spss使用教程_聚类分析与判别分析(新)-PPT课件
判别分析SPSS操作53页PPT

判别分析的SPSS操作
❖ §1. 基本原理 ❖ §2. 基本操作 ❖ §3. 选项设置 ❖ §4. 实例分析类似地 经计算源自(3)求线性判别函数W(X)
解线性方程组
得
(4)对已知类别的样品判别分类
对已知类别的样品(通常称为训练样品)用线性判别函数进行判 别归类,结果如下表,全部判对。
“Criteria”(准则)选项组用于选择逐步判别停止的判据,可 供选择的判据包括以下几项:
Use F value 默认选项。使用F值是系统默认的判据,当 加入一个变量(或剔除一个变量)后,对判别分析的变量进 行方差分析。当计算的F值大于指定的Entry值时,该变量保 存在函数中,默认Entry值是3.84;当该变量使计算的F值小 于指定的Removal值时,该变量从函数中剔除,默认 Removal值是2.71。即当被加入的变量F值为3.84时,才把 该变量加入到模型中,否则变量不能进入模型;或者当要从 模型中移出的变量F值为2.71时,该变量才被移出模型,否 则模型中的变量不会被移出。设置这两个值时应该注意 Entry值和Removal值。
Step4:选择变量值标识。 如果需要使用一部分个案参与判别函数的推导,而且有一个变
量的某个值可以作为这些观测量的标识,则用Select Variable功 能进行选择。方法为在变量列表中选择变量,单击右向箭头按钮, 将其移动至“Selection”(选择变量)文本框;然后单击 “Selection”文本框右侧的“Value”按钮,显示“Discriminant Analysis:Set Value”(判别分析:设定值)子对话框,如图 1.3所示,输入选择变量的标识。单击“Continue”按钮,返回主 对话框。
图1.2 “Discriminate Analysis:Define Range”对 话框
第十讲聚类分析SPSS操作1ppt课件

5.Centroid clustering 重心法
(欧式距离)
6.Median clustering
中间距离法 (欧式距离)
7.Ward Method
精选离课件差ppt 平方法 (欧式距8 离)
列表框
箭头键 按钮
从左边列表框中选择变量名 并用箭头键按钮转移到变量列 表框中作为聚类分析的变量
变量 列表框
所有个案 分为两类
所有个案 分为三类
所有个案 分为四类
生成新 变量保 存聚为 n类时 各案例 对应的
类
不保存新变量
生成新变量保存聚为n-m 类时各案例对应的类
解释 证实
给出类的特征准确的描述(名称) 计算各个类在各聚类变量上的均值 均值的比较分析
使用聚类变量以外的其他变量
保证聚类结果的可信性 同一总体的不同样本的聚类分析的比较 同一样本的不同分组的聚类分析比较 同一数据的不同方法的聚类分析比较
此课件下载可自行编辑修改,供参考! 感谢您的支持,我们努力做得更好!
29
用数据除以标准离差
综述表 聚结表 冰柱图 树状图
有效个案
缺失个案
某步合并 的个案
距离或者 相似系数
参与合并的个案 项中,若有新类, 该类在哪一步第 一次生成
对应新类将在 第几步与其他 个案合并
个案或者新类在 第n步合并,则第 (m-n+1)以上合并 项对应列之间用 “X”填充
清楚地显示了聚 类的全过程
精选课件ppt
5
聚类分析步骤
选择变量 距离与相似 聚类过程 解释与证实
选择变量原则
✓符 合 分 析 的 目 的 ✓反 映 对 象 的 特 征 ✓ 不同对象的变量有显著差异 ✓变 量 之 间 不 能 高 度 相 关
(汇总)spss聚类分析结果解释.ppt

数据同上〔data14-01a〕:以四个四类成绩突出者的数据为初始 聚类中心(种子)进展聚类。类中心数据文件data14-01b〔但缺一 列Cluster_,不能直接使用,要修改〕。对运发动的分类〔还是分 为4类〕
Analyze Classify K-Means Cluster
Variables: x1,x2,x3
三维或者更高维的情况也是类似;只不过三 维以上的图形无法直观地画出来而已。在饮 料数据中,每种饮料都有四个变量值。这就 是四维空间点的问题了。
..分割..
19
两个距离概念
按照远近程度来聚类需要明确两个概念:一个是点和点
之间的距离,一个是类和类之间的距离。
点间距离有很多定义方式。最简单的是歐氏距离,还有
..分割..
17
饮料数据〔drink.sav 〕
16种饮料的热量、咖啡因、钠及价格四种变量
..分割..
18
如何度量远近?
如果想要对100个学生进展分类,如果仅仅知 道他们的数学成绩,那么只好按照数学成绩 来分类;这些成绩在直线上形成100个点。这 样就可以把接近的点放到一类。
如果还知道他们的物理成绩,这样数学和物 理成绩就形成二维平面上的100个点,也可以 按照距离远近来分类。
产成为可能。
..分割..
2
14.1.2 判别分析
判别分析是根据说明事物特点的变量值和它们 所属的类,求出判别函数。根据判别函数对未 知所属类别的事物进展分类的一种分析方法。
在自然科学和社会科学的各个领域经常遇到需 要对某个个体属于哪一类进展判断。如动物学 家对动物如何分类的研究和某个动物属于哪一 类、目、纲的判断。
中最远点之间的距离作为这两类之间的距离;当然也可
SPSS聚类分析与判别分析

聚类分析是一种探索性的分析,在分类的 过程中,人们不必事先给出一个分类的标准, 聚类分析能够从样本数据出发,自动进行分类。 聚类分析所使用方法的不同,常常会得到不同 的结论。不同研究者对于同一组数据进行聚类 分析,所得到的聚类数未必一致。因此我们说 聚类分析是一种探索性的分析方法。
对个案的聚类分析类似于判别分析,都是 将一些观察个案进行分类。聚类分析时,个案 所属的群组特点还未知。也就是说,在聚类分 析之前,研究者还不知道独立观察组可以分成 多少个类,类的特点也无所得知。
8.1 聚类分析与判别分析的基本概念
统计学研究这类问题的常用分类统计方法 主要有聚类分析(cluster analysis)与判 别分析(discriminant analysis)。其中聚 类分析是统计学中研究这种“物以类聚”问题 的一种有效方法,它属于统计分析的范畴。聚 类分析的实质是建立一种分类方法,它能够将 一批样本数据按照他们在性质上的亲密程度在 没有先验知识的情况下自动进行分类。这里所 说的类就是一个具有相似性的个体的集合,不 同类之间具有明显的区别。
图8-4 “Hierarchical Cluster Analysis:Plots” 对话框(一)
图8-5 “Hierarchical Cluster Analysis:Statistics”对话框(一)
图8-6 “Hierarchical Cluster Analysis:Save New Var”对话框
变量的聚类分析类似于因素分析。两者都 可用于辨别变量的相关组别。不同在于,因素 分析在合并变量的时候,是同时考虑所有变量 之间的关系;而变量的聚类分析,则采用层次 式的判别方式,根据个别变量之间的亲疏程度 逐次进行聚类。
聚类分析的方法,主要有两种,一种是 “快速聚类分析方法”(K-Means Cluster Analy- sis),另一种是“层次聚类分析方法” (Hierarchical Cluster Analysis)。如果 观察值的个数多或文件非常庞大(通常观察值 在200个以上),则宜采用快速聚类分析方法。 因为观察值数目巨大,层次聚类分析的两种判 别图形会过于分散,不易解释。
spss判别分析(PPT)
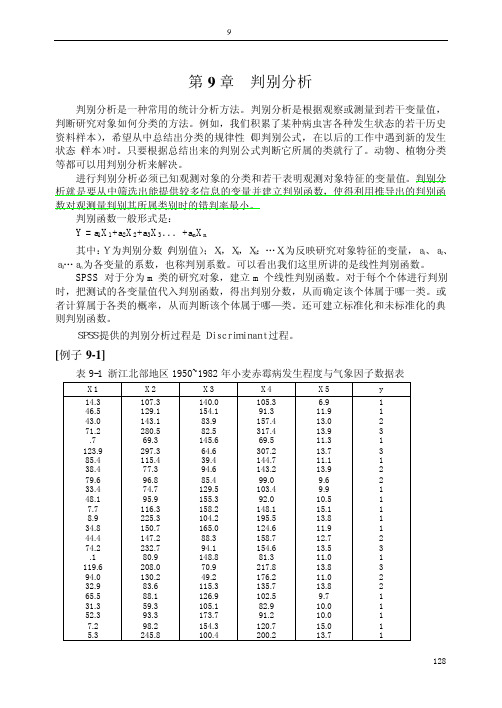
第9章判别分析判别分析是一种常用的统计分析方法。
判别分析是根据观察或测量到若干变量值,判断研究对象如何分类的方法。
例如,我们积累了某种病虫害各种发生状态的若干历史资料样本),希望从中总结出分类的规律性(即判别公式,在以后的工作中遇到新的发生状态(样本)时。
只要根据总结出来的判别公式判断它所属的类就行了。
动物、植物分类等都可以用判别分析来解决。
进行判别分析必须已知观测对象的分类和若干表明观测对象特征的变量值。
判别分析就是要从中筛选出能提供较多信息的变量并建立判别函数,使得利用推导出的判别函数对观测量判别其所属类别时的错判率最小。
判别函数一般形式是: Y = a1X1+a2X2+a3X3...+a n X n其中: Y为判别分数(判别值);X1,X2,X3:…Xn为反映研究对象特征的变量,a1、a2、a3…an为各变量的系数,也称判别系数。
可以看出我们这里所讲的是线性判别函数。
SPSS 对于分为m类的研究对象,建立m个线性判别函数。
对于每个个体进行判别时,把测试的各变量值代入判别函数,得出判别分数,从而确定该个体属于哪一类。
或者计算属于各类的概率,从而判断该个体属于哪—类。
还可建立标准化和未标准化的典则判别函数。
SPSS提供的判别分析过程是Discriminant过程。
[例子9-1]表9-1 浙江北部地区1950~1982年小麦赤霉病发生程度与气象因子数据表X1 X2 X3 X4 X5 y14.3 107.3 140.0 105.3 6.9 146.5 129.1 154.1 91.3 11.9 143.0 143.1 83.9 157.4 13.0 271.2 280.5 82.5 317.4 13.9 3.7 69.3 145.6 69.5 11.3 1123.9 297.3 64.6 307.2 13.7 385.4 115.4 39.4 144.7 11.1 138.4 77.3 94.6 143.2 13.9 279.6 96.8 85.4 99.0 9.6 233.4 74.7 129.5 103.4 9.9 148.1 95.9 155.3 92.0 10.5 17.7 116.3 158.2 148.1 15.1 18.9 225.3 104.2 195.5 13.8 134.8 150.7 165.0 124.6 11.9 144.4 147.2 88.3 158.7 12.7 274.2 232.7 94.1 154.6 13.5 3.1 80.9 148.8 81.3 11.0 1119.6 208.0 70.9 217.8 13.8 394.0 130.2 49.2 176.2 11.0 232.9 83.6 115.3 135.7 13.8 265.5 88.1 126.9 102.5 9.7 131.3 59.3 105.1 82.9 10.0 152.3 93.3 173.7 91.2 10.0 17.2 98.2 154.3 120.7 15.0 15.3 245.8 100.4 200.2 13.7 1128129浙江北部地区1950~1982年小麦赤霉病发生程度与气象因子研究,总结出上年12月将与(x1)、上年10月下旬至11月中旬和当年1~2月总降雨(x2)、上年10月下旬至11月上旬日照时数(x3)、上年10月下旬至12月中旬和当年2月总雨量(x4)以及当年3月中旬平均高文(x5)等5个因子,并将赤霉病情分为轻中重三级(y ,分别用1、2、3表示)。
spss第十六讲聚类分析与判别分析

步骤二:选择聚类变量
聚类类数
聚类个案标识
步骤三:指定聚类过程中类是否调整类中心点
给出聚类过程中两个 调整类中心点: 1、表示聚类过程中选 择或指定初始类中心 点,按照K-Means的 迭代算法不断调整类 中心点。
2、聚类过程中只使用 初始的类中心点而不 作调整,迭代次数也 进行一次
步骤四:类中心数据的输入与输出。
第十六讲聚类分析与判别分析
第一部分 上一讲回顾 第二部分 聚类分析概念 第三部分 聚类分析的SPSS过程 第四部分 判别分析
第一部分 上一讲回顾
1、回归分析及模型 2、线性回归 3、线性回归SPSS过程 4、曲线估计
第二部分 聚类分析概念
俗语说,物以类聚、人以群分。 但什么是分类的根据呢? 比如,要想把中国的县分成若干类,就有
1、快速聚类(K-Means Cluster): 观测量 快速聚类分析过程。
2、分层聚类(Hierarchical Cluster):分层 聚类(进行观测量聚类和变量聚类的过程。
快速聚类过程(Quick Cluster)
使用 k 均值分类法对观测量进行聚 类。可使用系统的默认选项或自己设 置选项,如分为几类、指定初始类中 心、是否将聚类结果或中间数据数据 存入数据文件等。 AnalyzeClassifyK-Means Cluster
(4)找出D(1)中非对角线最小元素是1.5, 则将G3和G6并 成一个新类,记为G7={X1, X2, X3}。
(5)计算新类G7与其它类之间的距离,按公式 Di7=min(Di1, Di2, Di3) (i=4,5) 得距离矩阵D(2) 表3
G7={X1, X2 ,X3} G4={X4} G5={X5}
i
xi2 yi2
SPSS聚类分析具体操作步骤课件

聚类分析概述
(一)概念 • (1)聚类分析是统计学中研究“物以类聚”的一种
方法,属多元统计分析方法.
– 例如:细分市场、消费行为划分
• 聚类分析是建立一种分类,是将一批样本(或变量) 按照在性质上的“亲疏”程度,在没有先验知识的 情况下自动进行分类的方法.其中:类内个体具有 较高的相似性,类间的差异性较大.
SPSS的聚类分析
• 俗语说,物以类聚、人以群分。
• 但什么是分类的根据呢?
• 举例:要想把中国的县分成若干类,就有很多种 分类法;
• 可以按照自然条件来分,
• 比如考虑降水、土地、日照、湿度等各方面;
• 也可以考虑收入、教育水准、医疗条件、基础设 施等指标;
• 既可以用某一项来分类,也可以同时考虑多项指 标来分类。
• 比如学生成绩数据就可以对学生按照理科或文科 成绩(或者综合考虑各科成绩)分类,
• 当然,并不一定事先假定有多少类,完全可以按 照数据本身的规律来分类。
快速聚类
• k-均值聚类(k-means cluster,也叫快速聚类,quick cluster)却要求你先说好要分多少类。看起来有些主观
• 假定你说分3类,这个方法还进一步要求你事先确定3个点 为“聚类种子”(SPSS软件自动为你选种子);也就是说, 把这3个点作为三类中每一类的基石。
SPSS中聚类分析分类
(一)按分类对象 对变量的聚类称为R型聚类 对观测值聚类称为Q型聚类 这两种聚类在数学上是对称的,没有什么不同。
(二)按聚类的方法分类 分层聚类或系统聚类分析 快速聚类分析 两步聚类分析:新型的
事先不用确定分多少类:分层聚类
分层聚类或系统聚类(hierarchical cluster)。 开始时,有多少点就是多少类。
SPSS聚类分析具体操作步骤PPT课件

(二)“亲疏”程度的衡量 (1)衡量指标
–相似性:数据间相似程度的度量 –距离: 数据间差异程度的度量.距离越近,越“亲密”,
聚成一类;距离越远,越“疏远”,分别属于不同的类
(2)衡量对象
–个体间距离 –个体和小类间、小类和小类间的距离
两个距离概念
• 按照远近程度来聚类需要明确两个概念:一个是点和点之 间的距离,一个是类和类之间的距离。
• 然后,根据和这三个点的距离远近,把所有点分成三类。 再把这三类的中心(均值)作为新的基石或种子(原来的 “种子”就没用了),重新按照距离分类。
• 如此叠代下去,直到达到停止叠代的要求. • 适合处理大样本数据。
• 特点
1. 聚类分析前所有个体所属的类别是未知的,类别个数 一般也是未知的,分析的依据只有原始数据,可能事 先没有任何有关类别的信息可参考
SPSS的聚类分析
• 俗语说,物以类聚、人以群分。
• 但什么是分类的根据呢?
• 举例:要想把中国的县分成若干类,就有很多种 分类法;
• 可以按照自然条件来分,
• 比如考虑降水、土地、日照、湿度等各方面;
• 也可以考虑收入、教育水准、医疗条件、基础设 施等指标;
• 既可以用某一项来分类,也可以同时考虑多项指 标来分类。
聚类分析概述
(一)概念 • (1)聚类分析是统计学中研究“物以类聚”的一种
方法,属多元统计分析方法.
– 例如:细分市场、消费行为划分
• 聚类分析是建立一种分类,是将一批样本(或变量) 按照在性质上的“亲疏”程度,在没有先验知识的 情况下自动进行分类的方法.其中:类内个体具有 较高的相似性,类间的差异性较大.
单击“方法”按钮弹出对话框
• 下拉框指定的是小类之间的距离计算方法7种供用 户选择