Hadoop中HDFS源代码分析
详解Hadoop核心架构HDFS

详解Hadoop核心架构HDFS+MapReduce+Hbase+Hive HDFS的体系架构整个Hadoop的体系结构主要是通过HDFS来实现对分布式存储的底层支持,并通过MR来实现对分布式并行任务处理的程序支持。
HDFS采用主从(Master/Slave)结构模型,一个HDFS集群是由一个NameNode和若干个DataNode组成的(在最新的Hadoop2.2版本已经实现多个NameNode的配置-这也是一些大公司通过修改hadoop源代码实现的功能,在最新的版本中就已经实现了)。
NameNode作为主服务器,管理文件系统命名空间和客户端对文件的访问操作。
DataNode 管理存储的数据。
HDFS支持文件形式的数据。
从内部来看,文件被分成若干个数据块,这若干个数据块存放在一组DataNode上。
NameNode执行文件系统的命名空间,如打开、关闭、重命名文件或目录等,也负责数据块到具体DataNode的映射。
DataNode负责处理文件系统客户端的文件读写,并在NameNode的统一调度下进行数据库的创建、删除和复制工作。
NameNode是所有HDFS 元数据的管理者,用户数据永远不会经过NameNode。
图中涉及三个角色:NameNode、DataNode、Client。
NameNode是管理者,DataNode是文件存储者、Client是需要获取分布式文件系统的应用程序。
文件写入:1)Client向NameNode发起文件写入的请求。
2)NameNode根据文件大小和文件块配置情况,返回给Client它管理的DataNode 的信息。
3)Client将文件划分为多个block,根据DataNode的地址,按顺序将block写入DataNode块中。
文件读取:1)Client向NameNode发起读取文件的请求。
2)NameNode返回文件存储的DataNode信息。
3)Client读取文件信息。
hadoop命令及使用方法

hadoop命令及使用方法Hadoop是一个分布式计算框架,用于存储和处理大规模数据集。
下面是一些常用的Hadoop命令及其使用方法:1. hdfs命令:- hdfs dfs -ls <路径>:列出指定路径下的文件和目录。
- hdfs dfs -mkdir <路径>:创建一个新的目录。
- hdfs dfs -copyFromLocal <本地路径> <HDFS路径>:将本地文件复制到HDFS 上。
- hdfs dfs -copyToLocal <HDFS路径> <本地路径>:将HDFS上的文件复制到本地。
- hdfs dfs -cat <文件路径>:显示HDFS上的文件内容。
2. mapred命令:- mapred job -list:列出当前正在运行的MapReduce作业。
- mapred job -kill <job_id>:终止指定的MapReduce作业。
3. yarn命令:- yarn application -list:列出当前正在运行的应用程序。
- yarn application -kill <application_id>:终止指定的应用程序。
4. hadoop fs命令(与hdfs dfs命令功能相似):- hadoop fs -ls <路径>:列出指定路径下的文件和目录。
- hadoop fs -cat <文件路径>:显示HDFS上的文件内容。
- hadoop fs -mkdir <路径>:创建一个新的目录。
- hadoop fs -put <本地文件路径> <HDFS路径>:将本地文件复制到HDFS上。
- hadoop fs -get <HDFS路径> <本地文件路径>:将HDFS上的文件复制到本地。
hadoop分布式实验总结

hadoop分布式实验总结Hadoop分布式实验总结一、实验目标本次实验的目标是深入理解Hadoop分布式文件系统(HDFS)和MapReduce计算模型,通过实际操作和案例分析,掌握Hadoop的基本原理和应用。
二、实验内容在本次实验中,我们主要完成了以下几个部分的内容:1. HDFS的基本操作:包括在HDFS中创建文件夹、上传和下载文件等。
2. MapReduce编程:编写Map和Reduce函数,实现对数据的处理和分析。
3. Hadoop集群搭建:配置Hadoop集群,了解节点间的通信和数据传输机制。
4. 性能优化:通过调整参数和优化配置,提高Hadoop集群的性能。
三、实验过程1. HDFS操作:首先,我们在本地机器上安装了Hadoop,并启动了HDFS。
然后,我们通过Hadoop命令行工具对HDFS进行了基本的操作,包括创建文件夹、上传和下载文件等。
在操作过程中,我们遇到了权限问题,通过修改配置文件解决了问题。
2. MapReduce编程:我们选择了一个经典的问题——单词计数作为案例,编写了Map和Reduce函数。
在编写过程中,我们了解了MapReduce的基本原理和编程模型,以及如何处理数据的分片和shuffle过程。
3. Hadoop集群搭建:我们在实验室的局域网内搭建了一个Hadoop集群,配置了各个节点之间的通信和数据传输。
在配置过程中,我们注意到了防火墙和网络通信的问题,通过调整防火墙规则和配置网络参数,解决了问题。
4. 性能优化:我们对Hadoop集群进行了性能优化,通过调整参数和优化配置,提高了集群的性能。
我们了解到了一些常用的优化方法,如调整数据块大小、优化网络参数等。
四、实验总结通过本次实验,我们深入了解了Hadoop分布式文件系统和MapReduce计算模型的基本原理和应用。
在实验过程中,我们遇到了一些问题,但通过查阅资料和互相讨论,最终解决了问题。
通过本次实验,我们不仅掌握了Hadoop的基本操作和编程技能,还提高了解决实际问题的能力。
Hadoop分布式文件系统(HDFS)详解

Hadoop分布式⽂件系统(HDFS)详解HDFS简介:当数据集的⼤⼩超过⼀台独⽴物理计算机的存储能⼒时,就有必要对它进⾏分区 (partition)并存储到若⼲台单独的计算机上。
管理⽹络中跨多台计算机存储的⽂件系统成为分布式⽂件系统 (Distributed filesystem)。
该系统架构于⽹络之上,势必会引⼊⽹络编程的复杂性,因此分布式⽂件系统⽐普通磁盘⽂件系统更为复杂。
HDFS是基于流数据模式访问和处理超⼤⽂件的需求⽽开发的,它可以运⾏于廉价的商⽤服务器上。
总的来说,可以将 HDFS的主要特点概括为以下⼏点:(1 )处理超⼤⽂件这⾥的超⼤⽂件通常是指数百 MB、甚⾄数百TB ⼤⼩的⽂件。
⽬前在实际应⽤中, HDFS已经能⽤来存储管理PB(PeteBytes)级的数据了。
在 Yahoo!,Hadoop 集群也已经扩展到了 4000个节点。
(2 )流式地访问数据HDFS的设计建⽴在更多地响应“⼀次写⼊,多次读取”任务的基础之上。
这意味着⼀个数据集⼀旦由数据源⽣成,就会被复制分发到不同的存储节点中,然后响应各种各样的数据分析任务请求。
在多数情况下,分析任务都会涉及数据集中的⼤部分数据,也就是说,对HDFS 来说,请求读取整个数据集要⽐读取⼀条记录更加⾼效。
(3 )运⾏于廉价的商⽤机器集群上Hadoop设计对硬件需求⽐较低,只须运⾏在廉价的商⽤硬件集群上,⽽⽆须昂贵的⾼可⽤性机器上。
廉价的商⽤机也就意味着⼤型集群中出现节点故障情况的概率⾮常⾼。
这就要求在设计 HDFS时要充分考虑数据的可靠性、安全性及⾼可⽤性。
正是由于以上的种种考虑,我们会发现现在的 HDFS在处理⼀些特定问题时不但没有优势,⽽且有⼀定的局限性,主要表现在以下⼏个⽅⾯。
(1 )不适合低延迟数据访问如果要处理⼀些⽤户要求时间⽐较短的低延迟应⽤请求,则 HDFS不适合。
HDFS 是为了处理⼤型数据集分析任务的,主要是为达到⾼的数据吞吐量⽽设计的,这就可能要求以⾼延迟作为代价。
Java大数据处理使用Hadoop和Spark进行数据分析

Java大数据处理使用Hadoop和Spark进行数据分析随着信息技术的迅速发展,海量数据的产生已经成为了一种普遍现象。
在这背景下,大数据处理技术逐渐崭露头角,并发挥着越来越重要的作用。
作为大数据处理的两个重要工具,Hadoop和Spark已经成为了众多企业和研究机构的首选。
本文将对Java大数据处理使用Hadoop和Spark进行数据分析进行探讨,旨在帮助读者更好地理解和应用这两种技术。
一、Hadoop介绍及使用1. Hadoop概述Hadoop是一个开源的、基于Java的大数据处理框架。
它的核心思想是将大数据分布式处理,通过搭建集群实现数据的存储和并行计算。
Hadoop包含了HDFS(Hadoop分布式文件系统)和MapReduce(分布式计算模型)两个核心组件。
2. Hadoop的安装和配置在使用Hadoop进行数据分析之前,我们首先需要完成Hadoop 的安装和配置。
这包括下载Hadoop压缩包、解压缩、配置环境变量和核心配置文件等步骤。
通过正确配置,我们可以保证Hadoop的正常运行和数据处理的准确性。
3. Hadoop与Java的结合由于Hadoop是基于Java的,因此我们可以利用Java语言编写Hadoop程序。
Java提供了丰富的类库和API,使得我们可以方便地开发和调试Hadoop应用。
在Java程序中,我们可以通过Hadoop的API实现数据的输入、输出、计算和结果的保存等功能。
二、Spark介绍及使用1. Spark概述Spark是一个快速、通用、可扩展的大数据处理引擎。
与Hadoop的MapReduce相比,Spark的优势在于其内存计算和任务调度的高效性。
Spark提供了丰富的编程接口,包括Java、Scala和Python等,使得开发者可以根据自己的需求选择最适合的语言进行编码。
2. Spark的安装和配置与Hadoop类似,我们在使用Spark之前也需要进行安装和配置工作。
hdfs命令应用的实验原理

HDFS命令应用的实验原理1. 实验目的本实验旨在探索和理解Hadoop分布式文件系统(HDFS)的常用命令应用原理,通过实验可以学习和掌握HDFS命令的使用方法以及其在大数据处理中的重要性。
2. 实验环境在进行HDFS命令应用实验前,需要先搭建Hadoop集群环境。
在本实验中,我们使用单节点的Hadoop伪分布式模式进行实验。
具体的环境要求如下:•操作系统:Linux(推荐使用Ubuntu或CentOS)•Java版本:Java 8或以上•Hadoop版本:Hadoop 2.x或以上3. HDFS命令简介HDFS是Hadoop框架的核心组件之一,它是一个分布式文件系统,用于存储和处理大规模数据。
HDFS命令是与HDFS交互的工具,可以通过命令行或脚本进行操作。
以下是HDFS常用命令示例:•hadoop fs:Hadoop分布式文件系统命令的入口。
通过该命令可以执行各种HDFS相关操作。
•hadoop fs -ls:列出HDFS指定目录下的文件和子目录。
•hadoop fs -mkdir:在HDFS中创建一个新目录。
•hadoop fs -put:将本地文件或目录上传到HDFS指定路径。
•hadoop fs -get:从HDFS下载文件或目录到本地文件系统。
•hadoop fs -rm:删除HDFS中的文件或目录。
•hadoop fs -mv:移动HDFS中的文件或目录。
•hadoop fs -cat:显示HDFS文件的内容。
•hadoop fs -tail:显示HDFS文件的尾部内容。
•hadoop fs -du:计算HDFS文件或目录的大小。
4. HDFS命令应用实验步骤步骤一:启动Hadoop集群在实验前,首先需要启动Hadoop集群。
执行以下命令启动HDFS和YARN服务:start-dfs.shstart-yarn.sh步骤二:创建HDFS目录使用hadoop fs命令创建HDFS目录。
Hadoop生态中的大数据处理与分析

Hadoop生态中的大数据处理与分析第一章介绍Hadoop生态Hadoop是由Apache基金会开发的一个开源Java框架,用于处理大数据。
Hadoop生态系统是由许多不同的组件组成的,包括Hadoop文件系统(HDFS)、MapReduce、Hive、Pig、HBase等。
每个组件都有不同的目的和特点。
Hadoop生态系统为大数据处理提供了一整套完备的工具。
在Hadoop生态系统中,MapReduce是最常用的一项工具,它提供了分布式的数据处理功能。
在大数据处理中,MapReduce通常用于将大量数据分解为不同的小块,并在不同的节点间并行运算和处理。
第二章大数据的处理与分析大数据处理和分析是指处理大量数据并提取有用信息的过程。
大数据处理和分析可以帮助企业了解其业务、排除风险和改进业务决策。
但是,对于大数据的处理和分析来说,非结构化数据和半结构化数据是一个巨大的挑战。
这时候Hadoop生态系统可以帮助企业解决这个问题。
Hadoop生态系统的组件,如Hive、Pig、Spark和Storm等可以处理非常大的数据集,并提供高效的并行计算。
这些工具可以从海量的数据中提取有用的信息。
Hive和Pig可以将非结构化数据转换成结构化数据,并通过SQL查询进行分析。
Spark和Storm可以通过Stream Processing技术进行数据分析和处理。
Hadoop生态系统可以帮助企业在分析和处理大数据时提高效率并节省成本。
第三章 Hadoop生态系统的组件1. Hadoop文件系统(HDFS)HDFS是Hadoop生态系统中的核心组件,用于存储和管理大量数据。
在HDFS中,数据被分解为多个块,并分布在不同的服务器上,使得数据存储和处理更加高效。
HDFS提供了高可靠性、高可用性和高扩展性。
HDFS可以容错处理所有的节点故障,同时支持横向扩展。
2. MapReduceMapReduce是Hadoop生态系统中最常用的一项组件,用于分布式计算。
hadoop大数据技术基础 python版

Hadoop大数据技术基础 python版随着互联网技术的不断发展和数据量的爆炸式增长,大数据技术成为了当前互联网行业的热门话题之一。
Hadoop作为一种开源的大数据处理评台,其在大数据领域的应用日益广泛。
而Python作为一种简洁、易读、易学的编程语言,也在大数据分析与处理中扮演着不可或缺的角色。
本文将介绍Hadoop大数据技术的基础知识,并结合Python编程语言,分析其在大数据处理中的应用。
一、Hadoop大数据技术基础1. Hadoop简介Hadoop是一种用于存储和处理大规模数据的开源框架,它主要包括Hadoop分布式文件系统(HDFS)和MapReduce计算框架。
Hadoop分布式文件系统用于存储大规模数据,而MapReduce计算框架则用于分布式数据处理。
2. Hadoop生态系统除了HDFS和MapReduce之外,Hadoop生态系统还包括了许多其他组件,例如HBase、Hive、Pig、ZooKeeper等。
这些组件形成了一个完整的大数据处理评台,能够满足各种不同的大数据处理需求。
3. Hadoop集群Hadoop通过在多台服务器上构建集群来实现数据的存储和处理。
集群中的各个计算节点共同参与数据的存储和计算,从而实现了大规模数据的分布式处理。
二、Python在Hadoop大数据处理中的应用1. Hadoop StreamingHadoop Streaming是Hadoop提供的一个用于在MapReduce中使用任意编程语言的工具。
通过Hadoop Streaming,用户可以借助Python编写Map和Reduce的程序,从而实现对大规模数据的处理和分析。
2. Hadoop连接Python除了Hadoop Streaming外,Python还可以通过Hadoop提供的第三方库和接口来连接Hadoop集群,实现对Hadoop集群中数据的读取、存储和计算。
这为Python程序员在大数据处理领域提供了更多的可能性。
Hadoop源代码分析之HDFS篇

Hadoop源代码分析之HDFS篇前言:网上已经有了一些技术博客来分析Hadoop,这里的分析基于以下的技术博客,并感谢,本文的源代码分析结合了技术博客和hadoop0.19.0版本的源代码,并融入了自己的理解。
汇总如下,/侧重HDFS的分析,是我学习的重要参考资料和起点。
/侧重MapReduce的分析,暂时还没有深入学习。
/javenstudio/有部分Hadoop,也有Lucene的分析。
暂时还没有深入学习。
/core/docs/current/api/hadoop的官方API说明本文的分析以/为基础,但侧重点不同。
本文分析的目标如下:1,删繁就简,考虑一个最简单、能跑起来的HDFS是如何实现的,对于一些系统升级等细节不涉及。
2,理清系统的主要模块之间的交互关系,便于从整体上把握系统。
对模块采用内外两种方式分析。
先搞明白模块的外部接口,干什么用,怎么用。
再考虑模块的内部是如何怎么实现的。
技术博客中对模块内部是如何实现的解释比较多,本文更多的从如何使用模块的角度讲3,从改进和研究的角度去看系统,重点关注有研究价值部分的代码(例如,块的放置策略,MapReduce 的调度策略)实现,找到相关的代码,搞清楚修改代码需要使用哪些API,目前的实现策略是什么。
目前状况:分析了部分代码,NameNode的分析只完成了部分,很多细节还没有看明白。
整体概览HDFS的设计概述:NameNode的设计维护名字空间,是HDFS中文件目录和文件分配的管理者。
保存的重要信息如下:文件名————> 数据块,NameNode在其本地磁盘上保存为文件(持久化)对目录树和文件名的更新——>数据块,使用操作日志来保存更新。
数据块————> DataNode列表,NameNode不存,通过DataNode上报建立起来。
一个HDFS集群上可能包含成千个DataNode节点,这些DataNode定时和NameNode通信,接受NameNode 的指令。
Hadoop实战应用与详解

Hadoop实战应用与详解Hadoop是一个由Apache软件基金会开发的开放源代码框架。
它能够存储和处理大量的数据集,这将是未来几年内的重要趋势之一。
Hadoop能够自动处理数据,将它们分布在跨越多个服务器的群集上,然后在群集上执行计算任务。
Hadoop已经被广泛应用于各大行业,包括政府、金融、医疗、广告、媒体、教育等,已经成为大数据时代的重要基础设施。
一、概述Hadoop主要有两个组成部分:HDFS和MapReduce。
HDFS是一个分布式文件系统,它将大文件切分成小块,然后分散在多台机器上,可以很好地解决文件系统容量的问题。
MapReduce则是一种计算模型,它基于分布式处理,并且能够优化数据的处理,MapReduce对非常大的数据集的处理非常有效。
Hadoop本身是使用Java语言书写的,因此需要在Java环境下使用。
然而,通过一些第三方开源工具,可以使Hadoop更灵活,更容易使用。
例如,有些工具可以在Hadoop上运行SQL查询,有些工具可以将数据从关系数据库移动到Hadoop中,有些工具可以轻松地使用Hadoop分析海量的日志数据。
二、Hadoop工具的使用1. SqoopSqoop是一种用于将数据从一个关系数据库中移动到Hadoop中的工具。
Sqoop可以与MySQL、PostgreSQL、Oracle等数据库共同使用。
使用Sqoop,您可以轻松地将数据从关系数据库中提取,然后将其放入HDFS文件系统中,以便MapReduce处理。
Sqoop是Hadoop中一大工具,日常使用中必不可缺的。
2. Hive和PigHive和Pig是两种比较流行的Hadoop上的数据分析工具。
Hive基于SQL-like查询语言,使得它与关系数据库非常相似。
其查询语言HiveQL 可以与Hadoop上的HDFS、Hbase、Amazon S3和其他存储系统上的数据交互。
Pig则可与Hadoop集成,用于生成数据流处理代码,可在Hadoop环境中进行数据加工和分析。
实验4HDFS常用操作

实验4HDFS常用操作Hadoop分布式文件系统(HDFS)是一个高度可靠、可扩展的分布式文件系统,为Hadoop集群提供了存储和处理大量数据的能力。
在Hadoop中,用户可以使用各种HDFS常用操作来管理和操作存储在HDFS上的数据。
本文将介绍HDFS中的一些常用操作方法。
1. 上传文件:使用命令`hadoop fs -put <local_file_path><hdfs_path>`将本地文件上传到HDFS。
例如,`hadoop fs -put/home/user/file.txt /user/hadoop/`将本地文件`file.txt`上传到HDFS的`/user/hadoop/`目录下。
3. 创建目录:使用命令`hadoop fs -mkdir <hdfs_path>`在HDFS上创建目录。
例如,`hadoop fs -mkdir /user/hadoop/data`将在HDFS的根目录下创建一个名为`data`的目录。
4. 删除文件或目录:使用命令`hadoop fs -rmr <hdfs_path>`删除HDFS上的文件或目录。
例如,`hadoop fs -rmr/user/hadoop/file.txt`将删除HDFS上的`/user/hadoop/file.txt`文件。
5. 列出目录内容:使用命令`hadoop fs -ls <hdfs_path>`列出指定目录下的文件和子目录。
例如,`hadoop fs -ls /user/hadoop/`将列出`/user/hadoop/`目录下的文件和子目录。
6. 查看文件内容:使用命令`hadoop fs -cat <hdfs_path>`将HDFS上的文件内容输出到控制台。
例如,`hadoop fs -cat/user/hadoop/file.txt`将显示`/user/hadoop/file.txt`文件的内容。
如何在Hadoop中使用MapReduce进行数据分析

如何在Hadoop中使用MapReduce进行数据分析在当今信息爆炸的时代,数据分析已经成为了企业和组织决策的重要工具。
而Hadoop作为一个开源的分布式计算框架,提供了强大的数据处理和分析能力,其中的MapReduce就是其核心组件之一。
本文将介绍如何在Hadoop中使用MapReduce进行数据分析。
首先,我们需要了解MapReduce的基本原理。
MapReduce是一种分布式计算模型,它将大规模的数据集划分成若干个小的数据块,然后通过Map和Reduce两个阶段进行并行处理。
在Map阶段,数据集会被分割成若干个键值对,每个键值对由一个键和一个值组成。
然后,Map函数会对每个键值对进行处理,生成一个新的键值对。
在Reduce阶段,相同键的值会被分组在一起,然后Reduce函数会对每个键的值进行聚合和处理,最终生成最终的结果。
在Hadoop中使用MapReduce进行数据分析的第一步是编写Map和Reduce函数。
在编写Map函数时,我们需要根据具体的数据分析任务来定义键值对的格式和生成方式。
例如,如果我们要统计某个网站的访问量,那么键可以是网站的URL,值可以是1,表示一次访问。
在Reduce函数中,我们需要根据具体的需求来定义对键的值进行聚合和处理的方式。
例如,如果我们要统计每个网站的总访问量,那么Reduce函数可以将所有的值相加得到最终的结果。
编写好Map和Reduce函数后,我们需要将数据加载到Hadoop中进行分析。
在Hadoop中,数据通常以HDFS(Hadoop Distributed File System)的形式存储。
我们可以使用Hadoop提供的命令行工具或者编写Java程序来将数据加载到HDFS 中。
加载完成后,我们就可以使用Hadoop提供的MapReduce框架来进行数据分析了。
在运行MapReduce任务之前,我们需要编写一个驱动程序来配置和提交任务。
在驱动程序中,我们需要指定Map和Reduce函数的类名、输入数据的路径、输出数据的路径等信息。
HDFS详解

HDFS详解1、HDFS 是做什么的HDFS(Hadoop Distributed File System)是Hadoop项⽬的核⼼⼦项⽬,是分布式计算中数据存储管理的基础,是基于流数据模式访问和处理超⼤⽂件的需求⽽开发的,可以运⾏于廉价的商⽤服务器上。
它所具有的⾼容错、⾼可靠性、⾼可扩展性、⾼获得性、⾼吞吐率等特征为海量数据提供了不怕故障的存储,为超⼤数据集(Large Data Set)的应⽤处理带来了很多便利。
2、HDFS 从何⽽来HDFS 源于 Google 在2003年10⽉份发表的GFS(Google File System)论⽂。
它其实就是 GFS 的⼀个克隆版本3、为什么选择 HDFS 存储数据之所以选择 HDFS 存储数据,因为 HDFS 具有以下优点: 1、⾼容错性数据⾃动保存多个副本。
它通过增加副本的形式,提⾼容错性。
某⼀个副本丢失以后,它可以⾃动恢复,这是由 HDFS 内部机制实现的,我们不必关⼼。
2、适合批处理它是通过移动计算⽽不是移动数据。
它会把数据位置暴露给计算框架。
3、适合⼤数据处理处理数据达到 GB、TB、甚⾄PB级别的数据。
能够处理百万规模以上的⽂件数量,数量相当之⼤。
能够处理10K节点的规模。
4、流式⽂件访问⼀次写⼊,多次读取。
⽂件⼀旦写⼊不能修改,只能追加。
它能保证数据的⼀致性。
5、可构建在廉价机器上它通过多副本机制,提⾼可靠性。
它提供了容错和恢复机制。
⽐如某⼀个副本丢失,可以通过其它副本来恢复。
当然 HDFS 也有它的劣势,并不适合所有的场合: 1、低延时数据访问⽐如毫秒级的来存储数据,这是不⾏的,它做不到。
它适合⾼吞吐率的场景,就是在某⼀时间内写⼊⼤量的数据。
但是它在低延时的情况下是不⾏的,⽐如毫秒级以内读取数据,这样它是很难做到的。
2、⼩⽂件存储存储⼤量⼩⽂件(这⾥的⼩⽂件是指⼩于HDFS系统的Block⼤⼩的⽂件(默认64M))的话,它会占⽤ NameNode⼤量的内存来存储⽂件、⽬录和块信息。
hdfs的文件操作命令以及mapreduce程序设计

hdfs的文件操作命令以及mapreduce程序设计Hadoop分布式文件系统(HDFS)是Hadoop框架的一部分,用于存储和处理大规模数据集。
以下是HDFS的一些常见文件操作命令:1. 查看文件和目录:- `hadoop fs -ls <path>`:列出指定路径下的文件和目录。
- `hadoop fs -du <path>`:查看指定路径下的文件和目录的大小。
2. 创建和删除目录:- `hadoop fs -mkdir <path>`:创建一个新目录。
- `hadoop fs -rmr <path>`:递归删除指定路径下的所有文件和目录。
3. 文件复制和移动:- `hadoop fs -cp <src> <dest>`:将源路径中的文件复制到目标路径。
- `hadoop fs -mv <src> <dest>`:将源路径中的文件移动到目标路径。
4. 文件上传和下载:- `hadoop fs -put <localSrc> <dest>`:将本地文件上传到HDFS中的指定路径。
- `hadoop fs -get <src> <localDest>`:将HDFS中的文件下载到本地目录。
5. 查看文件内容:- `hadoop fs -cat <path>`:显示指定路径下文件的内容。
- `hadoop fs -tail <path>`:显示指定文件的最后几行内容。
上述命令可以在命令行中使用。
此外,Hadoop还提供了Java 编程接口(API)和命令行工具(如`hadoop jar`)来编写和运行MapReduce程序。
以下是使用Java编写的简单MapReduce程序的示例:```javaimport org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException;public class WordCount {public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {private final IntWritable one = new IntWritable(1);private Text word = new Text();public void map(Object key, Text value, Context context) throws IOException, InterruptedException {String[] words = value.toString().split(" ");for (String w : words) {word.set(w);context.write(word, one);}}}public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {private IntWritable result = new IntWritable();public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0;for (IntWritable val : values) {sum += val.get();}result.set(sum);context.write(key, result);}}public static void main(String[] args) throws Exception {Job job = Job.getInstance();job.setJarByClass(WordCount.class);job.setMapperClass(TokenizerMapper.class);job.setCombinerClass(IntSumReducer.class);job.setReducerClass(IntSumReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);FileInputFormat.addInputPath(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));System.exit(job.waitForCompletion(true) ? 0 : 1);}}```该示例是一个简单的词频统计程序。
hadoop源码_hdfs启动流程_1_NameNode

hadoop源码_hdfs启动流程_1_NameNode执⾏start-dfs.sh脚本后,集群是如何启动的?本⽂阅读并注释了start-dfs脚本,以及namenode和datanode的启动主要流程流程源码。
阅读源码前准备源码获取拉取Apache Hadoop官⽅源码⽤idea打开...切换到想看的版本...这⾥⽤的最新版本3.3.1阅读⽬标本篇的阅读⽬标是搞明⽩hadoop中的start-dfs.sh启动脚本执⾏后都做了什么,hadoop中的NameNode,DataNode启动过程等⼤致流程,不会细追细节。
start-dfs.sh ⼲了什么hdfs集群的启动命令为:start-dfs.sh, 脚本的位置在下图中:![image-脚本中⼤致分位两块内容,第⼀部分是调⽤hdfs-config.sh脚本配置hdfs以及hadoop的参数以及环境等,第⼆部分是启动datanode、namenode以及secondary namenode等等。
我们的重点是看第⼆部分的启动流程。
hdfs-config 简述start-dfs.sh中启动hdfs-config.sh的代码如下:# let's locate libexec...if [[ -n "${HADOOP_HOME}" ]]; thenHADOOP_DEFAULT_LIBEXEC_DIR="${HADOOP_HOME}/libexec"elseHADOOP_DEFAULT_LIBEXEC_DIR="${bin}/../libexec"fiHADOOP_LIBEXEC_DIR="${HADOOP_LIBEXEC_DIR:-$HADOOP_DEFAULT_LIBEXEC_DIR}"# shellcheck disable=SC2034HADOOP_NEW_CONFIG=trueif [[ -f "${HADOOP_LIBEXEC_DIR}/hdfs-config.sh" ]]; then. "${HADOOP_LIBEXEC_DIR}/hdfs-config.sh"elseecho "ERROR: Cannot execute ${HADOOP_LIBEXEC_DIR}/hdfs-config.sh." 2>&1exit 1fi在hdfs-config.sh脚本中会尝试启动hdfs-evn.sh脚本(如果存在)之后会检查以及设置HDFS的各种参数,例如:# turn on the defaultsexport HDFS_AUDIT_LOGGER=${HDFS_AUDIT_LOGGER:-INFO,NullAppender}export HDFS_NAMENODE_OPTS=${HDFS_NAMENODE_OPTS:-"-Dhadoop.security.logger=INFO,RFAS"}export HDFS_SECONDARYNAMENODE_OPTS=${HDFS_SECONDARYNAMENODE_OPTS:-"-Dhadoop.security.logger=INFO,RFAS"}export HDFS_DATANODE_OPTS=${HDFS_DATANODE_OPTS:-"-Dhadoop.security.logger=ERROR,RFAS"}export HDFS_PORTMAP_OPTS=${HDFS_PORTMAP_OPTS:-"-Xmx512m"}# depending upon what is being used to start Java, these may need to be# set empty. (thus no colon)export HDFS_DATANODE_SECURE_EXTRA_OPTS=${HDFS_DATANODE_SECURE_EXTRA_OPTS-"-jvm server"}export HDFS_NFS3_SECURE_EXTRA_OPTS=${HDFS_NFS3_SECURE_EXTRA_OPTS-"-jvm server"}再之后会启动hadoop-config.sh脚本:# shellcheck source=./hadoop-common-project/hadoop-common/src/main/bin/hadoop-config.shif [[ -n "${HADOOP_COMMON_HOME}" ]] &&[[ -e "${HADOOP_COMMON_HOME}/libexec/hadoop-config.sh" ]]; then. "${HADOOP_COMMON_HOME}/libexec/hadoop-config.sh"elif [[ -e "${HADOOP_LIBEXEC_DIR}/hadoop-config.sh" ]]; then. "${HADOOP_LIBEXEC_DIR}/hadoop-config.sh"elif [ -e "${HADOOP_HOME}/libexec/hadoop-config.sh" ]; then. "${HADOOP_HOME}/libexec/hadoop-config.sh"elseecho "ERROR: Hadoop common not found." 2>&1exit 1fihadoop-config.sh是最基本的、公⽤的环境变量配置脚本,会再调⽤etc/hadoop/hadoop-env.sh脚本。
实验二 Hadoop环境下MapReduce并行编程

实验二Hadoop环境下MapReduce并行编程一. 实验目的1.学习MapReduce编程模型,理解MapReduce的编程思想。
会用MapReduce框架编写简单的并行程序。
2.熟悉使用eclipse编写、调试和运行MapReduce并行程序。
二. 实验内容1.登录Openstack云平台,进入搭建好Hadoop的虚拟机,按照实验指导说明,在终端启动hadoop、启动eclipse。
2.用MapReduce编程思想,修改hadoop自带的例子程序WordCount,实现如下功能:统计给定文件data.dat中出现频率最多的三个单词,并输出这三个单词和出现的次数。
(注:这里不区分字母大小写,如he与He当做是同一个单词计数)三. 实验指导1.进入虚拟机,打开终端,切换为root用户,命令使用:su root输入密码2.进入hadoop安装目录,本实验中hadoop安装目录为:/usr/local/hadoop-2.6.0/,使用ls命令查看该目录中的文件:3.所有与hadoop启动/关闭有关的脚本位于sbin目录下,所以继续进入sbin目录。
其中,hadoop2.X版本的启动命令主要用到start-dfs.sh和start-yarn.sh。
关闭hadoop主要用到stop-dfs.sh和stop-yarn.sh。
执行start-dfs.sh,然后使用jps命令查看启动项,保证NameNode和DataNode 已启动,否则启动出错:执行start-yarn.sh,jps查看时,保证以下6个启动项已启动:4.打开eclipse,在右上角进入Map/Reduce模式,建立eclispe-hadoop连接5.连接成功后,能够在(1)这个文件夹下再创建文件夹(创建后需refresh)6.建立wordcount项目,如下步骤:7.next,项目名任意(如wordcount),finish。
将WordCount.java文件复制到wordcount项目下src文件中,双击打开。
HDFS编程实践(Hadoop3.1.3)

HDFS编程实践(Hadoop3.1.3)⼀、使⽤ Eclipse 开发调试 HDFS Java 程序实验任务:1. 在分布式⽂件系统中创建⽂件并⽤ shell 指令查看;2. 利⽤ Java API 编程实现判断⽂件是否存在以及合并两个⽂件的内容成⼀个⽂件。
1、创建⽂件⾸先启动 hadoop,命令:$ cd /usr/local/hadoop/ ; $ ./sbin/start-dfs.sh,如图:在本地 Ubuntu ⽂件系统的/home/Hadoop/⽬录下创建两个⽂件 file_a.txt、file_b.txt:$ touch /home/Hadoop/file_a.txt$ touch /home/Hadoop/file_b.txt把本地⽂件系统的/home/Hadoop/file_a.txt、/home/Hadoop/file_b.txt上传到 HDFS 中的当前⽤户⽬录下,即上传到 HDFS 的/user/hadoop/⽬录下:./bin/hdfs dfs -put /home/Hadoop/file_a.txt./bin/hdfs dfs -put /home/Hadoop/file_b.txt在⽂件⾥编辑内容:gedit /home/Hadoop/file_a.txtgedit /home/Hdaoop/file_b.txt查看⽂件是否上传成功:./bin/hdfs dfs -ls可以看到,以上两个⽂件已经上传成功。
读取⽂件内容:./bin/hdfs dfs -cat file_a.txt./bin/hdfs dfs -cat file_b.txt上图暂时有个报错,我们可以看到,两个⽂件的读取已经成功。
2、利⽤Java API 编程实现在 Eclipse 中创建项⽬启动 Eclipse,启动后,会弹出如下图所⽰的界⾯,提⽰设置⼯作空间(workspace)直接采⽤默认设置,点击 OK 即可。
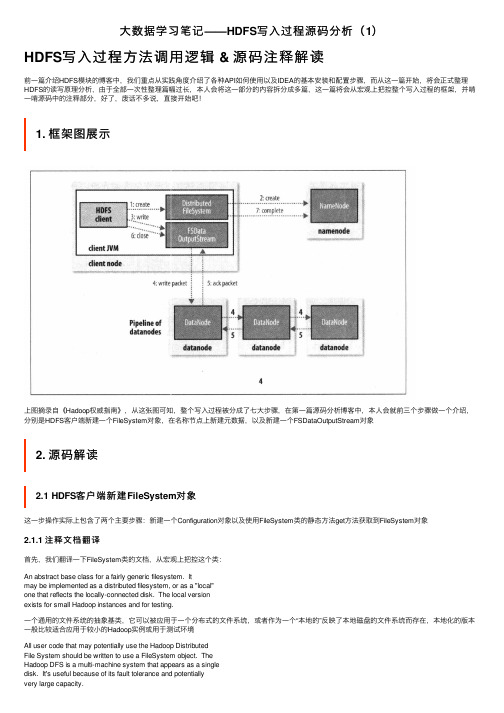
大数据学习笔记——HDFS写入过程源码分析(1)
⼤数据学习笔记——HDFS写⼊过程源码分析(1)HDFS写⼊过程⽅法调⽤逻辑 & 源码注释解读前⼀篇介绍HDFS模块的博客中,我们重点从实践⾓度介绍了各种API如何使⽤以及IDEA的基本安装和配置步骤,⽽从这⼀篇开始,将会正式整理HDFS的读写原理分析,由于全部⼀次性整理篇幅过长,本⼈会将这⼀部分的内容拆分成多篇,这⼀篇将会从宏观上把控整个写⼊过程的框架,并啃⼀啃源码中的注释部分,好了,废话不多说,直接开始吧!1. 框架图展⽰上图摘录⾃《Hadoop权威指南》,从这张图可知,整个写⼊过程被分成了七⼤步骤,在第⼀篇源码分析博客中,本⼈会就前三个步骤做⼀个介绍,分别是HDFS客户端新建⼀个FileSystem对象,在名称节点上新建元数据,以及新建⼀个FSDataOutputStream对象2. 源码解读2.1 HDFS客户端新建FileSystem对象这⼀步操作实际上包含了两个主要步骤:新建⼀个Configuration对象以及使⽤FileSystem类的静态⽅法get⽅法获取到FileSystem对象2.1.1 注释⽂档翻译⾸先,我们翻译⼀下FileSystem类的⽂档,从宏观上把控这个类:An abstract base class for a fairly generic filesystem. Itmay be implemented as a distributed filesystem, or as a "local"one that reflects the locally-connected disk. The local versionexists for small Hadoop instances and for testing.⼀个通⽤的⽂件系统的抽象基类,它可以被应⽤于⼀个分布式的⽂件系统,或者作为⼀个“本地的”反映了本地磁盘的⽂件系统⽽存在,本地化的版本⼀般⽐较适合应⽤于较⼩的Hadoop实例或⽤于测试环境All user code that may potentially use the Hadoop DistributedFile System should be written to use a FileSystem object. TheHadoop DFS is a multi-machine system that appears as a singledisk. It's useful because of its fault tolerance and potentiallyvery large capacity.所有的可能会使⽤到HDFS的⽤户代码在进⾏编写时都应该使⽤FileSystem对象,HDFS⽂件系统是⼀个跨机器的系统,并且是⼀个单独的磁盘(即根⽬录)的形式出现的,这样的⽅式⾮常有⽤,是因为它的容错机制和海量的容量2.1.2 新建Configuration对象我们将断点打到下图为⽌,进⾏调试,来看看新建Configuration对象时究竟发⽣了些什么关键代码如下:static{//print deprecation warning if hadoop-site.xml is found in classpathClassLoader cL = Thread.currentThread().getContextClassLoader();if (cL == null) {cL = Configuration.class.getClassLoader();}if(cL.getResource("hadoop-site.xml")!=null) {LOG.warn("DEPRECATED: hadoop-site.xml found in the classpath. " +"Usage of hadoop-site.xml is deprecated. Instead use core-site.xml, "+ "mapred-site.xml and hdfs-site.xml to override properties of " +"core-default.xml, mapred-default.xml and hdfs-default.xml " +"respectively");}addDefaultResource("core-default.xml");addDefaultResource("core-site.xml");}由此可见,Configuration对象会加⼊两个默认的配置⽂件,core-default.xml以及core-site.xml2.1.3 获取FileSystem对象现在我们将断点打到下图位置:经过⽅法的层层调⽤,我们最终找到了FileSystem对象是通过调⽤getInternal⽅法得到的⾸先在getInternal⽅法中调⽤了createFileSystem⽅法进⼊createFileSystem⽅法,关键的来了!private static FileSystem createFileSystem(URI uri, Configuration conf) throws IOException {Class<?> clazz = getFileSystemClass(uri.getScheme(), conf);FileSystem fs = (FileSystem)ReflectionUtils.newInstance(clazz, conf);fs.initialize(uri, conf);return fs;}原来,FileSystem实例是通过反射的⽅式获得的,具体实现是通过调⽤反射⼯具类ReflectionUtils的newInstance⽅法并将class对象以及Configuration 对象作为参数传⼊最终得到了FileSystem实例2.2 在名称节点上新建元数据2.2.1 注释⽂档翻译此步骤⼀共涉及到这⼏个类,DistributedFileSystem,DFSClient以及DFSOutputStreamDistributedFileSystem类Implementation of the abstract FileSystem for the DFS system.This object is the way end-user code interacts with a HadoopDistributedFileSystem.在分布式⽂件系统上,抽象的FileSystem类的实现⼦类,这个对象是末端的⽤户代码⽤来与Hadoop分布式⽂件系统进⾏交互的⼀种⽅式DFSClient类DFSClient can connect to a Hadoop Filesystem andperform basic file tasks. It uses the ClientProtocolto communicate with a NameNode daemon, and connectsdirectly to DataNodes to read/write block data.Hadoop DFS users should obtain an instance ofDistributedFileSystem, which uses DFSClient to handlefilesystem tasks.DFSClient类可以连接到Hadoop⽂件系统并执⾏基本的⽂件任务,它使⽤ClientProtocal来与⼀个NameNode进程通讯,并且直接连接到DataNodes上来读取或者写⼊块数据,HDFS的使⽤者应该要获得⼀个DistributedFileSystem的实例,使⽤DFSClient来处理⽂件系统任务DFSOutputStream类DFSOutputStream creates files from a stream of bytes.DFSOutputStream从字节流中创建⽂件The client application writes data that is cached internally bythis stream. Data is broken up into packets, each packet istypically 64K in size. A packet comprises of chunks. Each chunkis typically 512 bytes and has an associated checksum with it.客户端写被这个流缓存在内部的数据,数据被切分成packets的单位,每⼀个packet⼤⼩是64K,⼀个packet是由chunks组成的,每⼀个chunk为512字节⼤⼩并且伴随⼀个校验和When a client application fills up the currentPacket, it isenqueued into dataQueue. The DataStreamer thread picks uppackets from the dataQueue, sends it to the first datanode inthe pipeline and moves it from the dataQueue to the ackQueue.The ResponseProcessor receives acks from the datanodes. When asuccessful ack for a packet is received from all datanodes, theResponseProcessor removes the corresponding packet from theackQueue.当⼀个客户端进程填满了当前的包时,它就会被排⼊数据队列(dataQueue),DataStreamer线程从数据队列中获取包并在管线将它发送到第⼀个datanode中去,然后把它从数据队列移动⾄确认队列(ackQueue),响应处理器(ResponseProcessor)从datanodes中接收确认回执,当⼀个包成功确认的回执被从所有的datanodes接收到时,响应处理器就会从确认队列中移除相应的数据包In case of error, all outstanding packets are moved fromackQueue. A new pipeline is setup by eliminating the baddatanode from the original pipeline. The DataStreamer nowstarts sending packets from the dataQueue.如果出现错误,所有未完成的包都会从确认队列中移除(同时会将packet移动到数据队列的末尾),通过从原始的管线中消除坏掉的datanode,⼀个新的管线被重新架设起来,DataStreamer开始从数据队列中发送数据包2.2.2 新建元数据源码解读先将断点打到下图位置,然后debug第⼀步调试,我们⾸先进⼊到的是FileSystem类,经过create⽅法的层层调⽤,最终我们找到了出⼝public FSDataOutputStream create(Path f,boolean overwrite,int bufferSize,short replication,long blockSize,Progressable progress) throws IOException {return this.create(f, FsPermission.getFileDefault().applyUMask(FsPermission.getUMask(getConf())), overwrite, bufferSize,replication, blockSize, progress);}继续调试,我们发现FSDataOutputStream是⼀个包装类,它是通过调⽤DistributedFileSystem类的create⽅法返回的,⽽查看代码可知,这个包装类所包装的,正是DFSOutputStream于是乎,第⼆个出⼝也被我们找到了@Overridepublic FSDataOutputStream create(final Path f, final FsPermission permission,final EnumSet<CreateFlag> cflags, final int bufferSize,final short replication, final long blockSize, final Progressable progress,final ChecksumOpt checksumOpt) throws IOException {statistics.incrementWriteOps(1);Path absF = fixRelativePart(f);return new FileSystemLinkResolver<FSDataOutputStream>() {@Overridepublic FSDataOutputStream doCall(final Path p)throws IOException, UnresolvedLinkException {final DFSOutputStream dfsos = dfs.create(getPathName(p), permission,cflags, replication, blockSize, progress, bufferSize,checksumOpt);return dfs.createWrappedOutputStream(dfsos, statistics);}继续调试,我们发现这个DFSOutputStream是从DFSClient类的create⽅法中返回过来的public DFSOutputStream create(String src,FsPermission permission,EnumSet<CreateFlag> flag,boolean createParent,short replication,long blockSize,Progressable progress,int buffersize,ChecksumOpt checksumOpt,InetSocketAddress[] favoredNodes) throws IOException {checkOpen();if (permission == null) {permission = FsPermission.getFileDefault();}FsPermission masked = permission.applyUMask(dfsClientConf.uMask);if(LOG.isDebugEnabled()) {LOG.debug(src + ": masked=" + masked);}final DFSOutputStream result = DFSOutputStream.newStreamForCreate(this,src, masked, flag, createParent, replication, blockSize, progress,buffersize, dfsClientConf.createChecksum(checksumOpt),getFavoredNodesStr(favoredNodes));beginFileLease(result.getFileId(), result);return result;}查看已标记了的关键代码,我们⼜发现,DFSClient类中的DFSOutputStream实例对象是通过调⽤DFSOutputStream类的的newStreamForCreate⽅法产⽣的,于是乎,我们单步进⼊这个⽅法,⼀探究竟,终于,我们找到了新建元数据的关键代码static DFSOutputStream newStreamForCreate(DFSClient dfsClient, String src,FsPermission masked, EnumSet<CreateFlag> flag, boolean createParent,short replication, long blockSize, Progressable progress, int buffersize,DataChecksum checksum, String[] favoredNodes) throws IOException {TraceScope scope =dfsClient.getPathTraceScope("newStreamForCreate", src);try {HdfsFileStatus stat = null;// Retry the create if we get a RetryStartFileException up to a maximum// number of timesboolean shouldRetry = true;int retryCount = CREATE_RETRY_COUNT;while (shouldRetry) {shouldRetry = false;try {stat = node.create(src, masked, dfsClient.clientName,new EnumSetWritable<CreateFlag>(flag), createParent, replication,blockSize, SUPPORTED_CRYPTO_VERSIONS);break;} catch (RemoteException re) {IOException e = re.unwrapRemoteException(AccessControlException.class,DSQuotaExceededException.class,FileAlreadyExistsException.class,FileNotFoundException.class,ParentNotDirectoryException.class,NSQuotaExceededException.class,RetryStartFileException.class,SafeModeException.class,UnresolvedPathException.class,SnapshotAccessControlException.class,UnknownCryptoProtocolVersionException.class);if (e instanceof RetryStartFileException) {if (retryCount > 0) {shouldRetry = true;retryCount--;} else {throw new IOException("Too many retries because of encryption" +" zone operations", e);}} else {throw e;}}}Preconditions.checkNotNull(stat, "HdfsFileStatus should not be null!");final DFSOutputStream out = new DFSOutputStream(dfsClient, src, stat,flag, progress, checksum, favoredNodes);out.start();return out;} finally {scope.close();}}查看关键代码,我们发现这个stat对象是调⽤namenode的create⽅法产⽣的,⽽ctrl + 左键点击namenode后发现namenode正是之前注释⾥⾯提到的ClientProtocal的⼀个实例对象,⽽ClientProtocal是⼀个接⼝,它的⼀个实现⼦类名字叫做ClientNamenodeProtocalTranslatorPB就是我们想要的,我们找寻这个类的⽅法,最终发现了create⽅法⽽返回值是通过调⽤rpcProxy的create⽅法实现的,这⾥⽤到的是Google的Protobuf序列化技术@Overridepublic HdfsFileStatus create(String src, FsPermission masked,String clientName, EnumSetWritable<CreateFlag> flag,boolean createParent, short replication, long blockSize,CryptoProtocolVersion[] supportedVersions)throws AccessControlException, AlreadyBeingCreatedException,DSQuotaExceededException, FileAlreadyExistsException,FileNotFoundException, NSQuotaExceededException,ParentNotDirectoryException, SafeModeException, UnresolvedLinkException,IOException {CreateRequestProto.Builder builder = CreateRequestProto.newBuilder().setSrc(src).setMasked(PBHelper.convert(masked)).setClientName(clientName).setCreateFlag(PBHelper.convertCreateFlag(flag)).setCreateParent(createParent).setReplication(replication).setBlockSize(blockSize);builder.addAllCryptoProtocolVersion(PBHelper.convert(supportedVersions));CreateRequestProto req = builder.build();try {CreateResponseProto res = rpcProxy.create(null, req);return res.hasFs() ? PBHelper.convert(res.getFs()) : null;} catch (ServiceException e) {throw ProtobufHelper.getRemoteException(e);}}2.3 新建FSDataOutputStream对象之前讲解的是新建元数据的代码,⽽事实上,整个过程并未结束,还需要新建⼀个DFSOutputStream对象才⾏,同样在之前的newStreamForCreate ⽅法中,我们发现了以下⼏⾏代码,最终返回的是这个out对象,并且在返回之前,调⽤了out对象的start⽅法final DFSOutputStream out = new DFSOutputStream(dfsClient, src, stat,flag, progress, checksum, favoredNodes);out.start();return out;点进start⽅法,发现调⽤的是streamer对象的start⽅法private synchronized void start() {streamer.start();}点进streamer对象,发现它是DataStreamer类的⼀个实例,并且DataStreamer类是DFSOutputSteam的⼀个内部类,在这个类中,有⼀个⽅法叫做run⽅法,数据写⼊的关键代码就在这个run⽅法中实现@Overridepublic void run() {long lastPacket = Time.monotonicNow();TraceScope scope = NullScope.INSTANCE;while (!streamerClosed && dfsClient.clientRunning) {// if the Responder encountered an error, shutdown Responderif (hasError && response != null) {try {response.close();response.join();response = null;} catch (InterruptedException e) {DFSClient.LOG.warn("Caught exception ", e);}}DFSPacket one;try {// process datanode IO errors if anyboolean doSleep = false;if (hasError && (errorIndex >= 0 || restartingNodeIndex.get() >= 0)) {doSleep = processDatanodeError();}synchronized (dataQueue) {// wait for a packet to be sent.long now = Time.monotonicNow();while ((!streamerClosed && !hasError && dfsClient.clientRunning&& dataQueue.size() == 0 &&(stage != BlockConstructionStage.DATA_STREAMING ||stage == BlockConstructionStage.DATA_STREAMING &&now - lastPacket < dfsClient.getConf().socketTimeout/2)) || doSleep ) { long timeout = dfsClient.getConf().socketTimeout/2 - (now-lastPacket); timeout = timeout <= 0 ? 1000 : timeout;timeout = (stage == BlockConstructionStage.DATA_STREAMING)?timeout : 1000;try {dataQueue.wait(timeout);} catch (InterruptedException e) {DFSClient.LOG.warn("Caught exception ", e);}doSleep = false;now = Time.monotonicNow();}if (streamerClosed || hasError || !dfsClient.clientRunning) {continue;}// get packet to be sent.if (dataQueue.isEmpty()) {one = createHeartbeatPacket();assert one != null;} else {one = dataQueue.getFirst(); // regular data packetlong parents[] = one.getTraceParents();if (parents.length > 0) {scope = Trace.startSpan("dataStreamer", new TraceInfo(0, parents[0]));// TODO: use setParents API once it's available from HTrace 3.2// scope = Trace.startSpan("dataStreamer", Sampler.ALWAYS);// scope.getSpan().setParents(parents);}}}// get new block from namenode.if (stage == BlockConstructionStage.PIPELINE_SETUP_CREATE) {if(DFSClient.LOG.isDebugEnabled()) {DFSClient.LOG.debug("Allocating new block");}setPipeline(nextBlockOutputStream());initDataStreaming();} else if (stage == BlockConstructionStage.PIPELINE_SETUP_APPEND) { if(DFSClient.LOG.isDebugEnabled()) {DFSClient.LOG.debug("Append to block " + block);}setupPipelineForAppendOrRecovery();initDataStreaming();}long lastByteOffsetInBlock = one.getLastByteOffsetBlock();if (lastByteOffsetInBlock > blockSize) {throw new IOException("BlockSize " + blockSize +" is smaller than data size. " +" Offset of packet in block " +lastByteOffsetInBlock +" Aborting file " + src);}if (one.isLastPacketInBlock()) {// wait for all data packets have been successfully ackedsynchronized (dataQueue) {while (!streamerClosed && !hasError &&ackQueue.size() != 0 && dfsClient.clientRunning) {try {// wait for acks to arrive from datanodesdataQueue.wait(1000);} catch (InterruptedException e) {DFSClient.LOG.warn("Caught exception ", e);}}}if (streamerClosed || hasError || !dfsClient.clientRunning) {continue;}stage = BlockConstructionStage.PIPELINE_CLOSE;}// send the packetSpan span = null;synchronized (dataQueue) {// move packet from dataQueue to ackQueueif (!one.isHeartbeatPacket()) {span = scope.detach();one.setTraceSpan(span);dataQueue.removeFirst();ackQueue.addLast(one);dataQueue.notifyAll();}}if (DFSClient.LOG.isDebugEnabled()) {DFSClient.LOG.debug("DataStreamer block " + block +" sending packet " + one);}// write out data to remote datanodeTraceScope writeScope = Trace.startSpan("writeTo", span);try {one.writeTo(blockStream);blockStream.flush();} catch (IOException e) {// HDFS-3398 treat primary DN is down since client is unable to // write to primary DN. If a failed or restarting node has already // been recorded by the responder, the following call will have no // effect. Pipeline recovery can handle only one node error at a // time. If the primary node fails again during the recovery, it// will be taken out then.tryMarkPrimaryDatanodeFailed();throw e;} finally {writeScope.close();}lastPacket = Time.monotonicNow();// update bytesSentlong tmpBytesSent = one.getLastByteOffsetBlock();if (bytesSent < tmpBytesSent) {bytesSent = tmpBytesSent;}if (streamerClosed || hasError || !dfsClient.clientRunning) {continue;}// Is this block full?if (one.isLastPacketInBlock()) {// wait for the close packet has been ackedsynchronized (dataQueue) {while (!streamerClosed && !hasError &&ackQueue.size() != 0 && dfsClient.clientRunning) {dataQueue.wait(1000);// wait for acks to arrive from datanodes }}if (streamerClosed || hasError || !dfsClient.clientRunning) {continue;}endBlock();}if (progress != null) { progress.progress(); }// This is used by unit test to trigger race conditions.if (artificialSlowdown != 0 && dfsClient.clientRunning) {Thread.sleep(artificialSlowdown);}} catch (Throwable e) {// Log warning if there was a real error.if (restartingNodeIndex.get() == -1) {DFSClient.LOG.warn("DataStreamer Exception", e);}if (e instanceof IOException) {setLastException((IOException)e);} else {setLastException(new IOException("DataStreamer Exception: ",e)); }hasError = true;if (errorIndex == -1 && restartingNodeIndex.get() == -1) {// Not a datanode issuestreamerClosed = true;}} finally {scope.close();}}closeInternal();}private void closeInternal() {closeResponder(); // close and joincloseStream();streamerClosed = true;setClosed();synchronized (dataQueue) {dataQueue.notifyAll();}}。
CompressionCodec接口_MapReduce 2.0源码分析与编程实战_[共2页]
![CompressionCodec接口_MapReduce 2.0源码分析与编程实战_[共2页]](https://img.taocdn.com/s3/m/7dc9b02eaef8941ea66e05a3.png)
第3章 “吃下去吐出来”—Hadoop文件I/O系统详解或者牺牲压缩空间换取压缩时间。
例如,在对即时性要求比较高的数据库设计上,一般要求注重压缩与解压缩时间,则程序设计人员会选择压缩与解压缩速度快的压缩格式,而对一般大文件存储时,则更选用注重节省压缩空间的算法。
3.2H a d o o p的压缩类库3.2.1 从一个简单的例子开始压缩类的使用对于Hadoop来说是透明的,Hadoop提供的API可以根据文件后缀名自动识别出压缩格式,从而使用与压缩格式对应的算法进行解压缩。
程序3-1演示了使用Gzip类将内存中的数据写到HDFS中的具体方法。
程序3-1public class SimpleCompression {public static void main(String[] args) throws Exception {Configition conf = new Configition(); //生成环境变量Path outputPath = new Path("helloworld.gz"); //设置输出路径FileSystem fs = FileSystem.get(conf); //创建文件系统实例OutputStream os = fs.create(outputPath); //创建输出路径 CompressionCodec codec = new GzipCodec(); //生成压缩格式实例byte[] buff = "hello world".getBytes(); //将字符串转为字符数组CompressionOutputStream cos = codec.createOutputStream(os);//创建压缩环境地址 cos.write(buff); //开始写入数据cos.close(); //写入完成后关闭输出流}}我们希望将内存中的数据写入到HDFS中,并以gzip格式进行存储。
HDFSnamenode写editlog原理以及源码分析

HDFSnamenode写editlog原理以及源码分析这篇分析⼀下namenode 写edit log的过程。
关于namenode⽇志,集群做了如下配置<property><name>services</name><value>sync</value><description>Logical name for this new nameservice</description></property><property><name>.dir</name><value>file://home/wudi/hadoop/nn</value></property><property><name>node.shared.edits.dir</name><value>qjournal://host1:port1;host2:port2;host3:port3/sync</value></property>这个配置是说namenode写edit log需要往两个地⽅写,第⼀个是/home/wudi/hadoop/nn,namenode本地⽂件系统,另外⼀个qjournal,这是⼀个共享的edit log directory,namenode往多个JournalNode写edit log,namenode作为Paxos中的Proposer,JournalNode作为Acceptor,保证多点写时也能对edit log达成⼀致。
实际上,我的集群上起了3个JournalNode进程。
总体来说,namenode多线程写edit log,edit log维护双buffer,⼀个⽤于填充数据,另外⼀个⽤于flush。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Hadoop中HDFS源代码分析目录一、Hadoop系统基础 .............................................................................................................. - 1 -1.1、Hadoop简介 .............................................................................................................. - 1 -1.2、H a d o o p的项目组成................................................................... - 2 -1.3、Hadoop基本架构模型........................................................................................... - 3 -1.4、Hadoop集群 .............................................................................................................. - 5 -二、Hadoop文件系统(HDFS)...................................................................................... - 6 -2.1、HDFS主要功能组件................................................................................................ - 7 -2.2、HDFS体系结构 .................................................................................................... - 8 -2.3、NameNode ................................................................................................................... - 9 -2.4、DataNode ................................................................................................................... - 10 -三、HDFS的实现代码分析................................................................................................ - 11 -3.1、org.apache.hadoop.io................................................................................................ - 11 -3.2、RPC的实现方法 .................................................................................................... - 13 -3.2.1、Client类 ................................................................................................................... - 13 -3.2.2、Server类 .............................................................................................................. - 15 -3.2.3、RPC类 ................................................................................................................... - 17 -3.2.4、HDFS通信协议组........................................................................................... - 18 -3.3、名称节点的实现方法........................................................................................... - 20 -3.3.1、FSImage类 .............................................................................................................. - 21 -3.3.2、FSEditLog类 ......................................................................................................... - 22 -3.3.3、FSNamesystem类................................................................................................ - 23 -3.4、数据节点的实现方法........................................................................................... - 27 -3.4.1、数据节点的设计................................................................................................ - 27 -3.4.2、数据处理的设计................................................................................................ - 28 -3.5、客户端实现方法 .................................................................................................... - 30 -3.5.1、数据读取的设计................................................................................................ - 30 -3.5.2、数据写入的设计................................................................................................ - 32 -四、总结 ...................................................................................................................................... - 33 -一、Hadoop系统基础1.1、Had oop简介Hadoop由 Apache Software Foundation 公司于 2005 年秋天作为Lucene 的子项目 Nutch 的一部分正式引入。
它受到最先由 Google 开发的MapReduce 和GoogleFileSystem的启发,2006年3月份,MapReduce 和 Nutch Distributed File System (NDFS) 分别被纳入称为 Hadoop 的项目中。
Hadoop 是最受欢迎的在 Internet 上对搜索关键字进行内容分类的工具,但它也可以解决许多要求极大伸缩性的问题。
在Hadoop中实现了Google的MapReduce算法,它能够把应用程序分割成许多很小的工作单元,每个单元可以在任何集群节点上执行或重复执行。
此外,Hadoop还提供一个分布式文件系统用来在各个计算节点上存储数据,并提供了对数据读写的高吞吐率。
由于应用了map/reduce和分布式文件系统,使得Hadoop框架具有高容错性,它会自动处理失败节点。
Hadoop 是以一种可靠、高效、可伸缩的方式进行处理的。
Hadoop 是可靠的,因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理。
Hadoop 是高效的,因为它以并行的方式工作,通过并行处理加快处理速度。
Hadoop 还是可伸缩的,能够理 PB 级数据。
此外,Hadoop 依赖于社区服务器,因此它的成本比较低,任何人都可以使用。
Hadoop带有用Java 语言编写的框架,因此运行在 Linux 生产平台上是非常理想的。
Hadoop上的应用程序也可以使用其他语言编写,比如C++。
Hadoop 是一个能够对大量数据进行分布式处理的软件框架。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。
充分利用集群的威力高速运算和存储。
在很多大型网站上都已经得到了应用,如亚马逊,Facebook,雅虎,新浪,淘宝等。
1.2、Hadoop的项目组成Hadoop的子项目1. Hadoop Common:就是原来的Hadoop Core,它是一系列分布式文件系统和通用I/O 的组件和接口。
是整个Hadoop项目的核心,其他Hadoop子项目都是在Hadoop Common的基础上发展起来的。