2013数学建模必备spss翻译 指导
SPSS在数学建模中的应用

04 SPSS在数学建模中的实 践案例
案例一:利用SPSS进行市场细分
总结词
利用SPSS的统计分析功能,对市场进 行细分,为企业的市场策略提供依据。
详细描述
通过收集市场数据,利用SPSS的聚类 分析、因子分析等统计方法,将市场 划分为不同的细分市场,了解各细分 市场的特点,为企业制定针对性的市 场策略提供依据。
02 SPSS在数学建模中的优 势
强大的统计分析能力
描述性统计
SPSS提供了丰富的描述性统计功 能,如均值、中位数、方差等, 帮助用户快速了解数据的基本特 征。
推论性统计
SPSS支持多种推论性统计方法, 如回归分析、方差分析、卡方检 验等,能够揭示数据之间的内在 关系。
高级统计
SPSS还提供了许多高级统计方法, 如主成分分析、因子分析、聚类 分析等,能够满足复杂的数据分 析需求。
方便的数据处理功能
01
数据导入导出
数据清洗
02
03
数据转换
SPSS支持多种数据格式的导入和 导出,方便用户进行数据交换和 整合。
SPSS提供了数据筛选、缺失值处 理、异常值检测等功能,帮助用 户清洗和整理数据。
SPSS支持对数据进行分组、排序、 变量转换等操作,能够满足用户 对数据处理的各种需求。
03 SPSS在数学建模中的具 体应用
线性回归分析
总结词
线性回归分析是利用SPSS软件对因变量和自变量之间的关系进行建模的一种方法,通过最小二乘法拟合出最佳直 线,并计算出各因素对因变量的影响程度。
详细描述
在SPSS中,可以使用“回归”菜单下的“线性”命令来进行线性回归分析。用户需要指定因变量和自变量,并选 择适当的选项,如置信区间、模型拟合度等。SPSS将输出回归系数、标准误差、置信区间等统计量,帮助用户了 解自变量对因变量的影响程度。
2013年数学建模竞赛培训内容(新)

2013年数学建模竞赛培训内容建模竞赛概论(论文撰写,论文评阅及其注意事项)
一、图论
图论算法(包括最短路、网络流、二分图等算法)
二、数学软件
1.Matlab
2. 优化模型建立与求解及lingo软件运用
3.统计软件
SPSS统计软件聚类分析的基本操作介绍
SPSS统计软件主成分分析、因子分析的基本操作介绍
三、数据处理
1.数据的统计分析与描述
2.基于matlab的海量数据的处理方法
3.近年来全国大学生数学建模竞赛中大型数据的处理范例分析
四、运筹学:线性规划、动态规划、排队论
五、多项式插值、最小二乘曲线拟合、微分方程数值解法及其在数学建模中的应用
1.多项式插值的基本原理及MATLAB的实现
2.数据插值建模案例的分析与求解
3.最小二乘曲线拟合的基本原理及MATLAB实现
4.曲线拟合建模案例的分析与求解
5.微分方程数值解法及其MATLAB实现
6.微分方程建模案例分析与求解
六、模糊数学理论简介、灰色系统理论
1.模糊综合评价方法及应用案例
2.数学建模中常用的预测方法
3.灰色预测模型及其应用
4.评价与决策的数学模型
5.长江水质的综合评价分析
七、优化智能算法
1.模拟退火法算法、神经网络算法、遗传算法的Matlab实现
2.真题模型的遗传算法求解。
2013高教社杯全国大学生数学建模竞赛获奖名单(本科组)

浙江
浙江大学
余昉恒
梁梓鹏
张宇轩
数模组
108
浙江
浙江大学
方子君
郭俊宏
任青
数模组
109
浙江
浙江大学
沈剑飞
张仑
李拜
数模组
110
浙江
温州大学
翁雯雯
赵环
赵妙妙
数模组
111
浙江
温州大学
徐晶
石珍妮
陈斯定
连新泽
112
浙江
温州大学瓯江学院
曹晖晖
姜冬丽
孔晓栋
徐徐
113
安徽
安庆师范学院
张启军
万杨
汪严随
郝庆一
114
安徽
湖北
三峡大学
韩雪晨
李欢欢
刘军
指导教师组
163
湖北
三峡大学
李金武
杨志巧
马舒
指导教师组
164
湖北
中南民族大学
刘琴
亓晓同
黄强
教练组
165
湖北
华中农业大学
汪伟平
白婷
刘凌览
牛晓辉
166
湖北
华中农业大学
胡曹园
李扶摇
刘志祥
李治
167
湖北
华中农业大学
鲍晨
郑田蔚宝
韩以超
谭劲英
168
湖北
华中农业大学
王泷
陈攀
唐功宇
李治
169
徐志丹
刘晓峰
35
山西
太原理工大学
钟维坚
冯艳
万建
贺衎
36
山西
中北大学
建模常用的方法

数学建模常用方法三类最基本的必备知识(1)运筹学(matlab or lingo/lindo)(2)多元统计分析(spss)(3)微分方程(matlab)数学建模常用方法(1)类比法(2)量纲分析法(3)差分法(4)变分法(5)图论法(6)层次分析法(7)数据拟合法(8)回归分析法(9)数学规划(线性规划、非线性规划、整数规划、动态规划、目标规划)(10)机理分析法(11)排队方法(12)对策方法(13)决策方法(14)模糊评判方法(15)时间序列方法(16)灰色理论方法(17)现代优化算法(禁忌搜索算法,模拟退火算法,遗传算法,神经网络)数学模型分类(1)优化模型(2)微分方程模型(3)统计模型(4)概率模型(5)图论模型(6)决策模型拟合与插值方法问题-----给定一批数据点(输入变量与输出变量的数据),需确定满足特殊要求的曲线或曲面;插值问题-----要求所求曲线(面)通过所给所有数据点;数据拟合-----不要求曲线(面)通过所有数据点,而是要求它反映对象整体的变化趋势数据拟合一元函数拟合多项式拟合非线性函数拟合多元函数拟合(回归分析)MATLAB实现函数的确定插值方法一维插值的定义-----已知n个节点,求任意点处的函数值。
分段线性插值多项式插值样条插值y=interp1(x0,y0,x,’method’)二维插值----节点为网格节点z= interp2(x0,y0,z0,x,y,’method’)pp=csape({x0,y0},z0,conds,valconds)二维插值----节点为散点z1=griddata(x,y,z,x1,y1)优化方法优化模型四要素(1)决策变量(2)目标函数(尽量简单、光滑)(3)约束条件(建模的关键)(4)求解方法(MATLAB,LINGO)优化模型分类(1)线性规划模型(目标函数和约束条件都是线性函数的优化问题)(2)非线性规划模型(目标函数或者约束条件是非线性函数)(3)整数规划(决策变量是整数值的规划问题)(4)多目标规划(具有多个目标函数的规划问题)(5)目标规划(具有不同优先级的目标和偏差的规划问题)(6)动态规划(求解多阶段决策问题的最优化方法)优化模型求解无约束规划fminsearch fminbnd线性规划linprog非线性规划fmincon多目标规划(计算有效解)目标加权、效用函数动态规划(倒向、正向)整数规划(分支定界法、枚举法、LINDO)统计方法(回归分析)(1)回归分析----对具有相关关系的现象,根据其关系形态,选择一个合适的数学模型,用来近似地表示变量间的平均变化关系的一种统计方法(一元线性回归、多元线性回归、非线性回归)(2)回归分析在一组数据的基础上研究这样几个问题:建立因变量与自变量之间的回归模型(经验公式)对回归模型的可信度进行检验判断每个自变量对因变量的影响是否显著判断回归模型是否适合这组数据判断回归模型对进行预报或控制[b,bint,r,rint,stats]=regress。
SPSS双变量相关性分析

数学建模SPSS双变量相关性分析关键词: 数学建模相关性分析SPSS摘要: 在数学建模中, 相关性分析是很重要的一部分, 尤其是在双变量分析时, 要根据变量之间的联系建立评价指标, 并且通过这些指标来进行比对赋值而做出评价结果。
本文由数学建模中的双变量分析出发, 首先阐述最主要的三种数据分析: Pearson系数, Spearman系数和Kendall系数的原理与应用, 再由实际建模问题出发, 阐述整个建模过程和结果。
rs计算公式为:r s=∑(P i−P ave)(Q i−Q ave)√∑(P i−P ave)2(Q i−Q ave)2下面以2013年“五一”大学生数学建模大赛为例:要检验变量之间的相关性, 利用SPSS进行双变量相关分析即可。
因附录给出的数据存在许多错误, 因此在进行分析前需要进行简单筛选。
由于测量人数较多, 直接在EXCEL中将测量数据为0或者过大的行全部删除即可。
双变量相关分析中有三种数据分析: Pearson系数, Spearman系数和Kendall 系数。
为了确定合适的分析类型, 我们需要利用SPSS对数据进行正态检验。
通过观察发现, 附录中给出的男女体质指标是不一样的, 并且通过我们调查, 男女体质数据的分布会有很大不同, 因此在本问接下来的讨论中, 我们把男女分开讨论。
正太检验结果如下表5.1.1.1, Sig>0.05为符合正态分布:男生正态性检验Kolmogorov-Smirnov a Shapiro-Wilk统计量df Sig. 统计量df Sig.身高男总.032 762 .068 .982 762 .000台阶测试男总.120 762 .000 .906 762 .000体重男总.091 762 .000 .928 762 .000握力男总.075 762 .000 .923 762 .000肺活量男总.043 762 .002 .977 762 .000跳远男总.067 762 .000 .966 762 .000a.Lilliefors 显著水平修正女生正态性检验Kolmogorov-Smirnov a Shapiro-Wilk统计量df Sig. 统计量df Sig.身高女总.043 305 .200*.997 305 .770体重女总.076 305 .000 .915 305 .000跳远女总.045 305 .200*.981 305 .000位体前驱女总.056 305 .023 .984 305 .002台阶测试女总.109 305 .000 .919 305 .000肺活量女总.044 305 .200*.995 305 .445在SPSS中打开数据, 点击: 分析—>相关—>双变量, 打开对话窗口, 选择需要分析的两个变量、Spearman秩相关系数分析以及双侧检验。
以数学建模竞赛为例基于SPSS建立ARIMA模型

以数学建模竞赛为例基于SPSS建立ARIMA模型一、引言二、题目描述假设某市某项产品的月销售数据如下(单位:件):月份销售量1 2002 2203 2104 2405 2506 2607 2708 2809 29010 30011 32012 330请建立ARIMA模型预测未来3个月的销售量。
三、建立ARIMA模型1. 数据处理在SPSS软件中导入上述数据,然后对数据进行时间序列图的绘制和基本统计分析。
通过时间序列图可以观察到数据是否存在趋势和季节性,基本统计分析可以得到数据的均值、标准差等关键统计量。
2. 差分运算由于ARIMA模型对原始数据的平稳性要求比较高,因此在建立模型之前需要进行差分运算以确保数据的平稳性。
在SPSS软件中,可以使用“Transform”菜单中的“Difference”功能对数据进行一阶差分或二阶差分操作。
在这个例子中,我们选择进行一阶差分操作。
3. 自相关和偏自相关图在差分运算之后,需要使用自相关和偏自相关图来确定ARIMA模型的p和q值。
在SPSS软件中,可以使用“Analyze”菜单中的“Forecasting”功能来生成自相关和偏自相关图,并根据图形来判断p和q的取值。
4. 建立ARIMA模型在确定了差分次数、p和q的取值之后,可以使用“Analyze”菜单中的“Forecasting”功能来建立ARIMA模型。
在输入模型参数的时候,需要根据之前的分析结果来设定差分次数、自回归阶数和移动平均阶数。
四、结果分析通过以上步骤,我们成功地建立了ARIMA模型并进行了未来3个月销售量的预测。
预测结果显示未来3个月销售量分别为340、350和360件。
我们还对模型的拟合效果进行了检验,结果表明模型的残差序列符合白噪声特性,预测结果较为可靠。
五、总结本文以一次数学建模竞赛题目为例,介绍了如何使用SPSS软件建立ARIMA模型进行时间序列分析和预测。
通过差分运算、自相关和偏自相关分析、模型建立和诊断以及预测分析等步骤,我们成功地对未来3个月销售量进行了预测。
spss基本操作完整版

spss基本操作完整版SPSS(Statistical Package for the Social Sciences)是一款广泛应用于数据分析和统计建模的软件。
它提供了一系列强大的功能和工具,可以帮助用户处理和分析大量的数据,从而得到准确的结果并支持决策制定。
本文将介绍SPSS的基本操作,并分享一些常用功能的使用方法。
一、数据导入与编辑在使用SPSS进行数据分析之前,首先需要导入要分析的数据,并对其进行编辑和整理。
下面介绍SPSS中的数据导入与编辑的基本操作。
1. 导入数据打开SPSS软件后,点击菜单栏中的"文件"选项,再选择"打开",然后选择要导入的数据文件(一般为Excel、CSV等格式)。
点击"打开"后,系统将自动将数据导入到SPSS的数据视图中。
2. 数据编辑在数据视图中,我们可以对导入的数据进行编辑,例如添加变量、删除无效数据、更改数据类型等操作。
双击变量名或者右键点击变量名,可以对变量属性进行修改。
通过点击工具栏上的"变量视图"按钮,可以进入变量视图进行更复杂的编辑。
二、数据清洗与处理数据清洗和处理是数据分析的重要步骤,它们能够提高数据的质量和可靠性。
下面介绍SPSS中的数据清洗与处理的基本操作。
1. 缺失值处理在实际的数据分析过程中,往往会遇到一些数据缺失的情况。
SPSS 提供了处理缺失值的功能,例如可以使用平均值或众数填补缺失值,也可以剔除含有缺失值的样本。
2. 数据筛选与排序当数据量较大时,我们通常需要根据一定的条件筛选出符合要求的数据进行分析。
SPSS提供了数据筛选和排序的功能,可以按照指定的条件筛选数据,并可以按照某个或多个变量进行数据排序。
三、统计分析SPSS作为统计分析的重要工具,提供了丰富的统计分析功能,下面介绍部分常用的统计分析方法。
1. 描述统计描述统计是对数据进行整体概述的统计方法,包括计数、求和、平均值、中位数、标准差、最大值、最小值等指标。
统计分析入门与应用 SPSS 中文版 + SmartPLS 4 中文版说明书

統計分析入門與應用序科學研究就是不斷地探究人、事、物的真理,其目的在追求「真、善、美」即使無法達到盡善盡美,但是仍盡量貼近事實,我們經過20多年的多變量分析學習和實戰經歷,提供正確的多變量分析研究論文參考範例:有量表的發展、敘述性統計,相關分析、卡方檢定、平均數比較、因素分析、迴歸分析、區別分析和邏輯迴歸、單因素變異數分析、多變量變異數分析、典型相關分析、信度和效度分析、聯合分析多元尺度和集群分析,回歸(Regression) 模型、路徑分析(Path analysis) 和Process功能分析、第二代統計技術–結構方程模式(SEM),終於完成《統計分析入門與應用SPSS (中文版) + SmartPLS 4 (PLS-SEM)》,希望能幫助更多需要資料分析的人,尤其是正確的報告多變量分析的結果。
近年來,多變量統計分析慢慢地產生巨大變化,例如:SEM的演進、以評估研究模式的適配。
發展量表,CB_SEM和PLS_SEM的區別,辨別模式的指定,反映性和形成性指標的發展和模式的指定,二階和高階潛在變數的使用,中介和調節變數的應用,Formative (形成性) 的評估、中介因素的5種型態、調節效果的多種型態、測量恆等性(Measurement Invariance)、MGA呈現的範例、被中介的調節(中介式調節)、被調節的中介(調節式中介)。
作者歷經多場演講和工作坊,也參加多場講座,培訓班,研討會,很多參加者表示不清楚如何正確的提供分析結果,另外,我們審過很多投稿到期刊的論文後,發現很多論文寫得不錯,但是由於分析或報告結果不精確,而被拒稿了。
《統計分析入門與應用SPSS (中文版) + SmartPLS 4 (PLS-SEM)》的完成可以幫助更多需要正確報告多變量分析的研究者,順利發表研究成果於研討會、期刊和碩博士論文。
感謝眾多讀者對於《多變量分析最佳入門實用書SPSS + LISREL》、《統計分析SPSS (中文版) + PLS_SEM (SmartPLS)》和《統計分析入門與應用SPSS (中文版) + SmartPLS 3 (PLS_SEM)》第二版&第三版的厚愛,本書已經更新至SmartPLS 4版本。
SPSS的参数检验和非参数检验
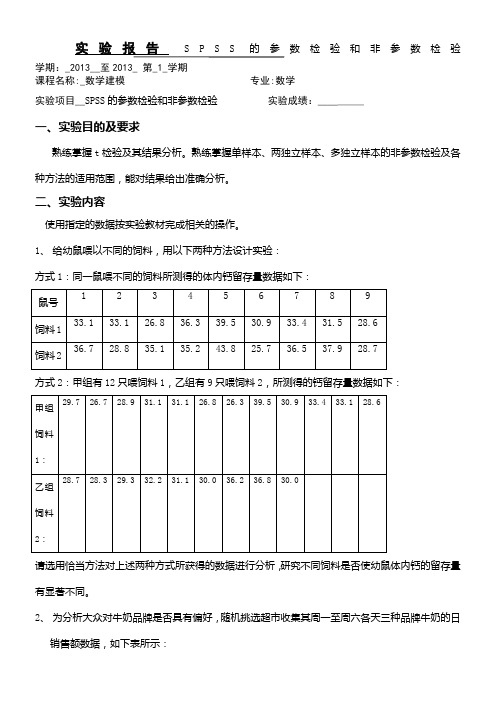
实验报告数检验和非参数检验学期:_2013__至2013_ 第_1_学期课程名称:_数学建模专业:数学实验项目__SPSS的参数检验和非参数检验实验成绩:_____一、实验目的及要求熟练掌握t检验及其结果分析。
熟练掌握单样本、两独立样本、多独立样本的非参数检验及各种方法的适用范围,能对结果给出准确分析。
二、实验内容使用指定的数据按实验教材完成相关的操作。
1、给幼鼠喂以不同的饲料,用以下两种方法设计实验:方式1:同一鼠喂不同的饲料所测得的体内钙留存量数据如下:方式2:甲组有12只喂饲料1,乙组有9只喂饲料2,所测得的钙留存量数据如下:请选用恰当方法对上述两种方式所获得的数据进行分析,研究不同饲料是否使幼鼠体内钙的留存量有显著不同。
2、为分析大众对牛奶品牌是否具有偏好,随机挑选超市收集其周一至周六各天三种品牌牛奶的日销售额数据,如下表所示:请选用恰当的非参数检验方法,以恰当形式组织上述数据进行分析,并说明分析结论。
实验报告附页三、实验步骤(一)方式1:1、打开SPSS软件,根据所给表格录入数据,建立数据文件;2、选择菜单Analyze-Compare means-Paired-Samples T Test,出现窗口;3、把检验变量饲料1,饲料2 选择到Paired Variables框,单击OK。
方式2:1、打开SPSS软件,根据所给表格录入数据,建立数据文件;2、选择菜单Analyze-Compare means-Independent-Samples T Test,出现窗口3、选择检验变量饲料到Test Variable(s)框中。
4、选择总体标志变量组号到Grouping Variables框中。
5、单击Define Groups按钮定义两总体的标志值1、2,单击OK。
(二)1、打开SPSS软件,根据所给表格录入数据,建立数据文件;2、选择菜单Analyze->Nonparametric->k Independent sample3、选择待检验的若干变量入包装1,包装2,包装3到Test Variable(s)框中;4、选择推广的平均秩检验(Friedman检验),单击OK。
SPSS术语中英文对照分析

SPSS术语中英文对照分析SPSS(Statistical Package for the Social Sciences)是一种功能强大的统计分析软件,常用于社会科学和商业领域的数据分析。
下面是一些SPSS术语的中英文对照分析:1. Data file - 数据文件2. Variable - 变量3. Value - 值4. Data view - 数据视图5. Variable view - 变量视图6. Case - 数据行(案例)7. Frequency - 频数8. Mean - 平均值9. Median - 中位数10. Mode - 众数11. Standard deviation - 标准偏差12. Minimum - 最小值13. Maximum - 最大值14. Range - 范围15. Missing values - 缺失值16. Transform - 转换17. Recode - 重新编码19. Merge files - 合并文件20. Split file - 分割文件21. Sort cases - 排序案例22. Descriptive statistics - 描述性统计23. Inferential statistics - 推断统计24. T-test - t检验25. Analysis of variance (ANOVA) - 方差分析26. Chi-square - 卡方检验27. Regression - 回归28. Correlation - 相关性分析29. Crosstabs - 交叉表30. Cluster analysis - 聚类分析31. Factor analysis - 因子分析32. Hypothesis testing - 假设检验33. Normal distribution - 正态分布34. Skewness - 偏度35. Kurtosis - 峰度36. Outliers - 异常值37. Confidence interval - 置信区间38. Significance level - 显著性水平39. Type I error - Ⅰ型错误40. Type II error - Ⅱ型错误这些术语是SPSS中经常使用的,掌握它们的中英文对照对于学习和使用SPSS非常重要。
数学建模 强大又简单spss统计分析

数学建模强大又简单spss统计分析一、软件介绍(一)简介SPSS(Statistical Product and Service Solutions),“统计产品与服务解决方案”软件,用于统计学分析运算、数据挖掘、预测分析和决策支持任务等相关数据统计分析。
SPSS是世界上最早采用图形菜单驱动界面的统计软件,它最突出的特点就是操作界面友好,输出结果美观。
它将几乎所有的功能都以统一、规范的界面展现出来,使用Windows的窗口方式展示各种管理和分析数据方法的功能,对话框展示出各种功能选择项。
用户只要掌握一定的Windows操作技能,精通统计分析原理,就可以使用该软件为特定的科研工作服务。
(二)操作窗口1.数据窗口也称为数据编辑器,此窗口类似于Excel窗口,SPSS处理数据的主要工作全在此窗口中进行。
又分为两个视图:数据视图用于显示具体的数据,一行代表个观测个体(在SPSS中称为Case),一列代表一个属性(在SPSS中称为 Variable);变量视图则专门显示有关变量的信息:变量名称、类型、格式等。
图1 数据窗口2.输出窗口也称为结果査看器,此窗口用于输出分析结果。
整个窗口分两个区:左边为目录区,是SPSS分析结果的一个目录;右边是内容区,是与目录一一对应的内容。
图2 输出窗口3.语法窗口也称为语法编辑器。
SPSS最大的优势在于其简单易用性,即菜单对话框式的操作。
语法编程适用于高级分析人员。
图3 语法窗口4.脚本窗口SPSS脚本是用Sax Basic语言编写的程序,它可构建一些新的自定义的对话框。
脚本可用于使SPSS内部操作自动化、使结果格式自定义化、实现SPSS新功能、将SPSS与VB和VBA兼容应用程序连接起来。
图4 脚本窗口二、主要功能(一)基本功能SPSS的基本功能包括数据管理、统计分析、图表分析、输出管理等等。
(二)统计分析功能SPSS统计分析过程包括描述性统计、均值比较、一般线性模型、相关分析、回归分析、对数线性模型、聚类分析、数据简化、生存分析、时间序列分析、多重响应等几大类,每类中又分好几个统计过程,比如回归分析中又分线性回归分析、曲线估计、Logistic回归、Probit回归、加权估计、两阶段最小二乘法、非线性回归等多个统计过程,而且每个过程中又允许用户选择不同的方法及参数。
SPSS在数学建模中的应用

1
SPSS简介
定义变量名(Name)时,应注意: (1)变量名可为汉字或英文,英文的第一个字 符必须为字母,后面可跟任意字母、数字、句 点或@、#、_、$等; (2)变量名不能以句点结尾; (3)定义时应避免最后一个字符为下划线“_” (因为某些过程运行时自动创建的变量名的最 后一个字符有可能为下划线); (4)变量的长度一般不能超过8个字符; (5)每个变量名必须保证是唯一的,不区分大 小写。
1
SPSS简介
应用
广泛的应用于统计、应用数学、经济、市 场营销、心理、卫生统计、生物、企业管理、 气象、社会学等领域。 其分析过程包括:调查设计、数据收集、 数据存取和管理、数据分析、数据检验、数据 挖掘、数据展示等。还有一系列附加模块和独 立模块产品以加强它的分析功能。它的图形窗 口界面使其非常简单易用但却具有满足各种分 析要求的数据管理、统计分析功能及各种报表 方法。
SPSS采用类似EXCEL表格的方式输入与管理数
据,数据接口较为通用,能方便的从其他数据库中
读入数据。
其统计过程包括了常用的、较为成熟的统计 过程,完全可以满足非统计专业人士的工作需要
1
SPSS简介
功能
样本数据的描述和预处理; 假设检验(包括参数检验、非参数检验及 其他检验); 方差分析 相关分析 回归分析 聚类分析 判别分析 因子分析 时间序列分析 可靠性分析
单击数据编辑窗口左下方的变量视图(Variable View)标 签,进入变量定义窗口。可定义: 变量名称(Name) 变量类型(Type) 变量宽度(Width) 小数点位数(Decimal) 变量标签(Label) 变量值标签(Values) 缺失值的定义方式(Missing) 变量的显示宽度(Columns) 变量显示的对齐方式(Align) 变量的度量标准(Measure) 变量的的应用
数学建模比赛需要什么软件及其介绍

数学建模比赛必备1matlab(矩阵实验室)2 lingo和lingo(线性规划)3 SPSS<统计)其中MATLAB是最重要的也是最常用的4还有就是最好学好c语言这个软件和有很多的相似之处其中统计软件:SPSS,SAS,STATA。
解决运筹学的模型:lingo5 PS:SAS很强大的,如果没有接触过还是不要学的好。
其实SPSS解决一下就可以了,只是SAS画出来的图很好看。
6另外还有时间可以看看另两个软件SMARTDRAWLATELX什么是数学建模数学建模(Mathematical Modelling)是一种数学的思考方法,是“对现实的现象通过心智活动构造出能抓住其重要且有用的特征的表示,常常是形象化的或符号的表示。
”从科学,工程,经济,管理等角度看数学建模就是用数学的语言和方法,通过抽象,简化建立能近似刻画并“解决”实际问题的一种强有力的数学工具。
顾名思义,modelling一词在英文中有“塑造艺术”的意思,从而可以理解从不同的侧面,角度去考察问题就会有不尽的数学模型,从而数学建模的创造又带有一定的艺术的特点。
而数学建模最重要的特点是要接受实践的检验,多次修改模型渐趋完善的过程。
3、竞赛的内容竞赛题目一般来源于工程技术和管理科学等方面经过适当简化加工的实际问题,不要求参赛者预先掌握深入的专门知识,只需要学过普通高校的数学课程。
题目有较大的灵活性供参赛者发挥其创造能力。
参赛者应根据题目要求,完成一篇包括模型假设、建立和求解、计算方法的设计和计算机实现、结果的分析和检验、模型的改进等方面的论文(即答卷)。
竞赛评奖以假设的合理性、建模的创造性、结果的正确性和文字表述的清晰程度为主要标准。
4、竞赛的步骤建模是一种十分复杂的创造性劳动,现实世界中的事物形形色色,五花八门,不可能用一些条条框框规定出各种模型如何具体建立,这里只是大致归纳一下建模的一般步骤和原则:1)模型准备:首先要了解问题的实际背景,明确题目的要求,收集各种必要的信息.2)模型假设:为了利用数学方法,通常要对问题做必要的、合理的假设,使问题的主要特征凸现出来,忽略问题的次要方面。
以数学建模竞赛为例基于SPSS建立ARIMA模型

以数学建模竞赛为例基于SPSS建立ARIMA模型引言数学建模竞赛在当前教育领域中占据着重要的地位,它不仅可以培养学生的数学建模能力,还可以锻炼他们的团队协作精神和解决实际问题的能力。
在竞赛中,构建合适的数学模型是至关重要的一环。
本文以数学建模竞赛为例,介绍如何基于SPSS软件建立ARIMA 模型,从而对数据进行预测和分析。
竞赛背景假设我们参加了一个数学建模竞赛,竞赛题目要求我们对某公司过去几年的销售数据进行建模,并对未来销售情况进行预测。
我们获得的数据包括了每个月的销售额,我们的任务是通过建立合适的数学模型来对未来的销售额进行预测。
ARIMA模型简介ARIMA(Autoregressive Integrated Moving Average)模型是一种常用的时间序列预测模型。
它的主要思想是根据历史数据的特点来拟合未来的数据,即通过过去的数据来预测未来的情况。
ARIMA模型是由自回归(AR)模型、差分(I)模型和移动平均(MA)模型三部分组成的。
AR模型表示时间序列数据与自身的滞后值相关,MA模型表示时间序列数据与滞后的预测误差相关,而I模型则是对时间序列数据进行差分操作,使其变得平稳。
建立ARIMA模型的步骤我们将要对竞赛中所提供的销售数据进行ARIMA模型的预测和分析。
下面是建立ARIMA模型的主要步骤:1. 数据的预处理我们需要对数据进行预处理,包括缺失值的处理、异常值的处理以及数据的平稳化等。
在SPSS软件中,我们可以通过数据清洗和处理模块进行相关的操作,确保数据的质量和可靠性。
2. 模型的识别接下来,我们需要对时间序列数据进行模型的识别,即确定ARIMA模型中的参数。
在SPSS软件中,我们可以通过自动识别ARIMA模型的功能来快速确定模型的参数,也可以通过ACF(自相关函数)和PACF(偏自相关函数)来进行手动识别。
3. 模型的估计确定了模型的参数后,我们需要对模型进行估计,即利用历史数据来拟合ARIMA模型。
以数学建模竞赛为例基于SPSS建立ARIMA模型

以数学建模竞赛为例基于SPSS建立ARIMA模型一、引言数学建模竞赛是在各种学科领域中,通过数学方法解决实际问题的一种竞赛形式。
参加数学建模竞赛需要队员具备一定的数学建模能力,包括数学建模的理论知识、数学工具的使用和数学模型的构建能力。
在数学建模竞赛中,队员需要根据给定的问题和数据,使用数学方法建立合适的数学模型,并进行模型的求解和分析。
数学建模竞赛中的数学建模和数据分析方法对于队员来说是至关重要的。
在本文中,我们将以数学建模竞赛的一个实际问题为例,演示如何利用SPSS软件建立ARIMA模型对相关数据进行预测和分析。
我们将首先介绍ARIMA模型的基本原理和建模流程,然后利用SPSS软件对给定的数据进行ARIMA模型的建立和检验,最后对模型的效果进行评价并给出相关建议。
二、ARIMA模型的基本原理ARIMA模型是时间序列分析中常用的一种模型,用于对时间序列数据进行预测和分析。
ARIMA模型包括自回归(AR)、差分(I)和移动平均(MA)三部分,分别表示时间序列数据中的自相关、季节性趋势和误差项。
ARIMA模型的建立包括模型的识别、参数的估计和模型的检验三个步骤。
1. 模型的识别:首先需要对时间序列数据进行平稳性和自相关性检验,确定ARIMA模型的参数p、d、q。
p表示自回归的阶数,d表示差分的阶数,q表示移动平均的阶数。
2. 参数的估计:利用最大似然估计等方法,对ARIMA模型中的参数进行估计,得到模型的估计系数。
3. 模型的检验:对估计的ARIMA模型进行残差分析和预测检验,对模型的拟合效果进行评价,并进行模型的调整和优化。
三、SPSS建立ARIMA模型的步骤在SPSS软件中,利用时间序列建模功能可以方便地进行ARIMA模型的建立和分析。
下面我们以一个实际的数据为例,演示在SPSS中建立ARIMA模型的具体步骤。
1. 数据导入:首先在SPSS中导入要分析的时间序列数据,可以是Excel表格或者文本文件格式。
以数学建模竞赛为例基于SPSS建立ARIMA模型

以数学建模竞赛为例基于SPSS建立ARIMA模型数学建模竞赛是一种学生利用数学方法和技巧解决实际问题的比赛形式,它旨在培养学生的数学建模能力和创新意识。
在数学建模竞赛中,参赛队伍通常需要根据提供的真实数据,通过建立数学模型来预测未来的趋势和变化。
时间序列分析是数学建模竞赛中常用的方法之一,而ARIMA模型则是时间序列分析中的经典模型之一。
本文将以数学建模竞赛为例,基于SPSS软件建立ARIMA模型,展示其在实际问题中的应用。
一、数学建模竞赛及其意义数学建模竞赛是在激发学生对数学的兴趣和学习热情的培养他们的数学建模能力和创新意识的一种有效途径。
通过竞赛形式,学生们能够在实际问题中应用所学的数学知识和技巧,从而提高解决实际问题的能力。
数学建模竞赛也为学生提供了展示自己才华的舞台,激发了他们的学习动力和创新潜力。
二、ARIMA模型简介ARIMA模型是一种常用的时间序列分析方法,其全称为自回归积分移动平均模型(Autoregressive Integrated Moving Average Model)。
ARIMA模型主要用于分析时间序列数据的趋势和周期性变化,能够帮助人们预测未来的趋势和变化。
ARIMA模型包括自回归项(AR项)、差分项(I项)、移动平均项(MA项)三个部分,分别代表了时间序列数据的自相关、趋势和随机性成分。
通过调整这些参数,可以建立不同的ARIMA模型来描述和预测时间序列数据。
三、基于SPSS建立ARIMA模型的步骤SPSS是一种常用的统计分析软件,其强大的数据处理和分析功能使得建立ARIMA模型变得简单可行。
下面将介绍基于SPSS建立ARIMA模型的步骤:1. 数据准备:需要准备好要分析的时间序列数据,确保数据完整、准确和连续。
在SPSS中,可以选择“导入数据”功能将数据导入软件中进行后续分析。
2. 检查时间序列数据的平稳性:在建立ARIMA模型之前,需要对时间序列数据进行平稳性检验。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第六章 聚类分析
词汇
Classify 聚类分析
K-Means Cluster 快速聚类法
Iterate 迭代
Convergence Criterion 收敛准则
Cluster membership 聚类成员
P-P plots P-P 图 Q-Q plots Q-Q 图
Options 选择项 Parametric 参数
Correlate 相关分析 Bivariate 两变量的
例:分析一元样本的一些数字特征:
单击 Analyze(分析)--Descriptive Statistics(描述性统计量)―Descriptive(描述)―Options(设置)
添入自变量、因变量和选择合适的方法,本例中选择
Stepwise(逐步回归)
然后单击 Statistics选择一些统计量 ,例如: Estimates (估计值 )、Confidence intervals (置信区间)、Covariance matrix (协方差矩阵 )
R squared change (修正的复相关系数平方)
3. 单击Analyze-Nonparametric Tests――1 sample K—S 接着展开One—sample Kolmogorov—Smirnov
Test对话框(选择合适的检验总体)――OK
?例:分析某组p元样本的相关矩阵:
单击Analyze(分析)-Correlate(相关)-Bivariate(两变量) 选择合适的相关系数:例如:Pearson (适合正态) or Spearman(适合非正态)――OK
然后单击 plots 选择合适的变量作图,例如:
X轴:DEPENDENT 因变量
Y轴:ZPRED:标准化预测值
Or X轴:DEPENDENT 因变量
Y轴:SRESID:学生(化)残差
并选中 Standardized Residual Plots中的 Histogram和 Normal Probability Plots
第二章 线性回归分析
词汇
Regression 回归 Liner 线性
Dependent 因变量 Independent 自变
Stepwise 逐步 Enter 强迫代入(自变量全选)
Statistics统计量 Estimates 估计值
单击 Statistics(统计量)在Function coefficients(判别函数系数)中选择Fisher’s
单击 Classify(分类)在 Use Covariance Matrix 中选择一个:
Within-groups 组内协方差矩阵(此题选择这个)
Separate-groups 分组协方差矩阵
单击Itertate(迭代),在Maximum Itertations(最大迭代数)中添入:20,在Convergence Criterion(收敛准则)中添入0.02。
根据SPSS的分析结果,首先看列文方差齐次性检验的结果,再看方差分析表ANOVA,读取p-值,给出结论。
图形表示法:
Histogram(直方图)
单击Graphs(图形)-Histogram(直方图),将变量Y添入Variable(变量),可以选择Display normal curve(显示正态曲线),然后在Panel by(版面)中将变量X添入Rows(行)或Columns(列)
Confidence intervals 置信区间
Covariance matrix 协方差矩阵
R squared change 修正的复相关系数平方
Plots 图 有如下选项:
DEPENDENT 因变量
ZPRED:标准化预测值
ZRESID:标准化残差
DRESID:删除残差
ADJPRED:修正后的预测值
接着单击Save 可以保存一些变量。
最后单击 OK
第三章 方差分析
one way ANOVA (analysis of variance)
单因素方差分析
Homogeneity of variance test ,Levene
列文方差齐性检验
Std. Deviation 标准差 std.=standard
Residual:残差。有以情况:
Unstandardized:未标准化残差
Standardized:标准化残差
Studentized:学生(化)残差
分析后的主要结果:
Descriptive Statistics 描述性统计量
Correlations 相关分析
Model Summary 模型主要结论
例子1:请将样本数据按快速聚类法进行聚类分析。根据变量:净资产收益率(X1)、净资产增长率(X2)、净利润增长率(X3)、主营业务收入增长率(X4)将样本分成三类。
单击Classify(分类)-K-Means Cluster(快速聚类法),将变量X1、X2、X3、X3,添入Variables框;在Number of Clusters(即聚类分析的类别数)处输入需要聚合的组数,本例为3;在聚类方法上有两种:Iterate and classify指先定初始类别中心点,而后按K-means算法作叠代分类,Classify only指仅按初始类别中心点分类,本例选用前一方法。
Hierarchical Cluster 系统聚类分析(谱系图法)
Dendrogram 系统树图(谱系图)
Icicle 冰柱图
Euclidean distance 欧氏距离
Between-groups linkage 类间平均链锁法;
Within-groups linkage 类内平均链锁法;
第一章ansform 转换 Analyze 分析 Graphs 图形
Descriptive Statistics 描述性统计量
Mean 均值 Median 中位数 Mode 众数
Sum 和 Std. deviation 标准差 Variance 方差
SRESID:学生(化)残差
SDRESID:学生(化)删除残差
Predicteds Values:预测值 有以下情况:
Unstandardized:未标准化的预测值。
Standardized:标准化的预测值。
Adjusted:修正后的预测值。
S.E.of Mean Prediction:预测值的标准误差。
Univariate descriptive 单变量描述性统计量
Principal components 主成分分析法
Correlation matrix 相关系数矩阵
Covariance matrix 协方差矩阵
Display 显示 Extract 提取
Unrotated factor solution 非旋转因子解
Nearest neighbor 最短距离法;
Furthest neighbor 最长距离法;
Centroid clustering:重心法,应与欧氏距离平方法一起使用;
Median clustering:类平均距离法,应与欧氏距离平方法一起使用;
Ward's method:离差平方和法,应与欧氏距离平方法一起使用。
(然后可选择某些数字特征)――OK
?例:分析某组样本是否来自一元正态分布:
1.数字特征:Skewness 偏度 Kurtosis 峰度(同上)
2. 图形 单击 Graphs (图形)选择合适的图形 例如
Histogram 直方图 P-P plots P-P 图
Q-Q plots Q-Q 图
Scree plot 碎石图
在 Extract 提取中
Number of factors添入公因子的数目,默认是2
单击 Continue 和 OK
分析结果中主要看1.Scree plot(此图中显示每个主成分的方差大小,即能看出每个主成分的贡献率) ponent Matrix 主成分关于原变量的线性关系
Scree plot 碎石图
Number of factors 公因子的数目
例子:请根据给出的数据进行主成分分析。
单击 Analyze(分析) ->Date reduction (数据简化(降维))-> Factor (因子);单击 Extraction(提取):
在 Method(方法) 中选择:
例子:请根据给出的数据进行单因素方差分析。分析在企业品牌的不同时,净资产收益率是否有差别?(记X为企业品牌是分类变量,Y为净资产收益率是数值变量)
单击 Analyze(分析)--Compare Means(均值比较) ―― One Way ANOVA (单因素方差分析) 将变量Y添入Dependent List(因变量),变量X添入Facter(因子)。 然后单击 Options(选项) ,选择Descriptive(描述行统计量)和Homogeneity of variance test ,Levene。 最后单击 OK
Function coefficients 判别函数系数
Fisher’s
Within-groups Covariance Matrix 组内协方差矩阵
Separate-groups Covariance Matrix 分组协方差矩阵
例子:请根据给出的数据进行判别分析。现有数据已按企业绩效的不同分为三类。每一类都有若干变量,请根据这56样本请给出判别函数。