linux集群部署
slurm集群搭建手册

slurm集群搭建手册在当今科学研究和工程领域,大规模计算是不可或缺的。
为了满足这种需求,搭建一个高效的集群系统是至关重要的。
Slurm(Simple Linux Utility for Resource Management)是一种常用的开源资源管理程序,可以帮助我们有效地管理和分配计算资源。
本文将介绍如何搭建一个Slurm集群,让您快速上手并进行计算任务。
第一步:准备工作在开始搭建Slurm集群之前,您需要准备以下工作:1. 服务器:至少两台服务器,其中一台作为控制节点,其他为计算节点。
2. 操作系统:建议使用Linux操作系统,如CentOS或Ubuntu。
3. 网络设置:确保服务器间可以互相访问,可以使用IP地址或主机名进行通信。
第二步:安装Slurm在控制节点上执行以下步骤来安装Slurm:1. 更新软件包:使用适当的命令更新系统软件包。
2. 下载Slurm:从Slurm官方网站下载最新的稳定版Slurm。
3. 解压文件:解压下载的Slurm文件。
4. 编译和安装:进入解压后的目录,执行配置,编译和安装Slurm。
第三步:配置Slurm在控制节点上进行Slurm配置:1. 设置控制节点:编辑slurm.conf文件,在其中定义控制节点的名称和IP地址。
2. 设置计算节点:编辑slurm.conf文件,添加每个计算节点的名称和IP地址。
3. 设置分区:在slurm.conf文件中定义分区以及其对应的计算节点。
4. 配置账户:使用Slurm提供的命令创建和配置用户账户。
第四步:启动Slurm在控制节点上启动Slurm服务:1. 启动控制节点:执行控制节点上的Slurm服务启动命令。
2. 启动计算节点:在每个计算节点上执行Slurm服务启动命令。
第五步:测试Slurm在集群中执行简单的计算任务来测试Slurm:1. 创建作业:使用sbatch命令创建一个作业文件,指定计算节点和要运行的任务。
Websphere for Linux集群安装和配置
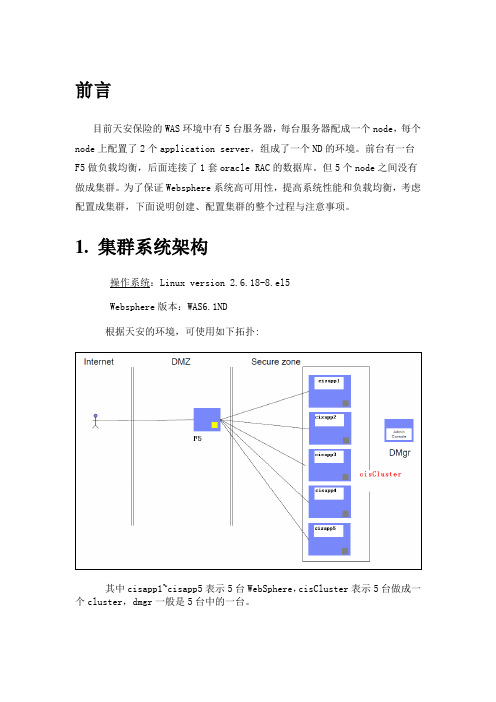
前言目前天安保险的WAS环境中有5台服务器,每台服务器配成一个node,每个node上配置了2个application server,组成了一个ND的环境。
前台有一台F5做负载均衡,后面连接了1套oracle RAC的数据库。
但5个node之间没有做成集群。
为了保证Websphere系统高可用性,提高系统性能和负载均衡,考虑配置成集群,下面说明创建、配置集群的整个过程与注意事项。
1. 集群系统架构操作系统:Linux version 2.6.18-8.el5Websphere版本:WAS6.1ND根据天安的环境,可使用如下拓扑:其中cisapp1~cisapp5表示5台WebSphere,cisCluster表示5台做成一个cluster,dmgr一般是5台中的一台。
2. 创建集群(含session复制)(截图为我本机测试截图,只是示意图,与天安保险的节点名和集群名不符)在DMGR控制台中,选择集群,然后新建。
注意:先创建一个空的集群,然后我们再向该集群中添加成员即可。
这里还要注意勾选“配置HTTP会话内存到内存复制”,这样就能使session 在集群内共享,比如用户登录,加入被集群分配给node1来处理,用户的登录信息就会被保存在session中,如果此时node1宕机了,用户就会被分配到其他节点来处理而不会要求重新登录。
如果在创建集群时没有勾选此选项,也可按如下方式操作:配置会话复制服务器 --> 应用程序服务器 --> 选择集群成员 --> 容器设置:会话管理--> 其他属性:分布式环境设置 --> 确认分布式会话选择的是内存到内存复制,其他属性:定制调整参数 -->调整级别:低(故障转移优化)写频率 servlet服务结束写内容所有会话调度会话清除:false对集群每个成员重复以上操作(建议在故障转移和系统性能之间取折中。
另:会话复制还有一种数据库方式,由于对性能影响较大,不推荐使用)添加集群如下。
MS Linux 集群安装手记

MS Linux 集群安装手记1、root 用户挂载iso光盘镜像:(超算中心帮助)# mount -o loop -t iso9660 <filename><directory>(GPU集群上iso镜像已挂载,在目录/mnt下)安装hpmpi:(在目录/mnt/UNIX/Linux_x86_64/hpmpi下)#rpm -ivh<directory>/hpmpi-2.03.01.00-20090402r.<i386|ia64|x86_64>.rpm2、安装程序:切换到用户账户,切换到安装目录里LINUX目录,运行Install --type cluster命令一路回车,注意在选择是否使用ssh时选择是,否则不能共享内存,在选择临时文件夹时不要选择./tmp,使用默认就好。
安装完后选择99,退出。
3、安装license:切换到目录~/Accelrys/LicensePack/linux/bin目录下,运行lp_install命令,格式为./lp_install<license file>。
4、修改machines.LINUX:编辑目录~/Accelrys/MaterialsStudio55/share/data下的machines.LINUX文件,添加各节点及其核心数并保存。
5、修改gateway数据:编辑目录~/Accelrys/MaterialsStudio55/etc/Gateway/root_default/dsd/conf 下的gw-info.sbd和gwparams.cfg文件,将其中的cpu总数改成machines.LINUX 文件中的总核心数,并将6、配置ssh:进入目录~/.ssh,编辑其中的known_hosts文件,将各节点全部添加进去(密匙相同)。
(用户目录下用ls–a命令可以看到以“.”开头的文件或目录。
)7、进入Gateway目录运行./gwrestart重新启动gateway。
Materials Studio Linux 集群安装手册(比较详细)

Materials Studio Linux集群安装手册一、安装Linux操作系统,进行系统配置一般都建议最小化安装,不用安装图形界面。
下面我以red hat enterprise linux 6.0 x86-64在AMD Athlon(tm)64 X2 Dual Core Processor 4400+ 电脑上的安装为例。
rhel6.0的安装过程和windows差不多,一路下一步(或Next)基本就ok了,在您要进行哪种类型的安装?你如果是第一次安装,是新硬盘的话可以选使用所有空间,并勾选下边的查看并修改分区布局,然后下一步,你可以看下大概的分区情况,在Red Hat Enterprise Linux 的默认安装是基本服务器安装。
如果对Linux不太熟的话,最好选择软件开发工作站(或Software Development Workstation),这样基本上把要用的软件都安装上了,然后再选上下边的现在自定义(或 Customize now),再下一步,然后把所有能选上的软件都选上,再一路下一步。
安装完以后,创建一个非root用户,比如创建一个msi用户,root和msi用户密码设的简单一些比较好,别一会儿你自己都忘了,我是root和msi用的一个密码,当然将来你自己真正组建集群用于计算的时候再设置复杂一些,这样课题提高系统的安全性。
gccglibc-2.3.4-2.43 (32-bit and 64-bit)libgcc-3.4.6-11 (32-bit and 64-bit)libstdc++-33-3.4.6-11 (32-bit and 64-bit)compat-libstdc++-33-3.2.3-47.3 (32-bit)hpmpi-2.03.01.00-20090402r.x86_64这几个补丁,好像除了hpmpi-2.03.01.00-20090402r.x86_64和libstdc++-33-3.4.6-11 (32-bit)没有装上之外,别的都给你装好了。
Linux环境resin部署集群系统手册OA

resin集群部署手册(linux环境下)目录1、配置resin (3)1.1配置startresin.sh (3)1.2启动和关闭resin (3)2、ecology在resin集群上需要共享的资源文件 (4)2.1.资源共享设置 (4)2.2、应用缓存同步设置 (6)四、升级集群补丁包 (6)五、测试故障切换 (6)1、配置resin前期的文件拷贝工作就不写了,直接配置resin1.1配置startresin.sh将启动脚本中添加以下标黄的文字,对于标绿的规则是如果有ABC三台应用,则A机器写BC的ecology访问地址,中间以逗号分隔,如192.168.52.10:8080,192.168.12:8080实例:配置192.168.52.10的/opt/Resin/bin/startresin.sh,内容如下:ulimit -n 65535export LANG=zh_CN.GBKnohup /opt/Resin/bin/httpd.sh -DsimpleMode=true -Dinitial_hosts=192.168.52.11:8080 start配置192.168.52.11的/opt/Resin/bin/startresin.sh,内容如下:ulimit -n 65535export LANG=zh_CN.GBKnohup /opt/Resin/bin/httpd.sh -DsimpleMode=true -Dinitial_hosts=192.168.52.10:8080 start1.2启动和关闭resinResin分别安装在192.168.52.10,192.168.52.11,分别以root身份登入系统。
进入/opt/Resin/bin。
启动:[root@OA-APP bin]# ./startresin.sh停止:[root@OA-APP bin]# ./stopresin.sh2、ecology在resin集群上需要共享的资源文件2.1.资源共享设置配置文件服务器的对外共享:步骤1:vi /etc/exports(按i,才能输入)输入需要共享的文件夹(注意空隙使用tab),格式如下:/data 192.168.52.13(rw,sync,no_root_squash)/data 192.168.52.14(rw,sync,no_root_squash)注:这句话的意思是将/data文件夹共享给192.168.52.13和14服务器,也可以用*号代替,如:/data *(rw,sync,no_root_squash)意思是将/data文件夹共享到所有和这个服务器网络通的机器步骤2:重新exportexportfs –rv步骤3:重启nfs服务service nfs restartservice portmap restart(针对rhel5)service rpcbind restart(针对rhel6以上版本)vi /etc/rc.local在文件末尾加上service nfs startservice portmap start(针对rhel5)service rpcbind start(针对rhel6以上版本)将共享出来的文件夹挂载到应用服务器上:步骤4:在需要共享节点挂载共享文件到对于目录(除主控节点外)mount -t nfs 192.168.52.10:/data /data步骤5:挂载完成后,需要将资源文件链接到ecology目录下对应文件1、将ecology以下目录拷贝到/data目录下email filesystem images images_face images_frame LoginTemplateFile messager m_img others page wui2、将ecology\WEB-INF下的service目录/data目录下备份mv images images.bakmv images_face images_face.bakmv images_frame images_frame.bakmv LoginTemplateFile LoginTemplateFile.bakmv m_img m_img.bakmv filesystem filesystem.bakmv page page.bakmv messager messager.bakmv email email.bakmv wui wui.bakmv others others.bakcd WEB-INFmv service service.bak链接ln -sf /data/filesystem /opt/ecologyln -sf /data/images /opt/ecologyln -sf /data/images_face /opt/ecologyln -sf /data/images_frame /opt/ecologyln -sf /data/LoginTemplateFile /opt/ecologyln -sf /data/messager /opt/ecologyln -sf /data/m_img /opt/ecologyln -sf /data/page /opt/ecologyln -sf /data/wui /opt/ecologyln -sf /data/email /opt/ecologyln -sf /data/others /opt/ecologyln -sf /data/service /opt/ecology/WEB-INF/如果是E8系统还需要做:将ecology/WEB-INF/hrmsettings.xml 做软连接mv hrmsettings.xml hrmsettings.xml.bakln -sf /data/hrmsettings.xml /opt/ecology/WEB-INF/hrmsettings.xml其他需要做软连接的访问域名/system/SystemSetEdit.jsp?_fromURL=52得到的结果类似这种,可以查看客户设置的附件目录然后针对这个目录做一下软连接步骤6:在需要共享节点随机启动时,挂载共享文件(除主控节点外)(注意空隙使用tab) vi /etc/fstab192.168.52.10:/data /data nfs defaults 0 02.2、应用缓存同步设置步骤1、编辑/etc/hosts,清空原有127默认配置,将集群各节点ip地址加入到hosts中(重要!!!)步骤2、修改/WEB-INF/prop/weaver.properties文件,加入以下内容:MainControlIP = 主节点ip(集群中任意一个节点,但有且只能有一个)ip = 本机ipbroadcast=231.12.21.132步骤3、为保证服务器间访问畅通,最好关闭linux自带防火墙。
Linux服务器集群系统――LVS(Linux Virtual Server)项目

背景当今计算机技术已进入以网络为中心的计算时期。
由于客户/服务器模型的简单性、易管理性和易维护性,客户/服务器计算模式在网上被大量采用。
在九十年代中期,万维网(World Wide Web)的出现以其简单操作方式将图文并茂的网上信息带给普通大众,Web也正在从一种内容发送机制成为一种服务平台,大量的服务和应用(如新闻服务、网上银行、电子商务等)都是围绕着Web进行。
这促进Internet用户剧烈增长和Internet流量爆炸式地增长,图1显示了1995至2000年与Internet连接主机数的变化情况,可见增长趋势较以往更迅猛。
Internet的飞速发展给网络带宽和服务器带来巨大的挑战。
从网络技术的发展来看,网络带宽的增长远高于处理器速度和内存访问速度的增长,如100M Ethernet、A TM、Gigabit Ethernet等不断地涌现,10Gigabit Ethernet即将就绪,在主干网上密集波分复用(DWDM)将成为宽带IP的主流技术[2,3],Lucent已经推出在一根光纤跑800Gigabit的WaveStar?OLS800G 产品[4]。
所以,我们深信越来越多的瓶颈会出现在服务器端。
很多研究显示Gigabit Ethernet 在服务器上很难使得其吞吐率达到1Gb/s的原因是协议栈(TCP/IP)和操作系统的低效,以及处理器的低效,这需要对协议的处理方法、操作系统的调度和IO的处理作更深入的研究。
在高速网络上,重新设计单台服务器上的网络服务程序也是个重要课题。
比较热门的站点会吸引前所未有的访问流量,例如根据Yahoo的新闻发布,Yahoo已经每天发送6.25亿页面。
一些网络服务也收到巨额的流量,如American Online的Web Cache 系统每天处理50.2亿个用户访问Web的请求,每个请求的平均响应长度为5.5Kbytes。
与此同时,很多网络服务因为访问次数爆炸式地增长而不堪重负,不能及时处理用户的请求,导致用户进行长时间的等待,大大降低了服务质量。
利用Linux操作系统进行服务器集群管理

利用Linux操作系统进行服务器集群管理在当今信息时代,服务器集群已经成为现代企业中不可或缺的一部分。
而要有效地管理服务器集群,利用Linux操作系统是一个明智的选择。
本文将介绍如何利用Linux操作系统进行服务器集群管理。
一、服务器集群管理的基本概念服务器集群是由多台服务器组成的,旨在提高系统的可靠性、可用性和性能。
服务器集群管理的核心目标是促进集群中服务器的协同工作以提供高负载、高性能和高可用性的服务。
二、Linux操作系统简介Linux操作系统是一个免费且开源的操作系统,具有出色的稳定性和安全性,广泛应用于服务器领域。
Linux操作系统提供了一系列工具和命令,用于管理集群中的多台服务器。
三、服务器集群管理工具1. SSH(Secure Shell)SSH是一种网络协议,可用于在两个网络设备之间进行加密通信。
通过SSH,管理员可以在远程终端登录服务器,执行管理操作。
2. Shell脚本Shell脚本是一种在Linux操作系统中编写的可执行脚本,用于批量执行一系列命令。
管理员可以编写Shell脚本来进行服务器集群管理任务,如自动化安装软件、配置系统参数等。
3. rsyncrsync是一种高效的文件复制工具,可用于在服务器之间同步文件和目录。
管理员可以使用rsync命令将文件从一台服务器复制到集群中的其他服务器,实现数据的同步和备份。
4. PacemakerPacemaker是一个开源的高可用性集群管理软件,可用于监控和管理服务器集群中的资源。
通过配置Pacemaker,管理员可以实现自动故障切换和负载均衡等功能。
四、利用Linux操作系统进行服务器集群管理的步骤1. 安装Linux操作系统首先,管理员需要在每台服务器上安装Linux操作系统。
可以选择适合企业需求的Linux发行版,如Ubuntu、CentOS等。
2. 配置SSH登录在每台服务器上,管理员需要配置SSH服务,以便能够通过SSH 协议远程登录服务器。
Linux高性能计算集群 Beowulf集群
Linux高性能计算集群 -- Beowulf集群/page/hardware_linux.html1 集群1.1 什么是集群简单的说,集群(cluster)就是一组计算机,它们作为一个整体向用户提供一组网络资源。
这些单个的计算机系统就是集群的节点(node)。
一个理想的集群是,用户从来不会意识到集群系统底层的节点,在他/她们看来,集群是一个系统,而非多个计算机系统。
并且集群系统的管理员可以随意增加和删改集群系统的节点。
1.2 为什么需要集群集群并不是一个全新的概念,其实早在七十年代计算机厂商和研究机构就开始了对集群系统的研究和开发。
由于主要用于科学工程计算,所以这些系统并不为大家所熟知。
直到Linux集群的出现,集群的概念才得以广为传播。
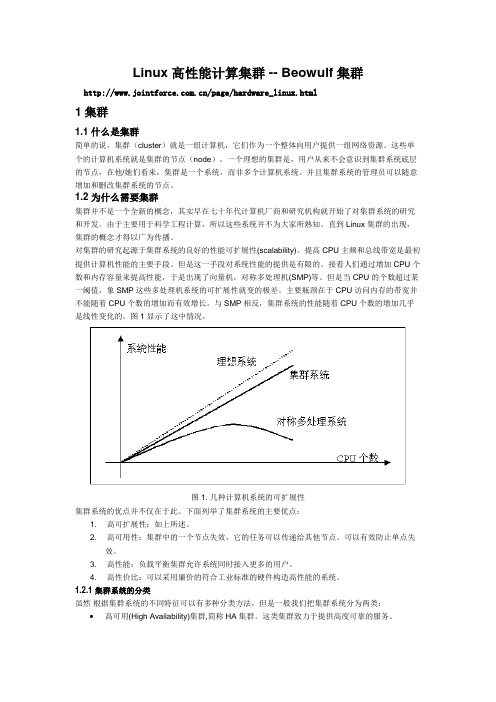
对集群的研究起源于集群系统的良好的性能可扩展性(scalability)。
提高CPU主频和总线带宽是最初提供计算机性能的主要手段。
但是这一手段对系统性能的提供是有限的。
接着人们通过增加CPU个数和内存容量来提高性能,于是出现了向量机,对称多处理机(SMP)等。
但是当CPU的个数超过某一阈值,象SMP这些多处理机系统的可扩展性就变的极差。
主要瓶颈在于CPU访问内存的带宽并不能随着CPU个数的增加而有效增长。
与SMP相反,集群系统的性能随着CPU个数的增加几乎是线性变化的。
图1显示了这中情况。
图1. 几种计算机系统的可扩展性集群系统的优点并不仅在于此。
下面列举了集群系统的主要优点:1.高可扩展性:如上所述。
2.高可用性:集群中的一个节点失效,它的任务可以传递给其他节点。
可以有效防止单点失效。
3.高性能:负载平衡集群允许系统同时接入更多的用户。
4.高性价比:可以采用廉价的符合工业标准的硬件构造高性能的系统。
1.2.1 集群系统的分类虽然根据集群系统的不同特征可以有多种分类方法,但是一般我们把集群系统分为两类:∙高可用(High Availability)集群,简称HA集群。
linux下weblogic集群部署

Weblogic集群安装手册(一)部署计划:10.2.66.88:6060 主控domain AdminServer10.2.66.88:7001 应用domain slave110.2.66.85:7001应用domain slave2(二)创建主控域运行$weblogic_home/common/bin/config.sh1、默认创建新的域2、选择默认模版3、默认选择创建基本的域4、调整域的名称,直接名称5、默认域创建目录6、设置weblogic用户和密码7、选择weblogic的启动模式,我这里选择的是生产模式8、选择jdk9、选择安装集群10、添加托管节点11、配置集群因为集群是通过广播(有unicast和multicast两种)来同步集群中的节点,并且把每个节点中的session通过这个广播地址来进行复制和同步,即主控域不断的时时刻刻的会和它下面的子节点间保持通讯、经常去询问各个子节点的。
集群信息传送模式:有unitcast与multicast两种,在11G版本前都是multicast10G后开始支持unicast 协议。
如果指定了multicast,就必须指定一个“多点传送地址”。
以下采用multicast方式,地址采用默认的,端口使用6060:12、关联集群与节点13、由于我们采取IP形式,不在这里指定计算机名,直接下一步,并创建域(三)创建节点(分别在10.2.66.88、10.2.66.85创建)1 – 3、和创建主控域一样4、调整域的名称为domain_70015 - 8、和创建主控域一样9、创建一般的应用域10、修改域名称和端口相关信息,并创建域(四)启动集群1、进入域目录启动主控weblogic输入(第6步设置的用户名密码) 用户名weblogic,密码weblogic1232、设置免密码登录,在AdmiServer下面创建security文件夹,里边包含boot.properties文件。
基于linux的大规模集群的搭建与管理

如下 图所 示 :
在 服 务器 上 完 全 安 装 l u i x后 ,首 先应 对 网络 I n P.主机 名 ,
N S服 务 及 N ' 务 进 行设 置 I F s服 1 网 络 配 置 )
系统 。 它 既可 以执 行 并 行 任 务 . 也 可 以执 行 串 行 任 务 。 中 高速 其 网络 提供 了集 群 的基 础 平 台 , 是 节 点 机 之 间 相 通 讯 的 硬 件 基 高 络 速网 图 l典 型集群 系统结 构 -
② 在 /c y Of/ to / e /S ng e r 日录下 , ts C in w k 输入主机名和域名。
1 集 群 的 体 系结构 : . 个 典 型 的 集 群 系 统 结 构
一
者和使用者不断追求的 目标。 然而 , 传统的并行计算机 由于其昂 行程序的快速启动 , 并行 Y 文件系统管理等因素 0.
的 网络 自动 安 装 模 式 。Kc s r 是 R dH t 发 的 网络 环境 下 i tt ka e a 开 自动 安 装 R dH tiu e a l x的方 法 。使 用 kcs r 系 统 管 理 员 可 n iktt. a 以 创 建单 个 文 件 。 文 件 包 括对 典 型 R dH t Ju 该 e a Inx安 装 中所 询 i 问 的 问题 的 回答 。 iktr文 件 通 常 被 保 留 在服 务 器 上 . 在 客 K cs t a 并 户 机 安装 过 程 中被 多个 客 户计 算 机 读 取
【 要】 摘 :本文指 出了搭建集群 系统 中应注 意的问题 , 了 l u(dht 9 ) E 论述 i xe a一 .  ̄JT大规模 集群 系统搭 建过程. n r 0 并对
Linux搭建jackrabbit集群配置

Linux搭建jackrabbit集群配置(仅供内部使用)V1.0目录目录 (1)1 引言 (2)1.1 编写目的 (2)1.2 项目背景 (2)1.3 定义 (2)1.4 参考资料 (2)1.5 变更历史 (2)2 技术介绍 (2)2.1 技术目标 (2)2.2 网络架构 (2)2.3 环境规划 (3)2.3.1 服务器规划 (3)2.4 软件架构 (3)3 详细步骤 (3)3.1 目录共享设置 (3)3.1.1 目录创建 (3)3.1.2 指定共享目录及权限 (4)3.1.3 启动共享服务 (4)3.1.4 客户端挂载共享目录 (4)3.2 修改目录创建文件和目录的默认权限 (5)3.2.1 修改/mnt/nfsdata (5)3.2.2 修改/home/sinocmsys2/nfsdata (5)3.3 配置应用服务 (6)3.3.1 用户sinocmsys1应用配置 (6)3.3.2 用户sinocmsys2应用配置 (7)1 引言1.1 编写目的本说明手册为了阐述Linux搭建jackrabbit集群环境。
1.2 项目背景无。
1.3 定义1.4 参考资料1.5 变更历史内容变更原因变更日期人员创建文档首次创建2013-10-282 技术介绍2.1 技术目标实现内容仓库在多个jackrabbit实例中实现集群访问。
2.2 网络架构采用局域网或单机环境。
文件名称出处服务器1(162.16.1.224)sinocmsys1服务器2 (162.16.1.225) sinocmsys2 共享目录/mnt/nfsdata挂载目录/home/sinocmsys2/nfsdata服务器1apacheTomcat1Tomcat2/home/sinocmsys1/sinodata/sinocm/home/sinocmsys2/sinodata/sinocm2.3 环境规划2.3.1 服务器规划服务器1:IP:162.16.1.224用户:sinocmsys1,apache目录:/mnt/nfsdata -jcr共享目录,所属用户sinocmsys1/mnt/nfsdata/workspaces -jcr仓库数据/mnt/nfsdata/versions -jcr仓库数据版本/mnt/nfsdata/repository -jcr集群管理文件/home/sinocmsys1/sinodata/sinocm -jcr仓库配置,所属用户sinocmsys1服务器2:IP:162.16.1.225用户:sinocmsys2目录:/home/sinocmsys2/nfsdata -挂载服务器1共享目录,所属用户sinocmsys2/home/sinocmsys2/sinodata/sinocm -jcr仓库配置,所属用户sinocmsys22.4 软件架构软件平台类型软件平台选型网络操作系统Red Hat Enterprise Linux 4Jackrabbit版本Jackrabbit 1.5Http 服务器httpd-2.2.22.tar.gzWEB应用服务apache-tomcat-6.0.35MOD_JK tomcat-connectors-1.2.31-src.tar.gzJDK jdk1.5.0_193 详细步骤3.1 目录共享设置3.1.1 目录创建【服务器1】使用root用户登录,创建目录/mnt/nfsdata,并赋予读写权限777,将目录赋予给用户组sinocmsys1下的用户sinocmsys1[root@cm01 ~]# mkdir /mnt/nfsdata[root@cm01 ~]# chmod -R 777 /mnt/nfsdata[root@cm01 ~]# chgrp -R sinocmsys1 /mnt/nfsdata[root@cm01 ~]# chown -R sinocmsys1 /mnt/nfsdata3.1.2 指定共享目录及权限【服务器1】打开 /etc/exports文件,添加“/mnt/nfsdata 162.16.1.*(rw,no_root_squash)”。
CAS集群部署(Linux)

安装CAS集群(v1.0)目录1部署操作 (2)1.1硬件及部署要求 (2)1.1.1部署图 (2)1.2操作系统安装—SERVER1,2 .................................................................................................. 错误!未定义书签。
1.3安装M EMCACHED (2)1.3.1安装环境 (2)1.3.2安装步骤 (3)1.4安装LVS (7)1.5配置CAS集群模式 (11)1 部署操作1.1 硬件及部署要求以下几种集群部署策略请根据实际情况选择确定。
(1)使用认证平台人数在3万人以下,并发5000以下,不推荐集群化部署,单台即可;节点服务器要求(2路4核,8G 内存以上)物理机优先。
1.1.1 部署图说明:此架构为CAS 的集群模式,考虑高并发的模式及双击热备的模式,Memcached 需要配置1-2G 内存,可以考虑单独部署服务器,可以与其中一台CAS 服务器进行一起部署。
如果Memcached 挂了或者不能访问了,CAS 服务器就不能访问。
● CPU 类型:Intel/AMD (64位,主频2.6GHz 以上,2核及以上) ● 内存容量:4GB 及以上● 硬盘容量:160GB 以上,Raid 1/5 ● 网络控制器:千兆以太网卡(两块以上) ● IP (对外提供服务):3个,其中一个为虚拟ip ● 集群策略:MirrorMode ● 拓扑图:PCSmart Phone IP :Memcached1.2 安装Memcached1.2.1 安装环境redhat server 6.3(64bit)/ Centos 6.3(64bit)1.2.2安装步骤(确认是用root用户登录)将memcached-1.4.0.tar.gz , libevent-2.0.13-stable.tar.gz上传至/root路径下1.2.2.1安装libevent注意:这里一定要注意指定--prefix,后面配置memcached的时候就有必要用到。
Linux下WebLogic集群的部署完整版
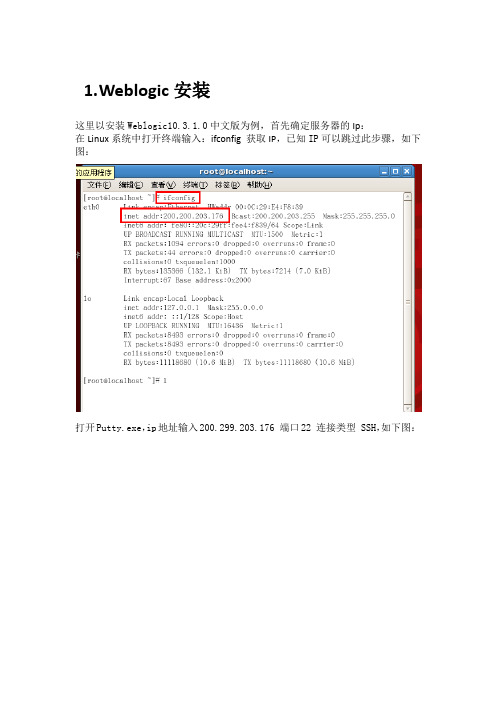
1.W eblogic安装这里以安装Weblogic10.3.1.0中文版为例,首先确定服务器的Ip:在Linux系统中打开终端输入:ifconfig 获取IP,已知IP可以跳过此步骤,如下图:打开Putty.exe,ip地址输入200.299.203.176 端口22 连接类型 SSH,如下图:点击打开输入用户名root 密码:1234htsd 温馨提示密码在输入时不显示,如下图然后用SSH工具将文件上传到Linux系统中,如下图进入之后点击New File Transfer Window按钮,如下图:在本地找到oepe11_ccjk_wls1031_linux32.bin文件右键将该文件上传到Linux系统root目录下,如图:回到putty 输入:cd /root找到oepe11_ccjk_wls1031_linux32.bin并赋予可执行权限:chmod u+x oepe11_ccjk_wls1031_linux32.bin,如下图:当前目录下执行./oepe11_ccjk_wls1031_linux32.bin 自解压过程开始,进度过100%后。
出现欢迎画面,如下图:第一步:输入next第二步:输入安装目录,选择中间件主目录:输入next,如下图:第三步:注册安全更新,需要把接收安全更新修改为No:a)输入3,如下图b)提示输入新值输入No,如下图c)提示是否希望绕过配置管理器的启动过程并且不接收配置中存在严重安全问题的通知输入Yes,如下图d)输入next ,如下图第四步:选择安装类型输入1典型安装,如下图第五步:选择产品安装目录默认输入next,如下图第六步开始安装WebLogic,JDK并创建默认domain 输入next,如下图第七步:安装完成输入next 退出安装1.1Weblogic主服务器域的创建1.进入刚刚创建的WebLogic安装目录如:/root/Oracle/Middleware/wlserver_10.3/common/bin 并执行./config.sh,如下图:2.欢迎界面,创建新的域输入1,如下图3.选择选择域源输入1,如下图:4.选择默认模版输入next,如下图:5.编辑域信息输入域的名字MyCluster_Domain,域名按照实际情况输入,如下图:6.输入next,如下图7.选择目标域目录默认输入next,如下图:8.配置管理员用户名和密码:根据提示分别选择1,2,3更改用户名和密码,密码至少是8位且包含字母和数字此处用户名设置为weblogic密码设置为1234htsd,1用户名:weblogic2密码:1234htsd3确认密码:1234htsd用户名密码可以自定义,如下图:9.选择生产模式输入2,如下图10.JDK选择第二个, 如下图11.择高级配置:分别输入1 2 如下图12.配置管理服务器:选择2配置地址:200.200.203.173 端口号为7001如下图13.配置受管服务器:Cluster_ManagedServer_1地址200.200.203.173 端口:7003Cluster_ManagedServer_2地址172.16.101.129 端口:7004Proxy_Server 地址200.200.203.173 端口:8080 根据实际情况设定如下图14.配置群集:Name:My_Cluster_1 消息传递模式:multicast 地址:239.192.0.1 端口7777集群地址:200.200.203.173:7003,172.16.101.129:7004,此处为所有节点的地址和端口如下图15.向域中的群集分配受管服务器,输入1 如下图16.向域中的群集分配受管服务器,输入1 如下图17.此处选择所有节点服务输入1,2 如下图18.确认并接受选择输入:Accept 如下图19.确认分配服务器:输入next 如下图20.创建HTTP代理输入1 如下图21.添加HTTP代理:输入Add 如下图:22.选择集群输入1 如下图:23.选择受管服务器, 输入1 如下图:24.回到添加或删除HTTP代理界面,输入next,如下图25.配置计算机:计算机名My_Machine_1 200.200.203.173 5556My_Machine_2 172.16.101.129 5557如下图26.无需配置Unix计算机. 输入next向计算机分配服务器:输入1.1 如图27.输入要选择的选项号: 输入1 如下图28.选择服务输入1,2,4 如下图29.接受选择输入Accept 如下图30.向My_Machine分配服务,输入1.2 如下图31.选择服务:输入1如下图32.分配服务器选择输入1 如下图33.接受分配输入Accept 如下图34.分配服务器完毕,输入next 如下图35.开始创建域…提示,至此weblogic域创建完成。
Linux系统RabbitMQ高可用集群安装部署文档

Linux系统RabbitMQ⾼可⽤集群安装部署⽂档RabbitMQ⾼可⽤集群安装部署⽂档架构图1)RabbitMQ集群元数据的同步RabbitMQ集群会始终同步四种类型的内部元数据(类似索引):a.队列元数据:队列名称和它的属性;b.交换器元数据:交换器名称、类型和属性;c.绑定元数据:⼀张简单的表格展⽰了如何将消息路由到队列;d.vhost元数据:为vhost内的队列、交换器和绑定提供命名空间和安全属性;2)集群配置⽅式cluster:不⽀持跨⽹段,⽤于同⼀个⽹段内的局域⽹;可以随意的动态增加或者减少;节点之间需要运⾏相同版本的 RabbitMQ 和 Erlang。
节点类型RAM node:内存节点将所有的队列、交换机、绑定、⽤户、权限和 vhost 的元数据定义存储在内存中,好处是可以使得像交换机和队列声明等操作更加的快速。
Disk node:将元数据存储在磁盘中,单节点系统只允许磁盘类型的节点,防⽌重启 RabbitMQ 的时候,丢失系统的配置信息。
解决⽅案:设置两个磁盘节点,⾄少有⼀个是可⽤的,可以保存元数据的更改。
Erlang Cookieerlang Cookie 是保证不同节点可以相互通信的密钥,要保证集群中的不同节点相互通信必须共享相同的 Erlang Cookie3)搭建RabbitMQ集群所需要安装的组件a.Jdk 1.8b.Erlang运⾏时环境c.RabbitMq的Server组件1、安装yum源⽂件2、安装Erlang# yum -y install erlang3、配置java环境 /etc/profileJAVA_HOME=/usr/local/java/jdk1.8.0_151PATH=$JAVA_HOME/bin:$PATHCLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar4、安装配置rabbitmq# tar -xf rabbitmq-server-generic-unix-3.6.15.tar -C /usr/local/# mv /usr/local/rabbitmq_server-3.6.15/ /usr/local/rabbitmq5、配置RabbitMQ环境变量/etc/profileRABBITMQ_HOME=/usr/local/rabbitmqPATH=$PATH:$ERL_HOME/bin:/usr/local/rabbitmq/sbin# source /etc/profile6、修改主机配置⽂件/etc/hosts192.168.2.208 rabbitmq-node1192.168.2.41 rabbitmq-node2192.168.2.40 rabbitmq-node3各个主机修改配置⽂件保持⼀致# /root/.erlang.cookie7、后台启动rabbitmq# /usr/local/rabbitmq/sbin/rabbitmq-server -detached添加⽤户# rabbitmqctl add_user admin admin给⽤户授权# rabbitmqctl set_user_tags admin administrator# rabbitmqctl set_permissions -p / admin ".*" ".*" ".*"启⽤插件,可以使⽤rabbitmq管理界⾯# rabbitmq-plugins enable rabbitmq_management查看⽤户列表# rabbitmqctl list_users查看节点状态# rabbitmqctl status查看集群状态# rabbitmqctl cluster_status查看插件# rabbitmq-plugins list添加防⽕墙规则/etc/sysconfig/iptables-A INPUT -m state --state NEW -m tcp -p tcp --dport 27017 -j ACCEPT -A INPUT -m state --state NEW -m tcp -p tcp --dport 28017 -j ACCEPT -A INPUT -m state --state NEW -m tcp -p tcp --dport 15672 -j ACCEPT -A INPUT -m state --state NEW -m tcp -p tcp --dport 5672 -j ACCEPT -A INPUT -m state --state NEW -m tcp -p tcp --dport 25672 -j ACCEPT8、添加集群node节点,从节点执⾏(⽬前配置2个节点)# rabbitmqctl stop_app# rabbitmqctl join_cluster --ram rabbit@rabbitmq-node2或者# rabbitmqctl join_cluster rabbit@rabbitmq-node2# rabbitmqctl change_cluster_node_type ram启动节点#rabbitmqctl start_app9、删除集群node 节点删除1. rabbitmq-server -detached2. rabbitmqctl stop_app3. rabbitmqctl reset4. rabbitmqctl start_app设置镜像队列策略在web界⾯,登陆后,点击“Admin--Virtual Hosts(页⾯右侧)”,在打开的页⾯上的下⽅的“Add a new virtual host”处增加⼀个虚拟主机,同时给⽤户“admin”和“guest”均加上权限1、2、# rabbitmqctl set_policy -p hasystem ha-allqueue "^" '{"ha-mode":"all"}' -n rabbit"hasystem" vhost名称, "^"匹配所有的队列, ha-allqueue 策略名称为ha-all, '{"ha-mode":"all"}' 策略模式为 all 即复制到所有节点,包含新增节点,则此时镜像队列设置成功.rabbitmqctl set_policy [-p Vhost] Name Pattern Definition [Priority]-p Vhost:可选参数,针对指定vhost下的queue进⾏设置Name: policy的名称Pattern: queue的匹配模式(正则表达式)Definition:镜像定义,包括三个部分ha-mode, ha-params, ha-sync-modeha-mode:指明镜像队列的模式,有效值为 all/exactly/nodesall:表⽰在集群中所有的节点上进⾏镜像exactly:表⽰在指定个数的节点上进⾏镜像,节点的个数由ha-params指定nodes:表⽰在指定的节点上进⾏镜像,节点名称通过ha-params指定ha-params:ha-mode模式需要⽤到的参数ha-sync-mode:进⾏队列中消息的同步⽅式,有效值为automatic和manualpriority:可选参数,policy的优先级注以上集群配置完成⾼可⽤HA配置Haproxy 负载均衡,keepalived实现健康检查HA服务安装配置解压⽂件# tar -zxf haproxy-1.8.17.tar.gz查看内核版本# uname –r# yum -y install gcc gcc-c++ make切换到解压⽬录执⾏安装# make TARGET=3100 PREFIX=/usr/local/haproxy # make install PREFIX=/usr/local/haproxy创建配置⽂件相关⽬录# mkdir /usr/local/haproxy/conf# mkdir /var/lib/haproxy/# touch /usr/local/haproxy/haproxy.cfg# groupadd haproxy# useradd haproxy -g haproxy# chown -R haproxy.haproxy /usr/local/haproxy# chown -R haproxy.haproxy /var/lib/haproxy配置⽂件globallog 127.0.0.1 local2chroot /var/lib/haproxypidfile /var/run/haproxy.pidmaxconn 4000user haproxygroup haproxydaemon# turn on stats unix socketstats socket /var/lib/haproxy/stats#---------------------------------------------------------------------defaultsmode httplog globaloption httplogoption dontlognulloption http-server-closeoption redispatchretries 3timeout http-request 10stimeout queue 1mtimeout connect 10stimeout client 1mtimeout server 1mtimeout http-keep-alive 10stimeout check 10smaxconn 3000#监控MQ管理平台listen rabbitmq_adminbind 0.0.0.0:8300 server rabbitmq-node1 192.168.2.208:15672 server rabbitmq-node2 192.168.2.41:15672 server rabbitmq-node3 192.168.2.40:15672#rabbitmq_cluster监控代理listen rabbitmq_local_clusterbind 0.0.0.0:8200#配置TCP模式mode tcpoption tcplog#简单的轮询balance roundrobin#rabbitmq集群节点配置 server rabbitmq-node1 192.168.2.208:5672 check inter 5000 rise 2 fall 2 server rabbitmq-node2 192.168.2.41:5672 check inter 5000 rise 2 fall 2 server rabbitmq-node3 192.168.2.40:5672 check inter 5000 rise 2 fall 2 #配置haproxy web监控,查看统计信息listen private_monitoringbind 0.0.0.0:8100mode httpoption httplogstats enablestats uri /statsstats refresh 30s#添加⽤户名密码认证stats auth admin:admin启动haproxy服务# /usr/local/haproxy/sbin/haproxy -f /usr/local/haproxy/conf/haproxy.cfg#Keepalived 源码安装软件包路径 /usr/local/src安装路径 /usr/local/keepalived配置⽂件/etc/keepalived/keeplived.conf# tar -zxf keepalived-2.0.10.tar.gz#安装依赖包# yum -y install openssl-devel libnl libnl-devel libnfnetlink-devel# ./configure --prefix=/usr/local/keepalived && make && make install创建keepalived配置⽂件⽬录#mkdir /etc/keepalived拷贝配置⽂件到/etc/keepalived⽬录下# cp /usr/local/keepalived/etc/keepalived/keepalived.conf /etc/keepalived/复制keepalived脚本到/etc/init.d/ ⽬录# cp /usr/local/src/keepalived-2.0.10/keepalived/etc/init.d/keepalived /etc/init.d/拷贝keepalived脚本到/etc/sysconfig/ ⽬录# cp /usr/local/keepalived/etc/sysconfig/keepalived /etc/sysconfig/建⽴软连接# ln -s /usr/local/keepalived/sbin/keepalived /sbin/添加到开机启动# chkconfig keepalived on查看服务状况# systemctl status keepalivedKeepalived启动# systemctl start keepalivedmaster 配置⽂件#Master :global_defs {notification_email {134********m@}notification_email_from 134********m@smtp_server 127.0.0.1smtp_connect_timeout 30router_id NGINX_DEVEL}vrrp_script chk_haproxy {script "/usr/local/keepalived/check_haproxy.sh"interval 2weight 2fall 3rise 2}vrrp_instance haproxy_1 {state MASTERinterface ens33virtual_router_id 104priority 150advert_int 1mcast_src_ip 192.168.2.41authentication {auth_type PASSauth_pass 1111}track_interface {ens33}track_script {check_haproxy.sh}virtual_ipaddress {192.168.33.110}}#virtual_server 192.168.2.110 80 {# delay_loop 6 # 设置健康检查时间,单位是秒# lb_algo wrr # 设置负载调度的算法为wlc# lb_kind DR # 设置LVS实现负载的机制,有NAT、TUN、DR三个模式# nat_mask 255.255.255.0# persistence_timeout 0# protocol TCP# real_server 192.168.220.128 80 { # 指定real server1的IP地址# weight 3 # 配置节点权值,数字越⼤权重越⾼#TCP_CHECK {# connect_timeout 10# nb_get_retry 3# delay_before_retry 3# connect_port 80# }# }# }}#Slave :global_defs {notification_email {134********m@}notification_email_from 134********m@smtp_server 127.0.0.1smtp_connect_timeout 30router_id NGINX_DEVEL}vrrp_script chk_haproxy {script "/usr/local/keepalived/check_haproxy.sh"interval 2weight 2fall 3rise 2}vrrp_instance haproxy_2 {state SLAVEinterface ens33virtual_router_id 104priority 150advert_int 1mcast_src_ip 192.168.2.208authentication {auth_type PASSauth_pass 1111}track_interface {ens33}track_script {check_haproxy.sh}virtual_ipaddress {192.168.2.246}}#virtual_server 192.168.2.110 80 {# delay_loop 6 # 设置健康检查时间,单位是秒# lb_algo wrr # 设置负载调度的算法为wlc# lb_kind DR # 设置LVS实现负载的机制,有NAT、TUN、DR三个模式# nat_mask 255.255.255.0# persistence_timeout 0# protocol TCP# real_server 192.168.220.128 80 { # 指定real server1的IP地址# weight 3 # 配置节点权值,数字越⼤权重越⾼#TCP_CHECK {# connect_timeout 10# nb_get_retry 3# delay_before_retry 3# connect_port 80# }# }# }}haproxy检测#!/bin/bashHaproxyStatus=`ps -C haproxy --no-header | wc -l`if [ $HaproxyStatus-eq 0 ];then/etc/init.d/haproxy startsleep 3if [ `ps -C haproxy --no-header | wc -l ` -eq 0 ];then/etc/init.d/keepalived stopfifi。
linux服务器集群的详细配置

linux服务器集群的详细配置一、计算机集群简介计算机集群简称集群是一种计算机系统, 它通过一组松散集成的计算机软件和/或硬件连接起来高度紧密地协作完成计算工作;在某种意义上,他们可以被看作是一台计算机;集群系统中的单个计算机通常称为节点,通常通过局域网连接,但也有其它的可能连接方式;集群计算机通常用来改进单个计算机的计算速度和/或可靠性;一般情况下集群计算机比单个计算机,比如工作站或超级计算机性能价格比要高得多;二、集群的分类群分为同构与异构两种,它们的区别在于:组成集群系统的计算机之间的体系结构是否相同;集群计算机按功能和结构可以分成以下几类:高可用性集群 High-availability HA clusters负载均衡集群 Load balancing clusters高性能计算集群 High-performance HPC clusters网格计算 Grid computing高可用性集群一般是指当集群中有某个节点失效的情况下,其上的任务会自动转移到其他正常的节点上;还指可以将集群中的某节点进行离线维护再上线,该过程并不影响整个集群的运行;负载均衡集群负载均衡集群运行时一般通过一个或者多个前端负载均衡器将工作负载分发到后端的一组服务器上,从而达到整个系统的高性能和高可用性;这样的计算机集群有时也被称为服务器群Server Farm; 一般高可用性集群和负载均衡集群会使用类似的技术,或同时具有高可用性与负载均衡的特点;Linux虚拟服务器LVS项目在Linux操作系统上提供了最常用的负载均衡软件;高性能计算集群高性能计算集群采用将计算任务分配到集群的不同计算节点而提高计算能力,因而主要应用在科学计算领域;比较流行的HPC采用Linux操作系统和其它一些免费软件来完成并行运算;这一集群配置通常被称为Beowulf集群;这类集群通常运行特定的程序以发挥HPC cluster的并行能力;这类程序一般应用特定的运行库, 比如专为科学计算设计的MPI 库集群特别适合于在计算中各计算节点之间发生大量数据通讯的计算作业,比如一个节点的中间结果或影响到其它节点计算结果的情况;网格计算网格计算或网格集群是一种与集群计算非常相关的技术;网格与传统集群的主要差别是网格是连接一组相关并不信任的计算机,它的运作更像一个计算公共设施而不是一个独立的计算机;还有,网格通常比集群支持更多不同类型的计算机集合;网格计算是针对有许多独立作业的工作任务作优化,在计算过程中作业间无需共享数据;网格主要服务于管理在独立执行工作的计算机间的作业分配;资源如存储可以被所有结点共享,但作业的中间结果不会影响在其他网格结点上作业的进展;三、linux集群的详细配置下面就以WEB服务为例,采用高可用集群和负载均衡集群相结合;1、系统准备:准备四台安装Redhat Enterprise Linux 5的机器,其他node1和node2分别为两台WEB服务器,master作为集群分配服务器,slave作为master的备份服务器;所需软件包依赖包没有列出:2、IP地址以及主机名如下:3、编辑各自的hosts和network文件mastervim /etc/hosts 添加以下两行vim /etc/sysconfig/networkHOSTNAME= slavevim /etc/hosts 添加以下两行vim /etc/sysconfig/network HOSTNAME= node1vim /etc/hosts 添加以下两行vim /etc/sysconfig/network HOSTNAME= node2vim /etc/hosts 添加以下两行vim /etc/sysconfig/networkHOSTNAME= 注:为了实验过程的顺利,请务必确保network文件中的主机名和hostname命令显示的主机名保持一致,由于没有假设DNS服务器,故在hosts 文件中添加记录;4、架设WEB服务,并隐藏ARPnode1yum install httpdvim /var//html/添加如下信息:This is node1.service httpd startelinks 访问测试,正确显示&nbs隐藏ARP,配置如下echo 1 >> /proc/sys/net/ipv4/conf/lo/arp_ignoreecho 1 >> /proc/sys/net/ipv4/conf/all/arp_ignore echo 2 >> /proc/sys/net/ipv4/conf/lo/arp_announce echo 2 >> /proc/sys/net/ipv4/conf/all/arp_announce ifconfig lo:0 netmask broadcast uproute add -host dev lo:0node2yum install httpdvim /var//html/添加如下信息:This is node2.service httpd startelinks 访问测试,正确显示隐藏ARP,配置如下echo 1 >> /proc/sys/net/ipv4/conf/lo/arp_ignore echo 1 >> /proc/sys/net/ipv4/conf/all/arp_ignore echo 2 >> /proc/sys/net/ipv4/conf/lo/arp_announce echo 2 >> /proc/sys/net/ipv4/conf/all/arp_announceifconfig lo:0 netmask broadcast uproute add -host dev lo:0mastervim /var//html/添加如下内容:The service is bad.service httpd startslavevim /var//html/添加如下内容:The service is bad.service httpd start5、配置负载均衡集群以及高可用集群小提示:使用rpm命令安装需要解决依赖性这一烦人的问题,可把以上文件放在同一目录下,用下面这条命令安装以上所有rpm包:yum --nogpgcheck -y localinstall .rpmmastercd /usr/share/doc/ cp haresources authkeys /etc/cd /usr/share/doc/ cp /etccd /etcvim开启并修改以下选项:debugfile /var/log/ha-debuglogfile /var/log/ha-logkeepalive 2deadtime 30udpport 694bcast eth0增加以下两项:node node vim haresources增加以下选项:ldirectord::/etc/为/etc/authkeys文件添加内容echo -ne "auth 1\n1 sha1 "注意此处的空格 >> /etc/authkeysdd if=/dev/urandom bs=512 count=1 | openssl md5 >> /etc/authkeys &nbs更改key文件的权限chmod 600 /etc/authkeysvim /etc/修改如下图所示:slave 注:由于slave的配置跟master配置都是一样的可以用下面的命令直接复制过来,当然想要再练习的朋友可以自己手动再配置一边;scp root:/etc/{,haresources} /etc/输入的root密码scp root:/etc/ /etc输入的root密码6、启动heartbeat服务并测试master & slaveservice heartbeat start这里我就我的物理机作为客户端来访问WEB服务,打开IE浏览器这里使用IE浏览器测试,并不是本人喜欢IE,而是发现用google浏览器测试,得出的结果不一样,具体可能跟两者的内核架构有关,输入,按F5刷新,可以看到三次是2,一次是1,循环出现;7、停止主服务器,再测试其访问情况masterifdown eth0再次访问,可以看到,服务器依然能够访问;。
大数据技术基础实验报告-Linux环境下hadoop集群的搭建与基本配置

大数据技术基础实验报告-Linux环境下hadoop集群的搭建与基本配置实验内容:(一)安装和配置CentOS(二)安装和配置Java环境(三)启动和配置SSH绵密登录(四)安装和配置Hadoop设置仅主机连接模式启动Linux虚拟机,手动设置IP地址,注意和windows下虚拟网卡地址一个网段;2. 安装winscp(windows和linux虚拟机传数据的小工具),pieTTY(linux小客户端),并使用工具连接到虚拟机linux,通过winscp上传jdk、hadoop到linux虚拟机;3. 永久关闭防火墙,和Selinux,不然ssh无密码连接时可能会无法连接。
执行如下命令/etc/init.d/iptables stopchkconfig iptables offvi /etc/sysconfig/selinux 设置SELINUX=disabled4. 进入/etc/hosts添加自己的IP地址和主机名。
如192.168.18.120 hadoop5. 安装jdk并配置环境变量。
(用RPM包或压缩包)。
rmp安装命令:rpm -ivh jdk-7u67-linux-x86.rpmmv命令jdk相关目录改名进入/etc/profile文件,添加Java环境变量vi /etc/profileexport JAVA_HOME=/usr/local/jdkexport PATH=$PATH:$JAVA_HOME/bin执行source /etc/profile 刷新配置文件验证jdk是否成功。
Java -version6. 配置用户免密码登录。
7.安装hadoop(安装版本hadoop 2.7版本以上)使用ssh上传文件到linux主机执行了mv命令解压后更改文件夹名为hadoop在/etc/profile文件下添加环境变量,如下export HADOOP_HOME=/home/hadoop/hadoopexport PATH=$PATH:$HADOOP_HOME/bin保存配置文件执行source /etc/profile 使其立即生效切换到hadoop_home 下etc/Hadoop下修改相关配置文件。
Linux下Redis集群安装部署及使用详解(在线和离线两种安装+相关错误解决方案)

Linux下Redis集群安装部署及使⽤详解(在线和离线两种安装+相关错误解决⽅案)⼀、应⽤场景介绍 本⽂主要是介绍Redis集群在Linux环境下的安装讲解,其中主要包括在联⽹的Linux环境和脱机的Linux环境下是如何安装的。
因为⼤多数时候,公司的⽣产环境是在内⽹环境下,⽆外⽹,服务器处于脱机状态(最近公司要上线项⽬,就是⽆外⽹环境的Linux,被离线安装坑惨了,⾛了很多弯路,说多了都是⾎泪史啊%>_<%)。
这也是笔者写本⽂的初衷,希望其他⼈少⾛弯路,下⾯就介绍如何在Linux安装部署Redis集群。
⼆、安装环境及⼯具 系统:Red Hat Enterprise Linux Server release 6.6 ⼯具:XShell5及Xftp5 安装包:GCC-7.1.0 Ruby-2.4.1 Rubygems-2.6.12 Redis-3.2.9(3.x版本才开始⽀持集群功能)三、安装步骤 要搭建⼀个最简单的Redis集群,我们⾄少需要6个节点:3个Master和3个Slave。
那为什么需要3个Master呢?其实就是⼀个“铁三⾓”的关系,当1个Master下线的时候,其他2个Master 和对应的Salve⽴马就能顶替上去,确保集群能够正常使⽤,如果你之前了解Mongodb/Hadoop/Strom这些的话,你就很容易⽬标⼀般分布式的最低要求基数个数节点,这样便于选举(少数服从多数的原则)。
本⽂当中,我们就偷下懒,在⼀台Linux虚拟机上搭建6个节点的Redis集群(实际真正⽣产环境,需要3台Linux服务器分布存放3个Master)1、安装GCC环境安装Redis需要依托GCC环境,先检查Linux是否已经安装了GCC,如果没有安装,则需要进⾏安装检查GCC是否安装,可以看看版本号$ gcc -v如果已经安装了GCC,则会显⽰以下信息如果没有任何信息,则我们可以通过命令yum install gcc-c++进⾏在线安装$ yum install gcc-c++如果没有⽹络的时候,我们就需要下载GCC的安装包进⾏⼿动安装了,具体⽅法还是⽐较复杂的,具体离线安装GCC的⽅法,请参考我的另外⼀篇⽂章《》2、安装Ruby和Rubygems如果有⽹的话,则通过yum命令进⾏安装,⾃动将关联的依赖包全部安装$ yum install ruby$ yum install rubygems如果是离线的状态,我们则可以选择下载Ruby和Rubygems,解压⼿动进⾏安装,具体的⽅法请参考我的另外两篇⽂件《》和《》,这⾥我们不做多讲解。
如何在Linux上搭建DNS服务器集群

如何在Linux上搭建DNS服务器集群在当今高度互联网化的环境下,DNS(域名系统)的作用日益重要。
它将域名转换为IP地址,使得用户能够轻松访问互联网上的各种资源。
然而,随着互联网规模的不断扩大,传统的单一DNS服务器已经无法满足高负载和高可用性的需求。
因此,在Linux上搭建DNS服务器集群已成为许多企业和组织提高性能和可靠性的关键步骤。
本文将介绍如何在Linux平台上搭建DNS服务器集群,以确保系统的高可用性和高性能。
一、DNS服务器集群的优势通过搭建DNS服务器集群,可以带来以下几个优势:1. 高可用性:DNS服务器集群可以通过冗余配置来提供高可用性。
当一个服务器发生故障时,其他服务器可以接管服务,确保用户的请求得到及时响应。
2. 负载均衡:DNS服务器集群可以通过负载均衡技术将用户的请求分散到集群中的各个服务器上,以提高系统的性能和响应速度。
3. 扩展性:通过增加或减少集群中的服务器数量,可以根据实际需求来调整系统的处理能力,提高系统的扩展性。
二、DNS服务器集群的搭建步骤1. 确定服务器数量:根据实际需求来确定搭建DNS服务器集群所需的服务器数量。
通常建议至少使用三台服务器,以实现高可用性和负载均衡。
2. 安装Linux操作系统:在每个服务器上安装适用的Linux发行版,如Ubuntu、CentOS等。
确保选择的发行版具有良好的稳定性和支持性。
3. 安装BIND软件:BIND(Berkeley Internet Name Domain)是Linux平台上最常用的DNS软件。
在每个服务器上安装BIND软件,并进行基本的配置。
4. 配置主从服务器:将一台服务器配置为主服务器,其他服务器配置为从服务器。
主服务器负责接收和处理用户的DNS请求,从服务器用于备份和冗余。
5. 设置域名解析:对每个要管理的域名进行解析和配置,将域名和IP地址进行关联。
确保域名解析的准确性和及时性。
6. 配置负载均衡:使用负载均衡技术,将用户的请求分发到集群中的各个服务器上。
Linux环境下基于Qt和xCAT的集群部署系统

Q t是 T r o l l t e c h 公司推出的一个 多平 台的 C + +
nd a d i s t ib r u t e c e n t r a l l y d i fe r e n t t y p e s o f n o de s i n t h e c l u s t e r .
K e y wo r d s : c l u s t e r d e p l o y me t n s y s t e m; L i n u x ; x C A T ; Q t
l 概述
集群 技术是指将一 组相互独立 的服务器在 网络 中 表 现 为单 一 的系 统,并 以单一 系统 的 模式 加 以管理 . 此 单一 系统 为客户 工 作站提 供高 效率 的服 务0 , 2 】 . 集 群 系统 以其高可扩展 性、高可用性 以及 高性价 比等优 点
2 Q t 和x C A T 简介
摘
要 :随着集群 技术在石油勘探 、航空航天工程 、生物 工程等领域 的应用越 来越 广泛,集群环境 中各种类型节
点 不 同 的应 用 需 求 使 得集 ห้องสมุดไป่ตู้ 系统 的管 理 难 度 也 越 来 越 大 .采 用 集群 技 术 的概 念 ,在 L i n u x 环境 下 ,利用
x C A T + s h e l l 技术 和 Q t 平 台,设计和 实现 了集群部署系统,对集群 中各种类型 的节 点进行集 中配置和分发.
2 0 1 3年 第 2 2卷 第 7期
h t t p : / / w ww . c — S - a . o r g . c a
计 算 机 系 统 应 用
L i n u x 环境下基 于 Qt 和x C A T的集群部署系统①
linux集群使用指南

linux集群使用指南Linux集群使用指南。
一、啥是Linux集群。
Linux集群呢,就像是一群小伙伴一起干活。
把好多台Linux计算机连接起来,让它们协同工作。
这就好比是一群超级英雄组成联盟,每个英雄都有自己的本事,合起来就能干大事啦。
比如说,有的计算机负责处理数据,有的负责存储,有的负责管理网络。
这样做的好处可多了去了。
就像大家一起抬重物,一个人可能抬不动,但是好多人一起就轻松搞定。
在处理大量数据或者需要高可靠性的任务时,Linux集群就超级有用。
二、硬件准备。
要搭建Linux集群,硬件可不能马虎。
首先得有几台计算机吧。
这些计算机的配置也有讲究哦。
如果是处理简单任务的小集群,普通配置的计算机就可以。
但要是处理大数据或者复杂计算,那就得要配置高一点的啦,像是有大容量内存、快速的CPU 还有大硬盘的计算机。
另外,这些计算机之间得能互相通信,这就需要网络设备啦。
像交换机之类的,就像它们之间的传声筒,把各个计算机连接起来,让它们能互相“聊天”。
而且呀,电源供应也很重要,要是突然断电,那可就麻烦了,所以最好有稳定的电源保障。
三、安装Linux系统。
有了硬件,就该给这些计算机装上Linux系统啦。
这就像是给每个小伙伴穿上合适的衣服一样。
可以选择一些流行的Linux发行版,像Ubuntu、CentOS之类的。
安装的时候要注意一些小细节哦。
比如说分区,要合理分配磁盘空间,给系统、数据和交换空间都留好地方。
要是分区不合理,就像衣服穿得不合身,干活的时候就会不舒服。
安装过程中,设置好用户名和密码也很重要,这就像是给你的小房子上把锁,只有你有钥匙才能进去。
而且呀,要把网络设置好,这样计算机们才能在网络的世界里找到彼此。
四、集群配置。
这可是个关键步骤呢。
要让这些计算机知道它们是一个团队。
可以使用一些工具来配置集群,像Puppet或者Ansible。
这些工具就像是指挥棒,告诉每台计算机该怎么做。
比如说,要配置好共享存储,这样大家都能访问到同样的数据。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
LINUX集群部署邱波2005-6-24第一部部分 公共部分一 系统环境1 Linux OS系统版本 RHEL AS3 UPDATES 4安装方式 最小安装系统内核 2.4.21-27.0.4二 服务组件1 LVS套件主机名 master slaver服务包 piranha-0.7.10-2ipvsadm-1.21-9依赖包 httpd-2.0.46-46php-4.3.2-23curl-7.10.6-62 GFS套件主机名 node01 node02 node03 node04 node05 node06 data01 data02服务包 GFSGFS-modules-smp依赖包 perl-Net-Telnet-3.03-1.13 MySQL CLUSTER 套件主机名 master slaver node01 node02 node03 node04 node05 node06 data01 data02 服务包 MySQL-bench-4.1.12-0MySQL-ndb-management-4.1.12-0MySQL-server-4.1.12-0MySQL-client-4.1.12-0MySQL-embedded-4.1.12-0MySQL-ndb-extra-4.1.12-0MySQL-ndb-storage-4.1.12-0MySQL-shared-4.1.12-0MySQL-devel-4.1.12-0MySQL-Max-4.1.12-0MySQL-ndb-tools-4.1.12-0依赖包 perl-DBI-1.32-94 WWW套件主机名 node01 node02 node03 node04 node05 node06服务包 httpd-2.0.46-46php-4.3.2-23php-mysql-4.3.2-23依赖包 curl-7.10.6-6三 基本配置1 主机名 master slaver node01 node02 node03 node04 node05 node06 data01 data022 配置文件 /etc/hosts3 脚本内容# Do not remove the following line, or various programs # that require network functionality will fail.127.0.0.1 localhost.localdomain localhost 192.168.70.1 node01192.168.70.2 node02192.168.70.3 node03192.168.70.4 node04192.168.70.5 node05192.168.70.6 node06192.168.70.100 data01192.168.70.200 data02192.168.70.254 master192.168.70.253 slaver第二部分LVS Linux Virtual Server负载均衡集群一LVS Linux Virtual Server概述1 基本构成图2 基本概念对于使用某个提供的服务的外界用户(如网站或数据库程序)来说,Linux 虚拟服务器(LVS)群集似乎是一个服务器。
事实上,该用户使用的是一对冗余 LVS 路由器之后的两个或多个服务器的群集。
LVS 群集至少包括两层。
第一层由一对配置相似的 Linux 机器或群集成员(cluster members)组成。
这些机器之一充当 LVS 路由器(LVS router),它用来把来自互联网的请求转到群集。
第二层包含一个叫做真实服务器(real servers)的机器群集。
3 技术特征高可用性群集(High-availability clustering)使用多个机器来为某个服务或某组服务提交额外的可靠性。
负载均衡群集(Load-balance clustering)使用特殊的选路技术来给一组服务器分配任务。
4 LVS调度算式循环调度把每项请求按顺序在真正服务器中循环分派。
加权循环调度每项请求按顺序在真正服务器中循环分派,但是给能力较大的服务器分派较多的作业。
加权最少连接法(默认)能力相比带有较少活跃连接的服务器分派较多的请求。
基于地区的最少连接调度目标 IP 相比带有较少活跃连接的服务器分派较多的请求。
带有复制调度的基于地区的最少连接调度目标 IP 相比带有较少活跃连接的服务器分派较多的请求。
目标散列调度通过在静态散列表中查看目标 IP 来给真正服务器分派请求。
源散列调度通过在静态散列表中查看源 IP 来给真正服务器分派请求。
5 LVS的选路方法使用网络地址转换(Network Address Translation)或 NAT 选路(NAT routing)来进行 LVS 集群。
6 LVS工作视图7 LVS 群集的部件pulse这是启动和 LVS 路由器相关的所有其它守护进程的控制进程。
lvslvs 守护进程被 pulse 调用后就会在活跃 LVS 路由器上运行。
ipvsadm该服务共享内核中的 IPVS 路由表。
nannynanny 监视运行在活跃 LVS 路由器上的守护进程。
二 配置LVS1 Piranha 配置工具设置口令piranha-passwd2 启动 Piranha 配置工具服务service piranha-gui start3 限制对 Piranha 配置工具的使用/etc/sysconfig/ha/web/secure/.htaccessOrder deny,allowDeny from allAllow from 127.0.0.14启用分组转发/etc/sysctl.conf 中的 net.ipv4.ip_forward = 0 这一行改为:net.ipv4.ip_forward = 15 分配防火墙标记iptables -t mangle -A PREROUTING -p tcp -d n.n.n.n/32 --dport 80 -j MARK --set-mark 80三 Piranha 配置工具1 登陆 打开 http://localhost:36362 GLOBAL SETTINGSPrimary server public IP主 LVS 节点的可公开选路的真正IP地址Primary server private IP主 LVS 节点上的另一个网络接口的真正 IP 地址NAT Router IP浮动 IP 地址NAT Router netmask子网掩码NAT Router device浮动 IP 地址的网络接口的设备名称3 REDUNDANCY 备份 LVS 路由器节点Redundant server public IP备份 LVS 路由器节点的公共真正 IP 地址。
Redundant server private IP备份节点的专用真正 IP 地址。
Heartbeat Interval (seconds)设置为心跳之间的时间Assume dead after (seconds)备份 LVS 路由器节点失效转移的时间。
Heartbeat runs on port主 LVS 节点的心跳通信端口4 VIRTUAL SERVERSName虚拟服务器名称。
Application port监听端口号ProtocolUDP 或 TCPVirtual IP Address虚拟服务器的浮动 IP 地址。
Virtual IP Network Mask虚拟服务器子网掩码。
Firewall Mark防火墙标记Device浮动 IP 地址绑定的网络设备Re-entry Time失效重新加载真正服务器的时间Service Timeout失效剔除真正服务器的时间Quiesce server防止了新服务器在进入群集的大量连接Load monitoring tool监视各个真正服务器的载量Scheduling调度算式Persistence连接超时前所允许经过的不活跃期间的秒数Persistence Network Mask限制某个特定子网的持续性的子网掩码。
5 REAL SERVERName真正服务器Address真正服务器的 IPWeight主机权值6同步配置文件scp /etc/sysconfig/ha/lvs.cf n.n.n.n:/etc/sysconfig/ha/lvs.cfscp /etc/sysconfig/iptables n.n.n.n:/etc/sysconfig/四 LVS部署1 路由转发vi /etc/sysctl.confnet.ipv4.ip_forward = 1sysctl –p2 iptables标记iptables -t mangle -A PREROUTING -p tcp -d 211.144.137.131/32 --dport 80 -j MARK --set-mark 81 iptables -t mangle -A PREROUTING -p tcp -d 211.144.137.232/32 --dport 80 -j MARK --set-mark 82 iptables -t mangle -A PREROUTING -p tcp -d 211.144.137.233/32 --dport 80 -j MARK --set-mark 83 iptables -t mangle -A PREROUTING -p tcp -d 211.144.137.234/32 --dport 80 -j MARK --set-mark 84 iptables -t mangle -A PREROUTING -p tcp -d 211.144.137.235/32 --dport 80 -j MARK --set-mark 853 配置lvs.cfserial_no = 40primary = 211.144.137.130primary_private = 211.144.137.130service = lvsbackup_active = 0backup = 0.0.0.0heartbeat = 1heartbeat_port = 539keepalive = 6deadtime = 18network = natnat_router = 192.168.70.254 eth1 debug_level = NONEvirtual [server_coolh] {active = 1address = 211.144.137.131 eth0:1 vip_nmask = 255.255.255.224fwmark = 81port = 80send = "GET / HTTP/1.0\r\n\r\n" expect = "HTTP"use_regex = 0load_monitor = nonescheduler = wlcprotocol = tcptimeout = 12reentry = 30quiesce_server = 0server [node01] {address = 192.168.70.11active = 1weight = 1}server [node02] {address = 192.168.70.21active = 1weight = 1}server [node03] {address = 192.168.70.31active = 1weight = 1}server [node04] {address = 192.168.70.41active = 1weight = 1}server [node05] {address = 192.168.70.51active = 1weight = 1}server [node06] {address = 192.168.70.61active = 1weight = 1}}virtual [server_ccg] {active = 1address = 211.144.137.132 eth0:2 vip_nmask = 255.255.255.224fwmark = 82port = 80send = "GET / HTTP/1.0\r\n\r\n" expect = "HTTP"use_regex = 0load_monitor = nonescheduler = wlcprotocol = tcptimeout = 12reentry = 30quiesce_server = 0server [node01] {address = 192.168.70.12active = 1weight = 1}server [node02] {address = 192.168.70.22active = 1weight = 1}server [node03] {address = 192.168.70.32active = 1weight = 1}server [node04] {address = 192.168.70.42active = 1weight = 1}server [node05] {address = 192.168.70.52active = 1weight = 1}server [node06] {address = 192.168.70.62active = 1weight = 1}}virtual [server_bbs] {active = 1address = 211.144.137.133 eth0:3 vip_nmask = 255.255.255.224fwmark = 83port = 80send = "GET / HTTP/1.0\r\n\r\n" expect = "HTTP"use_regex = 0load_monitor = nonescheduler = wlcprotocol = tcptimeout = 12reentry = 30quiesce_server = 0server [node01] {address = 192.168.70.13active = 1weight = 1}server [node02] {address = 192.168.70.23active = 1weight = 1}server [node03] {address = 192.168.70.33active = 1weight = 1}server [node04] {address = 192.168.70.43active = 1weight = 1}server [node05] {address = 192.168.70.53active = 1weight = 1}server [node06] {address = 192.168.70.63active = 1weight = 1}}virtual [server_download] {active = 1address = 211.144.137.134 eth0:4 vip_nmask = 255.255.255.224fwmark = 84port = 80send = "GET / HTTP/1.0\r\n\r\n" expect = "HTTP"use_regex = 0load_monitor = nonescheduler = wlcprotocol = tcptimeout = 12reentry = 30quiesce_server = 0server [node01] {address = 192.168.70.14active = 1weight = 1}server [node02] {address = 192.168.70.24active = 1weight = 1}server [node03] {address = 192.168.70.34active = 1weight = 1}server [node04] {address = 192.168.70.44active = 1weight = 1}server [node05] {address = 192.168.70.54active = 1weight = 1}server [node06] {address = 192.168.70.64active = 1weight = 1}}virtual [server_wlife] {active = 1address = 211.144.137.135 eth0:5 vip_nmask = 255.255.255.224fwmark = 85port = 80send = "GET / HTTP/1.0\r\n\r\n" expect = "HTTP"use_regex = 0load_monitor = nonescheduler = wlcprotocol = tcptimeout = 12reentry = 30quiesce_server = 0server [node01] {address = 192.168.70.15active = 1weight = 1}server [node02] {address = 192.168.70.25active = 1weight = 1}server [node03] {address = 192.168.70.35active = 1weight = 1}server [node04] {address = 192.168.70.45 active = 1weight = 1}server [node05] {address = 192.168.70.55 active = 1weight = 1}server [node06] {address = 192.168.70.65 active = 1weight = 1}}4 启动lvs服务lvs5 状态查看ipvsadm第三部分 GFS GFS Global File System数据存储一 GFS概述支持多方式存储,如下图GFS with a SANGFS and GNBD with a SANGFS and GNBD with Direct-Attached Storage二 GFS系统环境要素1系统需求Red Hat Enterprise Linux AS, ES, or WS, Version 3, Update 2 or 或更高 ia64, x86-64, x86 SMP supportedRAM 最低256M2 网络需求所有GFS节点必须接入TCP/IP网络,以便于支持GFS集群和lockgulm系统3 设备支持HBA (Host Bus Adapter)Fibre Channel switchFC RAID array or JBODSize 最大2 TB三 GFS安装1 软件需求perl-Net-Telnet Module时间同步软件Stunnel2 GFS组件GFSGFS-modules-smp3 模块加载depmod –a #在RPM安装后运行modprobe pool #盘区池模块modprobe lock_gulm # lock_gulm系统modprobe gfs #GFS模块lsmod #检查加载四 POOL的操作1 创建pool_tool -c [ConfigFile]poolname nameminor numbersubpools numbersubpool id stripe devices [type]pooldevice subpool id device2 激活pool_assemble –a [poolname] # Activatingpool_assemble –r [poolname] # Deactivating3 显示pool_tool -p [pool]4 更新配置pool_tool -g [NewConfigFile]5 删除pool_tool -e [PoolName]6 改名pool_tool -r [PoolName] [NewPoolName]7 镜像pool_tool -m [Number] [PoolName]8 显示信息pool_info -v [PoolName]9设备检索pool_info -s [PoolName]10 多路pool_mp -m {none | failover | n} [PoolName]五 GFS集群系统配置文件1 s配置文件cluster {name = "集群名"lock_gulm {servers = ["节点名",..., "节点名"]heartbeat_rate = 心跳时间 <-- 选项allowed_misses = 允许失效数 <-- 选项}}2 s配置文件 fence_devices, fence_gnbdfence_devices{DeviceName {agent = "fence_gnbd"server = "ServerName"..server = "ServerName"}DeviceName {..}}3 s配置文件GNBD Fencing Device Named gnbdfence_devices {gnbd {agent = "fence_gnbd"server = "nodea"server = "nodeb"}}六 集群系统配置1 创建ccs_tool create [Directory] [CCADevice]2 运行ccsd -d [CCADevice]3 导出ccs_tool extract [CCADevice] [Directory]4 显示ccs_tool list [CCADevice]5 比较ccs_tool diff [CCADevice] [Directory]七 GFS集群锁定系统1 模式LOCK_GULM RLM and SLM 集群模式LOCK_NOLOCK 单用户模式2 启动lock_gulmd #没有参数3 停止gulm_tool shutdown [IPAddress]八 GFS操作1 格式化gfs_mkfs -p [LockProtoName] -t [LockTableName] -j [Number] [BlockDevice]2 挂载mount -t gfs [BlockDevice] [MountPoint]3 卸载umount [MountPoint]4 配额gfs_quota limit -u [User] -l [Size] -f [MountPoint]gfs_quota limit -u [Group] -l [Size] -f [MountPoint]gfs_quota warn -u [User] -l [Size] -f [MountPoint]gfs_quota warn -g [Group] -l [Size] -f [MountPoint]5 显示gfs_quota get -u [User] -f [MountPoint]gfs_quota get -g [Group] -f [MountPoint]gfs_quota list -f [MountPoint]6 同步gfs_quota sync -f [MountPoint]gfs_tool settune [MountPoint] quota_quantum [Seconds]7 配额开关gfs_tool settune [MountPoin]t quota_enforce {0|1}8 更新gfs_grow [Options] {MountPoint | Device} [MountPoint | Device]9 增加加载点数量gfs_jadd -j [Number] [MountPoint]10 I/O标记gfs_tool setflag inherit_directio [Directory]gfs_tool clearflag inherit_jdata [Directory]gfs_tool setflag jdata [File]gfs_tool clearflag jdata [File]11 更新选项ctime — 最后改变时间状态mtime — 最后调整文件或目录时间atime — 最后访问文件或目录时间notime — 没有时间选项12 设置noatimemount -t gfs [BlockDevice] [MountPoin]t -o noatime13 显示状态gfs_tool gettune [MountPoint]14 设置atimegfs_tool settune [MountPoint] atime_quantum [Seconds]15 动态挂起gfs_tool freeze [MountPoint]gfs_tool unfreeze [MountPoint]16 容量大小gfs_tool counters [MountPoint]gfs_tool df [MountPoint]gfs_tool stat [File]18 修复gfs_fsck -y [BlockDevice]19 连接ln -s [Target] [LinkName]ln -s [Variable] [LinkName]九 Fencing 系统1 工作方式Removal — 从存储器中移除GFS节点Recovery — GFS节点安全恢复与存储器的连接2 模块列表Fending Method Fencing AgentAPC Network Power Switch fence_apcWTI Network Power Switch fence_wtiBrocade FC Switch fence_brocadeMcData FC Switch fence_mcdataVixel FC Switch fence_vixelHP RILOE fence_ribGNBD fence_gnbdxCAT fence_xcatFending Method Fencing AgentManual fence_manual十 GNBD (Global Network Block Device)1 模块gnbd.o — 在终端上GNBD设备工具,被用作在节点gnbd_serv.o — 在服务端上GNBD设备工具,被用作存储设备2 GNBD服务端gnbd_export -d [PathName] -e [GnbdName]3 GNBD 终端gnbd_import -i [Server]十一 init.d控制1 配置文件/etc/sysconfig/gfs2 启动service pool startservice ccsd startservice lock_gulmd start #节点同步启动service gfs start #设置/etc/fstab3 停止service gfs stopservice lock_gulmd stopservice ccsd stopservice pool stop十二 GFS部署1 系统版本RHEL AS3 Updates 42 内核版本kernel-smp-2.4.21-27.0.4.EL.i6863 GFS版本GFS-6.0.2-26.i686GFS-modules-smp-6.0.2-26.i6864 组件perl-Net-Telnet-3.03-1.1.el3.dag.noarch5 GFS集群方式LOCK_GULM, RLM Embedded, and GNBD6 拓扑结构图(GFS部分)7 服务器列表Host Name IP Address Lock Server Nodenode01 192.168.70.1 TRUEnode02 192.168.70.2 TRUEnode03 192.168.70.3 TRUEnode04 192.168.70.4 TRUEnode05 192.168.70.5 TRUEnode06 192.168.70.6 TRUEHost Name IP Address Gnbd_fencedata01 192.168.70.100 FALSEdata02 192.168.70.200 TRUE8 加载模块gfs.ognbd.olock_harness.olock_gulm.opool.o9 GNBD server (data02)gnbd_export -e cca -d /dev/sdb1 -cgnbd_export -e gfs -d /dev/sdb2 -c10 每个节点gnbd_import -i data0211 POOL(以下存为pool_gfs.cf)poolname pool_gfssubpools 1subpool 0 0 1pooldevice 0 0 /dev/gnbd/gfs12 CCS data(以下存为alpha_cca.cf)poolname ccasubpools 1subpool 0 0 1pooldevice 0 0 /dev/gnbd/cca13 创建pool_tool -c alpha_cca.cf pool_gfs.cf14 激活 (在每个节点)pool_assemble –a15 创建CCS文件(分别存在/root/alpha目录下的s s s)cluster {name = "alpha"lock_gulm {servers = ["node01", "node02", "node03", "node04", "node05", "node06"] }}————————————s————————————fence_devices {gnbd {agent = "fence_gnbd"server = "data02"}}————————————s————————————nodes {node01 {ip_interfaces {eth0 = "192.168.70.1"}fence {server {gnbd {ipaddr = "192.168.70.200" }}}}node02 {ip_interfaces {eth0 = "192.168.70.2"}fence {server {gnbd {ipaddr = "192.168.70.200" }}}}node03 {ip_interfaces {eth0 = "192.168.70.3"}fence {server {gnbd {ipaddr = "192.168.70.200" }}}}node04 {ip_interfaces {eth0 = "192.168.70.4"}fence {server {gnbd {ipaddr = "192.168.70.200" }}}}node05 {ip_interfaces {eth0 = "192.168.70.5"}fence {server {gnbd {ipaddr = "192.168.70.200"}}}}node06 {ip_interfaces {eth0 = "192.168.70.6"}fence {server {gnbd {ipaddr = "192.168.70.200"}}}}}———————————s————————————— 16 创建 CCS data 盘区(node01 only)ccs_tool create /root/alpha /dev/pool/alpha_cca17 启动ccsd (每个节点)ccsd -d /dev/pool/alpha_cca18 启动lock_gulmd(每个节点,至少2个节点同时启动)lock_gulmd19 格式化(node01 only)gfs_mkfs -p lock_gulm -t alpha:gfs -j 6 /dev/pool/pool_gfs 20 挂载(每个节点)mount -t gfs /dev/pool/pool_gfs /gfs21 init.d 控制参见十一中内容第四部分 MySQL CLUSTER数据库集群MySQL CLUSTER邱波2005-6-13一 MySQL CLUSTER概述1 MySQL CLUSTER结构图2 管理节点(MGM)任务 在MySQL CLUSTER中管理和配置其它节点:启动关闭节点、执行备份等状态 MGM管理和配置其它节点的的任务,必须在所有节点之前启动启动 ndb_mgmd3 数据节点(DB)任务 存储MySQL CLUSTER的数据,状态 在mysqld启动之前启动该服务启动 ndbd4 SQL节点(API)任务 SQL连接应用,通过NDBCLUSTER存储引擎连接到数据节点状态 最后启动启动 mysqld二 基本配置1 数据节点和SQL节点vi /etc/f[MYSQLD]ndbclusterndb-connectstring=n.n.n.n # 管理节点 IP [MYSQL_CLUSTER]ndb-connectstring=n.n.n.n # 管理节点 IP2 管理节点vi /etc/config.ini[NDBD DEFAULT]NoOfReplicas=2DataMemory=80MIndexMemory=52M[TCP DEFAULT]portnumber=PORT #端口[NDB_MGMD]hostname=MGM #管理节点[NDBD]hostname=DBA #存储节点[NDBD]hostname=DBB #存储节点[MYSQLD]hostname=SQL #SQL节点三 定义MySQL CLUSTER1 管理节点[NDB_MGMD]Id1到63之间[NDB_MGMD]ExecuteOnComputer主机名[NDB_MGMD]PortNumber监听端口[NDB_MGMD]LogDestination日志类型: CONSOLE, SYSLOG, and FILE:[NDB_MGMD]ArbitrationRank仲裁节点[NDB_MGMD]ArbitrationDelay0 一般没必要改变[NDB_MGMD]DataDir日志目录2 数据节点[NBDB]Id整数 代替主机名[NDBD]ExecuteOnComputer主机名[NDBD]HostName自定义主机名[NDBD]ServerPort监听端口[NDBD]NoOfReplicas拷贝数默认2 最大4[NDBD]DataDir日志目录[NDBD]FileSystemPath数据和UNDOLOG目录[NDBD]BackupDataDir备份目录[NDBD]DataMemory数据库容量默认80MB 最小1MB 最大等于RAM[NDBD]IndexMemory索引容量默认18MB 最小1MBThe default value for IndexMemory is 18MB. The minimum is 1MB. [NDBD]MaxNoOfConcurrentTransactions并发事物数默认 4096[NDBD]MaxNoOfConcurrentOperations最大并发操作数默认 32768[NDBD]MaxNoOfLocalOperations最大本地操作数没有具体限定[NDBD]MaxNoOfConcurrentIndexOperations最大索引并发操作数默认 8192[NDBD]MaxNoOfFiredTriggers最大触发数默认4000[NDBD]TransactionBufferMemory事物缓存存储器默认1MB[NDBD]MaxNoOfConcurrentScans最大并发检索数默认256最大500[NDBD]MaxNoOfLocalScans最大本地检索数[NDBD]BatchSizePerLocalScan本地检索批量默认64[NDBD]LongMessageBuffer消息缓存器默认1MB[NDBD]NoOfFragmentLogFiles REDO log 片段数默认8[NDBD]MaxNoOfSavedMessages最大被保存消息数默认25[NDBD]MaxNoOfAttributes最大属性数默认1000[NDBD]MaxNoOfTables最大所有表数默认128 最小8 最大1600 [NDBD]MaxNoOfOrderedIndexes最大请求索引数默认128[NDBD]MaxNoOfUniqueHashIndexes 最大独立索引数默认64[NDBD]MaxNoOfTriggers最大触发数默认 768[NDBD]MaxNoOfIndexes最大索引数默认128[NDBD]LockPagesInMainMemory锁定内存中进程默认 0[NDBD]StopOnError错误停止默认 1[NDBD]Diskless无盘默认 0[NDBD]RestartOnErrorInsert查入错误重起默认 0[NDBD]TimeBetweenWatchDogCheck 间隔检测时间[NDBD]StartPartialTimeout启动间隔时间默认30000毫秒[NDBD]StartPartitionedTimeout启动间隔后时间默认 60000毫秒[NDBD]StartFailureTimeout启动失败时间默认 60000毫秒[NDBD]HeartbeatIntervalDbDb心跳间隔 DB节点默认1500毫秒[NDBD]HeartbeatIntervalDbApi心跳间隔 SQL节点默认1500毫秒[NDBD]TimeBetweenLocalCheckpoints本地检测点间隔时间默认20 最大 31[NDBD]TimeBetweenGlobalCheckpoints全局检测点间隔时间默认 2000毫秒[NDBD]TimeBetweenInactiveTransactionAbortCheck 检测不活跃事物退出间隔默认1000毫秒[NDBD]TransactionInactiveTimeout不活跃事物超时时间默认 0[NDBD]TransactionDeadlockDetectionTimeout事物锁死侦测超时时间默认 1200毫秒[NDBD]NoOfDiskPagesToDiskAfterRestartTUP默认 40[NDBD]NoOfDiskPagesToDiskAfterRestartACC默认 20[NDBD]NoOfDiskPagesToDiskDuringRestartTUP默认 40[NDBD]NoOfDiskPagesToDiskDuringRestartACC默认 20[NDBD]ArbitrationTimeout默认 1000毫秒[NDBD]UndoIndexBuffer默认 2M 最小1M[NDBD]UndoDataBuffer[NDBD]RedoBuffer默认 8M 最小1M[NDBD]LogLevelStartup默认 1[NDBD]LogLevelShutdown默认 0[NDBD]LogLevelStatistic默认 0[NDBD]LogLevelCheckpoint 默认 0[NDBD]LogLevelNodeRestart 默认 0[NDBD]LogLevelConnection 默认 0[NDBD]LogLevelError默认 0[NDBD]LogLevelInfo默认0[NDBD]BackupDataBufferSize 默认 2M[NDBD]BackupLogBufferSize 默认2M[NDBD]BackupMemory默认4M[NDBD]BackupWriteSize默认32K3 SQL节点[MYSQLD]Id1 到 63[MYSQLD]ExecuteOnComputer hostname[MYSQLD]ArbitrationRank默认0[MYSQLD]ArbitrationDelay 默认 0[MYSQLD]BatchByteSize默认 32K[MYSQLD]BatchSize默认64最大992[MYSQLD]MaxScanBatchSize 默认256K最大16M四 MySQL Cluster部署1配置文件MGMf[ndb_mgm]connect-string=master[ndb_mgmd]config-file=/etc/config.iniconfig.ini[ndbd default]NoOfReplicas= 2MaxNoOfConcurrentOperations= 500000MaxNoOfLocalOperations= 100000MaxNoOfTables= 1600MaxNoOfAttributes= 5000MaxNoOfConcurrentIndexOperations= 100000 MaxNoOfFiredTriggers= 100000DataMemory= 1024MIndexMemory= 512MTimeBetweenWatchDogCheck= 30000DataDir= /var/lib/mysql-clusterMaxNoOfOrderedIndexes= 1024[ndb_mgmd default]DataDir= /var/lib/mysql-cluster[ndb_mgmd]Id=1HostName= master[ndbd]Id= 2HostName= data01[ndbd]Id= 3HostName= data02[mysqld]Id= 4[mysqld]Id= 5[mysqld]Id= 6[mysqld]Id= 7[mysqld]Id= 8[mysqld]Id= 9[tcp default]PortNumber= 63132NDB[mysqld]ndbclusterndb-connectstring=master[mysql_cluster]ndb-connectstring=masterSQL[mysqld]ndbclusterndb-connectstring = masterdefault_table_type = NDBCLUSTER[mysql_cluster]ndb-connectstring = master2 启动MGMmdb_mgmdNDBndbdSQLservice mysql start3 状态ndb_mgm> showConnected to Management Server at: master:1186Cluster Configuration---------------------[ndbd(NDB)] 2 node(s)id=2 @192.168.70.100 (Version: 4.1.12, Nodegroup: 0)id=3 @192.168.70.200 (Version: 4.1.12, Nodegroup: 0, Master)[ndb_mgmd(MGM)] 1 node(s)id=1 @192.168.70.254 (Version: 4.1.12)[mysqld(API)] 6 node(s)id=4 @192.168.70.1 (Version: 4.1.12) id=5 @192.168.70.3 (Version: 4.1.12) id=6 @192.168.70.5 (Version: 4.1.12) id=7 @192.168.70.2 (Version: 4.1.12) id=8 @192.168.70.6 (Version: 4.1.12) id=9 @192.168.70.4 (Version: 4.1.12) 4 关闭ndb_mgm --shutdow第五部分 集群优化和其它组件一 网络二 APACHE三 PHP四 MYSQL五 NTP六 LINUX七 备份八 安全九 aws apache日志分析。