classification and feature
胡壮麟语言学名词解释

胡壮麟语言学名词解释第一篇:胡壮麟语言学名词解释1.design feature:are features that define our human languages,such as arbitrariness,duality,creativity,displacement,cultural transmission,etc.2.function: the use of language tocommunicate,to think ,nguage functions inclucle imformative function,interpersonal function,performative function,interpersonal function,performative function,emotive function,phatic communion,recreational function and metalingual function.3.etic: a term in contrast with emic which originates from American linguist Pike’s distinction of phonetics and phonemics.Being etic mans making far too many, as well as behaviously inconsequential,differentiations,just as was ofter the case with phonetic vx.phonemic analysis in linguistics proper.4.emic: a term in contrast with etic which originates from American linguist Pike’s distinction of phonetics and phonemics.An emic set of speech acts and events must be one that is validated as meaningful via final resource to the native members of a speech communith rather than via qppeal to the investigator’s ingenuith or intuition alone.5.synchronic: a kind of description which takes a fixed instant(usually,but not necessarily,the present),as its point of observation.Most grammars are of this kind.6.diachronic:study of a language is carried through the course of its history.7.prescriptive: the study of a language is carried through the course of its history.8.prescriptive: a kind of linguistic study in which things are prescribed how ought to be,ying down rules for language use.9.descriptive: a kind of linguistic study in which things are justdescribed.10.arbitrariness: one design feature of human language,which refers to the face that the forms of linguistic signs bear no natural relationship to their meaning.11.duality: one design feature of human language,which refers to the property of having two levels of are composed of elements of the secondary.level and each of the two levels has its own principles of organization.12.displacement: one design feature of human language,which means human language enable their users to symbolize objects,events and concepts which are not present c in time and space,at the moment of communication.13.phatic communion: one function of human language,which refers to the social interaction of language.14.metalanguage: certain kinds of linguistic signs or terms for the analysis and description of particular studies.15.macrolinguistics: he interacting study between language and language-related disciplines such as psychology,sociology,ethnograph,science of law and artificial intelligence etc.Branches of macrolinguistics include psycholinguistics,sociolinguistics,anthropological linguistics,et petence: language user’s underlying knowledge about the system of rules.17.performance: the actual use of language in concrete ngue: the linguistic competence of the speaker.19.parole: the actual phenomena or data of linguistics(utterances).20.Articulatory phonetics: the study of production of speechsounds.21.Coarticulation: a kind of phonetic process in which simultaneous or overlapping articulations are involved..Coarticulation can be further divided into anticipatory coarticulation and perseverative coarticulation.22. Voicing: pronouncing a sound(usually a vowel or a voiced consonant)by vibrating the vocal cords.23.Broad and narrow transcription: the use of a simple set of symbols intranscription is called broad transcription;the use of a simple set of symbols in transcription is called broad transcription;while,the use of more specific symbols to show more phonetic detail is referred to as narrow transcription.24.Consonant: are sound segments produced by constricting or obstructing the vocal tract at some place to divert,impede,or completely shut off the flow of air in the oral cavity.25.Phoneme: the abstract element of sound, identified as being distinctive in a particular language.26.Allophone:any of the different forms of a phoneme(eg.is an allophone of /t/in English.When /t/occurs in words like step,it is unaspirated.Bothand are allophones of the phoneme/t/.27.Vowl:are sound segments produced without such obstruction,so no turbulence of a total stopping of the air can be perceived.28. Manner of articulation;in the production of consonants,manner of articulation refers to the actual relationship between the articulators and thus the way in which the air passes through certain parts of the vocal tract.29. Place of articulation: in the production of consonants,place of articulation refers to where in the vocal tract there is approximation,narrowing,or the obstruction of air.30.Distinctive features: a term of phonology,i.e.a property which distinguishes one phoneme from another.31. Complementary distribution: the relation between tow speech sounds that never occur in the same environment.Allophones of the same phoneme are usually in complementary distribution.32.IPA: the abbreviation of International Phonetic Alphabet,which is devised by the International Phonetic Association in 1888 then it has undergong a number of revisions.IPA is a comprised system employingsymbols of all sources,such as Roman small letters,italics uprighted,obsolete letters,Greek letters,diacritics,etc.33.Suprasegmental:suprasegmental featuresare those aspects of speech that involve more than single sound segments.The principal supra-segmental features aresyllable,stress,tone,and intonation.34.Suprasegmental:aspects of speech that involve more than single sound segments.The principle suprasegmental features are syllable,stress,tone,and intonation.35.morpheme:the smallest unit of language in terms of relationship between expression and content,a unit that cannot be divided into further small units without destroying or drastically altering the meaning,whether it is lexical or pound oly morphemic words which consist wholly of free morphemes,such as classroom,blackboard,snowwhite,etc.37.inflection: the manifestation of grammatical relationship through the addition of inflectional affixes,such as number,person,finiteness,aspect and case,which do not change the grammatical class of the stems to which they are attached.38.affix: the collective term for the type of formative that can be used only when added to another morpheme(the root or stem).39.derivation: different from compounds,derivation shows the relation between roots and affixes.40.root: the base from of a word that cannot further be analyzed without total lass of identity.41.allomorph:;any of the different form of a morpheme.For example,in English the plural mortheme is but it is pronounced differently in different environments as/s/in cats,as/z/ in dogs and as/iz/ in classes.So/s/,/z/,and /iz/ are all allomorphs of the plural morpheme.42.Stem: any morpheme or combination of morphemes to which an inflectional affix can be added.43.boundmorpheme: an element of meaning which is structurally dependent on the world it is added to,e.g.the plural morpheme in ―dog’s‖.44.free morpheme: an element of meaning which takes the form of an independent word.45.lexeme:A separate unit of meaning,usually in the form of a word(e.g.‖dog in the manger‖)46.lexicon: a list of all the words in a language assigned to various lexical categories and provided with semantic interpretation.47.grammatical word: word expressing grammatical meanings,such conjunction,prepositions,articles and pronouns.48.lexical word: word having lexical meanings,that is ,those which refer to substance,action and quality,such as nouns,verbs,adjectives,and verbs.49.open-class: a word whose membership is in principle infinite or unlimited,such as nouns,verbs,adjectives,and many adverbs.50.blending: a relatively complex form of compounding,in which two words are blended by joining the initial part of the first word and the final part of the second word,or by joining the initial parts of the two words.51.loanvoord: a process in which both form and meaning are borrowed with only a slight adaptation,in some cases,to eh phonological system of the new language that they enter.52.loanblend: a process in which part of the form is native and part is borrowed, but the meaning is fully borrowed.53.leanshift: a process in which the meaning is borrowed,but the form is native.54.acronym: is made up form the first letters of the name of an organization,which has a heavily modified headword.55.loss: the disappearance of the very sound as a morpheme in the phonological system.56.back-formation: an abnormal type of word-formation where a shorter word is derived by deleting an imagined affix from a long form already in the language.57.assimilation: the change of a sound as a resultof the influence of an adjacent sound,which is more specifically called.‖contact‖or‖contiguous‖assimilation.58.dissimilation: the influence exercised.By one sound segment upon the articulation of another, so that the sounds become less alike,or different.59.folk etymology: a change in form of a word or phrase,resulting from an incorrect popular nation of the origin or meaning of the term or from the influence of more familiar terms mistakenly taken to be analogous 60.category:parts of speech and function,such as the classification of words in terms of parts of speech,the identification of terms of parts of speech,the identification of functions of words in term of subject,predicate,etc.61.concord: also known as agreement,is the requirement that the forms of two or more words in a syntactic relationship should agree with each other in terms of some categories.62.syntagmatic relation between one item and others in a sequence,or between elements which are all present.63.paradigmatic relation: a relation holding between elements replaceable with each other at a particular place in a structure,or between one element present and he others absent.64.immediate constituent analysis: the analysis of a sentence in terms of its immediate constituents---word groups(or phrases),which are in trun analyzed into the immediate constituents of their own,and the process goes on until the ultimate constituents are reached.65.endocentric construction: one construction whose distribution is functionally equivalent,or approaching equivalence,to one of its constituents,which serves as the centre,or head, of the whole.Hence an endocentric construction is also known as a headed construction.66.exocentric construction: a construction whose distribution is not functionally equivalent to any to any of itsconstituents.67.deep structure: the abstract representation of the syntactic properties of a construction,i.e.the underlying level of structural relations between its different constituents ,such sa the relation between,the underlying subject and its verb,or a verb and its object.68.surfacte structure: the final stage in the syntactic derivation of a construction,which closely corresponds to the structural organization of a construction people actually produce and receive.69.c-command: one of the similarities,or of the more general features, in these two government relations,is technically called constituent command,c-command for ernment and binding theory: it is the fourth period of development Chomsky’s TG Grammar, which consists of X-bar theme: the basis,or the starting point,of the municative dynamism: the extent to which the sentence element contributes to the development of the communication.72.ideational function: the speaker’s experience of the real world,including the inner world of his own consciousness.73.interpersonal function: the use of language to establish and maintain social relations: for the expression of social roles,which include the communication roles created by language itself;and also for getting things done,by means of the interaction between one person and another..74.textual function: the use of language the provide for making links with itself and with features of the situation in which it is used.75.conceptual meaning: the central part of meaning, which contains logical,cognitive,or denotative content.76.denotation: the core sense of a word or a phrade that relates it to phenomena in the real world.77.connotation: a term in a contrast with denotation,meaning the properties of the entity a word denotes.78.reference: the use of language to express apropostion,meaning the properties of the entity a word denotes.79.reference: the use of anguage to express a proposition,i.e.to talk about things in context.80.sense: the literal meaning of a word or an expression,independent of situational context.81.synonymy: is the technical name for the sameness plentary antonymy: members of a pair in complementary antonymy are complementary to each field completely,such as male,female,absent.83.gradable antongymy: members of this kind are gradable,such as long:short,big;small,fat;thin,etc.84.converse antonymy: a special kind of antonymy in that memembers of a pair do not constitute a positive-negative opposition,such as buy;sell,lend,borrow,above,below,etc.85.relational opposites:converse antonymy in reciprocal social roles,kinship relations,temporal and spatial relations.There are always two entities involved.One presupposes the other.The shorter,better;worse.etc are instances of relational opposites.86.hyponymy: a relation between tow words,in which the meaning of one word(the superordinate)is included in the meaning of another word(the hyponym)87.superordinate: the upper term in hyponymy,i.e.the class name.A superordinate usually has several hyponyms.Under animal,for example,there are cats,dogs,pigs,etc, 88.semantic component: a distinguishable element of meaning in a word with two values,e.g positionality: a principle for sentence analysis, in which the meaning of a sentence depends on the meanings of the constituent words and the way they are combined.90.selection restriction:semantic restrictions of the noun phrases that a particular lexical item can take,e.g.regret requires a human subject.91.prepositional logic: also known as prepositionalcalculus or sentential calculus,is the study of the truth conditions for propositions:how the truth of a composite propositions and the connection between them.92.proposition;what is talk about in an utterance,that part of the speech act which has to do with reference.93.predicate logic: also predicate calculus,which studies the internal structure of simple.94.assimilation theory: language(sound,word,syntax,etc)change or process by which features of one element change to match those of another that precedes or follows.95.cohort theory: theory of the perception of spoken words proposed in the mid-1980s.It saaumes a ―recognition lexicon‖in which each word is represented by a full and independent‖recognistion element‖.When the system receives the beginning of a relevant acoustic signal,all elements matching it are fully acticated,and,as more of the signal is received,the system tries to match it independently with each of them,Wherever it fails the element is deactivated;this process continues until only one remains active.96.context effect: this effect help people recognize a word more readily when the receding words provide an appropriate context for it.97.frequency effect: describes the additional ease with which a word is accessed due to its more frequent usage in language.98.inference in context: any conclusion drawn from a set of proposition,from something someone has said,and so on.It includes things that,while not following logically,are implied,in an ordinary sense,e.g.in a specific context.99.immediate assumption: the reader is supposed to carry out the progresses required to understand each word and its relationship to previous words in the sentence as soon as that word in nguage perception:language awareness of things through the physical senses,esp,nguage comprehension: one of the threestrand of psycholinguistic research,which studies the understanding of nguage production: a goal-directed activety,in the sense that people speak and write in orde to make friends,influence people,convey information and so nguage production: a goal-directed activity,in the sense that people speak and write in order to make friends,influence people,concey information and so on.104.lexical ambiguity:ambiguity explained by reference to lexical meanings:e.g.that of I saw a bat,where a bat might refer to an animal or,among others,stable tennis bat.105.macroproposition:general propositions used to form an overall macrostructure of the story.106.modular:which a assumes that the mind is structuied into separate modules or components,each governed by its own principles and operating independently of others.107.parsing:the task of assigning words to parts of speech with their appropriate accidents,traditionally e.g.to pupils learning lat in grammar.108.propositions:whatever is seen as expressed by a sentence which makes a statement.It is a property of propositions that they have truth values.109.psycholinguistics: is concerned primarily with investigating the psychological reality of linguistic structure.Psycholinguistics can be divided into cognitive psycholing uistics(being concerned above all with making inferences about the content of human mind,and experimental psycholinguistics(being concerned somehow whth empirical matters,such as speed of response to a particular word).110.psycholinguistic reality: the reality of grammar,etc.as a purported account of structures represented in the mind of a speaker.Often opposed,in discussion of the merits of alternative grammars,to criteria of simplicity,elegance,and internalconsistency.111.schemata in text: packets of stored knowledge in language processing.112.story structure: the way in which various parts of story are arranged or organized.113.writing process: a series of actions or events that are part of a writing or continuing municative competence: a speaker’s knowledge of the total set of rules,conventions,erning the skilled use of language in a society.Distinguished by D.Hymes in the late 1960s from Chomsley’s concept of competence,in the restricted sense of knowledge of a grammar.115.gender difference: a difference in a speech between men and women is‖genden difference‖ 116.linguistic determinism: one of the two points in Sapir-Whorf hypothesis,nguage determines thought.117.linguistic relativity: one of the two points in Spir-Whorf hypotheis,i.e.there’s no limit to the structural diversity of languages.118.linguistic sexism:many differences between me and women in language use are brought about by nothing less than women’s place in society.119.sociolinguistics of language: one of the two things in sociolinguistics,in which we want to look at structural things by paying attention to language use in a social context.120.sociolinguistics of society;one of the two things in sociolinguistics,in which we try to understand sociological things of society by examining linguistic phenomena of a speaking community.121.variationist linguistics: a branch of linguistics,which studies the relationship between speakers’social starts and phonological variations.122.performative: an utterance by which a speaker does something does something,as apposed to a constative,by which makes a statement which may be true or false.123.constative: an utterance by which a speaker expresses aproposition which may be true or false.124.locutionary act: the act of saying something;it’s an act of conveying literal meaning by means of syntax,lexicon,and ly.,the utterance of a sentence with determinate sense and reference.125.illocutionary act: the act performed in saying something;its force is identical with the speaker’s intention.126.perlocutionary act: the act performed by or resulting from saying something,it’s the consequence of,or the change brought about by the utterance.127.conversational implicature: the extra meaning not contained in the literal utterances,underatandable to the listener only when he shares the speaker’s knowledge or knows why and how he violates intentionally one of the four maxims of the cooperative principle.128.entailment:relation between propositions one of which necessarily follows from the other:e.g.‖Mary is running‖entails,among other things,‖Mary is not sta nding still‖.129.ostensive communication: a complete characterization of communication is that it is municative principle of relevance:every act of ostensive communication communicates the presumption of its own optimal relevance.131.relevance: a property that any utterance,or a proposition that it communicates,must,in the nature of communication,necessarily have.132.Q-principle: one of the two principles in Horn’s scale,i.e.Make your contribution necessary(G.Relation,Quantity2,Manner);Say no more than you must(given Q).133.division of pragmatic labour: the use of a marked crelatively complex and/or expression when a corresponding unmarkeda(simpler,less‖effortful‖)alternate expression is available tends to be interpreted as conveying a marked message(one which the unmarked alternative would notor could not have conveyed).134.constraints on Horn scales:the hearer-based o-Principle is a sufficiency condition in the sense that information provided is the most the speaker is able to..135.third-person narrator: of the narrator is not a character in the fictional world,he or she is usually called a third –person narrator.136.I-narrator: the person who tells the story may also be a character in the fictional world of the story,relating the story after the event.137.direct speech: a kind of speech presentation in which the character said in its fullest form.138.indirect speech: a kind of speech presentation in which the character said in its fullest form.139.indirect speech: a kind of speech presentation which is an amalgam of direct speech.140.narrator’s repreaentation of speech acts: a minimalist kind of presentation in which a part of passage can be seen as a summery of a longer piece of discourse,and therefore even more backgruonded than indirect speech representation would be.141.narrator‖srepresentation of thought acts: a kind of categories used by novelists to represent the thoughts of their of characters are exactly as that used to present speech acts.For example,she considered his unpunctuality.142.indirect thought: a kind of categories used by novelist to represent the thoughts of their characters are exactly as that used to present indirect speech.For example,she thought that he woule be late.143.fee indirect speech: a further category which can occur,which is an amalgam of direct speech and indirect speech features.144.narrator’s representation of thought acts:a kind of the categories used by novelists to present the thoughts of therir characters are exactly the same as those used to represent a speech e.g.He spent the day thinking.145.indirect thought: a kind of categories used by novelist to represent the thoughts of theircharacters are exactly as that used to present indirect speech.For example,she thought that he would be late.146.fee indirect speech: a further category which can occur,which is an amalgam of direct speech and indirect speech features.147.narrator‖s representation of thought: the categories used by novelists to present the thoughts of their characters are exactly the same as those used to represent a speech e.g.He spent the day thinking.148.free indirect thought: the categories used by novelists to represent the thoughts of their characters are exactly the same as those used to represent a speech,e.g.He was bound to be late.149.direct thought: categories used by novelists to represent the thoughts of their characters are exactly the same as those used to represent a puter system: the machine itself together with a keyboard,printer,screen,disk drives,programs,puter literacy: those people who have sufficient knowledge and skill in the use of computers and computer puter linguistics: a branch of applied liguistics,dealing with computer processing of human language.153.Call: computer-assisted language learning(call),refers to the use of a computer in the teaching or learning of a second or foreign language.154.programnded instruction: the use of computers to monitor student progress,to direct students into appropriate lessons,material,etc.155.local area network: are computers linked together by cables in a classroom,lab,or building.They offer teachers a novel approach for creating new activities for students that provide more time and experience with target language.156.CD-ROM: computer disk-read only memory allows huge amount of information to be stored on one disk with quich access to the information.Students and teachers can access information quickly and efficiently foruse in and out of the classroom.157.machine translation: refers to the use of machine(usually computer)to translate texts from one language to another.158.concordance: the use of computer to search for a particular word,sequence of words.or perhaps even a part of speech in a text.The computer can also receive all examples of a particular word,usually in a context,which is a further aid to the linguist.It can also calculate the number of occurrences of the word so that information on the frequency of the word may be gathered.159.annotation: if corpora is said to be unannotated-it appears in its existing raw state of plain text,whereas annotated corpora has been enhanced with various type of linguistic information, 160.annotation: if corpora is said to be unannotated—it appears in its existing raw state of plain text,whereas annotated corpora has been enhanced with various type of linguistic rmational retrieval: the term conventionally though somewhat inaccurately,applied to the type of actrvity discussed in this volume.An information retrieval system does not infor(i.e.change the knowledge of)the user on the subject of his inquiry.it merely informs on the existence(or non-existence)and whereabouts of documents relating to his request.162.document representative: information structure is concerned with exploiting relationships,between documents to improve the efficiency and effectiveness of retrieval strategies.It covers specifically a logical organization of information,such as document representatives,for the purpose of information retrieval.163.precision: the proportion of retrieval documents which are relevant.164.recall: the proportion of retrieval documents which are relevant.165.applied linguistics: applications of linguistics to study of second and foreign language learning and teaching,and other areas such astranslation,the compiling of dictionaries,etc municative competence: as defined by Hymes,the knowledge and ability involved in putting language to communicative use.167.syllabus:the planning of course of instruction.It is a description of the cousr content,teaching procedures and learning experiences.168.interlanguage:the type of language constructed by second or foreign language learners who are still in the process of learning a language,i.e.the language system between the target language and the learner’s native language.169.transfer: the influence of mother tongue upon the second language.When structures of the two languages are similar,we can get positive transfer of facilitation;when the two languages are different in structures,negative transfer of inference occurs and result in errors.170.validity: the degree to which a test meansures what it is meant to measure.There are four kinds of validity,i.e.content validity,construct validity,empirical valiodity,and face validity.171.rebiability: can be defined as consistency.There are two kinds of reliability,i.e.stability reliability,and equiralence reliability.172.hypercorrection: overuse of a standard linguistic features,in terms of both frequency,i.e.overpassing the speakers of higher social status,and overshooting the target,i.e.extending the use of a form inalinguistic environment where it is not expected to occur,For example,pronouncing ideas as[ai’dier],extending pronouncing post-vocalic/r/ in an envorienment where it’s not sup posed to occur.173.discrete point test: a kind of test in which language structures or skills are further divided into individual points of phonology,syntax and lexis.174.integrative test: a kind of test in which language structures or skills are further divided into individual points of。
classification

classificationClassification is a fundamental task in machine learning and data analysis. It involves categorizing data into predefined classes or categories based on their features or characteristics. The goal of classification is to build a model that can accurately predict the class of new, unseen instances.In this document, we will explore the concept of classification, different types of classification algorithms, and their applications in various domains. We will also discuss the process of building and evaluating a classification model.I. Introduction to ClassificationA. Definition and Importance of ClassificationClassification is the process of assigning predefined labels or classes to instances based on their relevant features. It plays a vital role in numerous fields, including finance, healthcare, marketing, and customer service. By classifying data, organizations can make informed decisions, automate processes, and enhance efficiency.B. Types of Classification Problems1. Binary Classification: In binary classification, instances are classified into one of two classes. For example, spam detection, fraud detection, and sentiment analysis are binary classification problems.2. Multi-class Classification: In multi-class classification, instances are classified into more than two classes. Examples of multi-class classification problems include document categorization, image recognition, and disease diagnosis.II. Classification AlgorithmsA. Decision TreesDecision trees are widely used for classification tasks. They provide a clear and interpretable way to classify instances by creating a tree-like model. Decision trees use a set of rules based on features to make decisions, leading down different branches until a leaf node (class label) is reached. Some popular decision tree algorithms include C4.5, CART, and Random Forest.B. Naive BayesNaive Bayes is a probabilistic classification algorithm based on Bayes' theorem. It assumes that the features are statistically independent of each other, despite the simplifying assumption, which often doesn't hold in the realworld. Naive Bayes is known for its simplicity and efficiency and works well in text classification and spam filtering.C. Support Vector MachinesSupport Vector Machines (SVMs) are powerful classification algorithms that find the optimal hyperplane in high-dimensional space to separate instances into different classes. SVMs are good at dealing with linear and non-linear classification problems. They have applications in image recognition, hand-written digit recognition, and text categorization.D. K-Nearest Neighbors (KNN)K-Nearest Neighbors is a simple yet effective classification algorithm. It classifies an instance based on its k nearest neighbors in the training set. KNN is a non-parametric algorithm, meaning it does not assume any specific distribution of the data. It has applications in recommendation systems and pattern recognition.E. Artificial Neural Networks (ANN)Artificial Neural Networks are inspired by the biological structure of the human brain. They consist of interconnected nodes (neurons) organized in layers. ANN algorithms, such asMultilayer Perceptron and Convolutional Neural Networks, have achieved remarkable success in various classification tasks, including image recognition, speech recognition, and natural language processing.III. Building a Classification ModelA. Data PreprocessingBefore implementing a classification algorithm, data preprocessing is necessary. This step involves cleaning the data, handling missing values, and encoding categorical variables. It may also include feature scaling and dimensionality reduction techniques like Principal Component Analysis (PCA).B. Training and TestingTo build a classification model, a labeled dataset is divided into a training set and a testing set. The training set is used to fit the model on the data, while the testing set is used to evaluate the performance of the model. Cross-validation techniques like k-fold cross-validation can be used to obtain more accurate estimates of the model's performance.C. Evaluation MetricsSeveral metrics can be used to evaluate the performance of a classification model. Accuracy, precision, recall, and F1-score are commonly used metrics. Additionally, ROC curves and AUC (Area Under Curve) can assess the model's performance across different probability thresholds.IV. Applications of ClassificationA. Spam DetectionClassification algorithms can be used to detect spam emails accurately. By training a model on a dataset of labeled spam and non-spam emails, it can learn to classify incoming emails as either spam or legitimate.B. Fraud DetectionClassification algorithms are essential in fraud detection systems. By analyzing features such as account activity, transaction patterns, and user behavior, a model can identify potentially fraudulent transactions or activities.C. Disease DiagnosisClassification algorithms can assist in disease diagnosis by analyzing patient data, including symptoms, medical history, and test results. By comparing the patient's data againsthistorical data, the model can predict the likelihood of a specific disease.D. Image RecognitionClassification algorithms, particularly deep learning algorithms like Convolutional Neural Networks (CNNs), have revolutionized image recognition tasks. They can accurately identify objects or scenes in images, enabling applications like facial recognition and autonomous driving.V. ConclusionClassification is a vital task in machine learning and data analysis. It enables us to categorize instances into different classes based on their features. By understanding different classification algorithms and their applications, organizations can make better decisions, automate processes, and gain valuable insights from their data.。
机器学习与人工智能领域中常用的英语词汇

机器学习与人工智能领域中常用的英语词汇1.General Concepts (基础概念)•Artificial Intelligence (AI) - 人工智能1)Artificial Intelligence (AI) - 人工智能2)Machine Learning (ML) - 机器学习3)Deep Learning (DL) - 深度学习4)Neural Network - 神经网络5)Natural Language Processing (NLP) - 自然语言处理6)Computer Vision - 计算机视觉7)Robotics - 机器人技术8)Speech Recognition - 语音识别9)Expert Systems - 专家系统10)Knowledge Representation - 知识表示11)Pattern Recognition - 模式识别12)Cognitive Computing - 认知计算13)Autonomous Systems - 自主系统14)Human-Machine Interaction - 人机交互15)Intelligent Agents - 智能代理16)Machine Translation - 机器翻译17)Swarm Intelligence - 群体智能18)Genetic Algorithms - 遗传算法19)Fuzzy Logic - 模糊逻辑20)Reinforcement Learning - 强化学习•Machine Learning (ML) - 机器学习1)Machine Learning (ML) - 机器学习2)Artificial Neural Network - 人工神经网络3)Deep Learning - 深度学习4)Supervised Learning - 有监督学习5)Unsupervised Learning - 无监督学习6)Reinforcement Learning - 强化学习7)Semi-Supervised Learning - 半监督学习8)Training Data - 训练数据9)Test Data - 测试数据10)Validation Data - 验证数据11)Feature - 特征12)Label - 标签13)Model - 模型14)Algorithm - 算法15)Regression - 回归16)Classification - 分类17)Clustering - 聚类18)Dimensionality Reduction - 降维19)Overfitting - 过拟合20)Underfitting - 欠拟合•Deep Learning (DL) - 深度学习1)Deep Learning - 深度学习2)Neural Network - 神经网络3)Artificial Neural Network (ANN) - 人工神经网络4)Convolutional Neural Network (CNN) - 卷积神经网络5)Recurrent Neural Network (RNN) - 循环神经网络6)Long Short-Term Memory (LSTM) - 长短期记忆网络7)Gated Recurrent Unit (GRU) - 门控循环单元8)Autoencoder - 自编码器9)Generative Adversarial Network (GAN) - 生成对抗网络10)Transfer Learning - 迁移学习11)Pre-trained Model - 预训练模型12)Fine-tuning - 微调13)Feature Extraction - 特征提取14)Activation Function - 激活函数15)Loss Function - 损失函数16)Gradient Descent - 梯度下降17)Backpropagation - 反向传播18)Epoch - 训练周期19)Batch Size - 批量大小20)Dropout - 丢弃法•Neural Network - 神经网络1)Neural Network - 神经网络2)Artificial Neural Network (ANN) - 人工神经网络3)Deep Neural Network (DNN) - 深度神经网络4)Convolutional Neural Network (CNN) - 卷积神经网络5)Recurrent Neural Network (RNN) - 循环神经网络6)Long Short-Term Memory (LSTM) - 长短期记忆网络7)Gated Recurrent Unit (GRU) - 门控循环单元8)Feedforward Neural Network - 前馈神经网络9)Multi-layer Perceptron (MLP) - 多层感知器10)Radial Basis Function Network (RBFN) - 径向基函数网络11)Hopfield Network - 霍普菲尔德网络12)Boltzmann Machine - 玻尔兹曼机13)Autoencoder - 自编码器14)Spiking Neural Network (SNN) - 脉冲神经网络15)Self-organizing Map (SOM) - 自组织映射16)Restricted Boltzmann Machine (RBM) - 受限玻尔兹曼机17)Hebbian Learning - 海比安学习18)Competitive Learning - 竞争学习19)Neuroevolutionary - 神经进化20)Neuron - 神经元•Algorithm - 算法1)Algorithm - 算法2)Supervised Learning Algorithm - 有监督学习算法3)Unsupervised Learning Algorithm - 无监督学习算法4)Reinforcement Learning Algorithm - 强化学习算法5)Classification Algorithm - 分类算法6)Regression Algorithm - 回归算法7)Clustering Algorithm - 聚类算法8)Dimensionality Reduction Algorithm - 降维算法9)Decision Tree Algorithm - 决策树算法10)Random Forest Algorithm - 随机森林算法11)Support Vector Machine (SVM) Algorithm - 支持向量机算法12)K-Nearest Neighbors (KNN) Algorithm - K近邻算法13)Naive Bayes Algorithm - 朴素贝叶斯算法14)Gradient Descent Algorithm - 梯度下降算法15)Genetic Algorithm - 遗传算法16)Neural Network Algorithm - 神经网络算法17)Deep Learning Algorithm - 深度学习算法18)Ensemble Learning Algorithm - 集成学习算法19)Reinforcement Learning Algorithm - 强化学习算法20)Metaheuristic Algorithm - 元启发式算法•Model - 模型1)Model - 模型2)Machine Learning Model - 机器学习模型3)Artificial Intelligence Model - 人工智能模型4)Predictive Model - 预测模型5)Classification Model - 分类模型6)Regression Model - 回归模型7)Generative Model - 生成模型8)Discriminative Model - 判别模型9)Probabilistic Model - 概率模型10)Statistical Model - 统计模型11)Neural Network Model - 神经网络模型12)Deep Learning Model - 深度学习模型13)Ensemble Model - 集成模型14)Reinforcement Learning Model - 强化学习模型15)Support Vector Machine (SVM) Model - 支持向量机模型16)Decision Tree Model - 决策树模型17)Random Forest Model - 随机森林模型18)Naive Bayes Model - 朴素贝叶斯模型19)Autoencoder Model - 自编码器模型20)Convolutional Neural Network (CNN) Model - 卷积神经网络模型•Dataset - 数据集1)Dataset - 数据集2)Training Dataset - 训练数据集3)Test Dataset - 测试数据集4)Validation Dataset - 验证数据集5)Balanced Dataset - 平衡数据集6)Imbalanced Dataset - 不平衡数据集7)Synthetic Dataset - 合成数据集8)Benchmark Dataset - 基准数据集9)Open Dataset - 开放数据集10)Labeled Dataset - 标记数据集11)Unlabeled Dataset - 未标记数据集12)Semi-Supervised Dataset - 半监督数据集13)Multiclass Dataset - 多分类数据集14)Feature Set - 特征集15)Data Augmentation - 数据增强16)Data Preprocessing - 数据预处理17)Missing Data - 缺失数据18)Outlier Detection - 异常值检测19)Data Imputation - 数据插补20)Metadata - 元数据•Training - 训练1)Training - 训练2)Training Data - 训练数据3)Training Phase - 训练阶段4)Training Set - 训练集5)Training Examples - 训练样本6)Training Instance - 训练实例7)Training Algorithm - 训练算法8)Training Model - 训练模型9)Training Process - 训练过程10)Training Loss - 训练损失11)Training Epoch - 训练周期12)Training Batch - 训练批次13)Online Training - 在线训练14)Offline Training - 离线训练15)Continuous Training - 连续训练16)Transfer Learning - 迁移学习17)Fine-Tuning - 微调18)Curriculum Learning - 课程学习19)Self-Supervised Learning - 自监督学习20)Active Learning - 主动学习•Testing - 测试1)Testing - 测试2)Test Data - 测试数据3)Test Set - 测试集4)Test Examples - 测试样本5)Test Instance - 测试实例6)Test Phase - 测试阶段7)Test Accuracy - 测试准确率8)Test Loss - 测试损失9)Test Error - 测试错误10)Test Metrics - 测试指标11)Test Suite - 测试套件12)Test Case - 测试用例13)Test Coverage - 测试覆盖率14)Cross-Validation - 交叉验证15)Holdout Validation - 留出验证16)K-Fold Cross-Validation - K折交叉验证17)Stratified Cross-Validation - 分层交叉验证18)Test Driven Development (TDD) - 测试驱动开发19)A/B Testing - A/B 测试20)Model Evaluation - 模型评估•Validation - 验证1)Validation - 验证2)Validation Data - 验证数据3)Validation Set - 验证集4)Validation Examples - 验证样本5)Validation Instance - 验证实例6)Validation Phase - 验证阶段7)Validation Accuracy - 验证准确率8)Validation Loss - 验证损失9)Validation Error - 验证错误10)Validation Metrics - 验证指标11)Cross-Validation - 交叉验证12)Holdout Validation - 留出验证13)K-Fold Cross-Validation - K折交叉验证14)Stratified Cross-Validation - 分层交叉验证15)Leave-One-Out Cross-Validation - 留一法交叉验证16)Validation Curve - 验证曲线17)Hyperparameter Validation - 超参数验证18)Model Validation - 模型验证19)Early Stopping - 提前停止20)Validation Strategy - 验证策略•Supervised Learning - 有监督学习1)Supervised Learning - 有监督学习2)Label - 标签3)Feature - 特征4)Target - 目标5)Training Labels - 训练标签6)Training Features - 训练特征7)Training Targets - 训练目标8)Training Examples - 训练样本9)Training Instance - 训练实例10)Regression - 回归11)Classification - 分类12)Predictor - 预测器13)Regression Model - 回归模型14)Classifier - 分类器15)Decision Tree - 决策树16)Support Vector Machine (SVM) - 支持向量机17)Neural Network - 神经网络18)Feature Engineering - 特征工程19)Model Evaluation - 模型评估20)Overfitting - 过拟合21)Underfitting - 欠拟合22)Bias-Variance Tradeoff - 偏差-方差权衡•Unsupervised Learning - 无监督学习1)Unsupervised Learning - 无监督学习2)Clustering - 聚类3)Dimensionality Reduction - 降维4)Anomaly Detection - 异常检测5)Association Rule Learning - 关联规则学习6)Feature Extraction - 特征提取7)Feature Selection - 特征选择8)K-Means - K均值9)Hierarchical Clustering - 层次聚类10)Density-Based Clustering - 基于密度的聚类11)Principal Component Analysis (PCA) - 主成分分析12)Independent Component Analysis (ICA) - 独立成分分析13)T-distributed Stochastic Neighbor Embedding (t-SNE) - t分布随机邻居嵌入14)Gaussian Mixture Model (GMM) - 高斯混合模型15)Self-Organizing Maps (SOM) - 自组织映射16)Autoencoder - 自动编码器17)Latent Variable - 潜变量18)Data Preprocessing - 数据预处理19)Outlier Detection - 异常值检测20)Clustering Algorithm - 聚类算法•Reinforcement Learning - 强化学习1)Reinforcement Learning - 强化学习2)Agent - 代理3)Environment - 环境4)State - 状态5)Action - 动作6)Reward - 奖励7)Policy - 策略8)Value Function - 值函数9)Q-Learning - Q学习10)Deep Q-Network (DQN) - 深度Q网络11)Policy Gradient - 策略梯度12)Actor-Critic - 演员-评论家13)Exploration - 探索14)Exploitation - 开发15)Temporal Difference (TD) - 时间差分16)Markov Decision Process (MDP) - 马尔可夫决策过程17)State-Action-Reward-State-Action (SARSA) - 状态-动作-奖励-状态-动作18)Policy Iteration - 策略迭代19)Value Iteration - 值迭代20)Monte Carlo Methods - 蒙特卡洛方法•Semi-Supervised Learning - 半监督学习1)Semi-Supervised Learning - 半监督学习2)Labeled Data - 有标签数据3)Unlabeled Data - 无标签数据4)Label Propagation - 标签传播5)Self-Training - 自训练6)Co-Training - 协同训练7)Transudative Learning - 传导学习8)Inductive Learning - 归纳学习9)Manifold Regularization - 流形正则化10)Graph-based Methods - 基于图的方法11)Cluster Assumption - 聚类假设12)Low-Density Separation - 低密度分离13)Semi-Supervised Support Vector Machines (S3VM) - 半监督支持向量机14)Expectation-Maximization (EM) - 期望最大化15)Co-EM - 协同期望最大化16)Entropy-Regularized EM - 熵正则化EM17)Mean Teacher - 平均教师18)Virtual Adversarial Training - 虚拟对抗训练19)Tri-training - 三重训练20)Mix Match - 混合匹配•Feature - 特征1)Feature - 特征2)Feature Engineering - 特征工程3)Feature Extraction - 特征提取4)Feature Selection - 特征选择5)Input Features - 输入特征6)Output Features - 输出特征7)Feature Vector - 特征向量8)Feature Space - 特征空间9)Feature Representation - 特征表示10)Feature Transformation - 特征转换11)Feature Importance - 特征重要性12)Feature Scaling - 特征缩放13)Feature Normalization - 特征归一化14)Feature Encoding - 特征编码15)Feature Fusion - 特征融合16)Feature Dimensionality Reduction - 特征维度减少17)Continuous Feature - 连续特征18)Categorical Feature - 分类特征19)Nominal Feature - 名义特征20)Ordinal Feature - 有序特征•Label - 标签1)Label - 标签2)Labeling - 标注3)Ground Truth - 地面真值4)Class Label - 类别标签5)Target Variable - 目标变量6)Labeling Scheme - 标注方案7)Multi-class Labeling - 多类别标注8)Binary Labeling - 二分类标注9)Label Noise - 标签噪声10)Labeling Error - 标注错误11)Label Propagation - 标签传播12)Unlabeled Data - 无标签数据13)Labeled Data - 有标签数据14)Semi-supervised Learning - 半监督学习15)Active Learning - 主动学习16)Weakly Supervised Learning - 弱监督学习17)Noisy Label Learning - 噪声标签学习18)Self-training - 自训练19)Crowdsourcing Labeling - 众包标注20)Label Smoothing - 标签平滑化•Prediction - 预测1)Prediction - 预测2)Forecasting - 预测3)Regression - 回归4)Classification - 分类5)Time Series Prediction - 时间序列预测6)Forecast Accuracy - 预测准确性7)Predictive Modeling - 预测建模8)Predictive Analytics - 预测分析9)Forecasting Method - 预测方法10)Predictive Performance - 预测性能11)Predictive Power - 预测能力12)Prediction Error - 预测误差13)Prediction Interval - 预测区间14)Prediction Model - 预测模型15)Predictive Uncertainty - 预测不确定性16)Forecast Horizon - 预测时间跨度17)Predictive Maintenance - 预测性维护18)Predictive Policing - 预测式警务19)Predictive Healthcare - 预测性医疗20)Predictive Maintenance - 预测性维护•Classification - 分类1)Classification - 分类2)Classifier - 分类器3)Class - 类别4)Classify - 对数据进行分类5)Class Label - 类别标签6)Binary Classification - 二元分类7)Multiclass Classification - 多类分类8)Class Probability - 类别概率9)Decision Boundary - 决策边界10)Decision Tree - 决策树11)Support Vector Machine (SVM) - 支持向量机12)K-Nearest Neighbors (KNN) - K最近邻算法13)Naive Bayes - 朴素贝叶斯14)Logistic Regression - 逻辑回归15)Random Forest - 随机森林16)Neural Network - 神经网络17)SoftMax Function - SoftMax函数18)One-vs-All (One-vs-Rest) - 一对多(一对剩余)19)Ensemble Learning - 集成学习20)Confusion Matrix - 混淆矩阵•Regression - 回归1)Regression Analysis - 回归分析2)Linear Regression - 线性回归3)Multiple Regression - 多元回归4)Polynomial Regression - 多项式回归5)Logistic Regression - 逻辑回归6)Ridge Regression - 岭回归7)Lasso Regression - Lasso回归8)Elastic Net Regression - 弹性网络回归9)Regression Coefficients - 回归系数10)Residuals - 残差11)Ordinary Least Squares (OLS) - 普通最小二乘法12)Ridge Regression Coefficient - 岭回归系数13)Lasso Regression Coefficient - Lasso回归系数14)Elastic Net Regression Coefficient - 弹性网络回归系数15)Regression Line - 回归线16)Prediction Error - 预测误差17)Regression Model - 回归模型18)Nonlinear Regression - 非线性回归19)Generalized Linear Models (GLM) - 广义线性模型20)Coefficient of Determination (R-squared) - 决定系数21)F-test - F检验22)Homoscedasticity - 同方差性23)Heteroscedasticity - 异方差性24)Autocorrelation - 自相关25)Multicollinearity - 多重共线性26)Outliers - 异常值27)Cross-validation - 交叉验证28)Feature Selection - 特征选择29)Feature Engineering - 特征工程30)Regularization - 正则化2.Neural Networks and Deep Learning (神经网络与深度学习)•Convolutional Neural Network (CNN) - 卷积神经网络1)Convolutional Neural Network (CNN) - 卷积神经网络2)Convolution Layer - 卷积层3)Feature Map - 特征图4)Convolution Operation - 卷积操作5)Stride - 步幅6)Padding - 填充7)Pooling Layer - 池化层8)Max Pooling - 最大池化9)Average Pooling - 平均池化10)Fully Connected Layer - 全连接层11)Activation Function - 激活函数12)Rectified Linear Unit (ReLU) - 线性修正单元13)Dropout - 随机失活14)Batch Normalization - 批量归一化15)Transfer Learning - 迁移学习16)Fine-Tuning - 微调17)Image Classification - 图像分类18)Object Detection - 物体检测19)Semantic Segmentation - 语义分割20)Instance Segmentation - 实例分割21)Generative Adversarial Network (GAN) - 生成对抗网络22)Image Generation - 图像生成23)Style Transfer - 风格迁移24)Convolutional Autoencoder - 卷积自编码器25)Recurrent Neural Network (RNN) - 循环神经网络•Recurrent Neural Network (RNN) - 循环神经网络1)Recurrent Neural Network (RNN) - 循环神经网络2)Long Short-Term Memory (LSTM) - 长短期记忆网络3)Gated Recurrent Unit (GRU) - 门控循环单元4)Sequence Modeling - 序列建模5)Time Series Prediction - 时间序列预测6)Natural Language Processing (NLP) - 自然语言处理7)Text Generation - 文本生成8)Sentiment Analysis - 情感分析9)Named Entity Recognition (NER) - 命名实体识别10)Part-of-Speech Tagging (POS Tagging) - 词性标注11)Sequence-to-Sequence (Seq2Seq) - 序列到序列12)Attention Mechanism - 注意力机制13)Encoder-Decoder Architecture - 编码器-解码器架构14)Bidirectional RNN - 双向循环神经网络15)Teacher Forcing - 强制教师法16)Backpropagation Through Time (BPTT) - 通过时间的反向传播17)Vanishing Gradient Problem - 梯度消失问题18)Exploding Gradient Problem - 梯度爆炸问题19)Language Modeling - 语言建模20)Speech Recognition - 语音识别•Long Short-Term Memory (LSTM) - 长短期记忆网络1)Long Short-Term Memory (LSTM) - 长短期记忆网络2)Cell State - 细胞状态3)Hidden State - 隐藏状态4)Forget Gate - 遗忘门5)Input Gate - 输入门6)Output Gate - 输出门7)Peephole Connections - 窥视孔连接8)Gated Recurrent Unit (GRU) - 门控循环单元9)Vanishing Gradient Problem - 梯度消失问题10)Exploding Gradient Problem - 梯度爆炸问题11)Sequence Modeling - 序列建模12)Time Series Prediction - 时间序列预测13)Natural Language Processing (NLP) - 自然语言处理14)Text Generation - 文本生成15)Sentiment Analysis - 情感分析16)Named Entity Recognition (NER) - 命名实体识别17)Part-of-Speech Tagging (POS Tagging) - 词性标注18)Attention Mechanism - 注意力机制19)Encoder-Decoder Architecture - 编码器-解码器架构20)Bidirectional LSTM - 双向长短期记忆网络•Attention Mechanism - 注意力机制1)Attention Mechanism - 注意力机制2)Self-Attention - 自注意力3)Multi-Head Attention - 多头注意力4)Transformer - 变换器5)Query - 查询6)Key - 键7)Value - 值8)Query-Value Attention - 查询-值注意力9)Dot-Product Attention - 点积注意力10)Scaled Dot-Product Attention - 缩放点积注意力11)Additive Attention - 加性注意力12)Context Vector - 上下文向量13)Attention Score - 注意力分数14)SoftMax Function - SoftMax函数15)Attention Weight - 注意力权重16)Global Attention - 全局注意力17)Local Attention - 局部注意力18)Positional Encoding - 位置编码19)Encoder-Decoder Attention - 编码器-解码器注意力20)Cross-Modal Attention - 跨模态注意力•Generative Adversarial Network (GAN) - 生成对抗网络1)Generative Adversarial Network (GAN) - 生成对抗网络2)Generator - 生成器3)Discriminator - 判别器4)Adversarial Training - 对抗训练5)Minimax Game - 极小极大博弈6)Nash Equilibrium - 纳什均衡7)Mode Collapse - 模式崩溃8)Training Stability - 训练稳定性9)Loss Function - 损失函数10)Discriminative Loss - 判别损失11)Generative Loss - 生成损失12)Wasserstein GAN (WGAN) - Wasserstein GAN(WGAN)13)Deep Convolutional GAN (DCGAN) - 深度卷积生成对抗网络(DCGAN)14)Conditional GAN (c GAN) - 条件生成对抗网络(c GAN)15)Style GAN - 风格生成对抗网络16)Cycle GAN - 循环生成对抗网络17)Progressive Growing GAN (PGGAN) - 渐进式增长生成对抗网络(PGGAN)18)Self-Attention GAN (SAGAN) - 自注意力生成对抗网络(SAGAN)19)Big GAN - 大规模生成对抗网络20)Adversarial Examples - 对抗样本•Encoder-Decoder - 编码器-解码器1)Encoder-Decoder Architecture - 编码器-解码器架构2)Encoder - 编码器3)Decoder - 解码器4)Sequence-to-Sequence Model (Seq2Seq) - 序列到序列模型5)State Vector - 状态向量6)Context Vector - 上下文向量7)Hidden State - 隐藏状态8)Attention Mechanism - 注意力机制9)Teacher Forcing - 强制教师法10)Beam Search - 束搜索11)Recurrent Neural Network (RNN) - 循环神经网络12)Long Short-Term Memory (LSTM) - 长短期记忆网络13)Gated Recurrent Unit (GRU) - 门控循环单元14)Bidirectional Encoder - 双向编码器15)Greedy Decoding - 贪婪解码16)Masking - 遮盖17)Dropout - 随机失活18)Embedding Layer - 嵌入层19)Cross-Entropy Loss - 交叉熵损失20)Tokenization - 令牌化•Transfer Learning - 迁移学习1)Transfer Learning - 迁移学习2)Source Domain - 源领域3)Target Domain - 目标领域4)Fine-Tuning - 微调5)Domain Adaptation - 领域自适应6)Pre-Trained Model - 预训练模型7)Feature Extraction - 特征提取8)Knowledge Transfer - 知识迁移9)Unsupervised Domain Adaptation - 无监督领域自适应10)Semi-Supervised Domain Adaptation - 半监督领域自适应11)Multi-Task Learning - 多任务学习12)Data Augmentation - 数据增强13)Task Transfer - 任务迁移14)Model Agnostic Meta-Learning (MAML) - 与模型无关的元学习(MAML)15)One-Shot Learning - 单样本学习16)Zero-Shot Learning - 零样本学习17)Few-Shot Learning - 少样本学习18)Knowledge Distillation - 知识蒸馏19)Representation Learning - 表征学习20)Adversarial Transfer Learning - 对抗迁移学习•Pre-trained Models - 预训练模型1)Pre-trained Model - 预训练模型2)Transfer Learning - 迁移学习3)Fine-Tuning - 微调4)Knowledge Transfer - 知识迁移5)Domain Adaptation - 领域自适应6)Feature Extraction - 特征提取7)Representation Learning - 表征学习8)Language Model - 语言模型9)Bidirectional Encoder Representations from Transformers (BERT) - 双向编码器结构转换器10)Generative Pre-trained Transformer (GPT) - 生成式预训练转换器11)Transformer-based Models - 基于转换器的模型12)Masked Language Model (MLM) - 掩蔽语言模型13)Cloze Task - 填空任务14)Tokenization - 令牌化15)Word Embeddings - 词嵌入16)Sentence Embeddings - 句子嵌入17)Contextual Embeddings - 上下文嵌入18)Self-Supervised Learning - 自监督学习19)Large-Scale Pre-trained Models - 大规模预训练模型•Loss Function - 损失函数1)Loss Function - 损失函数2)Mean Squared Error (MSE) - 均方误差3)Mean Absolute Error (MAE) - 平均绝对误差4)Cross-Entropy Loss - 交叉熵损失5)Binary Cross-Entropy Loss - 二元交叉熵损失6)Categorical Cross-Entropy Loss - 分类交叉熵损失7)Hinge Loss - 合页损失8)Huber Loss - Huber损失9)Wasserstein Distance - Wasserstein距离10)Triplet Loss - 三元组损失11)Contrastive Loss - 对比损失12)Dice Loss - Dice损失13)Focal Loss - 焦点损失14)GAN Loss - GAN损失15)Adversarial Loss - 对抗损失16)L1 Loss - L1损失17)L2 Loss - L2损失18)Huber Loss - Huber损失19)Quantile Loss - 分位数损失•Activation Function - 激活函数1)Activation Function - 激活函数2)Sigmoid Function - Sigmoid函数3)Hyperbolic Tangent Function (Tanh) - 双曲正切函数4)Rectified Linear Unit (Re LU) - 矩形线性单元5)Parametric Re LU (P Re LU) - 参数化Re LU6)Exponential Linear Unit (ELU) - 指数线性单元7)Swish Function - Swish函数8)Softplus Function - Soft plus函数9)Softmax Function - SoftMax函数10)Hard Tanh Function - 硬双曲正切函数11)Softsign Function - Softsign函数12)GELU (Gaussian Error Linear Unit) - GELU(高斯误差线性单元)13)Mish Function - Mish函数14)CELU (Continuous Exponential Linear Unit) - CELU(连续指数线性单元)15)Bent Identity Function - 弯曲恒等函数16)Gaussian Error Linear Units (GELUs) - 高斯误差线性单元17)Adaptive Piecewise Linear (APL) - 自适应分段线性函数18)Radial Basis Function (RBF) - 径向基函数•Backpropagation - 反向传播1)Backpropagation - 反向传播2)Gradient Descent - 梯度下降3)Partial Derivative - 偏导数4)Chain Rule - 链式法则5)Forward Pass - 前向传播6)Backward Pass - 反向传播7)Computational Graph - 计算图8)Neural Network - 神经网络9)Loss Function - 损失函数10)Gradient Calculation - 梯度计算11)Weight Update - 权重更新12)Activation Function - 激活函数13)Optimizer - 优化器14)Learning Rate - 学习率15)Mini-Batch Gradient Descent - 小批量梯度下降16)Stochastic Gradient Descent (SGD) - 随机梯度下降17)Batch Gradient Descent - 批量梯度下降18)Momentum - 动量19)Adam Optimizer - Adam优化器20)Learning Rate Decay - 学习率衰减•Gradient Descent - 梯度下降1)Gradient Descent - 梯度下降2)Stochastic Gradient Descent (SGD) - 随机梯度下降3)Mini-Batch Gradient Descent - 小批量梯度下降4)Batch Gradient Descent - 批量梯度下降5)Learning Rate - 学习率6)Momentum - 动量7)Adaptive Moment Estimation (Adam) - 自适应矩估计8)RMSprop - 均方根传播9)Learning Rate Schedule - 学习率调度10)Convergence - 收敛11)Divergence - 发散12)Adagrad - 自适应学习速率方法13)Adadelta - 自适应增量学习率方法14)Adamax - 自适应矩估计的扩展版本15)Nadam - Nesterov Accelerated Adaptive Moment Estimation16)Learning Rate Decay - 学习率衰减17)Step Size - 步长18)Conjugate Gradient Descent - 共轭梯度下降19)Line Search - 线搜索20)Newton's Method - 牛顿法•Learning Rate - 学习率1)Learning Rate - 学习率2)Adaptive Learning Rate - 自适应学习率3)Learning Rate Decay - 学习率衰减4)Initial Learning Rate - 初始学习率5)Step Size - 步长6)Momentum - 动量7)Exponential Decay - 指数衰减8)Annealing - 退火9)Cyclical Learning Rate - 循环学习率10)Learning Rate Schedule - 学习率调度11)Warm-up - 预热12)Learning Rate Policy - 学习率策略13)Learning Rate Annealing - 学习率退火14)Cosine Annealing - 余弦退火15)Gradient Clipping - 梯度裁剪16)Adapting Learning Rate - 适应学习率17)Learning Rate Multiplier - 学习率倍增器18)Learning Rate Reduction - 学习率降低19)Learning Rate Update - 学习率更新20)Scheduled Learning Rate - 定期学习率•Batch Size - 批量大小1)Batch Size - 批量大小2)Mini-Batch - 小批量3)Batch Gradient Descent - 批量梯度下降4)Stochastic Gradient Descent (SGD) - 随机梯度下降5)Mini-Batch Gradient Descent - 小批量梯度下降6)Online Learning - 在线学习7)Full-Batch - 全批量8)Data Batch - 数据批次9)Training Batch - 训练批次10)Batch Normalization - 批量归一化11)Batch-wise Optimization - 批量优化12)Batch Processing - 批量处理13)Batch Sampling - 批量采样14)Adaptive Batch Size - 自适应批量大小15)Batch Splitting - 批量分割16)Dynamic Batch Size - 动态批量大小17)Fixed Batch Size - 固定批量大小18)Batch-wise Inference - 批量推理19)Batch-wise Training - 批量训练20)Batch Shuffling - 批量洗牌•Epoch - 训练周期1)Training Epoch - 训练周期2)Epoch Size - 周期大小3)Early Stopping - 提前停止4)Validation Set - 验证集5)Training Set - 训练集6)Test Set - 测试集7)Overfitting - 过拟合8)Underfitting - 欠拟合9)Model Evaluation - 模型评估10)Model Selection - 模型选择11)Hyperparameter Tuning - 超参数调优12)Cross-Validation - 交叉验证13)K-fold Cross-Validation - K折交叉验证14)Stratified Cross-Validation - 分层交叉验证15)Leave-One-Out Cross-Validation (LOOCV) - 留一法交叉验证16)Grid Search - 网格搜索17)Random Search - 随机搜索18)Model Complexity - 模型复杂度19)Learning Curve - 学习曲线20)Convergence - 收敛3.Machine Learning Techniques and Algorithms (机器学习技术与算法)•Decision Tree - 决策树1)Decision Tree - 决策树2)Node - 节点3)Root Node - 根节点4)Leaf Node - 叶节点5)Internal Node - 内部节点6)Splitting Criterion - 分裂准则7)Gini Impurity - 基尼不纯度8)Entropy - 熵9)Information Gain - 信息增益10)Gain Ratio - 增益率11)Pruning - 剪枝12)Recursive Partitioning - 递归分割13)CART (Classification and Regression Trees) - 分类回归树14)ID3 (Iterative Dichotomiser 3) - 迭代二叉树315)C4.5 (successor of ID3) - C4.5(ID3的后继者)16)C5.0 (successor of C4.5) - C5.0(C4.5的后继者)17)Split Point - 分裂点18)Decision Boundary - 决策边界19)Pruned Tree - 剪枝后的树20)Decision Tree Ensemble - 决策树集成•Random Forest - 随机森林1)Random Forest - 随机森林2)Ensemble Learning - 集成学习3)Bootstrap Sampling - 自助采样4)Bagging (Bootstrap Aggregating) - 装袋法5)Out-of-Bag (OOB) Error - 袋外误差6)Feature Subset - 特征子集7)Decision Tree - 决策树8)Base Estimator - 基础估计器9)Tree Depth - 树深度10)Randomization - 随机化11)Majority Voting - 多数投票12)Feature Importance - 特征重要性13)OOB Score - 袋外得分14)Forest Size - 森林大小15)Max Features - 最大特征数16)Min Samples Split - 最小分裂样本数17)Min Samples Leaf - 最小叶节点样本数18)Gini Impurity - 基尼不纯度19)Entropy - 熵20)Variable Importance - 变量重要性•Support Vector Machine (SVM) - 支持向量机1)Support Vector Machine (SVM) - 支持向量机2)Hyperplane - 超平面3)Kernel Trick - 核技巧4)Kernel Function - 核函数5)Margin - 间隔6)Support Vectors - 支持向量7)Decision Boundary - 决策边界8)Maximum Margin Classifier - 最大间隔分类器9)Soft Margin Classifier - 软间隔分类器10) C Parameter - C参数11)Radial Basis Function (RBF) Kernel - 径向基函数核12)Polynomial Kernel - 多项式核13)Linear Kernel - 线性核14)Quadratic Kernel - 二次核15)Gaussian Kernel - 高斯核16)Regularization - 正则化17)Dual Problem - 对偶问题18)Primal Problem - 原始问题19)Kernelized SVM - 核化支持向量机20)Multiclass SVM - 多类支持向量机•K-Nearest Neighbors (KNN) - K-最近邻1)K-Nearest Neighbors (KNN) - K-最近邻2)Nearest Neighbor - 最近邻3)Distance Metric - 距离度量4)Euclidean Distance - 欧氏距离5)Manhattan Distance - 曼哈顿距离6)Minkowski Distance - 闵可夫斯基距离7)Cosine Similarity - 余弦相似度8)K Value - K值9)Majority Voting - 多数投票10)Weighted KNN - 加权KNN11)Radius Neighbors - 半径邻居12)Ball Tree - 球树13)KD Tree - KD树14)Locality-Sensitive Hashing (LSH) - 局部敏感哈希15)Curse of Dimensionality - 维度灾难16)Class Label - 类标签17)Training Set - 训练集18)Test Set - 测试集19)Validation Set - 验证集20)Cross-Validation - 交叉验证•Naive Bayes - 朴素贝叶斯1)Naive Bayes - 朴素贝叶斯2)Bayes' Theorem - 贝叶斯定理3)Prior Probability - 先验概率4)Posterior Probability - 后验概率5)Likelihood - 似然6)Class Conditional Probability - 类条件概率7)Feature Independence Assumption - 特征独立假设8)Multinomial Naive Bayes - 多项式朴素贝叶斯9)Gaussian Naive Bayes - 高斯朴素贝叶斯10)Bernoulli Naive Bayes - 伯努利朴素贝叶斯11)Laplace Smoothing - 拉普拉斯平滑12)Add-One Smoothing - 加一平滑13)Maximum A Posteriori (MAP) - 最大后验概率14)Maximum Likelihood Estimation (MLE) - 最大似然估计15)Classification - 分类16)Feature Vectors - 特征向量17)Training Set - 训练集18)Test Set - 测试集19)Class Label - 类标签20)Confusion Matrix - 混淆矩阵•Clustering - 聚类1)Clustering - 聚类2)Centroid - 质心3)Cluster Analysis - 聚类分析4)Partitioning Clustering - 划分式聚类5)Hierarchical Clustering - 层次聚类6)Density-Based Clustering - 基于密度的聚类7)K-Means Clustering - K均值聚类8)K-Medoids Clustering - K中心点聚类9)DBSCAN (Density-Based Spatial Clustering of Applications with Noise) - 基于密度的空间聚类算法10)Agglomerative Clustering - 聚合式聚类11)Dendrogram - 系统树图12)Silhouette Score - 轮廓系数13)Elbow Method - 肘部法则14)Clustering Validation - 聚类验证15)Intra-cluster Distance - 类内距离16)Inter-cluster Distance - 类间距离17)Cluster Cohesion - 类内连贯性18)Cluster Separation - 类间分离度19)Cluster Assignment - 聚类分配20)Cluster Label - 聚类标签•K-Means - K-均值1)K-Means - K-均值2)Centroid - 质心3)Cluster - 聚类4)Cluster Center - 聚类中心5)Cluster Assignment - 聚类分配6)Cluster Analysis - 聚类分析7)K Value - K值8)Elbow Method - 肘部法则9)Inertia - 惯性10)Silhouette Score - 轮廓系数11)Convergence - 收敛12)Initialization - 初始化13)Euclidean Distance - 欧氏距离14)Manhattan Distance - 曼哈顿距离15)Distance Metric - 距离度量16)Cluster Radius - 聚类半径17)Within-Cluster Variation - 类内变异18)Cluster Quality - 聚类质量19)Clustering Algorithm - 聚类算法20)Clustering Validation - 聚类验证•Dimensionality Reduction - 降维1)Dimensionality Reduction - 降维2)Feature Extraction - 特征提取3)Feature Selection - 特征选择4)Principal Component Analysis (PCA) - 主成分分析5)Singular Value Decomposition (SVD) - 奇异值分解6)Linear Discriminant Analysis (LDA) - 线性判别分析7)t-Distributed Stochastic Neighbor Embedding (t-SNE) - t-分布随机邻域嵌入8)Autoencoder - 自编码器9)Manifold Learning - 流形学习10)Locally Linear Embedding (LLE) - 局部线性嵌入11)Isomap - 等度量映射12)Uniform Manifold Approximation and Projection (UMAP) - 均匀流形逼近与投影13)Kernel PCA - 核主成分分析14)Non-negative Matrix Factorization (NMF) - 非负矩阵分解15)Independent Component Analysis (ICA) - 独立成分分析16)Variational Autoencoder (VAE) - 变分自编码器17)Sparse Coding - 稀疏编码18)Random Projection - 随机投影19)Neighborhood Preserving Embedding (NPE) - 保持邻域结构的嵌入20)Curvilinear Component Analysis (CCA) - 曲线成分分析•Principal Component Analysis (PCA) - 主成分分析1)Principal Component Analysis (PCA) - 主成分分析2)Eigenvector - 特征向量3)Eigenvalue - 特征值4)Covariance Matrix - 协方差矩阵。
classification英语作文

classification英语作文Classification is a fundamental process in our understanding of the world around us. It is the act of organizing and grouping objects, ideas, or concepts based on their similarities and differences. This process allows us to make sense of the vast and complex universe we inhabit, providing a structure that helps us navigate and comprehend the myriad of information and phenomena we encounter.One of the primary reasons for classification is to facilitate learning and understanding. By grouping similar items together, we can more easily identify patterns, recognize relationships, and draw conclusions about the underlying principles that govern the world. This is particularly important in the field of science, where classification systems have been instrumental in advancing our knowledge of the natural world.For example, the Linnaean system of biological classification, developed by the Swedish naturalist Carl Linnaeus in the 18th century, has been a cornerstone of modern biology. By organizing living organisms into a hierarchical system of kingdoms, phyla,classes, orders, families, genera, and species, Linnaeus provided a framework for understanding the vast diversity of life on Earth. This classification system has facilitated the study of evolution, the identification of new species, and the understanding of the relationships between different organisms.Similarly, in the field of chemistry, the periodic table of elements has been a crucial tool for organizing and understanding the fundamental building blocks of matter. By arranging the elements based on their atomic structure and chemical properties, the periodic table has enabled scientists to predict the behavior of elements, discover new elements, and develop a deeper understanding of the underlying principles that govern chemical reactions.Beyond the scientific realm, classification is also essential in our everyday lives. We classify objects, ideas, and even people in order to make sense of the world and navigate our daily experiences. For instance, we might classify household items into categories such as furniture, appliances, and office supplies, or we might classify people based on their occupation, age, or socioeconomic status.One of the key benefits of classification is that it allows us to make informed decisions and take appropriate actions. By understanding the characteristics and relationships of different objects or concepts, we can more effectively solve problems, make predictions, anddevelop strategies. For example, a retailer might classify their products based on factors such as price, target audience, or product category in order to develop effective marketing and inventory management strategies.However, it is important to note that classification is not always a straightforward or unambiguous process. The criteria used for classification can be subjective, and the boundaries between different categories can be blurred. Additionally, as our understanding of the world evolves, the way we classify things may also change over time.For instance, the classification of living organisms has undergone significant revisions as new scientific discoveries and advancements in our understanding of genetics and evolutionary relationships have emerged. Similarly, the way we classify social and cultural phenomena can be influenced by our own biases, values, and perspectives.Despite these challenges, the process of classification remains a crucial tool for organizing and understanding the world around us. By identifying patterns, recognizing relationships, and developing taxonomies, we can better navigate the complexity of our existence and make more informed decisions.In conclusion, classification is a fundamental process that underpins our understanding of the world. Whether in the realm of science, technology, or our everyday lives, the act of organizing and grouping objects, ideas, and concepts based on their similarities and differences has been instrumental in advancing our knowledge and shaping our interactions with the world around us. As we continue to explore and discover new frontiers, the importance of classification will only grow, serving as a guiding light in our quest to make sense of the vast and intricate tapestry of our universe.。
GD&T,几何公差,中英文

RFS applies
RFS applies MMC is specified
24
定义 与 应用
Definition and Application
25
1.Form Controls 形状控制
Form controls never use a datum reference.
形状控制不使用基准面
27
1.1 Flatness 平面
1.1.2 Application 应用
0.1wide flatness tolerance zone
Limits set by Rule #1
The surface must lie between two parallel planes 0.1 apart
28
Modifier—Denotes shape of Tolerance zone
Modifier—Denotes Material condition
Tolerance value
Datum references
15
5.附加符号 Modifying symbols
Term
Abbreviation Symbol
S,L,or M must be specified If the datum is a feature-of-size
23
基本原则(4) Fundamental Rules
Rule #4 (除位置度以外几何公差之应用原则) 对于位置度以外的几何公差,沒有特殊标识的以RFS(不相关原則)处理
Rule #4 (Other than tolerance of position rule) For other than a tolerance of position, RFS applies with respect to the
classification and division

What We Want from EducationAs teenagers in today’s China, most of us have the same goal—to be enrolled by noted universities and further our educations. Why do so many people choose education as their most desirable thing ? according to different incentives of different groups of people to receive education, I think there are following kinds of purposes which motivate people in China to be obsessed with education.“N othing is more decent and distinguished than receiving education.” This is an old saying from ancient china, which can fully reflects a portion of Chinese people’s motivation to receive education, especially those students who are from remote and destitute family. Influenced by China’s ancient philosophy and world view, many of modern people consider education can change their whole life such as social status and salaries. Therefore, they dedicate their time and energy to studying. When some of them can not realize their dream, they will even choose extreme cruel way to end their lives. For example, we often heard news reports that many Chinese teenagers commit suicide after knowing they do not have a good performance in the college entrance examination. In those people’s eyes, education is more than a way to uplift themselves either in the aspect of morality or self-improvement, it become tool which can lead them to get everything they long for such as wealth or social status etc.For another group of people, they hold a completely reasonable and loft attitude toward their education motivation. They view education as their part of lives which can give them something beyond material. Just like a philosophy Francis Bacon said “Histories make men wise; poets witty; the mathematics subtile; natural philosophy deep; moral grave; logic and rhetoric able to contend”. In those people’s opinions, receiving education is a kind of lifestyle more than a torturing process. “never too old to learn” is the motto of these people. They just enjoy the process of studying and new knowledge can always refresh them. Education means more than reading a book or obtaining a new skill but a intimate companion who they can lose in their lives.No matter what kind of attitude people hold when they are receive education, there is one common factor, namely, they all manage to acquire new knowledge and master new skills, however their primary motivation will lead them to two different avenues.。
英语段落写作分类

由体操) and backstroke • Essential to a good classification is parallelism.
2) mini-van(旅行车) 3) sedan (小轿车)
Practபைடு நூலகம்ce for you • Neighbors
There are three types of neighbors according to their personalities: those who are always ready to help others, those who are indifferent to others, and those who are potential trouble— makers for others.
• Make sure all the categories follow a single organizing principle. The organizing principle is how you sort the groups. Do not allow a different principle to pop up unexpectedly.
• Then you want to write out your categories into logical order or least important to most important. Start with one category and explain it. Like "The second category is the funny teacher. This type of teacher brings a different environment to the classroom. They want their students to enjoy learning. They are smart and bring humor to their classrooms. "
写作 classification

About creating categories
Remember the categories of a classification must not overlap or contain items already contained within another entry. Otherwise, the classification will become illogical.
Exercise
Mattresses:queen; twin; firm; double;
Single basis:
size
Exercises: fatigue; swimming; jogging; gymnastics;
Single basis:
field
Churches: Roman Catholic; Baptism; Protestant; Orthodox;
Single basis:
branch
Vacation: Seashore; winter; summer; weekends;
Single basis:
time
Related Expression
About creating categories
Once you are given a topic, you will create categories by organizing elements according to a common feature. Decide how to organize elements of your topic into categories. With your categories created, identify common features of each category.
classification英文的缩写

一、 classification的定义classification是classify的名词形式,指的是将事物或者概念按照一定的标准或者特征进行分类和归类的行为。
在各个领域,classification都有着重要的应用,例如在生物学中对动植物的分类,图书馆中对图书的分类,电子产品中对设备的分类等等。
二、classification的英文缩写1. 在计算机科学中,classification常常被用作机器学习、数据挖掘等领域中的重要概念。
在这些领域中,classification通常被表示为"class."或者"cls."的缩写形式。
在Python语言的机器学习库scikit-learn中,classification模块就被命名为"sklearn.classification"。
2. 在图书馆学中,classification系统也有着特定的英文缩写形式。
我们熟知的图书馆分类系统中的Dewey Decimal Classification就常被简写为"DDC"。
3. 在医学领域,classification的英文缩写通常是"ICD",全称为"International Classification of Diseases",即国际疾病分类。
ICD 被世界卫生组织用于统计、分析和比较全球范围内的疾病数据,在国际上具有重要的影响力。
4. 在商业和市场营销领域,classification常常被简写为"class."或者"cls."。
对用户进行分类分析,以便进行精准营销的方法就被称为"consumer classification"。
5. 在法律领域,classification的英文缩写为"class."或者"cls.",主要用于法律文件或者文件分类系统中。
Classification &__ Identification

Molecular analysis
It would be ideal to compare sequences of entire bacterial chromosomal DNA.
Alternatively, genomic similarity has been assessed by the guanine (G)+ cytosine (C) content (% GC). This has been replaced by two alternatives: 1. Hybridization 2. Sequencing specific genes
Taxonomic characterization of bacteria
1. Comparisons of species involve comparisons of multiple strains for each species. 2. Comparisons are primarily based on chemical or molecular analysis.
Approaches to rapid diagnosis without prior culture
1. Certain human pathogens either a. can not be isolated in the laboratory b. grow extremely poor. 2. Successful isolation can be slow and in some instances impossible. 3. Direct detection of bacteria without culture is possible for some organisms.
Outof-domain detection based on confidence measures from multiple topic classification

OUT-OF-DOMAIN DETECTION BASED ON CONFIDENCE MEASURES FROMMULTIPLE TOPIC CLASSIFICATIONIan ne1,2,Tatsuya Kawahara1,2,Tomoko Matsui3,2,Satoshi Nakamura21School of Informatics,Kyoto UniversitySakyo-ku,Kyoto606-8501,Japan2ATR Spoken Language Translation Laboratories2-2-2Hikaridai,Seika-cho,Soraku-gun,Kyoto619-0288,Japan3The Institute of Statistical Mathematics4-6-7Minami-Azabu,Mitato-ku,Tokyo106-8569,JapanABSTRACTOne significant problem for spoken language systems is how to cope with users’OOD(out-of-domain)utterances which cannot be handled by the back-end system.In this paper,we propose a novel OOD detection framework,which makes use of classification con-fidence scores of multiple topics and trains a linear discriminant in-domain verifier using GPD.Training is based on deleted inter-polation of the in-domain data,and thus does not require actual OOD data,providing high portability.Three topic classification schemes of word N-gram models,LSA,and SVM are evaluated, and SVM is shown to have the greatest discriminative ability.In an OOD detection task,the proposed approach achieves an ab-solute reduction in EER of6.5%compared to a baseline method based on a simple combination of multiple-topic classifications. Furthermore,comparison with a system trained using OOD data demonstrates that the proposed training scheme realizes compara-ble performance while requiring no knowledge of the OOD data set.1.INTRODUCTIONMost spoken language systems,excluding general-purpose dicta-tion systems,operate over definite domains as a user interface to a service provided by the back-end system.However,users,es-pecially novice users,do not always have an exact concept of the domains served by the system.Thus,they often attempt utterances that cannot be handled by the system.These are referred to as OOD(out-of-domain)in this paper.Definitions of OOD for three typical spoken language systems are described in Table1.For an improved interface,spoken language systems should predict and detect such OOD utterances.In order to predict OOD utterances,the language model should allow some margin in its coverage.A mechanism is also required for the detection of OOD utterances,which is addressed in this paper.Performing OOD de-tection will improve the system interface by enabling users to de-termine whether to reattempt the current task after being confirmed as in-domain,or to halt attempts due to being OOD.For exam-ple,in a speech-to-speech translation system,an utterance may be in-domain but unable to be accurately translated by the back-end system;in this case the user is requested to re-phrase the input utterance,making translation possible.In the case of an OOD ut-terance,however,re-phrasing will not improve translation,so theTable1.Definitions of Out-of-domain for various systems System Out-of-Domain definition Spoken Dialogue User’s query does not relate to back-endinformation sourceCall Routing User’s query does not relate to anycall destinationSpeech-to-Speech Translation system does not provide Translation coverage for offered topicuser should be informed that the utterance is OOD and provided with a list of tractable domains.Research on OOD detection is limited,and conventional stud-ies have typically focused on using recognition confidences for re-jecting erroneous recognition outputs(e.g.,[1],[2]).In these ap-proaches there is no discrimination between in-domain utterances that have been incorrectly recognized and OOD utterances,and thus effective user feedback cannot be generated.One area where OOD detection has been successfully applied is call routing tasks such as that described in[3].In this work,classification models are trained for each call destination,and a garbage model is ex-plicitly trained to detect OOD utterances.To train these models,a large amount of real-world data is required,consisting of both in-domain and OOD training examples.However,reliance on OOD training data is problematic:first,an operational on-line system is required to gather such data,and second,it is difficult to gain an appropriate distribution of data that will provide sufficient cover-age over all possible OOD utterances.In the proposed approach,the domain is assumed to consist of multiple sub-domain topics,such as call destinations in call-routing,sub-topics in translation systems,and sub-domains in com-plex dialogue systems.OOD detection is performed byfirst cal-culating classification confidence scores for all in-domain topic classes and then applying an in-domain verification model to this confidence vector,which results in an OOD decision.The verifi-cation model is trained using GPD(gradient probabilistic descent) and deleted interpolation,allowing the system to be developed by using only in-domain data.2.SYSTEM OVERVIEWIn the proposed framework,the training set is initially split into multiple topic classes.In the work described in this paper,topic classes are predefined and the training set is hand-labeled appropri-«by applying topic-dependent language models.We demonstratedthe effectiveness of such an approach in[4].An overview of the OOD detection framework is shown inFigure1.First,speech recognition is performed by applying ageneralized language model that covers all in-domain topics,andN-best recognition hypotheses(s1,...,s N)are generated.Next, topic classification confidence scores(C(t1|X),...,C(t M|X)) are generated for each topic class based on these hypotheses.Fi-nally,OOD detection is performed by applying an in-domain veri-fication model G in−domain(X)to the resulting confidence vector. The overall performance of the proposed approach is affected by the accuracy of the topic classification method and the in-domain verification model.These aspects are described in detail in the following sections.3.TOPIC CLASSIFICATIONIn this paper three topic classification schemes are evaluated:topic-dependent word N-gram,LSA(latent semantic analysis),and SVM (support vector machines).Based on a given feature set,topic models are trained using the above methods.Topic classification is performed and confidence scores(in the range[0,1])are calculated by applying a sigmoid transform to these results.When classifica-tion is applied to an N-best speech recognition result,confidence scores are calculated as shown in Equation1.Topic classification is applied independently to each N-best hypothesis,and these are linearly combined by weighting each with the posterior probability of that hypothesis given by ASR.C(t j|X)=NXi=1p(s i|X)C(t j|s i)(1)C(t j|X):confidence score of topic t j for input utterance Xp(s i|X):posterior probability of i-th best sentencehypothesis s i by ASRN:number of N-best hypotheses3.1.Topic Classification FeaturesVarious feature sets for topic classification are investigated.A feature vector consists of either word baseform(word token with no tense information;all variants are merged),full-word(surface form of words,including variants),or word+POS(part-of-speech) tokens.The inclusion of N-gram features that combine multiple neighboring tokens is also investigated.Appropriate cutoffs are applied during training to remove features with low occurrence.3.2.Topic-dependent Word N-gramIn this approach,N-gram language models are trained for each topic class.Classification is performed by calculating the log-likelihood of each topic model for the input sentence.Topic clas-sification confidence scores are calculated by applying a sigmoid transform to this log-likelihood measure.tent Semantic AnalysisLSA(latent semantic analysis)[5]is a popular technique for topic classification.Based on a vector space model,each sentence is represented as a point in a large dimension space,where vector components relate to the features described in Section3.1.Be-cause the vector space tends to be extremely large(10,000-70,000 features),traditional distance measures such as the cosine distance become unreliable.To improve performance,SVD(singular value decomposition)is applied to reduce the large space to100-300di-mensions.Each topic class is represented as a single document vector composed of all training sentences,and projected to this reduced space.Classification is performed by projecting the vector represen-tation of the input sentence to the reduced space and calculating the cosine distance between this vector and each topic class vec-tor.The resulting distance is normalized by applying a sigmoid transform generating classification confidence scores.3.4.Support Vector MachinesSVM(support vector machines)[6]is another popular classifica-tion ing a vector space model,SVM classifiers are trained for each in-domain topic class.Sentences that occur in the training set of that topic are used as positive examples and the remainder of the training set is used as negative examples.Classification is performed by feeding the vector representa-tion of the input sentence to each SVM classifier.The perpendicu-lar distance between this vector and each SVM hyperplane is used as the classification measure.This value is positive if the input sen-tence is in-class and negative otherwise.Again,confidence scores are generated by applying a sigmoid transform to this distance.4.IN-DOMAIN VERIFICATIONThefinal stage of OOD detection consists of applying an in-domain verification model G in−domain(X)to the vector of confidence scores generated during topic classification.We adopt a linear dis-criminant model(Eqn.2).Linear discriminant weights (λ1,...,λM)are applied to the confidence scores from topic clas-sification(C(t1|X),...,C(t M|X)),and a threshold(ϕ)is ap-plied to obtain a binary decision of in-domain or OOD.G in−domain(X)=(1ifPMj=1λj C(t j|X)≥ϕ(in-domain)0otherwise.(OOD)(2)C(t j|X):confidence score of topic t j for input utterance XM:number of topic classes4.1.Training using Deleted InterpolationThe in-domain verification model is trained using only in-domain data.An overview of the proposed training method combining GPD(gradient probabilistic descent)[7]and deleted interpolation¬Table2.Deleted Interpolation based Training for each topic i in[1,M]set topic i as temporary OODset remaining topic classes as in-domaincalculate(λ1,...,λM)using GPD(λi excluded) average(λ1,...,λM)over all iterationsTable3.Experiment CorpusDomain:Basic Travel ExpressionsIn-Domain:11topics(transit,accommodation,...)OOD:1topic(shopping)Training Set:11topics,149540sentences(in-domain data only) Lexicon Size:17000wordsTest set:In-Domain:1852utterancesOOD:138utterancesis given in Table2.Each topic is iteratively set to be temporar-ily OOD,and the classifier corresponding to this topic is removed from the model.The discriminant weights of the remaining topic classifiers are estimated using GPD.In this step,the temporary OOD data is used as negative training examples,and a balanced set of the remaining topic classes are used as positive(in-domain) examples.Upon completion of estimation by GPD,thefinal model weights are calculated by averaging over all interpolation steps. In the experimental evaluation,a topic-independent class“basic”covering general utterances exists,which is not removed during deleted interpolation.4.2.Incorporation of Topic-dependent VerifierImproved OOD detection accuracy can be achieved by applying more elaborate verification models.In this paper,a model consist-ing of multiple linear discriminant functions is investigated.Topic dependent functions are added for topics not modeled sufficiently. Their weights are trained specifically for verifying that topic.For verification,the topic with maximum classification confidence is selected,and a topic-dependent function is applied if one exists, otherwise a topic-independent function(Eqn.2)is applied.5.EXPERIMENTAL EV ALUATIONThe ATR BTEC corpus[8]is used to investigate the performance of the proposed approach.An overview of the corpus is given in Table3.In this experiment,we use“shopping”as OOD of the speech-to-speech translation system.The training set consisting of11in-domain topics is used to train both the language model for speech recognition and the topic classification models.Recogni-tion is performed with the Julius recognition engine.The recognition performance for the in-domain(ID)and OOD test sets are shown in Table4.Although the OOD test set has much greater error rates and out-of-vocabulary rate compared with the in-domain test set,more than half of the utterances are correctly recognized,since the language model covers the general travel do-main.This indicates that the OOD set is related to the in-domain task,and discrimination between these sets will be difficult.System performance is evaluated by the following measures: FRR(False Rejection Rate):Percentage of in-domainutterances classified as OOD FAR(False Acceptance Rate):Percentage of OOD utterancesclassified as in-domainEER(Equal Error Rate):Error rate at an operating pointwhere FRR and FAR are equalTable4.Speech Recognition Performance#Utt.WER(%)SER(%)OOV(%) In-Domain18527.2622.40.71 Out-of-Domain13812.4945.3 2.56 WER:Word Error Rate SER:Sentence Error RateOOV:Out of V ocabularyparison of Feature Sets&Classification Models Method Token Set Feature Set#Feat.EER(%)SVM base-form1-gram877129.7SVM full-word1-gram989923.9SVM word+POS1-gram1000623.3SVM word+POS1,2-gram4075421.7SVM word+POS1,2,3-gram7306519.6LSA word+POS1-gram1000623.3LSA word+POS1,2-gram4075424.1LSA word+POS1,2,3-gram7306523.0 NGRAM word+POS1-gram1000624.8 NGRAM word+POS1,2-gram4075425.2 NGRAM word+POS1,2,3-gram7306524.2 SVM:Support Vector Machines LSA:Latent Semantic Analysis NGRAM:Topic-dependent Word N-gram5.1.Evaluation of Topic Classification and Feature Sets First,the discriminative ability of various feature sets as described in Section3.1were investigated.Initially,SVM topic classifica-tion models were trained for each feature set.A closed evaluation was performed for this preliminary experiment.Topic classifica-tion confidence scores were calculated for the in-domain and OOD test sets using the above SVM models,and used to train the in-domain verification model using GPD.During training,in-domain data were used as positive training examples,and OOD data were used as negative examples.Model performance was evaluated by applying this closed model to the same confidence vectors used for training.The performance in terms of EER is shown in thefirst section of Table5.The EER when word-baseform features were used was29.7%. Full-word or word+POS features improved detection accuracy sig-nificantly:with EERs of23.9%and23.3%,respectively.The in-clusion of context-based2-gram and3-gram features further im-proved detection performance.A minimum EER of19.6%was obtained when3-gram features were incorporated.Next,LSA and N-gram-based classification models were eval-uated.Both approaches showed lower performance than SVM, and the inclusion of context-based features did not improve per-formance.SVM with a feature set containing1-,2-,and3-gram offered the lowest OOD detection error rate,so it is used in the following experiments.5.2.Deleted Interpolation-based TrainingNext,performance of the proposed training method combining GPD and deleted interpolation was evaluated.We compared the OOD detection performances of the proposed method(proposed), a reference method in which the in-domain verification model was trained using both in-domain and OOD data(as described in Sec-tion5.1)(closed-model),and a baseline system.In the baseline system,topic detection was applied and an utterance was classi-fied as OOD if all binary SVM decisions were negative.Other-¬10203040506070010203040506070FRRF A RFig.2.OOD Detection Performance on Correct Transcriptions102030baselineproposedclosed-modelVerification MethodE r r o r R a t e (%)Fig.3.OOD Detection Performance on ASR Result wise it was classi fied as in-domain.The ROC graph of the three systems obtained by altering the veri fication threshold (ϕin Eqn.2)is shown in Figure 2.The baseline system has a FRR of 25.2%,a FAR of 29.7%,and an EER of 27.7%.The proposed method provides an abso-lute reduction in EER of 6.5%compared to the baseline system.Furthermore,it offers comparable performance to the closed eval-uation case (21.2%vs.19.6%)while being trained with only in-domain data.This shows that the deleted interpolation approach is successful in training the OOD detection model in the absence of OOD data.5.3.Evaluation with ASR ResultsNext,the performances of the above three systems were evaluated on a test set of 1990spoken utterances.Speech recognition was performed and the 10-best recognition results were used to gen-erate a topic classi fication vector.The FRR,FAR and percentage of falsely rejected utterances with recognition errors are shown in Figure 3.The EER of the proposed system when applied to the ASR re-sults is 22.7%,an absolute increase of 1.5%compared to the case for the correct transcriptions.This small increase in EER suggests that the system is strongly robust against recognition errors.Fur-ther investigation showed that the falsely rejected set had a SER of around 43%,twice that of the in-domain test set.This suggests that utterances that incur recognition errors are more likely to be rejected than correctly recognized utterances.5.4.Effect of Topic-dependent Veri fication ModelFinally,the topic-dependent in-domain veri fication model described in Section 4.2was also incorporated.Evaluation was performed on spoken utterances as in the above section.The addition of atopic-dependent function (for the topic “basic ”)reduced the EER to 21.2%.The addition of further topic-dependent functions,how-ever,did not provide signi ficant improvement in performance over the two function case.The topic class “basic ”is the most vague and is poorly modeled by the topic-independent model.A topic-dependent function effectively models the complexities of this class.6.CONCLUSIONSWe proposed a novel OOD (out-of-domain)detection method based on con fidence measures from multiple topic classi fication.A novel training method combining GPD and deleted interpolation was in-troduced to allow the system to be trained using only in-domain data.Three classi fication methods were evaluated (topic depen-dent word N-gram,LSA and SVM),and SVM-based topic classi fi-cation using word and N-gram features proved to have the greatest discriminative ability.The proposed approach reduced OOD detection errors by 6.5%compared to the baseline system based on a simple combination of binary topic classi fications.Furthermore,it provides similar per-formance to the same system trained on both in-domain and OOD data (EERs of 21.2%and 19.6%,respectively)while requiring no knowledge of the OOD data set.Addition of a topic dependent veri fication model provides a further reduction in detection errors.Acknowledgements:The research reported here was supported in part by a contract with the Telecommunications Advancement Organization of Japan entitled,”A study of speech dialogue trans-lation technology based on a large corpus”.7.REFERENCES[1]T.Hanzen,S.Seneff,and J.Polifroni.Recognition con fidenceand its use in speech understanding systems.In Computer Speech and Language ,2002.[2]C Ma,M.Randolph,and J.Drish.A support vector machines-based rejection technique for speech recognition.In ICASSP ,2001.[3]P.Haffner,G.Tur,and J.Wright.Optimizing svms for com-plex call classi fication.In ICASSP ,2003.[4]ne,T.Kawahara,and nguage model switch-ing based on topic detection for dialog speech recognition.In ICASSP ,2003.[5]S.Deerwester,S.Dumais,G.Furnas,ndauer,andR.Harshman.Indexing by latent semantic analysis.In Journ.of the American Society for information science,41,pp.391-407,1990.[6]T.Joachims.Text categorization with support vector ma-chines.In Proc.European Conference on Machine Learning ,1998.[7]S.Katagiri,C.-H.Lee,and B.-H.Juang.New discriminativetraining algorithm based on the generalized probabilistic de-scent method.In IEEE workshop NNSP ,pp.299-300,1991.[8]T.Takezawa,M.Sumita,F.Sugaya,H.Yamamoto,and Ya-mamoto S.Towards a broad-coverage bilingual corpus for speech translation of travel conversations in the real world.In Proc.LREC,pp.147-152,2002.¬。
新时代核心英语教程写作2教学课件U12 Division and classification

1. The qualities to look for in a translator D
2. Types of automobile drivers
C
3. Careers in the field of sports
C
4. Feature films
C
5. The characteristics of good news
Subject
Types/Parts
Subcompact cars, compact cars,
Cars
intermediate cars, full-sized
cars, front-wheel drives, luxury cars
Activity 3
Examine each of the following subjects carefully and tell whether the principle of division or classification is consistent and whether the resulting types or parts are mutually exclusive and complete. If your answer is “No,” redivide or reclassify the subject.
Subject
Types/Parts
Nomophobia
The first stage, the second stage, the third stage
Activity 3
Examine each of the following subjects carefully and tell whether the principle of division or classification is consistent and whether the resulting types or parts are mutually exclusive and complete. If your answer is “No,” redivide or reclassify the subject.
猴子的介绍英语作文

Monkeys are fascinating creatures that belong to the primate order,which also includes humans,apes,and prosimians.They are known for their agility,intelligence,and social behavior.Heres an introduction to these remarkable animals in English:1.Classification and Diversity:Monkeys are classified into two main groups:the New World monkeys,which are found in Central and South America,and the Old World monkeys,which are native to Africa and Asia.There are over260species of monkeys, each with unique characteristics and adaptations.2.Physical Characteristics:Monkeys exhibit a wide range of physical traits.They typically have long arms and legs,which are wellsuited for climbing and swinging through trees.Their hands and feet are equipped with opposable thumbs,allowing them to grasp objects and manipulate their environment with precision.3.Adaptations:Many monkeys have prehensile tails that they use for balance and as an additional limb for grasping.Their eyes are forwardfacing,providing them with excellent depth perception,which is crucial for navigating their arboreal habitats.4.Diet:Monkeys are omnivorous,with diets that vary depending on their species and habitat.Some are primarily frugivorous,feeding on fruits,while others consume a mix of leaves,seeds,insects,and occasionally small animals.5.Social Behavior:Monkeys are known for their complex social structures.They live in groups ranging from small troops to large communities.These social groups provide safety in numbers and facilitate cooperative behaviors such as grooming,which helps to reinforce social bonds.munication:Monkeys communicate through a variety of vocalizations,body language,and facial expressions.They use these methods to convey information about their emotional state,to coordinate group activities,and to establish dominance hierarchies.7.Reproduction:Monkeys have a gestation period that varies by species,typically ranging from five to seven months.They give birth to one or two offspring at a time,and the young are cared for by the mother and sometimes other members of the group.8.Conservation Status:Many monkey species are threatened by habitat loss,poaching, and the illegal pet trade.Conservation efforts are crucial to protect these animals and preserve the biodiversity of our planet.9.Cultural Significance:Monkeys have been revered and depicted in various cultures around the world.In Chinese mythology,the Monkey King is a popular figure,while in Hinduism,the god Hanuman is a revered monkey god.10.Research and Study:Due to their genetic and behavioral similarities to humans, monkeys are often used in scientific research to study diseases,genetics,and behavior. They are also studied in the wild to understand their ecology and social dynamics.In conclusion,monkeys are an integral part of many ecosystems and hold a special place in the animal kingdom for their intelligence and adaptability.Understanding their biology, behavior,and the challenges they face is essential for their conservation and our appreciation of the natural world.。
英语写作classification范文

一、概述语言作为人类交流的工具,其重要性不言而喻。
在学习过程中,英语写作是学习者必须掌握的重要技能。
在英语写作中,classification (分类)是一个常见的写作类型。
本文将以classification为主题,探讨英语写作中的分类写作,包括其概念、特点、结构和常见的写作方法,并通过范文进行示范。
二、概念分类写作是指按照一定的标准和规则将事物、现象进行分类,以便对其进行系统地组织和阐述。
在英语写作中,分类写作常常用于对事物进行归纳整理,使读者能够清晰地了解各类事物的特点和区别。
三、特点1. 清晰明了:分类写作通过对事物进行分类,可以使读者清晰地了解事物的特点和彼此间的区别。
2. 逻辑性强:分类写作需要按照一定的规则和标准对事物进行分类,因此逻辑性强,易于理解。
3. 实用性强:在生活和工作中,常常需要对各种事物进行分类整理,因此分类写作具有强烈的实用性。
四、结构分类写作的结构一般包括三部分:概述、正文和结论。
1. 概述:介绍分类写作的主题和意义,引出要分类的事物。
2. 正文:对事物按照一定的标准和规则进行分类,逐一进行阐述和说明。
3. 结论:对分类进行总结,强调各类事物之间的通联和区别,提出自己的见解或建议。
五、分类写作的常见方法在英语写作中,分类写作有着多种方法,常见的有:1. 单一原则法:按照事物的一个特征进行分类,比较简单明了。
2. 多种原则法:按照事物的多种特征进行分类,能够更全面地展现事物的特点。
3. 组合法:结合单一原则法和多种原则法,灵活运用。
4. 交叉法:按照事物的多种特征进行交叉分类,具有独特的阐述方式。
六、范文示范以下是一篇关于classification的范文示范:Classification of AnimalsAnimals can be classified into three m本人n categories: mammals, birds, and reptiles.Mammals: Mammals are warm-blooded animals that have h 本人r or fur. They give birth to live young and feed them withmilk. Some examples of mammals are dogs, cats, elephants, and humans.Birds: Birds are warm-blooded animals that have feathers and lay eggs. They have wings and can fly. Some examples of birds are eagles, parrots, and penguins.Reptiles: Reptiles are cold-blooded animals that have scaly skin. They lay eggs and most of them are carnivorous. Some examples of reptiles are snakes, lizards, and crocodiles.Conclusion: In conclusion, animals can be classified into mammals, birds, and reptiles based on their characteristics and features. Each category has its unique tr本人ts and plays an important role in the ecosystem.七、总结本文围绕classification这一主题,对英语写作中的分类写作进行了探讨。
耳机的分类英语作文

耳机的分类英语作文Title: Classification of Headphones。
Introduction:Headphones are essential accessories for music enthusiasts, gamers, professionals, and everyday users seeking immersive audio experiences. They come in various types, each designed to cater to specific needs and preferences. In this essay, we will explore the classification of headphones based on their design, technology, and usage.1. Classification by Design:Headphones can be categorized based on their design into three main types: over-ear, on-ear, and in-ear.Over-Ear Headphones:Over-ear headphones, also known as circumaural headphones, feature ear cups that enclose the ears entirely. They are known for their excellent sound isolation and comfort, making them ideal for prolonged use and immersive listening experiences. Over-ear headphones are favored by audiophiles and professionals due to their superior sound quality and noise-canceling capabilities.On-Ear Headphones:On-ear headphones, also called supra-aural headphones, have smaller ear cups that rest on the ears rather than enclosing them entirely. They are more compact and portable compared to over-ear headphones, making them suitable for users who prioritize mobility without compromising on audio quality. On-ear headphones provide a balance betweencomfort and portability, making them popular among commuters and casual listeners.In-Ear Headphones:In-ear headphones, commonly known as earbuds orearphones, are the most compact and lightweight option. They fit snugly inside the ear canal, providing a securefit and excellent noise isolation. In-ear headphones are highly portable and suitable for use during physical activities such as workouts or commuting. They areavailable in wired and wireless variants, with wireless earbuds gaining popularity due to their convenience and freedom from tangled cables.2. Classification by Technology:Headphones can also be classified based on the technology they incorporate, including wired, wireless, and true wireless.Wired Headphones:Wired headphones rely on physical cables to connect to audio sources such as smartphones, computers, or audio interfaces. They are known for their reliable audio quality and compatibility with a wide range of devices. Wired headphones come with various connector types, including3.5mm audio jack, USB, and proprietary connectors. While they may lack the convenience of wireless connectivity, wired headphones are favored by audiophiles and professionals for their fidelity and low latency.Wireless Headphones:Wireless headphones utilize Bluetooth or other wireless technologies to connect to audio sources without the need for physical cables. They offer freedom of movement and convenience, allowing users to enjoy audio content without being tethered to their devices. Wireless headphones come in various designs, including over-ear, on-ear, and in-ear models. They are ideal for users who value mobility and versatility, whether for commuting, exercising, or everyday use.True Wireless Earbuds:True wireless earbuds represent the latest advancement in headphone technology, featuring two separate earpieces that connect wirelessly to audio sources. They do not haveany cables connecting the earpieces, offering a truly wireless listening experience. True wireless earbuds are compact, lightweight, and highly portable, making themideal for on-the-go use. They often come with chargingcases that provide additional battery life, ensuring extended listening sessions without interruption.3. Classification by Usage:Headphones can also be classified based on their intended usage, including consumer, professional, and gaming headphones.Consumer Headphones:Consumer headphones are designed for everyday use, catering to the needs of casual listeners, commuters, and music enthusiasts. They prioritize features such as comfort, portability, and style, offering a balance between audio quality and affordability. Consumer headphones come in various designs and price ranges, allowing users to find options that suit their preferences and budget.Professional Headphones:Professional headphones are tailored for audio professionals, including musicians, sound engineers, and recording artists. They prioritize accuracy, clarity, and durability, ensuring reliable performance in critical listening environments such as recording studios or live sound stages. Professional headphones often feature high-quality drivers, robust construction, and ergonomic designs optimized for long hours of use.Gaming Headphones:Gaming headphones are specifically designed for gamers, offering immersive audio experiences and clear communication during gaming sessions. They often feature surround sound technologies, noise-canceling microphones, and customizable audio settings to enhance gameplay and communication with teammates. Gaming headphones may also incorporate ergonomic designs, breathable ear cushions, and adjustable headbands for comfort during extended gamingsessions.Conclusion:In conclusion, headphones come in various types, each catering to specific needs, preferences, and usage scenarios. By understanding the classification of headphones based on their design, technology, and usage, consumers can make informed decisions when choosing the right headphones for their audio needs. Whether for immersive listening experiences, professional audio work, or gaming adventures, there is a headphone type suitable for every user.。
机械密封用碳石墨环现状与展望_朱斌

收稿日期:2012-02-27修稿日期:2012-03-03文章编号:1005-0329(2012)檭檭檭檭檭檭檭檭檭檭檭檭殐殐殐殐03-0040-04技术进展机械密封用碳石墨环现状与展望朱斌,朱路,林建华,涂丽婵(福建省闽旋科技股份有限公司,福建泉州362000)摘要:介绍了碳石墨材料的分类、特点以及国内外碳石墨材料的生产概况,结合旋转接头用碳石墨环制造应用,提出了对现行机械密封用碳石墨环技术标准的补充修订建议,针对国内碳石墨材料存在问题的现状,向行业主管部门提出了攻关愿望,结合国内碳石墨材料的技术进展和发展趋势进行了展望。
关键词:碳石墨;机械密封;旋转接头;生产概况;展望中图分类号:TH136文献标识码:Adoi :10.3969/j.issn.1005-0329.2012.03.009Current Situation and Prospect of Carbon Graphite Ring for Mechanical SealZHU Bin ,ZHU Lu ,LIN Jian-hua ,TU Li-chan(Fujian Minxuan Technology Co.,Ltd ,Quanzhou 362000,China )Abstract :The classification ,feature and production overview in domestic and foreign of carbon graphite material were intro-duced ,combineing with the manufacturing application of carbon graphite ring in rotary joints ,it was propose supplement and a-mendment to the current standard of specification for carbon graphite ring for mechanical seals ,in the light of current situation that in domestic carbon graphite material exist problems ,it was propose to industry department to research ,look ahead the technical progress and development trend of current carbon graphite material.Key words :carbon graphite ;mechanical seal ;rotary joint ;production overview ;prospect1前言碳石墨环因具有优良的耐高温性、自润滑性、低摩擦系数、耐磨损性、耐化学介质腐蚀性和良好的导热性、热膨胀系数小、对高低温交变性能的适应性以及材料的物理力学性能,作为机械密封应用领域中的关键部件已有两千多年的历史,并广泛应用于造纸、纺织、医药、军工等各工业部门[1,2]。
CategoriesorClassification类别或分类
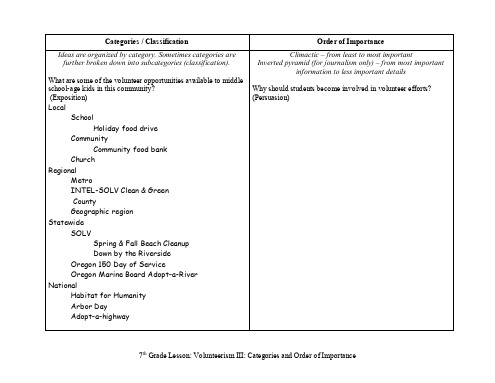
Climactic – from least to most important Inverted pyramid (for journalism only) – from most important
information to less important details
Why should students become involved in volunteer efforts? (Persuasion)
7th Grade Lesson: Volunteerism III: Categories and Order of Importance
information to less important details
Why should students become involved in volunteer efforts? (Persuasion)
Winter School food drive School adopt-a-family
Categories / Classification
Ideas are organized by category. Sometimes categories are further broken down into subcategories (classification).
What are some of the volunteer opportunities available to middle school-age kids in this community? (Exposition) Local
Mentoring Reading buddies for the elementary school
英文会议邀请函范文(精选10篇)

英文会议邀请函邀请函分为婚庆邀请函、商务邀请函、会议邀请函等。
在日常生活和工作中,各种邀请函频频出现,邀请函的`注意事项有许多,你确定会写吗?以下是小编收集整理的英文会议邀请函,仅供参考,欢迎大家阅读。
英文会议邀请函篇1dear sir/madam:thank you for your letter of [date].im glad that you are also going to [place] next month. it would be a great pleasure to meet you at the[exhibition/trade fair]. our company is having a reception at [hotel] on the evening of [date] and i would be very pleased if you could attend.i look forward to hearing from you soon.yours sincerely,[name] [title]英文会议邀请函篇2Dear Ms Wang:I have the great pleasure, on behalf of the International Conference on Medical Biometrics organization, of inviting you to contribute to the symposium on Medical device technologies, Medical data processing and management, Medical Pattern Recognition, Medical biometric systems and applications to be held in Shenzhen, between 30th May and 1th June 20xx We would like to invite you to submit a manuscript to the International Conference on Medical imaging devices, Medical information retrieval, Biometric technologies, Feature matching and classification, Computer-aided diagnosis and Other applications. The idea is to present originally contributed research, review, and short communication articles in the field ofMedical Biometrics. Deadline for submissions would be April 3, 20xx. Kindly submit your manuscripts as an E-mail attachment at ****************.cn.I will be looking forward to your favorable reply.Sincerely yours,Guangming Lu20xx-01-02英文会议邀请函篇3dear sir/madam:im delighted you have accepted our invitation to speak at the conference in [city] on [date]. as we agreed, youll be speaking on the topic from [time] to [time]. there will be an additional minutes for questions. would you please tell me what kind of audio-visual equipment youll need. if you could let me know your specific requirements by [date], ill have plenty of time to make sure that the hotel provides you with what you need.thank you again for agreeing to speak.i look forward to hearing from you.sincerely yours,name] [title]英文会议邀请函篇4Dear Lora,Will you come to luncheon on Friday, March 15th, at 12 o’clock?My niece Mary is visiting us and I think you will enjoy meeting her. She is a charming, very pretty girl … a nd very good company! John and Jane will be there as well, and perhaps we can go to an art gallery together after luncheon. Do say you’ll come!Affectionately yours,Li Ming英文会议邀请函篇5Dear [Mr. Hovell]:Please accept my apologies for the delay in acknowledging your invitation for [lunch/ dinner/ cocktails] on [September the fourth, this year]. I have been away form the office and only just returned.Unfortunately, I have other plans for the date you mention, but shall be happy to make a date for some other convenient time.Cordially,英文会议邀请函篇6Dear parents, how do you do?!When the flowers are blooming again, the annual "61" International Childrens Day is coming. This is a great festival for children.In this happy festival, please accept our deep blessing to each child in the center kindergarten of White Lake Town: wish the children to be healthy, happy and thriving under our care!Happy days without children figure, they are "61" arrival, carefully rehearsed various recreational activities:dance, singing, drama, model performance, tae kwon do they use their own unique way to greet the happy holiday!You must also want to see their dancing figures, to hear their loud and clear singing, and to spend this happy and important holiday with your babyPlease put aside your work at the moment and accept our sincere invitation with pleasure to invite you to feel your babys growth and happiness in your performance!Health and intelligence!Your arrival will certainly add luster to our kindergarten, and make the baby happier and happier!(Note:1. The children who are in the program must beadmitted before 8 to prepare for the performance.So parents should arrange their time and come to our art festival.2, participate in model performances of children, ask their parents to prepare for them usually the most fashionable clothing.3, we have a professional photographer to shoot the show, so this wonderful show will be a precious memory for every baby and parents.Parents who need CDS can pay 10 yuan to register in each classWhite Lake Town Center KindergartenMay 28th, 20xx英文会议邀请函篇7Dear Mr. Fisher,I would like to invite you to a meeting at our offices in Chicago on October 24.We want to discuss the launch of our new product, Chocolate Love Hearts.We would be happy to arrange a hotel for you during your stay here.Yours sincerely,Rose Clooney英文会议邀请函篇8Dear Professor John Doe,It is my pleasure,on behalf of the Organizing Committee,to invite you to attend the 21 International Conference on Chemical Education (19th ICCE),to be held in Beijing ,china,August 12-17,20XX.I am writing to ask whether you are willing to present a talk in English at the conference. Invited talks will be one hour long,followed by a 20-minute question and answer session.The theme of the 21th ICC E is “Chemistry and ChemicalEducation for Humanity”,in keeping up with our Fast-changing world and continually expanding scope of the chemistry and chemical field.Chemistry is not only an essential tool and language as well as basic knowledge for the most of science and technology of our everyday life,but also an essential science for future generations to ensure their quality of life.In appreciation of your agreement to give a talk,,the 19th ICCE will provide your local expenses,including hotel accommodations,and meals during the conference,and free registration to the conference.If you have any enquiries,please contact our Conference Convener Ms.Song Mei at(86)0108836 xxxx or visit .I am looking forward to seeing you in Beijing.Sincerely yours, (signature) Li Hou Chair,Organizing Committee of 21th ICCE英文会议邀请函篇9Dear professor wang,on behalf of the ohio state university and the ieee computer society, i would be very pleased to invite you to attend and chair a session of the forthcoming XX international conference on parallel data processing to be held in bellaire, michigan, from october 25 to october 28, XX.you are an internationally acclaimed scholar and educator. your participation will be among the highlights of the conference. we sincerely hope that you could accept our invitation. as you know, this is the 0th anniversary of the conference and we plan to make it a truly international meeting. we have accepted many papers from several foreign countries, including two from china. if you can come, please let us know as soon as possible, since we have to prepare the final program soon. we are looking forwardto your acceptance. sincerely yours, peter white英文会议邀请函篇10Dear Sir/Madam,I'm delighted you have accepted our invitation to speak at the conference in [city] on [date].As we agreed, you'll be speaking on the topic rdially invited to attend the celebration at [hotel], [location], on [date] from [time] to [time].[name] has been the President of [company] since [year]. During this period, [company] expanded its business greatly. Now it's our opportunity to thank him for his years of exemplary leadership and wish him well for a happy retirement. Please join us in saying good-bye to [name].See you on [date].Yours sincerely[name][title]。
SignalWhiteningPreprocessingfor:信号白化预处理

Signal Whitening Preprocessing for Improved Classification Accuracies in Myoelectric Control Lukai Liu1, Pu Liu1, Edward A. Clancy1, Erik Scheme2 and Kevin B. Englehart21Worcester Polytechnic Institute, 100 Institute Road, Worcester, MA 01609 U.S.A.2Institute of Biomedical Engineering, University of New Brunswick, Fredericton, NB E3B 5A3, Canada.Abstract— The surface electromyogram (EMG) signal collected from multiple channels has frequently been investigated for use in controlling upper-limb prostheses. One common control method is EMG-based motion classification. Time and frequency features derived from the EMG have been investigated. We propose the use of EMG signal whitening as a preprocessing step in EMG-based motion classification. Whitening decorrelates the EMG signal, and has been shown to be advantageous in other EMG applications. In a ten-subject study of up to 11 motion classes and ten electrode channels, we found that whitening improved classification accuracy by approximately 5% when small window length durations (<100ms) were considered.I.I NTRODUCTIONThe surface EMG has often been used in prosthesis control, ergonomics analysis and clinical biomechanics. Whitening has been used as a preprocessor to decorrelate the EMG signal. In the context of EMG-based motion selection for prosthetic control, we hypothesized that whitening would provide a decrease in the in-class variation of features leading to improved classification accuracy. The present study examined the influence of whitening on classification using time and frequency features of the EMG, in particular at shorter time durations. Three time domain features: mean absolute value (MAV), signal waveform length and zero-crossing rate; and 7th order autoregressive (AR) coefficients as frequency features, were used in our study. We observed an accuracy improvement of about 5% at smaller window lengths (less than 100 ms) with diminishing returns at longer window durations.II.M ETHODSA.Experimental Data and MethodsData from a prior study [1] were reanalyzed. The WPI IRB approved and supervised this reanalysis. Briefly, ten electrodes were applied transversely about the entire circumference of the proximal forearm. A custom electrode amplifier system provided a frequency response spanning approximately 30–450 Hz. Ten subjects with intact upper limbs began and ended each trial at "rest" with their elbow supported on an armrest. Each trial consisted of two repetitions of 11 sequential motion classes: 1, 2) wrist pronation/supination; 3, 4) wrist flexion/extension; 5) hand open; 6) key grip; 7) chuck grip; 8) power grip; 9) fine pinch grip; 10) tool grip; and 11) no motion. Each motion within a trial was maintained for 4 s, after which the subject returned to no motion for a specified inter-motion delay period. Trials 1–4 used an inter-motion delay of 3, 2, 1 and 0 s, respectively, and trials 5–8 used an inter-motion delay of 2 s. A minimum 2-min rest was given between trials. EMG data were sampled at 1000 Hz with a 16-bit ADC. Notch filters were used to attenuate power-line interference at the fundamental frequency and its harmonics.B.Methods of AnalysisThe inter-trial delay segments were removed from the data recordings, resulting in 22, four-second epochs per electrode, per trial (two repetitions of 11 motion classes). For all features, 0.5 seconds of data were truncated from the beginning and end of each epoch. Contiguous, non-overlapping windows were formed from the remaining 3-second epoch segments.Feature sets were computed for each window within an epoch. A time-domain feature set consisting of three features per window—MAV, signal length and zero-crossing [2] rate—was evaluated. A frequency domain feature set consisted of seven features per window, comprised of the coefficients of a seventh order autoregressive (AR) power spectral density estimate [3]. A third feature set concatenating the seven frequency domain features and the MAV was also evaluated.Trials 1–4 were used to train the coefficients of the classifier, and trials 5–8 were used to test classifier performance. Initially, all channels and all motions were included in the classifier. The models were trained and tested for each individual subject. Only the test results are reported. Ten window durations were used: 25, 50, 75, 100, 150, 200, 250, 300, 400 and 500 ms. The analysis was then repeated after the data had been whitened. When doing so, each epoch was high-pass filtered at 15Hz, then adaptively whitened using an algorithm that is tuned to the power spectrum of each EMG channel [4]. Two global variants were also considered. First, the entire analysis was repeated using only nine pre-selected motion classes (the classes denoted above as numbers 1–8 and 11), and again using only seven pre-selected motion classes (1–5, 8 and 11). Second, the entire analysis was repeated using a preselected set of six of the electrode channels. A linear discriminant classifier was used for the recognition task.Window length/ms Window length/ms A c c u r a c y (%)Fig. 1. Classification accuracies for intact subjects with (triangle)/without (circle) whitening used for pre-processing. The frequency feature set (Freq) iscomprised of the seven AR coefficients. The time domain feature set (TD) is comprised of three features, and the concatenated feature set (MAR) uses the AR coefficients and MAV. Window durations up to 300 ms are shown. Note the different y-axis scale for each plot.III. R ESULTS Fig. 1 shows the averaged test accuracies for the motion–channel combinations with lowest (left) and highest (right) overall performance. Classifying with more channels andfewer motion types (right) produced better overall performance. The concatenated (AR-MAV) feature set gave the highest overall classification accuracy, and the frequency domain feature set the lowest. A consistent 4–5% classification performance increase can be seen at shorterwindow durations for all three feature sets due to whitening, although the improvement decreases with longer windowduration. Paired t-tests (p <0.05) at all window lengths suggestthat use of whitening as a preprocessing stage provides a statistically significant performance improvement.IV. D ISCUSSIONWe have shown that the use of signal whitening prior toclassification analysis of the EMG system consistently improves the recognition accuracy, especially at shorter time durations. This improvement is modest (~5% for windowdurations less than 100 ms), but may help improve the accuracy of EMG-based artificial limb controllers. The factthat the most substantial improvement is seen with smallwindow lengths is important, as it may allow a control system to use less data, and therefore improve response time.Further work may apply to other EMG processing techniques, such as universal principal components analysis [1] and more sophisticated classifiers to further improve classification performance. R EFERENCES [1] L. J. Hargrove, G. Li, K. B. Englehart, B. S. Hudgins, “PrincipalComponents Analysis for Improved Classification Accuracies inPattern-Recognition-Based Myoelectric Control,” IEEE Trans. Biomed. Eng., Vol 56, pp. 1407–1414, 2009. [2] B. Hudgins, P. Parker, R. N. Scott, “A New Strategy for MultifunctionMyoelectric Control,” IEEE Trans. Biomed. Eng., Vol 40, pp 82–94,1993. [3] A. Neumaier, T. Schneider, “Estimation of Parameters and Eigenmodes of Multivariate Autoregressive Models,” ACM Trans. Math. Software , vol. 27, pp. 27–57, 2001.[4] E. A. Clancy, K. A. Farry, “Adaptive whitening of the electromyogramto improve amplitude estimation,” IEEE Trans. Biomed. Eng., vol. 47, pp. 709–719, 2000.。
基于机器视觉的作物多姿态害虫特征提取与分类方法_李文勇

(( I R (i, j ) I MRGB (i, j ))2 ( I G (i, j ) I MRGB (i, j ))2 ( I B (i, j ) I MRGB (i, j )) 2 )
15 N PW
( i , j )PW
虫中 23 只个体大小、姿态进行标准化处理以增强 特征提取效果,然后利用数字识别系统对活飞蛾进 Wang 等在目级昆虫开发了一个 行自动识别研究[5]。 昆虫图像自动识别系统,收集了来自 9 目 225 种昆 虫图像,人工将昆虫位置放好,将不完整的、粘连 在一块昆虫进行剔除,方便特征的自动提取[6]。邱 道尹等设计了一种基于机器视觉的害虫检测系统, 通过自动诱集并调整害虫姿态,以提取出的周长、 不变矩等特征,运用神经网络分类器对常见的 9 种 害虫进行分类[7]。 Wen 等[8-9]利用基于图像的方法对果树害虫进行 了基于全局特征和局部特征的害虫识别, 并指出害虫 存在多姿态,增加了害虫识别的难度。吕军等[10-11] 针对害虫正面和反面 2 种姿态进行了基于模板匹配 的多目标水稻灯诱害虫识别方法研究,但是野外害 虫还存在其他姿态样式 (躯干正反、 翅膀伸缩各异、 倾斜) 。在模式识别方面,近年来支持向量机 (support vector machine,SVM)在农业图像分析 和处理中得到了很广泛的应用[12-15],尤其是针对样 本 集 较 小 的情 况 下 , 分类 效 果 比 人工 神 经 网 络 (artificial neural network,ANN)更加有效[16-17]。 而且针对多类识别问题,可以在标准二分类支持向 量机的基础上构建多分类支持向量机( multi-class support vector machine,MSVM)进行多类目标的 分类。 综上所述,目前大部分研究都是基于害虫标本
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Signal Processing83(2003)729–743/locate/sigproSimultaneous classiÿcation andrelevant feature id entiÿcation in high-dimensional spaces:application to molecular proÿling dataC.Bhattacharyya a;e,L.R.Grate b,A.Rizki b,D.Radisky b,F.J.Molina b;c,M.I.Jordan a;d,M.J.Bissell b,I.S.Mian b;∗a Division of Computer Science,University of California Berkeley,Berkeley,CA94720,USAb Lawrence Berkeley National Laboratory,Life Sciences Division,Berkeley,CA94720,USAc Department of Mathematics,University of California Santa Cruz,Santa Cruz,CA95064,USAd Department of Statistics,University of California Berkeley,Berkeley,CA94720,USAe Current address:Department of CSA,Indian Institute of Science,Bangalore560012,IndiaReceived26May2002;receivedin revisedform6September2002AbstractMolecular proÿling technologies monitor many thousands of transcripts,proteins,metabolites or other species concurrently in a biological sample of interest.Given such high-dimensional data for di erent types of samples,classiÿcation methods aim to assign specimens to known categories.Relevant feature identiÿcation methods seek to deÿne a subset of molecules that di erentiate the samples.This work describes L IKNON,a speciÿc implementation of a statistical approach for creating a classiÿer and identifying a small number of relevant features simultaneously.Given two-class data,L IKNON estimates a sparse linear classiÿer by exploiting the simple andwell-known property that minimising an L1norm(via linear programming) yields a sparse hyperplane.It performs well when used for retrospective analysis of three cancer biology proÿling data sets, (i)small,round,blue cell tumour transcript proÿles from tumour biopsies and cell lines,(ii)sporadic breast carcinoma transcript proÿles from patients with distant metastases¡5years andthose with no d istant metastases¿5years and(iii) serum sample protein proÿles from una ectedandovarian cancer putationally,L IKNON is less demanding than the prevailingÿlter-wrapper strategy;this approach generates many feature subsets andequates relevant features with the subset yielding a classiÿer with the lowest generalisation error.Biologically,the results suggest a role for the cellular microenvironment in in uencing disease outcome and its importance in developing clinical decision support systems.?2002Elsevier Science B.V.All rights reserved.Keywords:L1norm minimisation;Molecular proÿling data;Feature selection;Classiÿcation;Cancer biology;L IKNON;Minimax probability machine1.IntroductionMolecular proÿling studies of di erent types of bi-ological specimens are both increasingly widespread∗Corresponding author.E-mail address:smian@(I.S.Mian).andimportant.In cancer biology for example,com-monplace investigations include monitoring the abundances of transcripts and/or proteins in nor-mal andaberrant(tumour)tissues,sera or cell lines [19,6,18,39,25,34,15,36,40,26,29,35].The adoption of proÿling technologies is motivatedlargely by a d esire to create clinical decision support systems for accurate0165-1684/03/$-see front matter?2002Elsevier Science B.V.All rights reserved. doi:10.1016/S0165-1684(02)00474-7730 C.Bhattacharyya et al./Signal Processing83(2003)729–743cancer classiÿcation anda needto id entify robust and reliable molecular targets(“biomarkers”)for interven-tion,diagnosis and imaging.Theÿrst attendant analyt-ical task is classiÿcation andpred iction,estimating a classiÿer from proÿling data which assigns accurately samples to known classes.The secondtask,relevant feature identiÿcation,involves deÿning a small subset of the molecules monitoredwhich best d i erentiate classes.The subject of this work is the tasks of classi-ÿcation andrelevant feature id entiÿcation in the context of two-class molecular proÿling data,i.e. samples are assignedto one of two categories such as normal or tumour specimens.Statistical challenges associatedwith solving these problems includ e the large number of features in an example vector(∼103–104molecular abundances)and the small number of high-dimensional example vectors(∼101–102sam-ples).The classiÿer underlying a clinical decision support system wouldbe expectedto make precise diagnoses for many more and diverse patient samples than hadbeen usedfor its estimation.This requirement for systems with goodpred ictive capability neces-sitates classiÿers which minimise misclassiÿcations on future data,namely those with low generalisation error.For two-class data,the classiÿcation and prediction problem is to learn a discriminating surface which separates the classes using a criterion such as gen-eralisation error.Support vector machines(SVMs) [14]are goodclassiÿers which achieve low gener-alisation error by minimising an associatedquantity termedthe margin.SVMs have been employedsuc-cessfully for cancer classiÿcation using transcript proÿles[10,31,36,40].In contrast to SVMs,the newly formulatedminimax probability machine(MPM) minimises directly an upper bound on the generali-sation error[28].As shown here,MPMs provide a viable alternative to SVMs for addressing classiÿ-cation andpred iction problems relatedto proÿling data.MPMs andSVMs cannot d eÿne biomarkers in their own right because each feature in an example vector contributes to delineating the discriminating surface. In transcript proÿling studies,relevant feature iden-tiÿcation has oft been addressed via aÿlter-wrapper strategy[17,31,42].Theÿlter generates candidate gene subsets whilst the wrapper runs an induction algorithm to determine the discriminative ability of a subset.This procedure computes a statistic from the empirical distribution of genes in the two classes and orders genes according to this metric.Forward or backward selection creates subsets by adding or deleting genes successively.Each subset is used to es-timate a classiÿer andto d etermine its generalisation error.A priori,the number of genes andwhich subset will produce a classiÿer with the lowest generalisa-tion error is unknown.Thus,many runs are required to converge upon a subset that constitutes biomark-ers.Although MPMs andSVMs are goodwrap-pers,the choice ofÿltering statistic remains an open question.This study shows the potential of sparse(linear) classiÿers as a framework for addressing simultane-ously the aforementionedproblems of classiÿcation and relevant feature identiÿcation.In so doing,con-siderable prior statistical research is exploited in a new application domain.Here,the focus is sparse hy-perplanes estimatedby minimising an L1norm via linear programming[4,14,16,20,24,38,3].L IKNON,1a speciÿc implementation of this strategy,is usedfor retrospective analysis of data from three exemplars of transcript[26,41]andprotein[35]proÿling stud-ies.L IKNON has non-trivial computational advantages over the prevailingÿlter-wrapper strategy because it creates a classiÿer andid entiÿes relevant features in one pass through two-class data.Reexamination of the transcript proÿles generates biological predictions for subsequent experimental andclinical investigation of two types of cancer andcellular microenvironments. Finally,the results reveal the ability of publishedd ata to answer unanticipatedquestions.2.Materials and methods2.1.Transcript proÿling data:small,round,blue cell tumoursPreviously[26],cDNA microarrays were usedto monitor tumour biopsy andcell line samples from1L IKNON is a wordfor a winnowing basket usedin ancient Greece.C.Bhattacharyya et al./Signal Processing83(2003)729–743731four distinct classes of small,round,blue cell tumours (SRBCTs)of childhood:neuroblastoma(NB),rhab-domyosarcoma(RMS),the Ewing family of tumors (EWS)andnon-Hod gkin lymphoma(NHL)[26].The transcript proÿles consistedof2308nucleic acidse-quences or“genes”monitoredin84samples.These data were used to categorise samples on the basis of their cancer class(EWS,RMS,NHL or NB)andto deÿne96genes which distinguished the four classes. Each class consistedof a mixture of tumour biopsy andcell lines samples,i.e.the origin of a specimen was ignoredd uring categorisation.Here,transcript proÿles for the84SRBCT samples were downloaded from / DIR/Microarray/Supplement/.For each sample,the features in the2308-dimensional example vectors were the log ratios of transcripts in the sample of interest comparedto a common reference[26].To determine whether proÿling data have the potential to answer unanticipatedquestions,the SRBCT sam-ples were partitionedso as to probe the interplay between tissue andcell culture cellular microenviron-ments,andcancer class.The seven,new,two-class data sets formulated by repartitioning the samples were as follows:Partition A,46EWS/RMS tumour biopsies and38EWS/RMS/NHL/NB cell lines;Par-tition B,21EWS/RMS cell lines and30EWS/RMS tumour biopsies;Partition C,28EWS tumour biop-sies/cell lines and23RMS tumour biopsies/cell lines; Partition D,17EWS tumour biopsies and13RMS tumour biopsies;Partition E,11EWS cell lines and 10RMS cell lines;Partition F,17EWS tumour biopsies and11EWS cell lines;andPartition G, 13RMS tumour biopsies and10RMS cell lines (for NHL andNB,only cell lines were available). The seven two-class data sets were analysed using L IKNON anda Fisher scoreÿlter-MPM/SVM wrapper strategy.2.2.Transcript proÿling data:sporadic breast carcinomasPreviously[41],cDNA microarrays were usedto monitor5192genes in97sporadic breast carcinoma samples.These data were used to deÿne70genes which discriminated between patients with distant metastases¡5yr andthose with no d istant metas-tases¿5yr.Here,transcript proÿles for the97sporadic breast carcinoma samples were downloaded from /publications/vantveer.htm.For each sample,the features in the5192-dimensional example vectors were the log ratios of the transcripts in the sample of interest comparedto a common reference[41].The two-class data set,46patients with distant metastases¡5yr and51patients with no distant metastases¿5yr,was analysedusing L IKNON.2.3.Protein proÿling data:ovarian cancerPreviously[35],SELDI-TOF mass spectroscopy was usedto generate spectra for serum samples from una ectedandovarian cancer patients.The protein proÿles consistedof15,154Mass/Charge(M=Z)val-ues measuredin200samples.These d ata were usedto deÿne5“proteins”which di erentiated non-maligant from ovarian cancer samples.Here,protein proÿles for the200serum samples were downloaded from http://clinicalproteomics.steem. com/.For each sample,the features in the15,154-dimensional example vectors were SELDI-TOF mass spectrum amplitudes representing15;154M=Z values in the sample of interest[35].Each M=Z value repre-sents a low molecular weight molecule.The two-class d ata set,100una ectedand100ovarian cancer serum samples,was analysedusing L IKNON.2.4.L IKNON:simultaneous classiÿcation and relevant feature identiÿcationConsider two-class data,{(x1;y1);:::;(x N;y N)}, consisting of N example vectors,x i∈R P.The label,y i∈{+1;−1},indicates whether the ex-ample vector x i is equatedwith class1or with class2.For the two-class proÿling data described above,the number of example vectors,N,andtheir dimensionality,P,are(i)small roundblue cell tu-mours,N=84;51;51;30;21;28and23,and P=2308, (ii)sporadic breast carcinomas,N=97and P=5192 and(iii)ovarian cancer,N=200and P=15;154. Each feature x p in a P-dimensional example vector corresponds to an observed transcript level or M=Z value.If two-class data can be separated by a linear deci-sion boundary,the discriminating surface has the form732 C.Bhattacharyya et al./Signal Processing 83(2003)729–743of a hyperplane,w T x =b ,parameterisedin terms of a weight vector,w ∈R P ,ando set term,b ∈R .A clas-siÿer is the hyperplane which satisÿes the N inequal-ities y i (w T x i −b )¿0∀i ={1;:::;N }.The learning problem is to estimate the optimal weight vector w ∗ando set b ∗.Given this hyperplane,a vector x is assignedto a class basedon the sign of the corre-sponding decision function.If sign(w T∗x −b ∗)=+1,x is id entiÿedwith class 1,otherwise it is assignedto class 2.The problems of classiÿcation andrelevant fea-ture identiÿcation can be solved concurrently by considering a sparse hyperplane,one for which the weight vector w has few non-zero elements.Recall that the class of a vector x is assignedaccord ing to sign(z ).z =w T x −b =P p =1w p x p −b =w p =0w p x p −b:If a weight vector element is zero,w p =0,then featurep in the example vector does not decide the class of x andis thus “irrelevant”.Only a feature for which the element is non-zero,w p =0,contributes to sign(z )andis thus useful for d iscrimination.Thus,the prob-lem of deÿning a small number of relevant features (biomarkers)can be thought of as synonymous with identifying a sparse hyperplane.Learning a sparse hyperplane can be formu-latedas an optimisation problem.Minimising the L 0norm of the weight vector, w 0,minimises the number of non-zero elements.The L 0norm is w 0=number of {p :w p =0}.Unfortunately,min-imising an L 0norm is NP-hard.However,a tractable,convex approximation is to replace the L 0norm with the L 1norm [16].Minimising the L 1norm of the weight vector, w 1,minimises the sum of the abso-lute magnitudes of the elements and sets most of the elements to zero.The L 1norm is w 1= P p =1|w p |.The optimisation problem becomes minw ;bw 1s :t :y i (w T x i −b )¿1∀i ∈{1;:::;N };(1)w 1=P p =1|w p |;|w p |=sign(w p )w p :Problem 1can viewedas a special case of minimis-ing a weighted L 1norm,min w P p =1a p |w p |,in whichthe vector of weighting coe cients a is a unit vec-tor,a p =1;∀p ∈{1;:::;P }.In other words,all genes are presumedto be equally goodrelevant feature can-didates.Prior knowledge about the (un)importance of feature p can be encoded by specifying the value of a p .If the data are not linearly separable,misclassiÿca-tion can be accounted for by adding a non-negative slack variable i to each constraint andintrod ucing a weightedpenalty term to the objective function minw ;b;w 1+CN i =1is :t :y i (w T x i −b )¿1− i ;i ¿0∀i ∈{1;:::;N }:(2)The term Ni =1 i is an upper boundon the number of misclassiÿcations.The parameter C represents a tradeo between misclassiÿcation and sparseness.The higher the value of C ,the less sparse the solution.Here,setting C =1classiÿedcorrectly all the points in the data sets encountered.However,the value of C can be chosen more systematically via cross validation.Problem (2)can be recast as a linear program-ming problem by introducing extra variables u p and v p where w p =u p −v p and |w p |=u p +v p .These variables are the p th elements of u ;v ∈R P .The L 1norm becomes w 1= Pp =1(u p +v p )=u +v and the problem can rewritten in a standard form as follows:min u ;v ;b;(u +v )+CN i =1is :t :y i ((u −v )T x i −b )¿1− i ; i ¿0∀i ∈{1;:::;N }u p ¿0;v p ¿0∀p ∈{1;:::;P }:(3)Problem (3)minimises a linear function sub-ject to linear constraints.This type of linear pro-gramming problem has been well studied inoptimisation theory.There are e cient algorithms for solving problems involving N ∼104constraints and (2∗P +1)∼104variables.The code for L IKNONC.Bhattacharyya et al./Signal Processing 83(2003)729–743733is available at /∼jordan/liknon/.2.5.Fisher score ÿlter-MPM/SVM wrapper:independent classiÿcation and relevant feature identiÿcationGiven linearly separable two-class data,the task is to determine a hyperplane w T z =b which separates example vectors belonging to class 1(x )andclass 2(y ).Both MPMs andSVMs attempt to minimise the generalisation error,i.e.misclassiÿcation on future data.The MPM framework seeks the hyperplane for which the misclassiÿcation probabilities for class 1,P (w T x 6b ),andclass 2,P (w T y ¿b ),are low.The SVM framework seeks the unique discriminating hy-perplane which maximises the margin separating the classes.MPMs andSVMs are comparable in com-plexity (detailed descriptions of these techniques are available in Appendix A ).Preliminary results (data not shown)indicated that the two-class proÿling data examinedhere were ind eedlinearly separable.Hence,the use of L IKNON andSVMs with linear kernels was justiÿed.MPMs and SVMs only address the problem of clas-siÿcation andpred iction.In the ÿlter-wrapper strat-egy,relevant feature identiÿcation is an independent,data preprocessing step.For simplicity and illustrative purposes,SVM/MPM wrappers were employedin conjunction with a Fisher score ÿlter.Given example vectors assignedto class x or class y ,the Fisherscore for feature p is given by F p =( xp − y p )2=( x p + y p ); xp and y p are the means of feature p in the respective classes,whereas x p and y p are standard deviations.Higher values signify more discriminative features.Given P features rankedin descending order according to their score F 1;:::;F P ,the Fisher score top-r rankedfeatures are those ranked1;:::;r .A particular value of r signiÿes a spe-ciÿc feature subset for use in estimating a classiÿer.Forwardselection creates feature subsets by progres-sively increasing the value of r in a user-deÿned manner.Although the recursive feature selection approach utilises a separating hyperplane w [23],it is closer to a ÿlter-wrapper strategy than to L IKNON .Features are ord eredbasedon |w p |,the absolute magnitude of the elements of the weight vector (the range ofvalues for each feature are assumedto be the same).Backwardelimination creates feature subsets by re-cursively removing the bottom 10%of features.The feature subsets are usedas input to a wrapper of choice.putational experiments:L IKNON and Fisher score ÿlter-SVM/MPM wrapperL IKNON creates a classiÿer andid entiÿes relevant features in a single pass through two-class data.The Fisher score ÿlter-MPM/SVM wrapper strategy has distinct feature subset generation and classiÿcation steps.A relevant subset is equatedwith the feature subset of smallest cardinality that yields a classiÿer with the lowest generalisation error.These simultane-ous and independent classiÿcation and relevant feature identiÿcation strategies were compared by means of the leave-one-out error,a surrogate for generalisation error.Given the choice of leave-one-out error as the per-formance metric,L IKNON needs to be run twice for a given two-class data set:ÿrst to identify relevant features (a small subset l of the P input features)andsecondas a classiÿer which uses the resultant l -dimensional vectors as e of the conven-tional error,number of misclassiÿcations on a test set,would require one pass through data.Results (data not shown),indicated that for SRBCT Problem A,all leave-one-out partitionings gave the same set of L IKNON relevant genes as when all N example vectors were used.For each of the seven partitionings of the SRBCT samples,Fisher scores for the P features in the ex-ample vectors were computed.The Fisher score top-r rankedfeatures were usedto generate 13gene subsets where r =1;2;4;8;16;32;64;128;256;512;1024;2048and2308.Thus,L IKNON andthe Fisher score ÿlter deÿned 14feature subsets that di ered only in their dimensionality and precise nature of the genes.The leave-one-out error of SVMs/MPMs trainedusing example vectors derived from every subset was ascertained.For a two-class data set,the leave-one-out error was determined as follows.The N example vectors were divided into an estimation set consisting of N −1ex-ample vectors anda test set composedof the remain-ing example.The MPM/SVM or L IKNON classiÿer was734 C.Bhattacharyya et al./Signal Processing83(2003)729–743usedto pred ict the(known)class of the example in the test set.This estimation andevaluation proced ure was repeated N times so that the class of each example was assignedby a classiÿer estimatedusing all other examples.The leave-one-out error is the number of misclassiÿcations out of N.3.Results3.1.Transcript proÿles:small round blue cell tumoursTwo approaches for performing classiÿcation andrelevant feature id entiÿcation given two-class high-dimensional molecular proÿling data were eval-uated.L IKNON creates a classiÿer andascertains a small number of relevant features simultaneously. The widely usedÿlter-wrapper strategy estimates a classiÿer for every feature subset generatedby an in-dependentÿltering step.The performances of L IKNON anda Fisher scoreÿlter-MPM/SVM wrapper were assessedby means of the leave-one-out error,a com-mon proxy for generalisation error when there are few example vectors.MPMs are a viable alternative to SVMs for solving the classiÿcation andpred iction problem in aÿlter-wrapper strategy.Table1presents the leave-one-out error when the seven problems were analysedusing these classiÿers as the wrapper.Irre-spective of the feature subset,MPMs andSVMs had similar performance andgeneralisedequally well. Whereas SVMs andMPMs couldoperate d irectly in high-dimensional spaces,the original study used the 10dominant Principal Component Analysis compo-nents of the2308-dimensional example vectors as input to artiÿcial neural networks(ANNs)[26].Since MPMs andSVMS solve convex optimisation prob-lems,they avoidthe local minima problems which plague ANNs.L IKNON is computationally less demanding than the ÿlter-MPM/SVM wrapper strategy in identifying rel-evant features.Table2tabulates the relevant features giving zero leave-one-out error for the seven two-class SRBCT data sets.For a given data set,similar num-bers of Fisher score andL IKNON relevant genes are requiredandthese are generally one to two ord ers of magnitude smaller than the2308input features.However,whilst L IKNON requiredone pass through data,theÿlter-wrapper approach required many runs to pinpoint its subset.For Partition A,the23L IKNON relevant features gave zero out of84leave-one-out error,whereas the top-16or top-32Fisher score ranked genes gave low,but not zero out of84leave-one-out error(Table1).L IKNON relevant features shouldbe regard edas a small,though not necessarily unique set of biomark-ers.Fig.1shows a histogram of Fisher scores for all 2308genes overlaidwith the Fisher scores of relevant genes.L IKNON relevant genes are not necessarily asso-ciatedwith high Fisher scores yet they yieldclassiÿers with zero leave-one-out error.Higher Fisher scores correspond to larger di erences in the empirical dis-tributions of transcript levels(more discriminative features)so classiÿers trainedwith top-rankedgenes might be expectedto generalise well.The results reinforce the notion that many distinct relevant feature subsets canÿt the data equally well(see for example[12]).From a numerical perspective,the84SRBCT tran-script proÿles are su ciently informative that biolog-ical questions not considered in the original study can be posedandanswered(see also[32]).3.2.Cellular microenvironment and SRBCT classiÿcationA biological assessment of the L IKNON relevant features reveals that the tissue or cell culture origin of a sample a ects the nature andnumber of rele-vant genes.Table3lists these genes for the seven two-class data sets.Four of these compared tumour biopsies with tumour-derived cell lines in the context of di erent numbers of SRBCT classes,four(Par-tition A:EWS,RMS,NHL,NB),two(Partition B: EWS,RMS)andone(Partition F:EWS;G:RMS). There were23relevant genes for Partition A,21for B,12for F and13for G.Tissue andcell culture microenvironments are manifestations of variations in cell shape andcell-extracellular matrix interac-tions.This di erence is re ected in relevant genes such as actin 2,SMA3(smooth muscle actin3), andcollagen type III .The relevant genes represent goodtargets for stud ying how tumour cells escape quiescence andevad e cell cycle arrest in vivo and in vitro.C.Bhattacharyya et al./Signal Processing83(2003)729–743735 Table1Prediction of SRBCT transcript proÿles using MPMs and SVMs.Rank A(N=84)B(N=51)C(N=51)D(N=30)E(N=21)F(N=28)G(N=23) SVM MPM SVM MPM SVM MPM SVM MPM SVM MPM SVM MPM SVM MPM 110107835221117222 299133321002111 465234221000001 894244120021000 1684300022062205 325221114212011401 64315320600001003 12812230331001201 25601000131011000 51200000132021100 102400000031012200 204821000121102200 230831************ The seven two-class data sets and numbers of example vectors in each class(total N)are Partition A,46EWS/RMS tumour biopsies and38EWS/RMS/NHL/NB cell lines;Partition B,21EWS/RMS cell lines and30EWS/RMS tumour biopsies;Partition C,28EWS tumour biopsies/cell lines and23RMS tumour biopsies/cell lines;Partition D,17EWS tumour biopsies and13RMS tumour biopsies; Partition E,11EWS cell lines and10RMS cell lines;Partition F,17EWS tumour biopsies and11EWS cell lines;andPartition G,13 RMS tumour biopsies and10RMS cell lines.For each partition,the table gives the leave-one-out error out of N for an SVM or MPM estimated using the feature subset indicated.Theÿrst12feature subsets are the Fisher score top-r rankedgenes where r takes on the value given.Theÿnal“subset”corresponds to all features in the original2308-dimensional example vectors[26].Table2Identiÿcation of relevant genes in SRBCT transcript proÿling data using L IKNON anda Fisher scoreÿlter-MPM/SVM wrapper strategy Name Class1samples Class2samples N ClassiÿerSVM MPM L IKNONA EWS/RMS tumour EWS/RMS/NHL/NB cell line8425651223B EWS/RMS cell line EWS/RMS tumour512561621C EWS tumour/cell line RMS tumour/cell line511688D EWS tumour RMS tumour3064648E EWS cell line RMS cell line21222F EWS tumour EWS cell line284412G RMS tumour RMS cell line234813For each of the seven two-class data sets,the total number of example vectors N is listed.“SVM”and“MPM”give the Fisher score feature subset of smallest cardinality that yielded a classiÿer with zero out of N leave-one-out error(taken from Table1).“L IKNON”gives the cardinality of the relevant features identiÿed;each feature subset yielded a L IKNON classiÿer with zero out of N leave-one-out error.Transcriptional di erences between tumour biop-sies andcell lines confoundattempts to d eÿne biomarkers for classifying SRBCTs.Three Partitions comparedEWS andRMS in the context of tumour biopsies andcell lines(Partition C),tumour biopsies (Partition D)andcell lines(Partition E).The relevant genes for EWS tumour biopsies andRMS tumour biopsies(Partition D)may constitute clinically useful biomarkers forÿne-grainedcancer class d iagnosis and/or imaging.Of the96EWS,RMS,NHL and NB cancer class markers identiÿed originally[26],11 are markers for the cellular microenvironment of the sample.The results reiterate the view that information pro-vided by interactions with neighbouring cells,the composition andorganisation of the surround ing736C.Bhattacharyya et al./Signal Processing 83(2003)729–743200400600800100012001400160018000.511.522.5200400600800100012001400160005001000150020002500020040060080020040060080000.51 1.52 2.53 3.5200400600800Fig.1.Histograms of Fisher scores for all 2308genes in the seven SRBCT binary problems.The abscissa represents the Fisher score and the ordinate the number of genes with that score.As might be expected,most genes have low scores and far fewer genes have high scores.Open triangles mark the Fisher scores of the L IKNON relevant genes.For each problem,the number of triangles is the same as the entry in the “L IKNON ”column of Table 2.。