实验二、运用DPS制作次数分布表和图共19页文档
实验二、运用DPS制作次数分布表和

VS
保存结果
生成的次数分布表可以通过DPS的“文件 ”菜单中的“保存”选项进行保存。可以 选择保存为图片、PDF、Word等多种格 式的文件,以便后续查看和使用。
05 次数分布表结果解读与分 析
解读次数分布表各项指标含义
频数
指某一特定数值或区间内数据出现的次数,反映数据的分 布情况。
频率
频数与总次数的比值,表示某一特定数值或区间内数据出 现的相对频率。
异常值处理
在数据集中可能存在一些异常值,如购买数量为负数或极大值等。对于这些异常值,需要进行识别和 处理。可以采用箱线图等方法识别异常值,并根据实际情况进行删除或替换等操作。
03 DPS软件介绍及操作指南
DPS软件概述
要点一
数据处理系统(Data Processing Syst…
DPS是一款功能强大的数据处理和分析软件,广泛应用于 科研、教育、工程等领域。它支持多种数据类型,提供丰 富的数据处理和分析工具,帮助用户高效地完成数据管理 和分析任务。
格式化时间戳
原始数据中的购买时间为时间戳格式,需要将其 转换为可读的日期时间格式,以便后续分析。
整理数据格式
将数据整理为以用户ID为行索引、商品ID为列索 引的二维表格形式,方便后续统计和分析。
缺失值与异常值处理
缺失值处理
对于数据集中存在的缺失值,需要根据实际情况进行处理。如果缺失值较少且对结果影响不大,可以 采用删除缺失值所在行的方法;如果缺失值较多或对结果影响较大,可以采用插值法等方法进行填充 。
DPS软件支持多种数据 输入方式,如手动输入 、导入外部数据文件等 。用户可以在数据编辑 区对数据进行增删改查 等操作。
DPS提供丰富的数据整 理工具,如排序、筛选 、分组等。同时,用户 还可以利用数据转换功 能将数据转换为适合分 析的格式。
DPS数据处理系统使用要点

DPS数据处理系统使用要点一..基本参数估计、异常值检基本参数估计将数据在电子表格区(即数据编辑器)输入后,定义成数据块,然后点数据分析→基本参数估计。
就会立即得到基本参数。
异常值检验先将待检验数据输入—→定义为数据块—→点数据分析—→点异常值检验。
如果有异常数据,则异常数据就会变为红色。
(异常值检验)⏹二、次数分布及t 检验1.样本次数分布DPS作次数分布表步骤:(1)输入数据并定义成数据块(2)试验统计→次数分布及平均数比较→次数分布→OK→输出样本次数分布表结果⏹2.单样本均数与总体均数比较的t检验⏹步骤:⏹按行输入7个数,第二行输入总体平均数→定义数据块→选试验统计→单样本平均数检验→在弹出的对话框中输入总体平均数→OK(不能做)⏹3.配对样本t检验⏹步骤:⏹输入数据→定义数据块→选试验统计→两样本比较→配对两处理t检验→输出结果配对样本t检验(不能做)4.两样本均值差异t检验方法:(1)将两个处理的样本观察值分两行输入,并定义成数据块。
(2)试验统计→次数分布及平均数比较→student t检验→输出结果(两样本t检验)5.小样本均值差异检验方法:(1)输入数据,并定义成数据块(2)试验统计→次数分布及平均数比较→样本较少时平均数差异检验→输出(显示)结果。
三、试验设计及统计分析一)全面试验设计(一)单因素完全随机设计 1.试验方案设计 用DPS 系统产生随机数:为安排试验中所有试验次数的试验随机顺序,DPS 系统操作步骤如下: 试验设计→完全随机及随机区组设计→完全随机分组→弹出“完全随机试验设计”对话框→输入“实验样本数”和“分组组数”→确认后就输出要试验的次数的随机顺序。
(样本数和分组数一般是一样的)DPS 单因素试验设计步骤(可以不看) 因素水平按列排列 A1 A2 . Am定义数据块 → 试验设计→完全随机及随机区组设计→单因素随机区组设计→在弹出对话框中输入重复数→OK2.统计分析(方差分析方法) 用DPS 对单因素试验资料分析步骤 ①数据输入格式在数据编辑器中按规定格式将试验资料整理表中的数据输入。
试验一 运用EXCEL制作次数分布表和图

②选取单元格区域A5:E7 数据,单击“图表 向导”图标 ,将弹出“步骤之1——图表类 型”对话框界面,采用簇状柱形图(默认) (见图2-10)。
③按下一步键,将弹出“步骤之2——图表源 数据”对话框(见图2-11)。数据区域将自动 显示Sheet1!$A$5:$E$7”,系列产生在“行”, 中部显示的“图形”符合比较甲乙丙三地的四 苗接种率要求(如果需要比较四苗接种率分别 在甲乙丙三地的情况则应改“系列产生在” 列)。在该对话框可以选择“系列”,建立具 有多个系列数据的统计图。
表2、输入组限
从工具栏里找到“数据分析”,选择“直 方图”,输入区域选择数据块,接受区域选 择组限部分或组中值,输出区域选择空白区 域。选中累积百分率和图表输出,点击确定, 得到结果。得到的直方图是间断的,可以手 动修改。点击图表内方柱形中部,出现一系 列数据点,单击右键,选择“数据系列格 式”—“选项”—将“分类间距”改为0。
例1 2000 年甲、乙、丙三地年报表资料显 示:卡介苗、脊髓灰质炎疫苗、百白破疫苗、 麻疹疫苗的接种率(%)见表2-1 所示,请 根据表中数据创建统计图,以此比较三地的 四苗接种率情况。
Excel 创建统计图按下列步骤进行: 创建统计图按下列步骤进行: ①按图2-9 键入表2-1 数据。如果已在Word 中建立了这样一张表格,复制粘贴到单元格 A2 后,当修改统计表的标题格式即可。
运用EXCEL制作次数分布表和图 运用EXCEL制作次数分布表和图 EXCEL
实验目的: 实验目的 熟练掌握运用EXCEL制作次数分布表
和图, 进行数据整理。
实验材料: 实验材料:计算机, EXCEL软件 实验地点: 实验地点:机房 实验内容: 实验内容:
一、制作次数分布表: 制作次数分布表:
DPS统计分析操作实验

统计量 2.8213 3.3338 3.3317
自由度 1 1 1
p值 0.093 0.0679 0.068
独立性检验
例1:巴中医生马廷思搜集到犯有各种贪污、行贿 罪的官员与廉洁官员的寿命的调查资料:580名贪 官中有348人的寿命短于外地平均寿命,232人的 寿命大于外地平均寿命,580名廉洁官员有93人的 寿命短于外地平均寿命,487人的寿命大于外地平 均寿命.。试剖析官员在经济上能否洁白与他们寿 命的长短之间能否独立?
输入数据
定义数据块
实验统计--完全随机设计--二要素有重复实验设计剖析
剖析结果
多要素方差剖析-正交实验
例 在中止矿物质元素对架子猪补饲实验中,调查补饲配方〔A〕、 用量〔B〕、食盐〔C〕3个要素,每个要素有3个水平(表5.19)。实 验采用正交设计,各处置号实验只中止一次,实验方案及实验结 果〔增重〕列于表5.20,试对其中止方差剖析。
项目
观察值(0) 理论值(e)
黄子叶苗 762 750
F2
绿子叶苗 38 50
合計
800 800
〔2〕数据陈列:在列
观察值(0) 762 38
理论值(e) 750 50
〔3〕选定区域,点击菜单上分类数据统计—模型拟合优度检验
〔4〕DPS剖析结果
检验方法 Pearson 卡方 似然比卡方G Williams校正G
采用单侧固定实验设计,设:H0为洁白与寿命长短 之间相互独立,H1为相互不独立。P>0.05,接受H0, P<0.05,接受H1。
〔1〕数据整理
廉洁与否
短寿
长寿
贪官
348
232
清官
93487DPS统源自分析操作实验2021/7/7
利用DPS数据处理系统进行均匀试验设计与分析
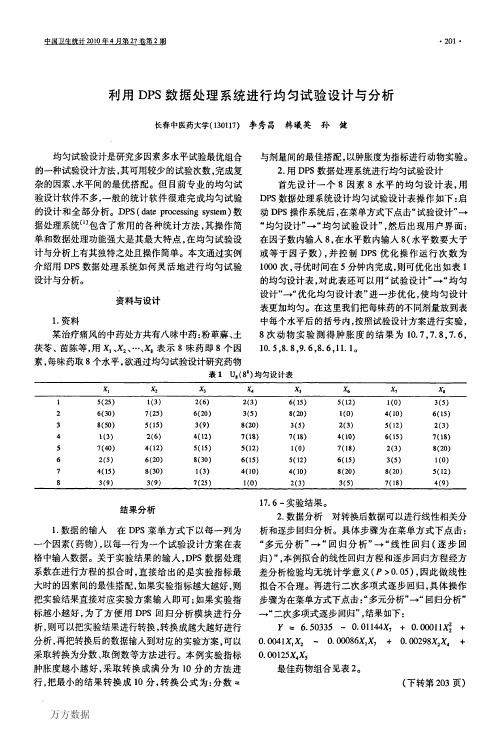
设计”一“优化均匀设计表”进一步优化,使均匀设计
表更加均匀。在这里我们把每味药的不同剂量放到表 中每个水平后的括号内,按照试验设计方案进行实验, 8次动物实验测得肿胀度的结果为10.7,7.8,7.6,
10.5,8.8,9.6,8.6,11.1。
U8(88)均匀设计表
l 2
3
4
5 6 7 8
墨墨一一删∽㈣㈣ ㈣㈤删㈣柳㈣∞㈣
方法,利用其回归模型来完成数据的分析并得到最佳 组合的方法,解决了在实验指标越小越好的情况下,用 DPS数据处理系统中的回归模型进行数据分析的过 程。此法操作简单,实用性强,对实际应用均匀试验设 计的工作者来说,是一种很实用的方法。
参考文献
1.唐启义,冯明光.DIS数据处理系统.北京:科学出版社.2(X}7. 2.方开泰,马长兴.正交与均匀试验设计.北京:科学出版社。2001.
一个因素(药物),以每一行为一个试验设计方案在表
格中输入数据。关于实验结果的输入,DPS数据处理 系数在进行方程的拟合时,直接给出的是实验指标最
“多元分析”叶“回归分析”_“线性回归(逐步回 归)”,本例拟合的线性回归方程和逐步回归方程经方 差分析检验均无统计学意义(P>0.05),因此做线性 拟合不合理。再进行二次多项式逐步回归,具体操作
252.253.
4.宋忙华,隋虹,汪婷婷,等.聚类分析在膳食模式研究中的应用.中国 卫生统计.2009,26(2).
5.Baeher
J,Wenzig K,Vogler M.SPSS TwoStep Cluster:A Fh'st
presente(i砒RC33 Sixth
International
Evalua-
法只适合于连续型变量。此外,两阶聚类法还能够对 数十万规模的数据进行聚类,这是层次聚类法所不能 媲美的。正因为如此,两阶聚类法一经提出就已在许
第二节 次数分布表

第二节次数分布表数据是我们了解事物和研究事物的第一手宝贵资料,含有许多有用的信息,有待人们采用特定的方式进行揭示和开发。
从技术上讲,就要采用一些必要的统计手段对数据进行整理与分析,以便揭示数据内部规律性,获取有价值的教育信息。
这一节我们首先介绍次数分布表,它是常用于整理数据的一种方法。
一、次数分布显然,研究一批数据时,我们首先关心的是这批数据中最小的是多小、最大的是多大,以及这批数据从小到大是如何演变的,这就是数据的分布。
例如,我们要研究某班52名学生在一项拼写测验上的分数,最基本、最自然的一种想法是把这52名学生的测验成绩按照分数高低依次排列,见表1-1。
从表1-1中,我们固然可以了解到诸如最高分和最低分是多少,所有的分数分布区间多大,不同的分数各自重复出现的次数多少,大多数学生的分数分布在什么区间等等;但这种单间地把所有数据按照高低顺序一一排列加以整理的方法,难以简要地表达一批数据的次数分布,使人阅读后难以达到印象深刻、一目了然的统计效果。
特别是对于一批为数众多的数据来讲,这种方法更是不能有效地达到整理数据的目的。
为此,我们常从计数角度统计与整理出数据的次数分布。
表1-1 某班52名学生拼写测验分数(从高到低依次排列)所谓次数分布,指的是一批数据中各个不同数值所出现次数多少的情况,或者是这批数据在数轴上各个区间内所出现的次数多少的情况。
由于次数分布是对数据分布最简单、最直接的描述,因此,在许多情形下,我们将把数据分布和次数分布看成同义词。
从次数分布的操作性定义来看,统计一批数据的次数分布有两种方法:第一种方法是按不同的测量值逐点统计次数。
例如表1-2就是根据表1-1的原始数据,从高到低详细地统计不同得分点次数所得到的次数分布表。
在心理测验和教育考试分数转换过程中(如高考的标准分数转换),常使用这种方法统计次数分布。
第二种方法是为了缩简数据,以区间跨度来统计次数,如平时人们常提到的分数段统计,就是这一类。
2试验二、运用DPS制作次数分布表和图概述

例 数据如下表140个玉米穗粒数。 将数据输入工作表,定义、然后进入下拉
式菜单后选择数据分析-连续变量数据-原始 数据统计分析,按提示操作如下图
方法:数据定义后,(1)按下鼠标右键,菜单里“基本
参数”项;(2)工具栏中执行“基本统计参数”按
钮
,即可
作业:
1、课本例题2-3(p13) 作出次数分布表和图 。 2、课本例题2-4(p18) 作出次数分布表和图 。 3、利用相关函数计算作业1、2题平均数、众数、 方差、标准差 等统计量
如输入的数据由数字与小数点构成,DPS自动将其识别为 数值型。数据数据统计分析要求是数值型数据。数值型数据 显示为蓝色。字符型数据显示为黑色。
数据复制:可以在不同单元格之间复制数据,也可以在不同工 作表之间复制数据。可以一次复制一个数据,也可以同时复 制一批数据。
复制方法: (1)同word; (2)利用填充柄复制
坐标轴代表的项目名称、符号、单位以及图题、
图注、图例等。
过程:
3、 DPS系统常用函数
函数名称 sqrt(x) ln(x) lg(x) abs(x) norm(x) pro(x) bin(n,m,p) probt(d,x) probchi(d,x)
ftest(d1,d2,a)
ttest(d,a) chitest(d,a)
1、DPS系统简介
1.1 DPS系统的不同版本 DPS采用不同版本:标准版、高级版、多用户高级版本
标准版采用注册机制,一机一号,在统计分析功能方面不能升级。电子 表格最大65535行*255列。 高级版采用软件狗加密技术,免费升级。电子表格最大可达数百万行、 数百万列。 多用户高级版可在多台机器上免费使用,免费升级。电子表格最大可达 20万行*20万列。
第二节 次数分布表
第二节次数分布表数据是我们了解事物和研究事物的第一手宝贵资料,含有许多有用的信息,有待人们采用特定的方式进行揭示和开发。
从技术上讲,就要采用一些必要的统计手段对数据进行整理与分析,以便揭示数据内部规律性,获取有价值的教育信息。
这一节我们首先介绍次数分布表,它是常用于整理数据的一种方法。
一、次数分布显然,研究一批数据时,我们首先关心的是这批数据中最小的是多小、最大的是多大,以及这批数据从小到大是如何演变的,这就是数据的分布。
例如,我们要研究某班52名学生在一项拼写测验上的分数,最基本、最自然的一种想法是把这52名学生的测验成绩按照分数高低依次排列,见表1-1。
从表1-1中,我们固然可以了解到诸如最高分和最低分是多少,所有的分数分布区间多大,不同的分数各自重复出现的次数多少,大多数学生的分数分布在什么区间等等;但这种单间地把所有数据按照高低顺序一一排列加以整理的方法,难以简要地表达一批数据的次数分布,使人阅读后难以达到印象深刻、一目了然的统计效果。
特别是对于一批为数众多的数据来讲,这种方法更是不能有效地达到整理数据的目的。
为此,我们常从计数角度统计与整理出数据的次数分布。
表1-1 某班52名学生拼写测验分数(从高到低依次排列)所谓次数分布,指的是一批数据中各个不同数值所出现次数多少的情况,或者是这批数据在数轴上各个区间内所出现的次数多少的情况。
由于次数分布是对数据分布最简单、最直接的描述,因此,在许多情形下,我们将把数据分布和次数分布看成同义词。
从次数分布的操作性定义来看,统计一批数据的次数分布有两种方法:第一种方法是按不同的测量值逐点统计次数。
例如表1-2就是根据表1-1的原始数据,从高到低详细地统计不同得分点次数所得到的次数分布表。
在心理测验和教育考试分数转换过程中(如高考的标准分数转换),常使用这种方法统计次数分布。
第二种方法是为了缩简数据,以区间跨度来统计次数,如平时人们常提到的分数段统计,就是这一类。
第三讲-DPS应用(2、试验统计分析)

(十一)裂区试验设计
3.裂-裂区试验统计分析
例如,在前面的3 因素裂区实验中,药剂不是种子处理,而 是出苗后喷洒施药,这时的试验设计可按裂裂区方式进行: 主区为播种期,分3个水平:A1,A2,A3;裂区为施药处 理,分2 个水平:B1,B2;再裂区为作物收获期,分3个 水平:C1,C2,C3。
若有两个因子,其A 因子有K 个处理,B 因子有L
个处理,各个处理重复N 次。其资料输入顺序为两
因素试验的扩展。
第七页,共62页。
(三)方差分析结果解释
在进行试验结果的分析之前,我们必须在思想上牢记:要尽量地利用你对 问题的非统计学知识。因为实验者在各自的领域内通常有独到的实践经验 、受过正规的科学训练、具有高深的知识,这些都可用来分析因素和响应 变量之间的关系,这在解释分析结果时是极其有用的,是统计学无法替代 的。在进行方差分析结果解释时要点如下: 显著水平p值:方差分析表中,显著水平p值是推断试验处理间差异程度的指
第十五页,共62页。
(十)多因素随机 区组设计
现有一试验结果,其中A 因素2 个处理水平,B 因素2 个处理水平,C 因素2 个处理水平,D 因素5 个处理水平,9 个重复。
分析时,按提示输入各 个处理及重复的个数(如 下图):
第十六页,共62页。
(十一)裂区试验设计
首先将整个试验区分成几个大区,在每个大区内安排比较 容易表现出差异的因素的几种处理,它们常称为主处理, 然后在主处理所在各区内引进第二类因素的各个处理,它 们称为副处理。
第十九页,共62页。
(十一)裂区试验设计
2.1 主区两因素、裂区一个 因素(AB+C )试验统计分析
某作物病害防治试验,主区 为作物播种期和种子药剂处 理,播种分3个时期:A1, A2,A3;种子药剂处理分2 个水平:B1,B2;裂区为 作物收获期,分3个水平: C1,C2,C3。
用Excel进行制作次数分布表

15.11.2020
4
2 排序
15.11.2020
5
3 求最大值、最小值、极差、组距、组中值
15.11.2020
6
4 组限、组中值
15.11.2020
7
5 次数
15.11.2020
8
COUNTIF(range,criteria)
Range 为需要计算其中满足条件的单元格数 目的单元格区域。(本例为A1:A150) Criteria 为确定哪些单元格将被计算在内的 条件,其形式可以为数字、表达式或文本。 例如,条件可以表示为 32、“32”、“>32” 或 “apples”。(本例“<40”、“<45”等)
实验一 用Excel制作
次数分布表(图)
15.11.2020
1
实验目的与意义
1.学会利用Excel制作次数分布表 2.学会利用Excel制作次数分布图
15.11.2020
2
用Excel制作次数分布表
以150尾鲢鱼的体长数据为例
56
49
62
78
41
47
65
45
58
52
52
60
51
62
78
66
45
58
56
46
58
70
72
76
77
56
66
63
57
65
85
59
58
54
62
48
58
52
54
55
66
52
48
56
75
63
75
65
48
52
DPS数据处理系统使用要点
DPS数据处理系统使用要点一..基本参数估计、异常值检基本参数估计将数据在电子表格区(即数据编辑器)输入后,定义成数据块,然后点数据分析→基本参数估计。
就会立即得到基本参数。
异常值检验先将待检验数据输入—→定义为数据块—→点数据分析—→点异常值检验。
如果有异常数据,则异常数据就会变为红色。
(异常值检验)⏹二、次数分布及t 检验1.样本次数分布DPS作次数分布表步骤:(1)输入数据并定义成数据块(2)试验统计→次数分布及平均数比较→次数分布→OK→输出样本次数分布表结果⏹2.单样本均数与总体均数比较的t检验⏹步骤:⏹按行输入7个数,第二行输入总体平均数→定义数据块→选试验统计→单样本平均数检验→在弹出的对话框中输入总体平均数→OK(不能做)⏹3.配对样本t检验⏹步骤:⏹输入数据→定义数据块→选试验统计→两样本比较→配对两处理t检验→输出结果配对样本t检验(不能做)4.两样本均值差异t检验方法:(1)将两个处理的样本观察值分两行输入,并定义成数据块。
(2)试验统计→次数分布及平均数比较→student t检验→输出结果(两样本t检验)5.小样本均值差异检验方法:(1)输入数据,并定义成数据块(2)试验统计→次数分布及平均数比较→样本较少时平均数差异检验→输出(显示)结果。
三、试验设计及统计分析一)全面试验设计(一)单因素完全随机设计 1.试验方案设计 用DPS 系统产生随机数:为安排试验中所有试验次数的试验随机顺序,DPS 系统操作步骤如下: 试验设计→完全随机及随机区组设计→完全随机分组→弹出“完全随机试验设计”对话框→输入“实验样本数”和“分组组数”→确认后就输出要试验的次数的随机顺序。
(样本数和分组数一般是一样的)DPS 单因素试验设计步骤(可以不看) 因素水平按列排列 A1 A2 . Am定义数据块 → 试验设计→完全随机及随机区组设计→单因素随机区组设计→在弹出对话框中输入重复数→OK2.统计分析(方差分析方法) 用DPS 对单因素试验资料分析步骤 ①数据输入格式在数据编辑器中按规定格式将试验资料整理表中的数据输入。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
作业:
1、课本p37(表 3.1) 、p38 (表 3.4) 、p47 (3.2题) 作出次 数分布表 2、根据1题的次数分布表作出次数分布图 3、分别对1题的数据进行描述统计
实验报告:
对p47 (3.2题) 作出次数分布表
谢,系统会出现如下图 的用户工作界面,包含如下内容:标 题栏、工具栏、下拉菜单、工作表、 当前工作表、活动单元格、工作表标 签及文本编辑区。
二、连续性变数次数分布表和图的制作 数据如下表140行水稻产量。 将数据输入工作表,定义、然后进入下
拉式菜单后选择试验统计-次数分布及平 均数比较-次数分布,按提示操作如下图
二、次数分布图
(一)图的类型主要有:直方图、折线图、 饼形图、三点图等。
二维图
三维图
(二)图的制作
根据次数分布表制作次数分布图
要点:选定次数分布表中的次数列, 在点击次数分布图的图标,按提示 操作即可
三 运用DPS制作进行统计数的计算
操作步骤:
输入数据 定义数据块 从菜单中找到“数据分析” 基本参数计算:(和,样本数,均值, 几何平均,平均偏差,极差,方差,标准 差,标准误,变异系数)。