hive自定义函数说明
Hive函数及语法说明

无线增值产品部Hive函数及语法说明版本:Hive 0.7.0.001eagooqi2011-7-19版本日期修订人描述V1.0 2010-07-20 eagooqi 初稿2012-1-4 Eagooqi ||、cube目录⏹函数说明 (2)⏹内置函数 (2)⏹增加oracle函数 (14)⏹增加业务函数 (17)⏹扩展函数开发规范 (19)⏹语法说明 (21)⏹内置语法 (21)⏹增加语法 (28)⏹扩展语法开发规范(语法转换) (29)⏹ORACLE sql 对应的hSQL语法支持 (29)⏹函数说明参考链接:https:///confluence/display/Hive/LanguageManualCLI下,使用以下命令显示最新系统函数说明SHOW FUNCTIONS;DESCRIBE FUNCTION <function_name>;DESCRIBE FUNCTION EXTENDED <function_name>;⏹内置函数数值函数Mathematical Functions集合函数Collection Functions类型转换函数Type Conversion Functions日期函数Date Functions条件判断函数Conditional Functions字符串函数String Functions其他函数Misc. FunctionsxpathThe following functions are described in [Hive-LanguageManual-XPathUDF]:∙xpath, xpath_short, xpath_int, xpath_long, xpath_float, xpath_double, xpath_number, xpath_stringget_json_objectA limited version of JSONPath is supported:∙$ : Root object∙. : Child operator∙[] : Subscript operator for array∙* : Wildcard for []Syntax not supported that's worth noticing:∙: Zero length string as key∙.. : Recursive descent∙@ : Current object/element∙() : Script expression∙?() : Filter (script) expression.∙[,] : Union operator∙[start:end.step] : array slice operatorExample: src_json table is a single column (json), single row table:json{"store":{"fruit":[{"weight":8,"type":"apple"},{"weight":9,"type":"pear"}], "bicycle":{"price":19.95,"color":"red"}},"email":"amy@only_for_json_udf_","owner":"amy"}The fields of the json object can be extracted using these queries:hive> SELECT get_json_object(src_json.json, '$.owner') FROM src_json; amyhive> SELECT get_json_object(src_json.json, '$.store.fruit[0]') FROM src_json;{"weight":8,"type":"apple"}hive> SELECT get_json_object(src_json.json, '$.non_exist_key') FROM src_json;NULL内置聚合函数Built-in Aggregate Functions (UDAF)增加oracle函数增加业务函数扩展函数开发规范提供以下两种实现方式:a继承org.apache.hadoop.hive.ql.exec.UDF类代码包为:package org.apache.hadoop.hive.ql.udf实现evaluate方法,根据输入参数和返回参数类型,系统自动转换到匹配的方法实现上。
hive函数大全

hive函数大全1.内置运算符1.1关系运算符运算符类型说明A =B 原始类型如果A与B相等,返回TRUE,否则返回FALSEA ==B 无失败,因为无效的语法。
SQL使用”=”,不使用”==”。
A <>B 原始类型如果A不等于B返回TRUE,否则返回FALSE。
如果A或B值为”NULL”,结果返回”NULL”。
A <B 原始类型如果A小于B返回TRUE,否则返回FALSE。
如果A或B值为”NULL”,结果返回”NULL”。
A <=B 原始类型如果A小于等于B返回TRUE,否则返回FALSE。
如果A或B值为”NULL”,结果返回”NULL”。
A >B 原始类型如果A大于B返回TRUE,否则返回FALSE。
如果A或B值为”NULL”,结果返回”NULL”。
A >=B 原始类型如果A大于等于B返回TRUE,否则返回FALSE。
如果A或B值为”NULL”,结果返回”NULL”。
A IS NULL 所有类型如果A值为”NULL”,返回TRUE,否则返回FALSEA IS NOT NULL 所有类型如果A值不为”NULL”,返回TRUE,否则返回FALSEA LIKEB 字符串如果A或B值为”NULL”,结果返回”NULL”。
字符串A与B通过sql 进行匹配,如果相符返回TRUE,不符返回FALSE。
B字符串中的”_”代表任一字符,”%”则代表多个任意字符。
例如:(…foobar‟ like …foo‟)返回FALSE,(…foobar‟ like …foo_ _ _‟或者…foobar‟ like …foo%‟)则返回TUREA RLIKEB 字符串如果A或B值为”NULL”,结果返回”NULL”。
字符串A与B通过java 进行匹配,如果相符返回TRUE,不符返回FALSE。
例如:(…foobar‟rlike …foo‟)返回FALSE,(‟foobar‟rlike …^f.*r$‟)返回TRUE。
hive caldate函数

hive caldate函数Hive是一个基于Hadoop的数据仓库系统,它提供了一个类SQL的接口,使用户可以用常用的SQL语句来操作存储在Hadoop集群中的数据。
Hive中的函数是用来处理数据的重要工具之一,在这里我们将会着重介绍Hive函数中的一个函数——caldate函数。
caldate函数是Hive提供的一个日期函数,它的作用是根据给定的年、月、日参数,返回该日期对应的日期值。
简单来说,就是将给定的年月日转化为Hive中的日期类型。
1. 语法caldate(year, month, day)参数说明:- year:年份,必选参数,整型。
- month:月份,必选参数,整型。
- day:日,必选参数,整型。
返回值类型:- date2. 示例-- 示例1:返回2021年8月23日的日期SELECT caldate(2021, 8, 23);-- 返回结果:2021-08-23需要注意的是,如果给定的年月日不合法,caldate函数会返回NULL。
上面的示例3中,2020年2月29日是一个闰年的特殊情况,因此该示例会返回正确的日期。
caldate函数的使用场景非常广泛,在Hive中,我们常常需要将日期相关的数据进行处理和分析,例如计算某一天的数据量、汇总某段时间内的销售额,等等。
这时我们就需要使用到caldate函数将日期类型转化为标准格式,进而进行统计计算。
下面我们将举一些实际的例子来展示caldate函数的使用场景。
1. 计算一段时间内的销售额SELECT SUM(total_sales)FROM sales_recordWHEREcaldate(year, month, day) BETWEEN '2021-08-01' AND '2021-08-31';在上面的示例中,我们使用了caldate函数将year、month、day转化为了标准的日期类型,然后使用了between关键字来筛选出2021年8月的数据,最后通过SUM函数来计算8月份的总销售额。
在Hive中创建使用自定义函数

在Hive中创建使用自定义函数目录在Hive中创建使用自定义函数 (1)实际情况 (2)网传的四种做法 (2)适宜做法 (3)原理(hive源代码) (4)实际情况Hive提供了不少的函数,但是针对比较复杂的业务,还需要我们手动去定义一些函数来进行一些数据分析处理。
Hive的自定义函数包括UDF、UDAF和UDTF,定义模板请参考/blog/1472371。
网传的四种做法1.在HIVE会话中add 自定义函数的jar文件,然后创建function,继而使用函数;2.在进入HIVE会话之前先自动执行创建function,不用用户手工创建;3.把自定义的函数写到系统函数中,使之成为HIVE的一个默认函数,这样就不需要create temporary function;4.在HIVE_HOME的bin目录下新建一个.hiverc的文件,把写好的注册语句写在里面。
1.在HIVE会话中add 自定义函数的jar文件,然后创建function,继而使用小结:这种方式的弊端是:每次打开新的会话,就要重新执行一遍如上的add jar和create temporary function的命令。
2.在进入HIVE会话之前先自动执行创建functionHIVE命令有个参数-i:在进入会话,待用户输入自己的HQL之前,先执行-i的参数。
我们只需要把add jar和create temporary function的命令写到一个文件中,并把这个文件传到-i的参数,如此一来省去了每次要手工创建的工作。
3.把自定义的函数写到系统函数中,使之成为HIVE的一个默认函数(1)编写自己的UDF/UDAF/UDTF,并把代码放到$HIVE_HOME/src/ql/src/java/org/apache/hadoop/hive/ql/udf路径下(2)修改$HIVE_HOME/src/ql/src/java/org/apache/hadoop/hive/ql/exec/FunctionRegis try.java以HIVE自带函数Trim()举例,自定义函数操作一样。
hive空间函数

Hive空间函数详解Hive是一个基于Hadoop的数据仓库基础设施,它提供了一种类似于SQL的查询语言HiveQL来进行数据查询和分析。
Hive空间函数是HiveQL中的一类特定函数,用于处理和操作空间数据。
本文将详细解释Hive空间函数的定义、用途和工作方式。
1. Hive空间函数的定义Hive空间函数是一类专门用于处理和操作空间数据的函数,它们提供了一系列用于计算和处理空间数据的功能。
Hive空间函数通常基于地理信息系统(Geographic Information System,简称GIS)的原理和算法,用于处理地理空间数据。
Hive空间函数可以用于处理各种类型的空间数据,包括点、线、面等。
它们可以计算空间数据的距离、面积、长度等属性,还可以进行空间数据的转换、裁剪、合并等操作。
2. Hive空间函数的用途Hive空间函数的主要用途是进行地理空间数据的计算和处理。
它们可以在Hive中对空间数据进行分析和查询,帮助用户更好地理解和利用地理空间数据。
以下是Hive空间函数的一些常见用途:2.1 空间数据计算Hive空间函数可以计算空间数据的各种属性,包括距离、面积、长度等。
例如,可以使用ST_Distance()函数计算两个点之间的距离,使用ST_Area()函数计算一个面的面积,使用ST_Length()函数计算一个线的长度等。
2.2 空间数据转换Hive空间函数可以进行空间数据的转换,将一个类型的空间数据转换为另一个类型。
例如,可以使用ST_Point()函数将经纬度坐标转换为点类型的空间数据,使用ST_PolygonFromEnvelope()函数将一个矩形范围转换为面类型的空间数据等。
2.3 空间数据裁剪Hive空间函数可以进行空间数据的裁剪,根据指定的条件对空间数据进行裁剪。
例如,可以使用ST_Intersection()函数计算两个面的交集,使用ST_Union()函数计算多个面的并集等。
hive常用函数

hive常用函数Hive一款建立在Hadoop之上的数据仓库分析软件,它为用户提供了一系列的函数,以满足用户的不同需求。
在这里,我们将重点介绍 Hive 中一些常用的函数,希望能够更好的帮助用户使用和熟悉Hive。
### 1.学函数数学函数是 Hive 中的一类经常被使用的函数,它们分为算术运算类函数、随机数类函数、对数类函数、三角函数类函数、取整函数类函数、科学计数法函数等,下面,我们将分别介绍这几类函数的语法以及用法。
####1)算术运算类函数算术运算类函数主要有如下:1. `ABS(x)`:返回x的绝对值2. `EXP(x)`:返回e的x次方3. `MOD(x, y)`:返回x除以y的余数4. `POWER(x,y)`:返回x的y次方5. `ROUND(x,d)`:返回x保留d位小数后的结果6. `LOG(x)`:返回x的自然对数####2)随机数类函数随机数类函数主要有`RAND()`,它用于生成一个0~1之间的随机数。
####3)对数类函数对数类函数主要有`LOG(x, base)` `LOG10(x)`,它们用于返回X的对数,其中base可以自定义,为空时,使用2作为默认值;而`LOG10(x)`则返回以10为底的x的对数。
####4)三角函数类函数三角函数类函数主要有`SIN(x)`,`COS(x)`,`TAN(x)`,它们分别用于返回x的正弦值、余弦值和正切值。
####5)取整函数类函数取整函数类函数主要有`CEIL(x)` `FLOOR(x)`,它们用于返回比x大的最小整数和比x小的最大整数。
####6)科学计数法函数科学计数法函数主要有`ROUND(x,s)`,其中x为一个数字,s代表保留小数点位数,用于表示数字的指数部分,即参数s代表相对于基数10的指数。
### 2.符串函数字符串函数是 Hive 中常用的一类函数,它们分为字符串处理类函数、字符和数值转换类函数、字符集转换类函数、正则表达式类函数等,下面,我们将分别介绍这几类函数的语法以及用法。
Hive(18)hive自定义函数

Hive(18)hive⾃定义函数hive⾃定义函数1、⾃定义函数的基本介绍Hive ⾃带了⼀些函数,⽐如:max/min等,但是数量有限,⾃⼰可以通过⾃定义UDF来⽅便的扩展。
当Hive提供的内置函数⽆法满⾜你的业务处理需要时,此时就可以考虑使⽤⽤户⾃定义函数(UDF:user-defined function)根据⽤户⾃定义函数类别分为以下三种:UDF(User-Defined-Function)⼀进⼀出UDAF(User-Defined Aggregation Function)聚集函数,多进⼀出,类似于:count/max/minUDTF(User-Defined Table-Generating Functions)⼀进多出,如lateral view explode()如lateral view explode()官⽅⽂档地址编程步骤:(1)继承org.apache.hadoop.hive.ql.UDF(2)需要实现evaluate函数;evaluate函数⽀持重载;注意事项(1)UDF必须要有返回类型,可以返回null,但是返回类型不能为void;(2)UDF中常⽤Text/LongWritable等类型,不推荐使⽤java类型;2、⾃定义函数开发第⼀步:创建maven java ⼯程,并导⼊jar包<repositories><repository><id>cloudera</id><url>https:///artifactory/cloudera-repos/</url></repository></repositories><dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.6.0-mr1-cdh5.14.2</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>2.6.0-cdh5.14.2</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>2.6.0-cdh5.14.2</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-core</artifactId><version>2.6.0-cdh5.14.2</version></dependency><dependency><groupId>org.apache.hive</groupId><artifactId>hive-exec</artifactId><version>1.1.0-cdh5.14.2</version></dependency><dependency><groupId>org.apache.hive</groupId><artifactId>hive-jdbc</artifactId><version>1.1.0-cdh5.14.2</version></dependency><dependency><groupId>org.apache.hive</groupId><artifactId>hive-cli</artifactId><version>1.1.0-cdh5.14.2</version></dependency></dependencies><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.0</version><configuration><source>1.8</source><target>1.8</target><encoding>UTF-8</encoding><!-- <verbal>true</verbal>--></configuration></plugin></plugins></build>第⼆步:开发java类继承UDF,并重载evaluate ⽅法package com.kkb.udf.MyUDF;public class MyUDF extends UDF {public Text evaluate(final Text s) {if (null == s) {return null;}//返回⼤写字母return new Text(s.toString().toUpperCase());}}第三步:项⽬打包使⽤maven的package进⾏打包将我们打包好的jar包上传到node03服务器的/kkb/install/hive-1.1.0-cdh5.14.2/lib 这个路径下第四步:添加我们的jar包重命名我们的jar包名称cd /kkb/install/hive-1.1.0-cdh5.14.2/libmv original-day_hive_udf-1.0-SNAPSHOT.jar udf.jarhive的客户端添加我们的jar包0: jdbc:hive2://node03:10000> add jar /kkb/install/hive-1.1.0-cdh5.14.2/lib/udf.jar;第五步:设置函数与我们的⾃定义函数关联0: jdbc:hive2://node03:10000> create temporary function touppercase as 'com.kkb.udf.MyUDF';第六步:使⽤⾃定义函数0: jdbc:hive2://node03:10000>select tolowercase('abc');hive当中如何创建永久函数在hive当中添加临时函数,需要我们每次进⼊hive客户端的时候都需要添加以下,退出hive客户端临时函数就会失效,那么我们也可以创建永久函数来让其不会失效创建永久函数-- 1、指定数据库,将我们的函数创建到指定的数据库下⾯0: jdbc:hive2://node03:10000>use myhive;-- 2、使⽤add jar添加我们的jar包到hive当中来0: jdbc:hive2://node03:10000>add jar /kkb/install/hive-1.1.0-cdh5.14.2/lib/udf.jar;-- 3、查看我们添加的所有的jar包0: jdbc:hive2://node03:10000>list jars;-- 4、创建永久函数,与我们的函数进⾏关联0: jdbc:hive2://node03:10000>create function myuppercase as 'com.kkb.udf.MyUDF';-- 5、查看我们的永久函数0: jdbc:hive2://node03:10000>show functions like 'my*';-- 6、使⽤永久函数0: jdbc:hive2://node03:10000>select myhive.myuppercase('helloworld');-- 7、删除永久函数0: jdbc:hive2://node03:10000>drop function myhive.myuppercase;-- 8、查看函数show functions like 'my*';Json数据解析UDF开发(作业)有原始json数据格式内容如下:{"movie":"1193","rate":"5","timeStamp":"978300760","uid":"1"}{"movie":"661","rate":"3","timeStamp":"978302109","uid":"1"}{"movie":"914","rate":"3","timeStamp":"978301968","uid":"1"}{"movie":"3408","rate":"4","timeStamp":"978300275","uid":"1"}{"movie":"2355","rate":"5","timeStamp":"978824291","uid":"1"}{"movie":"1197","rate":"3","timeStamp":"978302268","uid":"1"} {"movie":"1287","rate":"5","timeStamp":"978302039","uid":"1"}需求:创建hive表,加载数据,使⽤⾃定义函数来解析json格式的数据,最后接的得到如下结果movie rate timestamp uid1193597830076016613978302109191439783019681340849783002751235559788242911119739783022681128759783020391。
hive insert overwrite 动态分区原理-定义说明解析

hive insert overwrite 动态分区原理-概述说明以及解释1.引言概述部分的内容示例:1.1 概述在大数据技术领域,Hive是一种基于Hadoop的数据仓库工具,它提供了一个类似于SQL的查询语言来处理和分析大规模数据集。
而Hive 的动态分区功能是其重要的特性之一。
动态分区(Dynamic Partitioning)是指在将数据插入到Hive表中时,根据数据的某个字段自动生成分区。
相比于静态分区,动态分区更加灵活和方便,不需要提前对分区进行定义,可以根据数据的实际情况进行分区。
而Hive的Insert Overwrite命令是用来向表中插入新的数据的,当与动态分区功能结合使用时,能够实现根据数据自动生成和更新分区的能力。
本文将详细介绍Hive的Insert Overwrite动态分区的原理和工作机制,以帮助读者更好地理解并应用于实际的数据分析和处理任务中。
在接下来的章节中,我们将首先对Hive进行简要介绍,然后详细讲解Insert Overwrite动态分区的概念和原理,并在最后给出结论和应用场景,展望未来动态分区的发展趋势。
通过阅读本文,读者将能够掌握使用Hive的Insert Overwrite命令进行动态分区的方法,并了解其背后的原理和机制。
同时,还将能够运用这一功能解决实际的数据处理问题,并在今后的数据仓库建设和大数据分析中发挥重要的作用。
让我们开始深入探索Insert Overwrite动态分区的奥秘吧!文章结构部分的内容应该包括以下内容:1.2 文章结构本文将按照以下结构来介绍Hive中的Insert Overwrite动态分区原理:1. 引言:介绍本文要讨论的主题,并对文章进行概述,说明文章的结构和目的。
2. 正文:- 2.1 Hive简介:对Hive进行简要介绍,包括其定义、特点和主要应用场景,为后面动态分区的讨论提供背景信息。
- 2.2 Insert Overwrite动态分区概述:对Insert Overwrite动态分区进行基本概述,解释其作用和使用场景,引出后续原理的讨论。
hive 注册函数

hive 注册函数一、前言在Hive中,我们可以使用自定义函数来扩展Hive的功能。
本文将介绍如何在Hive中注册自定义函数。
二、创建自定义函数1. 编写Java代码首先,我们需要编写一个Java类来实现我们的自定义函数。
以下是一个示例代码:```package com.example.hive;import org.apache.hadoop.hive.ql.exec.UDF;public class MyFunction extends UDF {public String evaluate(String input) {return "Hello, " + input;}}```这个示例代码实现了一个名为MyFunction的函数,它接受一个字符串作为输入,返回“Hello, ”加上输入字符串的结果。
2. 编译Java代码编译Java代码时需要引入Hive相关的jar包,在终端中执行以下命令:```javac -cp /path/to/hive/lib/hive-exec-X.Y.Z.jar MyFunction.java ```其中,/path/to/hive/lib/hive-exec-X.Y.Z.jar是你本地Hive安装目录下的hive-exec-X.Y.Z.jar文件路径。
3. 打包Java代码打包Java代码时需要将编译后的.class文件打成jar包,在终端中执行以下命令:```jar cf myfunction.jar MyFunction.class```4. 将打包好的jar包上传到HDFS将打包好的myfunction.jar上传到HDFS上任意目录下。
三、注册自定义函数1. 在Hive中添加Jar包路径在启动Hive客户端之前,需要在Hive的配置文件hive-site.xml中添加以下配置:```<property><name>hive.aux.jars.path</name><value>/path/to/myfunction.jar</value></property>```其中,/path/to/myfunction.jar是你上传到HDFS上的myfunction.jar文件路径。
genericudf 与 普通的udf 函数

genericudf 与普通的udf 函数标题:深入理解GenericUDF与普通UDF函数的区别与应用在大数据处理和分析中,用户定义的函数(User Defined Function,简称UDF)扮演着至关重要的角色。
它们允许开发者根据特定的需求定制数据处理逻辑,极大地提升了数据处理的灵活性和效率。
在Hadoop生态系统中,主要有两种类型的UDF:普通UDF和GenericUDF。
本文将详细解析这两种UDF的区别,并通过实例一步步展示其应用。
一、普通UDF普通UDF是Hive中最基本的自定义函数类型。
它主要用于处理单个数据行或列,并返回一个单一的结果。
普通UDF需要开发者实现evaluate()方法,该方法接受一个或多个参数,并返回一个结果。
以下是一个简单的普通UDF示例,该函数接收一个字符串参数并返回其长度:javaimport org.apache.hadoop.hive.ql.exec.UDF;public class StringLengthUDF extends UDF {public int evaluate(String str) {if (str == null) {return 0;}return str.length();}}在这个例子中,我们定义了一个名为StringLengthUDF的类,它继承了UDF基类。
然后我们实现了evaluate()方法,该方法接受一个字符串参数,并返回其长度。
二、GenericUDF相比于普通UDF,GenericUDF提供了更大的灵活性和可扩展性。
GenericUDF可以处理多种数据类型,并且可以返回复杂的数据结构。
在GenericUDF中,开发者需要实现initialize()、getReturnType()和evaluate()方法。
以下是一个简单的GenericUDF示例,该函数接收两个整数参数并返回它们的和:javaimport org.apache.hadoop.hive.ql.udf.generic.GenericUDF; importorg.apache.hadoop.hive.serde2.objectinspector.ObjectInspector; importorg.apache.hadoop.hive.serde2.objectinspector.primitive.Primitive ObjectInspectorFactory;importorg.apache.hadoop.hive.serde2.objectinspector.primitive.IntObjectI nspector;public class AddUDF extends GenericUDF {private IntObjectInspector intOI1;private IntObjectInspector intOI2;Overridepublic ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {if (arguments.length != 2) {throw new UDFArgumentException("AddUDF accepts exactly 2 arguments");}if (!(arguments[0] instanceofIntObjectInspector) !(arguments[1] instanceof IntObjectInspector)) {throw new UDFArgumentException("Both arguments should be of int type");}this.intOI1 = (IntObjectInspector) arguments[0];this.intOI2 = (IntObjectInspector) arguments[1];returnPrimitiveObjectInspectorFactory.javaIntObjectInspector;}Overridepublic Object evaluate(DeferredObject[] arguments) throws HiveException {int arg1 = intOI1.get(arguments[0].get());int arg2 = intOI2.get(arguments[1].get());return arg1 + arg2;}Overridepublic String getDisplayString(String[] children) {return "add(" + children[0] + ", " + children[1] + ")";}}在这个例子中,我们定义了一个名为AddUDF的类,它继承了GenericUDF基类。
lateral view函数

lateral view函数LateralView函数是ApacheHive中的一个内置函数,用于将普通查询中的每一行转换为一个可用于带有多个表列的查询的虚拟行,从而实现更复杂的SQL语句。
它通过将一个用户自定义函数(UDF)与普通的select语句连接在一起,使用户可以处理例如JSON、XML 等结构化数据。
它也可以帮助用户将集合(arrays)或映射(maps)转换为多个行,从而可以使用横向视图函数查询它们。
Lateral View函数的作用Lateral View函数最主要的作用是可以用来将表中的数据拆分成多行,从而构成多个表列。
此外,它还可以用来处理复杂数据,例如JSON、XML等结构化数据,以及将集合(arrays)和映射(maps)转换为多行数据,这可以用来处理复杂的SQL语句。
Lateral View函数的应用Lateral View函数在数据挖掘和大数据分析过程中有着重要的作用。
它可以用来处理复杂的数据,提取所需的关键信息,进而帮助用户快速分析数据,提高数据分析的准确性和效率。
例如,在互联网行业的社交分析中,使用Lateral View函数可以从数据库中提取用户的基本信息,如性别、年龄、所在地、偏好等,并通过分析这些信息,为企业降低市场风险,提高市场投资回报率。
Lateral View函数的使用Lateral View函数的语法由两部分组成,分别是select语句和user-defined function(UDF)。
select语句用来从表中提取想要的字段,而UDF则用来处理JSON、XML等结构化数据,或将集合(arrays)或映射(maps)转换为多行数据。
例如,如果需要从表中提取“名字”和“地址”两个字段,以及将“喜好”字段中的JSON格式的数据转换为多行数据,则可以使用以下代码:SELECT name, address,LATERAL VIEW EXPLODE(preferences) table_name AS prefFROM table结论Lateral View函数是apache Hive中的一种内置函数,它可以实现将普通查询中的每一行转换为一个可用于带有多个表列的查询的虚拟行,从而使用户能够处理复杂的数据,如JSON、XML等结构化数据,以及将集合(arrays)或映射(maps)转换为多行数据。
hive unnest用法

hive unnest用法摘要:一、什么是hive unnest二、hive unnest的用法1.hive unnest基本语法2.hive unnest与json_extract的对比3.hive unnest的实际应用场景三、hive unnest的优缺点四、总结正文:Hive是大数据处理领域中非常流行的数据仓库工具,可以用来进行数据提取、转换和加载等操作。
在处理一些复杂的数据类型时,比如JSON和XML 等,hive提供了一些扩展函数来帮助我们处理这些数据。
其中,hive unnest 就是一种非常实用的扩展函数,可以用来展开数组或者集合。
一、什么是hive unnestHive unnest是一个可以将数组或集合中的元素展开为单独行的函数。
这个函数在处理JSON、XML等数据类型时非常有用,可以让我们更方便地处理这些数据。
二、hive unnest的用法1.hive unnest基本语法Hive unnest的基本语法如下:SELECT unnest(column_name) as unnested_columnFROM table_name;```其中,`column_name`是需要展开的数组或集合所在的列名,`table_name`是数据表的名称。
`unnested_column`是展开后的列名,可以自定义。
2.hive unnest与json_extract的对比Hive unnest和json_extract都可以用来处理JSON数据,但它们的作用和使用场景有所不同。
json_extract主要用于从JSON字符串中提取特定字段,而hive unnest主要用于展开JSON数组。
例如,假设我们有一个包含JSON数据的表`json_data`,其中有一个JSON数组`items`,我们可以使用hive unnest来展开这个数组:```SELECT unnest(items) as itemFROM json_data;```而如果我们要提取数组中的某个字段,比如``,我们可以使用json_extract:```SELECT json_extract(items, "$.name") as item_nameFROM json_data;3.hive unnest的实际应用场景Hive unnest在实际应用中有很多场景,比如:- 处理JSON或XML格式的数据,展开数组或集合;- 对数据进行分组、排序、聚合等操作,需要先将数组或集合展开;- 与其他Hive函数结合使用,实现更复杂的数据处理逻辑。
hive之加密自定义函数

hive之加密⾃定义函数1.Base64 <可逆不安全!>/*** Base64不是安全领域下的加解密算法,只是⼀个编码算法,* 通常⽤于把⼆进制数据编码为可写的字符形式的数据,* 特别适合在http,mime协议下的⽹络快速传输数据。
* UTF-8和GBK中⽂的Base64编码结果是不同的。
* 采⽤Base64编码不仅⽐较简短,同时也具有不可读性,* 即所编码的数据不会被⼈⽤⾁眼所直接看到,但这种⽅式很初级,* 很简单。
Base64可以对图⽚⽂件进⾏编码传输。
*/2.MD5 <不可逆!>/*** 散列算法(签名算法)有:MD5、SHA1、HMAC* ⽤途:主要⽤于验证,防⽌信息被修。
具体⽤途如:⽂件校验、数字签名、鉴权协议*/3.AES <可逆!>/*** 对称性加密算法有:AES、DES、3DES* ⽤途:对称加密算法⽤来对敏感数据等信息进⾏加密** AES 是⼀种可逆加密算法,对⽤户的敏感信息加密处理 \* 对原始数据进⾏AES加密后,再进⾏Base64编码转化;*/⼀、MD5public class MD5Enscript extends UDF {//md5+盐(salt)⾮对称加密private static final String SALT = "KGC#kb08@20200511@xxq@chy#=";public String evaluate(String pwd) throws IOException {return DigestUtils.md5Hex(SALT+pwd+SALT);}}⼆、Base64Encryptpublic class Base64Encrypt extends UDF {public String evaluate(String str) throws UnsupportedEncodingException {return Base64.encodeBase64String(str.getBytes("UTF-8"));}}public class Base64Decrypt extends UDF {public String evaluate(String str) throws UnsupportedEncodingException {return new String(Base64.decodeBase64(str));}}三、AESSuperpublic class AESSuper {private static final String SALT = "#./*KGC#kb08\\u1009889";private static final String ALGORITHM = "AES";private static final String CHAR_SET = "UTF-8";private static SecretKeySpec sks;private static Cipher cipher;static {try {KeyGenerator generator = KeyGenerator.getInstance(ALGORITHM);generator.init(128,new SecureRandom(SALT.getBytes()));SecretKey secretKey = generator.generateKey();byte[] encoded = secretKey.getEncoded();sks = new SecretKeySpec(encoded,ALGORITHM);cipher = Cipher.getInstance(ALGORITHM);} catch (Exception e) {e.printStackTrace();}}public static byte[] encrypt(String src) throws Exception{cipher.init(Cipher.ENCRYPT_MODE,sks);return cipher.doFinal(src.getBytes(CHAR_SET));}public static byte[] decrypt(byte[] src) throws Exception{cipher.init(Cipher.DECRYPT_MODE,sks);return cipher.doFinal(src);}}public class AESEncrypt extends UDF {public String evaluate(String src) throws Exception {return Base64.encodeBase64String(AESSuper.encrypt(src));}}public class AESDecrypt extends UDF {public String evaluate(String src) throws Exception {return new String(AESSuper.decrypt(Base64.decodeBase64(src.getBytes()))); }}。
Hive自定义UDF函数

Hive⾃定义UDF函数Hive的SQL可以通过⽤户定义的函数(UDF),⽤户定义的聚合(UDAF)和⽤户定义的表函数(UDTF)进⾏扩展。
当Hive提供的内置函数⽆法满⾜你的业务处理需要时,此时就可以考虑使⽤⽤户⾃定义函数(UDF)。
UDF、UDAF、UDTF的区别:UDF(User-Defined-Function)⼀进⼀出UDAF(User-Defined Aggregation Funcation)聚集函数,多进⼀出UDTF(User-Defined Table-Generating Functions)⼀进多出,如lateral view explore()⽤户⾃定义函数(user defined function),针对单条记录。
编写⼀个UDF,需要继承UDF类,并实现evaluate()函数。
在查询执⾏过程中,查询中对应的每个应⽤到这个函数的地⽅都会对这个类进⾏实例化。
对于每⾏输⼊都会调⽤到evaluate()函数。
⽽evaluate()函数处理的值会返回给Hive。
同时⽤户是可以重载evaluate⽅法的。
Hive会像Java的⽅法重载⼀样,⾃动选择匹配的⽅法.⼀、应⽤案例1)全⾓转半⾓package com.sjck.hive.udf;import ng.StringUtils;import org.apache.hadoop.hive.ql.exec.UDF;/*** 全⾓转半⾓* @author Administrator**/public class ToSingleByte extends UDF {public static String evaluate(String val) {if(StringUtils.isNotBlank(val)){char c[] = val.toCharArray();for (int i = 0; i < c.length; i++) {if (c[i] == '\u3000') {c[i] = ' ';} else if (c[i] > '\uFF00' && c[i] < '\uFF5F') {c[i] = (char) (c[i] - 65248);}}String returnString = new String(c);return returnString;}return "";}}View Code2)⾝份证信息验证package com.sjck.hive.udf.util;import java.text.ParseException;import java.text.SimpleDateFormat;import java.util.Calendar;import java.util.Date;import org.slf4j.Logger;import org.slf4j.LoggerFactory;/*** <p>* ⾝份证合法性校验* --15位⾝份证号码:第7、8位为出⽣年份(两位数),第9、10位为出⽣⽉份,第11、12位代表出⽣⽇期,第15位代表性别,奇数为男,偶数为⼥。
hive自定义分段函数(分箱)

hive⾃定义分段函数(分箱)分段函数常⽤于分箱中,统计分组在指定的区间中的占⽐。
⽐如有如下例⼦:统计某个班级中考试分数在各个阶段的占⽐。
准备的数据如下:使⽤如下⽂件在hive中建表。
class1,1,100class1,2,88class1,3,90class1,4,23class1,5,30class1,6,55class1,7,66class1,8,99class1,9,56class1,10,34这时候使⽤case when来计算每⾏记录分别在哪个区间如下:with tmp_a as(selectclazz,name,case when score <30 then '[0,30)'when score <60 then '[30,60)'when score < 80 then '[60,80)'when score <= 100 then '[80,100]'else 'none' end binsfrom dt_dwd.score)select clazz,bins,count(1)/sum(count(1)) over (partition by clazz) as rate,count(1)from tmp_a group by clazz,bins; 最后是统计结果如下:上述就是通常的分箱占⽐操作例⼦。
现在我有多组标签需要监控,每次写case when的,这⾥⾯的分段⾮常多,于是想到⽤hive udf来简化写法。
先看已经完成的⾃定义函数default.piecewise的sql写法如下:select clazz,name,default.piecewise('[0,30)|[30,60)|[60,80)|[80,100]',score) as binsfrom dt_dwd.score完整的sql如下:with tmp_a as(selectclazz,name,default.piecewise('[0,30)|[30,60)|[60,80)|[80,100]',score) as binsfrom dt_dwd.score)select clazz,bins,count(1)/sum(count(1)) over (partition by clazz) as rate,count(1)from tmp_a group by clazz,bins;这样我们可以将分箱抽象到变量中,在当做参数传⼊,就不要每次写很⼤段的case when了。
hive中function函数查询
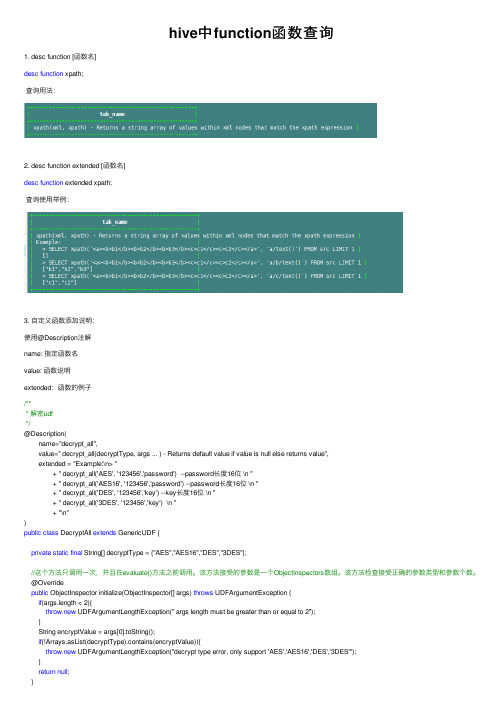
hive中function函数查询1. desc function [函数名]desc function xpath;查询⽤法:2. desc function extended [函数名]desc function extended xpath;查询使⽤举例:3. ⾃定义函数添加说明:使⽤@Description注解name: 指定函数名value: 函数说明extended:函数的例⼦/*** 解密udf*/@Description(name="decrypt_all",value=" decrypt_all(decryptType, args ... ) - Returns default value if value is null else returns value",extended = "Example:\n> "+ " decrypt_all('AES', '123456','password') --password长度16位 \n "+ " decrypt_all('AES16', '123456','password') --password长度16位 \n "+ " decrypt_all('DES', '123456','key') --key长度16位 \n "+ " decrypt_all('3DES', '123456','key') \n "+ "\n")public class DecryptAll extends GenericUDF {private static final String[] decryptType = {"AES","AES16","DES","3DES"};//这个⽅法只调⽤⼀次,并且在evaluate()⽅法之前调⽤。
hive 创建函数

在Hive中,您可以使用自定义函数(User Defined Functions, UDFs)来扩展Hive的内置功能。
自定义函数分为三类:UDF(User Defined Function)、UDAF(User Defined Aggregate Function)和UDTF(User Defined Table-Generating Function)。
这里我们将介绍如何创建一个简单的Hive UDF,并将其应用于查询中。
创建Hive UDF的步骤如下:1. 编写Java类实现自定义函数:首先,您需要使用Java编写自定义函数并打包成JAR文件。
以下是一个简单的字符串转大写的示例:import org.apache.hadoop.hive.ql.exec.UDF;import org.apache.hadoop.io.Text;public class UpperCase extends UDF {public Text evaluate(Text input) {if (input == null) {return null;}return new Text(input.toString().toUpperCase());}}当您完成编写Java类后,将其编译为字节码并打包成JAR文件。
以下是示例命令:javac -cp /path/to/hive/lib/hive-exec-<version>.jar UpperCase.javajar cf upper_case.jar UpperCase.class请确保将实际的hive-exec JAR文件路径及版本替换到命令中。
1. 在Hive中创建并使用函数:现在您已经有一个可以使用的JAR文件。
接下来,需要在Hive中创建并使用该自定义函数。
进入Hive Shell,执行以下命令:-- 添加 JAR 文件ADD JAR /path/to/upper_case.jar;-- 创建自定义函数到新创建的Java类CREATE TEMPORARY FUNCTION to_upper_case AS 'UpperCase';-- 使用自定义函数进行查询SELECT to_upper_case(some_column) FROM your_table;这里注意替换"/path/to/upper\_case.jar"为实际的JAR文件路径,以及使用实际的表名和列名。
复杂数据类型的hive udaf实现

Hive的用户自定义聚合函数(UDAF)是hive中非常重要的功能之一,可以方便地实现对数据的聚合分析。
与普通的UDF(用户自定义函数)不同,UDAF可以处理复杂的数据类型,如数组、结构体等。
在本文中,我们将介绍如何实现复杂数据类型的Hive UDAF。
一、什么是复杂数据类型在Hive中,复杂数据类型包括数组(array)、映射(map)和结构体(struct)。
这些类型都可以包含不同类型的数据,并且可以嵌套在一起。
例如,一个数组可以包含多个结构体,每个结构体又包含多个映射。
二、如何实现复杂数据类型的UDAF实现复杂数据类型的UDAF需要遵循以下步骤:1. 创建UDAF类首先,在Hive中创建UDAF需要创建一个继承自org.apache.hadoop.hive.ql.exec.UDAF类的Java类。
该类必须实现以下两个方法:- public void init():初始化UDAF函数。
- public void iterate(AggregationBuffer agg, Object[] parameters):对输入数据进行迭代,更新缓冲区中的聚合结果。
2. 定义缓冲区UDAF类中的缓冲区用于存储聚合结果。
缓冲区的类型应该和返回值的类型相同。
例如,如果UDAF的返回值是一个数组,则缓冲区应该是一个ArrayList对象。
3. 实现iterate()方法在iterate()方法中,我们需要将输入的数据进行处理,并将结果存储到缓冲区中。
对于数组、映射和结构体等复杂数据类型,我们可以使用Hive提供的各种集合类来处理数据。
例如,对于一个包含两个字段(name和age)的结构体,我们可以使用以下代码将输入数据添加到缓冲区中:```public void iterate(AggregationBuffer agg, Object[] parameters) {if (parameters == null || parameters.length != 2) { return;}String name = (String) parameters[0];int age = (int) parameters[1];StructObjectInspector soi = (StructObjectInspector) inputOI;List<? extends StructField> fields = soi.getAllStructFieldRefs();ArrayList<Object> struct = new ArrayList<Object>(fields.size());struct.add(name);struct.add(age);ArrayList<Object> list = (ArrayList<Object>) agg;list.add(struct);}```4. 实现terminatePartial()方法在terminatePartial()方法中,我们需要返回当前缓冲区的状态,以便Hive可以将其传递给其他节点进行合并。
自定义udf函数解析嵌套json数组

自定义udf函数解析嵌套json数组如何使用自定义UDF函数解析嵌套JSON数组为标题在数据处理中,JSON格式的数据已经成为了一种非常常见的数据格式。
而在JSON数据中,有时候会出现嵌套的数组,这就给数据的处理带来了一定的难度。
本文将介绍如何使用自定义UDF函数解析嵌套JSON数组为标题。
我们需要了解什么是UDF函数。
UDF函数是用户自定义函数的缩写,是一种自定义函数,可以根据自己的需求编写函数,以实现特定的功能。
在Hive中,UDF函数可以用来处理各种数据类型,包括字符串、数字、日期等。
接下来,我们需要了解如何解析嵌套JSON数组。
在Hive中,我们可以使用get_json_object函数来解析JSON数据。
但是,当JSON数据中存在嵌套的数组时,get_json_object函数就无法解析了。
这时,我们就需要使用自定义UDF函数来解析嵌套的JSON数组。
下面是一个示例JSON数据:{"name": "John","age": 30,"address": {"street": "123 Main St","city": "New York","state": "NY","zip": "10001"},"phone_numbers": [{"type": "home","number": "555-555-1234"},{"type": "work","number": "555-555-5678"}]}在这个JSON数据中,phone_numbers是一个嵌套的数组。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Hive自定义函数说明函数清单:
用法:
getID
通过UUID来生成每一行的唯一ID:
select getid() ;
oracle_concat
hive的concat函数遇到空值的情况下会直接返回空,而在oracle中对于字符串类型空字符串与null是等价对待的
select default.oracle_concat('ff-',null,'','--cc');
Select concat('ff-',null,'','--cc');
getBirthDay
从身份证号码中截取生日信息,返回日期格式为’yyyy-MM-dd’
getGoodsInfo
self_date_format
为格式化来自oracle的时间格式,将格式为’yyyy/MM/dd’和’yyyy/MM/dd HH:mm:ss’的日期格式转换为’yyyy-MM-dd’
Select default. self_date_format(‘2012-12-12’);
Select default. self_date_format(‘20121212’,’yyyyMMdd’);
oracle_months_between
由于当前版本hive不带months_between函数,所以添加
oracle_decode
hive中的decode函数为字符编码函数和encode对应。
Oracle中decode函数类似case when 函数,添加oracle_decode函数减少sql的改写。
与为与oracle功能同步,本函数将null和字符串’’等价对待。
select default.oracle_decode('',null,1,2) r1,
default.oracle_decode(null,'',1,2) r2,
default.oracle_decode('aaa','','Nnull','aaa','is a*3','aaa') r3,
default.oracle_decode('ccc','', 'Nnull','aaa','is a*3','aaa') r4,
default.oracle_decode('','', 'Nnull','aaa','is a*3','aaa') r5;
BinomialTest
_FUNC_(expr1, expr2, p_value, alternativeHypothesis)
alternativeHypothesis:
接受指定值的字符串
取值:TWO_SIDED , GREATER_THAN , LESS_THAN
二项分布检测函数。
实现oracle中的二项分布检测功能。
计算expr1 等于exper2 的值占数据总数的二项分布检测结果,类型依据alternativeHypothesis 确定
days_between_360
实现execl中的day360功能getbirthday
select default. getbirthday(身份证号码);
f_get_interest_effect
f_get_monthpay_bsm
f_get_monthpay_int
f_get_work_days
f_paymentschedule
SELECT
SRC.SERIALNO
,SRC.ACCT_LOAN_NO
,PDATE AS PAYDATE--SRC.PAYDATE ,SRC.PERIODS
,SRC.BUSINESSSUM
,SRC.BIR
,SRC.EIR
,SID--,SRC.SEQID
,PRINCIPAL-- SRC.PAYBUSINESSSUM ,INTEREST -- SRC.PAYINTEREST
,SRC.PAYCUSTOMERSERVICEFEE
,SRC.PAYACCOUNTMANAGEFEE
,SRC.PAYINSURANCEFEE
,SRC.PAYBUGPAYFEE
,TYPE
,CURRENT_DATE AS ETL_IN_DT
,src.CANCELEDDATE
FROM
FINANCE.FIN_ACCT_PAYMENT_SCHEDULE_FIX SRC
LATERAL VIEW
DEFAULT.F_PAYMENTSCHEDULE(SRC.PAYDATE,SRC.BIR/1200,SRC.PERIODS,SRC.BU SINESSSUM)
MYTABLE AS PRINCIPAL, INTEREST, PDATE,SID
WHERE SRC.P_DAY='2017-02-14'limit10
udf_dictionary
字典表: default.dictionary
字段: p_name 分区, key1 string, key2 string, value string
使用:
1.字典表插入数据
2.用udf_dictionary函数从字典表提取数据, 该函数接收3个参数, 第一、第二参数必须为
常量。
三个参数分别对应字典表的p_name,key1,key2。
注意:字典表数据需要扫描和加载至内存,注意大小。
加载至内存数据对应于通过p_name,key1过滤;字典表内数据可以反复使用;存储过程中setp1放置DataHome/DICTIONARY下,包含DICTIONARY时自动依赖
Step 1:
INSERT OVERWRITE TABLE default.dictionary
PARTITION(p_name='s3.CODE_LIBRARY_ITEMNAME')
SELECT
a.codeno
a.ITEMNO,
a.ITEMNAME
FROM s3.CODE_LIBRARY a;
Step 2:
Select DEFAULT.udf_dictionary('s3.CODE_LIBRARY_ITEMNAME ','Occupation',6);
default.ExtractCoordinates
单一参数入参:
select default.ExtractCoordinates('<126.542076,44.82494>');
select default.ExtractCoordinates('<+31.61328064,+120.47313897> +/- 1414.00m (speed -1.00 mps / course -1.00) @ 2017/1/22 中国标准时间19:27:16');
select default.ExtractCoordinates('<+31.61328064,+120.47313897> +/- 1414.00m (speed -1.00 mps / course -1.00) @ 2017/1/22 中国标准时间19:27:16');
双参数入参:
P1: 经度
P2:纬度
select default.ExtractCoordinates('东经120/26/39','北纬40/21/55')
select default.ExtractCoordinates('105.8490712595','31.8176806624')
查询结果使用:
select ll.lng,t from (select
default.ExtractCoordinates('105.8490712595','31.8176806624') as ll) a
default.distanceSimplify
select default.distanceSimplify(纬度1,经度1, 纬度2, 经度2) from table;
default.f_unpivot
实现行转列
select default.f_unpivot('key1','key1,value1,value2', key1,value1,value2) from tmp;
default.f_unpivot(键值名称,所有列名称(必须包含键值名称),所有列)
键值名称和列名称格式为字符串,由逗号分隔
default.f_unpivot2
实现行转列
select default.f_unpivot2('key1,key2','V1,V2,V3', K1,K2,V1,Value1,V2,Value2,V3,Value3) from tmp;。