详解大端模式和小端模式
大端模式与小端模式解析

大端模式与小端模式一、概念及详解在各种体系的计算机中通常采用的字节存储机制主要有两种:big-endian和little-endian,即大端模式和小端模式。
先回顾两个关键词,MSB和LSB:MSB:Most Significant Bit ------- 最高有效位LSB:Least Significant Bit ------- 最低有效位大端模式(big-edian)big-endian:MSB存放在最低端的地址上。
举例,双字节数0x1234以big-endian的方式存在起始地址0x00002000中:| data |<-- address| 0x12 |<-- 0x00002000| 0x34 |<-- 0x00002001在Big-Endian中,对于bit序列中的序号编排方式如下(以双字节数0x8B8A为例):----+---------------------------------------------------+bit | 00 01 02 03 04 05 06 07 | 08 09 10 11 12 13----+MSB---------------------------------------------LSB+val | 1 0 0 0 1 0 1 1| 1 0 0 0 1 0 1 0 |----+---------------------------------------------------+= 0x8B8A小端模式(little-endian)little-endian:LSB存放在最低端的地址上。
举例,双字节数0x1234以little-endian的方式存在起始地址0x00002000中:| data |<-- address| 0x34 |<-- 0x00002000| 0x12 |<-- 0x00002001在Little-Endian中,对于bit序列中的序号编排和Big-Endian 刚好相反,其方式如下(以双字节数0x8B8A为例):----+---------------------------------------------------+bit | 15 14 13 12 11 10 09 08 | 07 06 05 04 03 02----+MSB---------------------------------------------LSB+val | 1 0 0 0 1 0 1 1| 1 0 0 0 1 0 1 0 |----+---------------------------------------------------+= 0x8B8A二、数组在大端小端情况下的存储:以unsigned in t value = 0x12345678为例,分别看看在两种字节序下其存储情况,我们可以用unsigned char buf[4]来表示value:Big-Endian: 低地址存放高位,如下:高地址---------------buf[3] (0x78) -- 低位buf[2] (0x56)buf[1] (0x34)buf[0] (0x12) -- 高位---------------低地址Little-Endian: 低地址存放低位,如下:高地址---------------buf[3] (0x12) -- 高位buf[2] (0x34)buf[1] (0x56)buf[0] (0x78) -- 低位--------------低地址三、大端小端转换方法:Big-Endian转换成Little-Endian如下:#defineBigtoLittle16(A) ((((uint16)( A) & 0xff00) >> 8) | \(((uint16)(A) & 0x00ff) << 8))#defineBigtoLittle32(A) ((((uint32)( A) & 0xff000000) >> 24) | \(((uint32)(A) & 0x00ff0000) >> 8) | \(((uint32)(A) & 0x0000ff00) << 8) | \(((uint32)(A) & 0x000000ff) << 24))四、大端小端检测方法:如何检查处理器是big-endian还是little-endian?联合体union的存放顺序是所有成员都从低地址开始存放,利用该特性就可以轻松地获得了CPU对内存采用Little-endian还是Big-endian模式读写。
大端模式、小端模式及在QT中的转换

⼤端模式、⼩端模式及在QT中的转换转载于:https:///usownh/article/details/42614185⼤端模式和⼩端模式是计算机中经常涉及到的两种字节序,也有⼤端对齐、⼩端对齐、⼤尾、⼩尾等叫法。
⼀、起源说起这两种模式,就不得不提⼀下⼤端(Big-endian)和⼩端(Little-endian)这两个英⽂上的起源。
“endian”⼀词来源于乔纳森·斯威夫特的⼩说格列佛游记。
Lilliput和Blefuscu这两个强国在过去的36个⽉中⼀直在苦战。
战争的原因:⼤家都知道,吃鸡蛋的时候,原始的⽅法是打破鸡蛋较⼤的⼀端(Big-End),可以那时的皇帝的祖⽗由于⼩时侯吃鸡蛋,按这种⽅法把⼿指弄破了,因此他的⽗亲,就下令,命令所有的⼦民吃鸡蛋的时候,必须先打破鸡蛋较⼩的⼀端(Little-End),违令者重罚。
然后⽼百姓对此法令极为反感,期间发⽣了多次叛乱,其中⼀个皇帝因此送命,另⼀个丢了王位,产⽣叛乱的原因就是另⼀个国家Blefuscu的国王⼤⾂煽动起来的,叛乱平息后,就逃到这个帝国避难。
据估计,先后⼏次有11000余⼈情愿死也不肯去打破鸡蛋较⼩的端吃鸡蛋。
这个其实讽刺当时英国和法国之间持续的冲突。
(引⾃/ce123_zhouwei/article/details/6971544)其中两种⽅法吃鸡蛋的⼈分别被称为Big-endians和Little-endians。
1980年,Danny Cohen在其著名的论⽂”On Holy Wars and a Plea for Peace”中,为平息⼀场关于字节该以什么样的顺序传送的争论,⽽引⽤了该词。
⼆、存储模式接下来就说说为什么会有字节序的问题。
计算机在存储数据的时候,是以字节(byte)为基本单位来存储的,因此存储单字节类型的数据(⽐如char)不存在字节序的问题。
但存储多字节的数据的时候(⽐⽅说4字节的int变量),就涉及到了以⼀个什么样的顺序来存储。
大端模式和小端模式

⼤端模式和⼩端模式⼤端:低地址存⾼位(⾼地址存低位)⼩端:低地址存低位(⾼地址存⾼位)1.故事的起源“endian”这个词出⾃《格列佛游记》。
⼩⼈国的内战就源于吃鸡蛋时是究竟从⼤头(Big-Endian)敲开还是从⼩头(Little-Endian)敲开,由此曾发⽣过六次叛乱,其中⼀个皇帝送了命,另⼀个丢了王位。
我们⼀般将endian翻译成“字节序”,将big endian和little endian称作“⼤尾”和“⼩尾”。
2.什么是Big Endian和Little Endian?在设计计算机系统的时候,有两种处理内存中数据的⽅法。
⼀种叫为little-endian,存放在内存中最低位的数值是来⾃数据的最右边部分(也就是数据的最低位部分)。
⽐如某些⽂件需要在不同平台处理,或者通过Socket通信。
这⽅⾯我们可以借助ntohl(), ntohs(), htonl(), and htons()函数进⾏格式转换,个⼈补充:⼀个操作数作htonl或ntohl结果不⼀定相同,当机器字节序跟⽹络字节序刚好是仅仅big endian和little endian的区别时是相同的。
3. 如何理解Big Endian和Little Endian举个例⼦:int a = 1;a这个数本⾝的16进制表⽰是0x00 00 00 01在内存中怎么存储呢?如果你的CPU是intel x86架构的(基本上就是通常我们说的奔腾cpu),那么就是0x01 0x00 0x00 0x00 , 这也就是所谓的little-endian, 低字节存放在内存的低位.如果你的CPU是⽼式AMD系列的(很⽼很⽼的那种,因为最新的AMD系列已经是x86架构了), 它的字节序就是big-endian, 其内存存储就是0x00 0x00 0x00 0x01在内存中从⾼字节开始存放。
现在世界上绝⼤多数的CPU都是little-endian。
4. 了解big-endian和little-endian有什么作⽤?⼀个重要的作⽤就是了解在⽹络上不同的机器间的数据如何传输。
STM32和大小端模式

STM32和大小端模式
2016年11月04日17:28:50
阅读数:4051
1.大端模式
是指数据的高字节保存在内存的低地址中,
而数据的低字节保存在内存的高地址中,
这样的存储模式有点儿类似于把数据当作字符串顺序处理:地址由小向大增加,而数据从高位往低位放;
这和我们的阅读习惯一致。
例如
声明一个32位的变量
高地址0-7位
|/ 8-15位
|/ 16-23位
低地址24-31位
2.小端模式
是指数据的高字节保存在内存的高地址中,
而数据的低字节保存在内存的低地址中,
这种存储模式将地址的高低和数据位权有效地结合起来,高地址部分权值高,低地址部分权值低。
例如
声明一个32位的变量
低地址0-7位
|/ 8-15位
|/ 16-23位
高地址24-31位
STM32单片机的存储方式为小端模式。
大端模式与小端模式
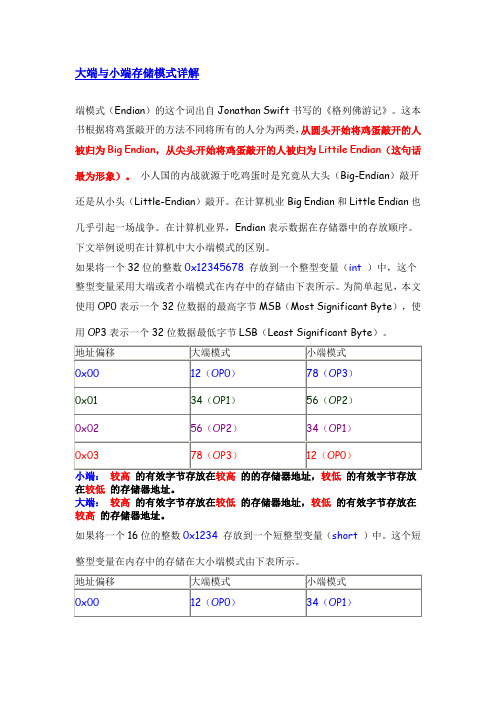
大端与小端存储模式详解端模式(Endian)的这个词出自Jonathan Swift书写的《格列佛游记》。
这本书根据将鸡蛋敲开的方法不同将所有的人分为两类,从圆头开始将鸡蛋敲开的人被归为Big Endian,从尖头开始将鸡蛋敲开的人被归为Littile Endian(这句话最为形象)。
小人国的内战就源于吃鸡蛋时是究竟从大头(Big-Endian)敲开还是从小头(Little-Endian)敲开。
在计算机业Big Endian和Little Endian也几乎引起一场战争。
在计算机业界,Endian表示数据在存储器中的存放顺序。
下文举例说明在计算机中大小端模式的区别。
如果将一个32位的整数0x12345678存放到一个整型变量(int)中,这个整型变量采用大端或者小端模式在内存中的存储由下表所示。
为简单起见,本文使用OP0表示一个32位数据的最高字节MSB(Most Significant Byte),使用OP3表示一个32位数据最低字节LSB(Least Significant Byte)。
在较低的存储器地址。
大端:较高的有效字节存放在较低的存储器地址,较低的有效字节存放在较高的存储器地址。
如果将一个16位的整数0x1234存放到一个短整型变量(short)中。
这个短整型变量在内存中的存储在大小端模式由下表所示。
大端方式将高位存放在低地址,小端方式将高位存放在高地址。
采用大端方式进行数据存放符合人类的正常思维,而采用小端方式进行数据存放利于计算机处理。
到目前为止,采用大端或者小端进行数据存放,其孰优孰劣也没有定论。
有的处理器系统采用了小端方式进行数据存放,如Intel的奔腾。
有的处理器系统采用了大端方式进行数据存放,如IBM半导体和Freescale的PowerPC处理器。
不仅对于处理器,一些外设的设计中也存在着使用大端或者小端进行数据存放的选择。
因此在一个处理器系统中,有可能存在大端和小端模式同时存在的现象。
高字节与低字节,高地址与低地址,大端模式与小端模式

字节顺序是指占内存多于一个字节类型的数据在内存中的存放顺序通常有小端大端两种字节顺序
高字节与低字节,高地址与低地址 ,大端模式与小端模式
高、低字节 :按平时书写习惯,从左到右是高位到低位的顺序 ห้องสมุดไป่ตู้,低地址:内存地址可以对应十六进制的数值,值大的为高地址,否则为低地址; 字节顺序是指占内存多于一个字节类型的数据在内存中的存放顺序,通常有小端、大端两种字节顺序。 小端字节序:指低字节数据存放在内存低地址处,高字节数据存放在内存高地址处; 大端字节序:是高字节数据存放在低地址处,低字节数据存放在高地址处。
什么是大端模式,和小端模式

熟练掌握网络字节序的转换
大端转换
当主机A要把数据发送到主机B时,主机A需要把本机的字节 序转换为网络字节序后才能发送。
小端转换
当主机A收到从主机B发送的数据时,主机A需要把网络字节 序转换为本机的字节序后才能处理。
THANKS
感谢观看
模式。
06
大端模式和小端模式对我们 的启示
深入了解计算机存储机制
大端模式一种数据存储方式,其中高位字节保存在内存的低 地址中,而低位字节保存在内存的高地址中。这种存储方式 在机器字长为16位或32位时比较常见,但现在几乎所有的计 算机都是小端模式。
小端模式一种数据存储方式,其中低位字节保存在内存的低 地址中,而高位字节保存在内存的高地址中。这种存储方式 在机器字长为16位或32位时比较常见,但现在几乎所有的计 算机都是小端模式。
什么是大端模式,和小端模 式
xx年xx月xx日
目 录
• 引言 • 大端模式 • 小端模式 • 大端模式和小端模式的差异 • 大端模式和小端模式的判断方法 • 大端模式和小端模式对我们的启示
01
引言
什么是端模式
• 端模式(Endianness)是指计算机系统在处理字节顺序的方 式,也就是多字节数据在内存中如何排列。
存储顺序
在内存中存储数据时,大端模式将数据的每个字节按照由高到低的顺序存储,以 实现数据的正确表示。
大端模式的应用场景
网络通信
在网络通信中,数据的传输通 常是按照大端模式进行的,因 此需要将数据进行字节序的转 换,以确保接收和发送两端的
数据一致性。
文件存储
在某些文件格式中,如网络协 议中的数据包格式,需要按照 大端模式来读取和解析数据。
小端模式的原理
说明x86、arm、powerpc芯片的大小端

说明x86、arm、powerpc芯片的大小端
大小端是指在存储和读取多字节数据时,字节的排列顺序。
具体来说,大小端指示了字节的高位或低位在存储或传输时的排列顺序。
- x86架构中的处理器通常采用小端模式(Little-Endian)。
在小端模式下,多字节数据的低字节存储在低地址处,高字节存储在高地址处。
- ARM架构中的处理器可以支持小端模式和大端模式(Big-Endian)。
大多数ARM处理器采用小端模式,但某些特殊的ARM芯片(如ARM Cortex-A系列)支持切换成大端模式。
- PowerPC架构中的处理器通常采用大端模式。
在大端模式下,多字节数据的高字节存储在低地址处,低字节存储在高地址处。
大小端模式并没有绝对的优劣之分,不同的架构在设计上选择不同的大小端模式主要是出于历史原因和硬件设计上的考虑。
在跨平台开发时,需要注意不同架构的大小端模式可能会导致数据读取和传输的问题。
大端存储模式和小端存储模式

⼤端存储模式和⼩端存储模式CPU存储数据操作的最⼩单位是⼀个字节。
⼤端存储模式(Big-Endian),⼩端存储模式(Little-Endian)是常见的⼆种字节序。
Little-Endian:低位字节排放在内存的低地址端,⾼位字节排放在内存的⾼地址端。
Big-Endian:⾼位字节排放在内存的低地址端,低位字节排放在内存的⾼地址端。
⽐如0x12345678在内存中的表⽰形式为:采⽤⼤端模式:低地址 --------------------> ⾼地址0x12 | 0x34 | 0x56 | 0x78采⽤⼩端模式:低地址 --------------------> ⾼地址0x78 | 0x56 | 0x34 | 0x12也就是说Big-Endian是指低地址存放最⾼有效字节(MSB),⽽Little-Endian则是低地址存放最低有效字节(LSB)。
⼀般操作系统采⽤的都是⼩端模式,⽽通讯协议采⽤⼤端模式。
1)常见的CPU的字节序Big-Endian : PowerPC,IBM,SunLittle-Endian:x86ARM既可以⼯作在⼤端模式,也可以⼯作在⼩端模式。
2)常见的⽂件的字节序Adobe PS : Big-EndianBMP :Little-EndianGIF : Little-EndianJPEG:Big-Endian此外Java和所有的⽹络通信协议都是使⽤⼤端模式的编码事实上存在字节序,也存在⽐特序。
CPU存储⼀个字节的数据时其字节内的8个⽐特之间的顺序也有Big-Endian和Little-Endian之分。
⽐如字节0xA0的存储格式如下:Big-EndianMSB LSB-------------------------------->1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |Little-EndianLSB MSB-------------------------------->0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 |实际上,由于CPU存储数据操作的最⼩单位是⼀个字节,其内部的⽐特序是什么样对我们的程序来说是⼀个⿊盒⼦,也就是说,你给我⼀个指向0xA0这个数的指针,对于Big-Endian⽅式的CPU来说,它是从左往右依次读取这个数的8个⽐特;⽽对于Little-Endian⽅式的CPU来说,则正好相反,是从右往左依次读取这个数的8个⽐特。
cpu的大端模式小端模式优劣对比

cpu的大端模式小端模式优劣对比一、大端模式和小端模式的起源二、什么是大端和小端Big-Endian和Little-Endian的定义如下:1) Little-Endian就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
2) Big-Endian就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
举一个例子,比如数字0x12 34 56 78在内存中的表示形式为:2)小端模式:3)下面是两个具体例子: 4)大端小端没有谁优谁劣,各自优势便是对方劣势:三、数组在大端小端情况下的存储:以unsigned int value = 0x12345678为例,分别看看在两种字节序下其存储情况,我们可以用unsigned char buf[4]来表示value:Big-Endian: 低地址存放高位,如下:高地址--------------- buf[3] (0x78) -- 低位buf[2] (0x56) buf[1] (0x34) buf[0] (0x12) -- 高位--------------- 低地址Little-Endian: 低地址存放低位,如下:高地址--------------- buf[3] (0x12) -- 高位buf[2] (0x34) buf[1] (0x56) buf[0] (0x78) -- 低位--------------低地址四、为什么会有大小端模式之分呢?这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为8bit。
但是在C语言中除了8bit 的char之外,还有16bit的short型,32bit的long型(要看具体的编译器),另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于五、如何判断机器的字节序可以编写一个小的BOOL IsBigEndian() { int a = 0x1234; char b = *(char *) //通过将int强制类型转换成char单字节,通过判断起始存储位置。
嵌入式之什么是大端序与小端序

则 u1.b 等于 0;
高地址
1.3、指针方式来测试机器的大小端
#include <stdio.h>
int is_little_endian2(void) {
int a = 1; char b = *((char *)(&a));
// 指针方式其实就是共用体的本质
return b; }
int main(void) {
int i = is_little_endian2(); if (1 == i) {
printf("小端模式\n"); } else {
printf("大端模式\n"); } return 0; 分析} :char b = *((char *)(&a));
i nt i = 1;
大端模式 0x0 0x0 0x0 0x1
高地址
以小端模式存储,其内存布局如下图:
i nt i = 1;
小端模式 0x1 0x0 0x0 0x0
高地址
大端模式和小端模式本身没有对错,没有优劣,理论上按照大端或小端都可 以,但是要求存储时和读取时必须按照同样的大小端模式来进行,否则会出错。
只能以字节为单位来发送,所以需要发 4 次;接收方分 4 次接收,内容分别是: 0x12 、 0x34 、 0x56 、 0x78. 接 收 方 接 收 到 这 4 个 字 节 之 后 需 要 去 重 组 得 到 0x12345678,而不是得到 0x78563412。
所以在通信双方需要有一个默契,就是:先发/先接的是高位还是低位?这 就是通信中的大小端问题。一般来说是:先发低字节叫小端;先发高字节就叫大 端。实际操作中,在通信协议里面会去定义大小端,明确告诉你先发的是低字节 还是高字节。
大小端模式——精选推荐

⼤⼩端模式什么是⼤⼩端模式(1)⼤端模式(big endian)和⼩端模式(little endian)(2)在计算机通信发展起来后,遇到⼀个问题就是:在串⼝通信中,⼀次只能发送⼀个字节。
如果要发送⼀个int类型的数据就会有⼀个问题。
int类型有四个字节,我是按照byte0 byte1 byte2 byte3这样的⽅式发送,还是按照byte3 byte2 byte1 byte0这样的顺序发送。
规则就是发送⽅和接收⽅必须按照同样的字节顺序来通信,否则就会出现错误。
(3)现在所说的⼤⼩端模式,更多的是指计算机存储系统的⼤⼩端。
因为存储系统是32位的,但是数据仍然是按照字节为单位的。
于是乎⼀个32位的⼆进制在内存存储时有2种分布⽅式:⾼字节对应低地址(⼤端模式)、⾼字节对应⾼地址(⼩端模式)(4)所以我们在写代码时,当不知道当前环境是⽤⼤端模式还是⼩端模式的时候,就需要⽤代码来检测当前系统的⼤⼩端。
1 #include <stdio.h>2//共⽤体中很重要的⼀点:a和b都是从u1的低地址开始的。
3 union myunion4 {5int a;6char b;7 };8int is_little_endian(void)9 {10 union myunion u1;11 u1.a = 1; //地址0的那个字节,⼩端模式会放1,⼤端模式会放012return u1.b;13 }14int is_little_endian2(void)15 {16int a = 1;17char b = *(char *)(&a); //指针⽅式是共⽤体⽅式的本质18return b;19 }20int main(void)21 {22int i = is_little_endian();23if(i == 1)24 {25 printf("⼩端模式.\n");26 }27else28 {29 printf("⼤端模式.\n");30 }31 }。
详解大端模式和小端模式

一、大端模式和小端模式的起源关于大端小端名词的由来,有一个有趣的故事,来自于Jonathan Swift的《格利佛游记》:Lilliput和Blefuscu这两个强国在过去的36个月中一直在苦战。
战争的原因:大家都知道,吃鸡蛋的时候,原始的方法是打破鸡蛋较大的一端,可以那时的皇帝的祖父由于小时侯吃鸡蛋,按这种方法把手指弄破了,因此他的父亲,就下令,命令所有的子民吃鸡蛋的时候,必须先打破鸡蛋较小的一端,违令者重罚。
然后老百姓对此法令极为反感,期间发生了多次叛乱,其中一个皇帝因此送命,另一个丢了王位,产生叛乱的原因就是另一个国家Blefuscu的国王大臣煽动起来的,叛乱平息后,就逃到这个帝国避难。
据估计,先后几次有11000余人情愿死也不肯去打破鸡蛋较小的端吃鸡蛋。
这个其实讽刺当时英国和法国之间持续的冲突。
Danny Cohen一位网络协议的开创者,第一次使用这两个术语指代字节顺序,后来就被大家广泛接受。
二、什么是大端和小端Big-Endian和Little-Endian的定义如下:1) Little-Endian就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
2) Big-Endian就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
举一个例子,比如数字0x12 34 56 78在内存中的表示形式为:1)大端模式:低地址-----------------> 高地址0x12 | 0x34 | 0x56 | 0x782)小端模式:低地址------------------> 高地址0x78 | 0x56 | 0x34 | 0x12可见,大端模式和字符串的存储模式类似。
3)下面是两个具体例子:16bit宽的数0x1234在Little-endian模式(以及Big-endian 模式)CPU内存中的存放方式(假设从地址0x4000开始存放)为:32bit宽的数0x12345678在Little-endian模式以及Big-endian 模式)CPU内存中的存放方式(假设从地址0x4000开始存放)为:4)大端小端没有谁优谁劣,各自优势便是对方劣势:小端模式:强制转换数据不需要调整字节内容,1、2、4字节的存储方式一样。
c语言大小端转换函数

c语言大小端转换函数摘要:1.概述2.C 语言大小端转换函数的原理3.大端模式和小端模式的定义4.大小端转换函数的实现5.应用实例6.总结正文:1.概述在计算机系统中,数据的存储和传输常常会涉及到字节序列的问题。
由于不同体系结构的计算机系统对字节序列的存储和传输有不同的顺序,因此需要进行大小端转换。
C 语言作为一种广泛应用的编程语言,提供了大小端转换函数以满足这一需求。
2.C 语言大小端转换函数的原理C 语言的大小端转换函数主要通过改变字节序列的顺序来实现数据的大小端转换。
具体来说,大端模式将数据的高位字节存储在低地址,低位字节存储在高地址;而小端模式则将数据的高位字节存储在高地址,低位字节存储在低地址。
大小端转换函数就是根据这两种模式进行字节序列的转换。
3.大端模式和小端模式的定义大端模式(Big-endian)是指数据的高位字节存储在低地址,低位字节存储在高地址。
这种模式在Motorola 68000 和PowerPC 系列处理器中使用。
小端模式(Little-endian)是指数据的高位字节存储在高地址,低位字节存储在低地址。
这种模式在Intel x86 系列处理器、ARM 和MIPS 处理器中使用。
4.大小端转换函数的实现C 语言中提供了一组大小端转换函数,包括`ntoh()`、`hton()`、`ntohs()`和`htons()`。
这四个函数分别用于实现大端到小端、小端到大端的转换。
- `ntoh()`函数:将网络字节序列转换为主机字节序列。
这里的网络字节序列指的是在网络传输中使用的字节序列,通常是大端模式。
主机字节序列指的是在本地计算机上使用的字节序列,可以是大端模式,也可以是小端模式。
- `hton()`函数:将主机字节序列转换为网络字节序列。
这里的主机字节序列指的是在本地计算机上使用的字节序列,可以是大端模式,也可以是小端模式。
网络字节序列指的是在网络传输中使用的字节序列,通常是大端模式。
大端模式和小端模式

⼤端模式和⼩端模式1.为什么存在⼤⼩端模式计算机系统中,每个地址单元对应⼀个字节(8bit),⼀种数据类型的数据可能占⽤若⼲字节。
如何安排这种数据类型中的各个字节,哪个字节在低地址哪个在⾼地址,以及⼀个字节中的各个⽐特的排列,这就牵涉到⼤⼩端模式。
也就是⼤家常说的字节序和⽐特序问题。
字节序和⽐特序⼀般是⼀致的,要么都是⼤端,要么都是⼩端。
2.什么是⼤端和⼩端⼤端模式:低位(字节/⽐特)放在⾼地址中,⾼位(字节/⽐特)放在低地址中。
⼩端模式:低位(字节/⽐特)放在低地址中,⾼位(字节/⽐特)放在⾼地址中。
⾼位和地位是对于我们正常阅读和书写来说,最开始是⾼位,例如int型数0x1234,0x12是字节的⾼位,0x34是字节的低位。
根据以上规则,我们给出在⼤、⼩端序系统中整数0x0a0b0c0d的表⽰⽅式。
对于⼤端系统:byte addr 0 1 2 3bit offset 01234567 01234567 01234567 01234567binary 00001010 00001011 00001100 00001101hex 0a 0b 0c 0d对于⼩端系统:byte addr 3 2 1 0bit offset 76543210 76543210 76543210 76543210binary 00001010 00001011 00001100 00001101hex 0a 0b 0c 0d3. 检测⼤⼩端联合体的存放顺序是所有成员都从低地址开始存放,利⽤该特性可以轻松获得当前系统采⽤⼤端还是⼩端模式BOOL IsBigEndian(){union NUM{int a;char b;}num;num.a = 0x1234;if( num.b == 0x12 ){return TRUE;}return FALSE;}4.常见的⼤⼩端⼀般操作系统都是⼩端模式;⽽通讯协议是⼤端模式;java和平台⽆关,默认是⼤端模式常见的cpu的⼤⼩端:⼤端:PowerPC、IBM、Sun⼩端:x86ARM既可以⼯作在⼤端模式,也可以⼯作在⼩端模式。
大端模式与小端模式理解

⼤端模式与⼩端模式理解字节序字节序指多字节数据在计算机内存储或者⽹络上传输时各字节的顺序。
(来源:百度百科)为了⽅便,逻辑上将字节序列⾥左边的字节称为⾼字节,右边的字节称为低字节,从左到右,由⾼到低,这样符合数学上的思维习惯,左边是⾼位,右边是地位。
⼤端模式与⼩端模式由于每个字节在内存中都是有地址的,并且内存的地址是顺序排列的,当我们在内存中保存数据时:如果,⾼字节存放在低地址,低字节存放在⾼地址,则为⼤端模式(big-endian)。
如果,低字节存放在低地址,⾼字节存放在⾼地址,则为⼩端模式(little-endian)。
数据从内存保存到⽂件(或发送到⽹络上)时,会受到内存的⼤端模式与⼩端模式的影响。
数据从⽂件读取到(或从⽹络接收到)内存时,需要知道之前是先保存的(或是先发送的)⾼字节还是低字节。
C++⽰例代码1//int 占 4 个字节,short 占 2 个字节int main(){printf("在栈上分配内存\n");int a = 0x11223344;short b = 0x5566;short c = 0x7788;unsigned char *pa = (unsigned char *)&a;unsigned char *pb = (unsigned char *)&b;unsigned char *pc = (unsigned char *)&c;printf("pa 0x%p 0x%x\n", pa, a);printf("pb 0x%p 0x%x\n", pb, b);printf("pc 0x%p 0x%x\n", pc, c);printf("按字节序打印所有字节(⾼字节->低字节)\n");printf("a0 0x%x\n", (a & 0xFF000000) >> (3 * 8));printf("a1 0x%x\n", (a & 0x00FF0000) >> (2 * 8));printf("a2 0x%x\n", (a & 0x0000FF00) >> (1 * 8));printf("a3 0x%x\n", (a & 0x000000FF));printf("b0 0x%x\n", (b & 0xFF00) >> (1 * 8));printf("b1 0x%x\n", (b & 0x00FF));printf("c0 0x%x\n", (c & 0xFF00) >> (1 * 8));printf("c1 0x%x\n", (c & 0x00FF));printf("根据地址顺序打印所有字节(低地址->⾼地址)\n");for (int i = 0; i < 4; i++) {printf("pa[%d] 0x%p 0x%02x\n", i, pa + i, pa[i]);}for (int i = 0; i < 2; i++) {printf("pb[%d] 0x%p 0x%02x\n", i, pb + i, pb[i]);}for (int i = 0; i < 2; i++) {printf("pc[%d] 0x%p 0x%02x\n", i, pc + i, pc[i]);}return 0;}⽰例代码1运⾏结果在栈上分配内存pa 0x007ffe24 0x11223344pb 0x007ffe22 0x5566pc 0x007ffe20 0x7788按字节序打印所有字节(⾼字节->低字节)a0 0x11a1 0x22a2 0x33a3 0x44b0 0x55b1 0x66c0 0x77c1 0x88根据地址顺序打印所有字节(低地址->⾼地址)pa[0] 0x007ffe24 0x44pa[1] 0x007ffe25 0x33pa[2] 0x007ffe26 0x22pb[0] 0x007ffe22 0x66pb[1] 0x007ffe23 0x55pc[0] 0x007ffe20 0x88pc[1] 0x007ffe21 0x77⽰例代码1结果分析a、b、c 在内存中的排列情况:---------------------------------------------------|低地址 -> ⾼地址|---------------------------------------------------|....|0x88|0x77|0x66|0x55|0x44|0x33|0x22|0x11|....|---------------------------------------------------a、b、c 是在栈中分配的,可以看到内存地址是连续的,且 a 的地址相对较⾼,c 的地址相对较低。
(转)大小端模式详解

(转)⼤⼩端模式详解int i=1;char *p=(char *)&i;if(*p==1)printf("1");elseprintf("2");⼤⼩端存储问题,如果⼩端⽅式中(i占⾄少两个字节的长度)则i所分配的内存最⼩地址那个字节中就存着1,其他字节是0.⼤端的话则1在i的最⾼地址字节处存放,char是⼀个字节,所以强制将char型量p指向i则p指向的⼀定是i的最低地址,那么就可以判断p中的值是不是1来确定是不是⼩端。
请写⼀个C函数,若处理器是Big_endian的,则返回0;若是Little_endian的,则返回1解答:int checkCPU( ){{union w{int a;char b;} c;c.a = 1;return(c.b ==1);}}剖析:嵌⼊式系统开发者应该对Little-endian和Big-endian模式⾮常了解。
采⽤Little-endian模式的CPU对操作数的存放⽅式是从低字节到⾼字节,⽽Big-endian模式对操作数的存放⽅式是从⾼字节到低字节。
例如,16bit宽的数0x1234在Little-endian模式CPU内存中的存放⽅式(假设从地址0x4000开始存放)为:内存地址0x40000x4001存放内容0x340x12⽽在Big-endian模式CPU内存中的存放⽅式则为:内存地址0x40000x4001存放内容0x120x3432bit宽的数0x12345678在Little-endian模式CPU内存中的存放⽅式(假设从地址0x4000开始存放)为:内存地址0x40000x40010x40020x4003存放内容0x780x560x340x12⽽在Big-endian模式CPU内存中的存放⽅式则为:内存地址0x40000x40010x40020x4003存放内容0x120x340x560x78联合体union的存放顺序是所有成员都从低地址开始存放,⾯试者的解答利⽤该特性,轻松地获得了CPU对内存采⽤Little-endian还是Big-endian模式读写。
CPU大小端模式及转换

CPU⼤⼩端模式及转换通信协议中的数据传输、数组的存储⽅式、数据的强制转换等这些都会牵涉到⼤⼩端问题。
CPU的⼤端和⼩端模式很多地⽅都会⽤到,但还是有许多朋友不知道,今天暂且普及⼀下。
⼀、为什么会有⼤⼩端模式之分呢?因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着⼀个字节,⼀个字节为8bit。
但是在C语⾔中除了8bit的char之外,还有16bit的short型,32bit的int型。
另外,对于位数⼤于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度⼤于⼀个字节,那么必然存在着⼀个如何将多个字节安排的问题。
因此就导致了⼤端存储模式和⼩端存储模式。
例如⼀个16bit的short型x,在内存中的地址为0x0010,x的值为0x1122,那么0x11为⾼字节,0x22为低字节。
对于⼤端模式,就将0x11放在低地址中,即0x0010中,0x22放在⾼地址中,即0x0011中。
⼩端模式,刚好相反。
⼆、什么是⼤端和⼩端?⼤端模式:是指数据的⾼字节保存在内存的低地址中,⽽数据的低字节保存在内存的⾼地址中。
⼩端模式:是指数据的⾼字节保存在内存的⾼地址中,⽽数据的低字节保存在内存的低地址中。
假如32位宽(uint32_t)的数据0x12345678,从地址0x08004000开始存放:再结合⼀张图进⾏理解:从上⾯表格、图可以看得出来,⼤⼩端的差异在于存放顺序不同。
三、数组在⼤端⼩端情况下的存储以unsigned int value = 0x12345678为例,分别看看在两种字节序下其存储情况,我们可以⽤unsigned char buf[4]来表⽰value。
1.⼤端模式下2.⼩端模式下不知道⼤家对数组进⾏强制转换成整型数据没有?如果你要进⾏强制转换,肯定要考虑⼤⼩端问题。
四、⼤⼩端谁更好?⼩端模式:强制转换数据不需要调整字节内容,1、2、4字节的存储⽅式⼀样。
⼤端模式:符号位的判定固定为第⼀个字节,容易判断正负。
大小端对齐问题

下面这个 C 函数, 若处理器是 Big_endian 的, 则返回 0; 若是 Little_endian 的,则返回 1:
int checkCPU( ) { { union w { int a; char b; } c; c.a = 1; return(c.b ==1); } }
C 代码:
#include "stdio.h" #include "conio.h" union { unsigned int Address; unsigned char addr[2]; }ADDR; main() { ADDR.Address=0x1234; printf("ADDR.addr[0]=0x%0x;\n",ADDR.addr[0]); printf("ADDR.addr[1]=0x%0x;\n",ADDR.addr[1]); getch(); } 1. )用 Win-TC 在电脑上测试,结果: ADDR.addr[0]=0x34; ADDR.addr[1]=0x12; 结论:电脑为小端存储模式。 2. )在 Keil C51 上测试,结果: ADDR.addr[0]=0x12; ADDR.addr[1]=0x34; 结论:C51 为大端存储模式。 3. )在 Keil ARM 上测试,结果: ADDR.addr[0]=0x34; ADDR.addr[1]=0x12; 结论:Keil ARM 为小端存储模式。 Win-TC 测试例程: #include "stdio.h" #include "conio.h" main() { union w { int a; char b; } c; c.a = 1; if(c.b ==1) {printf("Little_endian");} else {printf("Big_endian");} getch(); }
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
大端格式:
在这种格式中,字数据的高字节存储在低地址中,而字数据的低字节则存放在高地址中.
小端格式:
与大端存储格式相反,在小端存储格式中,低地址中存放的是字数据的低字节,高地址存放的是字数据的高字节。
请写一个C函数,若处理器是Big_endian的,则返回0;若是Little_endian 的,则返回1
解答:
int checkCPU( )
{
{
union w
{
int a;
char b;
} c;
c.a = 1;
return(c.b ==1);
}
}
剖析:
嵌入式系统开发者应该对Little-endian和Big-endian模式非常了解。
例如,16bit宽的数0x1234在Little-endian模式CPU内存中的存放方式(假设从地址0x4000开始存放)为:
而在Big-endian模式CPU内存中的存放方式则为:
联合体union的存放顺序是所有成员都从低地址开始存放。
=============== 呵呵还是附上另一段代码吧,摘自一个开源项目 ====
int big_endian (void)
{
union{
long l;
char c[sizeof(long)];
}u;
u.l = 1;
return (u.c[sizeof(long) - 1] == 1);
}
有时候,用C语言写程序时需要知道是大端模式还是小端模式。
所谓的大端模式,是指数据的低位保存在内存的高地址中,而数据的高位,保存在内存的低地址中;所谓的小端模式,是指数据的低位保存在内存的低地址中,而数据的高位保存在内存的高地址中。
为什么会有大小端模式之分呢?这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为8bit。
但是在C语言中除了8bit的char之外,还有16bit的short型,32bit的long型(要看具体的编译器),另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个
如果将多个字节安排的问题。
因此就导致了大端存储模式和小端存储模式。
例如一个16bit的short型x,在内存中的地址为0x0010,x的值为0x1122,那么0x11为高字节,0x22为低字节。
对于大端模式,就将0x11放在低地址中,即0x0010中,0x22放在高地址中,即
0x0011中。
小端模式,刚好相反。
我们常用的X86结构是小端模式,而KEIL C51则为大端模式。
很多的ARM,DSP都为小端模式。
有些ARM处理器还可以由硬件来选择是大端模式还是小端模式。
下面这段代码可以用来测试一下你的编译器是大端模式还是小端模式:
short int x;
char x0,x1;
x=0x1122;
x0=((char*)&x)[0]; //低地址单元
x1=((char*)&x)[1]; //高地址单元
若x0=0x11,则是大端; 若x0=0x22,则是小端......。