机器学习_SVM支持向量机MATLAB练习题
机器学习设计知识测试 选择题 53题

1. 在机器学习中,监督学习的主要目标是:A) 从无标签数据中学习B) 从有标签数据中学习C) 优化模型的复杂度D) 减少计算资源的使用2. 下列哪种算法属于无监督学习?A) 线性回归B) 决策树C) 聚类分析D) 支持向量机3. 在机器学习模型评估中,交叉验证的主要目的是:A) 增加模型复杂度B) 减少数据集大小C) 评估模型的泛化能力D) 提高训练速度4. 下列哪项不是特征选择的方法?A) 主成分分析(PCA)B) 递归特征消除(RFE)C) 网格搜索(Grid Search)D) 方差阈值(Variance Threshold)5. 在深度学习中,卷积神经网络(CNN)主要用于:A) 文本分析B) 图像识别C) 声音处理D) 推荐系统6. 下列哪种激活函数在神经网络中最为常用?A) 线性激活函数B) 阶跃激活函数C) ReLUD) 双曲正切函数7. 在机器学习中,过拟合通常是由于以下哪种情况引起的?A) 模型过于简单B) 数据量过大C) 模型过于复杂D) 数据预处理不当8. 下列哪项技术用于处理类别不平衡问题?A) 数据增强B) 重采样C) 特征选择D) 模型集成9. 在自然语言处理(NLP)中,词嵌入的主要目的是:A) 提高计算效率B) 减少词汇量C) 捕捉词之间的语义关系D) 增加文本长度10. 下列哪种算法不属于集成学习方法?A) 随机森林B) AdaBoostC) 梯度提升机(GBM)D) 逻辑回归11. 在机器学习中,ROC曲线用于评估:A) 模型的准确性B) 模型的复杂度C) 模型的泛化能力D) 分类模型的性能12. 下列哪项不是数据预处理的步骤?A) 缺失值处理B) 特征缩放C) 模型训练D) 数据标准化13. 在机器学习中,L1正则化主要用于:A) 减少模型复杂度B) 增加特征数量C) 特征选择D) 提高模型精度14. 下列哪种方法可以用于处理时间序列数据?A) 主成分分析(PCA)B) 线性回归C) ARIMA模型D) 决策树15. 在机器学习中,Bagging和Boosting的主要区别在于:A) 数据处理方式B) 模型复杂度C) 样本使用方式D) 特征选择方法16. 下列哪种算法适用于推荐系统?A) K-均值聚类B) 协同过滤C) 逻辑回归D) 随机森林17. 在机器学习中,A/B测试主要用于:A) 模型选择B) 特征工程C) 模型评估D) 用户体验优化18. 下列哪种方法可以用于处理缺失数据?A) 删除含有缺失值的样本B) 使用均值填充C) 使用中位数填充D) 以上都是19. 在机器学习中,偏差-方差权衡主要关注:A) 模型的复杂度B) 数据集的大小C) 模型的泛化能力D) 特征的数量20. 下列哪种算法属于强化学习?A) Q-学习B) 线性回归C) 决策树D) 支持向量机21. 在机器学习中,特征工程的主要目的是:A) 减少数据量B) 增加模型复杂度C) 提高模型性能D) 简化数据处理22. 下列哪种方法可以用于处理多分类问题?A) 一对多(One-vs-All)B) 一对一(One-vs-One)C) 层次聚类D) 以上都是23. 在机器学习中,交叉熵损失函数主要用于:A) 回归问题B) 分类问题C) 聚类问题D) 强化学习24. 下列哪种算法不属于深度学习?A) 卷积神经网络(CNN)B) 循环神经网络(RNN)C) 随机森林D) 长短期记忆网络(LSTM)25. 在机器学习中,梯度下降算法的主要目的是:A) 减少特征数量B) 优化模型参数C) 增加数据量D) 提高计算速度26. 下列哪种方法可以用于处理文本数据?A) 词袋模型(Bag of Words)B) TF-IDFC) 词嵌入D) 以上都是27. 在机器学习中,正则化的主要目的是:A) 减少特征数量B) 防止过拟合C) 增加数据量D) 提高计算速度28. 下列哪种算法适用于异常检测?A) 线性回归B) 决策树C) 支持向量机D) 孤立森林(Isolation Forest)29. 在机器学习中,集成学习的主要目的是:A) 提高单个模型的性能B) 结合多个模型的优势C) 减少数据量D) 增加模型复杂度30. 下列哪种方法可以用于处理高维数据?A) 主成分分析(PCA)B) 特征选择C) 特征提取D) 以上都是31. 在机器学习中,K-均值聚类的主要目的是:A) 分类B) 回归C) 聚类D) 预测32. 下列哪种算法适用于时间序列预测?A) 线性回归B) ARIMA模型C) 决策树D) 支持向量机33. 在机器学习中,网格搜索(Grid Search)主要用于:A) 特征选择B) 模型选择C) 数据预处理D) 模型评估34. 下列哪种方法可以用于处理类别特征?A) 独热编码(One-Hot Encoding)B) 标签编码(Label Encoding)C) 特征哈希(Feature Hashing)D) 以上都是35. 在机器学习中,AUC-ROC曲线的主要用途是:A) 评估分类模型的性能B) 评估回归模型的性能C) 评估聚类模型的性能D) 评估强化学习模型的性能36. 下列哪种算法不属于监督学习?A) 线性回归B) 决策树C) 聚类分析D) 支持向量机37. 在机器学习中,特征缩放的主要目的是:A) 减少特征数量B) 提高模型性能C) 增加数据量D) 简化数据处理38. 下列哪种方法可以用于处理文本分类问题?A) 词袋模型(Bag of Words)B) TF-IDFC) 词嵌入D) 以上都是39. 在机器学习中,决策树的主要优点是:A) 易于理解和解释B) 计算效率高C) 对缺失值不敏感D) 以上都是40. 下列哪种算法适用于图像分割?A) 卷积神经网络(CNN)B) 循环神经网络(RNN)C) 随机森林D) 支持向量机41. 在机器学习中,L2正则化主要用于:A) 减少模型复杂度B) 增加特征数量C) 特征选择D) 提高模型精度42. 下列哪种方法可以用于处理时间序列数据的季节性?A) 移动平均B) 季节分解C) 差分D) 以上都是43. 在机器学习中,Bagging的主要目的是:A) 减少模型的方差B) 减少模型的偏差C) 增加数据量D) 提高计算速度44. 下列哪种算法适用于序列数据处理?A) 卷积神经网络(CNN)B) 循环神经网络(RNN)C) 随机森林D) 支持向量机45. 在机器学习中,AdaBoost的主要目的是:A) 减少模型的方差B) 减少模型的偏差C) 增加数据量D) 提高计算速度46. 下列哪种方法可以用于处理文本数据的情感分析?A) 词袋模型(Bag of Words)B) TF-IDFC) 词嵌入D) 以上都是47. 在机器学习中,支持向量机(SVM)的主要优点是:A) 适用于高维数据B) 计算效率高C) 对缺失值不敏感D) 以上都是48. 下列哪种算法适用于推荐系统中的用户行为分析?A) 协同过滤B) 内容过滤C) 混合过滤D) 以上都是49. 在机器学习中,交叉验证的主要类型包括:A) K-折交叉验证B) 留一法交叉验证C) 随机划分交叉验证D) 以上都是50. 下列哪种方法可以用于处理图像数据?A) 卷积神经网络(CNN)B) 循环神经网络(RNN)C) 随机森林D) 支持向量机51. 在机器学习中,梯度提升机(GBM)的主要优点是:A) 适用于高维数据B) 计算效率高C) 对缺失值不敏感D) 以上都是52. 下列哪种算法适用于异常检测中的离群点检测?A) 线性回归B) 决策树C) 支持向量机D) 孤立森林(Isolation Forest)53. 在机器学习中,特征提取的主要目的是:A) 减少特征数量B) 提高模型性能C) 增加数据量D) 简化数据处理答案:1. B2. C3. C4. C5. B6. C7. C8. B9. C10. D11. D12. C13. C14. C15. C16. B17. D18. D19. C20. A21. C22. D23. B24. C25. B26. D27. B28. D29. B30. D31. C32. B33. B34. D35. A36. C37. B38. D39. D40. A41. A42. D43. A44. B45. B46. D47. A48. D49. D50. A51. D52. D53. B。
支持向量机期末试题及答案

支持向量机期末试题及答案[注:本文按照试题答案的形式来进行回答]1. 什么是支持向量机(SVM)?它的主要特点是什么?答:支持向量机(Support Vector Machine,SVM)是一种在机器学习领域中常用的监督学习模型。
其主要特点如下:- SVM 是一种二分类模型,但也可以扩展到多分类问题;- SVM的目标是寻找一个超平面(或称为决策边界),能够将不同类别的数据样本尽可能地分开,并最大化分类边界两侧的间隔;- SVM使用了一种称为“核函数”的技术,可以将数据映射到高维特征空间,使数据在低维度无法分开的情况下,在高维度中得到有效的分类;- SVM对于训练数据中的噪声和异常点具有较好的鲁棒性。
2. SVM的基本原理是什么?请简要描述其运行过程。
答:SVM的基本原理可以总结为以下几个步骤:- 将训练数据样本通过一个核函数映射到高维特征空间;- 在高维特征空间中,寻找一个超平面,使得不同类别的数据能够被最大化地分开,并使分类边界两侧的间隔最大化;- 对于线性可分的情况,可以直接找到一个超平面将数据完全分开;- 对于线性不可分的情况,通过引入松弛变量和惩罚项,在允许一定的误分类的情况下,寻找一个最佳的超平面;- 在找到超平面后,可以利用其支持向量(距离分类边界最近的样本点)来进行分类。
3. SVM中常用的核函数有哪些?请简要描述每种核函数的特点与使用场景。
答:SVM中常用的核函数包括线性核函数、多项式核函数和径向基函数(RBF)核函数。
- 线性核函数:特点是计算简单,适用于线性可分的情况,当数据特征维度较高时效果较好;- 多项式核函数:通过引入多项式的方式来进行特征映射,在一些非线性问题中表现良好,但计算复杂度较高;- RBF核函数:也称为高斯核函数,通过将数据映射到无限维的特征空间来实现非线性分类,适用于大部分场景。
4. SVM的损失函数是什么?请简要描述其作用并说明优化算法。
答:SVM的损失函数是Hinge Loss(合页损失函数)。
支持向量机matlab例题

支持向量机matlab例题当涉及到支持向量机(Support Vector Machine,简称SVM)的例题时,我们可以通过MATLAB来实现和解决。
SVM是一种常用的机器学习算法,用于分类和回归任务。
下面我将给出一个SVM的MATLAB例题,以帮助你更好地理解和应用该算法。
假设我们有一个二维数据集,其中包含两个类别的数据点。
我们的目标是使用SVM对这些数据进行分类。
首先,我们需要创建一个示例数据集。
在MATLAB中,我们可以使用`randn`函数生成随机数据。
假设我们有两个类别,每个类别有100个样本点。
代码如下:matlab.% 生成数据。
rng(1); % 设置随机种子,以确保结果可重现。
n = 100; % 每个类别的样本数量。
X1 = randn(n, 2) + repmat([1, 1], n, 1); % 类别1的数据点。
X2 = randn(n, 2) + repmat([-1, -1], n, 1); % 类别2的数据点。
X = [X1; X2]; % 合并数据。
y = [ones(n, 1); -ones(n, 1)]; % 类别标签。
接下来,我们可以使用`fitcsvm`函数来训练SVM模型,并进行分类。
代码如下:matlab.% 训练SVM模型。
svmModel = fitcsvm(X, y);% 预测分类结果。
y_pred = predict(svmModel, X);现在,我们已经得到了预测的分类结果。
我们可以使用`plot`函数将数据点和决策边界可视化。
代码如下:matlab.% 可视化结果。
figure;gscatter(X(:, 1), X(:, 2), y, 'rb', 'o');hold on;% 绘制决策边界。
h = svmModel.Beta(1);k = svmModel.Beta(2);x1 = linspace(min(X(:, 1)), max(X(:, 1)), 100);x2 = (-svmModel.Bias h x1) / k;plot(x1, x2, 'k--', 'LineWidth', 2);% 设置图形属性。
人工智能机器学习技术练习(习题卷10)

人工智能机器学习技术练习(习题卷10)第1部分:单项选择题,共155题,每题只有一个正确答案,多选或少选均不得分。
1.[单选题]如果SVM模型欠拟合, 以下方法哪些可以改进模型 :A)增大惩罚参数C的值B)减小惩罚参数C的值C)减小核系数(gamma参数)答案:A解析:2.[单选题]SVM中要寻找和计算的MMH是指()A)最大边缘超平面B)超平面C)最小边缘超平面答案:A解析:3.[单选题]一个SVM存在欠拟合问题,下面怎么做能提高模型的性能:A)增大惩罚参数CB)减小惩罚参数CC)减小核函数系数(gamma值)答案:A解析:C >0称为惩罚参数,是调和二者的系数,C值大时对误差分类的惩罚增大,C值小时对误差分类的惩罚减小。
当C越大,趋近无穷的时候,表示不允许分类误差的存在,margin越小,容易过拟合;当C趋于0时,表示我们不再关注分类是否正确,只要求margin越大,容易欠拟合。
4.[单选题]最佳分类是曲线下区域面积最大者,而黄线在曲线下面积最大.2、假设你在测试逻辑回归分类器,设函数H为style="width: 211px;" class="fr-fic fr-fil fr-dib cursor-hover">下图中的哪一个代表上述分类器给出的决策边界?A)style="width: auto;" class="fr-fic fr-fil fr-dib">B)style="width: auto;" class="fr-fic fr-fil fr-dib">C)style="width: auto;" class="fr-fic fr-fil fr-dib">答案:B解析:选项B正确。
虽然我们的式子由选项A和选项B所示的y = g(-6 + x2)表示,但是选项B才是正确的答案,因为当将x2 = 6的值放在等式中时,要使y = g(0)就意味着y = 0.5将在线上,如果你将x2的值增加到大于6,你会得到负值,所以输出将是区域y = 0。
人工智能机器学习技术练习(习题卷6)

人工智能机器学习技术练习(习题卷6)第1部分:单项选择题,共62题,每题只有一个正确答案,多选或少选均不得分。
1.[单选题]如果一个 SVM 模型出现欠拟合,那么下列哪种方法能解决这一问题?A)增大惩罚参数 C 的值B)减小惩罚参数 C 的值C)减小核系数(gamma参数)答案:A解析:2.[单选题]决策树每个非叶结点表示()A)某一个特征或者特征组合上的测试B)某个特征满足的条件C)某个类别标签答案:A解析:3.[单选题]以下不是开源工具特点的是A)免费B)可以直接获取源代码C)用户可以修改源代码并不加说明用于自己的软件中D)开源工具一样具有版权答案:C解析:4.[单选题]下列核函数特性描述错误的是A)只要一个对称函数所对应的核矩阵半正定,就能称为核函数;B)核函数选择作为支持向量机的最大变数;C)核函数将影响支持向量机的性能;D)核函数是一种降维模型;答案:D解析:5.[单选题]关于 Python 变量的使用,说法错误的是( )。
A)变量不必事先声明B)变量无需先创建和赋值即可直接使用C)变量无须指定类型D)可以使用del释放资源答案:B解析:6.[单选题]马尔可夫随机场是典型的马尔可夫网,这是一种著名的(__)模型。
A)无向图B)有向图C)树形图解析:7.[单选题]当k=3时,使用k近邻算法判断下图中的绿色方框属于()A)圆形B)三角形C)长方形D)以上都不是答案:B解析:8.[单选题](__)是具有适应性的简单单元组成的广泛并行互联的网络。
A)神经系统B)神经网络C)神经元D)感知机答案:B解析:9.[单选题]所有预测模型在广义上都可称为一个或一组(__)。
A)公式B)逻辑C)命题D)规则答案:D解析:10.[单选题]6. AGNES是一种()聚合策略的层次聚类算法A)A自顶向下B)自底向上C)由最近样本决定D)D最远样本决定答案:B解析:11.[单选题]互为对偶的两个线性规划问题的解存在关系()A)原问题无可行解,对偶问题也无可行解B)对偶问题有可行解,原问题可能无可行解C)若最优解存在,则最优解相同D)一个问题无可行解,则另一个问题具有无界解答案:B解析:12.[单选题]过滤式特征选择与学习器(),包裹式特征选择与学习器()。
SVM支持向量机题目

机器学习课程作业(1)提交截止日期:2017年10月10日周二1. 一个优化问题的原问题(Prime Problem )与对偶问题(Dual Problem )定义如下: 原问题Minimize: ()f ωSubject to: ()0,1,2,...,i g i K ω≤=()0,1,2,...,i h i M ω==对偶问题定义()()()()()()()11,,K MT T i i i i i i L f g h f g h ωαβωαωβωωαωβω===++=++∑∑对偶问题为:Maximize: ()(),inf ,,L ωθαβωαβ=Subject to:0,1,2,...,i i K α≥= (a) 证明:如果*ω是原问题的解,*α,*β是对偶问题的解,则有:()()***,f ωθαβ≥(b) 证明 (强对偶定理):如果()g A b ωω=+,()h C d ωω=+,且()fω为凸函数,即对任意1ω和2ω,有()()()()()121211f f f λωλωλωλω+-≤+-, 则有:()()***,f ωθαβ=2. 求下列原问题的对偶问题(a) (1l and 2l -norm SVM Classification) : Minimize: 22121112N N i i i i C C ωδδ==++∑∑ Subject to: 0,1,2,...,i i N δ≥=()1T i i i y x b ωϕδ⎡⎤+≥-⎣⎦(b) (SVM regression): Minimize: ()()222121112N N i i i i i i C C ωδζδζ==++++∑∑ Subject to: (),1,2,...,T i i i x b y i N ωϕεδ+-≤+=(),1,2,...,T i i i y x b i N ωϕεζ--≤+= 0i δ≥, 0i ζ≥(c) (Kernel Ridge Regression): Minimize: 22112N i i C ωδ=+∑ Subject to: (),1,2,...,T i i i y x i N ωϕδ-==(d) (Entropy Maximization Problem):Minimize: ()1log Ni ii x x =∑ Subject to: T x b ω≤11N i i x==∑3. 如图所示,平面上有N 个点12{,,...,}N x x x ,求一个半径最小的圆,使之能包含这些点。
机器学习题集

机器学习题集一、选择题1.机器学习的主要目标是什么?A. 使机器具备人类的智能B. 使机器能够自动学习和改进C. 使机器能够模拟人类的思维过程D. 使机器能够按照给定的规则执行任务答案:B2.下列哪项不是机器学习算法的分类?A. 监督学习B. 无监督学习C. 半监督学习D. 完全手动学习答案:D3.在机器学习中,以下哪项是指学习算法在给定训练集上的表现能力?A. 泛化能力B. 训练误差C. 过拟合D. 欠拟合答案:B4.哪种机器学习算法通常用于处理回归问题?A. 支持向量机(SVM)B. K-近邻(K-NN)C. 线性回归D. 决策树答案:C5.深度学习是机器学习的哪个子领域?A. 弱学习B. 表示学习C. 概率学习D. 规则学习答案:B6.在监督学习中,算法尝试从训练数据中学习什么?A. 数据的分布B. 数据的模式C. 输入到输出的映射D. 数据的统计特性答案:C7.以下哪项是机器学习模型评估中常用的交叉验证方法?A. 留出法B. 梯度下降C. 决策树剪枝D. K-均值聚类答案:A8.在机器学习中,正则化通常用于解决什么问题?A. 数据不足B. 过拟合C. 欠拟合D. 维度灾难答案:B9.以下哪项是深度学习中常用的激活函数?A. 线性函数B. Sigmoid函数C. 逻辑回归D. 梯度提升答案:B10.在机器学习中,特征工程主要关注什么?A. 数据的收集B. 数据的清洗C. 从原始数据中提取有意义的特征D. 模型的部署答案:C11.下列哪个算法通常用于分类问题中的特征选择?A. 决策树B. PCA(主成分分析)C. K-均值聚类D. 线性回归答案:A12.集成学习通过结合多个学习器的预测结果来提高整体性能,这种方法属于哪种策略?A. 监督学习B. 弱学习C. 规则学习D. 模型融合答案:D13.在深度学习中,卷积神经网络(CNN)主要用于处理哪种类型的数据?A. 文本数据B. 图像数据C. 时间序列数据D. 语音数据答案:B14.以下哪个指标用于评估分类模型的性能时,考虑到了类别不平衡的问题?A. 准确率B. 精确率C. 召回率D. F1分数答案:D15.在强化学习中,智能体通过什么来优化其行为?A. 奖励函数B. 损失函数C. 梯度下降D. 决策树答案:A16.以下哪项是机器学习中的无监督学习任务?A. 图像分类B. 聚类分析C. 情感分析D. 回归分析答案:B17.在机器学习中,梯度下降算法主要用于什么?A. 数据的收集B. 模型的训练C. 数据的清洗D. 模型的评估答案:B18.以下哪项是机器学习中常用的正则化技术之一?A. L1正则化B. 决策边界C. 梯度提升D. 逻辑回归答案:A19.在机器学习中,过拟合通常发生在什么情况?A. 模型太复杂,训练数据太少B. 模型太简单,训练数据太多C. 数据集完全随机D. 使用了不合适的激活函数答案:A20.以下哪个算法是基于树的集成学习算法之一?A. 随机森林B. 线性回归C. K-近邻D. 神经网络答案:A21.在机器学习中,确保数据质量的关键步骤之一是:A. 初始化模型参数B. 提取新特征C. 数据清洗D. 损失函数最小化答案:C22.监督学习中,数据通常被分为哪两部分?A. 训练集和验证集B. 输入特征和输出标签C. 验证集和测试集D. 数据集和标签集答案:B23.数据标注在机器学习的哪个阶段尤为重要?A. 模型评估B. 特征工程C. 数据预处理D. 模型训练答案:C24.下列哪项不是数据清洗的常用方法?A. 处理缺失值B. 转换数据类型C. 去除异常值D. 初始化模型参数答案:D25.数据分割时,以下哪个集合通常用于评估模型的最终性能?A. 训练集B. 验证集C. 测试集D. 验证集和测试集答案:C26.在数据标注过程中,为每个样本分配的输出值被称为:A. 特征B. 权重C. 损失D. 标签答案:D27.数据代表性不足可能导致的问题是:A. 过拟合B. 欠拟合C. 收敛速度过慢D. 模型复杂度过高答案:B28.下列哪项不是数据收集时应考虑的因素?A. 数据源的可靠性B. 数据的隐私保护C. 模型的复杂度D. 数据的完整性答案:C29.数据清洗中,处理缺失值的一种常用方法是:A. 删除包含缺失值的行或列B. 使用均值、中位数或众数填充C. 将缺失值视为新特征D. 停止模型训练答案:A, B(多选,但此处只选一个最直接的答案)A30.数据的泛化能力主要取决于:A. 模型的复杂度B. 数据的多样性C. 算法的先进性D. 损失函数的选择答案:B31.监督学习中,输入特征与输出标签之间的关系是通过什么来学习的?A. 损失函数B. 决策树C. 神经网络D. 训练过程答案:D32.数据标注的准确性对模型的什么能力影响最大?A. 泛化能力B. 收敛速度C. 预测精度D. 特征提取答案:C33.在数据预处理阶段,处理噪声数据的主要目的是:A. 提高模型训练速度B. 降低模型的复杂度C. 提高模型的预测准确性D. 减少数据存储空间答案:C34.下列哪项不属于数据清洗的范畴?A. 缺失值处理B. 异常值检测C. 特征选择D. 噪声处理答案:C35.数据标注的自动化程度受什么因素影响最大?A. 数据集的大小B. 数据的复杂性C. 标注工具的效率D. 模型的训练时间答案:B36.在数据分割时,为什么需要设置验证集?A. 仅用于训练模型B. 评估模型在未见过的数据上的表现C. 替代测试集进行最终评估D. 加速模型训练过程答案:B37.数据的标签化在哪些类型的机器学习任务中尤为重要?A. 无监督学习B. 半监督学习C. 监督学习D. 强化学习答案:C38.数据质量对模型性能的影响主要体现在哪些方面?A. 模型的收敛速度B. 模型的复杂度C. 模型的预测精度D. 模型的泛化能力答案:C, D(多选,但此处只选一个最直接的答案)D39.下列哪项不是数据清洗和预处理阶段需要完成的任务?A. 数据标注B. 缺失值处理C. 噪声处理D. 模型评估答案:D40.数据多样性对防止哪种问题有重要作用?A. 欠拟合B. 过拟合C. 收敛速度过慢D. 损失函数波动答案:B41.机器学习的基本要素不包括以下哪一项?A. 模型B. 特征C. 规则D. 算法答案:C42.哪种机器学习算法常用于分类任务,并可以输出样本属于各类的概率?A. 线性回归B. 支持向量机C. 逻辑回归D. 决策树答案:C43.模型的假设空间是指什么?A. 模型能够表示的所有可能函数的集合B. 数据的特征向量集合C. 算法的复杂度D. 损失函数的种类答案:A44.下列哪个是评估模型好坏的常用准则?A. 准确率B. 损失函数C. 数据集大小D. 算法执行时间答案:B45.哪种算法特别适合于处理非线性关系和高维数据?A. 朴素贝叶斯B. 神经网络C. 决策树D. 线性回归答案:B46.在机器学习中,特征选择的主要目的是什么?A. 减少计算量B. 提高模型的可解释性C. 提高模型的泛化能力D. 以上都是答案:D47.结构风险最小化是通过什么方式实现的?A. 增加训练数据量B. 引入正则化项C. 减小模型复杂度D. 改进损失函数答案:B48.哪种算法常用于处理时间序列数据并预测未来值?A. 朴素贝叶斯B. 随机森林C. ARIMAD. 逻辑回归答案:C49.在决策树算法中,分割数据集的标准通常基于什么?A. 损失函数B. 信息增益C. 数据的分布D. 模型的复杂度答案:B50.哪种策略常用于处理类别不平衡的数据集?A. 采样B. 特征缩放C. 交叉验证D. 正则化答案:A51.监督学习的主要任务是什么?A. 从无标签数据中学习规律B. 预测新数据的标签C. 自动发现数据中的模式D. 生成新的数据样本答案:B52.下列哪个是监督学习算法?A. K-means聚类B. 线性回归C. PCA(主成分分析)D. Apriori算法(关联规则学习)答案:B53.在监督学习中,标签(label)通常指的是什么?A. 数据的索引B. 数据的特征C. 数据的类别或目标值D. 数据的分布答案:C54.监督学习中的损失函数主要用于什么?A. 评估模型的复杂度B. 衡量模型预测值与真实值之间的差异C. 生成新的数据样本D. 划分数据集为训练集和测试集答案:B55.下列哪种方法常用于处理分类问题中的多类分类?A. 二元逻辑回归B. 一对多(One-vs-All)策略C. 层次聚类D. PCA降维答案:B56.在监督学习中,过拟合通常指的是什么?A. 模型在训练集上表现很好,但在测试集上表现不佳B. 模型在训练集和测试集上表现都很好C. 模型在训练集上表现很差D. 模型无法学习到任何有用的信息答案:A57.下列哪个技术常用于防止过拟合?A. 增加数据集的大小B. 引入正则化项C. 减少模型的特征数量D. 以上都是答案:D58.交叉验证的主要目的是什么?A. 评估模型的性能B. 划分数据集C. 选择最优的模型参数D. 以上都是答案:D59.在监督学习中,准确率(Accuracy)的计算公式是什么?A. 正确预测的样本数 / 总样本数B. 误分类的样本数 / 总样本数C. 真正例(TP)的数量D. 真正例(TP)与假负例(FN)之和答案:A60.下列哪个指标在分类问题中考虑了类别的不平衡性?A. 准确率(Accuracy)B. 精确率(Precision)C. 召回率(Recall)D. F1分数(F1 Score)(注意:虽然F1分数不完全等同于解决类别不平衡,但在此选项中,它相比其他三个更全面地考虑了精确率和召回率)答案:D(但请注意,严格来说,没有一个指标是专为解决类别不平衡设计的,F1分数是精确率和召回率的调和平均,对两者都给予了重视)61.监督学习中的训练集包含什么?A. 无标签数据B. 有标签数据C. 噪声数据D. 无关数据答案:B62.下列哪个不是监督学习的步骤?A. 数据预处理B. 模型训练C. 模型评估D. 数据聚类答案:D63.逻辑回归适用于哪种类型的问题?A. 回归问题B. 分类问题C. 聚类问题D. 降维问题答案:B64.监督学习中的泛化能力指的是什么?A. 模型在训练集上的表现B. 模型在测试集上的表现C. 模型的复杂度D. 模型的训练时间答案:B65.梯度下降算法在监督学习中常用于什么?A. 特征选择B. 损失函数最小化C. 数据划分D. 类别预测答案:B66.在处理多标签分类问题时,每个样本可能属于多少个类别?A. 0个B. 1个C. 1个或多个D. 唯一确定的1个答案:C67.下列哪个不是监督学习常用的评估指标?A. 准确率B. 精确率C. 召回率D. 信息增益答案:D68.监督学习中的偏差(Bias)和方差(Variance)分别指的是什么?A. 模型的复杂度B. 模型在训练集上的表现C. 模型预测值的平均误差D. 模型预测值的变化程度答案:C(偏差),D(方差)69.ROC曲线和AUC值主要用于评估什么?A. 回归模型的性能B. 分类模型的性能C. 聚类模型的性能D. 降维模型的性能答案:B70.在处理不平衡数据集时,哪种策略可能不是首选?A. 重采样技术B. 引入代价敏感学习C. 使用集成学习方法D. 忽略不平衡性直接训练模型答案:D二、简答题1.问题:什么是无监督学习?答案:无监督学习是一种机器学习方法,它使用没有标签的数据集进行训练,目标是发现数据中的内在结构或模式,如聚类、降维等。
Matlab考试题库及答案(教师出卷参考专用)

Matlab考试题库及答案(教师出卷参考专用)一、选择题1.以下哪个函数用于在Matlab中创建一个图形窗口?A. figureB. plotC. graphD. window答案:A2.在Matlab中,以下哪个选项可以用来定义一个矩阵?A. A = [1 2 3; 4 5 6]B. A = (1, 2, 3, 4, 5, 6)C. A = {1, 2, 3, 4, 5, 6}D. A = 1 2 3; 4 5 6答案:A3.以下哪个函数用于求解线性方程组Ax=b?A. solveB. linsolveC. solve(A, b)D. linsolve(A, b)答案:D4.在Matlab中,如何计算矩阵A和矩阵B的乘积?A. A BB. A \ BC. A . BD. A .\ B答案:A5.以下哪个函数用于在Matlab中绘制三维散点图?A. scatterB. scatter3C. plot3D. bar3答案:B二、填空题1.在Matlab中,要创建一个名为"myfig"的图形窗口,可以使用______函数。
答案:figure('Name', 'myfig')2.在Matlab中,要计算矩阵A的行列式,可以使用______函数。
答案:det(A)3.在Matlab中,若要计算变量x的平方,可以使用______运算符。
答案:.^24.在Matlab中,若要计算矩阵A的逆矩阵,可以使用______函数。
答案:inv(A)5.在Matlab中,要绘制一个正弦波形,可以使用______函数。
答案:plot(sin(x))三、判断题1.在Matlab中,矩阵的索引从1开始计数。
()答案:正确2.在Matlab中,可以使用逻辑运算符"&&"和"||"。
()答案:错误3.在Matlab中,矩阵乘法满足交换律。
MATLAB机试题及答案

上机题汇总1设置matlab 的工作环境,将工作目录设置为d:\work ,添加搜索目录d:\example设置当前目录:在Matlab 工具栏Current Directory 中输入或者浏览 设置搜索目录命令在资源管理器中创建work 文件夹 addpath('d:\work'); savepath;【也可以在file/ Set Path 路径设置窗口中完成】2在matlab 的命令窗口里完成如下计算,其中t 的值分别取-1,0,1,表达式如下:4/3)2ty eπ-=y=sqrt(2)/2*exp(-4*t).*sin(4*sqrt(3*t)+pi/3)3自行产生一个5行5列的数组,得到最中间的三行三列矩阵。
答:>>A=magic(5) I=[2 3 4];J=[2 3 4]; M=A(I,J)4用magic 产生一个5*5的矩阵,将这个矩阵的第二行与第三行互换位置答:>>A=magic(5) I=[1 3 2 4 5];J=[1 2 3 4 5]; M=A(I,J)5求方程组的根x 1+4x 2-3x 3=2 2x 1+5x 2-x 3=11 x 1+6x 2+x 3=12答:>>A=[1 4 -3;2 5 -1;-1 3 4];>>b=[2;11;12];>>x=A\b 或x=inv(A)*b6已知:一个多项式的系数向量是p=[1 -6-72 -27],求这个多项式的根。
答:>> p=[1 -6-72 -27] >> r=roots(p)7已经两个多项式的系数分别是:[1 2 3 4]和[1 4 9 16],请求这两个多项式的乘积,及商和余数。
答:>>p1=[1 2 3 4];p2=[1 4 9 16]; >>C=conv(p1,p2) >>[q,r]=deconv(p1,p2)8给定一个多项式的根是[-5 -3+4i -3-4i],求原来的多项式答:>>r=[-5 -3+4i -3-4i] >>p=poly(r) >>disp(poly2sym(p))9 A=[2 3 4;1 5 7;6 2 5]用什么函数,保证第一列排序的时候,其他列跟着变化。
svm例题计算

题目:二维空间中,存在两个类别分别为正样本和负样本的数据点。
其中正样本数据点为 (1,1) 和 (2,2),负样本数据点为(0,0) 和 (-1,0)。
任务:利用支持向量机(SVM)方法,求解分类决策超平面,将两类样本点进行分类。
首先,根据SVM的原理,需要找到一个超平面,使得该超平面能够最大化两类样本点到超平面的距离。
对于二维空间中的数据点,超平面可以用一个方程来表示,例如:ax + by + c = 0。
在这个例子中,有两个正样本点 (1,1) 和 (2,2),以及两个负样本点 (0,0) 和 (-1,0)。
我们可以将这些点代入超平面方程中,得到以下四个方程:
1. a + b + c = 0
2. 2a + 2b + c = 0
3. a - b + c = 0
4. -a + c = 0
由于正样本点到超平面的距离应该大于负样本点到超平面的距离,因此我们可以将这四个方程转化为约束条件:
1. a + b + c >= 0
2. 2a + 2b + c >= 0
3. a - b + c <= 0
4. -a + c <= 0
接下来,我们需要求解这个约束优化问题,找到最优的a、b、
c值。
这个过程可以使用拉格朗日乘数法或者梯度下降法等优化算法来完成。
最终,我们得到的超平面方程为:x - y = 0。
这个方程表示的是一个通过原点的直线,它可以很好地将两类样本点进行分类。
具体地,对于任何一个在直线x - y = 0上的点 (x, y),如果x > y,那么该点属于正样本类别;如果x < y,那么该点属于负样本类别。
机器学习模拟试题含答案

机器学习模拟试题含答案一、单选题(共50题,每题1分,共50分)1、同质集成中的个体学习器亦称()A、组件学习器B、基学习器C、异质学习器D、同质学习器正确答案:B2、假设我们使用原始的非线性可分版本的 Soft-SVM 优化目标函数。
我们需要做什么来保证得到的模型是线性可分离的?A、C = 0B、C = 1C、C 正无穷大D、C 负无穷大正确答案:C3、关于logistic回归和SVM不正确的是()A、Logistic 回归目标函数是最小化后验概率B、Logistic回归可以用于预测事件发生概率的大小C、SVM可以有效避免模型过拟合D、SVM目标是结构风险最小化正确答案:A4、构建一个最简单的线性回归模型需要几个系数(只有一个特征)?A、1 个B、2 个C、4 个D、3 个正确答案:B5、假如我们使用 Lasso 回归来拟合数据集,该数据集输入特征有 100 个(X1,X2,…,X100)。
现在,我们把其中一个特征值扩大 10 倍(例如是特征 X1),然后用相同的正则化参数对 Lasso 回归进行修正。
那么,下列说法正确的是?A、特征 X1 很可能被排除在模型之外B、特征 X1 很可能还包含在模型之中C、无法确定特征 X1 是否被舍弃D、以上说法都不对正确答案:B6、下面关于SVM算法叙述不正确的是()A、SVM是一种基于经验风险最小化准则的算法B、SVM求得的解为全局唯一最优解C、SVM在解决小样本、非线性及高维模式识别问题中具有优势D、SVM最终分类结果只与少数支持向量有关正确答案:A7、KNN算法属于一种典型的()算法A、无监督学习B、半监督学习C、弱监督学习D、监督学习正确答案:D8、关于BP算法特点描述错误的是 ( )A、输入信号顺着输入层、隐层、输出层依次传播B、计算之前不需要对训练数据进行归一化C、预测误差需逆向传播,顺序是输出层、隐层、输入层D、各个神经元根据预测误差对权值进行调整正确答案:B9、关于维数灾难说法错误的是?A、高维度数据可使得算法泛华能力变得越来越弱B、高维度数据增加了运算难度C、降低高维度数据会对数据有所损伤D、高维度数据难以可视化正确答案:A10、做一个二分类预测问题,先设定阈值为0.5,概率大于等于0.5的样本归入正例类(即1),小于0.5的样本归入反例类(即0)。
机器学习与人工智能(支持向量机与决策树)习题与答案

1.我们要用概率模型对数据和标签进行学习,需要数据/标签对服从某种概率分布,称为()。
正确答案:数据生成分布2.在决策树学习中将已生成的树进行简化的过程称为()。
正确答案:剪枝二、判断题1.支持向量分类器的判断规则只由训练观测的一部分(支持向量)确定。
正确答案:√2.支持向量机通过使用核函数来扩大特征空间。
正确答案:√3.支持向量机可看作是一类简单、直观的最大间隔分类器的推广。
正确答案:√4.支持向量是最靠近决策表面的数据点。
正确答案:√5.树的内部结点用特征作标签,树枝用是否符合特征来标签。
正确答案:√6.过拟合发生在模型太过偏向训练数据时,对于决策树可以采用修剪的方法阻止过拟合。
正确答案:√7.对于实值特征,可以用比较测试将数据划分为两部分,或者选择范围过滤。
正确答案:√8.决策树的节点有两种类型:内部节点和叶节点。
内部节点表示一个特征或属性,叶节点表示一个类。
9.过拟合发生在模型太过偏向训练数据时。
正确答案:√10.决策树的修剪可以采用正则化的方法。
正确答案:√三、单选题1.怎样理解非完美分类的超平面分类器?( )A.允许小部分训练观测被误分。
B.允许大部分训练观测被误分。
C.两种说法都对。
D.两种说法都不对。
正确答案:A2.SVM算法的性能取决于( )。
A.核函数的选择B.核函数的参数C.软间隔参数CD.以上都是正确答案:D3.SVM算法的最小时间复杂度是O(n*n)。
基于这一点,()规格的数据集并不适用于该算法。
A.大数据集B.小数据集C.中数据集D.不受数据集大小的影响正确答案:A4.假定现在有一个四分类问题,你要用One-vs-all策略训练一个SVM的模型,你需要训练几个SVM模型?()A.1B.2C.3D.4正确答案:D5.在构建决策树时,需要计算每个用来划分数据特征的得分,选择分数最高的特征,以下可以作为得分的是?()A.熵B.基尼系数C.训练误差D.以上都是正确答案:D6.在决策树学习过程中,哪些情况可能会导致问题数据(特征相同但是标签不同)?( )A.数据错误B.数据有噪音C.现有的特征不足以区分或决策D.以上都是正确答案:D7.在构建决策树时,以下属于处理有多个值的特征的方法的是( )。
机器学习练习题

机器学习练习题1. 请解释机器学习中的监督学习与非监督学习的区别。
2. 描述决策树的基本概念,并举例说明其在分类问题中的应用。
3. 给出支持向量机(SVM)的基本原理,并解释其在解决二分类问题中的作用。
4. 解释什么是过拟合,并讨论如何通过正则化来减少过拟合。
5. 描述随机森林算法的工作原理,并说明它如何提高模型的准确性。
6. 请解释交叉验证的概念,并讨论它在机器学习模型评估中的重要性。
7. 给出朴素贝叶斯分类器的基本原理,并讨论其在文本分类中的应用。
8. 解释梯度下降算法的工作原理,并说明它在优化机器学习模型参数中的作用。
9. 描述K-最近邻(KNN)算法的基本原理,并讨论其在回归和分类问题中的应用。
10. 请解释深度学习与机器学习的关系,并举例说明深度学习在图像识别中的应用。
11. 描述特征工程在机器学习中的重要性,并给出一些常见的特征工程方法。
12. 请解释模型的泛化能力,并讨论如何评估一个机器学习模型的泛化能力。
13. 给出一个例子,说明如何使用机器学习来解决一个实际问题,并描述所采用的算法和评估方法。
14. 请解释什么是降维,并讨论主成分分析(PCA)在降维中的作用。
15. 描述卷积神经网络(CNN)的结构,并解释它在处理图像数据时的优势。
16. 请解释什么是强化学习,并讨论其在游戏或机器人控制中的应用。
17. 给出一个例子,说明如何使用聚类算法来发现数据中的模式或群体。
18. 解释协同过滤在推荐系统中的作用,并讨论其在电子商务中的应用。
19. 描述深度学习中的卷积层、池化层和全连接层的作用及其在图像识别中的重要性。
20. 请解释什么是迁移学习,并讨论它在机器学习领域中的应用和优势。
人工智能机器学习技术练习(习题卷1)

人工智能机器学习技术练习(习题卷1)第1部分:单项选择题,共62题,每题只有一个正确答案,多选或少选均不得分。
1.[单选题]SVM在()情况下表现糟糕。
A)线性可分数据B)清洗过的数据C)含噪声数据与重叠数据点答案:C解析:2.[单选题]回归评估指标中RMSE和MSE的关系是()A)MSE是RMSE的平方B)没有关系C)RMSE是MSE的平方答案:A解析:3.[单选题]让学习器不依赖外界交互、自动地利用未标记样本来提升学习性能,就是(__)。
A)有监督学习B)全监督学习C)无监督学习D)半监督学习答案:D解析:4.[单选题]假设有矩阵a,则查看该矩阵有几个维度的是()。
A)ndimB)a.sizeC)a.ndim()D)a.size()答案:A解析:5.[单选题]在标准化公式z = 中,使用e 的目的是( )A)为了加速收敛B)如果 过小C)使结果更准确D)防止分母为零答案:D解析:6.[单选题]向量 X=[1,2,3,4,-9,0] 的 L1 范数为?A)1B)19解析:L0 范数表示向量中所有非零元素的个数;L1 范数指的是向量中各元素的绝对值之和,又称“稀疏矩阵算子”;L2 范数指的是向量中各元素的平方和再求平方根。
本例中,L0 范数为 5,L1 范数为 19,L2 范数为 √111。
7.[单选题]最早被提出的循环神经网络门控算法是什么。
()A)长短期记忆网络B)门控循环单元网络C)堆叠循环神经网络D)双向循环神经网络答案:A解析:8.[单选题]下面关于回归过程的说法,错误的是A)收集数据:采用任意方法收集数据B)分析数据:绘出数据的可视化二维图将有助于对数据做出理解和分析,在采用缩减法求得新回归系数之后, 可以 将新拟合线绘在图上作为对比C)训练算法:找到回归系数D)用算法:使用回归,可以在给定输入的时候预测出一个数值,这是对分类方法的提升,因为这样只可以预测连续型数据答案:D解析:9.[单选题]核矩阵是( )的。
svm 课程设计 资料 题目

svm 课程设计资料题目
一、SVM简介
支持向量机(Support Vector Machine,简称SVM)是一种经典的二分类机器学习算法。
它通过在特征空间中寻找一个最优的超平面,使得两个类别之间的距离(即几何间隔)最大化,从而实现分类。
SVM在模式识别、图像识别、文本分类等领域有着广泛的应用。
二、SVM原理
1.线性可分支持向量机:当数据集线性可分时,SVM通过找到一个最优超平面,使得两类数据之间的距离最大化。
2.线性支持向量机:当数据集线性不可分时,SVM通过核技巧将数据映射到高维空间,使得数据在该空间中线性可分。
3.非线性支持向量机:对于非线性数据,SVM通过核技巧将数据映射到高维特征空间,并在该空间中寻找一个最优超平面。
三、SVM在课程设计中的应用
在课程设计中,SVM可以应用于各种分类任务,如文本分类、图像识别等。
本文以文本分类为例,介绍SVM在课程设计中的应用。
四、课程设计实践步骤
1.数据预处理:对原始文本数据进行分词、去停用词等操作,提取特征。
2.训练集与测试集划分:将处理后的数据划分为训练集和测试集,用于模型训练和性能评估。
3.参数调优:根据实际任务调整SVM的参数,如核函数类型、惩罚系数
等。
4.模型训练:使用训练集对SVM模型进行训练。
5.模型评估:使用测试集评估模型性能,如准确率、召回率等。
机器学习作业(六)支持向量机——Matlab实现
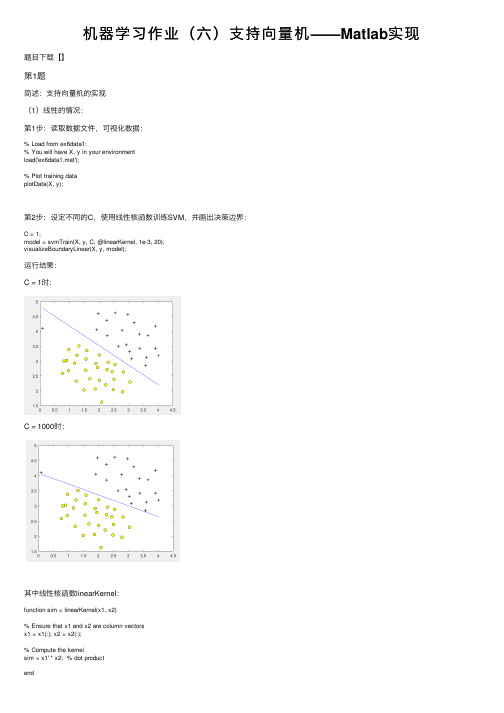
机器学习作业(六)⽀持向量机——Matlab实现题⽬下载【】第1题简述:⽀持向量机的实现(1)线性的情况:第1步:读取数据⽂件,可视化数据:% Load from ex6data1:% You will have X, y in your environmentload('ex6data1.mat');% Plot training dataplotData(X, y);第2步:设定不同的C,使⽤线性核函数训练SVM,并画出决策边界:C = 1;model = svmTrain(X, y, C, @linearKernel, 1e-3, 20);visualizeBoundaryLinear(X, y, model);运⾏结果:C = 1时:C = 1000时:其中线性核函数linearKernel:function sim = linearKernel(x1, x2)% Ensure that x1 and x2 are column vectorsx1 = x1(:); x2 = x2(:);% Compute the kernelsim = x1' * x2; % dot productend⾼斯核函数gaussianKernel实现:function sim = gaussianKernel(x1, x2, sigma)% Ensure that x1 and x2 are column vectorsx1 = x1(:); x2 = x2(:);% You need to return the following variables correctly.sim = 0;sim = exp(-norm(x1 - x2) ^ 2 / (2 * (sigma ^ 2)));end训练模型svmTrain函数(实现较为复杂,直接调⽤):function [model] = svmTrain(X, Y, C, kernelFunction, ...tol, max_passes)%SVMTRAIN Trains an SVM classifier using a simplified version of the SMO %algorithm.% [model] = SVMTRAIN(X, Y, C, kernelFunction, tol, max_passes) trains an % SVM classifier and returns trained model. X is the matrix of training% examples. Each row is a training example, and the jth column holds the % jth feature. Y is a column matrix containing 1 for positive examples% and 0 for negative examples. C is the standard SVM regularization% parameter. tol is a tolerance value used for determining equality of% floating point numbers. max_passes controls the number of iterations% over the dataset (without changes to alpha) before the algorithm quits.%% Note: This is a simplified version of the SMO algorithm for training% SVMs. In practice, if you want to train an SVM classifier, we% recommend using an optimized package such as:%% LIBSVM (.tw/~cjlin/libsvm/)% SVMLight (/)%%if ~exist('tol', 'var') || isempty(tol)tol = 1e-3;endif ~exist('max_passes', 'var') || isempty(max_passes)max_passes = 5;end% Data parametersm = size(X, 1);n = size(X, 2);% Map 0 to -1Y(Y==0) = -1;% Variablesalphas = zeros(m, 1);b = 0;E = zeros(m, 1);passes = 0;eta = 0;L = 0;H = 0;% Pre-compute the Kernel Matrix since our dataset is small% (in practice, optimized SVM packages that handle large datasets% gracefully will _not_ do this)%% We have implemented optimized vectorized version of the Kernels here so % that the svm training will run faster.if strcmp(func2str(kernelFunction), 'linearKernel')% Vectorized computation for the Linear Kernel% This is equivalent to computing the kernel on every pair of examplesK = X*X';elseif strfind(func2str(kernelFunction), 'gaussianKernel')% Vectorized RBF Kernel% This is equivalent to computing the kernel on every pair of examplesX2 = sum(X.^2, 2);K = bsxfun(@plus, X2, bsxfun(@plus, X2', - 2 * (X * X')));K = kernelFunction(1, 0) .^ K;else% Pre-compute the Kernel Matrix% The following can be slow due to the lack of vectorizationK = zeros(m);for i = 1:mfor j = i:mK(i,j) = kernelFunction(X(i,:)', X(j,:)');K(j,i) = K(i,j); %the matrix is symmetricendendend% Trainfprintf('\nTraining ...');dots = 12;while passes < max_passes,num_changed_alphas = 0;for i = 1:m,% Calculate Ei = f(x(i)) - y(i) using (2).% E(i) = b + sum (X(i, :) * (repmat(alphas.*Y,1,n).*X)') - Y(i);E(i) = b + sum (alphas.*Y.*K(:,i)) - Y(i);if ((Y(i)*E(i) < -tol && alphas(i) < C) || (Y(i)*E(i) > tol && alphas(i) > 0)), % In practice, there are many heuristics one can use to select% the i and j. In this simplified code, we select them randomly.j = ceil(m * rand());while j == i, % Make sure i \neq jj = ceil(m * rand());end% Calculate Ej = f(x(j)) - y(j) using (2).E(j) = b + sum (alphas.*Y.*K(:,j)) - Y(j);% Save old alphasalpha_i_old = alphas(i);alpha_j_old = alphas(j);% Compute L and H by (10) or (11).if (Y(i) == Y(j)),L = max(0, alphas(j) + alphas(i) - C);H = min(C, alphas(j) + alphas(i));elseL = max(0, alphas(j) - alphas(i));H = min(C, C + alphas(j) - alphas(i));endif (L == H),% continue to next i.continue;end% Compute eta by (14).eta = 2 * K(i,j) - K(i,i) - K(j,j);if (eta >= 0),% continue to next i.continue;end% Compute and clip new value for alpha j using (12) and (15).alphas(j) = alphas(j) - (Y(j) * (E(i) - E(j))) / eta;% Clipalphas(j) = min (H, alphas(j));alphas(j) = max (L, alphas(j));% Check if change in alpha is significantif (abs(alphas(j) - alpha_j_old) < tol),% continue to next i.% replace anywayalphas(j) = alpha_j_old;continue;end% Determine value for alpha i using (16).alphas(i) = alphas(i) + Y(i)*Y(j)*(alpha_j_old - alphas(j));% Compute b1 and b2 using (17) and (18) respectively.b1 = b - E(i) ...- Y(i) * (alphas(i) - alpha_i_old) * K(i,j)' ...- Y(j) * (alphas(j) - alpha_j_old) * K(i,j)';b2 = b - E(j) ...- Y(i) * (alphas(i) - alpha_i_old) * K(i,j)' ...- Y(j) * (alphas(j) - alpha_j_old) * K(j,j)';% Compute b by (19).if (0 < alphas(i) && alphas(i) < C),b = b1;elseif (0 < alphas(j) && alphas(j) < C),b = b2;elseb = (b1+b2)/2;endnum_changed_alphas = num_changed_alphas + 1;endendif (num_changed_alphas == 0),passes = passes + 1;elsepasses = 0;endfprintf('.');dots = dots + 1;if dots > 78dots = 0;fprintf('\n');endif exist('OCTAVE_VERSION')fflush(stdout);endendfprintf(' Done! \n\n');% Save the modelidx = alphas > 0;model.X= X(idx,:);model.y= Y(idx);model.kernelFunction = kernelFunction;model.b= b;model.alphas= alphas(idx);model.w = ((alphas.*Y)'*X)';end(2)⾮线性的情况:第1步:读取数据⽂件,并可视化数据:% Load from ex6data2:% You will have X, y in your environmentload('ex6data2.mat');% Plot training dataplotData(X, y);第2步:使⽤⾼斯核函数进⾏训练:% SVM ParametersC = 1; sigma = 0.1;% We set the tolerance and max_passes lower here so that the code will run % faster. However, in practice, you will want to run the training to% convergence.model= svmTrain(X, y, C, @(x1, x2) gaussianKernel(x1, x2, sigma)); visualizeBoundary(X, y, model);运⾏结果:(3)⾮线性情况2:第1步:读取数据⽂件,并可视化数据:% Load from ex6data3:% You will have X, y in your environmentload('ex6data3.mat');% Plot training dataplotData(X, y);第2步:尝试不同的参数,选取准确率最⾼的:% Try different SVM Parameters here[C, sigma] = dataset3Params(X, y, Xval, yval);% Train the SVMmodel= svmTrain(X, y, C, @(x1, x2) gaussianKernel(x1, x2, sigma)); visualizeBoundary(X, y, model);其中datasetParams函数:function [C, sigma] = dataset3Params(X, y, Xval, yval)% You need to return the following variables correctly.C = 1;sigma = 0.3;C_vec = [0.01, 0.03, 0.1, 0.3, 1, 3, 10, 30];sigma_vec = [0.01, 0.03, 0.1, 0.3, 1, 3, 10, 30];m = size(C_vec, 2);error_val = 1;for i = 1:mfor j = 1:mmodel= svmTrain(X, y, C_vec(i), @(x1, x2) gaussianKernel(x1, x2, sigma_vec(j))); pred = svmPredict(model, Xval);error_temp = mean(double(pred ~= yval));if error_temp < error_valC = C_vec(i);sigma = sigma_vec(j);error_val = error_temp;endendendend其中svmPredict函数:function pred = svmPredict(model, X)% Check if we are getting a column vector, if so, then assume that we only% need to do prediction for a single exampleif (size(X, 2) == 1)% Examples should be in rowsX = X';end% Datasetm = size(X, 1);p = zeros(m, 1);pred = zeros(m, 1);if strcmp(func2str(model.kernelFunction), 'linearKernel')% We can use the weights and bias directly if working with the% linear kernelp = X * model.w + model.b;elseif strfind(func2str(model.kernelFunction), 'gaussianKernel')% Vectorized RBF Kernel% This is equivalent to computing the kernel on every pair of examples X1 = sum(X.^2, 2);X2 = sum(model.X.^2, 2)';K = bsxfun(@plus, X1, bsxfun(@plus, X2, - 2 * X * model.X'));K = model.kernelFunction(1, 0) .^ K;K = bsxfun(@times, model.y', K);K = bsxfun(@times, model.alphas', K);p = sum(K, 2);else% Other Non-linear kernelfor i = 1:mprediction = 0;for j = 1:size(model.X, 1)prediction = prediction + ...model.alphas(j) * model.y(j) * ...model.kernelFunction(X(i,:)', model.X(j,:)');endp(i) = prediction + model.b;endend% Convert predictions into 0 / 1pred(p >= 0) = 1;pred(p < 0) = 0;end运⾏结果:第2题概述:实现垃圾邮件的识别第1步:读取数据⽂件,对单词进⾏处理:% Extract Featuresfile_contents = readFile('emailSample1.txt');word_indices = processEmail(file_contents);% Print Statsfprintf('Word Indices: \n');fprintf(' %d', word_indices);fprintf('\n\n');单词处理过程:去除符号、空格、换⾏等;识别出邮箱、价格、超链接、数字,替换为特定单词;在关键词列表中找出出现的关键词,并标记为出单词编号.function word_indices = processEmail(email_contents)% Load VocabularyvocabList = getVocabList();% Init return valueword_indices = [];% ========================== Preprocess Email =========================== % Find the Headers ( \n\n and remove )% Uncomment the following lines if you are working with raw emails with the% full headers% hdrstart = strfind(email_contents, ([char(10) char(10)]));% email_contents = email_contents(hdrstart(1):end);% Lower caseemail_contents = lower(email_contents);% Strip all HTML% Looks for any expression that starts with < and ends with > and replace% and does not have any < or > in the tag it with a spaceemail_contents = regexprep(email_contents, '<[^<>]+>', ' ');% Handle Numbers% Look for one or more characters between 0-9email_contents = regexprep(email_contents, '[0-9]+', 'number');% Handle URLS% Look for strings starting with http:// or https://email_contents = regexprep(email_contents, ...'(http|https)://[^\s]*', 'httpaddr');% Handle Email Addresses% Look for strings with @ in the middleemail_contents = regexprep(email_contents, '[^\s]+@[^\s]+', 'emailaddr');% Handle $ signemail_contents = regexprep(email_contents, '[$]+', 'dollar');% ========================== Tokenize Email =========================== % Output the email to screen as wellfprintf('\n==== Processed Email ====\n\n');% Process filel = 0;while ~isempty(email_contents)% Tokenize and also get rid of any punctuation[str, email_contents] = ...strtok(email_contents, ...[' @$/#.-:&*+=[]?!(){},''">_<;%' char(10) char(13)]);% Remove any non alphanumeric charactersstr = regexprep(str, '[^a-zA-Z0-9]', '');% Stem the word% (the porterStemmer sometimes has issues, so we use a try catch block)try str = porterStemmer(strtrim(str));catch str = ''; continue;end;% Skip the word if it is too shortif length(str) < 1continue;endfor i = 1:size(vocabList),if strcmp(str, vocabList(i)),word_indices = [word_indices i];endend% Print to screen, ensuring that the output lines are not too longif (l + length(str) + 1) > 78fprintf('\n');l = 0;endfprintf('%s ', str);l = l + length(str) + 1;end% Print footerfprintf('\n\n=========================\n');end其中读取关键字列表函数:function vocabList = getVocabList()%% Read the fixed vocabulary listfid = fopen('vocab.txt');% Store all dictionary words in cell array vocab{}n = 1899; % Total number of words in the dictionary% For ease of implementation, we use a struct to map the strings => integers% In practice, you'll want to use some form of hashmapvocabList = cell(n, 1);for i = 1:n% Word Index (can ignore since it will be = i)fscanf(fid, '%d', 1);% Actual WordvocabList{i} = fscanf(fid, '%s', 1);endfclose(fid);end第3步:对关键字进⾏特征值标记,出现的关键词标记为1:% Extract Featuresfeatures = emailFeatures(word_indices);% Print Statsfprintf('Length of feature vector: %d\n', length(features));fprintf('Number of non-zero entries: %d\n', sum(features > 0));其中emailFeatures函数为:function x = emailFeatures(word_indices)% Total number of words in the dictionaryn = 1899;% You need to return the following variables correctly.x = zeros(n, 1);for i = 1:size(word_indices),x(word_indices(i)) = 1;endend第4步:使⽤线性核函数进⾏训练,并分别计算训练集准确率和测试集准确率:% Load the Spam Email dataset% You will have X, y in your environmentload('spamTrain.mat');fprintf('\nTraining Linear SVM (Spam Classification)\n')fprintf('(this may take 1 to 2 minutes) ...\n')C = 0.1;model = svmTrain(X, y, C, @linearKernel);p = svmPredict(model, X);fprintf('Training Accuracy: %f\n', mean(double(p == y)) * 100); % Load the test dataset% You will have Xtest, ytest in your environmentload('spamTest.mat');fprintf('\nEvaluating the trained Linear SVM on a test set ...\n') p = svmPredict(model, Xtest);fprintf('Test Accuracy: %f\n', mean(double(p == ytest)) * 100);运⾏结果:第5步:找出最⾼权重的关键词:% Sort the weights and obtin the vocabulary list [weight, idx] = sort(model.w, 'descend');vocabList = getVocabList();fprintf('\nTop predictors of spam: \n');for i = 1:15fprintf(' %-15s (%f) \n', vocabList{idx(i)}, weight(i));endfprintf('\n\n');fprintf('\nProgram paused. Press enter to continue.\n'); pause;运⾏结果:。
svm 例题

svm 例题Support Vector Machines (SVM) ExampleIn machine learning, Support Vector Machines (SVM) are widely used for classification and regression analysis. SVM aims to find the best hyperplane that separates data points into different classes, maximizing the margin between them. In this article, we will discuss an example to demonstrate the application of SVM.Example Scenario:Suppose we have a dataset containing information about different fruits. Each fruit is described by two features: sweetness (x-axis) and acidity (y-axis). The goal is to build an SVM model to classify fruits into two categories: apples and oranges. We will use the SVM algorithm to find the decision boundary that best separates these two classes.Data Preprocessing:Before training our SVM model, it is essential to preprocess the data. Firstly, we need to collect a labelled dataset consisting of fruits, where each fruit is labelled as either an apple or an orange. Then, we perform feature scaling to normalize both the sweetness and acidity values within a specific range, such as between 0 and 1. This step ensures that the features contribute equally to the SVM model.Training the SVM Model:After preprocessing the data, we can proceed with training the SVM model. The SVM algorithm aims to find the optimal hyperplane thatmaximizes the margin between the classes. In our fruit classification example, the SVM model will determine the hyperplane that best separates the apples from the oranges in feature space.To find the optimal hyperplane, we need to choose a suitable kernel function. Commonly used kernel functions include the linear kernel, polynomial kernel, and radial basis function (RBF) kernel. The choice of the kernel function depends on the nature of the data and the desired decision boundary.Evaluating the SVM Model:Once the SVM model is trained, we can evaluate its performance using various evaluation metrics, such as accuracy, precision, recall, and F1-score. These metrics provide insights into how well the SVM model can classify new, unseen fruits.To evaluate the model, we can split our dataset into a training set and a testing set. The training set is used to train the SVM model, while the testing set is used to assess its performance. By comparing the predicted labels with the actual labels of the testing set, we can calculate the evaluation metrics and determine the accuracy of our model.Improving the Performance:In some cases, SVM may not perform optimally due to factors like imbalanced data or overlapping classes. To enhance the performance of the SVM model, we can employ techniques such as data resampling, feature engineering, or using a different kernel function.Conclusion:Support Vector Machines (SVM) offer an effective approach for classification and regression tasks. In this example, we showcased how SVM can be applied to classify fruits into apples and oranges based on their sweetness and acidity. By preprocessing the data, training the SVM model, and evaluating its performance, we can build a reliable fruit classification system. SVM can be further improved by utilizing various techniques to address specific challenges in different scenarios.Remember, the key to success with SVM lies in understanding the dataset, selecting appropriate features, and choosing the right kernel function. With proper implementation and careful evaluation, SVM can be a powerful tool in machine learning.。
机器学习SVM习题集
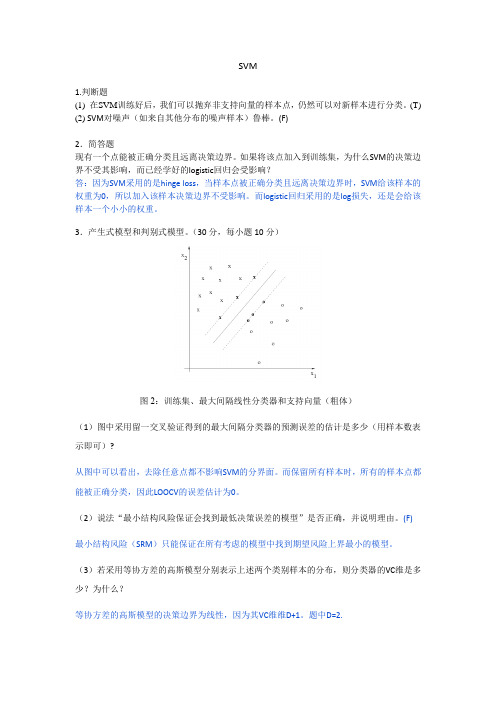
SVM1.判断题(1) 在SVM训练好后,我们可以抛弃非支持向量的样本点,仍然可以对新样本进行分类。
(T)(2) SVM对噪声(如来自其他分布的噪声样本)鲁棒。
(F)2.简答题现有一个点能被正确分类且远离决策边界。
如果将该点加入到训练集,为什么SVM的决策边界不受其影响,而已经学好的logistic回归会受影响?答:因为SVM采用的是hinge loss,当样本点被正确分类且远离决策边界时,SVM给该样本的权重为0,所以加入该样本决策边界不受影响。
而logistic回归采用的是log损失,还是会给该样本一个小小的权重。
3.产生式模型和判别式模型。
(30分,每小题10分)图2:训练集、最大间隔线性分类器和支持向量(粗体)(1)图中采用留一交叉验证得到的最大间隔分类器的预测误差的估计是多少(用样本数表示即可)?从图中可以看出,去除任意点都不影响SVM的分界面。
而保留所有样本时,所有的样本点都能被正确分类,因此LOOCV的误差估计为0。
(2)说法“最小结构风险保证会找到最低决策误差的模型”是否正确,并说明理由。
(F)最小结构风险(SRM)只能保证在所有考虑的模型中找到期望风险上界最小的模型。
(3)若采用等协方差的高斯模型分别表示上述两个类别样本的分布,则分类器的VC维是多少?为什么?等协方差的高斯模型的决策边界为线性,因为其VC维维D+1。
题中D=2.4、SVM 分类。
(第1~5题各4分,第6题5分,共25分)下图为采用不同核函数或不同的松弛因子得到的SVM 决策边界。
但粗心的实验者忘记记录每个图形对应的模型和参数了。
请你帮忙给下面每个模型标出正确的图形。
(1)、211min , s.t.2Ni i C ξ=⎛⎫+ ⎪⎝⎭∑w()00, 1, 1,....,, T i i i y w i N ξξ≥+≥-=w x其中0.1C =。
线性分类面,C 较小,正则较大,||w||较小,Margin 较大, 支持向量较多(c )(2)、211min , s.t.2Ni i C ξ=⎛⎫+ ⎪⎝⎭∑w()00, 1, 1,....,, T i i i y w i N ξξ≥+≥-=w x其中1C =。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Programming Exercise6:Support Vector MachinesMachine LearningIntroductionIn this exercise,you will be using support vector machines(SVMs)to build a spam classifier.Before starting on the programming exercise,we strongly recommend watching the video lectures and completing the review questions for the associated topics.To get started with the exercise,you will need to download the starter code and unzip its contents to the directory where you wish to complete the exercise.If needed,use the cd command in Octave/MATLAB to change to this directory before starting this exercise.You can alsofind instructions for installing Octave/MATLAB in the“En-vironment Setup Instructions”of the course website.Files included in this exerciseex6.m-Octave/MATLAB script for thefirst half of the exerciseex6data1.mat-Example Dataset1ex6data2.mat-Example Dataset2ex6data3.mat-Example Dataset3svmTrain.m-SVM rraining functionsvmPredict.m-SVM prediction functionplotData.m-Plot2D datavisualizeBoundaryLinear.m-Plot linear boundaryvisualizeBoundary.m-Plot non-linear boundarylinearKernel.m-Linear kernel for SVM[ ]gaussianKernel.m-Gaussian kernel for SVM[ ]dataset3Params.m-Parameters to use for Dataset3ex6spam.m-Octave/MATLAB script for the second half of the exer-cisespamTrain.mat-Spam training setspamTest.mat-Spam test setemailSample1.txt-Sample email1emailSample2.txt-Sample email2spamSample1.txt-Sample spam1spamSample2.txt-Sample spam2vocab.txt-Vocabulary listgetVocabList.m-Load vocabulary listporterStemmer.m-Stemming functionreadFile.m-Reads afile into a character stringsubmit.m-Submission script that sends your solutions to our servers [ ]processEmail.m-Email preprocessing[ ]emailFeatures.m-Feature extraction from emailsindicatesfiles you will need to completeThroughout the exercise,you will be using the script ex6.m.These scripts set up the dataset for the problems and make calls to functions that you will write.You are only required to modify functions in otherfiles,by following the instructions in this assignment.Where to get helpThe exercises in this course use Octave1or MATLAB,a high-level program-ming language well-suited for numerical computations.If you do not have Octave or MATLAB installed,please refer to the installation instructions in the“Environment Setup Instructions”of the course website.At the Octave/MATLAB command line,typing help followed by a func-tion name displays documentation for a built-in function.For example,help plot will bring up help information for plotting.Further documentation for Octave functions can be found at the Octave documentation pages.MAT-LAB documentation can be found at the MATLAB documentation pages.We also strongly encourage using the online Discussions to discuss ex-ercises with other students.However,do not look at any source code written by others or share your source code with others.1Octave is a free alternative to MATLAB.For the programming exercises,you are free to use either Octave or MATLAB.1Support Vector MachinesIn thefirst half of this exercise,you will be using support vector machines (SVMs)with various example2D datasets.Experimenting with these datasets will help you gain an intuition of how SVMs work and how to use a Gaussian kernel with SVMs.In the next half of the exercise,you will be using support vector machines to build a spam classifier.The provided script,ex6.m,will help you step through thefirst half of the exercise.1.1Example Dataset1We will begin by with a2D example dataset which can be separated by a linear boundary.The script ex6.m will plot the training data(Figure1).In this dataset,the positions of the positive examples(indicated with+)and the negative examples(indicated with o)suggest a natural separation indicated by the gap.However,notice that there is an outlier positive example+on the far left at about(0.1,4.1).As part of this exercise,you will also see how this outlier affects the SVM decision boundary.Figure1:Example Dataset1In this part of the exercise,you will try using different values of the C parameter with rmally,the C parameter is a positive value that controls the penalty for misclassified training examples.A large C parametertells the SVM to try to classify all the examples correctly.C plays a rolesimilar to1λ,whereλis the regularization parameter that we were usingpreviously for logistic regression.Figure2:SVM Decision Boundary with C=1(Example Dataset1)Figure3:SVM Decision Boundary with C=100(Example Dataset1) The next part in ex6.m will run the SVM training(with C=1)usingSVM software that we have included with the starter code,svmTrain.m.2 When C=1,you shouldfind that the SVM puts the decision boundary in the gap between the two datasets and misclassifies the data point on the far left(Figure2).Implementation Note:Most SVM software packages(including svmTrain.m)automatically add the extra feature x0=1for you and au-tomatically take care of learning the intercept termθ0.So when passing your training data to the SVM software,there is no need to add this ex-tra feature x0=1yourself.In particular,in Octave/MATLAB your code should be working with training examples x∈R n(rather than x∈R n+1); for example,in thefirst example dataset x∈R2.Your task is to try different values of C on this dataset.Specifically,you should change the value of C in the script to C=100and run the SVM training again.When C=100,you shouldfind that the SVM now classifies every single example correctly,but has a decision boundary that does not appear to be a naturalfit for the data(Figure3).1.2SVM with Gaussian KernelsIn this part of the exercise,you will be using SVMs to do non-linear clas-sification.In particular,you will be using SVMs with Gaussian kernels on datasets that are not linearly separable.1.2.1Gaussian KernelTofind non-linear decision boundaries with the SVM,we need tofirst im-plement a Gaussian kernel.You can think of the Gaussian kernel as a sim-ilarity function that measures the“distance”between a pair of examples, (x(i),x(j)).The Gaussian kernel is also parameterized by a bandwidth pa-rameter,σ,which determines how fast the similarity metric decreases(to0) as the examples are further apart.You should now complete the code in gaussianKernel.m to compute the Gaussian kernel between two examples,(x(i),x(j)).The Gaussian kernel 2In order to ensure compatibility with Octave/MATLAB,we have included this imple-mentation of an SVM learning algorithm.However,this particular implementation was chosen to maximize compatibility,and is not very efficient.If you are training an SVM on a real problem,especially if you need to scale to a larger dataset,we strongly recommend instead using a highly optimized SVM toolbox such as LIBSVM.function is defined as:K gaussian(x(i),x(j))=exp−x(i)−x(j) 22σ2=exp−nk=1(x(i)k−x(j)k)22σ2.Once you’ve completed the function gaussianKernel.m,the script ex6.m will test your kernel function on two provided examples and you should ex-pect to see a value of0.324652.You should now submit your solutions.1.2.2Example Dataset2Figure4:Example Dataset2The next part in ex6.m will load and plot dataset2(Figure4).From thefigure,you can obserse that there is no linear decision boundary that separates the positive and negative examples for this dataset.However,by using the Gaussian kernel with the SVM,you will be able to learn a non-linear decision boundary that can perform reasonably well for the dataset.If you have correctly implemented the Gaussian kernel function,ex6.m will proceed to train the SVM with the Gaussian kernel on this dataset.Figure5:SVM(Gaussian Kernel)Decision Boundary(Example Dataset2) Figure5shows the decision boundary found by the SVM with a Gaussian kernel.The decision boundary is able to separate most of the positive and negative examples correctly and follows the contours of the dataset well.1.2.3Example Dataset3In this part of the exercise,you will gain more practical skills on how to use a SVM with a Gaussian kernel.The next part of ex6.m will load and display a third dataset(Figure6).You will be using the SVM with the Gaussian kernel with this dataset.In the provided dataset,ex6data3.mat,you are given the variables X, y,Xval,yval.The provided code in ex6.m trains the SVM classifier using the training set(X,y)using parameters loaded from dataset3Params.m.Your task is to use the cross validation set Xval,yval to determine the best C andσparameter to use.You should write any additional code nec-essary to help you search over the parameters C andσ.For both C andσ,we suggest trying values in multiplicative steps(e.g.,0.01,0.03,0.1,0.3,1,3,10,30). Note that you should try all possible pairs of values for C andσ(e.g.,C=0.3 andσ=0.1).For example,if you try each of the8values listed above for C and forσ2,you would end up training and evaluating(on the cross validation set)a total of82=64different models.After you have determined the best C andσparameters to use,you should modify the code in dataset3Params.m,filling in the best parametersFigure6:Example Dataset3Figure7:SVM(Gaussian Kernel)Decision Boundary(Example Dataset3) you found.For our best parameters,the SVM returned a decision boundary shown in Figure7.Implementation Tip:When implementing cross validation to select the best C andσparameter to use,you need to evaluate the error on the cross validation set.Recall that for classification,the error is de-fined as the fraction of the cross validation examples that were classi-fied incorrectly.In Octave/MATLAB,you can compute this error using mean(double(predictions~=yval)),where predictions is a vector containing all the predictions from the SVM,and yval are the true labels from the cross validation set.You can use the svmPredict function to generate the predictions for the cross validation set.You should now submit your solutions.2Spam ClassificationMany email services today provide spamfilters that are able to classify emails into spam and non-spam email with high accuracy.In this part of the exer-cise,you will use SVMs to build your own spamfilter.You will be training a classifier to classify whether a given email,x,is spam(y=1)or non-spam(y=0).In particular,you need to convert each email into a feature vector x∈R n.The following parts of the exercise will walk you through how such a feature vector can be constructed from an email.Throughout the rest of this exercise,you will be using the the script ex6spam.m.The dataset included for this exercise is based on a a subset of the SpamAssassin Public Corpus.3For the purpose of this exercise,you will only be using the body of the email(excluding the email headers).2.1Preprocessing Emails>Anyone knows how much it costs to host a web portal?>Well,it depends on how many visitors youre expecting.This can be anywhere from less than10bucks a month to a couple of$100.You should checkout /or perhaps Amazon EC2ifyoure running something big..To unsubscribe yourself from this mailing list,send an email to: groupname-unsubscribe@Figure8:Sample EmailBefore starting on a machine learning task,it is usually insightful to take a look at examples from the dataset.Figure8shows a sample email that contains a URL,an email address(at the end),numbers,and dollar amounts.While many emails would contain similar types of entities(e.g., numbers,other URLs,or other email addresses),the specific entities(e.g., the specific URL or specific dollar amount)will be different in almost every email.Therefore,one method often employed in processing emails is to “normalize”these values,so that all URLs are treated the same,all numbers are treated the same,etc.For example,we could replace each URL in the email with the unique string“httpaddr”to indicate that a URL was present.3/publiccorpus/This has the effect of letting the spam classifier make a classification decision based on whether any URL was present,rather than whether a specific URL was present.This typically improves the performance of a spam classifier, since spammers often randomize the URLs,and thus the odds of seeing any particular URL again in a new piece of spam is very small.In processEmail.m,we have implemented the following email prepro-cessing and normalization steps:•Lower-casing:The entire email is converted into lower case,so that captialization is ignored(e.g.,IndIcaTE is treated the same as Indicate).•Stripping HTML:All HTML tags are removed from the emails.Many emails often come with HTML formatting;we remove all the HTML tags,so that only the content remains.•Normalizing URLs:All URLs are replaced with the text“httpaddr”.•Normalizing Email Addresses:All email addresses are replaced with the text“emailaddr”.•Normalizing Numbers:All numbers are replaced with the text “number”.•Normalizing Dollars:All dollar signs($)are replaced with the text “dollar”.•Word Stemming:Words are reduced to their stemmed form.For ex-ample,“discount”,“discounts”,“discounted”and“discounting”are all replaced with“discount”.Sometimes,the Stemmer actually strips offadditional characters from the end,so“include”,“includes”,“included”, and“including”are all replaced with“includ”.•Removal of non-words:Non-words and punctuation have been re-moved.All white spaces(tabs,newlines,spaces)have all been trimmed to a single space character.The result of these preprocessing steps is shown in Figure9.While pre-processing has left word fragments and non-words,this form turns out to be much easier to work with for performing feature extraction.anyon know how much it cost to host a web portal well it depend on how mani visitor your expect thi can be anywher from less than number buck a month to a coupl of dollarnumb you should checkout httpaddr or perhap amazon ecnumb if your run someth big to unsubscrib yourself from thi mail list send an email to emailaddrFigure9:Preprocessed Sample Email1aa2ab3abil...86anyon...916know...1898zero1899zipFigure10:Vocabulary List869167941077883370169979018221831883431117179410021893136459216762381628968894516631120106216993751162479189315107991182123781018951440154718116991758189668816769929611477715301699531Figure11:Word Indices for Sample Email2.1.1Vocabulary ListAfter preprocessing the emails,we have a list of words(e.g.,Figure9)for each email.The next step is to choose which words we would like to use in our classifier and which we would want to leave out.For this exercise,we have chosen only the most frequently occuring words as our set of words considered(the vocabulary list).Since words that occur rarely in the training set are only in a few emails,they might cause the model to overfit our training set.The complete vocabulary list is in thefile vocab.txt and also shown in Figure10.Our vocabulary list was selected by choosing all words which occur at least a100times in the spam corpus, resulting in a list of1899words.In practice,a vocabulary list with about 10,000to50,000words is often used.Given the vocabulary list,we can now map each word in the preprocessed emails(e.g.,Figure9)into a list of word indices that contains the index of the word in the vocabulary list.Figure11shows the mapping for the sample email.Specifically,in the sample email,the word“anyone”wasfirst normalized to“anyon”and then mapped onto the index86in the vocabulary list.Your task now is to complete the code in processEmail.m to performthis mapping.In the code,you are given a string str which is a single word from the processed email.You should look up the word in the vocabulary list vocabList andfind if the word exists in the vocabulary list.If the word exists,you should add the index of the word into the word indices variable. If the word does not exist,and is therefore not in the vocabulary,you can skip the word.Once you have implemented processEmail.m,the script ex6spam.m will run your code on the email sample and you should see an output similar to Figures9&11.Octave/MATLAB Tip:In Octave/MATLAB,you can compare two strings with the strcmp function.For example,strcmp(str1,str2)will return1only when both strings are equal.In the provided starter code, vocabList is a“cell-array”containing the words in the vocabulary.In Octave/MATLAB,a cell-array is just like a normal array(i.e.,a vector), except that its elements can also be strings(which they can’t in a normal Octave/MATLAB matrix/vector),and you index into them using curly braces instead of square brackets.Specifically,to get the word at index i,you can use vocabList{i}.You can also use length(vocabList)to get the number of words in the vocabulary.You should now submit your solutions.2.2Extracting Features from EmailsYou will now implement the feature extraction that converts each email into a vector in R n.For this exercise,you will be using n=#words in vocabulary list.Specifically,the feature x i∈{0,1}for an email corresponds to whether the i-th word in the dictionary occurs in the email.That is,x i=1if the i-th word is in the email and x i=0if the i-th word is not present in the email.Thus,for a typical email,this feature would look like:x=...1...1...∈R n.You should now complete the code in emailFeatures.m to generate a feature vector for an email,given the word indices.Once you have implemented emailFeatures.m,the next part of ex6spam.m will run your code on the email sample.You should see that the feature vec-tor had length1899and45non-zero entries.You should now submit your solutions.2.3Training SVM for Spam ClassificationAfter you have completed the feature extraction functions,the next step of ex6spam.m will load a preprocessed training dataset that will be used to train a SVM classifier.spamTrain.mat contains4000training examples of spam and non-spam email,while spamTest.mat contains1000test examples.Each original email was processed using the processEmail and emailFeatures functions and converted into a vector x(i)∈R1899.After loading the dataset,ex6spam.m will proceed to train a SVM to classify between spam(y=1)and non-spam(y=0)emails.Once the training completes,you should see that the classifier gets a training accuracy of about99.8%and a test accuracy of about98.5%.2.4Top Predictors for Spamour click remov guarante visit basenumb dollar will price pleas nbspmost lo ga dollarnumbFigure12:Top predictors for spam emailTo better understand how the spam classifier works,we can inspect the parameters to see which words the classifier thinks are the most predictiveof spam.The next step of ex6spam.mfinds the parameters with the largestpositive values in the classifier and displays the corresponding words(Figure12).Thus,if an email contains words such as“guarantee”,“remove”,“dol-lar”,and“price”(the top predictors shown in Figure12),it is likely to beclassified as spam.2.5Optional(ungraded)exercise:Try your own emailsNow that you have trained a spam classifier,you can start trying it out onyour own emails.In the starter code,we have included two email exam-ples(emailSample1.txt and emailSample2.txt)and two spam examples (spamSample1.txt and spamSample2.txt).The last part of ex6spam.mruns the spam classifier over thefirst spam example and classifies it usingthe learned SVM.You should now try the other examples we have providedand see if the classifier gets them right.You can also try your own emails byreplacing the examples(plain textfiles)with your own emails.You do not need to submit any solutions for this optional(ungraded) exercise.2.6Optional(ungraded)exercise:Build your own datasetIn this exercise,we provided a preprocessed training set and test set.Thesedatasets were created using the same functions(processEmail.m and emailFeatures.m) that you now have completed.For this optional(ungraded)exercise,you willbuild your own dataset using the original emails from the SpamAssassin Pub-lic Corpus.Your task in this optional(ungraded)exercise is to download the originalfiles from the public corpus and extract them.After extracting them,youshould run the processEmail4and emailFeatures functions on each emailto extract a feature vector from each email.This will allow you to build adataset X,y of examples.You should then randomly divide up the datasetinto a training set,a cross validation set and a test set.While you are building your own dataset,we also encourage you to trybuilding your own vocabulary list(by selecting the high frequency words 4The original emails will have email headers that you might wish to leave out.We haveincluded code in processEmail that will help you remove these headers.that occur in the dataset)and adding any additional features that you think might be useful.Finally,we also suggest trying to use highly optimized SVM toolboxes such as LIBSVM.You do not need to submit any solutions for this optional(ungraded) exercise.Submission and GradingAfter completing various parts of the assignment,be sure to use the submit function system to submit your solutions to our servers.The following is a breakdown of how each part of this exercise is scored.Part Submitted File Points Gaussian Kernel gaussianKernel.m25points Parameters(C,σ)for Dataset3dataset3Params.m25points Email Preprocessing processEmail.m25points Email Feature Extraction emailFeatures.m25points Total Points100pointsYou are allowed to submit your solutions multiple times,and we will take only the highest score into consideration.。