10练习题解答:第十章 交互分类与卡方检验
2018年4月高等教育自学考试教育统计与测量真题_真题(含答案与解析)-交互

2018年4月高等教育自学考试教育统计与测量真题(总分0, 做题时间150分钟)单项选择题心理测量跟物理测量相比,其突出差异之处是()。
SSS_SINGLE_SELA直接性B客观性C全面性D间接性该题您未回答:х该问题分值: 0答案:D物理测量是对物理属性的直接测量;心理测量是对心理特质的间接测量。
(2)测量工具:物理测量的工具制作相对简单,精确度高;心理测量的工具是量表,材料组织不易,制作困难。
(3)重复测量:物理测量可以进行并且很容易进行重复测量;心理测量进行重复测量相对比较困难,有时可能做不到。
(4)使用者:物理测量的使用者培训较为容易;心理测量的使用者需要经过专业培训,且有职业道德要求。
(5)误差:物理测量存在误差,但可对误差进行精确估计;心理测量的误差来源难以确认,对误差的估计没有那么精确。
(6)单位与参照点:物理测量的单位与参照点是公认的;心理测量没有零点,评价分数要与平均数或常模比较,单位不可互换。
心理测量跟物理测量相比,其突出差异之处是间接性。
下列数据中,属于顺序变量数据的是()。
SSS_SINGLE_SELA某项能力测试得6分B月工资3000元C羽毛球比赛得第2名D数学成绩为80分该题您未回答:х该问题分值: 0只说明某一事物与其他事物在属性上的不同或类别上的差异,它具有独立的分类单位,数值一般都是整数形式,只计算个数,并不说明事物之间差异的大小。
不能进行加、减、乘、除运算,只可对每一类别计算次数或个数。
顺序变量亦称“等级变量”,百分等级数值。
心理变量的一种。
其值仅表明事物属性在数量大小、多少上的次序的变量。
可通过顺序量表观测。
其各个数值之间的距离不一定相等,也没有一定的比例关系。
等距变量一译“定距变量”。
变量的一种。
既有测量单位、相对零点的变量。
其取值之间有“相等”、“不等”、“序”及“距离”的关系,数值间可施行加、减法两种运算。
比率变量是具有相等单位和绝对零点的变量,例如身高、体重等。
卡方检验及交互分析-Excel计算实例
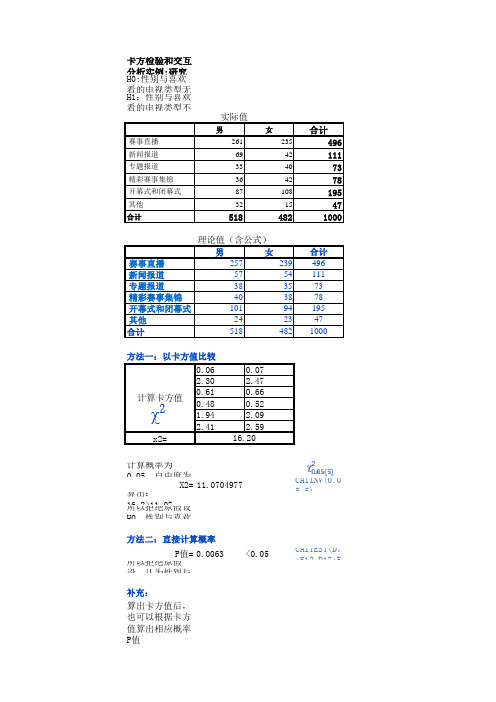
0.07 2.47 0.66 0.52 2.09 2.59 16.20
计算概率为
0.05,自由度为
算出:
X2= 11.0704977
1所6以.2拒>1绝1.原07假设
H0,性别与喜欢
方法二:直接计算概率
P值= 0.0063 所以拒绝原假 设,认为性别与
<0.05
补充:
算出卡方值后, 也可以根据卡方 值算出相应概率 P值
1000
理论值(含公式)
男
女
赛事直播
257
239
新闻报道
57
54
专题报道
38
35
精彩赛事集锦
40
38
开幕式和闭幕式
101
94
其他
24
23
合计
Hale Waihona Puke 518482合计 496 111 73 78 195 47 1000
方法一:以卡方值比较
计算卡方值
0.06 2.30 0.61 0.48 1.94
2.41
x2=
卡方检验和交互 分析实例:研究 H0:性别与喜欢 看的电视类型无 H1:性别与喜欢 看的电视类型不
赛事直播 新闻报道 专题报道 精彩赛事集锦 开幕式和闭幕式 其他 合计
实际值
男 261 69 33 36 87 32
518
女 235 42 40 42 108 15
482
合计 496 111 73 78 195 47
CHIINV(0.0 5,5)
CHITEST(D7 :E12,D17:E
P值=
0.0063
CHIDIST(16 .2,5)
《统计学》课后练习题答案

3.4统计图的规范
3.5如何用Excel做统计图
习题
一、单项选择题
1.统计表的结构从形式上看包括()、横行标题、纵栏标题、数字资料四个部分。(知识点3.1答案:D)
A.计量单位B.附录C.指标注释D.总标题
2.如果统计表中数据的单位都一致,我们可以把单位填写在()。(知识点3.1答案:C)
A.指标B.标志C.变量D.标志值
8.以一、二、三等品来衡量产品质地的优劣,那么该产品等级是()。(知识点:1.7答案:A)
A.品质标志B.数量标志C.质量指标D.数量指标
9.()表示事物的质的特征,是不能以数值表示的。(知识点:1.7答案:A)
A.品质标志B.数量标志C.质量指标D.数量指标
10.在出勤率、废品量、劳动生产率、商品流通费用额和人均粮食生产量五个指标中,属于数量指标的有几个()。(知识点:1.7答案:B)
1.统计调查方案的主要内容是( )( )( )( )( )。(知识点2.2答案:ABCDE)
A.调查的目的B.调查对象C.调查单位D.调查时间E.调查项目
2.全国工业普查中( )( )( )( )( )。(知识点2.2答案:ABCE)
A.所有工业企业是调查对象B.每一个工业企业是调查单位C.每一个工业企业是报告单位
频数f
(棵)
频率
(%)
向上累积
向下累积
频数(棵)
频率(%)
频数(棵)
频率(%)
80-90
8
7.3
8
7.3
110
100.0
90-100
9
8.2
17
15.5
102
92.7
100-110
10练习题解答:第十章交互分类与卡方检验
第十章交互分类与F检验练习题:1.为了研究婆媳分居对于婆媳关系的影响,在某地随机抽取了180个家庭,调查结果如下表所示:表10-26(1)计算变量X与Y的边际和(即边缘和)F x和F Y并填入上表。
(2)请根据表10-26的数据完成下面的联合分布的交互分类表。
表10-27(3)根据表10-27指出关于X的边缘分布和关于Y的边缘分布。
(4)根据表10-27指出关于X的条件分布和关于Y的条件分布。
解:(1)Fy(从上到下):50: 30: 100.竹(从左到右): 115: 65.(2) P n=15/180: P.35/1S0: ^.50/180:%P:c=20/180; P产 10/180:=30/180:5P沪80/180; P沪20/180:市二100/180:Fx\ Fx?N =115/180:=65/180.(3关于y的条件分布有两个:X2.一名社会学家关于“利他主义”的研究中,对被调查者的宗教信仰情况进行了分析,得到的结果如下表所示:表10-28(1)根据表10-28的观察频次,计算每一个单元格的期望频次并填入表10-29。
(3)若要对有无宗教信仰的人的利他主义程度有无显著性差异进行检验,请陈述研究假设0和虚无假设H{) o(4)本题口中的自山度为多少若显著性水平为,请查附录的才分布表, 找出相对应的临界值。
并判断有无宗教信仰的人的利他主义程度有无显著性差异。
(5)若变量“宗教信仰”和“利他主义程度”存在相关关系,请计算C系数。
解:(1)"信教” 一列(从上到下):,,9X,85 =61.67:357125X185 =64.78;357,,3X185=58.56.357'‘不信教” 一列(从上到下):1,9X172 =57.33:357EG"©:357(2)“2 _匸(亢一人)2力一乙r -_ (90-61.67)1 2 (60-64.78)2 (35-5S.56)2 (29—57.33)2 (65-60.22)2(7S-54.44)2=~6L671 6478 1 5^561 5733 1 602215444~=47.42(3)总体中有无宗教信仰的人的利他主义程度有显著性差异。
《统计分析与SPSS的应用(第五版)》课后练习答案

《统计分析与SPSS的应用(第五版)》课后练习答案第一章练习题答案1、SPSS的中文全名是:社会科学统计软件包(后改名为:统计产品与服务解决方案)英文全名是:Statistical Package for the Social Science.(Statistical Product and Service Solutions)2、SPSS的两个主要窗口是数据编辑器窗口和结果查看器窗口。
●数据编辑器窗口的主要功能是定义SPSS数据的结构、录入编辑和管理待分析的数据;●结果查看器窗口的主要功能是现实管理SPSS统计分析结果、报表及图形。
3、SPSS的数据集:●SPSS运行时可同时打开多个数据编辑器窗口。
每个数据编辑器窗口分别显示不同的数据集合(简称数据集)。
●活动数据集:其中只有一个数据集为当前数据集。
SPSS只对某时刻的当前数据集中的数据进行分析。
4、SPSS的三种基本运行方式:●完全窗口菜单方式、程序运行方式、混合运行方式。
●完全窗口菜单方式:是指在使用SPSS的过程中,所有的分析操作都通过菜单、按钮、输入对话框等方式来完成,是一种最常见和最普遍的使用方式,最大优点是简洁和直观。
●程序运行方式:是指在使用SPSS的过程中,统计分析人员根据自己的需要,手工编写SPSS命令程序,然后将编写好的程序一次性提交给计算机执行。
该方式适用于大规模的统计分析工作。
●混合运行方式:是前两者的综合。
5、.sav是数据编辑器窗口中的SPSS数据文件的扩展名.spv是结果查看器窗口中的SPSS分析结果文件的扩展名.sps是语法窗口中的SPSS程序6、SPSS的数据加工和管理功能主要集中在编辑、数据等菜单中;统计分析和绘图功能主要集中在分析、图形等菜单中。
7、概率抽样(probability sampling):也称随机抽样,是指按一定的概率以随机原则抽取样本,抽取样本时每个单位都有一定的机会被抽中,每个单位被抽中的概率是已知的,或是可以计算出来的。
方差分析卡方检验练习题
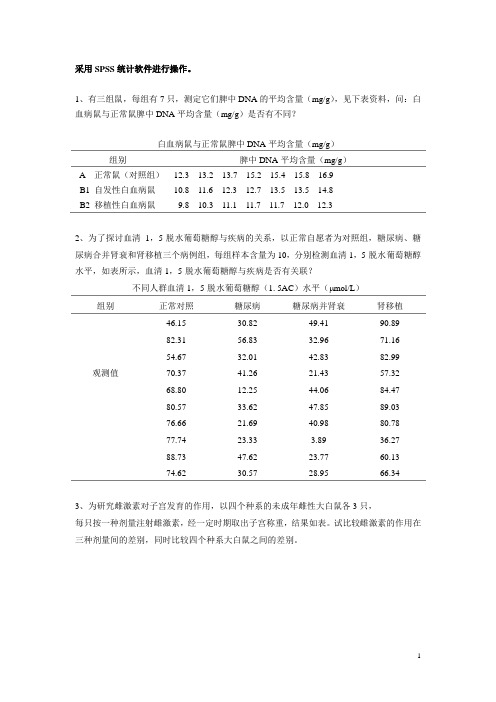
采用SPSS统计软件进行操作。
1、有三组鼠,每组有7只,测定它们脾中DNA的平均含量(mg/g),见下表资料,问:白血病鼠与正常鼠脾中DNA平均含量(mg/g)是否有不同?白血病鼠与正常鼠脾中DNA平均含量(mg/g)组别脾中DNA平均含量(mg/g)A 正常鼠(对照组)B1 自发性白血病鼠B2 移植性白血病鼠12.3 13.2 13.7 15.2 15.4 15.8 16.9 10.8 11.6 12.3 12.7 13.5 13.5 14.8 9.8 10.3 11.1 11.7 11.7 12.0 12.32、为了探讨血清1,5-脱水葡萄糖醇与疾病的关系,以正常自愿者为对照组,糖尿病、糖尿病合并肾衰和肾移植三个病例组,每组样本含量为10,分别检测血清1,5-脱水葡萄糖醇水平,如表所示,血清1,5-脱水葡萄糖醇与疾病是否有关联?不同人群血清1,5-脱水葡萄糖醇(1. 5AC)水平( mol/L)组别正常对照糖尿病糖尿病并肾衰肾移植观测值46.15 30.82 49.41 90.89 82.31 56.83 32.96 71.16 54.67 32.01 42.83 82.99 70.37 41.26 21.43 57.32 68.80 12.25 44.06 84.47 80.57 33.62 47.85 89.0376.66 21.69 40.98 80.7877.74 23.33 3.89 36.27 88.73 47.62 23.77 60.13 74.62 30.57 28.95 66.343、为研究雌激素对子宫发育的作用,以四个种系的未成年雌性大白鼠各3只,每只按一种剂量注射雌激素,经一定时期取出子宫称重,结果如表。
试比较雌激素的作用在三种剂量间的差别,同时比较四个种系大白鼠之间的差别。
雌激素对大白鼠子宫(重量g)的作用大白鼠种系雌激素剂量( g/100g)0.2 0.4 0.8甲106 116 145乙42 68 115丙70 111 133丁42 63 874、为研究胃癌与胃黏膜细胞中DNA含量(A.U)的关系,某医师测得数据如表,试问四组人群的胃黏膜细胞中DNA含量是否相同?四组人群的胃黏膜细胞中DNA含量(A.U)组别DNA含量(A.U)正常人11.9 13.4 9.0 10.7 13.7 12.2 12.8胃黏膜增生13.9 17.2 16.5 14.7 14.6 13.0 12.0 16.4 14.1早期胃癌20.3 17.8 23.4 17.1 32.2 20.6 23.5 13.4 27.2晚期胃癌25.1 28.6 27.2 22.9 19.9 23.9 23.1 21.1 15.6 19.4 18.8 16.45、某医师为研究脾切除手术过程中门静脉压力(kPa)的变化,测得数据表,请作统计分析。
第10章 交互表和 χ2检验

第一节 交互分类和交互分类表
一、交互分类作用
• 交互分类——调查所得的一组数据按照两个不同变量进行 综合的分类 • 交互分类表又叫列联表 • 适用于定类变量和定序变量
交互分类表的作用
对变量之间的关系进行分析和解释 表10-3和10-4 性别对流动意愿有影响 分组比较
第三节 关系强度测定
样本量足够大,很小的分布差也有可能有 显著性差异,因此对于大样本来说,关键 是要确定当变量之间存在关系时,其关系 强度大小 Φ系数和Q系数 V系数 C系数
Φ 系数和Q系数
二维表
Y1 Y2
X1 a c
X2 b d
若X和Y独立,则a/(a+b)= c/(c+d),即ad=bc
4. 做信教情况X利他主义程度的频数分布的 交互分类表 5.做信教情况X利他主义程度的频率分布的 交互分类表(联合分布,条件分布) 6.信教情况和利他主义程度之间是否相关? 相关性有多强?用SPSS完成 7. 请分对信教情况X利他主义做频率分布的 交互分类表 8.不同性别的人群,信教情况和利他主义程 度之间是否相关?相关性有多强?用SPSS 完成
需在建库的时候在data editor的Varialbe view的 “values”规定数字代表什么
卡方检验目的
对流行音乐的态度和年龄是否相关 H1:相关;H0:无关 χ2≥ χ2界值,拒绝H0 或P≤ ,拒绝H0 关系强度测定:列联系数,V系数等
2 ( f e ) 2 0 df (r-1)(c 1) e
小样本也可改用Fisher精确概率算法,略
2019年4月高等教育自学考试护理学研究真题_真题(含答案与解析)-交互

2019年4月高等教育自学考试护理学研究真题(总分100, 做题时间150分钟)单项选择题通过科学的方法系统地探究现存的或产生新的知识从而直接或间接地指导护理实践的活动过程,称为()。
SSS_SINGLE_SELA护理评估B护理研究C护理计划D护理理论分值: 1答案:B护理研究是指通过科学的方法有系统地探究现存的或产生新的知识从而以直接或间接地指导护理实践的活动过程。
研究者应告知研究对象整个研究的所有事宜,研究对象有权决定是否参加研究,并有权决定在任何时候都有权终止参与,并且不受到治疗和护理上的任何惩罚和歧视,这是研究对象的()。
SSS_SINGLE_SELA免于遭受伤害或不适的权利B不被剥削或利用的权利C自主决定权D充分认知的权利分值: 1答案:C自主决定权:指在研究中,研究对象是自主个体,研究者应告知整个研究的所有事宜,研究对象有权决定是否参加研究,并有权决定在任何时候都有权终止参与,并且不受到治疗和护理上的任何惩罚和歧视。
“中西医结合治疗结石病的疗效观察”这一科研选题存在的最主要问题是()。
SSS_SINGLE_SELA范围过小B不够明确C过于具体D不够深入分值: 1答案:B可经测量取得数值,多有度量衡单位,如身高(cm)、体重(kg)等,此类资料为()。
SSS_SINGLE_SELA分类变量B数值变量C计数资料D等级资料分值: 1答案:B数值变量:其变量值是定量的,表现为数值大小,可经测量取得数值,多有度量衡单位。
如身高(cm)、体重(b)、血压(mmHg、kPa)、脉搏(次/min)和白细胞计数等。
“自杀率与社会凝聚力成反比”这一研究假设的不足是()。
SSS_SINGLE_SELA不清晰B不具体C不容易被验证D不可以测量分值: 1答案:C“自杀率与社会凝聚力成反比”这个假设清晰、具体,但是不容易被验证。
此假设具有两个变量:“自杀率”及“社会凝聚力”,变量间关系是“反比”,找出自杀率,以及确定关系成反比,相对而言都较容易,但是确定社会凝聚力却是一个比较困难的问题。
北语2024春季《SPSS应用统计分析》作业满分解答

北语2024春季《SPSS应用统计分析》作业满分解答1. 描述统计分析1.1 数据录入首先,将数据导入SPSS中。
可以通过“文件”菜单中的“打开”选项,选择相应的数据文件进行导入。
1.2 基本描述性统计使用“描述统计”功能,可以得到各变量的均值、标准差、最小值、最大值等基本描述性统计量。
1.3 频数分布与交叉表分析通过“频数分布”功能,可以得到各变量的频数分布情况。
而交叉表分析则可以用于分析两个或多个变量之间的关系。
2. 假设检验2.1 单样本t检验当要比较一个样本均值与总体均值是否有显著差异时,可以使用单样本t检验。
在SPSS中,选择“假设检验”->“t检验”->“单样本t检验”,然后输入相应的样本数据和总体均值。
2.2 独立样本t检验当要比较两个独立样本的均值是否有显著差异时,可以使用独立样本t检验。
在SPSS中,选择“假设检验”->“t检验”->“独立样本t检验”,然后输入两个样本的数据。
2.3 配对样本t检验当要比较两个相关样本的均值是否有显著差异时,可以使用配对样本t检验。
在SPSS中,选择“假设检验”->“t检验”->“配对样本t检验”,然后输入两个相关样本的数据。
2.4 方差分析(ANOVA)当要比较三个或以上样本的均值是否有显著差异时,可以使用方差分析。
在SPSS中,选择“假设检验”->“方差分析”->“单因素方差分析”,然后输入各样本的数据。
2.5 卡方检验当要分析分类变量之间的关系时,可以使用卡方检验。
在SPSS中,选择“假设检验”->“非参数检验”->“卡方检验”,然后输入各分类变量的数据。
3. 回归分析3.1 一元线性回归当要分析一个自变量和一个因变量之间的线性关系时,可以使用一元线性回归。
在SPSS中,选择“回归”->“线性回归”->“估计”,然后输入自变量和因变量的数据。
3.2 多元线性回归当要分析两个或以上自变量和一个因变量之间的线性关系时,可以使用多元线性回归。
最新国家开放大学电大《社会统计学》期末题库及答案

最新国家开放大学电大《社会统计学》期末题库及答案考试说明:本人针对该科精心汇总了历年题库及答案,形成一个完整的题库,并且每年都在更新。
该题库对考生的复习、作业和考试起着非常重要的作用,会给您节省大量的时间。
做考题时,利用本文档中的查找工具,把考题中的关键字输到查找工具的查找内容框内,就可迅速查找到该题答案。
本文库还有其他网核及教学考一体化答案,敬请查看。
《社会统计学》题库及答案一一、单项选择题(每题只有一个正确答案,请将正确答案的字母填写在括号内。
每题2分,共20分)1.某班级有100名学生,为了了解学生消费水平,将所有学生按照学习成绩排序后,在前十名学生中随机抽出成绩为第3名的学生,后面以10为间隔依次选出第13、23、33、43、53、63、73、83、93九名同学进行调查。
这种调查方法属于( )。
A.简单随机抽样 B.整群抽样C.分层抽样 D.系统抽样2.以下关于因变量与自变量的表述不正确的是( )。
A.自变量是引起其他变量变化的变量B.因变量是由于其他变量的变化而导致自身发生变化的变量C.自变量的变化是以因变量的变化为前提D.因变量的变化不以自变量的变化为前提3.某地区2001- 2010年人口总量(单位:万人)分别为98,102,103,106,108,109,110,111,114,115,下列哪种图形最适合描述这些数据?( )A.茎叶图 B.环形图C.饼图 D.线图4.以下关于条形图的表述,不正确的是( )。
A.条形图中条形的宽度是固定的B.条形图中条形的长度(或高度)表示各类别频数的多少C.条形图的矩形通常是紧密排列的D.条形图通常是适用于所有类型数据5.某校期末考试,全校语文平均成绩为80分,标准差为3分,数学平均成绩为87分,标准差为5分。
某学生语文得了83分,数学得了97分,从相对名次的角度看,该生( )的成绩考得更好。
A.数学 B.语文c.两门课程一样 D.无法判断6.有甲、乙两人同时打靶,各打10靶,甲平均每靶为8环,标准差为2;乙平均每靶9环,标准差为3,以下关于甲、乙两人打靶的稳定性水平表述正确的是( )。
组织诊断模型-方法和流程

影响力
可执行性
低
团队激励
难
易
可执行性
• 此方案是否能在合理的时间内实现? • 组织是否具备实行此方案的资源?
对冒险者支付较高薪酬 弹性福利
202X年落地计划
企业文化项目落地计划
项目时间规划/月
项目
配套的落地项目
描述
3 4 5 6 7 8 9 10 11 12
组织能力
梳理支撑战略目标的核心组织能力
用户第一:将用户价值导入组织绩效关键指标
康
康
持
信
度
度
度
心
指
数
整体调研结果
以下表格中呈现的是员工对于组织能力调研问卷在互联网行业中分位值最高&分
位数最低的5道题。
一级维度 二级维度 题目
认同度
认同率高 员工思维维度 文化价值观
我认同公司的核心价值观和行为准则
员工思维维度 文化价值观
公司有清晰的核心价值观和行为准则
敬业指数维度 认同
我对公司未来的发展前景有信心
• 企业组织内部人 力资源的考核绩 效体系的完善 性,人员在管理 和其他技能方面 的发挥情况以及 企业对人员的职 业发展规划及激 励机制等方面地 做法等信息
组织诊断方法源于分析——四大分析
职能分析 (业务分析)
决策分析
关系分析
运行分析
(1)企业需要增加那些职能?企业需要减少那些职能?企业需要合并那些职能? 企业需要合并那些职能? (2)确定企业的关键职能,即对企业实现战略目标有关键作用的职能。 (3)分析职能的性质和类别。这里所说的职能指的是产生成果的职能、支援职能 和附属职能。
目梦标想企加业
25分位
配对四格表卡方检验例题

配对四格表卡方检验例题配对四格表卡方检验例题背景介绍配对四格表是一种常见的统计分析方法,用于比较两个分类变量之间的关系。
卡方检验是基于配对四格表的统计方法,用于判断两个分类变量之间是否存在显著关系。
本文将以例题的形式介绍配对四格表卡方检验的步骤和应用。
例题描述假设我们有一组数据,研究了食物种类和消化不良的关系。
我们记录了100个人的饮食习惯和是否有消化不良的情况。
数据如下:| 有消化不良 | 无消化不良 || | |热辣食物 | 30 | 20 |酸味食物 | 10 | 40 |现在我们想要判断食物种类和消化不良之间是否存在显著关系。
步骤一:设置假设我们首先需要设置原假设和备择假设。
在本例中,假设食物种类和消化不良之间是独立的,即两者没有关系。
设置假设如下:•原假设(H0):食物种类和消化不良之间独立。
•备择假设(H1):食物种类和消化不良之间存在关系。
步骤二:计算期望频数根据原假设的设置,我们可以通过计算期望频数来判断观察频数和期望频数之间的差异。
期望频数的计算公式为:期望频数 = (行总和 * 列总和) / 总样本数根据上述公式,我们可以计算得到期望频数如下:| 有消化不良 | 无消化不良 | 行总和 | | | | —— |热辣食物 | 25 | 25 | 50 |酸味食物 | 15 | 35 | 50 |列总和 | 40 | 60 | |步骤三:计算卡方值根据观察频数和期望频数的差异,我们可以计算卡方值来判断两个分类变量之间的关系。
卡方值的计算公式为:卡方值 = sum((观察频数 - 期望频数)^2 / 期望频数)根据上述公式,我们可以计算得到卡方值如下:卡方值 = (30 - 25)^2 / 25 + (20 - 25)^2 / 25 + (10 - 15)^2 / 15 + (40 - 35)^2 / 35 ≈步骤四:查表判断根据卡方值和自由度,我们可以查表来判断卡方值的显著性。
在本例中,自由度为1(df = (行数 - 1) * (列数 - 1) = 1 * 1 = 1),我们选择显著性水平为。
东北大学“工商管理”《应用统计X》23秋期末试题库含答案版

东北大学“工商管理”《应用统计X》23秋期末试题库含答案第1卷一.综合考核(共20题)1.卡方分析主要用来分析:()A.无法确定B.两个顺序变量之间的关系C.两个数值变量之间的关系D.两个分类变量之间的关系2.下列哪种图形不是用来表示数值变量的?()A.饼图B.直方图C.盒形图D.点线图3.列联表又称交互分类表,所谓交互分类,是指同时依据两个变量的值,将所研究的个案分类。
交互分类的目的是将两变量分组,然后比较各组的分布状况,以寻找变量间的关系。
()A.正确B.错误4.抛一个质量均匀的硬币,其正面向上的概率为1/2,因此在抛这个硬币100次时,不可能出现没有正面向上的情况。
()A.正确B.错误5.如果观察值有偶数个,通常取最中间的两个数值的平均数作为中位数。
()A.正确B.错误6.方差分析中,F统计量是由下面哪两个统计量相比得到的?()A.自变量平方和B.残差平方和C.平均自变量平方和D.平均残差变量平方和7.月收入属于()A.分类变量B.顺序变量C.数值型变量D.定比变量8.某厂生产的化纤纤度服从正态分布N(μ,σ²)。
现测得25根纤维的纤度的均值为1.39,如果要检验这些纤维的纤度与原设计的标准值1.40有无显著差异,则合理的零假设与备择假设应为:()A.H₀:μ≠1.40﹔H₁:μ=1.40B.H₀:μ≤1.40﹔H₁:μ>1.40C.H₀:μ≥1.40﹔H₁:μD.H₀:μ=1.40﹔H₁:μ≠1.409.下四分位数在数据中所处的位置是:()A.80%B.50%C.40%D.25%10.假设检验所依据的原则是小概率事件在一次试验中不应该发生。
()A.正确B.错误11.在关于比例的检验问题中,如果收集到的样本容量不太大时(不超过30),应该使用()计算有关的p-值A.二项分布B.t变量C.F变量D.z变量12.13.14.关于标准正态分布曲线下列说法正确的是:()A.关于直线x=0对称B.关于直线x=1对称C.是一个钟型曲线D.曲线下面的面积等于115.当样本量不大,并想快速收集整理信息时,此时适合用的图形是:()A.饼图B.直方图C.茎叶图D.盒形图16.一组人员每星期服用三次阿司匹林(样本1),另一组人员在相同的时间服用安慰剂(样本2)持续3年之后进行检测,样本1中有104人患心脏病,样本2中有189人患心脏病。
临床数学试题及答案详解

临床数学试题及答案详解一、单项选择题(每题2分,共20分)1. 在临床研究中,以下哪种统计方法适用于比较两个独立样本的均值差异?A. t检验B. 卡方检验C. 方差分析D. 相关分析答案:A2. 以下哪种情况下,使用配对t检验是合适的?A. 比较两个独立样本的均值B. 比较两个相关样本的均值C. 比较多个独立样本的均值D. 比较多个相关样本的均值答案:B3. 在描述数据集中趋势的统计量中,中位数和众数的主要区别是什么?A. 中位数是数据排序后中间的值,众数是出现次数最多的值B. 中位数是平均值,众数是数据排序后中间的值C. 中位数是数据排序后中间的值,众数是平均值D. 中位数和众数都是出现次数最多的值答案:A4. 以下哪种统计图最适合展示分类数据的分布情况?A. 散点图B. 条形图C. 折线图D. 直方图答案:B5. 以下哪种统计量用于衡量数据的离散程度?A. 平均值B. 中位数C. 标准差D. 众数答案:C6. 在回归分析中,以下哪个指标用于衡量模型的拟合优度?A. R平方B. 均方误差C. 标准差D. 相关系数答案:A7. 以下哪种检验用于评估两个分类变量之间的关联性?A. t检验B. 卡方检验C. 方差分析D. 相关分析答案:B8. 在临床试验中,以下哪种方法用于控制混杂变量的影响?A. 随机化B. 匹配C. 多变量分析D. 所有选项答案:D9. 以下哪种统计方法用于比较三个或更多独立样本的均值差异?A. t检验B. 配对t检验C. 方差分析D. 相关分析答案:C10. 在生存分析中,Kaplan-Meier曲线用于估计什么?A. 均值B. 中位数C. 生存概率D. 标准差答案:C二、多项选择题(每题3分,共15分)11. 在临床研究中,以下哪些因素可能影响样本量的确定?A. 效应大小B. 显著性水平C. 检验效能D. 研究成本答案:ABCD12. 以下哪些统计图可以用于展示变量之间的关系?A. 散点图B. 条形图C. 折线图D. 箱线图答案:AC13. 在描述数据分布的形状时,以下哪些统计量是有用的?A. 偏度B. 峰度C. 平均值D. 中位数答案:AB14. 以下哪些检验用于比较两个独立样本的比例?A. t检验B. 卡方检验C. Fisher精确检验D. 方差分析答案:BC15. 在多元回归分析中,以下哪些因素可能导致多重共线性问题?A. 两个或多个自变量高度相关B. 自变量的数量多于样本量C. 自变量之间存在线性关系D. 样本量过小答案:ABC三、填空题(每题2分,共20分)16. 在临床研究中,样本量计算的目的是为了确保研究具有足够的________来检测效应。
专题7 交叉分类和卡方检验

专题7 交叉分类(列联表)和卡方检验(本专题较深入的理论和分析可参考Bishop等的《离散多元分析》)(各部分较浅显、直观的说明可参考的资料在各部分列出)变量的测度交叉分类问题Crosstabs过程变量的测度注:1、这里是按测度由低级到高级排列的,高级测度的变量可以看作或转化为低级测度的变量。
2、SPSS中变量定义时,没有Interval Measure,只有ScaleMeasure。
3、社科研究中常常将不专门列出定比变量这一类,而将其包含在定距变量中。
返回交叉分类问题比较和对照是进行科学研究的基本手段。
对于间距测度和比例测度的资料,进行分组比较时可以用均数检验、方差分析等方法。
对于有较多可取值的序次测度资料,进行分组比较时可以用各种秩和检验方法。
而对于名义测度的资料、有序分类所得的资料(也属序次测度),分组比较时需用交叉分类进行统计描述,交叉分类所得的表格称为“列联表”,统计推断(检验)则要使用列联表分析的方法------卡方检验。
卡方分析是用来研究两个定类变量间是否独立即是否存在某种关联性的最常用的方法。
例:按“性别”和“肥胖程度”交叉分类所得列联表如下:肥胖程度性别不肥胖轻度肥胖中/重度肥胖Total 男19 9 15 43女49 14 43 106Total 68 23 58 149这里是按两个变量交叉分类的,该列联表称为两维列联表,若按3个变量交叉分类,所得的列联表称为3维列联表,依次类推。
3维及以上的列联表通常称为“多维列联表”或“高维列联表”,而一维列联表就是频数分布表。
卡方分析的方法:假设两个变量是相互独立,互不关联的。
这在统计上称为原假设;对于调查中得到的两个变量的数据,用一个表格的形式来表示它们的分布(频数和百分数),这里的频数叫观测频数,这种表格叫列联表;如果原假设成立,在这个前提下,可以计算出上面列联表中每个格子里的频数应该是多少,这叫期望频数;比较观测频数与期望频数的差,如果两者的差越大,表明实际情况与原假设相去甚远;差越小,表明实际情况与原假设越相近。
统计学教案习题08卡方检验

第八章 2χ检验一、教学大纲要求(一) 掌握内容 1. 2χ检验的用途。
2. 四格表的2χ检验。
(1) 四格表2χ检验公式的应用条件; (2) 不满足应用条件时的解决办法; (3) 配对四格表的2χ检验。
3. 行⨯列表的2χ检验。
(二) 熟悉内容频数分布拟合优度的2χ检验。
(三) 了解内容 1.2χ分布的图形。
2.四格表的确切概率法。
二、教学内容精要(一)2χ检验的用途2χ检验(Chi-square test )用途较广,主要用途如下:1.推断两个率及多个总体率或总体构成比之间有无差别 2.两种属性或两个变量之间有无关联性 3.频数分布的拟合优度检验 (二)2χ检验的基本思想1.2χ检验的基本思想是以2χ值的大小来反映理论频数与实际频数的吻合程度。
在零假设0H (比如0H :21ππ=)成立的条件下,实际频数与理论频数相差不应该很大,即2χ值不应该很大,若实际计算出的2χ值较大,超过了设定的检验水准所对应的界值,则有理由怀疑0H 的真实性,从而拒绝0H ,接受H 1(比如1H :21ππ≠)。
2. 基本公式:()∑-=TT A 22χ,A 为实际频数(Actual Frequency ),T 为理论频数(Theoretical Frequency )。
四格表2χ检验的专用公式正是由此公式推导出来的,用专用公式与用基本公式计算出的2χ值是一致的。
(三)率的抽样误差与可信区间 1.率的抽样误差与标准误样本率与总体率之间存在抽样误差,其度量方法: np )1(ππσ-=,π为总体率,或 (8-1)np p S p )1(-=, p 为样本率; (8-2) 2.总体率的可信区间当n 足够大,且p 和1-p 均不太小,p 的抽样分布逼近正态分布。
总体率的可信区间:(p p S u p S u p ⨯+⨯-2/2/,αα)。
(8-3) (四)2χ检验的基本计算表8-12检验的用途、假设的设立及基本计算公式01四格表①独立资料两样本率的比较②配对资料两 样本率的比较0H :两总体率相等 1H :两总体率不等①专用公式)(22nbc ad -=χ 1②当n ≥40但1≤T<5时,校正公式))()()(()2/(22d b c a d c b a n n bc ad ++++--=χ③配对设计cb c b +--=22)1(χR ⨯C 表①多个样本率、 构成比的比较②两个变量之 间关联性分析0H :多个总体率(构成比)相等(0H :两种属性间存在关联)1H :多个总体率(构成比)不全相等(0H :两种属性间存在关联))1(22-=∑CR n n A n χ (R-1)(C-1)频数分布表 频数分布的拟合优度检验0H :资料服从某已知的理论分布 1H :资料不服从某已知的理论分布∑-TT A 2)( 据频数表的组数而定(五)四格表的确切概率法:当四格表有理论数小于1或n <40时,宜用四格表的确切概率法。
交互分类的含义与作用

分类
40岁及以上
40岁以下
赞成
36.4
75.0
反对
59.1
17.5
不表态
4.5
7.5
合计
100
100
(n)
(220)
(80)
2. 交互分类的作用
交互分类表中应该通过计算百分比解释两个变量 之间的关系 问题:向哪个方向计算百分比?
分类 赞成 反对 不表态 合计
40岁及以上 40岁以下 合计
80
60
《社会调查与统计分析》
第九章 双变量分析
知识点2 交互分类的含义与作用
学习导航
交互分类的含义与作用
交互分类的含义 交互分类的作用
1. 交互分类的含义
所谓交互分类(cross classification),就是
将调查所得的一组数据按照两个不同的变量进行
综合的分类。
表1 性别与择业意愿的交互分类表 (人)
140
130
14
144
10
6
16
220
80
300
按横向计算
分类 赞成 反对 不表态
≥40岁 57.1% 90.3% 62.5%
<40岁 42.9% 9.7% 37.5%
合计 100% 100% 100%
按纵向计算
分类 赞成 反对 不表态 合计
≥40岁 36.4% 59.1% 4.5% 100%
<40岁 75.0% 17.5% 7.5% 100%
分类 赞成 反对 不表态 合计
人数 140 144 16 300
比例(%) 46.7 48.0 5.3 100
2. 交互分类的作用
表3 年龄与态度交互分类表(人)
2023年雨课堂(统计学与SPSS软件应用)答案

第1章课程习题---选择题第 1 题实验设计的基本原则不包括【】。
A 随机性原则B 对照原则C 重复原则D 多样性原则第 2 题要观察两种药物联合应用是否具有更好的治疗效果,在实验设计时应该设计【】个组。
A 2B 3C 4D 8第 3 题下列变量中,属于分类变量的是【】。
A 白细胞计数B 民族C 怀孕次数D 体重第 4 题要减小抽样误差,实际中可行的办法是【】。
A 减小系统误差B 适当增加样本量C 控制个体变异D 精选观察对象第 5 题标准正态分布曲线下横轴从 0 到 2 的曲线下面积大约是【】。
A 0.28B 0.48C 0.68D 0.88第 6 题最小组段无下限或最大组段无上限的频数分布资料可用【】描述集中趋势。
A 均数B 中位数C 标准差D 标准误第 7 题抽样误差是指【】。
A 不同样本指标之间的差别B 样本中每个个体之间的差别C 由于抽样产生的观测值之间的差别D 样本指标与总体指标之间由于抽样产生的差别第 8 题随机变量 X 的值同时乘以一个大于零的常数,则【】会改变。
A 均数B 标准差C 方差D 变异系数正确答案:ABC第 9 题以下指标中,一般用来描述定量资料离散趋势的是【】。
A 四分位数间距B P90-P10C P75-P25D 极差正确答案:ACD第 10 题当一组数据中有一个观察数值为零时,仍能计算【】。
A 算术均数B 几何均数C 中位数D 众数正确答案:ACD第1章课程习题---判断题第 1题当样本含量固定时,标准误大则样本均数作为总体均数的代表性差;反之,标准误小则样本均数作为总体均数的代表性好。
第 2题,在试验设计阶段估计样本量时,检验效能是一个重要的考虑因素,一般要求小于0.2。
第 3题在无效假设的假设检验中,第一类错误是指拒绝了一个正确的无效假设。
第2章课程习题---选择题第 1 题t 分布曲线是一簇曲线,这些曲线形状的差别取决于【】。
A 自由度B 均数C 标准差D 标准误第 2 题进行两个样本均数比较的 t 检验,差别有统计学意义,则P 值越小说明【】。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
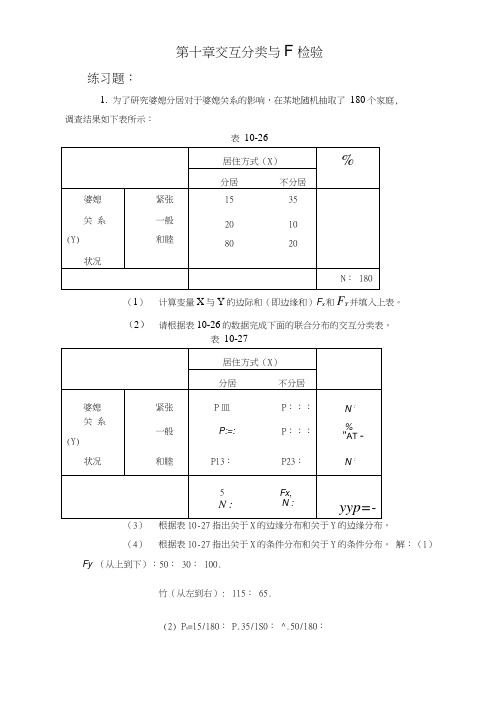
第十章 交互分类与2χ检验练习题:1. 为了研究婆媳分居对于婆媳关系的影响,在某地随机抽取了180个家庭,调查结果如下表所示:(1) 计算变量X 与Y 的边际和(即边缘和)X F 和Y F 并填入上表。
(2) 请根据表10-26的数据完成下面的联合分布的交互分类表。
10-27(4) 根据表10-27指出关于X 的条件分布和关于Y 的条件分布。
解:(1)Y F (从上到下):50;30;100.X F (从左到右):115;65.(2)P 11=15/180;P 21=35/180;1Y F N =50/180;P 12=20/180;P 22=10/180;2Y F N =30/180; P 13=80/180;P 23=20/180;3Y F N =100/180;1X F N =115/180;2X F N =65/180.(3)关于X 的边缘分布:x 分居 不分居 P(x)115/18065/180关于Y 的边缘分布: y 紧张 一般 和睦 P(y)50/18030/180100/180(4)关于X 的条件分布有三个:y=“紧张” x 分居 不分居 P(x) 15/5035/50y=“一般” x 分居 不分居 P(x) 20/3010/30y=“和睦” x 分居 不分居 P(x) 80/10020/100关于y 的条件分布有两个: X=“分居”y紧张 一般 和睦 P(y)15/11520/11580/115X=“不分居”y紧张 一般 和睦 P(y)35/6510/6520/652. 一名社会学家关于“利他主义”的研究中,对被调查者的宗教信仰情况进行 了分析,得到的结果如下表所示:10-29。
(2)根据表10-28和表10-29计算2χ,计算公式为2()2o e ef f f χ-=∑。
(3)若要对有无宗教信仰的人的利他主义程度有无显著性差异进行检验,请陈 述研究假设1H 和虚无假设0H 。
(4)本题目中的自由度为多少?若显著性水平为0.05,请查附录的2χ分布表, 找出相对应的临界值。
并判断有无宗教信仰的人的利他主义程度有无显著性差异。
(5)若变量“宗教信仰”和“利他主义程度”存在相关关系,请计算C 系数。
解:(1)“信教”一列(从上到下):11918561.67357⨯=;12518564.78357⨯=;11318558.56357⨯=.“不信教”一列(从上到下):11917257.33357⨯=;12517260.22357⨯=;11317254.44357⨯=.(2)2222222()2(9061.67)(6064.78)(3558.56)(2957.33)(6560.22)(7854.44)61.6764.7858.5657.3360.2254.44==47.42o e ef f f χ-------=+++++∑(3)1H :总体中有无宗教信仰的人的利他主义程度有显著性差异。
0H :总体中有无宗教信仰的人的利他主义程度没有显著性差异。
(4)df =(r -1)(c -1)=(3-1)⨯(2-1)=2;显著性水平为0.05时的临界值是5.991。
因为20χ=5.99<2χ=47.42,检验统计值落在否定域中,可以拒绝虚无假设,接受研究假设,即认为总体中有无宗教信仰的人的利他主义程度是有显著性差异的。
(5)0.342C==C 值要利用表“部分交互分类表C 值的上限”中的数值进行修正,本题的表格是3⨯2,对应的C 值上限是0.685,因此:C 0.3420.685新==0.49933. 某英语培训学校为了研究英语四级考试试卷客观选择题正确答案的设置在A 、B 、C 与D 的某一个选项上是否有偏好,对最近三年英语四级考试试卷做了分 析,258个单选题的正确答案在A 、B 、C 与D 四个选项上的分布情况如下表所示:答案选项 频次 A48 B 74 C 50 D 86 合计258(1)请陈述研究假设1H 和虚无假设0H 。
(2)A 、B 、C 与D 四个选项上的期望频次是多少。
(3)根据上表计算2χ值。
(4)若显著性水平为0.05,请判断英语四级考试试卷选择题的正确答案在A 、B 、C 与D 四个选项上的分配是否有显著的倾向。
解:(1)研究假设1H :正确答案在A 、B 、C 与D 四个选项中的设置有偏好。
虚无假设0H :正确答案在A 、B 、C 与D 四个选项中的设置没有偏好。
(2) A 、B 、C 与D 四个选项上的期望频次都是258/4=64.5 (3)22222()2(4864.5)(7464.5)(5064.5)(8664.5)64.564.564.564.5=16.05o e ef f f χ-----==+++∑(4) df=4-1=3,显著性水平为0.05时,查2χ分布表可知临界值是7.815,统计量落在否定域内,因此,拒绝虚无假设,接受研究假设,即认为正确答案在A 、B 、C 与D 四个选项上的分配是有偏好的。
4.某个电视节目收视率的商业调查,涉及到了儿童、少年、青年、中年、老年5个群体的收视习惯,调查结果如下表所示:(1)为了分析5个群体的收视习惯是否有显著差异,请陈述研究假设1H 和虚无假设0H 。
(2)根据上表计算2χ值。
(3)若显著性水平为0.05,请判断不同群体的收视习惯是否有显著性差异。
解:(1) 研究假设1H :5个群体的收视习惯有显著差异。
虚无假设0H :5个群体的收视习惯没有显著差异。
(2)22222222222()2(8961.5)(68.278)(61.556)(9567)(81.678)(39.512)(43.834)(4589)(8989)(52.456)61.568.261.59581.639.543.8458952.457.81o e ef f f χ-----------==+++++++++=∑(3) df =(r -1)(c -1)=(2-1)⨯(5-1)=4,显著性水平0.05下的临界值为9.448,很明显,检验统计值落在否定域内,因此,拒绝虚无假设,接受研究假设,即认为5个群体的收视习惯有显著差异。
5. 根据武汉市初中生日常行为状况调查的数据(data9),运用SPSS 检验是否 有自己的房间(C3)以供学习对学生在本班的学习层次(C2)有无显著影响,并计算 关系强度系数C 系数、V 系数和φ系数。
(显著性水平0.05α=)解:《武汉市初中生日常行为状况调查问卷》:C2 你的成绩目前在本班大致属于1)上等 2)中上等 3)中等 4)中下等 5)下等C3 你是否有自己的房间以供学习不被打扰1)有2)没有SPSS的操作步骤如下:○1点击Analyze→Descriptive Statistics→Crosstabs,打开Crosstabs对话框,如图10-1 (练习)所示。
将变量“是否有自己的房间以供学习不被打扰(c3)”放置在Column(s)框中,将变量“成绩目前在本班的大致层次(c2)”放置在Row(s)框中,如图10-1(练习)所示。
图10-1(练习)Crosstabs对话框○2点击Statistics按钮,分别点击Chi-square、Contingency coefficient、Phi and Cram ér’s V复选框,如图10-2(练习)所示。
图10-2(练习)Crosstabs:statistics对话框○3点击Cells按钮,对单元格进行设置,如图10-3(练习)所示,选择Column选项,选择的是在单元格中计算列百分比。
你的成绩目前在本班大致属于 * 你是否有自己的房间以供学习不被打扰 Crosstabu latio n% within 你是否有自己的房间以供学习不被打扰10.6%8.2%10.0%30.6%23.0%28.8%33.8%36.1%34.4%20.7%21.3%20.8%4.3%11.5% 6.0%100.0%100.0%100.0%上等中上等中等中下等下等你的成绩目前在本班大致属于Total有没有你是否有自己的房间以供学习不被打扰Total Chi-Square Tests10.605a 4.0319.6224.0476.2851.012518Pearson Chi-Square Likelihood Ratio Linear-by-Linear AssociationN of Valid CasesValuedfAsymp. Sig.(2-sided)0 cells (.0%) have expected count less than 5. The a.图10-3(练习) Crosstabs :Cell Display 对话框○4 Format 采取系统默认格式,点击OK ,提交运行,可得到如下的结果。
表10-1(练习) 是否拥有房间与在班上学习层次的交互分类表表10-2(练习) 卡方检验表从表10-2(练习)可以看出卡方值为10.605,自由度为4,卡方检验的P值为0.031,小于0.05,即通过了卡方检验,这意味着是否有自己的房间(C3)以供学习对学生在本班的学习层次(C2)有显著影响。
从表10-1(练习)可以看出“有”和“没有”自己房间的两组初中生各个成绩层次的学生在各组所占的比例,在有自己房间的学生中,学习成绩为上等和中上等的比例均高于没有自己房间的学生。
从表10-3(练习)可以看出,列联系数(Contingency coefficient)为0.142,Cramer’s V系数为0.143,φ系数(Phi系数)为0.143。
6. 根据武汉市初中生日常行为状况调查的数据(data9),运用SPSS检验在本班的学习层次(C2)对自己与母亲关系的好坏(D2)有无显著影响,并计算关系强α=)度系数C系数、V系数和φ系数。
(显著性水平0.05解:初中生学习成绩的层次与自己同母亲的关系存在着相互影响,这个题目假定学习层次(C2)为自变量,自己与母亲关系的好坏(D2)为因变量。
《武汉市初中生日常行为状况调查问卷》:C2你的成绩目前在本班大致属于1)上等2)中上等3)中等4)中下等5)下等D2 你对自己与母亲的关系1)非常满意2)比较满意3)一般4)不太满意5)很不满意SPSS的操作步骤如下:○1点击Analyze→Descriptive Statistics→Crosstabs,打开Crosstabs对话框,如图10-4(练习)所示。
将变量“成绩目前在本班的大致层次(c2)”放置在column(s)框中,将变量“自己与母亲的关系(d2)”放置在row(s)框中,如图10-4(练习)所示。
图10-4(练习)Crosstabs对话框○2点击Statistics按钮,分别点击Chi-square、Contingency coefficient、Phi and Cramr’V复选框,如图10-5(练习)所示。