cdh安装hadoop教程
CDH4.6安装文档

CDH4.6安装文档安装前准备工作1)修改防火墙,添加过滤端口修改防火墙,添加过滤端口(7180,7181,9000,9001等,其中7180主要是cdh控制台用的,9000和9001是通讯用的,可以在安装过程中报错之后再去添加或者直接关闭防火墙)2)配置系统互信●在做namenode的机器上运行ssh-keygen -t rsa然后选择保存路径以及验证口令(随意),生成密钥,注意记住保存路径以及验证口令●复制公钥到其他datanode上执行namenode: scp .ssh/id_rsa.pub hadoop@slave:~/master_keys(使用默认22端口,也可以在scp 后加-P 端口号)登录所有的datanode执行:datanode: mkdir ~/.sshchmod 700 ~/.sshmv ~/master_keys ~/.ssh/authorized_keyschmod 600 ~/.ssh/authorized_keys最后验证一下能不能互联:ssh hadoop@slave date回车就能登录到slave机器(如果有输入口令还要输入口令)注:最后记得下载私钥到本机,后续安装需要用到3)创建免密码的sudo用户每台机器上配置一个名称相同的用户,并且配置该用户可以免密码sudo(如果想直接使用root用户的话可以省略这一步骤)e.g.: useradd hadooppasswd hadoopvisudo(编辑添加%hadoop ALL=(ALL) NOPASSWORD:ALL##hadoop群组的用户都可以免密码sudo了)4)修改/etc/hosts文件修改各个主机上的/etc/hosts文件,增加集群内所有主机的ip-主机名映射注,此处的主机名必须与每台机器的主机名一致,否则后续的安装可能会报错5)安装postgresql8.1以上版本数据库6)安装系统rpm包安装CM4.8.2程序1)到cloudera官网下载安装文件cloudera-manager-installer.bin2)执行sudo chmod u+x cloudera-manager-installer.bin然后执行sudo ./cloudera-manager-installer.bin开始安装cloudera manager,一路选yes、回车就行了安装CDH4.6程序1)安装完成之后会提示登录到控制台上继续操作,打开浏览器输入地址,一般是安装cloudera manager主机的ip+端口(7180)如果打不开控制台的网页,查看iptables是否禁用了端口,并修改iptables过滤7180端口,重启iptables即可默认用户名密码为admin/admin2)登录之后开始安装集群以及CDH首先选择免费版,点继续地址)选择继续一般选择使用包裹(parcel),同时选择CDH4,不用选择Solr和Impala4)输入用户名密码根据一、准备工作中创建的用户来选择是用root用户还是其他用户,是所有主机相同密码还是接受相同私钥5)向每台主机安装一些元包(jdk,cloudera-agent等等)这个过程可能会耗时很长,主要是要下载几个安装包总共有几百兆,且每台机都要下载,同时还有可能会安装失败(有时可能是下载超时,或者防火墙问题)注,可参考三、问题汇总快速通过此步骤6)安装完成后会继续下载CDH包(7百多兆)后点继续,此时要求选择在CDH上的服务,根据需要选择,一般选择核心服务就行了,后续可以再添加7)数据库设置,可以选择使用嵌入式数据库(PostgreSQL,已经包含在cloudera中不用安装)也可以使用外部的数据库,点击测试连接,成功后点继续注,此处有可能会在点击测试连接之后提示Unknown host ':7432'. Unable to find it from host...,这个应该是个bug,解决方法在后面后续的安装一路点继续就可以了,最后安装成功。
CDH大数据集群环境搭建步骤

CDH大数据集群环境搭建步骤搭建CDH大数据集群环境需要进行以下步骤:1.准备硬件和操作系统:- 硬件要求:至少3台服务器,其中一台作为master节点,其他作为worker节点。
每台服务器至少具有4个CPU核心、16GB内存、100G以上硬盘空间。
- 操作系统要求:集群中的所有服务器需要运行相同的操作系统版本,推荐使用CentOS 7或者Red Hat Enterprise Linux 72.安装基础组件:- 使用root用户登录所有服务器,执行以下命令更新系统:`yum update -y`- 安装JDK:在每台服务器上执行以下命令安装JDK:`yum install-y java-1.8.0-openjdk-devel`- 安装其他依赖包:在每台服务器上执行以下命令安装其他依赖包:`yum install -y wget vim curl ntp`- 授予安装脚本执行权限:`chmod +x cloudera-manager-installer.bin`- 运行安装脚本:`./cloudera-manager-installer.bin`4.配置CDH集群管理器:- 打开Web浏览器,输入master节点的IP地址和端口号7180(默认)访问Cloudera Manager Web控制台。
- 在“Install a New Cluster”页面上,按照提示配置集群名称、选择操作系统等信息,并选择需要安装的组件(如HDFS、YARN、HBase 等)。
- 提供worker节点的主机名或IP地址,在设置完所有配置项后,点击“Continue”按钮。
5.配置集群节点:- 在“Choose Services”页面上,选择需要在集群中安装的服务。
- 在“Assign Roles”页面上,将角色分配给master节点和worker节点。
- 在“Check Configuration”页面上,检查配置项是否正确,如有错误,根据提示进行修改。
简单梳理hadoop安装流程文字

简单梳理Hadoop安装流程
今儿个咱们来简单梳理下Hadoop的安装流程,让各位在四川的兄弟姐妹也能轻松上手。
首先,你得有个Linux系统,比如说CentOS或者Ubuntu,这点很重要。
然后在系统上整个Java环境,Hadoop 是依赖Java运行的。
把JDK下载安装好后,记得配置下环境变量,就是修改`/etc/profile`文件,把Java的安装路径加进去。
接下来,你需要在系统上整个SSH服务,Hadoop集群内部的通信要用到。
安好SSH后,记得配置下无密钥登录,省得每次登录都要输密码,多麻烦。
Hadoop的安装包可以通过官方渠道下载,也可以在网上找现成的。
下载好安装包后,解压到你的安装目录。
然后就开始配置Hadoop的环境变量,跟配置Java环境变量一样,也是在
`/etc/profile`文件里加路径。
配置Hadoop的文件是重点,都在Hadoop安装目录下的`etc/hadoop`文件夹里。
有`hadoop-env.sh`、`core-site.xml`、`hdfs-site.xml`这些文件需要修改。
比如`core-site.xml`里要设置HDFS的地址和端口,`hdfs-site.xml`里要设置临时目录这些。
最后,就可以开始格式化HDFS了,用`hdfs namenode-format`命令。
然后启动Hadoop,用`start-all.sh`脚本。
如果一
切配置正确,你就可以用`jps`命令看到Hadoop的各个进程在运行了。
这整个过程看似复杂,但只要你跟着步骤来,注意配置文件的路径和内容,相信你也能轻松搞定Hadoop的安装。
CDH5.4.7安装部署手册

CDH5.4.7安装部署手册、修订记录目录1 软件介绍 (5)1.1 关于CDH和Cloudera Manager (5)2 环境准备 (5)2.1 集群规划 (5)2.2 环境部署 (7)2.2.1 MySQL下载 (7)2.2.2 JDK下载 (7)2.2.3 CDH下载 (7)2.2.4 JDK的安装 (所有节点) (8)2.2.5 关闭防火墙(所有节点) (9)2.2.6 SSH无密码登陆(所有节点) (10)2.2.7 安装NTP时间同步服务(所有节点) (11)2.2.8 安装MySQL (14)3 Cloudera Manager安装 (17)3.1 Cloudera Manager安装 (17)3.1.1 master配置 (18)3.1.2 agent配置 (19)3.2 安装Cloudera Manager所需的rpm包 (20)3.2.1 安装rpm文件 (20)3.2.2 本地源配置 (21)3.3 启动Cloudera Manager (22)3.3.1 开启Cloudera Manager 5 Server端 (22)3.3.2 重启Cloudera Manager 5 Server端 (23)3.3.3 启动Agent (23)4 安装CDH (23)5 CM卸载 (27)6 杂记:Namenode和Secondarynamenode的关系【转】 (27)1软件介绍1.1关于CDH和Cloudera ManagerCM:Cloudera Manager(Cloudera公司专有的Hadoop集群管控平台)。
CDH:Cloudera Distributed Hadoop(Cloudera公司重新打包发布的Hadoop版本)。
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。
充分利用集群的威力进行高速运算和存储。
hadoop集群安装配置的主要操作步骤-概述说明以及解释

hadoop集群安装配置的主要操作步骤-概述说明以及解释1.引言1.1 概述Hadoop是一个开源的分布式计算框架,主要用于处理和存储大规模数据集。
它提供了高度可靠性、容错性和可扩展性的特性,因此被广泛应用于大数据处理领域。
本文旨在介绍Hadoop集群安装配置的主要操作步骤。
在开始具体的操作步骤之前,我们先对Hadoop集群的概念进行简要说明。
Hadoop集群由一组互联的计算机节点组成,其中包含了主节点和多个从节点。
主节点负责调度任务并管理整个集群的资源分配,而从节点则负责实际的数据存储和计算任务执行。
这种分布式的架构使得Hadoop可以高效地处理大规模数据,并实现数据的并行计算。
为了搭建一个Hadoop集群,我们需要进行一系列的安装和配置操作。
主要的操作步骤包括以下几个方面:1. 硬件准备:在开始之前,需要确保所有的计算机节点都满足Hadoop的硬件要求,并配置好网络连接。
2. 软件安装:首先,我们需要下载Hadoop的安装包,并解压到指定的目录。
然后,我们需要安装Java开发环境,因为Hadoop是基于Java 开发的。
3. 配置主节点:在主节点上,我们需要编辑Hadoop的配置文件,包括核心配置文件、HDFS配置文件和YARN配置文件等。
这些配置文件会影响到集群的整体运行方式和资源分配策略。
4. 配置从节点:与配置主节点类似,我们也需要在每个从节点上进行相应的配置。
从节点的配置主要包括核心配置和数据节点配置。
5. 启动集群:在所有节点的配置完成后,我们可以通过启动Hadoop 集群来进行测试和验证。
启动过程中,我们需要确保各个节点之间的通信正常,并且集群的各个组件都能够正常启动和工作。
通过完成以上这些操作步骤,我们就可以成功搭建一个Hadoop集群,并开始进行大数据的处理和分析工作了。
当然,在实际应用中,还会存在更多的细节和需要注意的地方,我们需要根据具体的场景和需求进行相应的调整和扩展。
cdh大数据处理流程

CDH大数据处理流程Cloudera的CDH(Cloudera's Distribution Including Apache Hadoop)是一个基于Apache Hadoop的大数据平台。
使用CDH进行大数据处理的基本流程包括以下几个步骤:1.环境准备:首先需要准备服务器。
安装CDH集群至少需要三台服务器,每台服务器的内存一般选用64G或32G。
2.配置主机名称映射:修改每个节点的主机名称,并确保所有节点的hostname都是唯一的。
然后修改/etc/hosts/文件,将主机名称和对应的IP地址进行映射。
修改完成后需要重启服务器。
3.安装JDK:在所有节点上安装JDK,版本必须为1.8或以上。
CDH默认识别JDK的路径为/usr,如果安装到别的路径,可能启动CDH时会报错。
4.选择集群服务组合:在CDH Manager中,可以选择一种集群服务组合。
如果不确定哪个组合更合适,选择“全部服务”也可以。
5.分配集群角色:这一步比较关键,需要根据实际需求将不同的角色(如NameNode、SecondaryNameNode、DataNode等)分配到相应的节点上。
这样做是为了简化数据节点的角色和职责,便于维护。
6.数据库设置:按照实际配置信息填写数据库设置。
CDHManager使用MySQL作为其后端数据库,用于存储集群的配置信息、运行状况数据和指标信息。
7.审核更改:检查DataNode和NameNode的数据目录设置是否正确。
默认情况下,副本数是3。
8.启动和监控集群:使用CDH Manager启动集群,并通过其提供的Web界面和API接口监控集群的运行状况。
以上是CDH大数据处理的基本流程。
在实际应用中,可能还需要根据具体需求进行更多的配置和优化。
自制hadoop安装详细过程
cdHadoop单机版、伪分布、集群安装教程推荐链接:一、下载安装所需文件1.vmware10中文版2.centos6.43.jdk1.8-Linux-32位4.Hadoop2.7.1(要求jdk版本为1.7及以上)5.spark2.2.1(要求hadoop版本为2.7)二、安装虚拟机1.安装vmware(具体细节可百度vmware安装)。
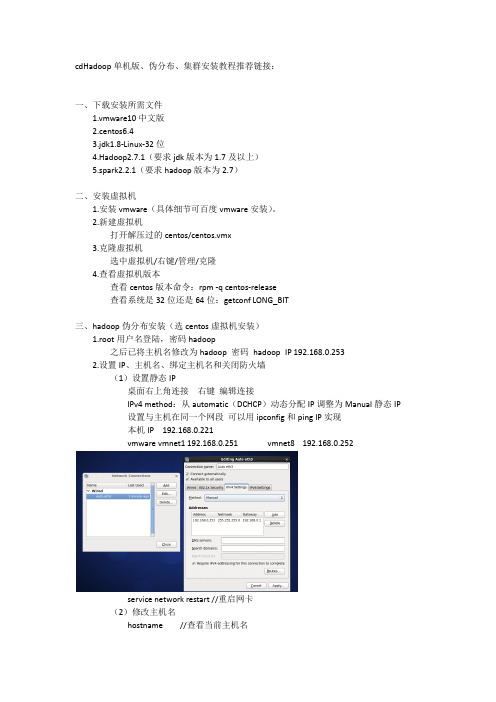
2.新建虚拟机打开解压过的centos/centos.vmx3.克隆虚拟机选中虚拟机/右键/管理/克隆4.查看虚拟机版本查看centos版本命令:rpm -q centos-release查看系统是32位还是64位:getconf LONG_BIT三、hadoop伪分布安装(选centos虚拟机安装)1.root用户名登陆,密码hadoop之后已将主机名修改为hadoop 密码hadoop IP 192.168.0.2532.设置IP、主机名、绑定主机名和关闭防火墙(1)设置静态IP桌面右上角连接右键编辑连接IPv4 method:从automatic(DCHCP)动态分配IP调整为Manual静态IP设置与主机在同一个网段可以用ipconfig和ping IP实现本机IP 192.168.0.221vmware vmnet1 192.168.0.251 vmnet8 192.168.0.252service network restart //重启网卡(2)修改主机名hostname //查看当前主机名hostname hadoop //对于当前界面修改主机名vi /etc/sysconfig/network 进入配置文件下修改主机名为hadoopreboot -h now //重启虚拟机//执行vi读写操作按a修改修改完之后Esc 输入:wq 回车保存退出3.hostname和主机绑定vi /etc/hosts //在前两行代码下添加第三行192.168.0.253 hadoop之后ping hadoop验证即可4.关闭防火墙service iptables stop //关闭防火墙service iptables status //查看防火墙状态chkconfig iptables off //关闭防火墙自动运行chkconfig --list | grep iptables //验证是否全部关闭5.配置ssh免密码登陆(centos默认安装了SSH client、SSH server)rpm -qa |grep ssh//验证是否安装SSH,若已安装,界面如下接着输入ssh localhost输入yes 会弹出以下窗体内容即每次登陆都需要密码exit //退出ssh localhostcd ~/.ssh/ //若不存在该目录,执行一次ssh localhostssh-keygen -t rsa 之后多次回车cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys //加入授权chmod 600 ~/.ssh/authorized_keys //修改文件权限注:在Linux 系统中,~ 代表的是用户的主文件夹,即"/home/用户名" 这个目录,如你的用户名为hadoop,则~ 就代表"/home/hadoop/"。
hadoop 操作手册

hadoop 操作手册Hadoop 是一个分布式计算框架,它使用 HDFS(Hadoop Distributed File System)存储大量数据,并通过 MapReduce 进行数据处理。
以下是一份简单的 Hadoop 操作手册,介绍了如何安装、配置和使用 Hadoop。
一、安装 Hadoop1. 下载 Hadoop 安装包,并解压到本地目录。
2. 配置 Hadoop 环境变量,将 Hadoop 安装目录添加到 PATH 中。
3. 配置 Hadoop 集群,包括 NameNode、DataNode 和 JobTracker 等节点的配置。
二、配置 Hadoop1. 配置 HDFS,包括 NameNode 和 DataNode 的配置。
2. 配置 MapReduce,包括 JobTracker 和 TaskTracker 的配置。
3. 配置 Hadoop 安全模式,如果需要的话。
三、使用 Hadoop1. 上传文件到 HDFS,使用命令 `hadoop fs -put local_file_path/hdfs_directory`。
2. 查看 HDFS 中的文件和目录信息,使用命令 `hadoop fs -ls /`。
3. 运行 MapReduce 作业,编写 MapReduce 程序,然后使用命令`hadoop jar my_` 运行程序。
4. 查看 MapReduce 作业的运行结果,使用命令 `hadoop fs -cat/output_directory/part-r-00000`。
5. 从 HDFS 中下载文件到本地,使用命令 `hadoop fs -get/hdfs_directory local_directory`。
6. 在 Web 控制台中查看 HDFS 集群信息,在浏览器中打开7. 在 Web 控制台中查看 MapReduce 作业运行情况,在浏览器中打开四、管理 Hadoop1. 启动和停止 Hadoop 集群,使用命令 `` 和 ``。
cdh运维手册

cdh运维手册一、简介CDH是指Cloudera Distribution Including Apache Hadoop,是一个大数据分析平台。
本手册旨在提供有关CDH运维的详细指南,包括安装、配置、监控、故障排除等方面的内容。
二、安装与配置1. 硬件要求CDH运维需要一定的硬件要求。
建议服务器拥有至少8GB内存、4核处理器和100GB可用磁盘空间。
2. 操作系统要求CDH支持多种操作系统,如CentOS、Red Hat Enterprise Linux等。
确保所选操作系统符合CDH的要求。
3. 安装步骤a) 下载CDH软件包并解压。
b) 配置操作系统环境变量。
c) 启动CDH安装向导,并按照提示进行安装和配置。
确保正确设置Hadoop、Hive、HBase等组件。
4. 高可用性设置对于大规模的部署,建议配置CDH集群的高可用性(HA)。
HA 可确保在故障发生时服务的连续性。
详细的HA配置步骤请参考官方文档。
三、监控与维护1. 集群监控CDH集成了Cloudera Manager,提供了全面的集群监控功能。
通过Cloudera Manager,可以实时查看集群各组件的状态、资源使用情况等。
2. 日志管理CDH将各个组件的日志集中管理,方便运维人员进行故障排查。
通过Cloudera Manager的日志管理功能,可以快速定位和解决问题。
3. 故障排除a) 检查集群状态和组件运行状况,确认是否有异常。
b) 查看日志文件,寻找异常或错误信息。
c) 根据错误信息和文档进行问题诊断和解决。
四、性能优化1. 资源管理合理配置集群的资源管理机制,如YARN和Fair Scheduler,以充分利用集群资源。
2. 数据压缩对于大型数据集,可以考虑启用数据压缩来减少存储空间的占用和提高读写效率。
3. 数据分区对数据进行合理的分区可以提高查询效率。
根据数据特点和查询需求,选择合适的分区策略。
五、安全与权限管理1. 集群安全CDH提供了多种安全机制,如Kerberos认证、SSL加密等,用于保护集群的安全性。
cdh5 使用手册

cdh5 使用手册CDH5(Cloudera Distribution for Hadoop 5)是Cloudera公司开发的一套基于Apache Hadoop的分布式计算平台。
以下为您提供CDH5使用手册:一、安装与配置CDH5的安装相对简单,只需按照官方提供的安装包进行安装即可。
只需简单的几个步骤,即可完成CDH5的安装。
首先需要下载CDH5的安装包,然后进行安装。
二、配置管理CDH5的配置主要集中在以下几个目录中:1. `/etc/cloudera-scm-server/db.properties`:数据库设置文件,用于配置Cloudera管理服务的数据库连接信息。
2. `/etc/hadoop/*`:Hadoop客户端配置目录,包含Hadoop集群的各种配置文件,如core-site.xml、hdfs-site.xml等。
3. `/etc/hive/`:Hive的配置目录,包含Hive服务的配置文件,如hive-site.xml等。
在安装完成后,Hadoop各组件的配置文件会被放置于`/var/run/cloudera-scm-agent/process/`目录下。
在Cloudera Manager的管理界面上更改配置并不会立即反映到配置文件中,这些信息会存储于数据库中,等下次重启服务时才会生成配置文件。
三、使用与管理使用CDH5时,可以通过Cloudera Manager的管理界面进行各种操作,如启动、停止服务,查看集群状态等。
在管理界面上,可以方便地对各个组件进行统一管理,同时也可以通过命令行工具进行操作。
四、常见问题与解决1. 如何解决Hadoop集群无法启动的问题?* 检查集群所有节点上的服务状态,查看是否有任何服务出现错误。
* 检查网络连接,确保所有节点之间的网络通讯没有问题。
* 查看日志文件,寻找错误信息。
Cloudera Manager的管理界面可以方便地查看各个服务的日志。
Hadoop安装配置超详细步骤

Hadoop安装配置超详细步骤Hadoop的安装1、实现linux的ssh无密码验证配置.2、修改linux的机器名,并配置/etc/hosts3、在linux下安装jdk,并配好环境变量4、在windows下载hadoop 1.0.1,并修改hadoop-env.sh,core-site.xml,hdfs-site.xml,mapred-site.xml,masters,slaves文件的配置5、创建一个给hadoop备份的文件。
6、把hadoop的bin加入到环境变量7、修改部分运行文件的权限8、格式化hadoop,启动hadoop注意:这个顺序并不是一个写死的顺序,就得按照这个来。
如果你知道原理,可以打乱顺序来操作,比如1、2、3,先哪个后哪个,都没问题,但是有些步骤还是得依靠一些操作完成了才能进行,新手建议按照顺序来。
一、实现linux的ssh无密码验证配置(1)配置理由和原理Hadoop需要使用SSH协议,namenode将使用SSH协议启动namenode和datanode进程,(datanode向namenode传递心跳信息可能也是使用SSH协议,这是我认为的,还没有做深入了解)。
大概意思是,namenode 和datanode之间发命令是靠ssh来发的,发命令肯定是在运行的时候发,发的时候肯定不希望发一次就弹出个框说:有一台机器连接我,让他连吗。
所以就要求后台namenode和datanode 无障碍的进行通信。
以namenode到datanode为例子:namenode作为客户端,要实现无密码公钥认证,连接到服务端datanode上时,需要在namenode上生成一个密钥对,包括一个公钥和一个私钥,而后将公钥复制到datanode上。
当namenode通过ssh连接datanode时,datanode就会生成一个随机数并用namenode的公钥对随机数进行加密,并发送给namenode。
hadoop安装流程简单描述

hadoop安装流程简单描述英文回答:Installing Hadoop can be a complex process, but I will try to simplify it for you. Here are the steps to install Hadoop:1. Download Hadoop: First, you need to download the Hadoop distribution from the Apache Hadoop website. Make sure to choose the appropriate version for your operating system.2. Set up Java: Hadoop requires Java to run, so you need to install Java Development Kit (JDK) on your system. Make sure to set the JAVA_HOME environment variable to the path of your JDK installation.3. Configure SSH: Hadoop uses SSH to communicate between nodes in the cluster. You need to set up passwordless SSH access to all the nodes in your cluster.This can be done by generating an SSH key pair and adding the public key to the authorized_keys file on each node.4. Configure Hadoop: Next, you need to configure Hadoop by editing the core-site.xml, hdfs-site.xml, and mapred-site.xml files in the Hadoop configuration directory. These files define various settings such as the location of Hadoop data and the number of map and reduce tasks.5. Format the Hadoop File System: Before you can start using Hadoop, you need to format the Hadoop DistributedFile System (HDFS). This can be done by running the command "hdfs namenode -format" on the master node.6. Start Hadoop: Once everything is set up and configured, you can start Hadoop by running the start-all.sh script on the master node. This will start all the necessary daemons, including the NameNode, DataNode, and ResourceManager.7. Test Hadoop: To make sure Hadoop is working correctly, you can run some sample MapReduce jobs. Forexample, you can use the WordCount example that comes with Hadoop to count the number of occurrences of each word in a text file.That's it! You have successfully installed Hadoop. Now you can start using it to process big data.中文回答:安装Hadoop可能是一个复杂的过程,但我会尽量简化它。
CDH大数据平台搭建终极版

CDH⼤数据平台搭建终极版经过⽆数次的失败,终于将CDH安装到两台普通的笔记本电脑上,主要失败原因有以下⼏点:1. 不熟悉安装过程,官⽅给出的安装⽅法有三种,所以都尝试了⼀遍,浪费了⼤量时间,所以有时候⽅法多不见得是⼀件好事。
2. 安装设备太差,有时会因为占⽤内存或者CPU占⽤过⾼⽽死机。
3. 安装⽹络环境太差,导致传输过程可能出现超时失败现象。
4. 安装时间过久,导致出错后重新再来时间付出太多。
以下讲的⽅法不是最优的⽅法,但是是我们最后的⽅法,可供参考。
1.搭建环境两台笔记本电脑A和B,⾃带内存分别为12G和8G,安装VMware 12。
A开⼀个虚拟机,2*CPU,8G内存,使⽤桥接⽹卡模式,安装CentOS6.5,充当主机Master。
B开两个虚拟机,1*CPU,2G内存,使⽤桥接⽹卡模式,安装CentOS6.5,充当分机Slave1,Slave2。
两台电脑通过⽹线连接到学校内⽹,使⽤内⽹⽹络环境搭建,三台虚拟机的root密码必须⼀致。
2.安装前的准备⾸先先下载以下安装包cloudera-manager-el6-cm5.8.0_x86_64.tar.gz (Cloudera Manager 安装包,el6代表使⽤的CentOs6.x,cm-5.8.0代表使⽤的Cloudera Manager版本为5.8.0)CDH-5.8.0-1.cdh5.8.0.p0.42-el6.parcel (CDH离线资源包)CDH-5.8.0-1.cdh5.8.0.p0.42-el6.parcel.sha1manifest.jsoncm5.8.0-centos6.tar.gz (⾥⾯有⼀些必要的环境)mysql-connector-java-5.1.6-bin.jar (JDBC)下载路径分别为注意:不要图⽅便少下什么,或者少安装什么,尤其是JDK⼀定要安装官⽅的,要不会导致后⾯Spark配制出错,这个地⽅我们起码失败了5、6次,⼀定要全部下下来,重来的代价会更⾼3.安装前的配置⾸先进⼊root权限:输⼊su,再输⼊密码即可3.1.配置主机名分别修改各节点/etc/sysconfic/network⽂件,设置主机名为Master,Slave1,Slave2。
CDH5.1.0hadoop-2.3.( 2+3 )0完全分布式集群配置及HA配置

Hadoop-2.3.0-cdh5.1.0完全分布式集群配置及HA配置(冰峰)方式: 2个master + 3个slave hadoop-2.3.0-cdh5.1.0完全分布式集群配置HA配置重点说明:为了部署HA集群,应该准备以下事情:* NameNode服务器:运行NameNode的服务器应该有相同的硬件配置。
* JournalNode服务器:运行的JournalNode进程非常轻量,可以部署在其他的服务器上。
注意:必须允许至少3个节点。
当然可以运行更多,但是必须是奇数个,如3、5、7、9个等等。
当运行N个节点时,系统可以容忍至少(N-1)/2个节点失败而不影响正常运行。
一、安装前准备:操作系统:CentOS 6.5 64位操作系统环境:jdk1.7.0_45以上,本次采用jdk-7u72-linux-x64.tar.gzmaster1 192.168.100.151 namenode 节点master2 192.168.100.152 namenode 节点slave1 192.168.100.153 datanode 节点slave2 192.168.100.154 datanode 节点slave3: 192.168.100.155 datanode 节点注:Hadoop2.0以上采用的是jdk环境是1.7,Linux自带的jdk卸载掉,重新安装下载地址:/technetwork/java/javase/downloads/index.html软件版本:hadoop-2.3.0-cdh5.1.0.tar.gz, zookeeper-3.4.5-cdh5.1.0.tar.gz下载地址:/cdh5/cdh/5/开始安装:二、jdk安装1、检查是否自带jdkrpm -qa | grep jdkjava-1.6.0-openjdk-1.6.0.0-1.45.1.11.1.el6.i6862、卸载自带jdkyum -y remove java-1.6.0-openjdk-1.6.0.0-1.45.1.11.1.el6.i686安装jdk-7u72-linux-x64.tar.gz在usr/目录下创建文件夹java,在java文件夹下运行tar –zxvf jdk-7u72-linux-x64.tar.gz解压到java目录下[root@master01 java]# lsjdk1.7.0_72三、配置环境变量远行vi /etc/profile# /etc/profile# System wide environment and startup programs, for login setup# Functions and aliases go in /etc/bashrcexport JA VA_HOME=/usr/local/java/jdk1.7.0_65export JRE_HOME=/usr/local/java/jdk1.7.0_65/jreexport CLASSPATH=/usr/local/java/jdk1.7.0_65/libexport PATH=$JA V A_HOME/bin: $PA TH保存修改,运行source /etc/profile 重新加载环境变量运行java -version[root@master01 java]# java -versionjava version "1.7.0_72"Java(TM) SE Runtime Environment (build 1.7.0_72-b13)Java HotSpot(TM) 64-Bit Server VM (build 24.55-b03, mixed mode)Jdk配置成功四、系统配置预先准备5台机器,并配置IP,以下是我对这5台机器的角色分配。
K清风CDH安装手册

CDH安装手册CDH安装手册一、前言1.1.什么是CDHApache Hadoop作为目前最主流、应用范围最广的分布式应用架构,根据Google公司发表的MapReduce和Google档案系统的论文自行实作而成,提供在x86效劳器上构建大型应用集群的能力,它采用Apache 2.0许可协议发布开源协议,官方版本也称为社区版Hadoop。
因为Hadoop采用Apache开源协议,用户可以免费地任意使用和修改Hadoop,市面上就出现了很多Hadoop版本。
其中有很多厂家在Apache Hadoop的根底上开发自己的Hadoop产品,比方Cloudera的CDH〔Cloudera’sDistributionIncludingApacheHadoop〕,Hortonworks的HDP,MapR的MapR产品等。
1.2.为什么使用CDH社区版本的Hadoop具备很多的优点,例如:完全的开源免费,活泼的社区,文档资料齐全。
但由于Hadoop的生态圈过于复杂,包括Hive、Habase、Sqoop、Flume、Spark、Hue、Oozie等,需要考虑版本和组件的兼容性;同时集群部署、安装、配置较为复杂,需要手工调整配置文件后,对每台效劳器的分发配置分发操作,较为容易出错;同时缺少配套的运行监控和运维工具,需要结合ganglia、nagois等实现运行监控,运维本钱较高。
而Cloudera的CDH版本为目前最成型的发行版本,拥有最多的部署案例。
通过CDH提供更为稳定商用的Hadoop版本;提供强大的部署、管理和监控工具,通过统一的可视化管理后台,实现集群的动态监控,大大提高了集群部署的效率;同时CDH Express版本完全免费,不涉及昂贵的商业授权费用。
1.3. 环境说明机器名IP地址操作系统BigDataServer1 10.68.128.215 CentOS 7BigDataServer2 10.68.128.216 CentOS 7BigDataServer3 10.68.128.217 CentOS 7二、环境准备2.1. 关闭防火墙停止firewall#禁止firewall开机启动#2.2. 修改hosts文件增加机器、IP映射#vi /etc/hosts10.68.128.215 BigDataServer110.68.128.216 BigDataServer210.68.128.217 BigDataServer3:wq. 设置SSH免登录在BigDataServer1上执行:#ssh-keygen -t rsa#ssh-copy-id -i BigDataServer2#ssh-copy-id -i BigDataServer32.4. 设置时间同步CentOS 7默认安装的时间同步软件为Chrony,不再是NTP,应该需要调整Chrony的配置。
hadoop安装CDH5

rpm -ivh jdk-7u60-linux-x64.rpm机器000创建hadoop用户useradd hadoop建立信任关系(本机也可以加上)ssh-keygen -t rsavim authorized_keyschmod 644 authorized_keys下载安装包cdh5.0.2并解压wget /cdh5/cdh/5/hadoop-2.3.0-cdh5.0.2.tar.gz修改hadoop-env.shexport JA VA_HOME=/home/q/java/default不需要修改yarn-env.sh增加一个不允许连接namenode的主机列表的文件修改配置文件hdfs-site.xml因为standby namenode已经执行了namespace状态的检查点,所以没有必要设置second namenode,设置的话也是错误的<property><name>services</name><value>mycluster</value></property><property><name>nodes.mycluster</name><value>nn1,nn2</value></property><property><name>dfs.replication</name><value>1</value></property><property><name>node.rpc-address.mycluster.nn1</name><value>0:8020</value><property><name>node.rpc-address.mycluster.nn2</name><value>0:8020</value></property><property><name>node.http-address.mycluster.nn1</name><value>0:50070</value></property><property><name>node.http-address.mycluster.nn2</name><value>0:50070</value></property><property><name>node.shared.edits.dir</name><value>qjournal://0:8485;0:8485; 0:8485/mycluster</value></property><property><name>dfs.client.failover.proxy.provider.mycluster</name><value>node.ha.ConfiguredFailoverProxyProvider</valu e></property><property><name>dfs.ha.fencing.methods</name><value>sshfence</value></property><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/home/hadoop/.ssh/id_rsa</value></property><property><name>dfs.ha.automatic-failover.enabled</name><value>true</value></property><property><name>dfs.journalnode.edits.dir</name><value>/home/q/pucong1/hadoop_data/journal</value></property>修改配置文件core-site.xml<property><name>fs.defaultFS</name><value>hdfs://mycluster</value></property><property><name>io.file.buffer.size</name><value>131072</value></property><property><name>hadoop.tmp.dir</name><value>/home/q/pucong1/hadoop_data</value></property><property><name>ha.zookeeper.quorum</name><value>0:2181,0:2181,0:2181</value> </property>修改配置文件yarn-site.xml<property><name>yarn.resourcemanager.hostname</name><value>0</value></property><property><name>yarn.resourcemanager.address</name><value>0:8032</value></property><property><name>yarn.resourcemanager.scheduler.address</name><value>0:8030</value></property><property><name>yarn.resourcemanager.resource-tracker.address</name><value>0:8031</value></property><property><name>yarn.resourcemanager.admin.address</name><value>0:8033</value></property><property><name>yarn.resourcemanager.webapp.address</name><value>0:8088</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property>(该选项必须加上)<property><name></name><value>yarn</value></property>将该配置文件拷贝到hbase的conf目录下修改配置文件slaves0安装zookeeper格式化ZooKeeper集群[hadoop@0/home/q/pucong1/hadoop-2.3.0-cdh5.0.2]$ ./bin/hdfs zkfc -formatZK验证[zk: localhost:2181(CONNECTED) 2] ls /hadoop-ha[mycluster]在格式化NameNode之前先启动journalnode服务分别在journalnode的各台机器上执行[hadoop@0/home/q/pucong1/hadoop-2.3.0-cdh5.0.2]$ ./sbin/hadoop-daemon. sh start journalnodestarting journalnode, logging to /home/q/pucong1/hadoop-2.3.0-cdh5.0.2/logs/0.o ut验证[hadoop@0/home/q/pucong1/hadoop-2.3.0-cdh5.0.2]$ /home/q/java/default/bin/jps24599 Jps32504 QuorumPeerMain24537 JournalNode格式化namenode在active节点上执行[hadoop@0 /home/q/pucong1/hadoop-2.3.0-cdh5.0.2]$ ./bin/hdfs namenode -format (这步格式化了namenode也格式化了journalnode)先启动namenode要不无法初始化bootstrapStandby在standby节点上执行[hadoop@0 /home/q/pucong1/hadoop-2.3.0-cdh5.0.2]$ ./bin/hdfs namenode -bootstrapStandby启动[hadoop@0 /home/q/pucong1/hadoop-2.3.0-cdh5.0.2]$ ./sbin/start-all.shThis script is Deprecated. Instead use start-dfs.sh and start-yarn.sh14/06/30 16:44:24 W ARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableStarting namenodes on [0 0]0: starting namenode, logging to /home/q/pucong1/hadoop-2.3.0-cdh5.0.2/logs/0.out 0: starting namenode, logging to /home/q/pucong1/hadoop-2.3.0-cdh5.0.2/logs/0.out 0: starting datanode, logging to /home/q/pucong1/hadoop-2.3.0-cdh5.0.2/logs/0.out Starting journal nodes [0 0 0]0: journalnode running as process 24775. Stop it first.0: journalnode running as process 23351. Stop it first.0: journalnode running as process 29689. Stop it first.14/06/30 16:44:35 W ARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableStarting ZK Failover Controllers on NN hosts [0 0]0: starting zkfc, logging to /home/q/pucong1/hadoop-2.3.0-cdh5.0.2/logs/0.out0: starting zkfc, logging to /home/q/pucong1/hadoop-2.3.0-cdh5.0.2/logs/0.out starting yarn daemonsstarting resourcemanager, logging to /home/q/pucong1/hadoop-2.3.0-cdh5.0.2/logs/0 .out0: starting nodemanager, logging to /home/q/pucong1/hadoop-2.3.0-cdh5.0.2/logs/0.ou t验证[hadoop@0/home/q/pucong1/hadoop-2.3.0-cdh5.0.2]$ /home/q/java/default/bi n/jps25445 DFSZKFailoverController25802 Jps25542 ResourceManager24775 JournalNode32504 QuorumPeerMain25134 NameNode:50070/:50070/关闭主节点的namenode,验证standby节点已经成为了active节点恢复就是重启原namenode节点[hadoop@0/home/q/pucong1/hadoop-2.3.0-cdh5.0.2]$./sbin/hadoop-daemon. sh start namenodestarting namenode, logging to /home/q/pucong1/hadoop-2.3.0-cdh5.0.2/logs/0.out 通过web页面可以查看该namenode节点已经变成了standby namenode若不设置自动切换,可以使用[hadoop@0 /home/q/pucong1/hadoop-2.3.0-cdh5.0.2]$ ./bin/hdfs haadmin -transitionToActive nn2命令强制进行切换。
CDH nameNode HA搭建过程

编码:MFG-BIGDATA-001 大数据梅峰谷项目组CDH Hadoop HA搭建过程欢迎大家关注我的个人公众号:大数据梅峰谷,分享更多由梅峰谷编辑书籍和文档。
目录前言 (3)1.环境准备 (3)1.1准备hadoop账号 (3)1.2配置静态IP及hosts (4)1.3安装ssh及免密码登录 (6)1.4关闭防火墙 (9)1.5关闭SELinux (10)1.6配置JDK环境 (11)1.7机器配置及ip规划 (12)1.8组件下载地址 (12)2.配置ZooKeeper (12)2.1 准备工作 (13)2.2 修改Zookeeper配置 (13)2.3启动Zookeeper集群 (13)2.4 验证ZK服务 (14)3. 配置Hadoop服务 (15)3.1 准备工作 (15)3.2 配置Hadoop参数 (15)3.3 启动Hadoop集群 (22)3.4 验证服务 (24)4. 配置时钟同步 (25)5. 配置机架感知 (26)5.1 修改配置文件 (26)5.2 建立感知脚本 (26)5.3 配置感知文件 (27)5.4 验证服务 (27)前言该文档为梅峰谷大数据测试集群手动安装文档,集群使用操作系统CetnOS 6.8,使用Hadoop版本为CDH5.4.5,测试集群实现Namenode 高可用(HA),ResourceManager 高可用(HA),作为测试集群里面相关参数配置持续优化中,目前配置仅供参考。
1.环境准备1.1准备hadoop账号(1)准备如下账号账号/密码:hadoop/hadoop账号/密码:root/hadoop(2)创建过程创建hadop账号,并创建hadoop组过程,切入到root用户先:·创建用户命令:useradd hadoop·设置hadop用户密码命令: passwd hadoop·新增hadoop用户组:groupadd hadoop·添加hadoop用户到hadoop组:usermod -a -G g组名用户名备注:删除用户:useradel hadoop,查看用户组:cat /etc/group详细文档参考《Linux常用命令参考手册》1.2配置静态IP及hosts1、修改IP及Mac(1)查看mac地址:cat /etc/udev/rules.d/70-persistent-net.rules(2)修改ifcfg-eth1,切换到root账号,vi /etc/sysconfig/network-scripts/ifcfg-eth1 注意a.文件名要和ifconfig的网关名称一样,b.注意修改mac地址,c.注意修改成响应的ip,以master01为例,配置如下:----------DEVICE="eth1"BOOTPROTO="static"HWADDR="00:0C:29:2D:70:E8"IPV6INIT="yes"NM_CONTROLLED="yes"ONBOOT="yes"TYPE="Ethernet"UUID="c9add972-111d-4ad9-86d1-4989997499b3"IPADDR=192.168.1.122NETMASK=255.255.255.0PREFIX=24----------2、修改网关命令:vi /etc/sysconfig/network----------NETWORKING=yesHOSTNAME=master01GATEWAY=192.168.1.254----------3、重启网关切换到root下,命令: /etc/rc.d/init.d/network restart4、修改hosts切换到root下命令:vi /etc/hosts----------------------127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.1.121 standard192.168.1.122 master01192.168.1.123 master02192.168.1.124 zk01192.168.1.125 zk02192.168.1.126 zk03192.168.1.127 slave01192.168.1.128 slave02----------------------备注:前面两行最好保留,不要注释掉5.保险起见,最好重启一下服务器切换到root下,执行命令:reboot6.其他节点通过该方式,一次配置好静态IP1.3安装ssh及免密码登录1、安装SSH服务·安装openssh-server切换到root,执行命令:a.安装:yum install openssh-serverb.启动:service sshd start或者/etc/init.d/sshd startc.配置开启启动:chkconfig sshd on备注:(1)ssh服务默认端口为22,修改端口命令:vi /etc/ssh/sshd_config,Protocol 2,1 允许SSH1和SSH2连接,建议设置成Protocal 2(2)命令帮助:man ssh_config(3)白名单和黑名单配置hosts.deny最后一行:sshd:Allhosts.allow最后一行:sshd:All2.配置ssh免密码登录(1)在每个节点上执行如下命令(切换到hadoop用户下执行)(各个节点执行)·生成共有密钥和私有密钥:ssh-keygen -t rsa·修改访问权限:chmod 700 ~/.ssh(2)在每个节点上都复制一份自己的公钥,并且重新命名一下(进入到相应的节点,执行响应的命令),(各个节点执行)cp ~/.ssh/id_rsa.pub ~/.ssh/master01_id_rsa.pubcp ~/.ssh/id_rsa.pub ~/.ssh/master02_id_rsa.pubcp ~/.ssh/id_rsa.pub ~/.ssh/zk01_id_rsa.pubcp ~/.ssh/id_rsa.pub ~/.ssh/zk02_id_rsa.pubcp ~/.ssh/id_rsa.pub ~/.ssh/zk03_id_rsa.pubcp ~/.ssh/id_rsa.pub ~/.ssh/slave01_id_rsa.pubcp ~/.ssh/id_rsa.pub ~/.ssh/slave02_id_rsa.pub(3)将各个节点的公钥复制本id_rsa.pub 拷贝到master01(各个节点执行)scp ~/.ssh/slave01_id_rsa.pub hadoop@master01: ~/.sshscp ~/.ssh/slave02_id_rsa.pub hadoop@master01: ~/.sshscp ~/.ssh/zk01_id_rsa.pub hadoop@master01: ~/.sshscp ~/.ssh/zk02_id_rsa.pub hadoop@master01: ~/.sshscp ~/.ssh/zk03_id_rsa.pub hadoop@master01: ~/.sshscp ~/.ssh/master02_id_rsa.pub hadoop@master01: ~/.ssh(4)生成通用认证文件authorized_keys(只在master01上执行)cat ~/.ssh/slave01_id_rsa.pub >> ~/.ssh/authorized_keyscat ~/.ssh/slave02_id_rsa.pub >> ~/.ssh/authorized_keyscat ~/.ssh/zk01_id_rsa.pub >> ~/.ssh/authorized_keyscat ~/.ssh/zk02_id_rsa.pub >> ~/.ssh/authorized_keyscat ~/.ssh/zk03_id_rsa.pub >> ~/.ssh/authorized_keyscat ~/.ssh/master02_id_rsa.pub >> ~/.ssh/authorized_keyscat~/.ssh/master01_id_rsa.pub >> ~/.ssh/authorized_keys chmod 600 ~/.ssh/authorized_keys(注意一定要修改权限)(5)分发到各个节点(只在master01上执行)scp ~/.ssh/authorized_keys hadoop@master02:~/.ssh/ scp ~/.ssh/authorized_keys hadoop@slave01:~/.ssh/scp ~/.ssh/authorized_keys hadoop@slave02:~/.ssh/scp ~/.ssh/authorized_keys hadoop@zk01:~/.ssh/scp ~/.ssh/authorized_keys hadoop@zk02:~/.ssh/scp ~/.ssh/authorized_keys hadoop@zk03:~/.ssh/1.4关闭防火墙(1) 查看防火墙状态,使用root账号执行service iptables status(2)关闭防火墙service iptables stop(3)查看防火墙开机启动状态chkconfig iptables --list(4)关闭防火墙开机启动chkconfig iptables off防火墙不关闭的影响:1.hdfs的web管理页面,打不开该节点的文件浏览页面2.后台运行脚本(HIVE的),会出现莫名其妙的假死状态3.在删除和增加节点的时候,会让数据迁移处理时间更长,甚至不能正常完成相关操作………..1.5关闭SELinux(1)查看SElinux状态getenforce(2)修改配置文件需要重启机器:修改/etc/selinux/config 文件,将SELINUX=enforcing改为SELINUX=disabled命令:vi /etc/selinux/config内容:SELINUX=disabled执行永久关闭(命令:setenforce 0 ,不推荐)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
cdh安装hadoop教程
CDH(Cloudera's Distribution including Apache Hadoop)是一
种基于Apache Hadoop的大数据处理平台,它提供了一套完整的Hadoop生态系统工具和组件。
CDH安装教程一共包含以下几个步骤:
1. 系统准备:在开始安装之前,我们需要确保系统满足CDH
的最低要求。
CDH要求操作系统为RHEL / CentOS 6或7,并
且至少有8GB的内存,2个vCPU,100GB的磁盘空间和64
位操作系统。
此外,还需要配置主机名、网络和防火墙设置。
2. JDK安装:CDH依赖于Java运行环境。
首先需要在系统上
安装JDK。
可以从Oracle官方网站或OpenJDK获取JDK安装包。
安装JDK后,还需要设置JAVA_HOME环境变量。
3. CDH下载:在安装CDH之前,我们需要从Cloudera官网下载CDH安装包。
Cloudera提供了几个版本,包括CDH4、CDH5和CDH6。
根据需要选择合适的版本下载。
4. 安装CDH:解压CDH安装包,并根据官方文档进行安装。
安装过程中需要指定一个安装目录和一个临时目录,还需要配置Hadoop配置文件如core-site.xml、hdfs-site.xml、yarn-
site.xml等。
这些配置文件用于定义Hadoop集群的相关属性,如数据节点、名称节点、资源管理器等。
5. 启动Hadoop集群:完成CDH安装后,我们需要启动
Hadoop集群。
首先启动HDFS服务,然后启动YARN服务。
可以使用启动脚本启动Hadoop集群,或者使用Cloudera Manager进行管理。
6. 验证集群状态:一旦Hadoop集群成功启动,我们需要验证
集群的状态。
可以通过命令行工具hdfs dfs -ls /或yarn node -
list来检查HDFS和YARN的状态。
如果一切正常,应该能够
看到节点列表和文件系统的目录。
7. 安装其他组件:CDH还提供了其他组件,如Hive、HBase、Spark等。
这些组件可以通过Cloudera Manager进行安装和配置。
安装其他组件前,需要确保集群已经启动并且正常运行。
8. 集群管理:Cloudera Manager是CDH的管理工具,它提供
了图形化界面用于集群的管理。
使用Cloudera Manager可以监控集群的各个组件、配置和执行管理任务。
9. 故障排除:在使用CDH过程中,可能会遇到一些问题。
可
以通过查看日志文件和使用Cloudera Manager的故障排除工具来诊断和解决问题。
10. 高级配置:CDH还提供了一些高级配置选项,如安全设置、备份和恢复、性能调优等。
这些配置可以根据实际需求进行设置。
总结起来,CDH的安装过程涉及到系统准备、JDK安装、CDH下载、CDH安装、启动Hadoop集群、验证集群状态、
安装其他组件、集群管理、故障排除和高级配置等步骤。
是一项相对复杂的任务,需要一定的技术知识和经验。
通过按照官方文档进行操作,可以成功完成CDH的安装,并搭建一个稳定可靠的Hadoop集群。