语音识别芯片资料
语音识别芯片原理

语音识别芯片原理
语音识别芯片原理主要包括语音信号采集、预处理、特征提取、模型训练和解码五个步骤。
首先,语音信号采集是通过麦克风将用户的语音信号转换为电信号。
采集到的语音信号是模拟信号,需要经过模数转换器(ADC)转换为数字信号。
然后,预处理阶段对数字化的语音信号进行一系列处理,包括去噪、降噪、音频增益控制等操作,以提高语音信号的质量和可靠性。
接下来,特征提取是将预处理后的语音信号转换为适合机器学习算法处理的特征向量。
常用的特征提取算法有MFCC(Mel
频率倒谱系数)和FBANK(滤波器组)
模型训练是使用机器学习算法,如支持向量机(SVM)或深
度学习算法(如循环神经网络RNN和卷积神经网络CNN)来训练一个模型,使其能够识别出各种语音的不同特征。
最后,解码阶段将输入的语音信号与训练好的模型进行匹配和识别,输出对应的文本结果。
综上所述,语音识别芯片通过采集、预处理、特征提取、模型训练和解码等步骤来实现语音转文本的功能。
这些步骤结合了信号处理、机器学习和模式识别等技术,可以实现高精度的语音识别。
语音识别芯片有哪些

语音识别芯片有哪些语音识别芯片是一种能够将语音信号转化为文本输出的芯片,近年来得到了广泛的应用和发展。
下面是一些常见的语音识别芯片。
1. 苹果A系列芯片 (Apple A-series chips)苹果公司在自家的A系列芯片上集成了自家的语音识别技术,包括Siri个人助理和其他语音相关功能。
2. 英伟达Tegra芯片 (NVIDIA Tegra Chips)英伟达公司的Tegra芯片系列也包含了语音识别的功能,可以在智能手机、平板电脑和其他移动设备上使用。
3. 高通骁龙芯片 (Qualcomm Snapdragon Chips)高通公司的骁龙芯片也具备语音识别功能,可以在手机、智能音箱等设备上使用。
4. 诺基亚发现芯片 (Nokia Discovery Chips)诺基亚的发现芯片系列主要用于智能音箱等语音控制设备,具备语音识别和语音指令功能。
5. 展讯( Spreadtrum)芯片展讯芯片是中国芯片厂商展讯科技生产的手机处理器,具备语音识别功能。
6. 英特尔酷睿 i7芯片 (Intel Core i7 Chips)英特尔的酷睿 i7芯片也支持语音识别技术,在台式机和笔记本电脑中使用。
7. 联发科技( MediaTek)芯片联发科技是台湾的一家芯片设计公司,其芯片也支持语音识别功能,在智能手机和其他智能设备上广泛应用。
8. 德州仪器(Texas Instruments)芯片德州仪器是一家全球性的半导体设计与制造公司,其芯片也集成了语音识别技术,可应用于各种电子设备。
总结:以上是一些常见的语音识别芯片,它们都具备将语音转化为文本的能力,广泛应用于智能手机、智能音箱、智能家居等设备中。
另外,随着人工智能和语音技术的不断发展,未来还会有更多类型的语音识别芯片出现。
常用的语音芯片有哪些

常用的语音芯片有哪些语音芯片是一种用于语音处理和识别的专用芯片,它能够将语音信号转换成数字信号,并通过相关算法对语音进行处理和分析。
随着语音技术的不断发展和应用场景的扩大,现在市面上有许多常用的语音芯片供开发者选择。
本文将介绍一些常见的语音芯片及其特点。
1. XMOS XS1系列XMOS XS1系列是一种高度灵活的语音芯片系列,它采用了多核架构和并行处理技术,能够实现实时性能要求较高的语音处理。
该系列芯片使用了XMOS公司自主开发的xFX技术,具有相对低的功耗和高的处理速度。
XS1系列芯片可以通过软件编程进行定制化开发,适用于不同的语音处理和识别应用。
2. Cirrus Logic CS48XX系列Cirrus Logic CS48XX系列是一种集成了高性能音频处理和语音识别功能的芯片系列。
这些芯片具有低功耗、高性能和灵活性的特点。
CS48XX系列芯片支持多种语音编码算法,可以实现高质量的语音信号处理和识别。
此外,这些芯片还提供了丰富的接口,方便与其他外部设备进行连接和通信。
3. NXP LPC800系列NXP LPC800系列是一种低功耗、高性能的语音处理芯片系列。
这些芯片采用了ARM Cortex-M0+内核,具有较高的计算能力和低功耗特性。
LPC800系列芯片支持多种语音编解码算法,可以实现实时语音处理和识别。
此外,该系列芯片还提供了丰富的外设接口,方便与其他外部设备进行连接和控制。
4. Intel Smart Sound TechnologyIntel Smart Sound Technology是一种集成了音频处理和语音识别功能的芯片技术。
这种技术可以用于手机、平板电脑、笔记本电脑等多种移动设备上。
通过Intel Smart Sound Technology,用户可以实现高质量的语音通信和语音指令识别。
该技术具有低功耗和高度集成的特点,适用于各种移动设备应用场景。
5. Knowles声学芯片Knowles是一家专注于声学技术研发的公司,他们的产品广泛用于语音处理和语音识别领域。
语音芯片原理

语音芯片原理
语音芯片是一种集成了语音识别、语音合成和语音处理等功能的集成电路芯片。
它通过将声音转换成数字信号,再通过一系列的算法进行处理,最终实现语音的识别、合成和处理。
语音芯片的原理主要包括声音采集、信号处理和语音识别三个方面。
首先,声音采集是语音芯片的第一步。
当人们说话时,声音会通过麦克风等声
音采集设备采集到,然后转换成模拟信号。
接着,模拟信号会经过模数转换器转换成数字信号,以便后续的数字信号处理。
其次,信号处理是语音芯片的核心部分。
经过模数转换器转换成的数字信号会
经过一系列的数字信号处理算法,包括滤波、降噪、特征提取等处理过程。
其中,滤波处理可以去除一些噪音干扰,降噪处理可以使得语音信号更加清晰,特征提取可以提取出语音信号的一些重要特征,以便后续的语音识别。
最后,语音识别是语音芯片的最终目的。
经过信号处理后的数字信号会被送入
语音识别算法中,通过比对语音库中的模型,最终确定输入语音的内容。
语音识别的过程中,需要考虑语音的韵律、音调、语速等多个方面,以提高识别的准确率。
而且,语音识别还需要考虑到不同的语音特点,比如口音、方言等,以便更好地适应不同的语音输入。
总的来说,语音芯片的原理是通过声音采集、信号处理和语音识别三个步骤来
实现的。
通过这些步骤,语音芯片可以实现从声音到数字信号再到语音识别的全过程,为人们提供了便利的语音交互方式。
在未来,随着人工智能和语音识别技术的不断发展,语音芯片的应用范围将会越来越广泛,为人们的生活带来更多的便利和乐趣。
WTN6系列语音芯片说明书

WTN6系列语音芯片说明书WTN6系列语音芯片:一种与世界交流的语言神器随着科技的不断发展,人们对于科学技术的需求也越来越多样化。
一项能够满足人类交流需求的科学技术,就是语音芯片。
WTN6系列语音芯片是目前市场上比较流行的语音芯片之一。
本文将重点讲述WTN6系列语音芯片的特点、功能及应用领域。
I. WTN6系列语音芯片的特点WTN6系列语音芯片是一种高性能、低功耗的语音识别和语音合成芯片。
它可以自主实现语音识别、语音合成,从而实现语音应用场景中的自动化控制。
其特点主要表现在以下方面:1. 硬件配置:WTN6系列语音芯片使用ARM内核,具有较高的计算速度和计算能力,可以满足一般语音应用场景的需求。
2. 语音识别技术:WTN6系列语音芯片使用了成熟的语音识别技术,支持中文普通话、英语等多种语言的识别,且支持自定义的指令词语。
3. 语音合成技术:WTN6系列语音芯片支持多种语音合成技术,如TTS技术、录音技术等。
且具有较高的合成效果和较好的语音效果。
4. 稳定性:WTN6系列语音芯片具有较高的稳定性和可靠性,外部干扰对其影响较小,适应多种环境。
II. WTN6系列语音芯片的功能WTN6系列语音芯片具有丰富多彩的功能,主要表现在以下几方面:1. 语音指令识别:WTN6系列语音芯片支持多种语音指令识别,如语音开机、语音关机、语音调节音量、语音播放音乐等。
2. 语音合成:WTN6系列语音芯片可以实现多种语音合成功能,如汉字转音频、语音播报时间、天气预报、新闻播报等。
3. 语音对话功能:WTN6系列语音芯片具有语音对话功能,可以实现人机对话、智能问答等多种应用场景。
4. 语音控制家居:WTN6系列语音芯片可以将语音指令和家居设备关联起来,实现语音控制家居设备的功能。
III. WTN6系列语音芯片的应用领域WTN6系列语音芯片的应用场景较多,主要涵盖以下几个方面:1. 智能家居:WTN6系列语音芯片可以实现智能家居的语音控制,如语音开关灯、语音调节温度、语音播报新闻等。
语音识别芯片LD3320介绍第一讲

语音识别芯片LD3320介绍语音识别芯片LD3320简介LD3320 芯片是一款“语音识别”芯片,集成了语音识别处理器和一些外部电路,包括AD、DA 转换器、麦克风接口、声音输出接口等。
LD3320不需要外接任何的辅助芯片如Flash、RAM 等,直接集成在LD3320中即可以实现语音识别/声控/人机对话功能。
并且,识别的关键词语列表是可以任意动态编辑的。
语音识别芯片LD3320实物图语音识别芯片LD3320主要特征1、特有的快速而稳定的优化算法,完成非特定人语音识别。
不需要用户事先训练和录音,识别准确率95%。
2、不需要外接任何辅助的Flash芯片,RAM芯片和AD芯片,就可以完成语音识别功能。
真正提供了单芯片语音识别解决方案。
3、每次识别最多可以设置50项候选识别句,每个识别句可以是单字,词组或短句,长度为不超过10个汉字或者79个字节的拼音串。
另一方面,识别句内容可以动态编辑修改, 因此可由一个系统支持多种场景。
4、芯片内部已经准备了16位A/D转换器、16位D/A转换器和功放电路,麦克风、立体声耳机和单声道喇叭可以很方便地和芯片管脚连接。
立体声耳机接口的输出功率为20mW,而喇叭接口的输出功率为550mW,能产生清晰响亮的声音。
5、支持并行和串行接口,串行方式可以简化与其他模块的连接。
6、可设置为休眠状态,而且可以方便地激活。
7、支持MP3播放,无需外围辅助器件,主控MCU将MP3数据依次送入LD3320芯片内部就可以从相应PIN输出声音。
可以选择从立体声耳机或者单声道喇叭获得声音输出。
支持MPEG1,MPEG2和MPEG 2.5等格式。
8、工作供电为3.3V,如果用于便携式系统,使用3节AA电池就可以满足供电需要。
语音识别芯片LD3320内部电路的简单逻辑图说明如下:一、电压要求:1、VDD 数字电路用电源输入 3.0 V–3.3 V。
2、VDDIO 数字I/O电路用电源输入 1.65 V–VDD。
常用语音芯片

常用语音芯片语音芯片是一种集语音识别、语音合成和语音处理功能于一体的集成电路芯片,被广泛应用于智能音箱、智能手机、车载电子、语音助手等领域。
随着人工智能技术的快速发展,语音芯片在人机交互、智能控制等方面发挥着重要作用。
下面是一些常用的语音芯片。
1. CMU Sphinx:CMU Sphinx是一种开源的语音识别系统,具有较高的识别准确率和良好的性能。
它适用于嵌入式设备和个人电脑,可实现连续语音识别和关键词检测等功能。
2. Microsoft Azure Speech:Microsoft Azure Speech是微软公司提供的一种云端语音服务。
它可以轻松实现语音转文本、文本转语音、关键词检测等功能,具有高度可定制性和强大的语音处理能力。
3. Google Cloud Speech:Google Cloud Speech是谷歌公司的语音识别服务,提供准确的语音转文本功能,并支持多种语言和实时音频流处理。
它适用于智能音箱、智能手机等领域,能够满足不同场景的需求。
4. Apple Siri:Apple Siri是苹果公司的语音助手,搭载在iPhone、iPad等设备上。
它采用自然语言处理和机器学习技术,可以回答问题、发送信息、设置提醒等,并支持多种语言。
5. Amazon Alexa:Amazon Alexa是亚马逊公司的语音助手,搭载在Echo智能音箱上。
它可以通过语音控制家居设备、播放音乐、查询天气等,具有丰富的技能和强大的智能控制能力。
6. Baidu DuerOS:Baidu DuerOS是百度公司的语音助手平台,提供语音识别、语音合成和语义理解等功能。
它支持人机对话、智能家居控制、在线购物等应用场景,是智能音箱等设备的理想选择。
7. iFLYTEK:iFLYTEK是中国科大讯飞公司开发的一种语音技术平台,提供语音识别、语音合成和语义理解等服务。
它在语音处理领域有着较高的影响力,被广泛应用于智能交互、教育培训等领域。
常用的语音芯片工作原理_分类为语音播报 语音识别 语音合成tts
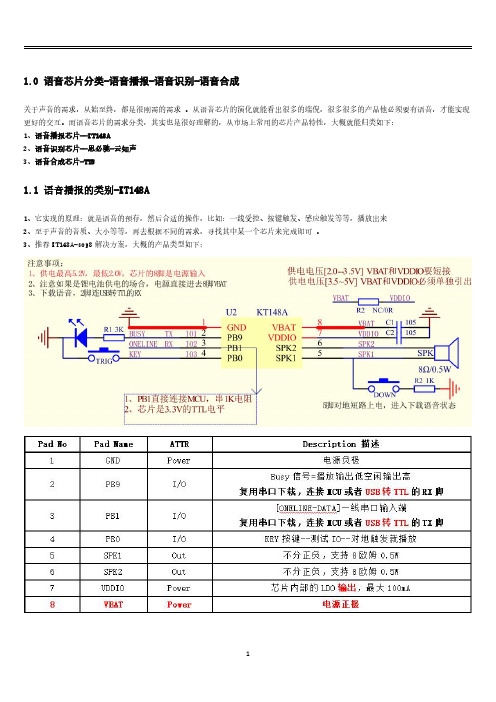
1.0语音芯片分类-语音播报-语音识别-语音合成关于声音的需求,从始至终,都是很刚需的需求。
从语音芯片的演化就能看出很多的端倪,很多很多的产品他必须要有语音,才能实现更好的交互。
而语音芯片的需求分类,其实也是很好理解的,从市场上常用的芯片产品特性,大概就能归类如下:1、语音播报芯片--KT148A2、语音识别芯片--思必驰-云知声3、语音合成芯片-TTS1.1语音播报的类别-KT148A1、它实现的原理:就是语音的预存,然后合适的操作,比如:一线受控、按键触发、感应触发等等,播放出来2、至于声音的音质、大小等等,再去根据不同的需求,寻找其中某一个芯片来完成即可。
3、推荐KT148A-sop8解决方案,大概的产品类型如下:1.2语音识别的类别-思必驰-云知声1、这个品类就很复杂了,是语音芯片里面最复杂的存在,常见的家电语音控制,设备的语音唤醒,在线识别和离线识别2、都是相差很多很多,包含技术难度,使用难度等等,还有最最重要的就是成本,简直是眼花缭乱。
3、因为市场太小,能做芯片的公司没有算法,而有算法的公司则没有能力做芯片,所以还在过渡阶段,同时对客户量的要求也比较高。
1.3语音合成的类别-TTS1、这个品类,其实是非常好的一个应用,但是还是因为市场太小,导致芯片的成本分摊不下来2、它实现的原理,就是将需要用到的音色库,存储在芯片或者外置存储器里面,需要播放的时候,取出不同音色库组合出来声音3、优点就是播放可以随意组合,非常好用,非常灵活4、缺点,就是贵,并且还没有太多选择,就科大讯飞、宇音天下在做,好像科大讯飞做不下去停产了1.4语音芯片的总结总之,需要这方面的需求,还是强烈推荐语音播报芯片,毕竟这个对芯片的要求相对低,所以成本控制的比较好如果需要医院叫号机类型的应用,那TTS就必须上了,没有什么比他还灵活的至于语音识别类型的应用,离线的应用还是推荐云知声,他们的平台做得好,前期验证的成本比较低还要分清楚您的需求,到底是离线,还是在线离线就是不联网,不连app,比如语音小夜灯那种产品在线,就是联网,联app,比如:小爱音箱那种产品。
常用离线语音识别芯片有哪些?

常用离线语音识别芯片有哪些?语音识别芯片也叫语音识别IC ,与传统的语音芯片相比,语音识别芯片最大的特点就是能够语音识别,它能让机器听懂人类的语音,并且可以根据命令执行各种动作,如眨眼睛、动嘴巴(智能娃娃)。
除此之外,语音识别芯片还具有高品质、高压缩率录音放音功能,可实现人机对话。
1、NRK10语音识别芯片模块:NRK10为九芯电子自主研发的一款语音识别芯片,无须外围元件,直接对接外部,集成了一颗高性能、低成本的离线语音识别芯片,具有语音识别及播报功能,需要外挂 SPI-Flash,存储词条或者语音播内容。
他具有识别率高,工业级性能、简单易用,更新词条方便等优势。
广泛应用在智能家居、AI人工智能、玩具等多种领域。
固定词条,非特定人识别可识别20个词条(每个词条建议三字或以上),总字数在50^ 60字之间。
识别环境:安静无回声。
识别效果:安静无回声环境,2米内识别率可达90%及以上,最远距离可以达到5米。
音频输出-PWM输出,可直接驱动8欧0. 5W喇叭; DAC 输出,可外接功放。
音频输出的内容需要放置在外挂的SPI_ Flash 中。
低电压复位:低于1.6V芯片进行复位内置低压差稳压器(LDO) -可在3.3V提供25ma负载电流-可配置的输出电压: 8个选项1.5v/1.7v/1. 8v/2.4v/2. 5v/2. 7v/3v/3. 3v,默认为3. 3V。
工作温度: -10° C~+70° C。
封装形式有LQFP32、COB。
2、NRK220X语音识别芯片;NRK220X系列语音识别芯片是一款适合工厂量产型的工业级语音识别芯片。
专用于语音处理的人工智能芯片可广泛应用于家电、家居、照明、音箱、玩具、穿戴设备、汽车等产品领域实现语音交互及控制。
NRK220X支持本地大词汇量语音识别和声纹识别和内置的CPU 核结合可以做各类智能语音方案应用。
NRK220X内置高性能低功耗Audio Codec模块和硬件音频处理模块可以外接麦克风实现单芯片远场降噪和回声消除等功能。
LD3320介绍

LD3320介绍LD3320是一颗功能强大的语音识别芯片,能够实现语音识别、语音合成和语音控制等功能。
该芯片采用了数字信号处理技术和嵌入式系统设计思想,具有高性能、低功耗和易于使用的特点。
接下来,我将详细介绍LD3320芯片的特点、应用领域和工作原理。
首先,LD3320芯片具有多种特点。
首先,该芯片集成了数字信号处理器(DSP),具有良好的信号处理能力和高性能。
其次,LD3320芯片采用了低功耗设计,能够满足低功耗应用的需求。
第三,该芯片支持多种语音格式的识别和合成,具有较高的语音识别精度和语音合成质量。
此外,LD3320还支持语音控制功能,可以通过语音指令来控制外部设备的运行。
LD3320芯片适用于多种场景和应用领域。
首先,它可广泛应用于智能家居领域,实现语音控制家电设备的功能,如通过语音指令控制灯光开关、调节温度等。
其次,LD3320芯片可以用于智能穿戴设备,如智能手表、智能眼镜等,实现语音交互、语音助手等功能。
此外,该芯片还可应用于教育领域,例如语音学习机、语音教具等,帮助儿童提高语言表达和听力能力。
总之,LD3320在智能化时代的各个领域都具有广阔的应用前景。
LD3320芯片的工作原理如下。
首先,通过麦克风采集声音信号,并进行预处理,包括信号增益调整、噪声抑制等操作。
然后,将预处理后的声音信号传输给LD3320芯片。
LD3320芯片内部的DSP通过提取音频特征、信号分析等算法对声音进行处理,并将处理后的音频信号与存储在芯片内的语音数据库进行匹配。
最后,LD3320芯片将识别出的语音结果输出给目标设备,如处理器或控制器。
在实际应用中,使用LD3320芯片还需要相应的开发工具和软件支持。
目前,市面上有一些基于LD3320芯片的开发板和开发套件,可以提供给开发者进行开发。
此外,LD3320芯片还需要配合相应的软件库和SDK进行编程和调试。
开发者可以根据具体的需求选择适合的开发工具和软件平台,来实现针对LD3320芯片的语音识别和语音控制应用。
语音芯片有哪些

语音芯片有哪些语音芯片是一种能够实现语音信号的采集、处理和分析的集成电路。
它通过将语音信号转化为数字信号,并利用算法进行处理,提取出有用的信息。
语音芯片在许多领域都有广泛的应用,如语音识别、语音合成、语音转换等。
下面是关于语音芯片的一些常见型号和应用的介绍。
1. Cirrus Logic CS42448:这是一款低功耗、高性能的音频DAC(数字模拟转换器)芯片。
它广泛应用于高品质音频设备,如家庭影院系统、音频放大器等。
2. Texas Instruments AIC3204:这是一款高性能、低功耗的音频编解码器。
它适用于各种语音和音频应用,如手机、无线耳机、手机扬声器等。
3. NXP Semiconductors UDA1334A:这是一款低功耗、高性能的音频DAC芯片。
它适用于音频系统、电视机、汽车音响等产品。
4. Analog Devices ADAU1787:这是一款高性能、低功耗的音频编解码器芯片。
它适用于语音识别、语音合成、噪声消除等应用。
5. Infineon Technologies CIC61508:这是一款高集成度、低功耗的语音识别芯片。
它广泛应用于智能家居、智能手机等产品。
6. Synaptics CX20924:这是一款高性能、低功耗的声音放大器芯片。
它适用于多媒体设备、高端耳机等产品。
7. STMicroelectronics MP23ABS1:这是一款低功耗、高性能的麦克风芯片。
它适用于语音识别、语音合成等应用。
8. Qualcomm QCC3020:这是一款低功耗、高性能的蓝牙音频芯片。
它适用于蓝牙耳机、蓝牙扬声器等产品。
9. Knowles SPH0645LM4H-B:这是一款高灵敏度、低功耗的数字麦克风芯片。
它适用于语音识别、语音合成等应用。
10. Intel IVAAP376AP:这是一款高性能、低功耗的语音处理器芯片。
它广泛应用于智能音箱、智能摄像头等产品。
这些语音芯片在不同的应用领域发挥着重要的作用,为我们提供了更加便捷、智能的语音交互体验。
asr芯片

asr芯片ASR(Automatic Speech Recognition)芯片是一种用于识别和处理人类语音的集成电路,通常会被用于语音识别、语音转换和语音命令等应用领域。
ASR芯片可以将人类语音转化为机器可读的数字信号,以便机器能够理解和执行相应的命令。
ASR芯片的核心是语音识别引擎,它由一系列算法和模型组成,用于对输入的语音信号进行分析和解码。
这些算法通常基于统计建模和机器学习技术,通过大量的训练数据使得ASR芯片具备较高的识别准确率和鲁棒性。
ASR芯片的工作流程通常包括以下几个步骤:1. 预处理: 对输入的语音信号进行预处理,包括去噪、降噪、特征提取等操作,以提高信号质量和特征的可区分度。
2. 特征提取: 从预处理后的语音信号中提取有价值的特征,通常使用MFCC(Mel Frequency Cepstral Coefficients)等特征表示方法。
3. 建模训练: 使用训练数据对ASR芯片进行建模训练,包括声学模型、语言模型和发音模型等。
这些模型可以捕捉语音信号和语言模式之间的统计关系,从而提高识别准确率。
4. 解码识别: 对提取的特征进行解码和识别,通过比较不同可能的识别结果,找到最有可能的识别结果。
解码过程通常使用动态规划算法,如维特比算法。
5. 后处理: 对解码得到的识别结果进行后处理,包括词图剪枝、语言模型重排等操作,以提高识别结果的准确性和流畅性。
6. 输出结果: 将识别得到的文字结果输出到外部系统,如文本编辑器、语音合成等。
ASR芯片在实际应用中有广泛的用途,例如语音助手、智能家居、智能驾驶、电话自动接听等。
它使得人机交互更加便捷和自然,提高了人们生活和工作的效率。
然而,ASR芯片在面临一些挑战和难题。
首先,不同语种和口音的语音信号具有很大的差异性,这增加了语音识别的难度。
其次,语音信号往往伴随着噪声、回声和变调等问题,这些都会降低识别的准确度。
另外,对于一些特殊领域和术语,ASR 芯片的识别效果可能较差,需要进行额外的训练和优化。
语音识别芯片

语音识别芯片语音识别芯片是指一种嵌入式芯片,用于将人类语音转化为机器可识别的数字信号。
随着人工智能技术的快速发展,语音识别技术也得到了广泛应用,语音识别芯片作为实现语音识别功能的重要设备,其重要性也逐渐得到了认可。
首先,语音识别芯片的原理是将声音转化为数字信号。
语音信号经过传感器采集后,通过模拟-数模转换器将声音信号转化为数字信号,然后再通过数字信号处理器进行声音分析和识别。
语音识别芯片通常采用高性能的数字信号处理器,以实现复杂的音频处理算法。
其次,语音识别芯片的应用场景非常广泛。
在智能家居领域,语音识别芯片可以被用于语音助手设备,如智能音箱、智能电视等,可以通过语音指令控制设备的开关、调节音量等功能。
在智能交通领域,语音识别芯片可以被用于车载语音助手,实现语音导航、语音拨号等功能。
在医疗领域,语音识别芯片可以被用于语音病历输入设备,方便医生进行记录和查询。
再次,语音识别芯片的发展面临一些挑战。
首先是语音识别的准确率限制,尤其是在复杂背景噪音下的识别效果不理想。
其次是语音识别的时延问题,尤其是对实时性要求较高的应用场景。
此外,语音识别芯片还需要满足低功耗和小尺寸等要求,以适应嵌入式设备的需求。
最后,对于未来的发展趋势,语音识别芯片还有很大的发展空间。
首先是算法的进一步提升和优化,可以通过深度学习等技术来提高语音识别的准确率和时延。
其次是硬件技术的改进,可以通过集成多种传感器和处理器,将语音识别芯片的功能拓展到更多领域。
此外,随着5G技术的普及,语音识别芯片可以通过云计算来实现更强大的计算能力和更全面的语言模型,提供更好的语音识别效果。
总之,语音识别芯片是一种重要的人工智能芯片,可以将人类语音转化为机器可识别的数字信号。
它的应用场景广泛,但也面临一些挑战。
随着技术的发展,语音识别芯片有望实现更高的准确率和更低的时延,为各种智能设备和应用提供更好的语音交互体验。
语音芯片简介

语音芯片简介语音芯片是一种通过极小的芯片尺寸和高性能晶体管集成电路技术实现的人工智能硬件设备。
它能够将用户语音转化为数字信号,并通过识别与之相应的语音模式来实现声音的识别和分析。
语音芯片的出现为语音识别、语音合成、声音分析等领域的发展提供了有力的支持。
语音芯片主要由模拟前端部分和数字后端部分组成。
模拟前端部分负责将声音信号转化为模拟电压信号,并对其进行过滤、放大、变换等处理,以提高语音信号的质量。
数字后端部分负责数字信号的接收、解码、处理和输出,以实现声音的识别、合成等功能。
模拟前端和数字后端的紧密结合使得语音芯片具有较高的实时性和准确性。
语音芯片的应用范围非常广泛。
首先,它可以被应用于智能家居领域,通过语音识别技术,用户可以通过语音控制家电设备,实现智能化的家居管理。
其次,语音芯片还可以用于智能手机和其他便携设备中,使得用户可以通过语音指令进行操作,提高使用便捷性。
此外,语音芯片还可以应用于智能车载系统中,用于语音导航、车载娱乐等功能的实现。
此外,语音芯片还可以被应用于安防领域,通过语音识别技术,将声音转化为文本或者指令,为安防监控提供更加便捷、智能的解决方案。
虽然语音芯片在人工智能领域的应用前景广阔,但目前仍然存在一些挑战和问题。
首先,语音芯片在环境噪声、语音口音等方面的适应性有待提高,目前还存在一定的误识别率。
其次,语音芯片的功耗问题也需要得到解决,目前一些高性能的语音芯片在工作时需要消耗大量的能量,这限制了其在一些移动设备上的应用。
此外,语音芯片的安全性和隐私保护问题也需要引起重视,避免用户的个人隐私被滥用。
总的来说,语音芯片作为一种先进的人工智能硬件设备,为语音识别、语音合成等领域的发展提供了有力的支持。
随着技术的进一步发展和突破,相信语音芯片将在未来的人机交互领域中发挥越来越重要的作用,为人们提供更加智能便捷的语音体验。
ld3320芯片资料

ld3320芯片资料LD3320芯片是一款针对语音识别技术的专用芯片,由浪潮公司开发。
它具有高度的集成度、低功耗、低成本等优点。
LD3320芯片可以广泛应用于智能家居、智能终端、汽车导航等领域。
首先,LD3320芯片具有高度的集成度。
它集成了语音识别引擎、音频解码器、音频编码器等多种功能模块。
通过这些模块的协同工作,实现了语音识别、语音合成、录音、解码等功能,大大简化了系统的设计和开发流程。
同时,LD3320芯片还支持多种通信接口,如UART、I2C、SPI等,方便与外部设备的连接和数据传输。
其次,LD3320芯片具有低功耗的特点。
这主要归功于其先进的电源管理技术和低功耗设计理念。
LD3320芯片在待机状态下,功耗非常低,几乎可以忽略不计。
在正常工作状态下,功耗也很低,可以满足绝大多数应用场景的需求。
此外,LD3320芯片还支持多种功耗管理模式,可以根据具体的应用需求进行配置。
此外,LD3320芯片具有低成本的优势。
这得益于浪潮公司在芯片设计和生产上的技术积累和成本控制能力。
相比于其他智能语音芯片,LD3320芯片的价格更低,更加适合大规模应用。
而且, LD3320芯片的性能和功能也不逊于其他同类产品,可以满足绝大多数应用需求。
最后,LD3320芯片还具备良好的兼容性和稳定性。
该芯片支持多种操作系统和开发环境,如Windows、Android、Linux等,可以方便地与其他硬件和软件进行集成。
同时,LD3320芯片在工作稳定性上也经过了严格测试和验证,具有良好的抗干扰和抗干扰能力。
综上所述,LD3320芯片是一款具有高度集成度、低功耗、低成本和良好兼容性的专用语音识别芯片。
它的出现为智能家居、智能终端、汽车导航等领域的发展提供了有力的技术支持,有望推动智能化产品的普及和应用。
同时,它的广泛应用也将进一步推动语音识别技术的发展和进步,为人们的生活带来更多的便利和舒适。
PM66语音模块参数

PM66语音模块参数1.芯片类型:采用高性能的数字信号处理器(DSP)芯片,可实现高质量的语音处理和嵌入式语音识别。
2.音频输入:支持多种音频输入方式,包括模拟音频输入和数字音频输入。
模拟音频输入可以通过电容麦克风或线性输入接口实现,数字音频输入可以通过I2S或PCM接口实现。
3.音频输出:支持多种音频输出方式,包括模拟音频输出和数字音频输出。
模拟音频输出可以通过DAC接口实现,数字音频输出可以通过I2S 或PCM接口实现。
4.语音压缩算法:内置多种高效的语音压缩算法,可以实现高品质的语音压缩和解压缩,支持音频文件的压缩和存储。
5.语音识别功能:支持实时语音识别和离线语音识别两种模式。
实时语音识别可以实现实时语音指令的识别和执行,离线语音识别可以实现离线语音识别和关键词唤醒等功能。
6.语音合成功能:支持多种语音合成算法和语音合成引擎,可以实现高质量的语音合成和语音播放,支持多种语音效果和音调变化。
7.语音编解码器:支持多种语音编解码器,包括AMR、G.711、G.729等标准语音编解码器,可以实现高质量的语音传输和语音通信。
8.接口类型:支持多种接口类型,包括UART、SPI、I2C等,可以方便地与主控芯片或其他外部设备进行通信和控制。
9.供电和工作电压:支持宽电压输入,可以适应不同的供电电压和电流要求,工作电压范围通常为3.3V至5V之间。
10.开发工具和软件支持:提供丰富的开发工具和软件支持,包括开发文档、SDK和示例代码等,方便开发人员进行快速开发和应用。
总结:PM66语音模块是一款功能强大、性能卓越的语音模块,具有高品质的语音处理和语音识别能力,适用于多种语音应用场景。
它具有多种接口类型、多种音频输入输出方式和多种语音编解码器,可以满足不同的应用需求。
开发工具和软件支持完善,便于开发人员进行开发和集成。
语音芯片常见的分类及应用

语音芯片常见的分类及应用
语音芯片是一种专门用于处理语音信号的集成电路,具有高精度、低功耗等特点。
随着人工智能、物联网和智能家居等技术的快速发展,语音芯片越来越广泛地应用于很多领域。
一、语音芯片的分类
按照用途和性质,语音芯片可以分为以下几类:
语音识别芯片:主要用于语音识别和语音指令控制,如启英泰伦。
语音合成芯片:主要用于语音合成和语音播报,广泛应用于各种语音提示系统、智能客服系统等。
语音编解码芯片:主要用于语音的压缩和解压缩,使语音数据传输更加高效、稳定。
语音增强芯片:主要用于语音信号的降噪、回声抑制、自适应滤波等处理,提高语音通信质量。
二、语音芯片的应用
智能音箱:智能音箱以语音交互为主要方式,内置语音识别和语音合成芯片,可实现人机对话、智能家居控制、音乐播放等功能。
语音助手:语音助手将语音识别技术应用于移动设备和电脑中,可以通过声音控制来完成打电话、发送短信、播放音乐等操作。
智能客服:智能客服系统利用语音合成技术进行人工智能问答,大大提高了服务效率和体验。
自动驾驶:自动驾驶汽车需要使用多种传感器和处理器,其中语音识别和语音合成芯片起到了非常重要的作用。
医疗康复:在医疗康复领域,语音识别芯片可以用于听力康复、言语康复等方面。
总的来说,随着科技的不断进步,语音芯片在生活中的应用越来越广泛,未来也仍然有着广阔的前景。
avs芯片

avs芯片AVS芯片是指集成语音识别和语音合成功能的专用芯片。
AVS芯片通常用于智能音箱、智能家居设备、车载娱乐系统等物联网设备上,可以实现对话交互、语音控制等功能。
以下是关于AVS芯片的一些详细信息:首先,AVS芯片是一种嵌入式系统芯片,采用低功耗的设计,能够在物联网设备上长时间稳定运行。
AVS芯片具有高性能和高集成度,可以实现快速的语音识别和语音合成。
这使得设备能够在实时环境下准确地识别用户的语音指令,并将相应的操作反馈给用户。
同时,AVS芯片还支持多种语言和方言的识别,使设备能够适应不同地区和用户的需求。
其次,AVS芯片采用了先进的深度学习和人工智能算法,能够实现更精准和自然的语音交互。
它能够识别用户的语音指令,并根据上下文理解用户的意图,提供符合用户需求的反馈。
同时,AVS芯片还可根据用户的需求进行自我学习和优化,提升语音交互的准确性和适应性。
第三,AVS芯片具有优秀的音频处理和噪声抑制能力。
由于嵌入式设备通常在复杂环境下使用,如嘈杂的家庭环境、车辆内部等,传统麦克风会受到环境噪声的影响,导致语音识别准确率降低。
而AVS芯片采用了先进的降噪技术,可以有效减少环境噪声的影响,提升语音识别的准确率。
最后,AVS芯片具有较低的功耗和成本。
由于物联网设备通常需要长时间运行,低功耗是非常重要的一个指标。
AVS芯片通过优化硬件设计和算法实现了较低的功耗,能够满足物联网设备长时间稳定运行的需求。
同时,AVS芯片的集成度较高,可以减少硬件组件和电路板面积,降低设备制造成本。
总之,AVS芯片是一种专用芯片,用于集成语音识别和语音合成功能的物联网设备上。
它具有高性能和高集成度,支持多种语言识别,能够实现精准、自然的语音交互。
AVS芯片还具有优秀的音频处理和降噪能力,以及低功耗和低成本的特点。
随着物联网技术的不断发展,AVS芯片将在智能家居、车载娱乐等领域发挥越来越重要的作用。
语音识别芯片的工作原理

语音识别芯片的工作原理语音识别芯片,听起来就很高大上,对吧?其实它的工作原理并没有那么复杂,咱们可以简单聊聊。
想象一下,你在家里懒洋洋地躺着,突然想听音乐,或者让家里的智能助手帮你查个天气,嘴一张,指令就飞出去了。
你说完后,等着的就是这小小的语音识别芯片,它可不是个小角色,里面的科学原理可多着呢。
它得听懂你说的每一个字。
这可不是简单的听,而是要从你说的语音中提取出信息。
声音一进来,芯片就像个聪明的小侦探,开始分析这个声音。
这时候,声音被转化成一系列数字,就像把你的话变成了一种独特的密码。
听着是不是有点神秘?其实就是这样。
它会把你说的话分成小块,每个小块再进一步分析,像拼图一样把这些拼块组合在一起。
它得知道你说的是什么。
这一步就像把字典翻开,找出你说的每一个词。
这里就需要用到一个叫“模式识别”的东西,听着高深,其实就是看你说的这句话在它脑海中的模样。
就好比你在找你最爱的那本书,它就会在心里有个目录,帮你迅速找到。
要知道,这个过程可是极其复杂的,毕竟每个人说话的方式、语气、甚至口音都不一样。
那可是千差万别,真是五花八门啊。
说到这里,有趣的是,语音识别芯片也会慢慢“学习”。
没错,就是那个“学”的过程。
你每次说话,它都在记录,不断改进。
就像你在学习骑自行车,摔了几次之后就能稳稳当当地骑上去。
芯片也是,经过无数次的训练,最终能准确理解你说的每一句话。
听着是不是有点励志?不过说实话,有时候它也会出错,比如你明明是想说“天气不错”,结果它听成了“骑马去”。
哈哈,尴尬得不要不要的。
语音识别芯片的“理解力”也和它的算法息息相关。
这些算法就像是它的大脑,负责处理和理解信息。
随着技术的发展,这些算法越来越聪明,就像换上了新的引擎,跑得更快,更准。
人们还在不断探索,想让这些芯片更加人性化,让它们能更好地理解我们的情感。
你说,哪天如果它能理解我说“我今天心情不好”,再给我推荐一些轻松的音乐,那可真是太棒了!说到这里,有时候我们还会发现,语音识别芯片在各种场合下的表现可真是让人啼笑皆非。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
/amwdnvfku/blog/item/4ada7807b6fb697d0308812c.html
语音识别芯片资料
产品介绍
应用于消费类电子产品上的交互式语音集成芯片(RSC-100/164T,RSC-300/364,RSC4XX)是一种高性能、低成本的8位MCU,所有这类芯片内部集成有ADC、DAC、ROM(除了RSC-100/300)、RAM和麦克风的预放大电路,并拥有以下多种功能:与说话者无关/有关的语音识别、语音确认(PASSWORD)、语音和音乐合成,录音和回放、快速数字拨号(只有RSC-300/364)、持续监听。
产品线有两种通用目的的微处理器(RSC系列)
1. RSC-100/164T—低成本的版本(只支持4.0版本技术)
2. RSC-300/364(支持最新版本的6.0版本技术),它有更快的响应时间、先进和附加的技术(包括数字拨号,固定单词触发,同时产生数字记录和识别模板)
3. RSC-164/364产品的特性
a) 有64k内置ROM的8位微处理器;
b) 集成有A/D和D/A转换器;
c) DAC或PWM(Pulse Width Modulation);
d) 可实现DTMF 拨号;
e) 音源的AGC功能;
f) 16个通用I/O端口;
g) 片上有输出放大器;
h) 省电模式-最小的功耗(小于5UA)。
RSC-300/364产品特性
RSC-300/364是专门为消费类电子产品应用而设计的,拥有高度集成和高识别率的系统化芯片。
RSC-300/364有额外的SDAM和硬件加速器去支持SENSORY的最新技术(5.0以上)。
这种特别设计的8位微处理器在拥有灵活的编程时支持一系列语音技术:与说话者无关/有关的识别、语音和音乐的合成、语音确认、语音提示、持续监听、快速数字拨号、录音和回放。
RSC-300/364允许在片上存储最多6个与说话者有关的短句。
RSC-300与RSC-364的区别就是少一个64K的ROM,根据封装和版本的不同,RSC-300/364的价格在2.2~3.9美元之间。
RSC-4x产品特性
RSC-4x是Sensory INC.第4代的语音识别产品,它具有所有RSC-300/364的所有特性之外,还增加了不少功能。
RSC-4x支持Sensory Speech™ 7技术,改进的算法使识别准确率得到提高。
新增的T2SI技术使得制作SI模版节省了时间和资金投入。
在语音合成算法上也作了改进,“SX™”压缩技术使得语音的压缩率可以达到3K-8K bps(bits-per-second),是原来的1/10-1/4,大大减少了存储空间,节约了成本。
RSC-4x有三种型号,RSC-4000不含程序存储空间,RSC-4128 内部含128K 程序存储空间,RSC-4256内部含256K程序存储空间,供用户灵活选用。
VOICE DAILER特性(ASSP)
VOICE DAILER364是为了增加语音拨号而设计的,它可应用在非手持的车载电话、手持电话、PDA、答录机和其它个人电子设备。
使用者只需说出名字便可拨出相关的电话;VOICE DAILER-364芯片可管理一整套电话目录,包括名字、电话号码和语音识别模板。
SENSORY技术
与说话者有关的语音识别(Speaker Dependent, SD)
在识别时,每个识别词语需要使用者训练两次来创建语音模板,一个模板需要占用128个字节的存储量。
由于练习的原因,一般把需识别的词汇量限制在60个以内,但超过100个也是完全可以的。
通过正常设计,SENSORY的SD技术能达到99%的准确率。
与说话者无关的语音识别(Speaker Independent, SI)
——不需要训练
SI技术是为一种指定的语系而设计的(如英语、汉语、德语),它最多能识别14条命令(识别数量由ROM的容量决定)。
通过正常设计,SENSORY的SI技术能达到97%的准确率
语音确认(Speaker Verification, SV)
同SD技术有点相似,SV能辨别出现在的一句话与原来说的是否相同。
使用者可以训练1~4级密码(密码级数越多越安全)来开启设备。
误识率大概在1~6%。
根据环境、使用者数量、要求的安全程度的不同可设定五级训练难度。
语音自适应技术(Speaker Adaptive, SA)
对于单用户来说,SA通过一段时间对环境和说话者声音的适应,改进相关的语音模板,从而提高识别准确率。
持续监听(Continuous Listening, CL)
持续监听技术不需按键便可对某个特别、非连续的命令(在这之前需要静音)产生响应,SENSORY 提供SI和SD两种持续监听技术。
WORD SPOTTING
——在一句话中响应某个指定词语。
WORD SPOTTING是持续监听的升级版本,它可以从正常的谈话中“捕捉”并响应某个关键词语,这种技术提供了更为自然、友好的人机界面。
快速数字拨号(Fast Digit)
——输入电话号码和数字串
快速数字拨号采用了优化的识别算法来实现快速数字串输入,这种技术对语音拨号应用是非常理想的,辟如用在手持通信设备、个人拨号器,手机、非手持设备。
录音和回放(Record & Playback)
——压缩的数字声音再现。
SENSORY的交互式语音处理器可以14Kbit/s的数据率来存储声音在外置的RAM上。
它可用在答录机、变音器、手持录音设备上。
根据回放的质量和数量要求,也可以改变片上的压缩率。
录音过程中出现完全静音时,微处理器会自动去掉静音这一段来改善声音质量,节约存储空间。
语音合成(Speech Synthesis)
——创建一个自然的使用界面。
语音效果合成是通过在片上的微处理器读取ROM上的数据实现的。
SENSORY合成技术使用了时域技术来压缩语音,使数据率在10kbit/s以下,另外使用了加强的ADPCM算法来回放声音。
语音合成技术降低了对手工指令的依赖,使人机界面更为友好。
音乐合成(Music Synthesis)
SENSORY的音乐合成技术能产生四首模拟乐曲,用户也可用一种乐器的声音和音阶来自定义乐库。
合成技术不同于数字录音,一首2~3分钟的歌曲只需5KB的片外存储容量,在电话机的应用中,这种功能还可以产生DTMF音,使RSC微处理器实现直接拨号功能。
产品控制
——完全的系统芯片解决方法。
RSC语音处理器可单独工作或作为协处理器来实现语音功能,通常,它是一个复杂系统的核心:它可提供可变长度的指令,传输率达到4MIPS 、两个计时器、外部存储器接口、DAC和PWM输出,麦克风预放大器、16个I/O端口等。
开发工具
演示模板164T和364 (Demo Unit)
通过演示模板,您能充分体会到SENSORY公司SR芯片的真正魅力。
每个模板都能单独演示独一
无二的技术,包括SI、SD、SV等,164T和364有着几乎相同的硬件,两者的主要区别是预编程的软件和相关库文件。
RSC-164T和RSC-364开发工具(Development Kit)
有着相同硬件平台的RSC-164T和RSC-364开发工具,提供了灵活、简便的开发环境,它包括硬件、软件两部分。
利用它可开发出用户想要的新颖语音产品。
软件开发人员可以无限制的接触到独特的语音技术。
Rapid Prototyping Module(适配器, RPM)
它用来连接164T/364演示模板和RSC-164T/364开发工具的,开发人员可以下载RSC软件到适配器,从而快速应用到自己的产品上。
Voice Dialer364开发工具
Voice Dialer364开发工具的硬件部分是演示模板364,利用这套工具可以开发出任何基于VD364芯片的语音拨号
RSC-4x开发工具(Development Tools)
仿真器(PICE)
PICE是第三方公司开发的RSC-4x的在线仿真器,功能强大,配有C编译器,更方便于开发。
RSC-4x Demo/Evaluation Board
此为功能演示及开发板,具有下载功能,适用于功能和效果评定和用于简单的开发。