主成分分析计算方法和步骤
主成分分析计算方法和步骤56323

主成分分析计算方法和步骤:在对某一事物或现象进行实证研究时,为了充分反映被研究对象个体之间的差异, 研究者往往要考虑增加测量指标,这样就会增加研究问题的负载程度。
但由于各指标都是对同一问题的反映,会造成信息的重叠,引起变量之间的共线性,因此,在多指标的数据分析中,如何压缩指标个数、压缩后的指标能否充分反映个体之间的差异,成为研究者关心的问题。
而主成分分析法可以很好地解决这一问题。
主成分分析的应用目的可以简单地归结为: 数据的压缩、数据的解释。
它常被用来寻找和判断某种事物或现象的综合指标,并且对综合指标所包含的信息给予适当的解释, 从而更加深刻地揭示事物的内在规律。
主成分分析的基本步骤分为: ①对原始指标进行标准化,以消除变量在数量极或量纲上的影响;②根据标准化后的数据矩阵求出相关系数矩阵R; ③求出R 矩阵的特征根和特征向量; ④确定主成分,结合专业知识对各主成分所蕴含的信息给予适当的解释;⑤合成主成分,得到综合评价值。
结合数据进行分析本题分析的是全国各个省市高校绩效评价,利用全国2014年的相关统计数据(见附录),从相关的指标数据我们无法直接评价我国各省市的高等教育绩效,而通过表5-6的相关系数矩阵,可以看到许多的变量之间的相关性很高。
如:招生人数与教职工人数之间具有较强的相关性,教育投入经费和招生人数也具有较强的相关性,教工人数与本科院校数之间的相关系数最高,到达了0.963,而各组成成分之间的相关性都很高,这也充分说明了主成分分析的必要性。
表5-6 相关系数矩阵本科院校数招生人数教育经费投入相关性师生比0.2790.3290.252重点高校数0.3450.2040.310教工人数0.9630.9540.896本科院校数 1.0000.9380.881招生人数0.938 1.0000.893教育经费投0.8810.893 1.000入师生比重点高校数教工人数相关性师生比 1.000-0.2180.208重点高校数-0.218 1.0000.433教工人数0.2080.433 1.000本科院校数0.2790.3450.963表5-7给出的是各主成分的方差贡献率和累计贡献率,我们选取主成分的标准有两个:第一,特征根大于1,因为,如果特征根小于1,说明该主成分的解释力度太弱,还比不上直接引入一个原始变量的平均解释力度大;第二,方差贡献率大于85%,如果这两个标准不能同时符合要求,则往往是因为选择的指标不合理或者样本容量太小,应继续调整。
主成分分析法pca的流程

主成分分析法pca的流程
主成分分析(PCA)是一种常见的数据降维方法,其主要流程如下:
1. 数据预处理:先对原始数据进行标准化(均值中心化和方差缩放),保证各个维度数据具有可比性。
2. 计算协方差矩阵:通过样本数据求解协方差矩阵,反映各个变量间的线性相关性。
3. 特征值与特征向量计算:对协方差矩阵进行特征值分解或奇异值分解,得到对应的特征值和特征向量。
4. 选择主成分:按照特征值大小排序,选择前k个最大特征值对应的特征向量作为新的坐标轴(主成分)。
5. 数据转换:将原始数据投影到选定的主成分上,实现降维,新坐标系下的数据称为主成分得分。
6. 解释主成分:根据特征向量的结构理解主成分代表的含义,并可能通过累计贡献率评估降维效果。
总之,PCA通过挖掘数据内在结构,将高维数据转换为低维表示,同时保留主要变异信息。
主成分分析的步骤与实施方法

主成分分析的步骤与实施方法主成分分析(Principal Component Analysis,简称PCA)是一种常用的降维数据分析方法,常用于数据预处理和特征提取。
本文将介绍主成分分析的基本步骤以及实施方法,帮助读者了解并应用于实际问题。
1. 数据预处理在进行主成分分析之前,首先需要进行数据预处理。
数据预处理包括数据清洗、归一化等操作,以确保数据的准确性和可靠性。
常见的数据预处理方法有:(1)数据清洗:排除异常值和缺失值,保证数据的完整性和一致性;(2)数据归一化:将数据转化为同一尺度,消除因为数据量纲不同而导致的误差;(3)数据标准化:将数据按照均值为0,方差为1进行线性变换,使得数据服从标准正态分布。
2. 计算协方差矩阵主成分分析的核心是通过计算协方差矩阵来确定数据之间的相关性。
协方差矩阵可以帮助我们找到数据的主要变化方向,进而找到主要成分。
协方差矩阵的计算步骤如下:(1)假设我们有m个n维数据,将其组成m×n的矩阵X;(2)计算X的协方差矩阵C,公式为:C = (X - μ)(X - μ)T / m,其中μ为X的均值向量;(3)计算协方差矩阵C的特征值和特征向量。
3. 计算主成分通过计算协方差矩阵的特征值和特征向量,我们可以得到数据的主成分。
主成分是协方差矩阵的特征向量按对应的特征值从大到小排列后所得到的矩阵。
计算主成分的步骤如下:(1)选择特征值较大的前k个特征向量,其中k为需要降维的维数;(2)将选择出的k个特征向量组成一个投影矩阵P;(3)对原始数据进行降维处理,将原始数据矩阵X与投影矩阵P相乘,得到降维后的数据矩阵Y。
4. 数据重构主成分分析完成后,我们可以通过数据重构来验证主成分的有效性。
重构后的数据尽量保持与原始数据的一致性,以确保降维后的数据仍能保持原有信息的完整性。
数据重构的步骤如下:(1)根据降维后的数据矩阵Y和投影矩阵P,计算重构矩阵X',公式为:X' = YP' + μ,其中P'为投影矩阵的转置;(2)将重构矩阵X'与原始数据矩阵X进行对比,评估主成分提取的效果。
(完整版)主成分分析法的步骤和原理

(一)主成分分析法的基本思想主成分分析(Principal Component Analysis )是利用降维的思想,将多个变量转化为少数几个综合变量(即主成分),其中每个主成分都是原始变量的线性组合,各主成分之间互不相关,从而这些主成分能够反映始变量的绝大部分信息,且所含的信息互不重叠。
[2]采用这种方法可以克服单一的财务指标不能真实反映公司的财务情况的缺点,引进多方面的财务指标,但又将复杂因素归结为几个主成分,使得复杂问题得以简化,同时得到更为科学、准确的财务信息。
(二)主成分分析法代数模型假设用p 个变量来描述研究对象,分别用X 1,X 2…X p 来表示,这p 个变量构成的p 维随机向量为X=(X 1,X 2…X p )t 。
设随机向量X 的均值为μ,协方差矩阵为Σ。
对X 进行线性变化,考虑原始变量的线性组合: Z 1=μ11X 1+μ12X 2+…μ1p X pZ 2=μ21X 1+μ22X 2+…μ2p X p…… …… ……Z p =μp1X 1+μp2X 2+…μpp X p主成分是不相关的线性组合Z 1,Z 2……Z p ,并且Z 1是X 1,X 2…X p 的线性组合中方差最大者,Z 2是与Z 1不相关的线性组合中方差最大者,…,Z p 是与Z 1,Z 2 ……Z p-1都不相关的线性组合中方差最大者。
(三)主成分分析法基本步骤第一步:设估计样本数为n ,选取的财务指标数为p ,则由估计样本的原始数据可得矩阵X=(x ij )m ×p ,其中x ij 表示第i 家上市公司的第j 项财务指标数据。
第二步:为了消除各项财务指标之间在量纲化和数量级上的差别,对指标数据进行标准化,得到标准化矩阵(系统自动生成)。
第三步:根据标准化数据矩阵建立协方差矩阵R ,是反映标准化后的数据之间相关关系密切程度的统计指标,值越大,说明有必要对数据进行主成分分析。
其中,R ij (i ,j=1,2,…,p )为原始变量X i 与X j 的相关系数。
主成分分析法的原理应用及计算步骤

主成分分析法的原理应用及计算步骤1.计算协方差矩阵:首先,我们需要将原始数据进行标准化处理,即使每个特征都有零均值和单位方差。
假设我们有m个n维样本,数据集为X,标准化后的数据集为Z。
那么,计算协方差矩阵的公式如下:Cov(Z) = (1/m) * Z^T * Z其中,Z^T为Z的转置。
2.计算特征向量:通过对协方差矩阵进行特征值分解,可以得到特征值和特征向量。
特征值表示了新坐标系中每个特征的重要性程度,特征向量则表示了数据在新坐标系中的方向。
将协方差矩阵记为C,特征值记为λ1, λ2, ..., λn,特征向量记为v1, v2, ..., vn,那么特征值分解的公式如下:C*v=λ*v计算得到的特征向量按特征值的大小进行排序,从大到小排列。
3.选择主成分:从特征向量中选择与前k个最大特征值对应的特征向量作为主成分,即新坐标系的基向量。
这些主成分可以解释原始数据中大部分的方差。
我们可以通过设定一个阈值或者看特征值与总特征值之和的比例来确定保留的主成分个数。
4.映射数据:对于一个n维的原始数据样本x,通过将其投影到前k个主成分上,可以得到一个k维的新样本,使得新样本的方差最大化。
新样本的计算公式如下:y=W*x其中,y为新样本,W为特征向量矩阵,x为原始数据样本。
PCA的应用:1.数据降维:PCA可以通过主成分的选择,将高维数据降低到低维空间中,减少数据的复杂性和冗余性,提高计算效率。
2.特征提取:PCA可以通过寻找数据中的最相关的特征,提取出主要的信息,从而减小噪声的影响。
3.数据可视化:通过将数据映射到二维或三维空间中,PCA可以帮助我们更好地理解和解释数据。
总结:主成分分析是一种常用的数据降维方法,它通过投影数据到一个新的坐标系中,使得投影后的数据具有最大的方差。
通过计算协方差矩阵和特征向量,我们可以得到主成分,并将原始数据映射到新的坐标系中。
PCA 在数据降维、特征提取和数据可视化等方面有着广泛的应用。
主成分分析(PCA)详解(附带详细公式推导)

主成分分析(PCA)详解(附带详细公式推导)1.假设有一个m维的数据集X,其中每个数据点有n个样本。
需要将其降维到k维,且k<m。
2. 首先需进行数据的中心化,即对每个维度的数据减去该维度的均值,即X' = X - mean(X)。
3.然后计算协方差矩阵C=(1/n)*X'*X'^T,其中X'^T表示X'的转置。
4.对协方差矩阵C进行特征值分解,得到特征值和对应的特征向量。
5.接下来,将特征值按从大到小的顺序排列,选取前k个最大的特征值及其对应的特征向量。
6. 最后,将选取的k个特征向量组成一个投影矩阵W =[e1,e2,...,ek],其中ei表示第i个特征向量。
7.对中心化的数据集进行降维,Y=W*X',其中Y即为降维后的数据。
上述推导过程中,协方差矩阵C的特征值代表了数据的方差,特征向量则代表了数据的主成分。
选取最大的k个特征值和对应的特征向量,即实现了数据的降维。
PCA的应用包括但不限于以下几个方面:1.数据可视化:PCA能够将高维度的数据映射到二维或三维空间,从而方便数据的可视化展示。
2.数据预处理:PCA能够降低数据的维度,从而减少噪声和冗余信息,提升后续模型的精度和效率。
3.特征提取:PCA能够提取数据中最重要的特征,从而辅助后续建模和特征工程。
4.噪声过滤:PCA能够降低数据的维度,从而过滤掉一些无关的噪声信息。
需要注意的是,PCA只能应用于线性数据,并且假设数据的方差和协方差是固定的。
同时,PCA对于数据中非线性关系的捕捉能力较弱,因此在处理非线性数据时,需考虑使用其他非线性降维方法,如核主成分分析(Kernel PCA)等。
综上所述,PCA是一种常用的多变量数据降维技术,在数据分析和机器学习领域有着广泛的应用。
通过线性变换,PCA将高维度的数据投影到低维空间中,从而减少数据的维度,并保留了数据中的主要信息。
主成分分析计算方法和步骤
主成分分析计算方法与步骤:在对某一事物或现象进行实证研究时,为了充分反映被研究对象个体之间得差异, 研究者往往要考虑增加测量指标,这样就会增加研究问题得负载程度。
但由于各指标都就是对同一问题得反映,会造成信息得重叠,引起变量之间得共线性,因此,在多指标得数据分析中,如何压缩指标个数、压缩后得指标能否充分反映个体之间得差异,成为研究者关心得问题。
而主成分分析法可以很好地解决这一问题。
主成分分析得应用目得可以简单地归结为: 数据得压缩、数据得解释。
它常被用来寻找与判断某种事物或现象得综合指标,并且对综合指标所包含得信息给予适当得解释, 从而更加深刻地揭示事物得内在规律。
主成分分析得基本步骤分为: ①对原始指标进行标准化,以消除变量在数量极或量纲上得影响;②根据标准化后得数据矩阵求出相关系数矩阵 R; ③求出 R 矩阵得特征根与特征向量; ④确定主成分,结合专业知识对各主成分所蕴含得信息给予适当得解释;⑤合成主成分,得到综合评价值。
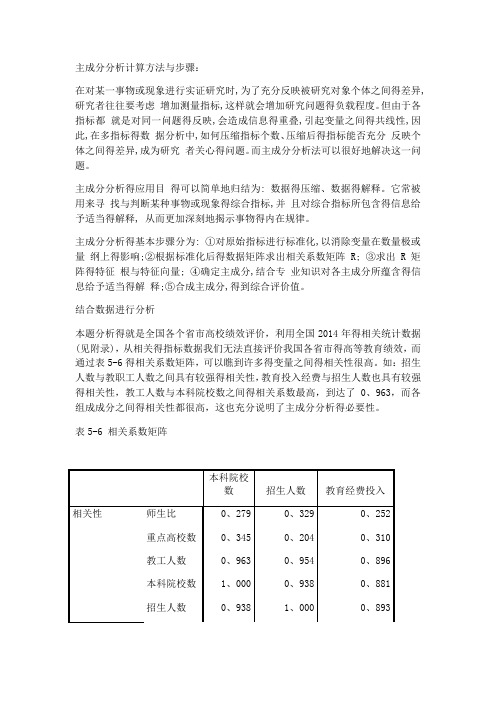
结合数据进行分析本题分析得就是全国各个省市高校绩效评价,利用全国2014年得相关统计数据(见附录),从相关得指标数据我们无法直接评价我国各省市得高等教育绩效,而通过表5-6得相关系数矩阵,可以瞧到许多得变量之间得相关性很高。
如:招生人数与教职工人数之间具有较强得相关性,教育投入经费与招生人数也具有较强得相关性,教工人数与本科院校数之间得相关系数最高,到达了0、963,而各组成成分之间得相关性都很高,这也充分说明了主成分分析得必要性。
表5-6 相关系数矩阵本科院校数招生人数教育经费投入相关性师生比0、279 0、329 0、252重点高校数0、345 0、204 0、310教工人数0、963 0、954 0、896本科院校数1、000 0、938 0、881招生人数0、938 1、000 0、893表5-7给出得就是各主成分得方差贡献率与累计贡献率,我们选取主成分得标准有两个:第一,特征根大于1,因为,如果特征根小于1,说明该主成分得解释力度太弱,还比不上直接引入一个原始变量得平均解释力度大;第二,方差贡献率大于85%,如果这两个标准不能同时符合要求,则往往就是因为选择得指标不合理或者样本容量太小,应继续调整。
主成分分析计算方法和步骤
主成分分析计算方法和步骤:在对某一事物或现象进行实证研究时,为了充分反映被研究对象个体之间的差异, 研究者往往要考虑增加测量指标,这样就会增加研究问题的负载程度。
但由于各指标都是对同一问题的反映,会造成信息的重叠,引起变量之间的共线性,因此,在多指标的数据分析中,如何压缩指标个数、压缩后的指标能否充分反映个体之间的差异,成为研究者关心的问题。
而主成分分析法可以很好地解决这一问题。
主成分分析的应用目的可以简单地归结为: 数据的压缩、数据的解释。
它常被用来寻找和判断某种事物或现象的综合指标,并且对综合指标所包含的信息给予适当的解释, 从而更加深刻地揭示事物的内在规律。
主成分分析的基本步骤分为: ①对原始指标进行标准化,以消除变量在数量极或量纲上的影响;②根据标准化后的数据矩阵求出相关系数矩阵 R; ③求出 R 矩阵的特征根和特征向量; ④确定主成分,结合专业知识对各主成分所蕴含的信息给予适当的解释;⑤合成主成分,得到综合评价值。
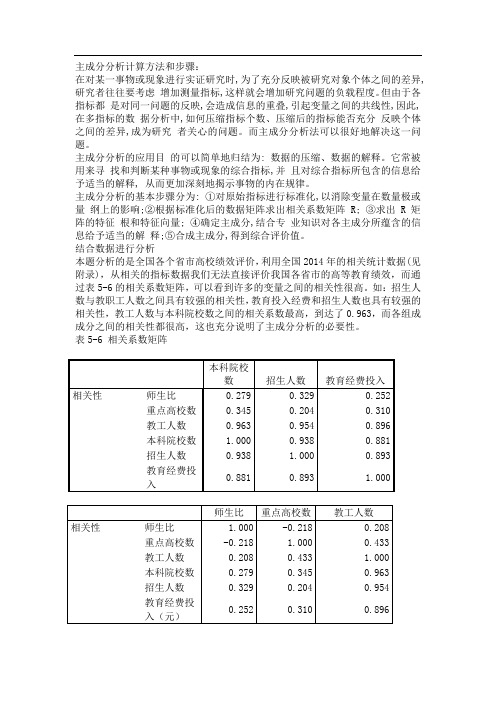
结合数据进行分析本题分析的是全国各个省市高校绩效评价,利用全国2014年的相关统计数据(见附录),从相关的指标数据我们无法直接评价我国各省市的高等教育绩效,而通过表5-6的相关系数矩阵,可以看到许多的变量之间的相关性很高。
如:招生人数与教职工人数之间具有较强的相关性,教育投入经费和招生人数也具有较强的相关性,教工人数与本科院校数之间的相关系数最高,到达了0.963,而各组成成分之间的相关性都很高,这也充分说明了主成分分析的必要性。
表5-6 相关系数矩阵本科院校数招生人数教育经费投入相关性师生比0.279 0.329 0.252重点高校数0.345 0.204 0.310教工人数0.963 0.954 0.896本科院校数 1.000 0.938 0.881招生人数0.938 1.000 0.893教育经费投0.881 0.893 1.000入师生比重点高校数教工人数相关性师生比 1.000 -0.218 0.208重点高校数-0.218 1.000 0.433教工人数0.208 0.433 1.000本科院校数0.279 0.345 0.963招生人数0.329 0.204 0.954教育经费投0.252 0.310 0.896入(元)表5-7给出的是各主成分的方差贡献率和累计贡献率,我们选取主成分的标准有两个:第一,特征根大于1,因为,如果特征根小于1,说明该主成分的解释力度太弱,还比不上直接引入一个原始变量的平均解释力度大;第二,方差贡献率大于85%,如果这两个标准不能同时符合要求,则往往是因为选择的指标不合理或者样本容量太小,应继续调整。
主成分分析的步骤与实施方法

主成分分析的步骤与实施方法主成分分析(Principal Component Analysis,PCA)是一种常用的降维技术,用于将高维数据转化为低维数据,并提取数据中最重要的特征。
本文将介绍主成分分析的步骤和实施方法。
一、主成分分析的步骤主成分分析的步骤通常包括以下几个部分:1. 数据准备首先,需要对数据进行准备工作。
这包括数据清洗、缺失值处理和数据标准化等。
数据清洗是指检查数据中是否存在异常值或者不一致的数据,并进行相应的处理。
缺失值处理是指对数据中的缺失值进行填充或删除,以确保数据的完整性。
数据标准化是指对数据进行归一化处理,消除不同变量之间的量纲差异。
2. 计算协方差矩阵在进行主成分分析之前,需要计算原始数据的协方差矩阵。
协方差矩阵反映了不同变量之间的相关性。
对于给定的数据集,假设有n个变量,那么协方差矩阵的维度为n×n。
3. 特征值分解接下来,对协方差矩阵进行特征值分解。
特征值分解可以得到协方差矩阵的特征值和特征向量。
特征值表示对应特征向量的重要程度,特征向量表示原始变量在新的主成分空间中的权重。
4. 选择主成分在进行主成分分析时,需要选择保留多少个主成分。
一般来说,我们选择特征值较大的前k个主成分,并将其对应的特征向量作为主成分。
选择主成分的主要标准是保留足够的信息量,即尽可能多地保留原始数据的方差。
5. 构建主成分根据所选择的主成分的特征向量,将原始数据转化为新的主成分空间。
这相当于将原始数据投影到主成分所张成的空间中。
二、主成分分析的实施方法主成分分析可以通过各种软件和编程语言来实施。
下面介绍两种常用的实施方法:1. 使用Python实施Python是一种简单易用且功能强大的编程语言,在进行主成分分析时非常方便。
可以使用Python中的科学计算库NumPy和数据分析库pandas来进行主成分分析。
具体步骤如下:(1) 导入所需的库```import numpy as npimport pandas as pdfrom sklearn.decomposition import PCA```(2) 读取数据```data = pd.read_csv('data.csv')```(3) 数据预处理对数据进行清洗、缺失值处理和数据标准化等预处理操作。
主成分分析计算方法和步骤
主成分分析计算方法与步骤:在对某一事物或现象进行实证研究时,为了充分反映被研究对象个体之间的差异, 研究者往往要考虑增加测量指标,这样就会增加研究问题的负载程度。
但由于各指标都就是对同一问题的反映,会造成信息的重叠,引起变量之间的共线性,因此,在多指标的数据分析中,如何压缩指标个数、压缩后的指标能否充分反映个体之间的差异,成为研究者关心的问题。
而主成分分析法可以很好地解决这一问题。
主成分分析的应用目的可以简单地归结为: 数据的压缩、数据的解释。
它常被用来寻找与判断某种事物或现象的综合指标,并且对综合指标所包含的信息给予适当的解释, 从而更加深刻地揭示事物的内在规律。
主成分分析的基本步骤分为: ①对原始指标进行标准化,以消除变量在数量极或量纲上的影响;②根据标准化后的数据矩阵求出相关系数矩阵 R; ③求出 R 矩阵的特征根与特征向量; ④确定主成分,结合专业知识对各主成分所蕴含的信息给予适当的解释;⑤合成主成分,得到综合评价值。
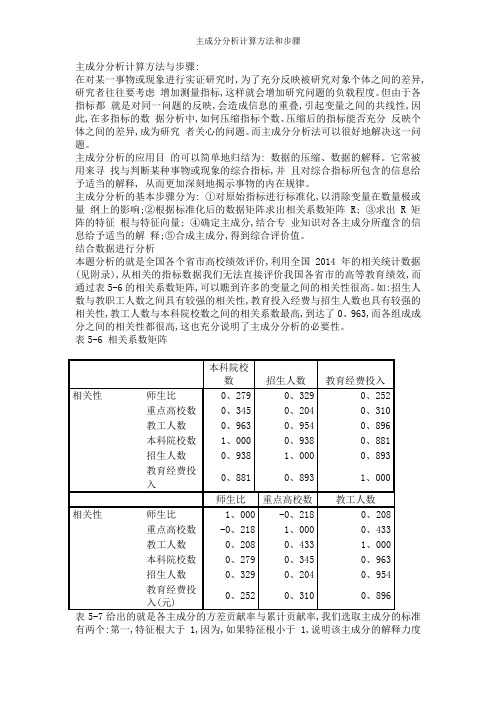
结合数据进行分析本题分析的就是全国各个省市高校绩效评价,利用全国2014年的相关统计数据(见附录),从相关的指标数据我们无法直接评价我国各省市的高等教育绩效,而通过表5-6的相关系数矩阵,可以瞧到许多的变量之间的相关性很高。
如:招生人数与教职工人数之间具有较强的相关性,教育投入经费与招生人数也具有较强的相关性,教工人数与本科院校数之间的相关系数最高,到达了0、963,而各组成成分之间的相关性都很高,这也充分说明了主成分分析的必要性。
表5-6 相关系数矩阵本科院校数招生人数教育经费投入相关性师生比0、279 0、329 0、252重点高校数0、345 0、204 0、310教工人数0、963 0、954 0、896本科院校数1、000 0、938 0、881招生人数0、938 1、000 0、893教育经费投0、881 0、893 1、000入师生比重点高校数教工人数相关性师生比1、000 -0、218 0、208重点高校数-0、218 1、000 0、433教工人数0、208 0、433 1、000本科院校数0、279 0、345 0、963招生人数0、329 0、204 0、954教育经费投0、252 0、310 0、896入(元)表5-7给出的就是各主成分的方差贡献率与累计贡献率,我们选取主成分的标准有两个:第一,特征根大于1,因为,如果特征根小于1,说明该主成分的解释力度太弱,还比不上直接引入一个原始变量的平均解释力度大;第二,方差贡献率大于85%,如果这两个标准不能同时符合要求,则往往就是因为选择的指标不合理或者样本容量太小,应继续调整。
主成分分析计算方法和步骤.docx
主成分分析计算方法和步骤:在对某一事物或现象进行实证研究时,为了充分反映被研究对象个体之间的差异, 研究者往往要考虑增加测量指标,这样就会增加研究问题的负载程度。
但由于各指标都是对同一问题的反映,会造成信息的重叠,引起变量之间的共线性,因此,在多指标的数据分析中,如何压缩指标个数、压缩后的指标能否充分反映个体之间的差异,成为研究者关心的问题。
而主成分分析法可以很好地解决这一问题。
主成分分析的应用目的可以简单地归结为: 数据的压缩、数据的解释。
它常被用来寻找和判断某种事物或现象的综合指标,并且对综合指标所包含的信息给予适当的解释, 从而更加深刻地揭示事物的内在规律。
主成分分析的基本步骤分为: ①对原始指标进行标准化,以消除变量在数量极或量纲上的影响;②根据标准化后的数据矩阵求出相关系数矩阵 R; ③求出 R 矩阵的特征根和特征向量; ④确定主成分,结合专业知识对各主成分所蕴含的信息给予适当的解释;⑤合成主成分,得到综合评价值。
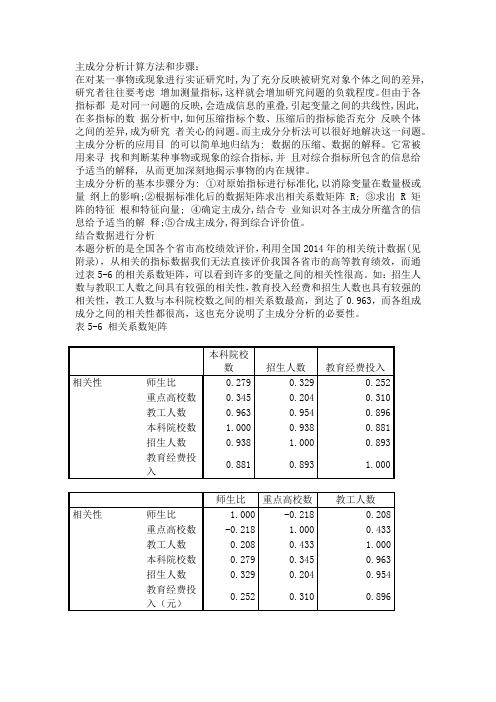
结合数据进行分析本题分析的是全国各个省市高校绩效评价,利用全国2014年的相关统计数据(见附录),从相关的指标数据我们无法直接评价我国各省市的高等教育绩效,而通过表5-6的相关系数矩阵,可以看到许多的变量之间的相关性很高。
如:招生人数与教职工人数之间具有较强的相关性,教育投入经费和招生人数也具有较强的相关性,教工人数与本科院校数之间的相关系数最高,到达了0.963,而各组成成分之间的相关性都很高,这也充分说明了主成分分析的必要性。
表5-6 相关系数矩阵本科院校数招生人数教育经费投入相关性师生比0.279 0.329 0.252重点高校数0.345 0.204 0.310教工人数0.963 0.954 0.896本科院校数 1.000 0.938 0.881招生人数0.938 1.000 0.893教育经费投0.881 0.893 1.000入师生比重点高校数教工人数相关性师生比 1.000 -0.218 0.208重点高校数-0.218 1.000 0.433教工人数0.208 0.433 1.000本科院校数0.279 0.345 0.963招生人数0.329 0.204 0.954教育经费投0.252 0.310 0.896入(元)表5-7给出的是各主成分的方差贡献率和累计贡献率,我们选取主成分的标准有两个:第一,特征根大于1,因为,如果特征根小于1,说明该主成分的解释力度太弱,还比不上直接引入一个原始变量的平均解释力度大;第二,方差贡献率大于85%,如果这两个标准不能同时符合要求,则往往是因为选择的指标不合理或者样本容量太小,应继续调整。
主成分分析法的步骤和原理

(一)主成分分析法的基本思想主成分分析(Principal Component Analysis)是利用降维的思想,将多个变量转化为少数几个综合变量(即主成分),其中每个主成分都是原始变量的线性组合,各主成分之间互不相关,从而这些主成分能够反映始变量的绝大部分信息,且所含的信息互不重叠。
[2]采用这种方法可以克服单一的财务指标不能真实反映公司的财务情况的缺点,引进多方面的财务指标,但又将复杂因素归结为几个主成分,使得复杂问题得以简化,同时得到更为科学、准确的财务信息。
(二)主成分分析法代数模型假设用p个变量来描述研究对象,分别用X1,X2…X p来表示,这p个变量构成的p维随机向量为X=(X1,X2…X p)t。
设随机向量X的均值为μ,协方差矩阵为Σ。
对X进行线性变化,考虑原始变量的线性组合:Z1=μ11X1+μ12X2+…μ1p X pZ2=μ21X1+μ22X2+…μ2p X p………………Z p=μp1X1+μp2X2+…μpp X p主成分是不相关的线性组合Z1,Z2……Z p,并且Z1是X1,X2…X p的线性组合中方差最大者,Z2是与Z1不相关的线性组合中方差最大者,…,Z p是与Z1,Z2……Z p-1都不相关的线性组合中方差最大者。
(三)主成分分析法基本步骤第一步:设估计样本数为n,选取的财务指标数为p,则由估计样本的原始数据可得矩阵X=(x ij)m×p,其中x ij表示第i家上市公司的第j项财务指标数据。
第二步:为了消除各项财务指标之间在量纲化和数量级上的差别,对指标数据进行标准化,得到标准化矩阵(系统自动生成)。
第三步:根据标准化数据矩阵建立协方差矩阵R ,是反映标准化后的数据之间相关关系密切程度的统计指标,值越大,说明有必要对数据进行主成分分析。
其中,R ij (i ,j=1,2,…,p )为原始变量X i 与X j 的相关系数。
R 为实对称矩阵(即R ij =R ji ),只需计算其上三角元素或下三角元素即可,其计算公式为:2211)()()()(j kj nk i kj j kj n k i kj ij X X X X X X X X R -=--=-=∑∑ 第四步:根据协方差矩阵R 求出特征值、主成分贡献率和累计方差贡献率,确定主成分个数。
主成分分析的计算步骤

主成分分析的计算步骤1.数据预处理:首先,对原始数据进行预处理,包括数据清洗、缺失值处理、标准化等。
确保数据的质量以及统一度,以便更好地进行后续计算。
2.计算协方差矩阵:得到预处理后的数据后,计算协方差矩阵。
协方差矩阵可以反映不同变量之间的相关性。
协方差矩阵大小为n×n,其中n 是原始变量的个数。
3.计算特征值和特征向量:通过对协方差矩阵进行特征值分解,得到特征值和对应的特征向量。
特征值是一个标量,表示对应特征向量的重要程度。
特征向量是一个n维列向量,代表主成分的方向。
4.特征值排序:将特征值按照大小降序排列,对应的特征向量也要相应地排序。
一般来说,特征值越大,对应的特征向量表示的主成分的重要性越高。
5.选择主成分数量:根据前面排好序的特征值和特征向量,确定需要选择的主成分数量。
一般可以根据累计贡献率来决定。
累计贡献率是指前k个主成分的特征值之和占总特征值之和的比例,一般要求累计贡献率达到一定的阈值,例如90%以上。
6.构建降维矩阵:根据选择的主成分数量,取对应的特征向量组成一个降维矩阵。
该降维矩阵的大小是n×k,其中n是原始变量的个数,k是选择的主成分数量。
7.数据降维:将原始数据与降维矩阵相乘,得到降维后的数据矩阵。
降维后的数据矩阵的大小是m×k,其中m是样本数量,k是选择的主成分数量。
8.主成分解释:计算降维后的数据矩阵的方差占比和累计方差占比。
方差占比是降维后的数据矩阵的方差占总方差的比例,累计方差占比是指前k个主成分的方差占总方差的比例。
通过方差占比和累计方差占比,可以评估主成分分析的效果和解释程度。
9.主成分得分:将降维后的数据矩阵乘以降维矩阵的转置,得到主成分得分矩阵。
主成分得分矩阵的大小是m×n,其中m是样本数量,n是原始变量的个数。
主成分得分表示每个样本在主成分上的投影值,可以用于后续的机器学习任务和数据可视化。
总结:主成分分析的计算步骤包括数据预处理、计算协方差矩阵、计算特征值和特征向量、特征值排序、选择主成分数量、构建降维矩阵、数据降维、主成分解释、主成分得分。
主成分分析法的原理应用及计算步骤

一、概述在处理信息时,当两个变量之间有一定相关关系时,可以解释为这两个变量反映此课题信息有一定重叠,例如,高校科研状况评价中立项课题数及项目经费、经费支出等之间会存在较高相关性;学生综合评价研究中专业基础课成绩及专业课成绩、获奖学金次数等之间也会存在较高相关性。
而变量之间信息高度重叠和高度相关会给统计方法应用带来许多障碍。
为了解决这些问题,最简单和最直接解决方案是削减变量个数,但这必然又会导致信息丢失和信息不完整等问题产生。
为此,人们希望探索一种更为有效解决方法,它既能大大减少参及数据建模变量个数,同时也不会造成信息大量丢失。
主成分分析正式这样一种能够有效降低变量维数,并已得到广泛应用分析方法。
主成分分析以最少信息丢失为前提,将众多原有变量综合成较少几个综合指标,通常综合指标(主成分)有以下几个特点:主成分个数远远少于原有变量个数原有变量综合成少数几个因子之后,因子将可以替代原有变量参及数据建模,这将大大减少分析过程中计算工作量。
主成分能够反映原有变量绝大部分信息因子并不是原有变量简单取舍,而是原有变量重组后结果,因此不会造成原有变量信息大量丢失,并能够代表原有变量绝大部分信息。
主成分之间应该互不相关通过主成分分析得出新综合指标(主成分)之间互不相关,因子参及数据建模能够有效地解决变量信息重叠、多重共线性等给分析应用带来诸多问题。
主成分具有命名解释性总之,主成分分析法是研究如何以最少信息丢失将众多原有变量浓缩成少数几个因子,如何使因子具有一定命名解释性多元统计分析方法。
二、基本原理主成分分析是数学上对数据降维一种方法。
其基本思想是设法将原来众多具有一定相关性指标X1,X2,…,XP (比如p 个指标),重新组合成一组较少个数互不相关综合指标Fm 来代替原来指标。
那么综合指标应该如何去提取,使其既能最大程度反映原变量Xp 所代表信息,又能保证新指标之间保持相互无关(信息不重叠)。
设F1表示原变量第一个线性组合所形成主成分指标,即11112121...p pF a X a X a X =+++,由数学知识可知,每一个主成分所提取信息量可用其方差来度量,其方差Var(F1)越大,表示F1包含信息越多。
主成分分析计算方法和步骤

主成分分析计算方法和步骤:在对某一事物或现象进行实证研究时,为了充分反映被研究对象个体之间的差异, 研究者往往要考虑增加测量指标,这样就会增加研究问题的负载程度。
但由于各指标都是对同一问题的反映,会造成信息的重叠,引起变量之间的共线性,因此,在多指标的数据分析中,如何压缩指标个数、压缩后的指标能否充分反映个体之间的差异,成为研究者关心的问题。
而主成分分析法可以很好地解决这一问题。
主成分分析的应用目的可以简单地归结为: 数据的压缩、数据的解释。
它常被用来寻找和判断某种事物或现象的综合指标,并且对综合指标所包含的信息给予适当的解释, 从而更加深刻地揭示事物的内在规律。
主成分分析的基本步骤分为: ①对原始指标进行标准化,以消除变量在数量极或量纲上的影响;②根据标准化后的数据矩阵求出相关系数矩阵 R; ③求出 R 矩阵的特征根和特征向量;④确定主成分,结合专业知识对各主成分所蕴含的信息给予适当的解释;⑤合成主成分,得到综合评价值。
结合数据进行分析本题分析的是全国各个省市高校绩效评价,利用全国2014年的相关统计数据(见附录),从相关的指标数据我们无法直接评价我国各省市的高等教育绩效,而通过表5-6的相关系数矩阵,可以看到许多的变量之间的相关性很高。
如:招生人数与教职工人数之间具有较强的相关性,教育投入经费和招生人数也具有较强的相关性,教工人数与本科院校数之间的相关系数最高,到达了0.963,而各组成成分之间的相关性都很高,这也充分说明了主成分分析的必要性。
表5-6 相关系数矩阵本科院校数招生人数教育经费投入相关性师生比0.279 0.329 0.252重点高校数0.345 0.204 0.310教工人数0.963 0.954 0.896本科院校数 1.000 0.938 0.881招生人数0.938 1.000 0.893教育经费投0.881 0.893 1.000入师生比重点高校数教工人数相关性师生比 1.000 -0.218 0.208重点高校数-0.218 1.000 0.433教工人数0.208 0.433 1.000本科院校数0.279 0.345 0.963招生人数0.329 0.204 0.954教育经费投0.252 0.310 0.896入(元)表5-7给出的是各主成分的方差贡献率和累计贡献率,我们选取主成分的标准有两个:第一,特征根大于1,因为,如果特征根小于1,说明该主成分的解释力度太弱,还比不上直接引入一个原始变量的平均解释力度大;第二,方差贡献率大于85%,如果这两个标准不能同时符合要求,则往往是因为选择的指标不合理或者样本容量太小,应继续调整。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
主成分分析计算方法和步骤:
在对某一事物或现象进行实证研究时,为了充分反映被研究对象个体之间的差异, 研究者往往要考虑增加测量指标,这样就会增加研究问题的负载程度。
但由于各指标都是对同一问题的反映,会造成信息的重叠,引起变量之间的共线性,因此,在多指标的数据分析中,如何压缩指标个数、压缩后的指标能否充分反映个体之间的差异,成为研究者关心的问题。
而主成分分析法可以很好地解决这一问题。
主成分分析的应用目的可以简单地归结为: 数据的压缩、数据的解释。
它常被用来寻找和判断某种事物或现象的综合指标,并且对综合指标所包含的信息给予适当的解释, 从而更加深刻地揭示事物的内在规律。
主成分分析的基本步骤分为: ①对原始指标进行标准化,以消除变量在数量极或量纲上的影响;②根据标准化后的数据矩阵求出相关系数矩阵 R; ③求出 R 矩阵的特征根和特征向量; ④确定主成分,结合专业知识对各主成分所蕴含的信息给予适当的解释;⑤合成主成分,得到综合评价值。
结合数据进行分析
本题分析的是全国各个省市高校绩效评价,利用全国2014年的相关统计数据(见附录),从相关的指标数据我们无法直接评价我国各省市的高等教育绩效,而通过表5-6的相关系数矩阵,可以看到许多的变量之间的相关性很高。
如:招生人数与教职工人数之间具有较强的相关性,教育投入经费和招生人数也具有较强的相关性,教工人数与本科院校数之间的相关系数最高,到达了0.963,而各组成成分之间的相关性都很高,这也充分说明了主成分分析的必要性。
表5-6 相关系数矩阵
本科院校
数招生人数教育经费投入
相关性师生比0.279 0.329 0.252
重点高校数0.345 0.204 0.310
教工人数0.963 0.954 0.896
本科院校数 1.000 0.938 0.881
招生人数0.938 1.000 0.893
教育经费投
0.881 0.893 1.000
入
师生比重点高校数教工人数
相关性师生比 1.000 -0.218 0.208
重点高校数-0.218 1.000 0.433
教工人数0.208 0.433 1.000
本科院校数0.279 0.345 0.963
招生人数0.329 0.204 0.954
教育经费投
0.252 0.310 0.896
入(元)
表5-7给出的是各主成分的方差贡献率和累计贡献率,我们选取主成分的标准有两个:第一,特征根大于1,因为,如果特征根小于1,说明该主成分的解释力度太弱,还比不上直接引入一个原始变量的平均解释力度大;第二,方差贡献率大于85%,如果这两个标准不能同时符合要求,则往往是因为选择的指标不合理或者样本容量太小,应继续调整。
表5-7还显示,只有前2个特征根大于1,因此SPSS 只提取了前两个主成分,而这两个主成分的方差贡献率达到了87.081%,因此选取前两个主成分已经能够很好地描述我国高等教育地区现状。
可以看出,标准化后的第一主成分( 简称1F ) 对所有变量都有载荷,且载荷绝对值几乎都在0.7以上, 因此可以说第一主成分是对人口结构的度量,代表了一个地区人口结构状况,可以称之为“综合因子”。
在综合因子中,平均每户人口,农业与非农业人口比例, 人口的自然增长率比重即 人口自然增长各指标具有较强的作用,人与经济等其他指标所起的作用次之,男女比例也起一定作用。
第二主成分( 简称 2F ) 对重点高校数和教工人数具有负载荷,其他变量具有正载荷,并且除 师生比和重点高校数载荷绝对值均小于0.2,有的甚至 接近于 0.1。
因此,第二个主成分只是汇集了第一主成分遗漏的部分信息,我们称之为“辅助 因子”。
表5-8主成分矩阵
成分
1F 2F 师生比
0.317 0.799 重点高校数
0.396 -0.759 教工人数
0.984 -0.095 本科院校数
0.973 0.005 招生人数
0.964 0.131 教育经费投
入
0.939 0.011
表5-9 主成分评分系数矩阵
成分
1F 2F 师生比
.079 .643 重点高校数
.099 -.612 教工人数
.247 -.077 本科院校数
.244 .004 招生人数
.242 .106 教育经费投
入
.236 .009
根据表5-9可以得到各主成分的表达式 1123456=0.0790.0990.2470.2440.2420.236F x x x x x x +++++
21234560.6430.6120.0770.0040.1060.009F x x x x x x =--+++
把变量分别代入以上表达式,可以得出1F 和2F 两个主成分得分,但单独一个主成分不能很好地评价十个地区人口结构的情况,因此需要按照各主成分对应的
方差贡献率为权数计算综合统计F ,(120.66390.206910.87081
F F F +=)
主成分分析法的优点:
1、 可消除评价指标之间的相关影响 因为主成分分析在对原指标变量进行变换后形成了彼此相互独立的主成分,而且实践证明指标之间相关程度越高,主成分分析效果越好。
2、 可减少指标选择的工作量 对于其它评价方法,由于难以消除评价指标间的相关影响,所以选择指标时要花费不少精力,而主成分分析由于可以消除这种相关影响,所以在指标选择上相对容易些。
3、 当评级指标较多时还可以在保留绝大部分信息的情况下用少数几个综合指标代替原指 标进行分析 主成分分析中各主成分是按方差大小依次排列顺序的,在分析问题时,可以舍弃一部分主成分,只取前后方差较大的几个主成分来代表原变
量,从而减少了计算工作量。
4、 在综合评价函数中,各主成分的权数为其贡献率,它反映了该主成分包含原始数据的信 息量占全部信息量的比重,这样确定权数是客观的、合理的,它克服了某些评价方法中认为确定权数的缺陷。
5、 这种方法的计算比较规范,便于在计算机上实现,还可以利用专门的软件
主成分分析法的缺点:
1、在主成分分析中,我们首先应保证所提取的前几个主成分的累计贡献率达到一个较高的水平(即变量降维后的信息量须保持在一个较高水平上),其次对这些被提取的主成分必须都能够给出符合实际背景和意义的解释(否则主成分将空有信息量而无实际含义)。
2、主成分的解释其含义一般多少带有点模糊性,不像原始变量的含义那么清楚、确切,这是变量降维过程中不得不付出的代价。
因此,提取的主成分个数m通常应明显小于原始变量个数p(除非p本身较小),否则维数降低的“利”可能抵不过主成分含义不如原始变量清楚的“弊”。
欢迎您的下载,
资料仅供参考!
致力为企业和个人提供合同协议,策划案计划书,学习资料等
等
打造全网一站式需求。