orcale和hive常用函数对照表
Hive常用函数大全-字符串函数

Hive常⽤函数⼤全-字符串函数1、字符串长度函数:length(X)(返回字符串X的长度)select length('qwerty') from table--62、字符串反转函数:reverse(X)(返回字符串X反转的结果)select reverse('qwerty') from table--ytrewq3、字符串连接函数:concat(X,Y,...)(返回输⼊字符串连接后的结果,⽀持任意个输⼊字符串连接)select concat('abc','qwe','rty') from table--abcqwerty4、带分隔符字符串连接函数:concat_ws(X,y,Z)(返回输⼊字符串连接后的结果,X表⽰各个字符串间的分隔符)select concat_ws('/','abc','qwe','rty') from table--abc/qwe/rty5、字符串截取函数:substr(X,Y,Z)/substring(X,Y,Z)(返回字符串X从Y位置开始,截取长度为Z的字符串)select substr('qwerty',1,3) from table--qwe6、字符串转⼤写函数:upper(X)/ucase(X)(返回字符串X的⼤写格式)select upper('qwERt') from table--QWERTselect ucase('qwERt') from table--QWERT7、字符串转⼩写函数:lower(X)/lcase(X)(返回字符串X的⼩写格式)select lower('qwERt') from table--qwertselect lcase('qwERt') from table--qwert8、去空格函数:trim(X)(去除X字符串两边的空格)select trim(' qwe rty uiop ') from table--'qwe rty uiop'左边去空格函数:ltrim(X)(去除X字符串左边的空格)select ltrim(' qwe rty uiop ') from table--'qwe rty uiop '右边去空格函数:rtrim(X)(去除X字符串右边的空格)select rtrim(' qwe rty uiop ') from table--' qwe rty uiop'9、正则表达式替换函数:regexp_replace(X,Y,Z)(将字符串X中的符合java正则表达式Y的部分替换为Z:将X中与Y相同的字符串⽤Z替换)select regexp_replace('foobar', 'o|ar', '234') from table--f234234b23410、正则表达式解析函数:regexp_extract(X,Y,Z)(将字符串X按照Y正则表达式的规则拆分,返回Z指定的字符)select regexp_extract('foothebar', 'foo(.*?)bar', 0) from table--foothebarselect regexp_extract('foothebar', 'foo(.*?)bar', 1) from table--theselect regexp_extract('foothebar', 'foo(.*?)bar', 2) from table--bar11、URL解析函数:parse_url(X,Y,Z)(返回URL中指定的部分。
hive函数大全

目录一、关系运算: (4)1. 等值比较: = (4)2. 不等值比较: <> (4)3. 小于比较: < (4)4. 小于等于比较: <= (4)5. 大于比较: > (5)6. 大于等于比较: >= (5)7. 空值判断: IS NULL (5)8. 非空判断: IS NOT NULL (6)9. LIKE比较: LIKE (6)10. JAVA的LIKE操作: RLIKE (6)11. REGEXP操作: REGEXP (7)二、数学运算: (7)1. 加法操作: + (7)2. 减法操作: - (7)3. 乘法操作: * (8)4. 除法操作: / (8)5. 取余操作: % (8)6. 位与操作: & (9)7. 位或操作: | (9)8. 位异或操作: ^ (9)9.位取反操作: ~ (10)三、逻辑运算: (10)1. 逻辑与操作: AND (10)2. 逻辑或操作: OR (10)3. 逻辑非操作: NOT (10)四、数值计算 (11)1. 取整函数: round (11)2. 指定精度取整函数: round (11)3. 向下取整函数: floor (11)4. 向上取整函数: ceil (12)5. 向上取整函数: ceiling (12)6. 取随机数函数: rand (12)7. 自然指数函数: exp (13)8. 以10为底对数函数: log10 (13)9. 以2为底对数函数: log2 (13)10. 对数函数: log (13)11. 幂运算函数: pow (14)12. 幂运算函数: power (14)13. 开平方函数: sqrt (14)14. 二进制函数: bin (14)15. 十六进制函数: hex (15)16. 反转十六进制函数: unhex (15)17. 进制转换函数: conv (15)18. 绝对值函数: abs (16)19. 正取余函数: pmod (16)20. 正弦函数: sin (16)21. 反正弦函数: asin (16)22. 余弦函数: cos (17)23. 反余弦函数: acos (17)24. positive函数: positive (17)25. negative函数: negative (17)五、日期函数 (18)1. UNIX时间戳转日期函数: from_unixtime (18)2. 获取当前UNIX时间戳函数: unix_timestamp (18)3. 日期转UNIX时间戳函数: unix_timestamp (18)4. 指定格式日期转UNIX时间戳函数: unix_timestamp (18)5. 日期时间转日期函数: to_date (19)6. 日期转年函数: year (19)7. 日期转月函数: month (19)8. 日期转天函数: day (19)9. 日期转小时函数: hour (20)10. 日期转分钟函数: minute (20)11. 日期转秒函数: second (20)12. 日期转周函数: weekofyear (20)13. 日期比较函数: datediff (21)14. 日期增加函数: date_add (21)15. 日期减少函数: date_sub (21)六、条件函数 (21)1. If函数: if (21)2. 非空查找函数: COALESCE (22)3. 条件判断函数:CASE (22)4. 条件判断函数:CASE (22)七、字符串函数 (23)1. 字符串长度函数:length (23)2. 字符串反转函数:reverse (23)3. 字符串连接函数:concat (23)4. 带分隔符字符串连接函数:concat_ws (23)5. 字符串截取函数:substr,substring (24)6. 字符串截取函数:substr,substring (24)7. 字符串转大写函数:upper,ucase (24)8. 字符串转小写函数:lower,lcase (25)9. 去空格函数:trim (25)10. 左边去空格函数:ltrim (25)11. 右边去空格函数:rtrim (25)12. 正则表达式替换函数:regexp_replace (26)13. 正则表达式解析函数:regexp_extract (26)14. URL解析函数:parse_url (26)15. json解析函数:get_json_object (27)16. 空格字符串函数:space (27)17. 重复字符串函数:repeat (27)18. 首字符ascii函数:ascii (28)19. 左补足函数:lpad (28)20. 右补足函数:rpad (28)21. 分割字符串函数: split (28)22. 集合查找函数: find_in_set (29)八、集合统计函数 (29)1. 个数统计函数: count (29)2. 总和统计函数: sum (29)3. 平均值统计函数: avg (30)4. 最小值统计函数: min (30)5. 最大值统计函数: max (30)6. 非空集合总体变量函数: var_pop (30)7. 非空集合样本变量函数: var_samp (31)8. 总体标准偏离函数: stddev_pop (31)9. 样本标准偏离函数: stddev_samp (31)10.中位数函数: percentile (31)11. 中位数函数: percentile (31)12. 近似中位数函数: percentile_approx (32)13. 近似中位数函数: percentile_approx (32)14. 直方图: histogram_numeric (32)九、复合类型构建操作 (32)1. Map类型构建: map (32)2. Struct类型构建: struct (33)3. array类型构建: array (33)十、复杂类型访问操作 (33)1. array类型访问: A[n] (33)2. map类型访问: M[key] (34)3. struct类型访问: S.x (34)十一、复杂类型长度统计函数 (34)1. Map类型长度函数: size(Map<K.V>) (34)2. array类型长度函数: size(Array<T>) (34)3. 类型转换函数 (35)一、关系运算:1. 等值比较: =语法:A=B操作类型:所有基本类型描述: 如果表达式A与表达式B相等,则为TRUE;否则为FALSE举例:hive> select 1 from lxw_dual where 1=1;12. 不等值比较: <>语法: A <> B操作类型: 所有基本类型描述: 如果表达式A为NULL,或者表达式B为NULL,返回NULL;如果表达式A与表达式B不相等,则为TRUE;否则为FALSE举例:hive> select 1 from lxw_dual where 1 <> 2;13. 小于比较: <语法: A < B操作类型: 所有基本类型描述: 如果表达式A为NULL,或者表达式B为NULL,返回NULL;如果表达式A小于表达式B,则为TRUE;否则为FALSE举例:hive> select 1 from lxw_dual where 1 < 2;14. 小于等于比较: <=语法: A <= B操作类型: 所有基本类型描述: 如果表达式A为NULL,或者表达式B为NULL,返回NULL;如果表达式A小于或者等于表达式B,则为TRUE;否则为FALSE举例:hive> select 1 from lxw_dual where 1 <= 1;15. 大于比较: >语法: A > B操作类型: 所有基本类型描述: 如果表达式A为NULL,或者表达式B为NULL,返回NULL;如果表达式A大于表达式B,则为TRUE;否则为FALSE举例:hive> select 1 from lxw_dual where 2 > 1;16. 大于等于比较: >=语法: A >= B操作类型: 所有基本类型描述: 如果表达式A为NULL,或者表达式B为NULL,返回NULL;如果表达式A大于或者等于表达式B,则为TRUE;否则为FALSE举例:hive> select 1 from lxw_dual where 1 >= 1;1注意:String的比较要注意(常用的时间比较可以先to_date之后再比较)hive> select * from lxw_dual;OK2011111209 00:00:00 2011111209hive> select a,b,a<b,a>b,a=b from lxw_dual;2011111209 00:00:00 2011111209 false true false7. 空值判断: IS NULL语法: A IS NULL操作类型: 所有类型描述: 如果表达式A的值为NULL,则为TRUE;否则为FALSE举例:hive> select 1 from lxw_dual where null is null;18. 非空判断: IS NOT NULL语法: A IS NOT NULL操作类型: 所有类型描述: 如果表达式A的值为NULL,则为FALSE;否则为TRUE举例:hive> select 1 from lxw_dual where 1 is not null;19. LIKE比较: LIKE语法: A LIKE B操作类型: strings描述: 如果字符串A或者字符串B为NULL,则返回NULL;如果字符串A符合表达式B 的正则语法,则为TRUE;否则为FALSE。
hive函数大全

hive函数大全1.内置运算符1.1关系运算符运算符类型说明A =B 原始类型如果A与B相等,返回TRUE,否则返回FALSEA ==B 无失败,因为无效的语法。
SQL使用”=”,不使用”==”。
A <>B 原始类型如果A不等于B返回TRUE,否则返回FALSE。
如果A或B值为”NULL”,结果返回”NULL”。
A <B 原始类型如果A小于B返回TRUE,否则返回FALSE。
如果A或B值为”NULL”,结果返回”NULL”。
A <=B 原始类型如果A小于等于B返回TRUE,否则返回FALSE。
如果A或B值为”NULL”,结果返回”NULL”。
A >B 原始类型如果A大于B返回TRUE,否则返回FALSE。
如果A或B值为”NULL”,结果返回”NULL”。
A >=B 原始类型如果A大于等于B返回TRUE,否则返回FALSE。
如果A或B值为”NULL”,结果返回”NULL”。
A IS NULL 所有类型如果A值为”NULL”,返回TRUE,否则返回FALSEA IS NOT NULL 所有类型如果A值不为”NULL”,返回TRUE,否则返回FALSEA LIKEB 字符串如果A或B值为”NULL”,结果返回”NULL”。
字符串A与B通过sql 进行匹配,如果相符返回TRUE,不符返回FALSE。
B字符串中的”_”代表任一字符,”%”则代表多个任意字符。
例如:(…foobar‟ like …foo‟)返回FALSE,(…foobar‟ like …foo_ _ _‟或者…foobar‟ like …foo%‟)则返回TUREA RLIKEB 字符串如果A或B值为”NULL”,结果返回”NULL”。
字符串A与B通过java 进行匹配,如果相符返回TRUE,不符返回FALSE。
例如:(…foobar‟rlike …foo‟)返回FALSE,(‟foobar‟rlike …^f.*r$‟)返回TRUE。
hive和oracle常用函数对照表
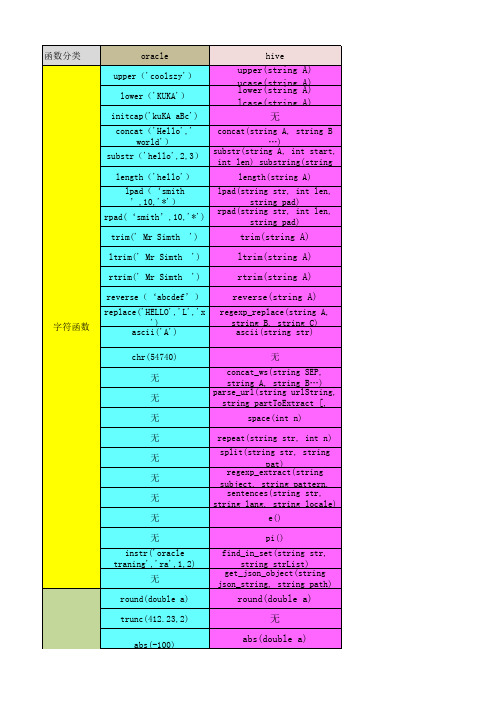
reverse(‘abcdef’) 字符函数 replace('HELLO','L','x ') ascii('A') chr(54740) 无 无 无 无 无 无 无 无 无 instr('o无 round(double a) trunc(412.23,2) abs(-100)
hive
upper(string ucase(string lower(string lcase(string 无
A) A) A) A)
concat(string A, string B „) substr(string A, int start, int len) substring(string length(string A) lpad(string str, int len, string pad) rpad(string str, int len, string pad)
trim(string A) ltrim(string A) rtrim(string A) reverse(string A)
regexp_replace(string A, string B, string C) ascii(string str) 无 concat_ws(string SEP, string A, string B„) parse_url(string urlString, string partToExtract [, space(int n) repeat(string str, int n) split(string str, string pat) regexp_extract(string subject, string pattern, sentences(string str, string lang, string locale) e() pi() find_in_set(string str, string strList) get_json_object(string json_string, string path)
hive函数用法

hive函数用法在Hive中,有许多内置函数,用于在Hive查询中执行各种操作。
这些函数可以用于字符串操作、数学运算、日期处理、聚合等多种用途。
以下是一些常见的Hive函数及其用法:1. 字符串函数:- `CONCAT(string A, string B)`: 将两个字符串连接起来。
```sqlSELECT CONCAT('Hello', ' ', 'World') AS result;```- `SUBSTR(string A, int start, int len)`: 从字符串中提取子字符串。
```sqlSELECT SUBSTR('Hive is powerful', 1, 4) AS result;```- `LOWER(string A)`, `UPPER(string A)`: 将字符串转换为小写或大写。
```sqlSELECT LOWER('Hello') AS lower_result, UPPER('World') AS upper_result;```2. 数学函数:- `ROUND(double A)`, `CEIL(double A)`, `FLOOR(double A)`: 对浮点数进行四舍五入、向上取整或向下取整。
```sqlSELECT ROUND(3.14159) AS round_result, CEIL(4.25) AS ceil_result, FLOOR(5.75) AS floor_result;```- `ABS(double A)`: 返回一个数的绝对值。
```sqlSELECT ABS(-10) AS abs_result;```3. 日期函数:- `CURRENT_DATE`: 返回当前日期。
```sqlSELECT CURRENT_DATE AS current_date;```- `DATEDIFF(string enddate, string startdate)`: 返回两个日期之间的天数差。
hive函数大全

hive函数⼤全在hive内部有许多函数,如下:1. 内置运算符1. 关系运算符2. 算术运算符3. 逻辑运算符4. 复杂类型函数2. 内置函数内置聚合函数1. 数学函数2. 收集函数3. 类型转换函数4. ⽇期函数5. 条件函数6. 字符函数3. 内置聚合函数4. 内置表⽣成函数1.1关系运算符1. 等值⽐较: =2. 等值⽐较:<=>3. 不等值⽐较: <>和!=4. ⼩于⽐较: <5. ⼩于等于⽐较: <=6. ⼤于⽐较: >7. ⼤于等于⽐较: >=8. 空值判断: IS NULL9. ⾮空判断: IS NOT NULL10. LIKE ⽐较: LIKE11. JAVA 的 LIKE 操作: RLIKE12. REGEXP 操作: REGEXP1.2算术运算符1. 加法操作: +2. 减法操作: –3. 乘法操作: *4. 除法操作: /5. 取余操作: %6. 位与操作: &7. 位或操作: |8. 位异或操作: ^9.位取反操作: ~1.3逻辑运算符1. 逻辑与: AND 、&&2. 逻辑或: OR 、|3. 逻辑⾮: NOT、!1.4复杂类型函数1. 获取array中的元素2. 获取map中的元素3. 获取struct中的元素2.1数学函数1. 取整函数: round(double a) 四舍五⼊2. 指定精度取整函数: round(double a,int d) ⼩数部分d位之后数字四舍五⼊3. 向下取整函数: floor(double a) 对给定数据进⾏向下舍⼊最接近的整数4. 向上取整函数: ceil(double a) 将参数向上舍⼊为最接近的整数5. 向上取整函数: ceiling(double a)6. 取随机数函数: rand7. ⾃然指数函数: exp(double a) 返回e的n次⽅8. 以 10 为底对数函数: log109. 以 2 为底对数函数: log210. 对数函数: log(double base,double a) 返回给定底数及指数返回⾃然对数11. 幂运算函数: pow(double a,double p) 返回某数的乘幂12. 幂运算函数: power(double a,double p)13. 开平⽅函数: sqrt 返回数值的平⽅根14. ⼆进制函数: bin15. ⼗六进制函数: hex16. 反转⼗六进制函数: unhex17. 进制转换函数: conv18. 绝对值函数: abs19. 正取余函数: pmod(int a,int b)20. 正弦函数: sin21. 反正弦函数: asin22. 余弦函数: cos23. 反余弦函数: acos24. positive 函数: positive(int a) 返回a的值25. negative 函数: negative(int a) 返回a的相反数2.2收集函数array/map类型⼤⼩: size 返回array/map类型的元素数量2.3类型转换函数基础类型之间强制转换:cast(field/expr as <type>)2.4⽇期函数1. UNIX 时间戳转⽇期函数: from_unixtime2. 获取当前 UNIX 时间戳函数: unix_timestamp3. ⽇期转 UNIX 时间戳函数: unix_timestamp4. 指定格式⽇期转 UNIX 时间戳函数: unix_timestamp5. ⽇期时间转⽇期函数: to_date6. ⽇期转年函数: year7. ⽇期转⽉函数: month8. ⽇期转天函数: day9. ⽇期转⼩时函数: hour10. ⽇期转分钟函数: minute11. ⽇期转秒函数: second12. ⽇期转周函数: weekofyear13. ⽇期⽐较函数: datediff14. ⽇期增加函数: date_add15. ⽇期减少函数: date_sub16. ⽇期查看函数: date_format17 ⽇期函数:last_day 返回当前⽉最后⼀天⽇期2.5条件函数1. if 函数: if(boolean condition,true_value,false_value)2. ⾮空查找函数: coalesce(v1,v2,v3...) 返回⼀组数据中第⼀个不为null的值3. 条件判断函数:case when a then b else c end 当值为a时返回b,否则返回c2.6字符函数1. 字符 ascii 码函数:ascii2. base64 字符串3. 字符串连接函数:concat(String a,String b) 连接多个字符串,合并为⼀个字符串4. 带分隔符字符串连接函数:concat_ws(joinstr,String a,String b) 连接多个字符串,字符串之间以指定的分隔符分开5. ⼩数位格式化成字符串函数:format_number6. 字符串截取函数:substr(String a,int start),substring(String a,int start)从⽂本字符串指定的起始位置后的字符7. 字符串查找函数:instr8. 字符串长度函数:length9. 字符串查找函数:locate10. 字符串格式化函数:printf11. 字符串转换成 map 函数:str_to_map12. base64 解码函数:unbase64(string str)13. 字符串转⼤写函数:upper,ucase14. 字符串转⼩写函数:lower,lcase15. 去空格函数:trim16. 左边去空格函数:ltrim17. 右边去空格函数:rtrim18. 正则表达式替换函数:regexp_replace(string a,string b,string c) 字符串a中的b字符被c字符替代19. 正则表达式解析函数:regexp_extract20. URL 解析函数:parse_url21. json 解析函数:get_json_object(string json_string,string path) 拆分取值22. 空格字符串函数:space 返回指定数量的空格23. 重复字符串函数:repeat(string a,int b) 重复b次a字符串24. 左补⾜函数:lpad25. 右补⾜函数:rpad26. 分割字符串函数: split27. 集合查找函数: find_in_set28. 分词函数:sentences(string a) 将字符串中内容按语句分组,每个单词间以逗号分隔,最后返回数组29. 分词后统计⼀起出现频次最⾼的 TOP-K30. 分词后统计与指定单词⼀起出现频次最⾼的 TOP-K31. 倒序字符串:reverse32. ngrams33. context_ngrams34. first_value/last_value 返回当前列第⼀个(最后⼀个)值35. lag/lead 返回当前值的前后值3.内置聚合函数1. 个数统计函数: count2. 总和统计函数: sum3. 平均值统计函数: avg4. 最⼩值统计函数: min5. 最⼤值统计函数: max6. 返回指定列的⽅差: var_pop7. 返回指定列的样本⽅差: var_samp8. 返回指定列的偏差: stddev_pop9. 返回指定列的样本偏差: stddev_samp10. 两列数值协⽅差:covar_pop11. 两列数值样本协⽅差:covar_samp12. 返回两列数值的相关系数:corr(col1,col2)13.中位数函数: percentile14. 近似中位数函数: percentile_approx15. 直⽅图: histogram_numeric16. 集合去重数:collect_set17. 集合不去重函数:collect_list4.内置表⽣成函数1. array/map拆分多⾏:explode测试:1.1关系运算符关系运算符:= <=> > >= < <=-- select5<=>5true-- select6>=5true-- select8<=7falselike/rlike⽐较-- select'football' like 'foot%'true-- select'2697566722@' rlike '\\@[0-9a-z]{2,}\.(com|cn|org|edu)' trueregexp-- select'football' regexp '\\w{9,}[a-z]'false1.2算术运算符-- select5+510-- select5-50-- select5*525-- select5/51-- select5%41-- select5&91-- select5|913-- select5^9121.4复杂类型函数-- select array(1,4,5,6,8) [1,4,5,6,8]-- select map('name','张三','age',18) {"name":"张三","age":"18"}-- select struct(array(1,3,5),map('name','张三','age',18)) {"col1":[1,3,5],"col2":{"name":"张三","age":"18"}} 2.1数学函数-- select round(5.3423) 5-- select round(5.345,2) 5.35-- select floor(5.9) 5-- select ceil(5.1) 6-- select rand() 0.7311469360199058-- select exp(2) 7.38905609893065-- select log(5,25) 2-- select pow(2,3) 8-- select sqrt(25) 5-- select bin(8) 1000-- select hex(16) 10-- select unhex(100)-- select abs(-10) 10-- select pmod(5,2) 1-- select sin(3.1415926/2) 0.9999999999999997-- select asin(0.9999999999999997) 1.5707963009853283-- select positive(10) 10-- select negative(10) -102.2收集函数-- select size(array(1,3,4,5,6,7,8)) 72.4⽇期函数-- select from_unixtime(0,'yyyy-MM-dd HH:mm:ss') 1969-12-3119:00:00-- select unix_timestamp() 1598707426-- select to_date('2020-1-1') 2020-01-01-- select year(current_date()) 2020-- select month(current_date()) 8-- select day(current_date()) 29-- select hour(current_timestamp()) 9-- select minute(current_timestamp()) 26-- select second(current_timestamp()) 15-- select weekofyear(current_date()) 35-- select datediff(current_date(),'2020-08-01') 28-- select date_add(current_date(),1) 2020-08-30-- select date_sub(current_date(),1) 2020-08-28-- select date_format(current_date(),'y') 2020-- select last_day('2020-01-02') 2020-01-31-- select if(1=3,3,2) 2-- select coalesce(null,3,null,4) 3-- select case when 5>9 then 4else0 end 02.6字符函数-- select ascii(',') 44-- select concat('张三','吃饭') 张三吃饭-- select concat_ws('-','张三','⼲嘛去了') 张三-⼲嘛去了-- select format_number(2.4234432532,3) 2.423-- select substr(87654321,3,2) 65-- select instr('张三在哪','在') 3-- select length('324322') 6-- select locate('吗','吃了吗') 3-- select printf('你好') 你好-- select str_to_map('name:李四,age:18',',',':') {"name":"李四","age":"18"}-- select upper('abc') ABC-- select lower('ABC') abc-- select trim(' 你好 ') 你好-- select regexp_replace('早上好','早','晚') 晚上好-- SELECT regexp_extract('100-200', '(\d+)-(\d+)', 1) FROM src LIMIT 1100-- select parse_url('https:///u/afeiiii/','PROTOCOL') https-- select id,get_json_object(line,'$.name') name,get_json_object(line,'$.age') age,get_json_object(line,'$.gender') gender from jsontest-- select repeat('a',4) aaaa-- select split('howAareByou','[AB]') ["how","are","you"]-- select find_in_set('aa','aa,bb,aa') 1-- select sentences('你,吃了吗') [["你","吃了吗"]]4.内置表⽣成函数--explode(a) - separates the elements of array a into multiple rows, or the elements of a map into multiple rows and columns explode适合array/map的拆分--select id,,t.age,t.gender from jsontest lateral view json_tuple(line,'name','age','gender')t as name,age,gender json_tuple适合String类型拆分。
Hive常用函数大全(窗口函数、分析函数)

Hive常⽤函数⼤全(窗⼝函数、分析函数)1、相关函数1.1 窗⼝函数FIRST_VALUE:取分组内排序后,截⽌到当前⾏,第⼀个值LAST_VALUE:取分组内排序后,截⽌到当前⾏,最后⼀个值LEAD(col,n,DEFAULT) :⽤于统计窗⼝内往后第n⾏值。
第⼀个参数为列名,第⼆个参数为往下第n⾏(可选,默认为1),第三个参数为默认值(当往下第n⾏为NULL时候,取默认值,如不指定,则为NULL)LAG(col,n,DEFAULT) :⽤于统计窗⼝内往前第n⾏值。
第⼀个参数为列名,第⼆个参数为往上第n⾏(可选,默认为1),第三个参数为默认值(当往上第n⾏为NULL时候,取默认值,如不指定,则为NULL)1.2 OVER从句1、使⽤标准的聚合函数COUNT、SUM、MIN、MAX、AVG2、使⽤PARTITION BY语句,使⽤⼀个或者多个原始数据类型的列3、使⽤PARTITION BY与ORDER BY语句,使⽤⼀个或者多个数据类型的分区或者排序列4、使⽤窗⼝规范,窗⼝规范⽀持以下格式:(ROWS | RANGE) BETWEEN (UNBOUNDED | [num]) PRECEDING AND ([num] PRECEDING | CURRENT ROW | (UNBOUNDED | [num]) FOLLOWING) (ROWS | RANGE) BETWEEN CURRENT ROW AND (CURRENT ROW | (UNBOUNDED | [num]) FOLLOWING)(ROWS | RANGE) BETWEEN [num] FOLLOWING AND (UNBOUNDED | [num]) FOLLOWING5、当ORDER BY后⾯缺少窗⼝从句条件,窗⼝规范默认是RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW.6、当ORDER BY和窗⼝从句都缺失, 窗⼝规范默认是ROW BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING.7、OVER从句⽀持以下函数,但是并不⽀持和窗⼝⼀起使⽤它们。
hive常用函数

hive常用函数Hive一款建立在Hadoop之上的数据仓库分析软件,它为用户提供了一系列的函数,以满足用户的不同需求。
在这里,我们将重点介绍 Hive 中一些常用的函数,希望能够更好的帮助用户使用和熟悉Hive。
### 1.学函数数学函数是 Hive 中的一类经常被使用的函数,它们分为算术运算类函数、随机数类函数、对数类函数、三角函数类函数、取整函数类函数、科学计数法函数等,下面,我们将分别介绍这几类函数的语法以及用法。
####1)算术运算类函数算术运算类函数主要有如下:1. `ABS(x)`:返回x的绝对值2. `EXP(x)`:返回e的x次方3. `MOD(x, y)`:返回x除以y的余数4. `POWER(x,y)`:返回x的y次方5. `ROUND(x,d)`:返回x保留d位小数后的结果6. `LOG(x)`:返回x的自然对数####2)随机数类函数随机数类函数主要有`RAND()`,它用于生成一个0~1之间的随机数。
####3)对数类函数对数类函数主要有`LOG(x, base)` `LOG10(x)`,它们用于返回X的对数,其中base可以自定义,为空时,使用2作为默认值;而`LOG10(x)`则返回以10为底的x的对数。
####4)三角函数类函数三角函数类函数主要有`SIN(x)`,`COS(x)`,`TAN(x)`,它们分别用于返回x的正弦值、余弦值和正切值。
####5)取整函数类函数取整函数类函数主要有`CEIL(x)` `FLOOR(x)`,它们用于返回比x大的最小整数和比x小的最大整数。
####6)科学计数法函数科学计数法函数主要有`ROUND(x,s)`,其中x为一个数字,s代表保留小数点位数,用于表示数字的指数部分,即参数s代表相对于基数10的指数。
### 2.符串函数字符串函数是 Hive 中常用的一类函数,它们分为字符串处理类函数、字符和数值转换类函数、字符集转换类函数、正则表达式类函数等,下面,我们将分别介绍这几类函数的语法以及用法。
hive常用窗口函数

hive常用窗口函数
Hive常用窗口函数指的是在Hive中使用频繁的窗口函数,窗口函数是一种用于分组数据并在特定数据范围内计算聚合值的函数。
在Hive中,窗口函数可以用于处理行级别的操作,例如计算移动平均值、排名和累计总和等。
常用的Hive窗口函数包括RANK、DENSE_RANK、ROW_NUMBER、NTILE、LAG、LEAD、FIRST_VALUE、LAST_VALUE、SUM、AVG等。
这些窗口函
数可以用于处理大型数据集,并生成高效的结果。
以SUM函数为例,SUM函数用于计算特定字段的总和。
当使用SUM 窗口函数时,需要使用PARTITION BY子句将数据分组,并使用ORDER BY子句指定数据排序顺序。
例如,可以使用以下语法来计算每个部
门的销售总额:
SELECT
department,
SUM(sales) OVER (PARTITION BY department ORDER BY date) as total_sales
FROM
sales_data;
在这个例子中,PARTITION BY子句将数据按部门进行分组,ORDER BY子句按日期排序。
然后,SUM函数计算每个部门的销售总额。
除了SUM函数,Hive还支持许多其他窗口函数,可以根据不同
的需求选择合适的窗口函数来处理数据。
hive数据类型函数

hive数据类型函数本文将为您介绍Hive中的数据类型和函数,包括数值类型、字符串类型、日期类型、数组类型、结构类型和转换函数等,共计1000字左右。
一、数值类型1. TINYINT:有符号8位整数,范围从-128到127。
2. SMALLINT:有符号16位整数,范围从-32768到32767。
3. INT或INTEGER:有符号32位整数,范围从-2147483648到2147483647。
4. BIGINT:有符号64位整数,范围从-9223372036854775808到9223372036854775807。
可以使用“L”作为后缀来指定该类型,例如:100L。
5. FLOAT:32位浮点数。
6. DOUBLE:64位浮点数。
7. DECIMAL:精确十进制数。
DECIMAL(precision, scale),其中precision为最大精度,scale为小数点后的位数。
二、字符串类型1. CHAR(n):固定长度字符串,有n个字符。
2. VARCHAR(n):可变长度字符串,有最大n个字符。
3. STRING:任意长度字符串。
三、日期类型1. TIMESTAMP:时间戳,表示自1970年1月1日以来的毫秒数。
2. DATE:日期,格式为“YYYY-MM-DD”。
1. ARRAY<data_type>:数组。
例如:ARRAY<INT>,表示一个整数数组。
五、结构类型1. STRUCT<field_name:data_type, field_name:data_type, ...>:结构。
例如:STRUCT<name:STRING, age:INT>,表示包含字符串类型的“name”和整数类型的“age”的结构体。
六、转换函数总结。
oracle数学函数

oracle数学函数
Oracle数据库提供了许多数学函数,可以对数据进行各种数学计算和操作。
这些函数可以用于数值计算、数值转换、值舍入等。
以下是一些常用的Oracle数学函数的介绍。
1.ABS(x):返回x的绝对值。
例如,ABS(-3)将返回3
2.CEIL(x):返回大于或等于x的最小整数值。
例如,CEIL(
3.14)将返回4
3.FLOOR(x):返回小于或等于x的最大整数值。
例如,FLOOR(3.14)将返回3
6.POWER(x,y):返回x的y次幂。
例如,POWER(2,3)将返回8
7.SQRT(x):返回x的平方根。
例如,SQRT(16)将返回4
8.MOD(x,y):返回x除以y的余数。
例如,MOD(10,3)将返回1
11.LOG(x[,y]):返回x的对数。
如果指定了可选参数y,则返回以y 为底的x的对数。
例如,LOG(100)将返回2,LOG(100,10)将返回2
12.SIGN(x):返回x的符号,如果x大于0则返回1,如果x等于0则返回0,如果x小于0则返回-1、例如,SIGN(-5)将返回-1这些函数可以通过SELECT语句中的数学表达式或条件中使用来对数据进行数学计算和操作。
它们可以用于计算表达式、生成报告、创建存储过程等各种情况。
通过灵活地使用这些数学函数,可以在Oracle数据库中进行各种数学运算,满足各种数学计算需求。
nlssort函数 hive

nlssort函数 hiveHive是一个开源的数据仓库平台,它能够将大规模的数据进行处理和分析。
在使用Hive的时候,我们经常需要将数据进行排序,这时候就需要用到nlssort函数。
本篇文章将详细介绍nlssort函数在Hive中的使用。
Nlssort函数是Oracle数据库中常见的函数,它用于按照指定的字符集对字符串进行排序。
在Hive中,nlssort函数也可以按照指定的排序规则来对字符串进行排序。
NLSSORT(string, charset_name)参数说明:string:需要排序的字符串charset_name:字符集名称,如'UTF8'、'GB2312'等返回值类型:binary1.对字符串进行排序:我们可以使用nlssort函数对字符串进行排序,如下所示:SELECT nlssort('张三', 'GB2312'),nlssort('李四', 'GB2312');结果如下所示:Binary_colum1 Binary_colum2bd50bbed bff1bec8可以看到,按照GB2312字符集的排序规则,'张三'的编码为'bd50bbed','李四'的编码为'bff1bec8'。
name age nlssort(name, 'GB2312')张三 18 bd50bbed李四 20 bff1bec8王五 22 cecfc0eb可以看到,按照GB2312字符集的排序规则,查询结果按照name字段进行了排序。
3.按照多个字段进行排序:在实际的项目中,我们也经常会需要按照多个字段进行排序。
这时候,我们可以使用nlssort函数对多个字段进行排序,如下所示:SELECT name, age, nlssort(name, 'GB2312'), nlssort(address, 'GB2312')FROM studentORDER BY nlssort(name, 'GB2312'), nlssort(address, 'GB2312');1.优点:nlssort函数可以对任意字符集进行排序,这对于非英文语言的排序十分有用。
hive和oracle常用函数对照表
unix_timestamp(string date) unix_timestamp() year month(string date) day(string date) dayofmonth(date) hour(string date) minute(string date) weekofyear(string date) datediff(string enddate, string startdate) date_sub(string startdate, int days) date_add(string startdate, int days) avg count max covar_samp(col1, col2) var_pop(col) var_pop(col) min sum percentile(col, p) stddev_pop(col) corr(col1, col2) 无 无 cast(expr as <type>) hex(BIGINT a) hex(string a) unhex(strindians(double a)
trim(string A) ltrim(string A) rtrim(string A) reverse(string A)
regexp_replace(string A, string B, string C) ascii(string str) 无 concat_ws(string SEP, string A, string B„) parse_url(string urlString, string partToExtract [, space(int n) repeat(string str, int n) split(string str, string pat) regexp_extract(string subject, string pattern, sentences(string str, string lang, string locale) e() pi() find_in_set(string str, string strList) get_json_object(string json_string, string path)
Hive函数大全-完整版

Hive函数⼤全-完整版Hive函数⼤全–完整版现在虽然有很多SQL ON Hadoop的解决⽅案,像Spark SQL、Impala、Presto等等,但就⽬前来看,在基于Hadoop的⼤数据分析平台、数据仓库中,Hive仍然是不可替代的⾓⾊。
尽管它的相应延迟⼤,尽管它启动MapReduce的时间相当长,但是它太⽅便、功能太强⼤了,做离线批量计算、ad-hoc查询甚⾄是实现数据挖掘算法,⽽且,和HBase、Spark都能整合使⽤。
如果你是做⼤数据分析平台和数据仓库相关的,就⽬前来说,我建议,Hive是必须的。
很早之前整理过Hive的函数,不过是基于0.7版本的,这两天抽时间更新了下,基于Hive0.13,⽐之前的完整了许多。
整理成⽂档,希望能给Hive初学者和Hive使⽤者有所帮助。
Hive⾃带的UDF函数⾮常多,整理出来有40多页。
下载地址在⽂章最后⾯。
如果该⽂档对你的学习和⼯作有所帮助,那么请多多⽀持我的博客。
Hive函数⼤全⽬录:⼀、关系运算:1. 等值⽐较: =2. 等值⽐较:<=>3. 不等值⽐较: <>和!=4. ⼩于⽐较: <5. ⼩于等于⽐较: <=6. ⼤于⽐较: >7. ⼤于等于⽐较: >=8. 区间⽐较9. 空值判断: IS NULL10. ⾮空判断: IS NOT NULL10. LIKE⽐较: LIKE11. JAVA的LIKE操作: RLIKE12. REGEXP操作: REGEXP⼆、数学运算:1. 加法操作: +2. 减法操作: –3. 乘法操作: *4. 除法操作: /5. 取余操作: %6. 位与操作: &7. 位或操作: |8. 位异或操作: ^9.位取反操作: ~三、逻辑运算:1. 逻辑与操作: AND 、&&2. 逻辑或操作: OR 、||3. 逻辑⾮操作: NOT、!四、复合类型构造函数1. map结构:map2. struct结构:struct3. named_struct结构:named_struct4. array结构:array5. create_union:create_union五、复合类型操作符1. 获取array中的元素:A[n]2. 获取map中的元素:M[key]3. 获取struct中的元素S.s六、数值计算函数1. 取整函数: round2. 指定精度取整函数: round3. 向下取整函数: floor4. 向上取整函数: ceil5. 向上取整函数: ceiling6. 取随机数函数: rand7. ⾃然指数函数: exp8. 以10为底对数函数: log109. 以2为底对数函数: log210. 对数函数: log11. 幂运算函数: pow12. 幂运算函数: power13. 开平⽅函数: sqrt14. ⼆进制函数: bin15. ⼗六进制函数: hex16. 反转⼗六进制函数: unhex17. 进制转换函数: conv18. 绝对值函数: abs19. 正取余函数: pmod20. 正弦函数: sin21. 反正弦函数: asin22. 余弦函数: cos23. 反余弦函数: acos24. positive函数: positive25. negative函数: negative七、集合操作函数1. map类型⼤⼩:size2. array类型⼤⼩:size3. 判断元素数组是否包含元素:array_contains4. 获取map中所有value集合5. 获取map中所有key集合6. 数组排序⼋、类型转换函数1. ⼆进制转换:binary2. 基础类型之间强制转换:cast九、⽇期函数1. UNIX时间戳转⽇期函数: from_unixtime2. 获取当前UNIX时间戳函数: unix_timestamp3. ⽇期转UNIX时间戳函数: unix_timestamp4. 指定格式⽇期转UNIX时间戳函数: unix_timestamp5. ⽇期时间转⽇期函数: to_date6. ⽇期转年函数: year7. ⽇期转⽉函数: month8. ⽇期转天函数: day9. ⽇期转⼩时函数: hour10. ⽇期转分钟函数: minute11. ⽇期转秒函数: second12. ⽇期转周函数: weekofyear13. ⽇期⽐较函数: datediff14. ⽇期增加函数: date_add15. ⽇期减少函数: date_sub⼗、条件函数1. If函数: if2. ⾮空查找函数: COALESCE3. 条件判断函数:CASE4. 条件判断函数:CASE⼗⼀、字符串函数1. 字符ascii码函数:ascii2. base64字符串3. 字符串连接函数:concat4. 带分隔符字符串连接函数:concat_ws5. 数组转换成字符串的函数:concat_ws6. ⼩数位格式化成字符串函数:format_number7. 字符串截取函数:substr,substring8. 字符串截取函数:substr,substring9. 字符串查找函数:instr10. 字符串长度函数:length11. 字符串查找函数:locate12. 字符串格式化函数:printf13. 字符串转换成map函数:str_to_map14. base64解码函数:unbase64(string str)15. 字符串转⼤写函数:upper,ucase16. 字符串转⼩写函数:lower,lcase17. 去空格函数:trim18. 左边去空格函数:ltrim19. 右边去空格函数:rtrim20. 正则表达式替换函数:regexp_replace21. 正则表达式解析函数:regexp_extract22. URL解析函数:parse_url23. json解析函数:get_json_object24. 空格字符串函数:space25. 重复字符串函数:repeat26. 左补⾜函数:lpad27. 右补⾜函数:rpad28. 分割字符串函数: split29. 集合查找函数: find_in_set30. 分词函数:sentences31. 分词后统计⼀起出现频次最⾼的TOP-K32. 分词后统计与指定单词⼀起出现频次最⾼的TOP-K⼗⼆、混合函数1. 调⽤Java函数:java_method2. 调⽤Java函数:reflect3. 字符串的hash值:hash⼗三、XPath解析XML函数1. xpath2. xpath_string3. xpath_boolean4. xpath_short, xpath_int, xpath_long5. xpath_float, xpath_double, xpath_number⼗四、汇总统计函数(UDAF)1. 个数统计函数: count2. 总和统计函数: sum3. 平均值统计函数: avg4. 最⼩值统计函数: min5. 最⼤值统计函数: max6. ⾮空集合总体变量函数: var_pop7. ⾮空集合样本变量函数: var_samp8. 总体标准偏离函数: stddev_pop9. 样本标准偏离函数: stddev_samp10.中位数函数: percentile11. 中位数函数: percentile12. 近似中位数函数: percentile_approx13. 近似中位数函数: percentile_approx14. 直⽅图: histogram_numeric15. 集合去重数:collect_set16. 集合不去重函数:collect_list⼗五、表格⽣成函数Table-Generating Functions (UDTF)1. 数组拆分成多⾏:explode2. Map拆分成多⾏:explode。
hive基本聚合函数

hive基本聚合函数数据聚合是按照特定条件将数据整合并表达出来,以总结出更多的组信息。
Hive包含内建的⼀些基本聚合函数,如MAX, MIN, AVG等等,同时也通过GROUPING SETS,ROLLUP, CUBE等函数⽀持更⾼级的聚合。
Hive基本内建聚合函数通常与GROUP BY连⽤,默认情况下是对整个表进⾏操作。
在使⽤GROUP BY时,除聚合函数外其他已选择列必须包含在GROUP BY⼦句中。
下表为Hive内置的聚合函数。
返回类型函数名描述BIGINTcount(*)count(expr)count(DISTINCT expr[, expr_.])count(*) –返回检索到的⾏的总数,包括含有NULL值的⾏。
count(expr) –返回expr表达式不是NULL的⾏的数量count(DISTINCTexpr[, expr]) –返回expr是唯⼀的且⾮NULL的⾏的数量DOUBLEsum(col)sum(DISTINCT col)对组内某列求和(包含重复值)或者对组内某列求和(不包含重复值)DOUBLEavg(col),avg(DISTINCT col)对组内某列元素求平均值者(包含重复值或不包含重复值)DOUBLEmin(col)返回组内某列的最⼩值DOUBLEmax(col)返回组内某列的最⼤值DOUBLEvariance(col),var_pop(col)返回组内某个数字列的⽅差DOUBLEvar_samp(col)返回组内某个数字列的⽆偏样本⽅差DOUBLEstddev_pop(col)返回组内某个数字列的标准差DOUBLEstddev_samp(col)返回组内某个数字列的⽆偏样本标准差DOUBLEcovar_pop(col1, col2)返回组内两个数字列的总体协⽅差DOUBLEcovar_samp(col1, col2)返回组内两个数字列的样本协⽅差DOUBLEcorr(col1, col2)返回组内两个数字列的⽪尔逊相关系数DOUBLEpercentile(BIGINT col, p)返回组内某个列精确的第p位百分数,p必须在0和1之间arraypercentile(BIGINT col, array(p1[, p2]...))返回组内某个列精确的第p1,p2,……位百分数,p必须在0和1之间DOUBLEpercentile_approx(DOUBLE col, p [, B])返回组内数字列近似的第p位百分数(包括浮点数),参数B控制近似的精确度,B值越⼤,近似度越⾼,默认值为10000。
hive常用函数参考手册

函数分类HIVE CLI命令显示当前会话有多少函数可用SHOW FUNCTIONS;显示函数的描述信息DESC FUNCTION concat;显示函数的扩展描述信息DESC FUNCTION EXTENDED concat; 简单函数函数的计算粒度为单条记录。
关系运算数学运算逻辑运算数值计算类型转换日期函数条件函数字符串函数统计函数聚合函数函数处理的数据粒度为多条记录。
sum()—求和count()—求数据量avg()—求平均直distinct—求不同值数min—求最小值max—求最人值集合函数复合类型构建复杂类型访问复杂类型长度特殊函数窗口函数应用场景用于分区排序动态Group ByTop N累计计算层次查询Windowing functionsleadlagFIRST_VALUELAST_VALUE分析函数Analytics functionsRANKROW_NUMBERDENSE_RANKCUME_DISTPERCENT_RANKNTILE混合函数java_method(class,method [,arg1 [,arg2])reflect(class,method [,arg1 [,arg2..]])hash(a1 [,a2...])UDTFlateralView: LATERAL VIEW udtf(expression) tableAlias AS columnAlias(‘,‘ columnAlias)*fromClause: FROM baseTable (lateralView)*ateral view用于和split, explode等UDTF一起使用,它能够将一行数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合。
lateral view首先为原始表的每行调用UDTF,UTDF会把一行拆分成一或者多行,lateral view再把结果组合,产生一个支持别名表的虚拟表。
hive常用函数总结

Hive是一个基于Hadoop的数据仓库工具,与SQL语言相似,提供了一套可扩展的SQL抽象层。
下面是Hive常用函数的总结。
一、数学函数:
Hive支持众多的数学函数,如ABS(取绝对值)、EXP(取e的指数)、CEIL(向上取整)、FLOOR(向下取整)等。
二、字符串函数:
Hive也支持强大的字符串函数,如LENGTH(返回字符串长度)、CONCAT(连接多个字符串)、SUBSTR(获取子串)、TRIM(去除空格)等。
三、日期函数:
Hive能够处理日期,时间和时间戳类型,内置了很多日期函数,比如CURRENT_DATE(获取当前日期)、YEAR/MONTH/DAY(从日期中获取年,月,日)、DATEDIFF(计算两个日期之间的差值)等。
四、类型转换函数:
在Hive中,可以通过CAST函数将一个类型转换为另一个类型,如CAST(‘123’ AS INT)。
五、聚合函数:
Hive聚合函数可用于所有基本数据类型,如COUNT(计算总数)、SUM(求和)、AVG(平均值)、MIN(最小值)、MAX(最大值)等。
六、模式匹配函数:
模式匹配函数主要用于查找和替换字符串,包括LIKE、RLIKE和REGEXP。
总的来说,Hive提供了众多丰富的内置函数,帮助用户更加方面和快速地处理数据。
oracle系统常用函数

1、数学函数
a、round(n,[m])四舍五入函数
b、trunc(n,[m])函数
c、 FLOOR() 向下取整与CEIL()向上取整
d、mod(n,m)取余函数
e、abs(n) 获取绝对值
2、字符串函数
a、ASCII(char)函数
b、chr(n)函数
c、LOWER() 函数
d、upper()函数
e、initcap()函数
f、substr(str,n,m)函数
对字符串进行截取操作 str表示要截取的字符串,n表示开始截取的位置,m
g、length(str)函数
h、replace(str,x,y)函数
i、组合使用以上函数
3、日期函数
a、sysdate使用SYSDATE函数可以获取当前的系统时间
b、months_between()
c、add_months()
d、last_day()
4、转换函数
a、to_date()
b、to_char()
c、to_number()
d、cast()
5、聚合函数
a、AVG()函数求平均值
b、min()函数求最小值
c、max()函数求最大值
d、sum()函数进行求和
e、count()函数
6、sys_context(conext_name,param)
是Oracle数据库中提供的一个获取环境上下文信息的系统函数(1)conext_name:环境信息名称,默认写为userenv。
(2)param:环境信息属性名,为固定可选参数。
hive 值转化函数

hive 值转化函数在Hive中,值转换函数主要用于对数据进行格式化或计算。
这类函数可以将原始数据转换为特定的数据类型或格式。
以下是一些常用的值转换函数:1. 字符串转换函数:- LOWER(将字符串转换为小写)- UPPER(将字符串转换为大写)- LENGTH(计算字符串长度)- SUBSTR(提取字符串的一部分)- REPLACE(替换字符串中的特定字符)- STRING(将字段转换为字符串)- FROM_UNIXTIME(将Unix时间戳转换为字符串)2. 数字转换函数:- TOINT(将字符串或数字转换为整数)- TFLOAT(将字符串或数字转换为浮点数)- TDOUBLE(将字符串或数字转换为双精度浮点数)- TSTRING(将数字或字符串转换为字符串)3. 日期和时间转换函数:- FROM_DATE(将日期字符串转换为DATE类型)- FROM_DATETIME(将日期时间字符串转换为DATETIME类型)- TO_DATE(将字符串转换为DATE类型)- TO_DATETIME(将字符串转换为DATETIME类型)4. 集合转换函数:- GROUP_CONCAT(将同一组内的多个值合并为一个字符串)5. 其他转换函数:- NULLIF(如果条件为真,则返回NULL,否则返回原始值)- CONCAT(合并两个或多个字符串)- FORMAT(格式化数字字符串)以下是一个使用Hive值转换函数的示例:```sqlSELECTNULLIF(TOINT(SUBSTR(column1, 1, 4)), 0) AS integer_value, TOFLOAT(SUBSTR(column1, 5, 10)) AS float_value,FORMAT(column2, '%Y-%m-%d') AS formatted_dateFROMyour_table;```在这个示例中,我们从名为`your_table`的表中选取数据,并使用值转换函数将字符串转换为整数、浮点数和格式化的日期。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
删除字符串两端的空格,字符之间的空 格保留 删除字符串左边的空格,其他的空格保 留 删除字符串右边的空格,其他的空格保 留 返回倒序字符串
字符串A中的B字符被C字符替代
返回字符串中首字符的数字值
给出整数,返回对应的字符 链接多个字符串,字符串之间以指定的分 隔符分开。 返回URL指定的部分。parse_url(‘ /path1/p.php?k1=v1 返回指定数量的空格 重复N次字符串 将字符串转换为数组。 通过下标返回正则表达式指定的部分。 regexp_extract(‘foothebar’, ‘ 将字符串中内容按语句分组,每个单词间 以逗号分隔,最后返回数组。 例如 返回e的值 返回pi的值 在一个字符串中搜索指定的字符,返回发现 指定的字符的位置 get_json_object('{"store":{"fruit":[{ "weight":8,"type":"apple"},{"weight":
hive
upper(string ucase(string lower(string lcase(string 无
A) A) A) A)
concat(string A, string B „) substr(string A, int start, int len) substring(string length(string A) lpad(string str, int len, string pad) rpad(string str, int len, string pad)
增加的hive 函数 MONTHS_BETWEEN (v_dealyyyymm1, v_dealyyyymm2) ?:未证实
说明 将文本字符串转换成字母全部大写形式
将文本字符串转换成字母全部小写形式 将每个单词的首字母大写,其他位置 的字母小写
连接多个字符串,合并为一个字符串,可 以接受任意数量的输入字符串 从文本字符串中指定的位置指定长度的字 符。 返回字符串的长度 返回指定长度的字符串,给定字符串长度 小于指定长度时,由指定字符从左侧填补 返回指定长度的字符串,给定字符串长度 小于指定长度时,由指定字符从右侧填补
指定日期参数调用UNIX_TIMESTAMP(), 它返回参数值’1970- 01 – 0100:00:00 如果不带参数的调用,返回一个Unix时间 戳(从’1970- 01 – 0100:00:00′到现 返回指定时间的年份,范围在1000到 9999,或为”零”日期的0。 返回指定时间的月份,范围为1至12月,或 0一个月的一部分,如’0000-00-00′或’ 返回指定时间的日期 返回指定时间的小时,范围为0到23。 返回指定时间的秒,范围为0到59。 返回指定日期所在一年中的星期号,范围 为0到53。 两个时间参数的日期之差。 给定时间,在此基础上减去指定的时间段 。 给定时间,在此基础上加上指定的时间段 。 求平均值 统计数据 求最大值 两列数值样本协方差 返回指定列的方差 求标准差,ALL表示对所有的值求标准 差,DISTINCT表示只对不同的值求标准差 求最小值 求和 返回数值区域的百分比数值点。0<=P<=1, 否则返回NULL,不支持浮点型数值。 返回指定列的偏差 返回两列数值的相关系数 st从字符型数据转换成按指定格式的数 值,缺省时数值格式串的大小正好为整个 m从一个数值转换为指定格式的字符串fmt 缺省时,fmt值的宽度正好能容纳所有的有 类型转换。例如将字符”1″转换为整 数:cast(’1′ as bigint),如果转换失 将整数或字符转换为十六进制格式 十六进制字符转换由数字表示的字符。 返回二进制格式 将值从弧度到度 将值从度转换为弧度
聚合函数
STDDEV(distinct|all) min sum 无 无 无 to_number(st[,fmt]) to_char(m[,fmt]) 无 无 无 无 无
转换函数
无
转换函数 nvl(m,n) 无 RAWTOHEXT HEXTORAW ROWIDTOCHAR TO_MULTI_BYTE CHARTOROWID GREATEST LEAST UID USER USEREVN GROUP BY 其他 HAVING ORDER BY DECODE ? ? ? 逻辑函数 ? ? ? 多表join ? ? colalese COALESCE(T v1, T v2, „) 无 无 无 无 无 无 无 无 无 无 GROUP BY 无(where子句代替) ORDER BY/sort by when\case distinct desc/asc or and not join left semi join left right outer join TO_DATE(v_txdate,'YYYYMMDD' ) 增加的hive 函数 ADD_MONTHS(TO_DATE(v_txdate ,0) LAST_DAY(v_dealyyyymm)
无 无 无 无 无 无 无 无 to_date(string timestamp) unix_timestamp(string date, string pattern)
日期函数
无 无 无 无 无 无 无 无 无 无 无 avg count max VARIANCE(DISTINCT|ALLห้องสมุดไป่ตู้ 无
unix_timestamp(string date) unix_timestamp() year month(string date) day(string date) dayofmonth(date) hour(string date) minute(string date) weekofyear(string date) datediff(string enddate, string startdate) date_sub(string startdate, int days) date_add(string startdate, int days) avg count max covar_samp(col1, col2) var_pop(col) var_pop(col) min sum percentile(col, p) stddev_pop(col) corr(col1, col2) 无 无 cast(expr as <type>) hex(BIGINT a) hex(string a) unhex(string a) bin(BIGINT a) degrees(double a) radians(double a)
trim(string A) ltrim(string A) rtrim(string A) reverse(string A)
regexp_replace(string A, string B, string C) ascii(string str) 无 concat_ws(string SEP, string A, string B„) parse_url(string urlString, string partToExtract [, space(int n) repeat(string str, int n) split(string str, string pat) regexp_extract(string subject, string pattern, sentences(string str, string lang, string locale) e() pi() find_in_set(string str, string strList) get_json_object(string json_string, string path)
asin(double a) acos(double a) ceil(3.1415927) sin(double a) cos(double a) sqrt(double a) exp(double a) floor(double a) rand(),rand(int seed) ln(double a) log(double base, double a) pow(double a, double p) power(double a, double p) round(double a)round(double a, int d) sign(double a) tan(double a) atan(1) conv(BIGINT num, int from_base, int to_base) positive(int a) positive(double a) negative(int a) negative(double a) pmod(int a, int b) pmod(double a, double b)
reverse(‘abcdef’) 字符函数 replace('HELLO','L','x ') ascii('A') chr(54740) 无 无 无 无 无 无 无 无 无 instr('oracle traning','ra',1,2) 无 round(double a) trunc(412.23,2) abs(-100)
函数分类
oracle upper('coolszy') lower('KUKA') initcap('kuKA aBc') concat('Hello',' world') substr('hello',2,3) length('hello') lpad(‘smith ’,10,'*') rpad(‘smith’,10,'*') trim(' Mr Simth ltrim(' Mr Simth rtrim(' Mr Simth ') ') ')