第13章-知识发现MSMiner
人工智能领域中英文专有名词汇总

名词解释中英文对比<using_information_sources> social networks 社会网络abductive reasoning 溯因推理action recognition(行为识别)active learning(主动学习)adaptive systems 自适应系统adverse drugs reactions(药物不良反应)algorithm design and analysis(算法设计与分析) algorithm(算法)artificial intelligence 人工智能association rule(关联规则)attribute value taxonomy 属性分类规范automomous agent 自动代理automomous systems 自动系统background knowledge 背景知识bayes methods(贝叶斯方法)bayesian inference(贝叶斯推断)bayesian methods(bayes 方法)belief propagation(置信传播)better understanding 内涵理解big data 大数据big data(大数据)biological network(生物网络)biological sciences(生物科学)biomedical domain 生物医学领域biomedical research(生物医学研究)biomedical text(生物医学文本)boltzmann machine(玻尔兹曼机)bootstrapping method 拔靴法case based reasoning 实例推理causual models 因果模型citation matching (引文匹配)classification (分类)classification algorithms(分类算法)clistering algorithms 聚类算法cloud computing(云计算)cluster-based retrieval (聚类检索)clustering (聚类)clustering algorithms(聚类算法)clustering 聚类cognitive science 认知科学collaborative filtering (协同过滤)collaborative filtering(协同过滤)collabrative ontology development 联合本体开发collabrative ontology engineering 联合本体工程commonsense knowledge 常识communication networks(通讯网络)community detection(社区发现)complex data(复杂数据)complex dynamical networks(复杂动态网络)complex network(复杂网络)complex network(复杂网络)computational biology 计算生物学computational biology(计算生物学)computational complexity(计算复杂性) computational intelligence 智能计算computational modeling(计算模型)computer animation(计算机动画)computer networks(计算机网络)computer science 计算机科学concept clustering 概念聚类concept formation 概念形成concept learning 概念学习concept map 概念图concept model 概念模型concept modelling 概念模型conceptual model 概念模型conditional random field(条件随机场模型) conjunctive quries 合取查询constrained least squares (约束最小二乘) convex programming(凸规划)convolutional neural networks(卷积神经网络) customer relationship management(客户关系管理) data analysis(数据分析)data analysis(数据分析)data center(数据中心)data clustering (数据聚类)data compression(数据压缩)data envelopment analysis (数据包络分析)data fusion 数据融合data generation(数据生成)data handling(数据处理)data hierarchy (数据层次)data integration(数据整合)data integrity 数据完整性data intensive computing(数据密集型计算)data management 数据管理data management(数据管理)data management(数据管理)data miningdata mining 数据挖掘data model 数据模型data models(数据模型)data partitioning 数据划分data point(数据点)data privacy(数据隐私)data security(数据安全)data stream(数据流)data streams(数据流)data structure( 数据结构)data structure(数据结构)data visualisation(数据可视化)data visualization 数据可视化data visualization(数据可视化)data warehouse(数据仓库)data warehouses(数据仓库)data warehousing(数据仓库)database management systems(数据库管理系统)database management(数据库管理)date interlinking 日期互联date linking 日期链接Decision analysis(决策分析)decision maker 决策者decision making (决策)decision models 决策模型decision models 决策模型decision rule 决策规则decision support system 决策支持系统decision support systems (决策支持系统) decision tree(决策树)decission tree 决策树deep belief network(深度信念网络)deep learning(深度学习)defult reasoning 默认推理density estimation(密度估计)design methodology 设计方法论dimension reduction(降维) dimensionality reduction(降维)directed graph(有向图)disaster management 灾害管理disastrous event(灾难性事件)discovery(知识发现)dissimilarity (相异性)distributed databases 分布式数据库distributed databases(分布式数据库) distributed query 分布式查询document clustering (文档聚类)domain experts 领域专家domain knowledge 领域知识domain specific language 领域专用语言dynamic databases(动态数据库)dynamic logic 动态逻辑dynamic network(动态网络)dynamic system(动态系统)earth mover's distance(EMD 距离) education 教育efficient algorithm(有效算法)electric commerce 电子商务electronic health records(电子健康档案) entity disambiguation 实体消歧entity recognition 实体识别entity recognition(实体识别)entity resolution 实体解析event detection 事件检测event detection(事件检测)event extraction 事件抽取event identificaton 事件识别exhaustive indexing 完整索引expert system 专家系统expert systems(专家系统)explanation based learning 解释学习factor graph(因子图)feature extraction 特征提取feature extraction(特征提取)feature extraction(特征提取)feature selection (特征选择)feature selection 特征选择feature selection(特征选择)feature space 特征空间first order logic 一阶逻辑formal logic 形式逻辑formal meaning prepresentation 形式意义表示formal semantics 形式语义formal specification 形式描述frame based system 框为本的系统frequent itemsets(频繁项目集)frequent pattern(频繁模式)fuzzy clustering (模糊聚类)fuzzy clustering (模糊聚类)fuzzy clustering (模糊聚类)fuzzy data mining(模糊数据挖掘)fuzzy logic 模糊逻辑fuzzy set theory(模糊集合论)fuzzy set(模糊集)fuzzy sets 模糊集合fuzzy systems 模糊系统gaussian processes(高斯过程)gene expression data 基因表达数据gene expression(基因表达)generative model(生成模型)generative model(生成模型)genetic algorithm 遗传算法genome wide association study(全基因组关联分析) graph classification(图分类)graph classification(图分类)graph clustering(图聚类)graph data(图数据)graph data(图形数据)graph database 图数据库graph database(图数据库)graph mining(图挖掘)graph mining(图挖掘)graph partitioning 图划分graph query 图查询graph structure(图结构)graph theory(图论)graph theory(图论)graph theory(图论)graph theroy 图论graph visualization(图形可视化)graphical user interface 图形用户界面graphical user interfaces(图形用户界面)health care 卫生保健health care(卫生保健)heterogeneous data source 异构数据源heterogeneous data(异构数据)heterogeneous database 异构数据库heterogeneous information network(异构信息网络) heterogeneous network(异构网络)heterogenous ontology 异构本体heuristic rule 启发式规则hidden markov model(隐马尔可夫模型)hidden markov model(隐马尔可夫模型)hidden markov models(隐马尔可夫模型) hierarchical clustering (层次聚类) homogeneous network(同构网络)human centered computing 人机交互技术human computer interaction 人机交互human interaction 人机交互human robot interaction 人机交互image classification(图像分类)image clustering (图像聚类)image mining( 图像挖掘)image reconstruction(图像重建)image retrieval (图像检索)image segmentation(图像分割)inconsistent ontology 本体不一致incremental learning(增量学习)inductive learning (归纳学习)inference mechanisms 推理机制inference mechanisms(推理机制)inference rule 推理规则information cascades(信息追随)information diffusion(信息扩散)information extraction 信息提取information filtering(信息过滤)information filtering(信息过滤)information integration(信息集成)information network analysis(信息网络分析) information network mining(信息网络挖掘) information network(信息网络)information processing 信息处理information processing 信息处理information resource management (信息资源管理) information retrieval models(信息检索模型) information retrieval 信息检索information retrieval(信息检索)information retrieval(信息检索)information science 情报科学information sources 信息源information system( 信息系统)information system(信息系统)information technology(信息技术)information visualization(信息可视化)instance matching 实例匹配intelligent assistant 智能辅助intelligent systems 智能系统interaction network(交互网络)interactive visualization(交互式可视化)kernel function(核函数)kernel operator (核算子)keyword search(关键字检索)knowledege reuse 知识再利用knowledgeknowledgeknowledge acquisitionknowledge base 知识库knowledge based system 知识系统knowledge building 知识建构knowledge capture 知识获取knowledge construction 知识建构knowledge discovery(知识发现)knowledge extraction 知识提取knowledge fusion 知识融合knowledge integrationknowledge management systems 知识管理系统knowledge management 知识管理knowledge management(知识管理)knowledge model 知识模型knowledge reasoningknowledge representationknowledge representation(知识表达) knowledge sharing 知识共享knowledge storageknowledge technology 知识技术knowledge verification 知识验证language model(语言模型)language modeling approach(语言模型方法) large graph(大图)large graph(大图)learning(无监督学习)life science 生命科学linear programming(线性规划)link analysis (链接分析)link prediction(链接预测)link prediction(链接预测)link prediction(链接预测)linked data(关联数据)location based service(基于位置的服务) loclation based services(基于位置的服务) logic programming 逻辑编程logical implication 逻辑蕴涵logistic regression(logistic 回归)machine learning 机器学习machine translation(机器翻译)management system(管理系统)management( 知识管理)manifold learning(流形学习)markov chains 马尔可夫链markov processes(马尔可夫过程)matching function 匹配函数matrix decomposition(矩阵分解)matrix decomposition(矩阵分解)maximum likelihood estimation(最大似然估计)medical research(医学研究)mixture of gaussians(混合高斯模型)mobile computing(移动计算)multi agnet systems 多智能体系统multiagent systems 多智能体系统multimedia 多媒体natural language processing 自然语言处理natural language processing(自然语言处理) nearest neighbor (近邻)network analysis( 网络分析)network analysis(网络分析)network analysis(网络分析)network formation(组网)network structure(网络结构)network theory(网络理论)network topology(网络拓扑)network visualization(网络可视化)neural network(神经网络)neural networks (神经网络)neural networks(神经网络)nonlinear dynamics(非线性动力学)nonmonotonic reasoning 非单调推理nonnegative matrix factorization (非负矩阵分解) nonnegative matrix factorization(非负矩阵分解) object detection(目标检测)object oriented 面向对象object recognition(目标识别)object recognition(目标识别)online community(网络社区)online social network(在线社交网络)online social networks(在线社交网络)ontology alignment 本体映射ontology development 本体开发ontology engineering 本体工程ontology evolution 本体演化ontology extraction 本体抽取ontology interoperablity 互用性本体ontology language 本体语言ontology mapping 本体映射ontology matching 本体匹配ontology versioning 本体版本ontology 本体论open government data 政府公开数据opinion analysis(舆情分析)opinion mining(意见挖掘)opinion mining(意见挖掘)outlier detection(孤立点检测)parallel processing(并行处理)patient care(病人医疗护理)pattern classification(模式分类)pattern matching(模式匹配)pattern mining(模式挖掘)pattern recognition 模式识别pattern recognition(模式识别)pattern recognition(模式识别)personal data(个人数据)prediction algorithms(预测算法)predictive model 预测模型predictive models(预测模型)privacy preservation(隐私保护)probabilistic logic(概率逻辑)probabilistic logic(概率逻辑)probabilistic model(概率模型)probabilistic model(概率模型)probability distribution(概率分布)probability distribution(概率分布)project management(项目管理)pruning technique(修剪技术)quality management 质量管理query expansion(查询扩展)query language 查询语言query language(查询语言)query processing(查询处理)query rewrite 查询重写question answering system 问答系统random forest(随机森林)random graph(随机图)random processes(随机过程)random walk(随机游走)range query(范围查询)RDF database 资源描述框架数据库RDF query 资源描述框架查询RDF repository 资源描述框架存储库RDF storge 资源描述框架存储real time(实时)recommender system(推荐系统)recommender system(推荐系统)recommender systems 推荐系统recommender systems(推荐系统)record linkage 记录链接recurrent neural network(递归神经网络) regression(回归)reinforcement learning 强化学习reinforcement learning(强化学习)relation extraction 关系抽取relational database 关系数据库relational learning 关系学习relevance feedback (相关反馈)resource description framework 资源描述框架restricted boltzmann machines(受限玻尔兹曼机) retrieval models(检索模型)rough set theroy 粗糙集理论rough set 粗糙集rule based system 基于规则系统rule based 基于规则rule induction (规则归纳)rule learning (规则学习)rule learning 规则学习schema mapping 模式映射schema matching 模式匹配scientific domain 科学域search problems(搜索问题)semantic (web) technology 语义技术semantic analysis 语义分析semantic annotation 语义标注semantic computing 语义计算semantic integration 语义集成semantic interpretation 语义解释semantic model 语义模型semantic network 语义网络semantic relatedness 语义相关性semantic relation learning 语义关系学习semantic search 语义检索semantic similarity 语义相似度semantic similarity(语义相似度)semantic web rule language 语义网规则语言semantic web 语义网semantic web(语义网)semantic workflow 语义工作流semi supervised learning(半监督学习)sensor data(传感器数据)sensor networks(传感器网络)sentiment analysis(情感分析)sentiment analysis(情感分析)sequential pattern(序列模式)service oriented architecture 面向服务的体系结构shortest path(最短路径)similar kernel function(相似核函数)similarity measure(相似性度量)similarity relationship (相似关系)similarity search(相似搜索)similarity(相似性)situation aware 情境感知social behavior(社交行为)social influence(社会影响)social interaction(社交互动)social interaction(社交互动)social learning(社会学习)social life networks(社交生活网络)social machine 社交机器social media(社交媒体)social media(社交媒体)social media(社交媒体)social network analysis 社会网络分析social network analysis(社交网络分析)social network(社交网络)social network(社交网络)social science(社会科学)social tagging system(社交标签系统)social tagging(社交标签)social web(社交网页)sparse coding(稀疏编码)sparse matrices(稀疏矩阵)sparse representation(稀疏表示)spatial database(空间数据库)spatial reasoning 空间推理statistical analysis(统计分析)statistical model 统计模型string matching(串匹配)structural risk minimization (结构风险最小化) structured data 结构化数据subgraph matching 子图匹配subspace clustering(子空间聚类)supervised learning( 有support vector machine 支持向量机support vector machines(支持向量机)system dynamics(系统动力学)tag recommendation(标签推荐)taxonmy induction 感应规范temporal logic 时态逻辑temporal reasoning 时序推理text analysis(文本分析)text anaylsis 文本分析text classification (文本分类)text data(文本数据)text mining technique(文本挖掘技术)text mining 文本挖掘text mining(文本挖掘)text summarization(文本摘要)thesaurus alignment 同义对齐time frequency analysis(时频分析)time series analysis( 时time series data(时间序列数据)time series data(时间序列数据)time series(时间序列)topic model(主题模型)topic modeling(主题模型)transfer learning 迁移学习triple store 三元组存储uncertainty reasoning 不精确推理undirected graph(无向图)unified modeling language 统一建模语言unsupervisedupper bound(上界)user behavior(用户行为)user generated content(用户生成内容)utility mining(效用挖掘)visual analytics(可视化分析)visual content(视觉内容)visual representation(视觉表征)visualisation(可视化)visualization technique(可视化技术) visualization tool(可视化工具)web 2.0(网络2.0)web forum(web 论坛)web mining(网络挖掘)web of data 数据网web ontology lanuage 网络本体语言web pages(web 页面)web resource 网络资源web science 万维科学web search (网络检索)web usage mining(web 使用挖掘)wireless networks 无线网络world knowledge 世界知识world wide web 万维网world wide web(万维网)xml database 可扩展标志语言数据库附录 2 Data Mining 知识图谱(共包含二级节点15 个,三级节点93 个)间序列分析)监督学习)领域 二级分类 三级分类。
华三路由器软件升级指南

DBI基于的Windows可执行文件拆包工具 PinDemonium 用户指南说明书

PinDemoniuma DBI-based generic unpacker for Windows executablesSebastiano Mariani - Lorenzo Fontana - Fabio Gritti - Stefano D’Alessio●Dynamic analysis : Analyze the malware while it isexecuted inside a controlled environment●Static analysis : Analyze the malware without executing it●Dynamic analysis : Analyze the malware while it isexecuted inside a controlled environment●Static analysis : Analyze the malware without executing itStatic Analysis●Analysis of disassembled code ●Analysis of imported functions ●Analysis of stringsMaybe in a fairy tale...What if the malware tries to hinder the analysis process?Packed Malware●Compress or encrypt the original code Code and strings analysisimpossible●Obfuscate the imported functions Analysis of the importedfunctions avoidedPacking TechniquesWe can classify three packing techniques based on the location where the payload is unpacked:●Unpack on the Main Image: The deobfuscated code is written inside amain Image section●Unpack on the Heap: The deobfuscated code is written in adynamically allocated memory area●Unpack inside remote process: The deobfuscated code is injected ina remote processSteps :Packed Program Memory spaceDecryption StubOEP 1.Start the execution of the decryption stubEncrypted PayloadMain ImageSteps :Packed Program Memory spaceDecryption Stub2.The decryption stub read data from an encrypted anddecrypt it in place inside a main image sectionMain ImageEncrypted PayloadPerforms the decryptionSteps :Packed Program Memory spaceDecryption Stub3.At the end of the decryption phase the stub jumps into the first instruction of the decrypted sectionDecrypted PayloadJumps into the decrypted areaMain ImageSteps :Packed Program Memory space1.Start the execution of the decryption stubMain Image Decryption StubOEPEncrypted PayloadSteps :Packed Program Memory space2.The decryption stub read data from an encrypted main image section and decrypt it on a dynamicallyallocated memory area (heap)Main ImageDecrypt the payload on theheapDecryption StubOEP Encrypted PayloadDecrypted PayloadUnpacking on the HeapSteps :Packed Program Memory space3.Main ImageJumps into the decrypted areaDecryption StubOEP Encrypted PayloadDecrypted PayloadAt the end of the decryption phase the stub jumps into the first instruction of the decrypted sectionSteps :Packed Program Memory space1.Create remotelegitimate process in a suspended stateStubOEPEncrypted PayloadOther Program Memory spaceMain ImageCreateProcessSteps :Packed Program Memory space2.Unmap thelegitimate code section of the processStubEncrypted PayloadOther Program Memory spaceMain ImageUnmapView OfSectionSteps :Packed Program Memory space3.Allocates and writes the decrypted payload in the remote process memory space.StubEncrypted PayloadOther Program Memory spaceMain ImageVirtuallocEx/WriteProcess MemoryDecrypted PayloadSteps :Packed Program Memory space4.Modify the thread context to execute code from the newly allocated are and resume the thread executionStubEncrypted PayloadOther Program Memory spaceMain ImageSetContext Thread/ResumeThreadDecrypted PayloadOEPSolutions●Very time consuming●Too many samples to beanalyzed every day●Adapt the approach to dealwith different techniques ●Fast analysis●Scale well on the number ofsamples that has to beanalyzed every day●Single approach to deals withmultiple techniquesManual approach Automatic approachAll hail PinDemoniumControl Flow GraphBasic Block BB1TraceBB3BB2BB4BB6BB7BB8Code CacheTrace is copied in the codecacheBB1BB3BB2BB4BB6BB7BB8BB1BB3BB2Code Cache DBI provides the possibility toadd user defined code after each:-Instruction-Basic Block-Trace User DefinedCodeBB1BB3BB2 BB4BB6BB7BB8BB1BB3BB2What is a DBI?Code CacheDBI starts executing the program from the code cacheBB1BB3BB2BB4BB6BB7BB8User DefinedCodeBB1BB3BB2Key ideaExploit the functionalities of the DBI to identify the common behaviour of packers:they have to write new code in memory and eventually executeitOur stairway to heavenPacked malwareOriginal malwareD e t e c t w r i t t e n a n d t h e n e x e c u t e d m e m o r y r e g i o n sD u m p t h e p r o c e s s c o r r e c t l yD e o b f u s c a t e I A TR e c o g n i z e t h e c o r r e c t d u m pOur journey beginsConcepts:●WxorX law broken:instruction written by theprogram itself and thenexecuted●Write Interval (WI): range ofcontinuously writtenaddresses Idea:Track each instruction of the program:●Write instruction: get the targetaddress of the write and updatethe write interval consequently.●All instructions: check if the EIPis inside a write interval. If thecondition is met then the WxorXlaw is broken.Write setCurrent instr.WRITE0x401000-0x402000WRITE0x402000-0x403000WRITE 0x412000-0x413000EXECPinDemoniumEXECWRITE Start addr.-End addr.Steps :0x4010040x4250080x4250040x425000Legend :Write instruction and its rangesGeneric instructionWrite setCurrent instr.WRITE0x401000-0x402000WRITE0x402000-0x403000WRITE 0x412000-0x413000EXECPinDemoniumEXECWRITE Start addr.-End addr.Steps :0x4010040x4250080x4250040x425000Legend :Generic instruction Write instruction and its rangesSteps :The current instruction is a write, no WIpresent, create the new WIWrite setCurrent instr.0x401000 - 0x402000Write interval 1PinDemoniumWRITE0x401000-0x402000WRITE0x402000-0x403000WRITE 0x412000-0x413000EXEC0x4010040x4250080x4250040x425000EXECWRITE Start addr.-End addr.Legend :Generic instruction Write instruction and its ranges1.Write setCurrent instr.PinDemoniumWrite interval 10x401000 - 0x403000WRITE0x402000-0x403000WRITE 0x412000-0x413000EXEC0x4010040x4250080x425004EXECWRITE Start addr.-End addr.Legend :Generic instruction Write instruction and its rangesSteps :2.The current instruction is awrite, the ranges of the write overlaps an existing WI, update the matched WIWrite setCurrent instr.PinDemoniumWrite interval 10x401000 - 0x4030000x412000 - 0x413000Write interval 2Steps :WRITE0x412000-0x413000EXEC0x4010040x425008EXECWRITE Start addr.-End addr.Legend :Generic instruction Write instruction and its ranges3.The current instruction is awrite, the ranges of the write don’t overlap any WI, create a new WIDetect WxorX memory regionsSteps :Write setCurrent instr.PinDemoniumWrite interval 10x400000 - 0x4030000x412000 - 0x413000Write interval 2EXEC0x401004EXECWRITE Start addr.-End addr.Legend :Generic instruction Write instruction and its ranges4.The EIP of thecurrent instruction is inside a WIWxorX RULE BROKENOk the core of the problem has been resolved...Steps :1Instrumented program memoryMain ModuleWritten MemoryIPPinDemonium 1.The execution of a written address is detected21Instrumented program memoryMain ModuleWritten MemoryIPPinDemonium Steps :2.PinDemonium get the addresses of the main module21Instrumented program memoryMain ModuleWritten MemoryPinDemonium Steps :3Main Module Written MemoryPinDemonium dumps these memory range3.IP21Instrumented program memoryMain ModuleWritten MemoryIPPinDemonium Steps :3Main Module Written Memory4OEP4.Scylla to reconstruct the PE and set the Original Entry PointHave we already finished?Steps :What if the original code is written on the heap?Instrumented program memoryPinDemonium Written MemoryHeapMain ModuleIPMain ModuleWhat if the original code is written on the heap?21Instrumentedprogram memoryPinDemonium34OEPSteps :1.The execution of awritten address is detected2.PinDemonium get the addresses of the main module3.PinDemonium dumps these memory range 4.Scylla to reconstruct the PE and set the Original Entry PointIPWritten MemoryHeapMain ModuleThe OEP doesn’t make sense!SolutionAdd the heap memory range in which the WxorX rule has been broken as a new section inside the dumped PE! 1.Keep track of write- intervalslocated on the heap2.Dump the heap-zone wherethe WxorX rule is broken3.Add it as a new section insidethe PE4.Set the OEP inside this newadded sectionThe OEP is correct!However, the dumped heap-zone can contain references to addresses inside other not dumped memory areas!SolutionDump all the heap-zones and load them in IDA in order to allow static analysis!1.Retrieve all the currentlyallocated heap-zones2.Dump these heap-zones3.Create new segments insidethe .idb for each of them4.Copy the heap-zones contentinside these new segments!Two down, two still standing!Deobfuscate the IATExtended Scylla functionalities:●IAT Search : Used Advanced and Basic IAT searchfunctionalities provided by Scylla●IAT Deobfuscation : Extended the plugin system of Scylla forIAT deobfuscationOne last step...We have to find a way to identify the correct dumpIdea1.Entropy differenceGive for each dump a “quality”index using the heuristicsdefined in our heuristicsmoduleWe have to find a way to identify the correct dumpIdeaGive for each dump a “quality” index using the heuristics defined in our heuristics module 1.Entropy difference2.Far jump。
史忠植 高级人工智能 电子课件(pdf)第一章

图灵测试
The Turing Test
•1950: Alan Turing的文章 “Computing Machinery and Intelligence.” Mind, Vol. 59, No. 236, pp. 433-460提出图灵测试
2012-02-26 史忠植 高级人工智能 8
2012-02-26 史忠植 高级人工智能 22
人工智能的五个基本问题
(1) 知识与概念化是否是人工智能的核心? (2) 认知能力能否与载体分开来研究? (3) 认知的轨迹是否可用类自然语言来描述? (4) 学习能力能否与认知分开来研究? (5) 所有的认知是否有一种统一的结构?
2012-02-26
2012-02-26 史忠植 高级人工智能 13
人工智能的发展
知识工程时期
•1981: 日本政府宣布日本五代机(first-generation computer) 计划(即智能计算机) •1982: John Hopfield 掀起神经网络的研究 •1983: MCC (Microelectronics and Computer Technology Corporation)成立(Bobby Inman 任主任) •1984: Doug Lenat在Bobby Ray Inman的劝说下在MCC开始Cyc的研 究 •1986: Thinking Machines Inc 研制联结机器 (Connection Machine) •1987: LISP机器市场开始暗淡 •1988: 386芯片使得PC机速度可以与LISP机器媲美 2012-02-26 14 史忠植 高级人工智能
高级人工智能
第一章 绪论
史忠植 中国科学院计算技术研究所
鸟哥的Linux私房菜_基础学习篇(第3版)

第0章计算机概论 10.1 计算机:辅助人脑的好工具20.1.1 计算机硬件的五大单元20.1.2 CPU的种类30.1.3 接口设备40.1.4 运作流程40.1.5 计算机分类50.1.6 计算机上面常用的计算单位(大小、速度等) 6 0.2 个人计算机架构与接口设备70.2.1 CPU 70.2.2 内存90.2.3 显卡110.2.4 硬盘与存储设备120.2.5 PCI适配卡140.2.6 主板150.2.7 电源160.2.8 选购须知160.3 数据表示方式170.3.1 数字系统170.3.2 文字编码系统180.4 软件程序运行180.4.1 机器程序与编译程序180.4.2 操作系统190.4.3 应用程序220.5 重点回顾220.6 本章习题230.7 参考数据与扩展阅读24第1章Linux是什么251.1 Linux是什么261.1.1 Linux是什么261.1.2 Linux之前UNIX的历史271.1.3 关于GNU项目321.2 Torvalds的Linux开发341.2.1 Minix 341.2.2 对386硬件的多任务测试351.2.3 初次释出Linux 0.02 361.2.4 Linux的开发:虚拟团队的产生371.2.5 Linux的内核版本381.2.6 Linux distributions 391.3 Linux的特色421.3.1 Linux的特色421.3.2 Linux的优缺点431.3.3 关于授权451.4 重点回顾461.5 本章习题461.6 参考数据与扩展阅读47第2章Linux如何学习482.1 Linux当前的应用角色492.1.1 企业环境的利用492.1.2 个人环境的使用502.2 鸟哥的Linux苦难经验回忆录512.2.1 鸟哥的Linux学习之路512.2.2 学习心态的分别532.2.3 X Window的学习542.3 有心向Linux操作系统学习者学习态度552.3.1 从头学习Linux基础562.3.2 选择一本易读的工具书572.3.3 实践再实践572.3.4 发生问题怎么处理.. 582.4 鸟哥的建议(重点在Solution的学习) 592.5 重点回顾602.6 本章习题612.7 参考数据与扩展阅读61第3章主机规划与磁盘分区623.1 Linux与硬件的搭配633.1.1 认识计算机的硬件配置633.1.2 选择与Linux搭配的主机配置643.1.3 各硬件设备在Linux中的文件名663.2 磁盘分区673.2.1 磁盘连接的方式与设备文件名的关系673.2.2 磁盘的组成复习683.2.3 磁盘分区表(partition table) 693.2.4 开机流程与主引导分区(MBR) 723.2.5 Linux安装模式下,磁盘分区的选择(极重要) 74 3.3 安装Linux前的规划763.3.1 选择适当的distribution 763.3.2 主机的服务规划与硬件的关系773.3.3 主机硬盘的主要规划793.3.4 鸟哥说:关于练习机的安装建议803.3.5 鸟哥的两个实际案例803.3.6 大硬盘配合旧主机造成的无法开机问题81 3.4 重点回顾823.5 本章习题823.6 参考数据与扩展阅读82第4章安装CentOS 5.x与多重引导小技巧834.1 本练习机的规划(尤其是分区参数) 844.2 开始安装CentOS 5 854.2.1 调整启动媒体(BIOS) 864.2.2 选择安装结构与开机874.2.3 选择语系数据894.2.4 磁盘分区904.2.5 引导装载程序、网络、时区设置与root密码954.2.6 软件选择984.2.7 其他功能:RAM testing、安装笔记本电脑的内核参数(Option) 99 4.3 安装后的首次设置1004.4 多重引导安装流程与技巧1044.4.1 新主机仅有一块硬盘1044.4.2 旧主机有两块以上硬盘1054.4.3 旧主机只有一块硬盘1054.5 关于大硬盘导致无法开机的问题1064.6 重点回顾1064.7 本章习题1074.8 参考数据与扩展阅读107第5章首次登录与在线求助man page 1085.1 首次登录系统1095.1.1 首次登录CentOS 5.x图形界面1095.1.2 GNOME的操作与注销1105.1.3 KDE的操作与注销1135.1.4 X Window与命令行模式的切换1155.1.5 在终端界面登录linux 1165.2 在命令行模式下执行命令1175.2.1 开始执行命令1175.2.2 基础命令的操作1185.2.3 重要的热键, -c, -d 1215.2.4 错误信息的查看1225.3 Linux系统的在线求助man page与info page 1225.3.1 man page 1235.3.2 info page 1275.3.3 其他有用的文件(documents) 1295.4 超简单文本编辑器:nano 1305.5 正确的关机方法1315.5.1 数据同步写入磁盘:sync 1325.5.2 惯用的关机命令:shutdown 1325.5.3 重启、关机:reboot, halt, poweroff 1335.5.4 切换执行等级:init 1335.6 开机过程的问题排解1345.6.1 文件系统错误的问题1345.6.2 忘记root密码1355.7 重点回顾1365.8 本章习题1365.9 参考数据与扩展阅读137第二部分Linux文件、目录与磁盘格式第6章Linux的文件权限与目录配置1386.1 用户与用户组1396.2 Linux文件权限概念1406.2.1 Linux文件属性1416.2.2 如何改变文件属性与权限1446.2.3 目录与文件的权限意义1476.2.4 Linux文件种类与扩展名1506.3 Linux目录配置1526.3.1 Linux目录配置标准:FHS 1526.3.2 目录树(directory tree) 1566.3.3 路径与相对路径1586.3.4 CentOS的查看1596.4 重点回顾1596.5 本章练习1606.6 参考数据与扩展阅读160第7章Linux文件与目录管理1617.1 目录与路径1627.1.1 相对路径与路径1627.1.2 目录的相关操作1627.1.3 关于执行文件路径的变量:$PATH 165 7.2 文件与目录管理1677.2.1 查看文件与目录:ls 1677.2.2 复制、删除与移动:cp, rm, mv 1697.2.3 取得路径的文件名与目录名称1737.3 文件内容查阅1737.3.1 直接查看文件内容1737.3.2 可翻页查看1757.3.3 数据选取1767.3.4 非纯文本文件:od 1777.3.5 修改文件时间或创建新文件:touch 178 7.4 文件与目录的默认权限与隐藏权限180 7.4.1 文件默认权限:umask 1817.4.2 文件隐藏属性:chattr, lsattr 1837.4.3 文件特殊权限:SUID, SGID, SBIT 184 7.4.4 查看文件类型:file 1877.5 命令与文件的查询1877.5.1 脚本文件名的查询1877.5.2 文件名的查找1887.6 权限与命令间的关系(极重要) 1927.7 重点回顾1937.8 本章习题1947.9 参考数据与扩展阅读195第8章Linux磁盘与文件系统管理1968.1 认识EXT2文件系统1978.1.1 硬盘组成与分区的复习1978.1.2 文件系统特性1978.1.3 Linux的EXT2文件系统(inode) 1998.1.4 与目录树的关系2048.1.5 EXT2/EXT3文件的访问与日志文件系统的功能206 8.1.6 Linux文件系统的操作2088.1.7 挂载点(mount point)的意义2088.1.8 其他Linux支持的文件系统与VFS 2098.2 文件系统的简单操作2108.2.1 磁盘与目录的容量:df, du 2108.2.2 连接文件:ln 2138.3 磁盘的分区、格式化、检验与挂载2178.3.1 磁盘分区:fdisk 2178.3.2 磁盘格式化2238.3.3 磁盘检验:fsck, badblocks 2258.3.4 磁盘挂载与卸载2268.3.5 磁盘参数修改2318.4 设置开机挂载2348.4.1 开机挂载/etc/fstab及/etc/mtab 2348.4.2 特殊设备loop挂载(镜像文件不刻录就挂载使用) 236 8.5 内存交换空间(swap)的构建2388.5.1 使用物理分区构建swap 2388.5.2 使用文件构建swap 2408.5.3 swap使用上的限制2418.6 文件系统的特殊查看与操作2418.6.1 boot sector与superblock的关系2418.6.2 磁盘空间的浪费问题2438.6.3 利用GNU的parted进行分区行为2438.7 重点回顾2458.8 本章习题2458.9 参考数据与扩展阅读246第9章文件与文件系统的压缩与打包2489.1 压缩文件的用途与技术2499.2 Linux系统常见的压缩命令2509.2.1 Compress 2509.2.2 gzip, zcat 2529.2.3 bzip2, bzcat 2539.3 打包命令:tar 2539.3.1 tar 2549.4 完整备份工具:dump 2599.4.1 dump 2599.4.2 restore 2629.5 光盘写入工具2659.5.1 mkisofs:新建镜像文件2659.5.2 Cdrecord:光盘刻录工具2679.6 其他常见的压缩与备份工具2699.6.1 dd 2699.6.2 Cpio 2709.7 重点回顾2729.8 本章习题2729.9 参考数据与扩展阅读273第三部分学习shell与shell script第10章vim程序编辑器27410.1 vi与vim 27510.1.1 为何要学vim 27510.2 vi的使用27610.2.1 简单执行范例27710.2.2 按键说明27810.2.3 一个案例练习28110.2.4 vim的保存文件、恢复与打开时的警告信息28210.3 vim的功能28410.3.1 块选择(Visual Block) 28510.3.2 多文件编辑28610.3.3 多窗口功能28610.3.4 vim环境设置与记录:~/.vimrc, ~/.viminfo 28710.3.5 vim常用命令示意图28910.4 其他vim使用注意事项28910.4.1 中文编码的问题28910.4.2 DOS与Linux的断行字符29010.4.3 语系编码转换29010.5 重点回顾29110.6 本章练习29110.7 参考数据与扩展阅读292第11章认识与学习bash 29311.1 认识bash这个shell 29411.1.1 硬件、内核与shell 29411.1.2 为何要学命令行界面的shell 29511.1.3 系统的合法shell与/etc/shells功能29511.1.4 bash shell的功能29611.1.5 bash shell的内置命令:type 29811.1.6 命令的执行29811.2 shell的变量功能29911.2.1 什么是变量29911.2.2 变量的显示与设置:echo, unset 30011.2.3 环境变量的功能30411.2.4 影响显示结果的语系变量(locale) 30811.2.5 变量的有效范围30911.2.6 变量键盘读取、数组与声明:read,array,declare 31011.2.7 与文件系统及程序的限制关系:ulimit 31211.2.8 变量内容的删除、替代与替换31311.3 命令别名与历史命令31711.3.1 命令别名设置:alias,unalias 31711.3.2 历史命令:history 31811.4 Bash Shell的操作环境32011.4.1 路径与命令查找顺序32011.4.2 bash的登录与欢迎信息:/etc/issue, /etc/motd 320 11.4.3 bash 的环境配置文件32111.4.4 终端机的环境设置:stty, set 32511.4.5 通配符与特殊符号32711.5 数据流重定向32811.5.1 什么是数据流重定向32911.5.2 命令执行的判断依据:;,&&, || 33111.6 管道命令(pipe) 33411.6.1 选取命令:cut, grep 33411.6.2 排序命令:sort,wc,uniq 33611.6.3 双向重定向:tee 33811.6.4 字符转换命令:tr,col,join,paste,expand 338 11.6.5 切割命令:split 34211.6.6 参数代换:xargs 34211.6.7 关于减号-的用途34311.7 重点回顾34411.8 本章习题34411.9 参考数据与扩展阅读345第12章正则表达式与文件格式化处理34612.1 前言:什么是正则表达式34712.1.1 什么是正则表达式34712.1.2 正则表达式对于系统管理员的用途34712.1.3 正则表达式的广泛用途34812.1.4 正则表达式与Shell在Linux当中的角色定位348 12.1.5 扩展的正则表达式34812.2 基础正则表达式34812.2.1 语系对正则表达式的影响34912.2.2 grep的一些高级参数34912.2.3 基础正则表达式练习35012.2.4 基础正则表达式字符(characters) 35612.2.5 sed工具35712.3 扩展正则表达式36112.4 文件的格式化与相关处理36212.4.1 格式化打印:printf 36212.4.2 awk:好用的数据处理工具36312.4.3 文件比较工具36612.4.4 文件打印准备:pr 36912.5 重点回顾36912.6 本章习题37012.7 参考数据与扩展阅读371第13章学习shell script 37213.1 什么是shell script 37313.1.1 为什么学习shell script 37313.1.2 个script的编写与执行37413.1.3 编写shell script的良好习惯37613.2 简单的shell script练习37613.2.1 简单范例37713.2.2 script的执行方式区别(source, shscript, ./script) 37813.3 善用判断式37913.3.1 利用test命令的测试功能38013.3.2 利用判断符号[] 38213.3.3 shell script的默认变量($0, $1...) 38313.4 条件判断式38513.4.1 利用if...then 38513.4.2 利用case...esac判断38913.4.3 利用function功能39113.5 循环(loop) 39313.5.1 while do done, until do done(不定循环) 39313.5.2 for...do...done(固定循环) 39413.5.3 for...do...done的数值处理39613.6 shell script的追踪与调试39713.7 重点回顾39813.8 本章习题39813.9 参考数据与扩展阅读399第四部分Linux使用者管理第14章Linux账号管理与ACL权限设置40014.1 Linux的账号与用户组40114.1.1 用户标识符:UID与GID 40114.1.2 用户账号40214.1.3 有效与初始用户组:groups, newgrp 40614.2 账号管理40914.2.1 新增与删除用户:useradd, 相关配置文件, passwd, usermod, userdel 409 14.2.2 用户功能41714.2.3 新增与删除用户组42014.2.4 账号管理实例42214.3 主机的具体权限规划:ACL的使用42314.3.1 什么是ACL 42314.3.2 如何启动ACL 42314.3.3 ACL的设置技巧:getfacl, setfacl 42414.4 用户身份切换42714.4.1 su 42814.4.2 sudo 42914.5 用户的特殊shell与PAM模块43314.5.1 特殊的shell, /sbin/nologin 43314.5.2 PAM模块简介43414.5.3 PAM模块设置语法43514.5.4 常用模块简介43714.5.5 其他相关文件43914.6 Linux主机上的用户信息传递44014.6.1 查询用户:w, who, last, lastlog 44014.6.2 用户对谈:write, mesg, wall 44114.6.3 用户邮件信箱:mail 44114.7 手动新增用户44314.7.1 一些检查工具44314.7.2 特殊账号(如纯数字账号)的手工新建44414.7.3 批量新建账号模板(适用于passwd --stdin参数) 44514.7.4 批量新建账号的范例(适用于连续数字,如学号) 446 14.8 重点回顾44814.9 本章习题44914.10 参考数据与扩展阅读450第15章磁盘配额(Quota)与高级文件系统管理45115.1 磁盘配额(Quota)的应用与实践45215.1.1 什么是Quota 45215.1.2 一个Quota范例45415.1.3 实践Quota流程1:文件系统支持45415.1.4 实践Quota流程2:新建Quota配置文件45515.1.5 实践Quota流程3:Quota启动、关闭与限制值设置456 15.1.6 实践Quota流程4:Quota限制值的报表45815.1.7 实践Quota流程5:测试与管理45915.1.8 不改动既有系统的Quota实例46215.2 软件磁盘阵列(Software RAID) 46315.2.1 什么是RAID 46315.2.2 software, hardware RAID 46615.2.3 软件磁盘阵列的设置46715.2.4 仿真RAID错误的救援模式47015.2.5 开机自动启动RAID 并自动挂载47215.2.6 关闭软件RAID(重要!) 47215.3 逻辑卷管理器(Logical V olume Manager) 47315.3.1 什么是LVM:PV, PE, VG, LV的意义47315.3.2 LVM实作流程47515.3.3 放大LV容量47915.3.4 缩小LV容量48115.3.5 LVM的系统快照48315.3.6 LVM相关命令汇整与LVM的关闭48815.4 重点回顾48915.5 本章习题48915.6 参考数据与扩展阅读491第16章例行性工作(crontab) 49216.1 什么是例行性工作49316.1.1 Linux工作调度的种类:at, cron 49316.1.2 Linux上常见的例行性工作49316.2 仅执行一次的工作调度49416.2.1 atd的启动与at运行的方式49416.2.2 实际运行单一工作调度49516.3 循环执行的例行性工作调度49816.3.1 用户的设置49816.3.2 系统的配置文件:/etc/crontab 50016.3.3 一些注意事项50116.4 可唤醒停机期间的工作任务50216.4.1 什么是anacron 50316.4.2 anacron与/etc/anacrontab 50316.5 重点回顾50416.6 本章习题505第17章程序管理与SELinux初探50617.1 什么是进程(process) 50717.1.1 进程与程序(process & program) 50717.1.2 Linux的多用户、多任务环境50917.2 工作管理(job control) 51117.2.1 什么是工作管理51117.2.2 job control的管理51117.2.3 脱机管理问题51517.3 进程管理51517.3.1 进程的查看51617.3.2 进程的管理52117.3.3 关于进程的执行顺序52317.3.4 系统资源的查看52517.4 特殊文件与程序53017.4.1 具有SUID/SGID权限的命令执行状态530 17.4.2 /proc/* 代表的意义53117.4.3 查询已打开文件或已执行程序打开的文件532 17.5 SELinux初探53417.5.1 什么是SELinux 53417.5.2 SELinux的运行模式53617.5.3 SELinux的启动、关闭与查看53817.5.4 SELinux网络服务运行范例54017.5.5 SELinux所需的服务54217.5.6 SELinux的策略与规则管理54417.6 重点回顾54717.7 本章习题54817.8 参考数据与扩展阅读550第18章认识系统服务(daemons) 55118.1 什么是daemon与服务(service) 55218.1.1 daemon的主要分类55218.1.2 服务与端口的对应55418.1.3 daemon的启动脚本与启动方式55518.2 解析super daemon的配置文件55818.2.1 默认值配置文件:xid.conf 55818.2.2 一个简单的rsync范例设置56118.3 服务的防火墙管理xid, TCP Wrappers 56218.3.1 /etc/hosts.allow, /etc/hosts.deny管理56318.3.2 TCP Wrappers特殊功能56518.4 系统开启的服务56518.4.1 查看系统启动的服务56618.4.2 设置开机后立即启动服务的方法56618.4.3 CentOS 5.x默认启动的服务简易说明56918.5 重点回顾57218.6 本章习题57318.7 参考数据与扩展阅读574第19章认识与分析日志文件57519.1 什么是日志文件57619.2 syslogd:记录日志文件的服务57819.2.1 日志文件内容的一般格式57819.2.2 syslog的配置文件:/etc/syslog.conf 57919.2.3 日志文件的安全性设置58319.2.4 日志文件服务器的设置58419.3 日志文件的轮替(logrotate) 58519.3.1 logrotate的配置文件58619.3.2 实际测试logrotate的操作58819.3.3 自定义日志文件的轮替功能58919.4 分析日志文件59019.4.1 CentOS默认提供的logwatch 59019.4.2 鸟哥自己写的日志文件分析工具59119.5 重点回顾59319.6 本章习题59419.7 参考数据与扩展阅读594第五部分Linux系统管理员第20章启动流程、模块管理与Loader 59520.1 Linux的启动流程分析59620.1.1 启动流程一览59620.1.2 BIOS,boot loader与kernel加载59620.1.3 个进程init及配置文件/etc/inittab与runlevel 60120.1.4 init处理系统初始化流程(/etc/rc.d/rc.sysinit) 60320.1.5 启动系统服务与相关启动配置文件(/etc/rc.d/rc N &/etc/sysconfig) 60420.1.6 用户自定义开机启动程序(/etc/rc.d/rc.local) 60520.1.7 根据/etc/inittab的设置加载终端机或X Window界面605 20.1.8 启动过程会用到的主要配置文件60620.1.9 Run level的切换60720.2 内核与内核模块60820.2.1 内核模块与依赖性60820.2.2 内核模块的查看60920.2.3 内核模块的加载与删除61020.2.4 内核模块的额外参数设置:/etc/modprobe.conf 61120.3 Boot Loader: Grub 61120.3.1 boot loader的两个stage 61120.3.2 grub的配置文件/boot/grub/menu.lst与菜单类型612 20.3.3 initrd的重要性与创建新initrd文件61620.3.4 测试与安装grub 61720.3.5 启动前的额外功能修改62020.3.6 关于内核功能当中的vga设置62120.3.7 BIOS无法读取大硬盘的问题62220.3.8 为某个菜单加上密码62320.4 启动过程的问题解决62420.4.1 忘记root密码的解决之道62420.4.2 init配置文件错误62520.4.3 BIOS磁盘对应的问题(device.map) 62520.4.4 因文件系统错误而无法启动62620.4.5 利用chroot切换到另一块硬盘工作62620.5 重点回顾62720.6 本章习题62720.7 参考数据与扩展阅读628第21章系统设置工具(网络与打印机)与硬件检测62921.1 CentOS系统设置工具:setup 63021.1.1 用户身份验证设置63121.1.2 网络配置选项(手动设置IP与自动获取) 63221.1.3 防火墙设置63321.1.4 键盘形式设置63421.1.5 系统服务的启动与否设置63521.1.6 系统时钟的时区设置63521.1.7 X窗口界面分辨率设置63521.2 利用CUPS设置Linux打印机63621.2.1 Linux的打印组件(打印操作、队列、服务与打印机) 636 21.2.2 CUPS支持的联机模式63921.2.3 以Web界面管理网络打印机64021.2.4 以Web界面管理USB本地打印机64321.2.5 将Linux本地打印机开放成为网络打印机64421.2.6 手动设置打印机64521.3 硬件数据收集与驱动及lm_sensors 64921.3.1 硬件信息的收集与分析64921.3.2 驱动USB设备65121.3.3 使用lm_sensors取得温度、电压等信息65321.3.4 udev与hal简介65521.4 重点回顾65621.5 本章习题65721.6 参考数据与扩展阅读657第22章软件安装:源码与Tarball 65822.1 开放源码的软件安装与升级简介65922.1.1 什么是开放源码、编译程序与可执行文件65922.1.2 什么是函数库66022.1.3 什么是make与configure 66122.1.4 什么是Tarball的软件66222.1.5 如何安装与升级软件66222.2 使用传统程序语言进行编译的简单范例66322.2.1 单一程序:打印Hello World 66322.2.2 主程序、子程序链接:子程序的编译66522.2.3 调用外部函数库:加入链接的函数库66622.2.4 gcc的简易用法(编译、参数与链接) 66722.3 用make进行宏编译66722.3.1 为什么要用make 66722.3.2 makefile的基本语法与变量66822.4 Tarball的管理与建议67022.4.1 使用源码管理软件所需要的基础软件67122.4.2 Tarball安装的基本步骤67122.4.3 一般Tarball软件安装的建议事项(如何删除、升级) 673 22.4.4 一个简单的范例(利用ntp来示范) 67422.4.5 利用patch更新源码67522.5 函数库管理67722.5.1 动态与静态函数库67722.5.2 ldconfig与/etc/ld.so.conf 67822.5.3 程序的动态函数库解析:ldd 67922.6 检验软件正确性68022.7 重点回顾68222.8 本章习题68222.9 参考数据与扩展阅读683第23章软件安装:RPM、SRPM与YUM功能68423.1 软件管理器简介68523.1.1 Linux界的两大主流:RPM与DPKG 68523.1.2 什么是RPM与SRPM 68623.1.3 什么是i386、i586、i686、noarch、x86_64 68723.1.4 RPM的优点68823.1.5 RPM属性依赖的解决方式:YUM在线升级68923.2 RPM软件管理程序:rpm 69023.2.1 RPM默认安装的路径69023.2.2 RPM安装(install) 69023.2.3 RPM升级与更新(upgrade/freshen) 69223.2.4 RPM查询(query) 69223.2.5 RPM验证与数字证书(Verify/Signature) 69423.2.6 卸载RPM与重建数据库(erase/rebuilddb) 69723.3 SRPM的使用:rpmbuild 69723.3.1 利用默认值安装SRPM文件(--rebuid/--repile) 69823.3.2 SRPM使用的路径与需要的软件69823.3.3 设置文件的主要内容(*.spec) 69923.3.4 SRPM的编译命令(-ba/-bb) 70323.3.5 一个打包自己软件的范例70323.4 YUM在线升级机制70523.4.1 利用yum进行查询、安装、升级与删除功能70523.4.2 yum的设置文件70923.4.3 yum的软件组功能71023.4.4 全系统自动升级71123.5 管理的抉择:RPM还是Tarball 71123.6 重点回顾71223.7 本章习题71323.8 参考数据与扩展阅读714第24章X Window设置介绍71524.1 什么是X Window System 71624.1.1 X Window的发展简史71624.1.2 主要组件:X Server/X Client/Window Manager/DisplayManager 717 24.1.3 X Window的启动流程71924.1.4 X启动流程测试72224.1.5 我是否需要启用X Window System 72324.2 X Server设置文件解析与设置72424.2.1 解析xorg.conf设置72424.2.2 X Font Server(XFS)与加入其他中文字体72724.2.3 设置文件重建与显示器参数微调72924.3 显卡驱动程序安装范例73024.3.1 NVidia 73024.3.2 ATI (AMD) 73224.3.3 Intel 73324.4 重点回顾73324.5 本章习题73424.6 参考数据与扩展阅读734第25章Linux备份策略73525.1 备份要点73625.1.1 备份资料的考虑73625.1.2 备份哪些Linux数据73725.1.3 选择备份设备73825.2 备份的种类、频率与工具的选择74025.2.1 完整备份的增量备份(Incremental backup) 740 25.2.2 完整备份的差异备份(differential backup) 742 25.2.3 关键数据备份74325.3 鸟哥的备份策略74325.3.1 每周系统备份的script 74425.3.2 每日备份数据的script 74525.3.3 远程备份的script 74625.4 灾难恢复的考虑74725.5 重点回顾74725.6 本章习题74825.7 参考数据与扩展阅读748第26章Linux内核编译与管理74926.1 编译前的任务:认识内核与取得内核源代码750 26.1.1 什么是内核(Kernel) 75026.1.2 更新内核的目的75126.1.3 内核的版本75226.1.4 内核源代码的取得方式75326.1.5 内核源代码的解压缩/安装/观察75426.2 内核编译的前处理与内核功能选择75526.2.1 硬件环境查看与内核功能要求75526.2.2 保持干净源代码:make mrproper 75526.2.3 开始挑选内核功能:make XXconfig 756 26.2.4 内核功能细项选择75726.3 内核的编译与安装76826.3.1 编译内核与内核模块76826.3.2 实际安装模块76926.3.3 开始安装新内核与多重内核菜单(grub) 770 26.4 额外(单一)内核模块编译77126.4.1 编译前注意事项77126.4.2 单一模块编译77226.4.3 内核模块管理77326.5 重点回顾77326.6 本章习题77326.7 参考数据与扩展阅读774一些基础的Linux 问题附录A:GNU 的GPL 条文version 2附录B:EXT2 / EXT3 文件系统一个简单的SPFdisk 分割实例。
挖矿僵尸网络WannaMine病毒查杀、防范步骤
挖矿僵尸网络WannaMine病毒查杀、防范步骤1、安装永恒之蓝MS17-010漏洞补丁,根据电脑操作系统版本下载对应的漏洞补丁进行安装,漏洞补丁下载网址见附录。
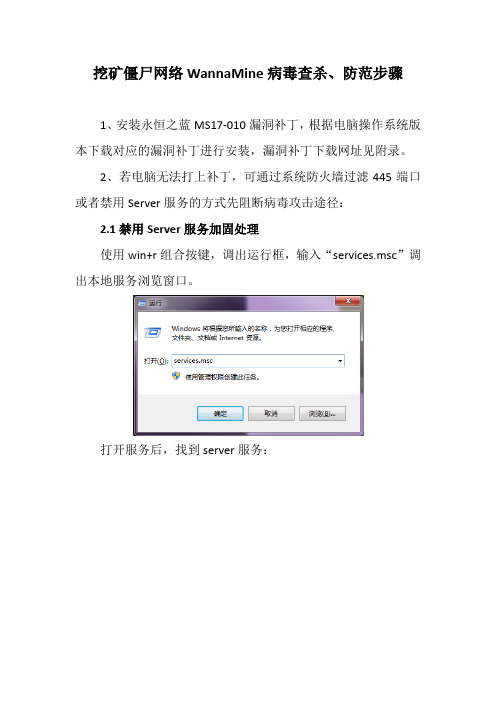
2、若电脑无法打上补丁,可通过系统防火墙过滤445端口或者禁用Server服务的方式先阻断病毒攻击途径:2.1禁用Server服务加固处理使用win+r组合按键,调出运行框,输入“services.msc”调出本地服务浏览窗口。
打开服务后,找到server服务:双击“Sever”,将启动类型修改为“禁用”,此操作会防止重启以后server服务重新启动。
点击“停止”按纽,将服务状态修改为‘已停止’状态。
如下图所示:2.2本机防火墙策略屏蔽445、135、137、138、139端口流量防护在控制面板中打开Windows防火墙:进入Windows防火墙配置界面,点击“高级设置”。
点击入站规则,再点击新建规则创建防火墙入站规则:在新建入站规则向导中,针对协议和端口步骤,选择对端口过滤。
选择TCP协议,并输入特定本地端口:445、135、137、138、139。
在操作步骤中,选择阻止连接。
在应用该规则处,勾选域、专用以及公用选项。
填入规则名称,完成创建。
规则创建完成后,可看到入站规则中存在445阻断规则。
3、安装最新版的杀毒软件(如金山毒霸、360杀毒软件、卡巴斯基等)进行病毒查杀。
4、如果第1、2步骤不会操作,也可通过离线补丁升级工具(离线版一键修复工具1.3(绿盟),请见附件1)自动检测系统是否已经安装MS17-010漏洞的补丁,若未安装,则自动判断系统版本并自动安装相应版本的补丁。
如果安装失败,工具会通过关闭Server服务,配置防火墙策略阻断端口进行防御。
在使用时,以管理员权限运行工具,对系统进行升级,运行效果如下图:附录MS17-010漏洞补丁下载地址操作系统版本对应KB号补丁下载链接Windows XP SP3 x86 KB4012598/d/csa/csa/secu/2017/02/windowsxp-kb4012598-x86-custom-chs_dca9b5adddad778cfd4b7349ff54b51677f36775.exeWindows XP SP2 x64 KB4012598/d/csa/csa/secu/2017/02/windowsserver2003-kb4012598-x64-custom-enu_f24d8723f246145524b9030e4752c96430981211.exe/d/csa/csa/secu/2017/02/windowsserver2003-kb4012598-x64-custom-jpn_9d5318625b20faa41042f0046745dff8415ab22a.exeWindows XP Embedded KB4012598/c/csa/csa/secu/2017/02/windowsxp-kb4012598-x86-embedded-custom-chs_41935edbcd6fa88a69718bc85ab5fd336445e7f9.exeWindowsServer 2003 x64 KB4012598/c/csa/csa/secu/2017/02/windowsserver2003-kb4012598-x64-custom-chs_68a2895db36e911af59c2ee133baee8de11316b9.exeWindows KB4012598 /c/csa/csa/secu/201信息化建设与管理中心2019.10.09。
蘑菇钉原理

蘑菇钉原理详解蘑菇钉(Matlock in English)是一种通过检测操作系统内存来发现恶意软件的工具。
它主要用于计算机取证,网络安全和恶意软件分析等领域。
蘑菇钉依赖于操作系统内部的技术,通过监控和分析内存中的数据和结构,检测恶意软件的活动,识别并分析恶意软件的行为。
1. 蘑菇钉的基本原理蘑菇钉的基本原理是通过扫描和分析操作系统内存中的数据,来检测并分析恶意软件的行为。
它利用了操作系统存储管理的特性,比如页表(Page Table)和虚拟内存(Virtual Memory)。
下面将详细解释蘑菇钉的基本原理。
1.1 页表和虚拟内存在操作系统中,虚拟内存是一种让应用程序能够访问比物理内存更大的地址空间的技术。
为了实现虚拟内存,操作系统将物理内存划分成固定大小的块,称为页面(Page),同时将应用程序的虚拟地址空间也划分成相同大小的块,称为虚拟页面(Virtual Page)。
为了管理虚拟地址和物理地址之间的映射关系,操作系统使用页表。
页表是一个数据结构,用于记录虚拟页面和物理页面之间的映射关系。
每个进程都有一个独立的页表,用于管理其虚拟内存。
1.2 蘑菇钉的工作原理当蘑菇钉启动时,它首先读取操作系统的页表,获取虚拟地址到物理地址的映射关系。
然后,它通过遍历页表中的所有项,扫描并分析每个虚拟页面的内容。
蘑菇钉的关键是检测虚拟页面中的恶意软件代码或行为。
为了实现这一点,蘑菇钉使用了几种技术,包括字符串匹配、API hooking和行为分析等。
1.3 字符串匹配字符串匹配是蘑菇钉用来检测恶意软件特征的一种技术。
蘑菇钉会搜索虚拟页面中的字符串,与预先定义的恶意软件特征进行匹配。
如果找到匹配的字符串,蘑菇钉就可以断定该虚拟页面可能包含恶意软件。
1.4 API hookingAPI hooking(应用程序编程接口钩子)是蘑菇钉用来监控和拦截恶意软件系统调用的一种技术。
蘑菇钉会通过修改操作系统的页表,将某些关键的系统调用重定向到自己的代码中。
人工智能6作业答案

人工智能有哪些主要的研究领域?
问题求解 机器学习 自然语言理解 专家系统 模式识别 计算机视觉 机器人学 搏弈 计算智能 人工生命
自动定理证明 自动程序设计 智能控制 智能检索 智能调度与指挥 智能决策支持系统 人工神经网络 数据挖掘和知识发现
第二章 作业
1、常用的知识表示方法都有哪些? 2、请把下列命题表示为谓词公式。
Kasparov • 2000:中科院计算所多主体环境MAGE知识发现系统
MSMiner
人工智能有哪些学派?各自认知观 是什么?
符号主义,又称为逻辑主义、心理学派、计算 机学派,其原理主要为物理符号系统假设和有 限合理性原理。 连接主义,又称为仿生学派、生理学派,其原 理主要为神经网络及神经网络间的连接机制与 学习算法。 行为主义,又称为进化主义、控制论学派,其 原理为控制论及感知-动作型控制系统。
第一章 作业及解答
1、什么是人工智能?发展过程中经历了哪些阶 段?每个阶段列举出其中有代表性的人物。
2、人工智能有哪些学派?各自认知观是什么?
3、人工智能有哪些主要的研究领域?
什么是人工智能?
人工智能(顾名思义):就是用人工的方法在计算 机上实现的智能。 人工智能(学科):人工智能是一门研究如何构造 智能机器或智能系统,使它能模拟、延伸、扩展人 类智能的学科。 人工智能(能力):智能机器所执行的通常与人类 智能有关的智能行为,如判断、推理、证明、识别、 感知、理解、设计、思考、规划、学习和问题求解 等思维活动。
◆ 英国的哲学家、自然科学家Bacon(培根)(1561-1626),系 统地给出了归纳法,强调了知识的作用,著名警句“知识就是力 量”。
◆ 德国数学家、哲学家Leibnitz(莱布尼茨)(1646-1716),把 形式逻辑符号化,从而能对人的思维进行运算和推理,做出了能 进行四则运算的手摇计算机。
多策略数据挖掘平台MSMiner

掘平台MSMiner
•与元数据管理模块交互用到时了COM技术,为了
降低开发负担,我们提供了CPublicFunc公共函数类,
提交要求和项目流程如下:
1)可以两至三人为一小组工程实现; 2)实现结果为符合MSMiner数据挖掘子系统挖
掘算法DLL接口规范要求的DLL文件。 3)开发完毕,在机房MSMiner环境下进行测试。 4)最后提交程序源码和实验报告,在实验报告
中要写清算法步骤、说明以及心得体会等,源码 要求有清晰明确的注释。
掘平台MSMiner
课程项目内容要求
对MSMiner数据挖掘子系统进行扩展开发,选择 实现下列某种算法:
• 1.聚类算法:k-means、k-harmonic
• 2.分类算法:C4.5、SVM、GA
• 3.关联规则:Apriori、FP-tree
• 4.神经网络
掘平MSMiner
常见问题解答
• 几个常见问题的说明:
•1)Q:为什么要实现DLL程序,可以实现成可执行程序吗?
•A:因为本次实验要开发算法DLL程序,目的正是用于封 装数据挖掘算法,并最终由MSMiner数据挖掘子系统所调 用。所以不能实现成可执行程序。
•2)Q:算法DLL接口规范是否很复杂,难以在短时期内实现?
•3)以对话框向导引导用户建立ETL和数据挖掘任务,以 面向对象的方式来组织和执行ETL和数据挖掘任务
•4)在挖掘任务执行引擎中,提供了任务调度功能,可以 定时定期地执行挖掘任务,同时采用多线程技术并发地执 行挖掘任务和任务中的步骤。
基于拉普拉斯机制的随机游走知识发现系统的优化研究

基于拉普拉斯机制的随机游走知识发现系统的优化研究作者:刘爱琴贾一帆来源:《新世纪图书馆》2021年第12期摘要文本聚類与知识获取所产生的知识发现系统需要更加快速、更加准确的算法支持,以满足用户知识需求准确性和关联性的不断增长。
论文基于随机游走知识发现系统,融合网络爬虫技术和学术资源网站结构化数据的特征,通过应用拉普拉斯机制,将所有图书馆文献通过关键词函数的设定和游走过程的通量化,确定图论下的拉普拉斯算子,对原有遍历所有文献节点并反复迭代完成聚类的运作模式添加游走终点判定,对其进行算法的优化,有效解决了随机游走知识发现系统的时间、空间复杂度过大的问题,增加了随机游走聚类的准确性。
关键词拉普拉斯机制随机游走模型知识发现系统分类号 G250.74DOI 10.16810/ki.1672-514X.2021.12.007Abstract With the increasing demand of user’s knowledge, the requirement of accuracy and relevance is higher and higher, the knowledge discovery system for text clustering and knowledge acquisition needs more fast and accurate algorithm support. Based on the random walk knowledge discovery system, this paper optimizes its algorithm: by using Laplace mechanism, all library documents are quantified by keyword function setting and walk process, the Laplace operator under graph theory is determined, and the accuracy of random walk clustering is increased by adding run end point judgment to the original operation mode of traversing all document nodes and increase the accuracy of random walk clustering.Keywords Laplace mechanism. Random walk model. Knowledge discovery system.0 引言用户知识需求的不断增加,要求获取信息的准确性和关联性越来越高,知识发现系统需要用高效的知识提取手段来解决用户的特定问题和满足用户日益增长的个性需求。
msf migrate命令原理

msf migrate命令原理
msf migrate命令是Metasploit框架中用于将恶意代码从一个
进程迁移到另一个进程的命令。
其原理涉及操作系统的进程管理和
内存分配。
当攻击者成功利用漏洞获得对目标系统的访问权限后,通常会
尝试将恶意代码注入到一个目标进程中,以便绕过防御机制并在目
标系统上持久地执行攻击。
然而,有些目标进程可能会受到保护或
者不够稳定,因此攻击者可能需要将恶意代码从一个进程迁移到另
一个进程,以确保攻击的持续性和成功性。
msf migrate命令通过利用操作系统提供的进程间通信机制
(如DLL注入、远程线程注入等)来实现进程迁移。
具体原理包括
以下几个步骤:
1. 选择目标进程,首先,攻击者需要选择一个合适的目标进程,通常会选择一个系统权限较高、稳定性较好的进程作为目标。
2. 注入恶意代码,msf migrate命令会将恶意代码注入到目标
进程的内存空间中,这通常涉及到操作系统的内存分配和权限管理。
3. 执行恶意代码,一旦恶意代码成功注入到目标进程中,msf migrate命令会触发目标进程执行恶意代码,从而实现进程迁移。
总的来说,msf migrate命令的原理是利用操作系统的进程管
理和内存分配机制,通过将恶意代码从一个进程迁移到另一个进程,来实现攻击的持久性和成功性。
这种技术在渗透测试和攻击中经常
被使用,因此对于安全人员来说也需要深入了解其原理和防御方法。
onnxruntime windows推理编译 -回复

onnxruntime windows推理编译-回复ONNX Runtime 是由微软开源的一个高性能的开源推理引擎。
它支持跨多个硬件平台的推理,并提供了一种简化模型部署和执行的方式。
对于Windows 平台,以下是一步一步的ONNX Runtime 推理编译过程。
第一步:安装ONNX Runtime在Windows 平台上运行ONNX Runtime 需要先安装相应的软件包。
从官方网站下载ONNX Runtime 的最新版本并按照官方文档提供的指南进行安装。
第二步:准备模型文件准备一个ONNX 模型文件,该文件包含了需要执行的计算图和相应的权重参数。
可以通过使用深度学习框架(如PyTorch, TensorFlow 等)训练好的模型,然后将其转换成ONNX 格式。
也可以从ONNX Model Zoo 获取一些已经训练好的模型来进行测试。
第三步:加载模型使用ONNX Runtime 提供的API 加载模型文件,并初始化一个推理会话。
这个推理会话将用于后续的推理操作。
第四步:配置硬件加速ONNX Runtime 支持多个硬件平台的加速。
可以通过配置运行时环境来选择合适的硬件加速选项。
例如,可以选择使用CUDA 或者OpenCL 来进行GPU 加速,或者选择使用特定的CPU 指令集(如AVX,AVX2 等)来进行CPU 加速。
具体的配置方式可以参考ONNX Runtime 的文档。
第五步:执行推理使用推理会话对象执行模型的推理操作。
可以根据模型的需求提供输入数据,并接收输出数据。
ONNX Runtime 提供了一系列的API 来方便进行输入和输出的设置。
第六步:释放资源在推理完成后,需要释放所有相关的资源,包括推理会话、输入输出张量等。
这样可以确保程序的正常退出,并避免内存泄漏等问题。
总结:ONNX Runtime 在Windows 平台上进行推理编译的过程可以分为:安装ONNX Runtime、准备模型文件、加载模型、配置硬件加速、执行推理以及释放资源。
多策略通用数据采掘工具MSMiner

多策略通用数据采掘工具MSMiner游湘涛;叶施仁;史忠植【期刊名称】《计算机研究与发展》【年(卷),期】2001(038)005【摘要】The design and implementation of MSMiner, a general multistrategy data mining tool, is proposed in this paper. MSMiner is founded on the basis of data warehouse, and integrated with several kinds of data mining algorithms, such as decision tree, association rule, statistical method, clustering, neural network and visualization. Also put forward is an object-oriented model to express and process metadata about data sources, algorithms and parameters, steps, tasks and users' information in data mining. The traits of MSMiner are the support of multiple data sources, i.e. data in database/warehouse, text and Web pages, the flexibility of the organization of data and mining strategies, and the powerful expandability of data mining algorithms and tasks.%介绍了一种多策略通用数据采掘工具MSMiner的设计与实现.MSMiner建立在数据仓库之上,采用面向对象的方法描述关于数据源、采掘算法、采掘步骤和用户的元数据.该系统集成决策树、关联规则、传统统计分析、聚类分析、神经网络和可视化等多种数据采掘算法,以任务模型的形式生成和执行数据采掘及决策支持任务.其特点是支持数据库、数据仓库、文本以及Web页面等形式数据源,可以动态地添加采掘算法,对数据和采掘策略的组织灵活有效,具有很好的可扩充性和通用性.【总页数】6页(P581-586)【作者】游湘涛;叶施仁;史忠植【作者单位】中国科学院计算技术研究所;中国科学院计算技术研究所;中国科学院计算技术研究所【正文语种】中文【中图分类】TP311.13【相关文献】1.规则型数据采掘工具集AMINER [J], 朱扬勇;周欣;施伯乐2.多策略数据挖掘平台MSMiner构建中若干问题的研究 [J], 王昌刚3.基于元数据驱动的多策略通用数据迁移模型 [J], 袁满;肖红凤4.一种多策略通用模式匹配方法 [J], 程伟;周龙骧;林河水;孙玉芳5.多策略数据挖掘平台MSMiner的元数据管理 [J], 秦亮曦;史忠植;刘少辉;黄友平;贾自艳;赵雷;李嘉佑因版权原因,仅展示原文概要,查看原文内容请购买。
MS中discovery模块

Discover模块(1)原子立场的分配:在使用 Discover 模块建立基于力场的计算中,涉及几个步骤。
主要有:选择力场、指定原子类型、计算或指定电荷、选择 non-bond cutoffs。
在这些步骤中,指定原子类型和计算电荷一般是自动执行的。
然而,在某些情形下需要手动指定原子类型。
原子定型使用预定义的规则对结构中的每个原子指定原子类型。
在为特定的系统确定能量和力时,定型原子使工作者能使用正确的力场参数。
通常,原子定型由 Discover 使用定型引擎的基本规则来自动执行,所以不需要手动原子定型。
然而,在特殊情形下,人们不得不手动定型原子,以确保它们被正确地设置。
①调出选择原子窗口;②选择原子窗口;③计算并显示原子类型;④编辑集合;⑤设定新集合;⑥给原子添加立场。
点击 Edit→Atom Selection;弹出对话框,从右边的的元素周期表中选择元素(例如Fe),再点 Select,此时所建晶胞中所有 Fe 原子都将被选中,原子被红色线圈住即表示原子被选中。
再编辑集合,点击 Edit→Edit Sets,弹出对话框,点击New,给原子集合设定一个名字,这里设置为Fe,则3D视图中会显示“Fe”字样。
再分配力场:在工具栏上点击discover 按钮,从下拉列表中选择set up,显示discover set up对话框,选择Typing选项卡,在 Forcefield types 里选择相应原子力场,再点 Assign(分配)按钮进行原子力场分配。
注意原子力场中的价态要与 Properties Project 里的原子价态(Formal charge)一致。
(2)体系立场的选择点击 Energy 选项卡,力场下拉菜单,进行力场选择。
力场的选择:力场是经典模拟计算的核心,因为它代表着结构中每种类型的原子与围绕着它的原子是如何相互作用的。
对系统中的每个原子,力场类型都被指定了,它描述了原子的局部环境。
nsenter用法

nsenter用法
nsenter 是一个用于进入 Linux 命名空间(namespace)的命令行工具。
命名空间是 Linux 内核中一种隔离和虚拟化资源的机制,允许在一个进程中创建一个独立的资源环境,如网络、进程、文件系统等。
nsenter 的基本用法如下:
nsenter [options] [program [arguments]]
其中:
options 是命令的选项。
program 是要执行的程序。
arguments 是要传递给程序的参数。
以下是一些常见的 nsenter 用法示例:
进入其他进程的 PID 命名空间:
nsenter --target <PID> --mount --uts --ipc --net --pid 这将使当前shell 进入到指定PID 的命名空间中,并包含了mount、uts、ipc、net 和 pid 命名空间。
通过进入已挂载的命名空间执行命令:
nsenter --target <PID> --mount --uts --ipc --net --pid command arguments
这会在指定 PID 的命名空间中执行给定的命令。
请注意,使用nsenter 需要具有足够的权限,通常需要root 或具有相应权限的用户才能进入其他进程的命名空间。
另外,具体的选项可能因 Linux 发行版和内核版本而有所不同,请查阅相应的文档以获取准确的信息。
nsenter 工作原理

nsenter是一个用于进入 Linux 命名空间的命令行工具。
Linux 命名空间是 Linux 内
核提供的一种资源隔离机制,允许将系统资源隔离开,使得不同的进程拥有独立的资源视图。
nsenter工具的主要作用是切换进程的命名空间,从而让当前的进程能够访问其他命名空间中的资源。
工作原理:
1.选择目标进程:使用nsenter命令时,首先需要指定一个目标进程的 PID。
这个目标进程通常是已经存在于目标命名空间中的一个进程。
2.选择命名空间:在进入命名空间之前,需要选择要进入的命名空间类型。
nsenter支持进入不同类型的命名空间,如进程命名空间、网络命名空间、挂
载命名空间等。
上述命令中的选项表示进入相应类型的命名空间。
3.进入命名空间:使用上述指定的目标进程和命名空间选项,nsenter将当前
进程切换到指定命名空间中。
如果需要执行一个命令并在新的命名空间中运行,可以使用--command选项,后面跟着要执行的命令。
示例:
注意事项:
▪nsenter需要在具有相应权限的情况下运行,通常需要 root 或具有CAP_SYS_ADMIN 权限的用户。
▪对于用户命名空间,可能需要额外的配置,因为用户命名空间中的用户映射需要进行匹配。
▪使用nsenter需要谨慎,确保了解目标命名空间的上下文和环境,以免对系统产生意外影响。
总体而言,nsenter是一个强大的工具,可以用于进入其他进程的命名空间,从而查看和操作其他命名空间中的资源,用于调试、管理和监控系统。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2010-8-1
史忠植 高级人工智能
38
数据挖掘集成工具:内嵌
决策树 SOM神经网络 粗糙集 关联规则
2010-8-1
史忠植 高级人工智能
39
决策树
2010-8-1
史忠植 高级人工智能
40
知识约简
知识约简——在保持知识库的分类或决策能力 不变的条件下,删除其中不相关或不重要知识 冗余知识——资源的浪费;干扰人们作出正确 而简洁的决策 Rough Set——把那些无法确认的个体都归属 于边界线区域,而这种边界线区域被定义为上 近似集和下近似集之差集(Z.Pawlak ) 知识约简是粗糙集的核心内容之一
数据挖掘集成工具:数据挖掘任务模型
DMTask = (V, R) V = {x | x ∈StepObjects} R = {<x, y> | P(x, y) ∧ x, y∈V} Step3 Step1 Step2 Step4 Step5
2010-8-1
史忠植 高级人工智能
32
数据挖掘集成工具:数据挖掘任务模型
产品数量 总价
星型模型
2010-8-1 史忠植 高级人工智能 27
OLAP
MOLAP, ROLAP, HOLAP OLAP 的操作
Slice (切片) Dice (切块) Roll up (上卷) Drill down (下钻) Pivot (旋转)
OLAP方案 采用了自主开发的 OLAP Server
2010-8-1 史忠植 高级人工智能 16
元数据:元数据库
2010-8-1
史忠植 高级人工智能
17
元数据:元数据对象模型
设计思路
一致性 完备性 易维护性
2010-8-1
史忠植 高级人工智能
18
元数据的结构
元数据是 层次的 嵌套的 封装的 互相联系的 采用面向对象的方法 共有60多个类
2010-8-1 史忠植 高级人工智能 19
数据仓库平台:结构
数据 OLAP 元 1 2 ... n 据 数
数据仓库
数据 数据 MSMiner数据仓库结构
2010-8-1 20
数据仓库平台:数据抽取和集成
数据的简单抽取和集成 数据的复杂处理 面向数据挖掘的数据预处理
2010-8-1
史忠植 高级人工智能
21
数据抽取和集成: MSETL
2010-8-1 史忠植 高级人工智能 33
数据挖掘集成工具:编辑任务模型
任务向导
2010-8-1
史忠植 高级人工智能
34
数据挖掘集成工具:编辑任务模型
任务编辑图板
2010-8-1
史忠植 高级人工智能
35
数据挖掘集成工具:处理任务模型
人机界面
规划器
主控模块
解释器
缓存
函数库
黑板
任务模型库
数据采掘任务处理引擎的结构
2010-8-1
史忠植 高级人工智能
47
数据挖掘集成工具:高级人工智能
48
MSMiner的应用:计算机选案
决策树选案
数据汇总表 定义样本模板 执行选案
样本数据表 训练样本数据
选案规则 选案结果分析
税务稽查计算机选案系统功能结构
2010-8-1 史忠植 高级人工智能 5
知识发现工具Intelligent Miner
IBM公司的Intelligent Miner具有典型数据 集自动生成,关联发现,序列规律发现, 概念性分类和可视化显示等功能.它可以 自动实现数据选择,数据转换,数据发掘 和结果显示.若有必要,对结果数据集还 可以重复这一过程,直至得到满意结果为 止.
2010-8-1 史忠植 高级人工智能 9
MSMiner的特点
提供决策树,支持向量机,粗糙集,模糊聚类,基于
范例推理,统计方法,神经计算等多种数据挖掘算法, 支持特征抽取,分类,聚类,预测,关联规则发现, 统计分析等数据挖掘功能,并支持高层次的决策分析 功能. 实现了可视化的任务编辑环境,以及功能强大的任务 处理引擎,能够快捷有效地实现各种数据转换和数据 挖掘任务. 可扩展性好.转换规则和挖掘算法是封装的,模块化 的,系统提供了一个开放的,灵活通用的接口,使用 户能够加入新的规则和算法. 容易进行二次开发.
2010-8-1 史忠植 高级人工智能 14
MSMiner体系结构
元 数 据 模 块 OLAP
OLE DB for ODBC
客户端
服务器端
MSMiner体系结构
2010-8-1 15
元数据的内容
关于外部数据源的 关于内部数据的(包括数据库,表,字段的信息) 关于数据仓库的(包括事实表,维表,立方以及 其它的中间表) 关于用户信息的 数据采掘算法(包括算法的参数信息) 关于采掘任务的(包括采掘步骤,每个步骤的所 用的参数)
2010-8-1
史忠植 高级人工智能
25
数据抽取和集成: MSETL
2010-8-1
史忠植 高级人工智能
26
数据仓库平台:数据仓库建模
产品维表 产品号 产品名称 产品目录 订货维表 订单号 订货日期 地区维表 地区名称 省别 事实表 产品号 客户号 订单号 时间标识 地区名称 客户维表 客户号 客户名称 客户地址 时间维表 时间标识 月 季度 年
2010-8-1
史忠植 高级人工智能
4
知识发现工具SAS(2)
SAS Enterprise Miner提供"抽样-探索-转换-建 模-评估"(SEMMA)的处理流程.数据挖掘算法有: 聚类分析,SOM/KOHONEN神经网络分类算法 关联模式/序列模式分析 多元回归模型 决策树模型(C45, CHAID, CART) 神经网络模型(MLP, RBF) SAS/STAT,SAS/ETS等模块提供的统计分析模型 和时间序列分析模型也可嵌入其中.
2010-8-1 史忠植 高级人工智能 7
数据挖掘工具: 公用系统
MLC++ Matlab Brute
2010-8-1
史忠植 高级人工智能
8
知识发现工具MSMiner
中科院计算技术研究所智能信息处理开放实验室开 发的MSMiner是一种多策略知识发现平台,能够提供 快捷有效的数据挖掘解决方案,提供多种知识发现方 法. MSMiner具有下列特点: .基于数据仓库和新型的元数据管理按照主题创建数 据仓库,并通过元数据进行管理和维护. .数据的抽取,转换,装载等预处理方便,支持OLAP 查询.
史忠植 高级人工智能
2010-8-1
41
Rough Set约简
2010-8-1
史忠植 高级人工智能
42
数据挖掘集成工具:外联
BP神经网络 统计分析 模糊聚类
超曲面分类 SVM 贝叶斯网络 基于范例推理(CBR) 隐马尔科夫模型(HMM)
2010-8-1
史忠植 高级人工智能
43
BP用于预测
2010-8-1
史忠植 高级人工智能
44
统计工具
线性回归模型 ——一元线性回归,多元线性回归,逐步回归 非线性回归模型——二次曲线,三次曲线,指数曲线, 幂指数曲线,生产函数等模型 确定型时间序列模型——指数平滑法,趋势移动平均 法(水平趋势,线性趋势和二次曲线趋势),成长曲 线模型(Compertz曲线,Logistic曲线和修正指数曲 线 ),季节指数法 随机型时间序列模型(自回归-移动平均模型ARMA) 相关分析
2010-8-1 史忠植 高级人工智能 28
数据立方体
2010-8-1
史忠植 高级人工智能
29
数据仓库平台:OLAP的实现
2010-8-1
史忠植 高级人工智能
30
数据挖掘集成工具:结构
元数据 任务模型库,算法描述 算法管理
任务编辑
任务规划 和执行 数据仓库平台
算法库
数据挖掘集成工具结构示意图
2010-8-1 史忠植 高级人工智能 31
知识发现 数据挖掘工具MSMiner
史忠植 中科院计算所
2010-8-1
史忠植 高级人工智能
1
主要内容
研究背景 MSMiner体系结构 元数据 数据仓库平台 数据采掘集成工具
2010-8-1
史忠植 高级人工智能
2
典型的知识发现系统(3)
SAS公司的SAS Enterprise Miner IBM公司的Intelligent Miner Solution公司的Clementine
MSETL系统作为MSMiner数据挖掘平台的一个
重要组成部分,主要完成从业务数据源到分析 数据源的转换功能.具体包括从异质业务数据 源中抽取需要的数据,对这些数据进行多种预 处理,把经过处理后的数据装载入指定数据仓 库/数据库
史忠植 高级人工智能
2010-8-1
22
数据抽取和集成: MSETL
步骤对象BNF语法定义: <StepObject> ::= <Attribute_List>;<Method_List> <Attribute_List> ::= [<Attribute>|<Attribute>;<Attribute_List>] <Attribute> ::= <Name>,<Value> <Method_List> ::= [<Method>|<Method>;<Method_List>] <Method> ::= <Name>,<Script> <Name> ::= [<char>|<string>] <Value> ::= [<char>|<string>|<integer>|<float>] <Script> ::= <DML_Sentence>*