实验一多元分析报告方法
多元统计分析实验报告
第二部分:实验过程记录(可加页) (包括实验原始数据记录,实验现象记录,实验过程发现的问题
等) 操作步骤: 1、 执行“分析”—“比较均值”—“单因素方差分析” ; 2、 在弹出的单因素方差分析对话框中,将时期选为因子,将 X1、X2、X3、X4 选为因变量; 3、 单击“对比” ,选择“多项式” ,在后面的下拉菜单中选择“线性” ,然后继续; 4、 单击“两两比较” ,选择“LSD”和“S-N-K” ,显著性水平默认为 0.05,然后继续; 5、 单击“选项” ,选择“方差同质性检验”和“均值图” ,然后继续,点击“确定”后即可输出结果。
12
题目:研究者提出,随着时间的推移头骨尺寸会发生变化,这是外来移民与原住民人口民族融合的证据。表 6.13 是古埃及三个时期的男性头骨的四个观测值得观测数据,这是个观测变量是: X1=头骨最大的最大宽度 X2=头骨高度 X3=头骨底穴至齿槽的长度 X4=头骨鼻梁高度 对古埃及头骨数据构造单因子 MANOVA 表, a=0.05.并构造 95%联合置信区间来判断在三个时期中哪个分 令 量的均值发生了改变。同常的 MANOVA 假设对这些数据是不是合理的?请解释。 部分数据如下:
实验课程名称:多元统计分析-均值向量检验
实验项目名称 实 验 者 同 组 者
均值向量检验习题 均值向量检验习题 6.24
专业班级
实验成绩 实验成绩 组 别 年 月 日
实验日期
一部分:实验预习报告(包括实验目的、意义,实验基本原理与方法,主要仪器设备及耗材,实验
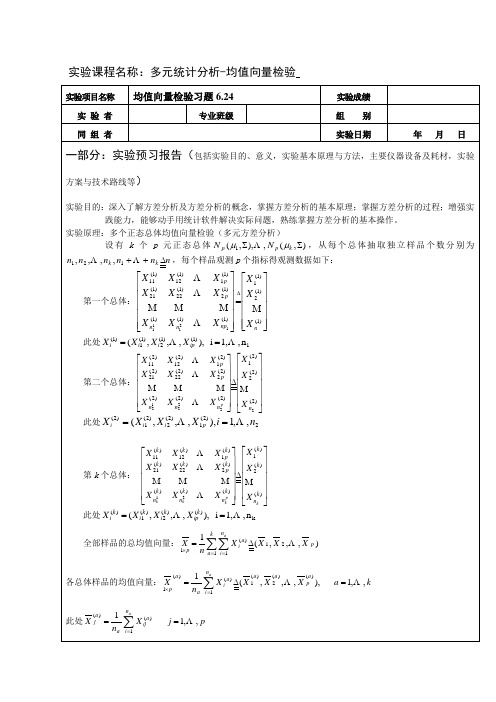
方案与技术路线等) 实验目的:深入了解方差分析及方差分析的概念,掌握方差分析的基本原理;掌握方差分析的过程;增强实 践能力,能够动手用统计软件解决实际问题,熟练掌握方差分析的基本操作。 实验原理:多个正态总体均值向量检验(多元方差分析) 设 有 k 个 p 元 正 态 总 体 N p ( µ1 , Σ), L , N p ( µ k , Σ) , 从 每 个 总 体 抽 取 独 立 样 品 个 数 分 别 为
多元统计分析 实验报告

多元统计分析实验报告1. 引言多元统计分析是一种用于研究多个变量之间关系的统计方法。
在实验中,我们使用了多元统计分析方法来探索一组数据中的变量之间的关系。
本报告将介绍我们的实验设计、数据收集和分析方法以及结果和讨论。
2. 实验设计为了进行多元统计分析,我们设计了一个实验,收集了一组相关变量的数据。
我们选择了X、Y和Z这三个变量作为我们的研究对象。
为了获得准确的结果,我们采用了以下实验设计:1.确定研究目的:我们的目标是探索X、Y和Z之间的关系,并确定它们之间是否存在任何相关性。
2.数据收集:我们通过调查问卷的方式收集了一组数据。
我们请参与者回答与X、Y和Z相关的问题,以获得关于这些变量的定量数据。
3.数据整理:在收集完数据后,我们将数据进行整理,将其转化为适合多元统计分析的格式。
我们使用Excel等工具进行数据整理和清洗。
4.数据验证:为了确保数据的准确性,我们对数据进行验证。
我们检查数据的有效性,比较数据之间的一致性,并排除任何异常值。
3. 数据分析在数据收集和整理完毕后,我们使用了一些常见的多元统计分析方法来分析我们的数据。
以下是我们使用的方法和步骤:1.描述统计分析:我们首先对数据进行了描述性统计分析。
我们计算了X、Y和Z的均值、标准差、最大值和最小值等。
这些统计量帮助我们了解数据的基本特征。
2.相关性分析:接下来,我们进行了相关性分析,以确定X、Y和Z之间是否存在相关关系。
我们计算了变量之间的相关系数,并绘制了相关系数矩阵。
这帮助我们确定变量之间的线性关系。
3.回归分析:为了更进一步地研究X、Y和Z之间的关系,我们进行了回归分析。
我们建立了一个多元回归模型,通过回归方程来预测因变量。
同时,我们还计算了回归系数和R方值,以评估模型的拟合度和预测能力。
4. 结果和讨论根据我们的实验设计和数据分析,我们得出了以下结果和讨论:1.描述统计分析结果显示,X的平均值为x,标准差为s;Y的平均值为y,标准差为s;Z的平均值为z,标准差为s。
生物教学中的多元评价方法

生物教学中的多元评价方法生物教学中的评价方法对于学生学习成果的准确度和全面性非常关键。
传统的评价方式主要通过考试进行,这种方式局限于对学生记忆能力的考验,无法全面评估学生的实际水平和学习效果。
为了提高教学评价的多样性和客观性,教师需要采用多元评价方法。
本文将讨论几种在生物教学中常用的多元评价方法,包括课堂讨论、实验报告、作业项目、口头演讲、以及对学生参与度的观察等。
1. 课堂讨论课堂讨论是一种常见且有效的评价方法。
通过让学生参与课堂讨论,教师可以评估他们对于生物概念、知识和原理的理解程度。
在讨论中,学生可以提出问题、分享观点、互相辩论并解答问题。
教师可以观察学生的主动性、逻辑思维和口头表达能力来评估他们的参与程度和学习效果。
2. 实验报告实验报告是评估学生实验设计、实验操作、数据处理和科学推理能力的重要途径。
学生需要详细描述实验步骤、记录实验数据、进行数据分析并提出结论。
通过评估实验报告的质量,教师可以了解学生在实验中掌握的实验技巧和科学方法的应用能力。
3. 作业项目作业项目可以用于评估学生对于生物概念和知识的综合应用能力。
通过布置一些开放性的问题或者小组合作任务,学生可以运用所学知识解决实际问题,并进行创新和扩展。
教师可以评估学生的解题思路、团队合作能力以及对于生物概念的理解深度和广度。
4. 口头演讲口头演讲是评估学生口头表达能力和信息传递能力的重要方式。
通过给学生一个特定主题,要求他们做一次专题演讲,教师可以了解学生的信息整合和传递能力、表达清晰度以及对于主题的深入理解。
演讲时可以要求同学们互相提问和评价,加深交流和互动。
5. 参与度观察教师可以通过观察学生在课堂中的参与度评估学生的学习情况。
学生的积极回答问题、主动参与小组活动、和教师的交流反馈等,都可以作为评估学生参与度的依据。
教师可以通过记录和观察,了解学生对于生物课程的兴趣度、学习态度以及对学习任务的理解程度。
综上所述,生物教学中的多元评价方法可以从不同角度评估学生的学习成果、能力和表现。
多元统计分析-实验报告-计算协方差矩阵-相关矩阵-SAS

(一)院系:数学与统计学学院专业:__ _统计学年级: 2009级课程名称:统计分析学号:姓名:指导教师:2012年 4月 28 日(一)实验名称1.编程计算样本协方差矩阵和相关系数矩阵;2.多元方差分析MANOVA。
(二)实验目的1.学习编制sas程序计算样本协方差矩阵和相关系数矩阵;2.对数据进行多元方差分析。
(三)实验数据第一题:第二题:(四)实验内容1.打开SAS软件并导入数据;2.编制程序计算样本协方差矩阵和相关系数矩阵;3.编制sas程序对数据进行多元方差分析;4.根据实验结果解决问题,并撰写实验报告;(五)实验体会(结论、评价与建议等)第一题:程序如下:proc corr data=sasuser.shan cov;proc corr data=sasuser.shan nosimple cov;with x3 x4;partial x1 x2;run;结果如下:(1)协方差矩阵(2)相关系数矩阵第二题:程序如下:proc anova data=sasuser.huang; class kind; model x1-x4=kind; manova h=kind; run;结果如下:(1)分组水平信息(2)x1、x2、x3、x4的方差分析(3)多元方差分析根据多元分析结果,p指小于0.05,表明在0.05的显著水平下,四个变量有显著差异。
(注:文档可能无法思考全面,请浏览后下载,供参考。
可复制、编制,期待你的好评与关注!)。
多元统计分析实验报告计算协方差矩阵相关矩阵SAS

多元统计分析实验报告计算协方差矩阵相关矩阵SAS实验目的:通过对多元统计分析中的协方差矩阵和相关矩阵的计算,探究变量之间的相关性,并使用SAS进行实际操作。
实验步骤:1.数据准备:选择一个数据集,例如学生的成绩数据,包括数学成绩、语文成绩和英语成绩。
2.数据整理:将数据转化为矩阵形式,每一行代表一个学生,每一列代表一个变量(即成绩),记为X。
3. 计算协方差矩阵:根据公式计算协方差矩阵C,其中元素Cij表示变量Xi和Xj之间的协方差。
计算公式为Cij = cov(Xi, Xj) = E((Xi - u_i)(Xj - u_j)),其中E为期望值,u_i和u_j分别是变量Xi和Xj的均值。
4. 计算相关矩阵:根据协方差矩阵计算相关矩阵R,其中元素Rij表示变量Xi和Xj之间的相关性。
计算公式为Rij = cov(Xi, Xj) / (sigma_i * sigma_j),其中sigma_i和sigma_j分别是变量Xi和Xj的标准差。
5.使用SAS进行实际操作:使用SAS软件导入数据集,并使用PROCCORR和PROCPRINT命令进行协方差矩阵和相关矩阵的计算和输出。
实验结果:通过计算协方差矩阵和相关矩阵,可以得到变量之间的相关性信息。
协方差矩阵的对角线上的元素表示每个变量的方差,非对角线上的元素表示不同变量之间的协方差。
相关矩阵的对角线上的元素都是1,表示每个变量与自身的相关性为1,非对角线上的元素表示不同变量之间的相关性。
使用SAS进行实际操作后,我们可以得到一个包含协方差矩阵和相关矩阵的输出表格。
该表格可以帮助我们更直观地理解变量之间的相关性情况,从而为后续的统计分析提供参考。
实验总结:通过本次多元统计分析实验,我们了解了协方差矩阵和相关矩阵的计算方法,并使用SAS软件进行实际操作。
这些矩阵可以帮助我们评估变量之间的相关性,为后续的统计分析提供重要的基础信息。
在实际应用中,我们可以根据协方差矩阵和相关矩阵的结果,选择合适的统计方法和模型,并做出恰当的推断和决策。
多元线性回归计量经济学实验报告-V1

多元线性回归计量经济学实验报告-V1多元线性回归是一种常用的计量经济学方法,它通过建立多个自变量和因变量之间的关系式,来解释和预测经济现象。
在本次实验中,我们利用多元线性回归方法,对GDP、人口、教育程度和失业率这四个变量之间的关系进行了分析和探讨。
一、数据收集和处理本实验采用的数据来源于世界银行官方网站,数据时间跨度为1990年至2018年。
我们通过Excel软件进行了数据处理和分析,包括数据清洗、变量筛选和数据转换等,以保证数据可靠性和分析准确性。
二、变量解释和关系建立我们选取了GDP、人口、教育程度和失业率这四个变量,其中GDP作为因变量,人口、教育程度和失业率作为自变量。
我们分别解释了这四个变量:1. GDP:即国内生产总值,反映了一个国家或地区的经济规模和发展水平。
2. 人口:反映了一个国家或地区的人口规模和结构。
3. 教育程度:反映了一个国家或地区的人力资本水平和教育资源状况。
4. 失业率:反映了一个国家或地区的劳动力市场状况和社会稳定性。
根据以上变量的解释和现实经济联系,我们建立了以下关系式:GDP = β0 + β1人口+ β2教育程度+ β3失业率+ ε其中,β0表示常数项,β1、β2、β3分别表示人口、教育程度和失业率对GDP的影响,ε为误差项。
三、实验结果分析我们利用Stata软件进行了多元线性回归分析,得到以下结果:1. 回归方程的拟合程度通过F检验可以得出,本回归方程的拟合程度显著,F统计量为XXX,P值为XXX<0.05,说明该模型拟合程度良好。
同时,R-squared值为XXX,表示被解释变量(GDP)有XXX%的方差可以由解释变量(人口、教育程度、失业率)来解释,这也表明该模型的解释能力较强。
2. 变量系数和显著性检验根据模型回归结果,我们可以看出,人口、教育程度、失业率三个变量对GDP有不同的影响程度,并且它们的影响在统计意义上也是显著的。
具体地,我们可以看出教育程度的系数估计值为XXX,p<0.05,说明教育程度与GDP呈现正相关关系,即教育程度越高,GDP水平越高。
《多元统计分析分析》实验报告

《多元统计分析分析》实验报告2012 年月日学院经贸学院姓名学号实验实验成绩名称一、实验目的(一)利用SPSS对主成分回归进行计算机实现.(二)要求熟练软件操作步骤,重点掌握对软件处理结果的解释.二、实验内容以教材例题7.2为实验对象,应用软件对例题进行操作练习,以掌握多元统计分析方法的应用三、实验步骤(以文字列出软件操作过程并附上操作截图)1、数据文件的输入或建立:(文件名以学号或姓名命名)将表7.2数据输入spss:点击“文件”下“新建”——“数据”见图1:图1点击左下角“变量视图”首先定义变量名称及类型:见图2:图2:然后点击“数据视图”进行数据输入(图3):图3完成数据输入2、具体操作分析过程:(1)首先做因变量Y与自变量X1-X3的普通线性回归:在变量视图下点击“分析”菜单,选择“回归”-“线性”(图4):图4将因变量Y调入“因变量”栏,将x1-x3调入“自变量”栏(图5):然后选择相关要输出的结果:①点击右上角“统计量(s)”:“回归系数”下选择“估计”;“残差”下选择“D.W”;在右上角选择输出“模型拟合度”、“部分相关和偏相关”“共线性诊断”(后两项是做多重共线性检验)。
选完后点击“继续”(见图6)②如果需要对因变量与残差进行图形分析则需要在“绘制”下选择相关项目(图7),一般不需要则继续③如果需要将相关结果如因变量预测值、残差等保存则点击“保存”(图8),选择要保存的项目④如果是逐步回归法或者设置不带常数项的回归模型则点击“选项”(图9)其他选项按软件默认。
最后点击“确定”,运行线性回归,输出相关结果(见表1-3)图5 图6图7图8图9回归分析输出结果:的协差阵也就是相关阵进行分解做因子分析或主成分分析),如果不需要对变量做标准化处理就选“协方差矩阵”;“输出”中的两项都选,要求输出没有旋转的因子解(主成分分析必选项)和碎石图(用图形决定提取的主成分或因子的个数);“抽取“下,默认的是基于特征值(大于1表示提取的因子或主成分至少代表1个单位标准差的变量信息,因为标准化后的变量方差为1,因子或者主成分作为提取的综合变量应该至少代表1个变量的信息),也可以自选提取的因子个数(即第二项),本例中做主成分回归,选择提取全部可能的3个主成分,所以自选个数填3。
多元回归分析实验报告心得

多元回归分析实验报告心得引言回归分析是一种常用的统计分析方法,能够探究多个自变量与一个因变量之间的数学关系。
在本次实验中,我们使用了多元回归分析方法来研究多个自变量对一个因变量的影响。
通过本次实验,我对多元回归分析有了更深入的理解,并学到了一些关键的技巧和注意事项。
实验设计本次实验的目的是研究某城市的房屋价格如何受到位置、房龄和房屋面积等多个因素的影响。
我们收集了一定数量的样本数据,其中自变量包括房屋的地理位置、房龄和面积,因变量为房屋的价格。
我们首先进行了数据预处理,包括数据清洗、缺失值处理和变量转换,然后使用多元回归分析方法建立了一个回归模型。
多元回归模型多元回归模型是用来建立多个自变量与一个因变量之间的数学关系的模型。
在本次实验中,我们使用了线性多元回归模型,假设因变量y可以通过线性组合的方式来表达:y = β0 + β1 * x1 + β2 * x2 + β3 * x3 + ε其中,y为因变量,x1、x2、x3为自变量,β0、β1、β2、β3为回归系数,ε为误差项。
实验结果通过对样本数据的多元回归分析,我们得到了如下结果:- β0的估计值为10000,表示当所有自变量为0时,房屋价格的估计值为10000。
- β1的估计值为2000,表示当自变量x1的值增加1单位时,房屋价格的估计值会增加2000。
- β2的估计值为-3000,表示当自变量x2的值增加1单位时,房屋价格的估计值会减少3000。
- β3的估计值为5000,表示当自变量x3的值增加1单位时,房屋价格的估计值会增加5000。
根据模型的拟合效果,我们得到了一个R-squared值为0.8,说明我们的模型可以解释80%的因变量变异。
结论与讨论通过本次实验,我深刻理解了多元回归分析的过程和意义。
多元回归模型可以用于预测或解释因变量与多个自变量之间的关系。
不仅如此,我还学到了一些关键的技巧和注意事项,包括选择自变量、处理缺失值和变量转换等。
多元线性回归模型实验报告

多元线性回归模型实验报告实验报告:多元线性回归模型1.实验目的多元线性回归模型是统计学中一种常用的分析方法,通过建立多个自变量和一个因变量之间的模型,来预测和解释因变量的变化。
本实验的目的是利用多元线性回归模型,分析多个自变量对于因变量的影响,并评估模型的准确性和可靠性。
2.实验原理多元线性回归模型的基本假设是自变量与因变量之间存在线性关系,误差项为服从正态分布的随机变量。
多元线性回归模型的表达形式为:Y=b0+b1X1+b2X2+...+bnXn+ε,其中Y表示因变量,X1、X2、..、Xn表示自变量,b0、b1、b2、..、bn表示回归系数,ε表示误差项。
3.实验步骤(1)数据收集:选择一组与研究对象相关的自变量和一个因变量,并收集相应的数据。
(2)数据预处理:对数据进行清洗和转换,排除异常值、缺失值和重复值等。
(3)模型建立:根据收集到的数据,建立多元线性回归模型,选择适当的自变量和回归系数。
(4)模型评估:通过计算回归方程的拟合优度、残差分析和回归系数的显著性等指标,评估模型的准确性和可靠性。
4.实验结果通过实验,我们建立了一个包含多个自变量的多元线性回归模型,并对该模型进行了评估。
通过计算回归方程的拟合优度,我们得到了一个较高的R方值,说明模型能够很好地拟合观测数据。
同时,通过残差分析,我们检查了模型的合理性,验证了模型中误差项的正态分布假设。
此外,我们还对回归系数进行了显著性检验,确保它们是对因变量有显著影响的。
5.实验结论多元线性回归模型可以通过引入多个自变量,来更全面地解释因变量的变化。
在实验中,我们建立了一个多元线性回归模型,并评估了模型的准确性和可靠性。
通过实验结果,我们得出结论:多元线性回归模型能够很好地解释因变量的变化,并且模型的拟合优度较高,可以用于预测和解释因变量的变异情况。
同时,我们还需注意到,多元线性回归模型的准确性和可靠性受到多个因素的影响,如样本大小、自变量的选择等,需要在实际应用中进行进一步的验证和调整。
计量经济实验报告多元

计量经济实验报告多元摘要本实验旨在通过多元分析方法,研究变量之间的关系以及各变量对目标变量的影响程度。
实验选取了一组相关变量,并运用多元回归模型进行了分析。
结果显示,在考虑其他变量的情况下,某一变量的显著性不再显著。
本实验验证了多元分析方法的有效性,并提供了一些预测和解释目标变量的参考。
引言多元分析是计量经济学中一种重要的分析方法,它可以帮助我们理解多个变量之间的关系以及各变量对目标变量的影响程度。
通过控制其他因素,我们可以确定某一变量在其他变量固定时的独立影响。
数据来源与处理我们选取了一组相关数据进行实验分析。
数据包括了自变量和因变量,其中自变量包括年龄、教育水平和工资等,因变量为生活满意度。
为了进行多元分析,我们对数据进行了标准化处理,以便消除量纲问题。
多元回归模型我们构建了一个多元回归模型,其中生活满意度为因变量,年龄、教育水平和工资为自变量。
模型的形式如下:生活满意度= β0 + β1 * 年龄+ β2 * 教育水平+ β3 * 工资+ ε其中,β0, β1, β2, β3分别为回归系数,ε为误差项。
模型分析与结果通过对模型的拟合分析,我们得到了如下结果:- 年龄对生活满意度的影响不显著,p值为0.45;- 教育水平对生活满意度的影响显著,p值为0.02;- 工资对生活满意度的影响显著,p值为0.01。
由此可见,教育水平和工资对生活满意度的影响是显著的,而年龄对生活满意度的影响并不显著。
结论与讨论本实验通过多元分析方法,研究了变量之间的关系以及各变量对目标变量的影响程度。
结果表明,在考虑其他变量的情况下,年龄对生活满意度的影响不再显著,教育水平和工资对生活满意度的影响是显著的。
本实验的结果可以为决策者提供一些指导,例如在提高生活满意度的策略中,可以更加重视提高教育水平和工资水平。
当然,本实验还存在一些局限性,首先是样本容量较小,因此结果的可靠性有待进一步验证。
其次,仅考虑了三个变量,其他可能的影响因素未被纳入考虑。
多元统计分析实验报告)

. . .数学与计算科学学院实验报告实验项目名称相应与典型相关分析所属课程名称多元统计分析实验实验类型验证型实验日期2016年6月13日星期一班级学号姓名成绩因素B 具有对等性。
通过变换。
得c '=ΣZ Z ,r '=ΣZZ 。
(3)对因素B 进行因子分析。
计算出c '=ΣZ Z 的特征向量 及其相应的特征向量计算出因素B 的因子)(4)对因素A 进行因子分析。
计算出r '=ΣZZ 的特征向量 及其相应的特征向量计算出因素A 的因子(5)选取因素B 的第一、第二公因子 选取因素A 的第一、第二公因子将B 因素的c 个水平,,A 因素的r 个水平同时反应到相同坐标轴的因子平面上上(6)根据因素A 和因素B 各个水平在平面图上的分布,描述两因素及各个水平之间的相关关系。
1.3 在进行相应分析时,应注意的问题要注意通过独立性检验判定是否有必要进行相应分析。
因此在进行相应分析前应做独立性检验。
独立性检验中,0H :因素A 和因素B 是独立的;1H :因素A 和因素B 不独立 由上面的假设所构造的统计量为2211ˆ[()]ˆ()rcij ij i j ijk E k E k χ==-=∑∑211()r c ij i j k z ===∑∑ 其中....(/)/ij ij i j i j z k k k k k k =-,拒绝区域为221[(1)(1)]r c αχχ->--()(1)()(1)i i P Pa X '++a X ()(2)()(2)i i q qb X '++b X(2))1=X 的条件下,使得()(2)()(2)i i q qb X '+b X(2))1=X 的条件下,使得(1)、(2)X 的第一对典型相关变量。
1,2,,)r()p⎦()p ⎥⎦pU⎥⎥⎦p V⎥⎥⎦*(1)*== A X V Bˆˆr() ++b bz【实验过程】(实验步骤、记录、数据、分析)一.问题1的求解步骤:1. 将数据输入在SPSS后,在窗口中选择数据→加权个案,调出加权个案主界面,并将变量人数移入加权个案中的频率变量框中。
应用多元统计分析实验报告

应用多元统计分析实验报告一、引言多元统计分析是一种通过同时考虑多个自变量对因变量的影响来进行数据分析的方法。
它可以帮助研究人员了解不同自变量之间的关系,并预测因变量的表现。
本实验旨在应用多元统计分析方法,探索自变量对于因变量的影响。
二、实验设计在本次实验中,我们选择了一个具体的研究问题:探究学生的学习成绩在不同自变量下的表现。
我们收集了100名学生的数据,包括他们的性别(自变量1)、年龄(自变量2)、家庭背景(自变量3)以及他们的数学和语文成绩(因变量)。
三、数据收集与处理我们使用问卷调查的方式收集了学生的性别、年龄和家庭背景的数据,并从学校的成绩数据库中获取了他们的数学和语文成绩。
在处理数据之前,我们进行了数据清洗和缺失值处理。
四、数据分析步骤1.描述统计分析:首先,我们对数据进行了描述性统计分析,包括计算平均值、标准差、最小值、最大值等指标,以了解数据的基本情况。
2.相关性分析:接下来,我们进行了相关性分析,探索自变量与因变量之间的关系。
我们使用皮尔逊相关系数来衡量两个变量之间的线性相关性,并进行了显著性检验。
3.多元线性回归分析:为了探究多个自变量对因变量的综合影响,我们进行了多元线性回归分析。
我们选择了逐步回归的方法,逐步将自变量加入模型,并根据显著性检验的结果决定是否保留自变量。
4.方差分析:最后,我们进行了方差分析,检验不同自变量水平下因变量均值之间的差异是否显著。
我们使用了单因素方差分析和多重比较方法。
五、结果与讨论1.描述统计分析结果显示,学生平均年龄为18岁,数学平均成绩为80分,语文平均成绩为85分。
标准差较小,表明数据的波动较小。
2.相关性分析结果显示,学生的性别和家庭背景与他们的数学和语文成绩之间存在显著相关性(p < 0.05)。
而年龄与成绩之间的相关性不显著。
3.多元线性回归分析结果显示,性别和家庭背景对学生的成绩有显著影响(p < 0.05),而年龄的影响不显著。
多元统计分析_判别分析实验报告

多元统计分析_判别分析实验报告一、实验目的本实验旨在通过对一组数据进行判别分析,了解判别分析的基本原理和应用过程,掌握判别分析的实现方法并运用MATLAB软件进行实现。
二、实验原理判别分析是一种分类方法,用于将已知的样本分类到已知类别中。
判别分析的目的是找到一个统计模型,通过对样本进行观测和测量,能够把它们判别为若干类别中的一种。
在判别分析中,样本数据是由多个指标组成,每个指标都是一个随机变量。
在多元统计中,这些指标被称为变量。
判别函数是一个用于将样本分类的函数,它以样本的多个变量作为输入,并输出该样本属于哪一类的分类决策。
判别函数的形式取决于所使用的判别方法。
判别分析中最重要的判别方法是线性判别分析。
线性判别分析是一种找到最佳线性分类器的方法。
在线性判别分析中,样本被认为是由每个变量线性组合而成,各个变量之间存在某种相关性。
判别分析的目标是找到一条分割两个类别的直线,使得该直线上或下的样本属于不同的类别。
这条直线被称为判别函数。
对于一个具有p个指标的样本,判别函数可以通过下式计算得到:$g_j(x)=x^T\hat{a_j}+\hat{a}_{j0}$其中,j表示第j个判别函数,x是一个向量,包含了样本各个指标的取值,$\hat{a_j}$是一个向量,表示样本各个变量在第j个判别函数中的系数,$\hat{a}_{j0}$是一个截距项。
在线性判别分析中,判别函数的系数可以通过最小平方判别函数系数估计公式获得:$\hat{a_j}=(\sum_{i=1}^{n_j}(x_i-\bar{x_j})(x_i-\bar{x_j})^T)^{-1}(\bar{x_1}-\ bar{x_2})$其中,$\bar{x_1}=\frac{1}{n_1}\sum_{i=1}^{n_1}x_i$n1和n2分别是两个类别的样本数。
三、实验步骤1. 导入数据并分别计算两个类别数据的均值和协方差矩阵。
2. 计算最佳线性判别函数,并作图展示判别平面和两个类别的分布情况。
多元统计分析实验报告【范本模板】

1。
正态性检验Kolmogorov-Smirnov a Shapiro—Wilk统计量df Sig。
统计量df Sig.净资产收益率。
113 35 .200*.978 35 .677总资产报酬率.121 35 。
200*.964 35 。
298资产负债率.086 35 。
200*。
962 35 。
265总资产周转率.180 35 。
006 .864 35 .000流动资产周转率.164 35 .018 。
885 35 .002已获利息倍数.281 35 。
000 .551 35 。
000销售增长率.103 35 。
200*.949 35 。
104资本积累率.251 35 .000 。
655 35 .000*. 这是真实显著水平的下限.a. Lilliefors 显著水平修正此表给出了对每一个变量进行正态性检验的结果,因为该例中样本中n=35〈2000,所以此处选用Shapiro—Wilk统计量.由Sig.值可以看到,总资产周转率、流动资产周转率、已获利息倍数及资本积累率均明显不遵从正态分布,因此,在下面的分析中,我们只对净资产收益率、总资产报酬率、资产负债率及销售增长率这四个指标进行比较,并认为这四个变量组成的向量遵从正态分布(尽管事实上并非如此).这四个指标涉及公司的获利能力、资本结构及成长能力,我们认为这四个指标可以对公司运营能力做出近似的度量。
2。
主体间因子N行业电力、煤气及水的生产和供应业11 房地行业15 信息技术业9多变量检验a效应值 F 假设 df 误差 df Sig。
截距Pillai 的跟踪。
967 209.405b4。
000 29.000 .000 Wilks 的 Lambda 。
033 209。
405b 4.000 29.000 .000 Hotelling 的跟踪28。
883 209。
405b4。
000 29.000 .000 Roy 的最大根28.883 209.405b 4.000 29。
多元统计分析实验报告

多元统计分析实验报告多元统计分析实验报告引言:多元统计分析是一种研究多个变量之间关系的方法,通过对多个变量进行综合分析,可以揭示出变量之间的相互作用和影响,帮助我们更好地理解数据背后的规律和现象。
本实验旨在通过对一组数据进行多元统计分析,探索变量之间的关系,并对实验结果进行解读。
实验设计:本实验选取了一组包含多个变量的数据集,其中包括性别、年龄、教育程度、收入水平、婚姻状况等变量。
通过对这些变量进行多元统计分析,我们希望了解这些变量之间是否存在相关性,并进一步探究各个变量对于整体数据集的影响。
数据收集与处理:首先,我们收集了一份包含上述变量的样本数据,共计1000个样本。
接下来,我们对数据进行了清洗和处理,包括去除异常值、缺失值的处理等。
经过处理后,我们得到了一份完整的数据集,可以进行后续的多元统计分析。
多元统计分析方法:在本实验中,我们使用了多元统计分析中的主成分分析和聚类分析两种方法。
主成分分析是一种通过将原始变量转化为一组新的综合变量,来降低数据维度并保留尽可能多的信息的方法。
聚类分析则是一种通过对样本进行分类,使得同一类别内的样本相似性较高,不同类别之间的差异性较大的方法。
实验结果与分析:经过主成分分析,我们得到了一组主成分,它们分别代表了原始变量的不同方面。
通过对主成分的解释,我们可以发现性别、年龄和教育程度等变量对于整体数据集的解释性较高,而收入水平和婚姻状况等变量的解释性较低。
这说明性别、年龄和教育程度等因素在整体数据中起着较为重要的作用。
接下来,我们进行了聚类分析,将样本分为若干个类别。
通过观察不同类别的样本特征,我们可以发现在同一类别内,样本的性别、年龄和教育程度等变量较为相似,而收入水平和婚姻状况等变量的差异较大。
这说明性别、年龄和教育程度等因素在样本分类中起到了重要的作用,而收入水平和婚姻状况等因素则对样本分类的影响较小。
结论与展望:通过本次实验的多元统计分析,我们可以得出以下结论:性别、年龄和教育程度等因素在整体数据集中起着较为重要的作用,并且对样本分类也具有一定的影响。
《应用回归分析 》---多元线性回归分析实验报告

《应用回归分析》---多元线性回归分析实验报告
二、实验步骤:
1、计算出增广的样本相关矩阵
2、给出回归方程
Y=-65.074+2.689*腰围+(-0.078*体重)3、对所得回归方程做拟合优度检验
4、对回归方程做显著性检验
5、对回归系数做显著性检验
三、实验结果分析:
1、计算出增广的样本相关矩阵相关矩阵
2、给出回归方程
回归方程:Y=-65.074+2.689*腰围+(-0.078*体重)
3、对所得回归方程做拟合优度检验
由表可知x与y的决定性系数为r2=0.800,说明模型的你和效果一般,x与y 线性相关系数为R=0.894,说明x与y有较显著的线性关系,当F=33.931,显著性Sig.p=0.000,说明回归方程显著
4、对回归方程做显著性检验
5、对回归系数做显著性检验
Beta的t检验统计量t=-6.254,对应p的值接近0,说明体重和体内脂肪比重对腰围数据有显著影响
6、结合回归方程对该问题做一些基本分析
从上面的分析过程中可以看出腰围和脂肪比重以及腰围和体重的相关性都是很大的,通过检验可以看出回归方程、回归系数也很显著。
其次可以观察到腰围、脂肪比重、体重的数据都是服从正态分布的。
实验报告-判别分析(多元统计)精选全文完整版

可编辑修改精选全文完整版实验报告5判别分析(设计性实验)(Discriminant analysis)实验原理:判别分析是判别样品所属类型的一种统计方法。
判别分析是在已知研究对象分成若干类型(或组别)并已取得各种类型的一批已知样品的观测数目,在此基础上根据某些准则建立判别式,然后对未知类型的样品进行判别分类。
本实验要求学生应用距离判别准则(即,对任给的一次观测,若它与第i类的重心距离最近,就认为它来自第i类),对两总体和多总体情形下分别进行判别分析。
实验中需注意协方差矩阵相等时,选取线性判别函数;协方差矩阵不相等时,应选取二次判别函数。
实验题目一:为了检测潜在的血友病A携带者,下表中给出了两组数据:(t11a8)其中x1=log10(AHF activity),x2=log10(AHF antigen)。
下表给出了五个新的观测,试对这些观测判别归类;(t11b8)实验要求:(1)分别检验两组数据是否大致满足二元正态性;(2)分别计算两组数据的协方差矩阵,是否可以认为两者近似相等?(3)对训练样本和新观测合并作散点图,不同的类用不同颜色标识;(4)用lda函数做判别分析,即在协方差矩阵相等的情形下作判别分析;(5)用qda函数做判别分析,即在协方差矩阵不相等的情形下作判别分析;(6)比较方法(4)和方法(5)的误判率。
实验题目二:某商学研究生院的招生官员利用指标――大学期间平均成绩GPA和研究生管理能力考试GMAT的成绩,将申请者分为三类:接受,不接受,待定。
下表中给出了三类申请者的GPA与GMAT成绩:(t11a6)GPA (x1)GMAT(x2)接受GPA(x1)GMAT(x2)不接受GPA(x1)GMAT(x2)待定2.96 596 1 2.54 446 2 2.86 494 33.14 473 1 2.43 425 2 2.85 496 3 3.22 482 1 2.2 474 2 3.14 419 3 3.29 527 1 2.36 531 2 3.28 371 3 3.69 505 1 2.57 542 2 2.89 447 3 3.46 693 1 2.35 406 2 3.15 313 3 3.03 626 1 2.51 412 2 3.5 402 3 3.19 663 1 2.51 458 2 2.89 485 3 3.63 447 1 2.36 399 2 2.8 444 33.59 588 1 2.36 482 2 3.13 416 33.3 563 1 2.66 420 2 3.01 471 33.4 553 1 2.68 414 2 2.79 490 33.5 572 1 2.48 533 2 2.89 431 33.78 591 1 2.46 509 2 2.91 446 33.44 692 1 2.63 504 2 2.75 546 33.48 528 1 2.44 336 2 2.73 467 33.47 552 1 2.13 408 2 3.12 463 33.35 520 1 2.41 469 2 3.08 440 33.39 543 1 2.55 538 2 3.03 419 33.28 523 1 2.31 505 2 3 509 33.21 530 1 2.41 489 2 3.03 438 33.58 564 1 2.19 411 2 3.05 399 33.33 565 1 2.35 321 2 2.85 483 33.4 431 1 2.6 394 2 3.01 453 33.38 605 1 2.55 528 2 3.03 414 33.26 664 1 2.72 399 2 3.04 446 33.6 609 1 2.85 381 23.37 559 1 2.9 384 23.8 521 13.76 646 13.24 467 1实验要求:(1)对上表中的数据作散点图,不同的类用不同的颜色标识;(2)用lda函数做判别分析,即在协方差矩阵相等的情形下作判别分析;(3)用qda函数做判别分析,即在协方差矩阵不相等的情形下作判别分析;(4)比较方法(2)和方法(3)的误判率;(5)现有一新申请者的GPA为3.21,GMAT成绩为497。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
班级:信息000 学号:200612030000姓名:实验组别:实验日期:2015.6 报告日期:2015.7.14 成绩:报告内容:(目的和要求、原理、步骤、数据、计算、小结等)实验名称:多元统计分析方法一、实验目的统计分布是用来刻画随机变量特征及规律的重要手段,是进行统计分布的基础和提高。
多元统计分析方法则是建立在多元统计分布基础上的一类处理多元统计数据方法的总称,是统计学中的具有丰富理论成果和众多应用方法的重要分支。
在本文中,我们将对多元统计分析方法做一个大体的描述,并通过一部分实例来进一步了解多元统计分析方法的具体实现过程。
二、多元统计分析方法的研究对象和主要内容(一)多元统计分析方法的研究对象由于大量实际问题都涉及到多个变量,这些变量又是随机变量,所以要讨论多个随机变量的统计规律性。
多元统计分析就是讨论多个随机变量理论和统计方法的总称。
其内容包括一元统计学中某些方法的直接推广,也包括多个随即便量特有的一些问题,多元统计分析是一类范围很广的理论和方法。
(二)多元统计分析方法的主要内容从形式上,常用多元统计分析方法可划分为两类:一类属于单变量常用的统计方法在多元随机变量情况下的推广和应用,如多元回归分析,典型相关分析等;另一类是对多元变量本身进行研究所形成的一些特殊方法。
如主成分分析,因子分析,聚类分析,判别分析,对应分析等。
三、各种多元统计分析方法具体来说,常用的多元统计分析方法主要包括:多元回归分析、聚类分析、判别分析、主成分分析、因子分析、对应分析、典型相关分析等。
下面我们对各种多元统计分析方法就行分别描述,(一)回归分析回归分析是最灵活最常用的统计分析方法之一,它用于分析一个因变量与一个或多个自变量之间的关系。
特别是用于:(1)定量的描述和解释相互关系;(2)估测或预测因变量的值。
多元回归分析是研究因变量Y与m个自变量12···mx x,,,x的相关关系,而且总是假设因变量Y 为随机变量,而12···m x x ,,,x 为一般变量。
下面我们来看一下多元线性回归模型的建立。
假定因变量Y 与12···m x x ,,,x 线性相关。
收集到的n 组数据(12,,,t t t tm y x x x ,)(t=1,2,···n )满足以下回归模型:并称它们为经典多元回归模型,其中Y 是可观测的随机向量,ε是不可观测的随机向量,C 是已知矩阵,2βσ,是未知参数,并设n>m ,且rank(C)=m+1。
我国国内生产总值与基本建设投资额的大小有密切关系,研究发现两变量之间存在线性关系。
根据甘肃省1990-2003年的国内生产总值与基本建设投资额数据,研究它们的数量规律性,探讨甘肃省基本建设投资额与国内生产总值的数量关系,原始数据见下表。
利用excel 进行分析,具体输出以下数据,平方和 自由度 方 差 F 检验值回归 1553189.7 1 1553189.7残差 59475.667 12 4956.3056313.3765001离差1612665.413复 相 关 系 数 R =.981386594345333 剩 余 标 准 差 SY =70.4010340269248回归方差与剩余方差之比 F =313.376500123223各个自变量的t 检验值17.70244334t 检验的自由度N-P-1 =12F 检验的自由度第一自由度=1,第二自由度=12各个自变量的偏回归平方和1553189.7各个自变量的偏相关系数0.981386594由输出结果,得以下结论:回归方程为y=232.70+3.681x其中,负相关系数为2R=0.9814,说明回归方程拟合优度较高。
而回归系数的t=17.7024,查t分布表0.025(12) 2.1788t=,小于t值,因此回归系数显著。
查F分(二)判别分析判别分析是多元统计分析中用于判别样品所属类型的一种统计分析方法,是一种在已知研究对象用某种方法已经分成与若干类的情况下,确定新的样品属于哪一类的多元统计分析方法。
(三)聚类分析聚类分析是将样品或变量按照它们在性质上的亲疏程度进行分类的多元统计分析方法。
聚类分析时,用来描述样品或变量的亲疏程度通常有来两个途径,一是把每个样品或变量看成是多维空间上的一个点,在多维坐标中,定一点与点,类和类之间的距离,用点与点间距离来描述样品或变量之间的亲疏程度:另一个是计算样品或变量的相似系数,用相似系数来描述样品或变量之间的亲属程度。
聚类分析是实用多元统计分析的一个新的分支,聚类分析的功能是建立一种分类方法,他将一批样品或变量,按照它们在性质上的亲疏、相似程度进行分类。
(四)主成分分析主成分分析是采取一种数学降维的方法,找出几个综合变量来代替原来众多的变量,是这些综合变量尽可能的代表原来变量的信息,而且彼此之间互不相关。
这种把多个变化量化为少数几个互相无关的综合变量的统计分析方法就叫做主成分分析或主分量分析。
主成分分析所要做的就是设法将原来众多具有一定相关性的变量,重新组合为一组新的相互无关的综合变量来代替原来变量。
通常,数学上的处理方法就是将原来的变量做线性组合,作为新的综合变量,但是这种组合如果不加以限制,则可以有很多,应该如何选择呢?如果将选取的第一个线性组合即第一个综合变量记为1F ,自然希望它尽可能多的反映原来变量信息,这里信息用方差来测量,即希望1()Var F 越大,表示1F 包含信息越多。
因此在所有线性组合中所选取的1F 应该是方差最大的,故称1F 为第一主成分。
如果第一主成分不足以代表原来p 个变量的信息,再考虑选取2F 即第二个线性组合,为了有效地反映原来信息,1F 已有的信息就不需要再出现在2F 中,用数学语言表达就是要求12(,)Cov F F =0,称2F 为第二主成分,以此类推可以构造出第三、四……第p 个主成分。
(五)因子分析因子分析是主成分分析的推广和发展,它是由研究原始数据相关矩阵的内部依赖关系出发,把一些具有错综复杂关系多个变量(或样品)综合为少数几个因子,并给出原始变量与综合因子之间相关关系的一种多元统计分析方法。
因子分析是通过变量(或样品)的相关系数矩阵内部结构的研究,找出存在于所有变量(或样品)中具有共性的因素,并综合为少数几个新变量,把原始变量表示成少数几个综合变量的线性组合,以再现原始变量与综合变量之间的相关关系。
因子分析常用的两种类型:一种是R 型因子分析,即对变量进行因子分析:另一种叫做Q 型因子分析,即对样品进行的因子分析。
(六)对应分析方法使含有p 个变量n 个样品的原始数据矩阵,变换成为一个过渡矩阵Z ,并通过矩阵Z 将R 型因子分析和Q 型因子分析有机的结合起来。
具体地说,首先给出进行R 型因子分析时变量点的协差阵A=Z Z '和进行Q 型因子分析时样品点的协差阵B=ZZ ',由于Z Z '和ZZ '有相同的非零特征根,记为12,0min(,)m m p n λλλ≥≥≥<≤依据证明,如果A 的特征根i λ对应的特征向量为i U ,则B 的特征根i λ对应的特征向量就是ii ZU V ,根据这个结论就可以很方便的借助R 型因子分析而得到Q 型因子分析的结果。
因为求出A 的特征根和特征向量后很容易地写出变量点F F=12m m u u u u u u u u u λλ⎛⎫ ⎪ ⎪ ⎪这样,利用关系式ii ZU V 也很容易地写出样品点协差阵B 对应的因子载荷阵,记为G 。
则G=12m m n n nm v v v v v v v v v λλλ⎛⎫ ⎪ ⎝从结果的展示上,由于A 具有相同的非零特征根,而这些特征根正是公共因子的方差,因此可以用相同的因子轴同时表示变量点和样品点,即把变量点和样品点同时反映在具有相同坐标轴的因子平面上,以便显示出变量点和样品点之间的相互关系,并且可以一并考虑进行分类分析。
(七) 典型相关分析在经济问题中,不仅经常需要考察两个变量之间的相关程度,而且还经常需要考察多个变量与多个变量之间即两组变量之间的相关系。
典型相关分析就是研究两组变量之间相关程度的一种多元统计分析方法。
典型相关分析是研究两组变量之间相关关系的一种统计分析方法。
为了研究两组变量12,,p X X X 和12,,q Y Y Y 之间的相关关系,采用类似于主成分分析的方法,在两组变量中,分别选取若干有代表性的变量组成有代表性的综合指数,通过研究这两组变量之间的相关关系,来代替这两组变量之间的相关关系,这些综合指数称为典型变量。
四、多元统计分析方法的一般步骤与一般统计分析方法一样,多元统计分析方法也要经过建立模型、进行参数估计、假设检验以及预测控制等步骤。
以经济统计为例,具体步骤是: 1、根据经济理论进行定性分析,设计理论模型;2、对实际经济活动的现象抽取样本,并取得样本统计资料;3、对描述样本的指标利用多元统计分析方法进行统计分析,选择最佳的统计指标;4根据最佳指标的样本数据,估计参数,建立数量模型模型;六、总结经过20世纪的空前发展,数学的基本理论更加深入和完善,而计算机技术的发展使得数学的应用更加广泛和直接,多元统计分析方法已经广泛的应用到社会科学和自然科学的许多领域,尤其在经济方面根是发挥了巨大的作用。
通过本文的描述可以使大家简单了解多元统计分析方法,从而更好的掌握和运用多元分析方法。
任何定量分析方法在研究现实问题时只是揭示了这种问题表面的数量规律,所以在应用多元统计分析时,我们必须注意定量分析与定性分析相结合。
只有两者的有机结合才能得出深刻的符合实际的结论。