Segmentation and Classification of Human Activities
教育游戏化:将课堂变成一场协同冒险游戏——以Classcraft为例

28 |
PUBLISHING REFERENCE
海外市场
“对战”形式完成教学评测。学生按时完成任务可 以获得奖励,并用来升级角色的经验值(Experience Points,XP)——这将使其角色提高战斗水平并学 习新的技能。如果一个学生违反了课堂纪律,就会 失去生命值,甚至最终导致角色在“对战”中失败。 如果学生获得经验值点数,对相应角色及其团队都 有益处;相反,如果一个学生失去了生命值点数, 其团队的其他成员角色也会受到伤害,并且大家必 须完成各种额外任务。无论如何,学生们需要共同 努力才能使团队获得成功。一般而言,没有学生愿 意自己的不当行为损害团队利益,导致他人失败。 游戏团队中,学生还可以帮助彼此成长。例如,如 果学生的虚拟角色是一名战士,而队友因为上课迟 到面临生命值点数降低,则该学生可以通过完成额 外的学习任务来挽救队友。学生知道他们在课堂上 的行为会影响整个团队的进度、这会激励他们强化 课堂上的积极行为和团队合作,提升课堂学习效率。 Classcraft 每个月都会发布新的故事情节和场景供教 育工作者选择,帮助提升学生的课堂参与感 [19]。除 了在预制故事中添加课程任务外,Classcraft 还允许 教师自己编写课程,通过上传不同的学习任务来教 授不同的科目。根据在课堂活动中收集的数据,教 师还可以查看学生的行为并进行分析。
是以游戏软件为基础的学习,教育游戏(Educational Games)的设
计与开发是当前研究的主流方向。教育游戏模糊了学习与游戏、正式 学习与非正式学习的边界 [13];但是有别于教育游戏的软件性质(见表
1),教育游戏化是一套解决方案,服务于教育情境中的各类问题,
如激发学习者动机和兴趣、引导学习者面对学业失败、激发其学校生
研究表明,随着游戏在当代文化中的地位日益 提高,其在教育中能够扮演的角色也越来越多样化。 Classcraft 作为受到游戏启发开发的教育解决方案, 它对于学习的积极作用和游戏非常相似。
Detection, segmentation and classification of heart sounds

…
•ห้องสมุดไป่ตู้When an interval exceeds the high-level limit, it is assumed that a peak has been lost and the threshold is decreased by a certain amount. It is repeated until the lost peaks are found or a certain limit is reached.
• Extra peaks were rejected by the following rules: if t2 −t1 ≤ 50ms (splitted peak) if a(t1) > 0.6a(t2 ) choose t1 else choose t2 else choose t2 (not splitted)
• Used narrow sliding windows (25ms) to compute 8th order AR model. • Features used : dominant poles (below 80Hz) and bandwidth. • Detected S1, S2 and murmurs.
Segmentation and Event Detection Cons
Suggested Methods
• Waveshape analysis – Homomorphic Filtering. • Temporal Model – (Semi) Hidden Markov Models.
Waveshape analysis - Homomorphic filtering
• Express the PCG signal x(t) by
eCognition算法

原文地址:ecognition 常用算法介绍作者:fucupChessboard SegmentationSplit the pixel domain or an image object domain into square image objects. A square grid aligned to the image left and top borders of fixed size is applied to all objects in the domain and each object is cut along these grid lines.Quad Tree Based SegmentationSplit the pixel domain or an image object domain into a quad tree grid formed by square objects.A quad tree grid consists of squares with sides each having a power of 2 and aligned to the image left and top borders is applied to all objects in the domain and each object is cut along this grid lines. The quad tree structure is build in a way that each square has first maximum possible size and second fulfills the homogeneity criteria as defined by the mode and scale parameter.Contrast Split SegmentationUse the contrast s plit segmentation algorithm to segment an image or an image object into dark and bright regions.The algorithm achieves the optimization by considering different pixel values as potential thresholds. The test thresholds range from the minimum threshold to the maximum threshold, with intermediate values chosen according to the step size and stepping type parameter. If a test threshold sati sfies the minimum dark area and minimum bright area criterion, the contrast between bright and dark objects is evaluated. The test threshold causing the largest contrast is chosen as best threshold and used for splitting.Spectral Difference SegmentationMerge neighboring image objects according to their mean image layer intensity values. Neighboring image objects are merged if the difference between their layer mean intensities is below the value given by the maximum spectral difference.NoteThis algorithm cannot be used to create new image object levels based on the pixel level domain.Contrast Filter SegmentationUse pixel filters to detect potential objects by contrast and gradient and create suitable object primitives. An integrated reshaping operation modifies the shape of image objects to help form coherent and compact image objects.The resulting pixel classification is stored in an internal thematic layer. Each pixel is classified as oneof the following classes: no object, object in first layer, object in second layer, object in both layers, ignored by threshold.Finally a chessboard segmentation is used to convert this thematic layer into an image object level.Use this algorithm as first step of your analysis to improve overall image analysis performance substantially.Assign ClassAssign all objects of the image object domain to the class specified by the Use class parameter.The membership value for the assigned class is set to 1 for all objects independent of the class description. The second and third best classification results are set to 0 .ClassificationEvaluates the membership value of an image object to a list of selected classes. The classification result of the image object is updated according to the class evaluation result. The three best classes are stored in the image object classification result. Classes without a class description are assumed to have a membership value of 1.Hierarchical ClassificationEvaluate the membership value of an image object to a list of selected classes. The classification result of the image object is updated according to the class evaluation result. The three best classes are stored as the image object classification result. Classes without a class description are assumed to have a membership value of 0. Class related features are considered only if explicitly enabled by the according parameter.NoteThis algorithm is optimized for applying complex class hierarchies to entire image object levels. This reflects the classification algorithm of eCognition Professional 4. When working with domain specific classification in processes the algorithms assign class and classification are recommended.Find Domain ExtremaClassify image objects fulfilling a local extrema condition within the image object domain according to an image object feature. This means that either the image object with smallest or the largest feature value within the domain will be classified according to the classification settings.Find Local ExtremaClassify image objects fulfilling a local extrema condition according to an image object feature within a search domain in their neighborhood. Image objects with either the smallest or the largest feature value within a specific neighborhood will be classified according to the classification settings.Find Enclosed by ClassFind and classify image objects that are completely enclosed by image objects belongin g to certain classes. If an image object is located at the border of the image, it will not be found and classified by find enclosed by class. The shared part of the outline with the image border will not be recognized as enclosing border.ConnectorClassify the image objects which connect the current image object with the shortest path to another image object that meets the conditions described by the connection settings.The process starts from the current image object to search along objects that meet th e conditions as specified by Connect via and Super object mode via until it reaches image objects that meet the conditions specified by Connect to and Super object mode to. The maximum search range can be specified in Search range in pixels. When the algorithm has found the nearest image object that can be connected to it classifies all image objects of the connection with the selected class.Optimal BoxGenerate member functions for classes by looking for the best separating features based upon sample training.Update VariablePerform an arithmetic operation on a variable.Compute Statistical ValuePerform a statistical operation on the feature distribution within an image object domain and stores the result in a scene variable.Grow RegionEnlarge image objects defined in the image object domain by merging them with neighboring image objects ("candidates") that match the criteria specified in the parameters.The grow region algorithm works in sweeps. That means each execution of the algorithm merges all direct neighboring image objects according to the parameters. To grow image objects into a larger space, you may use the Loop while something changes check box or specify a specific number of cycles.Multiresolution Segmentation Region GrowGrow image objects according to the multiresolution segmentation criteria. Precondition: The project must first be segmented by another segmentation process. For detailed description of all parameters see the algorithm multiresolution segmentation.Image Object FusionDefine a variety of growing and merging methods and specify in detail the conditions for merger of the current image object with neighboring objects.TipIf you do not need a fitting functions, we recommend that you use the algorithms merge region and grow regions. They require fewer parameters for configuration and provide higher performance.Convert to SubobjectsSplit all image objects of the image object domain into their subobjects.Precondition: The image objects in the domain need to have subobjects.Border OptimizationChange the image object shape by either adding subobjects from the outer border to the image object or removing subobjects from the inner border from the image object.DestinationChoose the classes you wish to consider for the neighboring objects of the current image object. To be considered by the Dilatation, subobjects need to be part of an image object classified with one of the selected classes. To be considered by the E rosion subobjects need to be moveable to an image object classified with one of the selected classes. This parameter has no effect for the E xtraction.MorphologyPerform the pixel based binary morphology operations Opening or Closing on all image objects of an image object domain. Both will result in a smoothed border of the image objectWatershed TransformationCalculate an inverted distance map based on the inverted distances for each pixel to the image object border. Afterwards, the minima are flooded by increasing the level (inverted distance). Where the individual catchment basins touch each other (watersheds), the image objects are split.Example of purpose: The watershed transformation algorithm is used to separate image objects from others.Precondition: Image objects that you wish to split should already be identif ied and classified.Configure Object TableDisplay a list of all image objects together with selected feature values in the Image Object Table window .Classified Image Objects to SamplesCreate a sample for each classified image object in the image object domain.Cleanup Redundant SamplesRemove all samples with membership values higher than the membership threshold.Nearest Neighbor ConfigurationSelect classes, features and function slope to use for nearest neighbor classification.Disconnect All SamplesDisconnect samples from image objects, to enable creation of samples that are not lost when image objects are deleted. They are stored in the solution file.Create Temporary Image LayerCreate a temporary image layer with values calculated from a selected feature for the image objects selected in the image object domain.Delete Image LayerDelete one selected image layer.TipThis algorithm is often used in conjunction with the create temporary image layer algorithm to remove this image layer after you finished working with it.Convolution FilterApply a convolution filter to the image. It offers two options; a preset Gaussian smoothing filter and a user-defined kernel.A convolution filter uses a kernel, which is a square matrix of a values that is applied to the image pixels. Each pixel value is replaced by the average of the square area of the matrix centered on the pixel.Layer NormalizationThe layer normalization algorithm offers two options to normalize images. The linear normalization filter stretches pixel values to the entire pixel value range. The histogram normalization changes pixel values based on the accumulated histogram of the image.Median FilterUse the median filter algorithm to replace the pixel value with the median value of neighboring pixels.The median filter may preserve image detail better than a mean filter. Both can be used to reduce noise.Pixel Frequency FilterThe pixel frequency filter algorithm scans the input layer and select the color that is found in the greatest number of pixels. The frequency is checked in the area defined by the size of the kernel.Edge Extraction Lee SigmaExtract edges using a specific edge filter that creates two individual layers from the original image. One layer represents bright edges, the other one dark edges.To extract two layers, one with bright, one with dark edges, this algorithm must be applied two times with the appropriate settings changed.If two edge layers are created, it is important to give them two individual image layer aliases. Otherwise, the first existing layer would be overwritten by the second generated layer.Edge Extraction CannyEnhance or extract feature boundaries, using Canny's algorithm. Edge extraction filters may be used to enhance or extract feature boundaries.Surface CalculationUse the surface calculation algorithm to derive the slope for each pixel of a digital elevation model (DEM). This can be used to determine whether an area within a landscape is flat or steep and is independent from the absolute height values.Layer ArithmeticsThe layer arithmetic algorithm uses a pixel-based operation that enables the merger of up to four layers by mathematical operations (+– * /). The layer created displays the result of this mathematical operation. This operation is performed on the pixel level which means, that all pixels of the image layers are used.For example Layer 2 can be subtracted from Layer 1. This would mean that whenever the same pixel value in both layers exist, the result would be 0.Before or after the operation, the layers can be normalized. Furthermore, weights can be used for each individual layer to influence the result.Synchronize Image Object HierarchyChange an image object level to exactly represent the thematic layer. Image objects smaller than the overlapping thematic object will be merged, image objects intersecting with several thematic objects will be cut.Read Thematic AttributesCreate and assign local image object variables according to a thematic layer attribute table. A variable with the same name as the thematic attribute will be created, attached to each image object in the domain and filled with the value given by the attribute table.Write Thematic AttributesGenerate a attribute column entry from an image object feature. The updated attribu te table can be saved to a.shp file.Export Object StatisticsExport image object statistics of selected features to file. This generates one file per project.Export Object Statistics for ReportExport image object statistics to a file. This generates one file per workspace.Submit Scenes for AnalysisExecute a subroutine.This algorithm enables you to connect subroutines with any process of the main process tree or other subroutines. You also can also choose whether to stitch the results of the analysi s of subset copies.NoteA rule set that contains the submit scenes for analysis algorithm can only be executed if you are connected to Definiens eCognition Server. Rule sets that include subroutines cannot be process on a local machine.Read Subscene StatisticsRead in exported result statistics and perform a defined mathematical summary operation. The resulting value is stored as a variable that can be used for further calculations or export operations concerning the main scene.This algorithm summarizes all values in the selected column in selected export item, using the selected summary type.In cases the analysis of subscenes results in exporting statistics per each scene, the algorithm allows you to collect and merge the statistical results of multiple files. The advantage is that you do not need to stitch the subscenes results for result operations concerning the main scene.。
Introducing Music English

A Russian composer knowledge for his flush, romantic style, and his use of folk music in his works His most rapid compositions include balls such as "Swan Lake" and "The Nutcracker," as well as symphonies and considerations
02
Wts Expressions
Characteristics and Representative Works of Classical Music
Harmony and memory
Classical music is characterized by its use of complex harmony and memories that create a rich, emotional soundscape
Composition and Performance Techniques of
Symphony Orchestra
Composition
Performance
techniques
Conducting
Symphony Orchestras typologically consistent of four sections: strings, woodwinds, brass, and discussion Each section plays a specific role in creating the overall sound of the Orchestra
北京大学现代汉语语料库基本加工规范

北京大学现代汉语语料库基本加工规范俞士汶段慧明朱学锋孙斌(北京大学计算机系,北京大学计算语言学研究所 北京 100871)摘要:北京大学计算语言学研究所已经完成了一个有2700万汉字的现代汉语语料库的基本加工。
加工项目除词语切分和词性标注外,还包括专有名词(人名、地名、团体机构名称等)标注、语素子类标注以及动词、形容词的特殊用法标注。
这项大规模语言工程的顺利完成得益于事先制订并不断完善的规范。
发表《北京大学现代汉语语料库基本加工规范》是为了抛砖引玉,更广泛地向专家、同行征询意见,以便进一步修订。
关键词:现代汉语;语料库;词语切分;词性标注;规范中图分类号:TP391The Basic Processing of Contemporary Chinese Corpus at Peking UniversitySPECIFICATIONYU Shi-wen DUAN Hui-ming ZHU Xue-feng Bing SWEN(Institute of Computational Linguistics, Peking University, Beijing, 100871) Abstract: The Institute of Computational Linguistics, Peking University has completed the basic processing of a contemporary Chinese corpus that has 27 million Chinese Characters. In addition to word segmentation and part-of-speech tagging, the processing involves the tagging of proper nouns (person names, place names, organization names and so on), morpheme subcategories and the special usages of verbs and adjectives. The success of this large-scale language engineering is attributed to the SPECIFICATION, which had been made beforehand and was being perfected while in use. We are hereby making an introduction to the SPECIFICA TION through this publication, thus inviting the comments from all the experts and our colleagues for the improvement of it.Keywords: contemporary Chinese; corpus; word segmentation; part-of-speech tagging; specification⒈ 前言关于汉语语料库的全面情况,冯志伟教授的文章已有详细介绍[1]。
classification

classificationClassification is a fundamental task in machine learning and data analysis. It involves categorizing data into predefined classes or categories based on their features or characteristics. The goal of classification is to build a model that can accurately predict the class of new, unseen instances.In this document, we will explore the concept of classification, different types of classification algorithms, and their applications in various domains. We will also discuss the process of building and evaluating a classification model.I. Introduction to ClassificationA. Definition and Importance of ClassificationClassification is the process of assigning predefined labels or classes to instances based on their relevant features. It plays a vital role in numerous fields, including finance, healthcare, marketing, and customer service. By classifying data, organizations can make informed decisions, automate processes, and enhance efficiency.B. Types of Classification Problems1. Binary Classification: In binary classification, instances are classified into one of two classes. For example, spam detection, fraud detection, and sentiment analysis are binary classification problems.2. Multi-class Classification: In multi-class classification, instances are classified into more than two classes. Examples of multi-class classification problems include document categorization, image recognition, and disease diagnosis.II. Classification AlgorithmsA. Decision TreesDecision trees are widely used for classification tasks. They provide a clear and interpretable way to classify instances by creating a tree-like model. Decision trees use a set of rules based on features to make decisions, leading down different branches until a leaf node (class label) is reached. Some popular decision tree algorithms include C4.5, CART, and Random Forest.B. Naive BayesNaive Bayes is a probabilistic classification algorithm based on Bayes' theorem. It assumes that the features are statistically independent of each other, despite the simplifying assumption, which often doesn't hold in the realworld. Naive Bayes is known for its simplicity and efficiency and works well in text classification and spam filtering.C. Support Vector MachinesSupport Vector Machines (SVMs) are powerful classification algorithms that find the optimal hyperplane in high-dimensional space to separate instances into different classes. SVMs are good at dealing with linear and non-linear classification problems. They have applications in image recognition, hand-written digit recognition, and text categorization.D. K-Nearest Neighbors (KNN)K-Nearest Neighbors is a simple yet effective classification algorithm. It classifies an instance based on its k nearest neighbors in the training set. KNN is a non-parametric algorithm, meaning it does not assume any specific distribution of the data. It has applications in recommendation systems and pattern recognition.E. Artificial Neural Networks (ANN)Artificial Neural Networks are inspired by the biological structure of the human brain. They consist of interconnected nodes (neurons) organized in layers. ANN algorithms, such asMultilayer Perceptron and Convolutional Neural Networks, have achieved remarkable success in various classification tasks, including image recognition, speech recognition, and natural language processing.III. Building a Classification ModelA. Data PreprocessingBefore implementing a classification algorithm, data preprocessing is necessary. This step involves cleaning the data, handling missing values, and encoding categorical variables. It may also include feature scaling and dimensionality reduction techniques like Principal Component Analysis (PCA).B. Training and TestingTo build a classification model, a labeled dataset is divided into a training set and a testing set. The training set is used to fit the model on the data, while the testing set is used to evaluate the performance of the model. Cross-validation techniques like k-fold cross-validation can be used to obtain more accurate estimates of the model's performance.C. Evaluation MetricsSeveral metrics can be used to evaluate the performance of a classification model. Accuracy, precision, recall, and F1-score are commonly used metrics. Additionally, ROC curves and AUC (Area Under Curve) can assess the model's performance across different probability thresholds.IV. Applications of ClassificationA. Spam DetectionClassification algorithms can be used to detect spam emails accurately. By training a model on a dataset of labeled spam and non-spam emails, it can learn to classify incoming emails as either spam or legitimate.B. Fraud DetectionClassification algorithms are essential in fraud detection systems. By analyzing features such as account activity, transaction patterns, and user behavior, a model can identify potentially fraudulent transactions or activities.C. Disease DiagnosisClassification algorithms can assist in disease diagnosis by analyzing patient data, including symptoms, medical history, and test results. By comparing the patient's data againsthistorical data, the model can predict the likelihood of a specific disease.D. Image RecognitionClassification algorithms, particularly deep learning algorithms like Convolutional Neural Networks (CNNs), have revolutionized image recognition tasks. They can accurately identify objects or scenes in images, enabling applications like facial recognition and autonomous driving.V. ConclusionClassification is a vital task in machine learning and data analysis. It enables us to categorize instances into different classes based on their features. By understanding different classification algorithms and their applications, organizations can make better decisions, automate processes, and gain valuable insights from their data.。
人工智能术语中英文对照

boundary mutation 边界变异
building block hypothesis 基因块假设,积木块假设
cell 细胞
character genes 符号编码基因
chromosome 染色体
classifier system,CS 分类器系统
reproduction 复制
ribonucleic acid,RNA 核糖核酸
robustness 稳健性
roulette wheel selection 赌盘选择
scaling with sigma truncation O~截断尺度变换
schema 模式
schema defining length 模式定义长度
function optimization 函数最优化
GA deceptive problem 遗传算法欺骗问题
Gaussian mutation 高斯变异
gene 基因
generation gap 代沟
genetic algorithms,GAs 遗传算法
genetic operators 遗传算子
population size 群体大小
power law scaling 乘幂尺度变换
premature convergence 早熟现象,早期收敛
preselection 预选择
probabilistic algorithms 概率算法
probabilistic operator 概率算子
random walks 随机游走
rank-based model 排序选择模型
Segmentation和DEMOGRAPHIC 的解释

Segmentation, Targeting, and PositioningSegmentation, targeting, and positioning together comprise a three stage process. We first (1) determine which kinds of customers exist, then (2) select which ones we are best off trying to serve and, finally, (3) implement our segmentation by optimizing our products/services for that segment and communicating that we have made the choice to distinguish ourselves that way.Segmentation involves finding out what kinds of consumers with different needs exist. In the auto market, for example, some consumers demand speed and performance, while others are much more concerned about roominess and safety. In general, it holds true that “You can’t be all things to all people,” and experience has demonstrated that firms that specialize in meeting the needs of one group of consumers over another tend to be more profitable.Generically, there are three approaches to marketing. In the undifferentiated strategy, all consumers are treated as the same, with firms not making any specific efforts to satisfy particular groups. This may work when the product is a standard one where one competitor really can’t offer much that another one can’ually, this is the case only for commodities. In the concentrated strategy, one firm chooses to focus on one of several segments that exist while leaving other segments to competitors. For example, Southwest Airlines focuses on price sensitive consumers who will forego meals and assigned seating for low prices. In contrast, most airlines follow the differentiated strategy: They offer high priced tickets to those who are inflexible in that they cannot tell in advance when they need to fly and find it impractical to stay over a Saturday. These travelers—usually business travelers—pay high fares but can only fill theplanes up partially. The same airlines then sell some of the remaining seats to more price sensitive customers who can buy two weeks in advance and stay over.Note that segmentation calls for some tough choices. There may be a large number of variables that can be used to differentiate consumers of a given product category; yet, in practice, it becomes impossibly cumbersome to work with more than a few at a time. Thus, we need to determine which variables will be most useful in distinguishing different groups of consumers. We might thus decide, for example, that the variables that are most relevant in separating different kinds of soft drink consumers are (1) preference for taste vs. low calories, (2) preference for Cola vs. non-cola taste, (3) price sensitivity—willingness to pay for brand names; and (4) heavy vs. light consumers. We now put these variables together to arrive at various combinations.Several different kinds of variables can be used for segmentation.•Demographic variablesessentially refer to personalstatistics such as income,gender, education, location(rural vs. urban, East vs.West), ethnicity, and familysize. Campbell’s soup, forinstance, has found thatWestern U.S. consumers onthe average prefer spiciersoups—thus, you get adifferent product in the samecans at the East and Westcoasts. Facing flat sales ofguns in the traditional maledominated market, amanufacturer came out withthe Lady Remmington, a morecompact, handier gun moreattractive to women. Takingthis a step farther, it is alsopossible to segment onlifestyle and values.”•Some consumers want to beseen as similar to others,while a different segmentwants to stand apart from thecrowd.•Another basis forsegmentation isbehavior. Some consumersare “brand loyal”—i.e., theytend to stick with theirpreferred brands even when acompeting one is onsale. Some consumers are“heavy” users while othersare “light” users.Forexample, research conductedby the wine industry showsthat some 80% of the productis consumed by 20% of theconsumers—presumably arather intoxicated group.•One can also segment onbenefits sought, essentiallybypassing demographicexplanatory variables. Someconsumers, for example, likescented soap (a segment likelyto be attracted to brands suchas Irish Spring), while othersprefer the “clean” feeling ofunscented soap (the “Ivory”segment). Some consumersuse toothpaste primarily topromote oral health, whileanother segment is moreinterested in breathfreshening.In the next step, we decide to target one or more segments. Our choice should generally depend on several factors. First, how well are existing segments served by other manufacturers? It will be more difficult to appeal to a segment that is already well served than to one whose needs are not currently being served well. Secondly, how large is the segment, and how can we expect it to grow? (Note that a downside to a large, rapidly growing segment is that it tends to attract competition). Thirdly, do we have strengths as a company that will help us appeal particularly to one group of consumers? Firms may already have an established reputation. WhileMcDonald’s has a great reputation for fast, consistent quality, family friendly food, it would be difficult to convince consumers that McDonald’s now offers gourmet food. Thus, McD’s would probably be better off targeting families in search of consistent quality food in nice, clean restaurants.Positioning involves implementing our targeting. For example, Apple Computer has chosen to position itself as a maker of user-friendly computers. Thus, Apple has done a lot through its advertising to promote itself, through its unintimidating icons, as a computer for “non-geeks.”The Visual C software programming language, in contrast, is aimed a “techies.”Michael Treacy and Fred Wiersema suggested in their 1993 book The Discipline of Market Leaders that most successful firms fall into one of three categories:•Operationally excellent firms,which maintain a strongcompetitive advantage bymaintaining exceptionalefficiency, thus enabling thefirm to provide reliableservice to the customer at asignificantly lower cost thanthose of less well organizedand well runcompetitors. The emphasishere is mostly on low cost,subject to reliableperformance, and less value isput on customizing theoffering for the specificcustomer. Wal-Mart is anexample of thisdiscipline. Elaboratelogistical designs allow goodsto be moved at the lowestcost, with extensive systemspredicting when specificquantities of supplies will beneeded.•Customer intimate firms,which excel in serving thespecific needs of theindividual customerwell. There is less emphasison efficiency, which issacrificed for providing moreprecisely what is wanted bythe customer. Reliability isalso stressed. Nordstrom’sand IBM are examples of thisdiscipline.•Technologically excellentfirms, which produce themost advanced productscurrently available with thelatest technology, constantlymaintaining leadership ininnovation. These firms,because they work with costlytechnology that need constantrefinement, cannot be asefficient as the operationallyexcellent firms and oftencannot adapt their products aswell to the needs of theindividual customer. Intel isan example of this discipline. Treacy and Wiersema suggest that in addition to excelling on one of the three value dimensions, firms must meet acceptable levels on the othertwo. Wal-Mart, for example, does maintain some level of customer service. Nordstrom’s and Intel both must meet some standards of cost effectiveness. The emphasis, beyond meeting the minimum required level inthe two other dimensions, is on the dimension of strength.Repositioning involves an attempt to change consumer perceptions of a brand, usually because the existing position that the brand holds has become less attractive. Sears, for example, attempted to reposition itself from a place that offered great sales but unattractive prices the rest of the time to a store that consistently offered “everyday low prices.”Repositioning in practice is very difficult to accomplish. A great deal of money is often needed for advertising and other promotional efforts, and in many cases, the repositioning fails.To effectively attempt repositioning, it is important to understand how one’s brand and those of competitors are perceived. One approach to identifying consumer product perceptions is multidimensional scaling. Here, we identify how products a re perceived on two or more “dimensions,” allowing us to plot brands against each other. It may then be possible to attempt to “move” one’s brand in a more desirable direction by selectively promoting certain points. There are two main approaches to multi-dimensional scaling. In the a priori approach, market researchers identify dimensions of interest and then ask consumers about their perceptions on each dimension for each brand. This is useful when (1) the market researcher knows which dimensions are of interest and (2) the customer’s perception on each dimension is relatively clear (as opposed to being “made up” on the spot to be able to give the researcher a desired answer). In the similarity rating approach, respondents are not asked about their perceptions of brands on any specific dimensions. Instead, subjects are asked to rate the extent of similarity of different pairs of products (e.g., How similar, on a scale of 1-7, is Snicker’s to Kitkat, and how similar is Toblerone to Three Musketeers?) Using a computer algorithms, the computer then identifies positions of each brand on a map of a given number of dimensions. The computer does not reveal what each dimension means—that must be left to human interpretation based on what the variations in each dimension appears to reveal. This second method is more useful when no specific product dimensions have been identified as being of particular interest or when it is not clear what the variables of difference are for the product category. DemographicsDemographics are clearly tied to subculture and segmentation. Here, however, we shift our focus from analyzing specific subcultures to trying to understand the implications for an entire population of its makeup.Some articles of possible interest:Coffee, Lipsticks, and the EconomyThe 2008 Tax Rebate and Consumer BehaviorGasoline Prices and Consumer BehaviorSeveral issues are useful in the structure of a population. For example, in some rapidly growing countries, a large percentage of the population is concentrated among younger generations. In countries such as Korea, China, and Taiwan, this has helped stimulate economic growth, while in certain poorer countries, it puts pressures on society to accommodate an increasing number of people on a fixed amount of land. Other countries such as Japan and Germany, in contrast, experience problems with a "graying" society, where fewer non-retired people are around to support an increasing number of aging seniors. Because Germany actually hovers around negative population growth, the German government has issued large financial incentives, in the forms of subsidies, for women who have children. In the United States, population growth occurs both through births and immigration. Since the number of births is not growing, problems occur for firms that are dependent on population growth (e.g., Gerber, a manufacturer of baby food).Social class is a somewhat nebulous subject that involves stratifying people into groups with various amounts of prestige, power, and privilege. In part because of the pioneering influence in American history, status differentiations here are quite vague. We cannot, for example, associate social class with income, because a traditionally low status job as a plumber may today come with as much income as a traditionally more prestigious job as a school teacher. In certain other cultures, however, stratification is more clear-cut. Although the caste system in India is now illegal, it still maintains a tremendous influence on that society. While some mobility exists today, social class awareness is also somewhat greater in Britain, where social status is in part reinforced by the class connotations of the accent with which one speaks.Textbooks speak of several indices that have been used to "compute" social class in the United States, weighing factors such as income, the nature of one’s employment, and level of education. Taken too literally, these indices are not very meaningful; more broadly speaking, they illustrate the reality that social status is a complex variable that is determined, not always with consensus among observers, by several different variables.。
形态学(英文版)

• • • • •
• •
• • •
Morpheme: two kinds Free morpheme,it is a word, can be used individually class, very, good, girl, 看,山,美,猫, 已经 Bound morphemes:two types Roots and Affixes Root(based morpheme) is part of a word to which an inflectional affix can be added,but can never stand by itself, though has clear meaning. geo, aqu, mur,vade, noct, plore,preda,semin, two-root word “geo”(the earth)+”-ology”(a branch of learning): toler-(root)+”affix”(-ate), audi-: audit+or, +ence, sym+(the same)+pathy (emotion), empathy
• Words are essential to English sentences characterized by subject and predicate. Noun used as subject & object, Verb predicate. But Chinese N can be used as predicative, and V can be used Subjects and Objects. • Words and parts of speech mean nothing to Chinese sentences characterized of topic and comment. • Students read the interesting articles carefully • 一篇文章两种写法 • 今天天晴 • 唱歌跳舞是我的爱好 • 咳嗽不宜抽烟。 • 这事危险。 他近视眼。 • 顽皮是他的特点。
语言学Categorization

subordinate level
a composite form typically combines two or more words that signify basis level categories,like rain coat, apple juice, and wheel chair.
subordinate categories are less good categories than basic
1
categories, because although their members have high
mutual resemblance, they have low distinctiveness from
Categorization
definition:
is the process in which ideas and objects are recognized, differentiated, and understood. is a major ingredient in the creation of human knowledge.
1
the basic level
2
Lorem
the superordinate level
ipsum
3
the subordinate level
The characteristic can be summed up under Croft and Cruse’s four points :
图像分割研究综述

编者按:在人类接收的信息中有80%来自视觉或者说为图像(Image)信息,这包括图像、图形(动画)、视频、文本、数据等,这是人类最有效和最重要的信息获取和交流方式。
随着计算机的普及,人们越来越多地利用计算机来帮助人类获取与处理视觉(图像)信息。
图像技术是对视觉图像获取与加工处理技术的总称。
图像技术近年来受到人们广泛的关注,它包括图像的采集获取;图像编码存储和传输;图像的产生、显示与变换;图像的分割,图像的特征提取与测量;图像数据库的建立、索引和抽取;图像的分类、表示和识别;图像的模型匹配;图像的质量评价;图像的解释与理解等。
根据抽象程度和处理方法的不同,图像技术可分为三个层次:图像处理,图像分析和图像理解。
这三个层次的有机结合也可称为图像工程。
图像处理是较低层的操作,主要在图像像素级上进行处理。
比较狭义的图像处理主要包括对图像分割以改善视觉效果,或对图像压缩编码以减少传输时间或存储容量。
图像分析则是进入中层的操作,分割和特征提取把原来以像素描述的图像转变成简洁的非图形式的符号描述。
即图像分析是一个图像进而数据出的处理,数据可以是特征测量的结果,或是基于测量的符号表示。
图像理解也经常被称为计算机视觉,这主要是高层操作。
图像理解进一步研究图像中的目标和它们之间的联系,其处理过程与方法与人类的思维推理往往有不少类似之处。
根据以上所述,本专辑有以下文章:①图像分割研究综述;②视觉计算———人类感知能力的延伸;③数字图像的质量评价;④基于数码相机的图像采集系统;⑤神经递质释放的计算机图像分析系统;⑥计算机视觉技术在智能交能系统中的应用;⑦点光源视景图像的控制与实现图像分割研究综述3Study Surveys on Image Segmentation北京工业大学信号与信息处理研究室(100022) 王爱民 沈兰荪【摘要】图像分割是指将一幅图像分解为若干互不交迭区域的集合,是图像处理与机器视觉的基本问题之一。
新概念商务英语词汇大全(下载点击自动朗诵)
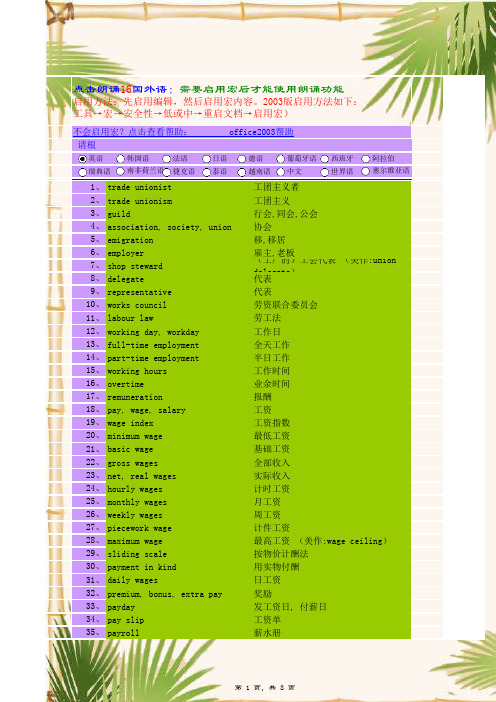
工团主义者 工团主义 行会,同会,公会 协会 移,移居 雇主,老板 (工厂的)工会代表 (美作:union delegate) 代表 代表 劳资联合委员会 劳工法 工作日 全天工作 半日工作 工作时间 业余时间 报酬 工资 工资指数 最低工资 基础工资 全部收入 实际收入 计时工资 月工资 周工资 计件工资 最高工资 (美作:wage ceiling) 按物价计酬法 用实物付酬 日工资 奖励 发工资日, 付薪日 工资单 薪水册
第 2 页,共 4 页
79、 80、 81、 82、 83、 84、 85、 86、 87、 88、 89、 90、 91、 92、 93、 94、 95、 96、 97、 98、 99、 100、 101、 102、 103、 104、 105、 106、 107、 108、 109、 110、 111、 112、 113、 114、 115、 116、 117、 118、 119、 120、 121、
trade unionist trade unionism guild association, society, union emigration employer shop steward delegate representative works council labour law working day, workday full-time employment part-time employment working hours overtime remuneration pay, wage, salary wage index minimum wage basic wage gross wages net, real wages hourly wages monthly wages weekly wages piecework wage maximum wage sliding scale payment in kind daily wages premium, bonus, extra pay payday pay slip payroll
China in the International Segmentation

Françoise Lemoine Deniz Ünal-Kesenci
No 2001 – 02 March
4
CEPII, Working Paper No 2002-02
TABLE OF CONTENTS
S UMMARY ............................................................................................................................................ 5 ABSTRACT ........................................................................................................................................... 6 RÉSUMÉ ............................................................................................................................................... 7 RÉSUMÉ COURT .................................................................................................................................. 8 CHINA IN THE INTERNATIONAL S EGMENTATION OF PRODUCTION PROCESSES ................. 9 INTRODUCTION .................................................................................................................................. 9 1. GLOBALISATION AND THE INTERNATIONAL S EGMENTATION OF PRODUCTION PROCESSES ................................................................................................................................... 9 1.1. Analytical Framework ........................................................................................................9 1.2. Case Studies .......................................................................................................................11 3. CHINA’S SPECIALISATION IN PROCESSING ACTIVITIES ...................................................12 3.1. A Selective Trade Policy in Favour of Processing Activities ...................................12 3.2. Impact on the Commodity Structure of China’s Foreign Trade ................................15 Sectoral Changes in Processing Trade ......................................................................15 Increased Local Content ...............................................................................................18 3.3. Effects on the Geographic Pattern of China’s Foreign Trade ....................................21 The Reorganisation of Production in Asia .................................................................21 A Distorted Trade Pattern ............................................................................................22 The Potential Impact of Further Trade Liberalisation ............................................24 4. CHINA’S INVOLVEMENT IN THE INTERNATIONAL DIVISION OF PRODUCTION PROCESSES .................................................................................................................................25 4.1. China’s Specialisation Profile by Stage of Production ...............................................26 4.2. The Geographic Dimension of China’s Specialisation by Stage of Production ..........................................................................................................................27 4.3. China’s Trade by Sector and Stage of Production .......................................................30 4.4. The Splitting-up of the Value-Added Chain Between China’s and its Partners in Selected Sectors ............................................................................................32 Electrical Machinery (HS 85) ......................................................................................32 Machinery (HS 84) .........................................................................................................33 Textile and Clothing Industry .......................................................................................33 Summing up .....................................................................................................................34 4.5. China’s Trade in High Technology Products ...............................................................35 5. CONCLUSION ..............................................................................................................................37 3
信息科学与电子工程专业英语

5. The sampling rate limit the frequency range of the audio file; to reproduce a given frequency, the sampling rate must be at least twice that frequency. For example, if the audio contains audible frequencies as high as 8,000 Hz, your need a sample rate of 16,000 samples per second to reproduce this audio accurately in digital form. This calculation comes from the Nyquist Theorem, and the highest frequency that can be reproduced by a given sample rate is known as the Nyquist Frequency. CDs have a sampling rate of 44,100 samples per second that allows samples up to 22,050 Hz, which is higher than the limit of human hearing, 20,000Hz.
分子等等,导致一波高压进入空气; 高压力波通过空气移动,他们身后留下低压区域。当这 些压力低点和高点——或波动——到达我们,他们在我们的耳朵振动接收,我们听到时发 出的震动声。
课程思政视域下非遗融入艺术设计专业教学实践与探索

课程思政视域下非遗融入艺术设计专业教学实践与探索TEACHING PRACTICE AND EXPLORATION OF INTEGRATING NON-LEGACY INTO ART DESIGN MAJOR IN THE PERSPECTIVE OF CURRICULUM IDEOLOGY AND POLITICS 引言非物质文化遗产作为中华优秀传统文化的重要组成部分,具有得天独厚的民族文化资源优势,是提升民族凝聚力、增强文化自信的重要载体,将其融入高职院校艺术设计教育教学中,是结合专业特点分类推进课程思政[1],把中华优秀传统文化全方位融入艺术教育各环节[2]的具体实践,将两者互融互通,有利于增强文化自信,落实立德树人根本任务,全面提高人才自主培养质量。
一、非遗融入艺术设计专业教育教学的必要性和可行性非遗蕴含着中华民族独特的价值追求、思想观念、人文精神和道德规范,具有深刻而丰富的教育内容,是课程思政的不竭源泉,其内在的文化艺术价值对现代艺术设计具有重大的启示作用,为艺术设计教育提供了更为丰富的创意元素和艺术素材。
将非遗融入高职院校艺术设计专业教育教学,是实现非遗传承和创新发展的有效途径,其教学成果可以反哺地方经济文化发展,践行课程思政成效,如图 1 所示。
非遗蕴含的中华优秀传统文化与高等教育追求的育人目标是高度一致的,两者存在教学内容的交叉性、育人功能的契合性和相互发展的依存性,将非遗融入地方高职院校艺术设计专业教育教学是必要且可行的。
二、非遗融入地方高职院校艺术设计专业的现状调查为了更好地了解非遗融入高职院校艺术设计专业的教育教学情况,作者对云南省高职院校在校大学生进行了问卷调查,对云南省艺术设计专业教师进行了访谈,调查情况如下:(一)学生问卷调查对象为云南省职业院校艺术设计专业的在校大学生,主要采取网络问卷的形式,发出问卷480份,收回有效问卷467份,数据反馈真实可信。
有效问卷中有64.49%的同学愿意将非遗植入专业课程,丰富设计素材,激发创作灵感,创新设计理念,提升文化内涵,有31.16%的同学表示视情况而定,而将非遗相关知识运用于课堂教学的教师占比仅为20%。
三维网格模型的分割及应用技术综述

第17卷第8期2005年8月计算机辅助设计与图形学学报JOURNAL OF COMPU TER 2AIDED DESIGN &COMPU TER GRAPHICSVol 117,No 18Aug 1,2005 收稿日期:2004-03-09;修回日期:2004-07-08 基金项目:国家“八六三”高技术研究发展计划重点项目(2001AA231031,2002AA231021);国家重点基础研究发展规划项目(G1998030608);国家科技攻关计划课题(2001BA904B08);中国科学院知识创新工程前沿研究项目(20006160,20016190(C ))三维网格模型的分割及应用技术综述孙晓鹏1,2) 李 华1)1(中国科学院计算技术研究所智能信息处理重点实验室 北京 100080)2(中国科学院研究生院 北京 100039)(xpsun @ict 1ac 1cn )摘要 对三维网格模型分割的定义、分类和应用情况做了简要回顾,介绍并评价了几种典型的网格模型分割算法,如分水岭算法、基于拓扑和几何信息的分割算法等;同时,对网格分割在几种典型应用中的研究工作进行了分类介绍和评价1最后对三维分割技术今后的发展方向做出展望1关键词 分割Π分解;三维分割;形状特征;网格模型中图法分类号 TP391A Survey of 3D Mesh Model Segmentation and ApplicationSun Xiaopeng 1,2) Li Hua 1)1(Key L aboratory of Intelligent Inf ormation Processi ng ,Instit ute of Com puti ng Technology ,Chi nese Academy of Sciences ,Beiji ng 100080)2(Graduate School of the Chi nese Academy of Sciences ,Beiji ng 100039)Abstract In this paper ,we present a brief summary to 3D mesh model segmentation techniques ,includ 2ing definition ,latest achievements ,classification and application in this field 1Then evaluations on some of typical methods ,such as Watershed ,topological and geometrical !method ,are introduced 1After some ap 2plications are presented ,problems and prospect of the techniques are also discussed 1K ey w ords segmentation Πdecomposition ;3D segmentation ;shape features ;mesh model1 引 言基于三维激光扫描建模方法的数字几何处理技术,继数字声音、数字图像、数字视频之后,已经成为数字媒体技术的第四个浪潮,它需要几何空间内新的数学和算法,如多分辨率问题、子分问题、第二代小波等,而不仅仅是欧氏空间信号处理技术的直接延伸[1]1在三维网格模型已成为建模工作重要方式的今天,如何重用现有网格模型、如何根据新的设计目标修改现有模型,已成为一个重要问题1网格分割问题由此提出,并成为近年的热点研究课题[223]12 网格分割概述三维网格模型分割(简称网格分割),是指根据一定的几何及拓扑特征,将封闭的网格多面体或者可定向的二维流形,依据其表面几何、拓扑特征,分解为一组数目有限、各自具有简单形状意义的、且各自连通的子网格片的工作1该工作被广泛应用于由点云重建网格、网格简化、层次细节模型、几何压缩与传输、交互编辑、纹理映射、网格细分、几何变形、动画对应关系建立、局部区域参数化以及逆向工程中的样条曲面重建等数字几何处理研究工作中[223]1同时,三维网格模型的局部几何拓扑显著性也是对三维网格模型进行检索的一种有效的索引[4]1与网格曲面分割有关、并对其影响巨大的一个早期背景工作是计算几何的凸分割,其目的是把非凸的多面体分解为较小的凸多面体,以促进图形学的绘制和渲染效率1该工作已经有了广泛的研究,但多数算法难以实现和调试,实际应用往往不去分割多面体,而是分割它的边界———多边形网格1多面体网格边界的分割算法有容易实现、复杂形体输出的计算量往往是线性的等优势[5]1另外一个早期背景工作是计算机视觉中的深度图像分割,其处理的深度图像往往具有很简单的行列拓扑结构,而不是任意的,故其分割算法相对简单[6]1三维网格模型的分割算法一般是从上述两类算法推广而来1心理物理学认为:人类对形状进行识别时,部分地基于分割,复杂物体往往被看作简单的基本元素或组件的组合[728]1基于这个原理,Hoffman 等[9]于1984年提出人类对物体的认知过程中,倾向于把最小的负曲率线定义为组成要素的边界线,并据此将物体分割为几个组成要素,即视觉理论的“最小值规则”1由此得到的分割结果称为“有意义的”分割,它是指分割得到的子网格必须具有和其所在应用相关的相对尺寸和组织结构1由于曲率计算方法不同,很多算法给出的有意义的分割结果也存在差异1诸多应用研究[10214]证明,网格模型基于显著性特征的形状分割,是物体识别、分类、匹配和跟踪的基本问题1而有意义的分割对于网格模型显著占优特征的表示和提取、多尺度的存储和传输以及分布式局部处理都是十分有意义的1211 网格分割的发展较早的三维网格分割工作可以追溯到1991年,Vincent 等[15]将图像处理中的分水岭算法推广到任意拓扑连接的3D 曲面网格的分割问题上11992年,Falcidieno 等[16]按照曲率相近的原则,把网格曲面分割为凹面片、凸面片、马鞍面片和平面片11993年,Maillot 等[17]将三角片按法向分组,实现了自动分割;1995年,Hebert 等[18]给出了基于二次拟合曲面片的曲率估计方法,并把区域增长法修改推广应用到任意拓扑连接的网格曲面分割问题中;1995年,Pedersen [19]和1996年Krishnamurthy 等[20]在他们的动画的变形制作过程中,给出了用户交互的分割的方法11997年,Wu 等[3]模拟电场在曲面网格上的分布,给出了基于物理的分割方法;1998年Lee 等[21]和2000年Guskov 等[22]给出了几个对应于简化模型的多分辨率方法;1999年Mangan 等[2]使用分水岭算法实现网格分割,并较好地解决了过分割问题;2001年,Pulla 等[23224]改进了Mangan 的曲率估计工作;1999年,Gregory 等[25]提出一个动画设计中的交互应用,根据用户选择的特征点将网格曲面分割为变形对应片;1999年,Tan 等[26]基于顶点的简化模型建立了用于碰撞检测的、更紧致于网格曲面分割片的层次体包围盒12000年,Rossl 等[27]在逆向工程应用中,在网格曲面上定义了面向曲率信号的数学形态学开闭操作,从而得到去噪后的特征区域骨架,并实现了网格分割;2001年,Yu 等[28]的视觉系统自动将几何场景点云分割为独特的、用于纹理映射和绘制的网格曲面片二叉树;Li 等[29]为了碰撞检测,给出了基于边收缩得到描述几何和拓扑特征的骨架树,然后进行空间扫描自动分割;Sander 等[30]使用区域增长法,按照分割结果趋平、紧凑的原则分割、合并分割片1所有这些方法都是为了使分割的结果便于参数化,即只能产生凸的分割片1由此产生边界不连续的效果12002年,Werghi 等[31]识别三维人体扫描模型的姿态,根据人体局部形状索引进行网格模型的分割;Bischoff 等[32]和Alface 等[33]分别给出了网格分割片光谱在几何压缩和传输中的应用;Levy 等[34]在纹理生成工作中,以指定的法向量的夹角阈值对尖锐边滤波,对保留下来的边应用特征增长算法,最后使用多源Dijkstra 算法扩张分割片实现了网格模型的分割;2003年,Praun 等[35]将零亏格网格曲面投影到球面上,然后把球面投影到正多面体上得到与多面体各面对应的网格模型分割,最后将多面体平展为平面区域以进行参数化,但其结果不是有意义的分割1212 网格分割的分类早期的网格分割算法多为手工分割或者半自动分割,近两年出现了基于自动分割的应用工作1从网格模型的规则性来看,可将分割算法分为规则网格分割、半规则网格分割和任意结构的网格分割算法,根据分割结果可以分为有意义的分割和非有意义的分割1同时,面向不同的应用目标出现了不同的分割策略(见第4节)1目前,网格分割的质量指标主要有三个方面:边界光顺程度、是否有意义、过分割处理效果1多数分8461计算机辅助设计与图形学学报2005年割算法以边界光顺为目标,采用的方法有在三角网格上拟合B样条曲面然后采样[20],逼近边界角点(两个以上分割片的公共顶点)间的直线段[30]等1近年来多数分割算法都追求产生有意义的分割结果1对于过分割的处理方法目前主要有忽略、合并和删除三种方式1多数三维网格分割算法是从二维图像分割的思想出发,对图像分割算法作三维推广得到其三维网格空间的应用1如分水岭算法[2,15,23224,36239]、K2 means算法[40]、Mean2shift算法[41]以及区域增长算法[18,30]等1同样,与图像处理问题类似,光谱压缩[33,42243]、小波变换[31]等频谱信息处理方法在三维网格分割中也有算法1除此之外,同时考虑几何与拓扑信息的分割会产生较好的结果1这方面的工作主要有基于特征角和测地距离度量[44]、基于高斯曲率平均曲率[45247]、基于基本体元[32]、基于Reeb图[48250]、基于骨架提取和拓扑结构扫描[27,29,51252]等使用三维网格曲面形状特征的算法1作为网格模型的基础几何信息,曲率估计方法目前主要为曲面拟合、曲线拟合以及离散曲率等三种1其中曲面拟合法较为健壮,但是计算量大;离散曲率法计算量小,但是除个别算法外都不是很健壮,且无主方向主曲率信息;曲线拟合的曲率估计方法则集中了上述两种方法的优势[3],实际研究中使用较多13 典型三维网格分割算法311 分水岭算法1999年,Mangan等[2]的工作要求输入的是三角网格曲面,以及任何一种可以用来计算每个顶点曲率的附加信息(如曲面法向量等),并针对体数据和网格数据给出了两种曲率计算方法;但是分水岭算法本身和曲率的类型无关1首先,计算每个顶点的曲率(或者其他高度函数),寻找每个局部最小值,并赋予标志,每一个最小值都作为网格曲面的初始分割;然后,开始自下而上或者自上而下地合并分水岭高度低于指定阈值的区域,有时平坦的部分也会得到错误的分割,后处理解决过分割问题1分割为若干简单的、无明确意义的平面或柱面,属于非有意义的分割1Rettmann等[36237]结合测地距离,并针对分水岭算法的过分割给出一个后处理,实现了MRI脑皮层网格曲面的分割12002年,Marty[38]以曲率作为分水岭算法的高度函数,给出了有意义的分割结果1 2003年,Page等[39]的算法同样只分割三角网格,依据最小值规则,他们试图得到网格模型高层描述1其主要贡献为:创建了一个健壮的、对三角网格模型进行分割的贪婪分水岭法;使用局部主曲率定义了一个方向性的、遵循最小值规则的高度图;应用形态学操作,改进了分水岭算法的初始标识集1文献[39]在网格的每一个顶点计算主方向和主曲率,根据曲率阈值,使用贪婪的分水岭算法分割出由最小曲率等高线确定的区域1形态学的开闭操作应用于网格模型每个顶点的k2ring碟状邻域,闭操作会连接空洞,而开操作会消除峡部1创建了标识集后,依据某顶点与其邻接顶点之间的方向,由欧拉公式和已知主曲率计算该顶点在该方向上的法曲率从而得到在该方向上、该顶点与邻接顶点之间的方向曲率高度图,并将其作为方向梯度1对该顶点所在的标识区域使用分水岭算法得到分割片1上述工作表明,分水岭算法在改进高度函数的定义后,可以得到有意义的分割效果1312 基于拓扑信息的网格分割基于几何以及拓扑信息的形状分割方法可以归结为Reeb图[50]、中轴线[52]和Shock图[53254]等1基于拓扑信息的形状特征描述主要有水平集法[55]和基于拓扑持久性的方法[56]11999年,Lazarus等[51]提出从多面体顶点数据集提取轴线结构,在关键点处分割网格的水平集方法,如图1所示1这种轴线结构与定义在网格模型顶点集上的纯量函数关联,称之为水平集图,它能够为变形和动画制作提供整体外形和拓扑信息1图1 人体网格模型及其水平集图文献[51]针对三角剖分的多面体,使用与源点之间的最短路径距离作为水平集函数,基于Dijkstra 算法构造记录水平集图的结构树,其根结点、内部结点和叶子分别表示源点、水平集函数的鞍点和局部最大值点1该工作可以推广到非三角网格模型1 2001年,Li等[29]基于PM算法[57]的边收缩和94618期孙晓鹏等:三维网格模型的分割及应用技术综述空间扫掠,给出了一个有效的、自动的多边形网格分割框架1该工作基于视觉原理,试图将三维物体分割为有视觉意义和物理意义的组件1他们认为三维物体最显著的特征是几何特征和拓扑特征,由此,定义几何函数为扫掠面周长在扫掠结点之间的积分为骨架树中分支的面积;定义拓扑函数为相邻两个扫掠面拓扑差异的符号函数,并定义了基于微分几何和拓扑函数的关键点1文献[29]首先基于PM算法将每条边按照其删除误差函数排序,具有最小函数值的边收缩到边中点,删除其关联的三角形面片;如果某边没有关联任何三角片则指定为骨架边,保持其顶点不变;循环上述过程,得到一个新的、通过抽取给定多边形网格曲面骨架的方法1其次,加入虚拟边连接那些脱节的骨架边,称这些虚拟边以及原有的骨架边组成的树为骨架树,即为扫掠路径1扫掠路径为分段线条1然后,定义骨架树中分支面积(扫掠面周长函数在扫掠结点之间的积分),分支面积较小的首先扫掠,以保证小的、但是重要的分割片被首先抽取出来,以免被其他较大的分割片合并1最后,沿扫掠路径计算网格的几何、拓扑函数的函数值1一旦发现几何函数、拓扑函数的关键点,抽取两个关键点之间的网格曲面得到一个新的分割片1整个过程无需用户干涉12003年,Xiao等[48249]的工作基于人体三维扫描点云的离散Reeb图,给出了三维人体扫描模型的一个拓扑分割方法:通过探测离散Reeb图的关键点,抽取表示身体各部分的拓扑分支,进而进行分割1水平集法具有较高的计算速度和健壮的计算精度1基于拓扑持久性的方法结合代数学,能更准确地计算形状特征,但是没有解决分割问题[55256]1 313 基于实体表示的网格分割2002年,Bischoff等[32]把几何形状分割为表示其粗糙外形的若干椭球的集合,并附加一个独立的网格顶点的采样集合来表示物体的细节1生成的椭球完全填充了物体的内部,采样点就是原始的网格顶点1该方法的步骤如下:Step11首先,在物体原始网格的每一顶点上生成一个椭球,或者随机在物体原始网格上采样选择种子点;每个种子点作为球面上的一个顶点,沿该点的网格法向做球面扩展,直至与网格上另外一个顶点相交;然后沿此两点的垂直方向将球面扩张为最大椭球,直至与第三个网格顶点相交;最后沿此三点平面的法向(即该三点所在平面的柱向)扩张,直至与第四个网格顶点相近,由此得到一个椭球1Step21对生成的椭球进行优化选择,体积最大的椭球首先被选中,以后每一次都将选出对累计体积贡献最大的椭球1如果有若干体积累计贡献相近的椭球同时出现的情况发生,则最小半径最短的椭球被选出1为了简化体积累计贡献的计算,对椭球体素化后计算完全包含在椭球内的体素的数目进行堆排序1发送方传送选出的椭球集合;接收方得到包含基本几何和拓扑信息的椭球集合后,使用Marching Cubes算法或者Shrink2wrapping算法抽取0等值面1显然即使部分椭球丢失,工作依然可以继续:因为椭球是互相重叠的,抽取等值面不影响它们的拓扑关系,而且如果重叠充分,丢失少部分椭球不会影响重要形状信息的重构1如图2所示1图2 以不同数目椭球表示的网格分割Step31在生成很好地逼近原始物体的初始网格后,开始将采样点(即原始网格顶点)插入网格[58]1为了提高最终重构结果的质量,由Marching Cubes算法生成的临时网格顶点在网格原始顶点陆续到来后,最终被删除,因为它们不是物体的原始顶点1314 基于模糊聚类的层次分解2003年,Katz等[44]提出了模糊聚类的层次分解算法,算法处理由粗到精,得到分割片层次树1层次树的根表示整个网格模型S1在每个结点,首先确定需要进一步分割为更精细分割片的数目,然后执行一个k2way分割1如果输入的网格模型S由多个独立网格构成,则分别对每个网格进行同样的操作1分割过程中,算法不强调每个面片必须始终属于特定的分割片1大规模网格模型的分割在其简化模型上进行,然后将分割片投影到原始网格模型上,在不同的尺度下计算分割片之间的精确边界1文献[44]算法优点是:可以对任意拓扑连接的或无拓扑连接的、可定向的网格进行处理;避免了过分割和边界锯齿;考虑测地距离和凸性,使分割边界通过凹度最深的区域,从而得到有意义的分割结果1分割结果适用于压缩和纹理映射14 三维网格分割应用411 三维检索中的网格分割算法在三维VRML数据库中寻找一个与给定物体0561计算机辅助设计与图形学学报2005年相似的模型的应用需求,随着WWW的发展正变得越来越广泛,如计算生物学、CAD、电子商务等1形状描述子和基于特征的表示是实体造型领域中基本的研究问题,它们使对物体的识别和其他处理变得容易1因为相似的物体有着相似的分割,所以分割结构形状描述子可以用于匹配算法1中轴线、骨架等网格模型拓扑结构的形状描述子在三维模型检索中也得到研究,它可以从离散的体数据以及边界表示数据(网格模型)中抽取出来1对于后者,目前还没有精确、有效的结果[39]1但我们相信,依据拓扑信息进行分割得到的分布式形状描述子也是一种值得尝试的三维模型检索思路1 2002年,Bischoff等[32]提出从椭球集合中得到某种统计信息,如椭球半径的平均方差或者标准方差,以及它们的比率,由于这些统计信息在不同的形状修改中都保持不变,作为一种检索鉴别的标识的想法1但是没有严格的理论或者实验结果证明1 2002年,Zuckerberger等[59]在一个拥有388个VRML三维网格模型的数据库上,进行基于分割的变形、简化、检索等三个应用1首先将三维网格模型分割为数目不多的有意义的分割片,然后评价每一个分割片形状,确定它们之间的关系1为每个分割建立属性图,看作是与原模型关联的索引,当数据库中检索到与给定网格模型相似的物体时,只是去比较属性图相似的程度1属性图与其三维模型的关联过程分为三步:(1)分割网格曲面为有限数目的分割片;(2)每一个分割片拟合为基本二次曲面形状;(3)依据邻接分割片的相对尺寸关系进行过分割处理,最后构造网格曲面模型的属性图1对分割片作二次拟合,由此产生检索精确性较差的问题;分割片属性图的比较采用图同构的匹配方法,计算量较大,且是一个很困难的问题;从其实验结果看,有意义的分割显然还不够,出现飞机、灯座等模型被检索为与猫相似的结构;区分坐、立不同的人体模型效果显然也很差等12003年,Dey等[4]基于网格模型的拓扑信息,给出了名为“动力学系统”的形状特征描述方法,并模拟连续形状定义离散网格形状特征1实验表明该算法十分有效地分割二维及三维形状特征1他们还给出了基于此健壮特征分割方法的形状匹配算法1 412 几何压缩传输中的网格分割健壮的网格模型压缩传输方法必须保证即使部分几何信息丢失,剩下的部分至少能够得到一个逼近原始物体的重构,即逼近的质量下降梯度,要大大滞后于信息丢失梯度1无论是层次结构的还是过程表示的多边形网格模型,它们的缺陷是:严格的拓扑信息一致性要求1顶点和面片之间的交叉引用导致即使在传输中丢失了1%的网格数据,也将导致无法从99%的剩余信息里重建网格曲面的任何一部分1对此可以考虑引入高度的冗余信息,即使传输中丢失一定额度的数据,接收方依然可以重构大部分的几何信息1问题的关键是将几何体分割为相互独立的大块信息,如单个点,这样接收方可以在不依赖相关索引信息的情况下,重构流形的邻域关系1为了避免接收方从点云重构曲面的算法变得复杂,早期的健壮传输方法总假设至少整体拓扑信息可以无损地传送1一旦知道了粗糙的形状信息,接收方可以插入一些附加点生成逼近网格12002年,Bischoff等[32,58]在网格分割工作中将每个椭球互相独立地定义自己的几何信息1由于椭球的互相重叠,冗余信息由此产生,因此如果只有很少的椭球丢失,网格曲面的拓扑信息和整体形状不会产生变化1冗余信息不会使存储需求增加,因为每个椭球和三角网格中每个顶点一样,只需要9个存储纯量1其传送过程如下:种子点采样生成椭球集合;传送优化选择的椭球子集;接收方抽取等值面重构逼近网格;以陆续到来的原始网格顶点替换临时网格顶点11996年,Taubin等[42]首先在几何压缩处理中提出光谱压缩,其工作在三维网格模型按如下方式应用傅里叶变换:由任意拓扑结构的网络顶点邻接矩阵及其顶点价数,得到网格Laplacian矩阵的定义及由其特征向量构成的R n空间的正交基底,相对应的特征值即为频率1三维网格顶点的坐标向量在该空间的投影即为该网格模型的几何光谱1网格表面较为光顺的区域即为低频信号12000年,Karni等[43]将几何网格分割片光谱推广到传输问题上1光谱直接应用于定义几何网格的拓扑信息时,会产生伪频率信息1对于大规模的网格,由于在网格顶点数目多于1000时,Laplacian矩阵特征向量的计算几乎难以进行,因此该工作在最小交互前提下,将网格模型分割为有限数目的分割片1该方法有微小的压缩损失,且在分割片边界出现人工算法痕迹12003年,Alface等[33]提出了光谱表示交叠方法:扩张分割片,使分割片之间产生交叠1具体方法是把被分割在其他邻接分割片中的、但与该分割片15618期孙晓鹏等:三维网格模型的分割及应用技术综述邻接的三角片的顶点,按旋转方向加入到该分割片中,从而由于分割片重叠搭接产生冗余信息,并称这种分割片扩展冗余处理的光谱变换为交叠的正交变换1该工作在几何网格压缩和过程传输的应用中明显地改进了Karni等的工作1显然上述工作的基础是良好的网格分割1建立分片独立的基函数将使得分割效果更为理想1413 纹理贴图中的网格分割如果曲面网格的离散化是足够精细的,如细分网格,那么直接对顶点进行纹理绘制就足够了;否则就要把网格模型分割为一组与圆盘同胚的、便于进行参数化的分割片,再对每片非折叠的分割片参数化,最后分割片在纹理空间里拼接起来1网格模型的分割显然会因其局部性而降低纹理映射纹理贴图、网格参数化的扭曲效果1面向纹理的分割算法一般要求满足两个条件:(1)分割片的不连续边界不能出现人工算法痕迹;(2)分割片与圆盘同胚,而且不引入太大的变形就可以参数化1不要求有意义的分割结果12001年,Sander等[30]基于半边折叠的PM算法,使用贪婪的分割片合并方法(区域增长法)对网格模型进行分割1首先将网格模型的每一个面片都看作是独立的分割片,然后每个分割片与其邻接分割片组对、合并1在最小合并计算量的前提下,循环执行分割片对的合并操作,并更新其他待合并分割片的计算量1当计算量超出用户指定的阈值时,停止合并操作1分割片之间的边界为逼近角点间直线段的最短路径,从而减轻了锯齿情况12002年,Levy等[34]将网格模型分割为具有自然形状的分割片,但仍然没有得到有意义的分割结果1为了与圆盘同胚,该算法自动寻找位于网格模型高曲率区域的特征曲线,避免了在平展区域内产生分割片边界,并增长分割片使他们在特征曲线上相交,尽量获得尺寸较大的分割片1414 动画与几何变形中的网格分割影视动画制作中,多个对象间的几何变形特技使用基于网格分割的局部区域预处理1如建立动画区域对应关系,对多个模型进行一致分割,然后在多个模型的对应分割片之间做变形,将提高动画制作的精度和真实性;且每个“Polygon Soup”模型都可用来建立分割片对应;模型间的相似分割有利于保持模型的总体特征1目前,多数的自动对应算法精度较低,手工交互指定对应关系的效率又太低1 1996年,Krishnamurthy等[20]从高密度、非规则、任意拓扑结构的多边形网格出发,手工指定分割边界,构造张量积样条曲面片的动画模型1文献[20]首先在多边形网格的二维投影空间交互选择一个顶点序列,然后自动地将顶点序列关联到网格上最近的顶点上;对于序列中前后两个顶点计算在网格曲面上连接它们的最短路径;对该路径在面片内部进行双三次B样条曲面拟合、光顺、重新采样,得到分割片在两个顶点之间的边界曲线1但计算量的付出依然是非常昂贵的11999年,Gregory等[25]在两个输入的多面体曲面上交互选择多面体顶点,作为一个对应链的端点,对应链上其他顶点通过计算曲面上端点对之间的最短路径上的顶点确定,由此得到这些顶点和边构成的多面体表面网格的连通子图;然后将每一个多面体分割为相同数目的分割片,每个分割片都与圆盘同胚;在分割片之间建立映射、重构、局部加细,完成对应关系的建立;最后插值实现两个多面体之间的变形12002年,Shlafman等[40]的工作不再限制输入网格必须是零亏格或者是二维流形1该算法通过迭代,局部优化面片的归属来改进某些全局函数,因此与图像分割K2means方法相近,属于非层次聚类算法1最终分割片的数目可以由用户预先指定,从而避免了过分割,且适用于动画制作的需求1分割过程的关键在于确认给定的两个面片是否属于同一个分割片1其分割工作是非层次的,因为面片可能会在优化迭代中被调整到另外一个分割片去1该工作表明,基于分割的变形对于保持模型的特征有着重要的意义1局部投影算法能够产生精细的对应区域,且能自动产生有意义的分割片1415 模型简化中的网格分割网格简化是指把给定的一个有n个面片的网格模型处理为另一个保持原始模型特征的、具有较少面片、较大简化Π变形比的新模型1三维网格分割显然可以被看作是一种网格简化,其基本思想是在简化中增加一个预处理过程,先按模型显著特征将其分割为若干分割片,然后在每个分割片内应用简化算法,由此保持了模型的显著特征,如特征边、特征尖锐以及其他精细的细节1例如,把曲率变化剧烈的区域作为分割边界,将曲率变化平缓的区域各自分割开来,就是基于曲率阈值的网格简化方法1网格曲面分割结果的分割片数目在去除过分割后被限制在指定的范围内12561计算机辅助设计与图形学学报2005年。
基于CorVis ST测量人角膜的弹性模量

( 1 天 津 大 学 机 械 工 程 学 院 力 学 系 3 0 0 3 5 0 天津; 2 天津市眼科医院天津市眼科学与视觉科学重点实验室3 0 0 0 2 2 天津)
摘 要 :根据临床可视化角膜生物力学分析仪(CorVis ST)检測得到近视患者屈光手术前角膜动态变形
历程曲线,采用有限元数值模拟逆解方法确定其角膜在体有效弹性模量。采用计算流体动力学(CFD)
第3 期
泼宋鑫,等:基于CorVisST测量人角膜的弹性模量
863
(
1 )劉 亙
入 (i莲niets>
善
X
B
-sui
E
X
S
)
出 U (outlet)
( I 0 3 P P
角膜(cornea)
巩 膜 (sclera)
巩 膜 的 平 均 厚 度 为 〇 .75_,半 径 为 12mm。 在生理状态下,角膜受到丨O P 的作用而产生初
测量角膜弹性力学性能的实验包括离体实验 和 在 体 实 验 。采 用 较 广 泛 的 离 体 实 验 有 单 轴 拉 伸 实 验 [M]和 膨 胀 实 验 [5]。单 轴 拉 伸 试 验 可 以 通 过 由 拉 伸 切割得到的角膜矩形条带获得角膜沿拉伸方向的应 力-应 变 关 系 。膨 胀 实 验 可 模 拟 角 膜 的 生 理 状 态 ,在 角膜的后表面施加压力使角膜变形,通过比较数值 模拟结果和实验结果逆解角膜材料参数。离体测量 可以加深对角膜生物力学特性的了解,但不同患者 角膜的弹性性能具有个体化差异,因此将离体实验 结 果 用 于 临 床 实 践 会 有 误 差 。在 体 实 验 方 法 众 多 , 例 如 逐 步 压 痕 法 W、用 于 测 量 角 膜 杨 氏 模 量 的 剪 切 波成像技术[7],以 及 使 用 光 学 相 干 弹 性 成 像 (OCE) 测量角膜不同厚度位置的位移[8]等 。这些方法的缺 点是不能得到角膜的非线性弹性材料特性,只能测 量角膜局部的弹性性能。
business area 分类 英语表达 -回复

business area 分类英语表达-回复Business area classification: English expressionsIntroductionIn the world of business, classification plays a crucial role in organizing information and analyzing market trends. Business area classification is the process of categorizing different types of businesses based on their products, services, or industries. This article aims to provide a comprehensive guide to business area classification and explore the English expressions commonly used in this context.1. Types of businessesThere are various types of businesses that exist, each falling into a specific category. Let's take a look at some of the most common classifications:a) Retail: Retail businesses involve the sale of goods or services directly to consumers. Expressions associated with this category include "brick-and-mortar stores" and "e-commerce platforms."b) Manufacturing: Manufacturing businesses are involved in the production of goods from raw materials. Common expressions used in this category include "assembly lines" and "production facilities."c) Finance: Finance businesses deal with financial transactions, such as banking, investment, and insurance. Expressions commonly used in this context include "financial institutions" and "stock markets."d) Technology: Technology businesses focus on the development and sale of innovative products and services. Expressions used in this category include "tech startups" and "software development."e) Hospitality: Hospitality businesses offer accommodation, food, and beverage services. Expressions associated with this category include "hotels and resorts" and "restaurants and bars."2. Industry sectorsAnother way to classify businesses is through industry sectors. Let's explore some of the key industry sectors and the expressionsassociated with them:a) Healthcare: The healthcare industry includes hospitals, clinics, pharmaceutical companies, and medical device manufacturers. Expressions commonly used in this sector include "healthcare providers" and "medical research."b) Energy: The energy sector encompasses businesses involved in producing and distributing energy, such as oil and gas companies, renewable energy firms, and utility companies. Expressions used in this context include "energy production" and "power grids."c) Transportation: The transportation industry involves businesses that provide passenger and freight transportation services, such as airlines, shipping companies, and logistics providers. Expressions associated with this sector include "transportation infrastructure" and "freight forwarding."d) Retail: The retail industry includes businesses that sell goods directly to consumers, such as department stores, supermarkets, and online retailers. Expressions used in this context include "retail sales" and "consumer behavior."e) Agriculture: The agriculture sector comprises businesses involved in farming and agricultural production, including crop cultivation, livestock rearing, and agricultural equipment manufacturing. Expressions associated with this sector include "agricultural productivity" and "food security."3. Market segmentationMarket segmentation is the process of dividing a broader market into smaller, more defined segments based on specific criteria. Here are some expressions commonly used in market segmentation:a) Demographic segmentation: This segmentation strategy involves dividing the market based on demographic factors such as age, gender, income, and education level. Expressions associated with this strategy include "target audience" and "demographic trends."b) Psychographic segmentation: Psychographic segmentation categorizes consumers based on their personalities, lifestyles, andvalues. Expressions commonly used in this context include "consumer preferences" and "lifestyle segmentation."c) Geographic segmentation: Geographic segmentation involves dividing the market based on geographical location, such as countries, regions, or cities. Expressions associated with this strategy include "local market analysis" and "regional expansion."d) Behavioral segmentation: Behavioral segmentation classifies consumers based on their purchasing behavior, brand loyalty, and usage patterns. Expressions used in this context include "customer loyalty programs" and "purchase patterns analysis."4. Business area analysisOnce businesses are classified into specific categories, it becomes easier to analyze market trends, identify competition, and make informed business decisions. Here are some expressions commonly used in business area analysis:a) SWOT analysis: SWOT (Strengths, Weaknesses, Opportunities, and Threats) analysis is a framework used to evaluate a company'sinternal strengths and weaknesses as well as external opportunities and threats. Expressions associated with SWOT analysis include "competitive advantage" and "market opportunities."b) Market research: Market research involves gathering and analyzing data to understand customers, competitors, and market trends. Expressions commonly used in this context include "market surveys" and "consumer insights."c) Competitive analysis: Competitive analysis involves evaluating the strengths and weaknesses of competitors to develop strategies and improve market positioning. Expressions associated with competitive analysis include "competitor benchmarking" and "market share analysis."d) Trend analysis: Trend analysis involves studying market trends over time to identify patterns and make accurate forecasts. Expressions commonly used in this context include "market trends analysis" and "predictive modeling."ConclusionBusiness area classification is essential in organizing and understanding the diverse world of businesses. The variations in products, services, and industries make it imperative to categorize and analyze them effectively. By using the English expressions provided in this article, individuals can communicate and understand the nuances of business area classification, market segmentation, and business analysis.。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
HAREM 2005 - International Workshop on Human Activity Recognition and Modelling,Oxford, UK, September 2005 Segmentation and Classification of Human Activities∗J.C.Nascimento1M.A.T.Figueiredo2J.S.Marques3jan@isr.ist.utl.pt mtf@lx.it.pt jsm@isr.ist.utl.pt1,3Instituto de Sistemas e Rob´o tica2Instituto de Telecomunicac¸˜o esInstituto Superior T´e cnico1049-001LisboaPORTUGALAbstractThis paper describes an algorithm for segmenting and classifying human activities from video sequencesof a shopping center.These activities comprise entering or exiting a shop,passing,or browsing in frontof shop windows.The proposed approach recognizes these activities by using a priori knowledge of thelayout of the shopping view.Human actions are represented by a bank of switch dynamical models,each tailored to describe a specific motion regime.Experimental tests illustrate the effectiveness of theproposed approach with synthetic and real data.Keywords:Surveillance,Segmentation,Classification,Human Activities,Minimum Description Length.1IntroductionThe analysis of human activities is an important computer vision research topic with applications in surveillance,e.g.in developing automated security applications.In this paper,we focus on recognizing human activities in a shoppingcenter.In commercial spaces,it is common to have many surveillance cameras.The monitor room is usually equippedwith a large set of monitors which are used by a human operator to watch over the areas observed by the cameras.This requires a considerable effort of the human operator,who has to somehow multiplex his/her attention.In recentyears a considerable effort was devoted to develop automatic surveillance systems providing information about whichactivities take place in a given space.With such a system,it would be possible to monitor the actions of individuals, determining its nature and discerning common activities from inappropriate behavior(for example,standing for a largeperiod of time at the entrance of a shop,fighting).In this paper,we aim at labelling common activities taking place in the shopping space.1Activities are recog-nized from motion patterns associated to each person tracked by the system.Motion is described by a sequence of displacements of the2D centroid(mean position)of each person’s blob.The trajectory is modelled by using multiple dynamical models with a switching mechanism.Since the trajectory is described by its appearance,we compute thestatistics for the identification of the dynamical models involved in a trajectory.The rest of the paper is organized as follows.Section2deals with related work.Section3,describes the statisticalactivity model.Section4derives the segmentation algorithm.Section5reports experimental results with syntheticdata and real video sequences.Section6concludes the paper.2Related WorkThe analysis of human activities has been extensively addressed in several ways using different types of features and inference methods.Typically,a set of motion features is extracted from the video signal and an inference model isused to classify it into one of c possible classes.For example in[16]the human body is approximated by a set of segments and atomic activities are then defined asvectors of temporal measurements which capture the evolution of thefive body parts.In other works the human bodyis simply represented by the mass center of its active region(blob)in the image plane[12]or the body blob as in[4].The activity is then represented by the trajectory obtained from the blob center,or from the correspondence of bodyblob regions respectively.Other works try to characterize the human activity directly from the video signal without segmenting the active regions.In[2]human activities are characterized by temporal templates.These templates try to convey informationabout“where”and“how”motion is performed.Two templates are created:a binary motion-energy-image which represents where the motion has occurred in the whole sequence,and a scalar motion-history-image which represents ∗This work was partially supported by FCT under project CA VIAR(IST-2001-37540)1This work is integrated in project CA VIAR,which has the general goal of representing and recognizing contexts and situations.An introductionand the main goals of the project can be found in h ttp:///rbf/CA VIAR/caviar.htmhow motion occurs for each activity.Motion patterns have also been used in [9]based on the concept of “recency”.This work integrates several frames into a single image,assigning higher weights to the most recent frames.In [10],the human motion is characterized by the optical flow.Several inference techniques have been used for the recognition of human activities using static and dynamic techniques.In [12]a single-person or person-to-person interactions are modelled by Hidden Markov Models (HMMs)and Coupled Hidden Markov Models (CHMMs).Both techniques are used to characterize the evolution of the person mass center along the video sequence.In [4]a Bayesian networks are used to for making inference about the events.In [11]activities are modelled using banks of switched dynamic models each of which tailored to a specific motion regime.Geometric constraints have also been used e.g.,using the layout of the surveillance region [13,3].In [1,3]Finite State Machines (FSM)are used for gesture and activity recognition.The later uses prior knowledge about the scene,where regions of interest are defined (e.g.,entrances and exits).When the human motion is characterized by global features static pattern recognition methods can be used to classify the human activities.In [15]neural networks are used for this purpose.The previous methods have been used to deal with single pedestrians or a very limited number of pedestrians [12].To deal with the interaction among multiple pedestrians Bayesian networks have been proposed [8]since they are able to represent the dependencies among several random variables.3Statistical ModelWe represent the human activity by the trajectory of its centroid.The time evolution of this feature is modelled by a dynamical model.Since a single model may not suffice to describe an entire trajectory,we use multiple dynamical models and a switching mechanism.In this paper,a trajectory will be represented by a sequence of 2D locations,x =(x 1,...,x n ),with x t ∈I R 2.We assume that the trajectory is the output of a bank of switched dynamical systems of the formx t −x t −1=∆x t =µk t +w t ,(1)where k t ∈{1,...,c }is the label of the active model at time instant t ,µk t is a (model-dependent)displacement vector,and the w t ∼N (0,Q k t )are independent Gaussian random variable,with covariances Q k t .Since the observations are {∆x t ;t ∈N },∆x t ∈R d (d is the dimension of the observation vector),instead of x t ,equation (1)describes an independent increment process,given k t ,as shown in Fig.1......Figure 1:Architecture of the proposed approach.Finally we assume that the sequence of model labels is composed of T constant segments:{k 1,...,k 1,k 2,...,k 2,...,k T ,...,k T }.4Segmentation and classification AlgorithmIn order to segment and classify the different activities,we first observed that all trajectories concerning a common activity follow a typical route.Fig.2shows trajectories corresponding to a person entering a shop (left),leaving a shop (middle)or just passing in front of a shop (right).This work demonstrates that elementary actions such as:“moving upwards”,“stopped”,“moving downwards”,“moving left”and “moving right”(i.e., M =5),are representatives of the trajectories.The underlying idea is:given a test trajectory x t =(x 1,...,x n ),segment it into its elementary actions and classify the activity .The number of segments will depend on the activity being considered,as described later.4.1Model Parameter EstimationTo segment and classify a given trajectory we have to previously obtain the parameters of each dynamic model.To accomplish this,we collect tens of trajectory samples from each model.Figure2:Examples of three different activities(entering,exiting,passing).From x t we can obtain∆x i t,where∆x i t contains the displacements of x t known to have been generated by the i th model.Defining∆X i={∆x i1,∆x i2,...,∆x i N}as the vector containing all the displacements in i th model of the training set,we have,for the i th model:ˆµi=1∆X i∑∆X i t,ˆQ i=1∆X i∑(∆X i−ˆµi)(∆X i−ˆµi)T,(2) whereˆµi andˆQ i are standard estimates of the mean and the covariance matrix respectively.4.2Segmentation and ClassificationHaving defined the set of models and the corresponding parameters,one can now classify a test trajectory x t.One way to attain this goal is to compute the likelihood of x t into the model space.In this paper,the activity depends on the number of the model switchings.In Fig.2,we see that“passing”can be described by using just one model.The activities“entering”and“exiting”can be described by using two dynamical models.The fourth activity considered “browsing”,requires three models to be described;we define“browsing”when the person is walking,stop to see the shop-window and restarts walking.This behavior was observed in all the other samples of the activities which come about in this context.This means that we have to estimate the time instants in which the model switching happens.Assuming that the sequence x t has n samples and is described by T segments(and T is known)the log-likelihood isL(m1,...,m T,t1,...,t T−1)=log p(∆x1,...,∆x n|m1,m2,...,m T,t1,t2,...,t T−1)(3) where m1,...,m T is the sequence of model labels describing the trajectory and t i for i=1,...,T−1is the time instant when switching from model m i to m i+1occurs.If T=1,there is no switching.Due to the conditional independence assumption underlying(1),the log-likelihood can be written asL(∆x1,...,∆x n|m1,...,m T,t1,...,t T−1)=T∑j=1t j∑i=t j−1log p(∆x i|m j)=T∑j=1t j∑i=t j−1log N(∆x i|µmj,Q mj)(4)where we define t0=1,T is the number of segments and t j the switch time.Assuming that T is known,we can “segment”the sequence(i.e.,estimate m1,...,m T and t1,...,t T−1)using the maximum-likelihood approach:ˆm1,...,ˆm T,ˆt1,...,ˆt T−1=argmax L(∆x1,...,∆x n|m1,...,m T,t1,...,t T−1)(5) This maximization can be performed in a nested way,ˆt1,...,ˆt T−1=arg maxt1,...,t T−1maxm1,...,m TL(∆x1,...,∆x n|m1,...,m T,t1,...,t T−1)(6) In fact,the inner maximization can be decoupled asmaxm1,...,m TL(∆x1,...,∆x n|m1,...,m T,t1,...,t T−1)=T∑j=1maxm jt j∑i=t j−1log p(∆x i|m j)(7)where the maximization with respect to each of m j is a simple maximum likelihood classifier of sub-set of samples (∆x tj−1,...,∆x tj)into one of a set of Gaussian classes.Finally,the maximization with respect to t1,...,t T−1is done by exhaustive search(this is never too expensive,since we consider a maximum of three segments).4.3Estimating the number of models of the activity4.3.1MDL CriterionIn the previous section,we derived the segmentation criterion assuming that the number of segments T is known.As is well known,the same criterion can not be used to select T ,as this would always return the largest possible number of segments.We are thus in the presence of a model selection problem,which we address by using the minimum description length (MDL)criterion [14].The MDL criterion for selecting T isˆT =argmin T −log p (∆x 1,...,∆x n |ˆm 1,...,ˆm T ,ˆt 1,...,ˆt T −1)+M (ˆm 1,...,ˆm T ,ˆt1,...,ˆt T −1) (8)where M (ˆm 1,...,ˆm T ,ˆt 1,...,ˆt T −1)is the number of bits required to encode the selected model indeces and the estimated switching times.Notice that we do not have the usual 12log n term because the real-valued model parameters (meansand covariances)are assumed fixed (previously estimated).Finally,it is easy to conclude thatM (ˆm 1,...,ˆm T ,ˆt 1,...,ˆt T −1)≈T log c +(T −1)log n (9)where T log c is the code length for the model indeces m 1,...,m T ,since each belongs to {1,...,c },and (T −1)log n isthe code length for ˆt1,...,ˆt T −1,because each belongs to {1,...,n };we have ignored the fact that two switchings can not occur at the same time,because T <<n .5Experimental resultsThis section presents results with synthetic and real data.In the synthetic case,we have performed Monte Carlo tests.We have considered five models (c =5)shown in Fig.3.The synthetic models shown in Fig.3(a)were obtained by simulating four activities of a person,using the generation model in (1).Fig.4shows examples of activities (the trajectory shape of “Leaving”is the same as “Entering”,however with opposite direction).Here,the thin (green)rectangles correspond to areas where the trajectory begins.The first sample of x t in these areas is random,because the agent may appears at random places in the scene.The wide (yellow)rectangle is the area in which occurs a model switching.In this figure the trajectories are generated with two segments (“Entering”,“Leaving”,“Passing”)and with three segments (“Browsing”).For each activity we generate 100test samples using (1)and classify each of them in one of the four classes.Fig.5shows the displacements ∆x t (black dots)of the test sequences (“Entering”and “Passing”)overlapped with the five models.We can see that the displacements lie on right -up clusters (“Entering”)and right cluster (“Passing”).In this experiment,all the test sequences were correctly classified (%100accuracy).−10−8−6−4−20246810−10−8−6−4−2246810−50−40−30−20−1001020304050−50−40−30−20−1001020304050(a)(b)Figure 3:Five models are considered to describe trajectory.Each color corresponds to a different model.Synthetic case (a),real case (b).We also generated different test trajectories,this is because the exiting and entering may occur in different direction from the ones in Fig.4.These examples are illustrated in Fig.6.In this new experiment,the same 100%accuracy was also obtained.(a)(b)(c)Figure4:Examples of synthetic activities(performed in left-right direction):(a)entering,(b)passing,(c)browsing.(a)(b)Figure5:Five models with the displacements(black dots)of the test activities:(a)entering,(b)passing.The proposed algorithm was also tested with real data.The video sequences were acquired in the context of the EC funded project CA VIAR.All the video sequences comprise human activities in indoor plaza and shopping center observations of individuals and small groups of people.Ground truth was hand-labelled for all sequences2.Fig.7 shows the bounding boxes as well as the centroid,which is the information used for the segmentation.As in the synthetic case,we also generate the statistics of the considered models.The procedure is the same as in the previous case using training sequences.Fig.3(b)shows the clusters of the models.Fig.8shows several activities performed at the shopping center with the time instants of the model switching marked with small red circle.From this experiment,it can be seen that the proposed approach correctly determines the switching times between models.We have tested the proposed approach in more than40trajectories from25movies of about5minutes each.We just present the results of some of those activities in Tables1and2.These Tables show the penalized log-likelihood values(8)of each test sequence.Thefirst table refers to all activities performed in the left-right direction,whilst the second table reports all activities performed in the opposite direction.In thefirst table the classes referring to entering, exiting,passing and browsing are right-upwards,downwards-right,right,right-stop-right respectively,whereas in the second table the classes are left-upwards,downwards-left,left and left-stop-left.It can be observed that the output classifier correctly assigns the activities into the corresponding classes,exhibiting good results as in the previous synthetic examples.6ConclusionsIn this paper we have proposed and tested an algorithm for modelling,segmentation,and classification of human activities in a constrained environment.The proposed approach uses a switched dynamical models to represent the human trajectories.It was illustrated that the time instants are effectively well determined,despite of the significant random perturbations that the trajectory may contain.It is demonstrated that the proposed approach provides good 2The ground truth labelled video sequences is provided at /rbf/CAVIAR/.(a)(b)(c)Figure6:Synthetic activities with different dynamic models(entering,exiting,passing).Figure7:Bounding boxes and centroids of the pedestrians performing activities.results with synthetic and real data obtained in a shopping center.The proposed method is able to effectively recognize instances of the learned activities.The activities studied herein can be interpreted as atomic,in the sense that they are simple pound actions or complex events can be represented as concatenations of the activities studied in this paper.This is one of the issues to be addressed in the future.Acknowledgement:We would like to thank Prof.Jos´e Santos Victor of ISR and the members of CA VIAR project, for providing video data of human activities with the ground truth information.Figure8:Samples of different activities.The large circles are the computed times instants where the model switches: Entering(first column);exiting(second column);browsing(third column).Test trajectoriesClasses E1E2Ex1Ex2P1P2BEntering187.2157.3212.7217.0100.3107.4169.1Exiting401.0340.0116.1102.4104.693.8178.7Passing359.7311.0232.5183.388.890.2147.7Browsing299.1265.6196.5180.0160.7156.098.1Table1:Penalized Log-likelihood of several real activities performed in left-right direction:E-entering,Ex-exiting, P-passing,B-browsing.Test trajectoriesClasses E1E2Ex1Ex2P1P2BEntering116.2115.0337.7358.289.390.9211.7Exiting277.6284.6151.0127.498.696.6297.4Passing210.0224.4350.1362.063.464.7358.4Browsing207.4197.3343.2286.7188.9179.0170.1Table2:Penalized Log-likelihood of several real activities performed in right-left direction:E-entering,Ex-exiting, P-passing,B-browsing.References[1]D.Ayers and M.Shah,“Monitoring Human Behavior from Video Taken in an Office Environment”,Image andVision Computing,vol.19,Issue12,1,pp.833-846,Oct,2001.[2]A.Bobick and J.Davis,“The Recognition of Human Movement using Temporal Templates”,in IEEE Transac-tion on Pattern Analysis and Machine Intelligence,pp.257-267,vol.23,no.3,March2001.[3]J.Davis and M.Shah,“Visual Gesture Recognition”,IEE Proc.Vision,Image and Signal Processing,V ol.141,No.2,pp.101-106,April1994.[4]S.Hongeng and R.Nevatia,“Multi-Agent Event Recognition”,in Proc.of the8th IEEE Int.Conf.on ComputerVision(ICCV’01),pp.84-91,vol.2,2001.[5]M.Isard and A.Blake,“A Mixed-state Condensation Tracker with Automatic Model-switching”,Proc.of the Int.Conf.on Computer Vision,pp.107-112,1998.[6]J.S.Marques and J.M.Lemos,“Optimal and Suboptimal Shape Tracking Based on Switched Dynamic Models”,Image and Vision Computing,pp.539-550,june,2001.[7]N.Johnson and D.Hogg,“Representation and Synthesis of Behaviour using Gaussian Mixtures”,in Image andVision Computing,pp.889-894,vol.20,no12,2002.[8]A.J.Abrantes,J.S.Marques,J.M.Lemos,“Long Term Tracking Using Bayesian Networks”,in Proc.of IEEEInt.Conf.on Image Processing,Rochester,609-612,vol.III,Sept.2002.[9]O.Masoud and N.P.Papanikolopoulos,“A Method for Human Action Recognition”,in Image and Vision Com-puting,pp.729-743,vol.21,no.8,August2003.[10]A.Nagai,Y.Kuno and Y.Suirai,“Surveillance Systems based on Spatio-temporal Information”,Proc.IEEE Int.Conf.Image Processing,pp.593-596,1996.[11]J.C.Nascimento and M.A.T.Figueiredo and J.S.Marques,“Recognition of Human Activities with SpaceDependent Switched Dynamical Models”,Proc.IEEE Int.Conf.Image Processing,September,2005.[12]N.M.Oliver and B.Rosario and A.P.Pentland,“A Bayesian Computer Vision System for Modeling HumanInteractions”,in IEEE Trans.on Pattern Anal.and Machine Intell.,pp.831-843,vol.22,no.8,August2000. [13]T.J.Olson and F.Z.Brill,“Moving Object Detection and Event Recognition for smart Cameras”,Proc.ImageUnderstanding Workshop,pp.159-175,1997.[14]J.Rissanen,“Stochastic Complexity in Statistical Inquiry.”Singapore:World Scientific,1989.[15]M.Rosenblum and Y.Yacoob and L.S.Davis,“Human expression recognition from motion using a radial basisfunction network architecture”,IEEE Trans.Neural Networks,no.7,pp.1121-1138,1996.[16]Y.Yacoob and M.J.Black,“Parameterized Modeling and Recognition of Activities”,in Computer Vision andImage Understanding,pp.232-247,vol.73,no.2,February1999.。