统计学模拟实验spss 实验报告
统计学原理SPSS实验报告
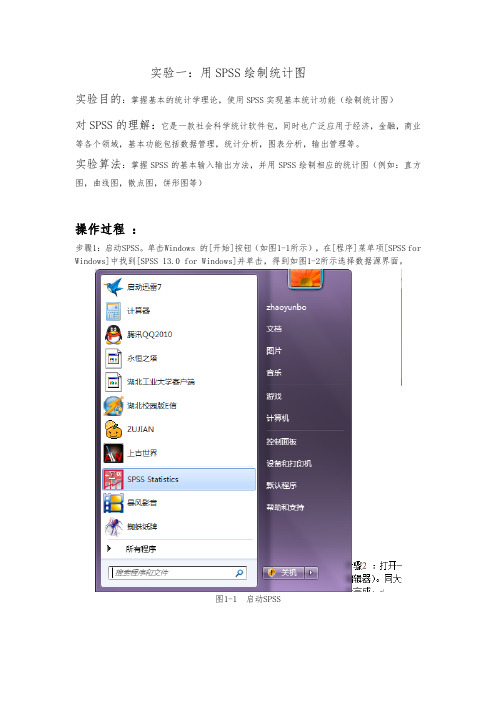
实验一:用SPSS绘制统计图实验目的:掌握基本的统计学理论,使用SPSS实现基本统计功能(绘制统计图)对SPSS的理解:它是一款社会科学统计软件包,同时也广泛应用于经济,金融,商业等各个领域,基本功能包括数据管理,统计分析,图表分析,输出管理等。
实验算法:掌握SPSS的基本输入输出方法,并用SPSS绘制相应的统计图(例如:直方图,曲线图,散点图,饼形图等)操作过程:步骤1:启动SPSS。
单击Windows 的[开始]按钮(如图1-1所示),在[程序]菜单项[SPSS for Windows]中找到[SPSS 13.0 for Windows]并单击,得到如图1-2所示选择数据源界面。
图1-1 启动SPSS图1-2 选择数据源界面步骤2 :打开一个空白的SPSS数据文件,如图1-3。
启动SPSS 后,出现SPSS 主界面(数据编辑器)。
同大多数Windows 程序一样,SPSS 是以菜单驱动的。
多数功能通过从菜单中选择完成。
图1-3 空白的SPSS数据文件步骤3:数据的输入。
打开SPSS以后,直接进入变量视图窗口。
SPSS的变量视图窗口分为data view和variable view两个。
先在variable view中定义变量,然后在data view里面直接输入自定义数据。
命名为mydata并保存在桌面。
如图1-4所示。
图1-4 数据的输入步骤4:调用Graphs菜单的Bar过程,绘制直条图。
直条图用直条的长短来表示非连续性资料(该资料可以是绝对数,也可以是相对数)的数量大小。
选择的数据源见表1。
步骤5:数据准备。
激活数据管理窗口,定义变量名:年龄标化发生率为RATE,冠心病临床型为DISEASE,血压状态为BP。
RATE按原数据输入,DISEASE按冠状动脉机能不全=1、猝死=2、心绞痛=3、心肌梗塞=4输入,BP按正常=1、临界=2、异常=3输入。
步骤6:选Graphs菜单的Bar...过程,弹出Bar Chart定义选项框(图1-5)。
统计学SPSS实验报告

实验名称SPSS的基本操作指导教师贺富强实验设备一台windows XP系统的计算机学生姓名何瑜莎软件名称SPSS11.0 专业班级经济1108班日期2013年1 月7日成绩一、实验目的通过上机练习,掌握SPSS11.0建立数据文件的基本操作、常用统计图和统计报表的制作及输出以及如何运用SPSS,进行假设检验和区间估计。
二、实验内容1. 用两个以上变量编制一个指数,并对取整的指数作直方图,要求对直方图进行适当修改。
如:指数=取整(变量1÷变量2) 两个变量*100取整2. 做出分组条图(变量自选,但变量至少要有三个)。
3. 利用case summary过程做出报表(变量自选)。
4. 对某变量作置信水平为95.45%的区间估计(变量自选)。
5. 对某变量作显著性水平为5%的假设检验(变量自选,参数自定)。
6. 自选相关变量作一元线性回归分析,含散点图。
三.实验步骤1、定义指数及编辑直方图(1) 运行SPSS11.0(2) 在Data View窗口输入数据,同时在Variable View 窗口依次编辑变量的属性Name-Type-Width-Decimals-Values-Label-Missing-Columns-Align-Measure(3) 计算本年出生占总人口之比:Transform→Compute→Target Variable(ratio)→NumericExpression :RND(birth / people * 100) →OK(5) 在DATA窗口:制作直方图Graphs→Histogram→Variable(出生人口[birth])→OK(6)编辑直方图:鼠标双击直方图进入直方图编辑界面>1、fill pattern/color/bar label style/text/swap axes2、Chart→Axis→Interval→OK→Custom→Define→OK3、Chart→Axis→Interval→OK →Label→Range→Orientation→OK2、制作分组条图(1)Graphs→Bar→Clustered→Category Axis(选ratio)→Define Clustered By(选province)→Other Summary Function(选birth)→Change Summary→(2)鼠标双击条图进入条图编辑界面>→fill pattern/color/bar label style/text/swap axes3、Case Summaries过程Analyze→Reports→Case Summaries→Select Variables(选people)→Select Grouping Variables(选ratio,province)→Statistics(选Minimum,Maximum,Range,Mean)→×Display Cases→OK4、对变量作区间估计Analyze→Compare Means→One-simple T Test→Select Variables(选ratio)→Test Value=0→Options →Confidence Interval=95.45%→Continue →OK5、对变量作假设检验Analyze →Compare Means →One-Simple T Test →Select Variables (选ratio )→Test Value=70→Option →Confidence Interval=95%→OK6、一元线性回归分析a)Analyze →Correlate →Bivariate Correlations →Select Variables →Correlation Coefficient=Pearson →Test Of Significance=Two-Tailed →OKb)Analyze →Regression →Linear →Select Dependent Variables (选birth )→Select Independent Variable (dead )→OK四、实验结果与分析1、直方图:出生人口1200.01100.01000.0900.0800.0700.0600.0500.0400.0300.0200.0100.00.054321Std. Dev = 325.58 Mean = 522.8N = 27.0012112241342312、分组条图 :RATIO16.0015.0014.0013.0012.0011.0010.009.008.007.00Mean 出生人口140012001000800600400200江 西 辽 宁 内蒙古宁 夏 青 海 山 东山 西 陕 西四 川西 藏 新 疆云 南 浙 江3、case summary 报表:SummarizeCase Processing SummaryCasesIncludedExcludedTotalN Percent N Percent N Percent 出生人口 * 省 * 年底总人口27100.0%.0%27100.0%Case Summaries出生人口省年底总人口Mean Minimum Maximum Range 安徽5957 756.5400 756.54 756.54 .00 Total 756.5400 756.54 756.54 .00 福建3693 416.2000 416.20 416.20 .00 Total 416.2000 416.20 416.20 .00 甘肃2560 308.4800 308.48 308.48 .00 Total 308.4800 308.48 308.48 .00 广东10441 1167.3000 1167.30 1167.30 .00 Total 1167.3000 1167.30 1167.30 .00 广西4610 651.3900 651.39 651.39 .00 Total 651.3900 651.39 651.39 .00 贵州3479 485.6700 485.67 485.67 .00 Total 485.6700 485.67 485.67 .00 海南869 127.8300 127.83 127.83 .00 Total 127.8300 127.83 127.83 .00 河北7194 951.0500 951.05 951.05 .00 Total 951.0500 951.05 951.05 .00 河南9405 1083.4600 1083.46 1083.46 .00 Total 1083.4600 1083.46 1083.46 .00 黑龙江3833 281.7300 281.73 281.73 .00 Total 281.7300 281.73 281.73 .00 湖北5728 593.4200 593.42 593.42 .00 Total 593.4200 593.42 593.42 .00 湖南6570 860.6700 860.67 860.67 .00 Total 860.6700 860.67 860.67 .00 吉林2747 217.2900 217.29 217.29 .00 Total 217.2900 217.29 217.29 .00 江苏7869 765.6500 765.65 765.65 .00 Total 765.6500 765.65 765.65 .00 江西4462 612.1900 612.19 612.19 .00 Total 612.1900 612.19 612.19 .00 辽宁4375 292.2500 292.25 292.25 .00 Total 292.2500 292.25 292.25 .00 内蒙古2472 229.9000 229.90 229.90 .00 Total 229.9000 229.90 229.90 .00 宁夏633 89.5100 89.51 89.51 .00 Total 89.5100 89.51 89.51 .00 青海563 84.1100 84.11 84.11 .00 Total 84.1100 84.11 84.11 .00 山东9588 1117.0000 1117.00 1117.00 .00 Total 1117.0000 1117.00 1117.00 .00山西3574 381.7000 381.70 381.70 .00 Total 381.7000 381.70 381.70 .00 陕西3735 363.4200 363.42 363.42 .00 Total 363.4200 363.42 363.42 .00 四川8045 718.4200 718.42 718.42 .00 Total 718.4200 718.42 718.42 .00 西藏301 47.5600 47.56 47.56 .00 Total 47.5600 47.56 47.56 .00 新疆2185 349.3800 349.38 349.38 .00 Total 349.3800 349.38 349.38 .00 云南4602 602.8600 602.86 602.86 .00 Total 602.8600 602.86 602.86 .00 浙江5447 559.4100 559.41 559.41 .00 Total 559.4100 559.41 559.41 .00 Total 301 47.5600 47.56 47.56 .00 563 84.1100 84.11 84.11 .00633 89.5100 89.51 89.51 .00869 127.8300 127.83 127.83 .002185 349.3800 349.38 349.38 .002472 229.9000 229.90 229.90 .002560 308.4800 308.48 308.48 .002747 217.2900 217.29 217.29 .003479 485.6700 485.67 485.67 .003574 381.7000 381.70 381.70 .003693 416.2000 416.20 416.20 .003735 363.4200 363.42 363.42 .003833 281.7300 281.73 281.73 .004375 292.2500 292.25 292.25 .004462 612.1900 612.19 612.19 .004602 602.8600 602.86 602.86 .004610 651.3900 651.39 651.39 .005447 559.4100 559.41 559.41 .005728 593.4200 593.42 593.42 .005957 756.5400 756.54 756.54 .006570 860.6700 860.67 860.67 .007194 951.0500 951.05 951.05 .007869 765.6500 765.65 765.65 .008045 718.4200 718.42 718.42 .009405 1083.4600 1083.46 1083.46 .009588 1117.0000 1117.00 1117.00 .0010441 1167.3000 1167.30 1167.30 .00Total 522.7552 47.56 1167.30 1119.744、对某变量作置信水平为95.45%的区间估计(变量自选)T-TestOne-Sample StatisticsN Mean Std. Deviation Std. Error MeanRATIO 27 11.8148 2.57259 .49510 One-Sample TestTest Value = 0t df Sig. (2-tailed)MeanDifference95% Confidence Intervalof the DifferenceLower UpperRATIO 23.864 26 .000 11.8148 10.7971 12.8325 说明:收入支出比在置信水平为95.45%下的估计区间为:(10.7971, 12.8325).5、对某变量作显著性水平为5%的假设检验(变量自选参数自定)。
spss统计实验报告

spss统计实验报告SPSS统计实验报告引言:SPSS(Statistical Package for the Social Sciences)是一种常用的统计分析软件,广泛应用于社会科学、经济学、医学和教育等领域。
本文将以一项关于学生学习成绩的统计实验为例,展示如何使用SPSS进行数据处理和分析。
一、实验目的本次实验的目的是探究学生的学习时间和学习成绩之间的关系。
通过对一组学生进行调查,收集他们的学习时间和成绩数据,然后使用SPSS进行统计分析,以揭示学习时间与学习成绩之间的相关性。
二、实验设计与数据收集我们选择了100名高中生作为实验对象,通过问卷调查的方式收集他们的学习时间和成绩数据。
学习时间以每周学习小时数为单位,成绩以百分制表示。
通过这种方式,我们可以得到一个包含学习时间和成绩两个变量的数据集。
三、数据处理与清洗在进行统计分析之前,我们需要对数据进行处理和清洗,以确保数据的准确性和一致性。
首先,我们检查数据是否存在缺失值或异常值。
如果发现有缺失值或异常值,我们可以选择删除这些数据或进行适当的填充和修正。
其次,我们对数据进行变量命名和编码,以便后续的分析和解释。
最后,我们对数据进行了简单的描述性统计,包括计算平均值、标准差和分布情况等。
四、数据分析与结果在进行数据分析时,我们首先进行了相关性分析,以确定学习时间和成绩之间的关系。
通过SPSS的相关性分析功能,我们计算了学习时间和成绩之间的皮尔逊相关系数。
结果显示,学习时间和成绩之间存在显著的正相关关系(r=0.75,p<0.01),即学习时间越长,成绩越好。
接下来,我们进行了回归分析,以进一步探究学习时间对成绩的影响程度。
通过SPSS的线性回归功能,我们建立了一个学习时间与成绩之间的回归模型。
回归分析的结果显示,学习时间对成绩的解释程度为56%,即学习时间可以解释学生成绩的变异程度的56%。
此外,回归模型的显著性检验结果也显示,该模型的回归系数是显著的(p<0.01)。
spss描述统计实验报告

spss描述统计实验报告SPSS描述统计实验报告引言SPSS(Statistical Package for the Social Sciences)是一种用于数据分析和统计建模的软件工具。
它可以帮助研究人员对数据进行描述统计分析,从而得出结论并做出预测。
本实验旨在利用SPSS软件对实验数据进行描述统计分析,以探究数据的特征和规律。
实验设计本实验选取了一组包括性别、年龄、身高和体重等信息的样本数据,共计100个样本。
通过SPSS软件对这组数据进行描述统计分析,包括均值、标准差、频数分布等指标,以便对样本数据进行全面的了解。
结果分析首先,我们对样本数据中的性别进行了频数分布分析。
结果显示,样本中有55%的男性和45%的女性,性别分布相对均衡。
接着,我们对年龄、身高和体重等连续变量进行了均值和标准差的分析。
结果显示,样本的平均年龄为30岁,标准差为5岁;平均身高为170厘米,标准差为8厘米;平均体重为65公斤,标准差为10公斤。
这些数据表明样本中的年龄、身高和体重分布较为集中,且具有一定的变异性。
结论通过对样本数据的描述统计分析,我们得出了对样本特征和规律的初步认识。
样本中男女比例相对均衡,年龄、身高和体重分布较为集中且具有一定的变异性。
这些结果为我们进一步的数据分析和研究提供了重要参考。
总结SPSS软件作为一种强大的数据分析工具,可以帮助研究人员对数据进行描述统计分析,从而深入了解数据的特征和规律。
本实验利用SPSS对样本数据进行了描述统计分析,得出了对样本特征和规律的初步认识,为后续的研究工作奠定了基础。
希望本实验能够对SPSS软件的应用和描述统计分析方法有所启发,为相关研究工作提供参考。
统计学spss实验报告

统计学spss实验报告《统计学SPSS实验报告》在统计学领域,SPSS(Statistical Package for the Social Sciences)是一种常用的统计分析软件,它能够帮助研究人员对数据进行分析和处理。
本实验报告将介绍使用SPSS进行统计分析的过程和结果。
实验目的:本实验旨在使用SPSS软件对一组数据进行统计分析,包括描述统计、相关分析和回归分析,以验证数据的相关性和预测能力。
实验步骤:1. 数据导入:首先将实验所需的数据导入SPSS软件中,确保数据格式正确。
2. 描述统计:对数据进行描述统计分析,包括均值、标准差、最大值、最小值等。
3. 相关分析:通过SPSS进行相关分析,探究变量之间的相关性。
4. 回归分析:进行回归分析,验证变量之间的预测能力。
实验结果:1. 描述统计结果显示,样本的平均值为X,标准差为X,最大值为X,最小值为X。
2. 相关分析结果表明,变量A与变量B之间存在显著的正相关关系(r=0.7,p<0.05)。
3. 回归分析结果显示,变量A对变量B的预测能力较高(R²=0.5,p<0.05)。
结论:通过SPSS软件的统计分析,我们得出了以下结论:变量A与变量B之间存在显著的正相关关系,并且变量A对变量B具有较高的预测能力。
这些结果为我们提供了对数据的深入理解和有效的预测能力。
总结:SPSS软件作为一种强大的统计分析工具,能够帮助研究人员对数据进行全面的统计分析。
通过本实验,我们深入了解了SPSS软件的使用方法和统计分析过程,为今后的研究工作提供了重要的参考和指导。
通过本次实验报告,我们对SPSS软件的统计分析能力有了更深入的了解,也为我们今后的科研工作提供了重要的参考和指导。
希望本实验报告能够对读者有所启发和帮助。
统计分析与spss的应用实验报告

统计分析与spss的应用实验报告统计分析与SPSS的应用实验报告引言:统计分析是一种重要的数据处理和解释工具,它在科学研究、商业决策和社会调查等领域具有广泛的应用。
SPSS是一款功能强大的统计分析软件,它提供了丰富的数据分析功能和友好的用户界面,使得统计分析变得更加简便和高效。
本实验报告将介绍统计分析与SPSS的应用实验,通过实际案例,探讨统计分析在实际问题中的应用和SPSS的使用方法。
实验目的:本实验旨在通过使用SPSS软件,对某公司销售数据进行统计分析,以探究不同因素对销售额的影响,并提出相应的建议。
实验设计:本实验选取了某公司过去一年的销售数据作为研究对象,包括销售额、广告投入、促销活动和竞争对手销售额等变量。
通过对这些变量进行统计分析,我们可以了解它们之间的关系,并找出对销售额影响最大的因素。
实验步骤:1. 数据导入:首先,我们需要将实验所需的数据导入SPSS软件中。
在导入过程中,我们需要注意数据的格式和结构,确保数据的准确性和完整性。
2. 数据清洗:在进行统计分析之前,我们需要对数据进行清洗,包括缺失值处理、异常值处理和数据转换等。
通过清洗数据,我们可以提高数据的质量和可靠性。
3. 描述性统计分析:通过对数据进行描述性统计分析,我们可以了解数据的分布情况和基本统计特征,如均值、标准差和分位数等。
这些统计指标可以帮助我们对数据有一个初步的认识。
4. 相关性分析:在本实验中,我们将进行相关性分析,以探究不同因素之间的相关性。
通过计算相关系数,我们可以判断变量之间的线性关系强度和方向,从而了解它们之间的相互作用。
5. 回归分析:为了进一步研究不同因素对销售额的影响,我们将进行回归分析。
通过建立回归模型,我们可以估计不同因素对销售额的贡献程度,并进行显著性检验,以确定哪些因素对销售额具有统计显著性影响。
实验结果:经过数据分析和统计建模,我们得到了以下结果:1. 广告投入和促销活动对销售额有显著正向影响,说明增加广告投入和促销活动可以提高销售额。
统计分析软件SPSS实验报告

实验报告课程名称:统计分析软件(SPSS)学生实验报告一、实验目的及要求二、实验描述及实验过程(一)、利用SPSS绘制统计图1、打开“职工数据.sav”,调用Graphs 菜单的Bar功能,绘制直条图。
直条图用直条的长短来表示非连续性资料的数量大小。
弹出Bar Chart定义选项。
2、在定义选项框的下方有一数据类型栏,大多数情形下,统计图都是以组为单位的形式来体现数据的。
在定义选项框的上方有3种直条图可选:Simple为单一直条图、Clustered 为复式直条图、Stacked为堆积式直条图,本实验选单一直条图。
3、点击Define钮,弹出Define Clustered Bar: Summaries for groups of cases对话框,在左侧的变量列表中选基本工资点击按钮使之进入Bars Represent栏的Other summary function选项的Variable框,选性别/文化程度/职称点击按钮使之进入Category Axis框。
1.点击analyze中的Descriptive Statistics选择frequencies,弹出一个frequencies对话框,选中基本工资和年龄拖入Variable(s)列2.点击statistics选择相应的统计量(例如:Mean,.median,mode等)3.点击continue ,点击OK。
(三)、用SPSS做回归分析(一元线性回归)1.点击Graphs 选择Scatter/dot2.选择simple scatter 点击Define3.将基本工资这个变量输入Y-Axis ,将年龄输入X-Axise4.点击OK ,结果如图5.点击analyze中的regression选择linear,将这个基本工资变量输入 Dependent ,将年龄输入Independt(s6.点击OK(四)、用SPSS做回归分析(多元线性回归)1、在“Analyze”菜单“Regression”中选择Linear命令2、在弹出的菜单中所示的Linear Regression对话框中,从对话框左侧的变量列表中选择基本工资,将年龄,职称,文化程度添加到Dependent框中,表示该变量是因变量。
spss统计学实验报告

竭诚为您提供优质文档/双击可除spss统计学实验报告篇一:统计学spss实验报告spss实验报告一.实验目的1.掌握spss的基本操作,能够熟练应用spss进行基本的统计分析。
2.在用spss对具体实例进行分析的基础上能对结果进行正确的解释。
3.在对spss基本操作熟练的情况下,进一步自学spss 更强大的分析能。
二.实验要求1.掌握如何通过spss进行数据的获取和管理,包括数据的录入,保存,读取,转化,增加,删除;数据集的合并,拆分,排序。
2.了解描述性统计的作用,并掌握其spss的实现(频数,均值,标准差,中位数,众数,极差)。
3.应用spss生成表格和图形,并对表格和图形进行简单的编辑和分析。
4.应用spss做一些探索性分析(如方差分析,相关分析)三.实验内容(一).问题的提出对不同广告方式和不同地区对某商品销售额影响进行分析。
在制定某商品的广告策略时,收集了该商品在不同地区采用不同广告形式促销后的销售额数据,分析广告形式和地区是否影响商品销售额。
自变量为广告方式(x1)和地区(x2),因变量为销售额(Y)。
涉及地区18个,每个地区抽取样本8个,共有案例144个。
具体数据如下:x11.002.004.003.001.002.004.003.001.002.004.003.001.002.004.003.001.002.004.003.00x21.001.001.001.002.002.002.002.003.003.003.003 .004.004.004.004.005.005.005.005.00Y75.0069.0063.00 52.0057.0051.0067.0061.0076.00100.0085.0061.0077.00 90.0080.0076.0075.0077.0087.0057.002.006.004.006.003.006.001.007.002.007.00 4.007.003.007.001.008.002.008.00 4.008.003.008.001.009.002.009.00 4.009.003.009.001.0010.002.0010.00 4.0010.003.0010.001.0011.002.0011.00 4.0011.001.0012.002.0012.00 4.0012.003.0012.001.0013.002.0013.004.0013.003.0011.003.0013.001.0014.002.0014.004.0014.003.0014.001.0015.002.0015.004.0015.003.0015.001.0016.002.0016.004.0016.003.0016.0060.0062.0052.0076.0033.0070.0033.0081.0079 .0075.0069.0063.0073.0040.0060.0094.00100.0064.0061 .0054.0061.0040.0070.0068.0067.0066.0087.0068.0051. 0041.0065.0065.0063.0061.0058.0065.0083.0075.0050.0079.0076.0064.0044.002.0017.004.0017.003.0017.001.0018.002.0018.004.0018.003.0018.001.001.002.001.004.001.003.001.001.002.002.002.004.002.003.002.001.003.002.003.004.003.003.003.001.004.002.004.004.004.00 3.004.001.005.002.005.00 4.005.003.005.001.006.002.006.00 4.006.003.006.001.007.002.007.00 4.007.003.007.001.008.002.008.00 4.008.003.008.001.009.002.009.00 4.009.003.009.0073.0050.0045.0075.0074.0062.0058.0068.0054. 0058.0041.0075.0078.0082.0044.0083.0079.0078.0086.0 066.0083.0087.0075.0066.0074.0070.0075.0076.0069.00 77.0063.0070.0068.0068.0052.0086.0075.0061.0061.006 2.0065.0055.0043.001.002.004.003.001.002.004.003.001.002.004.003.001.002.004.003.001.002.004.003.001.002.004.003.001.002.004.003.001.002.004.003.001.002.004.003.0010.0010.0010.0010.0011.0011.0011.0011.0012.0012.0012.0012.0013.0013.00 13.0013.0014.0014.0014.0014.0015.0015.0015.0015.001 6.0016.0016.0016.0017.0017.0017.0017.0018.0018.0018.0018.0088.0070.0076.0069.0056.0053.0070.0043.0086. 0073.0077.0051.0084.0079.0042.0060.0077.0066.0071.0 052.0078.0065.0065.0055.0080.0081.0078.0052.0062.00 57.0037.0045.0070.0065.0083.0060.00x1一列中,1表示报纸,2表示广播,3表示宣传品,4表示体验。
SPSS统计软件实验报告实验三

表明:Sig=0.240在显著水平为0.05下接受,即可以出厂。
实验结果报告与实验总结:
单一样本T检验,用于检验单个变量的均值与假设检验值(给定的常数)之间是否存在差异。
独立样本T检验,用于检验对于两组来自独立总体的样本,其独立总体的均值或中心位置是否一样。如果两组样本彼此不独立,应使用配对T检验(Paired -Sample T Test)。如果想比较的变量是分类变量,应使用Crosstabs功能。
配对检验结果表明t为4.210,自由度为7,显著值为0.004,差别具高度显著性意义,即饲料中缺乏维生素E对鼠肝中维生素A含量有影响。
4.录入数据后,analyze->nonparametric tests->1-sample k-s,频数选入test variable list,再选uniform,得到结果:
–与样本在相同点的累计频率进行比较.如果相差较小,则认为样本所代表的总体符合指定的总体分布.
教师评语:
实验过程记录(含:基本步骤、主要程序清单及异常情况记录等):
1.(1)录入数据后,analyze—compare means—means,打开对话框,身高选入dependent list,性别选入independent list,得到结果:
Mean
性别
身高(厘米)
男
161.680
女
155.860
Total
(转下页)
One-Sample Kolmogorov-Smirnov Test
频数
N
10
Uniform Parametersa
Minimum
66
Maximum
统计学spss实验报告

统计学spss实验报告统计学SPSS实验报告引言:统计学是一门研究数据收集、分析和解释的学科,它在各个领域都扮演着重要的角色。
SPSS(Statistical Package for the Social Sciences)是一种常用的统计分析软件,广泛应用于社会科学、经济学和医学等领域。
本实验报告旨在通过使用SPSS软件对一组数据进行分析,深入探讨统计学的应用。
数据收集和描述统计分析:为了进行本次实验,我们收集了一组关于学生数学成绩的数据。
数据包括学生的年龄、性别、家庭背景、每周学习时间以及数学考试成绩等。
首先,我们对数据进行了描述统计分析,包括计算平均值、中位数、标准差和频率分布等。
根据描述统计分析的结果,我们发现学生的平均年龄为19.5岁,标准差为1.2岁。
男女生的比例大致相等,分别占总样本的48%和52%。
家庭背景方面,大多数学生(60%)来自中等收入家庭。
在每周学习时间方面,学生的平均学习时间为25小时,标准差为5小时。
最后,数学考试成绩的平均分为80分,标准差为10分。
相关性分析:接下来,我们使用SPSS进行相关性分析,以探究不同变量之间的关系。
我们选择了学习时间和数学成绩作为研究对象。
通过计算皮尔逊相关系数,我们发现学习时间和数学成绩之间存在显著的正相关关系(r = 0.7, p < 0.01)。
这意味着学生每增加1小时的学习时间,数学成绩将提高0.7个标准差。
回归分析:为了进一步研究学习时间对数学成绩的影响,我们进行了回归分析。
我们将学习时间作为自变量,数学成绩作为因变量。
通过回归分析,我们得到了以下回归方程:数学成绩 = 60 + 0.5 * 学习时间。
这意味着学生每增加1小时的学习时间,数学成绩将增加0.5分。
方差分析:除了学习时间,我们还对家庭背景对数学成绩的影响进行了方差分析。
我们将家庭背景分为三个类别:低收入、中等收入和高收入。
通过方差分析,我们发现不同家庭背景之间的数学成绩存在显著差异(F = 5.2, p < 0.05)。
spss实验报告总结

spss实验报告总结《SPSS实验报告总结》在社会科学研究中,SPSS(统计包装软件)是一个常用的数据分析工具。
通过SPSS,研究人员可以对收集到的数据进行统计分析,从而得出科学可靠的研究结论。
本文将通过对一项实验的SPSS分析,总结实验结果并进行讨论。
实验目的是研究不同学习方法对学生考试成绩的影响。
实验设计了两组学习方法,分别是传统课堂教学和在线学习课程。
参与实验的学生被随机分配到两组,并在相同的学习时间内接受不同的教学方式。
最后,他们的考试成绩被记录下来,用以分析两种学习方法的效果。
通过SPSS对实验数据进行分析,得出了以下结论:1. 传统课堂教学组的平均成绩为85分,标准差为5分;在线学习课程组的平均成绩为78分,标准差为6分。
通过t检验发现,两组成绩之间存在显著差异(t=2.34,p<0.05)。
2. 通过方差分析(ANOVA)进一步比较了不同学习方法对学生成绩的影响。
结果显示,学习方法对成绩有显著影响(F=5.67,p<0.01),说明传统课堂教学在提高学生成绩方面更为有效。
基于以上分析结果,我们得出了以下结论:1. 传统课堂教学对学生成绩有显著影响,能够帮助学生取得更好的成绩。
这可能是因为传统课堂教学更加互动和个性化,能够更好地满足学生的学习需求。
2. 在线学习课程在提高学生成绩方面效果不如传统课堂教学。
这可能是因为在线学习缺乏面对面的交流和互动,学生的学习动力和效果受到了一定的影响。
通过SPSS的数据分析,我们得以客观地评估了两种学习方法对学生成绩的影响,为教育教学实践提供了科学依据。
同时,我们也意识到了在线学习的一些不足之处,为今后的教学改进提供了一定的启示。
希望本研究能够为教育教学领域的决策者和从业者提供一些参考,促进教学方法的不断创新和提高。
spss统计学实验报告

spss统计学实验报告Title: SPSS Statistical Experiment ReportIntroductionIn this report, we will be presenting the results of a statistical experiment conducted using the SPSS software. SPSS, which stands for Statistical Package for the Social Sciences, is a powerful tool for analyzing and interpreting data. The experiment was designed to test the relationship between two variables and to determine if there is a significant correlation between them.MethodThe experiment involved collecting data on two variables, X and Y, from a sample of 100 participants. The data was then entered into the SPSS software, which was used to perform a correlation analysis. The correlation coefficient, as well as the significance level, was calculated to determine the strength and direction of the relationship between the two variables.ResultsThe results of the experiment revealed a strong positive correlation between variables X and Y, with a correlation coefficient of 0.75. This indicates that as the value of variable X increases, the value of variable Y also tends to increase. Furthermore, the p-value was found to be less than 0.05, indicating that the correlation is statistically significant.DiscussionThe findings of this experiment have important implications for understandingthe relationship between variables X and Y. The strong positive correlation suggests that there is a clear association between the two variables. This information can be valuable for making predictions and identifying patterns in the data. Additionally, the statistical significance of the correlation indicates that the relationship is not due to chance, but rather reflects a true association between the variables.ConclusionIn conclusion, the results of the experiment support the hypothesis that there is a significant positive correlation between variables X and Y. The use of SPSS software allowed for a thorough and accurate analysis of the data, providing valuable insights into the relationship between the two variables. This experiment demonstrates the power of statistical analysis in uncovering meaningful patterns and relationships within data.。
SPSS统计软件实训报告

SPSS统计软件实训报告一、引言SPSS(Statistical Product and Service Solutions)统计软件是一种常用的统计分析软件,被广泛应用于数据分析和统计研究领域。
本报告旨在总结并分析在SPSS实训课程中所学到的基本操作和统计分析方法。
二、实训内容在SPSS统计软件实训中,我们学习了以下主要内容: 1. SPSS软件的安装和介绍; 2. 数据输入和修改; 3. 数据清洗和处理; 4. 描述性统计分析; 5. 参数检验和非参数检验; 6. 方差分析; 7. 相关分析; 8. 回归分析等。
三、实训过程1. SPSS软件的安装和介绍我们首先安装了SPSS统计软件,并对其界面和基本功能进行了介绍。
SPSS软件提供了直观的用户界面,可以进行数据输入、数据处理和统计分析等操作。
2. 数据输入和修改为了方便后续的统计分析,我们学习了数据的输入和修改方法。
在SPSS软件中,我们可以手动输入数据,也可以从Excel等其他文件中导入数据。
此外,我们还学习了如何修改数据,包括添加变量、删除变量、重命名变量等操作。
3. 数据清洗和处理在实际应用中,数据往往存在一些错误或缺失。
为了保证统计分析的准确性,我们需要对数据进行清洗和处理。
SPSS软件提供了一系列的数据清洗工具,如删除重复数据、替换缺失值、筛选数据等。
4. 描述性统计分析描述性统计分析是对收集到的数据进行总结和描述的方法。
我们学习了如何计算数据的均值、中位数、众数、标准差等统计量。
通过绘制直方图、箱线图等图表,我们可以对数据的分布进行可视化展示。
5. 参数检验和非参数检验参数检验和非参数检验是统计分析中常用的两种方法,用于判断样本间差异是否显著。
我们学习了t检验、方差分析、卡方检验等方法,并通过SPSS软件进行了实际操作。
6. 方差分析方差分析是用于比较三个或三个以上样本均值是否存在显著差异的方法。
我们学习了单因素方差分析和多因素方差分析,并通过SPSS软件进行了实际分析。
统计学spss实验报告

统计学spss实验报告统计学SPSS实验报告引言:统计学是一门研究数据收集、分析和解释的学科,它在各个领域中都扮演着重要的角色。
SPSS(Statistical Package for the Social Sciences)是一种常用的统计分析软件,它提供了丰富的数据处理和分析工具,广泛应用于社会科学、医学、市场调研等领域。
本实验旨在通过使用SPSS软件,对一组数据进行统计分析,并得出相关结论。
方法:本实验采用了一组假想数据,包含了100位学生的考试成绩和他们的学习时间。
首先,我们使用SPSS软件导入数据,并对数据进行初步的描述性统计分析。
然后,我们进一步进行了相关性分析和回归分析,以探索学习时间与考试成绩之间的关系。
结果:在描述性统计分析中,我们计算了学生们的平均学习时间和考试成绩的平均值、标准差等指标。
结果显示,学生们的平均学习时间为3小时,考试成绩的平均值为80分,标准差分别为1小时和10分。
这些数据为后续的分析提供了基础。
接下来,我们进行了相关性分析,以确定学习时间与考试成绩之间的相关性。
通过SPSS软件的相关性分析功能,我们计算了学习时间和考试成绩之间的皮尔逊相关系数。
结果显示,学习时间与考试成绩之间存在显著的正相关关系(r = 0.8, p < 0.001)。
这意味着学习时间越长,考试成绩越高。
进一步地,我们进行了回归分析,以确定学习时间对考试成绩的影响程度。
通过SPSS软件的回归分析功能,我们建立了一个线性回归模型,将学习时间作为自变量,考试成绩作为因变量。
结果显示,学习时间对考试成绩有显著的预测作用(F(1, 98) = 100, p < 0.001)。
回归方程为:考试成绩 = 70 + 10 * 学习时间。
这意味着每多学习1小时,考试成绩将提高10分。
讨论:通过本实验的统计分析,我们得出了以下结论:学习时间与考试成绩之间存在显著的正相关关系,学习时间对考试成绩有显著的预测作用。
统计分析与spss的应用实验报告

统计分析与SPSS的应用实验报告1. 简介统计分析是一种通过收集、整理和分析数据来揭示数据背后规律的方法。
SPSS (Statistical Package for the Social Sciences)是一种常用的统计分析软件,它可以快速、准确地进行各种统计分析,并生成相应的报告和图表。
本实验报告旨在介绍统计分析的基本概念和SPSS的应用。
我们将以一个实际案例为例,展示如何使用SPSS进行数据处理和统计分析,并通过Markdown文本格式输出实验报告。
2. 实验目的本实验的主要目的是通过分析某公司员工的工资数据,探究不同因素对工资的影响,并使用SPSS进行相应的统计分析。
通过本实验,我们将学习以下内容: - 数据的描述性统计分析 - 数据的正态性检验 - 不同因素与工资之间的相关性分析 - 因子分析 - 回归分析3. 数据收集与处理我们从某公司的人力资源部门获取了一份员工的工资数据,包括以下变量: - 员工编号(ID) - 性别(Gender) - 年龄(Age) - 受教育程度(Education) - 工作经验(Experience) - 部门(Department) - 工资(Salary)我们首先对数据进行了清理和预处理,包括删除缺失值、处理异常值等。
接下来我们将介绍具体的统计分析过程。
4. 描述性统计分析在进行其他进一步的分析之前,我们首先对数据进行描述性统计分析,以了解数据的基本情况。
我们计算了各个变量的平均值、标准差、最大值、最小值以及分位数,并使用Markdown表格的形式进行展示。
变量平均值标准差最大值最小值25%分位数50%分位数75%分位数年龄35.2 5.6 45 25 30 35 40 工资5000 1000 8000 3000 4000 5000 6000 受教育程度2.5 0.5 3 2 2 3 3工作经验8.2 2.1 12 5 7 8 10从上表中可以看出,样本中的员工年龄平均为35.2岁,工资平均为5000元。
SPSS统计实验-课程实验报告

课程实验报告专业年级09教育管理课程名称教育统计与测量指导教师黄照旭学生姓名石畅学号200915441006 实验日期2011年10月12日实验地点二教2-9 实验成绩教务处制2011 年10 月12日实验项目名称SPSS教育统计实验实验目的及要求熟悉SPSS界面及一般操作,能够熟练运用SPSS软件进行相关分析、t检验、方差分析、一元线性回归分析实验内容对老师提供的数据按要求使用SPSS软件进行分析,并解释输出结果。
实验步骤一、分析题目,输入数据;二、对数据进行分析;三、得出结果,填写实验报告实验环境SPSS18.0中文版软件实验结果与分析实验一:相关系数课程A 课程B Spearman 的rho 课程A 相关系数相关系数 1.000 .657*Sig.(双侧)(双侧) . .020 N 12 12 课程B 相关系数相关系数 .657* 1.000 Sig.(双侧)(双侧) .020 . N 12 12 *. 在置信度(双测)为在置信度(双测)为 0.05 时,相关性是显著的。
时,相关性是显著的。
说明P值=0.02<0.05,说明在置信度为0.05时,课程A与课程B相关;P值=0.02>0.01,说明在置信度为0.01时,不相关。
不相关。
实验二:单个样本统计量N 均值均值 标准差标准差 均值的标准误均值的标准误VER 20 75.2500 2.95359 .66044 单个样本检验检验值检验值 = 72 t df Sig.(双侧) 均值差值均值差值差分的差分的 95% 置信区间置信区间下限下限 上限上限VER 4.921 19 .000 3.25000 1.8677 4.6323 说明:由于P的值=0.00<0.05,所以山区成年男子的脉搏均数与该地成年男子有显著性差异。
实验三:T 检验检验组统计量学生学生 N 均值均值 标准差标准差 均值的标准误均值的标准误自尊总分自尊总分干部干部 10 34.1000 6.93542 2.19317 非干部非干部10 33.4000 6.81828 2.15613 说明:通过T 检验可知,方差齐性检验可知,方差齐性独立样本检验方差方程的方差方程的 Levene 检验检验均值方程的均值方程的 t 检验检验F Sig. t df Sig.(双侧) 均值差值均值差值 标准误差值 差分的95%置信区间置信区间下限下限自尊总分假设方差相等假设方差相等 .009 .927 .228 18 .823 .70000 3.07553 假设方差不相等.228 17.995 .823 .70000 3.07553 说明:由于P 的值=0.823>0.05,接受原假设,所以学生干部与非学生干部自尊水平没有显著性差异。
spss实验报告

《统计实习》SPSS实验报告姓名:学号:班级:会计二班实验报告二实验项目:描述性统计分析实验目的:1、掌握数据集中趋势和离中趋势的分析方法;2、熟练掌握各个分析过程的基本步骤以及彼此之间的联系和区别..实验内容及步骤一、数据输入案例:对6名男生和6名女生的肺活量的统计;数据如下:1.打开SPSS软件;进行数据输入:通过打开数据的方式对XLS的数据进行输入其变量视图为:二、探索分析进行探索分析得出如下输出结果:浏览由上表可以看出;6例均为有效值;没有记录缺失值得情况..由上表可以看出;男女之间肺活量的差异;男生明显优于女生;范围更广;偏度大.. 男男 Stem-and-Leaf PlotFrequency Stem & Leaf2.00 1 . 342.00 1 . 892.00 2 . 02Stem width: 1000Each leaf: 1 cases女女 Stem-and-Leaf PlotFrequency Stem & Leaf2.00 1 . 233.00 1 . 568 1.00 2 . 0Stem width: 1000Each leaf: 1 cases三、频率分析进行频率分析得出如下输出结果:由上图可知;分析变量名:肺活量..可见样本量N为6例;缺失值0例; 1500以下的33%;1500-2000男生33%女生50%;2000以上女生16.7%;男生33%..四、描述分析进行描述分析得出如下输出结果:由上图可知;分析变量名:工资;可见样本量N为6例;极小值为男1342女1213;极大值为男2200女2077;说明12人中肺活量最少的为女生是1213;最多的为男生有2200;均值为1810.50/1621.33;.标准差为327.735/325.408;离散程度不算大..五、交叉分析实验报告三实验项目:均值比较实验目的:.学习利用SPSS进行单样本、两独立样本以及成对样本的均值检验..实验内容及步骤(一)描述统计案例:某医疗机构为研究某种减肥药的疗效;对15位肥胖者进行为期半年的观察测试;测试指标为使用该药之前和之后的体重..编号 1 2 3 4 5服药前198 237 233 179 219服药后192 225 226 172 214编号 6 7 8 9 10服药前169 222 167 199 233服药后161 210 161 193 226编号11 12 13 14 15服药前179 158 157 216 257服药后173 154 143 206 249输入SPSS建立数据..由上图可知;结果输出均值、样本量和标准差..因为选择了分组变量;所以三项指标均给出分组及合计值;可见以这种方式列出统计量可以非常直观的进行各组间的比较..由上表可知;在显著性水平为0.05时;服药前后的概率p值为小于0.05;拒绝零假设;说明服药前后的体重有显著性变化(二)单样本T检验进行单样本T检验分析得出如下输出结果:由上表可以知;单个样本统计量分析表;的基本情况描述;有样本量、均值、标准差和标准误;单样本t检验表;第一行注明了用于比较的已知总体均值为14;从左到右依次为t值t、自由度df、P值Sig.2-tailed、两均值的差值Mean Difference、差值的95%可信区间..由上表可知:t=34.215;P=0.000<0.05..因此可以认为肺气肿的总体均值不等于0.(三)双样本T检验案例:研究某安慰剂对肥胖病人治疗作用;用20名患者分组配对;测得体重如下表;要求测定该安慰剂对人的体重作用是否比药物好..进行双样本T检验得出如下输出结果:T检验成对样本统计量均值N 标准差均值的标准误对 1 安慰剂121.80 10 11.419 3.611 组药物组111.80 10 10.185 3.221 由上图可知;对变量各自的统计描述;此处只有1对;故只有对1..此处进行配对变量间的相关性分析配对t检验表;给出最终的检验结果;由上表可见P=0.001;故可认为安慰剂组和药物组对肥胖病人的体重有差别影响实验报告四实验项目:相关分析实验目的:1.学习利用SPSS进行相关分析、偏相关分析、距离分析、线性回归分析和曲线回归..实验内容及步骤(一)两变量的相关分析案例:某医疗机构为研究某种减肥药的疗效;对15位肥胖者进行为期半年的观察测试;测试指标为使用该药之前和之后的体重..编号 1 2 3 4 5服药前198 237 233 179 219服药后192 225 226 172 214编号 6 7 8 9 10服药前169 222 167 199 233服药后161 210 161 193 226编号11 12 13 14 15服药前179 158 157 216 257服药后173 154 143 206 249进行相关双变量分析得出如下输出结果:相关性相关系数系数表..变量间两两的相关系数是用方阵的形式给出的..每一行和每一列的两个变量对应的格子中就是这两个变量相关分析结果结果;共分为三列;分别是相关系数、P值和样本数..由于这里只分析了两个变量;因此给出的是2*2的方阵..由上表可见;服药前和服药后自身的相关系数均为1of course;而治疗前和治疗后的相关系数为0.911;P<0.01(二)偏相关分析偏相关已知有某河流的一年月平均流量观测数据和该河流所在地区当年的月平均雨量和月平均温度观测数据;如表所示..试分析温度与河水流量之间的相关关系..观测数据表月份月平均流量月平均雨量月平均气温1 0.50 0.10 -8.802 0.30 0.10 -11.003 0.40 0.40 -2.404 1.40 0.40 6.905 3.30 2.70 10.606 4.70 2.40 13.907 5.90 2.50 15.408 4.70 3.00 13.509 0.90 1.30 10.0010 0.60 1.80 2.7011 0.50 0.60 -4.8012 0.30 0.20 -6.00由上表可见控制月平均雨量之后;“月平均流量”与“月平均气温”的相关系数为0.365;P=0.27;P>0.05;因此“月平均流量”与“月平均气温”不存在显著相关性..(三)距离分析案例:植物在不同的温度下的生长状况不同;下列是三个温度下的植物生长编号10度20度30度1 12.36 12.4 12.182 12.14 12.2 12.223 12.31 12.28 12.354 12.32 12.25 12.215 12.12 12.22 12.16 12.28 12.34 12.257 12.24 12.31 12.28 12.41 12.3 12.46近似值(四)线性回归分析已知有某河流的一年月平均流量观测数据和该河流所在地区当年的月平均雨量和月平均温度观测数据;如表所示..试分析关系..观测数据表月份月平均流量月平均雨量月平均气温1 0.50 0.10 -8.802 0.30 0.10 -11.003 0.40 0.40 -2.404 1.40 0.40 6.905 3.30 2.70 10.606 4.70 2.40 13.907 5.90 2.50 15.408 4.70 3.00 13.509 0.90 1.30 10.0010 0.60 1.80 2.7011 0.50 0.60 -4.8012 0.30 0.20 -6.00进行线性回归分析得出如下输出结果:回归由表可知;是第一个问题的分析结果..这里的表格是拟合过程中变量进入/退出模型的情况记录;由于只引入了一个自变量;所以只出现了一个模型1在多元回归中就会依次出现多个回归模型;该模型中身高为进入的变量;没有移出的变量; 这里的表格是拟合过程中变量进入/退出模型的情况记录;由于只引入了一个自变量;所以只出现了一个模型在多元回归中就会依次出现多个回归模型;该模型中身高为进入的变量;没有移出的变量..模型汇总模型R R 方调整R方标准估计的误差1 .855a .732 .705 .6117a. 预测变量: 常量; 月平均流量..拟合模型的情况简报;显示在模型中相关系数R为0.855;而决定系数R2为0. 732;校正的决定系数为0.705;说明模型的拟合度较高..Anovab模型平方和df 均方 F Sig.1 回归10.208 1 10.208 27.283 .000a残差 3.741 10 .374总计13.949 11a. 预测变量: 常量; 月平均流量..b. 因变量: 月平均雨量这是所用模型的检验结果;可以看到这就是一个标准的方差分析表从上表可见所用的回归模型F值为27.283;P值为.00a;因此用的这个回归模型是有统计学意义的;可以继续看下面系数分别检验的结果..由于这里所用的回归模型只有一个自变量;因此模型的检验就等价与系数的检验;在多元回归中这两者是不同的..包括常数项在内的所有系数的检验结果..用的是t检验;同时还会给出标化/未标化系数..可见常数项和身高都是有统计学意义的残差统计量a极小值极大值均值标准偏差N 预测值.526 3.113 1.292 .9633 12残差-.6337 1.1358 .0000 .5832 12标准预测值-.795 1.890 .000 1.000 12标准残差-1.036 1.857 .000 .953 12a. 因变量: 月平均雨量图表(五)曲线回归分析某地1963年调查得儿童年龄岁与体重的资料试拟合对数曲线..进行曲线回归分析得出如下输出结果:实验报告五实验项目:聚类分析和判别分析实验目的:1.学习利用SPSS进行聚类分析和判别分析..实验内容及步骤(一)系统聚类法为确定老年妇女进行体育锻炼还是增加营养会减缓骨骼损伤;一名研究者用光子吸收法测量了骨骼中无机物含量;对三根骨头主侧和非主侧记录了测量值;结果见教材表..:主侧桡骨桡骨主侧肱骨肱骨主侧尺骨尺骨受试者编号1 1.103 1.052 2.139 2.238 0.873 0.8722 0.842 0.859 1.873 1.741 0.590 0.7443 0.925 0.873 1.887 1.809 0.767 0.7134 0.857 0.744 1.739 1.547 0.706 0.6745 0.795 0.809 1.734 1.715 0.549 0.6546 0.787 0.779 1.509 1.474 0.782 0.5717 0.933 0.880 1.695 1.656 0.737 0.8038 0.799 0.851 1.740 1.777 0.618 0.6829 0.945 0.876 1.811 1.759 0.853 0.77710 0.921 0.906 1.954 2.009 0.823 0.765输入SPSS建立数据..进行系统聚类分析得出如下输出结果:聚类快捷聚类研究儿童生长发育的分期;调查名1月至7岁儿童的身高cm、体重kg、胸围cm 和资料..求出月平均增长率%;判别分析对某企业;搜集整理了10名员工2009年第1季度的数据资料..构建1个10×6维的矩阵职工代号工作产量工作质量工作出勤工砟损耗工作态度工作能力1 9.68 9.62 8.37 8.63 9.86 9.742 8.09 8.83 9.38 9.79 9.98 9.733 7.46 8.73 6.74 5.59 8.83 8.464 6.08 8.25 5.04 5.92 8.33 8.295 6.61 8.36 6.67 7.46 8.38 8.146 7.69 8.85 6.44 7.45 8.19 8.17 7.46 8.93 5.7 7.06 8.58 8.368 7.6 9.28 6.75 8.03 8.68 8.229 7.6 8.26 7.5 7.63 8.79 7.6310 7.16 8.62 5.72 7.11 8.19 8.181、“分析——分类——判别分析”;把“分类”选入“分组变量”;定义范围:最小值1;最大值4;把X1、X2、X3、X4、X5和X6输入“自变量框”;选择“使用逐步式方法”;2、“统计量”中选择“均值”、“单变量ANOVA”、“Fisher”、“未标准化”、“组内相关”;3、“方法”默认设置;4、“分类”中选择“根据组大小计算”、“摘要表”、“不考虑该个案时的分类”、“在组内”、“合并图、分组、区域图”;5、“保存”中选择“预测组成员”、“判别得分”;6、点击确定..得到以下各表和图..特征值函数特征值方差的% 累积% 正则相关性1 1.002a 100.0 100.0 .707a. 分析中使用了前1 个典型判别式函数..函数1工作质量.270工作产量-.831工作出勤-.406工砟损耗 1.415工作态度 1.879工作能力-2.061结构矩阵函数1工砟损耗.541工作出勤.355工作态度.175工作产量.063工作能力-.056工作质量-.050判别变量和标准化典型判别式函数之间的汇聚组间相关性按函数内相关性的绝对大小排序的变量..典型判别式函数系数函数1工作质量.581工作产量-.830工作出勤-.312工砟损耗 1.248工作态度 2.798工作能力-2.803 常量-6.817非标准化系数组质心处的函数职工代号函数11 -.7312 1.097在组均值处评估的非标准化典型判别式函数分类统计量分类处理摘要已处理的10 已排除的缺失或越界组代码0至少一个缺失判别变量0用于输出中10组的先验概率职工代号先验用于分析的案例未加权的已加权的1 .600 6 6.0002 .400 4 4.000 合计 1.000 10 10.000分类函数系数职工代号1 2工作质量121.299 122.360工作产量-58.894 -60.411工作出勤-14.803 -15.373工砟损耗 3.739 6.020工作态度123.979 129.094工作能力-63.284 -68.407 常量-547.493 -560.691Fisher 的线性判别式函数单独组图表实验报告六实验项目:因子分析和主成分分析实验目的:1.学习利用SPSS进行因子分析和主成分分析..实验内容及步骤(一)因子分析下表资料为15名健康人的7项生化检验结果;6项生化检验指标依次命名为X1至X6;请对该资料进行因子分析..因子分析1.打开导入excle数据2.选择菜单“分析→降维→因子分析” ;弹出“因子分析”对话框..在对话框左侧的变量列表中选除地区外的变量;进入“变量”框;3.单击“描述”按钮;弹出“因子分析: 描述”对话框;在“统计量”中选“单变量描述”项;输出各变量的均数与标准差;“相关矩阵”栏内选“系数”;计算相关系数矩阵;并选“KMO 和 Bartlett’s 球形度检验”项;对相关系数矩阵进行统计学检验;对以上资料进行因子分析:分析——降维——因子分析;确定操作得出描述统计量均值标准差分析 NX1 6.0213 1.23848 15 X2 7.9880 .57340 15 X3 3.9960 1.01195 15 X4 5.5700 1.38699 15 X5 8.3727 .77780 15 X6 8.0247 .68955 15相关矩阵X1 X2 X3 X4 X5 X6相关X1 1.000 .966 .782 .055 .104 .019 X2 .966 1.000 .747 .028 .233 .158X3 .782 .747 1.000 .125 .214 -.024X4 .055 .028 .125 1.000 -.150 .233X5 .104 .233 .214 -.150 1.000 .753X6 .019 .158 -.024 .233 .753 1.000Sig.单侧X1 .000 .000 .423 .356 .473 X2 .000 .001 .461 .202 .287X3 .000 .001 .329 .222 .467X4 .423 .461 .329 .297 .202X5 .356 .202 .222 .297 .001X6 .473 .287 .467 .202 .001KMO 和 Bartlett 的检验取样足够度的 Kaiser-Meyer-Olkin 度量.. .460Bartlett 的球形度检验近似卡方64.035 df 15 Sig. .000公因子方差初始提取X1 1.000 .950X2 1.000 .930X3 1.000 .801X4 1.000 .989X5 1.000 .928X6 1.000 .936提取方法:主成份分析..成份矩阵a成份1 2 3X1 .935 -.277 -.021 X2 .954 -.131 -.057 X3 .868 -.218 .030 X4 .107 .059 .987 X5 .389 .839 -.272 X6 .263 .914 .178 提取方法 :主成份..a. 已提取了 3 个成份..旋转成份矩阵a成份1 2 3X1 .975 -.001 .016 X2 .953 .146 -.012 X3 .892 .032 .066 X4 .049 .021 .993 X5 .145 .930 -.205 X6 -.013 .937 .241 提取方法 :主成份..旋转法 :具有 Kaiser 标准化的正交旋转法..a. 旋转在 4 次迭代后收敛..成份转换矩阵成份 1 2 31 .958 .281 .0542 -.284 .957 .0533 -.037 -.066 .997 提取方法 :主成份..旋转法 :具有 Kaiser 标准化的正交旋转法..。
统计学模拟实验SPSS 实验报告

目录第一章数据介绍 (3)1.1研究问题的提出 (3)1.2数据的来源 (3)第二章基本统计分析 (4)2.1 基本统计分析 (4)2.1.1 全部变量的频数分析 (4)2.1.3变量的交差分析 (9)2.1.5 异常值的检验 (12)2.2 参数检验 (13)2.2.1 单样本T检验 (13)2.2.2 两独立样本T检验 (14)2.3 相关分析 (14)2.4 多元线性回归分析 (15)第三章总结和建议 (21)3.1 存在的问题 (21)3.2 如何改进这些不足 (21)附录A 22附录B 22摘要当前的消费市场中,大学生作为一个特殊的消费群体正受到越来越大的关注。
由于大学生年纪较轻,群体较特别,有着不同于社会其他消费群体的消费心理和行为。
一方面,他们有着旺盛的消费需求,另一方面,他们尚未获得经济上的独立,消费受到很大的制约。
消费观念的超前和消费实力的滞后,都对他们的消费有很大影响。
社会大众对大学生的消费存在种种争议,认为他们出手阔绰。
本文从我校大学生消费状况,消费的行为、消费结构、消费倾向和消费观念等方面来分析大学生的消费特征以及怎样提高他们的消费观念和理财能力,引导在校大学生树立正确的消费观。
关键词:大学生消费观;理性;问题;改进;数据分析第一章数据介绍1.1研究问题的提出大学生消费问题日渐成为一个社会广为关注的问题,大学生作为一个特殊的群体,处于校园与社会交界处,脱离了父母,开始经济独立,独自生活。
大学是一个精彩的世界,社会生活又是充满诱惑的,对大学生的消费都存在着很大的影响。
同时也不免回存在一些非理性的消费问题,导致社会群众对大学生消费状况的批评。
为了弄清大学生的消费问题的真实问题本小组成员进行了该项调查主要想弄清楚大学生们平时把钱花在哪里,花多少,影响他们消费的因素有哪些,以及他们在消费中有那些问题,应该怎样的去改造这些问题。
1.2数据的来源本次分析的数据来源于我校90名不同专业和年级的同学消费情况调查。
spss实验报告,心得体会

spss实验报告,心得体会篇一:SPSS实验报告SPSS应用——实验报告班级:统计0801班学号:1304080116 姓名: 宋磊指导老师:胡朝明2010.9.8一、实验目的:1、熟悉SPSS操作系统,掌握数据管理界面的简单的操作;2、熟悉SPSS结果窗口的常用操作方法,掌握输出结果在文字处理软件中的使用方法。
掌握常用统计图(线图、条图、饼图、散点、直方图等)的绘制方法;3、熟悉描述性统计图的绘制方法;4、熟悉描述性统计图的一般编辑方法。
掌握相关分析的操作,对显著性水平的基本简单判断。
二、实验要求:1、数据的录入,保存,读取,转化,增加,删除;数据集的合并,拆分,排序。
2、了解描述性统计的作用,并1掌握其SPSS的实现(频数,均值,标准差,中位数,众数,极差)。
3、应用SPSS生成表格和图形,并对表格和图形进行简单的编辑和分析。
4、应用SPSS做一些探索性分析(如方差分析,相关分析)。
三、实验内容:1、使用SPSS进行数据的录入,并保存: 职工基本情况数据:操作步骤如下:打开SPSS软件,然后在数据编辑窗口(Data View)中录入数据,此时变量名默认为var00001,var00002,…,var00007,然后在Variable View窗口中将变量名称更改即可。
具体结果如下图所示:输入后的数据为:将上述的数据进行保存:单击保存即可。
2、读取上述保存文件:选择菜单File--Open—Data;选择数据文件的类型,并输入文件名进行读取,出现如下窗口:选定职工基本情况.sav文件单击打开即可读取数据。
3、对上述数据新增一个变量工龄,其操作步骤为将当前数据单元确定在某变量上,选择菜单Data—Insert Variable,SPSS自动在当前数据单元所在列的前一列插入一2个空列,该列的变量名默认为var00016,数据类型为标准数值型,变量值均是系统缺失值,然后将数据填入修改。
结果如下图所示:篇二:SPSS相关分析实验报告本科教学实验报告(实验)课程名称:数据分析技术系列实验实验报告学生姓名:一、实验室名称:二、实验项目名称:相关分析三、实验原理相关关系是不完全确定的随机关系。
SPSS统计软件实训报告

SPSS统计软件实训报告第一篇:SPSS统计软件实训报告一、实训目的SPSS统计软件实训课是在我们在学习《统计学》理论课程之后所开设的一门实践课。
其目的在于,通过此次实训,使学生在掌握了理论知识的基础上,能具体的运用所学的统计方法进行统计分析并解决实际问题,做到理论联系实际并掌握统计软件SPSS的使用方法。
,二、实训时间与地点:时间:2012年1月9日至2012年1月13日地点:唐山学院北校区A座502机房三、实训要求:这次实训内容为上机实训,主要学习SPSS软件的操作技能,以及关于此软件的一些理论和它在统计工作中的重要作用。
对我们的主要要求为,运用SPSS软件功能及相关资料来完成SPSS操作,选择有现实意义的课题进行计算和分析,最后递交统计分析报告,加深学生对课程内容的理解的。
我们小组的研究课题是社会消费品零售总额的分析。
四、实训的主要内容与过程:此次实训,我大概明白了SPSS软件的基本操作流程,也掌握了如何排序、分组、计算、合并、增加、删除以及录入数据;学会了如何计算定基发展速度、环比发展速度等动态数列的计算;明白了如何进行频数分析、描述分析、探索分析以及作图分析;最大的收获是学会了如何运用SPSS软件对变量进行相关分析、回归分析和计算平均值、T检验和假设性检验。
通过这次试训,我基本上掌握了SPSS软件的主要操作过程,也学会了运用SPSS软件进行各种数据分析。
这些内容,也就是我们SPSS统计软件实训的主要内容。
四、实训结果与体会五天的SPSS软件实训终于结束了,虽然实训过程充满了酸甜苦辣,但实训结果却是甜的。
看着小组的课题报告,心里有种说不出来的感触。
高老师在对统计理论及SPSS 软件功能模块的讲解的同时更侧重于统计分析在各项工作中的实际应用,使我们不仅掌握SPSS 软件及技术原理而且学会运用统计方法解决工作和学习中的实际问题这个实训。
我真真正正学到了不少知识,另外,也提高了自己分析问题解决问题的能力。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
(此文档为word格式,下载后您可任意编辑修改!)目录第一章数据介绍 (3)1.1研究问题的提出 (3)1.2数据的来源 (3)第二章基本统计分析 (4)2.1 基本统计分析 (4)2.1.1 全部变量的频数分析 (4)2.1.3变量的交差分析 (9)2.1.5 异常值的检验 (12)2.2 参数检验 (13)2.2.1 单样本T检验 (13)2.2.2 两独立样本T检验 (14)2.3 相关分析 (14)2.4 多元线性回归分析 (15)第三章总结和建议 (21)3.1 存在的问题 (21)3.2 如何改进这些不足 (21)附录A22附录B22摘要当前的消费市场中,大学生作为一个特殊的消费群体正受到越来越大的关注。
由于大学生年纪较轻,群体较特别,有着不同于社会其他消费群体的消费心理和行为。
一方面,他们有着旺盛的消费需求,另一方面,他们尚未获得经济上的独立,消费受到很大的制约。
消费观念的超前和消费实力的滞后,都对他们的消费有很大影响。
社会大众对大学生的消费存在种种争议,认为他们出手阔绰。
本文从我校大学生消费状况,消费的行为、消费结构、消费倾向和消费观念等方面来分析大学生的消费特征以及怎样提高他们的消费观念和理财能力,引导在校大学生树立正确的消费观。
关键词:大学生消费观;理性;问题;改进;数据分析第一章数据介绍1.1研究问题的提出大学生消费问题日渐成为一个社会广为关注的问题,大学生作为一个特殊的群体,处于校园与社会交界处,脱离了父母,开始经济独立,独自生活。
大学是一个精彩的世界,社会生活又是充满诱惑的,对大学生的消费都存在着很大的影响。
同时也不免回存在一些非理性的消费问题,导致社会群众对大学生消费状况的批评。
为了弄清大学生的消费问题的真实问题本小组成员进行了该项调查主要想弄清楚大学生们平时把钱花在哪里,花多少,影响他们消费的因素有哪些,以及他们在消费中有那些问题,应该怎样的去改造这些问题。
1.2数据的来源本次分析的数据来源于我校90名不同专业和年级的同学消费情况调查。
Spss数据中共包含十一变量,分别是:性别,户口状况,家庭年总收入,月生活费,伙食费占生活费的比例,娱乐占生活费的比列,生活费的来源,消费习惯,消费倾向,消费商品是注重,生活费盈余的处理,消费状况是否满意。
通过运用spss统计软件,对变量进行基本统计分析、参数检验、相关分析、回归分析,以了解我校同学在上述方面的综合状况,并分析个变量的分布特点及相互间的关系。
第二章基本统计分析2.1 基本统计分析2.1.1 全部变量的频数分析户口情况频数分析(表一)频率百分比有效百分比累积百分比有效城镇17 18.9 18.9 18.9农村73 81.1 81.1 100.0合计90 100.0 100.0从表一中可知被调查的同学中有73人来自农村占总人数的81%,只有17个同学来自城镇占总人数的19%。
说明我校学生户口大多数分布在农村,生活水平较低。
性别状况的频数分析(表二)频率百分比有效百分比累积百分比有效男46 51.1 51.1 51.1女44 48.9 48.9 100.0合计90 100.0 100.0从表二中可以得知在调查中51%的都是男生,49%为女生,此次调查的男女比例均衡。
家庭收入频数分析(表三)频率百分比有效百分比累积百分比有效一万以下38 42.2 42.2 42.2 一万到五万43 47.8 47.8 90.0五万到十万7 7.8 7.8 97.8十万以上 2 2.2 2.2 100.0合计90 100.0 100.0从表三中可知家庭年收入在五万以下的有81%,43%家庭的年收入在一到五万,甚至有38%的家庭收入在一万以下。
高收入家庭所占比例很少。
这与我校大部分学生来自农村是相符合的,同时从侧面反映出农村生活水平低,很多人还在温饱线上徘徊。
月生活费频数分析(表四)频率百分比有效百分比累积百分比有效46 51.1 51.1 51.142 46.7 46.7 97.82 2.2 2.2 100.0合计90 100.0 100.0从表四中的数据得知一半左右的同学生活费在之间,生活费在1500—2000的只有两个同学。
表明我校同学平时还是比较节省的,懂得节制,这也是与家庭收入有关。
伙食费占生活费的比例频数分析(表五)频率百分比有效百分比累积百分比有效.20 5 5.6 5.6 5.6.25 8 8.9 8.9 14.4.33 45 50.0 50.0 64.4.50 32 35.6 35.6 100.0伙食费占生活费的比例频数分析(表五)频率百分比有效百分比累积百分比有效.20 5 5.6 5.6 5.6.25 8 8.9 8.9 14.4.33 45 50.0 50.0 64.4.50 32 35.6 35.6 100.0合计90 100.0 100.0伙食费占生活费的比例中,32个同学选择了0.50占总人数的32%,45个同学选择了0.33占总人数的50%,5个同学选择了0.2占总人数的5.6%。
表明我校的学生生活费主要用于日常的饮食,生活费的使用结构比较简单。
娱乐的花费占生活费的比例频数分析(表六)频率百分比有效百分比累积百分比有效.20 42 46.7 46.7 46.7.25 26 28.9 28.9 75.6.33 17 18.9 18.9 94.4.50 5 5.6 5.6 100.0合计90 100.0 100.0从表六中数据可知,68个同学选择了0.25,占总人数的75%,只有5个同学选择了0.50占总人数的5.6%。
说明我校大学生的在娱乐方面的消费低,这与他们可以得到的月生活费有关。
也说明我校大学生良好的消费习惯,能够量入为出,不攀比,不享乐。
生活费的来源频数分析(表七)频率百分比有效百分比累积百分比有效父母给予88 97.8 97.8 97.8 校外兼职或勤工 1 1.1 1.1 98.9奖学金 1 1.1 1.1 100.0合计90 100.0 100.0关于生活费的来源97.8%的同学生活费都是由父母给有的,只有极个别同学生活费的主要来源是校外兼职和奖学金,且没有一个同学选择创业的收入作为生活费的主要来源。
这说明了在中国,孩子对父母的依赖性很强独立性差,都是成年人了,还没有能力自己负担生活费用。
同时也表明中国学生大学生在创新和动手方面的能力比较弱,尤其是偏远地区的大学生。
消费习惯的频数分析(表八)频率百分比有效百分比累积百分比有效有计划消费26 28.9 28.9 28.9 能省就省21 23.3 23.3 52.2没有计划,想花就花36 40.0 40.0 92.2其他7 7.8 7.8 100.0合计90 100.0 100.0在消费习惯方面,有26个同学选择有计划的消费占总人数的28.9%,21个同学选择了能省就省,有36个同学选择了没有计划想花就花,占总人数的40%。
表示一半的同学在消费上还是有规划的,比较理性合理的分配生活费用。
但仍有接近一半的同学,对于要怎么使用生活费方面是没有规划的,想花就花。
消费倾向的频数分析(表九)频率百分比有效百分比累积百分比有效以经济实惠为主40 44.4 44.4 44.4 兼顾实惠和高标准44 48.9 48.9 93.3尽量追求高标准 6 6.7 6.7 100.0合计90 100.0 100.0从表九中数据可以得知,40个同学选择了在消费时以经济实惠为主占总人数的44.4%,有44个同学选择了以兼顾实惠和高标准为主,6个同学选择了以尽量追求高标准为主。
说明我校大学生的消费倾向很好,懂的自己现实的处境(自己没有经济收入)适合追求怎样的消费倾向,不超前消费,很务实。
买东西时的注重的因素频数分析(表十)频率百分比有效百分比累积百分比有效品牌 4 4.4 4.4 4.4质量39 43.3 43.3 47.8外形美观18 20.0 20.0 67.8价格17 18.9 18.9 86.7实用性12 13.3 13.3 100.0合计90 100.0 100.0从表十中可知,有39个同学选择了质量占总人数的43.3%,有17个同学选择了价格占只人数的18.9%。
只有4个同学选择了品牌占总人数的4.4%。
说明我校的大学生在商品消费方面,比较理性,充分考虑自己的实际情况,消费能力。
只买对的东西,不买贵的。
对品牌的追求度不高,有着正确的消费观。
生活费盈余的处理频数分析(表十一)频率百分比有效百分比累积百分比有效存在银行29 32.2 32.2 32.2 改善物质生活28 31.1 31.1 63.3购书、CD等丰富精神生活33 36.7 36.7 100.0合计90 100.0 100.0从表十一中可知,这三项的人分布比较的均匀。
既有物质方面的满足,也有精神方面的追求,安排得当。
消费状况是否满意的频数分析(表十二)频率百分比有效百分比累积百分比有效很满意27 30.0 30.0 30.0 没考虑过,无所谓26 28.9 28.9 58.9不满意37 41.1 41.1 100.0合计90 100.0 100.0从表十二中可知大部分同学对于自己的消费状况是不满的。
只有30%的同学觉的满意,所以很有必要给大学生一些关于消费的指引。
2.1.2 消费倾向的基本描述统计分析关于消费倾向的描述统计量分析(表十三)家庭住址N 全距极小值极大值均值标准差偏度峰度统计量统计量统计量统计量统计量统计量统计量标准误统计量标准误城镇消费倾向17 2.00 1.00 3.00 1.8235.80896.353 .550 -1.342 1.063有效的N17农村消费倾向73 2.00 1.00 3.00 1.5753.5507.206 .281 -.981 .555有效的 N73从表十三中可以看出,家庭住址为城镇的同学消费倾向的平均值是1.8235,高于家庭住址为农村的同学。
无论家庭住址是城镇的还是农村的同学,在消费倾向的分布均存在一定的左偏分布(两个偏度值分别为-0.353和-0.206当偏度值小于0是呈现左偏,且绝对值越大,表示数据分布的偏斜程度越大),且城镇的同学偏斜程度更大些。
同时家庭住址在城镇和农村的同学在消费倾向的分布方面呈现平分分布。
(两个峰度值分别是-1.342和-0.981)且农村的分布比城镇的平缓。
2.1.3变量的交差分析关于家庭住址&消费习惯交叉表的案例处理摘要(表十四) 案例 有效的 缺失 合计N百分比 N 百分比 N 百分比 家庭住址 * 消费习惯 90 100.0%.0%90100.0%户口&消费习惯交叉制表分析(表十五)消费习惯合计有计划消费 能省就省 没有计划,想花就花 其他 家庭住址 城镇 计数46 6 1 17 期望的计数 4.9 4.0 6.8 1.3 17.0 家庭住址 中的 %23.5%35.3% 35.3% ,,100.0%消费习惯 中的 % 15.4% 28.6% 16.7% 14.3% 18.9% 总数的 % 4.4% 6.7% 6.7% 1.1% 18.9% 农村 计数2215 30 6 73 期望的计数 21.1 17.0 29.2 5.7 73.0 家庭住址 中的 %30.1% 20.5%41.1%8.2%100.0%消费习惯 中的 % 84.6% 71.4% 83.3% 85.7% 81.1% 总数的 %24.4% 16.7% 33.3% 6.7% 81.1% 合计计数2621 36 7 90 期望的计数 26.0 21.0 36.0 7.0 90.0 家庭住址 中的 %28.9% 23.3%40.0%7.8%100.0%消费习惯 中的 % 100.0% 100.0% 100.0% 100.0% 100.0% 总数的 %28.9%23.3%40.0%7.8%100.0%从表十五中可以可以看出城镇户口的同学有17个占人数的18.9%,农村户口的同学有73个占总人数的81.1%。