Abstract Composing Software Systems from Adaptable Software Components WPI-CS-TR-97-9
ABSTRACT UniTherapy Software Design and Hardware Tools of Teletherapy

UniTherapy: Software Design and Hardware Tools of TeletherapyXin Feng, Christopher Ellsworth, Laura Johnson, Jack M. WintersDepartment of Biomedical Engineering, Marquette University, Milwaukee, WI 53233ABSTRACTThis paper presents the design and implementation of Unitherapy, a platform utilizing mass-marketed force-reflecting joysticks and other input devices to provide interactive upper limb assessment and therapy. Included among the input devices is the TheraJoy, a larger version of a remodeled joystick that includes additional motors, and operation in both horizontal and vertical modes. UniTherapy includes a Patient Interface (PI) and Local Practitioner Interface (LPI) /TelePractitioner Interface (TI), with assistive and accessibility features. This software suite includes a number of control modes and assessment protocols, all aimed at making Computer-Assisted Motivating Rehabilitation (CAMR) techniques more viable for home-based upper limb neurorehabilitation with teleassessment capabilities.KEYWORDS: Telerehabilitation, input devices, neurorehabilitation, impedance control, joysticksBACKGROUNDThe prevalence of stroke in American society is increasing, and over half of those who survive have arm impairment. Clinical trials with upper limb “rehabilitators” developed by several groups have provided evidence of improvement in the subjects’ motor recovery of performance (1,2). However, with the dramatic reduction of inpatient rehabilitation length of stay following stroke, as well as inadequately supported self-therapy protocols for outpatients, it is now critical to develop cost-effective, easily used and scientifically-validated interventions (2,3). There is also evidence that carefully-designed computer-assisted home-based rehabilitation programs can work (1, 4), and that telerehabilitation-based therapeutic interventions can be effective (5). This project builds on other efforts at web-based therapy (6), and targets software development for Computer-Assisted Motivating Rehabilitation (CAMR) technologies (1) intended specifically for individuals with stroke-induced disability.METHODTo maximize input device connectivity within the Windows environment, we use Microsoft’s DirectX SDK, a library of multimedia development tools that is now used widely in the PC gaming industry. Coding is mostly in C#, within the Visual Studio .Net programming environment. Input devices can be connected to a single PC or multiple PCs. UniTherapy software (see Figure 1) supports multiple platforms, which include desktop, laptop, tablet PC and PDA touchscreen pointers (PocketPC).An infrastructure between PI and LPI/TI is successfully implemented. PI supports force-reflecting joysticks, which are used as upper limb rehabilitators. LPI/TI supports a variety of interfaces, which range from joysticks to touch screen pointers on a mobile device. Both PI and TI support a network connection. The local practitioner/telepractitioner can change the patient’s force-field and rehabilitator impedance settings. Wireless connectivity (WLAN IEEE 802.11 or Bluetooth) is also supported, as is a simple voice-control mode. It also includes graphics tools for displaying targets and signals in various forms.Four modes of robot assistance are defined; fine-tuning these modes remains an ongoing research and development activity: (1) Bi-manual mode: The subject at the PI uses two force-reflecting joysticks together, with the non-impaired arm able to assist and “feel” the impaired arm. (2) Assessment mode:The subject at the PI completes goal-directed tracking tasks intended to evaluate neuromotor performance, with the practitioner able to selectively observe and record patient’s performance data and change control settings. (3) Passive training mode: The subject at PI uses one force-reflecting joystick with his impaired arm, with a predefined therapy program prescribed for the joystick that provides automated therapy (under supervision by practitioner). (4) Interactive control mode: Telepractitioner participates in therapy by cooperative assistance or resistance with the subject during goal-directed computer-assisted therapy.Performance data is displayed in real-time, with additional approaches for viewing data available afterward for both patients and practitioners to observe, including through telerehabilitation. Accessible features are to be integrated into the design. One example, already implemented, is the use of voice control for the force-reflecting joystick. Also, the user can take advantage of embedded mouse accessibility features (e.g., to adjust the mouse pointer’s speed).In addition to use of standard commercial computer input device, our group has designed a larger, customized device called the TheraJoy (7). This device extends a commercial mass-market force-reflecting joystick so that it is applicable to arm movements that include the shoulder. The joystick shaft and handle were lengthened to roughly 1 meter to accommodate a larger range of motion, with a telescoping component allowing shorter or longer lengths. Springs were added to create a mild potential energy field that more than compensates for a slight “inverse pendulum” linkage effect in what are nearly horizontal plane movements (Figure 2, left), and thus the device automatically returns to a centered resting position. In a second-generation version, linear motors were added, controlled through the parallel port, which added a user-centered potential energy field effect that could move within the user’s workspace. Also, an arm attachment, first designed with a three-dimensional mechanical modeling package, has been added to convert this motion into the vertical plane as well (Figure 2, right). Kinematic mapping between the new hand interface and the original joystick has been accounted for through the use of a combination of sliding and pin joints. An additional variable spring has been added from the joystick to the fixed post to allow the device to be tuned to remain at its centered “resting” position with the addition of telescoping extension or for persons who need “anti-gravity” assistance to hold up their arm. The user may also adjust the handle grip angle for ease of use.RESULTS AND DISCUSSIONWhile our primary focus has been on force-reflecting joysticks (of which the TheraJoy is one example), we now can access any Windows USB “plug and play” device that interfaces to the joystick and mouse ports, as well as pointing devices on PocketPC devices and certain technologies interfacing through the parallel port. With basic controller settings, the unloaded joystick at PI can be made to follow the position of TI closely. Further work is needed to refine impedance controller modes. Software interface windows have been customized for both PI and TI, with the telepractitioner terminal having more features and the ability to change options for the “patient/client” terminal. By using forces, we have taken advantage of DirectX capabilities to implement “stiffness,” “dashpot” and “inertia” modes for each terminal device, and can additionally pass forces that depend on the kinematics of the initial device.A variation of this software has been used in a study involving six subjects with varying degrees of stroke-induced hemiparesis that were first assessed by several standard neurorehabilitation assessment instruments. The assessment tasks started with systematic marker tracking to identify the subject’s arm workspace. This was repeated with different “force assist” settings for subjects lacking a full range. In this way subsequent tracking tasks could be adjusted so that targets didn’t move into regions that were impossible for the subject. This study focused on usability and performance for a suite of two-dimensional tracking tasks. Performance metrics were quite similar to those used for Java Therapy (6),such as movement times and path errors were gathered for a protocol of tasks. Subjects also completed a questionnaire, and were found to be quite enthusiastic about the potential of the TheraJoy technology.In summary, a basic software infrastructure for a low-cost rehabilitator platform has been successfully implemented. Further work is necessary to provide interactive assessment and therapy. UniTherapy provides a universal interface for all DirectX-compliant joysticks and pointing devices, and other rehabilitators or wireless sensors could integrate into this platform seamlessly.REFERENCES1.Bach y Rita P, Wood S, Leder R, Paredes O, Bahr D, Bach-y-Rita EW, Murillo N. (2002) Computerassisted motivating rehabilitation for institutional, home, and educational late stroke programs. Top Stroke Rehabil. 8(4):1–10.2.Reinkensmeyer D, Lum P, Winters JM. (2001) Emerging Technologies for Improving Access toMovement Therapy following Neurologic Injury. In Emerging and Accessible Telecommunications, Information and Healthcare Technologies, ed. JM Winters C Robinson, R Simpson, G Vanderheiden, Arlington: RESNA Press.3.Winters, J.M., Wang, Y. and Winters, J.M. (2003) “Wearable Sensors and Telerehabilitation:Integrating Intelligent Telerehabilitation Assistants With a Model for Optimizing Home Therapy,”IEEE/EMBS Magazine, Special Issue on Wearable Medical Techn., 22: 56-65.4.Widén-Holmqvist L, von Koch L, Kostulas V, Holm M, Widsell G, Tegle RH, Johansson K, AlmazanJ, & de Pedro Cuesta J. (1998). A randomized controlled trial of rehabilitation at home after stroke in south-west Stockholm. Stroke, 29, 591-597.5.Rosen MJ, Lauderdale D, Winters JM. (2002) Summary of the State of the Science Conference onTelerehabilitation, in Emerging and Accessible Telecommunications, Information and HealthTechnologies, ed,JM Winters, C. Robinson, R. Simpson, G. Vanderheiden. Chapter 18, pp. 220-245, Arlington: RESNA Press6.Reinkensmeyer, D.J., Pang, C.R., Nessler, C.A., Painter, C.C. (2002) Web-based telerehabilitation forthe upper-extremity after stroke, IEEE Trans Neural Science & Rehabil. Engng., 10: 102-108.7.Ellsworth C. and Winters JM. (2003) An Innovative System to Enhance Upper-Extremity StrokeRehabilitation, Proc. IEEE/EMBS, 4 p, Cancun, IEEE Press.ACKNOWLEDGMENTSThis work is supported in part by the Falk Medical Trust Foundation, Rehabilitation Engienering Research Center on Accessible Medical Instrumentation H133E020729, and the Rehabilitation Engineering Research Center on Telerahabilitation H133E99007.Author Contact Information:Xin Feng, MS, Marquette Univeristy, Biomedical Eng. Dept, 1515W, Wisconsin Ave, WI, 53233 EMAIL: xinfeng@Graphics PageFigure 1 UniTherapy ArchitectureIt shows the upperlimb movement information at TI and PI; it also allows practitioner to set controller settings on TI and PI.Figure 2: TheraJoy TechnologyLeft: Photograph showing how technology builds around a low-cost ($80) commercial force-reflecting joystick. Top right: Photograph showing TheraJoy with vertical extension. Bottom right: simulation with 3D mechanical model (using Unigraphics).。
计算机基础双语练习题

1. A handheld computer is essentially a PDA enhanced with features such as removable storage,e-mail, Web access, voice communications, built-in camera, and GPS. ______A True2.It is important to turn on all peripheral devices before you turn on the system unit. ______A True3. A screen saver will be displayed on a computer monitor after a specified period of inactivityon your computer. ______A True4.Windows allows you to select a different screen saver, but you cannot change the wait timebefore a screen saver is displayed. ______B Falseputer scientists have proposed that the term kilobyte be used to refer to 1024 bytes.______A True6.Icons on the Windows Taskbar require a double-click to start the associated program. ______B False7.Which of the following is considered a good tip to use when selecting a secure password?_________A Use a password that is eight characters or more8.To turn on a desktop computer, you need to press the _________.C Power button for the system unit and Power button for the monitor9.All of the following are peripheral devices EXCEPT a(n) _________.C System unit10.During the Windows "boot process"the computer_______D All of the above11.When a computer is in "sleep"mode it_______.C Conserves power by not turning off the monitor or disk drives12.Screen savers were originally designed to_______.D Prevent an image from being permanently “burned” onto the screen13.To clear a screen saver, you would_______.D Move the mouse and Press any key14.The typing keys on a computer keyboard include the ______.D All of the above15.The ______ key deletes one character to the left of the "insertion point"that marks yourplace on the screen.B Backspace16.The ______ key deletes characters to the right of the "insertion point"that marks yourplace on the screen.D Delete17.The ______ provides a calculator-style keypad for efficiently entering numbers.D Numeric keypad18.The ______ key captures the image on the screen and stores it in memory.A PrtSc19.Technologies used to equip devices with location awareness include ______D All of the above20.The _____ system has only two digits: 0 and 1.A binary21.The Windows desktop contains small pictures called________, which represent hardwaredevices, programs, and data files.C Icons22.By pressing the key combination _______, you can close a program that has stoppedresponding.C Ctrl, Alt, Del23.The reset button performs a(n) ________by reinitiating(重启) your Windows desktopB Hard boot(硬启动)24.Most cultures use the decimal number system because_____.A People started counting on ten fingers25.In a(n)______number system, such as the binary number system or the decimal numbersystem, the value of a digit is determined by its position in relation to other digits.C Positional26.When you add 1+1 in the binary number system, the answer is _____.C 1027.When you counting in binary, the next number after 101 is _____.B 11028.The place values for the binary number system are ______.A 32,16,8,4,2,129.Binary digits are also called ______.A Bits30.The binary digits 0 and 1 can correspond to the “on ” and “off” states of ______ when data isheld in memory.A Capacitors(电容)31.The binary 0 and 1 can correspond to the negatively and positively charged magnetic particlesthat ______.B Store data on diske paper and pencil to convert the binary number 1111000 to its decimal equivalent. Youanswer is _____.B 120e paper and pencil to convert the binary number 101010 to its decimal equivalent. Youanswer is _____.C 42e paper and pencil to convert the binary number 11101 to its decimal equivalent. Youanswer is _______.B 29D 567e paper and pencil to convert the binary number 11000111 to its decimal equivalent. Youanswer is _____.A 199e paper and pencil to convert the binary number 00001111 to its decimal equivalent. YouA 15Use paper and pencil to convert the decimal number 84 to its binary equivalent. You answer is ______.C 01010100e paper and pencil to convert the decimal number 21 to its binary equivalent. You answer is_____.C 00010101e paper and pencil to convert the decimal number 60 to its binary equivalent. You answer is_____.C 00111100e paper and pencil to convert the decimal number 137 to its binary equivalent. You answeris _____.C 10001001e paper and pencil to convert the decimal number 247 to its binary equivalent. You answeris _____.A 1111011141.______ supplies an accessory program called Calculator that can be used to convert decimalto binary and binary to decimal.C The Windows operating system42.The _____ view helps you convert binary numbers to decimal numbers and decimal numbersto binary numbers.D Scientific1.Typically, today’s microprocessors are housed in a PGA(pin grid array) chip package. ______A True2.Floppy disks are also considered hard disks because they have a “hard’ or rigid plastic case.______A True3.Peripheral devices can be added to a computer system to enhance the system’s functionality.______A True4.Pointing sticks and trackpads(触摸板) are typically supplied with notebook computers to saveyou from having to carry a mouse as an extra component. ______A True5.The term_______refers to the specifications of the components that are installed in a computersystem.D System configuration(系统配置)6.The System Information utility is able to identify a computer’s microprocessorbecause______.B A microprocessor contains a CPUID(CPU的标识符)that can be accessed by theSystem Information utility7.“Physical Memory”(物理内存)refers to _____.B RAM8.You can measure processor speed, disk access speed, 3D graphics capabilities, and more usingB Benchmark test(标准检查)9. A benchmark test can be appropriately used for all of the following EXCEPT _______.C To change the performance of a particular computer component10.If you would like an overall picture of how well your computer will run application software,you’ll get the best data by looking at the results of a(n)_______.A Application-based benchmark test11.________ tests are typically used to gauge(测量) microprocessor performance.C Synthetic12.Because microprocessor manufacturers have found ways to tailor their products to excel at theoperations measured by benchmark tests, ______.A The results of a single benchmark test may not provide an accurate picture of overallperformance13.Microprocessors work with two kinds of numbers, _______ and _______, so it is importantfor a processor benchmark to measure processing speed for both types of numbers.C Integer, floating point14.A computer creates _______ by rendering a surface over a wireframe(线框).C Objects that appear to be three-dimensional15.A(n) _______ is one screenful of data or its equivalent storage space.B Frame16.Fast frame rates are important for displaying _______.A Smooth video and animations17.If you are interested in the speed of your computer in accessing Web pages and e-mail, youshould run ______.A A bandwidth test18.There are three types of storage technologies commonly used for personal computers_______,optical, and solid state.B Magnetic19.A personal computer display system consists of ______D A graphics card and A display device20._______ mode is a limited version of Windows that allows you to use your mouse, monitor,and keyboard, but no other peripheral devices.B Safeually all the files for downloaded software are zipped to consolidate them into one largefile. ______A True2.Presentation software assists you with composing, editing, designing, printing, andelectronically publishing document. ______B False3.It is good practice to scan downloaded filled for viruses before installing them. ______A True4._______ software is an example of utility software.B Security5.All the files needed for new software are _______ to consolidate them into one large file.6.On PCs, executable programs are stored in files with a(n) _______ extension.A .exe7.Both open source and _______ can be copied an unlimited number of times, distributed forfree, sold, and modified.B freeware1.When using Windows, you cannot use a reserved word, such as Aux, as a file name. ______A True2.Software applications, such as word processing or graphics software, do not allow you torename or delete files. ______B False3.In Windows Explorer, you can work with only one file or folder at a time. ______B False4.You can use spaces in file names. ______A True5.The earliest user interface was a command-line interface that required users to typememorized commands to run programs and accomplish tasks. ______A True6.Desktop operating systems typically are designed to accommodate a single user, but also mayprovide networking capability. ______A True7.The plus-sign icon in Windows Explorer can be used to collapse a device or folder to hidelevels of the hierarchy. ______B False8.Linux may be used as a desktop operating system. ______A True9.The main hard disk drive on a PC is usually referred to as “drive C”. ________A True10.Which of the following is responsible for allocating specific areas of memory for eachprogram running on your computer? _______B The operating system11.If you want to rename a file that you are currently editing in Microsoft Word, which is thebest command to use? _______B Save As12.Which of the following cannot be done through the “Save As” dialog box? ______D None of the above13.System Restore(系统还原)can be accessed from the Start menu by choosing _______ andthen selecting System Tools.B Accessories(附件)14.Which of the following describes an interface that uses menus and icons that you canmanipulate by pointing and clicking with a mouse? _______B A graphical user interface15.A(n) ______ operating system provides communications and routing services that allowcomputers to share data, programs, and peripheral devices.1.In a client/server network, the server is the most important resource. ____A True2.To install a Wi-Fi network, it is necessary to run wires and cables between network devices.____B False3.The main advantage of wireless networks is speed. ____B False4.Wireless networks are more secure than wired networks. ____B False5.To access shared data on other workstations, you can use My Computer to access sharedresources under the _________ folder.C. My Network Places。
英语作文关于职业爱好介绍

英语作文关于职业爱好介绍英文:As for my career, I am currently working as a software engineer in a technology company. I have always been passionate about technology and computer programming since I was young. I enjoy the process of solving complex problems and creating innovative solutions through coding. In my job, I have the opportunity to work on various projects, from developing mobile applications to designing software systems. One of the most rewarding aspects of my job is seeing the impact of my work, as the software I develop can improve efficiency and productivity for businesses and individuals.In addition to my career, I also have a strong interest in photography. I find joy in capturing beautiful moments and expressing my creativity through photography. Whetherit's a stunning landscape or a candid portrait, I love the process of composing the perfect shot and editing theimages to bring out their full potential. Photography allows me to explore different perspectives and showcase the beauty of the world through my lens.中文:至于我的职业,我目前在一家科技公司担任软件工程师。
模糊逻辑系统的C 语言实现方法

模糊逻辑系统的C语言实现方法贺维,江汉红,王海峰,张朝亮(武汉海军工程大学湖北武汉 430033)摘要:本文首先介绍了三种专门用于模糊逻辑控制系统设计的软件系统。
详细地介绍了利用软件进行模糊逻辑控制系统设计的基本原理以及模糊控制器的软件程序设计方法。
实验表明,模糊逻辑系统的C语言实现方法是完全可行的,并且能够大大减少工作量。
关键词:模糊逻辑C语言C Language Realize Method of Fuzzy Logic SystemHE-wei JIANG Han-hong WANG Hai-feng ZHANG Chao-liang(Naval University of Engineering, Wuhan 430033, China)Abstract: This paper presents three special software systems for the the design of hardware circuit of Fuzzy Logic control system. The paper introduced the composing and working principle in detail . The way of designing and programming of Fuzzy Logic control system is also presented in detail in the paper. In the end the results of experiment shows that C Language realize method is completely viable,and can reduce lots of workload.Key words: Fuzzy Control C Language1.引言对于模糊控制的实现是模糊控制在实际应用中的一个重要环节。
计算机操作系统英文论文

Introduction to the operating system of the new technology Abstract:the Operating System (Operating System, referred to as OS) is an important part of a computer System is an important part of the System software, it is responsible for managing the hardware and software resources of the computer System and the working process of the entire computer coordination between System components, systems and between users and the relationship between the user and the user. With the appearance of new technology of the operating system functions on the rise. Operating system as a standard suite must satisfy the needs of users as much as possible, so the system is expanding, function of increasing, and gradually formed from the development tools to system tools and applications of a platform environment. To meet the needs of users. In this paper, in view of the operating system in the core position in the development of computer and technological change has made an analysis of the function of computer operating system, development and classification of simple analysis and elaborationKey words: computer operating system, development,new technology Operating system is to manage all the computer system hardware resources include software and data resources; Control program is running; Improve the man-machine interface; Provide support for other application software, etc., all the computer system resourcesto maximize the role, to provide users with convenient, efficient, friendly service interface.The operating system is a management computer hardware and software resources program, is also the kernel of the computer system and the cornerstone. Operating system have such as management and configuration memory, decided to system resources supply and demand of priorities, control input and output devices, file system and other basic network operation and management affairs. Operating system is to manage all the computer system hardware resources include software and data resources; Control program is running; Improve the man-machine interface; Provide support for other application software, etc., all the computer system resources to maximize the role, to provide users with convenient, efficient, friendly service interface. Operating system is a huge management control procedures, including roughly five aspects of management functions, processes and processor management, operation management, storage management, equipment management, file management. At present the common operating system on microcomputer DOS, OS / 2, UNIX, XENIX, LINUX, Windows, Netware, etc. But all of the operating system with concurrency, sharing, four basic characteristics of virtual property and uncertainty. At present there are many different kinds of operating system, it is difficultto use a single standard unified classification. Divided according to the application field, can be divided into the desktop operating system, server operating system, the host operating system, embedded operating system.1.The basic introduction of the operating system(1)The features of the operating systemManagement of computer system hardware, software, data and other resources, as far as possible to reduce the work of the artificial allocation of resources and people to the machine's intervention, the computer automatically work efficiency into full play.Coordinate the relationship between and in the process of using various resources, make the computer's resources use reasonable scheduling, both low and high speed devices running with each other.To provide users with use of a computer system environment, easy to use parts of a computer system or function. Operating system, through its own procedures to by all the resources of the computer system provides the function of the abstract, the function of the formation and the equivalent of the operating system, and image, provide users with convenient to use the computer.(2)The development of the operating systemOperating system originally intended to provide a simple sorting ability to work, after updating for auxiliary more complex hardwarefacilities and gradual evolution.Starting from the first batch mode, also come time sharing mechanism, in the era of multiprocessor comes, the operating system also will add a multiprocessor coordination function, even the coordination function of distributed systems. The evolution of the other aspects also like this.On the other hand, on a personal computer, personal computer operating system of the road, following the growth of the big computer is becoming more and more complex in hardware, powerful, and practice in the past only large computer functions that it step by step.Manual operation stage. At this stage of the computer, the main components is tube, speed slow, no software, no operating system. User directly using a machine language program, hands-on completely manual operation, the first will be prepared machine program tape into the input, and then start the machine input the program and data into a computer, and then through the switch to start the program running and computing, after the completion of the printer output. The user must be very professional and technical personnel to achieve control of the computer.Batch processing stage. Due to the mid - 1950 - s, the main components replaced by the transistor computer, running speed hadthe very big enhancement, the software also began to develop rapidly, appeared in the early of the operating system, it is the early users to submit the application software for management and monitoring program of the batch.Multiprogramming system phase. As the medium and small-scale integrated circuit widely application in computer systems, the CPU speed is greatly increased, in order to improve the utilization rate of CPU and multiprogramming technology is introduced, and the special support multiprogramming hardware organization, during this period, in order to further improve the efficiency of CPU utilization, a multichannel batch system, time-sharing system, etc., to produce more powerful regulatory process, and quickly developed into an important branch of computer science, is the operating system. Collectively known as the traditional operating system.Modern operating systems. Large-scale, the rapid development of vlsi rapidly, a microprocessor, optimization of computer architecture, computer speed further improved, and the volume is greatly reduced, for personal computers and portable computer appeared and spread. Its the biggest advantage is clear structure, comprehensive functions, and can meet the needs of the many USES and operation aspects.2. New technology of the operating systemFrom the standpoint of the operating system of the new technology, it mainly includes the operating system structure design of the micro kernel technology and operating system software design of the object-oriented technology.(1) The microkernel operating system technologyA prominent thought in the design of modern operating systems is the operating system of the composition and function of more on a higher level to run (i.e., user mode), and leave a small kernel as far as possible, use it to complete the core of the operating system is the most basic function, according to the technology for micro kernel (Microkernel) technology.The microkernel structure(1) Those most basic, the most essential function of the operatingsystem reserved in the kernel(2)Move most of the functionality of the operating system intothe kernel, and each operating system functions exist in theform of a separate server process, and provide services.(3)In user space outside of the kernel including all operatingsystem, service process also includes the user's applicationprocess. Between these processes is the client/server mode.Micro kernel contains the main ingredient(1) Interrupt and the exception handling mechanism(2)Interprocess communication mechanisms(3)The processor scheduling mechanism(4)The basic mechanism of the service functionThe realization of the microkernelMicro kernel implementation "micro" is a major problem and performance requirements of comprehensive consideration. To do "micro" is the key to implementation mechanism and strategy, the concept of separation. Due to the micro kernel is the most important of news communication between processes and the interrupt processing mechanism, the following briefly describes the realization of both.Interprocess communication mechanismsCommunication service for the client and the server is one of the main functions of the micro kernel, is also the foundation of the kernel implement other services. Whether to send the request and the server reply messages are going through the kernel. Process of news communication is generally through the port (port). A process can have one or more ports, each port is actually a message queue or message buffer, they all have a unique port ID (port) and port authority table, the table is pointed out that this process can be interactive communications and which process. Ports ID and kernel power table maintenance.Interrupt processing mechanismMicro-kernel structure separation mechanism will interrupt and the interrupt processing, namely the interrupt mechanism on micro kernel, and put the interrupt handling in user space corresponding service process. Micro kernel interruption mechanism, is mainly responsible for the following work:(1) When an interrupt occurs to identify interrupt;(2) Put the interrupt signal interrupt data structure mapping tothe relevant process;(3) The interrupt is transformed into a message;(4) Send a message to the user space in the process of port, butthe kernel has nothing to do with any interrupt handling.(5) Interrupt handling is to use threads in a system.The advantages of the microkernel structure(1) Safe and reliableThe microkernel to reduce the complexity of the kernel, reduce the probability of failure, and increases the security of the system.(2) The consistency of the interfaceWhen required by the user process services, all based on message communication mode through the kernel to the server process. Therefore, process faces is a unified consistent processescommunication interface.(3) Scalability of the systemSystem scalability is strong, with the emergence of new hardware and software technology, only a few change to the kernel.(4) FlexibilityOperating system has a good modular structure, can independently modify module and can also be free to add and delete function, so the operating system can be tailored according to user's need.(5) CompatibilityMany systems all hope to be able to run on a variety of different processor platform, the micro kernel structure is relatively easy to implement.(6) Provides support for distributed systemsOperating under the microkernel structure system must adopt client/server mode. This model is suitable for distributed systems, can provide support for distributed systems.The main drawback of microkernelUnder the micro-kernel structure, a system service process need more patterns (between user mode and kernel mode conversion) and process address space of the switch, this increases costs, affected the speed of execution.3 .Object-oriented operating system technologyObject-oriented operating system refers to the operating system based on object model. At present, there have been many operating system used the object-oriented technology, such as Windows NT, etc. Object-oriented has become a new generation of an important symbol of the operating system.The core of object-oriented conceptsIs the basic idea of object-oriented to construct the system as a series of collections of objects. The object refers to a set of data and the data of some basic operation encapsulated together formed by an entity. The core of object-oriented concept includes the following aspects:(1) EncapsulationIn object-oriented encapsulation is the meaning of a data set and the data about the operation of the packaging together, form a dynamic entity, namely object. Encapsulated within the request object code and data to be protected.(2) InheritanceInheritance refers to some object can be inherited some features and characteristics of the object.(3) PolymorphismPolymorphism refers to a name a variety of semantics, or the same interface multiple implementations. Polymorphism inobject-oriented languages is implemented by overloading and virtual functions.(4) The messageNews is the way of mutual requests and mutual cooperation between objects. An object through the message to activate another object. The message typically contains a request object identification and information necessary to complete the work.Object-oriented operating systemIn object-oriented operating system, the object as a concurrent units, all system resources, including documents, process and memory blocks are considered to be an object, such as the operating system resources are all accomplished through the use of object services.The advantages of object-oriented operating system:(1)Can reduce operating system throughout its life period whena change is done to the influence of the system itself.For example, if the hardware has changed, will force the operating system also changes, in this case, as long as change the object representing the hardware resources and the operation of the object of service, and those who use only do not need to change the object code.(2)Operating system access to its resources and manipulation are consistent .Operating system to produce an event object, delete, and reference, and it produces reference, delete, and a process object using the same method, which is implemented by using a handle to the object. Handle to the object, refers to the process to a particular object table in the table.(3)Security measures to simplify the operating system.Because all the objects are the same way, so when someone tries to access an object, security operating system will step in and approved, regardless of what the object is.(4)Sharing resources between object for the process provides a convenient and consistent approach.Object handle is used to handle all types of objects. The operating system can by tracking an object, how many handle is opened to determine whether the object is still in use. When it is no longer used, the operating system can delete the object.ConclusionIn the past few decades of revolutionary changes have taken place in the operating system: technological innovation, the expansionof the user experience on the upgrade, application field and the improvement of function. As in the past few decades, over the next 20 years there will be huge changes in operating system. See we now use the operating system is very perfect. Believe that after the technology of the operating system will still continue to improve, will let you use the more convenient. Believe that the operating system in the future will make our life and work more colorful.。
软件工程复习资料英文

Lecture 1 An Introduction to Software Engineering1 what does software engineering concern?1) Software engineering is concerned with theories, methods and tools for professionalsoftware development.2) Software engineering is concerned with cost-effective software development.2 What is software?Software includes:①computer programs②data structures③documents3 What is the two types of software productsGeneric software(通用软件) and custom software(定制软件)4 The three key elements of a successful software project are:on time, within budget, satisfies the user’s needs5 Generic activities in all software processes are:Specification(描述), Development(开发), Validation(有效性验证), Evolution(进化)6 The attributes of good software include:Maintainability(可维护性), Dependability(可依赖性), Efficiency(有效性), Acceptability(可接受性)Lecture 2 Software Processes1 What is a software process modelA software process model is an abstract representation of a software process. It presents a description of a process from some particular perspective.2 Draw the graphic presentation of Waterfall model and describe its character.1)这种模型把软件过程划分成几个顺序的阶段。
On the relation of refactoring and software defects

On the Relation of Refactoring and Software DefectsJacek Ratzinger,Thomas Sigmund Vienna University of T echnologyInformation Systems InstituteA-1040Vienna,Austriaratzinger@infosys.tuwien.ac.atHarald C.GallUniversity of Zurich Department of Informatics CH-8050Zurich,Switzerland gall@ifi.uzh.chABSTRACTThis paper analyzes the influence of evolution activities such as refactoring on software defects.In a case study offive open source projects we used attributes of software evolu-tion to predict defects in time periods of six months.We use versioning and issue tracking systems to extract110data mining features,which are separated into refactoring and non-refactoring related features.These features are used as input into classification algorithms that create prediction models for software defects.We found out that refactoring related features as well as non-refactoring related features lead to high quality prediction models.Additionally,we discovered that refactorings and defects have an inverse cor-relation:The number of software defects decreases,if the number of refactorings increased in the preceding time pe-riod.As a result,refactoring should be a significant part of both bugfixes and other evolutionary changes to reduce software defects.Categories and Subject DescriptorsD.2.8[Software Engineering]:Evolution—software defects,pre-dictionGeneral TermsSoftware evolution,refactoring,mining software archives1.INTRODUCTIONWe investigate the influence of evolution activities such as refactoring on bugfixes required in the future.Prediction models can help us tofind out characteristics offiles(or Java classes)with or without bugfixes in their history,es-pecially in relation to rmation gained from that models can support software developers to apply refac-toring in a way that reduces error-proneness of software to-gether with an optimization of efforts.In this work we analyze data from versioning and issue tracking systems offive open source projects:ArgoUML, Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on thefirst page.To copy otherwise,to republish,to post on servers or to redistribute to lists,requires prior specific permission and/or a fee.MSR’08,May10-11,2008,Leipzig,Germany.Copyright2008ACM978-1-60558-024-1/08/05...$5.00.JBoss Cache,Liferay Portal,the Spring framework,and XDoclet.These projects are developed in Java,whereby each class is usually placed in a separatefile.We per-form some preprocessing steps to derive non-refactoring and refactoring attributes from that data.These attributes are input into WEKA[11]that generates prediction models. Our research hypotheses for our case study evaluation are as follows:H0:There is no relation between refactorings and the qual-ity of defect prediction.H1:Refactoring reduces the probability of software defects. H2:Refactoring is more important than bugfixing for soft-ware quality.The remainder of the paper is organized as follows:Sec-tion2briefly discusses related work with respect to our re-search question.Then,we describe our prediction model (Section3),the used methodology(Section4),and present the results of thefive case studies(Section5).Finally,we draw our conclusions and indicate future work(Section6).2.RELATED WORKPrevious works have addressed areas such as refactor-ing analysis,change type analysis,software metrics,or bug prediction.Some researchers have investigated refactorings based on history information.For example,van Ryssel-berghe has found methods to identify move and inheritance change operations as well as refactorings[9].The qualification of refactorings also has been addressed in[10]where it was investigated whether or not refactor-ings are less error-prone than other changes.In contrast to our work,their approach did not use feature and prediction models and did not come to a uniform conclusion for defect prediction.Fluri et al.developed an approach that investigates change types between releases of software entities[3].In a case study of a medium-sized open source project more than50% of all change transactions turned out not to be significant structural changes[2].According to this ChangeDistilling approach,we trace change couplings back to co-changedfiles that correspond to a change transaction.But we do not filter out change coupling groups that were not structurally changed,e.g.changes to Javadoc.Nagappan et al.[6]predict the pre-release defect density. They revealed a strong positive correlation between the de-fect density determined by static analysis and the pre-release defect density gained from testing.Kim et al.[5]screened the versioning history of several open source projects to predict entities andfiles most fault-prone.In contrast,we do not detect bug-introducing changes, but use the number of bugfixes,detected in the respective target period for our predictions.In line with[5]we iden-tify bugfix revisions by analyzing logfiles from versioning history.Khoshgoftaar et al.[4]use classification trees to predict fault-prone modules.The generated trees describe impor-tant points of interest(e.g.characteristics of the software). Fenton and Neil give a good review of several software met-rics and a wide range of prediction models[1].In previous work[8]we analyzed the versioning history of ArgoUML and the Spring framework to predict refactor-ing activities.There we used evolution measures extracted from versioning systems as input into classification algo-rithms to generate the prediction models.These models enable to predict refactorings with high accuracy.Addition-ally,refactoring-prone and non-refactoring-prone classes can be identified accurately.In addition to[8],in this paper we are interested in pre-dicting software defects,and therefore we enhanced our evo-lution measures with refactoring related features.3.DATA AND PREDICTION MODELSIn this section we describe the formal modeling stage of our data preparation and analysis.3.1Evolution DataThe model of the evolution data is composed of infor-mation extracted from versioning systems in the following way:Versioning systems such as CVS contain data about files and the change attributes,e.g.change dates,authors of changes,commit messages,and lines of code changed.In afirst step we have to reconstruct the change transactions as described in[3]:Two entities(e.g.files)are change cou-pled,if modifications of one entity usually also affect the other entity.The intensity of change coupling between two entities a,b can be determined by counting all change sets where a and b are members of the same transaction T n,i.e. C={ a,b |a,b∈T n}is the set of change coupling and|C| is the intensity of the change coupling.To compute our attribute targetBugs we search for changes that have an issue attached of type”bugfix.”Additionally, we investigate the commit messages and add changes that do not provide a reference to an issue but contain terms such as”bug”,”fix”,”solv”,etc.The details of the algorithm are described in[8].3.2Time Periods and FeaturesWe used two consecutive time periods for our prediction:•Feature Period in which certain properties of softwareevolution are accumulated into attributes(features)toserve as input to our prediction.All source code mod-ifications within this time period are used to computea condensed history of eachfile.•Target Period as the time frame immediately follow-ing the feature period,when we count the number ofbugfixes.This number defines the data mining targetattribute for our case studies.3.3Data Mining FeaturesFrom the evolution data we compute110features that are used for data mining.We separate these features into two groups:non-refactoring and refactoring related features. For the purpose of creating a balanced prediction model,as argued in[1],the features represent several domains such as code measures,team and co-change aspects,or complexity of implemented solution.For a detailed description of the features we refer to[7].3.4Classifiers—Data Mining Algorithms These classifiers separate entities into different groups such as classes with or without bugfixes.•C4.5induces decision trees:it compares one of the in-put attributes against a threshold value and partitionsthe input space into distinctive sets.•LMT is a data mining algorithm for building logisticmodel trees,which are classification trees with logisticregression functions at the leaves.•Rip(Repeated Incremental Pruning)is a propositionalrule learner.It uses a growth phase,in which an-tecedents are greedily added until the rule reaches100% accuracy.Then in the pruning phase,metrics are usedto prune rules until a defined length is reached.•In NNge a nearest-neighbor algorithm is used to buildrules using non-nested generalized exemplars.3.5Evaluation of Prediction ModelsIn our analysis of prediction models for bugfixes we use precision,recall,and F-measure as three essential markers characterizing model performance.These evaluation mea-sures are defined based on rates for true positives,false pos-itives,true negatives,and false negatives[11].4.METHODOLOGY4.1Identifying RefactoringFor generation of refactoring features we do not distin-guish between different types of refactorings(e.g.extract class or method,etc.).These features cover the fact that devel-opers try to improve the quality of code.Similar to our previous work[8]we start our identifica-tion by searching for texts including”refactor”and then we exclude phrases such as”needs refactoring”to improve the results.For each project we developed between10and20 SQL queries to mark modifications as refactorings.We used a statistical evaluation to estimate the number of refactor-ings that we correctly identified with our method.There-fore,we took a random sample of100modifications for each project and checked whether it was a refactoring or not. Table1shows high rates of correct classifications for each investigated project.As an example,in ArgoUML and Lif-eray Portal all revisions labeled as“refactoring”actually were refactorings.4.2Data Processing with WekaWeka is a collection of machine learning algorithms for data mining and is used to generate prediction models dis-tinguishing between the class offiles”No bugs”and the class”One or more bugs.”Next we describe our two steps of creating and analyzing the section models.(1)In thefirst step we create section models:If two classes (”No bugs”and”One or more bugs”)do not have the sameProject Modifications Identified Refactorings Other Changes False Positives False Negatives ArgoUML100128802 JBoss Cache100227813 Liferay Portal100109001 Spring Framework100148621 XDoclet100217913 Table1:Evaluation to Classify Modifications as Refactoringssize,the set containing more instances is subdivided into sections that consist of the same number of instances as in the small set.For example,Project Liferay Portal contains 1816files that have been changed during the feature period. 1338files exhibited no bugfixes and478files had one or more bugfixes in the corresponding target period The set of instances with no bugfixes is decomposed into three differ-ent sections each holding478instances,where the last one contains the remaining382instances.For thefirst evalua-tion we use thefirst data set with the topmost478files of class”No bugs”,for the second we use the next478files, and for the third we use the bottommost478files.As we see,96files are used two times,for data set two and data set three.After the splitting three different models can be generated based on those three sections.Such a model made up of the same number of non-error-pronefiles(”Bugfixes=0”)and error-pronefiles(”Bugfixes>=1”)is called section model.(2)In the second step we analyze the section models:To investigate our hypothesis we apply a statistic analysis on the sections models.For hypothesis H0we compare the number of experiments where prediction models based only on refactoring related features perform better than predic-tion models based on non-refactoring features.Hypothesis H1is investigated based on a feature indicating the number of refactorings compared to the overall number of changes. For each class offiles(”No bugs”and”One or more bugs”) we analyze the number of predicted instances where the number of refactorings is above a threshold value.The ratio between refactorings and bugfixes isfinally used to address hypothesis H2.5.RESULTSWe analyzed three different time frames for each project. Every time frame consisted of a feature period and a target period and spanned one year.5.1Do refactoring and non-refactoring relatedfeatures lead to high quality predictionmodels?(H0)We decided to exemplary display the results for section model1of one out of the three analyzed time periods per investigated project,whereby classification algorithm C4.5 is used to generate the respective section models(Table2). Although this is only a small sample of the available predic-tion models,the results are representative for all generated models with respect to model quality.The results of models generated from refactoring and non-refactoring features are presented using two main columns that are subdivided in a column for”No bugs”and a col-umn for”One or more bugs”.Each line provides informa-tion about model quality through the F-measure.All mod-els show sufficient good prediction results to form a basis for a further analysis.Especially,the balanced distribution between both bins(files with and without bugfixes)is sat-isfying.The project Liferay Portal exhibits extraordinary good prediction results with a maximum F-measure of0.925. Next,the composition of the model trees can be examined more closely,since concrete sequences of the decision rules lead to promising prediction results.Thus we reject the null hypothesis and conclude:Both refactoring and non-refactoring related features lead to high quality defect prediction models.For H1and H2we investigated section models of all ana-lyzed projects that contain the refactoring feature of interest (H1:number refactoringChanges,H2:ratio bugfixRefactor-ing)together with a respective threshold value.5.2Is refactoring related with the number offuture software defects?(H1)The majority of model sequences using the feature refac-toringChanges shows that instances holding a value equal or below a certain threshold value are assigned to bin”One or more bugs”(71.7%),and instances above are assigned to bin”No bugs”(75.0%)(see Figure1).Figure1:Distribution of non-defect-prone(green) and defect-prone(red)instances in case of a low and a high level of refactorings.This is an essential result since refactoring can positively influence the software quality by decreasing the occurrence of bugfixes.Additionally,it seems to be generally good when the number of total changes remains low with respect to bugfix reduction.Thus we conclude:The number of software defects in the target period de-creases if the number of refactorings increases as overall change type.5.3Does refactoring in contrast to bugfixingreduce software defects?(H2)Most of the model sequences,using feature bugfixRefactor-ings(i.e.the ratio between bugfixes and refactorings)show thatfiles that have a value equal or below the threshold are assigned to bin”No bugs”(69.2%),andfiles above are assigned to bin”One or more bugs”(77.8%)(see Figure2). Again,refactoring helps to decrease bugfixes in the target period.Furthermore the number of bugfixes in the feature period directly correlates to the number of bugfixes in theProject Refactoring Models Non-Refactoring ModelsBugfixes=0Bugfixes>=1Bugfixes=0Bugfixes>=1ArgoUML0.7180.7160.7250.718JBoss Cache0.7470.7450.7580.742Liferay Portal0.9250.9250.9160.918 Spring Framework0.8590.8510.8870.890 XDoclet0.7980.7940.8620.845Table2:Predicting non Bugfix prone vs Bugfix prone Classes for each project using C4.5Figure2:Distribution of non-defect-prone(green) and defect-prone(red)instance in case of a low and a high ratio between bugfixes and refactorings. target period.This result is well known to the scientific community since defect-pronefiles tend to stay defect-prone in the course of time.A balanced fraction of refactoring and bugfixes is necessary to support understandability and maintainability of source code,as well as to solve actual or upcoming problems.Thus,we conclude:The number of software defects in the target period decreases,if the number of refactorings in-creases compared to bugfixes.5.4Threats to validityAs many of such studies also our study is undermined by external and internal threats to validity ranging from the case studies chosen to the prediction models computed.For a detailed discussion of all features,classifiers,prediction models and the threats to validity we refer to[7].6.CONCLUSIONS AND FUTURE WORK In this paper we investigated the interrelationship of evo-lution activities such as refactoring to predict software de-fects in the near future.Our study is based onfive open source projects originating from different domains to sup-port some level of generality.Our work extends previous work on refactoring qualification to evaluate the impact on software defect prediction.We use versioning and issue tracking data to extract110 data mining features to predict medium-term defects.These features are separated in refactoring and non-refactoring re-lated features and cover software characteristics such as code measures,team and co-change aspects,or complexity of im-plemented solution.We found that refactoring related features as well as non-refactoring related features produce high quality prediction models.Thesefindings support our hypotheses that the number of software defects in the target period decreases, if more refactorings are applied and if these refactorings in-crease compared to bugfixes.This means that an increase in refactorings has a significant positive impact on the quality of the software.In our future work we will further integrate attributes of software change such as severity levels and improve our queries to further reduce false positives and false negatives with respect to refactoring as well as bugfix detection. AcknowledgementsWe are grateful to the reviewers for their valuable com-ments.This project was supported by the Hasler Founda-tion Switzerland as part of the project“ProMedServices.”7.REFERENCES[1]N.E.Fenton and M.Neil.A critique of softwaredefect prediction models.IEEE Transactions onSoftware Engineering,25(5):675–689,September1999.[2]B.Fluri,H.C.Gall,and M.Pinzger.Fine-grainedanalysis of change couplings.In Proceedings of theFifth IEEE International Workshop on Source CodeAnalysis and Manipulation(SCAM’05),2005.[3]B.Fluri,M.W¨u rsch,M.Pinzger,and H.C.Gall.Change distilling—tree differencing forfine-grainedsource code change extraction.Transactions onSoftware Engineering,33(11):725–743,November2007.[4]T.M.Khoshgoftaar,X.Yuan,E.B.Allen,W.D.Jones,and J.P.Hudepohl.Uncertain classification of fault-prone software modules.Empirical SoftwareEngineering,7(4):297–318,December2002.[5]S.Kim,T.Zimmermann,E.J.Whitehead,Jr.,andA.Zeller.Predicting faults from cached history.InProceedings of the International Conference onSoftware Engineering,May2007.[6]N.Nagappan and T.Ball.Static analysis tools asearly indicators of pre-release defect density.InProceedings of the International Conference onSoftware Engineering,May2005.[7]J.Ratzinger.sPACE–Software Project Assessmentin the Course of Evolution.PhD thesis,ViennaUniversity of Technology,Austria,October2007. [8]J.Ratzinger,T.Sigmund,P.Vorburger,and H.Gall.Mining software evolution to predict refactoring.InProceedings of the International Symposium onEmpirical Software Engineering and Measurement(ESEM),September2007.[9]F.Van Rysselberghe.Studying Historic ChangeOperations:Techniques and Observations.PhD thesis, Universiteit Antwerpen,2008.[10]P.Weißgerber and S.Diehl.Are refactorings lesserror-prone than other changes?In Proceedings of the International Workshop on Mining SoftwareRepositories(MSR’06).ACM,2006.[11]I.H.Witten and E.Frank.Data Mining:Practicalmachine learning tools and techniques.MorganKaufmann,2005.。
Whatarecomponent...

Component-based Architecture“Buy, don’t build”Fred Broks1.Why use components? (2)2.What are software components? (3)ponent-based Systems: A Reality!! [SEI reference] (4)4.Major elements of a component: (5)ponent Architecture (9)6.Blackbox vs. Whitebox (12)ponents vs. Objects (14)ponents in industry verses in-house solutions (15)ponent disadvantages (16)10.Summary (17)1.W hy use components?∙Problem with OOP:*Objects are too complicated and provide too limitedfunctionality to be useful to many clients, whilecomponents such as plug-ins provide a high-level featurethat can be installed and configured by users (such as web-browser plug-ins).*Objects do not allow for plug-and-play, integrating anobject into a particular system may not be possible andtherefore objects cannot be provided independently.∙Composition and assembly of components can be done by a largergroup of people who do not have to have the specialist skillsrequired for component development.∙Component-based development is a critical part of the maturingprocess of developing and managing distributed applications.∙Where are we in the software life cycle?Requirements Design Implementation ….SoftwareArchitecturesComponentsSoftware Component ArchitectureDSSA: Domain-Specific SoftwareArchitecturesFrameworksDesign PatternsWhichProgramminglanguage?2.What are software components?∙“A software c omponent is a unit of composition with contractuallyspecified interfaces and explicit context dependencies only. Asoftware component can be deployed independently and is subjectto composition by third parties.” (Workshop on Component-Oriented Programming, ECOOP, 1996.)∙ A component is a software object, meant to interact with othercomponents, encapsulating certain functionality or a set offunctionalities. A component has a clearly defined interface andconforms to a prescribed behavior common to all componentswithin an architecture. Multiple components may be composed tobuild other components.∙Components are expected to exhibit certain behaviors andcharacteristics that let them participate in the component structure and interact with its environment and other components.ponent-based Systems: A Reality!! [SEI reference]∙Component-based systems encompass both commercial-off-the-shelf (COTS) products and components acquired through othermeans, such as existing applications.∙ Developing component-based systems is becoming feasible due to the following:▪the increase in the quality and variety of COTSproducts economic pressures to reduce systemdevelopment and maintenance costs▪the emergence of component integration technology▪the increasing amount of existing software inorganizations that can be reused in new systems.∙CBSD shifts the development emphasis from programmingsoftware to composing software systems [Clements 95].4.Major elements of a component:∙Specification:It is more than just list of available operations. It describesthe expected behavior of the component for specificsituations, constraints the allowable states of thecomponent, and guides the clients in appropriateinteractions with the component. In some cases thesedescriptions may be in some formal notation. Most oftenthey are informally defined.∙One or more implementations:The component must be supported by one or moreimplementations. These must conform to the specification.The implementer can choose any programming language.∙Component Model:o Software components exist within a defined environment,or component model.o Established component models include MS’s COM+, Sun’sJava J2EE or JEE 5, and the Object Management GroupOMG’s CORBA component standard.o A component model is a set of services that support thesoftware, plus a set of rules that must be obeyed by thecomponent in order for it to take advantage of the services.o Each of these component models addresses the followingissues:✓How a component makes its services available toothers?✓How component are named?✓How new components and their services arediscovered at runtime.✓Component Types: [Felix Bachman et al. 2000]o A component’s type may be defined interms of the interfaces it implements.o If a component implements three differentinterfaces X, Y and Z, then it is of type X, Yand Z. We say that this component ispolymorphic with respect to these types (itcan play the role of an X, Y, or Z at differenttimes.o Component types are found in bothMicrosoft/COM and Sun/Java technologies.o A component model requires thatcomponents implement one or moreinterfaces, and in this way a componentmodel can be seen to define one or morecomponent types. Different componenttypes can play different roles in systems, andparticipate in different types of interactionschemes.o Each model also provides other capabilities such as:✓Transaction management,✓persistence, and✓Security.A packaging approach:o Components must be grouped to provide a set of services.It is these packages that are bought and sold whenacquiring from a third-party sources. They represent unitsof functionality that must be installed on the system.o A J2EE application is packaged as an E nterprise AR chive(EAR) file, a standard Java JAR file with an .ear extension.The goal of this file format is to provide an applicationdeployment unit that is assured of being portable.o Different components (modules) of an application may bepackaged separated to achieve maximum reusability.A deployment approach:o Once the packaged components are installed in an operationalenvironment, they will be deployed. This occurs by creatingan executable instance of a component and allowinginteractions with it to occur. Note that we might havedifferent instances of a component running on the samemachine.o J2EE uses deployment descriptors that are defined as in XML files named ejb-jar.xml. Example:<?xml version="1.0" encoding="UTF-8"?><application xmlns="/xml/ns/j2ee"xmlns:xsi="/2001/XMLSchema-instance"xsi:schemaLocation="/xml/ns/j2ee/xml/ns/j2ee/application_1_4.xsd"version="1.4"><display-name>Simple example of application</display-name><description>Simple example</description><module><ejb>ejb1.jar</ejb></module><module><ejb>ejb2.jar</ejb></module><module><web><web-uri>web.war</web-uri><context-root>web</context-root> </web></module></application>5.C omponent Architecture∙ A component architecture is a system defining the rules oflinking components together.∙ A standard component model includes definitions for the following(WebSphere Advisor 2000):✓How each component must make its services available toothers?✓How to connect one component to another.✓Which common utility services can be assumed to beprovided by the infrastructure supporting the componentmodel?✓How new components announce their availability toothers?∙Component Architecture Principles (Rijsenbrij)✓Component architecture is a set of principles and rulesaccording to which a software system is designed and builtwith the use of components.✓It must be independent from the business domain or thetechnology of the application.✓The component architecture covers three aspects of a softwaresystem. These are:▪Building blocks:The architecture specifies the type of building blockssystems are composed of.▪Construction of the software system:The architecture specifies how the buildingblocks are joined together when developing anapplication. The architecture describes the rolethat the building blocks play in the system.Organisation:Components are divided in categories based ontheir functionality.∙The component interface is a set of methods supported by a component, and type definitions for the data used for arguments to those methods. An interface itself is a type and can be an argument for a component method.∙The Common Component Architecture Forum(/glossary/index.html)o An Interface Definition Language understandable to allcomponents. Interface definitions expressed in a languageallow components to find out about each other either throughintrospection or through consulting a repository, and givecomponent architecture the potential to dynamically add anddelete components in multi-component applications (whetherthis potential is actually realized or not depends on a specificimplementation of the architecture).o Introspection: Inspection is the process of exposing theproperties, methods, and Events that a component supports.Example: Java provides Java provide an interfacejava.beans.BeanInfo to accomplish it.o A Reusable Combining Infrastructure provides theimplementation necessary to link components. It containsmechanisms enabling the components to reference each other,understands the interface definition syntax and is capable oftransferring data types and component references betweencomponents.o A Binding between the interface definition syntax and a language or framework of actual component implementation. o A Composition API allows the programmer to link components into multi-component applications and save those compositions. Such a mechanism could be provided for example by a GUI or a scripting language. Examples:▪BML (Bean Markup language) from IBM▪CoML:(/content/k4hy95n563m8agv8/)6.Blackbox vs. Whitebox∙Abstractions and Reuse Blackbox vs. whitebox abstractionrefers to the visibility of an implementation behind its interface.∙Ideally, a blackbox’s clients don’t know any details beyond theinterface and its specification.∙For a whitebox, the interface may still enforce encapsulation andlimit what clients can do (although implementation inheritanceallows for substantial interference). However, the whiteboximplementation is available and you can study it to betterunderstand what the box does.∙Blackbox reuse refers to reusing an implementation without relyingon anything but its interface and specification. For example, typicalapplication programming interfaces (APIs) reveal no implementationdetails. Building on such an API is thus blackbox reuse of the API’simplementation.∙In contrast, whitebox reuse refers to using a software fragment,through its interfaces, while relying on the understanding yougained from studying the actual implementation. Most classlibraries and application frameworks are delivered in sourceform and application developers study a class implementationto understand what a subclass can or must do.∙There are serious problems with whitebox reuse acrosscomponents, since whitebox reuse renders it unlikely that thereused software can be replaced by a new release. Such areplacement will likely break some of the reusing clients, asthese depend on implementation details that may have changedin the new release.Some authors further distinguish between whiteboxes and glassboxes where a whitebox lets you manipulate the implementation, and a glass merely lets you study the implementation.7.C omponents vs. Objects∙How does component architecture differ from object architecture?∙An object is built around the following ideas:o Inheritanceo Needs other objects to be (re)used properlyo The interface defines only methodso Has only properties (state) and behavior.∙ A component differs in the following ways:o No inheritance (although the object that make up thecomponent may inherit behavior from other objects, possiblyin other components.o The component always appears as one of multiple interfaces.o The interface formalizes properties, events and behavior.o Easily reused due to its well-defined interface.o Flat hierarchy: no direct dependencies on other externalobjects.o Guaranteed to function in any configuration.o Has the ability to describe its own interface at runtime.∙List of properties contrasting Components and Objects:ponents in industry verses in-house solutions∙Fixed-price contracts can be agreed on, limiting financial risks.∙Existing software can be customized to business needs.∙Interoperability problems are left to vendor∙In-house developers may not have the required skill. In this casecomponent vendors may provide better solutions.ponent disadvantages∙Must upgrade configuration for next release∙Business processes may have to be changed to suit software(rather than developing software to suit business processes)∙Fully testing components for integration testing will beinfeasible, customers may have to proceed on a most-likely willwork basis (compare with applets and browsers).∙Components must handle downloading and dynamic (late)integration with other components.∙Reliance on vendors may make adjustments to software slower.10.Summary∙Why use components?∙Major elements of a component:o Specificationo One or more implementationso Component Model:▪Each of these component models addresses thefollowing issues:✓How a component makes its services available toothers?✓How component are named?✓How new components and their services arediscovered at runtime.o A packaging approach:▪Example: 2EE application is packaged as anE nterprise AR chive (EAR) file, a standard Java JARfile with an .ear extension.o A deployment approach:▪J2EE uses deployment descriptors that are defined as in XMLfiles named ejb-jar.xml.∙Component Architecture∙Blackbox vs. Whitebox∙Components vs. Objects∙Components in industry verses in-house solutions∙Component disadvantages。
Consensus and Cooperation in Networked Multi-Agent Systems

Consensus and Cooperation in Networked Multi-Agent SystemsAlgorithms that provide rapid agreement and teamwork between all participants allow effective task performance by self-organizing networked systems.By Reza Olfati-Saber,Member IEEE,J.Alex Fax,and Richard M.Murray,Fellow IEEEABSTRACT|This paper provides a theoretical framework for analysis of consensus algorithms for multi-agent networked systems with an emphasis on the role of directed information flow,robustness to changes in network topology due to link/node failures,time-delays,and performance guarantees. An overview of basic concepts of information consensus in networks and methods of convergence and performance analysis for the algorithms are provided.Our analysis frame-work is based on tools from matrix theory,algebraic graph theory,and control theory.We discuss the connections between consensus problems in networked dynamic systems and diverse applications including synchronization of coupled oscillators,flocking,formation control,fast consensus in small-world networks,Markov processes and gossip-based algo-rithms,load balancing in networks,rendezvous in space, distributed sensor fusion in sensor networks,and belief propagation.We establish direct connections between spectral and structural properties of complex networks and the speed of information diffusion of consensus algorithms.A brief introduction is provided on networked systems with nonlocal information flow that are considerably faster than distributed systems with lattice-type nearest neighbor interactions.Simu-lation results are presented that demonstrate the role of small-world effects on the speed of consensus algorithms and cooperative control of multivehicle formations.KEYWORDS|Consensus algorithms;cooperative control; flocking;graph Laplacians;information fusion;multi-agent systems;networked control systems;synchronization of cou-pled oscillators I.INTRODUCTIONConsensus problems have a long history in computer science and form the foundation of the field of distributed computing[1].Formal study of consensus problems in groups of experts originated in management science and statistics in1960s(see DeGroot[2]and references therein). The ideas of statistical consensus theory by DeGroot re-appeared two decades later in aggregation of information with uncertainty obtained from multiple sensors1[3]and medical experts[4].Distributed computation over networks has a tradition in systems and control theory starting with the pioneering work of Borkar and Varaiya[5]and Tsitsiklis[6]and Tsitsiklis,Bertsekas,and Athans[7]on asynchronous asymptotic agreement problem for distributed decision-making systems and parallel computing[8].In networks of agents(or dynamic systems),B con-sensus[means to reach an agreement regarding a certain quantity of interest that depends on the state of all agents.A B consensus algorithm[(or protocol)is an interaction rule that specifies the information exchange between an agent and all of its neighbors on the network.2 The theoretical framework for posing and solving consensus problems for networked dynamic systems was introduced by Olfati-Saber and Murray in[9]and[10] building on the earlier work of Fax and Murray[11],[12]. The study of the alignment problem involving reaching an agreement V without computing any objective functions V appeared in the work of Jadbabaie et al.[13].Further theoretical extensions of this work were presented in[14] and[15]with a look toward treatment of directed infor-mation flow in networks as shown in Fig.1(a).Manuscript received August8,2005;revised September7,2006.This work was supported in part by the Army Research Office(ARO)under Grant W911NF-04-1-0316. R.Olfati-Saber is with Dartmouth College,Thayer School of Engineering,Hanover,NH03755USA(e-mail:olfati@).J.A.Fax is with Northrop Grumman Corp.,Woodland Hills,CA91367USA(e-mail:alex.fax@).R.M.Murray is with the California Institute of Technology,Control and Dynamical Systems,Pasadena,CA91125USA(e-mail:murray@).Digital Object Identifier:10.1109/JPROC.2006.8872931This is known as sensor fusion and is an important application of modern consensus algorithms that will be discussed later.2The term B nearest neighbors[is more commonly used in physics than B neighbors[when applied to particle/spin interactions over a lattice (e.g.,Ising model).Vol.95,No.1,January2007|Proceedings of the IEEE2150018-9219/$25.00Ó2007IEEEThe common motivation behind the work in [5],[6],and [10]is the rich history of consensus protocols in com-puter science [1],whereas Jadbabaie et al.[13]attempted to provide a formal analysis of emergence of alignment in the simplified model of flocking by Vicsek et al.[16].The setup in [10]was originally created with the vision of de-signing agent-based amorphous computers [17],[18]for collaborative information processing in ter,[10]was used in development of flocking algorithms with guaranteed convergence and the capability to deal with obstacles and adversarial agents [19].Graph Laplacians and their spectral properties [20]–[23]are important graph-related matrices that play a crucial role in convergence analysis of consensus and alignment algo-rithms.Graph Laplacians are an important point of focus of this paper.It is worth mentioning that the second smallest eigenvalue of graph Laplacians called algebraic connectivity quantifies the speed of convergence of consensus algo-rithms.The notion of algebraic connectivity of graphs has appeared in a variety of other areas including low-density parity-check codes (LDPC)in information theory and com-munications [24],Ramanujan graphs [25]in number theory and quantum chaos,and combinatorial optimization prob-lems such as the max-cut problem [21].More recently,there has been a tremendous surge of interest V among researchers from various disciplines of engineering and science V in problems related to multia-gent networked systems with close ties to consensus prob-lems.This includes subjects such as consensus [26]–[32],collective behavior of flocks and swarms [19],[33]–[37],sensor fusion [38]–[40],random networks [41],[42],syn-chronization of coupled oscillators [42]–[46],algebraic connectivity 3of complex networks [47]–[49],asynchro-nous distributed algorithms [30],[50],formation control for multirobot systems [51]–[59],optimization-based co-operative control [60]–[63],dynamic graphs [64]–[67],complexity of coordinated tasks [68]–[71],and consensus-based belief propagation in Bayesian networks [72],[73].A detailed discussion of selected applications will be pre-sented shortly.In this paper,we focus on the work described in five key papers V namely,Jadbabaie,Lin,and Morse [13],Olfati-Saber and Murray [10],Fax and Murray [12],Moreau [14],and Ren and Beard [15]V that have been instrumental in paving the way for more recent advances in study of self-organizing networked systems ,or swarms .These networked systems are comprised of locally interacting mobile/static agents equipped with dedicated sensing,computing,and communication devices.As a result,we now have a better understanding of complex phenomena such as flocking [19],or design of novel information fusion algorithms for sensor networks that are robust to node and link failures [38],[72]–[76].Gossip-based algorithms such as the push-sum protocol [77]are important alternatives in computer science to Laplacian-based consensus algorithms in this paper.Markov processes establish an interesting connection between the information propagation speed in these two categories of algorithms proposed by computer scientists and control theorists [78].The contribution of this paper is to present a cohesive overview of the key results on theory and applications of consensus problems in networked systems in a unified framework.This includes basic notions in information consensus and control theoretic methods for convergence and performance analysis of consensus protocols that heavily rely on matrix theory and spectral graph theory.A byproduct of this framework is to demonstrate that seem-ingly different consensus algorithms in the literature [10],[12]–[15]are closely related.Applications of consensus problems in areas of interest to researchers in computer science,physics,biology,mathematics,robotics,and con-trol theory are discussed in this introduction.A.Consensus in NetworksThe interaction topology of a network of agents is rep-resented using a directed graph G ¼ðV ;E Þwith the set of nodes V ¼f 1;2;...;n g and edges E V ÂV .TheFig.1.Two equivalent forms of consensus algorithms:(a)a networkof integrator agents in which agent i receives the state x j of its neighbor,agent j ,if there is a link ði ;j Þconnecting the two nodes;and (b)the block diagram for a network of interconnecteddynamic systems all with identical transfer functions P ðs Þ¼1=s .The collective networked system has a diagonal transfer function and is a multiple-input multiple-output (MIMO)linear system.3To be defined in Section II-A.Olfati-Saber et al.:Consensus and Cooperation in Networked Multi-Agent Systems216Proceedings of the IEEE |Vol.95,No.1,January 2007neighbors of agent i are denoted by N i ¼f j 2V :ði ;j Þ2E g .According to [10],a simple consensus algorithm to reach an agreement regarding the state of n integrator agents with dynamics _x i ¼u i can be expressed as an n th-order linear system on a graph_x i ðt Þ¼X j 2N ix j ðt ÞÀx i ðt ÞÀÁþb i ðt Þ;x i ð0Þ¼z i2R ;b i ðt Þ¼0:(1)The collective dynamics of the group of agents following protocol (1)can be written as_x ¼ÀLx(2)where L ¼½l ij is the graph Laplacian of the network and itselements are defined as follows:l ij ¼À1;j 2N i j N i j ;j ¼i :&(3)Here,j N i j denotes the number of neighbors of node i (or out-degree of node i ).Fig.1shows two equivalent forms of the consensus algorithm in (1)and (2)for agents with a scalar state.The role of the input bias b in Fig.1(b)is defined later.According to the definition of graph Laplacian in (3),all row-sums of L are zero because of P j l ij ¼0.Therefore,L always has a zero eigenvalue 1¼0.This zero eigenvalues corresponds to the eigenvector 1¼ð1;...;1ÞT because 1belongs to the null-space of L ðL 1¼0Þ.In other words,an equilibrium of system (2)is a state in the form x üð ;...; ÞT ¼ 1where all nodes agree.Based on ana-lytical tools from algebraic graph theory [23],we later show that x Ãis a unique equilibrium of (2)(up to a constant multiplicative factor)for connected graphs.One can show that for a connected network,the equilibrium x üð ;...; ÞT is globally exponentially stable.Moreover,the consensus value is ¼1=n P i z i that is equal to the average of the initial values.This im-plies that irrespective of the initial value of the state of each agent,all agents reach an asymptotic consensus regarding the value of the function f ðz Þ¼1=n P i z i .While the calculation of f ðz Þis simple for small net-works,its implications for very large networks is more interesting.For example,if a network has n ¼106nodes and each node can only talk to log 10ðn Þ¼6neighbors,finding the average value of the initial conditions of the nodes is more complicated.The role of protocol (1)is to provide a systematic consensus mechanism in such a largenetwork to compute the average.There are a variety of functions that can be computed in a similar fashion using synchronous or asynchronous distributed algorithms (see [10],[28],[30],[73],and [76]).B.The f -Consensus Problem and Meaning of CooperationTo understand the role of cooperation in performing coordinated tasks,we need to distinguish between un-constrained and constrained consensus problems.An unconstrained consensus problem is simply the alignment problem in which it suffices that the state of all agents asymptotically be the same.In contrast,in distributed computation of a function f ðz Þ,the state of all agents has to asymptotically become equal to f ðz Þ,meaning that the consensus problem is constrained.We refer to this con-strained consensus problem as the f -consensus problem .Solving the f -consensus problem is a cooperative task and requires willing participation of all the agents.To demonstrate this fact,suppose a single agent decides not to cooperate with the rest of the agents and keep its state unchanged.Then,the overall task cannot be performed despite the fact that the rest of the agents reach an agree-ment.Furthermore,there could be scenarios in which multiple agents that form a coalition do not cooperate with the rest and removal of this coalition of agents and their links might render the network disconnected.In a dis-connected network,it is impossible for all nodes to reach an agreement (unless all nodes initially agree which is a trivial case).From the above discussion,cooperation can be infor-mally interpreted as B giving consent to providing one’s state and following a common protocol that serves the group objective.[One might think that solving the alignment problem is not a cooperative task.The justification is that if a single agent (called a leader)leaves its value unchanged,all others will asymptotically agree with the leader according to the consensus protocol and an alignment is reached.However,if there are multiple leaders where two of whom are in disagreement,then no consensus can be asymptot-ically reached.Therefore,alignment is in general a coop-erative task as well.Formal analysis of the behavior of systems that involve more than one type of agent is more complicated,partic-ularly,in presence of adversarial agents in noncooperative games [79],[80].The focus of this paper is on cooperative multi-agent systems.C.Iterative Consensus and Markov ChainsIn Section II,we show how an iterative consensus algorithm that corresponds to the discrete-time version of system (1)is a Markov chainðk þ1Þ¼ ðk ÞP(4)Olfati-Saber et al.:Consensus and Cooperation in Networked Multi-Agent SystemsVol.95,No.1,January 2007|Proceedings of the IEEE217with P ¼I À L and a small 90.Here,the i th element of the row vector ðk Þdenotes the probability of being in state i at iteration k .It turns out that for any arbitrary graph G with Laplacian L and a sufficiently small ,the matrix P satisfies the property Pj p ij ¼1with p ij !0;8i ;j .Hence,P is a valid transition probability matrix for the Markov chain in (4).The reason matrix theory [81]is so widely used in analysis of consensus algorithms [10],[12]–[15],[64]is primarily due to the structure of P in (4)and its connection to graphs.4There are interesting connections between this Markov chain and the speed of information diffusion in gossip-based averaging algorithms [77],[78].One of the early applications of consensus problems was dynamic load balancing [82]for parallel processors with the same structure as system (4).To this date,load balancing in networks proves to be an active area of research in computer science.D.ApplicationsMany seemingly different problems that involve inter-connection of dynamic systems in various areas of science and engineering happen to be closely related to consensus problems for multi-agent systems.In this section,we pro-vide an account of the existing connections.1)Synchronization of Coupled Oscillators:The problem of synchronization of coupled oscillators has attracted numer-ous scientists from diverse fields including physics,biology,neuroscience,and mathematics [83]–[86].This is partly due to the emergence of synchronous oscillations in coupled neural oscillators.Let us consider the generalized Kuramoto model of coupled oscillators on a graph with dynamics_i ¼ Xj 2N isin ð j À i Þþ!i (5)where i and !i are the phase and frequency of the i thoscillator.This model is the natural nonlinear extension of the consensus algorithm in (1)and its linearization around the aligned state 1¼...¼ n is identical to system (2)plus a nonzero input bias b i ¼ð!i À"!Þ= with "!¼1=n P i !i after a change of variables x i ¼ð i À"!t Þ= .In [43],Sepulchre et al.show that if is sufficiently large,then for a network with all-to-all links,synchroni-zation to the aligned state is globally achieved for all ini-tial states.Recently,synchronization of networked oscillators under variable time-delays was studied in [45].We believe that the use of convergence analysis methods that utilize the spectral properties of graph Laplacians willshed light on performance and convergence analysis of self-synchrony in oscillator networks [42].2)Flocking Theory:Flocks of mobile agents equipped with sensing and communication devices can serve as mobile sensor networks for massive distributed sensing in an environment [87].A theoretical framework for design and analysis of flocking algorithms for mobile agents with obstacle-avoidance capabilities is developed by Olfati-Saber [19].The role of consensus algorithms in particle-based flocking is for an agent to achieve velocity matching with respect to its neighbors.In [19],it is demonstrated that flocks are networks of dynamic systems with a dynamic topology.This topology is a proximity graph that depends on the state of all agents and is determined locally for each agent,i.e.,the topology of flocks is a state-dependent graph.The notion of state-dependent graphs was introduced by Mesbahi [64]in a context that is independent of flocking.3)Fast Consensus in Small-Worlds:In recent years,network design problems for achieving faster consensus algorithms has attracted considerable attention from a number of researchers.In Xiao and Boyd [88],design of the weights of a network is considered and solved using semi-definite convex programming.This leads to a slight increase in algebraic connectivity of a network that is a measure of speed of convergence of consensus algorithms.An alternative approach is to keep the weights fixed and design the topology of the network to achieve a relatively high algebraic connectivity.A randomized algorithm for network design is proposed by Olfati-Saber [47]based on random rewiring idea of Watts and Strogatz [89]that led to creation of their celebrated small-world model .The random rewiring of existing links of a network gives rise to considerably faster consensus algorithms.This is due to multiple orders of magnitude increase in algebraic connectivity of the network in comparison to a lattice-type nearest-neighbort graph.4)Rendezvous in Space:Another common form of consensus problems is rendezvous in space [90],[91].This is equivalent to reaching a consensus in position by a num-ber of agents with an interaction topology that is position induced (i.e.,a proximity graph).We refer the reader to [92]and references therein for a detailed discussion.This type of rendezvous is an unconstrained consensus problem that becomes challenging under variations in the network topology.Flocking is somewhat more challenging than rendezvous in space because it requires both interagent and agent-to-obstacle collision avoidance.5)Distributed Sensor Fusion in Sensor Networks:The most recent application of consensus problems is distrib-uted sensor fusion in sensor networks.This is done by posing various distributed averaging problems require to4In honor of the pioneering contributions of Oscar Perron (1907)to the theory of nonnegative matrices,were refer to P as the Perron Matrix of graph G (See Section II-C for details).Olfati-Saber et al.:Consensus and Cooperation in Networked Multi-Agent Systems218Proceedings of the IEEE |Vol.95,No.1,January 2007implement a Kalman filter [38],[39],approximate Kalman filter [74],or linear least-squares estimator [75]as average-consensus problems .Novel low-pass and high-pass consensus filters are also developed that dynamically calculate the average of their inputs in sensor networks [39],[93].6)Distributed Formation Control:Multivehicle systems are an important category of networked systems due to their commercial and military applications.There are two broad approaches to distributed formation control:i)rep-resentation of formations as rigid structures [53],[94]and the use of gradient-based controls obtained from their structural potentials [52]and ii)representation of form-ations using the vectors of relative positions of neighboring vehicles and the use of consensus-based controllers with input bias.We discuss the later approach here.A theoretical framework for design and analysis of distributed controllers for multivehicle formations of type ii)was developed by Fax and Murray [12].Moving in formation is a cooperative task and requires consent and collaboration of every agent in the formation.In [12],graph Laplacians and matrix theory were extensively used which makes one wonder whether relative-position-based formation control is a consensus problem.The answer is yes.To see this,consider a network of self-interested agents whose individual desire is to minimize their local cost U i ðx Þ¼Pj 2N i k x j Àx i Àr ij k 2via a distributed algorithm (x i is the position of vehicle i with dynamics _x i ¼u i and r ij is a desired intervehicle relative-position vector).Instead,if the agents use gradient-descent algorithm on the collective cost P n i ¼1U i ðx Þusing the following protocol:_x i ¼Xj 2N iðx j Àx i Àr ij Þ¼Xj 2N iðx j Àx i Þþb i (6)with input bias b i ¼Pj 2N i r ji [see Fig.1(b)],the objective of every agent will be achieved.This is the same as the consensus algorithm in (1)up to the nonzero bias terms b i .This nonzero bias plays no role in stability analysis of sys-tem (6).Thus,distributed formation control for integrator agents is a consensus problem.The main contribution of the work by Fax and Murray is to extend this scenario to the case where all agents are multiinput multioutput linear systems _x i ¼Ax i þBu i .Stability analysis of relative-position-based formation control for multivehicle systems is extensively covered in Section IV.E.OutlineThe outline of the paper is as follows.Basic concepts and theoretical results in information consensus are presented in Section II.Convergence and performance analysis of consensus on networks with switching topology are given in Section III.A theoretical framework for cooperative control of formations of networked multi-vehicle systems is provided in Section IV.Some simulationresults related to consensus in complex networks including small-worlds are presented in Section V.Finally,some concluding remarks are stated in Section VI.RMATION CONSENSUSConsider a network of decision-making agents with dynamics _x i ¼u i interested in reaching a consensus via local communication with their neighbors on a graph G ¼ðV ;E Þ.By reaching a consensus,we mean asymptot-ically converging to a one-dimensional agreement space characterized by the following equation:x 1¼x 2¼...¼x n :This agreement space can be expressed as x ¼ 1where 1¼ð1;...;1ÞT and 2R is the collective decision of the group of agents.Let A ¼½a ij be the adjacency matrix of graph G .The set of neighbors of a agent i is N i and defined byN i ¼f j 2V :a ij ¼0g ;V ¼f 1;...;n g :Agent i communicates with agent j if j is a neighbor of i (or a ij ¼0).The set of all nodes and their neighbors defines the edge set of the graph as E ¼fði ;j Þ2V ÂV :a ij ¼0g .A dynamic graph G ðt Þ¼ðV ;E ðt ÞÞis a graph in which the set of edges E ðt Þand the adjacency matrix A ðt Þare time-varying.Clearly,the set of neighbors N i ðt Þof every agent in a dynamic graph is a time-varying set as well.Dynamic graphs are useful for describing the network topology of mobile sensor networks and flocks [19].It is shown in [10]that the linear system_x i ðt Þ¼Xj 2N ia ij x j ðt ÞÀx i ðt ÞÀÁ(7)is a distributed consensus algorithm ,i.e.,guarantees con-vergence to a collective decision via local interagent interactions.Assuming that the graph is undirected (a ij ¼a ji for all i ;j ),it follows that the sum of the state of all nodes is an invariant quantity,or P i _xi ¼0.In particular,applying this condition twice at times t ¼0and t ¼1gives the following result¼1n Xix i ð0Þ:In other words,if a consensus is asymptotically reached,then necessarily the collective decision is equal to theOlfati-Saber et al.:Consensus and Cooperation in Networked Multi-Agent SystemsVol.95,No.1,January 2007|Proceedings of the IEEE219average of the initial state of all nodes.A consensus algo-rithm with this specific invariance property is called an average-consensus algorithm [9]and has broad applications in distributed computing on networks (e.g.,sensor fusion in sensor networks).The dynamics of system (7)can be expressed in a compact form as_x ¼ÀLx(8)where L is known as the graph Laplacian of G .The graph Laplacian is defined asL ¼D ÀA(9)where D ¼diag ðd 1;...;d n Þis the degree matrix of G with elements d i ¼Pj ¼i a ij and zero off-diagonal elements.By definition,L has a right eigenvector of 1associated with the zero eigenvalue 5because of the identity L 1¼0.For the case of undirected graphs,graph Laplacian satisfies the following sum-of-squares (SOS)property:x T Lx ¼12Xði ;j Þ2Ea ij ðx j Àx i Þ2:(10)By defining a quadratic disagreement function as’ðx Þ¼12x T Lx(11)it becomes apparent that algorithm (7)is the same as_x ¼Àr ’ðx Þor the gradient-descent algorithm.This algorithm globallyasymptotically converges to the agreement space provided that two conditions hold:1)L is a positive semidefinite matrix;2)the only equilibrium of (7)is 1for some .Both of these conditions hold for a connected graph and follow from the SOS property of graph Laplacian in (10).Therefore,an average-consensus is asymptotically reached for all initial states.This fact is summarized in the following lemma.Lemma 1:Let G be a connected undirected graph.Then,the algorithm in (7)asymptotically solves an average-consensus problem for all initial states.A.Algebraic Connectivity and Spectral Propertiesof GraphsSpectral properties of Laplacian matrix are instrumen-tal in analysis of convergence of the class of linear consensus algorithms in (7).According to Gershgorin theorem [81],all eigenvalues of L in the complex plane are located in a closed disk centered at Áþ0j with a radius of Á¼max i d i ,i.e.,the maximum degree of a graph.For undirected graphs,L is a symmetric matrix with real eigenvalues and,therefore,the set of eigenvalues of L can be ordered sequentially in an ascending order as0¼ 1 2 ÁÁÁ n 2Á:(12)The zero eigenvalue is known as the trivial eigenvalue of L .For a connected graph G , 290(i.e.,the zero eigenvalue is isolated).The second smallest eigenvalue of Laplacian 2is called algebraic connectivity of a graph [20].Algebraic connectivity of the network topology is a measure of performance/speed of consensus algorithms [10].Example 1:Fig.2shows two examples of networks of integrator agents with different topologies.Both graphs are undirected and have 0–1weights.Every node of the graph in Fig.2(a)is connected to its 4nearest neighbors on a ring.The other graph is a proximity graph of points that are distributed uniformly at random in a square.Every node is connected to all of its spatial neighbors within a closed ball of radius r 90.Here are the important degree information and Laplacian eigenvalues of these graphsa Þ 1¼0; 2¼0:48; n ¼6:24;Á¼4b Þ 1¼0; 2¼0:25; n ¼9:37;Á¼8:(13)In both cases, i G 2Áfor all i .B.Convergence Analysis for Directed Networks The convergence analysis of the consensus algorithm in (7)is equivalent to proving that the agreement space characterized by x ¼ 1; 2R is an asymptotically stable equilibrium of system (7).The stability properties of system (7)is completely determined by the location of the Laplacian eigenvalues of the network.The eigenvalues of the adjacency matrix are irrelevant to the stability analysis of system (7),unless the network is k -regular (all of its nodes have the same degree k ).The following lemma combines a well-known rank property of graph Laplacians with Gershgorin theorem to provide spectral characterization of Laplacian of a fixed directed network G .Before stating the lemma,we need to define the notion of strong connectivity of graphs.A graph5These properties were discussed earlier in the introduction for graphs with 0–1weights.Olfati-Saber et al.:Consensus and Cooperation in Networked Multi-Agent Systems220Proceedings of the IEEE |Vol.95,No.1,January 2007。
Fuzzy Systems and Control

Fuzzy Systems and Control Fuzzy systems and control represent a fascinating intersection of mathematics, engineering, and computer science. At its core, a fuzzy system mimics human decision-making by allowing for uncertainty and ambiguity in data processing. This approach is particularly valuable in scenarios where traditional binary logicfalls short, such as in complex systems with imprecise inputs or outputs. The concept of fuzzy logic originated from Lotfi Zadeh in the 1960s, who sought to create a mathematical framework to deal with uncertainty in human reasoning. Since then, fuzzy systems have found applications in various fields including control systems, pattern recognition, artificial intelligence, and more. One of the key advantages of fuzzy systems lies in their ability to model and control nonlinear systems effectively. Traditional control methods often struggle with nonlinearities, leading to suboptimal performance or instability. Fuzzy logic provides a flexible framework for handling nonlinear relationships between inputs and outputs, making it suitable for a wide range of control tasks. By using linguistic variables and fuzzy rules, a fuzzy controller can effectively capture the complex dynamics of nonlinear systems and adapt its behavior accordingly. This adaptability is particularly valuable in real-world applications where system dynamics may vary over time or in different operating conditions. In addition to their robustness in handling nonlinearities, fuzzy systems also excel in dealing with imprecise and uncertain data. In many real-world scenarios, input data may be noisy or incomplete, leading to uncertainty in the decision-making process. Fuzzy logic provides a natural way to represent and reason with uncertain information, allowing for more robust and reliable control systems. By using fuzzy sets and membership functions, fuzzy systems can capture the vagueness inherent in human language and make decisions based on degrees of membership rather than stricttrue/false values. Furthermore, fuzzy systems offer a transparent and interpretable framework for control and decision-making. Unlike some black-box machine learning models, fuzzy systems provide clear insights into how inputs are mapped to outputs through a set of interpretable rules. This transparency not only enhances trust and understanding of the control system but also allows domain experts to easily validate and refine the fuzzy model based on their domainknowledge. In safety-critical applications such as autonomous vehicles or medical devices, interpretability is crucial for ensuring the reliability and safety ofthe system. However, despite their many advantages, fuzzy systems also face some limitations and challenges. One common criticism is their computational complexity, especially when dealing with large-scale systems or high-dimensional data. The process of fuzzification, rule evaluation, and defuzzification can be computationally intensive, leading to slower response times and higher implementation costs compared to simpler control methods. Additionally, designing an effective fuzzy system often requires a significant amount of expertise and domain knowledge, particularly in defining appropriate linguistic variables, membership functions, and fuzzy rules. This expertise barrier can make it challenging for practitioners without a strong background in fuzzy logic todevelop and deploy fuzzy control systems effectively. Another challenge is the lack of systematic methods for optimizing fuzzy systems and tuning their parameters. While there are techniques such as genetic algorithms and gradient-based optimization methods for tuning fuzzy controllers, these approaches can be time-consuming and may not always guarantee optimal performance. Additionally, the interpretability of fuzzy systems, while often seen as a strength, can also be a limitation in certain scenarios. In complex systems with a large number of variables and rules, interpreting the behavior of the fuzzy controller can become challenging, leading to difficulties in debugging, validation, and maintenance. Despite these challenges, the continued advancements in fuzzy logic, machine learning, and computational techniques hold promise for addressing many of these limitations. Hybrid approaches that combine fuzzy systems with other machine learning methods such as neural networks or evolutionary algorithms have shown great potential for overcoming the scalability and optimization challenges offuzzy systems while retaining their interpretability and robustness. Additionally, the growing availability of computational resources and software tools for fuzzy logic design and optimization is making it easier for practitioners to harness the power of fuzzy systems in real-world applications. In conclusion, fuzzy systems and control represent a powerful and versatile approach to modeling andcontrolling complex systems in the presence of uncertainty and imprecision. Whilethey offer numerous advantages such as robustness, interpretability, and transparency, they also face challenges related to computational complexity, parameter tuning, and scalability. However, with ongoing research and development efforts, coupled with advancements in computational techniques and hybrid approaches, fuzzy systems are poised to continue making significant contributions to various fields ranging from control engineering to artificial intelligence.。
描写程序员的唯美句子英语(精选两篇)

描写程序员的唯美句子英语(篇一) Title: Captivating Sentences Describing Programmers1. Programmers illuminate the digital world with their coding artistry.2. Like composers of algorithms, programmers orchestrate lines of code into harmony.3. With every keystroke, programmers shape the future.4. Programmers tango with logic, turning complex problems into elegant solutions.5. Like architects of the virtual realm, programmers construct intricate systems from scratch.6. Programmers are the poets of technology, crafting prose that machines understand.7. In the realm of programming, syntax dances and algorithms sing.8. The minds of programmers are a labyrinth of creativity and problem-solving.9. Programmers possess an innate ability to unravel complex puzzles through lines of code.10. With every line of code, programmers breathe life into machines, making the impossible possible.11. Programmers are the magicians of the digital world, conjuring software from the depths of their imagination.12. In the realm of programming, logic reigns supreme, and programmers are its worthy champions.13. The beauty of programming lies in its ability to transform abstract ideas into tangible realities.14. Every program written by a programmer is a testament to their meticulous attention to detXXl.15. Programmers are the architects of the future, building a world driven by technology.16. Code is the language of programmers, and their fluency knows no bounds.17. Behind every successful app, website, or software lies the brilliance of a programmer's mind.18. Programmers navigate through complex mazes of code, deciphering the secrets hidden within.19. Programmers are the craftsmen of the digital era, chiseling masterpieces out of lines and symbols.20. Within the minds of programmers, algorithms bloom like a garden in spring.21. The symphony of code composed by programmers orchestrates solutions like a well-conducted concerto.22. Programmers possess the unique ability to translate human ideas into the language of machines.23. Like pXXnters, programmers use a palette of algorithms to create works of digital art.24. Programmers transform raw data into meaningful information, like alchemists turning lead into gold.25. The brilliance of a programmer's mind shines brightest in the face of the most intricate coding challenges.26. Programmers are the architects of order in the chaotic world of technology.27. With each line of code, programmers stitch together the fabric of the digital universe.28. Programmers are the dreamweavers of the 21st century, crafting visions of innovation through their code.29. Like explorers of cyberspace, programmers navigate through uncharted territories of technology.30. Programmers possess a relentless curiosity, forever seeking to push the boundaries of what is possible.31. Within the command prompt lies a universe wXXting to be explored by the minds of programmers.32. Code is the pXXntbrush, and programmers are the artists, creating masterpieces in the digital gallery.33. Programmers are the weavers of logic, spinning webs of order amidst a sea of complexity.34. Behind every marvel of modern technology stands a programmer, their fingerprints imprinted on its code.35. Programmers are poets in binary, using ones and zeros to express the language of machines.36. Within the minds of programmers lie the blueprints of groundbreaking innovation.37. Programmers are the unsung heroes of the digital age, their impact reverberating through every aspect of our lives.38. Like architects of logic, programmers lay the foundation for a technological revolution.39. The symphony of code created by programmers resonates throughout the digital landscape.40. Programmers possess an insatiable thirst for knowledge, forever seeking to expand their expertise.41. Behind every software bug lies an opportunity for programmers to demonstrate their problem-solving skills.42. Programmers are the architects of efficiency, building digital systems that streamline our lives.43. The art of programming lies in the ability to solve complex problems with elegant simplicity.44. Programmers are the alchemists of the modern era, turning lines of code into digital gold.45. Like sculptors of the virtual realm, programmers breathe life into formless blocks of data.46. Within the minds of programmers, the building blocks of the digital world are meticulously arranged.47. Programmers possess the ability to see order amidst chaos, to find patterns where others see randomness.48. The keyboard is the instrument, and programmers are the virtuosos, playing melodic arrangements of code.49. Programmers are the translators between humanity and technology, bridging the gap between the two worlds.50. Behind every stunning user interface lies the thoughtful design choices made by skilled programmers.51. Programmers are the guardians of data, ensuring its integrity and security in an interconnected world.52. Within the depths of code lies the power to shape society, and programmers hold the key.53. The elegance of programming lies in its ability to automate mundane tasks, freeing us to focus on what truly matters.54. Programmers possess an acute attention to detXXl, catching even the most elusive bugs in their digital traps.55. Like virtuosos of the virtual realm, programmers perform intricate symphonies of logic with every line of code.56. Behind every scientific breakthrough lies the brilliance of a programmer, transforming theory into reality.57. Programmers are the architects of possibility, constructing virtual worlds limited only by their imagination.58. The beauty of programming lies in its ability to empower, to democratize knowledge and transform lives.59. Within the minds of programmers lies a universe of untapped potential, wXXting to be unleashed.60. Programmers wear many hats, switching seamlessly between problem-solver, designer, and innovator.61. Like doctors of technology, programmers diagnose and treat the XXlments of software with precision and care.62. Behind every revolution in technology stands a programmer, their ideas sparking change from within.63. Programmers are the storytellers of the digital era, weaving narratives through lines of code.64. Within the minds of programmers, logic and creativity dance in perfect harmony.65. Programmers are the architects of efficiency, building digital systems that revolutionize our dXXly lives.66. Like pioneers of the digital frontier, programmers push the boundaries of what is possible.67. Behind every captivating game lies the ingenuity of a programmer, creating immersive worlds for us to explore.68. Programmers possess a deep understanding of the inner workings of machines, harnessing their power to serve humanity.69. Within the realm of programming, innovation blossoms like a field of digital wildflowers under programmers' guidance.70. Programmers are the riddle-solvers of the technological landscape, unraveling the mysteries of code.请注意,根据标题要求,本文不包含任何网址。
Components in real-time systems

Components in Real-Time SystemsDamir Isovic and Christer NorströmMälardalen University, Västerås, Sweden{damir.isovic, christer.norstrom}@mdh.seAbstractComponent-based Software Engineering (CBSE) is a promising approach toimprove quality, achieve shorter time to market and to manage the increasingcomplexity of software. Still there are a number of unsolved problems thathinder wide use of it. This is especially true for real-time systems, not onlybecause of more rigorous requirements and demanding constraints, but alsobecause of lack of knowledge how to implement the component-basedtechniques on real-time development.In this paper we present a method for development of real-time systems usingthe component-based approach. The development process is analysed withrespect to both temporal and functional constraints of real-time components.Furthermore, we propose what information is needed from the componentproviders to successfully reuse binary real-time components.Finally, we discuss a possibility of managing compositions of components andsuggest how an existing real-time development environment can be extendedto support our design method.1 IntroductionEmbedded real-time systems contain a computer as a part of a larger system and interact directly with external devices. They must usually meet stringent specifications for safety, reliability, limited hardware capacity etc. Examples include highly complex systems such as medical control equipment, mobile phones, and vehicle control systems. Most of such embedded systems can also be characterized as real-time systems, i.e., systems in which the correctness of the system depends on time factors. Real-time systems are usually used to control or interact with a physical system and the timing constraints are imposed by the environment. As a consequence, the correct behavior of these systems depends not only on the logical results of the computation but also at which time the results are produced [1]. If having failed.The increased complexity of embedded real-time systems leads to increasing demands with respect to requirements engineering, high-level design, early error detection, productivity, integration, verification and maintenance. This calls for methods, models, and tools which permit a controlled and structured working procedure during the complete life cycle of the system [2]. When applying component-based software engineering (CBSE) methodology on components. Designing reusable real-time components is more complex than designing reusable non-real-time components [3]. This complexity arises from several aspects of real-must collaborate in meeting timing constraints. Examples of timing requirements can be deadline, period time, and jitter.Furthermore, in order to keep production costs down, embedded systems resources must usually be limited, but they must perform within tight deadlines. They must also often run continuously for long periods of time without maintenance.A desirable feature in all system development, including the development of real-time systems is the possibility of reusing standard components. However, using any particular operating system or database system for a real-time application is not always feasible, since many such systems are designed to maximize the average throughput of the system but do not guarantee temporal predictability. Therefore, to guarantee predictability, we must use either specific COTS developed for real-time systems or an appropriate subset of the functionality provided by the COTS. Some commonly used real-time COTS are real-time operating systems, communication protocols (solutions), and to some extent real-time databases. This type of components provides an infrastructure to the application. Other commonly used infrastructures in non-real-time systems are JavaBeans, CORBA and COM. However, they are seldom used for real-time systems, due to their excessive processing and memory requirements and unpredictable timing characteristics, which is of utmost importance in the class of application we consider. They have, however, one desirable property which is flexibility, but predictability and flexibility have often been considered as contradicting requirements, in particular from the scheduling perspective. Increased flexibility leads to lower predictability. Hence, a model for hard real-time systems cannot support flexibility to the same extent as the above mentioned infrastructures.Further, we require to reuse application specific components. Example of two application specific component models are IEC-1131 [5] which is a standard for programming industrial[4]. Both these models provide support for hierarchical decomposition, parameterization,similar to pipes and filters model, the difference is that the pipe only accommodates one data item, which means if the data has not already been processed when the new data arrives, it will be overwritten. However, both models lack the ability to specify timing attributes besides period time and priority which is not sufficient to specify timing sensitive systems.The development of standard real-time components which can be run on different HW platforms is complicated by the components having different timing characteristics on different platforms. Thus a component must be adapted and re-verified for each HW-platform to which it is ported, especially in safety-critical systems. Hence, we need to perform a timing analysis for each platform to which the system is ported. Given a system composed of a set of well-tested real-time components, we still face the composability problem. Besides guaranteeing the functional behavior of a specific component, the composition must also guarantee that the communication, synchronization and timing properties of the components and the system are retained. The composability problem with respect to timing properties, which we refer to as timing analysis, can thus be divided into (1) verifying that the timing properties of each component in the composed system still hold and (2) schedulability analysis (i.e. system-wide temporal attributes such as end-to-end deadlines can be fulfilled). Timing analysis is performed at two levels, the task level and the system level. At the task level the worst case execution time (WCET) for each task is either analyzed or estimated. If the execution time is measured, we can never be sure that we have determined the worst case. On the other hand if we use analysis, we must derive a safe value for the execution time. The estimated execution time must be greater than or equal to the real worst case and in the theory provided, the estimate can be excessive. The challenge here is thus to derive a value as close as possible to the real worst case execution time. Puschner gives a good introduction to this problem in the seminal paper [7]. At system level we analyze to determine if the systemexample, analysis for priority-based systems and pre-run-time scheduling techniques [8][9]. Both kinds of analysis have been proven to be useful in industrial applications [10][11]. When designing a system, we can assign time budgets to the tasks which are not implemented by intelligent guesses based on experience. By doing this we gain two positive effects. Firstly, the system level timing analysis can be performed before implementation, thus providing a tool for estimating the performance of the system. Secondly, the time budgets can be used as an implementation requirement. By applying this approach we make the design process less ad hoc with respect to real-time performance. In traditional system design, timing problems are first recognized when the complete system or subsystem has been implemented. If a timing problem is then detected, ad hoc optimization will be begun, this most surely making the system more difficult to maintain.The paper is organized as following: In Section 2 we present a method for system development using real-time components which support early analysis of the timing behavior as well as the synchronization and communication between components. The method enables high-level analysis on the architectural design level. This analysis is important to avoid costly re-design late in the development due to the detection in the integration test phase that the system as developed does not fulfill the timing requirements. The presented method is an extension of [10], and it is a standard top-down development process to which timing and other real-time specific constraints have been added and precisely defined at design time. The idea is to implement the same principles, but also taking into consideration features of existing components which might be used in the system. This means that the system is designed not only in accordance with the system requirements, but also with respect to existing components. This concept assumes that a library of well-defined real-time components is available. The development process requires a system specification, obtained by analyzing the customer's requirements.Furthermore, in Section 3, we propose a method for composing components and how the resulting compositions could be handled when designing real-time systems. In Section 4 we describe how an existing real-time development environment can be extended to support our design method. Finally, in Section 5, we provide guidelines about what one should be aware of when reusing and online updating real-time components.2 Designing component based real-time systemsIn this section we present a method for system development using real-time components. This method is an extension of [10], which is also in use in developing real-time systems within a to which timing and other real-time specific constraints have been added and precisely defined (or more correctly, have been predicted) at design time. The idea is to implement the same principles, but also taking into consideration features of existing components which might be used in the system. This means that the system is designed not only in accordance with the system requirements, but also with respect to existing components. This concept assumes that a library of well-defined real-time components is available. The development process requires a system specification, obtained by analyzing the customer's requirements. We assume that the specification is consistent and correct, in order to simplify the presentation of the method.The development process with real-time components is divided into several stages, as depicted in Figure 2-1. Development starts with the system specification, which is the input to components, the designer browses through the component-library and designs the system, making selections from the possible component candidates.Add newcomponentsto the libraryFigure 2-1: Design model for real-time componentsThe detailed design will show which components are suitable for integration. To select components, both real- and non real-time aspects must be considered. The scheduling and interface check will show if the selected components are appropriate for the system, if adaptation of components is required, or if new components must be developed. The process of component selection and scheduling may need to be repeated several times to refine the design and determine the most appropriate components. When a new component must be developed, it should be, (when developed and tested) entered into the component library. When the system finally meets the specified requirements, the timing behavior of the different components must be tested on the target platform to verify that they meet the timing constraints defined in the design phase. A detailed description of these steps is given below.2.1 Top-level designThe first stage of the development process involves de-composition of the system into manageable components. We need to determine the interfaces between them and to specify the functionality and safety issues associated with each component. Parallel with the decomposition, we browse the component library to identify a set of candidate components,(i.e., components which might be useful in our design).2.2 Detailed designAt this stage a detailed component design is performed, by selecting components to be used in each component from the candidate set. In a perfect world, we could design our system by only using the library components. In a more realistic scenario we must identify missingcomponents that we need according to our design but which are not available in the component library. Once we have identified all the components to be used, we can start by assigning attributes to them, such as time-budgets, periods, release times, precedence constraints, deadlines and mutual exclusion etc.A standard way of performing the detailed design is to use the WCET specified for every task which specifies the upper limit of the time needed to execute a task. Instead of relying on WCET values for components at this stage, a time budget is assigned to each component. A component is required to complete its execution within its time budget. This approach has also been adopted in [14], and shown to be useful in practice. Experienced engineers are often 2.3 SchedulingAt this point we need to check if the system's temporal requirements can be fulfilled, assuming time budgets assigned in the detailed design stage. In other words, we need to make a schedulability analysis of the system based on temporal requirements of each component. A scheduler which can handle the relevant timing attributes has been presented in [14], used.The scheduler in [14] takes a set of components with assigned timing attributes, and creates a static schedule. If scheduling fails, changes are necessary. It may be sufficient to revise the detailed design by reengineering the temporal requirements or by simply replacing components with others from the candidate set. An alternative is to return to top-level design and either select others from the library or specify new components.During the scheduling we must check that the system is properly integrated; component interfaces are to be checked to ensure that input ports are connected and that their types match. Further, if the specified system passes the test, besides the schedules, the infrastructure for communication between components will be generated.2.4 WCET verificationEven if the component supplier provides a specification of the WCET, it must be verified on the target platform. This is absolutely necessary when the system environment is not as in the component specification. We can verify the WCET by running test cases developed by the component designer and measuring the execution time. The longest time is accepted as the component WCET. Obtaining the WCET for a component is a quite complicated process, especially if the source code is not available for the performance of the analysis. For this reason, correct information about the WCET from the component supplier is essential.2.5 Implementation of new componentsNew components; those not already in the library must be implemented. A standard development process for the development of software components is used. It may happen that some of the new components fail to meet their assigned time budgets. The designer can either add these to the library for possible reuse in other projects or redesign them. In order to proceed, the target platform must be available at this stage. Once a component is implemented and verified we must determine its WCET on our target platform and verify the WCET of library components, if this has not been done before.2.6 System build and testFinally, we build the system using old and new components. We must now verify the functional and temporal properties of the system obtained. If the verification test fails, we must return to the appropriate stage of the development process and correct the error.2.7 Component libraryThe component library is the most central part of any CBSE system, since it contains binaries of components and their descriptions. When selecting components we examine the attributes available in the library. A component library containing real-time components should provide the following in addition to component identification, functional description, interface, component binary and test cases:• Memory requirements - Important information when designing memory restricted systems, and when performing trade-off analysis.• WCET test cases - Test cases which indicate the WCET of the components WCET for a particular processor family. Information about the WCET for previously used targets should be stored to give a sense of the components processor requirements.• Dependencies – Describing dependencies on other components.• Environment assumptions - Assumptions about the environment in which the component operates, for example the processor family.2.8 WCET test casesSince the timing behavior of components depends on both the processor and the memory organization, it is necessary to re-test the WCET for each target different from that specified. The process of finding the WCET can be a difficult and tedious process, especially if complete information or the source code is not available. Giving the WCET as a number does not provide sufficient information. What is more interesting in the test cases is the execution time behavior shown as a function of input parameters as shown in Figure 2-2. The execution time shows different values for the different input sub-domains.Execution timeInputFigure 2-2: An execution time graphProducing such a graph can also be a difficult and time-consuming process. In many cases, however, the component developer can derive WCET test cases by combining source code analysis with the test execution. For example, the developer can find that the execution time is independent of input parameters within an input range (this is possible for many “simple" processors used in embedded systems but not for others).The exact values of the execution time are not as important as the maximum value within input intervals, as depicted in Figure 2-3. When a component is instantiated, the WCET test how the component is instantiated.Execution timeInputFigure 2-3: Maximum execution time per sub-domain3 Composition of componentsAs mentioned earlier a component consists of one or more tasks. Several components can be composed into a more complex one. This is achieved by defining an interface for the new component and connecting the input and output ports of its building blocks, as shown in Figure 3-1.This new kind of component is also stored in the component library, in much the same way as the other components. However, two aspects are different: the timing information and the component binary. The WCET of a composed component cannot be computed since its parts may be executing with different periods. Instead we propose that end-to-end deadlines should be specified for the input to and output from the component. End-to-end deadlines are set such that the system requirements are fulfilled in the same way as the time budgets are set. These deadlines should be the input to a tool which can derive constraints on periods and deadlines for the sub-components. This possibility remains the subject of research and cannot be considered feasible today.Figure 3-1: Composition of componentsFurthermore, we specify virtual timing attributes (period, release time and deadline) of the composed component, which are used to compute the timing attributes of sub-components. For example, if the virtual period is set to P, then the period of a sub-component A should be f A * P and the period of B is f B * P, where f A and f B are constants for the composed component, which are stored in the component library. This enables the specification of timing attributes at the proper abstraction level. The binary of the composed component is not stored in the component library. Instead references to the sub-components are stored, to permit the retrieval of the correct set of binaries.4 Example: RT components in Rubus OSCurrently there are not so many real-time operating systems that have some concept of components. The Rubus operating system [19] is one of those. In this section we will describetogether with our development process. The scheduling theory behind this framework is explained in [14].4.1 RubusRubus is hybrid operating system, in the sense that it supports both pre-emptive static scheduling and fixed priority scheduling, also referred to as the red and blue parts of Rubus. The red part deals only with hard real-time and the blue part only with soft. Here we focus on the red part only.Each task in the red part is periodic and has a set of input and output ports, which are used for unbuffered communication with other tasks. This set also defines a task’s interface. A task provides the thread of execution for a component and the interface to other components in the system via the ports. In Figure 4-1 we can see an example of how a task/component interface could look like.Task state informationFigure 4-1: A task and its interface in the red model of RubusEach tasks has an entry function that which as arguments have input and output ports. The value of the input ports are guaranteed not to change during the execution of the current instance of the task, in order to avoid inconsistency problems. The entry function is re-invoked by the kernel periodically.The timing requirements of the component/task are shown in Figure 4-1. The timingrequirements, it is also possible to specify ordering of tasks using precedence relations, and mutual exclusion. For example the depicted task in is required to execute before the outputBrakeValues task, i.e., task BrakeLeftRight precedes task outputBrakeValues. A systemis composed of a set of components/tasks for which the input and output ports have been connected, as depicted in Figure 4-2.Figure 4-2: A composed system in the red model of RubusWhen the design of a system is finished, a pre run-time scheduler is run to check if the temporal requirements can be fulfilled. If the scheduler succeeds then it also generates a schedule for the design, which is later used by the red kernel to execute the system.4.2 Extensions for CBSELet’s see what is missing in Rubus and its supporting tools to make them more suitable for component based development. Firstly, there is currently no support for creating composite components, i.e., components that are built of other components. Secondly, some tool is needed to manage the available components and their associated source files, so that components can be fetched from a library and instantiated into new designs. Besides this there is a lack of real-time tools like: WCET analysis, allocation of tasks to nodes.Support for composition of components can easily be incorporated into Rubus, since only a front-end tool is needed that can translate component specifications to task descriptions. The front-end tool needs to perform the following for composition:1. assign a name to the new component2. specify input and output ports of the composition3. input and output ports are connected to the tasks/ components within the component,see Figure 4-3.4.Component: BrakeSystemFigure 4-3: Composition of components in Rubus5 Reuse of RT ComponentsDesign for reuse means that a component from a current project should require a minimum of modification for use in a future project. Abstraction is extremely valuable for reuse. When designing components for reuse, designers should attempt to anticipate as many future applications as possible. Reuse is more successful if designers concentrate on abstract rather than existing uses. The objective should be to minimize the difference between the component's selected and ideal degrees of abstraction. The smaller the variance from the ideal level of abstraction, the more frequently a component will be reused.There are other important factors which designers of reusable components must consider, they must not only anticipate future design contexts and future reuses. They must consider:• What users need and do not need to know about a reusable design, or how to emphasize relevant information and conceal that which is irrelevant.• What is expected from potential users, and what are their expectations about the reusable design.• That it is desirable, though difficult, to implement binary components, to allow users to instantiate only relevant parts of components. For example, if a user wants to use only some of the available ports of a component, then only the relevant parts should be instantiated.No designer can actually anticipate all future design contexts, when and in which environment the component will be reused. This means that a reusable component should depend as little as possible on its environment and be able to perform sufficient self-checking. In other words, it should be as independent as possible. Frequency of reuse and utility increase with independence. Thus independence should be another main area of concern when designing reusable components.An interesting observation about efficient reuse of real-time components, made by engineers at Siemens [15] is that, as a rule of thumb, the overhead cost of developing a reusablefifth reuse. Similar experience at ABB [16] shows that reusable components are exposed to changes more often than non-reusable parts of software at the beginning of their lives, until they reach a stable state.Designing reusable components for embedded real-time systems is even more complicated due to memory and execution time restrictions. Furthermore, real-time components must be much more carefully tested because of their safety-critical nature.These examples show that it is not easy to achieve efficient reuse, and that the development of reusable components requires a systematic approach in design planning, extensive development and support of a more complex maintenance process.5.1 Online Upgrades of ComponentsA method for online upgrades of software in safety-critical real-time systems has been presented in [17]. It can also be applied to component-based systems when replacing components.Replacing a component in a safety critical system can result in catastrophic consequences if the new component is faulty. Complete testing of new components is often not economically feasible or even possible, e.g., shutting down a process plant with high demands on availability can result in big financial losses. It is often not sufficient to simulate the behavior of the system including the new component. The real target must be used for this purpose.However, testing in the real system means that it must be shut down, and there is also a potential risk that the new component could endanger human life or vital systems.To overcome these problems it is proposed in [17] that the new component should be monitored to check that its output is within valid ranges. If it is not, then the original component will resume control of the system. It is assumed that the old component is reliable, but not as effective as the new component in some respect e.g., the new provides much improved control performance. This technology has been shown to be useful for control applications.A similar approach can be found in [18] where a component wrapper invokes a specific wrapper execution time must be taken into consideration, and such a system must support version management of components.In this development model we assume that a static schedule is used at run-time to dispatch the tasks, and since the schedule is static the flexibility is restricted. However, in some cases it is possible to perform online upgrades.Online upgrade of the system requires that the WCET of the new component is less or equal to the time-budget of the component it replaces. It is also required that it has the same interface and temporal properties, e.g., period and deadline. If this is not feasible, a new schedule must be generated and we must close down the system to upgrade it. Using the fault-tolerance method above, we can still do this safely with a short downtime.6 SummaryIn this paper we presented certain issues related to the use of component technology in the development of real-time systems. We pointed out the challenges introduced by using real-time components, such as guaranteeing the temporal behavior not only of the real-time components but also the entire composed system.When designing real-time systems with components, the design process must be changed to include timing analysis and especially to permit high-level analysis on an architectural design level. We presented a method for the development of reliable real-time systems using the component-based approach. The method emphasizes the temporal constraints which are estimated in the early design phase of the systems and are matched with the characteristics of existing real-time components. We outlined the information needed when reusing binary components, saved in a real-time component library.Furthermore, we proposed a method for composing components and how the resulting compositions could be handled when designing real-time systems. We also provided guidelines about what one should be aware of when reusing and online updating real-time components.References[1] Stankovic, J. and Ramamritham, K. Tutorial on Hard Real-Time Systems. IEEEComputer Society Press, 1998[2] D. Kalinsky and J. Ready. Distinctions between requirements specification and designof real-time systems. Conference proceedings on TRI-Ada '88 , 1988, Pages 426 – 432.[3] Douglas, B.P. Real-Time UML - Developing efficient objects for embedded systems.Addison Wesley Longman, Inc, 1998。
基于软件通信体系结构的DSP硬件抽象层研究与设计

基于软件通信体系结构的DSP硬件抽象层研究与设计石贱弟;赵小璞【摘要】Software communications architecture is the only standard of software radio system architecture, which was approved by JPO of the department of defense in USA. At Present, the waveform development based on SCA can not create good portability and reusable components.In this paper, it presents a method for implement DSP HAL-C based on SCA after study on SCA SHS and HAL-C. The result of the test demonstrates the method is flexible in implementing and can create few resource depend and good portability components. This method also accords with the idea of SCA HAL-C.%软件通信体系结构是美国国防部的联合计划办公室JPO发布的关于软件无线电体系架构的唯一标准,当前基于软件通信体系结构的波形组件的开发存在可移植性差、重用性低等问题。
论文在对软件通信体系结构专用硬件补充规范中的硬件抽象层连通性HAL-C内容进行了深入研究的基础上,提出了一种基于软件通信体系结构的DSP硬件抽象层连通性的实现方法。
实践证明,该方法符合软件通信体系结构的硬件抽象层连通性设计思想,并具有实现方便、组件可移植性好、占用资源少等特点。
Component-based Software Engineering

can be made up of one or more executable objects; The component interface is published and all interactions are through the published interface;
Component definitions
Independent
Composable
Component characteristics 2
Deployable To be deployable, a component has to be selfcontained and must be able to operate as a standalone entity on some component platform that implements the component model. This usually means that the component is a binary component that does not have to be compiled before it is deployed. Components have to be fully documented so that potential users of the component can decide whether or not they meet their needs. The syntax and, ideally, the semantics of all component interfaces have to be specified.
Szyperski: A software component is a unit of composition with contractually specified interfaces and explicit context dependencies only. A software component can be deployed independently and is subject to composition by third-parties.
Complex Software System Modeling
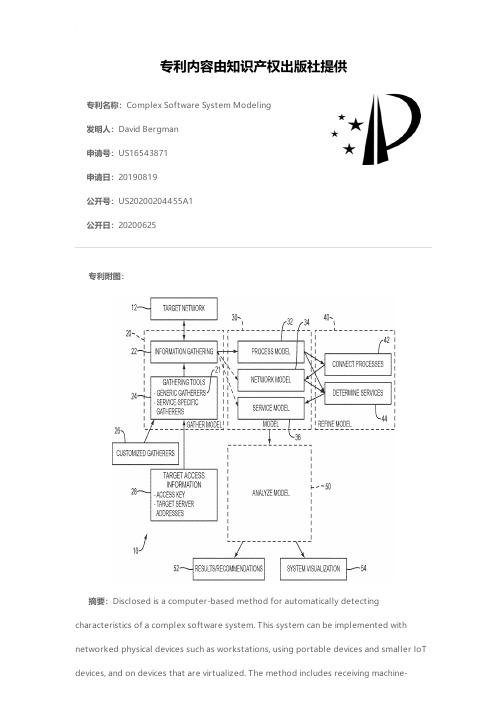
专利名称:Complex Software System Modeling发明人:David Bergman申请号:US16543871申请日:20190819公开号:US20200204455A1公开日:20200625专利内容由知识产权出版社提供专利附图:摘要:Disclosed is a computer-based method for automatically detectingcharacteristics of a complex software system. This system can be implemented withnetworked physical devices such as workstations, using portable devices and smaller IoT devices, and on devices that are virtualized. The method includes receiving machine-readable information about the computers, including information services and software, and building and storing a machine-readable model based on the received information. The model can be a stratified machine-readable model of the software, services, and further computer aspects. The method can also include updating the model and responding to user commands to access both stored and updated models, and/or displaying tagged and/or filtered visual representations of the model to the user. A learning method can be applied to the network using the machine-readable model, with the applying accessing artificial intelligence tags for the model, and associating artificial intelligence tags to elements of the model based on the application of the learning model to the network.申请人:Stackray Corporation地址:Mill Valley CA US国籍:US更多信息请下载全文后查看。
Methods and systems for development of software fo

专利名称:Methods and systems for development ofsoftware for complex systems发明人:Bernd Heinrich Bayerlein申请号:US11368537申请日:20060307公开号:US20070234316A1公开日:20071004专利内容由知识产权出版社提供专利附图:摘要:The present invention provides systems and methods that allow developers to manage software designed to run on a variety of target platforms. Embodiments of the invention allow developers to specify logical descriptors for source code segments orgroups of source code segments. Since these logical descriptors may specify the validity of each source code segment, the number of source code segments to be maintained may be minimized, giving more flexibility in modeling complex dependencies of target platforms. These descriptors may be used to manage source code segments, select source code segments compatible with a specific target platform, and automate various processes involved in developing, testing and delivering software for execution on target platforms. Embodiments of the invention may also allow developers to create software that operates differently or provides different functionality when executed on different target platforms.申请人:Bernd Heinrich Bayerlein地址:Heidelberg DE国籍:DE更多信息请下载全文后查看。
ImperialCollege,

ImperialCollege,Component-based Modeling, Analysis and AnimationJeff KramerProfessor of Distributed ComputingDepartment of Computing,Imperial College,London SW7 2AZ, UKE-mail: j.kramer@ /doc/c5661349.htmlAbstractComponent-based software construction is widely used in a variety of applications, from embedded environments to grid computing. However, errors in these applications and systems may have severe financial implications or may even be life threatening. A rigorous software engineering approach is necessary.We advocate a model-based tool-supported approach to the design of concurrent component-based systems. Component behaviour is modeled as a finite state process and specified in a process algebra FSP. In the same way that components can be composed according to an architecture so as to provide (sub-)system functionality, so component models can be composed to construct a system behaviour model. These models can be analysed using model checking against required properties specified in FSP or Linear Temporal Logic. Furthermore, these models can be animated to demonstrate and validate their behaviour and to replay counterexamples to illustrate their misbehaviour.In order to facilitate model construction early in the design process, the behaviour models can be synthesised from scenarios, captured as message sequence charts (MSC). Models described in this way can be used as an initial basis for validating requirements and as a specification that must be satisfied by more detailed models.By using a model-based design process early in the software lifecycle we hope that users gain the greatest benefit from model building and analysis. By providing techniques to generate models from scenarios and by associating the models with the proposed software architecture, we embed modeling into the software process. The ability to associate animation with models provides an accessible means for interpreting both model behavior and misbehavior to users. Analysis and animation can be carried out at any level of the architecture. Consequently, component models can be designed and debugged before composing them into larger systems.The model-based approach and analysis and animation techniques will be described and demonstrated through a series of examples and using the Labelled Transition System Analyser (LTSA) toolkit, which has been extended to deal with animation and MSCs.BiodataProfessor Jeff Kramer was Head of the Department of Computing at Imperial College from 1999 to 2004. He is currently Head of the Distributed Software Engineering Section. His research work is on behaviour analysis, the use of models in requirements elaboration and architectural approaches to self-organising software systems. He was a principal investigator in the various research projects that led to the development of the CONIC and DARWIN environments for distributed programming and the associated research into software architectures and their analysis. The work on the Darwin Software Architecture led to its commercial use by Philips in their new generation of consumer television products.Jeff Kramer is a Chartered Engineer, Fellow of the IEE and Fellow of the ACM. He was program co-chair of the 21st ICSE (International Conference on Software Engineering) in Los Angeles in 1999, Chair of the Steering Committee for ICSE from 2000 to 2002. He was associate editor and member of the editorial board of ACM TOSEM from 1995 to 2001 and is currently Editor in Chief of IEEE TSE. He was awarded the IEE Informatics Premium prize for 1998/99, the Most Influential Paper Award at ICSE 2003 and the 2005 ACM SIGSOFTOutstanding Research Award Award for significant and lasting research contributions to software engineering. He is co-author of a recent book on Concurrency, co-author of a previous book on Distributed Systems and Computer Networks, and the author of over 150 journal and conference publications.Bibliography[1] S. C. Cheung and J. Kramer, “Checking Safety Properties Using Compositional Reachability Analysis”, ACM Transactionson Software Engineering and Methodology, Vol. 8, No. 1, pp. 49-78, 99.[2] H. Foster, S. Uchitel, J. Magee and J. Kramer, “LTSA-WS: A Tool for Model-Based Verification of Web Service Compositions and Choreography”, (Formal Research Demo, 28th IEEE/ACM Int. Conf. on Software Engineering (ICSE-2006), Shanghai, May 2006).[3] D. Giannakopoulou and J. Magee, “Fluent Model-checking for Event-based Systems”, ESEC/FSE, Helsinki, Sept. 2003.[4] D. Giannakopoulou, J. Magee and J. Kramer, “Checking Progress with Action Priority: Is it Fair?”, 7th European Software Engineering Conference held jointly with the 7th ACM SIGSOFT Symposium on the Foundations of Software Engineering (ESEC/FSE'99), Toulouse, France, 1687, pp. 511-527, September 1999.[5] J. Kramer and J. Magee, “Exposing the Skeleton in the Coordination Closet”, Coordination'97, Second International Conference on Coordination Models and Languages, Berlin, Germany, 1282, pp. 18-31, September 1997.[6] J. Magee, N. Dulay, S. Eisenbach and J. Kramer, “Specifying Distributed Software Architectures”, 5th European Software Engineering Conference (ESEC'95), Sitges, Spain, 989, pp. 137-153, September 1995.[7] J. Magee, N. Dulay and J. Kramer, Regis, “A Constructive Development Environment for Parallel and Distributed Programs”, Distributed Systems Engineering Journal, Special Issue on Configurable Distributed Systems, Vol. 1, No. 5, pp. 304-312, 94.[8] J. Magee and J. Kramer, Concurrency - State Models & Java Programs, Chichester, John Wiley & Sons, 1999.[9] J. Magee, J. Kramer, D. Giannakopoulou and N. Pryce, “Graphical Animation of Behavior Models”, 22nd International Conference on Software Engineering (ICSE'00), Limerick, pp. 499-508, June 2000.[10] K. Ng, J. Kramer and J. Magee, “Automated Support for the Design of Distributed Systems”, Journal of Automated Software Engineering (JASE), Vol. 3, No. 4, pp. 261-284, 1996.[11] S. Uchitel, J. Kramer and J. Magee, “Detecting Implied Scenarios in Message Sequence Chart Specifications”, Joint 8th European Software Engineering Conference (ESEC'01) and 9th ACM SIGSOFT Symposium on the Foundations of Software Engineering (FSE'01), Vienna, pp. 74-82.[12] S. Uchitel, J. Kramer and J. Magee, “Negative Scenarios for Implied Scenario Elicitation”, ACM SIGSOFT 10th International Symposium on the Foundations of Software Engineering (FSE-10), Charleston, South Carolina, November 18-22, 2002).[13] S. Uchitel, J. Kramer and J. Magee, “Synthesis of Behavioural Models from Scenarios”, IEEE Transactions on Software Engineering, Vol. 29, No. 2, pp. 99-115, 2003.[14] J. Kramer, J. Magee and S. Uchitel, “Software Architecture Modeling and Analysis: A Rigorous Approach”, Formal Methods for Software Architectures (SFM-03:SA Lectures), Marco Bernardo and Paola Inverardi, Springer, LNCS 2804, 2003, 45-52.[15] S. Uchitel, J. Kramer and J. Magee, “Incremental Elaboration of Scenario-based Specifications and Behaviour Models usingImplied Scenarios”, ACM Transactions on Software Engineering Methodology TOSEM, 13 (1), January 2004.[16] S. Uchitel, R. Chatley, J. Kramer and J. Magee, “Fluent-Based Animation: Exploiting the Relation between Goals and Scenarios for Requirements Validation”, Requirements Engineering (RE ’04), Kyoto, September 2004.)[17] S. Uchitel S., R. Chatley, J. Kramer, and J. Magee, “System Architecture: the Context for Scenario-based Model Synthesis”,ACM SIGSOFT 12th International Symposium on the Foundations of Software Engineering (FSE-12), Newport Beach, California, October 31 – November 5, 2004.。
擅长电脑英语作文

擅长电脑英语作文Proficient in ComputerComputers have become an integral part of our daily lives, revolutionizing the way we work, communicate, and access information. As technology continues to advance, the importance of being proficient in computer skills has become increasingly crucial. In today's fast-paced and highly digitalized world, individuals who possess a strong command of computer-related knowledge and abilities are at a distinct advantage.One of the primary reasons why being proficient in computers is so valuable is the sheer ubiquity of technology in the modern workplace. Regardless of the industry or field, the majority of jobs now require the use of computers for tasks ranging from data entry and analysis to communication and project management. Employees who are adept at navigating various software programs, troubleshooting technical issues, and utilizing digital tools are often more productive, efficient, and valuable to their employers.Moreover, the digital transformation of many industries has led to the emergence of new job roles and career paths that are heavilyreliant on computer skills. From web development and software engineering to cybersecurity and data science, a wide range of exciting and lucrative career opportunities have arisen that require a deep understanding of computer systems, programming languages, and digital technologies. By developing proficiency in these areas, individuals can position themselves for success in these in-demand and rapidly growing fields.Beyond the professional realm, computer skills also play a crucial role in our personal lives. In an age where the internet has become the primary source of information, entertainment, and communication, being able to effectively navigate and utilize digital platforms is essential. From online banking and shopping to social media and video streaming, the ability to confidently and securely use computers and the internet can greatly enhance our quality of life and provide us with a wealth of opportunities for learning, connecting, and engaging with the world around us.Furthermore, the development of computer skills can also foster important cognitive abilities, such as problem-solving, critical thinking, and logical reasoning. As individuals engage with various software, hardware, and programming concepts, they are often required to analyze complex problems, break them down into manageable parts, and devise creative solutions. These skills not only benefit individuals in their professional pursuits but also contributeto their overall intellectual growth and adaptability.In addition to the practical and cognitive benefits, being proficient in computers can also open up a world of creative possibilities. With the rise of digital art, music production, and video editing software, individuals with computer skills can unleash their artistic talents and explore new forms of self-expression. Whether it's designing stunning visuals, composing captivating soundtracks, or crafting engaging multimedia content, the integration of computer technology has revolutionized the creative landscape and provided individuals with unprecedented opportunities to showcase their talents.It is important to note that the concept of computer proficiency is not limited to a specific set of skills or knowledge. Rather, it encompasses a broad range of competencies that can be continuously expanded and refined through ongoing learning and practice. From mastering the basics of operating systems and productivity software to delving into more advanced programming, cybersecurity, or data analysis techniques, the opportunities for growth and development in the realm of computer skills are vast and ever-evolving.In conclusion, being proficient in computers is a valuable asset in today's digital age. It enhances our professional prospects, expandsour personal capabilities, fosters cognitive development, and opens up creative possibilities. As technology continues to shape and transform our world, the importance of developing and maintaining computer skills will only continue to grow. By embracing the power of technology and dedicating ourselves to ongoing learning and skill development, we can unlock a world of opportunities and position ourselves for success in the rapidly changing digital landscape.。
手机写英语作文分段的软件

手机写英语作文分段的软件英文回答:Introduction。
As we navigate the digital age, our smartphones have become indispensable tools for various aspects of our lives, including composing written pieces. Whether it's for work, school, or personal communication, having a reliable software assistant to help with grammar, punctuation, and overall writing quality can be invaluable. In this essay, I will delve into the benefits and drawbacks of using smartphone software for English essay writing, supported by examples and personal experiences.Benefits of Smartphone Writing Software。
1. Enhanced Grammar and Punctuation。
Smartphone writing software often incorporates advancedgrammar and punctuation checkers that can detect andcorrect errors in your writing. This feature can be particularly helpful for non-native English speakers or individuals who may struggle with grammar and punctuation. By identifying and rectifying errors, the software can significantly enhance the clarity and professionalism of your writing.2. Real-Time Feedback and Suggestions。
如何说电脑英语作文

如何说电脑英语作文英文回答:In the realm of digital communication, the ability to articulate ourselves effectively in computer terminology has become an indispensable skill. Whether we are composing emails, navigating the intricacies of software applications, or troubleshooting technical glitches, mastering the language of computing empowers us to interact with technology seamlessly.Embarking on this linguistic odyssey begins with understanding the fundamental vocabulary associated with different components of a computer system. The "hardware" refers to the tangible physical elements such as the processor, memory, and storage devices. The "software" encompasses the operating systems, applications, and programs that run on the hardware, providing the necessary functionalities.As we delve deeper into the world of computers, we encounter an array of terms that describe specific actions and processes. For instance, we may "boot up" a computer to initiate its startup sequence or "shut down" to power it off. We "install" software applications to add new capabilities to our systems and "uninstall" them when we no longer require them.Effective computer communication also involves understanding the nuances of technical jargon. Terms like "firewall," "antivirus," and "cloud computing" have become commonplace, yet their precise meanings may not always be clear. By actively seeking definitions and exploring online resources, we can expand our vocabulary and gain a comprehensive grasp of these concepts.Furthermore, cultivating strong written communication skills in computer English is crucial for conveying technical information accurately and concisely. Whether we are drafting user manuals, troubleshooting guides, or collaborating with colleagues on software developmentprojects, the ability to express ourselves clearly and coherently ensures that our ideas are effectively communicated.In today's digital age, proficiency in computer English is an invaluable asset that empowers us to navigate the complexities of computing and effectively communicate in this rapidly evolving technological landscape. By embracing the language of computers, we not only enhance our technical abilities but also expand our capacity for collaboration and innovation.中文回答:在数字通信领域,用计算机术语有效地表达自己已经成为一项必不可少的技能。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Composing Software Systems from Adaptable Software ComponentsWPI-CS-TR-97-9George T. HeinemanWorcester Polytechnic InstituteWorcester, MA 01609/~heinemanAbstractThe construction of software systems from pre-existing, independently developed software components will only occur when application builders can adapt software components to suit their needs. Our ADAPT framework [Hein97] supports both component designers in creating components that can easily be adapted, and application builders in adapting software components. We propose that software components provide two interfaces -- one for behavior and one for adapting that behavior as needed. In this position paper, we outline some requirements for composing software systems from components and suggest that adaptation be recognized as a significant factor.1 IntroductionThe goal of constructing software applications from reusable software components is proving to be very challenging. We believe that adapting software components for use by a particular application is a key enabling technology towards realizing this goal. Using a software component in a different manner than for which it was designed, however, is challenging because the new context may be inconsistent with implicit assumptions made by the component. Techniques such as component adaptors [Yell97] that overcome syntactic incompatibilities between components do not address the need to adapt software components.Our focus is on supporting both component designers and application builders: the designers will be aided in creating components that can easily be adapted (thus increasing reuse), and for the first time, application builders will have mechanisms for adapting software components. By design, black box components often only allow minimal customization and are reusable if they exactly match a particular need in an application. However, the use of the component is also heavily dependent on the ability for application builders to adapt the component for use in different applications.We make a distinction between software evolution, where the software component is modified by the component designer, and adaptation, where an application builder adapts the component for a different use. We also differentiate adaption from customization; an end-user customizes a software component by choosing from a fixed set of options (such as OIA/D [Kicz97]). An end-user adapts a software component by writing new code to alter existing functionality.1.1 ADAPTThe goal of the ADAPT framework is to increase the feasibility of component-based software development by showing how to design adaptable software components. The main idea is that component designers must provide mechanisms that allow application builders to incorporate and adapt these components into their application. Two research directions for the ADAPT project that arerelevant to the discussion of compositional software architecture are:A Component specification language for specifying the interface of a component and how it isadapted.Active interfaces1.1.1 Component Specification Languagecomponent Spreadsheet {implements Serializable,SpreadsheetListener;// one-dimensional property.indexedProperty Function function(String)// one-dimensional property.indexedProperty String Value(String);// Basic state properties of this componentproperty boolean debug;// Methodsfloat getNumericValue(String);void installFunctions();float evaluateConstant(String);void evaluate(Node);float calculateFunction(Expression);// expects add/removevoid addSpreadsheetListener(SpreadsheetListener);void removeSpreadsheetListener(SpreadsheetListener);// SpreadsheetListener Interfacevoid handleSpreadsheetEvent(SpreadsheetEventObject);}The ADAPT (Architectural Description of adAPTable components) language is used to describe the interface for a component and its adaptations. If the component is written in a reflective language, such as Java, then the specification for a component can initially be generated directly from the component. The above figure describes one such specification generated for a Spreadsheet Bean. This Bean supports a set of spreadsheet services, allowing clients to set individual cell values (through the Value property), and allows external client Beans to become listeners for refresh requests as new values are added and computed. An ADAPT description provides a convenient place to specify adaptations to the component, as we now describe.1.1.2 Active InterfacesThe interface must play a greater role in helping application builders adapt the component. The component interface is more than a syntactic description of the method invocations accepted by the component. As defined in [Abow95], components are active computational entities whose interfaces defines methods to invoke, events to receives and/or send, or complex access protocols. An active interface decides whether to take action when a method is called, an event is announced, or a protocolexecutes. There are two phases to all interface requests: the "before-phase" occurs before the component performs any steps towards executing the request; the "after-phase" occurs when the component has completed all execution steps for the request. These phases are similar to the Lisp advice facility described in [Rama97]. A standard way to alter the behavior of a component is to interpose an entity to intercept messages and/or events. Because such adaptation is likely to occur, the component should provide an interface for this purpose.Suppose that the application builder wishes to modify the Spreadsheet Bean in Figure 1 so that it generates an event whenever the particular value of a cell changes (for example, because the cell contains a calculated formula), not just when the contents change; for example, changing a cell from "(+ 2 3)" to "(* 5 1)" changes the contents, but not the value. The application builder could modify the component directly (which we are trying to avoid) or filter out messages from the Spreadsheet (but this would require the client to store duplicate values to detect differences, and is space/time inefficient). We use an active interface to insert a before-evaluate function that has the Spreadsheet component record the value of the cell before its update and an after-evaluate function that compares the new value against the old; if the values are different, the after-evaluate function generates the appropriate notification. These functions would then be incorporated into the object ss, the instantiation of the Spreadsheet component. With this scheme, different component objects from the same class can be adapted in different ways, offering even more flexibility to the application builder.component ss adapts Spreadsheet {code code.jar;action storeValue (in Node);action compareValue (in Node);void evaluate (Node node) {before storeValue(node);after compareValue(node);};};Active interfaces are different from the pre-packaged implementation strategies of OIA/D [Kicz97]. OIA/D sketches a solution showing how the client can provide their own implementation strategy, but typically an entire method for a component is replaced. Our approach is more fine-grained, allowing adaptation to occur when needed. We do not violate the encapsulation of the component, since the methods invoked within the active interface do not directly access private information in the component. Thus the component designer has great flexibility, and can place the responsibility for correctness on the application builders that adapt the component.1.2 ContextOur ADAPT framework [Hein97] is independent of the particular programming language and architectural style, and is thus widely applicable. For our initial prototype, we have chosen to use the JavaBeans [SUN97] software component model. A Java Bean is a reusable software component written in Java that can be manipulated visually in a design environment, such as the sample Bean Developers Kit (BDK) shipped with the initial release of JavaBeans. BDK allows application builders to instantiate a collection of Beans that communicate with each other using events. The JavaBeans event model provides a convenient mechanism for components to propagate state change notifications to one or more listeners. Each Bean contains a set of state properties (i.e., named attributes) and BDK allowsapplication builders to customize a Bean by modifying its properties.We are interested in extending the JavaBean component model to distributed applications. In particular, we are designing a message framework called SOWER on which a distributed application composed of beans can be built. SOWER is based on the Event-Based Software Integration (EBI) described in [Barr96]. The key features of SOWER are:It is integrated with the BDK.JavaBean components can be used as is without modification.Connector code is automatically generated as needed to deliver JavaBean events between remote components.The registration of the communication between Beans is separate from the actual delivery of Bean events.In this way, we can experiment with constructing distributed applications from components and investigate the evolvability of such software systems.2 RequirementsFor this position paper, we identify the following requirements for compositional software architectures. We discuss these requirements in the context of JavaBeans, but they apply equally regardless of programming language.2.1 Core Requirements1.Separation of physical composition from logical composition. JavaBeans provides a convenientabstraction for communication between two components, and the distribution mechanism must maintain this separation.ing JavaBeans without design modification. The JavaBeans standard is gathering support inindustry, so any approach to building distributed applications must be compatible with the basic Bean model.3.Support for dynamic configuration. The framework enabling communication between distributedBeans must allow the application builder to deploy and move Beans between each site. The virtual communication between Beans should be flexible enough to be reconfigured when Beans move.2.2 Advanced RequirementsAs part of our efforts towards building adaptable software components, we feel the following requirements are essential for realizing the goal of building distributed applications from software components.1.In Situ Adaptation. When adapting the behavior of a class C, object-oriented design methodologiessuggest that a new subclass SC be created that extends C to create the new, desired functionality.This approach does not work when we wish to adapt the behavior of a component. First, eventhough a component may syntactically be equivalent to a class (as in JavaBeans), inheritance is ill-suited for such adaptation. Consider a component constructed using the Facade design pattern [Gamm95]; creating a subclass of the Facade class complicates the design. Second, once acomponent is deployed, the application builder should be able to adapt the component bysupplying new code to be integrated into the component; inheritance is strictly a compile-time mechanism.3. ConclusionsIn this paper, we outlined some requirements for compositional software architectures. We are focused on creating design methods and implementation mechanisms that allow application builders to adapt software components in their applications. We showed that component models must provide some mechanism for adaptation, and we introduced active interfaces for this purposes. We sketched the ADAPT and SOWER frameworks, and described their usefulness in constructing distributed applications from software components.References1.[Abow95]Formalizing Style to Understand Descriptions of Software Architecture. ACMTransactions on Software Engineering and Methodology, 4(4):319-364, October 1995.2.[Barr96]A Framework for Event-Based Software Integration. Daniel Barrett, Lori Clarke, PeriTarr, Alexander Wise. ACM Transactions on Software Engineering and Methodology,5(4):378-421, October 1996.3.[Gamm95]Design Patterns: Elements of Reusable Object-Oriented Software. Erich Gamma,Richard Helm, Ralph Johnson, John Vlissides. Addison-Wesley, 1995.4.[Hein97]A Model for Designing Adaptable Software Components. George Heineman. Submittedfor Publication.5.[Kicz97]Open Implementation Design Guidelines. Gregor Kiczales, et al. 19th InternationalConference on Software Engineering, pages 481-490, May 1997.6.[Rama97]A Emacspeak: A Speech-Enabling Interface. Dr. Dobb’s Journal, 22(1):18-23,September 1997.7.[SUN97]JavaBeans 1.0 API Specification. Sun Microsystems, Inc. December 4, 1996.8.[Yell97]Protocol Specification and Component Adaptors. Daniel Yellin and Robert Strom. ACMTransactions on Programming Languages and Systems, 19(2):292-333, March 1997.。