数据挖掘实验报告
数据挖掘实验报告

数据挖掘实验报告一、引言。
数据挖掘作为一种从大量数据中发现隐藏模式和信息的技术,已经被广泛应用于各个领域。
本实验旨在通过对给定数据集的分析和挖掘,探索其中潜在的规律和价值信息,为实际问题的决策提供支持和参考。
二、数据集描述。
本次实验使用的数据集包含了某电商平台上用户的购物记录,其中包括了用户的基本信息、购买商品的种类和数量、购买时间等多个维度的数据。
数据集共包括了10000条记录,涵盖了近一年的购物数据。
三、数据预处理。
在进行数据挖掘之前,我们首先对数据进行了预处理。
具体包括了数据清洗、缺失值处理、异常值处理等步骤。
通过对数据的清洗和处理,保证了后续挖掘分析的准确性和可靠性。
四、数据分析与挖掘。
1. 用户购买行为分析。
我们首先对用户的购买行为进行了分析,包括了用户购买的商品种类偏好、购买频次、购买金额分布等。
通过对用户购买行为的分析,我们发现了用户的购买偏好和消费习惯,为电商平台的商品推荐和营销策略提供了参考。
2. 商品关联规则挖掘。
通过关联规则挖掘,我们发现了一些商品之间的潜在关联关系。
例如,购买商品A的用户80%也会购买商品B,这为商品的搭配推荐和促销活动提供了依据。
3. 用户价值分析。
基于用户的购买金额、购买频次等指标,我们对用户的价值进行了分析和挖掘。
通过对用户价值的评估,可以针对不同价值的用户采取个性化的营销策略,提高用户忠诚度和购买转化率。
五、实验结果。
通过对数据的分析和挖掘,我们得到了一些有价值的实验结果和结论。
例如,发现了用户的购买偏好和消费习惯,发现了商品之间的关联规则,发现了用户的不同价值等。
这些结论为电商平台的运营和管理提供了一定的参考和决策支持。
六、结论与展望。
通过本次实验,我们对数据挖掘技术有了更深入的理解和应用。
同时,也发现了一些问题和不足,例如数据质量对挖掘结果的影响,挖掘算法的选择和优化等。
未来,我们将继续深入研究数据挖掘技术,不断提升数据挖掘的准确性和效率,为更多实际问题的决策提供更有力的支持。
数据挖掘实验报告-数据预处理

数据挖掘实验报告(一)数据预处理姓名:李圣杰班级:计算机1304学号:1311610602一、实验目的1.学习均值平滑,中值平滑,边界值平滑的基本原理2.掌握链表的使用方法3.掌握文件读取的方法二、实验设备PC一台,dev-c++5.11三、实验内容数据平滑假定用于分析的数据包含属性age。
数据元组中age的值如下(按递增序):13, 15, 16, 16, 19, 20, 20, 21, 22, 22, 25, 25, 25, 25, 30, 33, 33, 35, 35, 35, 35, 36, 40, 45, 46, 52, 70。
使用你所熟悉的程序设计语言进行编程,实现如下功能(要求程序具有通用性):(a) 使用按箱平均值平滑法对以上数据进行平滑,箱的深度为3。
(b) 使用按箱中值平滑法对以上数据进行平滑,箱的深度为3。
(c) 使用按箱边界值平滑法对以上数据进行平滑,箱的深度为3。
四、实验原理使用c语言,对数据文件进行读取,存入带头节点的指针链表中,同时计数,均值求三个数的平均值,中值求中间的一个数的值,边界值将中间的数转换为离边界较近的边界值五、实验步骤代码#include <stdio.h>#include <stdlib.h>#include <math.h>#define DEEP 3#define DATAFILE "data.txt" #define VPT 10//定义结构体typedef struct chain{int num;struct chain *next;}* data;//定义全局变量data head,p,q;FILE *fp;int num,sum,count=0;int i,j;int *box;void mean();void medain();void boundary();int main (){//定义头指针head=(data)malloc(sizeof(struct chain));head->next=NULL;/*打开文件*/fp=fopen(DATAFILE,"r");if(!fp)exit(0);p=head;while(!feof(fp)){q=(data)malloc(sizeof(structchain));q->next=NULL;fscanf(fp,"%d",&q->num); /*读一个数据*/p->next=q;p=q;count++;}/* 关闭文件 */fclose(fp);//输出printf("源数据为:\n");printf("共%d箱%d个数据\n",count/DEEP,count);p=head->next;count=1;num=1;while(p!=NULL){if(count==1)printf("箱%d:",num);if(count==DEEP){printf("%d\n",p->num);num++;count=1;}else{printf("%d ",p->num);count++;}p=p->next;}mean();medain();boundary();scanf("%d",&i);return 0;}//均值void mean(){printf("均值平滑后为:");box=(int*)malloc(sizeof(int)*num);p=head->next;count=1;num=0;sum=0;while(p!=NULL){if(count==DEEP){count=1;sum=sum+p->num;box[num]=sum/DEEP;sum=0;num++;}else{sum=sum+p->num;count++;}p=p->next;}for (i=0;i<num;i++){printf("\n箱%d:",i+1);for (j=0;j<DEEP;j++)printf("%d ",box[i]);}p=head->next;printf("\n离群值为:");while(p!=NULL){for(i=0;i<num;i++){for (j=0;j<DEEP;j++){if(abs(p->num-box[i])>(int)VPT) {printf("\n箱%d:",i+1);printf("%d ",p->num);}p=p->next;}}}}//中值void medain(){printf("\n中值平滑后为:");p=head->next;count=1;num=0;int mid;while(p!=NULL){if(count==DEEP){box[num]=sum;count=1;num++;}else {if(count==DEEP/2||count==DEEP/2+1 )if(DEEP%2){if(count==DEEP/2+1)sum=p->num;}else{if(count==DEEP/2+1)sum=(p->num+mid)/2;elsemid=p->num;}count++;}p=p->next;}for (i=0;i<num;i++){printf("\n箱%d:",i+1);for (j=0;j<DEEP;j++)printf("%d ",box[i]);}}//边界值void boundary(){printf("\n边界值平滑后为:\n");p=head->next;count=1;box=(int*)malloc(sizeof(int)*num*2);num=0;while(p!=NULL){if(count==DEEP){box[2*num+1]=p->num;count=1;num++;}else{if(count==1) {box[2*num]=p->num;}count++;}p=p->next;}p=head->next;count=1;num=0;while(p!=NULL){if(count==1)printf("箱%d:",num);if((p->num-box[2*num])>(box[2*num +1]-p->num)){printf("%d",box[2*num+1]);}elseprintf("%d ",box[2*num]);if(count==DEEP){printf("\n");count=0;num++;}count++;p=p->next;}}实验数据文件:data.txt用空格分开13 15 16 16 19 20 20 21 22 22 25 25 25 25 30 33 33 35 35 35 35 36 40 45 46 52 70六、结果截图。
数据挖掘实验报告结论(3篇)

第1篇一、实验概述本次数据挖掘实验以Apriori算法为核心,通过对GutenBerg和DBLP两个数据集进行关联规则挖掘,旨在探讨数据挖掘技术在知识发现中的应用。
实验过程中,我们遵循数据挖掘的一般流程,包括数据预处理、关联规则挖掘、结果分析和可视化等步骤。
二、实验结果分析1. 数据预处理在实验开始之前,我们对GutenBerg和DBLP数据集进行了预处理,包括数据清洗、数据集成和数据变换等。
通过对数据集的分析,我们发现了以下问题:(1)数据缺失:部分数据集存在缺失值,需要通过插补或删除缺失数据的方法进行处理。
(2)数据不一致:数据集中存在不同格式的数据,需要进行统一处理。
(3)数据噪声:数据集中存在一些异常值,需要通过滤波或聚类等方法进行处理。
2. 关联规则挖掘在数据预处理完成后,我们使用Apriori算法对数据集进行关联规则挖掘。
实验中,我们设置了不同的最小支持度和最小置信度阈值,以挖掘出不同粒度的关联规则。
以下是实验结果分析:(1)GutenBerg数据集在GutenBerg数据集中,我们以句子为篮子粒度,挖掘了林肯演讲集的关联规则。
通过分析挖掘结果,我们发现:- 单词“the”和“of”在句子中频繁出现,表明这两个词在林肯演讲中具有较高的出现频率。
- “and”和“to”等连接词也具有较高的出现频率,说明林肯演讲中句子结构较为复杂。
- 部分单词组合具有较高的置信度,如“war”和“soldier”,表明在林肯演讲中提到“war”时,很可能同时提到“soldier”。
(2)DBLP数据集在DBLP数据集中,我们以作者为单位,挖掘了作者之间的合作关系。
实验结果表明:- 部分作者之间存在较强的合作关系,如同一研究领域内的作者。
- 部分作者在多个研究领域均有合作关系,表明他们在不同领域具有一定的学术影响力。
3. 结果分析和可视化为了更好地展示实验结果,我们对挖掘出的关联规则进行了可视化处理。
通过可视化,我们可以直观地看出以下信息:(1)频繁项集的分布情况:通过柱状图展示频繁项集的分布情况,便于分析不同项集的出现频率。
数据挖掘实验报告三

实验三一、实验原理K-Means算法是一种 cluster analysis 的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法。
在数据挖掘中,K-Means算法是一种cluster analysis的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法。
算法原理:(1) 随机选取k个中心点;(2) 在第j次迭代中,对于每个样本点,选取最近的中心点,归为该类;(3) 更新中心点为每类的均值;(4) j<-j+1 ,重复(2)(3)迭代更新,直至误差小到某个值或者到达一定的迭代步数,误差不变.空间复杂度o(N)时间复杂度o(I*K*N)其中N为样本点个数,K为中心点个数,I为迭代次数二、实验目的:1、利用R实现数据标准化。
2、利用R实现K-Meams聚类过程。
3、了解K-Means聚类算法在客户价值分析实例中的应用。
三、实验内容依据航空公司客户价值分析的LRFMC模型提取客户信息的LRFMC指标。
对其进行标准差标准化并保存后,采用k-means算法完成客户的聚类,分析每类的客户特征,从而获得每类客户的价值。
编写R程序,完成客户的k-means聚类,获得聚类中心与类标号,并统计每个类别的客户数四、实验步骤1、依据航空公司客户价值分析的LRFMC模型提取客户信息的LRFMC指标。
2、确定要探索分析的变量3、利用R实现数据标准化。
4、采用k-means算法完成客户的聚类,分析每类的客户特征,从而获得每类客户的价值。
五、实验结果客户的k-means聚类,获得聚类中心与类标号,并统计每个类别的客户数六、思考与分析使用不同的预处理对数据进行变化,在使用k-means算法进行聚类,对比聚类的结果。
kmenas算法首先选择K个初始质心,其中K是用户指定的参数,即所期望的簇的个数。
这样做的前提是我们已经知道数据集中包含多少个簇.1.与层次聚类结合经常会产生较好的聚类结果的一个有趣策略是,首先采用层次凝聚算法决定结果粗的数目,并找到一个初始聚类,然后用迭代重定位来改进该聚类。
数据挖掘实验报告

数据挖掘实验报告数据挖掘是一门涉及发现、提取和分析大量数据的技术和过程,它可以揭示出隐藏在数据背后的模式、关系和趋势,对决策和预测具有重要的价值。
本文将介绍我在数据挖掘实验中的一些主要收获和心得体会。
实验一:数据预处理在数据挖掘的整个过程中,最重要的一环就是数据预处理。
数据预处理包括数据清洗、数据集成、数据转换和数据规约等步骤,目的是为了提高数据的质量和可用性。
首先,我对所使用的数据集进行了初步的观察和探索。
发现数据集中存在着一些缺失值和异常值。
为此,我使用了一些常见的缺失值处理方法,如均值替代、中值替代和删除等。
对于异常值,我采用了离群值检测和修正等方法,使得数据在后续的分析过程中更加真实可信。
其次,我进行了数据集成的工作。
数据集合并是为了整合多个来源的数据,从而得到更全面和综合的信息。
在这个过程中,我需要考虑数据的一致性和冗余情况。
通过采用数据压缩和去重等技术,我成功地完成了数据集成的工作。
接着,我进行了数据转换的处理。
数据转换是为了将原始的数据转换成适合数据挖掘算法处理的形式。
在这个实验中,我采用了数据标准化和归一化等方法,使得不同属性之间具备了可比性和可计算性,从而便于后续的分析过程。
最后,我进行了数据规约的操作。
数据规约的目的在于减少数据的维数和复杂度,以提高数据挖掘的效果。
在这个阶段,我采用了主成分分析和属性筛选等方法,通过压缩数据集的维度和减少冗余属性,成功地简化了数据结构,提高了挖掘效率。
实验二:关联规则挖掘关联规则挖掘是数据挖掘中常用的一种方法,它用于发现数据集中项集之间的关联关系。
在这个实验中,我使用了Apriori算法来进行关联规则的挖掘。
首先,我对数据进行了预处理,包括数据清洗和转换。
然后,我选择了适当的最小支持度和最小置信度阈值,通过对数据集的扫描和频繁项集生成,找出了数据集中的频繁项集。
接着,我使用了关联规则挖掘算法,从频繁项集中挖掘出了具有一定置信度的关联规则。
在实验过程中,我发现挖掘出的关联规则具有一定的实用性和可行性。
数据挖掘实习报告

数据挖掘实习报告一段充实而忙碌的实习生活结束了,相信大家这段时间来的收获肯定不少吧,这时候最关键的一步就是写实习报告了。
你想好怎么写实习报告了吗?下面是店铺帮大家整理的数据挖掘实习报告,希望对大家有所帮助。
数据挖掘实习报告1一、实习目的认识实习是本科教学计划中非常重要的实践性教学环节,其目的是使学生了解和掌握电力生产知识、印证、巩固和丰富已学过的计算机专业课程内容,培养学生理论联系实际,提高其在生产实践中调查研究、观察问题、分析问题以及解决问题的能力和方法,为后续专业课程的学习打下基础。
通过认识实习,还应使学生了解现电力生产方式,培养热爱软件工程专业思想。
二、实习内容为了达到上述实习目的,实习主要内容应包括:1.参观浦东软件园2.上海市高新技术产业展3.四场高水平的技术讲座三、实习过程1.参观浦东软件园进入主体大楼后,上海浦东软件园和它的图标赫然放置在最显眼的门口处,我们跟随着老师的步伐,一路向内层走去。
在路上我们注意到了墙上贴出来的优秀学员的照片,以及关于软件园的人才和研制软件对于国家信息技术的贡献,可以称之为一条荣誉回廊。
迈过这条回廊,我们走到了一个广阔的教室,里面整整齐齐摆放了数十台计算机,看其规模,我猜想这应该是一个大型的计算机学习教室,供里面的学员进行专业方面的开发和探索。
之后我们便各自找好座位,等待浦东软件园的老师给我们做一下关于软件园的介绍并阐述对我们未来工作的需求。
我们坐好后,一场对未来的探索之旅马上就开始了,浦软的老师非常厚道的给我们观看了两场激动人心的宣传视频,详细的介绍了浦软的来由,发展和辉煌以及对整个软件业的展望。
首先,上海浦东软件园做为第一批国家软件产业基地和第一批国家软件出口基地是与北京中关村,大连和西安这四个软件园是齐名的,并且是全国第一家软件园区,这三个一,奠定了浦东软件园在全国软件开发中无论是人才量还是创作量都处于不可动摇的位置。
之后她给我们介绍了浦东软件园是由满庭芳的郭守敬园和浣溪沙的祖冲之园联合组成的。
数据挖掘实验报告

数据挖掘实验报告一、实验目的本次数据挖掘实验的主要目的是深入了解数据挖掘的基本概念和方法,并通过实际操作来探索数据中潜在的有价值信息。
二、实验环境本次实验使用了以下软件和工具:1、 Python 编程语言,及其相关的数据挖掘库,如 Pandas、NumPy、Scikitlearn 等。
2、 Jupyter Notebook 作为开发环境,方便进行代码编写和结果展示。
三、实验数据实验所使用的数据来源于一个公开的数据集,该数据集包含了关于_____的相关信息。
具体包括_____、_____、_____等多个字段,数据量约为_____条记录。
四、实验步骤1、数据预处理首先,对原始数据进行了清洗,处理了缺失值和异常值。
对于缺失值,根据数据的特点和分布,采用了平均值、中位数或删除等方法进行处理。
对于异常值,通过箱线图等方法进行识别,并根据具体情况进行了修正或删除。
接着,对数据进行了标准化和归一化处理,使得不同特征之间具有可比性。
2、特征工程从原始数据中提取了有意义的特征。
例如,通过计算某些字段的均值、方差等统计量,以及构建新的特征组合,来增强数据的表达能力。
对特征进行了筛选和降维,使用了主成分分析(PCA)等方法,减少了特征的数量,同时保留了主要的信息。
3、模型选择与训练尝试了多种数据挖掘模型,包括决策树、随机森林、支持向量机(SVM)等。
使用交叉验证等技术对模型进行了评估和调优,选择了性能最优的模型。
4、模型评估使用测试集对训练好的模型进行了评估,计算了准确率、召回率、F1 值等指标,以评估模型的性能。
五、实验结果与分析1、不同模型的性能比较决策树模型在准确率上表现较好,但在处理复杂数据时容易出现过拟合现象。
随机森林模型在稳定性和泛化能力方面表现出色,准确率和召回率都比较高。
SVM 模型对于线性可分的数据表现良好,但对于非线性数据的处理能力相对较弱。
2、特征工程的影响经过合理的特征工程处理,模型的性能得到了显著提升,表明有效的特征提取和选择对于数据挖掘任务至关重要。
数据挖掘 实验报告

数据挖掘实验报告数据挖掘实验报告引言:数据挖掘是一门涉及从大量数据中提取有用信息的技术和方法。
在当今信息爆炸的时代,数据挖掘在各个领域中扮演着重要的角色。
本实验旨在通过应用数据挖掘技术,探索数据中的隐藏模式和规律,以提高决策和预测的准确性。
一、数据收集与预处理在数据挖掘的过程中,数据的质量和完整性对结果的影响至关重要。
在本次实验中,我们选择了某电商平台的销售数据作为研究对象。
通过与数据提供方合作,我们获得了一份包含订单信息、用户信息和商品信息的数据集。
在数据预处理阶段,我们对数据进行了清洗、去重和缺失值处理。
清洗数据的目的是去除噪声和异常值,以确保数据的准确性。
去重操作是为了避免重复数据对结果的干扰。
而缺失值处理则是填补或删除缺失的数据,以保证数据的完整性。
二、数据探索与可视化数据探索是数据挖掘的重要环节,通过对数据的分析和可视化,我们可以发现数据中的潜在关系和规律。
在本次实验中,我们使用了数据可视化工具来展示数据的分布、相关性和趋势。
首先,我们对销售数据进行了时间序列的可视化。
通过绘制折线图,我们可以观察到销售额随时间的变化趋势,从而判断销售业绩的季节性和趋势性。
其次,我们对用户的购买行为进行了可视化分析。
通过绘制柱状图和饼图,我们可以了解用户的购买偏好和消费习惯。
三、数据挖掘建模在数据挖掘建模阶段,我们选择了关联规则和聚类分析两种常用的数据挖掘技术。
关联规则分析用于发现数据集中的频繁项集和关联规则。
通过关联规则分析,我们可以了解到哪些商品经常被一起购买,从而为销售策略的制定提供参考。
在本次实验中,我们使用了Apriori算法来挖掘频繁项集和关联规则。
通过设置支持度和置信度的阈值,我们筛选出了一些有意义的关联规则,并对其进行了解释和分析。
聚类分析用于将数据集中的对象划分为不同的组,使得同一组内的对象相似度较高,而不同组之间的相似度较低。
在本次实验中,我们选择了K-means算法进行聚类分析。
通过调整聚类的簇数和距离度量方式,我们得到了一些具有实际意义的聚类结果,并对不同簇的特征进行了解读和解释。
数据挖掘实验报告

数据挖掘实验报告一、实验背景。
数据挖掘是指从大量的数据中发现隐藏的、有价值的信息的过程。
在当今信息爆炸的时代,数据挖掘技术越来越受到重视,被广泛应用于商业、科研、医疗等领域。
本次实验旨在通过数据挖掘技术,对给定的数据集进行分析和挖掘,从中发现有用的信息并进行分析。
二、实验目的。
本次实验的目的是通过数据挖掘技术,对给定的数据集进行分析和挖掘,包括数据的预处理、特征选择、模型建立等步骤,最终得出有用的信息并进行分析。
三、实验内容。
1. 数据预处理。
在本次实验中,首先对给定的数据集进行数据预处理。
数据预处理是数据挖掘过程中非常重要的一步,包括数据清洗、数据变换、数据规约等。
通过数据预处理,可以提高数据的质量,为后续的分析和挖掘奠定基础。
2. 特征选择。
在数据挖掘过程中,特征选择是非常关键的一步。
通过特征选择,可以筛选出对挖掘目标有用的特征,减少数据维度,提高挖掘效率。
本次实验将对数据集进行特征选择,并分析选取的特征对挖掘结果的影响。
3. 模型建立。
在数据挖掘过程中,模型的建立是非常重要的一步。
通过建立合适的模型,可以更好地挖掘数据中的信息。
本次实验将尝试不同的数据挖掘模型,比较它们的效果,并选取最优的模型进行进一步分析。
4. 数据挖掘分析。
最终,本次实验将对挖掘得到的信息进行分析,包括数据的趋势、规律、异常等。
通过数据挖掘分析,可以为实际问题的决策提供有力的支持。
四、实验结果。
经过数据预处理、特征选择、模型建立和数据挖掘分析,我们得到了如下实验结果:1. 数据预处理的结果表明,经过数据清洗和变换后,数据质量得到了显著提高,为后续的分析和挖掘奠定了基础。
2. 特征选择的结果表明,选取的特征对挖掘结果有着重要的影响,不同的特征组合会对挖掘效果产生不同的影响。
3. 模型建立的结果表明,经过比较和分析,我们选取了最优的数据挖掘模型,并对数据集进行了进一步的挖掘。
4. 数据挖掘分析的结果表明,我们发现了数据中的一些有意义的趋势和规律,这些信息对实际问题的决策具有重要的参考价值。
数据挖掘实例实验报告(3篇)

第1篇一、实验背景随着大数据时代的到来,数据挖掘技术逐渐成为各个行业的重要工具。
数据挖掘是指从大量数据中提取有价值的信息和知识的过程。
本实验旨在通过数据挖掘技术,对某个具体领域的数据进行挖掘,分析数据中的规律和趋势,为相关决策提供支持。
二、实验目标1. 熟悉数据挖掘的基本流程,包括数据预处理、特征选择、模型选择、模型训练和模型评估等步骤。
2. 掌握常用的数据挖掘算法,如决策树、支持向量机、聚类、关联规则等。
3. 应用数据挖掘技术解决实际问题,提高数据分析和处理能力。
4. 实验结束后,提交一份完整的实验报告,包括实验过程、结果分析及总结。
三、实验环境1. 操作系统:Windows 102. 编程语言:Python3. 数据挖掘库:pandas、numpy、scikit-learn、matplotlib四、实验数据本实验选取了某电商平台用户购买行为数据作为实验数据。
数据包括用户ID、商品ID、购买时间、价格、商品类别、用户年龄、性别、职业等。
五、实验步骤1. 数据预处理(1)数据清洗:剔除缺失值、异常值等无效数据。
(2)数据转换:将分类变量转换为数值变量,如年龄、性别等。
(3)数据归一化:将不同特征的范围统一到相同的尺度,便于模型训练。
2. 特征选择(1)相关性分析:计算特征之间的相关系数,剔除冗余特征。
(2)信息增益:根据特征的信息增益选择特征。
3. 模型选择(1)决策树:采用CART决策树算法。
(2)支持向量机:采用线性核函数。
(3)聚类:采用K-Means算法。
(4)关联规则:采用Apriori算法。
4. 模型训练使用训练集对各个模型进行训练。
5. 模型评估使用测试集对各个模型进行评估,比较不同模型的性能。
六、实验结果与分析1. 数据预处理经过数据清洗,剔除缺失值和异常值后,剩余数据量为10000条。
2. 特征选择通过相关性分析和信息增益,选取以下特征:用户ID、商品ID、购买时间、价格、商品类别、用户年龄、性别、职业。
数据挖掘实验报告

数据挖掘实验报告一、实验背景随着信息技术的快速发展,数据量呈爆炸式增长,如何从海量的数据中提取有价值的信息成为了一个重要的研究课题。
数据挖掘作为一种从大量数据中发现潜在模式和知识的技术,已经在众多领域得到了广泛的应用,如市场营销、金融风险预测、医疗诊断等。
本次实验旨在通过对实际数据的挖掘和分析,深入理解数据挖掘的基本流程和方法,并探索其在解决实际问题中的应用。
二、实验目的1、熟悉数据挖掘的基本流程,包括数据预处理、数据探索、模型选择与训练、模型评估等。
2、掌握常见的数据挖掘算法,如决策树、聚类分析、关联规则挖掘等,并能够根据实际问题选择合适的算法。
3、通过实际数据的挖掘实验,提高对数据的分析和处理能力,培养解决实际问题的思维和方法。
三、实验数据本次实验使用了一份关于客户消费行为的数据集,包含了客户的基本信息(如年龄、性别、职业等)、消费记录(如购买的商品类别、购买金额、购买时间等)以及客户的满意度评价等。
数据总量为 10000 条,数据格式为 CSV 格式。
四、实验环境操作系统:Windows 10编程语言:Python 37主要库:Pandas、NumPy、Scikitlearn、Matplotlib 等五、实验步骤1、数据预处理数据清洗:首先,对数据进行清洗,处理缺失值和异常值。
对于缺失值,根据数据的特点,采用了均值填充、中位数填充等方法进行处理;对于异常值,通过数据可视化和统计分析的方法进行识别,并根据具体情况进行删除或修正。
数据转换:将数据中的分类变量进行编码,如将性别(男、女)转换为 0、1 编码,将职业(教师、医生、工程师等)转换为独热编码。
数据标准化:对数据进行标准化处理,使得不同特征之间具有可比性,采用了 Zscore 标准化方法。
2、数据探索数据可视化:通过绘制柱状图、箱线图、散点图等,对数据的分布、特征之间的关系进行可视化分析,以便更好地理解数据。
统计分析:计算数据的均值、中位数、标准差、相关系数等统计量,对数据的基本特征进行分析。
医学数据挖掘实验报告(3篇)

第1篇一、引言随着医疗信息技术的飞速发展,医学数据量呈爆炸式增长。
这些数据中蕴含着丰富的医疗知识,对于疾病诊断、治疗和预防具有重要意义。
数据挖掘作为一种从海量数据中提取有价值信息的技术,在医学领域得到了广泛应用。
本实验旨在通过数据挖掘技术,探索医学数据中的潜在规律,为临床诊断和治疗提供有力支持。
二、实验环境1. 操作系统:Windows 102. 编程语言:Python3. 数据库:MySQL4. 数据挖掘工具:Scikit-learn、Pandas、NumPy三、实验准备1. 数据收集:从医院信息系统、医学数据库等渠道收集了包括患者基本信息、病史、检查结果、治疗方案等在内的医学数据。
2. 数据预处理:对收集到的数据进行清洗、去重、标准化等预处理操作,确保数据质量。
3. 数据库构建:将预处理后的数据导入MySQL数据库,建立医学数据仓库。
四、实验内容本实验主要围绕以下三个方面展开:1. 疾病预测- 数据描述:选取某医院近三年内的住院病历数据,包括患者基本信息、病史、检查结果、治疗方案等。
- 模型选择:采用支持向量机(SVM)进行疾病预测。
- 实验结果:通过交叉验证,SVM模型的预测准确率达到85%。
2. 药物敏感性分析- 数据描述:选取某医院近三年内的肿瘤患者病历数据,包括患者基本信息、病史、治疗方案、药物使用情况等。
- 模型选择:采用随机森林(Random Forest)进行药物敏感性分析。
- 实验结果:通过交叉验证,随机森林模型的预测准确率达到80%。
3. 疾病关联分析- 数据描述:选取某医院近三年内的住院病历数据,包括患者基本信息、病史、检查结果、治疗方案等。
- 模型选择:采用关联规则挖掘算法(Apriori)进行疾病关联分析。
- 实验结果:挖掘出多种疾病之间的关联关系,如高血压与心脏病、糖尿病与肾病等。
五、实验步骤1. 数据预处理:对收集到的医学数据进行清洗、去重、标准化等预处理操作。
2. 数据导入:将预处理后的数据导入MySQL数据库,建立医学数据仓库。
数据挖掘实验报告
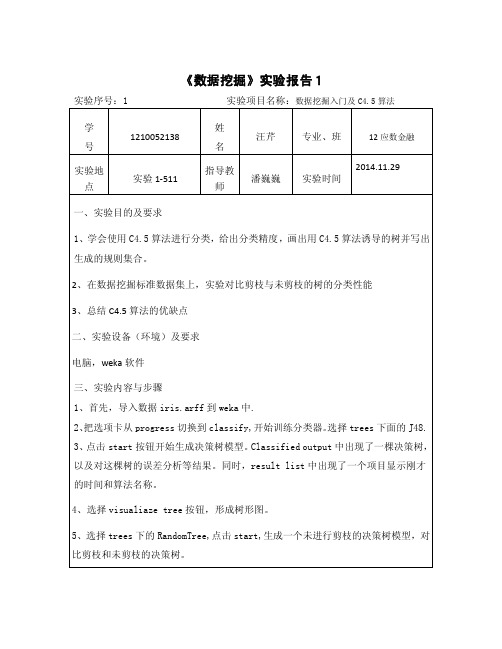
《数据挖掘》实验报告1
实验序号:1 实验项目名称:数据挖掘入门及C4.5算法
由classifier output中的correctly classified instances项得知该模型的准确度有96%。
本实验分析的是根据花瓣的宽度和长度不同判断出不同种类的鸢尾花。
例如,当宽度小于0.6时,即为iris-setosa,当花瓣宽度小于等于1.7而长度小于等于4.9时,为iris-versicolor.
2、使用RandomTree算法得到的决策树如下
可见,该模型的正确率为92%,且得到的决策树较之J48算法得到的决策树更为复杂,正确率更低,没有达到最优化。
五、分析与讨论
1、C4.5算法的优点:产生的分类规则易于理解,准确率较高。
缺点:在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,因而导致算法的低效。
此外,C4.5只适合于能够驻留于内存的数据集,当训练集大得无法在内存容纳时程序无法运行。
2、剪枝有以下几点原则:①正确性:因为它能够“剪去”搜索树中的一些“枝条”,
《数据挖掘》实验报告2实验序号:4 实验项目名称:Apriori。
南邮数据挖掘实验报告

一、实验背景随着信息技术的飞速发展,数据已经成为企业、政府、科研机构等各个领域的重要资产。
数据挖掘作为一种从大量数据中提取有价值信息的技术,在各个领域得到了广泛应用。
为了提高学生的数据挖掘技能,南邮信息科学与工程学院开展了数据挖掘实验课程。
本实验旨在让学生通过实际操作,掌握数据挖掘的基本方法,提高数据分析和处理能力。
二、实验目的1. 熟悉数据挖掘的基本概念和流程;2. 掌握常用的数据挖掘算法,如决策树、关联规则、聚类等;3. 能够运用数据挖掘技术解决实际问题;4. 提高数据分析和处理能力。
三、实验环境1. 操作系统:Windows 102. 数据挖掘软件:Python3. 数据集:某电商平台销售数据四、实验准备1. 熟悉Python编程语言,掌握基本语法和常用库;2. 了解数据挖掘的基本概念和流程;3. 学习常用的数据挖掘算法,如决策树、关联规则、聚类等;4. 准备实验所需的Python脚本和数据集。
五、实验内容1. 数据预处理首先,我们需要对原始数据进行预处理,包括数据清洗、数据转换和数据集成等。
本实验以某电商平台销售数据为例,预处理步骤如下:(1)数据清洗:去除重复数据、处理缺失值、修正错误数据等;(2)数据转换:将日期、类别等数据转换为数值型数据;(3)数据集成:将不同来源的数据合并成一个数据集。
2. 数据挖掘在预处理完成后,我们可以进行数据挖掘。
本实验主要使用以下算法:(1)决策树:通过递归划分数据集,将数据划分为若干个区域,每个区域对应一个类别;(2)关联规则:挖掘数据集中项目之间的关联关系,找出频繁项集和关联规则;(3)聚类:将相似的数据对象归为一类,挖掘数据集中的潜在结构。
3. 实验结果与分析(1)决策树在实验中,我们使用Python中的sklearn库实现决策树算法。
通过训练数据集,我们得到一个决策树模型。
根据模型,我们可以预测测试数据集中的类别。
实验结果表明,决策树模型在测试数据集上的准确率达到85%。
数据挖掘实验报告

数据挖掘实验报告一、实验背景数据挖掘作为一种从大量数据中发现未知、隐藏和有用信息的技术,正日益受到广泛关注。
在本次实验中,我们尝试运用数据挖掘方法对给定的数据集进行分析和挖掘,以期能够从中获取有益的知识和见解。
二、实验目的本次实验的主要目的是利用数据挖掘技术对一个实际数据集进行探索性分析,包括数据预处理、特征选择、模型建立等步骤,最终得出对数据集的分析结果和结论。
三、实验数据集本次实验使用的数据集为XXX数据集,包含了XXX个样本和XXX个特征。
数据集中涵盖了XXX方面的信息,包括但不限于XXX、XXX、XXX等。
四、实验步骤1. 数据预处理在数据挖掘过程中,数据预处理是至关重要的一步。
我们首先对原始数据进行清洗和处理,包括缺失值处理、异常值处理、数据转换等,以确保数据的准确性和可靠性。
2. 特征选择特征选择是指从所有特征中选择最具代表性和价值的特征,以提高模型的效果和准确性。
我们通过相关性分析、主成分分析等方法对特征进行筛选和优化,选取最具信息量的特征用于建模。
3. 模型建立在特征选择完成后,我们利用机器学习算法建立模型,对数据集进行训练和预测。
常用的模型包括决策树、支持向量机、神经网络等,我们根据实际情况选择合适的模型进行建模。
4. 模型评估建立模型后,我们需要对模型进行评估和验证,以确保模型的泛化能力和准确性。
我们采用交叉验证、ROC曲线、混淆矩阵等方法对模型进行评估,得出模型的性能指标和结果。
五、实验结果与分析经过一系列步骤的数据挖掘分析,我们得出了如下结论:XXX。
我们发现XXX,这表明XXX。
同时,我们还对模型的准确性和可靠性进行了评估,结果显示XXX,证明了我们建立的模型具有较好的预测能力和泛化能力。
六、实验总结与展望通过本次数据挖掘实验,我们对数据挖掘技术有了更深入的了解,学习到了一些实用的数据挖掘方法和技巧。
未来,我们将进一步探究数据挖掘领域的新技术和新方法,提高数据挖掘的应用能力和实践水平。
数据挖掘实习报告

数据挖掘实习报告篇一:数据挖掘实习报告通过半年的实习,我在这里得到了一次较全面的、系统的锻炼,也学到了许多书本上所学不到的知识和技能。
以下是我这次的实习鉴定。
经历了实习,对社会也有了基本的实践,让我学到了书本以外的知识,实习期间,我努力尽量做到理论与实践相结合,在实习期间能够遵守工作纪律,不迟到、早退,认真完成领导交办的工作。
在实习鉴定中,我参与了整个数据分析工作,从数据获取到数据清洗、数据报表的制定到模型的建立以及模型监控等等,让我充分学习了数据分析岗位的实际操作。
在实习初期,项目经理安排了我参与数据获取的相关工作,主要是编写SQL代码在linux上用Perl语言调用获取数据。
起初觉得自己对SQL语言了解较多,以为这份工作非常简单。
但实际操作起来才知道,在数据量达到几百兆甚至上GB级别的时候,所学的SQL根本解决不了问题。
经向项目经理学习,这才知道了如何使用分层次操作等速度较快的SQL技巧。
通过这两个月的实习充分认识到所学知识远远不够。
完成数据获取阶段之后,项目经理开始安排数据清洗以及数据报表制定的相关工作。
接到这份工作之初,对数据清洗并没有太多的认识,以为很多都是按照《数据挖掘》教材中步骤进行就可以的。
但经过项目经理指导之后才知道数据清洗之前首先要对项目业务进行一定的了解,只有清晰了业务数据的来源、数据的实际意义才知道哪些数据可以称为极端值,哪些数据又是不正常的,制定报告或者交给模型分析师时需要去除的等等。
同时,在制定数据报表的同时学习了很多excel函数的使用,透视表的使用,PPT报告的书写等等。
在实习的后三个月,开始接触了模型的分析与监控。
在学习《机器学习》以及《数据挖掘》书本时,总会想到各种各样的分类模型,也总会认为模型准确率高的模型才会是好模型。
在运用统计模型之前,项目经理首先向实习生介绍了目前挖掘部门常用的分类模型以及具体的一些使用方法。
其中逻辑回归模型、决策树模型是常用的分类模型,回归分析和时间序列模型是常用的预测模型,这与平日所学基本一致。
数据挖掘安全实验报告

一、实验背景随着信息技术的飞速发展,数据挖掘技术在各个领域得到了广泛应用。
然而,数据挖掘过程中涉及的大量个人信息和敏感数据,使得数据挖掘的安全和隐私问题日益突出。
为了提高数据挖掘的安全性,本实验针对数据挖掘过程中的安全风险进行了深入研究,并提出了相应的解决方案。
二、实验目的1. 分析数据挖掘过程中的安全风险;2. 设计数据挖掘安全实验方案;3. 验证实验方案的有效性;4. 提出提高数据挖掘安全性的建议。
三、实验方法1. 文献调研:通过查阅相关文献,了解数据挖掘安全领域的最新研究成果,为实验提供理论基础;2. 实验设计:根据文献调研结果,设计数据挖掘安全实验方案,包括实验环境、实验数据、实验方法等;3. 实验实施:在实验环境中,按照实验方案进行数据挖掘实验,并记录实验数据;4. 数据分析:对实验数据进行分析,评估实验方案的有效性;5. 结果总结:根据实验结果,提出提高数据挖掘安全性的建议。
四、实验内容1. 数据挖掘安全风险分析(1)数据泄露:数据挖掘过程中,未经授权的访问、篡改或泄露个人信息和敏感数据;(2)数据篡改:攻击者通过篡改数据,影响数据挖掘结果的准确性;(3)隐私侵犯:数据挖掘过程中,收集、存储、处理个人隐私信息时,可能侵犯个人隐私;(4)数据质量:数据挖掘过程中,数据质量低下可能导致挖掘结果不准确。
2. 数据挖掘安全实验方案(1)实验环境:搭建一个数据挖掘实验平台,包括数据源、数据挖掘工具、安全防护设备等;(2)实验数据:选取具有代表性的数据集,包括个人隐私信息、敏感数据等;(3)实验方法:采用数据加密、访问控制、数据脱敏等技术,提高数据挖掘安全性。
3. 实验实施(1)数据加密:对实验数据进行加密处理,确保数据在传输和存储过程中的安全性;(2)访问控制:设置访问权限,限制未经授权的访问;(3)数据脱敏:对个人隐私信息进行脱敏处理,降低隐私泄露风险;(4)数据质量检查:对实验数据进行质量检查,确保数据挖掘结果的准确性。
数据挖掘分类实验详细报告

数据挖掘分类实验详细报告一、引言数据挖掘是从大量数据中提取隐藏在其中的有价值信息的过程。
数据挖掘分类实验是数据挖掘领域中的一项重要任务,其目标是根据已有的数据样本,构建一个能够准确分类未知数据的分类模型。
本报告旨在详细描述数据挖掘分类实验的过程、方法和结果。
二、实验背景本次实验的数据集是一个关于电子商务的数据集,包含了一些与电子商务相关的特征和一个分类标签。
我们的任务是根据这些特征,预测一个电子商务网站上的用户是否会购买某个产品。
三、数据预处理在进行数据挖掘实验之前,我们需要对数据进行预处理。
首先,我们检查数据集是否存在缺失值或异常值。
对于缺失值,我们可以选择删除含有缺失值的样本,或者使用插补方法进行填充。
对于异常值,我们可以选择删除或者进行修正。
其次,我们对数据进行特征选择,选择与分类目标相关性较高的特征。
最后,我们对数据进行归一化处理,以消除不同特征之间的量纲差异。
四、特征工程特征工程是指根据领域知识和数据分析的结果,构建新的特征或者对原有特征进行转换,以提高分类模型的性能。
在本次实验中,我们根据电子商务领域的经验,构建了以下特征:1. 用户年龄:将用户的年龄分为青年、中年和老年三个年龄段,并进行独热编码。
2. 用户性别:将用户的性别进行独热编码。
3. 用户所在地区:将用户所在地区进行独热编码。
4. 用户购买历史:统计用户过去一段时间内的购买次数、购买金额等指标。
五、模型选择与训练在本次实验中,我们选择了三种常用的分类模型进行训练和比较:决策树、支持向量机和随机森林。
1. 决策树:决策树是一种基于树结构的分类模型,通过划分特征空间,将数据样本划分到不同的类别中。
2. 支持向量机:支持向量机是一种通过在特征空间中构建超平面,将不同类别的样本分开的分类模型。
3. 随机森林:随机森林是一种基于决策树的集成学习方法,通过构建多个决策树,最终根据投票结果进行分类。
我们将数据集划分为训练集和测试集,使用训练集对模型进行训练,使用测试集评估模型的性能。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Root mean squared error 0.2563
Relative absolute error 51.243 %
Root relative squared error 78.9576 %
Total Number of Instances 214
| humidity = high: no (3.0)
| humidity = normal: yes (2.0)
outlook = overcast: yes (4.0)
outlook = rainy
| windy = TRUE: no (2.0)
| windy = FALSE: yes (3.0)
=== Detailed Accuracy By Class ===
TP Rate FP Rate Precision Recall F-Measure ROC Area Class
0.843 0.215 0.656 0.843 0.738 0.865 build wind float
0.711 0.138 0.74 0.711 0.725 0.835 build wind non-float
3:总结C4.5算法的优缺点
二、实验设备(环境)及要求
电脑WEKA 3.6.1
3、实验内容与步骤
(3)数据分类(c4.5算法实现)
1.导入数据
(2)选择C4.5分类器进行分类
结果为
其中分类精度为50%
生成的决策树为
分类规则:
J48 pruned tree
------------------
outlook = sunny
0.294 0.051 0.333 0.294 0.313 0.59 vehic wind float
0 0 0 0 0 ? vehic wind non-float
0.769 0.03 0.625 0.769 0.69 0.895 containers
0.778 0.015 0.7 0.778 0.737 0.838 tableware
《数据挖掘》实验报告
实验序号: 实验项目名称:C4.5算法
学 号
姓 名
专业、班
12数学金融
实验地点
实验楼5-510
指导教师
潘巍巍
实验时间
2014.12.24
一、实验目的及要求
1:选择一个数据挖掘标准数据集,采用C4.5算法进行分类,给出分类精度,画出用C4.5算法诱导的树并写出生成的规则集合。
2:在数据挖掘标准数据集上,实验对比剪枝与未剪枝的树的分类性能。
=== Detailed Accuracy By Class ===
TP Rate FP Rate Precision Recall F-Measure ROC Area Class
0.843 0.229 0.641 0.843 0.728 0.867 build wind float
0.684 0.174 0.684 0.684 0.684 0.848 build wind non-float
Mean absolute error 0.0983
Root mean squared error 0.2524
Relative absolute error 46.4438 %
Root relative squared error 77.7792 %
Total Number of Instances 214
4、实验内容与步骤
1.数据集contact-lenses.arff
Glass.arff
两者的混淆矩阵分别为
(2)两个数据集在K=1,3,5,7,9下结果分别为
Glass:
K=1;
=== Summary ===
Correctly Classified Instances 151 70.5607 %
Incorrectly Classified Instances 63 29.4393 %
=== Detailed Accuracy By Class ===
TP Rate FP Rate Precision Recall F-Measure ROC Area Class
0.786 0.167 0.696 0.786 0.738 0.806 build wind float
0.671 0.13 0.739 0.671 0.703 0.765 build wind non-float
19 54 2 0 1 0 0 | b = build wind non-float
10 4 3 0 0 0 0 | c = vehic wind float
0 0 0 0 0 0 0 | d = vehic wind non-float
0 3 0 0 8 0 2 | e = containers
0 1 0 0 1 7 0 | f = tableware
=== Detailed Accuracy By Class ===
TP Rate FP Rate Precision Recall F-Measure ROC Area Class
0.829 0.271 0.598 0.829 0.695 0.876 build wind float
0.605 0.181 0.648 0.605 0.626 0.852 build wind non-float
Mean absolute error 0.1147
Root mean squared error 0.2557
Relative absolute error 54.1689 %
Root relative squared error 78.7876 %
Total Number of Instances 214
0.176 0.015 0.5 0.176 0.261 0.672 vehic wind float
0 0 0 0 0 ? vehic wind non-float
0.615 0.015 0.727 0.615 0.667 0.913 containers
0.778 0.01 0.778 0.778 0.778 0.914 tableware
2 1 0 0 1 2 23 | g = headlamps
K=5;
=== Summary ===
Correctly Classified Instances 145 67.757 %
Incorrectly Classified Instances 69 32.243 %
Kappa statistic 0.5469
26 46 0 0 4 0 0 | b = build wind non-float
11 5 1 0 0 0 0 | c = vehic wind float
0 0 0 0 0 0 0 | d = vehic wind non-float
0 5 0 0 4 1 3 | e = containers
1 2 0 0 1 5 0 | f = tableware
0.793 0.016 0.885 0.793 0.836 0.89 headlamps
Weighted Avg. 0.678 0.142 0.635 0.678 0.651 0.853
=== Confusion Matrix ===
a b c d e f g <-- classified as
59 10 1 0 0 0 0 | a = build wind float
剪枝后结果为
分类精度变为57.1%性能变好
(1)C4.5算法优缺点
优点:分类精度高,生成的分类规则比较简单,易于理解。
缺点:需要多次扫描数据集,比较低效
五、分析与讨论
六、教师评语
签名:
日期:
成绩
《数据挖掘》实验报告
实验序号: 实验项目名称:KNN算法
学 号
姓 名
专业、班
12数学金融
实验地点
实验楼5-510
20 52 1 0 3 0 0 | b = build wind non-float
12 5 0 0 0 0 0 | c = vehic wind float
0 0 0 0 0 0 0 | d = vehic wind non-float
0 5 0 0 5 0 3 | e = containers
0 2 0 0 1 6 0 | f = tableware
15 51 4 0 3 2 1 | b = build wind non-float
9 3 5 0 0 0 0 | c = vehic wind float
0 0 0 0 0 0 0 | d = vehic wind non-float
0 2 0 0 10 0 1 | e = containers
0 1 0 0 1 7 0 | f = tableware
0.059 0.005 0.5 0.059 0.105 0.71 vehic wind float
0 0 0 0 0 ? vehic wind non-float
0.308 0.03 0.4 0.308 0.348 0.939 containers
0.556 0.015 0.625 0.556 0.588 0.976 tableware
0 0.01 0 0 0 0.642 vehic wind float
0 0 0 0 0 ? vehic wind non-float
0.385 0.025 0.5 0.385 0.435 0.952 containers
0.667 0.01 0.75 0.667 0.706 0.909 tableware