spss作业
SPSS假设检验作业

统计作业(假设检验)1、应用SPSS计算下题:已知某炼铁厂的铁水含碳量服从正态分布,在正常情况下,其总体均值为 4.55。
现在测了10炉铁水,其含碳量分别为4.42, 4.38, 4.28, 4.40, 4.42, 4.35, 4.37, 4.52, 4.47, 4.56 ,试问总体均值是否发生了显著变化(α=0.05)?One-Sample Test此题为双侧检验,因此P=0.001<0.025,拒绝H0,所以总体均值发生了显著变化2、文件名:DATA11-01文件说明:从一所学校中抽取27名男女学生身高数据。
变量说明:no: 编号;sex:性别;age:年龄;h:身高;w:体重。
假设该学校身高服从正态分布,请问能否认为该学校学生平均身高为1.57m(α=0.01)。
One-Sample Test此题为双侧检验,P=.003<.005,拒绝H0,所以不能认为该学校学生平均身高为1.57m3、文件名:DATA11-02文件说明:1973年某市测量120名12岁男孩身高资料。
变量说明:height: 12岁男孩身高当显著性水平分别为α=0.05与0.01时,该市12岁男孩平均身高与该地区男孩平均身高(142.3cm)有无显著差异,并说明所得结论的理由。
当α=0.05时One-Sample Statistics此题为双侧检验,因此P=.162>.025,所以该市12岁男孩平均身高与该地区男孩平均身高(142.3cm)无显著差异当α=0.01时One-Sample StatisticsOne-Sample Test此题为双侧检验,因此P=.162>.005,所以该市12岁男孩平均身高与该地区男孩平均身高(142.3cm)无显著差异4、文件名:DATA09-03文件说明:1969-1971年美国一家银行的474名雇员情况的调查数据,其中包括工资、受教育水平、工作经验、种族等数据。
SPSS作业(1-5章)3.27

第一章 SPSS概述1. SPSS有哪些主要窗口?它们的作用和特点各是什么?2. SPSS有哪三种主要使用方式?各自的特点是什么?3. .sav,.spo,.sps分别是哪类文件的扩展名?4.在SPSS的输出窗口中应如何操作才能将不同的分析结果保存到不同的文件中?5.SPSS的数据加工和管理功能主要集中在哪些菜单中?统计绘图和分析功能主要集中在哪些菜单中?6.利用SPSS进行数据分析的一般基本步骤是什么?第二章SPSS数据文件的建立和管理1. SPSS中有哪两种基本数据组成方式?各自的特点和应用场合是什么?2. 在定义SPSS数据结构时,默认的变量名和变量类型是什么?如果希望增强SPSS统计分析结果的易读性,还需要对数据结构的哪些方面进行必要说明?3你认为SPSS数据窗口与Excel工作表在基本操作方式和数据组织方式方面有什么异同?4.先自己建立两个数据文件:“学生成绩一.sav”和“学生成绩二.sav”,分别存放关于学生学号、性别、和若干门课程成绩的数据,然后将这两个数据文件横向合并,形成一个完整的数据文件。
6根据P18案例2-2建立数据文件,要求完整的数据结构。
7针对当前社会或社会关心的热点问题,以小组形式设计一份调查问卷并进行调查。
试在SPSS中录入所获得的调查数据形成一份SPSS数据文件。
其中,变量的类型应包括字符型和数字型,变量的计量尺度应包括定距型、定类型和定序型。
如果调查资料中存在缺失数据,应在SPSS数据文件的建立过程中进行必要的定义说明。
第三章SPSS数据的预处理1.利用数据筛选功能,将住房状况调查.sav生成两个文件,其中第一个文件存储户口为“外地户口”且家庭收入在10000-15000之间的数据;第二个文件存储按简单随机抽样抽取的70%的样本数据2.利用住房状况调查.sav 将其按家庭收入(升序)、现住面积(升序)、计划面积(降序)进行多重排序。
3.利用学生成绩表.sav 对每个学生计算得优课程数和得良课程数,并按得优课程数进行降序排列。
spss作业

八、上机作业
1、自学报告分析的各项命令。
2、以“职工数据.sav”为例,要求用基本统计分析完成以下任务:(1)求出性别、工资等级的频次分布表,并用工资等级做条形图、饼形图。
表2 性别表
求工资的均值、中位数、众数、最大值、最小值、标准差、四分位数、十分位数,并用工资做带正态曲线的
F r e q u e n c y
表3 工资的各种数值表
平均值 中位数 众数 标准差 峰度 偏度 最小值 最大值 四分位
数
十分位
数 3130
3100
1800
1073
201
970
1500 5000 1500
1800
F r e q u e n c y
分性别求工资的标准分。
表4 Descriptive Statistics(a)
表5 Descriptive Statistics(a)
3、依据“保险市场调查”数据,对变量q13a、q13b、q13c进行多选项分析,了解人们购买商业养老保险的原因。
①定义多选项变量集
②多选项频数分析
③以工作单位性质(q34)和购买商业养老保险的原因为变量,进行列联表分析。
SPSS操作实验作业1(附答案)

SPSS操作实验 (作业1)作为华夏儿女都曾为有着五千年的文化历史而骄傲过,作为时代青年都曾为中国所饱受的欺压而愤慨过,因为我们多是炎黄子孙。
然而,当代大学生对华夏文明究竟知道多少呢某研究机构对大学电气、管理、电信、外语、人文几个学院的同学进行了调查,各个学院发放问卷数参照各个学院的人数比例,总共发放问卷250余份,回收有效问卷228份。
调查问卷设置了调查大学生对传统文化了解程度的题目,如“佛教的来源是什么”、“儒家的思想核心是什么”、“《清明上河图》的作者是谁”等。
调查问卷给出了每位调查者对传统文化了解程度的总得分,同时也列出了被调查者的性别、专业、年级等数据信息。
请利用这些资料,分析以下问题。
问题一:分析大学生对中国传统文化的了解程度得分,并按了解程度对得分进行合理的分类。
问题二:研究获得文化来源对大学生了解传统文化的程度是否存在影响。
要求:直接导出查看器文件为.doc后打印(导出后不得修改)对分析结果进行说明,另附(手写、打印均可)。
于作业布置后,1周内上交本次作业计入期末成绩答案问题一操作过程1.打开数据文件作业。
同时单击数据浏览窗口的【变量视图】按钮,检查各个变量的数据结构定义是否合理,是否需要修改调整。
2.选择菜单栏中的【分析】→【描述统计】→【频率】命令,弹出【频率】对话框。
在此对话框左侧的候选变量列表框中选择“X9”变量,将其添加至【变量】列表框中,表示它是进行频数分析的变量。
3.单击【统计量】按钮,在弹出的对话框的【割点相等组】文本框中键入数字“5”,输出第20%、40%、60%和80%百分位数,即将数据按照题目要求分为等间隔的五类。
接着,勾选【标准差】、【均值】等选项,表示输出了解程度得分的描述性统计量。
再单击【继续】按钮,返回【频率】对话框。
4.单击【图表】按钮,勾选【直方图】和【显示正态曲线】复选框,即直方图中附带正态曲线。
再单击【继续】按钮,返回【频率】对话框。
最后,单击【确定】按钮,操作完成。
SPSS简单的练习作业

在上图中,分别显示了两两广告形式下销售额均值检验的结果。在SPSS中全部采用了LSD方法中的分布标准误,因此各种方法的前两列计算结果完全相同。表中第三列是检验统计量观测值在不同分布中概率值p,可以发现各种方法在检验敏感度上市存在差异的。以报纸广告与其他三种广告形式的两两检验结果为例,如果显著性水平α=0.05,在LSD方法中,报纸广告和广播广告的效果没有显著性差异,p值为0.412,与宣传品和体验均有显著性差异,概率p值分别是0.00,接近和0.021;但是在其他三种方法中,报纸广告只与宣传品广告存在显著性差异,而与体验无显著性差异。表中第一列星号的含义是,在显著性水平α=0.05的情况下,相应两总体的均值存在显著性差异,与第三列的结果相对应。
实验一SPSS的方差分析、相关分析与线性回归分析………………………17
1.单因素方差分析的基本操作……………………………………………17
2.单因素方差分析进一步分析的操作……………………………………18
作业一SPSS数据文件的建立和管理、数据的预处理
实验一SPSS数据文件的建立和管理、数据的预处理
【实验目的】
【实验结果与分析】
以上结果是广告形式对销售额的单因素方差的分析结果。可以看到,观测变量销售额的总离差平方和为26169.306;如果仅考虑“广告形式”单个因素的影响,则销售额总变差中,广告形式可解释的变差为5866.083,抽样误差引起的变差为20303.222,它们的方差(平均变差)分别为1955.361和145.023,相除所得的F统计量的观测值为13.483,对应的概率p值近似为0。如果显著性水平α为0.05,由于概率p值小于显著性水平α,则应拒绝零假设,认为不同广告形式对销售产生显著影响,它对销售额的影响效应不全为0。
spss作业完整版

均值比较与样本T检验1、(1)执行Transform—>Replace Missing Varies,将“机械化程度”移入NewVariables中,在Method中选择Mean of nearby points,单击change,单击OK提交系统。
(2)执行analyze->compare means->mean,将“户主年龄”、“文化程度”、“家庭人口”和“家庭总收入”移入 indenpendent List,将“机械化程度”移入dependent list(3)单击options,选择statistics for first layer 下的 anova table and eta, 单击 continue(4)单击ok数据分析:缺失值由3.8代替,所以用无任何机械代替。
年龄:显著性水平Sig.=0.572>0.05,说明不同户主年龄的机械化程度没有显著的差异。
文化程度:显著性水平Sig.=0.453,说明不同文化程度的机械化程度没有显著性差异;家庭人口:Sig.=0.625,说明不同家庭人口数的机械化程度没有显著性差异;家庭总收入:Sig.=0.139,说明不同家庭收入的农户的机械化程度没有显著性差异。
2、(1)执行analyze->compare means->independent-sample T Test(2)将“效果”移入test variables 框内(3)将“方法”移入grouping variables框内,单击define groups按钮,并在group1和group2框中分别输入有效值,单击continue (4)单击ok数据分析:显著性Sig.=0.128,所以在0.05的显著性水平上,两种激励方法的效果没有有显著差异。
3、(1)执行analyze->compare means->paird sample T Test,将“方案1”“方案3”移入paired variables(2)单击ok(3)以同样的方法比较“方案2”“方案3”数据分析:方案1与方案3的检验中,Sig.=0.044,说明方案1与方案3有显著性差异,所以均值相等的0假设不成立。
最新spss作业.doc解析

s p s s作业.d o c解析第六章SPSS参数检验——均值比较1、某公司经理宣称他的雇员英语水平很高,如果按照英语六级考试的话,一般平均得分为75分。
现从雇员中随机选出11人参加考试,得分如下:80, 81, 72, 60, 78, 65, 56, 79, 77,87, 76 请问该经理的宣称是否可信。
操作:分析→比较均值→单样本T均值为73.7273,Q值为0.668大于0.05,均值预75没有显著性差异,接受原假设。
即该经理的宣称是可信的。
2、经济学家认为决策者是对事实做出反应,不是对提出事实的方式做出反应。
然而心理学家则倾向于认为提出事实的方式是有关系的。
为验证哪种观点更站得住脚,调查者分别以下面两种不同的方式随机访问了足球球迷。
l 方式一:假设你已经买了100元一张的足球票,当你来到足球场门口时,发现票丢了且再也找不到了。
球场还有票出售。
你会再掏出100元买一张球票吗?(1.买 0.不买)。
随机访问了200人,其中:92人回答买;l 方式二:你想看足球赛,100元一张票。
当你来到足球场买票时,发现丢了100元钱。
你口袋中还有钱,此时你还会付100元买一张球票吗?(1.买0.不买)。
随机访问了183人,其中:161人回答买;请恰当建立SPSS数据文件,并利用本章所学习的参数检验方法,说明你更倾向于那种观点,为什么?操作:输入数据→分析→比较均值→独立样本T检验3、一种植物只开兰花和白花。
按照某权威建立的遗传模型,该植物杂交的后代有75%的几率开兰花,25%的几率开白花。
现从杂交种子中随机挑选200颗,种植后发现142株开了兰花,请利用SPSS进行分析,说明这与遗传模型是否一致?操作:输入数据→分析→比较均值→独立T检验(输入值为0.75)即:0.215大于0.05,预遗传模型没有差异性4、给幼鼠喂以不同的饲料,用以下两种方法设计实验:方式1:同一鼠喂不同的饲料所测得的体内钙留存量数据如下:鼠号饲料1饲料2 133.136.7233.13 4 5 6 7 8 926.8 36.3 39.5 30.925.733.4 34.5 28.628.8 35.1 35.2 43.8 36.5 37.9 28.7配对样本T检验l 方式2:甲组有12只喂饲料1,乙组有9只喂饲料2所测得的钙留存量数据如下甲组饲料1 29.726.728.9 31.1 31.1 26.8 26.3 39.5 30.9 33.433.128.6乙组饲料2 28.728.329.3 32.2 31.1 30.0 36.2 36.8 30.0请选用恰当方法对上述两种方式所获得的数据进行分析,研究不同饲料是否使幼鼠体内钙的留存量有显著不同。
SPSS作业

4-4 用药治疗6名高血压病人,对每一个人治疗前、后的舒张压进行了测量,结果如表4-4 所示(2)治疗前后病人的血压是否有显著变化?解:(1)经过统计分析的到如下结果:Statistics用药前用药后N Valid 6 6Missing 0 0Mean 124.67 118.67Variance 175.467 331.867从表中可以看出:用药前,6名病人的血压的均值是124.67,而用药后的均值则是118.67,。
可以看出均值由大变小:同理,6名病人的血压的方差则是由小变大。
以认为用药前和用药后的血压值无显著差异;T统计量的相伴概率是0.529,大于显著性水平0.05,不能拒绝T假设的零假设,即用药前和用药后病人的血压值不存在显著变化。
4-5A学校要对两位数学老师的教学质量进行评价,这两位老师分别教甲班和乙班,这两班的数学课的成绩如表4-5所示,这两个班的成绩是否存在显著差异?Group Statistics序号N Mean Std. Deviation Std. Error Mean分数甲班20 83.60 6.700 1.498乙班20 75.45 9.179 2.053和9.179.题中的F的相伴概率是0.299,大于显著性水平0.05,不能拒绝方差相等的假设,可以认为两个班的成绩无显著性差异;然后看T的相伴概率是0.003,显然小于显著性水平0.05,可以接受T的零假设,即,两个班存在显著性。
二者相互矛盾,所以不能判断出两个班成绩存在显著性差异。
5-4 谋职业病研究所对29名矿工中肺夕病患者、可疑患者和非患者进行了用力肺活量(L)测定,如表5-4所示,问三名矿工的的用力肺活量有无差别?从表中可以看出:相伴概率是0.669,大于显著性水平,可以认为总体方差是相等的,这组数据可以进行单因素分析ANOVA肺活量,表示拒绝零假设,也就是说这三组中至少有一组和其他两组有明显区别。
这是LSD法多重比较的结果,从中可以看出3个组之间的相伴概率都小于显著性水平0.05,说明这3组之间有显著差异。
SPSS期末大作业-完整版

第1题:基本统计分析1分析:本题要求随机选取80%的样本,因而需要选用随机抽样的方法,在此选择随机抽样中的近似抽样方法进行抽样。
其基本操作步骤如下:数据→选择个案→随机个案样本→大约(A)80 所有个案的%。
1、基本思路:(1)由于存款金额为定距型变量,直接采用频数分析不利于对其分布形态的把握,因而采用数据分组,先对数据进行分组再编制频数分布表。
此处分为少于500元,500~2000元,2000~3500元,3500~5000元,5000元以上五组。
分组后进行频数分析并绘制带正态曲线的直方图。
(2)进行数据拆分,并分别计算不同年龄段储户的一次存取款金额的四分位数,并通过四分位数比较其分布上的差异。
操作步骤:(1)数据分组:【转换→重新编码为不同变量】,然后选择存取款金额到【数字变量→输出变量(V)】框中。
在【名称(N)】中输入“存取款金额1”,单击【更改(H)】按钮;单击【旧值和新值】按钮进行分组区间定义。
存取款金额1频率百分比有效百分比累积百分比有效1.00 82 34.6 34.6 34.62.00 76 32.1 32.1 66.73.00 104.2 4.2 70.94.00 22 9.3 9.3 80.25.00 47 19.8 19.8 100.0 合计237 100.0 100.0(2)【分析→描述统计→频率】;选择“存款金额分组”变量到【变量(V)】框中;单击【图标(C)】按钮,选择【直方图】和【在直方图上显示正态曲线】;选中【显示频率表格】,确定。
(3)【数据→拆分文件】,选择“年龄”变量到【分组方式】框中,选中【比较组】和【按分组变量排序文件】,确定;【分析→描述统计→频率】,选择“存款金额”到【变量】框中,单击【统计量】按钮,选择【四分位数】→继续→确定。
统计量存(取)款金额20岁以下N有效1缺失0 百分位数25 50.00 50 50.00 7550.00 20~35岁N有效 131 缺失0 百分位数25 500.00 50 1000.00 755000.0035~50岁N有效 73 缺失0 百分位数25 500.00 50 1000.00 75 4500.0050岁以上N有效32缺失0 百分位数25 525.00 50 1000.00 752000.00结果及结果描述:频数分布表表明,有一半以上的人的一次存取款金额少于2000元,且有34.6%的人的存取款金额少于500元,19.8%的人的存取款金额多于5000元,下图为相应的带正态曲线的直方图。
SPSS选修作业完整版

1、现有我国31个省、市、自治区2021年的GDP统计数据,数据中包括“省份〞、“GDP〞、“人口〞三个变量,数据见1.sav,试计算出人均GDP(人均GDP=GDP/人口)作为新变量保存。
解:如下列图:图1:数据1.sav2.数据2.sav显示了2021年我国各个地区制造业的就业人数,利用频数分析对不同地区的就业情况进行分析,显示四分位数、均值、标准差和偏度,绘制频率分布直方图和正态曲线,并判断分布形态。
图2:数据2.sav解:制造业万频率百分比有效百分比累积百分比有效.8 1111111111111111111111111111111 合计31统计量制造业万N有效31缺失0 均值标准差偏度偏度的标准误.421百分位数25 50 75分析:如上图所示,其分布形态为偏左分布,说明大多数地区在制造业就业的人数集中在100万左右,说明我国还有很大一局部地区在制造业行业还是比拟欠缺的,如果加强那么可以在很大一定程度上提高就业率。
3、数据3.sav记录了两个班级学生的数学和语文成绩,利用探索性分析该数据数学和语文成绩的最大值、最小值、众数和平均数,并检验样本数据的正态性。
图3:数据解:描述统计量标准误数学均值均值的 95% 置信区间下限上限5% 修整均值中值方差标准差极小值46极大值99范围53四分位距15偏度.269 峰度.228 .532语文均值均值的 95% 置信区间下限上限5% 修整均值中值方差标准差极小值47极大值99范围52四分位距14偏度.269 峰度.405 .5324、某地区水样中某种元素的含量为72毫克/升,现从某化工厂下游水域中抽取了20个水样,数据见4.sav,对样本数据进行单样本T检验,判断化工厂是否造成了下游水域水质的变化。
图4:数据:解:单个样本统计量N 均值标准差均值的标准误水样中某元素含量20 .647分析:在上图中,P值为0.000<0.05因此拒绝原假设,认为样本均值与总体均值有所不同,即判定化工厂造成了下游水域水质的变化。
spss作业题目

1、纵向合并:将数据集PKC2.sav中的记录添加到PKC1.sav中2、横向合并:将数据集bran包含ID号1—90的病人性别、年龄和血小板,bran2含ID号11—100号病人收缩压、舒张压和迟发性脑损伤结果,将俩数据按ID号合并3、数据集manovo.sav中erda、dancan、medgude三个变量设为一个集合并使该集合生效。
(这是黑板上的练习题,ppt上的没来得及抄,不好意思啦)第三周:某克山病区测得1例克山病患者与13名健康人的血磷值如下(mmol/L),问该地区与健康人的血磷值是否不同?患者:0.84 ,1.05,1.20,1.20,1.39,1.53,1.67,1.80,1.87,2.07,2.11健康:0.54,0.64,0.64,0.75,0.76,0.81,1.16,1.2,1.34,1.35,1.48,1.56,1.87一、1、建立数据文件xuelin.sav,要求:定义变量xuelin、group(测量长度为ordinal measurem end)均价标签2、比较该地克山病患者与健康人的血磷值是否不同二、1、在xuelin.sav中建立新变量temp1,当血磷值大于1是令其值为2,否则为1(compute)2、在xuelin.sav中建立新变量temp2,当血磷值大于2小于3时令其值为1,否则为0(count)3、在xuelin.sav中建立temp3,当血磷值小于1时取值为0,1~2时取值为10,大于2时取值为20(recode)4、对xuelin值按患者和健康人进行分类汇总5、对xuelin按group升序,x降序第四周:1、课堂上的题目:某地健康男子血清总胆固醇值测定结果见案例数据中dgucun.sav,请绘制频数表、直方图、计算平均数、标准差、中位数M p2.5和p97.52、书上题目:P114练习题第1、2题(希望大家都认真完成)实验四1.用职工基本情况数据(职工数据.sav)编制一张涉及两变量的二维交叉列联表,反映不同职称和不同文化程度交叉分组下的职工频数分布情况,并做解释。
北语2024春《SPSS统计与分析应用》作业满分答案文档

北语2024春《SPSS统计与分析应用》作业满分答案文档问题一: 描述性统计分析数据收集首先,我们需要收集一组数据以进行描述性统计分析。
在此作业中,我们收集了100个学生的数学成绩数据。
描述性统计分析使用SPSS软件进行描述性统计分析,我们得到了以下结果:- 平均数:78.5- 标准差:9.2- 最小值:60- 最大值:95- 中位数:80- 四分位数:- 第一四分位数:72.5- 第二四分位数:80- 第三四分位数:85结论根据描述性统计分析结果,我们可以得出以下结论:- 这组学生的平均数成绩为78.5,说明整体水平中等偏上。
- 标准差为9.2,说明学生的成绩相对分散。
- 最低分为60,最高分为95,成绩分布较为广泛。
- 中位数为80,说明成绩的中等水平集中在80左右。
- 第一四分位数为72.5,第三四分位数为85,说明成绩的大部分集中在72.5到85之间。
问题二: 相关性分析数据收集我们收集了100个学生的数学成绩和英语成绩数据。
相关性分析使用SPSS软件进行相关性分析,我们得到了以下结果:- 相关系数:0.75- p值:0.001结论根据相关性分析结果,我们可以得出以下结论:- 数学成绩和英语成绩之间存在较强的正相关关系。
- 相关系数为0.75,接近于1,说明两个变量之间的关联程度较高。
- p值为0.001,小于显著性水平0.05,因此可以得出该相关关系是显著的。
问题三: T检验数据收集我们收集了两组学生的数学成绩数据:男生组和女生组。
T检验使用SPSS软件进行T检验,我们得到了以下结果:- T值:2.16- 自由度:98- p值:0.034结论根据T检验结果,我们可以得出以下结论:- 男生组和女生组的数学成绩之间存在显著差异。
- T值为2.16,自由度为98,p值为0.034,小于显著性水平0.05,因此可以得出这种差异是显著的。
问题四: 方差分析数据收集我们收集了三个不同班级的学生的数学成绩数据。
spss练习题(打印版)

spss练习题(打印版)SPSS练习题一、选择题1. 在SPSS中,数据视图(Data View)显示的是:- A. 变量标签- B. 变量名- C. 观察值- D. 变量类型2. 以下哪个命令可以用来计算描述性统计量?- A. `DESCRIPTIVES`- B. `FREQUENCIES`- C. `CORRELATIONS`- D. `T-TEST`3. 如果你想要在SPSS中查看数据集的变量信息,你应该使用:- A. `DATASET`- B. `VARIABLE`- C. `VIEW`- D. `INFO`二、填空题1. 在SPSS中,使用________命令可以进行变量的转换和计算。
2. 当你想要对数据进行分组分析时,可以使用SPSS的________功能。
3. 为了在SPSS中创建一个新的数据集,可以使用________命令。
三、简答题1. 描述如何在SPSS中进行单样本t检验,并解释其应用场景。
2. 解释在SPSS中使用交叉表(Crosstabs)的目的,并说明如何解读交叉表的结果。
四、操作题1. 假设你有一个包含学生成绩的数据集,变量包括:学生ID(ID),姓名(Name),数学成绩(Math),英语成绩(English)。
请写出在SPSS中计算数学和英语成绩平均值的步骤。
2. 如果你想要在SPSS中删除一个名为“Math”的变量,应该如何操作?参考答案一、选择题1. D2. A3. C二、填空题1. `COMPUTE`2. `SPLIT FILE`3. `SAVE AS`三、简答题1. 在SPSS中进行单样本t检验的步骤如下:- 首先,确保你的数据已经正确输入到SPSS的数据视图中。
- 选择“分析”菜单下的“比较均值”选项。
- 选择“单样本t检验...”。
- 将需要检验的变量移动到“检验变量”框中。
- 在“测试值”框中输入你想要比较的均值。
- 点击“确定”进行检验。
单样本t检验通常用于检验单个样本的均值是否显著不同于已知的总体均值。
SPSS操作练习——作业示例 (1)

SPSS操作练习(t检验)要求:1、用SPSS进行统计分析;2、分析说明使用某一统计处理方法的依据;3、将统计结果正确地在论文中进行表达并进行结果分析。
----------------------------------------------------------------------------------1.计算下列两个玉米品种10个果穗长度(cm)的平均值、标准差和变异系数,并解释两个玉米品种的果穗长度有无差异。
【变异系数C·V=(标准偏差SD/平均值MN)×100%】玉米24号:19,21,20,20,18,19,22,21,21,19金皇后玉米:16,21,24,15,26,18,20,19,22,19解:(1)选择分析方法:被比较的玉米24号、金皇后玉米是两个品种的玉米,试验中彼此独立、无配对关系。
先用SPSS对数据是否服从正态分布进行Kolmogorov-Smirnov 检验,得到,玉米24号的p=0.869>0.05,金皇后玉米的p=0.99>0.05,说明两个样本均服从正态分布(来自正态总体),因此选择独立样本t检验进行数据分析。
经Levene方差齐性检验,得P=0.028<0.05,表明方差不齐,因此选择t检验的结果,使用方差不齐时的计算结果。
(2)结果:为比较玉米24号、金皇后两个品种果穗长度的差异,分别随机选定10株进行测定,结果见表1。
表1 玉米24号与金皇后玉米果穗长度的差异性比较(X±SD)品种样品数/株果穗长度/cm 变异系数/% P值(双侧)24号玉米10 20±1.25 6.241.00金皇后玉米10 20±3.40 17.00(3)分析与结论:从表1可以看出,果穗的长度,玉米24号为20±1.25cm,C·V 是6.00%,金皇后为20±3.40cm,C·V为17.00%,虽然两个品种玉米的果穗长度平均值一样,但是,与玉米24号比较,金皇后玉米的标准差、变异系数都较大,表明金皇后玉米果穗长度的变异程度大。
SPSS回归分析作业

b. Dependent Variable: 资产评估增值率
Coefficientsa
Standardized Unstandardized Coefficients Coefficients
Model
B
Std. Error
Beta
1
(Constant)
.396
.145
固定资产比重
.079
.082
权益与负债比
从系数的 t 检验可以看出,只有固定资产比重 的 sig 值=0.339>0.05,说明只有固定资产比重对资 产评估增值率的影响是不显著的,其他自变量对固 定资产增值的比率均有显著的影响。
线性回归方程为:
pg=0.396+0.079gz+0.063fz+ 0.602bc-0.044gm
α1=0.079 表示,在权益与负债比、总资产投 资报酬率和公司规模不变的条件下,固定资产比重 每增加 1 个单位,资产评估增值率增加 0.079。
Minimum Maximum Mean Std. Deviation
Predicted Value
-.084652 .494055 .172240
Residual
-1.5000236 E-1
.1493797 .0000000
Std. Predicted Value
-1.957
2.452
.000
Std. Residual
Std. Residual
-1.915
a. Dependent Variable: 销售价格
1.06E5 1.387E4
2.330 1.679
5.67E4 .000 .000 .000
北语2024春季《统计分析SPSS应用》作业满分答案

北语2024春季《统计分析SPSS应用》作业满分答案问题一: 描述统计分析1. 计算每个变量的均值、中位数、标准差和极差。
- 变量1:均值为X1_mean,中位数为X1_median,标准差为X1_std,极差为X1_range。
- 变量2:均值为X2_mean,中位数为X2_median,标准差为X2_std,极差为X2_range。
- 变量3:均值为X3_mean,中位数为X3_median,标准差为X3_std,极差为X3_range。
2. 绘制每个变量的直方图和盒图。
- 变量1的直方图和盒图见附件1。
- 变量2的直方图和盒图见附件2。
- 变量3的直方图和盒图见附件3。
3. 计算变量之间的相关系数矩阵。
- 相关系数矩阵为:| | 变量1 | 变量2 | 变量3 |问题二: 参数估计1. 使用线性回归模型对变量1和变量2进行拟合。
- 回归方程为:Y = 0.5X1 + 0.3X2 + 0.12. 使用二元Logistic回归模型对变量1和变量3进行拟合。
- 回归方程为:P = 1 / (1 + exp(-0.8X1 + 0.6X3))问题三: 假设检验1. 对比变量1的均值与总体均值是否有显著差异。
- 假设检验结果为:显著差异(p < 0.05)。
2. 对比变量2和变量3的均值是否有显著差异。
- 假设检验结果为:无显著差异(p > 0.05)。
问题四: 方差分析1. 对比不同组别之间的均值是否有显著差异。
- 方差分析结果为:组别间有显著差异(p < 0.05)。
问题五: 交叉分析1. 统计不同性别下不同年龄段的人数分布。
- 交叉分析结果见附件4。
以上为作业满分答案,如有任何问题,请及时与我联系。
SPSS统计软件练习作业
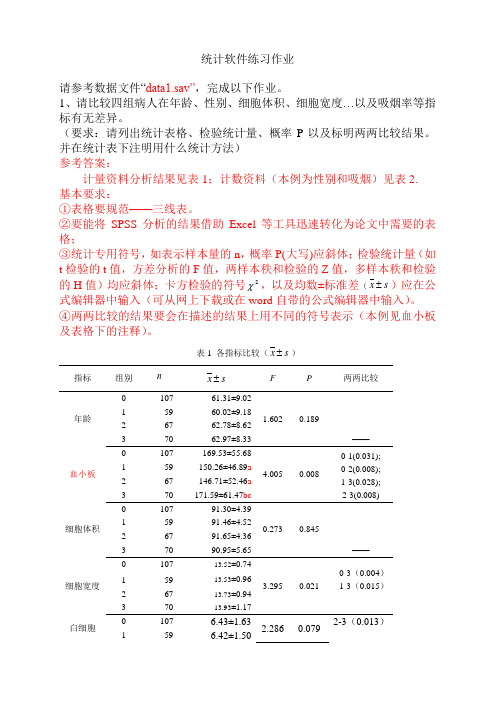
统计软件练习作业请参考数据文件“data1.sav”,完成以下作业。
1、请比较四组病人在年龄、性别、细胞体积、细胞宽度…以及吸烟率等指标有无差异。
(要求:请列出统计表格、检验统计量、概率P以及标明两两比较结果。
并在统计表下注明用什么统计方法)参考答案:计量资料分析结果见表1;计数资料(本例为性别和吸烟)见表2.基本要求:①表格要规范——三线表。
②要能将SPSS分析的结果借助Excel等工具迅速转化为论文中需要的表格;③统计专用符号,如表示样本量的n,概率P(大写)应斜体;检验统计量(如t检验的t值,方差分析的F值,两样本秩和检验的Z值,多样本秩和检验的H值)均应斜体;卡方检验的符号2χ,以及均数±标准差(sx±)应在公式编辑器中输入(可从网上下载或在word自带的公式编辑器中输入)。
④两两比较的结果要会在描述的结果上用不同的符号表示(本例见血小板及表格下的注释)。
表1 各指标比较(sx±)指标组别n sx± F P 两两比较年龄0 107 61.31±9.021.602 0.189——1 59 60.02±9.182 67 62.78±8.623 70 62.97±8.33血小板0 107 169.53±55.684.005 0.0080-1(0.031);0-2(0.008);1-3(0.028);2-3(0.008)1 59 150.26±46.89a2 67 146.71±52.46a3 70 171.59±61.47bc细胞体积0 107 91.30±4.390.273 0.845——1 59 91.46±4.522 67 91.65±4.363 70 90.95±5.65细胞宽度0 107 13.52±0.743.295 0.0210-3(0.004)1-3(0.015)1 59 13.53±0.962 67 13.73±0.943 70 13.93±1.17白细胞0 107 6.43±1.632.286 0.0792-3(0.013)1 59 6.42±1.502 67 6.23±1.383 70 6.90±1.69心厚度1 0 107 1.32±0.201.924 0.1261-3(0.042)2-3(0.047)1 59 1.27±0.222 67 1.28±0.213 70 1.51±1.35心厚度2 0 107 1.31±0.182.899 0.0350-1(0.008)1 59 1.23±0.172 67 1.26±0.193 70 1.30±0.19心功能0 107 66.77±7.553.772 0.0110-1(0.001)1 59 62.44±8.452 67 65.23±8.223 70 64.63±8.27心直径1 0 107 3.40±0.483.330 0.020-1(0.003)0-2(0.038)1 59 3.64±0.452 67 3.57±0.613 70 3.54±0.48心直径2 0 107 4.67±0.695.174 0.0020-1(<0.001)0-2(0.011)0-3(0.015)1 59 5.07±0.692 67 4.94±0.643 70 4.93±0.756血糖0 107 5.25±0.923.731 0.0120-1(0.001)1-2(0.021)1-3(0.031)1 59 5.73±0.852 67 5.36±0.933 70 5.38±0.87总胆固醇0 107 4.60±0.931.068 0.363——1 59 4.08±1.002 67 4.61±3.633 70 4.46±1.40低密度脂蛋白0 107 2.62±0.692.960 0.0330-1(0.011)1-3(0.029)1 59 2.30±0.682 67 2.40±0.763 70 2.60±0.93高密度脂蛋白0 107 1.19±0.232.138 0.0960-3(0.028)1 59 1.08±0.242 67 1.12±0.523 70 1.08±0.33注:与第0组比较,a P<0.05;与第1组比较,b P<0.05;与第2组比较,c P<0.05;统计方法:组间比较采用单因素方差分析(或完全随机设计方差分析);组间两两比较采用LSD-t 法;表2 四组性别分布和吸烟率的比较组别性别吸烟合计男女不吸烟吸烟0 49(70.3)58(36.7)82(63.6)25(43.4)1071 45(38.7)14(20.3)33(35.0) 26(24.0) 592 55(44.0)12(23.0)32(39.8) 35(27.2) 673 50(46.0)20(24.0)33(41.6) 37(28.4) 702χ30.735 21.599P <0.001 <0.001注:2χ检验2、请完成细胞宽度与心厚度1、心厚度2、心直径1、心直径2间的相关分析。
SPSS上机作业

SPSS上机作业
一、将文本数据“wb.txt”读入spss,命名为“消费”数据保存。
二、将SPSS自带数据中的“cars.sav”打开,对“weight”变量进行由高到低的排序,新生成的数据命名为“汽车”保存。
三、将练习题中的“期中成绩”和“期末成绩”进行合并,命名为“合成成绩”保存。
并分别计算语文、数学和英语的总分、平均分。
四、利用第三题的“合成成绩”数据统计90分以上的学生数。
五、对“期中成绩”中的性别进行自动赋值,生成新的数据命名为“一班成绩”保存。
六、单选题、多选题的数据录入。
录入数据后命名为“选择题”保存。
1、单选题
公务员的学历结构:①中学②中专;③大专;④大学本科;⑤硕士;⑥博士;⑦博士后。
2、多选题
节假日你到超市购物的原因:①促销活动;②购物环境;③服务质量;④有班车接送;⑤打折较多;⑥品牌效应;⑦其他
七、利用第三题的“合成成绩”数据计算三门课的平均分,中位数、众数,标准差、方差等。
八、利用SPSS自带数据“Employee.sav”,按照“性别”变量对数据进行数据的拆分。
北语2024春《SPSS统计分析实践》满分作业答案

北语2024春《SPSS统计分析实践》满分
作业答案
一、问题描述:
作业要求对一份调查问卷数据进行统计分析,包括描述统计、
相关分析和回归分析。
数据集包含了以下变量:性别、年龄、收入、教育水平、购物偏好、购买力、满意度等。
二、数据预处理:
1. 查看数据集的整体情况,包括数据类型、缺失值等。
2. 处理缺失值,可以选择删除含有缺失值的样本或使用插值法
进行填充。
三、描述统计分析:
1. 性别比例统计:计算男女比例并绘制饼图。
2. 年龄分布统计:计算年龄的平均值、标准差,并绘制年龄分
布直方图。
3. 收入水平统计:计算收入的最大值、最小值、中位数和四分
位数。
4. 教育水平统计:计算各教育水平的人数比例,并绘制教育水平柱状图。
四、相关分析:
1. 计算各变量之间的相关系数矩阵。
2. 绘制变量之间的散点图,并观察相关关系。
五、回归分析:
1. 选择一个自变量和一个因变量进行回归分析。
2. 计算回归方程的斜率、截距和决定系数。
3. 绘制回归线和残差图,并观察拟合情况。
六、结论:
根据以上统计分析结果,可以得出一些结论和建议,如性别比例接近1:1,年龄主要分布在30-40岁之间,收入水平较为分散,教育水平以本科为主等。
以上是《SPSS统计分析实践》满分作业的答案,希望能对你有所帮助。
北语2024春季《SPSS应用统计分析》作业满分解答

北语2024春季《SPSS应用统计分析》作业满分解答1. 描述统计分析1.1 数据录入首先,将数据导入SPSS中。
可以通过“文件”菜单中的“打开”选项,选择相应的数据文件进行导入。
1.2 基本描述性统计使用“描述统计”功能,可以得到各变量的均值、标准差、最小值、最大值等基本描述性统计量。
1.3 频数分布与交叉表分析通过“频数分布”功能,可以得到各变量的频数分布情况。
而交叉表分析则可以用于分析两个或多个变量之间的关系。
2. 假设检验2.1 单样本t检验当要比较一个样本均值与总体均值是否有显著差异时,可以使用单样本t检验。
在SPSS中,选择“假设检验”->“t检验”->“单样本t检验”,然后输入相应的样本数据和总体均值。
2.2 独立样本t检验当要比较两个独立样本的均值是否有显著差异时,可以使用独立样本t检验。
在SPSS中,选择“假设检验”->“t检验”->“独立样本t检验”,然后输入两个样本的数据。
2.3 配对样本t检验当要比较两个相关样本的均值是否有显著差异时,可以使用配对样本t检验。
在SPSS中,选择“假设检验”->“t检验”->“配对样本t检验”,然后输入两个相关样本的数据。
2.4 方差分析(ANOVA)当要比较三个或以上样本的均值是否有显著差异时,可以使用方差分析。
在SPSS中,选择“假设检验”->“方差分析”->“单因素方差分析”,然后输入各样本的数据。
2.5 卡方检验当要分析分类变量之间的关系时,可以使用卡方检验。
在SPSS中,选择“假设检验”->“非参数检验”->“卡方检验”,然后输入各分类变量的数据。
3. 回归分析3.1 一元线性回归当要分析一个自变量和一个因变量之间的线性关系时,可以使用一元线性回归。
在SPSS中,选择“回归”->“线性回归”->“估计”,然后输入自变量和因变量的数据。
3.2 多元线性回归当要分析两个或以上自变量和一个因变量之间的线性关系时,可以使用多元线性回归。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
因子分析和聚类分析实验结果
实验三细分市场:
最终聚类中心
聚类
1 2 3 4 5
-.26315 -.30404 .14466 .44654 .05989 REGR factor score 1 for
analysis 1
-.07182 .23828 -.26630 -.16127 .33259 REGR factor score 2 for
analysis 1
-.19328 -.28719 .63660 -.02573 -.18672 REGR factor score 3 for
analysis 1
.50829 -.00331 -.00021 -.34847 .11851 REGR factor score 4 for
analysis 1
.40420 -.21962 -.11076 -.04081 .64739 REGR factor score 5 for
analysis 1
-.30952 -.04110 .31218 -.10849 .13244 REGR factor score 6 for
analysis 1
.10254 -.14466 -.45953 .38182 .64683 REGR factor score 7 for
analysis 1
.26405 .22806 -.18056 -.42420 .29452 REGR factor score 8 for
analysis 1
REGR factor score 9 for
.79807 .18796 -.27608 -.03549 -1.28644 analysis 1
.19929 .31480 .22201 -.87975 .19295 REGR factor score 10 for
analysis 1
-.25574 .37900 -.66646 .46458 -.57422 REGR factor score 11 for
analysis 1
.37639 -.42108 -.22475 .55670 .17524 REGR factor score 12 for
analysis 1
REGR factor score 13 for
-.91613 .37980 -.04371 .18781 -.41194 analysis 1
-.33164 -.10366 .36184 -.09906 .26576 REGR factor score 14 for
analysis 1
REGR factor score 15 for
.09687 -.14233 .41251 .02394 -.80211 analysis 1
-.41177 .11759 -.37624 .09560 1.01041 REGR factor score 16 for
analysis 1
最终聚类中心
聚类
1 2 3 4 5
-.26315 -.30404 .14466 .44654 .05989 REGR factor score 1 for
analysis 1
REGR factor score 2 for
-.07182 .23828 -.26630 -.16127 .33259 analysis 1
REGR factor score 3 for
-.19328 -.28719 .63660 -.02573 -.18672 analysis 1
.50829 -.00331 -.00021 -.34847 .11851 REGR factor score 4 for
analysis 1
.40420 -.21962 -.11076 -.04081 .64739 REGR factor score 5 for
analysis 1
-.30952 -.04110 .31218 -.10849 .13244 REGR factor score 6 for
analysis 1
.10254 -.14466 -.45953 .38182 .64683 REGR factor score 7 for
analysis 1
REGR factor score 8 for
.26405 .22806 -.18056 -.42420 .29452 analysis 1
.79807 .18796 -.27608 -.03549 -1.28644 REGR factor score 9 for
analysis 1
REGR factor score 10 for
.19929 .31480 .22201 -.87975 .19295 analysis 1
-.25574 .37900 -.66646 .46458 -.57422 REGR factor score 11 for
analysis 1
.37639 -.42108 -.22475 .55670 .17524 REGR factor score 12 for
analysis 1
REGR factor score 13 for
-.91613 .37980 -.04371 .18781 -.41194 analysis 1
-.33164 -.10366 .36184 -.09906 .26576 REGR factor score 14 for
analysis 1
REGR factor score 15 for
.09687 -.14233 .41251 .02394 -.80211 analysis 1
-.41177 .11759 -.37624 .09560 1.01041 REGR factor score 16 for
analysis 1
REGR factor score 17 for
-.33057 .23704 .20568 -.24020 -.32299 analysis 1
每个聚类中的案例数
聚类 1 19.000
2 46.000
3 31.000
4 31.000
5 11.000
有效138.000
缺失 3.000
实验四细分市场分析:
细分市场1:受到因素4和因素9的影响,因素4即消费者总是要比较价格,即使在小商店也是如此;当经常购买的产品发生价格变动时,会注意到这一现象;会比较不同产品类型的价格,以便购买最有价值的食品。
因素9即消费者吃零食已经取代了吃正餐了;出去吃晚餐是我们家的生活习惯;他们通常和朋友们一起享受速食、方便的食品。
因此该细分市场是价格敏感性且具快速消费习惯。
细分市场2:受到因素10和因素13的影响,因素10即消费者觉得天然的食品是一个重要的质量标准;会尽力避免购买有添加剂的食品;只要有机会,我总是购买有机食品。
因素13即消费者偏向喜欢购买食品等购物活动。
因此该细分市场是注重健康型。
细分市场3:受到因素3,14,15的影响。
因素3即消费者觉得产品信息非常重要,需要了解产品含有什么成分;会比较产品的标签来选择最有营养的视频;
会比较产品的信息标签来决定购买什么品牌。
因素14即消费者认为上厨房是女人的事情;烹饪有营养的饭菜以保持家人的健康是女人的责任和义务。
因素15即消费者会受到人们对于某些产品进行讨论的影响。
因此该细分市场是女性居多且钟情于厨房,注重细节。
细分市场4:受到因素1,11,12的影响。
因素1即在消费者家里,吃零食很大部分已经取代了吃正餐;出去吃晚餐是成为他们的生活习惯了;他们通常和朋友们一起享受速食、方便的食品。
因素11即消费者的家人经常帮忙做其他的家务;当我确实不想做饭的时候,我的家人会帮我做饭。
因素12即消费者会尽量避免复杂的配方;在家里我通常会吃烹饪程序简单的食品,而不是需要复杂程序进行准备的食品。
因此该细分市场是追求快速,简单的食品。
细分市场5:受到因素5,7,8,16的影响. 因素5即消费者每天至少有一餐试吃冰冻过的事物;微波炉是烹饪的必须的电器;通常使用许多的调拌原材料。
因素7即消费者在购买大宗食品之前,会经常列一个购物清单;会尽力对于家庭所需要的食品的数量和种类做一个计划。
因素8即消费者觉得广告
中的信息有助于他们做出更好的决策;总是会购买最好的质量最好的价格的食品。
因素16即消费者觉得没必要去食品专门店去购物。
因此该细分市场是对食品烹饪比较讲究,注重性价比。