社工SPSS作业
SPSS作业2

二.
1〕.试录入以下数据文件,保存为“数据1.sav”。
2〕.试录入以下数据文件,保存为“数据2.sav”。
3〕.试将数据2合并到数据1,合并后的数据文件另存为“数据3.sav”。
4〕.将工资进行重编码,2000以下〔含2000〕为1,2000-3000为2,3000-4000为 3,4000以上为4,重编码的结果保存为“工资等级”。
新数据文件保存为“数据4.sav”。
5〕.求出各职工刚进入公司时的年龄,保存为“初入年龄”。
新数据文件保存为“数据5.sav”。
6〕.试按各职员的工资数进行排秩,排秩要求工资最高的排为第一,相同数额取平均等级。
排秩后的数据文件保存为“数据6.sav”。
7〕.试按各职员的工资数分性别进行排序,要求先排男性,后排女性。
同一性别按工资从高到低排列。
排序后的数据文件保存为“数据7.sav”。
8〕.试寻找一个新数据文件,将其中一些新变量合并到数据文件7中,合并后的新数据文件保存为“数据8.sav”。
北语21春《SPSS统计分析进阶》离线作业满分答案

北语21春《SPSS统计分析进阶》离线作业满分答案第一题:描述性统计分析数据准备操作步骤1. 打开SPSS,导入数据集。
2. 在菜单栏中选择“分析”→“描述性统计”→“频率”。
3. 将年龄、性别、收入和受教育程度变量拖动到“变量”框中。
4. 点击“确定”执行分析。
满分答案根据分析结果,我们可以得到以下描述性统计结果:- 年龄的平均值为35岁,标准差为10岁。
- 性别的分布中,男性占60%,女性占40%。
- 收入的平均值为5000元,标准差为2000元。
- 受教育程度的分布中,初中及以下占30%,高中/中专占40%,大专占20%,本科及以上占10%。
第二题:t检验数据准备我们需要准备一份数据集,数据集中包含两个变量:治疗前得分(pre_score)和治疗后得分(post_score)。
操作步骤1. 打开SPSS,导入数据集。
2. 在菜单栏中选择“分析”→“比较平均值”→“独立样本t检验”。
3. 将治疗前得分和治疗后得分变量拖动到“变量”框中。
4. 点击“确定”执行分析。
满分答案根据分析结果,我们可以得到以下t检验结果:- t值为2.56,p值为0.01。
- 治疗后的得分显著高于治疗前的得分(p<0.05)。
第三题:方差分析数据准备我们需要准备一份数据集,数据集中包含两个变量:组别(group)和得分(score)。
操作步骤1. 打开SPSS,导入数据集。
2. 在菜单栏中选择“分析”→“比较平均值”→“单因素方差分析”。
3. 将组别变量拖动到“因子”框中,将得分变量拖动到“变量”框中。
4. 点击“确定”执行分析。
满分答案根据分析结果,我们可以得到以下方差分析结果:- F值为3.34,p值为0.03。
- 组别对得分有显著影响(p<0.05)。
第四题:回归分析数据准备操作步骤1. 打开SPSS,导入数据集。
2. 在菜单栏中选择“分析”→“回归”→“线性”。
3. 将年龄、性别、收入和受教育程度变量拖动到“自变量”框中,将目标变量拖动到“因变量”框中。
SPSS操作实验作业1(附答案)

SPSS操作实验 (作业1)作为华夏儿女都曾为有着五千年的文化历史而骄傲过,作为时代青年都曾为中国所饱受的欺压而愤慨过,因为我们多是炎黄子孙。
然而,当代大学生对华夏文明究竟知道多少呢某研究机构对大学电气、管理、电信、外语、人文几个学院的同学进行了调查,各个学院发放问卷数参照各个学院的人数比例,总共发放问卷250余份,回收有效问卷228份。
调查问卷设置了调查大学生对传统文化了解程度的题目,如“佛教的来源是什么”、“儒家的思想核心是什么”、“《清明上河图》的作者是谁”等。
调查问卷给出了每位调查者对传统文化了解程度的总得分,同时也列出了被调查者的性别、专业、年级等数据信息。
请利用这些资料,分析以下问题。
问题一:分析大学生对中国传统文化的了解程度得分,并按了解程度对得分进行合理的分类。
问题二:研究获得文化来源对大学生了解传统文化的程度是否存在影响。
要求:直接导出查看器文件为.doc后打印(导出后不得修改)对分析结果进行说明,另附(手写、打印均可)。
于作业布置后,1周内上交本次作业计入期末成绩答案问题一操作过程1.打开数据文件作业。
同时单击数据浏览窗口的【变量视图】按钮,检查各个变量的数据结构定义是否合理,是否需要修改调整。
2.选择菜单栏中的【分析】→【描述统计】→【频率】命令,弹出【频率】对话框。
在此对话框左侧的候选变量列表框中选择“X9”变量,将其添加至【变量】列表框中,表示它是进行频数分析的变量。
3.单击【统计量】按钮,在弹出的对话框的【割点相等组】文本框中键入数字“5”,输出第20%、40%、60%和80%百分位数,即将数据按照题目要求分为等间隔的五类。
接着,勾选【标准差】、【均值】等选项,表示输出了解程度得分的描述性统计量。
再单击【继续】按钮,返回【频率】对话框。
4.单击【图表】按钮,勾选【直方图】和【显示正态曲线】复选框,即直方图中附带正态曲线。
再单击【继续】按钮,返回【频率】对话框。
最后,单击【确定】按钮,操作完成。
SPSS简单的练习作业

在上图中,分别显示了两两广告形式下销售额均值检验的结果。在SPSS中全部采用了LSD方法中的分布标准误,因此各种方法的前两列计算结果完全相同。表中第三列是检验统计量观测值在不同分布中概率值p,可以发现各种方法在检验敏感度上市存在差异的。以报纸广告与其他三种广告形式的两两检验结果为例,如果显著性水平α=0.05,在LSD方法中,报纸广告和广播广告的效果没有显著性差异,p值为0.412,与宣传品和体验均有显著性差异,概率p值分别是0.00,接近和0.021;但是在其他三种方法中,报纸广告只与宣传品广告存在显著性差异,而与体验无显著性差异。表中第一列星号的含义是,在显著性水平α=0.05的情况下,相应两总体的均值存在显著性差异,与第三列的结果相对应。
实验一SPSS的方差分析、相关分析与线性回归分析………………………17
1.单因素方差分析的基本操作……………………………………………17
2.单因素方差分析进一步分析的操作……………………………………18
作业一SPSS数据文件的建立和管理、数据的预处理
实验一SPSS数据文件的建立和管理、数据的预处理
【实验目的】
【实验结果与分析】
以上结果是广告形式对销售额的单因素方差的分析结果。可以看到,观测变量销售额的总离差平方和为26169.306;如果仅考虑“广告形式”单个因素的影响,则销售额总变差中,广告形式可解释的变差为5866.083,抽样误差引起的变差为20303.222,它们的方差(平均变差)分别为1955.361和145.023,相除所得的F统计量的观测值为13.483,对应的概率p值近似为0。如果显著性水平α为0.05,由于概率p值小于显著性水平α,则应拒绝零假设,认为不同广告形式对销售产生显著影响,它对销售额的影响效应不全为0。
北语20春《SPSS统计应用与分析》离线作业全分答案

北语20春《SPSS统计应用与分析》离线作业全分答案作业一题目一答案:根据题目要求,我们需要计算A组和B组的均值和标准差,并进行假设检验。
下面是具体步骤:1. 使用SPSS打开数据文件。
2. 在分析菜单中选择描述统计->描述。
3. 将变量A和B添加到变量框中。
4. 点击统计按钮,选择均值和标准差,并点击确定。
5. 点击图表按钮,选择直方图,并点击确定。
6. 点击OK按钮,进行数据分析。
7. 分析结果将会显示A组和B组的均值和标准差。
根据假设检验的要求,我们需要计算两组数据的t值和p值,下面是具体步骤:1. 在分析菜单中选择比较均值->独立样本t检验。
2. 将变量A和B添加到变量框中。
3. 点击OK按钮,进行数据分析。
4. 分析结果将会显示t值和p值。
题目二答案:根据题目要求,我们需要进行相关性分析。
下面是具体步骤:1. 使用SPSS打开数据文件。
2. 在分析菜单中选择相关->相关。
3. 将变量X和Y添加到变量框中。
4. 点击OK按钮,进行数据分析。
5. 分析结果将会显示相关系数和p值。
作业二题目一答案:根据题目要求,我们需要进行方差分析。
下面是具体步骤:1. 使用SPSS打开数据文件。
2. 在分析菜单中选择比较均值->单因素方差分析。
3. 将变量A添加到因子框中,将变量B添加到因变量框中。
4. 点击OK按钮,进行数据分析。
5. 分析结果将会显示方差分析表和p值。
题目二答案:根据题目要求,我们需要进行回归分析。
下面是具体步骤:1. 使用SPSS打开数据文件。
2. 在分析菜单中选择回归->线性。
3. 将变量X添加到因变量框中,将变量Y1和Y2添加到自变量框中。
4. 点击OK按钮,进行数据分析。
5. 分析结果将会显示回归方程和相关统计信息。
以上是《SPSS统计应用与分析》离线作业的全分答案。
SPSS期末大作业-完整版

第1题:基本统计分析1分析:本题要求随机选取80%的样本,因而需要选用随机抽样的方法,在此选择随机抽样中的近似抽样方法进行抽样。
其基本操作步骤如下:数据→选择个案→随机个案样本→大约(A)80 所有个案的%。
1、基本思路:(1)由于存款金额为定距型变量,直接采用频数分析不利于对其分布形态的把握,因而采用数据分组,先对数据进行分组再编制频数分布表。
此处分为少于500元,500~2000元,2000~3500元,3500~5000元,5000元以上五组。
分组后进行频数分析并绘制带正态曲线的直方图。
(2)进行数据拆分,并分别计算不同年龄段储户的一次存取款金额的四分位数,并通过四分位数比较其分布上的差异。
操作步骤:(1)数据分组:【转换→重新编码为不同变量】,然后选择存取款金额到【数字变量→输出变量(V)】框中。
在【名称(N)】中输入“存取款金额1”,单击【更改(H)】按钮;单击【旧值和新值】按钮进行分组区间定义。
存取款金额1频率百分比有效百分比累积百分比有效1.00 82 34.6 34.6 34.62.00 76 32.1 32.1 66.73.00 104.2 4.2 70.94.00 22 9.3 9.3 80.25.00 47 19.8 19.8 100.0 合计237 100.0 100.0(2)【分析→描述统计→频率】;选择“存款金额分组”变量到【变量(V)】框中;单击【图标(C)】按钮,选择【直方图】和【在直方图上显示正态曲线】;选中【显示频率表格】,确定。
(3)【数据→拆分文件】,选择“年龄”变量到【分组方式】框中,选中【比较组】和【按分组变量排序文件】,确定;【分析→描述统计→频率】,选择“存款金额”到【变量】框中,单击【统计量】按钮,选择【四分位数】→继续→确定。
统计量存(取)款金额20岁以下N有效1缺失0 百分位数25 50.00 50 50.00 7550.00 20~35岁N有效 131 缺失0 百分位数25 500.00 50 1000.00 755000.0035~50岁N有效 73 缺失0 百分位数25 500.00 50 1000.00 75 4500.0050岁以上N有效32缺失0 百分位数25 525.00 50 1000.00 752000.00结果及结果描述:频数分布表表明,有一半以上的人的一次存取款金额少于2000元,且有34.6%的人的存取款金额少于500元,19.8%的人的存取款金额多于5000元,下图为相应的带正态曲线的直方图。
社会统计学与SPSS应用作业(二)

社会统计与SPSS应用练习(二)1.已知十名学生身高和体重资料如下表,(1)根据下述资料算出身高和体重的皮尔逊相关系数和斯皮尔曼相关系数;(2)根据下述资料求出两变量之间的回归方程(设身高为自变量,体重为因变量)。
2.以下是婚姻美满与文化程度的抽样调查的结果,请计算婚姻美满与文化程度之3.以下为两位评判员对10名参赛人名次的打分。
试用斯皮尔曼等级相关系数来描述两评判员打分的接近程度。
要求:(1)求回归方程;(2)这是正相关还是负相关;(3)求估计标准误差;(4)用积差法求相关系数。
6.某10户家庭样本具有下列收入(元)和食品支出(元/周)数据:2)在95.46%把握下,当X=45时,写出Y的预测区间。
社会统计与SPSS 应用练习(二)参考答案1.已知十名学生身高和体重资料如下表,(1)根据下述资料算出身高和体重的皮尔逊相关系数和斯皮尔曼相关系数;(2)根据下述资料求出两变量之间的回归方程(设身高为自变量,体重为因变量)。
皮尔逊相关系数与回归方程n xy x y r 0.89-==22n xy x y b 0.659n x (x)y x a=b 54.479n ny=a+bx=-54.479+0.659x-==--=-∑∑∑∑∑∑∑斯皮尔曼相关系数2s 26d r 1-0.94n(n -1)==∑2.以下是婚姻美满与文化程度的抽样调查的结果,请计算婚姻美满与文化程度之s n =9×(30+18+4+7)+16×(18+7)+8×(4+7)+30×7=1229 d n =5×(30+8+3+4)+18×(3+4)+16×(8+3)+30×3=617[]s dc 2n n 1n (m 1)/m 2τ-==-0.183.以下为两位评判员对10名参赛人名次的打分。
试用斯皮尔曼等级相关系数来描述两评判员打分的接近程度。
2s 26d r 1-0.95n(n -1)==∑4.某原始资料为:22n xy x y r 0.95n xy x y b 0.267n x (x)y x a=b 11.477n ny=a+bx=-11.477+0.267x-==-==--=-∑∑∑∑∑∑∑22n xy x yb 0.782n x (x)y x a=b 22.014n ny=a+bx=22.014+0.782x-==--=∑∑∑∑∑∑∑要求:1)写出最小平方法计算的回归直线方程;2)在95.46%把握下,当X =45时,写出Y 的预测区间。
SPSS选修作业完整版

1、现有我国31个省、市、自治区2021年的GDP统计数据,数据中包括“省份〞、“GDP〞、“人口〞三个变量,数据见1.sav,试计算出人均GDP(人均GDP=GDP/人口)作为新变量保存。
解:如下列图:图1:数据1.sav2.数据2.sav显示了2021年我国各个地区制造业的就业人数,利用频数分析对不同地区的就业情况进行分析,显示四分位数、均值、标准差和偏度,绘制频率分布直方图和正态曲线,并判断分布形态。
图2:数据2.sav解:制造业万频率百分比有效百分比累积百分比有效.8 1111111111111111111111111111111 合计31统计量制造业万N有效31缺失0 均值标准差偏度偏度的标准误.421百分位数25 50 75分析:如上图所示,其分布形态为偏左分布,说明大多数地区在制造业就业的人数集中在100万左右,说明我国还有很大一局部地区在制造业行业还是比拟欠缺的,如果加强那么可以在很大一定程度上提高就业率。
3、数据3.sav记录了两个班级学生的数学和语文成绩,利用探索性分析该数据数学和语文成绩的最大值、最小值、众数和平均数,并检验样本数据的正态性。
图3:数据解:描述统计量标准误数学均值均值的 95% 置信区间下限上限5% 修整均值中值方差标准差极小值46极大值99范围53四分位距15偏度.269 峰度.228 .532语文均值均值的 95% 置信区间下限上限5% 修整均值中值方差标准差极小值47极大值99范围52四分位距14偏度.269 峰度.405 .5324、某地区水样中某种元素的含量为72毫克/升,现从某化工厂下游水域中抽取了20个水样,数据见4.sav,对样本数据进行单样本T检验,判断化工厂是否造成了下游水域水质的变化。
图4:数据:解:单个样本统计量N 均值标准差均值的标准误水样中某元素含量20 .647分析:在上图中,P值为0.000<0.05因此拒绝原假设,认为样本均值与总体均值有所不同,即判定化工厂造成了下游水域水质的变化。
spss第二版习题及答案

spss第二版习题及答案SPSS第二版习题及答案SPSS(Statistical Package for the Social Sciences)是一种统计分析软件,广泛应用于社会科学领域的数据分析和研究中。
对于学习SPSS的人来说,掌握习题并查看答案是提高技能的重要途径之一。
本文将为大家介绍一些SPSS第二版习题及其答案,希望能够帮助读者更好地理解和应用SPSS。
一、描述统计学习题1. 对于以下数据集,请计算平均数、中位数、众数、标准差和极差。
数据集:12,15,18,20,22,25,25,27,30,30答案:平均数:23.4,中位数:24,众数:25和30,标准差:6.89,极差:18 2. 对于以下数据集,请计算四分位数和箱线图。
数据集:10,12,15,18,20,22,25,25,27,30,30,32,35,40,45答案:第一四分位数(Q1):18.5,第二四分位数(Q2):25,第三四分位数(Q3):32.5,箱线图:参考附图1。
二、假设检验学习题1. 一个研究人员想要确定一种新的药物是否对治疗抑郁症有效。
他随机选择了100名患有抑郁症的患者,并将他们分为两组:实验组和对照组。
实验组接受新药物治疗,对照组接受安慰剂。
请使用SPSS进行假设检验,判断新药物是否显著改善了患者的抑郁症状。
答案:使用t检验进行假设检验。
设定零假设(H0):新药物对抑郁症状无显著改善;备择假设(H1):新药物对抑郁症状有显著改善。
根据样本数据计算得到t值和p值,如果p值小于设定的显著性水平(通常为0.05),则拒绝零假设,认为新药物对抑郁症状有显著改善。
三、相关性分析学习题1. 一个市场研究人员想要确定广告投入和销售额之间的相关性。
他收集了10个不同广告投入和销售额的数据。
请使用SPSS进行相关性分析,并解释结果。
答案:使用Pearson相关系数进行相关性分析。
根据样本数据计算得到相关系数r,r的取值范围为-1到1,如果r接近1,则表示广告投入和销售额之间存在正相关关系;如果r接近-1,则表示存在负相关关系;如果r接近0,则表示不存在线性相关关系。
SPSS测试题及答案

SPSS测试题及答案一、单项选择题(每题2分,共10题)1. 在SPSS中,数据视图和变量视图分别对应于哪种视图?A. 表格视图和属性视图B. 表格视图和字段视图C. 数据视图和属性视图D. 数据视图和字段视图答案:C2. SPSS中,哪个命令用于描述性统计分析?A. DESCRIPTIVESB. FREQUENCIESC. CROSSTABSD. MEANS答案:A3. 在SPSS中,如何将数据文件保存为Excel格式?A. 通过“文件”菜单选择“导出数据”B. 通过“文件”菜单选择“另存为”C. 通过“编辑”菜单选择“复制”D. 通过“视图”菜单选择“导出数据”答案:A4. SPSS中,哪个命令用于执行相关性分析?A. CORRELATIONSB. REGRESSIONC. T-TESTD. ANOVA答案:A5. 在SPSS中,如何对数据进行排序?A. 通过“数据”菜单选择“排序案例”B. 通过“分析”菜单选择“排序案例”C. 通过“转换”菜单选择“排序案例”D. 通过“文件”菜单选择“排序案例”答案:A6. SPSS中,哪个命令用于执行因子分析?A. FACTORB. CLUSTERC. DISCRIMINANTD. MANOVA答案:A7. 在SPSS中,如何创建一个新的变量?A. 通过“数据”菜单选择“计算变量”B. 通过“分析”菜单选择“计算变量”C. 通过“转换”菜单选择“计算变量”D. 通过“文件”菜单选择“计算变量”答案:C8. SPSS中,哪个命令用于执行聚类分析?A. CLUSTERB. FACTORC. DISCRIMINANTD. MANOVA答案:A9. 在SPSS中,如何对数据进行分组?A. 通过“数据”菜单选择“分组案例”B. 通过“分析”菜单选择“分组案例”C. 通过“转换”菜单选择“分组案例”D. 通过“文件”菜单选择“分组案例”答案:C10. SPSS中,哪个命令用于执行方差分析?A. ANOVAB. T-TESTC. CORRELATIONSD. REGRESSION答案:A结束语:以上是SPSS测试题及答案,希望能够帮助您更好地掌握SPSS 软件的使用方法和技巧。
spss统计分析习题答案

spss统计分析习题答案SPSS统计分析习题答案在统计学中,SPSS(Statistical Package for the Social Sciences)是一种常用的统计分析软件。
它提供了一系列功能强大的工具,用于数据处理、数据可视化和统计分析。
对于学习和实践统计分析的人来说,掌握SPSS的使用是非常重要的。
在学习SPSS统计分析过程中,我们常常会遇到一些习题,用以巩固和应用所学的知识。
下面,我将提供一些SPSS统计分析习题的答案,希望能对你的学习和实践有所帮助。
习题一:假设你有一份关于某个班级学生的成绩数据,包括数学成绩、语文成绩和英语成绩。
请使用SPSS计算每个学生的总分,并计算班级的平均总分。
答案:首先,打开SPSS软件并导入数据集。
然后,依次点击"Transform"、"Compute Variable"。
在弹出的对话框中,输入一个新的变量名,比如"Total_Score",然后在"Numeric Expression"框中输入数学成绩、语文成绩和英语成绩的变量名,并使用"+"符号将它们连接起来,最后点击"OK"按钮。
这样,SPSS将会计算每个学生的总分,并将结果保存在新的变量"Total_Score"中。
接下来,点击"Analyze"、"Descriptive Statistics"、"Frequencies"。
在弹出的对话框中,将"Total_Score"变量拖动到"Variables"框中,并点击"OK"按钮。
SPSS将会计算班级的平均总分,并在输出结果中显示。
习题二:假设你有一份关于某个公司员工的工资数据,包括性别、年龄和工资水平。
spss练习题(打印版)

spss练习题(打印版)SPSS练习题一、选择题1. 在SPSS中,数据视图(Data View)显示的是:- A. 变量标签- B. 变量名- C. 观察值- D. 变量类型2. 以下哪个命令可以用来计算描述性统计量?- A. `DESCRIPTIVES`- B. `FREQUENCIES`- C. `CORRELATIONS`- D. `T-TEST`3. 如果你想要在SPSS中查看数据集的变量信息,你应该使用:- A. `DATASET`- B. `VARIABLE`- C. `VIEW`- D. `INFO`二、填空题1. 在SPSS中,使用________命令可以进行变量的转换和计算。
2. 当你想要对数据进行分组分析时,可以使用SPSS的________功能。
3. 为了在SPSS中创建一个新的数据集,可以使用________命令。
三、简答题1. 描述如何在SPSS中进行单样本t检验,并解释其应用场景。
2. 解释在SPSS中使用交叉表(Crosstabs)的目的,并说明如何解读交叉表的结果。
四、操作题1. 假设你有一个包含学生成绩的数据集,变量包括:学生ID(ID),姓名(Name),数学成绩(Math),英语成绩(English)。
请写出在SPSS中计算数学和英语成绩平均值的步骤。
2. 如果你想要在SPSS中删除一个名为“Math”的变量,应该如何操作?参考答案一、选择题1. D2. A3. C二、填空题1. `COMPUTE`2. `SPLIT FILE`3. `SAVE AS`三、简答题1. 在SPSS中进行单样本t检验的步骤如下:- 首先,确保你的数据已经正确输入到SPSS的数据视图中。
- 选择“分析”菜单下的“比较均值”选项。
- 选择“单样本t检验...”。
- 将需要检验的变量移动到“检验变量”框中。
- 在“测试值”框中输入你想要比较的均值。
- 点击“确定”进行检验。
单样本t检验通常用于检验单个样本的均值是否显著不同于已知的总体均值。
spss软件练习题

spss软件练习题SPSS(Statistical Package for the Social Sciences)是一款广泛使用的统计分析软件,被广泛应用于社会科学、商业研究、医学研究等领域。
本文将为您提供SPSS软件练习题,帮助您熟悉和掌握该软件的使用。
1.数据导入与变量设置打开SPSS软件,导入名为"survey_data.sav"的数据文件。
该文件包含了一份调查问卷的数据,我们将使用这些数据进行后续的分析。
首先,通过菜单栏中的"File"→"Open"→"Data",选择并打开数据文件。
2.数据查看与描述性统计分析2.1 查看数据菜单栏的"Data"→ "View Data"可以查看数据的完整信息,包括各个变量和对应的取值。
2.2 描述性统计分析菜单栏的"Analyze"→ "Descriptive Statistics"→ "Explore"可以进行描述性统计分析,如变量的均值、标准差、最大值和最小值等。
选择需要分析的变量并点击"OK"按钮,SPSS会生成相应的结果报告。
3.数据筛选与排序3.1 数据筛选菜单栏的"Data"→"Select Cases"可以进行数据筛选,筛选出符合特定条件的数据记录。
选择"Based on conditions"并输入筛选条件,点击"OK"按钮即可得到筛选后的数据。
3.2 数据排序菜单栏的"Data"→ "Sort Cases"可以对数据进行排序,按照指定的变量进行升序或降序排序。
选择排序的变量,并设置升序或降序的方式,点击"OK"按钮即可实现排序。
spss作业3习题及答案
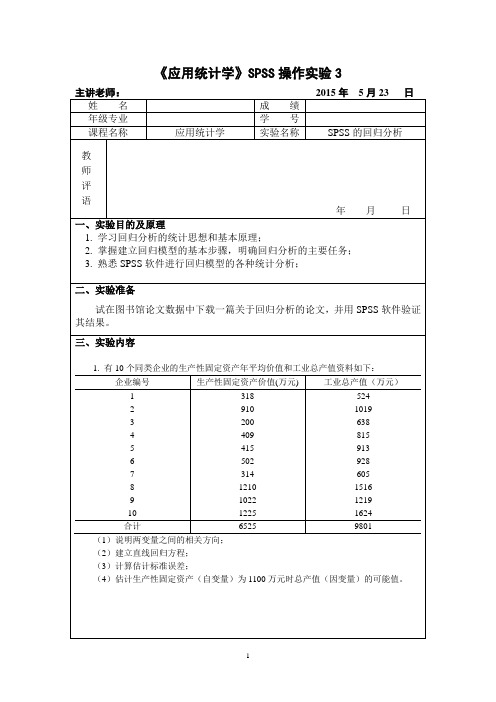
《应用统计学》SPSS操作实验3主讲老师:2015年5月23 日姓名成绩年级专业学号课程名称应用统计学实验名称SPSS的回归分析教师评语年月日一、实验目的及原理1. 学习回归分析的统计思想和基本原理;2. 掌握建立回归模型的基本步骤,明确回归分析的主要任务;3. 熟悉SPSS软件进行回归模型的各种统计分析;二、实验准备试在图书馆论文数据中下载一篇关于回归分析的论文,并用SPSS软件验证其结果。
三、实验内容1. 有10个同类企业的生产性固定资产年平均价值和工业总产值资料如下:企业编号生产性固定资产价值(万元) 工业总产值(万元)1 2 3 4 5 6 7 8 9 10 3189102004094155023141210102212255241019638815913928605151612191624合计6525 9801(1)说明两变量之间的相关方向;(2)建立直线回归方程;(3)计算估计标准误差;(4)估计生产性固定资产(自变量)为1100万元时总产值(因变量)的可能值。
2. 某公司的下属企业的产量与生产费用之间关系如附件1:产量/万件 40 42 48 55 65 79 88 100 120 单位生产费用/元 150 140 138 135 120 110 105 98 88 要求:(1)画出相关图,并判断产量与单位生产费用之间对相关方向;(2)计算相关系数,指出产量与单位生产费用之间的相关方向和相关程度;(3)确定自变量和因变量,拟合直线回归方程;(4)计算估计标准误差;(5)对相关系数进行检验(显著性水平取0.05);(6)对回归系数进行检验(显著性水平取0.05).3. 试在图书馆论文数据中下载一篇关于回归分析的论文,并用SPSS软件验证其结果。
四、实验结果1.实验过程:第一题:(1)在 SPSS软件中先输入相关数据,得到如图所示:(2)点击图形→旧对话框→散点、点状→简单分布→定义按钮。
spss习题及其答案

spss习题及其答案SPSS习题及其答案SPSS(Statistical Package for the Social Sciences)是一种广泛应用于社会科学研究领域的统计分析软件。
它提供了强大的数据处理和统计分析功能,使得研究人员能够更加准确地分析和解释数据。
在学习和使用SPSS的过程中,习题是一种非常有效的练习方式,能够帮助我们巩固所学知识并提高数据分析的能力。
下面将介绍几个常见的SPSS习题及其答案。
习题一:描述性统计分析某研究人员对一组学生的成绩进行了调查,并得到了以下数据:70、85、90、65、78、92、80、75、88、82。
请使用SPSS计算出这组数据的均值、标准差、最大值和最小值。
答案:打开SPSS软件,依次点击“数据”-“数据编辑器”,在变量视图中创建一个名为“成绩”的变量。
在数据视图中输入上述数据,然后点击“分析”-“描述性统计”-“描述性统计”。
将“成绩”变量移动到“变量”框中,点击“统计”按钮,在弹出的对话框中勾选“均值”、“标准差”、“最大值”和“最小值”,最后点击“确定”按钮。
SPSS将会输出这组数据的均值为80.7,标准差为8.77,最大值为92,最小值为65。
习题二:相关性分析某研究人员想要了解两个变量之间的相关性,他收集了一组学生的数学成绩和语文成绩数据。
请使用SPSS计算出这两个变量之间的相关系数。
答案:打开SPSS软件,依次点击“数据”-“数据编辑器”,在变量视图中创建两个变量分别为“数学成绩”和“语文成绩”。
在数据视图中输入相应的数据,然后点击“分析”-“相关”-“双变量”。
将“数学成绩”和“语文成绩”变量分别移动到“变量”框中,点击“确定”按钮。
SPSS将会输出这两个变量之间的相关系数,以及相关系数的显著性水平。
习题三:t检验某研究人员想要了解男性和女性在数学成绩上是否存在显著差异。
他收集了一组男性学生和一组女性学生的数学成绩数据。
请使用SPSS进行独立样本t检验。
北语2024春《SPSS统计分析实践》满分作业答案

北语2024春《SPSS统计分析实践》满分
作业答案
一、问题描述:
作业要求对一份调查问卷数据进行统计分析,包括描述统计、
相关分析和回归分析。
数据集包含了以下变量:性别、年龄、收入、教育水平、购物偏好、购买力、满意度等。
二、数据预处理:
1. 查看数据集的整体情况,包括数据类型、缺失值等。
2. 处理缺失值,可以选择删除含有缺失值的样本或使用插值法
进行填充。
三、描述统计分析:
1. 性别比例统计:计算男女比例并绘制饼图。
2. 年龄分布统计:计算年龄的平均值、标准差,并绘制年龄分
布直方图。
3. 收入水平统计:计算收入的最大值、最小值、中位数和四分
位数。
4. 教育水平统计:计算各教育水平的人数比例,并绘制教育水平柱状图。
四、相关分析:
1. 计算各变量之间的相关系数矩阵。
2. 绘制变量之间的散点图,并观察相关关系。
五、回归分析:
1. 选择一个自变量和一个因变量进行回归分析。
2. 计算回归方程的斜率、截距和决定系数。
3. 绘制回归线和残差图,并观察拟合情况。
六、结论:
根据以上统计分析结果,可以得出一些结论和建议,如性别比例接近1:1,年龄主要分布在30-40岁之间,收入水平较为分散,教育水平以本科为主等。
以上是《SPSS统计分析实践》满分作业的答案,希望能对你有所帮助。
spss练习题及答案

spss练习题及答案SPSS(Statistical Package for the Social Sciences)是一种统计分析软件,被广泛应用于社会科学研究和数据分析领域。
本文将提供一些SPSS练习题和对应的答案,以帮助读者提升SPSS使用和数据分析能力。
题目1:数据导入与基本操作问题描述:使用SPSS软件,将一组身高数据导入并进行基本操作。
解答:1. 打开SPSS软件并创建一个新的数据文件。
2. 在数据编辑栏中创建一个名为"Height"的变量,并设置其数据类型为数值型。
3. 逐行输入以下身高数据:165、170、180、155、168、175、185、162。
4. 在数据编辑栏中创建一个名为"Gender"的变量,并设置其数据类型为标签型(男性、女性)。
5. 逐行输入以下性别数据:男性、女性、女性、男性、男性、女性、男性、女性。
6. 完成数据输入后,保存文件并命名为"Height_Data.sav"。
题目2:数据清理与缺失值处理问题描述:使用SPSS软件,清理一组包含缺失值的数据并进行处理。
解答:1. 打开SPSS软件,并导入包含缺失值的数据文件。
2. 在数据编辑栏中,检查数据是否存在缺失值,采用统计分析方法得到具体的缺失值情况。
3. 处理缺失值的方法之一是删除带有缺失值的行。
在数据编辑栏中选择"数据",然后点击"选择特定行",在弹出窗口中选择"删除缺少变量值",点击确定。
4. 另一种处理缺失值的方法是用合适的数据填充缺失位置。
在数据编辑栏中选择"数据",然后点击"选择特定行",在弹出窗口中选择"选中缺少变量值的行",点击确定。
然后选择"数据",再点击"修改变量",选择合适的填充方法(如平均值、中位数等),点击确定。
spss练习题及答案

spss练习题及答案SPSS练习题及答案SPSS(Statistical Package for the Social Sciences)是一款广泛应用于数据分析和统计的软件工具。
它提供了丰富的功能和强大的统计算法,帮助研究者和数据分析师快速、准确地处理和分析大量数据。
为了帮助大家更好地掌握SPSS的使用技巧,下面将给出一些SPSS练习题及答案,供大家参考。
练习题一:描述性统计分析某公司对员工的工资进行了调查,收集了100位员工的薪资数据,请根据以下数据,使用SPSS进行描述性统计分析。
薪资数据:5000,5500,6000,6500,7000,7500,8000,8500,9000,9500,10000,10500,11000,11500,12000,12500,13000,13500,14000,14500,15000,15500,16000,16500,17000,17500,18000,18500,19000,19500,20000,20500,21000,21500,22000,22500,23000,23500,24000,24500,25000,25500,26000,26500,27000,27500,28000,28500,29000,29500,30000答案:1. 打开SPSS软件,新建数据集,将薪资数据输入到数据集中。
2. 在菜单栏选择"分析",然后选择"描述统计",再选择"频数"。
3. 将薪资数据变量拖动到"变量"框中,点击"统计"按钮,在弹出的对话框中勾选"平均值"、"中位数"、"标准差"、"最小值"、"最大值"等选项,点击"确定"。
4. 点击"图表"按钮,选择"直方图",点击"确定"。
SPSS作业(1-5章)3.27

第一章 SPSS概述1. SPSS有哪些主要窗口?它们的作用和特点各是什么?2. SPSS有哪三种主要使用方式?各自的特点是什么?3. .sav,.spo,.sps分别是哪类文件的扩展名?4.在SPSS的输出窗口中应如何操作才能将不同的分析结果保存到不同的文件中?5.SPSS的数据加工和管理功能主要集中在哪些菜单中?统计绘图和分析功能主要集中在哪些菜单中?6.利用SPSS进行数据分析的一般基本步骤是什么?第二章SPSS数据文件的建立和管理1. SPSS中有哪两种基本数据组成方式?各自的特点和应用场合是什么?2. 在定义SPSS数据结构时,默认的变量名和变量类型是什么?如果希望增强SPSS统计分析结果的易读性,还需要对数据结构的哪些方面进行必要说明?3你认为SPSS数据窗口与Excel工作表在基本操作方式和数据组织方式方面有什么异同?4.先自己建立两个数据文件:“学生成绩一.sav”和“学生成绩二.sav”,分别存放关于学生学号、性别、和若干门课程成绩的数据,然后将这两个数据文件横向合并,形成一个完整的数据文件。
6根据P18案例2-2建立数据文件,要求完整的数据结构。
7针对当前社会或社会关心的热点问题,以小组形式设计一份调查问卷并进行调查。
试在SPSS中录入所获得的调查数据形成一份SPSS数据文件。
其中,变量的类型应包括字符型和数字型,变量的计量尺度应包括定距型、定类型和定序型。
如果调查资料中存在缺失数据,应在SPSS数据文件的建立过程中进行必要的定义说明。
第三章SPSS数据的预处理1.利用数据筛选功能,将住房状况调查.sav生成两个文件,其中第一个文件存储户口为“外地户口”且家庭收入在10000-15000之间的数据;第二个文件存储按简单随机抽样抽取的70%的样本数据2.利用住房状况调查.sav 将其按家庭收入(升序)、现住面积(升序)、计划面积(降序)进行多重排序。
3.利用学生成绩表.sav 对每个学生计算得优课程数和得良课程数,并按得优课程数进行降序排列。
spss课后作业答案

SPSS课后作业第一章1-1、spss的运行方式有几种?分别是什么?答:SPSS的运行方式有三种,分别是批处理方式、完全窗口菜单运行方式、程序运行方式。
1-2、SPSS中“DataView”所对应的表格与一般的电子处理软件有什么区别?答:与一般电子表格处理软件相比,SPSS的“Data View”窗口还有以下一些特性:(1)一个列对应一个变量,即每一列代表一个变量(Variable)或一个被观测量的特征;(2)行是观测,即每一行代表一个个体、一个观测、一个样品,在SPSS中称为事件(Case);(3)单元包含值,即每个单元包括一个观测中的单个变量值;(4)数据文件是一张长方形的二维表。
第二章2-1、在SPSS中可以使用那些方法输入数据?答:SPSS中输入数据一般有以下三种方式:(1)通过手工录入数据;(2)可以将其他电子表格软件中的数据整列(行)的复制,然后粘贴到SPSS中;(3)通过读入其他格式文件数据的方式输入数据。
2-2、对于缺失值,如何利用SPSS进行科学替代?答:选择“Transform”菜单的Replace Missing Values命令,弹出Replace Missing Values 对话框。
先在变量名列中选择1个或多个存在缺失值的变量,使之添加到“New Variable(s)”框中,这时系统自动产生用于替代缺失值的新变量。
最后选择合适的替代方式即可。
2-3、在计算数据的加权平均数时,如何对变量进行加权?答:选择“Data”菜单中的Weight Cases命令,出现如图2-22所示的Weight Cases对话框。
其中, Do not weight cases项表示不做加权,这可用于取消加权;Weight cases by 项表示选择1个变量做加权。
2-4、如何对变量进行自动赋值?答:变量的自动赋值可以将字符型、数字型数值转变成连续的整数,并将结果保存在一个新的变量中。
具体操作的过程如下:选择“Transform”菜单中的Automatic Recode命令,在出现的对话框中,从左边的变量列表中选择需要自动赋值的变量,将它添加到Variable -> New Name框中,然后在下面New Name右边的文本框中输入新的变量名称,单击New Name 按钮,将新的变量名添加到上面的框中。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
《SPSS原理与应用》
柴瑞格
社工2班
1220602239
大学生毕业前景选择与是否独生的调查研究
一、导言:
面临毕业,每个人都不知前路去向会有何种发展,只能在风险中战战兢兢地估量着胆量选择着未来。
而对于独生子女来说,前路要考虑的问题是否会更多?对于非独生子女来说,未来的方向是否有更多的机会?这一问题将在调查研究中讨论。
现在一大批独生子女和非独生子女都即将进入社会,很多人都带着有色眼镜看待这两个群体。
是否独生子女比非独生有更多劣势?面对社会的压力,刚走出单纯干净的校园环境的大学生们是否会因为是否独生的问题而受到议论?
但据调查可知,是否独生对大学生毕业方向和前景的选择还有有一定影响。
本文就大学毕业生就业前景选择与是否是独生子女的关系进行调查研究。
二、样本构成情况描述:
三、
本次调查报告有1000名对象,缺失2人,共计998人,其中独生子女560人,非独生子女438人。
以下是各题样本的总体分布情况。
四、结果与分析:
1.大学生毕业后大多数人都选择参加工作,有475人。
也有很大一部分人选择考研,共有382人。
其他的人中有75人准备出国深造,而60人还有其他的出路打算。
卡方检验
值Df 渐进 Sig.
Pearson 卡方50.919a 3 .000
似然比52.683 3 .000
线性和线性组合22.830 1 .000
有效案例中的 N 992
通过卡方检验可知,大学生是否是独生子女与他们的毕业业前景选择具有很大的联系。
没有兄弟姐妹的人更多地选择直接工作,而选择考研的大多数都是非独生子女。
由此可见,家庭的压力与学生是否是独生子女有很大关联,也影响了是否考研或工作的选择。
1、父母的教育期望
由表可知,父母对子女的学历要求都是越高越好。
对而独生子女的要求更多集中在研究生毕业的层次,而非独生子女家庭的父母责要求相对较低。
独生子女家庭有近40%要求在本科或研究生,而非独生子女家庭则是27%。
卡方检验
值df 渐进 Sig.
Pearson 卡方49.295a 5 .000
似然比49.817 5 .000
线性和线性组合.175 1 .676
有效案例中的 N 993
通过卡方检验可以得出独生子女和非独生子女在父母对他们的期望值方面的关联性还是很大的。
由统计分析可知,养育独生子女的家庭期望只能寄予在一处,所以背负更多期待。
而非独生子女家庭因为有兄弟姐妹所以可以分担父母的期望,压力则相对偏小。
3.大学生对自己的教育期望:
从上表的统计表可以得出,大学生期望自己本科以上的有681人,占总体68.6%。
而独生子女有21.6%希望自己研究生毕业,相对而言非独生子女只有14.4%有这种想法。
卡方检验
值df 渐进 Sig.
Pearson 卡方 2.206a 4 .698
似然比 2.215 4 .696
.923 1 .337
线性和线性组
合
从上表可知,60%以上的大学生认为自己的专业能找着工作,其中是否是独生子女在这一点上不存在显著差异。
卡方检验
值df 渐进 Sig.
Pearson 卡方 1.382a 5 .926
似然比 1.397 5 .925
.553 1 .457
线性和线性组
合
980
有效案例中的
N
通过上表可知,60%以上的大学生认为个人的知识技能及素养等的因素影响将来就业,可以看出大部分大学生都从自身方面去考虑就业因素,都希望通过提高个人能力来就业。
另外,从卡方检验可以得出是否是独生子女在考虑未来就业因素上不存在显著差异。
卡方检验
值df 渐进 Sig.
Pearson 卡方 5.107a 3 .164
似然比 5.459 3 .141
2.994 1 .084
线性和线性组
合
有效案例中的
993
N
通过上表可知,是否是独生子女在大学生最想去的单位类型上并无太大差异。
线性和线性组
2.179 1 .140
合
986
有效案例中的
N
从上表可知,接近35%的大学生认为未来的工作要能一个人自我价值的体现,而接近19%的大学生则更看重未来的工作是否能成为谋生的手段。
而是否是独生子女在这方面的选择上差异不大。
五、小结与讨论:
当前社会上对独生子女和非独生子女在未来工作的适应性上的争议依然十分多,而新一代的独生子女则总是被贴上有色标签的那一群人。
很多人都觉得独生子女的脾气更加娇生惯养,在未来就业选择的方面会更加懦弱不前。
但通过此次调查可知,除了毕业后的打算之外,独生子女和非独生子女大学生在“父母教育期望”“自己的教育期望”“是否认为本专业好找工作”“影响就业的因素”“择业时首先看中的条件”“工作对人生的意义”方面都没有很大差异。
而毕业打算方面的差异更体现出独生子女为了家庭压力而愿意更早地进入社会,承担起家庭责任的一面。