2010澳门特别行政区数据分析入门
澳门特别行政区历年生产法本地生产总值①统计(2003-2007)
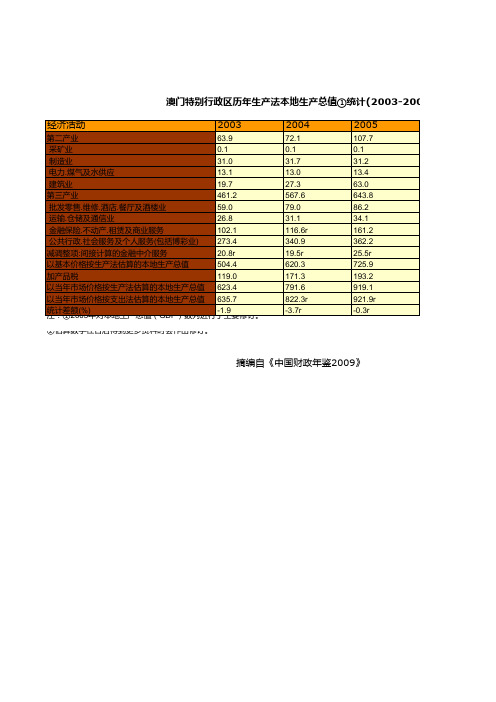
摘编自《中国财政年鉴2009》
2003-2007)
2006r
170.8 0.1 35.4 14.7 120.6 775.4 103.4 37.9 210.6 423.5 34.5 911.6 227.5 1139.1 1137.1.1 32.7 12.4 161.9 1006.4 136.8 43.3 266.3 560.1 43.0 1170.5 339.1 1509.6 1494.6 1.0
单位:亿澳门元
澳门特别行政区历年生产法本地生产总值①统计(2003-2007)
经济活动
2003
第二产业
63.9
采矿业
0.1
制造业
31.0
电力.煤气及水供应
13.1
建筑业
19.7
第三产业
461.2
批发零售.维修.酒店.餐厅及酒楼业
59.0
运输.仓储及通信业
26.8
金融保险.不动产.租赁及商业服务
102.1
②估算数字在日后得到更多资料时会作出修订。
2004
72.1 0.1 31.7 13.0 27.3 567.6 79.0 31.1 116.6r 340.9 19.5r 620.3 171.3 791.6 822.3r -3.7r
2005
107.7 0.1 31.2 13.4 63.0 643.8 86.2 34.1 161.2 362.2 25.5r 725.9 193.2 919.1 921.9r -0.3r
公共行政.社会服务及个人服务(包括博彩业) 273.4
减调整项:间接计算的金融中介服务
20.8r
以基本价格按生产法估算的本地生产总值
504.4
加产品税
2010人口普查数据

四、性别构成
• 大陆31个省、自治区、直辖市和现役军人的人口中,男性 人口为686852572人,占51.27%;女性人口为 652872280人,占48.73%。 • 总人口性别比(以女性为100,男性对女性的比例)由 2000年第五次全国人口普查的106.74下降为105.20。 • 人口学家认为新生儿正常的人口比约为105,在人口统计 学上,一般正常范围则在102至107之间。
第六次人口普查数据分析
李宁
一、总人口
• 全国总人口为1370536875人。 • 普查登记的大陆31个省、自治区、直辖市和现役军人的人 口[3]共1339724852人。 • 香港特别行政区人口为7097600人。 • 澳门特别行政区人口为552300人。 • 台湾地区人口为23162123人。
二、人口增长
八、城乡人口
• 大陆31个省、自治区、直辖市和现役军人的人口 中,居住在城镇的人口为665575306人,占 49.68%; • 居住在乡村的人口为674149546人,占50.32%。 • 同2000年第五次全国人口普查相比,城镇人口增 加207137093人,乡村人口减少133237289人, 城镇人口比重上升13.46个百分点。
• 比2000年第五次人口普查相比,10年增加7390万人,增 长5.84%,年平均增长0.57%,比1990年到2000年年均 1.07%的长率下降了0.5个百分点。
三、家庭户人口
• 大陆31个省、自治区、直辖市共有家庭户[7]401517330户, 家庭户人口为1244608395人,平均每个家庭户的人口为 3.10人,比2000年第五次全国人口普查的3.44人减少0.34 人。
十、登记误差
• 普查登记结束后,全国统一随机抽取402个普查小区进行 了事后质量抽样调查。抽查结果显示,人口漏登率为 0.12%。
2011澳门特别行政区数据分析高级

1、二部图(bipartite graph) G=(V,E)是一个能将其结点集V分为两不相交子集V 1和V2=V-V1的无向图,使得:V1中的任何两个结点在图G中均不相邻,V2中的任何结点在图G中也均不相邻。
(1).请各举一个结点个数为5的二部图和非二部图的例子。
(2).请用C或PASCAL编写一个函数BIPARTITE判断一个连通无向图G是否是二部图,并分析程序的时间复杂度。
设G用二维数组A来表示,大小为n*n(n为结点个数)。
请在程序中加必要的注释。
若有必要可直接利用堆栈或队列操作。
【2、设t是给定的一棵二叉树,下面的递归程序count(t)用于求得:二叉树t中具有非空的左,右两个儿子的结点个数N2;只有非空左儿子的个数NL;只有非空右儿子的结点个数NR和叶子结点个数N0。
N2、NL、NR、N0都是全局量,且在调用count(t)之前都置为0.typedef struct node{int data; struct node *lchild,*rchild;}node;int N2,NL,NR,N0;void count(node *t){if (t->lchild!=NULL) if (1)___ N2++; else NL++;else if (2)___ NR++; else (3)__ ;if(t->lchild!=NULL)(4)____; if (t->rchild!=NULL) (5)____;}26.树的先序非递归算法。
void example(b)btree *b;{ btree *stack[20], *p;int top;if (b!=null){ top=1; stack[top]=b;while (top>0){ p=stack[top]; top--;printf(“%d”,p->data);if (p->rchild!=null){(1)___; (2)___;}if (p->lchild!=null)(3)___; (4)__;}}}}3、证明由二叉树的中序序列和后序序列,也可以唯一确定一棵二叉树。
2010年澳门特别行政区数据概述高级

while(f<r)
{v=Q[++f]; if (s[v]==1) jh=2; else jh=1;//准备v的邻接点的集合号
if (!visited[v])
{visited[v]=1; //确保对每一个顶点,都要检查与其邻接点不应在一个集合中
10、 将顶点放在两个集合V1和V2。对每个顶点,检查其和邻接点是否在同一个集合中,如是,则为非二部图。为此,用整数1和2表示两个集合。再用一队列结构存放图中访问的顶点。
int BPGraph (AdjMatrix g)
//判断以邻接矩阵表示的图g是否是二部图。
{int s[]; //顶点向量,元素值表示其属于那个集合(值1和2表示两个集合)
#include<stdlib.h>
typedef int datatype;
typedef struct node
{datatype data;
struct node *next;
}listnode;
typedef listnode *linklist;
void jose(linklist head,int s,int m)
2、(1)p->rchild (2)p->lchild (3)p->lchild (4)ADDQ(Q,p->lchild) (5)ADDQ(Q,p->rchild)
25. (1)t->rchild!=null (2)t->rchild!=null (3)N0++ (4)count(t->lchild) (5)count(t->rchild)
数据分析入门学习指南

数据分析入门学习指南数据分析是当今信息时代的核心技能之一,它帮助我们从大量的数据中提取有价值的信息和洞察力。
无论是企业决策、市场营销还是科学研究,数据分析都扮演着重要的角色。
本文将为初学者提供一份数据分析入门学习指南,帮助他们快速入门并掌握基本的数据分析技能。
1. 数据分析的基础知识在开始学习数据分析之前,我们需要了解一些基础知识。
首先是统计学的基本概念和方法。
统计学是数据分析的基础,它提供了处理数据、推断结果和评估不确定性的工具和技术。
了解统计学的基本概念和方法,对于理解数据分析的原理和应用至关重要。
其次是数学的基础知识,包括概率论、线性代数和微积分等。
数学是数据分析的核心工具,它帮助我们理解和应用各种数据分析模型和算法。
虽然不需要深入掌握高级数学,但对于基本的数学概念和方法的理解是必不可少的。
2. 数据收集与清洗数据分析的第一步是收集和清洗数据。
数据可以来自各种来源,如数据库、网站、传感器等。
在收集数据之前,我们需要明确分析的目标和问题,以确定需要收集什么样的数据。
然后,我们需要对收集到的数据进行清洗和预处理,以去除噪声、处理缺失值和异常值等。
数据清洗是数据分析的重要环节,它直接影响到后续分析的准确性和可靠性。
在数据清洗过程中,我们需要运用各种技术和工具,如数据转换、数据插补和数据集成等,以确保数据的质量和一致性。
3. 数据探索与可视化在数据收集和清洗之后,我们需要对数据进行探索和可视化。
数据探索帮助我们了解数据的特征、分布和关系,从而为后续的分析和建模提供基础。
数据可视化则是将数据以图表、图形等形式展示出来,帮助我们更直观地理解数据。
在数据探索和可视化过程中,我们可以使用各种统计图表和可视化工具,如柱状图、散点图、箱线图和热力图等。
此外,还可以运用统计方法和分析技术,如描述统计、相关分析和聚类分析等,来揭示数据的规律和趋势。
4. 数据分析与建模数据分析的核心是运用各种分析方法和建模技术来揭示数据的内在规律和关联。
数据分析入门之常用方法

数据分析入门之常用方法数据分析是指根据收集到的数据,运用统计学和数学模型等方法,对数据进行整理、分析和解释的过程。
数据分析是现代社会中各行各业所必需的一项能力,适用于市场调研、商业决策、运营优化等领域。
下面是数据分析入门的一些常用方法。
1.描述统计分析:描述统计是对数据的集中趋势、离散程度和分布形态等进行统计描述的方法。
常用的描述统计方法有均值、中位数、众数、方差、标准差、偏度和峰度等。
通过这些统计量,可以对数据的整体情况进行了解。
2.可视化分析:可视化分析是通过图表等方式,将数据进行可视化展示的方法。
常见的可视化图表包括柱状图、折线图、散点图、饼图和箱线图等。
可视化分析可以帮助我们更直观地理解数据的分布和趋势,并发现异常值和规律。
3.相关性分析:相关性分析用于研究两个或多个变量之间的相关程度和相关方向。
常用的相关性分析方法包括皮尔逊相关系数和斯皮尔曼等级相关系数。
相关性分析可以帮助我们判断变量之间的关联程度,从而找出变量之间的因果关系。
4.回归分析:回归分析用于研究一个或多个自变量与因变量之间的关系,并通过拟合一个数学模型来预测因变量。
常见的回归分析方法包括线性回归、多元回归和逻辑回归等。
回归分析可以帮助我们理解变量之间的关系,并进行预测和预测。
5.时间序列分析:时间序列分析是对时间序列数据进行建模和预测的方法。
常用的时间序列分析方法包括移动平均、指数平滑和ARIMA模型等。
时间序列分析可以揭示数据的季节性和趋势性,从而帮助我们进行未来的预测。
6.聚类分析:聚类分析用于将数据集中的个体按照相似性进行分类。
常用的聚类方法包括K均值聚类、层次聚类和密度聚类等。
聚类分析可以帮助我们发现数据中的潜在分组,从而更好地理解数据。
7.因子分析:因子分析用于降维和变量选择。
通过因子分析,可以将多个变量转化为少数几个综合变量,从而减少数据维度和解释变量之间的关系。
因子分析可以帮助我们提取主要信息,提高分析效率。
数据分析的基础知识和技巧

数据分析的基础知识和技巧数据分析是指对收集来的数据进行解析、整理、分析和推断,以便从中提取有用的信息,并为决策和业务发展提供支持的过程。
在当今信息爆炸的时代,数据分析已成为各个领域中不可或缺的一项技能。
本文将介绍数据分析的基础知识和技巧,帮助读者了解和掌握这一重要的能力。
一、数据收集与处理1. 数据来源数据分析的第一步是收集数据。
数据可以来自各种渠道,比如企业内部的数据库、互联网上的公开数据、调查问卷等。
在收集数据时,需要注意数据的来源和真实性,确保数据的准确性和完整性。
2. 数据清洗收集到的数据往往存在噪声、缺失值、异常值等问题。
在进行数据分析之前,需要对数据进行清洗。
清洗的过程包括去除重复数据、填充缺失值、处理异常值等操作,以确保数据的可靠性和一致性。
3. 数据转换有些数据可能不符合分析的需求,需要进行转换。
比如将日期类型数据转换为时间序列,将文本数据转换为数值型数据等。
数据转换的目的是使数据适应分析模型和方法的要求,便于后续的分析工作。
二、数据探索与描述1. 数据可视化数据可视化是数据分析中的重要手段之一。
通过图表、图像等可视化工具,可以更直观地展示数据的特征和规律。
常用的数据可视化方法包括柱状图、折线图、散点图、饼图等。
通过数据可视化,可以帮助分析人员更好地理解数据,并发现其中的关联和趋势。
2. 描述统计描述统计是对数据进行总结和概括的方法。
常用的描述统计指标包括均值、中位数、标准差、相关系数等。
通过描述统计,可以了解数据的中心趋势、离散程度和相关关系,为后续的分析和推断提供基础。
三、数据分析与建模1. 统计分析统计分析是数据分析的核心内容之一。
通过应用概率统计理论和方法,对数据进行推断和预测。
常用的统计分析方法包括假设检验、方差分析、回归分析等。
通过统计分析,可以揭示数据中的规律和趋势,并进行可靠的推断和预测。
2. 机器学习机器学习是近年来发展迅猛的分析方法之一。
通过构建模型和算法,让机器从数据中学习,自动发现规律和模式。
数据分析的基础知识和技巧

数据分析的基础知识和技巧1. 引言1.1 概述数据分析是指通过收集、清理、处理和解释数据,来获取有关现象、趋势和模式的见解的过程。
随着大数据时代的到来,数据分析已成为各行各业中不可或缺的工作。
它可以帮助组织做出基于事实而非主观臆断的决策,提高业务运营效率,并发现潜在机遇。
在进行数据分析之前,我们需要了解一些基础知识和技巧,以便能够正确地收集、处理和解读数据。
本文将介绍数据分析的基本概念、数据收集与清理技术、数据可视化方法以及一些常用的统计学技巧和工具。
1.2 文章结构本文将按照以下顺序讲述数据分析的基础知识和技巧:- 第二部分将介绍数据分析的基本概念,包括定义和目标;- 第三部分将探讨如何进行有效的数据收集与清理;- 第四部分将介绍常用的数据可视化方法;- 第五部分将重点讲解统计学基础知识,在此基础上逐步介绍假设检验与推断统计;- 第六部分将介绍回归分析和预测的方法;- 第七部分将介绍一些必备的数据分析工具和技术,包括Excel、SQL以及Python与R语言;- 最后一部分将对全文进行总结,并展望数据分析未来的发展趋势。
1.3 目的本文旨在为读者提供关于数据分析基础知识和技巧方面的全面介绍,帮助读者掌握从数据收集到结果解释的整个过程。
无论是初学者还是有经验的数据分析人员,都可以通过本文获得有关数据分析领域最新发展和最佳实践的宝贵信息。
我们希望通过这篇文章能够激发你对数据分析的兴趣,并帮助你在实际工作中更好地运用数据来支持决策。
2. 数据分析基础知识:2.1 数据分析概念:数据分析是一种通过收集、清理、处理和解释数据以获得有价值信息的过程。
它可以帮助我们发现模式、趋势和关联,并从数据中提取洞察力,以对业务决策做出更明智的选择。
在数据分析中,有两种主要类型的数据:定量数据和定性数据。
定量数据是通过测量或计数来表示的,例如销售额、年龄或数量。
而定性数据则是非数值化描述的,例如产品品牌、用户评论等。
为了有效地进行数据分析,需要具备良好的统计学基础知识和技巧。
数据分析技巧 掌握解读数据的方法和技术

数据分析技巧掌握解读数据的方法和技术数据分析技巧掌握解读数据的方法和技术在当今信息爆炸的时代,数据已经成为各行各业决策和发展的基础。
掌握解读数据的方法和技术已经成为了一项关键的能力。
本文将介绍一些数据分析的基本技巧,帮助读者理解和应用数据,从而做出更准确的决策。
一、数据收集和整理数据分析的第一步是数据的收集和整理。
在进行数据收集时,需要确定数据的来源、范围和采集方式。
常见的数据来源包括数据库、调查问卷、日志文件等。
在数据整理阶段,需要对收集到的数据进行清洗和处理。
清洗数据是指排除错误、不完整或冗余的数据,确保数据的准确性。
处理数据包括对数据进行分类、筛选和转换,以便进一步分析。
二、数据可视化数据可视化是通过图表、图形和图像等方式,将数据以直观的形式展示出来,帮助人们更好地理解数据。
常见的数据可视化工具包括表格、柱状图、折线图、饼图等。
在进行数据可视化时,需要根据分析目的选择合适的图表类型,并注意图表的排版和颜色搭配。
同时,要确保图表的标题、标签和刻度清晰易懂,以避免读者对图表的误解。
三、统计分析统计分析是通过对数据进行整合、摘要和推断,揭示数据内在的规律和趋势。
常用的统计分析方法包括描述性统计、假设检验和回归分析等。
描述性统计是对数据进行基本的统计描述,包括均值、中位数、标准差等。
假设检验是根据样本数据对总体参数进行推断,判断样本与总体之间是否存在显著差异。
回归分析是通过建立数学模型,研究自变量和因变量之间的关系。
在进行统计分析时,需要注意选择适当的统计方法和模型,并进行数据的验证和效果评估。
四、趋势分析趋势分析是通过对过去的数据进行分析和预测,寻找和预测未来的发展趋势。
常用的趋势分析方法包括移动平均、指数平滑和时间序列分析等。
移动平均是利用一定时间内的平均值来描述数据的趋势变化。
指数平滑是根据权重将过去的数据平均化,对未来进行预测。
时间序列分析是通过对数据的时间依赖性进行建模,进行未来趋势的预测。
数据分析方法快速入门

数据分析方法快速入门简介数据分析是一种从大量数据中提取有用信息的方法。
数据分析可以帮助我们了解数据背后的模式、关系和趋势,从而做出基于数据的决策。
本文将介绍一些常用的数据分析方法,以帮助初学者快速入门。
1. 描述性统计分析描述性统计分析是分析数据的基本方法之一。
它可以帮助我们了解数据的基本特征,如数据的分布、中心趋势和变异程度。
常用的描述性统计方法包括:- 平均值:计算数据的平均值,衡量数据的中心趋势。
- 中位数:找出数据的中间值,衡量数据的中心趋势。
- 众数:出现频率最高的值,衡量数据的典型值。
- 方差:衡量数据的离散程度。
- 标准差:方差的平方根,衡量数据的离散程度。
2. 数据可视化数据可视化是将数据转换为图形或图表的方法,以便更好地理解数据。
常用的数据可视化方法包括:- 折线图:用于显示随时间变化的数据趋势。
- 柱状图:用于比较不同类别之间的数据。
- 散点图:用于显示两个变量之间的关系。
- 饼图:用于显示数据的相对比例。
数据可视化可以帮助我们更直观地理解数据,发现数据中的模式和趋势,并将复杂的数据信息传达给他人。
3. 假设检验假设检验是用来验证关于数据总体或总体参数的假设的方法。
通过假设检验,我们可以判断某个假设是否可以被接受或拒绝。
常用的假设检验方法包括:- t检验:用于比较两个样本的均值是否有显著差异。
- 卡方检验:用于检验观察值和期望值之间的差异是否显著。
- 方差分析:用于比较多个样本的均值是否有显著差异。
假设检验可以帮助我们进行数据的统计推断,并支持我们对数据背后的真相作出有根据的决策。
4. 回归分析回归分析是用来探索变量之间关系的方法。
通过回归分析,我们可以建立一个数学模型,以预测一个变量如何随其他变量的变化而变化。
常用的回归分析方法包括:- 简单线性回归分析:用于建立一个自变量和一个因变量之间的线性关系模型。
- 多元线性回归分析:用于建立多个自变量和一个因变量之间的线性关系模型。
快速学会数据分析方法

快速学会数据分析方法数据分析是当今信息时代中不可或缺的技能之一。
随着越来越多的数据被产生和收集,掌握数据分析方法已经成为了许多行业中的必备技能。
本文将介绍一些快速学会数据分析方法的技巧和步骤,帮助读者快速掌握这一技能。
第一步:明确分析目标在进行数据分析之前,我们首先需要明确自己的分析目标。
分析目标可以是回答某个具体问题、找出某个现象的原因,或是发现潜在的商业机会等。
明确分析目标有助于我们在整个分析过程中保持清晰的思路和方向。
第二步:收集数据数据是进行数据分析的基础。
我们可以通过多种途径来收集数据,如从公司内部数据库中提取数据、在网络上搜索相关数据、通过调查问卷采集数据等。
无论数据的来源如何,我们需要确保数据的质量和可靠性,以免影响后续的分析结果。
第三步:数据清洗与预处理在进行数据分析之前,我们需要对数据进行清洗和预处理的工作。
数据清洗主要是指去除数据中的无效值、处理重复数据、处理缺失数据等。
数据预处理则包括数据的归一化、标准化、离散化等操作,以便让数据更好地适应后续的分析需求。
第四步:选择适当的分析方法根据我们的分析目标和数据的性质,我们需要选择适当的分析方法。
常用的数据分析方法包括统计分析、机器学习、文本挖掘等。
在选择分析方法时,我们可以根据数据的特点和分析目标来选取相应的方法。
第五步:进行数据分析在选择了适当的分析方法后,我们可以开始进行数据分析。
根据所选择的分析方法,我们可以进行数据可视化、模型建立、参数调整等操作。
通过数据分析,我们可以获取到有关数据的各种信息和洞察,从而进一步回答我们的分析目标。
第六步:解读和呈现分析结果数据分析的最终目的是为了获得有关数据的洞察和结论。
在得到分析结果后,我们需要对分析结果进行解读和呈现。
解读分析结果时,我们可以采用故事化的方式,将数据的洞察融入到故事中,以便更好地向他人传达我们的分析结果。
呈现分析结果时,我们可以使用图表、可视化工具等方式,使得分析结果更加直观和易懂。
澳门特别行政区主要社会经济指标
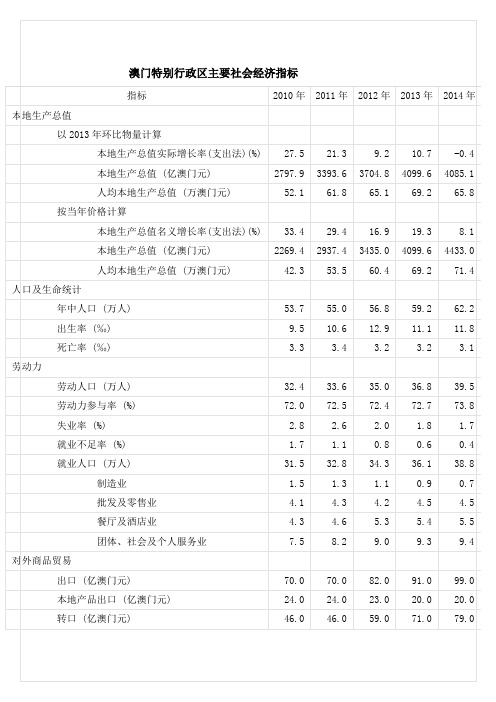
1.8
1.7
就业不足率 (%)
1.7
1.1
0.8
0.6
0.4
就业人口 (万人)
31.5
32.8
34.3
36.1
38.8
制造业
1.5
1.3
1.1
0.9
0.7
批发及零售业
4.1
4.3
4.2
4.5
4.5
餐厅及酒店业
4.3
4.6
5.3
5.4
5.5
团体、社会及个人服务业
7.5
8.2
9.0
9.3
9.4
对外商品贸易
澳门特别行政区主要社会经济指标
指标
2010年
2011年
2012年
2013年
2014年
本地生产总值
以2013年环比物量计算
本地生产总值实际增长率(支出法)(%)
27.5
21.3
9.2
10.7
-0.4
本地生产总值 (亿澳门元)
2797.9
3393.6
3704.8
4099.6
4085.1
人均本地生产总值 (万澳门元)
17093
32193
运输、通讯、旅游
进出澳门货运车辆数目(万辆)
35.8
33.4
32.5
31.1
35.7
领牌车辆 (万辆)
19.7
20.6
21.7
22.8
24.0
电话线 (万条)
129.1
152.0
177.6
188.1
210.0
访澳旅客(万人次)
2497.0
2800.0
从入门到精通数据分析的完整指南

从入门到精通数据分析的完整指南数据分析已经成为当今社会中不可或缺的技能之一。
无论是企业还是个人,都需要通过数据分析来获取有价值的信息和洞察,帮助做出更为明智的决策。
本文将为您提供从入门到精通数据分析的完整指南,帮助您掌握这一重要技能。
1. 数据分析的基础知识1.1 数据类型和数据收集:数据分析的基础是数据本身。
了解不同类型的数据(如数值型、分类型、时间序列等)以及如何收集数据是第一步。
1.2 数据清洗和整理:清洗和整理数据是保证数据质量的关键。
删除重复值、处理缺失值和异常值,以及统一数据格式是常见的数据清洗任务。
1.3 数据可视化工具:数据可视化是将数据转化为可理解的图表和图形的过程。
掌握数据可视化工具(如Tableau、Power BI等)可以使数据更加直观和易于理解。
2. 探索性数据分析(EDA)2.1 描述性统计分析:通过计算平均值、中位数、标准差等指标,了解数据的分布和集中趋势。
2.2 数据可视化:利用直方图、散点图、箱线图等图表,探索变量之间的关系和趋势。
2.3 探索性数据分析技术:使用相关性分析、聚类分析、主成分分析等方法,挖掘数据中隐藏的模式和结构。
3. 数据预处理3.1 特征选择:选择对目标变量有预测能力的特征,减少模型训练的维度。
3.2 特征缩放:对特征进行缩放,以便于模型的训练和收敛。
3.3 数据转换:根据具体情况,对数据进行平滑、离散化、标准化等处理,以便于模型的应用和解释。
4. 数据建模4.1 建立模型:选择适合问题的模型,如线性回归、逻辑回归、决策树、支持向量机等。
4.2 模型训练与评估:使用训练数据对模型进行训练,并利用测试数据对模型进行评估和验证。
4.3 模型优化与调参:根据模型在验证集上的表现,调整模型参数以优化模型性能。
5. 模型解释和应用5.1 特征重要性分析:通过分析模型中的特征重要性,了解哪些特征对模型预测结果有重要影响。
5.2 模型解释与可解释性:对于一些黑盒模型(如深度学习模型),可以使用解释性技术(如LIME、SHAP)解释模型的预测过程。
快速掌握数据分析的核心技巧

快速掌握数据分析的核心技巧数据分析是当今信息时代的核心工具之一,它可以帮助我们从庞大的数据中快速获取有价值的信息和洞见。
无论是从商业领域还是科学研究中,数据分析都扮演着至关重要的角色。
然而,对于初学者来说,掌握数据分析的核心技巧可能会感到困难。
本文将介绍一些快速掌握数据分析的核心技巧,帮助初学者在数据分析的世界中取得成功。
1. 学习基础的统计学知识统计学是数据分析的基础,了解统计学的基本概念和方法对于进行数据分析是至关重要的。
首先,你需要了解统计学中的概率、样本与总体、方差和标准差等基本概念。
其次,学习如何使用常见的统计学方法,例如假设检验、置信区间和回归分析等。
掌握这些基础知识将为你后续的数据分析工作打下坚实的基础。
2. 掌握常用的数据分析工具数据分析过程中,使用一些常用的数据分析工具将大大提高你的工作效率。
例如,Python是一种流行的编程语言,有许多强大的数据分析库,如NumPy、Pandas和Matplotlib等。
通过学习Python和这些库的使用,你可以快速处理和分析大量的数据。
此外,还有其他工具如R语言和Excel等,它们也具备强大的数据分析功能。
根据你的需求和兴趣选择合适的工具,并花些时间学习它们的使用方法。
3. 剖析数据集在进行数据分析之前,你需要先了解你手上的数据集。
浏览数据集的内容、查看列名、了解数据的组织结构和变量类型等,都是非常重要的。
一些常见的数据集包含着大量的信息,对数据集的熟悉程度将决定你在后续分析中是否能够找到关键点。
因此,在进行其他分析之前,首先要剖析数据集,熟悉数据的特点,并做好必要的预处理工作。
4. 数据可视化数据可视化是将数据以图形形式呈现出来的一种方法。
它可以帮助我们更直观地理解数据,并找出其中的规律和趋势。
在数据分析中,使用适当的图表、图像和图形来可视化数据是非常重要的。
例如,通过绘制柱状图、折线图、散点图和饼图等,我们可以清晰地看到数据的分布情况、变化趋势和关联关系。
2010年香港特别行政区数据总结入门

1、已知有向图G=(V,E),其中V={V1,V2,V3,V4,V5,V6,V7},E={<V1,V2>,<V1,V3>,<V1,V4>,<V2,V5>,<V3,V5>,<V3,V6>,<V4,V6>,<V5,V7>,<V6,V7>}写出G的拓扑排序的结果。
G拓扑排序的结果是:V1、V2、V4、V3、V5、V6、V72、已知有向图G=(V,E),其中V={V1,V2,V3,V4,V5,V6,V7},E={<V1,V2>,<V1,V3>,<V1,V4>,<V2,V5>,<V3,V5>,<V3,V6>,<V4,V6>,<V5,V7>,<V6,V7>}写出G的拓扑排序的结果。
G拓扑排序的结果是:V1、V2、V4、V3、V5、V6、V73、对二叉树的某层上的结点进行运算,采用队列结构按层次遍历最适宜。
int LeafKlevel(BiTree bt, int k) //求二叉树bt 的第k(k>1) 层上叶子结点个数{if(bt==null || k<1) return(0);BiTree p=bt,Q[]; //Q是队列,元素是二叉树结点指针,容量足够大int front=0,rear=1,leaf=0; //front 和rear是队头和队尾指针, leaf是叶子结点数int last=1,level=1; Q[1]=p; //last是二叉树同层最右结点的指针,level 是二叉树的层数while(front<=rear){p=Q[++front];if(level==k && !p->lchild && !p->rchild) leaf++; //叶子结点if(p->lchild) Q[++rear]=p->lchild; //左子女入队if(p->rchild) Q[++rear]=p->rchild; //右子女入队if(front==last) {level++; //二叉树同层最右结点已处理,层数增1last=rear; } //last移到指向下层最右一元素if(level>k) return (leaf); //层数大于k后退出运行}//while }//结束LeafKLevel。
2010澳门特别行政区数据要领入门

1、约瑟夫环问题(Josephus问题)是指编号为1、2、…,n的n(n>0)个人按顺时针方向围坐成一圈,现从第s个人开始按顺时针方向报数,数到第m个人出列,然后从出列的下一个人重新开始报数,数到第m的人又出列,…,如此重复直到所有的人全部出列为止。
现要求采用循环链表结构设计一个算法,模拟此过程。
2、二叉树的层次遍历序列的第一个结点是二叉树的根。
实际上,层次遍历序列中的每个结点都是“局部根”。
确定根后,到二叉树的中序序列中,查到该结点,该结点将二叉树分为“左根右”三部分。
若左、右子树均有,则层次序列根结点的后面应是左右子树的根;若中序序列中只有左子树或只有右子树,则在层次序列的根结点后也只有左子树的根或右子树的根。
这样,定义一个全局变量指针R,指向层次序列待处理元素。
算法中先处理根结点,将根结点和左右子女的信息入队列。
然后,在队列不空的条件下,循环处理二叉树的结点。
队列中元素的数据结构定义如下:typedef struct{ int lvl; //层次序列指针,总是指向当前“根结点”在层次序列中的位置int l,h; //中序序列的下上界int f; //层次序列中当前“根结点”的双亲结点的指针int lr; // 1—双亲的左子树 2—双亲的右子树}qnode;BiTree Creat(datatype in[],level[],int n)//由二叉树的层次序列level[n]和中序序列in[n]生成二叉树。
n是二叉树的结点数{if (n<1) {printf(“参数错误\n”); exit(0);}qnode s,Q[]; //Q是元素为qnode类型的队列,容量足够大init(Q); int R=0; //R是层次序列指针,指向当前待处理的结点BiTree p=(BiTree)malloc(sizeof(BiNode)); //生成根结点p->data=level[0]; p->lchild=null; p->rchild=null; //填写该结点数据for (i=0; i<n; i++) //在中序序列中查找根结点,然后,左右子女信息入队列if (in[i]==level[0]) break;if (i==0) //根结点无左子树,遍历序列的1—n-1是右子树{p->lchild=null;s.lvl=++R; s.l=i+1; s.h=n-1; s.f=p; s.lr=2; enqueue(Q,s);}else if (i==n-1) //根结点无右子树,遍历序列的1—n-1是左子树{p->rchild=null;s.lvl=++R; s.l=1; s.h=i-1; s.f=p; s.lr=1; enqueue(Q,s);}else //根结点有左子树和右子树{s.lvl=++R; s.l=0; s.h=i-1; s.f=p; s.lr=1;enqueue(Q,s);//左子树有关信息入队列s.lvl=++R; s.l=i+1;s.h=n-1;s.f=p; s.lr=2;enqueue(Q,s);//右子树有关信息入队列}while (!empty(Q)) //当队列不空,进行循环,构造二叉树的左右子树{ s=delqueue(Q); father=s.f;for (i=s.l; i<=s.h; i++)if (in[i]==level[s.lvl]) break;p=(bitreptr)malloc(sizeof(binode)); //申请结点空间p->data=level[s.lvl]; p->lchild=null; p->rchild=null; //填写该结点数据if (s.lr==1) father->lchild=p;else father->rchild=p; //让双亲的子女指针指向该结点if (i==s.l){p->lchild=null; //处理无左子女s.lvl=++R; s.l=i+1; s.f=p; s.lr=2; enqueue(Q,s);}else if (i==s.h){p->rchild=null; //处理无右子女s.lvl=++R; s.h=i-1; s.f=p; s.lr=1; enqueue(Q,s);}else{s.lvl=++R; s.h=i-1; s.f=p; s.lr=1; enqueue(Q,s);//左子树有关信息入队列s.lvl=++R; s.l=i+1; s.f=p; s.lr=2; enqueue(Q,s); //右子树有关信息入队列}}//结束while (!empty(Q))return(p);}//算法结束3、请编写一个判别给定二叉树是否为二叉排序树的算法,设二叉树用llink-rlink法存储。
学习数据分析的基本方法

学习数据分析的基本方法数据分析作为一门重要的技能,已经在各行各业中得到广泛应用。
无论是市场调研、业务分析还是决策制定,数据分析都扮演着至关重要的角色。
对于想要学习数据分析的人来说,掌握一些基本的方法和技巧是非常必要的。
本文将介绍学习数据分析的一些基本方法,帮助读者建立起自己的数据分析思维和技能。
首先,合理收集和清理数据是进行数据分析的第一步。
无论是从互联网上获取数据,还是通过内部系统收集数据,都需要保证数据的完整性和准确性。
在收集数据时,要注意避免数据的缺失和错误。
对于缺失数据,可以根据预测模型或者删除法进行填补;对于错误数据,可以通过数据校验和异常值处理等方式进行清理。
其次,掌握基本的统计学知识和技巧对于数据分析至关重要。
统计学是数据分析的核心基础,只有掌握了统计学的基本概念和方法,才能够正确地分析数据。
例如,了解均值、标准差、概率分布等统计概念,可以帮助我们对数据进行描述和理解。
掌握t检验、方差分析等基本统计方法,可以帮助我们对数据的差异和关联进行验证和分析。
另外,数据可视化也是进行数据分析的重要手段之一。
通过将数据可视化为图表、图像等形式,可以更直观地理解数据的特征和规律。
常用的数据可视化工具包括Excel、Tableau、Python的Matplotlib等。
选择合适的数据可视化工具,能够帮助我们更好地展示和传达数据分析结果,提高分析的效果和效率。
此外,掌握数据分析建模方法也非常重要。
通过建立适当的模型,可以对数据进行预测和分析。
常用的数据分析建模方法包括回归分析、分类分析、时间序列分析等。
这些方法可以帮助我们理解数据的发展趋势和影响因素。
对于不同的问题和数据类型,选择合适的模型进行建模和分析,可以提高分析的准确性和可靠性。
另外,要注重数据分析思维的培养。
数据分析不仅仅是运用工具和方法,更是一种思维方式和逻辑思维的训练。
在进行数据分析时,要注重逻辑性、连续性和系统性。
要从整体和细节的角度来分析问题,善于找到问题的本质和关键。
澳门特别行政区历年生产法本地生产总值统计(2010-2014)
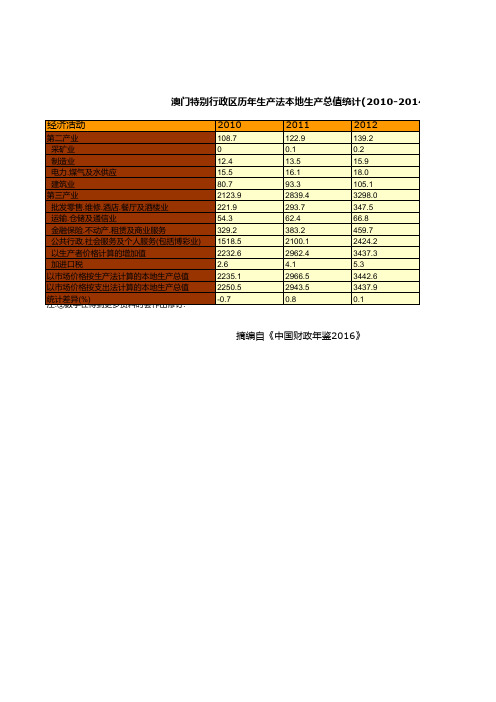
摘编自《中国财政年鉴2016》
010-2014)
2013
153.2 0 16.4 19.5 117.3 3952.0 410.8 73.1 590.7 2877.3 4105.2 4.7 4109.8 4118.4 -02
2014①
226.2 18.4 22.3 185.4 4133.9 450.8 89.3 732.2 2861.6 4360.1 4.6 4364.6 4434.7 -1.6
122.9 0.1 13.5 16.1 93.3 2839.4 293.7 62.4 383.2 2100.1 2962.4 4.1 2966.5 2943.5 0.8
2012
139.2 0.2 15.9 18.0 105.1 3298.0 347.5 66.8 459.7 2424.2 3437.3 5.3 3442.6 3437.9 0.1
以市场价格按生产法计算的本地生产总值 以市场价格按支出法计算的本地生产总值 统 注计:①差数异字(在%)得到更多资料时会作出修订.
2010
108.7 0 12.4 15.5 80.7 2123.9 221.9 54.3 329.2 1518.5 2232.6 2.6 2235.1 2250.5 -0.7
单位:亿澳门元
澳门特别行政区历年生产法本地生产总值统计(2010-2014)
经济活动
第二产业 采矿业 制造业 电力.煤气及水供应 建筑业
第三产业 批发零售.维修.酒店.餐厅及酒楼业 运输.仓储及通信业 金融保险.不动产.租赁及商业服务 公共行政.社会服务及个人服务(包括博彩业) 以生产者价格计算的增加值 加进口税
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1、因为后序遍历栈中保留当前结点的祖先的信息,用一变量保存栈的最高栈顶指针,每当退栈时,栈顶指针高于保存最高栈顶指针的值时,则将该栈倒入辅助栈中,辅助栈始终保存最长路径长度上的结点,直至后序遍历完毕,则辅助栈中内容即为所求。
void LongestPath(BiTree bt)//求二叉树中的第一条最长路径长度{BiTree p=bt,l[],s[]; //l, s是栈,元素是二叉树结点指针,l中保留当前最长路径中的结点int i,top=0,tag[],longest=0;while(p || top>0){ while(p) {s[++top]=p;tag[top]=0; p=p->Lc;} //沿左分枝向下if(tag[top]==1) //当前结点的右分枝已遍历{if(!s[top]->Lc && !s[top]->Rc) //只有到叶子结点时,才查看路径长度if(top>longest) {for(i=1;i<=top;i++) l[i]=s[i]; longest=top; top--;}//保留当前最长路径到l栈,记住最高栈顶指针,退栈}else if(top>0) {tag[top]=1; p=s[top].Rc;} //沿右子分枝向下}//while(p!=null||top>0)}//结束LongestPath2、矩阵中元素按行和按列都已排序,要求查找时间复杂度为O(m+n),因此不能采用常规的二层循环的查找。
可以先从右上角(i=a,j=d)元素与x比较,只有三种情况:一是A[i,j]>x,这情况下向j 小的方向继续查找;二是A[i,j]<x,下步应向i大的方向查找;三是A[i,j]=x,查找成功。
否则,若下标已超出范围,则查找失败。
void search(datatype A[ ][ ], int a,b,c,d, datatype x)//n*m矩阵A,行下标从a到b,列下标从c到d,本算法查找x是否在矩阵A中.{i=a; j=d; flag=0; //flag是成功查到x的标志while(i<=b && j>=c)if(A[i][j]==x) {flag=1;break;}else if (A[i][j]>x) j--; else i++;if(flag) printf(“A[%d][%d]=%d”,i,j,x); //假定x为整型.else printf(“矩阵A中无%d 元素”,x);}算法search结束。
[算法讨论]算法中查找x的路线从右上角开始,向下(当x>A[i,j])或向左(当x<A[i,j])。
向下最多是m,向左最多是n。
最佳情况是在右上角比较一次成功,最差是在左下角(A[b,c]),比较m+n次,故算法最差时间复杂度是O(m+n)。
3、证明由二叉树的中序序列和后序序列,也可以唯一确定一棵二叉树。
当n=1时,只有一个根结点,由中序序列和后序序列可以确定这棵二叉树。
设当n=m-1时结论成立,现证明当n=m时结论成立。
设中序序列为S1,S2,…,Sm,后序序列是P1,P2,…,Pm。
因后序序列最后一个元素Pm是根,则在中序序列中可找到与Pm相等的结点(设二叉树中各结点互不相同)Si(1≤i≤m),因中序序列是由中序遍历而得,所以Si是根结点,S1,S2,…,Si-1是左子树的中序序列,而Si+1,Si+2,…,Sm是右子树的中序序列。
若i=1,则S1是根,这时二叉树的左子树为空,右子树的结点数是m-1,则{S2,S3,…,Sm}和{P1,P2,…,Pm-1}可以唯一确定右子树,从而也确定了二叉树。
若i=m,则Sm是根,这时二叉树的右子树为空,左子树的结点数是m-1,则{S1,S2,…,Sm-1}和{P1,P2,…,Pm-1}唯一确定左子树,从而也确定了二叉树。
最后,当1<i<m时,Si把中序序列分成{S1,S2,…,Si-1}和{Si+1,Si+2,…,Sm}。
由于后序遍历是“左子树—右子树—根结点”,所以{P1,P2,…,Pi-1}和{Pi,Pi+1,…Pm-1}是二叉树的左子树和右子树的后序遍历序列。
因而由{S1,S2,…,Si-1}和{P1,P2,…,Pi-1}可唯一确定二叉树的左子树,由{Si+1,Si+2,…,Sm}和{Pi,Pi+1,…,Pm-1}可唯一确定二叉树的右子树。
4、矩阵中元素按行和按列都已排序,要求查找时间复杂度为O(m+n),因此不能采用常规的二层循环的查找。
可以先从右上角(i=a,j=d)元素与x比较,只有三种情况:一是A[i,j]>x,这情况下向j 小的方向继续查找;二是A[i,j]<x,下步应向i大的方向查找;三是A[i,j]=x,查找成功。
否则,若下标已超出范围,则查找失败。
void search(datatype A[ ][ ], int a,b,c,d, datatype x)//n*m矩阵A,行下标从a到b,列下标从c到d,本算法查找x是否在矩阵A中.{i=a; j=d; flag=0; //flag是成功查到x的标志while(i<=b && j>=c)if(A[i][j]==x) {flag=1;break;}else if (A[i][j]>x) j--; else i++;if(flag) printf(“A[%d][%d]=%d”,i,j,x); //假定x为整型.else printf(“矩阵A中无%d 元素”,x);}算法search结束。
[算法讨论]算法中查找x的路线从右上角开始,向下(当x>A[i,j])或向左(当x<A[i,j])。
向下最多是m,向左最多是n。
最佳情况是在右上角比较一次成功,最差是在左下角(A[b,c]),比较m+n次,故算法最差时间复杂度是O(m+n)。
5、题目中要求矩阵两行元素的平均值按递增顺序排序,由于每行元素个数相等,按平均值排列与按每行元素之和排列是一个意思。
所以应先求出各行元素之和,放入一维数组中,然后选择一种排序方法,对该数组进行排序,注意在排序时若有元素移动,则与之相应的行中各元素也必须做相应变动。
void Translation(float *matrix,int n)//本算法对n×n的矩阵matrix,通过行变换,使其各行元素的平均值按递增排列。
{int i,j,k,l;float sum,min; //sum暂存各行元素之和float *p, *pi, *pk;for(i=0; i<n; i++){sum=0.0; pk=matrix+i*n; //pk指向矩阵各行第1个元素.for (j=0; j<n; j++){sum+=*(pk); pk++;} //求一行元素之和.*(p+i)=sum; //将一行元素之和存入一维数组.}//for ifor(i=0; i<n-1; i++) //用选择法对数组p进行排序{min=*(p+i); k=i; //初始设第i行元素之和最小.for(j=i+1;j<n;j++) if(p[j]<min) {k=j; min=p[j];} //记新的最小值及行号.if(i!=k) //若最小行不是当前行,要进行交换(行元素及行元素之和){pk=matrix+n*k; //pk指向第k行第1个元素.pi=matrix+n*i; //pi指向第i行第1个元素.for(j=0;j<n;j++) //交换两行中对应元素.{sum=*(pk+j); *(pk+j)=*(pi+j); *(pi+j)=sum;}sum=p[i]; p[i]=p[k]; p[k]=sum; //交换一维数组中元素之和.}//if}//for ifree(p); //释放p数组.}// Translation[算法分析] 算法中使用选择法排序,比较次数较多,但数据交换(移动)较少.若用其它排序方法,虽可减少比较次数,但数据移动会增多.算法时间复杂度为O(n2).6、设有一个数组中存放了一个无序的关键序列K1、K2、…、Kn。
现要求将Kn放在将元素排序后的正确位置上,试编写实现该功能的算法,要求比较关键字的次数不超过n。
51. 借助于快速排序的算法思想,在一组无序的记录中查找给定关键字值等于key的记录。
设此组记录存放于数组r[l..h]中。
若查找成功,则输出该记录在r数组中的位置及其值,否则显示“not find”信息。
请编写出算法并简要说明算法思想。
7、数组A和B的元素分别有序,欲将两数组合并到C数组,使C仍有序,应将A和B拷贝到C,只要注意A和B数组指针的使用,以及正确处理一数组读完数据后将另一数组余下元素复制到C中即可。
void union(int A[],B[],C[],m,n)//整型数组A和B各有m和n个元素,前者递增有序,后者递减有序,本算法将A和B归并为递增有序的数组C。
{i=0; j=n-1; k=0;// i,j,k分别是数组A,B和C的下标,因用C描述,下标从0开始while(i<m && j>=0)if(a[i]<b[j]) c[k++]=a[i++] else c[k++]=b[j--];while(i<m) c[k++]=a[i++];while(j>=0) c[k++]=b[j--];}算法结束4、要求二叉树按二叉链表形式存储。
15分(1)写一个建立二叉树的算法。
(2)写一个判别给定的二叉树是否是完全二叉树的算法。
BiTree Creat() //建立二叉树的二叉链表形式的存储结构{ElemType x;BiTree bt;scanf(“%d”,&x); //本题假定结点数据域为整型if(x==0) bt=null;else if(x>0){bt=(BiNode *)malloc(sizeof(BiNode));bt->data=x; bt->lchild=creat(); bt->rchild=creat();}else error(“输入错误”);return(bt);}//结束 BiTreeint JudgeComplete(BiTree bt) //判断二叉树是否是完全二叉树,如是,返回1,否则,返回0{int tag=0; BiTree p=bt, Q[]; // Q是队列,元素是二叉树结点指针,容量足够大if(p==null) return (1);QueueInit(Q); QueueIn(Q,p); //初始化队列,根结点指针入队while (!QueueEmpty(Q)){p=QueueOut(Q); //出队if (p->lchild && !tag) QueueIn(Q,p->lchild); //左子女入队else {if (p->lchild) return 0; //前边已有结点为空,本结点不空else tag=1; //首次出现结点为空if (p->rchild && !tag) QueueIn(Q,p->rchild); //右子女入队else if (p->rchild) return 0; else tag=1;} //whilereturn 1; } //JudgeComplete8、设计一个尽可能的高效算法输出单链表的倒数第K个元素。