补充数据图
modis数据补充技术方案

现有的Modis数据与现有的国界不能完全覆盖完全。
需要将modis数据的与国界不能完全覆盖完全的地方需要补充数据。
现在采用下述方法进行数据补充。
Modis数据:modis数据是分幅数据,我们采用某一分幅数据为例进行说明。
其技术路线如下图。
图表1modis数据处理技术路线图1.利用标准国界矢量图层,在arcgis中进行缓冲,先向内外同时缓冲10km,形成新的图层“国界_buffer_insideAndOut.shp”。
2.然后只向内缓冲10km,形成另一个缓冲图层“国界_buffer_inside.shp”。
3.用“国界_buffer_inside.shp”和已知的modis数据,利用arcgis 软件中的“Extract by Mask”工具,裁切modis数据(为了减少数据后期的处理量),形成“modis_mask.tiff”图层。
4.将“modis_mask.tiff”数据转为矢量的点图层“modis_Raster_Point.shp”,用Raster to Point工具完成。
5.用arcgis软件中的克里金插值方法,利用“modis _Raster_Point.shp”图层进行插值,以“国界_buffer_insideAndOut.shp”图层为范围,进行插值,形成新的栅格图层“modis_Kriging.tiff”。
这这样,新形成的栅格图层“modis_Kriging.tiff”数据就完全覆盖了“国界.shp”,不会出现漏空。
6.为了不改变原有的modis数据,将原始modis数据与“国界.shp”数据的无数据值得不分用“modis_Kriging.tiff”数据代替,其他部分仍然采用原始的modis数据。
利用栅格计算器Raster Calculator完成。
7.利用掩膜提取工具裁切处理过的modis数据。
存在问题:由于在栅格数据转点的过程中,所转的点图层数据量较大,因此,在用该点图层插值的过程中,数据处理速度很慢,一幅60.2MB的数据,大概需要3——5个小时的处理时间。
【软考】——数据流图

【软考】——数据流图
在软考学习中,下午题的前三道:数据流图,ER模型,UML图是基本上不能失分的,这⼏个题是最基本的题,出题的形式都是固定的,⽽数据流图这道题拿满分最重要的是耐⼼和细⼼的分析试题。
考点突破
①补充数据流图的缺失部分,包括补充数据流、补充外部实体及补充数据存储。
——实体出现的频率⽐较多
②数据流图的改错,包括改正数据流名称,数据流的起始点与终点及删除多余数据流——通过仔细分析题就可以找到错误。
③附加与数据流图相关的概念简答题。
——积累的过程
基础
数据流图(Data Flow Diagram):简称DFD,它从数据传递和加⼯⾓度,以图形⽅式来表达系统的逻辑功能、数据在系统内部的逻辑流向和逻辑变换过程,是结构化系统分析⽅法的主要表达⼯具及⽤于表⽰软件模型的⼀种图⽰⽅法。
【基本图形符号】
【分层数据流图】
分层的数据流图主要分为:顶层图和0层图。
顶层图是确定与外部实体之间的输⼊和输出数据流。
0层图是将顶层图中的加⼯分解成若⼲个加⼯,并⽤数据流连接这些加⼯。
是顶层图的细化过程。
满⾜结构化⽅法原则中的⾃顶向下,逐层分局的原则。
【数据平衡原则】
1、分层数据流图中的数据平衡原则
⽗类和⼦类之间的数据流必须保持⼀致,包括数量和内容上⼀致,或者上(下)层输出等于上(下)层的输出。
2、每张数据流图的数据平衡原则
加⼯的输⼊数据流和输出数据流要平衡,保证加⼯的输出数据流都有对应的输⼊和输出数据流。
⿊洞:只进不出
奇迹:只出不进
灰洞:加⼯不出输出流
答题技巧总结
详细分析试题说明,充分利⽤数据平衡原则!。
小升初复习:知识点14统计

统计与概率领域:统计第十四节:统计与概率(一)统计数据的收集和整理【例1】学校要举行跳绳比赛,丫丫练习1分钟跳绳的成绩如下。
(单位:下)48505254455452504944 43525455485251485658整理以上数据,完成下面的统计表。
丫丫练习一分钟跳绳的统计表成绩(下)次数(次)思路引导所统计数据中最大值是58,最小值是43,并且56以上的数据只有2个,可以按照每5下为一组,分为45以下、46-50、51-55、56及以上,分段整理数据。
整理数据时,可以采用写“正”字的方法,以免重复和遗漏。
正确解答:成绩(下)45及以下46-5051-5556及以上次数(次)3692研究问题往往需要调查足够多的数据。
当整理的数据有很多时,为了避免重复和遗漏,我们常常采用写“正”字或画“V”等方法统计。
【变式1】(2022六上·武汉汉江)1. 下面是新兴小学六(1)班学生在收集塑料袋活动中,每个学生一周收集塑料袋的个数。
128165186205197136200167157142 167153129149127139195156173163 135176158179170143152174201155请对上面的数据进行整理,完成下面的统计表。
新兴小学六(1)班学生一周收集塑料袋数量统计表_____年_____月个数/个()()()()()合计人数()()()()()()统计表、统计图【例2】要表示几座大山高度的情况,选择用()统计图更合适。
A.条形B.折线C.扇形思路引导条形统计图用直条的长短表示数量的多少,从图中直观地看出数量的多少,便于比较;折线统计图不仅能看清数量的多少,还能通过折线的上升和下降表示数量的增减变化情况;扇形统计图可以清楚地看出各部分数量与总数量之间,部分与部分之间的关系,据此选择合适的统计图。
正确解答:要表示几座大山高度的情况,选择用条形统计图更合适。
掌握各统计图的特点及作用是解答题目的关键。
苏教版六年级上册数学补充习题答案

苏教版六年级上册数学补充习题答案第一章数与式1. 小数的加法和减法1.1 加法•例题1: 0.3 + 0.6 = 0.91.2 减法•例题2: 1.2 - 0.7 = 0.52. 分数2.1 分数的大小比较•例题1: 比较大小:1/3 ___ 1/2–答案:1/3 < 1/22.2 分数的加法和减法•例题2: 1/4 + 1/3 = 7/123. 乘法和除法3.1 乘法•例题1: 2.5 × 3 = 7.53.2 除法•例题2: 3.6 ÷ 1.2 = 3第二章数量关系1. 分组与配对1.1 分组问题•例题1: 有24个小朋友,分成4组,每组有几个?–答案:每组有6个小朋友。
1.2 配对问题•例题2: 有18支铅笔,可以配对几次?–答案:可以配对9次。
2. 比例与倍数2.1 比例•例题1: 如果2本书的价格是15元,4本书的价格是多少?–答案:4本书的价格是30元。
2.2 倍数•例题2: 6是12的几倍?–答案:6是12的1/2倍。
第三章几何图形1. 角与三角形1.1 角的分类•例题1: 判断角的大小:锐角、直角、钝角–答案:锐角 < 直角 < 钝角1.2 三角形的特性•例题2: 判断三角形的类型:等边三角形、等腰三角形、直角三角形–答案:等边三角形、等腰三角形、直角三角形2. 线段与圆2.1 线段的概念•例题1: 判断线段AB与线段CD的长度大小:AB > CD–答案:AB的长度大于CD2.2 圆的相关知识•例题2: 判断圆O与圆P的大小关系:O包围P–答案:圆O包围圆P第四章数据与图表1. 统计与概率1.1 数据的收集和整理•例题1: 将以下数据按升序排列:5, 8, 1, 3, 7–答案:1, 3, 5, 7, 81.2 概率的计算•例题2: 掷一枚骰子,统计点数为6的概率是多少?–答案:点数为6的概率是1/62. 图表的分析与应用2.1 条形图与折线图•例题1: 根据以下数据,绘制条形图或折线图:–数据:A: 10, B: 15, C: 8, D: 12–答案:(根据题目提供的实际数据,绘制条形图或折线图)2.2 饼图与扇形图•例题2: 根据以下数据,绘制饼图或扇形图:–数据:A: 30%,B: 20%,C: 15%,D: 35%–答案:(根据题目提供的实际数据,绘制饼图或扇形图)以上是苏教版六年级上册数学的补充习题答案,希望对您的学习有所帮助!。
生态保护红线本底调查统计表、补充指标

附录A(资料性附录)数据资料收集说明根据生态保护红线本底调查内容,搜集各类数据。
进行资料收集时,应保证资料的时效性和准确性。
省级人民政府有关部门在制定生态保护红线本底调查工作方案过程中,应统一提供本辖区的生态保护红线划定方案、国土调查及变更数据、生态环境遥感调查评估数据结果等已有数据资料。
其中,涉密数据应严格按照相关保密规定使用。
B.1 专题图件专题图件包括但不局限于:1:1万(或1:5万)国家基本比例尺地形图、国土调查及变更数据、地理国情普查和监测数据、国家基础地理信息数据、生态系统类型与分布数据、生态保护红线划定成果、林地变更调查数据。
B.2 遥感影像遥感影像一般包括:中分辨率卫星遥感影像、高分辨率卫星遥感影像或航片等。
生态保护红线本底调查应采用空间分辨率优于30 m的遥感影像,有条件的区域优先选取10 m及更高空间分辨率的遥感影像或航片。
B.3 统计年鉴统计年鉴一般包括:国家、省及市县编制的近期统计年鉴。
包括:人口、国民经济核算、财政、资源环境、能源、农业、工业、建筑业、住宿、餐饮、旅游业等数据。
B.4 现有各部门开展的权威调查监测结果充分结合现有各部门开展的权威调查监测结果,调查监测结果包括但不局限于:全国生态环境遥感调查评估数据(生态环境部门),全国生物物种资源调查数据(生态环境部门),大气环境质量监测数据(生态环境部门),水环境质量监测数据(生态环境部门),土壤环境质量监测数据(生态环境部门),自然保护区人类活动遥感监测及核查数据(生态环境部门),全国污染源普查数据(生态环境部门、农业部门),全国、省、市县野生动植物资源调查数据(林草部门),全国、省、市县森林资源二类调查数据(林草部门),全国气象数据(气象部门),全国、省、市县水资源调查数据(水利部门),全国国土调查数据(自然资源部门)等。
9附录B(规范性附录)生态保护红线本底调查统计表1)按照生态保护红线图斑逐个进行调查登记。
2)生态保护红线编码、名称、主导生态功能或保护对象按照生态保护红线划定成果进行填写。
第二章补充数据流图精品PPT课件

• 下面给出二种方案
方案1:第一步
数据流图的画法和范例
主要内容
• 数据流图中的符号 • 画数据流图的方法 • 数据流的注意事项 • 举例
– 定货系统 – 患者监护系统
• 数据流图的作用
数据流图中的符号
• 组成元素:四种成分
数据的源点/终点 ————————
数据的外部来源和去处,通常是系统之外的人 员或组织,不受系统控制
变换数据的处理 ————————
病人 时钟
生理信号
1
接受信号
正确的生理信号
2
分析信号
危重病人信息
3
产生警告信息
生理信号1
日期 时间
4
定时取样生 理信号
D1 患者安全范围
日志数据
D2 患者日志
处理 定货
产生 定货报表 采购员 报表
定货信息
定货信息
定货信息
划分边界方法2 (方案2)——以联机方式更新库存清单
库存清单
库存清单
仓库 事务 接受 事务
管理员
事务
更新 库存 清单
库存信息
处理 定货
产生 定货报表 采购员 报表
定货信息
定货信息
定货信息
划分边界方法3 (方案3)—— 集中处理定货
患者监护系统
次定货。
事务 仓库管理员
定货报表
定货系统
采购员
定货系统基本系统模型
第7单元:条形统计图的实际应用专项练习-四年级数学上册典型例题系列(原卷版)人教版
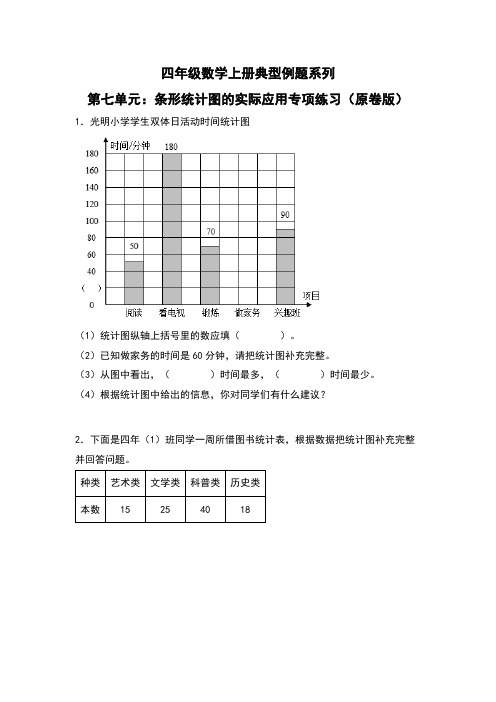
四年级数学上册典型例题系列第七单元:条形统计图的实际应用专项练习(原卷版)1.光明小学学生双体日活动时间统计图(1)统计图纵轴上括号里的数应填()。
(2)已知做家务的时间是60分钟,请把统计图补充完整。
(3)从图中看出,()时间最多,()时间最少。
(4)根据统计图中给出的信息,你对同学们有什么建议?2.下面是四年(1)班同学一周所借图书统计表,根据数据把统计图补充完整(1)每格代表()本。
(2)四(1)班同学最喜欢看()类的图书。
(3)你获得了什么信息?(写出2条)(4)对于四(1)班同学的阅读情况,你有什么建议?(1)根据如表中的数据完成下面条形统计图。
(2)上面的条形统计图中,每格代表()人。
(3)喜欢吃()的人数最多,喜欢吃()的人数最少。
(4)小刚说:“我们班一共有33名同学?”你认为小刚说得对吗?①你的判断结论:()。
(填上“对”或“不对”)②说说你判断的理由。
4.下面是四年级学生最喜欢的体育项目统计情况。
(每人只选一项)(1)请你用下面的条形图把上面的数据表示出来。
四年级学生最喜欢的体育项目统计图(2)条形图中每格代表()人。
(3)最喜欢()运动的人数最多,最喜欢()运动和()运动的人数同样多。
(4)一共调查了()人。
5.观察统计图,再回答问题。
(1)每格代表()人。
(2)四(1)班一共有48人,最喜欢故事书的有()人,请你把上面(1)根据统计表完成下面的统计图。
(2)()级植树最多,()年级植树最少。
(3)上图中,每格代表()棵。
(4)你能提出一个数学问题并解答吗?7.下面是小明和小青6岁至9岁的体重统计表。
(1)根据上表制成统计图。
小明和小青6岁至9岁的体重统计图(2)小明从6岁到9岁体重增加了多少千克?(3)小青哪一年比上一年体重增加得最多?增加了多少千克?(1)请把合计填入上表中。
(2)根据各家用水合计数据,制作条形统计图。
四位同学家庭今年第四季度用水情况统计图(1)请根据上面的数据完成条形图。
sci补充数据类型

sci补充数据类型
SCI补充数据类型主要包括以下几种:
1.补充材料:这是最常见的一种补充数据类型,通常以图、表、文本甚至视频的形式提交。
这些材料不能在正文中全部展示,因此以补充材料的形式提交。
在投稿的时候,这些补充材料需要随同正文一起上传系统,并经过同行评议。
这些材料在出版前不会直接排版到论文的PDF文件中,而是在论文在线发表的网址中可以找到。
2.图注:这是对图形的解释和说明,可以帮助读者更好地理解图形所表达的含义。
3.表格:表格可以用来展示实验数据、统计结果等,以便读者更好地了解实验过程和结果。
4.视频:视频可以用来展示实验过程、技术操作等,以便读者更好地了解实验和技术。
需要注意的是,补充材料并非越多越好,过多的补充材料可能会增加阅读论文的困难,因此杂志社通常会对补充材料的数量进行限制。
对于理解文本非必要的原始数据不用以补充材料的形式提交,即使提交也可能被编辑要求删除。
stata 面板数据补充缺失值

stata 面板数据补充缺失值Stata是一种广泛使用的统计分析软件,它可以处理各种类型的数据,包括面板数据。
面板数据是指在时间和空间上都有变化的数据,例如跨越多年的公司财务数据或跨越多个国家的经济数据。
在面板数据中,有时会出现缺失值,这可能会影响数据的准确性和可靠性。
因此,补充缺失值是面板数据分析中的一个重要步骤。
在Stata中,补充面板数据的缺失值有多种方法。
下面将介绍其中的两种方法。
方法一:使用插值法补充缺失值插值法是一种常用的补充缺失值的方法。
它基于已有数据的趋势,通过数学模型来预测缺失值。
在Stata中,可以使用命令“ipolate”来进行插值。
该命令的语法如下:ipolate varname [if exp] [in range], gen(newvarname) [options]其中,“varname”是要插值的变量名,“if exp”是可选的条件表达式,“in range”是可选的数据范围,“gen(newvarname)”是生成新变量的选项,“options”是可选的插值选项。
例如,假设有一个面板数据集“mydata.dta”,其中包含变量“year”和“income”,其中“income”有一些缺失值。
要使用插值法补充缺失值,可以使用以下命令:use mydata.dta, clearxtset yearipolate income, gen(income_interp)该命令将使用默认的线性插值方法来补充缺失值,并生成一个新变量“income_interp”。
方法二:使用多重插补法补充缺失值多重插补法是一种更复杂的补充缺失值的方法。
它基于多个模型来预测缺失值,并通过多次模拟来生成多个可能的数据集。
在Stata中,可以使用命令“mi impute”来进行多重插补。
该命令的语法如下:mi impute varlist [if exp] [in range], [options]其中,“varlist”是要插补的变量列表,“if exp”是可选的条件表达式,“in range”是可选的数据范围,“options”是可选的插补选项。
数据透析表的自动填充与数据补充技巧

数据透析表的自动填充与数据补充技巧在处理大量数据的过程中,需要使用数据透析表(Pivot Table)来分析和汇总数据。
然而,手动填充数据和补充缺失的数据可能会非常耗时和繁琐。
为了提高工作效率,我们可以利用自动填充和数据补充技巧来简化这一过程。
1. 数据透析表的自动填充技巧数据透析表的自动填充技巧可以帮助我们快速完成表格的创建和填充,以下是一些实用的技巧:1.1 利用数据源中的表格结构自动生成数据透析表当我们选择要创建数据透析表的数据源时,可以选择其中一个表格,然后通过“插入数据透析表”选项自动生成数据透析表。
这样,Excel会根据表格的结构自动创建数据透析表,并将数据源的字段添加到数据透析表中。
1.2 利用字段拖拽进行数据透析表的快速填充在数据透析表中,我们可以利用字段拖拽的功能来快速填充数据。
只需要将字段从数据源区域拖放到行区域、列区域和值区域中,数据透析表就会自动填充相应的数据内容。
通过拖拽和重新排列字段,我们可以轻松调整数据透析表的结构和内容。
1.3 使用“字段列表”面板进行数据透析表的动态填充在Excel的数据透析表工具栏中,有一个名为“字段列表”的面板,通过它我们可以动态地选择和调整数据透析表的字段。
在这个面板中,我们可以快速添加或删除数据透析表的字段,以及进行字段之间的交换和重新排序。
这使我们能够实时更新数据透析表的内容,快速获取新的数据展示结果。
2. 数据透析表的数据补充技巧在处理数据时,经常会遇到一些缺失或错误的数据,需要进行补充或修正。
以下是一些数据透析表的数据补充技巧:2.1 使用“计算字段”在数据透析表中补充数据数据透析表工具栏中的“计算字段”功能可以帮助我们在数据透析表中补充数据。
通过创建计算字段,我们可以使用数学运算、逻辑运算和字符串操作等公式来计算或补充数据。
例如,我们可以利用计算字段来补充缺失的数据项或进行一些复杂的数据操作。
2.2 利用“补充数据”选项进行数据透析表的数据补充数据透析表工具栏中的“补充数据”选项提供了一种简单的方法来补充数据。
数据处理中使用众数补齐缺失值

数据处理中使用众数补齐缺失值
在数据处理中,当我们遇到缺失值时,常常需要进行填充操作以保证数据的完整性和准确性。
而使用众数来补齐缺失值是一种常见的方法。
众数指的是数据集中出现次数最多的数值。
当数据集中有大量的重复数值时,使用众数进行填充可以在一定程度上保持数据的分布特征,不会对整体数据的分布产生过大的影响。
使用众数进行填充的好处在于,它可以保持数据的一致性和稳定性。
当数据集中存在一些异常值或者极端值时,使用平均数可能会受到这些值的影响,而使用众数则可以避免这种情况。
另外,如果数据集中的数值呈现一定的集中趋势,使用众数进行填充也可以更好地反映数据的整体情况。
然而,使用众数进行填充也有一些限制。
例如,当数据集中的众数过于集中,数据分布不均匀时,使用众数可能会导致填充后的数据失去一定的代表性。
此外,如果数据集中存在多个众数,选择哪一个作为填充值也需要谨慎考虑。
在实际操作中,我们可以先对数据集进行分析,了解数据的分布情况和特点,再决定是否使用众数进行填充。
如果数据集符合使
用众数填充的条件,我们可以通过统计分析或者数据可视化的方法来确定众数,并将其应用于缺失值的填充操作中。
总之,使用众数进行数据处理是一种常见且有效的方法,但在实际应用中需要结合数据的特点和实际情况来进行选择和操作。
希望这些信息能够对你有所帮助。
引用文献补充实验数据的方法

引用文献补充实验数据的方法引文文献补充实验数据的方法是指在实验过程中,为了更全面、准确地了解实验结果,需要引用相关的文献来补充实验数据。
这种方法可以帮助研究人员更好地理解实验结果,并更好地进行实验设计和后续研究。
正文:1. 选择合适的文献在选择文献时,需要根据实验的目的、研究问题和实验设计来选择。
例如,如果实验目的是研究某种药物的疗效,那么需要选择相关的临床试验或学术文章来补充数据。
如果实验设计有缺陷,那么需要选择相关的文献来修正设计。
2. 引用文献的摘要在引用文献的摘要时,需要将其复制并粘贴到补充数据表格中。
摘要应该包括实验设计、实验方法、实验结果和结论。
这样可以让读者更好地了解文献的主要内容,并方便查阅。
3. 引用文献的详细数据在引用文献的详细数据时,需要包括实验参与者、实验时间、实验条件、实验结果和数据分析等内容。
这些数据可以通过电子表格或数据库软件来保存和展示。
在展示数据时,需要注意数据的准确性和完整性,并确保数据的可视化和排版符合实验设计的要求。
4. 引用文献的结论在引用文献的结论时,需要明确结论的可靠性和重要性。
例如,如果结论是“实验结果表明,该药物能够显著提高患者的生活质量”,那么需要明确结论的可靠性和重要性,并强调该结论对于后续研究的重要性。
5. 引用文献的来源在引用文献的来源时,需要明确引用文献的来源和作者。
例如,如果引用文献是A. Smith和B.虎杖的文章,那么需要将作者和文献来源标注为A. Smith和B.虎杖。
这样可以让读者更好地了解引用文献的来源和作者,并避免混淆。
拓展:引用文献补充实验数据的方法是一种有效的方式,可以帮助研究人员更全面、准确地了解实验结果。
在引用文献时,需要注意文献的准确性和可靠性,以确保实验结果的准确性和可信度。
此外,在引用文献时,还需要考虑文献的局限性,以确保补充数据的准确性和完整性。
统计的表表示与应用

统计的表表示与应用统计学是一门研究数据收集、整理、分析和解释的学科。
而统计的表是统计学中最常用的工具之一,用于以简洁明了的方式呈现统计数据。
本文将探讨统计的表表示与应用,并以实例说明其重要性和用途。
一、统计的表表示的作用统计的表作为一种信息呈现的形式,可以将大量的数据有条理地组织起来,减少数据的繁杂性。
统计表常用于以下几个方面:1. 比较和对比:通过统计表可以将不同数据进行对比和分析,帮助人们直观地了解各种数据之间的差异和关联,从中发现规律和趋势。
2. 总结和概括:统计表可以将大量的细节信息汇总到一张表格中,使得人们能够通过简单的浏览就能够了解到数据的总体情况,从而得出结论和概括。
3. 补充和辅助:统计表有助于补充和辅助文字说明,通过数据的形式来支持和证明已经提出的论点和观点,提高信息的说服力和可信度。
二、常见的统计表格式1. 表格:表格是最常见的统计表形式,通常以行和列的形式展示数据。
表格中的每个单元格通常包含一个数据项,行和列的标题则用于解释数据的含义。
2. 折线图:折线图通过连续的折线来展示数据的变化趋势,最常见的应用是时序数据的展示和比较分析。
3. 条形图:条形图适用于离散数据的展示和比较分析,通过不同长度的条形来表示不同的数据值,从而直观地展示出数据之间的差异。
4. 饼图:饼图是用来展示各个部分在整体中的比例关系,适合于展示百分比或比例数据。
5. 散点图:散点图适用于展示两个变量之间的关系,将每个数据点绘制在坐标系中,以观察它们的分布规律和相关性。
三、统计表的应用案例1. 经济数据分析:统计表在经济领域中广泛使用,例如用来表示国内生产总值、就业率、通货膨胀率等经济指标,以便政府和研究机构进行宏观经济的分析和预测。
2. 调查统计:统计表在调查和市场研究中也得到广泛应用,可以用于呈现并比较不同调查对象的数据结果,从中分析受调查者的态度、偏好、购买行为等信息。
3. 学术研究:统计表可以用于展示实验数据和结果,帮助学术界和研究人员进行数据分析和学术成果的展示。
补充数据流图例子

时间
医院病房监护系统分层DFD图
第一层
1
局部监视
病员极限 生理信号 极限值
第二层:加工“中央监视”分解
3.1 开解信号
病员
病员 数据 3 中央监视 病症报告
病员数据
脉搏
病员极限 生理信号 极限值
护士
格式化 病员数据
血压
体温
3.2 计算超过 极限值否
超过极限值 日期 时钟 时间 3.4
2 护士 生成报告 日志数据
例1:图书预定系统(顶层DFD图)
图书目录文件 出版社档案文件
顾 客
订单
验证 订单
正确 订单
一批 订单
汇总 订单
出版社 订单
出 版 社
待处理订单文件
顾客档案
订货存根文件
画图步骤 : 1、确定外部实体及输入、输出数据流。 2、确定分解顶层的加工。 3、确定使用的文件。 4、用数据流将各部分连接起来,形成数据封闭。 注意:标注各加工框及数据流名称。
4 更新日志
3.3 产生 报警信息
病员日志
报警
格式化 病员数据
格式化 病员数据
图 2..15
图 2..16
情景教学
例2 医院病房监护系统
监视病情
产生 病情报告 图 2.13
经过初步的需求分析,得到系统功能要求: 请对系统需求进行分析! 1、监视病员的病症(血压、体温、脉搏等) 2、定时更新病历 3、病员出现异常情况时报警。 4、随机地产生某一病员的病情报告。
stata 面板数据补充缺失值

stata 面板数据补充缺失值面板数据是一种在经济学和社会科学研究中常用的数据类型,它包含了多个个体在不同时间点上的观测值。
然而,由于各种原因,面板数据中经常存在缺失值。
缺失值的存在会导致分析结果不准确或失去一部分信息,因此需要对面板数据进行缺失值的补充。
面板数据的缺失值补充是指通过一定的方法将缺失的观测值填补完整,以便进行后续的数据分析和建模。
下面将介绍一些常用的面板数据缺失值补充方法。
一、删除法删除法是最简单的缺失值处理方法之一。
当缺失值的比例较小且缺失的观测值对后续分析的影响较小时,可以选择直接删除包含缺失值的观测。
二、均值法均值法是一种常用的缺失值补充方法,它的思想是用该变量在其他时间点上的观测值的均值来代替缺失值。
这种方法假设缺失值与其他观测值的均值是相等的,适用于缺失值随机分布的情况。
三、回归法回归法是一种常用的面板数据缺失值补充方法,它的思想是利用其他变量的信息来预测缺失值。
具体而言,可以建立一个回归模型,将含有缺失值的变量作为因变量,将其他观测完整的变量作为自变量,通过回归模型来预测缺失值。
四、插值法插值法是一种常用的缺失值补充方法,它的思想是通过已有观测值之间的插值来估计缺失值。
常用的插值方法有线性插值、多项式插值和样条插值等。
五、最大似然估计法最大似然估计法是一种常用的面板数据缺失值补充方法,它的思想是通过最大化观测值的似然函数来估计缺失值。
最大似然估计法能够充分利用已有观测值的信息,对缺失值进行较为准确的估计。
在补充缺失值时,需要根据具体情况选择合适的方法。
同时,还需要注意以下几点:补充缺失值的方法应该符合数据的分布特征和缺失的机制。
不同的数据类型和缺失机制可能需要不同的补充方法。
补充缺失值的方法应该尽量减小补充后数据的偏差和方差。
补充的值应该尽量接近真实的观测值,同时尽量减小补充后数据的不确定性。
补充缺失值的方法应该经过严谨的检验和验证。
可以通过交叉验证等方法来评估补充后数据的质量和可靠性。
stata 面板数据补充缺失值

stata 面板数据补充缺失值在面板数据分析中,我们经常会遇到数据缺失的情况。
缺失值可能是由于记录错误、调查中的遗漏或者其他原因导致的。
然而,缺失值会对分析结果产生不良影响,因此我们需要进行合理的缺失值处理,以确保分析的准确性和可靠性。
一、了解面板数据缺失情况在开始处理缺失值之前,我们首先要了解数据缺失的情况。
通过检查数据集中的缺失值情况,我们可以了解到缺失值的类型、缺失值的分布以及可能出现缺失的原因。
二、处理面板数据缺失值的方法针对面板数据中的缺失值,我们可以采用以下几种方法进行处理:1. 删除含有缺失值的观测当数据缺失的比例较小且缺失的数据没有明显的规律时,我们可以选择直接删除含有缺失值的观测。
这样做的好处是可以保留大部分的有效数据,但也可能会导致样本的减少。
2. 插补法插补法是指利用已有的数据来估计缺失值。
常见的插补方法有:均值插补、回归插补、多重插补等。
这些方法根据数据的特点和研究问题的需要选择合适的插补方法。
3. 分组插补法在面板数据分析中,我们还可以利用分组插补法来处理缺失值。
分组插补法是指根据面板数据的特点,将数据按照一定的规则进行分组,并在每个分组内进行插补。
这样可以更好地利用数据的特点和结构来进行插补。
三、面板数据缺失值处理的实例为了更好地说明面板数据缺失值的处理方法,下面我们以一个实例来进行说明。
假设我们研究了某个公司的销售数据,其中包括了每个销售员在一年内的销售额。
然而,由于某些原因,部分销售员的销售额数据出现了缺失。
我们的目标是通过合理的方法对缺失值进行处理,以得到准确的销售数据。
我们可以通过检查数据集中的缺失值情况来了解缺失值的类型和分布情况。
可以发现,缺失值主要集中在某个销售员的销售额数据上,而其他销售员的数据并没有缺失。
接下来,我们可以采用插补法来处理缺失值。
由于缺失值集中在某个销售员上,我们可以根据其他销售员的销售数据来估计该销售员的销售额。
可以选择使用均值插补法或者回归插补法来进行处理。
stata 面板数据补充缺失值

stata 面板数据补充缺失值面板数据是一种常见的数据形式,它包含多个个体在多个时间点上的观测值。
然而,由于各种原因,面板数据中常常存在缺失值。
在实际研究中,处理面板数据的缺失值是一项重要的任务,因为缺失值可能会导致结果的偏差或估计的不准确性。
因此,本文将介绍如何使用Stata软件来处理面板数据中的缺失值。
我们需要了解面板数据中缺失值的类型。
面板数据的缺失值可以分为两种类型:一种是个体缺失,即某些个体在某些时间点上没有观测值;另一种是时间缺失,即某些时间点上没有对所有个体的观测值。
在处理面板数据中的缺失值时,我们需要根据缺失值的类型采取不同的方法。
对于个体缺失,我们可以使用Stata中的`xtset`命令来设置面板数据的结构,然后使用`xtline`命令来查看个体是否有缺失值。
如果个体缺失的比例较大,我们可以考虑删除这些个体,以避免对结果产生较大的偏差。
如果个体缺失的比例较小,我们可以使用`xtreg`命令进行面板数据的回归分析,Stata会自动忽略个体缺失的观测值。
对于时间缺失,我们可以使用`xtset`命令来设置面板数据的结构,然后使用`xtline`命令来查看时间点是否有缺失值。
如果时间点缺失的比例较大,我们可以考虑删除这些时间点,以避免对结果产生较大的偏差。
如果时间点缺失的比例较小,我们可以使用`xtreg`命令进行面板数据的回归分析,Stata会自动忽略时间缺失的观测值。
除了删除缺失值,我们还可以使用插补方法来填补面板数据中的缺失值。
Stata提供了多种插补方法,包括最近邻插补、线性插值、多重插补等。
这些插补方法可以根据面板数据的特点来选择合适的方法。
例如,如果面板数据的缺失值是随机缺失的,我们可以使用最近邻插补方法来填补缺失值;如果面板数据的缺失值是非随机缺失的,我们可以使用多重插补方法来填补缺失值。
在使用插补方法填补缺失值之前,我们需要进行一些前期处理。
首先,我们可以使用`xtset`命令来设置面板数据的结构,然后使用`xtline`命令来查看缺失值的分布情况。
图注要求及示例

图注要求及示例图注是指在一张图片或图表下方,对其进行文字说明和描述。
在科研、学术论文和报告中,图注通常用于补充、说明或强化图表数据。
图注的作用图注的作用让阅读者更容易了解图片或图表的含义、叙述和信息。
它可以包含以下内容:•标题信息:图片标题和编号,以及一些基本信息的描述•基本特征以及描述:描述图片和图表以及内容所显示的表现,形式,数据等等•对数据内容的补充:这个数据或者的细节信息,一些未充分显示的数据•或者解释数据:将所述数据和图表的说明联系在一起,解释图表的原因因此,图注使得读者站在更加丰富的角度来理解数据,并帮助其更高效地阅读学术材料。
图注的基本格式图注在精确描述图片或图表数据的同时,也遵循特定的格式规范。
下面是图注的正式格式要求:•它必须位于图片/表格下方并嵌入在文本的主体中。
•图片必须包含图片编号,标题和描述。
表格应有表格编号,标题和描述。
•图示(标签)必须清晰、简单明了,不能模棱两可或不清楚。
•图片或图表的描述必须准确,简练,但不能过于含糊。
图注示例下面是一些示例图注,以说明它们的格式和内容:图片1:折线图图1图1图1:折线图描述:本图显示了某公司在2016年至2020年间的营业额。
绿色线代表广告收入,蓝色线代表销售收入。
数据是统计每年的平均月收入。
表格1:商品销售数据表1:商品销售数据类别数量价格传统家具500,000 ¥300,000现代家具1,000,000 ¥400,000家居装饰200,000 ¥100,000描述:表格显示了三种商品的数量和花费。
数据是根据学校内的数据统计得出的。
在撰写学术论文或报告中,提供的图表和图片必须是缜密和精确的,而图注可以让这些信息清晰地呈现在读者面前。
如果图注显示的数据、图标或表格信息不够准确,那么人们是无法完全理解科学论文的内容。
因此,在撰写图文论文、科学报告和其他学术讲稿时,图注的准确性、完整性和规范性必须得到特殊关注。
数学建模缺失数据补充及异常数据修正-异常数据补充算法之欧阳历创编

题目:数据的预处理问题摘要数据处理贯穿于社会生产和社会生活的各个领域。
数据处理技术的发展及其应用的广度和深度,极大地影响着人类社会发展的进程。
数据补充,异常数据的鉴别及修正,在各个领域也起到了重要作用。
对于第一问,我们采用了多元线性回归的方法对缺失数据进行补充,我们将1960-2015.xls(见附表一)中的数据导入matlab。
首先作出散点图,设定y(X59287)与x1(X54511)、x2(X57494)的关系为二元线性回归模型,即y=b0+b1x1+b2x2。
之后作多元回归,求出系数b0=18.014,b1=0.051,b2=0.354,所以多元线性回归多项式为:Y=18.014+0.051*x1+0.354*x2。
再作出残差分析图验证拟合效果,残差较小,说明回归多项式与源数据吻合得较好。
若x1=30.4,x2=28.6时,y的数据缺失,则将x1,x2带入回归多项式,算出缺失值y=29.6888。
类似地,若x1=40.6,x2=30.4时,y的数据缺失,则将x1,x2带入回归多项式,算出缺失值y=30.8462,即可补充缺失数据。
关键词:多元线性回归,t检验法,分段线性插值,最近方法插值,三次样条插值,三次多项式插值一、问题重述1.1背景在数学建模过程中总会遇到大数据问题。
一般而言,在提供的数据中,不可避免会出现较多的检测异常值,怎样判断和处理这些异常值,对于提高检测结果的准确性意义重大。
1.2需要解决的问题(1)给出缺失数据的补充算法;(2)给出异常数据的鉴别算法;(3)给出异常数据的修正算法。
二、模型分析2.1问题(1)的分析属性值数据缺失经常发生甚至不可避免。
(一)较为简单的数据缺失(1)平均值填充如果空值为数值型的,就根据该属性在其他所有对象取值的平均值来填充缺失的属性值;如果空值为非数值型的,则根据众数原理,用该属性在其他所有对象的取值次数最多的值(出现频率最高的值)来补齐缺失的属性值。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
30.某市园林处去年植树节在滨海路两侧栽了A,B,C三个品种的树苗.栽种的A,B,C三个品种树苗数量的扇形统计图如图(1),其中B种树苗数量对应的扇形圆心角为120°.今年植树节前管理员调查了这三个品种树苗的成活率情况,准备今年从三个品种中选成活率最高的品种再进行栽种.经调查得知:A品种的成活率为85%,三个品种的总成活率为89%,但三个品种树苗成活数量统计图尚不完整,如图(2).
请你根据以上信息帮管理员解决下列问题:
(1)三个品种树苗去年共栽多少棵?
(2)补全条形统计图,并通过计算,说明今年应栽哪个品种的树苗.
30.某市园林处去年植树节在滨海路两侧栽了A,B,C三个品种的树苗.栽种的A,B,C三个品种树苗数量的扇形统计图如图(1),其中B种树苗数量对应的扇形圆心角为120°.今年植树节前管理员调查了这三个品种树苗的成活率情况,准备今年从三个品种中选成活率最高的品种再进行栽种.经调查得知:A品种的成活率为85%,三个品种的总成活率为89%,但三个品种树苗成活数量统计图尚不完整,如图(2).
请你根据以上信息帮管理员解决下列问题:
(1)三个品种树苗去年共栽多少棵?
(2)补全条形统计图,并通过计算,说明今年应栽哪个品种的树苗.
【分析】(1)根据成活率求出A种树苗栽种的棵数,再用A种树苗的栽种棵数除以所占的百分比,进行计算即可得解;
(2)根据总成活率求出三种树苗成活的棵数,然后减去A、C两种的成活棵数即可得到B种树苗成活的棵数,即可补全条形统计图;根据B种树苗数量对应的扇形圆心角为120°求出B种树苗栽种的棵数,然后求出其成活率,再求出C种树苗的成活率,根据成活率即可作出正确选择.
【解答】解:(1)A品种树苗棵数为1020÷85%=1200(棵),
所以,三个品种树苗共栽棵数为1200÷40%=3000(棵);
(2)B品种树苗成活棵数为
3000×89%﹣1020﹣720=930(棵),
补全条形统计图,如图,…(7分)
B品种树苗成活率为×100%=93%;
C品种树苗成活率为×100%=×100%=90%.
所以,B品种成活率最高,今年应栽B品种树苗.
【点评】本题考查的是条形统计图和扇形统计图的综合运用,读懂统计图,从不同的统计图中得到必要的信息是解决问题的关键.条形统计图能清楚地表示出每个项目的数据;扇形统计图直接反映部分占总体的百分比大小,本题易错点在于要先利用成活率求出A种树苗栽种的棵数.。