Multiple Description Video
NVIDIA VIDEO CODEC SDK - ENCODER vNVENC_DA-6209-00

Application NoteTable of Contents Chapter 1. NVIDIA Hardware Video Encoder (1)1.1. Introduction (1)1.2. NVENC Capabilities (1)1.3. NVENC Licensing Policy (4)1.4. NVENC Performance (4)1.5. Programming NVENC (5)1.6. FFmpeg Support (6)Chapter 1.NVIDIA Hardware VideoEncoder1.1.IntroductionNVIDIA GPUs - beginning with the Kepler generation - contain a hardware-based encoder (referred to as NVENC in this document) which provides fully accelerated hardware-based video encoding and is independent of graphics/CUDA cores. With end-to-end encoding offloaded to NVENC, the graphics/CUDA cores and the CPU cores are free for other operations. For example, in a game recording scenario, offloading the encoding to NVENC makes the graphics engine fully available for game rendering. In the video transcoding use-case, video encoding/decoding can happen on NVENC/NVDEC in parallel with other video post-/pre-processing on CUDA cores. The hardware capabilities available in NVENC are exposed through APIs referred to as NVENCODE APIs in the document. This document provides information about the capabilities of the hardware encoder and features exposed through NVENCODE APIs.1.2.NVENC CapabilitiesNVENC can perform end-to-end encoding for H.264, HEVC 8-bit, HEVC 10-bit, AV1 8-bit and AV1 10-bit. This includes motion estimation and mode decision, motion compensation and residual coding, and entropy coding. It can also be used to generate motion vectors between two frames, which are useful for applications such as depth estimation, frame interpolation, encoding using other codecs not supported by NVENC, or hybrid encoding wherein motion estimation is performed by NVENC and the rest of the encoding is handled elsewhere in the system. These operations are hardware accelerated by a dedicated block on GPU silicon die. NVENCODE APIs provide the necessary knobs to utilize the hardware encoding capabilities. Table 1 summarizes the capabilities of the NVENC hardware exposed through NVENCODE APIs and Table 2 lists the features exposed in Video Codec SDK 12.0.Table 1.NVENC Hardware Capabilities‣Y : Supported, N : Not supported‣*Supported in select Pascal generation GPUs Table 2.What’s new in Video Codec SDK 12.01.3.NVENC Licensing PolicyThere is no change in licensing policy in the current SDK in comparison to the previous SDK. The licensing policy is as follows:As far as NVENC hardware encoding is concerned, NVIDIA GPUs are classified into two categories: “qualified” and “non-qualified”. On qualified GPUs, the number of concurrent encode sessions is limited by available system resources (encoder capacity, system memory, video memory etc.). On non-qualified GPUs, the number of concurrent encode sessions is limited to 3 per system. This limit of 3 concurrent sessions per system applies to the combined number of encoding sessions executed on all non-qualified cards present in the system.For a complete list of qualified and non-qualified GPUs, refer to https:/// nvidia-video-codec-sdk..For example, on a system with one Quadro RTX4000 card (which is a qualified GPU) and three GeForce cards (which are non-qualified GPUs), the application can run N simultaneous encode sessions on Quadro RTX4000 card (where N is defined by the encoder/memory/hardware limitations) and 3 sessions on all the GeForce cards combined. Thus, the limit on the number of simultaneous encode sessions for such a system is N + 3.1.4.NVENC PerformanceWith every generation of NVIDIA GPUs (Maxwell 1st/2nd gen, Pascal, Volta, Turing, Ampere and Ada), NVENC performance has increased steadily. Table 3provides indicative1NVENC performance on Pascal, Turing, and Ada GPUs for different presets and rate control modes (these two factors play a major role in determining the performance and quality). Note that performance numbers in Table 3 are measured on GeForce hardware with assumptions listed under the table. The performance varies across GPU classes (e.g. Quadro, Tesla), and scales (almost) linearly with the clock speeds for each hardware.While first-generation Maxwell GPUs had one NVENC engine per chip, certain variants of the second-generation Maxwell, Pascal, Volta and Ada GPUs have two/three NVENC engines per chip. This increases the aggregate encoder performance of the GPU. NVIDIA driver takes care of load balancing among multiple NVENC engines on the chip, so that applications don’t require any special code to take advantage of multiple encoders and automatically benefit from higher encoder capacity on higher-end GPU hardware. The encode performance listed in Table 3 is given per NVENC engine. Thus, if the GPU has 2 NVENCs (e.g. GP104, AD104), multiply the corresponding number in Table 3 by the number of NVENCs per chip to get aggregate maximum performance (applicable only when running multiple simultaneous encode sessions). Note that unless Split Frame Encoding is enabled, performance with single encoding session cannot exceed performance per NVENC, regardless of the number of NVENCs present on the GPU. Multi NVENC Split Frame Encoding is a feature introduced in SDK12.0 on Ada GPUs for HEVC and AV1. Refer to the NVENC Video Encoder API Programming Guide for more details on this feature.1Encoder performance depends on many factors, including but not limited to: Encoder settings, GPU clocks, GPU type, video content type etc.NVENC hardware natively supports multiple hardware encoding contexts with negligible context-switching penalty. As a result, subject to the hardware performance limit and available memory, an application can encode multiple videos simultaneously. NVENCODE API exposes several presets, rate control modes and other parameters for programming the hardware. A combination of these parameters enables video encoding at varying quality and performance levels. In general, one can trade performance for quality and vice versa.Table 3.NVENC encoding performance in frames/second (fps)‣Resolution/Input Format/Bit depth: 1920 × 1080/YUV 4:2:0/8-bit‣Above measurements are made using the following GPUs: GTX 1060 for Pascal, RTX 8000 for Turing, RTX 3090 for Ampere, and RTX 4090 for Ada. All measurements are done at the highest video clocks as reported by nvidia-smi (i.e. 1708 MHz, 1950 MHz, 1950 MHz, 2415 MHz for GTX 1060, RTX 8000, RTX 3090, and RTX 4090 respectively). The performance should scale according to the video clocks as reported by nvidia-smi for other GPUs of every individual family. Information on nvidia-smi can be found at https:/// nvidia-system-management-interface.‣H.264 and HEVC encoding fps for Volta GPU can be obtained by multiplying the Pascal fps in the above table by ratio of the clocks, as reported by nvidia-smi.‣Software: Windows 11, Video Codec SDK 12.0, NVIDIA display driver: 522.25‣CBR: Constant bitrate rate control mode, VBR: Variable bitrate rate control mode, LL : Low latency tuning info, HQ: High quality tuning info1.5.Programming NVENCRefer to the SDK release notes for information regarding the required driver version.Refer to the documents and the sample applications included in the SDK package for details on how to program NVENC.1.6.FFmpeg SupportFFmpeg is the most popular multimedia transcoding tool used extensively for video and audio transcoding.The video hardware accelerators in NVIDIA GPUs can be effectively used with FFmpeg to significantly speed up the video decoding, encoding and end-to-end transcoding at very high performance. For more information on how to use NVENC or NVDEC with FFmpeg, please refer to the FFmpeg guide in the Video Codec SDK.Note that FFmpeg is open-source project and its usage is governed by specific licenses and terms and conditions for FFmpeg.NoticeThis document is provided for information purposes only and shall not be regarded as a warranty of a certain functionality, condition, or quality of a product. NVIDIA Corporation (“NVIDIA”) makes no representations or warranties, expressed or implied, as to the accuracy or completeness of the information contained in this document and assumes no responsibility for any errors contained herein. NVIDIA shall have no liability for the consequences or use of such information or for any infringement of patents or other rights of third parties that may result from its use. This document is not a commitment to develop, release, or deliver any Material (defined below), code, or functionality.NVIDIA reserves the right to make corrections, modifications, enhancements, improvements, and any other changes to this document, at any time without notice. Customer should obtain the latest relevant information before placing orders and should verify that such information is current and complete.NVIDIA products are sold subject to the NVIDIA standard terms and conditions of sale supplied at the time of order acknowledgment, unless otherwise agreed in an individual sales agreement signed by authorized representatives of NVIDIA and customer (“Terms of Sale”). NVIDIA hereby expressly objects to applying any customer general terms and conditions with regards to the purchase of the NVIDIA product referenced in this document. No contractual obligations are formed either directly or indirectly by this document.NVIDIA products are not designed, authorized, or warranted to be suitable for use in medical, military, aircraft, space, or life support equipment, nor in applications where failure or malfunction of the NVIDIA product can reasonably be expected to result in personal injury, death, or property or environmental damage. NVIDIA accepts no liability for inclusion and/or use of NVIDIA products in such equipment or applications and therefore such inclusion and/or use is at customer’s own risk. NVIDIA makes no representation or warranty that products based on this document will be suitable for any specified use. Testing of all parameters of each product is not necessarily performed by NVIDIA. It is customer’s sole responsibility to evaluate and determine the applicability of any information contained in this document, ensure the product is suitable and fit for the application planned by customer, and perform the necessary testing for the application in order to avoid a default of the application or the product. Weaknesses in customer’s product designs may affect the quality and reliability of the NVIDIA product and may result in additional or different conditions and/or requirements beyond those contained in this document. NVIDIA accepts no liability related to any default, damage, costs, or problem which may be based on or attributable to: (i) the use of the NVIDIA product in any manner that is contrary to this document or (ii) customer product designs.TrademarksNVIDIA, the NVIDIA logo, and cuBLAS, CUDA, CUDA Toolkit, cuDNN, DALI, DIGITS, DGX, DGX-1, DGX-2, DGX Station, DLProf, GPU, Jetson, Kepler, Maxwell, NCCL, Nsight Compute, Nsight Systems, NVCaffe, NVIDIA Deep Learning SDK, NVIDIA Developer Program, NVIDIA GPU Cloud, NVLink, NVSHMEM, PerfWorks, Pascal, SDK Manager, Tegra, TensorRT, TensorRT Inference Server, Tesla, TF-TRT, Triton Inference Server, Turing, and Volta are trademarks and/or registered trademarks of NVIDIA Corporation in the United States and other countries. Other company and product names may be trademarks of the respective companies with which they are associated.Copyright© 2010-2022 NVIDIA Corporation. All rights reserved.NVIDIA Corporation | 2788 San Tomas Expressway, Santa Clara, CA 95051。
视频编码

视频编码多媒体数据量大的特点给多媒体存储和传输带来了很大的障碍,多媒体数字压缩技术的出现使多媒体存储和传输成为可行。
压缩编码技术主要利用了数据之间的冗余、人类的心理感知的冗余等原理,使人们在降低多媒体数据大小的情况下,还能够获得很好的音视频质量。
视频编码属于压缩编码,它将原始视频进行编码从而获得一定压缩比和质量的编码后视频。
目前视频编码标准主要有MPEG-1、MPEG-2、MPEG-4,以及可视电话会议电视的H.261、H.264等等,采用的一些压缩技术有分层编码、多描述编码等等。
⏹MPEG-4标准与编码器XVIDMEPG-4的目标是针对极低码率(<64kbps),这是视频压缩标准的最后一个比特率范围。
MPEG-4与MPEG-1、MPEG-2的最根本区别是,MPEG-4是基于内容的压缩编码方法,它将一幅图像按内容分割成子块,将感兴趣的物体从场景中截取出来,进行编码处理,同时基于内容或物体截取的子块内信息相关性强,可以产生高压缩比效果。
另外,基于物体的子块,其运动的估计和表示就有可能使用物体的刚性运动或非刚性运动模型来描述,它比基于宏块的描述要高效的多。
MPEG-4具有高压缩性、基于内容交互以及基于内容分级扩展,具有基于内容方式表示的视频数据。
它引入了视频物体(VO)和视频物体平面(VO Plane)等概念来实现基于内容表示。
基于内容分级扩展使用了分层可扩展和精细可扩展编码FGSC技术,它将视频分为基本层和增强层,在基本码率之上的任何带宽增加都可以得到视频质量的改善,这对适应网络状态随时变化的特性十分有益。
Xvid是一种视频编解码器(codec),它是一款开放源代码的MPEG-4视频编解码器,创建于2001年,通过GPL协议发布。
Xvid关注MPEG-4视频压缩,早期的Xvid version0.9x版本实现了MPEG-4 simple profile(SP)的编解码,而在1.0版本中引入了MEPG-4 的advanced simple profile(ASP),其中包括了所有高级编码工具,如1/4像素运动补偿和GMC等等。
Video outdoor panels VPM.1FR02, VPM.2SR02, VPM.3FR
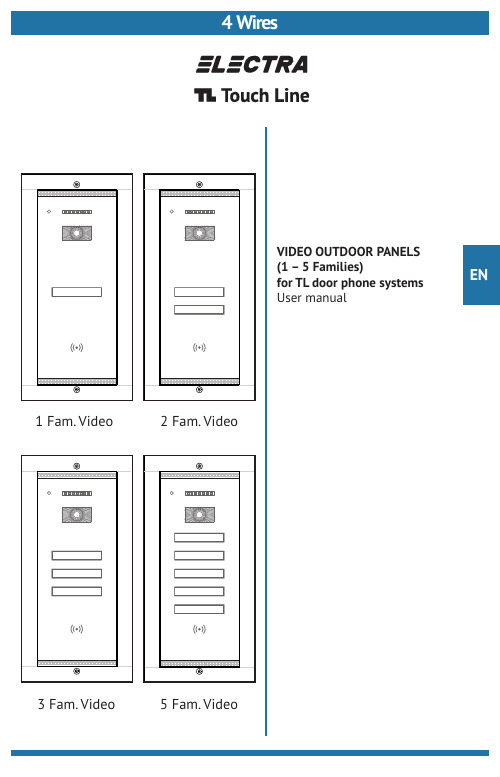
41 Fam. Video2 Fam. Video3 Fam. Video 5 Fam. VideoEN VIDEO OUTDOOR PANELS(1 – 5 Families)for TL door phone systemsUser manual2Description of the video outdoor panels 4Recommended cables. Installation3Functions of the video outdoor panelsAny intervention on the installation must be performed by AUTHORIZED PERSONNEL!DO NOT power the product at 110 – 230 Va.c.!DO NOT hit the glass screen with hard objects!If the glass screen is broken, DO NOT touch the product.Protect the products against lime and dust during renovation activities.6Maintenance of the video outdoor panels 7Warranty24 wires x 0.5 mm(type H03VV-F4G 0.5) for maximum 75 ml or another type of equivalent cable24 wires x 0.75 mm (type H05VV-F4G 0.75) for maximum 100 ml or another type of equivalent cableGenerally, any type of 4-wire cable with a 0.5 mm section is accepted. T elephone cables type TCYY - 2x2x0.5-24 AWG (max. 30ml); TCYY - 3x2x0.5-24 AWG (max. 50ml);TCYY - 4x2x0.5-24 AWG (max. 100ml) can also be used.aSolid mechanical construction, built in embedded technology, with chemically toughened glass. Weatherproof, waterproof and with an operating temperature range between -30º…+ 60º C.Electronic anti-condensation system for the video camera screen.Anti-theft sensor that is activated during unauthorized unmounting from the wall.Day/night sensor for the command of TOUCH keyboard backlighting and the lighting of the IR LEDs and IR-CUT. TOUCH keyboard with the name of the resident, backlighted during night.1/3 CMOS, 900TVL color video camera and IR LEDs for b/w image during night.Blinking red LED, signaling the presence of potential video monitoring from the panel.In-built RFID reader. Access by secured RFID tag/card.Allows the connection of a DVR, for extended monitoring and video recording from the panel.Settings/ProgrammingProgramming and deletion of RFID building access tags/cards.Programming of new address 2, 3 or 4, for parallel connected panels, in case of buildings with multiple entrances. (maximum 4 outdoor panels for one building).Enabling or disabling of video monitoring signaling (Red LED ON/OFF), through the J P1: RED LED/0. (ch. 4.1-step 4)Enabling or disabling DVR video recording (ON/OFF) through the jumper JP40: 1-2 (OFF) / 2-3(ON) (ch. 4.1) ExtensionsAllows the parallel connection of maximum 4 outdoor panels, through a video selection box (VSB).Allows the connection of an additional video camera directly to the central supply unit (SCU), or of 4 additional video cameras, through a video selection box (VSB).*Important:Maintain the same colors for the same connections.Example: +U = Red, C/D = Blue, GND = Black, Vin/Vout = Green.For electrical safety reasons, we recommend installing an earthing cable between the panel and the SCU, connected to an earth grounding (ISO - IEC 60950-1:2005)Option 3) UTP cat5e (AWG24) or UTP cat6e (AWG23), for maximum 250 lmThe wires will be arranged as per the below table:Connectionsto the VPMoutdoor panel+UC/DGNDConnectionsto the SCUcentral supply unitConnectionsto the VPMoutdoor panelConnectionsto the SCUcentral supply unitNote: Any type of TL terminal can be mounted indoors.For Fam. 1, the terminal has address 1, which is set by the producer.The additional terminals mounted in parallel will have the address of the main terminal For Fam. 2, the terminal will be programmed with address 2. See Ch. 6 of the user manual for TL audio-video terminals.O N G 2O N G 1B L 1B L 2O N G 2O N G 1B L 1B L 2O N G 2O N G 1B L 1B L 2N o t e : F o r r e s i d e n c e s w i t h 3 f a m i l i e s a n d o n e e n t r a n c e (e n t r a n c e 1), t h e o u t d o o r p a n e l h a s a d d r e s s 1, w h i c h i s s e t b y t h e p r o d u c e r. F o r m u l t i p l e e n t r a n c e s : E n t r a n c e 2, E n t r a n c e 3, E n t r a n c e 4, p a n e l s 2, 3 a n d 4 w i l l b e p r o g r a m m e d a c c o r d i n g t o t h e p r o c e d u r e i n C h . 4.6.F o r F a m . 1, t h e t e r m i n a l h a s a d d r e s s 1, w h i c h i s s e t b y t h e p r o d u c e r. T h e a d d i t i o n a l t e r m i n a l s m o u n t e d i n p a r a l l e l w i l l h a v e t h e a d d r e s s o f t h e m a i n t e r m i n a l F o r F a m . 2 a n d F a m . 3, t h e t e r m i n a l w i l l b e p r o g r a m m e d w i t h a d d r e s s 2, r e s p e c t i v e l y . 6 o f t h e u s e r m a n u a l f o r T L a u d i o -v i d e o t e r m i n a l s .F a m . 3more familiesImportant: One VPM outdoor panel and one SCU central unit will be mounted at each entrance.The VPM1 panel keeps address 1, which is set from the factory.The VPM2 panel with address 2 Long press the PROG. button at SCU 2 Long touch the Fam.1 key at the VPM2 panel. long beep Short touch the Fam.1 key, twice T wo short beeps confirmation.The VPM3 panel with address 3 Long press the PROG. button at SCU 3 Long touch the Fam.1 key at the VPM3 panel. long beep Short touch the Fam.1 key, three times Three short beeps confirmation.The VPM4 panel with address 4 Long press the PROG. button at SCU 4 Long touch the Fam.1 key at the VPM4 panel. long beep Short touch the Fam.1 key, four times Four short beeps confirmation.Not e : After the beep confirmation of the new address in the panel, go to the SCU of the panel and short press the PROG. button. The programming of the address is finished.The programming of the addresses for the panels connected in parallel is done as follows:The call keys with the name of the residents are permanently backlighted during night. The Red LED2. CALL: Touch the key corresponding to the name of the family you are looking for. The call is acoustically signaledwith a ding-dong. Each touch of the key reinitiates the call.4. END OF TALK: - After 1 min. from the call, if the resident does not answer. - At 10 sec. after the door/gate is opened.- Immediately, if the resident decides to end the talk without opening the door/gate.3. TALK: If the resident answers, talk is initiated. The maximum duration of the talk is 2 min.5. ACCESS: The door/gate will be open during the time set at the SCU (maximum 10 sec.). Access granting is acoustically signaled through a confirmation beep sequence.6. RFID TAG/CARD ACCESS:symbol blinks white.In order to have access in the building after installation, it is mandatory to program the RFID tags/cards in the outdoor panel.During programming the installation has to be connected to the grid (110V/230Va.c.) and fully operational.1. Go to the place where the SCU central unit of the installation is mounted. Long press (3 sec.) the PROG button on the SCU . The Red LED turns on.2. To program them, approach every tag/card for one second to the For each programmed tag/card, the panel issues two short beeps. Repeat this step3. Go to the place where the SCU central unit of the installation is mounted. Short press the PROG button on the SCU . The Red LED turns off. The installation returns to normal functioning, successfully ending the programming modeOrientable video cameraMicrophone Torx screw IR LEDs(night lighting )Touch keys for call,with the name of the residents Fastening Torx screwThis procedure applies when you wish to give up access with RFID tags/cards . During the deletion of the RFID tags/cards , the installation has to be connected to the grid (110V/230Va.c.) and fully operational.1. Go to the place where the SCU central unit of the installation is mounted. Long press (3 sec.) the PROG button on the SCU . The Red LED turns on. The installation enters programming mode:Not e : The Red LED can be disabled through jumper JP1 (RED LED) on the board of the keyboard, when the2. To delete the RFID access tags/cards from the memory of the panel:- Long touch the Fam. 1 key until the acoustic confirmation of the panel with a long beep.- Short touch the Fam. 1 key 7 times. The panel issues two short confirmation beeps.- Immediately after, long touch (2-3 sec.) the Fam. 1 key. All the codes of the RFID access tags/cards are deleted permanently. The action is acoustically confirmed by a long beep.3. Go to the place where the SCU central unit of the installation is mounted. Short press the PROG button on the SCU . The Red LED turns off. The installation returns to normal functioning mode.4. Optional: From the outdoor panel, check if the old RFID tags/cards grant access. When each RFID tag/card that hasThis procedure applies when you wish toadd new RFID access tags/cards in the outdoor panel.1. Collect all the RFID tags/cards from all the people who have access in the building and prepare the new access tags/cards.2. First, follow the procedure described in chapter 5.2 for deleting all the tags/cards from the memory of the panel.3. Follow the procedure described in chapter 5.1. In this case, when you perform point 2 of chapter 5.1to approach both the new access tags/cards, and the old tags/cards to the RFID area of the panel, for reprogramming.4. After performing point 3 of chapter5.1, check if access is granted for all the programmed and reprogrammed dust etc. For cleaning the glass screens, use a clean cloth and a special solution for glass washing. In case of renovation activities, the entire surface of the panels will be protected with plastic foil. DO NOT undo the electrical connections of the video door phone installation components. DO NOT short-circuit the electrical connections of the video door phone installation components.b. Warranty is granted for the hidden defects of the components used in production and in case of the system not functioning according to the present user manual.WARRANTY IS NOT GRANTED FOR:c. Inappropriate installation and use.d. Deterioration, intentional blows.e. Unauthorized interventions to any of the components of the installationf. Theft, fire, natural disastersg. Lack of protection of the installation components in case of renovation activities.10.2018 USM.VPM.5XR02.ELY04ELECTRA s.r.l Bd. Chimiei nr.8,IaRO+40 232 214.370**************** www.electra.roELECTRA Bischoffgasse 5/3-4, 1120 Wien - AT +43 1 810 20 99*************************** www.electra-automation.at Building Communications GmbH Certificate no. E307311ISO 9001:2015ISO 14001:2015Certificates no. 73 100 4856, 73 104 4856by TÜV HESSEN The products are manufactured under Quality and Environment Management SystemThe products are CE certified.The products contain UL-compliant printed circuit boards.Certificate R 709 ELECTRA is a trademark of ELECTRA Group - No. 008958332 EUIPO - Alicante, Spain ELECTRA products are registered as Industrial Models at EUIPO - Alicante, SpainDesigned and produced by ELECTRA Made in EU。
VGA接口资料
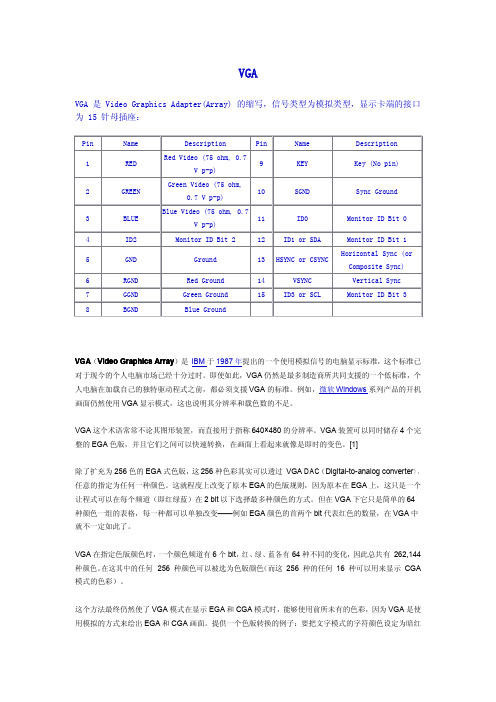
VGAVGA 是Video Graphics Adapter(Array)的缩写,信号类型为模拟类型,显示卡端的接口为15针母插座:VGA (Video Graphics Array )是IBM 于1987年提出的一个使用模拟信号的电脑显示标准,这个标准已对于现今的个人电脑市场已经十分过时。
即使如此,VGA 仍然是最多制造商所共同支援的一个低标准,个人电脑在加载自己的独特驱动程式之前,都必须支援VGA 的标准。
例如,微软Windows 系列产品的开机画面仍然使用VGA 显示模式,这也说明其分辨率和载色数的不足。
VGA 这个术语常常不论其图形装置,而直接用于指称640×480的分辨率。
VGA 装置可以同时储存4个完整的EGA 色版,并且它们之间可以快速转换,在画面上看起来就像是即时的变色。
[1]除了扩充为256色的EGA 式色版,这256种色彩其实可以透过VGA DAC (Digital-to-analog converter ),任意的指定为任何一种颜色。
这就程度上改变了原本EGA 的色版规则,因为原本在EGA 上,这只是一个让程式可以在每个频道(即红绿蓝)在2bit 以下选择最多种颜色的方式。
但在VGA 下它只是简单的64种颜色一组的表格,每一种都可以单独改变——例如EGA 颜色的首两个bit 代表红色的数量,在VGA 中就不一定如此了。
VGA 在指定色版颜色时,一个颜色频道有6个bit ,红、绿、蓝各有64种不同的变化,因此总共有262,144种颜色。
在这其中的任何256种颜色可以被选为色版颜色(而这256种的任何16种可以用来显示CGA 模式的色彩)。
这个方法最终仍然使了VGA 模式在显示EGA 和CGA 模式时,能够使用前所未有的色彩,因为VGA 是使用模拟的方式来绘出EGA 和CGA 画面。
提供一个色版转换的例子:要把文字模式的字符颜色设定为暗红Pin Name Description Pin Name Description 1REDRed Video (75ohm,0.7V p-p)9KEYKey (No pin)2GREEN Green Video (75ohm,0.7V p-p)10SGND Sync Ground3BLUE Blue Video (75ohm,0.7V p-p)11ID0Monitor ID Bit 04ID2Monitor ID Bit 212ID1or SDA Monitor ID Bit 15GND Ground 13HSYNC or CSYNCHorizontal Sync (or Composite Sync)6RGND Red Ground 14VSYNC Vertical Sync 7GGND Green Ground 15ID3or SCLMonitor ID Bit 38BGNDBlue Ground色,暗红色就必须是CGA16色集合中的一种颜色(譬如说,取代CGA默认的7号灰色),这个7号位置将被指定为EGA色版中的42号,然后VGA DAC将EGA#42指定为暗红色。
基于无线视频传感器网络的失真优化路由算法

基于无线视频传感器网络的失真优化路由算法陈旭;沈军;罗护;付新华【摘要】According to the characteristics of wireless sensor network link with video transmission instability and poor reconstruction quality, this paper proposed an reliable transmission of routing algorithm ( EDLOR) which is adaptive to Multiple Description Coding ( MDC). Firstly, it took fully consideration about the video coding rate, delay-constrained, network packet loss and other factors. Secondly, it aimed at how to optimize multiple description of the Peak Signal-to-Noise Ratio( PSNR). As a result, the overall video distortion minimization was gained. Thirdly, these MDCs would be assigned to designed path for transmission according the computed results. It is shown from experimental results that EDLOR can improve the overall video quality through promoting the average PSNR and lowering packet loss rate.%针对无线视频传感器网络链路不稳定、重建质量要求不高的特点,提出一种适应多描述编码(MDC)可靠传输的路由算法EDLOR.该算法充分考虑了视频编码速率、时延受限、网络丢包等因素,以多描述峰值信噪比(PSNR)作为优化目标,使视频总体失真最小化;然后根据计算结果,将多描述编码分配到指定的路径进行传输.实验结果表明,EDLOR路由算法能够提高平均PSNR,降低了网络丢包率,提升了总体视频质量.【期刊名称】《计算机应用》【年(卷),期】2012(032)005【总页数】4页(P1232-1235)【关键词】无线视频传感器网络;多描述编码;视频传输;路由;峰值信噪比【作者】陈旭;沈军;罗护;付新华【作者单位】桂林电子科技大学计算机科学与工程学院,广西桂林541004;桂林空军学院科研部,广西桂林541003;桂林空军学院科研部,广西桂林541003;桂林空军学院科研部,广西桂林541003【正文语种】中文【中图分类】TP3930 引言随着多媒体应用的增加,对网络服务实时通信的要求也越来越高。
Freeport Technologies Multi-Domain Video Network S

Multi ‐Domain Video Network SwitchMDVNSThe Freeport Technologies Multi ‐Domain Video Network Switch (MDVNS) provides an automated periods processing procedure to safely and securely switch between numerous video networks of varying classification levels using a single video CODEC. The MDVNS is the only secure VTC switching solution that has been approved by the Defense Intelligence Agency for use on the JWICS Top Secret network. It has also been approved for operation by DISA for NIPR, SIPR, NRO, NGA, Coalition Forces, and many other classified networks.The MDVNS adheres to the DISA approved periods processing procedure (as detailed in the STIG dated January 2015 Version 1, Release 5) when traversing video networks, which is consistent throughout every system configuration regardless of the number of networks or network type being utilized (IP or ISDN). The period processing procedures along with the unique design of the Freeport MDVNS hardware components ensures that security requirements will be met during the switching and operational processes.Security Risk MitigationIn an environment where a single video CODEC is used to support multiple video communication networks, security related risks can be minimized. A system design based on a single video CODEC utilizing a multi ‐domain switching system alleviates a majority of the security requirements involved with the sharing of AV resources (inputs, outputs, control). It also alleviates the high cost associated with purchasing multiple video CODECs, and if implemented correctly, provides an automated set of procedures to traverse those networks thus eliminating manual errors while maximizing data security.Design ApproachThe MDVNS design approach focuses on ensuring physical video network security, video CODEC information security, inter ‐unit isolation, hardware fail safes and redundant isolation. This approach provides electrical and data isolation between all video networks. Data isolation is achieved through the use of multiple processor and memory units, where each unit is dedicated to a particular network. Data from a particular video network is never stored in more than one place and data from different networks is never intermingled into one processor and memory unit.FeaturesSecureConforms to the DISA periods processing procedures and satisfies related IA security requirementsFailsafe ProcessEliminates residual settings or data from being transferred from one network to anotherRed/Black SeparationProvides true red/black air gap separation and isolated grounds between networks and all system componentsApproved IsolationUtilizes a CCEVS/NIAP validated and DISA approved fiber based switching unit to manage and isolate all video networksISDN CapableAutomated Unclassified ISDN management and isolation including support of third party Secure/Non ‐secure switchesSource ManagementAutomated control of source management isolation devicesScalabilityCan be configured to operate across numerous video networksStand ‐Alone or API ControlFront panel operation or API integration with AMX, Crestron, and Extron AV room control systemsDATASHEET Freeport Technologies Multi‐Domain Video Network SwitchProduct SpecificationsComponents and FunctionsFreeport SCC5NET Switch∙Enforces and initiates all switching tasks and the order in which they occur∙Validates that all tasks are executed as intended∙Manages room classification signage∙Provides the RS‐232 connection path between the video CODEC and all other system components∙Controls the removal and application of power to the video CODEC, Freeport SCC units, and media converters ∙Provides dry contact closures for managing source isolation devices∙Manages the fiber optic network switch∙Manages all ISDN related components∙Responsible for enabling/disabling a POTS, VOIP or unclassified ISDN line∙Front panel LCD provides access to system information, network selection, and maintenance∙Manages and isolates the connection of an external room control system to the video CODECFreeport Secure CODEC Configurator (SCC)∙Used to capture, clean and restore the configuration settings of the video CODEC for a specific video networkor domain∙Provides data isolation of video CODEC configuration settings between all video networks∙Capable of capturing and restoring all video CODEC configuration settings provided by the manufacturer ∙Capable of restoring video CODEC passwords∙Firmware management provides the ability to support various video CODEC makes/modelsFiber Optic A/B/C Switch∙NIAP validated and DISA approved switch manages and isolates all IP video network connections∙Only hardware component in the MDVNS system that physically connects to a customer’s network(s)Fiber Optic Media Converters∙Enables/Disables the network connection between the Fiber Optic Network Switch and the video CODEC∙Provides second layer of isolation between the customer’s IP video network connections and the Fiber Optic NetworkSwitchRoom Signage∙Provides the ability to display Joining, Leaving, and Network Classification messages for classification awareness∙Provides switching process feedback such as Preparing System, System Off, and ErrorPhysical Characteristics∙Freeport SCC5NET Switch – 1 RU∙Freeport SCC Unit – .25 RU each∙3 Network Fiber Optic Switch – 1 RU∙CODEC Fiber Optic Media Converter – .25 RU∙Network Fiber Optic Media Converter – .25 RU each Electrical∙Freeport SCC5NET Switch – 63W∙Freeport SCC Unit – Powered by SCC5Net Switch∙3 Network Fiber Optic Switch – 60W∙CODEC Fiber Optic Media Converter – 60W∙Network Fiber Optic Media Converter – 60W Environmental∙Heat Dissipation – 1033.88 BTU/hr Max (2 Network IP Only) ∙Operating Temperature – 32° to 104°F (0° to 40°C)∙Storage Temperature – 0° to 122°F (‐18° to 50°C)∙Humidity – 10% to 90% RH (non‐condensing)∙Made in the U.S.AWarranty and SupportService and support agreements provide technical telephone support, onsite troubleshooting, and software updates asneeded.。
The H.264 AVC Advanced Video Coding Standard-Overview and Introduction to the Fidelity Range Extensi

Presented at the SPIE Conference on Applications of Digital Image Processing XXVII Special Session on Advances in the New Emerging Standard: H.264/AVC, August, 2004The H.264/AVC Advanced Video Coding Standard: Overview and Introduction to the Fidelity Range ExtensionsGary J. Sullivan*, Pankaj Topiwala†, and Ajay Luthra‡*Microsoft Corporation, One Microsoft Way, Redmond, WA 98052 † FastVDO LLC, 7150 Riverwood Dr., Columbia, MD 21046 ‡ Motorola Inc., BCS, 6420 Sequence Dr., San Diego, CA 92121ABSTRACTH.264/MPEG-4 AVC is the latest international video coding standard. It was jointly developed by the Video Coding Experts Group (VCEG) of the ITU-T and the Moving Picture Experts Group (MPEG) of ISO/IEC. It uses state-of-the-art coding tools and provides enhanced coding efficiency for a wide range of applications, including video telephony, video conferencing, TV, storage (DVD and/or hard disk based, especially high-definition DVD), streaming video, digital video authoring, digital cinema, and many others. The work on a new set of extensions to this standard has recently been completed. These extensions, known as the Fidelity Range Extensions (FRExt), provide a number of enhanced capabilities relative to the base specification as approved in the Spring of 2003. In this paper, an overview of this standard is provided, including the highlights of the capabilities of the new FRExt features. Some comparisons with the existing MPEG-2 and MPEG-4 Part 2 standards are also provided. Keywords: Advanced Video Coding (AVC), Digital Video Compression, H.263, H.264, JVT, MPEG, MPEG-2, MPEG-4, MPEG-4 part 10, VCEG.1. INTRODUCTIONSince the early 1990s, when the technology was in its infancy, international video coding standards – chronologically, H.261 [1], MPEG-1 [2], MPEG-2 / H.262 [3], H.263 [4], and MPEG-4 (Part 2) [5] – have been the engines behind the commercial success of digital video compression. They have played pivotal roles in spreading the technology by providing the power of interoperability among products developed by different manufacturers, while at the same time allowing enough flexibility for ingenuity in optimizing and molding the technology to fit a given application and making the cost-performance trade-offs best suited to particular requirements. They have provided much-needed assurance to the content creators that their content will run everywhere and they do not have to create and manage multiple copies of the same content to match the products of different manufacturers. They have allowed the economy of scale to allow steep reduction in cost for the masses to be able to afford the technology. They have nurtured open interactions among experts from different companies to promote innovation and to keep pace with the implementation technology and the needs of the applications. ITU-T H.264 / MPEG-4 (Part 10) Advanced Video Coding (commonly referred as H.264/AVC) [6] is the newest entry in the series of international video coding standards. It is currently the most powerful and state-of-the-art standard, and was developed by a Joint Video Team (JVT) consisting of experts from ITU-T’s Video Coding Experts Group (VCEG) and ISO/IEC’s Moving Picture Experts Group (MPEG). As has been the case with past standards, its design provides the most current balance between the coding efficiency, implementation complexity, and cost – based on state of VLSI design technology (CPU's, DSP's, ASIC's, FPGA's, etc.). In the process, a standard was created that improved coding efficiency by a factor of at least about two (on average) over MPEG-2 – the most widely used video coding standard today – while keeping the cost within an acceptable range. In July, 2004, a new amendment was added to this standard, called the Fidelity Range Extensions (FRExt, Amendment 1), which demonstrates even further coding efficiency against MPEG-2, potentially by as much as 3:1 for some key applications. In this paper, we develop an outline of the first version of the H.264/AVC standard, and provide an introduction to the newly-minted extension, which, for reasons we explain, is already receiving wide attention in the industry.1.1. H.264/AVC History H.264/AVC was developed over a period of about four years. The roots of this standard lie in the ITU-T’s H.26L project initiated by the Video Coding Experts Group (VCEG), which issued a Call for Proposals (CfP) in early 1998 and created a first draft design for its new standard in August of 1999. In 2001, when ISO/IEC’s Moving Pictures Experts Group (MPEG) had finished development of its most recent video coding standard, known as MPEG-4 Part 2, it issued a similar CfP to invite new contributions to further improve the coding efficiency beyond what was achieved on that project. VCEG chose to provide its draft design in response to MPEG's CfP and proposed joining forces to complete the work. Several other proposals were also submitted and were tested by MPEG as well. As a result of those tests, MPEG made the following conclusions that affirmed the design choices made by VCEG for H.26L: ♦ The motion compensated Discrete Cosine Transform (DCT) structure was superior to others, implying there was no need, at least at that stage, to make fundamental structural changes for the next generation of coding standard. ♦ Some video coding tools that had been excluded in the past (for MPEG-2, H.263, or MPEG-4 Part 2) due to their complexity (hence implementation cost) could be re-examined for inclusion in the next standard. The VLSI technology had advanced significantly since the development of those standards and this had significantly reduced the implementation cost of those coding tools. (This was not a "blank check" for compression at all costs, as a number of compromises were still necessary for complexity reasons, but it was a recognition that some of the complexity constraints that governed past work could be re-examined.) ♦ To allow maximum freedom of improving the coding efficiency, the syntax of the new coding standard could not be backward compatible with prior standards. ♦ ITU-T’s H.26L was a top-performing proposal, and most others that showed good performance in MPEG had also been based on H.26L (as it had become well-known as an advance in technology by that time). Therefore, to allow speedy progress, ITU-T and ISO/IEC agreed to join forces together to jointly develop the next generation of video coding standard and use H.26L as the starting point. A Joint Video Team (JVT), consisting of experts from VCEG and MPEG, was formed in December, 2001, with the goal of completing the technical development of the standard by 2003. ITU-T planned to adopt the standard under the name of ITU-T H.264, and ISO/IEC planned to adopt the standard as MPEG-4 Part 10 Advanced Video Coding (AVC), in the MPEG-4 suite of standards formally designated as ISO/IEC 14496. As an unwanted byproduct, this standard gets referred to by at least six different names – H.264, H.26L, ISO/IEC 14496-10, JVT, MPEG-4 AVC and MPEG-4 Part 10. In this paper we refer it as H.264/AVC as a balance between the names used in the two organizations. With the wide breadth of applications considered by the two organizations, the application focus for the work was correspondingly broad – from video conferencing to entertainment (broadcasting over cable, satellite, terrestrial, cable modem, DSL etc.; storage on DVDs and hard disks; video on demand etc.) to streaming video, surveillance and military applications, and digital cinema. Three basic feature sets called profiles were established to address these application domains: the Baseline, Main, and Extended profiles. The Baseline profile was designed to minimize complexity and provide high robustness and flexibility for use over a broad range of network environments and conditions; the Main profile was designed with an emphasis on compression coding efficiency capability; and the Extended profile was designed to combine the robustness of the Baseline profile with a higher degree of coding efficiency and greater network robustness and to add enhanced modes useful for special "trick uses" for such applications as flexible video streaming. 1.2. The FRExt Amendment While having a broad range of applications, the initial H.264/AVC standard (as it was completed in May of 2003), was primarily focused on "entertainment-quality" video, based on 8-bits/sample, and 4:2:0 chroma sampling. Given its time constraints, it did not include support for use in the most demanding professional environments, and the design had not been focused on the highest video resolutions. For applications such as content-contribution, content-distribution, and studio editing and post-processing, it may be necessary to ♦ Use more than 8 bits per sample of source video accuracy ♦ Use higher resolution for color representation than what is typical in consumer applications (i.e., to use 4:2:2 or 4:4:4 sampling as opposed to 4:2:0 chroma sampling format)-2-♦ ♦ ♦ ♦ ♦ ♦Perform source editing functions such as alpha blending (a process for blending of multiple video scenes, best known for use in weather reporting where it is used to super-impose video of a newscaster over video of a map or weather-radar scene) Use very high bit rates Use very high resolution Achieve very high fidelity – even representing some parts of the video losslessly Avoid color-space transformation rounding error Use RGB color representationTo address the needs of these most-demanding applications, a continuation of the joint project was launched to add new extensions to the capabilities of the original standard. This effort took about one year to complete – starting with a first draft in May of 2003, the final design decisions were completed in July of 2004, and the editing period will be completed in August or September of 2004. These extensions, originally known as the "professional" extensions, were eventually renamed as the "fidelity range extensions" (FRExt) to better indicate the spirit of the extensions. In the process of designing the FRExt amendment, the JVT was able to go back and re-examine several prior technical proposals that had not been included in the initial standard due to scheduling constraints, uncertainty about benefits, or the original scope of intended applications. With the additional time afforded by the extension project, it was possible to include some of those features in the new extensions. Specifically, these included: ♦ Supporting an adaptive block-size for the residual spatial frequency transform, ♦ Supporting encoder-specified perceptual-based quantization scaling matrices, and ♦ Supporting efficient lossless representation of specific regions in video content. The FRExt project produced a suite of four new profiles collectively called the High profiles: ♦ The High profile (HP), supporting 8-bit video with 4:2:0 sampling, addressing high-end consumer use and other applications using high-resolution video without a need for extended chroma formats or extended sample accuracy ♦ The High 10 profile (Hi10P), supporting 4:2:0 video with up to 10 bits of representation accuracy per sample ♦ The High 4:2:2 profile (H422P), supporting up to 4:2:2 chroma sampling and up to 10 bits per sample, and ♦ The High 4:4:4 profile (H444P), supporting up to 4:4:4 chroma sampling, up to 12 bits per sample, and additionally supporting efficient lossless region coding and an integer residual color transform for coding RGB video while avoiding color-space transformation error All of these profiles support all features of the prior Main profile, and additionally support an adaptive transform blocksize and perceptual quantization scaling matrices. Initial industry feedback has been dramatic in its rapid embrace of FRExt. The High profile appears certain to be incorporated into several important near-term application specifications, particularly including ♦ The HD-DVD specification of the DVD Forum ♦ The BD-ROM Video specification of the Blu-ray Disc Association, and ♦ The DVB (digital video broadcast) standards for European broadcast television Several other environments may soon embrace it as well (e.g., the Advanced Television Systems Committee (ATSC) in the U.S., and various designs for satellite and cable television). Indeed, it appears that the High profile may rapidly overtake the Main profile in terms of dominant near-term industry implementation interest. This is because the High profile adds more coding efficiency to what was previously defined in the Main profile, without adding a significant amount of implementation complexity.-3-2. CODING TOOLSAt a basic overview level, the coding structure of this standard is similar to that of all prior major digital video standards (H.261, MPEG-1, MPEG-2 / H.262, H.263 or MPEG-4 part 2). The architecture and the core building blocks of the encoder are shown in Fig. 1 and Fig. 2, indicating that it is also based on motion-compensated DCT-like transform coding. Each picture is compressed by partitioning it as one or more slices; each slice consists of macroblocks, which are blocks of 16x16 luma samples with corresponding chroma samples. However, each macroblock is also divided into sub-macroblock partitions for motion-compensated prediction. The prediction partitions can have seven different sizes – 16x16, 16x8, 8x16, 8x8, 8x4, 4x8 and 4x4. In past standards, motion compensation used entire macroblocks or, in the case of newer designs, 16x16 or 8x8 partitions, so the larger variety of partition shapes provides enhanced prediction accuracy. The spatial transform for the residual data is then either 8x8 (a size supported only in FRExt) or 4x4. In past major standards, the transform block size has always been 8x8, so the 4x4 block size provides an enhanced specificity in locating residual difference signals. The block size used for the spatial transform is always either the same or smaller than the block size used for prediction. The hierarchy of a video sequence, from sequence to samples1 is given by: sequence (pictures (slices (macroblocks (macroblock partitions (sub-macroblock partitions (blocks (samples)))))). In addition, there may be additional structures such as packetization schemes, channel codes, etc., which relate to the delivery of the video data, not to mention other data streams such as audio. As the video compression tools primarily work at or below the slice layer, bits associated with the slice layer and below are identified as Video Coding Layer (VCL) and bits associated with higher layers are identified as Network Abstraction Layer (NAL) data. VCL data and the highest levels of NAL data can be sent together as part of one single bitstream or can be sent separately. The NAL is designed to fit a variety of delivery frameworks (e.g., broadcast, wireless, storage media). Herein, we only discuss the VCL, which is the heart of the compression capability. While an encoder block diagram is shown in Fig. 1, the decoder conceptually works in reverse, comprising primarily an entropy decoder and the processing elements of the region shaded in Fig. 1.Input Video+Transform/ Scaling/ Quant.Scaling/ Inv .Quant./ Inv. TransformEntropy Coder+Intra (Spatial) Prediction DeblockingC o m p r e s s e d V i d e o b i t sMotion Comp. Decoded Video Motion Vector Info Motion EstimationFig. 1: High-level encoder architecture1We use the terms sample and pixel interchangeably, although sample may sometimes be more rigorously correct.-4-Prediction Spatial/Temporal2-D TransformQuantizationScanningVLC / Arithmetic Entropy CodeFig. 2: Higher-level encoder block diagramIn the first version of the standard, only the 4:2:0 chroma format (typically derived by performing an RGB-to-YCbCr color-space transformation and subsampling the chroma components by a factor of 2:1 both horizontally and vertically) and only 8 bit sample precision for luma and chroma values was supported. The FRExt amendment extended the standard to 4:2:2 and 4:4:4 chroma formats and higher than 8 bits precision, with optional support of auxiliary pictures for such purposes as alpha blending composition. The basic unit of the encoding or decoding process is the macroblock. In 4:2:0 chroma format, each macroblock consists of a 16x16 region of luma samples and two corresponding 8x8 chroma sample arrays. In a macroblock of 4:2:2 chroma format video, the chroma sample arrays are 8x16 in size; and in a macroblock of 4:4:4 chroma format video, they are 16x16 in size. Slices in a picture are compressed by using the following coding tools: ♦ "Intra" spatial (block based) prediction o Full-macroblock luma or chroma prediction – 4 modes (directions) for prediction o 8x8 (FRExt-only) or 4x4 luma prediction – 9 modes (directions) for prediction ♦ "Inter" temporal prediction – block based motion estimation and compensation o Multiple reference pictures o Reference B pictures o Arbitrary referencing order o Variable block sizes for motion compensation Seven block sizes: 16x16, 16x8, 8x16, 8x8, 8x4, 4x8 and 4x4 o 1/4-sample luma interpolation (1/4 or 1/8th-sample chroma interpolation) o Weighted prediction o Frame or Field based motion estimation for interlaced scanned video ♦ Interlaced coding features o Frame-field adaptation Picture Adaptive Frame Field (PicAFF) MacroBlock Adaptive Frame Field (MBAFF) o Field scan ♦ Lossless representation capability o Intra PCM raw sample-value macroblocks o Entropy-coded transform-bypass lossless macroblocks (FRExt-only) ♦ 8x8 (FRExt-only) or 4x4 integer inverse transform (conceptually similar to the well-known DCT) ♦ Residual color transform for efficient RGB coding without conversion loss or bit expansion (FRExt-only) ♦ Scalar quantization ♦ Encoder-specified perceptually weighted quantization scaling matrices (FRExt-only)-5-♦ ♦ ♦ ♦♦♦ ♦ ♦ ♦Logarithmic control of quantization step size as a function of quantization control parameter Deblocking filter (within the motion compensation loop) Coefficient scanning o Zig-Zag (Frame) o Field Lossless Entropy coding o Universal Variable Length Coding (UVLC) using Exp-Golomb codes o Context Adaptive VLC (CAVLC) o Context-based Adaptive Binary Arithmetic Coding (CABAC) Error Resilience Tools o Flexible Macroblock Ordering (FMO) o Arbitrary Slice Order (ASO) o Redundant Slices SP and SI synchronization pictures for streaming and other uses Various color spaces supported (YCbCr of various types, YCgCo, RGB, etc. – especially in FRExt) 4:2:0, 4:2:2 (FRExt-only), and 4:4:4 (FRExt-only) color formats Auxiliary pictures for alpha blending (FRExt-only)Of course, each slice need not use all of the above coding tools. Depending upon on the subset of coding tools used, a slice can be of I (Intra), P (Predicted), B (Bi-predicted), SP (Switching P) or SI (Switching I) type. A picture may contain different slice types, and pictures come in two basic types – reference and non-reference pictures. Reference pictures can be used as references for interframe prediction during the decoding of later pictures (in bitstream order) and non-reference pictures cannot. (It is noteworthy that, unlike in prior standards, pictures that use bi-prediction can be used as references just like pictures coded using I or P slices.) In the next section we describe the coding tools used for these different slice types. This standard is designed to perform well for both progressive-scan and interlaced-scan video. In interlaced-scan video, a frame consists of two fields – each captured at ½ the frame duration apart in time. Because the fields are captured with significant time gap, the spatial correlation among adjacent lines of a frame is reduced in the parts of picture containing moving objects. Therefore, from coding efficiency point of view, a decision needs to be made whether to compress video as one single frame or as two separate fields. H.264/AVC allows that decision to be made either independently for each pair of vertically-adjacent macroblocks or independently for each entire frame. When the decisions are made at the macroblock-pair level, this is called MacroBlock Adaptive Frame-Field (MBAFF) coding and when the decisions are made at the frame level then this is called Picture-Adaptive Frame-Field (PicAFF) coding. Notice that in MBAFF, unlike in the MPEG-2 standard, the frame or field decision is made for the vertical macroblock-pair and not for each individual macroblock. This allows retaining a 16x16 size for each macroblock and the same size for all submacroblock partitions – regardless of whether the macroblock is processed in frame or field mode and regardless of whether the mode switching is at the picture level or the macroblock-pair level. 2.1. I-slice In I-slices (and in intra macroblocks of non-I slices) pixel values are first spatially predicted from their neighboring pixel values. After spatial prediction, the residual information is transformed using a 4x4 transform or an 8x8 transform (FRExt-only) and then quantized. In FRExt, the quantization process supports encoder-specified perceptual-based quantization scaling matrices to optimize the quantization process according to the visibility of the specific frequency associated with each transform coefficient. Quantized coefficients of the transform are scanned in one of the two different ways (zig-zag or field scan) and are compressed by entropy coding using one of two methods – CAVLC or CABAC. In PicAFF operation, each field is compressed in a manner analogous to the processing of an entire frame. In MBAFF operation, if a macroblock pair is in field mode then the field neighbors are used for spatial prediction and if a macroblock pair is in frame mode, frame neighbors are used for prediction. The frame or field decision is made before applying the rest of the coding tools described below. Temporal prediction is not used in intra macroblocks, but it is for P and B macroblock types, which is the main difference between these fundamental macroblock types. We therefore review the structure of the codec for the I-slice first, and then review the key differences for P and B-slices later.-6-2.1.1. Intra Spatial Prediction To exploit spatial correlation among pixels, three basic types of intra spatial prediction are defined: ♦ Full-macroblock prediction for 16x16 luma or the corresponding chroma block size, or ♦ 8x8 luma prediction (FRExt-only), or ♦ 4x4 luma prediction. For full-macroblock prediction, the pixel values of an entire macroblock of luma or chroma data are predicted from the edge pixels of neighboring previously-decoded macroblocks (similar to what is shown in Fig. 3, but for a larger region than the 4x4 region shown in the figure). Full-macroblock prediction can be performed in one of four different ways that can be selected by the encoder for the prediction of each particular macroblock: (i) vertical, (ii) horizontal, (iii) DC and (iv) planar. For the vertical and horizontal prediction types, the pixel values of a macroblock are predicted from the pixels just above or to the left of the macroblock, respectively (like directions 0 and 1 in Fig. 3). In DC prediction (prediction type number 2, not shown in Fig. 3), the luma values of the neighboring pixels are averaged and that average value is used as predictor. In planar prediction (not shown in Fig. 3), a three-parameter curve-fitting equation is used to form a prediction block having a brightness, slope in the horizontal direction, and slope in the vertical direction that approximately matches the neighboring pixels. Full-macroblock intra prediction is used for luma in a macroblock type called the intra 16x16 macroblock type. Chroma intra prediction always operates using full-macroblock prediction. Because of differences in the size of the chroma arrays for the macroblock in different chroma formats (i.e., 8x8 chroma in 4:2:0 macroblocks, 8x16 chroma in 4:2:2 macroblocks, and 16x16 chroma in 4:4:4 macroblocks), chroma prediction is defined for three possible block sizes. The prediction type for the chroma is selected independently of the prediction type for the luma. 4x4 intra prediction for luma can be alternatively selected (on a macroblock-by-macroblock basis) by the encoder. In 4x4 spatial prediction mode, the values of each 4x4 block of luma samples are predicted from the neighboring pixels above or left of a 4x4 block, and nine different directional ways of performing the prediction can be selected by the encoder (on a 4x4 block basis) as illustrated in Fig. 3 (and including a DC prediction type numbered as mode 2, which is not shown in the figure). Each prediction direction corresponds to a particular set of spatially-dependent linear combinations of previously decoded samples for use as the prediction of each input sample. In FRExt profiles, 8x8 luma intra prediction can also be selected. 8x8 intra prediction uses basically the same concepts as 4x4 prediction, but with a prediction block size that is 8x8 rather than 4x4 and with low-pass filtering of the predictor to improve prediction performance.M A B C D E F G H8 1 6 3 7 0 5 4I J K La e i mb f j nc g k od h l pFig. 3: Spatial prediction of a 4x4 block.-7-2.1.2. Transform and Quantization After spatial prediction, a transform is applied to decorrelate the data spatially. There are several unique features about the transform selected for this coding standard. Some of these features are listed below. ♦ It is the first video standard fundamentally based on an integer inverse transform design for its main spatial transforms, rather than using idealized trigonometric functions to define the inverse transform equations and allowing implementation-specific approximations within some specified tolerances.2 The forward transform that will typically be used for encoding is also an integer transform. A significant advantage of the use of an integer is that, with an exact integer inverse transform, there is now no possibility of a mismatch between then encoder and decoder, unlike for MPEG-2 and ordinary MPEG-4 part 2. ♦ In fact, the transform is specified so that for 8-bit input video data, it can be easily implemented using only 16-bit arithmetic, rather than the 32-bit or greater precision needed for the transform specified in prior standards. ♦ The transform (at least for the 4x4 block size supported without FRExt) is designed to be so simple that it can be implemented using just a few additions, subtractions, and bit shifts. ♦ A 4x4 transform size is supported, rather than just 8x8. Inconsistencies between neighboring blocks will thus occur at a smaller granularity, and thus tend to be less noticeable. Isolated features can be represented with greater accuracy in spatial location (reducing a phenomenon known as "ringing"). For certain hardware implementations, the small block size may also be particularly convenient. Thus, while the macroblock size remains at 16x16, these are divided up into 4x4 or 8x8 blocks, and a 4x4 or 8x8 block transformation matrix T4x4 or T8x8 is applied to every block of pixels, as given by:T4 x 41 ⎡ 1 ⎢ 2 1 =⎢ ⎢ 1 −1 ⎢ ⎣ 1 −21⎤ − 1 − 2⎥ ⎥, T 8 x8 1⎥ −1 ⎥ 2 − 1⎦ 18 8 8 ⎡ 8 ⎢ 12 10 6 3 ⎢ ⎢ 8 4 − 4 −8 ⎢ 10 − 3 − 12 − 6 =⎢ ⎢ 8 −8 −8 8 ⎢ 3 10 ⎢ 6 − 12 ⎢ 4 −8 8 −4 ⎢ ⎢ 3 −6 10 − 12 ⎣8 −3 −8 6 8 10 −48 −4 12 −8 −3 88 4 3 −8 12 −8 6− 6 − 1012 − 108⎤ − 12⎥ ⎥ 8⎥ ⎥ − 10⎥ 8⎥ ⎥ − 6⎥ 4⎥ ⎥ − 3⎥ ⎦The 4x4 transform is remarkably simple, and while the 8x8 transform (used in FRExt profiles only) is somewhat more complex, it is still remarkably simple when compared to an ordinary 8x8 IDCT. The transform T is applied to each block within the luma (16x16) and chroma (8x8, or in FRExt, 8x16 or 16x16) samples for a macroblock by segmenting the full sample block size into smaller blocks for transformation as necessary. In addition, when the 16x16 Intra prediction mode is used with the 4x4 transform, the DC coefficients of the sixteen 4x4 luma blocks in the macroblock are further selected and transformed by a secondary Hadamard transform using the H4x4 matrix shown below (note the basic similarity of T4x4 and H4x4). The DC coefficients of the 4x4 blocks of chroma samples in all macroblock types are transformed using a secondary Hadamard transform as well. For 4:2:0 video, this requires a 2x2 chroma DC transformation specified by the Hadamard matrix H2x2 (below); for 4:4:4, the chroma DC uses the same 4x4 Hadamard transformation as used for luma in 16x16 intra mode; and for 4:2:2 video, the chroma DC transformation uses the matrices H2x2 and H4x4 to perform a 2x4 chroma DC secondary transformation.2MPEG-4 part 2 and JPEG2000 had previously included integer wavelet transforms. But JPEG2000 is an image coding standard without support for interframe prediction, and in MPEG-4, the integer transforms are used only rarely for what is called texture coding (somewhat equivalent to the usual I-frame coding, but not found in most implementations of MPEG-4), and the main transform used for nearly all video data was still specified as an ideal 8x8 IDCT with rounding tolerances. The integer transform concept had also been previously applied in H.263 Annex W, but only as an after-thefact patch to a prior specification in terms of the 8x8 floating point IDCT.-8-。
index of avi

index of aviIntroductionWhen working with audiovisual data, especially videos, it is important to keep track of the various video files in a systematic manner. One commonly used method to organize and manage video files is by creating an index. This document will discuss the concept of an index of avi files and how it can be beneficial for managing audiovisual data effectively.What is an index of avi?An index of avi is a structured list or database that contains information about avi files. An avi file, short for Audio Video Interleave, is a multimedia container format that is widely used for storing video and audio data. The index of avi provides a centralized location to store metadata about the video files, making it easier to search, locate, and manage the files.Benefits of creating an index of aviThere are several benefits to creating an index of avi files. Some of the key advantages include:1.Easy Accessibility: By having an index of avi files,users can quickly search for specific videos based onvarious criteria such as file name, duration, resolution, or any custom tags. This saves time and effort in manuallybrowsing through folders to find a specific video file.anized Storage: With an index, videos can be categorized and organized based on different attributes such as genre, date, location, or any other relevant information. This ensures that videos are stored in a systematic manner, making it easier to browse and retrieve the required files.3.Metadata Management: An index of avi files allows for the management of metadata associated with each video. Metadata can include details such as title, description, keywords, creator, date of creation, etc. Having this information readily available in the index facilitates effective searching and provides context for videos.4.Version Control: In scenarios where multiple versions of the same video exist, an index can help keep track of different versions and their respective metadata. This is particularly useful in situations where revisions or edits of videos are required, ensuring that the correct version is used.5.Collaboration: If multiple users are working with the same set of video files, an index can serve as a central point of reference for everyone. Users can add comments, annotations, or feedback directly in the index, facilitating collaboration and coordination in a shared video project.6.Backup and Recovery: By maintaining an index along with the video files, it becomes easier to create backups and restore the data in case of any accidental loss. The index acts as a reference for the entire collection, making recovery more streamlined and efficient.Implementing an index of aviThe implementation of an index of avi files can be done using various methods, depending on the requirements and available resources. Here are a few approaches to consider:1. Spreadsheet-based IndexOne simple approach is to create an index using a spreadsheet tool such as Microsoft Excel or Google Sheets. Each row in the spreadsheet represents a video file, and each column represents a metadata attribute (e.g., file name, duration, resolution, etc.).2. Metadata Extraction ToolsThere are specialized software tools available that can extract metadata from avi files and generate a structured index automatically. These tools can scan through a folder or a directory containing the video files, extract metadata attributes, and create an index with minimal user intervention.3. Custom Database or LibraryFor more advanced requirements, developing a custom database or library can provide more flexibility and control over the index structure and functionality. This approach requires programming skills and knowledge of database systems.4. Existing Digital Asset Management (DAM) SystemsIf already using a Digital Asset Management (DAM) system for managing audiovisual assets, it may be possible to leverage its capabilities to create and maintain an index of avi files. DAM systems often have built-in features for creating metadata and indexing assets.ConclusionAn index of avi files can greatly assist in managing and organizing audiovisual data effectively. It provides users with easy accessibility, helps in organizing videos, manages metadata, facilitates collaboration, ensures version control, and aids in backup and recovery. Implementing an index can be done through spreadsheet-based methods, metadata extraction tools, custom databases/libraries, or existing DAM systems. Regardless of the method chosen, creating an index of avi files is a valuable practice to enhance the management of audiovisual data.。
html5 video 标签的用法

HTML5 的`<video>` 标签用于在网页上嵌入视频内容。
它有一些常用的属性,可以用来控制视频的播放行为。
下面是 `<video>` 标签的基本语法:```html<video [属性列表]></video>```常用的属性包括:1. `src`:指定视频文件的路径。
可以是一个相对路径或绝对路径,也可以是一个网络链接。
例如:`<video src="movie.mp4"></video>`2. `width` 和 `height`:指定视频播放器的宽度和高度。
例如:`<video width="320" height="240"></video>`3. `controls`:显示视频播放器的控制面板,包括播放、暂停、音量调节等按钮。
例如:`<video controls></video>`4. `autoplay`:自动播放视频,不需要用户点击播放按钮。
例如:`<video autoplay></video>`5. `loop`:循环播放视频。
例如:`<video loop></video>`6. `muted`:默认静音视频。
例如:`<videomuted></video>`7. `poster`:指定视频的封面图像,在视频加载完成之前显示。
例如:`<video poster="poster.jpg"></video>`除了上述属性,还有其他一些属性可以用于更高级的控制,例如:* `preload`:指定视频是预先加载还是按需加载。
可选值包括"none"(不预加载)、"metadata"(只加载视频的元数据)、"auto"(自动加载整个视频)。
怎样做视频的英语作文

怎样做视频的英语作文Creating a video is an exciting endeavor that requires careful planning and execution. In this essay, I willoutline the steps involved in making a video in English.1. Pre-production: Planning is Key。
Before diving into filming, it's essential to plan out your video thoroughly. This includes brainstorming ideas, defining your target audience, and drafting a script. Research your topic extensively to ensure accuracy and credibility in your content.2. Scriptwriting。
A well-written script forms the backbone of your video. It should be engaging, concise, and clearly convey your message. Consider the tone and style appropriate for your audience and purpose. Remember to include an introduction, body, and conclusion in your script tomaintain coherence.3. Storyboarding。
Storyboarding involves creating a visual representation of each scene in your video. Sketch out each shot, including camera angles, transitions, and any visual effects or graphics you plan to incorporate. This serves as a roadmap during filming and ensures continuity in your video.4. Gathering Equipment。
Multiple video playback devices and multiple video

专利名称:Multiple video playback devices and multiple video playback method发明人:中島 健治,大松 彰申请号:JP特願平10-141588申请日:19980522公开号:JP特許第3369469号(P3369469)B2公开日:20030120专利内容由知识产权出版社提供摘要:PROBLEM TO BE SOLVED: To reproduce a required video signal from a recording tape that stores video signals with different formats of identification ID signals by receiving sequentially the identification signals recorded on a video tape in the unit of frames, comparing past and newest identification signals and deciding number of video images equivalent to number of photographing devices based on an elapsed frame number between the past and the newest identification signals that are matching with each other. SOLUTION: When a video signal on a video tape recorded by each supervisory camera system is given to a video input terminal 20, a CPU 11 references a format of each ID signal stored in advance in a RAM 13 and stores ID data of the video signal to the RAM 13 through an ID control circuit 30, a parallel/ serial conversion circuit 15 and an FIFO memory 16. Then the CPU 11 compares the ID codes having been stored so far in the RAM 13 with the ID code stored this time and increments the content of a camera number register in the RAM 13 when they do not match. Thus, a numeral in the camera number register indicates number of photographing cameras when they match.申请人:日本ビクター株式会社地址:神奈川県横浜市神奈川区守屋町3丁目12番地国籍:JP代理人:三好 秀和 (外9名)更多信息请下载全文后查看。
电视新概念及交互电视

第二是指在闭路电视上加上电脑交互功能,所 以又叫交互式多媒体电视。特别用于电化教学。
传统的闭路系统只能被动地收看电视节目,交 互式多媒体教学系统却具有系统交互式功能。 中心控制室能控制教室内的节目播放,老师在 教室内也能够任意点播中心控制室的教学节目。 还可以快进、快退,反复播放,这样老师在教 学的时候就能够更加主动地组织自己的授课内 容,提高课堂教学效果。
MultiMedia TV 多媒体电视
交互式多媒体电视系统是建立在校园智能广播 网的基础之上的。
该系统可以让公共课和基础课老师讲课时不受 学生人数的限制。还可以把大量的视频或语音 教学光盘存放在大容量硬盘里反复使用。还可 以实现定时播放上、下课铃声、播放午间操音 乐和休闲音乐。校长还可以发表广播讲话,广 播通知。
点播窗口
三维动画
三维动画 视频选择
电子商务
多播窗口
环绕声 广告窗口
多播窗口 矢量字幕
MPEG-4 video bit rates
Low : <64 kbps For wireless and PSTN applications Intermediate : 64kbps –384 kbps High : 384 kbps –4 Mbps
如果与多媒体教室结合起来,支持师生之间 的互动,就可以达到面授的效果。
Web TV 网络电视 / 在线电视
网络电视是基于流媒体技术和宽带网络 技术的在计算机网络上观看视音频的技 术。
Digital TV 数字电视
数字电视是采用数字信号广播图像和声音的电 视系统,它在电视信号的获取、产生、处理、 传输、接收和存储的各个环节中都采用数字信 号或对数字信号进行处理。我们现在推广的 “数字电视”主要是指在传输阶段使用数字技术。 它是一个可以承载综合业务,以视频业务为主, 可以采用多种传输媒介,结合单向广播与各种 回传通道技术的数字平台。
通信专业部分术语英文简写

multiple description coding前向纠错码(FEC)或自动要求重发机制(ARQ。
FEC要求带宽比较多.而且FEC的设计和网络的状态密切相关.而网络的状态恰恰是最难估量的。
采用ARQ带来的问题是丢失包重新收到的时延比较长运动补偿内插(MC.1单描述符(SD,single description)压缩原理,现有传输层解决丢包问题的主要方法包括:自动重传请求(auto retransmission request,ARQ)、采用纠错码进行前向纠错 J(forward error corection,FEC)以及混合ARQ与离散余弦变换(discrete cosine transform,DCT3.3 数据分组数据分组的方法是利用码流中不同部分重要性不同的特点来将码流中不同重要性的部分分开分别打包,并运用不等错误保护(unequal error protection,UEP)的编码方法来对不同重要性的包给予不同程度的差错保护,例如,一般来说,图像编码的码流中的运动矢量对重建图像质量的贡献要大于离散余弦变换(discrete cosine transform,DCT)系数的贡献,因而可以将运动矢量与DCT系数区分开来分别打包,并给予不同程度的差错保护。
用不等错误保护(unequal errorprotection,UEP)的编码方法来对不同重要性的包给予不同程度的差错保护精细可伸缩编码(fine granular scalability,FGS3.4 可伸缩编码可伸缩编码是将编码的码流分为基本层和若干增强层分别进行编码,其中基本层满足最基本的要求,而且越多的增强层将使解码端重建信号的质量越好。
一种较好的可伸缩编码方法是精细可伸缩编码(fine granular scalability,FGS)。
FGS的基本层编码与普通的视频编码是一样的,而增强层则采用了比特平面的编码方法。
FGS编码虽取得了较好的可伸缩性,但是由于FGS编码的运动估计补偿是基于基本层进行的,因而运动补偿之后的残差较大,这就降低了编码效率。
基于模式复制的H.264多描述视频编码

基于模式复制的H.264多描述视频编码董萌;蔡灿辉【期刊名称】《信号处理》【年(卷),期】2011(027)011【摘要】本文提出了一种新的基于H.264的多描述视频编码算法——基于模式复制的多描述编码算法.首先对输入视频序列中的每一帧图像分别进行水平方向下采样和垂直方向下采样,形成四个子图像.相应的子图像构成四个视频子序列.把这四个子序列两两组合,形成两个描述,每个描述包含两个子序列.由于每个描述中两个子序列之间具有很强的空间相关性和时间相关性,其对应宏块的最佳模式和运动矢量基本相同,因此只需用H.264编码器对其中一个子序列进行编码,另一子序列则可直接采用上述已编码子序列的最佳模式和运动向量对其进行预测编码.这样只需要对其中一个子序列进行模式选择,也只需要对一个子序列的最佳模式和运动向量进行编码传输,既降低了计算复杂度,又提高了编码效率.实验结果表明,在中高码率下,本文算法与同类算法在相同比特率情况下,PSNR有明显的提高,并且比特率越高,这种优势就越明显.%This paper presents a novel multiple description video coding algorithm for H. 264, called mode duplication based multiple description coding. Each frame in the input video sequence is down-sampled first horizontally and then vertically to form four sub-frames. The resulted four sub-sequences are pair-wisely grouped to form two descriptions. Considering that two sub-sequences in a description have strong spatial correlation and temporal correlation, so the best modes and motion vectors in corresponding macro-blocks are basically the same. In thispaper, only one sub-sequence per description is coded by a H. 264 coder, and the other sub-sequence is coded by using the best modes and motion vectors of the aforementioned encoded subsequence. Consequently, only one sub-sequence per description needs to perform mode decision, reducing the computational complexity and bit rates. The experimental results have shown that at moderate and high rates, the proposed algorithm achieves a higher coding quality compared with other H. 264 based MDC algorithms.【总页数】5页(P1675-1679)【作者】董萌;蔡灿辉【作者单位】华侨大学信息科学与工程学院,厦门,361021;华侨大学信息科学与工程学院,厦门,361021【正文语种】中文【中图分类】TP309.7【相关文献】1.一种兼容H.264标准的多描述视频编码方法 [J], 卓力;王仕宝2.基于H.264视频编码的快速模式决策算法 [J], 吴桂清;陈彦芳;厉振武3.H.264视频编码帧间与帧内预测模式算法的改进 [J], 魏晨;王民4.基于H.264和双树小波的多描述视频编码 [J], 陈婧;李莉;蔡灿辉5.基于CDN和H.264的多描述视频编码方法 [J], 杨任尔;肖方明;郁梅因版权原因,仅展示原文概要,查看原文内容请购买。
21.5英寸全高清直播多视图监控器说明书

重要安全说明该设备已经通过安全性法规的要求和相关的测试,并已通过国际认证。
就如所有电子设备一样,应当谨慎小心地使用该设备。
请阅读并遵守安全说明,以保护自己免受潜在的伤害并最大程度地降低损坏设备的风险。
请勿将显示器的屏幕朝向地面放置,以免刮伤LCD表面。
请避免设备遭受重击。
请勿使用化学溶液清洁本产品。
只需用软布擦拭即可清洁表面。
请勿将显示器放置在不平坦的表面上。
请勿将显示器与尖锐的金属物品一起存放。
请按照说明和故障排除的内容调整调整显示器设置。
调整或维修机器内部必须由合格的技术人员进行。
请保留用户指南,以备参考。
如果长期不使用或雷雨天气时,请拔下电源并取出电池。
旧电子设备的安全处置请不要将旧的电子设备视为普通生活垃圾,也不要焚化旧的电子设备。
同时,请始终遵循当地的相关法规,并将其移交给恰当的收集站以安全回收。
确保可以有效地处理和回收旧物,以防止我们的环境和家庭受到负面影响。
IntroductionThe 21.5 inch Full HD live streaming multiview monitor can be switched live up to 4 1080P high quality video signal inputs, which make it easy to create professional multi camera events for live streaming. At a time when live stream in mobile phone is popular, monitor innovatively built in phone mode so as to directly display a vertical video in multi camera. All-in-one capability greatly reduces the cost of productions.Features21.5 inch 1920x1080 physical resolution500cd/m² brightness, 1500:1 contrastSupports multiple video signal input:3G-SDI*2、HDMI*2、USB TYPE-CSupports PGM (SDI/HDMI) outputSupports HDMI and SDI signal cross conversion (Output 1080p60/50/30/25/24 through PGM)Automatic backlight adjustmentSupports vertical display: Camera Mode and Phone ModeSupports multiview display: Full screen/Vertical/Dual-1/Dual-2/Triple/QuadSupports level meter for multiviewSupports UMD editingPVW and PGM video signals can be switched at a shortcutColor temperature (6500K, 7500K, 9300K, User)Camera assist functions, for example, peaking, false color, exposure, histogram, etc.Supports VESA 100mm and 75mm optional bracket with swivel and load-bearing actionApplications: Mobile phone live, multi camera live, broadcast, TV, film and video switchingContents1. Product Description (3)1.1 Front Panel and Buttons (3)1.2 Rear Enclosure and Interfaces (4)1.3 Supported Installations (5)2. Menu Settings (6)2.1 User-definable Function Buttons (6)2.2 MENU and ▷/ ◁Buttons (6)2.3 Menu Operation (7)2.3.1 Information (7)2.3.2 Multiview (8)2.3.3 UMD (10)2.3.4 Picture (11)2.3.5 Marker (12)2.3.6 Function (13)2.3.7 Audio (17)2.3.8 System (18)3. Specifications (19)4. Accessories (20)5. Trouble Shooting (21)1. Product Description1.1 Front Panel and Buttons1) A window for brightness sensing2) INPUT : Signal switching sequence: SDI 1, SDI 2, HDMI 1, HDMI 2, USB Type-C.Note! INPUT is available only in Full Screen or Vertical mode3) MENU : Bring up the menu or confirm the options4) ◁ : Select option in the menu. Decrease the option value5) ▷ : Select option in the menu. Increase the option value6) EXIT : To return or exit the menu function7, 8) User-definable function button, default as● F1: [Multiview Mode]● F2: [PGM Cut]9) Power: Power on/off (green light for on, red light for off)1.2 Rear Enclosure and Interfaces1) 3G-SDI output interface (PGM output)2) 3G-SDI 2 loop output interface3) 3G-SDI 2 input interface4) 3G-SDI 1 loop output interface5) 3G-SDI 1 input interface6) HDMI output interface (PGM output)7) HDMI 2 input interface8) HDMI 1 input interface9) 3.5mm Ear Jack10) USB TYPE-C input interface11) Upgrade port12) Power input: DC 12-24V1.3 Supported Installations●VESA mount bracketMounting through standard VESA 75mm/100mm holes on the back of monitor:(The bracket is an optional part and supports multi-angle rotation and height adjustment)●Base stand bracketMounting through the screw holes left in the bottom of monitor:2. Menu Settings2.1 User-definable Function ButtonsPress either F1, F2 for 3-5 seconds to bring up the function setting. Press [▷] or [◁] to select the desired option; Press [MENU] to confirm the option and set it as a shortcut function.Press [EXIT] to close the function setting.User settable function buttons to suit individual needs: Center Marker, Aspect Marker, Safety Marker, overscan, Aspect Ratio, Check Field, Freeze, Peaking, False Color, Exposure, Histogram, Multiview Mode, Vertical Display, PGM Cut, UMD, Audio Source, Mute, Level Meter.Note! F1 default: [Multiview Mode], F2 default: [PGM Cut], [PGM Cut] is only available in shortcut function2.2 MENU and ▷/ ◁ButtonsTurn on the power, press [MENU] to display the OSD; Press [▷] or [◁] to select between Information, Multiview, UMD, Picture, Marker, Function, Audio and System; Press [MENU] again after selection to enterthe sub-menu.●The [▷] or [◁] buttons allow to switch or adjust the options and values in the menu, press [MENU] toconfirm or [EXIT] to exit.●When the OSD is not displayed, press the [▷] or [◁] button to adjust the volume. Press [MENU] again toswitch between Volume, Brightness, Contrast, Saturation, Tint, Sharpness and Exit in that order. Select the desired option and adjust the value of the option switched to by using [▷] or [◁].2.3 Menu Operation2.3.1 Information(Showing the resolution and fresh rate of each video signal)●3G-SDI supported signal formats: 1080p60/59.94/50/30/29.97/25/24/23.98; 1080i60/59.94/50; 720p60/59.94/50; Backwards compatible with other formats.●HDMI supported signal formats: 1080p60/59.94/50/30/29.97/25/24/23.98; 1080i60/59.94/50; 720p60/59.94/50; Backwards compatible with other formats.●USB Type-C supported signal formats: 1080p60/59.94/50/30/29.97/25/24/23.98; 1080i60/59.94/50;720p 60/59.94/50; Backwards compatible with other formats.2.3.2 MultiviewTo set the multiview mode, preset values for the input signal and switch between different signals.●PGM source: default value is SDI1/SDI2/HDMI1/HDMI2/TYPE-C, select the source for PGM output.●PVW source: default value is SDI1/SDI2/HDMI1/HDMI2/TYPE-C, select PVW preview signal source,through the [PGM Cut] function can realize the PGM source and PVW source signal switch each other. Note! The PGM source is marked with a red frame and PVW source is marked with a green frame●PGM Frame: default is 60p/50p/30p/25p/24p, select the source frame rate for PGM output●Multiview Mode:Full Screen (Horizontal screen) Vertical (Vertical screen)Dual-1 Dual-2Triple Quad●Vertical Display: default is Camera/Phone. In phone mode, the vertical phone signal from USB Type-Coutput can be displayed in full screen.●MV1 source selectable from SDI1/SDI2/HDMI1/HDMI2/TYPE-C, default is SDI1.●MV2 source selectable from SDI1/SDI2/HDMI1/HDMI2/TYPE-C, default is SDI2.●MV3 source selectable from SDI1/SDI2/HDMI1/HDMI2/TYPE-C, default is HDMI1.●MV4 source selectable from SDI1/SDI2/HDMI1/HDMI2/TYPE-C, default is HDMI2.(Multiview signal source sequencing)2.3.3 UMDSelect to turn UMD on or off. When turn on, each source will display the selected UMD information, the UMD font color can be changed from white/red/green/blue/yellow/cyan/magenta, default is green.(Current demo UMD color is yellow, characters are typed as CAM1~4)Character Editing Method.:Select [SDI1], press [MENU] to switch the character object; Press [▷] or [◁] to change the current character; Long press [MENU] to add a new character after the current character object, maximum support 16 characters; Long press [EXIT] to delete the current character.2.3.4 Picture●Brightness selectable from 0 to 100●Contrast selectable from 0 to 100●Saturation selectable from 0 to 100●Tint selectable from 0 to 100●Sharpness selectable from 0 to 100●Color TemperatureAdjustable color temperature level: 6500K, 7500K, 9300K, User.Note! User can only adjust the gain or offset values for red, green and blue in "User" mode- Red, Green and Blue GainAdjustment range 0-255, default value is 128.- Red, Green and Blue OffsetAdjustment range 0-511, default value is 255.2.3.5 Marker●Center MarkerSelect On, it will appear "+" marker on center of screen.●Aspect MarkerThe Aspect Marker provides various aspect ratios.Selectable from: 16:9/1.85:1/2.35:1/4:3/3:2/1.3X/2.0X/2.0X MAG●Safety MakrerUsed to select and control the size and availability of the safety area. Available type are: 95%/93%/90%/88%/85%/80%. Default is Off.●Marker ColorThe colors for Center Marker, Aspect Marker and Safety Marker are available in red, green, blue, white and black. Default is white.●Aspect Mat.Aspect Mat darkens the area of the outside of Marker. The degrees of darkness are between [0] to [7].●ThicknessThickness of marker line is selectable from 1 to 7, default value is 2.Note! The Marker function is not available in Multiview Mode2.3.6 Function●AspectSelect display ratio: Full/1.85:1/2.35:1/4:3/3:2/1.3X/2.0X/2.0X MAG. Default is Full.Note! The Aspect is not available in Multiview Mode●OverscanSome edge of image may be clipped after turning on overscan. Default is Off.Note! The Overscan is not available in Multiview Mode●Check FieldUsed to calibrate or analyse the accuracy of the screen color when Check Field is switched on. Selectable: Off/Red/Green/Blue/Mono. Default is Off.●FreezeTurn on to capture and display a frame of the current signal at any time. Default is Off.●PeakingUsed to assist in tracking the focus of subject. Default is Off.●Peaking ColorAvailable colors: red/green/blue/white/black. Default is red.●Peaking LevelUse this setting to adjust the level of focus sensitivity from [0]-[100]. If there are plenty of details of image with high contrast, it will display lots of focus assist lines that may cause visual interference. So, decrease the value of peaking level to reduce the focus lines to see clearly. Conversely, if the image has less details with low contrast, it should be increase the value of peaking level to see the focus lines clearly.●False ColorThis monitor has a false color filter to aid in the setting of camera exposure. As the camera Iris is adjusted, elements of the image will change color based on the luminance or brightness values. This enables proper exposure to be achieved without the use of costly, complicated external equipment. Selectable from: Off/Spectrum/ARRI/RED/Default. Default is Off.●False Color TableTurn on or off False Color reference tables.●ExposureThe exposure feature helps the user achieve optimum exposure by displaying diagonal lines over areas of the image that exceed the setting exposure level.●Exposure LevelThe Exposure Level can be set from 50 to 100IRE. Default is 100IRE.HistogramThe horizontal axis of histogram represents the luminance, from left to right indicating low to high luminance. The vertical axis of histogram indicates the number of pixels, from bottom to top indicating the number of pixels from less to more. The higher the histogram bumps in a certain luminance range, the more pixels there are in that luminance range. For example, if the histogram's bumps are mainly on the left side, this means that the overall brightness of the image is low; if it is on the right side, the overall brightness is high; if it is in the middle, the brightness is comfortable.(Actual distribution is white, black for demonstration reference)2.3.7 Audio●VolumeAdjusts the volume of built-in speaker and headphone, selectable range: 0-100. Default is 50.●MuteDisable any sound output when turn it off.●Level MeterTo achieve optimum audio quality, ensure the audio levels do not reach 0.This is the maximum level, meaning that any audio that exceeds this level willbe clipped, resulting in distortion. Ideally peak audio levels should fall in theupper end of the green zone. If the peaks enter into the yellow or red zones,the audio is in danger of clipping.●Audio SourceSelectable range: SDI1/SDI2/HDMI1/HDMI2/TYPE-C, Full Screen or Verticalmode default to current audio source, Multiview mode defaults to SDI12.3.8 System●LanguageAvailable in both Chinese and English.●Back Light ModeOptional: Custom/AutoLightAutoLight mode allows the backlight value to be adjusted automatically according to the ambient brightness. Manual adjustment of the backlight value in Custom mode●Back LightAdjusts the level of the back light from 0-100. Default is 100.●OSD TimerSelect the displaying time of the OSD. It has 10s, 20s, 30s preset to choose.●OSD TransparencySelect the transparency of the OSD from Off, 25% to 50%.●ResetIf there is any problem unknown, press to confirm after selected. The monitor will return to default settings.3. Specifications DISPLAYVIDEO INPUTVIDEO OUTPUTAUDIO IN/OUTPOWERENVIRONMENTOTHERS4. AccessoriesStandard Accessories1) DC 15V Power Adapter 1 pair2) Base Stand 1 pair3) USB Type-C Cable 1 pc4) Electronic User Manual 1 pc Optional Accessories1) V-mount or Anton Bauer Battery Plate 1 pc2) D-tap Cable 1 pc3) Swivel Bracket 1 pc4) Suitcase (Sunshade, frame brackets are included) 1 pc5. Trouble Shooting1. Only black-and-white display:Check whether the color saturation and check field are properly setup or not.2. Power on but no pictures:Check whether the cables of HDMI, and 3G-SDI are correctly connected or not. Please use the standard power adapter coming with the product package. Improper power input may cause damage.3. Wrong or abnormal colors:Check whether the cables are correctly and properly connected or not. Broken or loose pins of the cables may cause a bad connection.4. When on the picture shows size error:Press [MENU] →[Function] →[Overscan] to zoom in picture automatically.5. Other problems:Please try to press Menu button and choose [MENU] →[System] →[Reset] →[ON].6. Image Ghosting:If the same image or text continues to be displayed on the screen for an extended period of time, part of that image or text may burn into the screen and leave a ghost image, which is not a quality issue but a characteristic of some screens. It is simply a matter of turning the monitor off for a half hour to recover. Therefore no warranty/return/replacement will be made in this case.7. Some options can not be select in the Menu:Some options are only available in certain modes, for example the Center Marker function can only be used in full screen.8. Not working properly:If there is a problem that cannot be solved, please contact the relevant sales for after-sales service and leave the serial number to make it easier to locate the components so that the problem can be dealt with more quickly. The serial number is located on the back of monitor under the barcode.Note: Due to constant effort to improve products and product features, specifications may change without priority notice.。
SmartAVI 9-Port KVM HD Multiviewer 产品说明书

TECHNICAL SPECIFICATIONS_____________________________________________________________3 WHAT’S IN THE BOX?_____________________________________________________________________4 FRONT AND REAR________________________________________________________________________4 INSTALLATION____________________________________________________________________________5 SYSTEM OPERATION______________________________________________________________________6 SELECTING VIEWING MODES_____________________________________________________________6 RESOLUTION BUTTON____________________________________________________________________7 RS-232 AND HOTKEY COMMANDS_______________________________________________________7 TROUBLESHOOTING______________________________________________________________________8 TECHNICAL SUPPORT_____________________________________________________________________8 LIMITED WARRANTY STATEMENT________________________________________________________9VIDEOFormat HDMIVideo Bandwidth3GbpsInput Interface(9) HDMI 19-pin (female)Output Interface(1) HDMI 19-pin (female)HDMI Compliance HDMI 1.4bHDCP Compliance HDCP 1.4Resolution Up to 4K2K @ 30 HzDDC 5 volts p-p (TTL)Input Equalization AutomaticInput Cable Length Up to 20 ft.Output Cable Length Up to 20 ft.AUDIOInput From HDMI InputsOutput(1) Connector Stereo 3.5 mm FemaleUSBSignal Type USB 2.0, 1.1 and 1.0 Keyboard and Mouse only. Input Interface (9) USB Type B (female)Output Interface (2) USB 1.1 Type A (female) for keyboard/mouse;(2) USB 2.0POWERPower Requirements12V DC, 3A power adapter with center-pin positive polarity ENVIRONMENTOperating Temperature23 to 95°F (-5 to 35°C)Storage Temperature -4 to 185 °F (-20 to 85 °C)Humidity Up to 95% (No Condensation)CONTROLFront panel Push Buttons with LED indicatorsRS-232 Via Serial @ 115200 bpsHotkey Via KeyboardHDMV-9X-PLUS9-Port HDMI, USB Real-Time Multiviewer and KVM Switch.PS12VD3A12V DC, 3A (minimum) power adapter with center-pin positive polarity. User Manual1.Ensure that power is turned off or disconnected from the unit and the computers.e a HDMI cable to connect the HDMI output port from each computer to thecorresponding HDMI IN ports of the unit.e a USB cable (Type-A to Type-B) to connect a USB port on each computer to the re-spective USB ports of the unit.4.Optionally connect a stereo audio cable (3.5mm to 3.5mm) to connect the audio output ofthe computers to the AUDIO IN ports of the unit.5.Connect a monitor to the HDMI OUT console port of the unit using a HDMI cable.6.Connect a USB keyboard and mouse to the two USB console ports.7.Optionally connect stereo speakers to the AUDIO OUT port of the unit.8.Optionally connect a RS-232 Cable to the RS-232 port.9.Finally, power on the KVM by connecting a 12VDC power supply to the powerconnector, and then turn on all the computers.HDMV-9X-PLUS ShownWhen selecting a channel by pressing buttons 1-9 on the front panel, the blue backlight LED will light up to indicate that input is selected.There are a total of 8 viewing modes within the 4 categories, this is a list of all the modes based on the Number given in the command protocol:1 - Full Screen2 - Dual (Split)3 - Dual (PiP)4 - Quad (Equal)5 - Quad (T-Quad Right)6 - Quad (T-Quad Left)7 - Quad (T-Quad Bottom)8 - 9XOne of the four Mode Select buttons (FULL, DUAL, QUAD, and 9X) can be used to switch the current viewing mode. For the options with multiple viewing modes, multiple presses of the mode button will switch to a different variation within that same mode. Please refer to the viewing mode list above for more detail on these modes.When in viewing modes with multiple screens on the display, any specific input can be assigned to any specific position on the display. For example, the 9x Mode (Mode #8) can be divided in the following way:Each section of the display can be considered a separate “output”. To configure input and output for any of the 8 display modes the following command is used:IN -> [select input 1-9] -> OUT -> [select output 1-9]ex. Dual Mode (split)Input 1 is display on Output 1. Input 2 is displayed on Output 2To change Output 1 to display Input 3INPUT -> 3 -> OUTPUT -> 1To change Output 2 to display Input 4INPUT -> 4 -> OUTPUT -> 2Pressing the Resolution button (RES) cycles between the available resolutions. Here is a chart of the resolution options and the numbers associated with them. To view the current resolution, use the RS -232 command (//r?).The HDMV -9X -PLUS may also be controlled via RS -232 and Hotkey commands.For RS -232, you must use HyperTerminal or an alternative terminal application. The settings for the connection are as follows:Baudrate 115200; Data Bits 8; Parity None ; Stop Bits 1; Flow Control None .To use the HotKey commands, the keyboard must be connected to the designated keyboard or mouse USB slot.The following commands can be used for RS -232 and Hotkey control:Resolution Number Specifications 1 4K2 1080p3 1080i4 720p5 1360 x 7686 1024 x 768Command DescriptionRS -232HotkeySwitch USB and Video //m [in#][ENTER] [ctrl][ctrl]m [in#][ENTER] Switch Only Video IN //c [in#][ENTER] [ctrl][ctrl]c [in#][ENTER] Switch Only Video IN/OUT //i [in#][out#][ENTER] [ctrl][ctrl]i [in#][out#][ENTER] Switch to Video Mode [1-8] //x [mode #][ENTER] [ctrl][ctrl]x [mode #][ENTER] Get Current Video Mode //x?[ENTER] -Switch KM Devices Only //k [in#][ENTER] [ctrl][ctrl]k [in#][ENTER] Switch USB 2.0 Devices Only//u [in#][ENTER][ctrl][ctrl]u [in#][ENTER]Switch Resolution //p [1-6] [ENTER] [ctrl][ctrl]p [1-6][ENTER] Resolution Status //p?[ENTER] -Set EDID//e [1-2][ENTER][ctrl][ctrl]e [1-2][ENTER]———————————————————————————————- 1: EDID 1.42: EDID copy HDMI out EDID Status //e?[ENTER] -Audio SET //a [1-9][ENTER] [ctrl][ctrl]a [1-9][ENTER] Audio Status//a?-No Power∙ Make sure that the power adapter is securely connected to the power connector of the unit.∙ Check the output voltage of the power supply and make sure that the voltage value is around 12VDC.∙ Replace the power supply.No Video∙ Check if all the video cables are connected properly.∙ Connect the computer directly to the monitor to verify that your monitor and computer are functioning properly.∙ Restart the computersKeyboard is not working∙ Check if the keyboard is properly connected to the unit.∙ Check if the USB cables connecting the unit and the computers are properly connected.∙ Try connecting the USB on the computer to a different port.∙ Make sure that the keyboard works when directly connected to the computer.∙ Replace the keyboard.Mouse is not working∙ Check if the mouse is properly connected to the unit.∙ Try connecting the USB on the computer to a different port.∙ Make sure that the mouse works when directly connected to the computer.∙ Replace the mouse.No Audio∙ Check if all the audio cables are connected properly.∙ Connect the speakers directly to the computer to verify that the speakers and the computer audio are functioning properly.∙ Check the audio settings of the computer and verify that the audio output is through the speakers.For product inquiries, warranty questions, or technical questions, please contact *****************.A.Extent of limited warrantySmartAVI, Inc. warrants to the end-user customers that the SmartAVI product specified above will be free from defects in materials and workmanship for the duration of 1 year, which duration begins on the date of purchase by the customer. Customer is responsible for maintaining proof of date of purchase.SmartAVI limited warranty covers only those defects which arise as a result of normal use of the prod-uct, and do not apply to any:a. Improper or inadequate maintenance or modificationsb. Operations outside product specificationsc. Mechanical abuse and exposure to severe conditionsIf SmartAVI receives, during applicable warranty period, a notice of defect, SmartAVI will at its discretion replace or repair defective product. If SmartAVI is unable to replace or repair defective product covered by the SmartAVI warranty within reasonable period of time, SmartAVI shall refund the cost of the product.SmartAVI shall have no obligation to repair, replace or refund unit until customer returns defective product to SmartAVI.Any replacement product could be new or like new, provided that it has functionality at least equal to that of the product being replaced.SmartAVI limited warranty is valid in any country where the covered product is distributed by SmartA-VI.B. Limitations of warrantyTo the extant allowed by local law, neither SmartAVI nor its third party suppliers make any other warranty or condition of any kind whether expressed or implied with respect to the SmartAVI product, and specifically disclaim implied warranties or conditions of merchantability, satisfactory quality, and fitness for a particular purpose.C. Limitations of liabilityTo the extent allowed by local law the remedies provided in this warranty statement are the customers sole and exclusive remedies.To the extant allowed by local law, except for the obligations specifically set forth in this warranty statement, in no event will SmartAVI or its third party suppliers be liable for direct, indirect, special, incidental, or consequential damages whether based on contract, tort or any other legal theory and whether advised of the possibility of such damages.D. Local lawTo the extent that this warranty statement is inconsistent with local law, this warrantystatement shall be considered modified to be consistent with such law.The information contained in this document is subject to change without notice. SmartAVI makes no warranty of any kind with regard to this material, including but not limited to, implied warranties of merchantability and fitness for particular purpose. SmartAVI will not be liable for errors contained herein or for incidental or consequential damages in connection with the furnishing, performance or use of this material. No part of this document may be photocopied, reproduced, or translated into another language without prior written consent from SmartAVI, Inc.20180109Tel: (800) AVI-2131 • (702) 800-00052455 W Cheyenne Ave, Suite 112North Las Vegas, NV 890329-Port KVM HD Multiviewer for a Single Monitor 11。
Hikvision 8MP H.265 Pro+ 智能网络视频记录器说明书

Key Features● Support H.265 Pro+/H.265 Pro/H.265 video compression. ● Support HDTVI/AHD/CVI/CVBS/IP video input. ● Max 40/48 IP cameras input (up to 8 MP).● Max 800 m for 1080p and 1200 m for 720p HDTVI signal. ● Up to 10 TB capacity per HDD.● Support POS triggered recording and POS information overlay.Compression and Recording● H.265 Pro+ can improve encoding efficiency and reduce the data storage cost. ● Full channel recording at up to 8 MP resolution.Storage and Playback● 4 SATA interfaces and 1 eSATA interface. ● Smart search for efficient playback.● RAID 0, RAID 1, RAID 5, RAID 6 and RAID 10 storage scheme.Smart Function● Support multiple VCA (Video Content Analytics) events for both analog and smart IP cameras.● Supports line crossing detection and intrusion detection of all channels, and 2-ch sudden scene change detection.Network & Ethernet Access● Hik-Connect & DDNS (Dynamic Domain Name System) for easy network management. ● Output bandwidth limit configurable.SpecificationsModel DS-7324HUHI-K4DS-7332HUHI-K4 Perimeter Protection¹Line crossingdetection/intrusion detection 2-chEnhanced VCA mode on: 24-ch2-chEnhanced VCA mode on: 32-chRecordingVideo compression H.265 Pro+/H.265 Pro/H.265/H.264+/H.264Encoding resolution8 MP/5 MP/4 MP/3 MP/1080p/720p/WD1/4CIF/VGA/CIFFrame rate Main stream:8 MP@8 fps/5 MP@12 fps; 4 MP@15 fps; 3 MP@18 fps; 1080p/720p/WD1/4CIF/VGA/CIF@25 fps (P)/30 fps (N) Sub-stream:WD1/4CIF/CIF@25 fps (P)/30 fps (N)Video bit rate32 Kbps to 10 Mbps Dual stream SupportStream type Video, Video & Audio Audio compression G.711uAudio bit rate64 KbpsVideo and AudioIP video input 16-ch (up to 40-ch)16-ch (up to 48-ch) Up to 8 MP resolutionSupport H.265+/H.265/H.264+/H.264 IP camerasAnalog video input 24-ch32-chBNC interface (1.0 Vp-p, 75 Ω), supporting coaxitron connectionHDTVI input8 MP, 5 MP, 4 MP, 3 MP, 1080p25, 1080p30, 720p25, 720p30, 720p50, 720p60 AHD input 5 MP, 4 MP, 1080p25, 1080p30, 720p25, 720p30HDCVI input 4 MP, 1080p25, 1080p30, 720p25, 720p30CVBS input PAL/NTSCCVBS output1-ch, BNC (1.0 Vp-p, 75 Ω), resolution: PAL: 704 × 576, NTSC: 704 × 480HDMI1/VGA output 1-ch, 1920 × 1080/60Hz, 1280 × 1024/60Hz, 1280 × 720/60Hz, 1024 × 768/60HzHDMI2 output 1-ch, 4K (3840 × 2160)/30Hz, 2K (2560 × 1440)/60Hz, 1920 × 1080/60Hz, 1280 × 1024/60Hz, 1280 × 720/60Hz, 1024 × 768/60HzAudio input4-ch, RCA (2.0 Vp-p, 1 KΩ)Audio output1-ch, RCA (Linear, 1 KΩ)Two-way audio1-ch, RCA (2.0 Vp-p, 1 KΩ) (independent) Synchronous playback16-chNetworkRemote connections128Network protocols TCP/IP, PPPoE, DHCP, Hik-Connect, DNS, DDNS, NTP, SADP, NFS, iSCSI, UPnP™, HTTPS, ONVIF, SNMPNetwork interface2, RJ45 10M/100M/1000M self-adaptive Ethernet interface Auxiliary interfaceNote:1: Enabling enhanced VCA mode will maximize the connectable channel number for perimeter protection (line crossing detection and intrusion detection), but disable 2K/4K HDMI output resolution and the signal inputs which are not less than 4 MP .SATA 4 SATA interfaces eSATA SupportCapacity Up to 10 TB capacity for each disk Serial interface RS-232, RS-485 (full-duplex), Keyboard Alarm in/out 16/4USB interface Front panel: 2 × USB 2.0 Rear panel: 1 × USB 3.0General Power supply 100 to 240 VAC, 50 to 60 Hz, 1.3 AConsumption (without HDD) ≤ 74 WWorking temperature -10 °C to +55 °C (+14 °F to +131 °F) Working humidity 10% to 90%Dimensions (W × D × H) 440 × 390 × 70 mm (17.3 × 15.4 × 2.8 inch) Weights (without HDD)≤ 7 kg (15.4 lb)The rear panel of DS-7324HUHI-K4 provides 24 video input interfaces.Physical InterfacesAvailable ModelsDS-7324HUHI-K4, DS-7332HUHI-K4IndexDescription IndexDescription 1 VIDEO IN9 eSATA Interface 2 AUDIO IN, RCA Connector 10 HDMI1 Interface 3 LINE IN 11 HDMI2 Interface4 AUDIO OUT 12 LAN1 and LAN2 Network Interfaces5 VIDEO OUT 13 USB Interface6 RS-485SerialInterface,KeyboardInterface, ALARM IN and ALARM OUT 14 GND7 RS-232 Serial Interface 15 100 to 240 VAC Power Input 8 VGA Interface16Power Switch。
tomas rivera课文

tomas rivera课文一、课文背景知识。
1. 作者简介。
- Tomas Rivera的生平经历,包括他的出生年份、成长环境、教育背景等。
例如,Tomas Rivera was born in [birth year] in [place]. He was influenced by [mention relevant factors like his family, cultural environment]. He received his education at [name of educational institutions], which might have shaped his writing style.2. 创作背景。
- 了解这篇课文创作的时代背景,如当时的社会、政治、文化状况。
如果是反映某个特定群体的生活,解释这个群体在当时社会中的地位和面临的问题。
For example, if the story is set in a particular era of immigration, explain how immigration policies and social attitudes towards immigrants at that time affected the story.二、课文内容分析。
1. 主题。
- 概括课文的主题思想。
It could be about themes like family, identity, the pursuit of the American Dream, or the struggle against discrimination. For example, if the story is about a family's journey in a new country, the theme might be about the challenges and hopes of immigrant families.2. 情节结构。
(转)mp4编码全介绍(二)

(转)mp4编码全介绍(⼆)Mp4⽂件格式1. Mp4⽂件格式简介1.1概述1.2媒体⽂件的物理结构1.3常见的box的树结构图2. Mp4⽂件存储结构2.1 Mp4⽂件组成2.2. ⽂件类型包2.3媒体数据包2.4影⽚包2.5影⽚头包2.6轨迹包2.7轨迹头包2.8媒体包2.9媒体头包2.10处理器引⽤包2.11媒体信息包2.12媒体信息头包2.13数据信息包2.14例⼦表包3.Mp4⽂件信息获取及定位随机播放点4.Mp4流⽂件的组成机制5. 简单MP4制作⽂档的参考例⼦6asf与mp47参考⽂献Mp4⽂件格式简介1.1概述MP4是遵循MPEG-4(ISO 14496-14)的官⽅容器格式定义的⼴义⽂件扩展名。
Mp4流媒体化并⽀持众多多媒体的内容(多⾳轨(multiple audio)、视频流(video)、字幕(subtitlestreams)、图⽚(pictures)、可变桢率(variable-framerates)、码率(bitrates)、采样率(samplerates)等)和⾼级内容(advanced content).Mp4⽂件扩展名: .mp41.2媒体⽂件的物理结构MP4⽂件中所有的数据都封装在⼀些box中(以前叫atom)。
Box定义了如何在sample table中找到媒体数据的排列。
这包括data reference(数据引⽤), the sample size table, the sample to chunk table, and the chunk offset table. 这些表就可以找到track中每个sample在⽂件中的位置和⼤⼩。
data reference允许在第⼆个媒体⽂件中找到媒体的位置。
⼀个track的连续⼏个sample组成的单元就被称为chunk。
每个chunk在⽂件中有⼀个偏移量,这个偏移量是从⽂件开头算起的,在这个chunk内,sample是连续存储的。
索尼IR-210B IR-210P日夜防线IP网络摄像头产品说明说明书

»»Deliver up to 30 FPS high res de-interlaced video @ full D1, 720x480
»»Featuring H.264 compression technology for optimized image quality, and lower bandwidth and storage requirements
»»Advanced features include digital slow shutter and motion detection
Product Overview
This IR-210B/IR-210P features latest H.264 compression to optimize image quality, and lower network bandwidth and storage capacity requirements. Durable and weatherproof, the camera is designed to operate in harsh outdoor environments. IR-210B/IR-210P is easy to set up and produce crystal clear high resolution video day or night, indoors or out. The Sony CCD offers up to 30fps at full D1 resolution for great light sensitivity and the ability to multi-stream H.264, MPEG4, or MJPEG video image at 30 fps. The IR210B is integrated with EDIMAX NVR and CMS video management solutions.
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Multiple Description Video Coding with H.264/A VCRedundant PicturesIvana Radulovic,Pascal Frossard,Ye-Kui Wang,Miska M.Hannuksela,and Antti HallapuroAbstract—Multiple description coding offers interesting solu-tions for error resilient multimedia communications as well as for distributed streaming applications.In this letter,we propose a scheme based on H.264/A VC for encoding of image sequences into multiple descriptions.The pictures are split into multiple coding threads.Redundant pictures are inserted periodically in order to increase the resilience to loss and to reduce the error propagation.They are produced with different reference frames than the corresponding primary pictures.We show,given the channel conditions,how to optimally allocate the rates to primary and redundant pictures,such that the total distortion at the receiver is minimized.Extensive experiments demonstrate that the proposed scheme outperforms baseline solutions based on loss and content-adaptive intra coding.Finally,we show how to further reduce the distortion by efficient combination of primary and redundant pictures,if both are available at the decoder.Index Terms—H.264/A VC,multiple description video coding, redundant pictures.I.IntroductionT HERE has been recently a rapid development of multime-dia services and applications such as video conferencing, mobile video,or Internet Protocol TV(IPTV).These applica-tions are often subject to packet loss and bandwidth varia-tions on current packet networks.Error resilience techniques have been shown to provide elegant solutions that offer a sustained quality to the users in the absence of guarantee from the transmission channels.Among these,multiple description coding(MDC)[1]has recently emerged as a promising solu-tion,especially in low-latency applications.It offers improvedManuscript received January25,2008;revised December20,2008.First version published July7,2009;current version published January7,2010. This work was supported in part by the Swiss National Science Foundation grant PP-002-68737.This paper was recommended by Associate Editor G. Wen.I.Radulovic was with the Signal Processing Laboratory(LTS4),Ecole Polytechnique Federale de Lausanne,Lausanne1015,Switzerland.She is now with Ericsson Research,Stockholm16480,Sweden(e-mail: ivana.radulovic@).P.Frossard is with the Signal Processing Laboratory(LTS4),Ecole Polytechnique Federale de Lausanne,Lausanne1015,Switzerland(e-mail: pascal.frossard@epfl.ch).Y.-K.Wang was with Nokia Research Center,Tampere33720,Finland. He is now with Huawei Technologies,Bridgewater,NJ08807USA(e-mail: yekuiwang@).M.M.Hannuksela and A.Hallapuro are with Nokia Research Center,Tampere33720,Finland(e-mail:antti.hallapuro@; miska.hannuksela@).Color versions of one or more of thefigures in this letter are available online at .Digital Object Identifier10.1109/TCSVT.2009.2026815performance compared to schemes based on forward error correction,especially when the channel conditions are not accurately estimated[2].The most popular MDC schemes for video,such as video redundancy coding(VRC)[3]or multiple state video cod-ing(MSVC)[4],split the input video sequence into subse-quences of frames that are independently coded,with their own prediction process and state.With this solution,even if one description is completely lost,another one can be independently decoded and reconstructed at half of the frame rate.Moreover,the frames lost in one description can be reconstructed by interpolation from the neighboring frames in another description.Other examples of multiple description video coding schemes based on information splitting in the temporal domain include multiple description motion compen-sation schemes[5],[6],rate-distortion optimized unbalanced MDC[7],and the optimal selection of different MDC coding modes,investigated in[8].In this letter,we propose a standard compatible MDC video scheme for low-delay applications over lossy networks.We build on our previous work[9]and use H.264/A VC redundant pictures to provide robustness to transmission errors.The video information is split into several encoding threads,and redundant pictures are inserted to reduce the error drift in case of packet loss.In contrary to the classical construction, redundant pictures are coded in a different thread than the corresponding primary pictures.Given the channel conditions, we show how to allocate the coding rate to primary and redundant pictures,such that the total distortion experienced at the receiver is minimized.Wefinally show how the decoding quality can be further improved by a proper handling of the different versions of received pictures available at the decoder. Extensive simulations demonstrate that our MDC algorithm outperforms state-of-the-art single and two-description video coding schemes in terms of average quality,as well as quality variation and resiliency to incorrect estimation of the channel state.It is worth noting that a parallel work of Tillo et al.[10] also proposes an MDC video coding scheme based on redun-dant pictures.The descriptions are however not completely independent,and the decoding process does not exploit all the information available at the decoder.This rest of this letter is organized as follows.Section II describes the proposed scheme in detail,while in Section III we compare its performance with state-of-the-art techniques. We discuss decoder improvements in Section IV.Finally, Section V summarizes the letter.1051-8215/$26.00c 2010IEEEII.MDC with Redundant PicturesWe extend the MSVC scheme[4]and increase the resiliency to temporal propagation of errors by the addition of redundant pictures.Redundant pictures(RP)are one of tools included in H.264/A VC that can be used efficiently for error resilient video coding[11]–[13].Typically,each(primary)picture in the encoded video sequence may be associated with one or more RPs.The decoder can reconstruct the redundant picture in case a primary picture(or parts thereof)is missing.On the other hand,RPs are usually discarded by the decoder if the corresponding primary picture is correctly received.The proposed coding scheme(MSVC-RP)is illustrated in Fig.1.We consider a simple I-P-P-...scenario with a single reference frame,since we mostly target low-delay applications. It can be noted,however,that MSVC-RP can be extended to B-pictures or multiple reference frames.The input video sequence is split into sequences of odd and even source pictures.When encoding,each primary picture in the even/odd description is predicted only from other pictures of the same description,typically the previous picture.In ad-dition,redundant pictures are included in the bitstream of each description,thus carrying the information from the alternate description.In the time domain,they are positioned such that they can replace a lost primary picture.Unlike the primary pictures,which use the previous primary frames from the same thread as a reference,redundant pictures are predicted from the previous frame in the input sequence.Redundant pictures are coded as P pictures(except thefirst two,which are intra coded)and each primary frame has its redundant version.Redundant pictures are not used as a reference for any subsequent picture.The descriptions are typically placed in different transmission packets and sent to the network. They could be transmitted over two different lossy channels, if such an arrangement is supported by the network.Sending the descriptions over a single link consists of sending primary pictures followed by their corresponding redundant pictures, which is the normal decoding order of H.264/A VC bitstreams. If the descriptions are sent over independent paths,pictures within a description are sent in their decoding order(from left to right in Fig.1).The redundant pictures typically use the same coding modes as the corresponding primary pictures,but they are more coarsely quantized in order to save on the overall coding rate. Naturally,the quality of redundant pictures should be chosen by taking the network loss rate into account.If the loss rate is very low,the probability that a primary picture is lost and has to be replaced by the corresponding RP is also low,and this is why RPs should be quantized coarsely.On the other hand, as the loss rate increases,better quality of RPs becomes more advisable.Clearly,this comes at a price of reducing the quality of primary pictures when the total rate isfixed.On average, having better quality RPs is however beneficial,since there is a higher probability that a primary picture is lost and replaced by a RP.The receiver can face three different situations,depending on if the primary and redundant pictures are lost or not.First,if primary pictures are received error-free,the standard suggests that the RPs should be discarded.In our letter,we willfirst Fig.1.Proposed scheme for MDC video.follow this approach,thus keeping the decoding process as simple as possible,which can be of great importance for delay-sensitive applications.In Section IV,we will eventually improve the decoding process with more efficient handling of all the received pictures.Second,if a primary picture (or parts thereof)has been lost,the corresponding redundant picture is decoded and used to replace its missing parts.Since the quantization is generally coarser in RPs,this operation typically leads to artifacts in the decoded sequence.However, the degradation is generally smaller than the error generated by simple concealment with the information from the neigh-boring macroblocks from the same and/or subsequent frames. Third,if both primary and redundant parts of a picture are lost,the missing information is reconstructed using an error concealment algorithm,e.g.,by copying the closest available previous frame from either description.After the necessary discarding/replacement/concealment,the two descriptions are subsequently interleaved to produce thefinal reconstruction.III.Performance EvaluationIn this section,we compare our scheme with three solutions proposed in the literature that represent viable solutions for low-delay applications.We start by describing the testing conditions.Then,we compare the average quality,as well as quality variation and resiliency to incorrect estimation of the channel state for all the schemes.For the detailed analysis of MSVC-RP,including redundancy analysis,source and channel distortion models,and optimal rate allocation between primary and redundant pictures,please refer to[14].A.TestbedOur testbed corresponds to the common error resilience testing conditions specified in JVT-P206[15],which specifies the required testing sequences,together with the corresponding bitrates and frame rates,as well as the bitstream packetization. The NAL unit size is limited to1400bytes,and the maximal size of each slice is chosen such that itfits in one NAL unit. Therefore,depending on the bitrate and the sequence format, there may be several slices per frame.Finally,an overhead of40bytes for the RTP/UDP/IPv4headers is also taken into account when calculating the total bitrates.We compare our MSVC-RP with three state-of-the-art schemes.1)MSVC scheme:the video is encoded into two indepen-dent coding threads,without redundant pictures.Note that the author in[4]considers several error concealment strategies when an entire frame is lost.In our work weonly consider the simple scheme,where a lost frame is replaced with the closest possible received frame from either description,similarly to [8].2)Adaptive intra refresh (AIR)scheme [16],which takes into account both the source distortion and the expected channel distortion (due to losses)and chooses an optimal mode for each macroblock based on Lagrange optimiza-tion.Therefore,it is likely to place intra macroblocks in more “active”areas.3)Random intra refresh (RIR)scheme,which increases the robustness to losses by randomly inserting macroblocks whose number is proportional to a packet loss rate.To have a fair comparison,we fix the total bit rates for all the schemes to be equal.In case of loss,parts or entirely lost pictures are replaced with their redundant versions taken from the alternate description in our MSVC-RP implementation.If both primary and redundant pictures are lost,we copy the temporally closest decoded picture from either description.For the other schemes,in case of partial frame losses,the missing pieces are copied from the corresponding places in the previous pictures.If an entire picture is lost,we copy the entire previous picture,as it is implemented in the MSVC-RP scheme.In addition,only the first frames in all the video sequences are encoded as I pictures.We have tested all the sequences specified in JVT-P206and at several loss rates [15].To obtain statistically meaningful results,all the bitstreams are concatenated and tested with the entire loss patterns containing 10000binary characters,for all the packet loss rates.We show here the results for the three sequences:News QCIF ,Foreman QCIF ,and Stefan CIF ,while similar results for other test sequences can be found in [14].B.Selecting Q p and Q rThe optimal values Q p and Q r are obtained by full search over all combinations of quantization parameters that satisfy the total bitrate constraint.Table I shows these optimal pa-rameters for the Foreman QCIF sequence,encoded at 7.5fps and 144kbits/s and Stefan CIF sequence at 30fps and 512kbits/s.We can observe that the value of Q r decreases when the loss rate increases,as expected.When the losses are very high (20%),the primary and redundant pictures are coded with very similar quantization parameters.The increase in quality of redundant pictures comes clearly at the expense of decreasing the quality of primary pictures when the overall bit rate is con-strained.This however improves the average distortion,since the probability of using the redundant pictures becomes signif-icant.On the other hand,when the loss rate is low,the optimal allocation tends to give as much rate as possible to primary pictures,while the redundant pictures are made very coarse.In this case,the system avoids wasting bits on the redundant pictures that are unlikely to be used in the decoding process.C.End-to-End Distortion AnalysisWe analyze here the performance of the different error resilient coding solutions in terms of average distortion,for different loss ratios.The average PSNR is illustrated in Fig.2for the Foreman QCIF test sequence.We compare our optimalTABLE IOptimal Quantization Parameters That Minimize the Average Distortion,As A Function of p .Sequences Foreman QCIF at 7.5fps and 144kbits/s and Stefan CIF at 30fps and 512kbits/sForeman QCIF Stefan CIF p Q opt pQ opt rQ optpQ optr3%254241495%2634414910%2829424420%28294244Fig.2.Average PSNR versus loss probability.Sequence:Foreman QCIF ,7.5fps,144kbits/s.MSVC-RP solution with the MSVC,RIR,and AIR schemes,as well as with MSVC-RP with maximal redundancy (i.e.,Q p =Q r ).It can be seen that the MSVC-RP scheme performs generally the best at all packet loss rates,and that the AIR scheme also provides an efficient solution at either low or high packet loss rate,depending on the activity in the vide sequence.At 10%loss probability,the MSVC-RP scheme outperforms the AIR and MSVC schemes by approximately 3and 8dB for the Foreman sequence.The quality gain due to MSVC-RP generally increases with the loss rate,since the redundancy offered by the design of two descriptions is really beneficial in this case,compared to joint coding with only one coding thread.For the complex sequences like Stefan encoded at medium bitrate,we can see that the performance of the MSVC-RP stays close to the AIR scheme,due to the limitations of the simple error concealment method that is unable to provide a sustainable quality when the loss of one description becomes frequent.On the contrary,the coding of intra blocks in areas of high activity helps to improve the quality for the AIR scheme at high loss rates.We further study the performance of the proposed scheme in a wider range of rates,and we compare it to the AIR scheme.Fig.3shows the average PSNR as a function of the rate constraint R ,for the Foreman sequence,when the loss rate is equal to p =5%.We can see that our approach gives the best performance in the whole range of bitrates,from 0.6dB at 32kbits/s up to 2.7dB at 192kbits/s.Moreover,the gain increases as the bitrate increases.Finally,Fig.4presents the temporal evolution of the PSNR for the different encoding schemes,for the same loss trace.TheFig.3.Average PSNR,as a function of encoding rate,when PLR =5%.Sequence:Foreman QCIF ,7.5fps.Fig.4.Reconstructed video quality,on a frame basis,when PLR =10%.Sequence:Foreman QCIF ,7.5fps,144kbits/s.error pattern is taken from a random entry in the error pattern file.The MSVC-RP scheme generally gives the best decoding quality.We can also notice that the AIR succeeds in catching up with our scheme,but with big variations in quality and with the performance similar to MSVC-RP in short intervals.The MSVC scheme performs very bad before the scene change around the frame 45.Then it recovers,thanks to inserted intra macroblocks after the scene change,but the frame-by-frame quality varies in significant amounts,up to 12dB between two consecutive frames.Overall,it can be observed that the variations of quality for the MSVC-RP scheme are much smaller than for the other schemes.This illustrates the benefits of the design of two descriptions that can be decoded independently.Similar results have been observed for other loss rates,other sequences,and other video formats [14].D.Robustness to Inexact Loss Rate EstimationWe finally discuss the robustness of the encoding schemes to incorrect loss rate estimation,which is likely to happen in practical scenarios.We compare the MSVC-RP and the AIR approaches that are optimized for a given loss ratio p ,but where the actual loss rate is different from the ex-pected one.This is actually a common situation in practical scenarios.Fig.5presents the end-to-end quality fortheFig.5.Actual and minimal distortion versus the actual PLR,when all the schemes are optimized for PLR =5%.Sequence:Foreman QCIF ,7.5fps,144kbits/s.Fig.6.Reconstruction of the (n +2)th frame from the Foreman QCIF sequence (Q p =28,Q r =29)when its both primary and redundant pictures are received.Here the n th frame,used as a reference for the (n +2)th primary frame,is entirely lost,while the (n +1)th frame,used as a reference for the (n +2)th redundant frame is correctly received.Foreman sequence,when all the schemes are optimized for p =5%,but when the actual loss ratio varies from 3%to 20%.For the sake of completeness,we also plot the best performance of MSVC-RP and AIR at each loss ratio.The differences between the optimized and actual performance for both schemes are 0.39dB and 0.14dB respectively,when p =3%.Not surprisingly,the gap between the optimized and actual performance increases as the actual loss ratio moves away from 5%.At p =10%,these gaps for both schemes are 0.9dB and 1.33dB respectively,while at p =20%the corresponding gaps are 1.32and 2.78dB.Therefore,we can conclude that MSVC-RP is more robust to unknown network conditions.This can be a very desirable property,especially if the sender cannot change the encoding parameters as fast as the network conditions change.A similar behavior is observed for the other test sequences.IV .Improved Frame Reconstructionbination of PicturesIn the first part of this letter,we discarded redundant pictures if the corresponding primary pictures were available at theFig.7.Minimal achievable average distortion,as a function of a probability of loss,p(sequence:Foreman QCIF,7.5fps,144kbits/s).decoder.This solution has an advantage of simplicity,but it is clearly suboptimal.Although a primary picture is correctly received,it may happen that its reference frames are affected by losses,which causes error propagation that also affects the primary picture.At the same time,it may happen that the thread from which a redundant picture is decoded is error-free or less affected by transmission errors.In these scenarios, choosing a redundant instead of a primary picture may be beneficial.This especially makes sense if the quantization parameters for primary and redundant pictures of the same original picture are very similar,which further induces similar visual qualities for both frames.Since primary and redundant pictures are decoded from different threads,the transmission error propagates only in one thread or description.We can therefore choose to use the best possible frame in case of loss in the reference frames,as depicted in Fig.6.A model that addresses rate-distortion optimal macroblock selection between a primary coded picture and the respective redundant coded picture is detailed in[14].However,it can be noted that the improved solution is not standard-compatible anymore, since both primary and redundant pictures need to be decoded in this case.We report in Fig.7the benefits of the improved decoding process in terms of average distortion for Foreman QCIF sequence,while similar results can be found in[14].We can see that the PSNR quality improvement ranges from0.07dB when p=3%to1.14dB when p=20%.In general,the improvement at low loss rates is rather small,and gets more important at high loss rates.As the loss rate gets higher,it becomes very likely that an entire frame can be lost,in which case a serious quality degradation can be seen in subsequent frames.At the same time,the probability that both threads are simultaneously affected stays small,so that the possibility of choosing the frame to decode becomes beneficial.We conclude that discarding the redundant pictures by default is not optimal, as the additional information provided by these pictures can be very helpful against temporal error propagation.V.ConclusionIn this letter,we have proposed a simple and H.264/A VC compatible Multiple Description Video Coding scheme based on redundant pared to the state-of-the-art error resilient coding for low-latency applications,the proposed scheme offers significant gains in terms of average PSNR, fewer temporalfluctuations in the picture quality,and im-proved robustness to bad estimation of the loss probability in the network.Wefinally propose an improved decoding process that exploits the best information available at the decoder in primary or redundant picture.We plan to further study the efficient and adaptive allocation of redundant pictures in the video descriptions,based on the scene content.References[1]V.K.Goyal,“Multiple description coding:Compression meets thenetwork,”IEEE Signal Process.Mag.,vol.18,no.5,pp.74–93,Sep.2001.[2]Y.Wang,A.R.Reibman,and S.Lin,“Multiple description coding forvideo delivery,”Proc.IEEE,vol.93,no.1,pp.57–70,Jan.2005. [3]S.Wenger,“Video redundancy coding in H.263+,”in Proc.WorkshopAudio-Visual Services Packet Netw.,1997,pp.23–28.[4]J.Apostolopoulos,“Reliable video communication over lossy packetnetworks using multiple state encoding and path diversity,”in Proc.Vis.Commun.Image Process.,Jan.2001,pp.392–409.[5]Y.Wang and S.Lin,“Error-resilient video coding using multipledescription motion compensation,”IEEE Trans.Circuits Syst.Video Technol.,vol.12,no.6,pp.438–452,Jun.2002.[6] C.-S.Kim and S.-U.Lee,“Multiple description motion coding algorithmfor robust video transmission,”in Proc.IEEE Int.Symp.Circuits Syst., vol.4.Mar.2000,pp.717–720.[7] as,R.Singh,A.Ortega,and F.Marques,“Unbalanced multiple-description video coding with rate-distortion optimization,”EURASIP J.Appl.Signal Process.,vol.2003,no.1,pp.81–90,Jan.2003.[8] B.Heng,J.Apostolopoulos,and J.S.Lim,“End-to-end rate-distortionoptimized MD mode selection for multiple description video coding,”EURASIP J.Appl.Signal Process.,vol.2006,no.Article ID32592, p.12.[9]I.Radulovic,Y.-K.Wang,S.Wenger,A.Hallapuro,M.M.Hannuksela,and P.Frossard,“Multiple description H.264video coding with redun-dant pictures,”in Proc.ACM Multimedia2007,Sep.2007,pp.37–42.[10]T.Tillo,M.Grangetto,and G.Olmo,“Redundant slice optimal allocationfor H.264multiple description coding,”IEEE Trans.Circuits Syst.Video Technol.,vol.18,no.1,pp.59–70,Jan.2008.[11]Y.-K.Wang,M.M.Hannuksela,and M.Gabbouj,“Error resilient videocoding using unequally protected key pictures,”in Proc.Very Low Bit Rate Video,Sep.2003,pp.290–297.[12]P.Baccichet,S.Rane,and B.Girod,“Systematic lossy error protectionbased on H.264/A VC redundant slices and fexible macroblock ordering,”in Proc.Packet Video Workshop,Hangzhou,China,Apr.2006. [13] C.Zhu,Y.-K.Wang,M.Hannuksela,and H.Li,“Error resilient videocoding using redundant pictures,”IEEE Trans.Circuits Syst.Video Technol.,vol.19,no.1,pp.3–14,Jan.2009.[14]I.Radulovic,“Balanced multiple description coding in image commu-nications,”Ph.D.thesis,Ecol.Polytech.Federale Lausanne,Lausanne, Switzerland,Dec.2007.[15]Y.-K.Wang,S.Wenger,and M.M.Hannuksela,“Common conditionsfor SVC error resilience testing,”JVT Output Document,JVT-P206,Aug.2005.[16]Y.Zhang,W.Gao,H.Sun,Q.Huang,and Y.Lu,“Error resilience videocoding in H.264encoder with potential distortion tracking,”in Proc.Int.Conf.Image Process.,vol.1,Oct.2004,pp.163–166.。