欠费预测用户的目标变量
电力用户欠费预警基本问题的探讨

蠕 —耋 蕊蠹
曩。 量
澎 一 撼
~
型比 困 较难
… ,
而 计 警 用 比 广故 用 统 预 应 面 较 ,采 统
三 差 ,
注① 表 对 指 值 大 好 示 小 好 :f示 应 标 越 越 ;表 越 越J o
…
蕃 I
‘
磊 警与 区
计 坝詈 刀瓦 。
从 每月的经济景气月报 中获取 , 可对辖区内 同类行业的用户做局部调整 ; 从调查 中获取 , 对 于 工业 企业 ,可采 用用 电产值 单耗 来 代替 ; 从 每 年财务部公布的企业效绩评价表中获取 , 它是一个 复杂 的指标体系,可选取主要指标后形成一个综合 指标 ; 从 权 威 的信 用 网站 中获 取 ; 从 电力 公 司 的电费数据库中经计算获得 。 确定警限与划分警区时, 对于 , , — 可按专业 领 域 的划 分方 法 来确 定 ; 由 电费 管 理人 员根 据经 墨 验来定 , 在一 段 时问 内通常应 该保 持稳定 , 一个 客 是 观的值 ,如可以设 6 0以上为无警 , 3 0以下为重警 , 则 3 ~ 0 间 为轻警 。 06 之 1 . 算例 .4 3 假设 有 5个不 同行业 用户 某月 的预警 指标取 值 如表 2 所示 , 同时警限和警区事先也已确定 , 则这 5 个用户是否有警 , 警度状况如何 , 目了然 。 一
相 同 日 善 由 林 { I m 阜 n +士i f E 害 由 蜘 棚 互 林
绩效指数 ,其值大表示资金等各方面正常 ; 表示 社会信用 的信用评分 ,其值高 , 说明社会信用表现 好 ; 表示缴费状况的交费得分[, 引 采用文献[ ] 3的 计算方法 , 可以较好地区分各种复杂 的缴费行为 , 其 值 高 , 明该用 户 累计缴 费情况 良好 。 说 监测 这些影 响 到用户 欠费 的参数 ,通过 掌握 这 些参数的变化特点 ,可以了解到每一个用户在不同 时段 的缴 费状况 ,。 对应 于每 次欠 费是何 种 因素 以及 影 响所 造成 的 。由于拆 迁 问题所 引起 的欠 费 比例 比 较 高 , 以把 它作 为一 个单 独的部 分来处 理 。 可 1 - 系统的预 警条件 设计 .3 3 是 否需要 预警 , 主要 取决 于预警 条件 的设定 , 因 此需 要设 定每 一个 指标 的警 限 ( 者划定警 区 )如 或 , 表I 所示 。 表 1 欠费预 警指标的警限和警区 设计
客户流失分析(数据挖掘-第1讲)

预测自变量时间窗口
间隔
预测目标变量时间窗口
商业理解
如何从分析结果中获取实际收益 得到了流失预测结果,如何使用?如何事先预估市场 挽留活动的收益?通过数据挖掘得到流失分析的结果往往有 两类: 一类是流失客户的特征描述 另一类是针对每一个客户的流失评分。 流失客户的特征描述可用来帮助市场部业务人员在制订 挽留性营销策略时参考,从而制订出有针对性的挽留策略; 而流失评分结合其它变量(例如客户价值)可以员的讨 论,我们得知针对特定客户的挽留措施往往是给他们一定折 扣或者优惠政策,这样就大体上得到了预估市场挽留活动预 期收益的数据公式: 预期收益=流失客户预期收入-流失客户挽留预期成本 其中,流失客户预期收入可以用流失客户过去若干个月的 总花费或者平均花费来表示,流失客户挽留预期成本包括: 电信公司进行时常挽留活动的总体策划、宣传成本;针对客 户的集体折扣或优惠成本。
数据理解与数据准备
在数据理解与数据准备阶段,我们将 对数据做初步探索性分析,了解数据质量 状况,考察数据的大致分布情况,此外还 要将各方面的数据进行合并,整理成可以 进行数据挖掘的宽表形式(即行代表记录, 列代表变量的二维表),并进一步根据业 务上的考虑,生成一些有业务含义的衍生 变量。在实际的数据挖掘项目中,我们会 发现,数据理解和数据准备的时间经常会 占到整个项目周期的60%~70%,甚至更多。
指标变量获取
2、衍生变量 对时间序列数据有以下一些常用的生成衍生变量的方 法: ①、滞后类指标:对于时间序列数据,各条记录之间 联系更加紧密,我们通常会取上一条记录(例如代表上月 取值)及上年同期(例如去年同月),与当前记录相比得 到环比增长率(例如本月值/上月值)和同比增长率(例如 本月值/上年同期值);为了消除波动,有时我们还对多个时 间段数值进行求和、平均等操作。例如股市中常用的股价 5日平均值,这类指标可以被归结为滞后类指标。 ②、汇总类指标: 汇总类指标:求和,平均值,最小值,最大值,标 准差,记录数等。
降低集团客户欠费率成果演示

示2023-10-30CATALOGUE 目录•引言•集团客户欠费现状分析•新解决方案的提出与实施•实施效果评估•结论与展望01引言集团客户欠费问题一直是各大运营商面临的难题,过高的欠费率不仅影响公司的收入和现金流,还可能导致客户流失。
随着市场竞争的加剧,降低集团客户欠费率已成为运营商提升服务质量、加强客户黏性的重要手段。
背景介绍通过研究和分析集团客户欠费的原因,提出针对性的解决方案。
通过实施欠费率降低措施,实现公司收入的稳定增长,提高客户满意度。
研究目的研究方法案例分析挑选典型的集团客户作为研究对象,深入剖析其欠费原因,为后续解决方案提供参考。
数据分析收集实验过程中的数据,运用统计分析方法对实验结果进行评估和解释。
实验设计制定欠费率降低措施的实施计划,明确实验目标和变量,确保实验过程的可控性。
文献综述搜集与集团客户欠费相关的研究资料,了解已有研究成果和经验。
02集团客户欠费现状分析03内部管理企业内部管理存在问题,如员工考核机制不合理、服务水平不高、响应速度慢等,也可能导致客户欠费。
欠费原因分析01客户需求客户可能会因为对产品或服务的不满意、对价格的不认同等原因而产生欠费。
02合同管理合同条款的模糊、责任不清、权利义务不明确等,可能导致客户不履行义务,产生欠费。
通过对历年集团客户欠费数据的分析,了解当前欠费率的现状,为制定解决方案提供数据支持。
行业对比与同行业其他企业进行对比,了解企业在行业中的欠费率水平,为企业改进提供参考。
历史数据欠费率现状统计VS现有解决方案的不足实施难度大有些解决方案需要投入大量人力物力,实施起来难度较大,且难以持续。
缺乏有效的监督机制有些解决方案只是单方面采取行动,没有建立有效的监督机制,无法保证实施的成效。
缺乏针对性现有的解决方案往往是一刀切的,没有针对不同客户的具体情况采取个性化的措施,效果不明显。
03新解决方案的提出与实施解决方案一:改进收费系统总结词提高收费效率、减少欠费情况详细描述采用先进的收费系统,实现自动化、智能化的收费管理,提高收费效率,减少因人为错误或漏收导致的欠费情况。
社交网络数据分析中的用户行为预测模型

社交网络数据分析中的用户行为预测模型社交网络的快速发展使得海量的用户行为数据得以收集和分析。
这些用户行为数据蕴含着宝贵的信息,可以帮助我们深入了解用户的兴趣、喜好和行为模式。
通过数据分析,我们可以建立用户行为预测模型,从而预测用户未来的行为,为社交网络平台的运营和决策提供依据。
用户行为预测是指通过分析用户之前的行为特征,预测其未来的行为。
常见的用户行为包括浏览、点赞、评论、分享等。
这些行为的预测可以帮助社交网络平台推荐个性化的内容、优化用户体验、增加用户黏性和活跃度。
下面将介绍一些常用的社交网络数据分析中的用户行为预测模型。
1.协同过滤模型协同过滤是一种通过分析用户行为模式来预测用户未来行为的方法。
该方法假设用户的行为倾向于与与其兴趣相似的其他用户的行为一致。
在社交网络中,用户之间的关联度较高,因此协同过滤模型可以较准确地预测用户的行为。
在协同过滤模型中,首先需要构建用户间的相似度矩阵,衡量用户之间的行为相似性。
可以通过计算用户之间的余弦相似度或欧几里德距离来得到相似度矩阵。
然后,根据与目标用户最相似的一组用户的行为,预测目标用户的未来行为。
2.基于内容的推荐模型基于内容的推荐模型是另一种常用的用户行为预测模型。
该模型通过分析用户对内容的兴趣和喜好,预测用户对未来内容的喜好程度。
在基于内容的推荐模型中,首先需要对内容进行特征提取。
可以通过分析内容的关键词、主题、情感等特征来建立内容的特征向量。
然后,通过分析用户对不同内容的评价和喜好,建立用户的兴趣模型。
利用特征向量和用户兴趣模型,可以计算用户与不同内容之间的相似度,进而预测用户对未来内容的喜好程度。
基于内容的推荐模型可以为用户推荐个性化的内容,提供更好的用户体验。
3.时序模型时序模型是一种通过分析用户的历史行为模式,预测用户未来行为的方法。
该模型采用时间序列的思想,通过分析时间段内的用户行为规律,预测用户在未来时间段内的行为。
在时序模型中,首先需要进行数据的时间切片,将用户的行为数据按照时间维度进行分段。
如何控制用户的欠费概要

如何控制用户的欠费随着电信业务的发展、资本市场的运作,很多运营商都把目光盯在了一些具体的数字上,如欠费率。
控制欠费慢慢成为运营商的紧迫要求,在欠费的控制上,业界有几种思路,或者说几种方向在去做这个事情,这个方向并不是互先冲突的,而是互相补充的。
背景:欠费其实是一种社会现象,有一个前提是必须明确的,那就是用户的欠费是不能完全控制的,因为正常的社会活动和经济活动中,欠费行为有其发生的现实原因,不可避免。
我们需要做的是怎么改进管理水平、信用管理、技术提升等各领域方法和技巧,减少用户不希望的欠费,减少恶意的欠费等。
欠费其实是一种社会现象,由于用户的欠费而造成收入的降低,或者坏帐。
有些东西要具体分析。
上次碰到一个银行做信用卡的,说他们的系统很奇怪,给一个单位做信用卡,员工都通过了,惟独几个老总没通过,后来查原因,说他们的电话费有拖欠几个月的行为。
大家可以想一下要解决欠费的目的?至于解决手段,实时计费/智能网都是手段,但成本比较高,还有一种是用DM技术,可以降低成本。
总的说来,要考虑成本跟收益的问题。
1、管理水平方面管理水平提高的包括建立信用度管理,配合相应的奖励和惩罚措施,这个行为需要和社会其它领域配合,也需要社会的共同进步带动;管理水平包括设计出更合适、更灵活的计费方式和缴费方式,满足不同客户的偏好和具体脚尖,减少客户不希望的缴费(有的欠费是客户被迫的,或者客户不能在一定条件下实现的)。
具体说来,可以有如下方法:a)提供更加先进、灵活的缴费方式。
用户方便了,自然也就可以勤快的缴费了。
这方面,比较好的例子是缴费卡,二卡合一等业务。
b)完善黑名单管理。
业务上增强跨地区,跨运营商之间的合作。
前期可以强调数据的共享,后期可以强调管理流程上执行的力度。
c)有效核实用户资料,避免只注重数量,不注重质量的做法。
通过和其他系统的合作,如公安系统的合作,对用户进一步身份判断,减少可能发生的恶意欠费。
d)完善信用度管理、提出完善的信誉度计算模型。
欠费风险专题分析

欠费风险专题分析中国移动通信集团河北有限公司衡水分公司网络部设备维护中心刘娜2009年1月15日业务背景OCS(online charging system)被广泛认为是3G中的一种重要的计费方式,可以对用户进行实时计费,且不受用户申请业务的限制。
在目前网络侧设备短期仍不能大规模进入3G应用的条件下,如何将OCS的部分功能应用到现在的2G网络,是移动运营商迫切需要解决的问题,而欠费风险控制系统,就是这一问题的解决方案。
话务控制流程主要用于MSC/SSP、SCP、MGW三者之间配合,根据用户的资料和帐户情况对用户的通话进行实时的控制,当余额不足时,能够及时切断呼叫,避免欠费。
问题引出08年12月中旬,华为智能网割接上线,在配合测试过程中,我们发现当欠费风险用户账户余额仅够通话三分钟时,建立一个正常的呼叫,当账户余额仅够一分钟时:(1)北电端局下,用户可以听到“滴滴”的余额不足警告音;(2)中兴软交换端局下,听不到“滴滴”的警告音;一分钟过完后,两种端局下都可以正常切断呼叫。
在同一个地区(衡水地区),业务类型相同,放音却有差别。
这一方面造成了提示音的不规范,另一方面还有可能引起客户投诉。
鉴于此,我方立即组织人员进行处理。
问题分析1.预付费业务智能呼叫对于预付费业务,MSC/VLR/SSP收到呼叫请求,根据主教签约信息O-CSI 触发业务,直接将MSC/VLR/SSP所在位置长途区号放在IDP消息中的,LocationNumber参数中,并向SCP发送IDP消息。
SCP受到IDP消息后,先分析主叫用户账户,账户有效,则根据主叫用户拜访地的长途区号和被叫区号确定主叫费率,并将余额折算成通话时长发送RRBE、AC、和Contiune到MSC/VLR/SSP。
然后根据ISUP中的被叫号码进行接续,折算通话时长不足一分钟时系统会播放录音通知或发出分钟提示音,耗尽时切断呼叫。
2.MSCServer控制MGW放音对于软交换端局来讲,什么时候放音以及放什么音是由H.248来控制的。
《管理统计学》期末(参考答案)
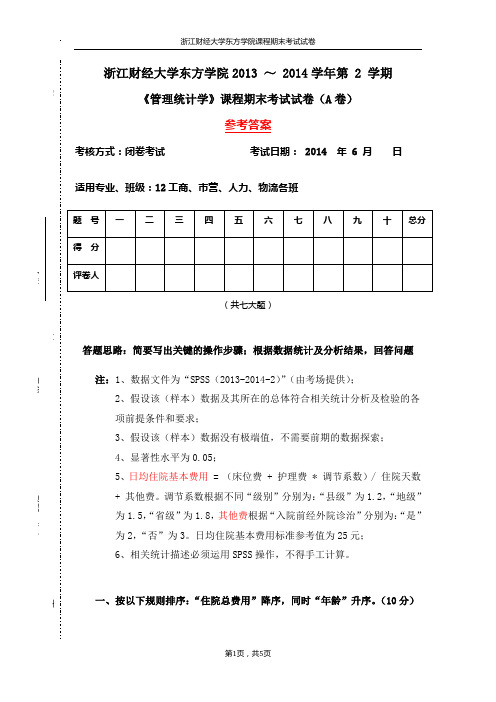
浙江财经大学东方学院2013 ~ 2014学年第 2 学期《管理统计学》课程期末考试试卷(A 卷)参考答案考核方式:闭卷考试 考试日期: 2014 年 6 月 日适用专业、班级:12工商、市营、人力、物流各班答题思路:简要写出关键的操作步骤;根据数据统计及分析结果,回答问题注:1、数据文件为“SPSS (2013-2014-2)”(由考场提供);2、假设该(样本)数据及其所在的总体符合相关统计分析及检验的各 项前提条件和要求;3、假设该(样本)数据没有极端值,不需要前期的数据探索;4、显著性水平为0.05;5、日均住院基本费用 = (床位费 + 护理费 * 调节系数)/ 住院天数 + 其他费。
调节系数根据不同“级别”分别为:“县级”为1.2,“地级” 为1.5,“省级”为1.8,其他费根据“入院前经外院诊治”分别为:“是” 为2,“否”为3。
日均住院基本费用标准参考值为25元; 6、相关统计描述必须运用SPSS 操作,不得手工计算。
一、按以下规则排序:“住院总费用”降序,同时“年龄”升序。
(10分)执行“数据→排序个案”,将“住院总费用”移入“排序依据”框,“排列顺序”选择“降序”,再将“年龄”移入“排序依据”框,“排列顺序”选择“升序”。
二、按“治疗类别”分组,分别对“治疗费”求秩,将秩值1赋给最大值,结的处理方式为“低”。
(10分)执行“转换→个案排秩”,将“治疗费”移入“变量”框,将“治疗类别”移入“排序标准”框,“将秩1指定给”选择“最大值”,“结”按钮中选择“低”。
三、描述统计不同“入院情况”的病人的“日均住院基本费用”的:均值(数)、中位值(数)、标准差、四分位距。
(15分)执行“转换→计算变量”,“目标变量”输入“qtf”,“数字表达式”输入“2”,单击“如果”,选择“如果个案满足条件则包括”,输入“v73=1”,同理计算得到全部“qtf”。
再次执行“转换→计算变量”,“目标变量”输入“rjzyjbfy”,“数字表达式”输入“(v84+v97*1.2)/v29+qtf”,单击“如果”,选择“如果个案满足条件则包括”,输入“level=3”,同理计算得到全部“rjzyjbfy”。
商务智能及大数据-贷款拖欠者风险预测

贷款拖欠者风险预测名称:贷款拖欠者风险预测目的:使用现有贷款拖欠数据来预测今后出现的潜在的贷款拖欠者使用方法及工具:使用贝叶斯网络,通过将观察到并记录下的证据与实际常识结合起来构建概率模型,以通过使用表面看上去不相关的属性确定发生的可能性。
贝叶斯网络是一种概率网络,它是基于概率推理的图形化网络,而贝叶斯公式则是这个概率网络的基础。
贝叶斯网络是基于概率推理的数学模型,所谓概率推理就是通过一些变量的信息来获取其他的概率信息的过程,基于概率推理的贝叶斯网络(Bayesian network)是为了解决不定性和不完整性问题而提出的,它对于解决复杂设备不确定性和关联性引起的故障有很大的优势,在多个领域中获得广泛应用。
所谓贝叶斯定理,通俗地讲就是当你不能确定某一个事件发生的概率时,你可以依靠与该事件本质属性相关的事件发生的概率去推测该事件发生的概率。
用数学语言表达就是:支持某项属性的事件发生得愈多,则该事件发生的可能性就愈大。
这个推理过程有时候也叫贝叶斯推理。
本作业使用了三个贝叶斯网络模型,分别为:树扩展朴素贝叶斯模型,具有马尔可夫覆盖结构贝叶斯网络模型和具有马尔可夫覆盖结构,同时也使用了特征选择预处理来选择与目标变量有重大关联的输入。
完成本次作业主要使用的工具是:IBM SPSS Modeler具体流程:1.创建源statistics文件,本次作业引用的为系统自带的bankloan.sav的数据文件,取自Demos目录下。
2.在源节点后,添加类型节点。
将拖欠情况作为目标,其他雇佣情况、收入、住址等相关变量作为输入值。
3. 在类型节点,添加选择节点。
选择节点的模式选择为丢弃,即对不符合条件的情况给予丢弃。
同时设定的条件为default=’$null$’,具体情况如下图:4. 在选择节点后,添加模型节点,构建模型。
根据本文的目的,选择了贝叶斯网络模型。
同时,分别选择了三种贝叶斯网络模型,并对它们进行比较,以确保选择最好的模型,进行最准确的风险排查。
运营商用户流失预测项目意义及目标

运营商用户流失预测项目意义及目标以运营商用户流失预测项目意义及目标为标题,本文将探讨该项目的重要性以及目标。
一、意义:随着通信技术的不断发展,运营商行业竞争日益激烈。
为了保持市场份额和提高用户黏性,运营商们需要更好地了解用户的需求和行为,以便提供更好的服务和产品。
用户流失是运营商面临的一个重要问题,因此,运营商用户流失预测项目具有以下重要意义:1. 提前预测用户流失:通过分析用户的行为数据和消费习惯,可以提前预测哪些用户有可能流失,从而采取针对性措施,提高用户满意度和留存率。
2. 降低用户流失成本:运营商在用户流失后需要重新吸引新用户或挽留离去的用户,这需要付出一定的成本。
因此,通过预测用户流失,可以采取相应措施,降低流失率,减少后续的成本投入。
3. 提升竞争力:用户流失预测项目可以帮助运营商更好地了解用户需求和偏好,根据用户的特点和意愿,调整产品和服务策略,提升竞争力。
二、目标:运营商用户流失预测项目的目标是通过对用户数据的分析和建模,实现准确预测用户流失,并制定相应的应对策略。
1. 数据收集和整理:首先,需要收集用户的行为数据、消费习惯、使用时长等信息,并对数据进行清洗和整理,以确保数据的准确性和完整性。
2. 特征选择和建模:运营商用户流失预测需要选取合适的特征,并建立合适的模型。
特征选择要考虑到对用户流失预测具有重要影响的因素,如用户的历史消费金额、使用时长、投诉情况等。
建模可以使用机器学习算法,如逻辑回归、决策树等,通过训练数据来建立模型。
3. 模型评估和优化:建立模型后,需要对模型进行评估和优化。
评估可以使用一些指标,如准确率、召回率、F1值等,来衡量模型的预测效果。
如果模型效果不理想,可以通过调整特征选择、改进算法等方式进行优化。
4. 流失用户预测和策略制定:通过建立的模型,可以对未来用户的流失情况进行预测。
根据预测结果,可以制定相应的应对策略,如向潜在流失用户提供个性化的优惠活动、改进产品和服务质量等,以挽留用户。
基于多尺度特征提取的电力客户欠费风险预测

成因素在时间上的波动特征及规律ꎬ是研究电力客
图 1 风险预测流程
Fig.1 Flow chart of risk forecasting
2 数据预处理及特征工程
2.1 数据预处理
根据业务逻辑从多个渠道收集的原始高压用
户数据主要有 2 类:包含了用户基本信息的静态数
识别规则可以由机器学习算法习得ꎮ 逻辑回归算
近年来ꎬ长短期记忆网络 [8] 和反向传播( back propa ̄
学者关注的重点ꎮ 此类研究的共同特点是强调算
法的改进和参数调整设置ꎬ但是对电力客户欠费风
收稿日期:2019 ̄09 ̄27ꎻ修回日期:2019 ̄11 ̄04
来筛选特征集ꎬ降低数据规模ꎮ 再次ꎬ风险用户的
的多维度数据集ꎮ 其次ꎬ用户风险特征不能由数据
直观地显示ꎬ需要分析或加工提取出能影响风险预
测的特征ꎬ作为预测用户风险的依据ꎮ 此外ꎬ如果
数据规模很大ꎬ高维度特征会带来计算效率低下以
Bagging 算法 [7] 建立的电力客户欠费风险预测模型ꎮ
及模型预测精度降低的问题ꎬ因此还需要借助算法
gationꎬBP) 神经网络 [9] 等算法的建模是众多专家、
对于高压用户来说ꎬ电费逾期次数和电费逾期
天数等动态信息是衡量欠费风险的重要的因素ꎬ文
中将考虑对其进行多尺度、有目的地提取特征ꎮ 首
先ꎬ用户的用电行为数据在动态生成中ꎬ不同时期
的用电行 为 数 据 对 用 户 风 险 有 不 同 程 度 的 影 响ꎮ
例如ꎬ低风险用户可能因近期的不良用电行为导致
欠费风险升高ꎬ而高风险用户也可能因近期持续良
(1. 国网江苏省电力有限公司扬州供电分公司ꎬ江苏 扬州 225009ꎻ
面向电费风险防控的欠费及补缴费实时推送系统研究

电力管理Power Management电力系统装备Electric Power System Equipment2020年第24期2020 No.24电费是电网公司的主要收入,是现金流的重要来源,能否有效地控制和管理电费风险,不仅直接决定公司流动资金地周转水平和最终经营利润,而且还直接影响到公司销售收入和整体效益地的提高。
随着深圳经济的快速发展,全市用电需求不断增长,电费回收也成为供电企业生产经营最重要的环节之一[1]。
为保证电费回收率,需要提前人工介入催收。
现有条件下,催缴员一般通过营销系统手动统计欠费用户然后电催,再更新回款数据及欠费清单,然后再进行下一轮电费催收。
现有的催收计费方式效率较低且容易出现重复催费情况导致用户投诉,除此之外,催收人员还需要具备操作数据库的技能,不容易上手。
其次,没有对用户进行细分,催收效果不佳。
因此,加强电力企业电费回收管理是提高企业生存和发展的关键。
本文结合当前供电企业电费回收存在的问题,就如何开发出一种根据催收优先级将欠费用户进行排序然后将待催缴用户信息列表发送到相应片区催缴员,在被催缴用户发生缴费后,催缴员能够及时获取到用户补缴费信息的实时推送系统进行了详细的描述。
本系统的目的在于提供一种能够根据风险等级将欠费用户进行细分从而提升催收效果,同时在标签库系统的后台设置定时任务每隔14分钟扫描收款记录表生成提醒短信,然后定时发送,从而能够及时使催缴员获取到缴费信息避免出现多次催费,从而提升了客户满意度。
最终效果如下:(1)欠费列表样例2020-07-03,当日待催缴总数2条,明细如下:1)低压居民用户,张三,0947000047020000,地址:深圳市龙岗区龙岭山庄1号,总欠费额:500,逾期数:2期。
202005期,欠费200元。
202006期,欠费300元。
2)低压居民用户,李四,0947000047020001,地址:深圳市龙岗区龙岭山庄2号,总欠费额:600,逾期数:3期。
基于支持向量机的电信欠费用户分析模型

第26卷计算机应用V01.26 2006年12月Com pu te r Ap p li ca t io n s Dec.2006文蕈编号:1001—9081(2006)12Z一0214一02基于支持向量机的电信欠费用户分析模型李学鹏,张国基(华南理工大学数学科学学院,广东广州510640) (jarodxp@163.com)摘要:客户欠费是电信公司面临的一大难题。
针对目前客户恶意欠费预测方法的不足,建立了一种基于支持向量机的客户欠费预测模型,支持向量机具有全局收敛性和良好推广能力,因此基于支持向量机评估模型具有较强的实用性。
最后通过对某直辖市郊区县的用户数据分析实验,证明了基于SVM的预测模型的可行性,且具有较高的预测精度。
关键词:客户欠费;支持向量机;预测中图分类号:TP39文献标识码:A布无任何要求的非线性技术,它能有效解决非正态分布、非线0引言性的分类问题,但它存在黑箱性(即不具解释性),结构确定随着电信服务市场的竞争日趋激烈,电信行业在采取灵困难等缺点,易出现过学习现象,推广能力较差。
活有效的市场营销策略来争取有价值的客户同时,话费拖欠为弥补神经网络出现的过学习现象,提高模型的推广能一直是电信部门的老大难问题,虽然预付费用户的数量和比力,由AT&T Beu实验室V8pnik针对分类和回归问题,提出例在上升,但是还是有大量用户采取先消费后缴费的传统模了支持向量机方法。
支持向量机方法是基于结构风险最小化式,因此常常出现用户欠费,导致电信运营商出现呆帐坏帐,原理sRM的方法,明显优于传统的基于经验风险ERM的常造成资金流失。
通过数据挖掘,充分提取客户信息,避免欠费规神经网络方法。
s RM使Vc维数(泛化误差)的上限最小出现是一项预防为先方法。
化,而ERM使相对训练数据的误差最小化。
这使得SvM具对不同类型客户的欠费情况进行跟踪分析,对欠费用户有更好的泛化能力,较好的分类精确性,在解决模式识别中小进行分类。
欠费预测用户的目标变量

一、模型规则( 1)目标用户群全省在网且入网满 6 个月以上用户,剔除以下状态:红名单用户、黑名单用户、全世界通 A 账期用户、全世界通 B 账期用户、公司统付用户;( 2)信誉 Good和 Bad标准全世界通:信誉 Good:用户在 2011 年 1-3月份未发生停机,或停机时长不超出50天的用户;信誉 Bad:用户在 2011 年 1-3月份停机时长超出50 天的用户;非全世界通:信誉 Good:用户在 2011 年 1-3月份未发生停机,或停机时长不超出40天的用户;信誉 Bad:用户在 2011 年 1-3月份停机时长超出40 天的用户;( 3)模型类型全世界通讯用评分模型非全世界通讯用评分模型( 4)模型建立窗口建模数据: 2010 年 6 月-2010 年 12 月表现期: 2011 年 1 月-2011 年 3 月( 5)变量要求最后模型的变量不超出15 个二、模型成效(请依据表格要求,填写有关数据)( 1)单变量剖析请计算最后模型每个变量与BAD用户的关系,以下表所示:网龄小于 1 年1~2 年2~3 年 3 年 +总用户数BAD用户数BAD 用户占比( 2) 整体成效剖析a. 将展望为 BAD 的概率 >阀值的用户归类为 “展望 BAD 用户”,依据设置的每个阀值,计算展望结果的用户数、欠费停机总次数、欠费总金额展望为 GOOD 用户且真 展望为 GOOD 用户且真切 展望为 BAD 用户且真 展望为 BAD 用户且真切 实为 GOOD 用户为 BAD 用户实为 GOOD 用户为 BAD 用户用户用户用户 阀值用户 用户用户用户 用 欠费用户欠用 欠费 用 欠费欠费用户 欠费 欠费欠费户停机 费停机 户停机 户 停机总金 数总金总金 总金数总次总次数数总次 数总次额额额额数数数1b.将展望结果(概率值)分段,计算每个分段的真切(GOOD/BAD)的用户数、欠费停机总次数、欠费总金额;真切 GOOD真切 BAD用户欠费用户欠费展望概率用户欠费用户欠费用户数停机总次用户数停机总次总金额总金额数数[[[[[[[ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [[ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [ [[[[[[[[]c. 将展望 BAD 的概率按降序排序,设置分位数分段,计算每个分段的真实( GODD/BAD)的用户数、欠费停机总次数、欠费总金额真切 GOOD真切 BAD分位数用户欠费用户欠费用户欠费用户数用户欠费用户数停机总次停机总次总金额总金额数数5% 10% 15% 20% 25% 30% 35% 40% 45% 50% 55% 60% 65% 70% 75% 80% 85% 90% 95% 100%。
欠费预测用户的目标变量

欠费预测用户的目标变量File modification on June 16, 2021 at 16:25 pm
一、模型规则
(1)目标用户群
全省在网且入网满6个月以上用户,剔除以下状态:红名单用户、黑名单用户、全球通A账期用户、全球通B账期用户、集团统付用户;
(2)信用Good和Bad标准
➢全球通:
●信用Good:用户在2011年1-3月份未发生停机,或停机时长不超过50天的用
户;
●信用Bad:用户在2011年1-3月份停机时长超过50天的用户;
➢非全球通:
●信用Good:用户在2011年1-3月份未发生停机,或停机时长不超过40天的用
户;
●信用Bad:用户在2011年1-3月份停机时长超过40天的用户;
(3)模型类别
➢全球通信用评分模型
➢非全球通信用评分模型
(4)模型构建窗口
➢建模数据:2010年6月-2010年12月
➢表现期:2011年1月-2011年3月
(5)变量要求
➢最终模型的变量不超过15个
二、模型效果请根据表格要求,填写相关数据
(1)单变量分析
请计算最终模型每个变量与BAD用户的关系,如下表所示:
(2)整体效果分析
a.将预测为BAD的概率>阀值的用户归类为“预测BAD用户”,根据设置的每个阀值,
计算预测结果的用户数、欠费停机总次数、欠费总金额
b.将预测结果概率值分段,计算每个分段的真实GOOD/BAD的用户数、欠费停机
总次数、欠费总金额;
将预测BAD的概率按降序排序,设置分位数分段,计算每个分段的真实GODD/BAD 的用户数、欠费停机总次数、欠费总金额。
目标变量和

目标变量和
目标变量是指在统计学和机器学习中,希望预测或估计的变量。
它是研究或分析的主要对象,是研究或分析的目标。
目标变量也被称为被解释变量、响应变量、因变量或预测变量。
在统计学中,通过建立一个数学模型来描述目标变量与自变量(也称为解释变量、预测变量或独立变量)之间的关系。
模型可以是线性的、非线性的、多变量的等等。
通过将自变量输入模型中,可以预测目标变量的值。
在机器学习中,目标变量是需要学习和预测的变量。
通过提供有标签的训练数据,机器学习算法可以学习目标变量与自变量之间的关系,并用于预测新的未标记数据的目标变量的值。
在监督学习中,目标变量可分为分类问题的类别标签和回归问题的数值。
目标变量的选择对于建立准确和有效的模型非常重要。
一个好的目标变量应该能够反映出所关心的问题的核心方面,并且在给定的数据和背景下是可测量的。
例如,如果想预测一个人的收入水平,目标变量可以选择为年收入数值。
如果想预测一个电影的用户评分,目标变量可以选择为评分数值。
在实际应用中,确定目标变量通常需要考虑多个因素,包括研究目的、数据可用性和实际可行性等。
此外,目标变量的定义和测量还需要遵循一定的科学原则和方法,以保证预测结果的可靠性和可解释性。
综上所述,目标变量在统计学和机器学习中起着重要的作用。
它是研究或分析的主要对象,通过目标变量与自变量之间的关系,可以预测或估计目标变量的值,从而实现预测和决策的目的。
基于组合模型的电力欠费风险指数和欠费客户分群

基于组合模型的电力欠费风险指数和欠费客户分群摘要:电费是供电企业收入的主要来源,是供电企业经济效益的最终体现。
由于内外部诸多因素共同影响,特别是2020年初疫情的发生,电费回收难已经直接影响到国家电网的利益。
本文运用大数据分析方法,例如层次分析法、随机森林等构建了疫情形势下电力客户欠费风险指数,详细并定量地描述了在新形势下企业客户的欠费风险,并且用聚类的方法细致分析了企业欠费的来源和成因,为供电公司的电费回收提供风险预警。
关键词:客户欠费风险;层次分析法;随机森林;疫情;客户分群A combined model for identifying payment default risk and a method for clustering defaulting customersAbstract: Electricity charge is the main source of the income of power supply companies, and it is the final measurement of theeconomic benefits of power supply companies. Due to the jointinfluence of many internal and external factors, especially the occurrence of the epidemic situation in the early 2020, the difficulty of electricity payment recovery has directly affected the interests of the State Grid. This paper uses big data analysis methods, such as AHP, Random Forest, to construct a risk model of customers defaulting payment under epidemic situation. The risk of enterprise customers owing charges under the new situation is described and quantified in details, and the sources and causes of enterprise defaulting paymentare analyzed in detail by using clustering method, which providesearly warning for electricity charge recovery.0引言在电力经营中, 由于长期采用“先用电, 后付费”的交易规则, 电力商品不能像其他商品那样实行“一手交钱一手交货”的现场等价交换原则, 因此, 无法完全避免客户拖欠甚至逃避缴纳电费的现象, 从而使供电企业承担着不能及时或根本无法回收电费的经营风险。
基于.NET的电力客户欠费指标预测系统

基于.NET的电力客户欠费指标预测系统
贺萌
【期刊名称】《黑龙江科技信息》
【年(卷),期】2009(000)034
【摘要】针对电力用户欠费问题,选取5个主要特征变量,建立基于电力客户欠费特征变量的灰色系统预警模型.并基于.NET开发平台,使用警告参数,实现欠费预警管理.
【总页数】2页(P69,273)
【作者】贺萌
【作者单位】常州信息职业技术学院,江苏,常州,213164
【正文语种】中文
【中图分类】TP3
【相关文献】
1.基于决策树算法的电力客户欠费风险预测 [J], 黄文思;郝悍勇;李金湖;柯华强;于佳琦;王伟;
2.基于决策树算法的电力客户欠费风险预测 [J], 黄文思;郝悍勇;李金湖;柯华强;于佳琦;王伟
3.基于.NET框架的经济指标预测系统的设计与开发 [J], 余盛明;吴静
4.基于多尺度特征提取的电力客户欠费风险预测 [J], 葛安同; 谢晓慧; 谭忠恒; 李铁香; 张云; 黄睿
5.基于多尺度特征提取的电力客户欠费风险预测 [J], 葛安同; 谢晓慧; 谭忠恒; 李铁香; 张云; 黄睿
因版权原因,仅展示原文概要,查看原文内容请购买。
电费回收风险预测的大数据方法应用 仲慧 陈丹丹 裔宁 吴浩然

电费回收风险预测的大数据方法应用仲慧陈丹丹裔宁吴浩然摘要:电费回收管理一直是供电企业的工作重点,且是供电企业经营活动中最为重要的环节之一。
长期以来,供电企业一直采用先用电后缴费的市场规则,因此存在电费回收周期长及催费措施落后等隐患,使电费回收逐渐成为困扰电力企业的一大问题。
为了解决此问题,各电力公司纷纷提出了各种行政管理手段和技术手段,并建立了基于客户风险的电费回收策略,以防范电费回收风险。
关键词:电费回收;风险预测;大数据;应用一、主要方法(一)最优变量分组方法变量分组是将分类变量的某些类别合并以降低其基数, 或者将数值型变量分段将其转换为分类变量的过程。
变量分组的方法是基于决策树模型的分裂找到最优的分组方案, 通过合并变量的类别使得预测力指标最大化, 即首先以使某预测力指标最大为原则找出最优的二元分割点, 然后在每个子类别中重复上一步骤, 当达到最大分组个数时停止分割。
(二)WOE证据权重转化方法将分类变量转化为数值型变量, 以降低建模程序的复杂性, 同时可以将Logistic回归模型转变为标准评分卡格式, 以利于后续模型结果的解释及应用。
对于某分类自变量的第i组, WOE的计算式如下。
其中, ix为某组分类自变量, ip和iq分别是x中第i类在目标变量Y中的响应个数占总体响应个数概率和未响应个数占总体未响应个数概率, in和*n均表示个数值。
信息值表示的是当前这个组中响应的客户和未响应客户的比值和所有样本中这个比值的差异。
WOE越大, 信息值越大, 这个分组里的样本响应的可能性就越大。
经过WOE转换, 将分类变量转化为数值型变量, 同时不影响原始分布。
(三)逻辑回归方法逻辑回归是一种研究二分变量Y与一系列影响因素nx之间关系的多变量分析方法, 是在线性模型基础上的进一步发展。
其一般形式如下:其中, P是变量Y发生的概率, 取值为0~1, β为模型建立后得到的自变量系数。
逻辑回归模型的计算速度快, 结果显性化且拟合效果好, 目前在大数据、机器学习、经济学等领域得到了广泛应用。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一、模型规则
(1)目标用户群
全省在网且入网满6个月以上用户,剔除以下状态:红名单用户、黑名单用户、全球通A账期用户、全球通B账期用户、集团统付用户;
(2)信用Good和Bad标准
全球通:
●信用Good:用户在2011年1-3月份未发生停机,或停机时长不超过50
天的用户;
●信用Bad:用户在2011年1-3月份停机时长超过50天的用户;
非全球通:
●信用Good:用户在2011年1-3月份未发生停机,或停机时长不超过40
天的用户;
●信用Bad:用户在2011年1-3月份停机时长超过40天的用户;
(3)模型类别
全球通信用评分模型
非全球通信用评分模型
(4)模型构建窗口
建模数据:2010年6月-2010年12月
表现期:2011年1月-2011年3月
(5)变量要求
最终模型的变量不超过15个
二、模型效果(请根据表格要求,填写相关数据)
(1)单变量分析
请计算最终模型每个变量与BAD用户的关系,如下表所示:
(2)整体效果分析
a.将预测为BAD的概率>阀值的用户归类为“预测BAD用户”,根据设置的每
个阀值,计算预测结果的用户数、欠费停机总次数、欠费总金额
b.将预测结果(概率值)分段,计算每个分段的真实(GOOD/BAD)的用
户数、欠费停机总次数、欠费总金额;
c.将预测BAD的概率按降序排序,设置分位数分段,计算每个分段的真实(GODD/BAD)的用户数、欠费停机总次数、欠费总金额。