定义基于预测分析 器,该分析器在解析文法时, 可以查看未来的k个符号来决定 如何进行解析。
02
LL(k)文法的识别
预测分析算法
预测分析算法是一种用于判断文法是否为LL(k)文法的算法,其基本思想是通过预测下一个产生式来逐个排除非LL(k)文法的可 能性。
预测分析算法的步骤包括:对文法的每个产生式进行编号,并按照左部符号的字典序对所有产生式进行排序;然后从文法的 第一个产生式开始,逐个判断每个产生式的预测情况,如果所有产生式的预测情况都满足LL(k)文法的条件,则该文法为LL(k) 文法。
05
LL(k)文法的优缺点
优点
预测性
LL(k)文法具有预测性,可以在语 法分析过程中提前预测可能的语 法结构,从而提高语法分析的效 率和准确性。
简洁性
LL(k)文法的语法规则通常比较简 洁,易于理解和实现,降低了语 法分析的复杂度。
可维护性
由于LL(k)文法的规则相对较少, 因此更易于维护和修改,适应了 语言的发展和变化。
规范分析算法
规范分析算法是一种基于自顶向下的语法分析算法, 其基本思想是从文法的起始符号出发,按照文法的产 生式逐步推导,直到推导出输入符号串为止。
规范分析算法的步骤包括:从文法的起始符号开始, 依次匹配输入符号串中的每个符号,并按照文法的产 生式进行推导;在推导过程中,需要记录下当前已经 匹配的符号串和产生式编号,以便于回溯和判断是否 能够成功匹配整个输入符号串。如果能够成功匹配整 个输入符号串,则说明该文法是LL(k)文法。
03
当k=1时,表示预测分析器在任何时候都可以查看一 个符号或两个连续的符号。
LL(k)文法的定义
01
LL(k)文法是一种形式文法,其 中LL表示“Left to Right, Leftmost derivation”,即从 左到右、最左推导。
编译原理实验LL(1)文法的判断及转换

2016.11.30LL(1)文法的判断及转换目录一、实验名称 (2)二、实验目的 (2)三、实验原理 (2)1、First集定义 (2)2、Follow集定义 (2)3、Select集定义 (3)4、含左递归文法 (3)四、实验思路 (3)1、求非终结符是否能导出空 (3)2、求First集算法 (3)3、求Follow集算法 (3)4、求Select集算法 (4)五、实验小结 (4)六、附件 (4)1、源代码 (4)2、运行结果截图 (10)一、实验名称LL(1)文法的判断及转换二、实验目的输入:任意一个文法输出:(1)是否为LL(1)文法(2)若是,给出每条产生式的select集(3)若不是,看看是否含有左公共因子或者含有左递归,并用相应的方法将非LL(1)文法变成LL(1)文法,并输出新文法中每条产生式的select集。
三、实验原理1、First集定义令X为一个文法符号(终止符或非终止符)或ε,则集合First(X)有终止符组成,此外可能还有ε,它的定义如下:1.若X是终止符或ε,则First(X)={X}。
2.若X是非终结符,则对于每个产生式X—>X1X2…Xn,First(X)包含了First (X1)-{ε}。
若对于某个i<n,所有的集合First(X1),...,First(Xi)都包含了ε,则First(X)也包括了First(Xi+1)- {ε}。
若所有集合First(X1),...,First (Xn)都包括了ε,则First(X)也包括了ε。
2、Follow集定义给出一个非终结符A,那么集合Follow(A)则是由终结符组成,此外可能还含有#(#是题目约定的字符串结束符)。
集合Follow(A)的定义如下:1. 若A是开始符号,则#在Follow(A)中。
2. 若存在产生式B—>αAγ,则First(γ)- {ε}在Follow(A)中。
3. 若存在产生式B—>αAγ,且ε在First(γ)中,则Follow(A)包括Follow (B)。
第五章 语法分析(自上而下分析法)

解: 这里P=exp , α 1=+term , α 2=-term, β =term 改写: exp → term exp' , exp' → +term exp' | - term exp' | ε
(3)间接左递归的消除 例如文法G(S): S→Qc|c Q→Rb|b R→Sa|a
虽没有直接左递归,但S、Q、R都是左递归的
例:简单的表达式文法 exp → exp addop term | term 消除其左递归。 解:属于格式P → Pα | β 这里 P=exp , α =addop term , β =term 改写: exp → term exp' exp' → addop term exp' | ε
例 文法G(E): E→E+T | T T→T*F | F F→(E) | i 经消去直接左递归后变成: E→TE′ E′→+TE′ | ε T→FT′ T′→*FT′ | ε F→(E) | i 不变
例1 假定有文法G(S): (1) S→xAy (2) A→** | * 分析输入串x*y(记为α)。 ① 按文法的开始符号产生语法树的根节点S,根据规 则,S有三个子孙,于是此时的语法树如图所示; 并把指示器IP指向串α的第一个符号x x*y IP S x*y IP S x A y
把语法树的子节点从左至右对IP所指向的符号进行匹 配。第一符号匹配,于是,IP向后移动一个符号。
是递归下降分析法和预测分析法的基础
LL(1)分析法
构造不带回溯的自上而下分析算法 要消除文法的左递归性 克服回溯
1 左递归的消除
(1)简单直接左递归 直接消除见诸于产生式中的左递归:假定关于非 终结符P的规则为
LL(1)文法分析表的构造和分析过程示例

LL(1)⽂法分析表的构造和分析过程⽰例在考完编译原理之后才弄懂,悲哀啊。
不过懂了就好,知识吗,不能局限于考试。
⽂法:E→TE'E'→+TE'|εT→FT 'T'→*FT'|εF→id| (E)⼀、⾸先判断是不是 LL(1)⽂法--------------------------------------------------------------------------------------------------------⽂法G的任意两个具有相同左部的产⽣式 A --> α|β满⾜下列条件:1、如果α和β不能同时推导出ε,则 FIRST(α)∩FIRST(β) = 空2、α和β⾄多有⼀个能推导出ε3、如果β --*--> ε ,则 FIRST(α)∩ FOLLOW(A)=空--------------------------------------------------------------------------------------------------------对于 E'→+TE'|ε,显然ε --> ε, First(+TE') = {+} ,Follow(E') = {{),#} 显然⼆者交集为空满⾜。
对于 F→id|(E) ,First(id) = {id} First((E)) = {(} 显然⼆者交集为空满⾜。
所以该⽂法是LL(1)⽂法。
⼆、计算出First集和Follow集参考:三、构建LL(1)分析表输⼊:⽂法G输出:分析表M步骤:1、对G中任意⼀个产⽣式 A --> α执⾏第2步和第3步2、for 任意a ∈ First(α),将 A --> α填⼊M[A,a]3、if ε∈ First(α) then 任意a ∈ Follow(A),将 A --> α填⼊M[A,a]if ε∈ First(α) & # ∈Follow(A), then 将 A --> α填⼊M[A,#] (觉得这步没⽤)4、将所有没有定义的M[A,b] 标上出错标志(留空也可以)--------------------------------------------------------------------------------------------------------过程就不赘述了,结果:四、分析过程步骤:1、如果 X = a = # 则分析成功并停机2、如果 X = a != # 则弹出栈顶符号X, 并将输⼊指针移到下⼀个符号上3、如果 X != a,查询分析表M[X,a] , 如果 M[X,a] = {X --> UVW},则⽤UVW (U在栈顶) 替换栈顶符号 X。
实验五 LL(1)分析步骤和讲解

实验五LL(1) 分析法一、实验目的:一、实验目的:根据某一文法编制调试LL (1)分析程序,以便对任意输入的符号串进行)分析程序,以便对任意输入的符号串进行析。
本次实验的目主要是加深对预测分析。
本次实验的目主要是加深对预测分LL (1)分析法的理解。
)分析法的理解。
(所需学时:4学时)二、实验二、实验原理1、LL (1)分析法的功能)分析法的功能LL (1)分析法的功能是利用)分析法的功能是利用)分析法的功能是利用LL (1)控制程序根据显示栈顶内容、向前)控制程序根据显示栈顶内容、向前)控制程序根据显示栈顶内容、向前)控制程序根据显示栈顶内容、向前看符号以及LL (1)分析表,对输入符号串自上而下的过程。
)分析表,对输入符号串自上而下的过程。
2、LL (1)分析法的前提)分析法的前提改造文法:消除二义性、左递归提取因子,判断是否为改造文法:消除二义性、左递归提取因子,判断是否为改造文法:消除二义性、左递归提取因子,判断是否为改造文法:消除二义性、左递归提取因子,判断是否为改造文法:消除二义性、左递归提取因子,判断是否为LL (1)文法,3、LL (1)分析法实验设计思想及算)分析法实验设计思想及算X∈VN‘#’‘ S’ 进栈,当前输入符送进栈,当前输入符送进栈,当前输入符送进栈,当前输入符送a栈顶符号放入栈顶符号放入X若产生式为若产生式为X X1X2…X n按逆序即Xn…X 2X1入栈出错X=’ X=’ X=’ #’X∈VTX=aX=aM[X,a] M[X,a]M[X,a] M[X,a]是产生式吗是产生式吗出错X=a读入下一个符号读入下一个符号结束是是是是否否否否否是三、实验要求对文法G(E) 如下,用LL(1)分析法对任意输入的符号串进行分析:E→E+T│TT→T*F│FF→(E)│i消除文法左递归,改写为:E →TE'E' →+TE' | εT →FT'T' →*FT' | εF →( E ) | i(1)计算每个语法单位的first 和follow 集合;(2)构造预测分析表;(3)写出分析程序。
LL(1)文法分析.

构造预测分析表
在确定的自顶向下分析方法中,又有递归子程序法和预测分 析方法,我们采用的是预测分析的方法。一个预测分析器 由三部分组成: (1)预测分析程序 (2)先进后出栈 (3)预测分析表 其中,只有预测分析表与文法有关。分析表可用矩阵M 表示。M(A,a)中的下标A表示非终结符,a为终结符 或括号,矩阵元素M(A,a)中的内容是一条关于A的产 生式,表明当用非终结符A往下推导时,面临输入符A时, 所应采取的候选产生式,元素内容无产生式时,则表明出 错。为便于辨认,我们令M数组为 Analyze数组。
算法介绍
1、在对输入序列进行LL(1)文法分析之前,首先要对文法进行判 别,看文法是不是LL(1)文法。这个文法应该满足无二义性,无 左递归,无公因子。具体的判别过程是,求出能推出ε的非终结 符,求出FIRST集,求出FOLLOW集,求出SELLECT集,看相 同左部的产生式的SELLECT集是否有交集,有就不是LL(1)文 法。 2、如果输入文法不是LL(1)文法,可以进行转换,转换一般有两 种方法:提取左公因子法和消除左递归法。 3、构造预测分析表,设二维矩阵M。
4、预测分析。
人员分工
• 负责MFC界面制作,程序总控,各个非终结 符能否推出ε的计算,判断是否LL(1),以及人员 分工。 • 消除左递归的实现 • 提取公因子的实现 • 求FIRST集 • 求FOLLOW集 • 求SELLECT集 • 构造预测分析表,分析输入的句子
程序流程
程序开始 InitAndConvertPt(); //读入文法、消除左递归、提取公因子 InitArray(); //初始化N[ ]数组 VnRefresh(Pt); //构造非终结符集 VtRefresh(Pt);//构造终结符集 Create_N_Table(); //判断哪些非终结符可以推出空,存入N[ ]
编译原理课程设计LL1文法

LL(1)文法分析及程序设计1.设计目的通过设计、编制、调试LL(1)语法分析程序,加深对LL(1) 语法分析原理的理解。
2.设计要求(1)写出符合LL(1)分析方法要求的文法,给出分析的算法思想、步骤、程序结构以及最终完成语法分析程序设计。
(2)编制完成分析程序后,选取几个例子,上机测试并通过所设计的分析程序。
3.设计方案用LL(1)分析法判别给定文法是否为LL(1)文法,提供其分析过程与结果,最终根据结果设计算法分析程序,对输入的符号串进行分析。
4.设计内容4.1 设计基本思想设计一个LL(1)文法分析器,构造出预测分析表,通过预测分析表,判别用户输入的字符串是否符合LL(1)文法。
并给出分析过程与结果。
4.2 LL(1)文法的基本原理与算法一个上下无关的文法是LL(1)文法的充要条件时,对每个非终结符A的两个不同产生式,A->α,A->β满足SELECT(A->α)∩SELECT(A->β)=φ,其中α和β不同时推出ξ。
如果某个文法满足上述条件,称该文法为LL(1)文法。
LL(1)分析法是一种采用确定的自顶向下的语法分析技术,其含义是:第一个L表明自顶向下分析是从左向右扫描输入串,第二个L表明分析过程中将用最左推导,1表明只需向右看一个符号便可以决定如何推导,即便选择哪个产生式规则进行推导。
4.3 LL(1)判别分析步骤(1)将数组X[]中对应的每一个非终结符的标记为“未定”。
(2)扫描文法中的产生式。
1.删除所有右部含有终结符的产生式。
若使得以某一非终结符为左部的所有产生式都被删除,则将数组中对应的非终结符的标记值改为“否”,说明该终结符不能推出ξ。
2.若某一非终结符的某一个产生式右部为ξ,则将数组中对应该非终结符的标志置为“是”,并从文法中删除该非终结符的所有产生式。
(3)扫描产生式右部的每一个符号。
1.若所扫描到的非终结符号在数组中对应的标志是“是”,则删去该非终结符,若使得产生式右部为空,则对产生式右部的非终结符在数组中对应的标志改为“是”,并删除该非终结符为左部的所有的产生式。
LL(1)语法分析程序实验报告

LL1实验报告1.设计原理所谓LL(1)分析法,就就是指从左到右扫描输入串(源程序),同时采用最左推导,且对每次直接推导只需向前瞧一个输入符号,便可确定当前所应当选择得规则。
实现LL(1)分析得程序又称为LL(1)分析程序或LL1(1)分析器。
我们知道一个文法要能进行LL(1)分析,那么这个文法应该满足:无二义性,无左递归,无左公因子。
当文法满足条件后,再分别构造文法每个非终结符得FIRST与FOLLOW集合,然后根据FIRST与FOLLOW集合构造LL(1)分析表,最后利用分析表,根据LL(1)语法分析构造一个分析器。
LL(1)得语法分析程序包含了三个部分,总控程序,预测分析表函数,先进先出得语法分析栈,本程序也就是采用了同样得方法进行语法分析,该程序就是采用了C++语言来编写,其逻辑结构图如下:LL(1)预测分析程序得总控程序在任何时候都就是按STACK栈顶符号X与当前得输入符号a做哪种过程得。
对于任何(X,a),总控程序每次都执行下述三种可能得动作之一:(1)若X = a =‘#’,则宣布分析成功,停止分析过程。
(2)若X = a ‘#’,则把X从STACK栈顶弹出,让a指向下一个输入符号。
(3)若X就是一个非终结符,则查瞧预测分析表M。
若M[A,a]中存放着关于X得一个产生式,那么,首先把X弹出STACK栈顶,然后,把产生式得右部符号串按反序一一弹出STACK 栈(若右部符号为ε,则不推什么东西进STACK栈)。
若M[A,a]中存放着“出错标志”,则调用出错诊断程序ERROR。
事实上,LL(1)得分析就是根据文法构造得,它反映了相应文法所定义得语言得固定特征,因此在LL(1)分析器中,实际上就是以LL(1)分析表代替相应方法来进行分析得。
2、分析LL ( 1) 分析表就是一个二维表,它得表列符号就是当前符号,包括文法所有得终结与自定义。
得句子结束符号#,它得表行符号就是可能在文法符号栈SYN中出现得所有符号,包括所有得非终结符,所有出现在产生式右侧且不在首位置得终结符, 自定义得句子结束符号#表项。
LL 文法及其分析程序

改写为:P → βQ Q → αQ|
其中Q为新增加的非终结符
33
消除文法中左递归规则举例
例:E → E+T|T T →T*F|F F →(E)| a
G[ E]: (1) E → TE’ (2) E’ → +TE’ (3) E’ → (4) T → FT’ (5) T’ → *FT’ (6) T’ → (7) F → (E) (8) F →a
24
G[ E]: (1) E –> TE’ (2) E’ –> +TE’ (3) E’ –> (4) T –> FT’ (5) T’ –> *FT’ (6) T’ –> (7) F –> (E) (8) F –> a
·各非终结符的FIRST集 合如下:
FIRST(E)={(,a} FIRST(E′)={+,ε} FIRST(T)={(,a} FIRST(T′)={*,ε} FIRST(F)={(,a}
自上而下分析又可分为确定的和不确定的两种 不确定的分析方法称为带回溯的分析方法,这
种方法实际上是一种穷举的试探方法 确定的分析方法需对文法有一定的限制
11
3。自上而下的语法分析面临的问题实现考虑
回溯 文法的左递归性
S→Sa
12
自上而下分析对文法的要求
例文法G0[S]: (1) S→Sa (2) S→b 分析baa是不是文法的句子
按照自上而下的分析思想 选用产生式(1)来推导SSa
语法树末端结点最左符号为非终结符,所以选用(1)继续推导
SSaSaa
此时语法树末端结点最左符号仍为非终结符,所以选用(1)继续推导
LL(1)语法分析程序实验报告

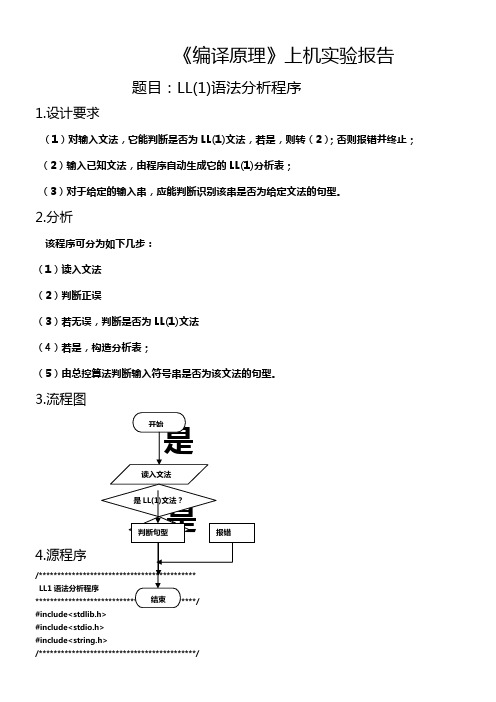
1.设计要求(1)对输入文法,它能判断是否为LL(1)文法,若是,则转(2);否则报错并终止;(2)输入已知文法,由程序自动生成它的LL(1)分析表;(3)对于给定的输入串,应能判断识别该串是否为给定文法的句型。
2.分析该程序可分为如下几步:(1)读入文法(2)判断正误(3)若无误,判断是否为LL(1)文法(4)若是,构造分析表;(5)由总控算法判断输入符号串是否为该文法的句型。
3.流程图4.源程序/********************************************/#include<stdlib.h>#include<stdio.h>#include<string.h>/*******************************************/int count=0; /*分解的产生式的个数*/int number; /*所有终结符和非终结符的总数*/char start; /*开始符号*/char termin[50]; /*终结符号*/char non_ter[50]; /*非终结符号*/char v[50]; /*所有符号*/char left[50]; /*左部*/char right[50][50]; /*右部*/char first[50][50],follow[50][50]; /*各产生式右部的FIRST和左部的FOLLOW集合*/ char first1[50][50]; /*所有单个符号的FIRST集合*/char select[50][50]; /*各单个产生式的SELECT集合*/char f[50],F[50]; /*记录各符号的FIRST和FOLLOW是否已求过*/char empty[20]; /*记录可直接推出^的符号*/char TEMP[50]; /*求FOLLOW时存放某一符号串的FIRST集合*/int validity=1; /*表示输入文法是否有效*/int ll=1; /*表示输入文法是否为LL(1)文法*/int M[20][20]; /*分析表*/char choose; /*用户输入时使用*/char empt[20]; /*求_emp()时使用*/char fo[20]; /*求FOLLOW集合时使用*//*******************************************判断一个字符是否在指定字符串中********************************************/int in(char c,char *p){int i;if(strlen(p)==0)return(0);for(i=0;;i++){if(p[i]==c)return(1); /*若在,返回1*/if(i==strlen(p))return(0); /*若不在,返回0*/}}/*******************************************得到一个不是非终结符的符号********************************************/char c(){char c='A';while(in(c,non_ter)==1)c++;return(c);}/*******************************************分解含有左递归的产生式********************************************/void recur(char *point){ /*完整的产生式在point[]中*/int j,m=0,n=3,k;char temp[20],ch;ch=c(); /*得到一个非终结符*/k=strlen(non_ter);non_ter[k]=ch;non_ter[k+1]='\0';for(j=0;j<=strlen(point)-1;j++){if(point[n]==point[0]){ /*如果‘|’后的首符号和左部相同*/ for(j=n+1;j<=strlen(point)-1;j++){while(point[j]!='|'&&point[j]!='\0')temp[m++]=point[j++];left[count]=ch;memcpy(right[count],temp,m);right[count][m]=ch;right[count][m+1]='\0';m=0;count++;if(point[j]=='|'){n=j+1;break;}}}else{ /*如果‘|’后的首符号和左部不同*/ left[count]=ch;right[count][0]='^';right[count][1]='\0';count++;for(j=n;j<=strlen(point)-1;j++){if(point[j]!='|')temp[m++]=point[j];else{left[count]=point[0];memcpy(right[count],temp,m);right[count][m]=ch;right[count][m+1]='\0';printf(" count=%d ",count);m=0;count++;}}left[count]=point[0];memcpy(right[count],temp,m);right[count][m]=ch;right[count][m+1]='\0';count++;m=0;}}}/*******************************************分解不含有左递归的产生式********************************************/void non_re(char *point){int m=0,j;char temp[20];for(j=3;j<=strlen(point)-1;j++){if(point[j]!='|')temp[m++]=point[j];else{left[count]=point[0];memcpy(right[count],temp,m);right[count][m]='\0';m=0;count++;}}left[count]=point[0];memcpy(right[count],temp,m);right[count][m]='\0';count++;m=0;}/*******************************************读入一个文法********************************************/char grammer(char *t,char *n,char *left,char right[50][50]){char vn[50],vt[50];char s;char p[50][50];int i,j,k;printf("\n请输入文法的非终结符号串:");scanf("%s",vn);getchar();i=strlen(vn);memcpy(n,vn,i);n[i]='\0';printf("请输入文法的终结符号串:");scanf("%s",vt);getchar();i=strlen(vt);memcpy(t,vt,i);t[i]='\0';printf("请输入文法的开始符号:");scanf("%c",&s);getchar();printf("请输入文法产生式的条数:");scanf("%d",&i);getchar();for(j=1;j<=i;j++){printf("请输入文法的第%d条(共%d条)产生式:",j,i);scanf("%s",p[j-1]);getchar();}for(j=0;j<=i-1;j++)if(p[j][1]!='-'||p[j][2]!='>'){ printf("\ninput error!");validity=0;return('\0');} /*检测输入错误*/for(k=0;k<=i-1;k++){ /*分解输入的各产生式*/if(p[k][3]==p[k][0])recur(p[k]);elsenon_re(p[k]);}return(s);}/*******************************************将单个符号或符号串并入另一符号串********************************************/void merge(char *d,char *s,int type){ /*d是目标符号串,s是源串,type=1,源串中的‘^ ’一并并入目串;type=2,源串中的‘^ ’不并入目串*/int i,j;for(i=0;i<=strlen(s)-1;i++){if(type==2&&s[i]=='^');else{for(j=0;;j++){if(j<strlen(d)&&s[i]==d[j])break;if(j==strlen(d)){d[j]=s[i];d[j+1]='\0';break;}}}}}/*******************************************求所有能直接推出^的符号********************************************/void emp(char c){ /*即求所有由‘^ ’推出的符号*/ char temp[10];int i;for(i=0;i<=count-1;i++){if(right[i][0]==c&&strlen(right[i])==1){temp[0]=left[i];temp[1]='\0';merge(empty,temp,1);emp(left[i]);}}}/*******************************************求某一符号能否推出‘^ ’********************************************/int _emp(char c){ /*若能推出,返回1;否则,返回0*/ int i,j,k,result=1,mark=0;char temp[20];temp[0]=c;temp[1]='\0';merge(empt,temp,1);if(in(c,empty)==1)return(1);for(i=0;;i++){if(i==count)return(0);if(left[i]==c) /*找一个左部为c的产生式*/{j=strlen(right[i]); /*j为右部的长度*/if(j==1&&in(right[i][0],empty)==1)return(1);else if(j==1&&in(right[i][0],termin)==1)return(0);else{for(k=0;k<=j-1;k++)if(in(right[i][k],empt)==1)mark=1;if(mark==1)continue;else{for(k=0;k<=j-1;k++){result*=_emp(right[i][k]);temp[0]=right[i][k];temp[1]='\0';merge(empt,temp,1);}}}if(result==0&&i<count)continue;else if(result==1&&i<count)return(1);}}}/*******************************************判断读入的文法是否正确********************************************/int judge(){int i,j;for(i=0;i<=count-1;i++){if(in(left[i],non_ter)==0){ /*若左部不在非终结符中,报错*/printf("\nerror1!");validity=0;return(0);}for(j=0;j<=strlen(right[i])-1;j++){if(in(right[i][j],non_ter)==0&&in(right[i][j],termin)==0&&right[i][j]!='^'){ /*若右部某一符号不在非终结符、终结符中且不为‘^ ’,报错*/ printf("\nerror2!");validity=0;return(0);}}}return(1);}/*******************************************求单个符号的FIRST********************************************/void first2(int i){ /*i为符号在所有输入符号中的序号*/ char c,temp[20];int j,k,m;c=v[i];char ch='^';emp(ch);if(in(c,termin)==1) /*若为终结符*/{first1[i][0]=c;first1[i][1]='\0';}else if(in(c,non_ter)==1) /*若为非终结符*/{for(j=0;j<=count-1;j++){if(left[j]==c){if(in(right[j][0],termin)==1||right[j][0]=='^'){temp[0]=right[j][0];temp[1]='\0';merge(first1[i],temp,1);}else if(in(right[j][0],non_ter)==1){if(right[j][0]==c)continue;for(k=0;;k++)if(v[k]==right[j][0])break;if(f[k]=='0'){first2(k);f[k]='1';}merge(first1[i],first1[k],2);for(k=0;k<=strlen(right[j])-1;k++){empt[0]='\0';if(_emp(right[j][k])==1&&k<strlen(right[j])-1){for(m=0;;m++)if(v[m]==right[j][k+1])break;if(f[m]=='0'){first2(m);f[m]='1';}merge(first1[i],first1[m],2);}else if(_emp(right[j][k])==1&&k==strlen(right[j])-1){temp[0]='^';temp[1]='\0';merge(first1[i],temp,1);}elsebreak;}}}}}f[i]='1';}/*******************************************求各产生式右部的FIRST********************************************/void FIRST(int i,char *p){int length;int j,k,m;char temp[20];length=strlen(p);if(length==1) /*如果右部为单个符号*/{if(p[0]=='^'){if(i>=0){first[i][0]='^';first[i][1]='\0';}else{TEMP[0]='^';TEMP[1]='\0';}}else{for(j=0;;j++)if(v[j]==p[0])break;if(i>=0){memcpy(first[i],first1[j],strlen(first1[j]));first[i][strlen(first1[j])]='\0';}else{memcpy(TEMP,first1[j],strlen(first1[j]));TEMP[strlen(first1[j])]='\0';}}}else /*如果右部为符号串*/ {for(j=0;;j++)if(v[j]==p[0])break;if(i>=0)merge(first[i],first1[j],2);elsemerge(TEMP,first1[j],2);for(k=0;k<=length-1;k++){empt[0]='\0';if(_emp(p[k])==1&&k<length-1){for(m=0;;m++)if(v[m]==right[i][k+1])break;if(i>=0)merge(first[i],first1[m],2);elsemerge(TEMP,first1[m],2);}else if(_emp(p[k])==1&&k==length-1){temp[0]='^';temp[1]='\0';if(i>=0)merge(first[i],temp,1);elsemerge(TEMP,temp,1);}else if(_emp(p[k])==0)break;}}}/*******************************************求各产生式左部的FOLLOW********************************************/void FOLLOW(int i){int j,k,m,n,result=1;char c,temp[20];c=non_ter[i]; /*c为待求的非终结符*/temp[0]=c;temp[1]='\0';merge(fo,temp,1);if(c==start){ /*若为开始符号*/temp[0]='#';temp[1]='\0';merge(follow[i],temp,1);}for(j=0;j<=count-1;j++){if(in(c,right[j])==1) /*找一个右部含有c的产生式*/{for(k=0;;k++)if(right[j][k]==c)break; /*k为c在该产生式右部的序号*/ for(m=0;;m++)if(v[m]==left[j])break; /*m为产生式左部非终结符在所有符号中的序号*/ if(k==strlen(right[j])-1){ /*如果c在产生式右部的最后*/if(in(v[m],fo)==1){merge(follow[i],follow[m],1);continue;}if(F[m]=='0'){FOLLOW(m);F[m]='1';}merge(follow[i],follow[m],1);}else{ /*如果c不在产生式右部的最后*/for(n=k+1;n<=strlen(right[j])-1;n++){empt[0]='\0';result*=_emp(right[j][n]);}if(result==1){ /*如果右部c后面的符号串能推出^*/if(in(v[m],fo)==1){ /*避免循环递归*/merge(follow[i],follow[m],1);continue;}if(F[m]=='0'){FOLLOW(m);F[m]='1';}merge(follow[i],follow[m],1);}for(n=k+1;n<=strlen(right[j])-1;n++)temp[n-k-1]=right[j][n];temp[strlen(right[j])-k-1]='\0';FIRST(-1,temp);merge(follow[i],TEMP,2);}}}F[i]='1';}/*******************************************判断读入文法是否为一个LL(1)文法********************************************/int ll1(){int i,j,length,result=1;char temp[50];for(j=0;j<=49;j++){ /*初始化*/first[j][0]='\0';follow[j][0]='\0';first1[j][0]='\0';select[j][0]='\0';TEMP[j]='\0';temp[j]='\0';f[j]='0';F[j]='0';}for(j=0;j<=strlen(v)-1;j++)first2(j); /*求单个符号的FIRST集合*/ printf("\nfirst1:");for(j=0;j<=strlen(v)-1;j++)printf("%c:%s ",v[j],first1[j]);printf("\nempty:%s",empty);printf("\n:::\n_emp:");for(j=0;j<=strlen(v)-1;j++)printf("%d ",_emp(v[j]));for(i=0;i<=count-1;i++)FIRST(i,right[i]); /*求FIRST*/printf("\n");for(j=0;j<=strlen(non_ter)-1;j++){ /*求FOLLOW*/if(fo[j]==0){fo[0]='\0';FOLLOW(j);}}printf("\nfirst:");for(i=0;i<=count-1;i++)printf("%s ",first[i]);printf("\nfollow:");for(i=0;i<=strlen(non_ter)-1;i++)printf("%s ",follow[i]);for(i=0;i<=count-1;i++){ /*求每一产生式的SELECT集合*/ memcpy(select[i],first[i],strlen(first[i]));select[i][strlen(first[i])]='\0';for(j=0;j<=strlen(right[i])-1;j++)result*=_emp(right[i][j]);if(strlen(right[i])==1&&right[i][0]=='^')result=1;if(result==1){for(j=0;;j++)if(v[j]==left[i])break;merge(select[i],follow[j],1);}}printf("\nselect:");for(i=0;i<=count-1;i++)printf("%s ",select[i]);memcpy(temp,select[0],strlen(select[0]));temp[strlen(select[0])]='\0';for(i=1;i<=count-1;i++){ /*判断输入文法是否为LL(1)文法*/length=strlen(temp);if(left[i]==left[i-1]){merge(temp,select[i],1);if(strlen(temp)<length+strlen(select[i]))return(0);}else{temp[0]='\0';memcpy(temp,select[i],strlen(select[i]));temp[strlen(select[i])]='\0';}}return(1);}/*******************************************构造分析表M********************************************/void MM(){int i,j,k,m;for(i=0;i<=19;i++)for(j=0;j<=19;j++)M[i][j]=-1;i=strlen(termin);termin[i]='#'; /*将#加入终结符数组*/termin[i+1]='\0';for(i=0;i<=count-1;i++){for(m=0;;m++)if(non_ter[m]==left[i])break; /*m为产生式左部非终结符的序号*/for(j=0;j<=strlen(select[i])-1;j++){if(in(select[i][j],termin)==1){for(k=0;;k++)if(termin[k]==select[i][j])break; /*k为产生式右部终结符的序号*/ M[m][k]=i;}}}}/*******************************************总控算法********************************************/void syntax(){int i,j,k,m,n,p,q;char ch;char S[50],str[50];printf("请输入该文法的句型:");scanf("%s",str);getchar();i=strlen(str);str[i]='#';str[i+1]='\0';S[0]='#';S[1]=start;S[2]='\0';j=0;ch=str[j];while(1){if(in(S[strlen(S)-1],termin)==1){if(S[strlen(S)-1]!=ch){printf("\n该符号串不是文法的句型!");return;}else if(S[strlen(S)-1]=='#'){printf("\n该符号串是文法的句型.");return;}else{S[strlen(S)-1]='\0';j++;ch=str[j];}}else{for(i=0;;i++)if(non_ter[i]==S[strlen(S)-1])break;for(k=0;;k++){if(termin[k]==ch)break;if(k==strlen(termin)){printf("\n词法错误!");return;}}if(M[i][k]==-1){printf("\n语法错误!");return;}else{m=M[i][k];if(right[m][0]=='^')S[strlen(S)-1]='\0';else{p=strlen(S)-1;q=p;for(n=strlen(right[m])-1;n>=0;n--)S[p++]=right[m][n];S[q+strlen(right[m])]='\0';}}}printf("\nS:%s str:",S);for(p=j;p<=strlen(str)-1;p++)printf("%c",str[p]);printf(" ");}}/*******************************************一个用户调用函数********************************************/void menu(){syntax();printf("\n是否继续?(y or n):");scanf("%c",&choose);getchar();while(choose=='y'){menu();}}/*******************************************主函数********************************************/void main(){int i,j;start=grammer(termin,non_ter,left,right); /*读入一个文法*/ printf("count=%d",count);printf("\nstart:%c",start);strcpy(v,non_ter);strcat(v,termin);printf("\nv:%s",v);printf("\nnon_ter:%s",non_ter);printf("\ntermin:%s",termin);printf("\nright:");for(i=0;i<=count-1;i++)printf("%s ",right[i]);printf("\nleft:");for(i=0;i<=count-1;i++)printf("%c ",left[i]);if(validity==1)validity=judge();printf("\nvalidity=%d",validity);if(validity==1){printf("\n该文法是一个LL(1)文法");ll=ll1();printf("\nll=%d",ll);if(ll==0)printf("\n该文法不是一个LL1文法!");else{MM();printf("\n");for(i=0;i<=19;i++)for(j=0;j<=19;j++)if(M[i][j]>=0)printf("M[%d][%d]=%d ",i,j,M[i][j]);printf("\n");menu();}}}5.执行结果(1)输入一个文法(2)输入一个符号串(3)再次输入一个符号串,然后退出程序。
LL(1)语法分析程序
《编译原理》上机实验报告题目:LL(1)语法分析程序1.设计要求(1)对输入文法,它能判断是否为LL(1)文法,若是,则转(2);否则报错并终止;(2)输入已知文法,由程序自动生成它的LL(1)分析表;(3)对于给定的输入串,应能判断识别该串是否为给定文法的句型。
2.分析该程序可分为如下几步:(1)读入文法(2)判断正误(3)若无误,判断是否为LL(1)文法(4)若是,构造分析表;(5)由总控算法判断输入符号串是否为该文法的句型。
3.流程图4.源程序LL1语法分析程序#include<stdio.h>#include<string.h>int count=0; /*分解的产生式的个数*/int number; /*所有终结符和非终结符的总数*/char start; /*开始符号*/char termin[50]; /*终结符号*/char non_ter[50]; /*非终结符号*/char v[50]; /*所有符号*/char left[50]; /*左部*/char right[50][50]; /*右部*/char first[50][50],follow[50][50]; /*各产生式右部的FIRST和左部的FOLLOW集合*/ char first1[50][50]; /*所有单个符号的FIRST集合*/char select[50][50]; /*各单个产生式的SELECT集合*/char f[50],F[50]; /*记录各符号的FIRST和FOLLOW是否已求过*/char empty[20]; /*记录可直接推出^的符号*/char TEMP[50]; /*求FOLLOW时存放某一符号串的FIRST集合*/int validity=1; /*表示输入文法是否有效*/int ll=1; /*表示输入文法是否为LL(1)文法*/int M[20][20]; /*分析表*/char choose; /*用户输入时使用*/char empt[20]; /*求_emp()时使用*/char fo[20]; /*求FOLLOW集合时使用*//*******************************************判断一个字符是否在指定字符串中********************************************/int in(char c,char *p){//int i;size_t i;if(strlen(p)==0)return(0);for(i=0;;i++){if(p[i]==c)return(1); /*若在,返回1*/if(i==strlen(p))return(0); /*若不在,返回0*/}}/*******************************************得到一个不是非终结符的符号********************************************/char c(){char c='A';while(in(c,non_ter)==1)c++;return(c);}分解含有左递归的产生式********************************************/void recur(char *point){ /*完整的产生式在point[]中*/int j,m=0,n=3,k;char temp[20],ch;ch=c(); /*得到一个非终结符*/k=strlen(non_ter);non_ter[k]=ch;non_ter[k+1]='\0';for(j=0;size_t(j)<=strlen(point)-1;j++){if(point[n]==point[0]){ /*如果'|'后的首符号和左部相同*/ for(j=n+1;size_t(j)<=strlen(point)-1;j++){while(point[j]!='|'&&point[j]!='\0')temp[m++]=point[j++];left[count]=ch;memcpy(right[count],temp,m);right[count][m]=ch;right[count][m+1]='\0';m=0;count++;if(point[j]=='|'){n=j+1;break;}}}else{ /*如果'|'后的首符号和左部不同*/ left[count]=ch;right[count][0]='^';right[count][1]='\0';count++;for(j=n;size_t(j)<=strlen(point)-1;j++){if(point[j]!='|')temp[m++]=point[j];else{left[count]=point[0];memcpy(right[count],temp,m);right[count][m]=ch;right[count][m+1]='\0';m=0;count++;}}left[count]=point[0];memcpy(right[count],temp,m);right[count][m]=ch;right[count][m+1]='\0';count++;m=0;}}}/*******************************************分解不含有左递归的产生式********************************************/void non_re(char *point){int m=0,j;char temp[20];for(j=3;size_t(j)<=strlen(point)-1;j++){if(point[j]!='|')temp[m++]=point[j];else{left[count]=point[0];memcpy(right[count],temp,m);right[count][m]='\0';m=0;count++;}}left[count]=point[0];memcpy(right[count],temp,m);right[count][m]='\0';count++;m=0;}/*******************************************读入一个文法********************************************/char grammer(char *t,char *n,char *left,char right[50][50]) {char vn[50],vt[50];char s;char p[50][50];printf("\n请输入文法的非终结符号串:");scanf("%s",vn);getchar();i=strlen(vn);memcpy(n,vn,i);n[i]='\0';printf("请输入文法的终结符号串:");scanf("%s",vt);getchar();i=strlen(vt);memcpy(t,vt,i);t[i]='\0';printf("请输入文法的开始符号:");scanf("%c",&s);getchar();printf("请输入文法产生式的条数:");scanf("%d",&i);getchar();for(j=1;j<=i;j++){printf("请输入文法的第%d条(共%d条)产生式:",j,i);scanf("%s",p[j-1]);getchar();}for(j=0;j<=i-1;j++)if(p[j][1]!='-'||p[j][2]!='>'){ printf("\ninput error!");validity=0;return('\0');} /*检测输入错误*/for(k=0;k<=i-1;k++){ /*分解输入的各产生式*/if(p[k][3]==p[k][0])recur(p[k]);elsenon_re(p[k]);}return(s);}/*******************************************将单个符号或符号串并入另一符号串********************************************/void merge(char *d,char *s,int type){ /*d是目标符号串,s是源串,type=1,源串中的' ^ '一并并入目串;type=2,源串中的' ^ '不并入目串*/int i,j;for(i=0;size_t(i)<=strlen(s)-1;i++)if(type==2&&s[i]=='^');else{for(j=0;;j++){if(size_t(j)<strlen(d)&&s[i]==d[j])break;if(size_t(j)==strlen(d)){d[j]=s[i];d[j+1]='\0';break;}}}}}/*******************************************求所有能直接推出^的符号********************************************/void emp(char c){ /*即求所有由' ^ '推出的符号*/ char temp[10];int i;for(i=0;i<=count-1;i++){if(right[i][0]==c&&strlen(right[i])==1){temp[0]=left[i];temp[1]='\0';merge(empty,temp,1);emp(left[i]);}}}/*******************************************求某一符号能否推出' ^ '********************************************/int _emp(char c){ /*若能推出,返回1;否则,返回0*/ int i,j,k,result=1,mark=0;char temp[20];temp[0]=c;temp[1]='\0';merge(empt,temp,1);if(in(c,empty)==1)for(i=0;;i++){if(i==count)return(0);if(left[i]==c) /*找一个左部为c的产生式*/{j=strlen(right[i]); /*j为右部的长度*/if(j==1&&in(right[i][0],empty)==1)return(1);else if(j==1&&in(right[i][0],termin)==1)return(0);else{for(k=0;k<=j-1;k++)if(in(right[i][k],empt)==1)mark=1;if(mark==1)continue;else{for(k=0;k<=j-1;k++){result*=_emp(right[i][k]);temp[0]=right[i][k];temp[1]='\0';merge(empt,temp,1);}}}if(result==0&&i<count)continue;else if(result==1&&i<count)return(1);}}}/*******************************************判断读入的文法是否正确********************************************/int judge(){int i,j;for(i=0;i<=count-1;i++){if(in(left[i],non_ter)==0){ /*若左部不在非终结符中,报错*/ printf("\nerror1!");return(0);}for(j=0;size_t(j)<=strlen(right[i])-1;j++){if(in(right[i][j],non_ter)==0&&in(right[i][j],termin)==0&&right[i][j]!='^'){ /*若右部某一符号不在非终结符、终结符中且不为' ^ ',报错*/ printf("\nerror2!");validity=0;return(0);}}}return(1);}/*******************************************求单个符号的FIRST********************************************/void first2(int i){ /*i为符号在所有输入符号中的序号*/char c,temp[20];int j,k,m;c=v[i];char ch='^';emp(ch);if(in(c,termin)==1) /*若为终结符*/{first1[i][0]=c;first1[i][1]='\0';}else if(in(c,non_ter)==1) /*若为非终结符*/{for(j=0;j<=count-1;j++){if(left[j]==c){if(in(right[j][0],termin)==1||right[j][0]=='^'){temp[0]=right[j][0];temp[1]='\0';merge(first1[i],temp,1);}else if(in(right[j][0],non_ter)==1){if(right[j][0]==c)continue;for(k=0;;k++)if(v[k]==right[j][0])if(f[k]=='0'){first2(k);f[k]='1';}merge(first1[i],first1[k],2);for(k=0;size_t(k)<=strlen(right[j])-1;k++){empt[0]='\0';if(_emp(right[j][k])==1&&size_t(k)<strlen(right[j])-1){for(m=0;;m++)if(v[m]==right[j][k+1])break;if(f[m]=='0'){first2(m);f[m]='1';}merge(first1[i],first1[m],2);}else if(_emp(right[j][k])==1&&size_t(k)==strlen(right[j])-1){temp[0]='^';temp[1]='\0';merge(first1[i],temp,1);}elsebreak;}}}}}f[i]='1';}/*******************************************求各产生式右部的FIRST********************************************/void FIRST(int i,char *p){int length;int j,k,m;char temp[20];length=strlen(p);if(length==1) /*如果右部为单个符号*/{{if(i>=0){first[i][0]='^';first[i][1]='\0';}else{TEMP[0]='^';TEMP[1]='\0';}}else{for(j=0;;j++)if(v[j]==p[0])break;if(i>=0){memcpy(first[i],first1[j],strlen(first1[j]));first[i][strlen(first1[j])]='\0';}else{memcpy(TEMP,first1[j],strlen(first1[j]));TEMP[strlen(first1[j])]='\0';}}}else /*如果右部为符号串*/{for(j=0;;j++)if(v[j]==p[0])break;if(i>=0)merge(first[i],first1[j],2);elsemerge(TEMP,first1[j],2);for(k=0;k<=length-1;k++){empt[0]='\0';if(_emp(p[k])==1&&k<length-1){for(m=0;;m++)if(v[m]==right[i][k+1])break;if(i>=0)elsemerge(TEMP,first1[m],2);}else if(_emp(p[k])==1&&k==length-1){temp[0]='^';temp[1]='\0';if(i>=0)merge(first[i],temp,1);elsemerge(TEMP,temp,1);}else if(_emp(p[k])==0)break;}}}/*******************************************求各产生式左部的FOLLOW********************************************/void FOLLOW(int i){int j,k,m,n,result=1;char c,temp[20];c=non_ter[i]; /*c为待求的非终结符*/temp[0]=c;temp[1]='\0';merge(fo,temp,1);if(c==start){ /*若为开始符号*/temp[0]='#';temp[1]='\0';merge(follow[i],temp,1);}for(j=0;j<=count-1;j++){if(in(c,right[j])==1) /*找一个右部含有c的产生式*/{for(k=0;;k++)if(right[j][k]==c)break; /*k为c在该产生式右部的序号*/for(m=0;;m++)if(v[m]==left[j])break; /*m为产生式左部非终结符在所有符号中的序号*/ if(size_t(k)==strlen(right[j])-1){ /*如果c在产生式右部的最后*/if(in(v[m],fo)==1){merge(follow[i],follow[m],1);continue;}if(F[m]=='0'){FOLLOW(m);F[m]='1';}merge(follow[i],follow[m],1);}else{ /*如果c不在产生式右部的最后*/for(n=k+1;size_t(n)<=strlen(right[j])-1;n++){empt[0]='\0';result*=_emp(right[j][n]);}if(result==1){ /*如果右部c后面的符号串能推出^*/if(in(v[m],fo)==1){ /*避免循环递归*/merge(follow[i],follow[m],1);continue;}if(F[m]=='0'){FOLLOW(m);F[m]='1';}merge(follow[i],follow[m],1);}for(n=k+1;size_t(n)<=strlen(right[j])-1;n++)temp[n-k-1]=right[j][n];temp[strlen(right[j])-k-1]='\0';FIRST(-1,temp);merge(follow[i],TEMP,2);}}}F[i]='1';}/*******************************************判断读入文法是否为一个LL(1)文法********************************************/int ll1(){int i,j,length,result=1;char temp[50];for(j=0;j<=49;j++){ /*初始化*/first[j][0]='\0';follow[j][0]='\0';first1[j][0]='\0';select[j][0]='\0';TEMP[j]='\0';temp[j]='\0';f[j]='0';F[j]='0';}for(j=0;size_t(j)<=strlen(v)-1;j++)first2(j); /*求单个符号的FIRST集合*/ printf("\nfirst1:");for(j=0;size_t(j)<=strlen(v)-1;j++)printf("%c:%s ",v[j],first1[j]);printf("\nempty:%s",empty);printf("\n:::\n_emp:");for(j=0;size_t(j)<=strlen(v)-1;j++)printf("%d ",_emp(v[j]));for(i=0;i<=count-1;i++)FIRST(i,right[i]); /*求FIRST*/printf("\n");for(j=0;size_t(j)<=strlen(non_ter)-1;j++){ /*求FOLLOW*/if(fo[j]==0){fo[0]='\0';FOLLOW(j);}}printf("\nfirst:");for(i=0;i<=count-1;i++)printf("%s ",first[i]);printf("\nfollow:");for(i=0;size_t(i)<=strlen(non_ter)-1;i++)printf("%s ",follow[i]);for(i=0;i<=count-1;i++){ /*求每一产生式的SELECT集合*/ memcpy(select[i],first[i],strlen(first[i]));select[i][strlen(first[i])]='\0';for(j=0;size_t(j)<=strlen(right[i])-1;j++)result*=_emp(right[i][j]);if(strlen(right[i])==1&&right[i][0]=='^')result=1;if(result==1){for(j=0;;j++)if(v[j]==left[i])break;merge(select[i],follow[j],1);}}printf("\nselect:");for(i=0;i<=count-1;i++)printf("%s ",select[i]);memcpy(temp,select[0],strlen(select[0]));temp[strlen(select[0])]='\0';for(i=1;i<=count-1;i++){ /*判断输入文法是否为LL(1)文法*/length=strlen(temp);if(left[i]==left[i-1]){merge(temp,select[i],1);if(strlen(temp)<length+strlen(select[i]))return(0);}else{temp[0]='\0';memcpy(temp,select[i],strlen(select[i]));temp[strlen(select[i])]='\0';}}return(1);}/*******************************************构造分析表M********************************************/void MM(){int i,j,k,m;for(i=0;i<=19;i++)for(j=0;j<=19;j++)M[i][j]=-1;i=strlen(termin);termin[i]='#'; /*将#加入终结符数组*/termin[i+1]='\0';for(i=0;i<=count-1;i++){for(m=0;;m++)if(non_ter[m]==left[i])break; /*m为产生式左部非终结符的序号*/ for(j=0;size_t(j)<=strlen(select[i])-1;j++){if(in(select[i][j],termin)==1){for(k=0;;k++)if(termin[k]==select[i][j])break; /*k为产生式右部终结符的序号*/ M[m][k]=i;}}}}/*******************************************总控算法********************************************/void syntax(){int i,j,k,m,n,p,q;char ch;char S[50],str[50];printf("请输入该文法的句型:");scanf("%s",str);getchar();i=strlen(str);str[i]='#';str[i+1]='\0';S[0]='#';S[1]=start;S[2]='\0';j=0;ch=str[j];while(1){if(in(S[strlen(S)-1],termin)==1){if(S[strlen(S)-1]!=ch){printf("\n该符号串不是文法的句型!");return;}else if(S[strlen(S)-1]=='#'){printf("\n该符号串是文法的句型.");return;}else{S[strlen(S)-1]='\0';j++;ch=str[j];}}else{for(i=0;;i++)if(non_ter[i]==S[strlen(S)-1])break;for(k=0;;k++){if(termin[k]==ch)break;if(size_t(k)==strlen(termin)){printf("\n词法错误!");return;}}if(M[i][k]==-1){printf("\n语法错误!");return;}else{m=M[i][k];if(right[m][0]=='^')S[strlen(S)-1]='\0';else{p=strlen(S)-1;q=p;for(n=strlen(right[m])-1;n>=0;n--)S[p++]=right[m][n];S[q+strlen(right[m])]='\0';}}}printf("\nS:%s str:",S);for(p=j;size_t(p)<=strlen(str)-1;p++)printf("%c",str[p]);printf(" ");}}/*******************************************一个用户调用函数********************************************/void menu(){syntax();printf("\n是否继续?(y or n):");scanf("%c",&choose);getchar();while(choose=='y'){menu();}}/*******************************************主函数********************************************/void main(){int i,j;start=grammer(termin,non_ter,left,right); /*读入一个文法*/ printf("count=%d",count);printf("\nstart:%c",start);strcpy(v,non_ter);strcat(v,termin);printf("\nv:%s",v);printf("\nnon_ter:%s",non_ter);printf("\ntermin:%s",termin);printf("\nright:");for(i=0;i<=count-1;i++)printf("%s ",right[i]);printf("\nleft:");for(i=0;i<=count-1;i++)printf("%c ",left[i]);if(validity==1)validity=judge();printf("\nvalidity=%d",validity);if(validity==1){printf("\n文法有效");ll=ll1();printf("\nll=%d",ll);if(ll==0)printf("\n该文法不是一个LL1文法!");else{MM();printf("\n");for(i=0;i<=19;i++)for(j=0;j<=19;j++)if(M[i][j]>=0)printf("M[%d][%d]=%d ",i,j,M[i][j]);printf("\n");menu();}}}5.执行结果(1)输入一个文法(2)输入一个符号串(3)再次输入一个符号串,然后退出程序。
编译原理课件-LL(1)文法及其分析程序

例 5.3
若有文法G3[S]: S → aA|d A →bAS|ε 識別輸入串w=abd是否是G3[S]的句子 試探推導出abd的推導過程為: S => aA => abAS => abS => abd 試探推導成功。
1
文法G3[S]的特點:
文法中含有空產生式。
由此可以看出,當某一非終結符的產生式 中含有空產生式時,它的非空產生式右部的 首符號集兩兩不相交,並與在推導過程中緊 跟該非終結符後邊可能出現的終結符集也不 相交,則仍可構造確定的自頂向下分析。
1
用產生式(1)、(2)的右部代替產生式(3)中
的非終結符A得到左部為B的產生式為:
(1) B→aBc
(1) A→aB
(2) B→Bbc (3) B→d
(2) A→Bb (3) B→Ac (4) B→d
消除左遞歸後得:
B→(aBc|d)B′ B′→bcB′|ε 再把原來其餘的產生式A→aB,
A→Bb加入,最終文法為:
1
語法樹-推導的幾何表示
句型aabbaa的可能推導序列和語法樹
例: G[S]: S→aAS A→SbA A→SS S→a A→ba
S
aA
S
S bAa
a
ba
SaASaAaaSbAaaSbbaaaabbaa
SaASaSbASaabASaabbaSaabbaa
SaASaSbASaSbAaaabAaaabbaa
用Ai-->1| 2r…| k r替代 形如Ai--> Ajr的規則,其中 Aj--> 1| 2…| k是關於Aj的全部產生式;
消除Ai規則的直接左遞歸;
end;
(3)化簡由2得到的文法
编译原理LL语法分析代码及结果

LL语法分析:源代码#include "stdio.h"#include "stdlib.h"#define MaxRuleNum 8#define MaxVnNum 5#define MaxVtNum 5#define MaxStackDepth 20#define MaxPLength 20#define MaxStLength 50struct pRNode /*产生式右部结构*/{int rCursor;struct pRNode *next;};struct pNode{int lCursor;int rLength; /*右部长度*/struct pRNode *rHead; /*右部结点头指针*/};char Vn[MaxVnNum + 1]; /*非终结符集*/int vnNum;char Vt[MaxVtNum + 1]; /*终结符集*/int vtNum;struct pNode P[MaxRuleNum];int PNum;char buffer[MaxPLength + 1];char ch;char st[MaxStLength]; /*要分析的符号串*/struct collectNode{int nVt;struct collectNode *next;};struct collectNode* first[MaxVnNum + 1]; /*first集*/struct collectNode* follow[MaxVnNum + 1]; /*follow集*/int analyseTable[MaxVnNum + 1][MaxVtNum + 1 + 1];int analyseStack[MaxStackDepth + 1]; /*分析栈*/int topAnalyse; /*分析栈顶*/void Init();/*初始化*/int IndexCh(char ch);void InputVt(); /*输入终结符*/void InputVn();/*输入非终结符*/void ShowChArray(char* collect, int num);/*输出Vn或Vt的内容*/ void InputP();/*产生式输入*/bool CheckP(char * st);/*判断产生式正确性*/void First(int U);void AddFirst(int U, int nCh); /*加入first集*/bool HaveEmpty(int nVn);void Follow(int V);/*计算follow集*/void AddFollow(int V, int nCh, int kind);void ShowCollect(struct collectNode **collect);/*输出first或follow集*/ void FirstFollow();/*计算first和follow*/void CreateAT();/*构造预测分析表*/void ShowAT();/*输出分析表*/void Identify(char *st);void InitStack();void ShowStack();void Pop();void Push(int r);void main(void){char todo,ch;Init();InputVn();InputVt();InputP();getchar();FirstFollow();printf("所得first集为:");ShowCollect(first);printf("所得follow集为:");ShowCollect(follow);CreateA T();ShowA T();todo = 'y';while('y' == todo){printf("\n是否继续进行句型分析?(y / n):"); todo = getchar();while('y' != todo && 'n' != todo){printf("\n(y / n)? ");todo = getchar();}if('y' == todo){int i;InitStack();printf("请输入符号串(以#结束) : ");ch = getchar();i = 0;while('#' != ch && i < MaxStLength){if(' ' != ch && '\n' != ch){st[i++] = ch;}ch = getchar();}if('#' == ch && i < MaxStLength){st[i] = ch;Identify(st);}elseprintf("输入出错!\n");}}getchar();}{int i,j;vnNum = 0;vtNum = 0;PNum = 0;for(i = 0; i <= MaxVnNum; i++)Vn[i] = '\0';for(i = 0; i <= MaxVtNum; i++)Vt[i] = '\0';for(i = 0; i < MaxRuleNum; i++) {P[i].lCursor = NULL;P[i].rHead = NULL;P[i].rLength = 0;}PNum = 0;for(i = 0; i <= MaxPLength; i++) buffer[i] = '\0';for(i = 0; i < MaxVnNum; i++){first[i] = NULL;follow[i] = NULL;}for(i = 0; i <= MaxVnNum; i++) {for(j = 0; j <= MaxVnNum + 1; j++) analyseTable[i][j] = -1;}}int IndexCh(char ch){int n;n = 0; /*is Vn?*/while(ch != Vn[n] && '\0' != Vn[n]) n++;if('\0' != Vn[n])return 100 + n;n = 0; /*is Vt?*/while(ch != Vt[n] && '\0' != Vt[n]) n++;if('\0' != Vt[n])return n;}/*输出Vn或Vt的内容*/void ShowChArray(char* collect){int k = 0;while('\0' != collect[k]){printf(" %c ", collect[k++]);}printf("\n");}/*输入非终结符*/void InputVn(){int inErr = 1;int n,k;char ch;while(inErr){printf("\n请输入所有的非终结符,注意:");printf("请将开始符放在第一位,并以#号结束:\n"); ch = ' ';n = 0;/*初始化数组*/while(n < MaxVnNum){Vn[n++] = '\0';}n = 0;while(('#' != ch) && (n < MaxVnNum)){if(' ' != ch && '\n' != ch && -1 == IndexCh(ch)){Vn[n++] = ch;vnNum++;}ch = getchar();}Vn[n] = '#'; /*以"#"标志结束用于判断长度是否合法*/ k = n;if('#' != ch){if( '#' != (ch = getchar())){while('#' != (ch = getchar()));printf("\n符号数目超过限制!\n");inErr = 1;continue;}}/*正确性确认,正确则,执行下下面,否则重新输入*/ Vn[k] = '\0';ShowChArray(Vn);ch = ' ';while('y' != ch && 'n' != ch){if('\n' != ch){printf("输入正确确认?(y/n):");}scanf("%c", &ch);}if('n' == ch){printf("录入错误重新输入!\n");inErr = 1;}else{inErr = 0;}}}/*输入终结符*/void InputVt(){int inErr = 1;int n,k;char ch;while(inErr){printf("\n请输入所有的终结符,注意:");printf("以#号结束:\n");ch = ' ';n = 0;/*初始化数组*/while(n < MaxVtNum){Vt[n++] = '\0';}n = 0;while(('#' != ch) && (n < MaxVtNum)){if(' ' != ch && '\n' != ch && -1 == IndexCh(ch)) {Vt[n++] = ch;vtNum++;}ch = getchar();}Vt[n] = '#';k = n;if('#' != ch){if( '#' != (ch = getchar())){while('#' != (ch = getchar()));printf("\n符号数目超过限制!\n");inErr = 1;continue;}}Vt[k] = '\0';ShowChArray(Vt);ch = ' ';while('y' != ch && 'n' != ch){if('\n' != ch){printf("输入正确确认?(y/n):");}scanf("%c", &ch);}if('n' == ch){printf("录入错误重新输入!\n");inErr = 1;}{inErr = 0;}}}/*产生式输入*/void InputP(){char ch;int i = 0, n,num;printf("请输入文法产生式的个数:");scanf("%d", &num);PNum = num;getchar(); /*消除回车符*/printf("\n请输入文法的%d个产生式,并以回车分隔每个产生式:", num); printf("\n");while(i < num){printf("第%d个:", i);/*初始化*/for(n =0; n < MaxPLength; n++)buffer[n] = '\0';/*输入产生式串*/ch = ' ';n = 0;while('\n' != (ch = getchar()) && n < MaxPLength){if(' ' != ch)buffer[n++] = ch;}buffer[n] = '\0';if(CheckP(buffer)){pRNode *pt, *qt;P[i].lCursor = IndexCh(buffer[0]);pt = (pRNode*)malloc(sizeof(pRNode));pt->rCursor = IndexCh(buffer[3]);pt->next = NULL;P[i].rHead = pt;n = 4;while('\0' != buffer[n])qt = (pRNode*)malloc(sizeof(pRNode));qt->rCursor = IndexCh(buffer[n]);qt->next = NULL;pt->next = qt;pt = qt;n++;}P[i].rLength = n - 3;i++;}elseprintf("输入符号含非法在成分,请重新输入!\n"); }}/*判断产生式正确性*/bool CheckP(char * st){int n;if(100 > IndexCh(st[0]))return false;if('-' != st[1])return false;if('>' != st[2])return false;for(n = 3; '\0' != st[n]; n ++){if(-1 == IndexCh(st[n]))return false;}return true;}void First(int U){int i,j;for(i = 0; i < PNum; i++){if(P[i].lCursor == U){struct pRNode* pt;pt = P[i].rHead;j = 0;while(j < P[i].rLength){if(100 > pt->rCursor){AddFirst(U, pt->rCursor);break;}else{if(NULL == first[pt->rCursor - 100]){First(pt->rCursor);}AddFirst(U, pt->rCursor);if(!HaveEmpty(pt->rCursor)){break;}else{pt = pt->next;}}j++;}if(j >= P[i].rLength) /*当产生式右部都能推出空时*/ AddFirst(U, -1);}}}/*加入first集*/void AddFirst(int U, int nCh){struct collectNode *pt, *qt;int ch; /*用于处理Vn*/pt = NULL;qt = NULL;if(nCh < 100){pt = first[U - 100];while(NULL != pt){if(pt->nVt == nCh)break;else{qt = pt;pt = pt->next;}}if(NULL == pt){pt = (struct collectNode *)malloc(sizeof(struct collectNode));pt->nVt = nCh;pt->next = NULL;if(NULL == first[U - 100]){first[U - 100] = pt;}else{qt->next = pt; /*qt指向first集的最后一个元素*/}pt = pt->next;}}else{pt = first[nCh - 100];while(NULL != pt){ch = pt->nVt;if(-1 != ch){AddFirst(U, ch);}pt = pt->next;}}}bool HaveEmpty(int nVn){if(nVn < 100)return false;struct collectNode *pt;pt = first[nVn - 100];while(NULL != pt){if(-1 == pt->nVt)return true;pt = pt->next;}return false;}void Follow(int V){int i;struct pRNode *pt ;if(100 == V) /*当为初始符时*/AddFollow(V, -1, 0 );for(i = 0; i < PNum; i++){pt = P[i].rHead;while(NULL != pt && pt->rCursor != V)pt = pt->next;if(NULL != pt){pt = pt->next;if(NULL == pt){if(NULL == follow[P[i].lCursor - 100] && P[i].lCursor != V) {Follow(P[i].lCursor);}AddFollow(V, P[i].lCursor, 0);}else{while(NULL != pt && HaveEmpty(pt->rCursor)){AddFollow(V, pt->rCursor, 1);pt = pt->next;}if(NULL == pt){if(NULL == follow[P[i].lCursor - 100] && P[i].lCursor != V) {Follow(P[i].lCursor);}AddFollow(V, P[i].lCursor, 0);}else{AddFollow(V, pt->rCursor, 1);}}}}}void AddFollow(int V, int nCh, int kind){struct collectNode *pt, *qt;int ch;pt = NULL;qt = NULL;if(nCh < 100) /*为终结符时*/{pt = follow[V - 100];while(NULL != pt){if(pt->nVt == nCh)break;else{qt = pt;pt = pt->next;}}if(NULL == pt){pt = (struct collectNode *)malloc(sizeof(struct collectNode));pt->nVt = nCh;pt->next = NULL;if(NULL == follow[V - 100]){follow[V - 100] = pt;}else{qt->next = pt; /*qt指向follow集的最后一个元素*/ }pt = pt->next;}}else{if(0 == kind){pt = follow[nCh - 100];while(NULL != pt){ch = pt->nVt;AddFollow(V, ch, 0);pt = pt->next;}}else{pt = first[nCh - 100];while(NULL != pt){ch = pt->nVt;if(-1 != ch){AddFollow(V, ch, 1);}pt = pt->next;}}}}/*输出first或follow集*/void ShowCollect(struct collectNode **collect){int i;struct collectNode *pt;i = 0;while(NULL != collect[i]){pt = collect[i];printf("\n%c:\t", Vn[i]);while(NULL != pt){{printf(" %c", Vt[pt->nVt]);}elseprintf(" #");pt = pt->next;}i++;}printf("\n");}/*计算first和follow*/void FirstFollow(){int i;i = 0;while('\0' != Vn[i]){if(NULL == first[i])First(100 + i);i++;}i = 0;while('\0' != Vn[i]){if(NULL == follow[i])Follow(100 + i);i++;}}/*构造预测分析表*/void CreateAT(){int i;struct pRNode *pt;struct collectNode *ct;for(i = 0; i < PNum; i++){pt = P[i].rHead;while(NULL != pt && HaveEmpty(pt->rCursor)) {ct = first[pt->rCursor - 100];{if(-1 != ct->nVt)analyseTable[P[i].lCursor - 100][ct->nVt] = i; ct = ct->next;}pt = pt->next;}if(NULL == pt){ct = follow[P[i].lCursor - 100];while(NULL != ct){if(-1 != ct->nVt)analyseTable[P[i].lCursor - 100][ct->nVt] = i; elseanalyseTable[P[i].lCursor - 100][vtNum] = i;ct = ct->next;}}else{if(100 <= pt->rCursor) /*不含空的非终结符*/ {ct = first[pt->rCursor - 100];while(NULL != ct){analyseTable[P[i].lCursor - 100][ct->nVt] = i;ct = ct->next;}}else /*终结符或者空*/{if(-1 == pt->rCursor){ct = follow[P[i].lCursor - 100];while(NULL != ct){if(-1 != ct->nVt)analyseTable[P[i].lCursor - 100][ct->nVt] = i;else /*当含有#号时*/analyseTable[P[i].lCursor - 100][vtNum] = i;ct = ct->next;}}else /*为终结符*/{analyseTable[P[i].lCursor - 100][pt->rCursor] = i;}}}}}/*输出分析表*/void ShowAT(){int i,j;printf("构造预测分析表如下:\n");printf("\t|\t");for(i = 0; i < vtNum; i++){printf("%c\t", Vt[i]);}printf("#\t\n");printf("- - -\t|- - -\t");for(i = 0; i <= vtNum; i++)printf("- - -\t");printf("\n");for(i = 0; i < vnNum; i++){printf("%c\t|\t", Vn[i]);for(j = 0; j <= vtNum; j++){if(-1 != analyseTable[i][j])printf("R(%d)\t", analyseTable[i][j]);elseprintf("error\t");}printf("\n");}}void Identify(char *st){int current,step,r; /*r表使用的产生式的序号*/printf("\n%s的分析过程:\n", st);printf("步骤\t分析符号栈\t当前指示字符\t使用产生式序号\n");step = 0;current = 0;printf("%d\t",step);ShowStack();printf("\t\t%c\t\t- -\n", st[current]);while('#' != st[current]){if(100 > analyseStack[topAnalyse]){if(analyseStack[topAnalyse] == IndexCh(st[current])){Pop();current++;step++;printf("%d\t", step);ShowStack();printf("\t\t%c\t\t出栈、后移\n", st[current]);}else{printf("%c-%c不匹配!", analyseStack[topAnalyse], st[current]);printf("此串不是此文法的句子!\n");return;}}else /*当为非终结符时*/{r = analyseTable[analyseStack[topAnalyse] - 100][IndexCh(st[current])]; if(-1 != r){Push(r);step++;printf("%d\t", step);ShowStack();printf("\t\t%c\t\t%d\n", st[current], r);}else{return;}}}if('#' == st[current]){if(0 == topAnalyse && '#' == st[current]){step++;printf("%d\t", step);ShowStack();printf("\t\t%c\t\t分析成功!\n", st[current]);printf("%s是给定文法的句子!\n", st);}else{while(topAnalyse > 0){if(100 > analyseStack[topAnalyse]){printf("此串不是此文法的句子!\n");return;}else{r = analyseTable[analyseStack[topAnalyse] - 100][vtNum];if(-1 != r){Push(r); /*产生式右部代替左部,指示器不移动*/step++;printf("%d\t", step);ShowStack();if(0 == topAnalyse && '#' == st[current]){printf("\t\t%c\t\t分析成功!\n", st[current]);printf("%s是给定文法的句子!\n", st);}elseprintf("\t\t%c\t\t%d\n", st[current], r);}else{return;}}}}}}/*初始化栈及符号串*/void InitStack(){int i;/*分析栈的初始化*/for(i = 0; i < MaxStLength; i++)st[i] = '\0';analyseStack[0] = -1; /*#(-1)入栈*/ analyseStack[1] = 100; /*初始符入栈*/ topAnalyse = 1;}/*显示符号栈中内容*/void ShowStack(){int i;for(i = 0; i <= topAnalyse; i++){if(100 <= analyseStack[i])printf("%c", Vn[analyseStack[i] - 100]); else{if(-1 != analyseStack[i])printf("%c", Vt[analyseStack[i]]);elseprintf("#");}}}/*栈顶出栈*/void Pop(){topAnalyse--;}void Push(int r){int i;struct pRNode *pt;Pop();pt = P[r].rHead;if(-1 == pt->rCursor)return;topAnalyse += P[r].rLength;for(i = 0; i < P[r].rLength; i++){analyseStack[topAnalyse - i] = pt->rCursor;/*逆序入栈*/ pt = pt->next;}}执行结果:。
思考题第5、6、7章

思考题第5、6、7章第一篇:思考题第5、6、7章思考题第五章建设中国特色社会主义总依据一、单项选择题1.现阶段中国最大的实际是()A.生产力水平低,经济发展落后B.人口数量多,素质不高 C.社会主义市场经济体制还不完善 D.处于并将长期处于社会主义初级阶段2.在社会主义思想发展史上,最早提到社会主义发展阶段问题的是(A.马克思B.恩格斯C.列宁D3.我国社会主义初级阶段基本路线中确立的奋斗目标是()A.建设成为富强、民主、文明、和谐的社会主义现代化国家 B.建设成为小康社会C.建设成为农业、工业、国防和科技现代化的国家 D.建设成为人均国民生产总值达到发达国家水平的社会4.我国社会主义初级阶段的主要矛盾是()A.落后的生产力同先进的生产关系的矛盾B.人民日益增长的物质文化需要同落后社会生产之间的矛盾C.商品经济和计划经济的矛盾 D.无产阶级和资产阶级的矛盾 5.我国社会主义初级阶段是指()A.从社会主义制度建立到基本实现四个现代化B.从新中国成立到社会主义制度建立C.从社会主义改造完成到进入小康社会 D.从新中国成立到社会主义现代化基本实现 6.无产阶级政党的最高纲领是()A.中国特色社会主义B.和谐的社会主义C.民族复兴D.7.我们强调社会主义初级阶段的长期性,下列选项不是原因的是(A.社会主义社会是一个相当长期的.独立的社会形态B.我国是一个经济文化落后的国家C.在这个阶段需要对资本主义进行补课D.要防止急躁、冒进超越社会发展阶段8.社会主义初级阶段是不可逾越的,这主要取决于()A.市场经济的不可逾越性B.生产力发展的不可逾越性C.生产关系发展的不可逾越性 D.文化传统的不可逾越性 9.社会主义社会的基本矛盾是指()A.人民群众日益增长的物质文化需要与落后的社会生产力之间的矛盾B.先进的社会生产关系与落后的社会生产力之间的矛盾C.生产关系与生产力之间的矛盾,上层建筑与经济基础之间的矛盾D.社会主义与资本主义之间的矛盾,无产阶级与资产阶级之间的矛盾10.在我国社会主要矛盾中,矛盾的主要方面是()A.落后的社会生产).毛泽东共产主义)B.生产力的组织、经营和管理落后C.人民物质文化需要的日益增长D.人口的不断增加和物质文化需要的日益增长11.党的第八次全国代表大会指出:社会主义制度在我国已经基本上建立起来,国内主要矛盾已经转变为()A.社会主义和资本主义的矛盾 B.工人阶级和资产阶级之间的矛盾C.人民对于经济文化迅速发展的需要同当前经济文化不能满足人民需要的状况之间的矛盾D.生产关系和生产力之间的矛盾,上层建筑和经济基础之间的矛盾 12.毛泽东第一次系统地提出社会主义社会矛盾的学说是在()A.《论十大关系》 B.《湖南农民运动考察报告》 C.《关于正确处理人民内部矛盾的问题》 D.《新民主主义论》 13.社会主义社会发展的动力是()A.阶级斗争 B.改革 C.物质利益原则 D.对外开放 14.解决社会主义初级阶段主要矛盾的根本手段是()A.号召人民生活节俭,抑制社会需求B.用发购物票的方法计划分配社会产品 C.发展生产力D.要求企业增加产品数量,减少花色品种15.现阶段,我国处在社会主义初级阶段,是邓小平同志和我们党对当代中国的()科学判断A.基本情况B.基本矛盾C.基本国情D.基本任务16.在党的基本路线中,“一个中心,两个基本点”是最主要的内容,是实现社会主义现代化的()A.基本途径B.奋斗目标C.根本立足点D.施政纲领 17.坚持党的基本路线不动摇的关键是()A.坚持以经济建设为中心不动摇B.坚持两手抓.两手都要硬的方针不动摇 C.坚持四项基本原则不动摇 D.坚持改革开放不动摇18.坚持党的基本路线必须坚持四项基本原则,下列命题中不属于四项基本原则的是()A.坚持中国共产党的领导B.坚持社会主义道路C.坚持人民民主专政D.坚持改革开放二、多项选择题1.社会主义初级阶段包括的两层含义是()A.我国是社会主义社会,我们必须坚持而不能离开社会主义B.我国社会主义社会还处在初级阶段,我们必须从这个实际出发,而不能超越这个阶段C.我国是社会主义社会国家,需要通过改革开放以效仿资本主义D.我国社会主义社会还处在初级阶段,需要加快向共产主义社会发展 2.社会主义初级阶段是()A.我国最大的实际 B.我国最基本的国情C.我们党对社会主义和中国国情认识上的一次飞跃 D.我们党制定路线方针政策的基本依据和根本出发点3.党在社会主义初级阶段的基本路线指出()A.初级阶段的奋斗目标是:建设“富强民主文明和谐的社会主义现代化国家” B.实现目标的基本途径是:“一个中心,两个基本点”C.实现目标的领导力量和依靠力量是:“领导和团结全国各族人民”D.实现目标的根本立足点是,“自力更生,艰苦创业” 4.社会主义初级阶段理论包含这样几层含义()A.已经是社会主义社会B.社会主义制度缺乏客观必然性C.需要补资本主义的课D.尚属于社会主义初级阶段三、判断题1.社会主义初级阶段就是指每个进入社会主义社会的国家都必须经历的起始阶段。
ll1文法的三个条件

ll1文法的三个条件
LL(1)文法是一种常用的上下文无关文法,它具有一些特殊的性质,可以方便地进行语法分析。
LL(1)文法需要满足以下三个条件: 1.左递归和间接左递归消除:LL(1)文法不允许存在左递归或者间接左递归的情况,因为这样会导致分析器无法正确地判断应该使用哪一个产生式来推导符号串。
2.First集不相交:对于每一个非终结符号A,任意两个以A为左部的产生式的First集必须没有交集。
如果存在交集,则在进行预测分析时无法确定使用哪一个产生式进行推导,从而导致分析失败。
3.Follow集合并:对于每一个非终结符号A,将所有以A为左部的产生式的Follow集合并起来,得到的结果就是A的Follow集。
在进行预测分析时,需要用到Follow集来确定何时结束某个非终结符的展开,以及应该采用哪个产生式进行推导。
以上三个条件都是LL(1)文法必须满足的基本要求,只有同时满足才能保证分析的准确性和可行性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
计算FIRST集
1.若XV,则FIRST(X)={X} 2.若XVN,且有产生式Xa…,则把a加入到 FIRST(X)中;若X也是一条产生式,则把也 加到FIRST(X)中. 3.若XY…是一个产生式且YVN,则把FIRST(Y) 中的所有非元素都加到FIRST(X)中;若X Y1Y2…YK 是一个产生式,Y1,Y2,…,Y(i-1)都是 非终结符,而且,对于任何j,1≤j ≤i-1, FIRST(Yj)都含有 (即Y1..Y(i-1) =>* ),则 把FIRST(Yj)中的所有非元素都加到FIRST(X) 中;特别是,若所有的FIRST(Yj , j=1,2,…,K) 均含有,则把加到FRIST(X)中. 22
8
例:递归子程序实现 表达式的语法分析
表达式的EBNF 〈表达式〉∷=[+|-]〈项〉{(+|-)〈项〉} 〈项〉∷=〈因子〉{(*|/)〈因子〉} 〈因子〉∷=ident|number|‘(’〈表达式〉 ‘)’
9
procedure expr; begin if sym in [ plus, minus ] then begin getsym; term; end else term; while sym in [plus, minus] do begin getsym; term; end end;
7
void MatchToken(int expected) { if (lookahead != expected) { printf("syntax error \n"); exit(0); } else // if match, consume token and move on lookahead = yylex(); }
begin getsym; if sym<>lparen then error(34) else repeat getsym; if sym <> ident then error(35) else getsym until sym<>comma; if sym<>rparen then error(33); end
15
例:Pda P=({A,B,C),{a,b,c),f,{h,i},i A,{ })
f(A,a,i) = (B,h) f(C,b,h) = (C, ) f(B,c,h) = (C,h) f(B,a,h) = (B,hh) f(A,c,i) = (A, )
接受输入串aacbb的过程
(A,aacbb,i) 读a, pop i, push h, goto B (B,acbb,h) 读a, pop h, push hh, goto B (B,cbb,hh) 读c, pop h, push h , goto C (C,bb,hh) 读b, pop h, push , goto C (C,b,h) 读b ,pop h, push , goto C (C, , )
10
Procedure term; begin factor; while sym in [times,slash] do begin getsym;factor end end;
11
Procedure factor; begin if sym=ident then getsym else if sym=number then getsym else if sym=‘(‘ then begin getsym; expr; if sym=‘)’ then getsym else error end else error end;
–
12
表驱动予测分析程序模型
Input
#
总控程序
stack 预测分析表
13
识别程序的数学模型下推自 动机
带 a0 a1 a2 a3 a4 a5 a6 a7 a8
磁头
…
an-1 an
有限控制器
14
上下文无关语言句型分析(识别)程序的数 学模型
下推自动机Pda=(K,Σ ,f,H,h0,S,Z) H:下推栈符号的有穷字母表 h0 :H中的初始符号 f: K (Σ {}) H –> K H* Pda的一个组态是K Σ * H 中的一个(k,w,) k:当前状 态,w:余留输入串, :栈中符号,最左边的符号在栈顶。 Pda的一次移动用组态表示 终止和接受的条件: 1.到达输入串结尾时,处在Z中的一个状态 或 2.某个动作序列导致栈空时
第五章 LL(1)文法及其分析程序
5.1 预测分析程序 5.2 LL(1)文法 • FIRST和FOLLOW集定义和计 算 • LL(1) 文法定义 • LL(1)分析程序的生成 5.3 非LL(1)文法的改造
1
自上而下分析算法
要点: .由根向下构造语法树 .构造最左推导 .推导出的终结符是否与 当前输入符匹配 S aaab A B a A
无回溯的自顶向下分析程序
特征——根据下一个输入符号为当前要处理 的非终结符选择产生式 要求——文法是LL(1)的 第一个L 从左到右扫描输入串 第二个L 生成的是最左推导 1 向前看一个输入符号(lookahead) 预测分析程序的实现技术 1 递归下降子程序 2 表驱动分析程序
4
PL/0语言的EBNF
〈程序〉∷=〈分程序〉. 〈分程序〉∷=[〈常量说明部分〉][〈变量说明部 分〉][〈过程说明部分〉]〈语句〉 〈常量说明部分〉∷=CONST〈常量定义部分〉{,〈常 量 定义〉}; 〈变量说明部分〉∷=VAR〈标识符〉{,〈标识符〉}; 〈过程说明部分〉∷= PROCEDURE 〈标识符〉〈分程序〉 {;〈过程说明部分〉}; 〈语句〉∷= 〈标识符〉:=〈表达式〉 |IF 〈条件〉 then〈语句〉|CALL…|READ…|BEGIN 〈语句〉{;〈语 句〉} END|WHILE…|…
23
一个文法G是LL(1)的,当且仅当对于G的每一个 非终结符A的任何两个不同产生式A α β , 下面的条件成立: 1.FIRST(α )∩FIRST(β )=,也就是α 和β 推 导不出以同一个终结符a为首的符号串;它们不 应该都能推出空字. 2.假若β =>* ,那么, FIRST(α )∩FOLLOW(A)=. 也就是, 若β =>* .则α 所能推出的串的首符号不应在 FOLLOW(A)中. .
分析输入串#a+a#
栈内容 栈顶符号 当前输入 余留串 M[X,b ]
1 #E 2 #E’T E T a a +a# +a# E –> TE’ T –> FT’
3 #E’T’F 4 #E’T’a 5 # E’T’ 6 #E’ 7 #E’T+ 8 # E’T 9 #E’T’F 10 #E’T’a 11 #E’T’ 12 #E’ 13 #
计算FOLLOW集
1.对于文法的开始符号S,置#于FOLLOW(S) 中; 2.若A α B β 是一个产生式,则把 FIRST(β )\{}加至FOLLOW(B)中; 3.若A α B是一个产生式,或A α Bβ 是 一个产生式而β =>* (即FIRST(β )), 则把FOLLOW(A)加至FOLLOW(B)中.
aaabb. S (1) A... (2) aA... (3) aaA... (4) aaaA... (5) aaa B (6’) aaa b B (7) aaabb
S –> AB A –> aA A –> aA A –> aA A –> B –> bB B –> b
3
预测分析程序Predictive parser
(2) E’ –> +TE’ (3) (5) T’ –> *FT’ (6) (8) F –> a
E’ –> T’ –>
a E
E’ T T’ (4)
+
(2)
*
( (1)
)
(3)
#
(3) (6)
(1)
(4) (6) (5) (6)
F
(8)
(7)
18
分析算法
BEGIN 首先把’#‘然后把文法开始符号推入栈;把第一个输入 符号读进b; FLAG:=TRUE; WHILE FLAG DO BEGIN 把栈顶符号上托出去并放在X中; IF X Vt THEN IF X=b THEN 把下一个输入符号读进a ELSE ERROR ELSE IF X=‘#’ THEN IF X=b THEN FLAG:=FALSE ELSE ERROR ELSE IF [X,b]={X –> X1X2..XK} THEN 把XK,X K-1,..,X1一一推进栈 ELSE ERROR END OF WHILE; STOP/*分析成功,过程完毕*/ END 19
24
G[ E]:
(1) E –> TE’ (4) T –> FT’ (7) F –> (E)
(2) E’ –> +TE’ (3) E’ –> (5) T’ –> *FT’ (6) T’ –> (8) F –> a
· 各非终结符的FOLLOW集合为: · 各非终结符的FIRST集合 FOLLOW(E)={),#} 如下: FOLLOW(E′)={),#} FIRST(E)={(,i} FOLLOW(T)={+,),#} FIRST(E′)={+,ε } FOLLOW(T′)={+,),#} FIRST(T)={(,i} FOLLOW(F)={*,+,),#} FIRST(T′)={*,ε } FIRST(F)={(,i}
F a T’ E’ + T F a T’+ a a a # # #
+a# +a# a# a# a# # # #