CDC增量集成示例
CDC概述文档

1、CDC概述 、 概述
CDC有两个模式:同步和异步。两种模式的实现机制 是截然不同的。 同步CDC主要是采用触发器记录新增数据,基本能够 做到实时增量抽取,同步CDC在企业版或者标准版中 都可以使用。 异步CDC则是通过分析已经提交的日志记录来得到增 量数据信息,有一定的时间延迟,异步CDC只包含在 企业版中。 注意CDC在9i和10g中有了比较大的改变,异步CDC 主要采用了和Streams相同的技术。
1、CDC概述 、 概述
CDC中将系统分为两个角色:发布者和订阅者。 发布者主要负责捕获增量数据。能决定哪些源数据库 和表是订阅者关心的,以及要使用的 CDC 的模式, 使用Oracle 提供的包 DBMS_CDC_PUBLISH 从源表 中建立 CDC 系统通过 GRANT 和 REVOKE 这样的 SQL 语句来管理订阅者访问变更表的权限 订阅者则将增量数据传递给实际应用,是已经发布的 并更数据的用户。订阅者需要完成下面的任务:使用 Oracle 提供的包 DBMS_CDC_SUBSCRIBE 来完成 创建订阅:通知CDC准备接收变更的数据、通知CDC 完成一组变更数据;使用 SELECT 语句从订阅者视 图中抽取变化的数据。
CDC模式分为同步CDC模式和异步CDC模式。 同步模式相对简单,就是通过触发器捕获增量数据, 类似于物化视图的实现机制。而异步CDC根据实现的 内部机制区别,又可以分为异步HotLog模式,异步分 布式HotLog模式和异步AutoLog模式。 有些模式有固定的预先定义change source,有些则 没有。比如同步CDC的change source是 SYNC_SOURCE,异步HotLog模式则是 HOTLOG_SOURCE,这是因为这两种模式都只有一 个source database。而其他的,像异步分布式Hotlog 模式和异步AutoLog模式,除了source database,还 需要一个staging database。
CDC增量集成(ODI-12C)
1简单增量集成示例
这里给个简单CDC的实例,并且将该简单增量设置成包轮询方式,以实现实时同步需求,具体步骤如下:
1.1数据服务器,模型,项目
创建源和目标的数据服务器,物理架构,逻辑架构,创建模型反向表,以及创建项目,步骤都同简单全量集成一样。
1.2配置JKM
KM 是为表生成并捕获日志的知识模块,需要在模型和表上面进行配置。
目中导入JKM。
请导入JKM Oracle Consistent,JKM Oracle Simple两个KM,
编辑模型mod_test的日记记录,选择简单日记记录模式,并选择JKM Oracle Simple:
1.3启用CDC
ODI启用CDC,包括下面的步骤:添加到CDC,订阅CDC,启动日记。
首先在模型mod_test的弹出菜单中选择添加到CDC:
接下来从模型mod_test的弹出菜单中选择启动日记
在弹出的窗口中录入订阅的用户名,如SUNOPSIS,点击添加订户:
将“SUNOPSIS”订户添加进所示区域后点击确定即可;同时这将会启动一个会话,请在Operator 中查看会话是否成功完成。
这个会话会在数据库中创建一些对象:CDC 的数据字典表(SNP开头),日记表和视图(通常是J$和JV$开头),trigger(通常以T$开头)。
1.4创建接口接口常见如下图所示:
LKM选择
IKM选择:。
oracle cdc 原理

oracle cdc 原理Oracle CDC(Change Data Capture)是一种数据捕获技术,用于捕获数据库中的数据变化,并将这些变化应用于其他系统中。
它可以实时监控数据库的变化,并将这些变化记录下来,以便后续的分析和处理。
Oracle CDC的原理是通过在数据库中创建日志来实现的。
当数据库中的数据发生变化时,Oracle会将这些变化写入日志文件中。
CDC 通过解析这些日志文件来获取数据的变化,并将其应用于其他系统中,以保持数据的一致性。
为了实现CDC,Oracle会记录以下三种类型的日志:1. Redo Log:这是Oracle数据库中最重要的日志类型之一。
当数据发生变化时,Oracle会将变化前后的数据记录到Redo Log中。
CDC 通过解析Redo Log来获取数据的变化。
2. Undo Log:Undo Log记录了事务的撤销信息。
当数据库中的数据发生变化时,Oracle会将原始数据保存到Undo Log中。
CDC可以通过解析Undo Log来获取数据的变化。
3. Archive Log:Archive Log是将Redo Log保存到磁盘上的一种机制。
通过将Redo Log保存到磁盘上,可以确保即使数据库崩溃,数据的变化也不会丢失。
CDC可以通过解析Archive Log来获取数据的变化。
通过解析这些日志文件,CDC可以获取数据的变化信息,并将其应用于其他系统中。
它可以实时监控数据库的变化,并将这些变化同步到其他系统中,以保持数据的一致性。
使用Oracle CDC可以带来许多好处。
首先,它可以实现实时数据同步,确保数据在不同系统之间的一致性。
其次,它可以降低数据同步的延迟,使得数据可以更快地在系统之间流动。
此外,Oracle CDC还可以提供增量备份和恢复的功能,以及实时数据分析和报告的能力。
总结起来,Oracle CDC是一种通过解析数据库日志来捕获数据变化的技术。
它可以实时监控数据库的变化,并将这些变化应用于其他系统中。
数据湖的增量与全量数据同步方法(九)

数据湖是指一个包含各种类型和格式的大量数据的存储系统。
数据湖的设计目的是将数据存储在原始、未加工的状态下,以便将来进行分析和处理。
然而,在实际应用中,数据湖需要与其他系统保持同步,以确保数据的准确性和一致性。
因此,本文将探讨数据湖的增量与全量数据同步方法。
1. 增量数据同步方法增量数据同步是指将新产生或更新的数据同步到数据湖的过程。
在数据湖中,增量数据同步对于保持数据的最新状态至关重要。
以下是几种常见的增量数据同步方法:a) 变更数据捕获(CDC)CDC是一种通过捕获数据库中的变更来实现数据同步的方法。
它通过监视数据库事务日志来捕获数据变更,然后将这些变更应用到数据湖中。
CDC方法可以很好地支持增量数据同步,但它需要数据库支持日志记录功能。
b) 基于时间戳的同步这种方法通过比较源系统和数据湖中数据的时间戳来确定需要同步的数据。
只有时间戳在某个阈值之后的数据才被同步到数据湖中。
这种方法简单易懂,但如果源系统的时间戳不准确,会导致数据同步的错误和延迟。
c) 增量数据抽取(IDE)IDE是一种将增量数据从源系统抽取到数据湖的方法。
它通过比较源系统和数据湖中的数据,然后将差异数据抽取到数据湖中。
IDE方法可以根据业务需求自定义增量抽取策略,但如果源系统的数据量很大,会对系统性能产生影响。
2. 全量数据同步方法全量数据同步是指将源系统中的所有数据同步到数据湖的过程。
全量数据同步方法可以确保数据湖中的数据完整和一致。
以下是几种常见的全量数据同步方法:a) 批量导入批量导入是将源系统中的数据按照批次导入到数据湖的方法。
通过将数据分成多个批次,可以降低对源系统和数据湖的压力。
批量导入方法适用于数据量较小的场景,但如果源系统的数据量非常大,导入过程可能需要很长时间。
b) 增量+全量导入这种方法将增量数据和全量数据结合起来进行同步。
首先,使用增量数据同步方法将增量数据同步到数据湖中。
然后,使用全量导入方法将源系统中的所有数据导入到数据湖中。
同步CDC模式(案例)

通过一个例子来演示实现同步模式的CDC的基本步骤。
第一步:查看数据库版本SYS-->SQL:select * from v$version;第二步:创建发布者并授权1.在源数据库下创建一个用户,作为发布者。
SYS-->SQL:create user cdcpub identified by cdcpub;2.授予相应的权限SYS-->SQL:grant execute_catalog_role to cdcpub;grant select_catalog_role to cdcpub;grant create table to cdcpub;grant create session to cdcpub;grant execute on dbms_cdc_publish to cdcpub;第三步:设置初始化参数同步CDC,需要将java_pool_size设置为合适的大小,估计是其内部是采用java存储过程来实现的。
SYS-->SQL:alter system set java_pool_size=48M;第四步:发布变化数据(例如要发布用户CDC_SCOTT下的EMP表)1.发布前准备。
创建一个用户和用户下的一个表SYS-->SQL:create user CDC_SCOTT identified by CDC_SCOTT;grant resource to CDC_SCOTT;grant connect to CDC_SCOTT;CDC_SCOTT-->SQL:create table EMP(EMPNO NUMBER(4) not null,ENAME V ARCHAR2(10),JOB V ARCHAR2(9),MGR NUMBER(4),HIREDATE DATE,SAL NUMBER(7,2),COMM NUMBER(7,2),DEPTNO NUMBER(2));insert into emp (EMPNO, ENAME, JOB, MGR, HIREDA TE, SAL, COMM, DEPTNO) values (7369, 'SMITH', 'CLERK', 7902, to_date('17-12-1980', 'dd-mm-yyyy'), 800.00, null, 20);insert into emp (EMPNO, ENAME, JOB, MGR, HIREDA TE, SAL, COMM, DEPTNO) values (7698, 'BLAKE', 'MANAGER', 7839, to_date('01-05-1981', 'dd-mm-yyyy'), 2850.00, null, 30); insert into emp (EMPNO, ENAME, JOB, MGR, HIREDA TE, SAL, COMM, DEPTNO) values (7782, 'CLARK', 'MANAGER', 7839, to_date('09-06-1981', 'dd-mm-yyyy'), 2450.00, null, 10); insert into emp (EMPNO, ENAME, JOB, MGR, HIREDA TE, SAL, COMM, DEPTNO) values (7788, 'SCOTT', 'ANAL YST', 7566, to_date('19-04-1987', 'dd-mm-yyyy'), 3000.00, null, 20); COMMIT;2.授予cdcpub用户对于该表的权限CDC_SCOTT-->SQL:grant all on EMP to cdcpub;3.创建变更集SYS-->SQL:begindbms_cdc_publish.create_change_set(change_set_name =>'CDC_SCOTT_EMP',description =>'change set for CDC_SCOTT.EMP',change_source_name =>'SYNC_SOURCE');end;/注:同步CDC的chang source必须是SYNC_SOURCE。
flinkcdc断点续传案例

flinkcdc断点续传案例摘要:1.Flink CDC简介2.断点续传原理3.实现步骤4.总结与展望正文:随着大数据时代的到来,实时数据处理变得越来越重要。
Flink作为一款开源的流处理框架,在大数据领域得到了广泛的应用。
Flink CDC(Change Data Capture)提供了实时增量数据捕获功能,使我们能够轻松地获取源系统中的数据变化。
本文将介绍如何使用Flink CDC实现断点续传功能,从而提高数据处理任务的可靠性。
一、Flink CDC简介Flink CDC是Flink提供的一种数据捕获机制,可以实时捕获源系统中数据的变化。
Flink CDC支持多种数据源,如Kafka、Kinesis、MySQL等。
通过Flink CDC,我们可以轻松地构建实时数据处理管道,满足各种业务需求。
二、断点续传原理断点续传的核心思想是在数据处理任务失败时,可以从上次成功的进度开始继续处理,避免从头开始重新执行。
在Flink CDC中,我们可以通过以下两种方式实现断点续传:1.使用检查点(Checkpoint):检查点是Flink中用于保存数据状态的一种机制。
在数据处理任务中定期生成检查点,以便在任务失败时恢复到上次成功的检查点。
2.使用输出端存储(Output State):输出端存储是Flink中的一种状态管理机制,可以将数据处理过程中的结果暂存在外部存储系统中。
当任务失败时,可以从输出端存储中恢复数据,继续执行后续任务。
三、实现步骤1.构建实时数据处理任务:首先,根据业务需求构建实时数据处理任务,使用Flink CDC读取数据源,并进行相应的转换和处理。
2.配置检查点:在实时数据处理任务中配置检查点,设置检查点间隔和存储位置。
确保在任务运行过程中,定期生成检查点文件。
3.配置输出端存储:根据实际需求,选择合适的输出端存储系统(如HDFS、Kafka等),并配置相关参数。
4.监控任务运行:在任务运行过程中,实时监控任务状态。
数据实时增量同步之CDC工具—Canal、mysql_stream、go-mysql-tr。。。

数据实时增量同步之CDC⼯具—Canal、mysql_stream、go-mysql-tr。
@⽬录[Mysql数据实时增量同步之CDC⼯具—Canal、mysql_stream、go-mysql-transfer、Maxwell:什么是CDC?CDC(Change Data Capture)是变更数据获取的简称。
可以基于增量⽇志,以极低的侵⼊性来完成增量数据捕获的⼯作。
核⼼思想是,监测并捕获数据库的变动(包括数据或数据表的插⼊、更新以及删除等),将这些变更按发⽣的顺序完整记录下来,写⼊到消息中间件中以供其他服务进⾏订阅及消费。
简单来讲:CDC是指从源数据库捕获到数据和数据结构(也称为模式)的增量变更,近乎实时地将这些变更,传播到其他数据库或应⽤程序之处。
通过这种⽅式,CDC能够向数据仓库提供⾼效、低延迟的数据传输,以便信息被及时转换并交付给专供分析的应⽤程序。
与批量复制相⽐,变更数据的捕获通常具有如下三项基本优势:CDC通过仅发送增量的变更,来降低通过⽹络传输数据的成本。
CDC可以帮助⽤户根据最新的数据做出更快、更准确的决策。
例如,CDC会将事务直接传输到专供分析的应⽤上。
CDC最⼤限度地减少了对于⽣产环境⽹络流量的⼲扰。
CDC⼯具对⽐特⾊Canal mysql_stream go-mysql-transfer Maxwell开发语⾔Java Python Golang Java⾼可⽤⽀持⽀持⽀持⽀持接收端编码定制Kafka等(MQ)Redis、MongoDB、Elasticsearch、RabbitMQ、Kafka、RocketMQ、HTTP API 等Kafka,Kinesis、RabbitMQ、Redis、GoogleCloud Pub/Sub、⽂件等全量数据初始化不⽀持⽀持⽀持⽀持数据格式编码定制Json(固定格式)Json(规则配置) 模板语法 Lua脚本JSON性能(4-8TPS)实现原理:1、go-mysql-transfer将⾃⼰伪装成MySQL的Slave,2、向Master发送dump协议获取binlog,解析binlog并⽣成消息3、将⽣成的消息实时、批量发送给接收端Mysql binlog 讲解:MySQL的⼆进制⽇志可以说MySQL最重要的⽇志了,它记录了所有的DDL和DML(除了数据查询语句)语句,以事件形式记录,还包含语句所执⾏的消耗的时间,MySQL的⼆进制⽇志是事务安全型的。
数据集成开发手册

集成开发手册编制人员:金立军编制部门:软件工程研发中心模版文件版本:V1.3.0适用项目范围:研发项目文件修改记录表文件审批表目录目录 (4)1前言 (6)1.1背景与说明 (6)1.2文章结构安排 (7)1.3术语定义 (8)2集成方式说明及示例 (8)2.1集成方式说明 (9)2.1.1全量集成 (9)2.1.2增量集成 (9)2.2集成周期 (10)2.2.1实时集成 (10)2.2.2定期集成 (10)2.3开发示例 (11)2.3.1全量集成示例 (11)2.3.2简单增量集成示例 (40)2.3.3多用户一致性增量集成示例 (51)3集成场景描述及分析 (64)3.1数据源场景 (64)3.1.1关系型数据库数据集成 (64)3.1.2非关系型数据集成 (66)3.2清洗转换场景 (67)3.2.1映射转换 (68)3.2.2筛选过滤 (69)3.3部署运行场景 (72)3.3.1代理发布 (72)3.3.2项目导入导出 (72)3.4常见业务场景 (74)4集成处理策略及示例 (74)4.1关系型数据库数据集成 (74)4.1.1BLOB类型的集成 (74)4.1.2CLOB类型的集成 (83)4.2非关系型数据集成 (91)4.2.1TXT文件集成 (92)4.2.2EXCEL数据文件集成 (122)4.2.3ACCESS集成(远程ODBC说明) (144)4.2.4Web Service数据集成 (165)4.2.5XML数据文件集成 (194)4.2.6本地图片文件集成 (214)4.2.7FTP上单个图片文件集成 (226)4.2.8FTP上多图片文件集成 (238)4.3部署运行 (275)4.3.1CMD启动代理 (276)4.3.2Windows下代理发布为服务 (278)4.3.3Linux下代理发布为服务 (295)4.4其他常见业务场景 (305)4.4.1ODI中OCI方式连接Oracle (305)4.4.2ODI目标数据删除事务保证 (316)4.4.3代码映射为空报错处理解决办法 (326)4.4.4Linux下ODBC的配置 (337)4.4.5一致性增量创建包轮询 (350)5KM场景调用 (353)5.1JKM调用 (354)5.1.1触发器方式 (354)5.1.2日志位方式 (355)5.2LKM及IKM调用 (355)5.2.1关系型数据库数据集成 (356)5.2.2其他文件数据集成 (358)5.3CKM调用 (359)6FAQ问题整理 (359)6.1配置问题 (360)6.1.1Nvavigator的配置、使用问题 (360)6.1.2EXCEL数据集成时的配置问题 (361)6.1.3Oracle SID改写问题 (363)6.2数据库连接问题 (364)6.2.1Mysql远程访问授权问题 (364)6.2.2SQL server 2000连接问题 (365)6.2.3SQL server 2005 JDBC 问题 (368)6.2.4OCI方式连接数据库JDBC问题 (370)6.2.5OCI方式连接数据库问题 (371)6.3数据类型问题 (371)6.3.1数据类型转换错误 (371)6.3.2目标表某字段的长度小于实际长度 (372)6.4A GENT代理问题 (372)6.4.1Agent配置问题 (372)6.4.2Linux下代理无法发布的问题 (373)6.4.3Linux下多个代理发布问题 (373)6.5W EB S ERVICE数据集成问题 (375)6.5.1ODI中发布数据Web服务问题 (375)6.6BLOB同步问题 (376)6.6.1BLOB不能同步问题 (376)6.6.2BLOB同步数BLOB字段变少问题 (377)6.6.3BLOB同步批量取数据问题 (377)6.6.4BLOB同步中插入数据问题 (379)6.6.5BLOB同步时执行ftp读取到本地目录时报错: (380)6.6.6BLOB同步执行Insert binary file into target操作时报错: (381)6.6.7BLOB同步执行create directory object操作时报错: (382)6.6.8照片往数据库集成找不到路径问题 (383)6.7同步过程中其他问题 (384)6.7.1临时对象无法创建问题 (384)6.7.2做简单CDC同步订户问题 (385)6.7.3方案更新以及代理计划更新问题 (385)6.8项目导入导出问题 (387)6.8.1项目导入违反唯一性报错问题 (387)6.9约束过滤条件问题 (388)6.9.1增量同步时关系图中过滤条件问题 (388)7其他 (388)8参考资料 (388)1前言1.1背景与说明数据集成平台在ODI工具使用方面,前期已经形成了大部分文档和操作手册,这些文档和操作手册虽然已覆盖了ODI工具使用的大部分内容,但这些文档显得的相对独立和零散,工程实施人员在项目现场进行项目开发和部署时,仍然不知从何下手,找不到相对应的操作手册和指导说明,遇到问题时更无法找到相应的资料进行查阅和参照。
增量集成测试用例 -回复

增量集成测试用例-回复什么是增量集成测试用例增量集成测试用例是指在软件开发过程中,根据软件系统的不同模块和功能的增加,逐步添加和执行的测试用例。
增量集成测试的目的是确保软件系统的各个模块之间能够正确地协同工作,同时对整个系统进行全面测试,以及尽早发现和解决可能存在的问题。
通过逐步增加和执行集成测试用例,开发团队可以在软件开发过程中逐渐完善和改进系统,提高软件的质量和稳定性。
如何编写增量集成测试用例编写增量集成测试用例是一个复杂和繁琐的过程,需要开发人员、测试人员和产品负责人共同合作,确保测试用例能够覆盖到系统的各个模块和功能,并且能够检测到潜在的问题。
下面是编写增量集成测试用例的一般步骤:1. 确定测试目标:在编写测试用例之前,需要明确测试的目标和要求。
测试目标可以是验证新添加的功能是否正常工作,或者确定系统的各个模块之间是否能够正确地进行通信和交互。
同时,还需确定测试的覆盖范围和测试的时间安排。
2. 理解系统结构和模块:在编写测试用例之前,需要深入理解系统的结构和各个模块之间的关系。
了解每个模块的功能和输入输出要求,以及模块之间的依赖关系,对于编写有效和全面的测试用例非常重要。
3. 设计测试用例:根据测试目标和对系统的理解,开始设计测试用例。
测试用例应该包括测试的输入和预期输出,以及执行测试的步骤和条件。
测试用例应该尽可能覆盖系统的各个功能和边界情况,以及针对可能存在的异常情况。
4. 执行测试用例:一旦测试用例编写完成,就可以开始执行测试用例。
在执行测试用例之前,需要确保测试环境的准备工作已经完成,包括安装和配置必要的软件和硬件环境。
同时,还需要编写测试报告,记录测试的过程、结果和问题。
5. 分析测试结果:在执行测试用例之后,需要分析测试结果,并对问题进行排查和修复。
如果测试用例中发现问题,则需要及时报告给开发人员,以便尽快解决。
分析测试结果的目的是找出系统存在的缺陷和问题,并确保这些问题得到妥善解决。
CDC实现数据同步,增量更新(转)

CDC实现数据同步,增量更新(转)CDC 实现数据同步,增量更新在Sqlserver2008上利⽤CDC实现了数据更新的跟踪,⽐以往的利⽤时间戳,触发器实现更加⽅便快捷.参考资料:实现步骤如下:1.配置cdc-- 开启cdcUSE db1GOEXEC sys.sp_cdc_enable_db--验证--0 :未开启cdc 1:开启cdcSELECT is_cdc_enabled FROM sys.databases WHERE database_id=DB_ID()--表开启cdcUSE db1;GOEXEC sys.sp_cdc_enable_table@source_schema ='dbo',@source_name='t_cdc_ta',@role_name=null,@capture_instance=NULL,@supports_net_changes=1,@index_name=null,@captured_column_list=null,@filegroup_name=default,@allow_partition_switch=1/*开启之后会⽣成cdc构架,并⽣成查询函数和变更数据表cdc.captured_columnscdc.change_tablescdc.ddl_historycdc.index_columnscdc.lsn_time_mappingdbo.systranschemascdc.dbo_t_cdc_ta_CT 以构架名和表名组合的变更数据表*/--表结构CREATE TABLE [t_cdc_ta]([id] [int] IDENTITY(1,1) PRIMARY KEY NOT NULL,[name] [varchar](20) NULL,[addr] [varchar](20) NULL,[ttime] [datetime] NULL)2.跟踪变更数据当往源表t_cdc_ta中新增,插⼊,删除数据时,可以在变更数据表[cdc].[dbo_t_cdc_ta_CT]中看到如下数据__$operation:1-删除,2-新增,4-更新3.根据变更数据,利⽤ETL可以实现数据的增量更新脚本如下:USE [db1]CREATE TABLE [dbo].[cdc_capture_log]([cdc_capture_log_id] [int] IDENTITY(1,1) NOT NULL,[capture_instance] [nvarchar](50) NOT NULL,[start_time] [datetime] NOT NULL,[min_lsn] [binary](10) NOT NULL,[max_lsn] [binary](10) NOT NULL,[end_time] [datetime] NULL,[status_code] [int] NOT NULL DEFAULT(0))CREATE PROCEDURE [dbo].[usp_init_cdc_capture_log]@capture_instance NVARCHAR(50)ASBEGINSET nocount ON ;DECLARE @start_lsn BINARY(10),@end_lsn BINARY(10),@prev_max_lsn BINARY(10)--get the max LSN for the capture instance from --the last extractSELECT @prev_max_lsn = MAX(max_lsn)FROM dbo.cdc_capture_logWHERE capture_instance = @capture_instance-- if no row found in cdc_capture_log get the min lsn -- for the capture instance IF @prev_max_lsn IS NULLSET @start_lsn = sys.fn_cdc_get_min_lsn(@capture_instance)ELSESET @start_lsn = sys.fn_cdc_increment_lsn(@prev_max_lsn)-- get the max lsnSET @end_lsn = sys.fn_cdc_get_max_lsn()IF @start_lsn>=@end_lsnSET @start_lsn=@end_lsnINSERT INTO dbo.cdc_capture_log(capture_instance,start_time,min_lsn,max_lsn)VALUES (@capture_instance,GETDATE(),@start_lsn,@end_lsn)SELECT CAST(SCOPE_IDENTITY() AS INT) cdc_capture_log_idENDGOcreate procedure [dbo].[usp_extract_userm_capture_log]@cdc_capture_log_id INTASBEGINset nocount on;DECLARE @start_lsn binary(10),@end_lsn binary(10)-- get the lsn range to process SELECT @start_lsn = min_lsn,@end_lsn = max_lsn from dbo.cdc_capture_log where cdc_capture_log_id = @cdc_capture_log_id-- extract and return the changesselect m.tran_end_time modified_ts,x.*from cdc.fn_cdc_get_all_changes_dbo_t_cdc_ta(@start_lsn, @end_lsn, 'all') xjoin cdc.lsn_time_mapping m on m.start_lsn = x.__$start_lsn ;endCREATE PROCEDURE [dbo].[usp_end_cdc_capture_log]@cdc_capture_log_id INTASBEGINSET nocount ON ;UPDATE dbo.cdc_capture_logSET end_time = GETDATE(),status_code = 1WHERE cdc_capture_log_id = @cdc_capture_log_idENDGO--在另⼀个库上建⼀个相同的结构的表作为同步数据测试⽤表USE montiorGOCREATE TABLE [dbo].[t_cdc_ta]([id] [int] PRIMARY KEY NOT NULL,[name] [varchar](20) NULL,[addr] [varchar](20) NULL,[ttime] [datetime] NULL)GOCREATE PROC [dbo].[p_merge]@oper INT,@id INT,@name VARCHAR(20),@addr VARCHAR(20),@ttime DATETIMEAS-- 删除IF @oper=1BEGINDELETE FROM dbo.t_cdc_taWHERE id=@idENDELSE IF @oper=2 -- 新增BEGININSERT INTO dbo.t_cdc_ta(id,NAME,addr,ttime)VALUES(@id,@name,@addr,@ttime)ENDELSE IF @oper=4 -- 更新BEGINUPDATE dbo.t_cdc_taSET NAME=@name,addr=@addr,ttime=@ttimeWHERE id=@idENDGO停⽤cdcEXEC sp_cdc_disable_tableEXEC sp_cdc_disable_db这样能实现⼀个定时的同步更新,利⽤作业来不断的读取新增加的lsn来更新⽬的数据表,当然同步的时间⼀定要⼤于数据变更的清理作业的时间,默认配置cdc的时候会配置两个jobcdc.db1_capture :捕获变更的作业cdc.db1_cleanup :数据清理作业,每天凌晨两天清理之前看到⼀个哥们在同步数据的时候⽤的 SSIS的条件拆分组件,我测试了下这个数据变更是有先后顺序的,不能直接拆分数据集直接执⾏,这⾥我时显得⽅式是利⽤循环组件⼀条⼀条数据处理,希望能有更好的办法。
flinkcdc原理实践和优化

flinkcdc原理实践和优化Flink CDC(Change Data Capture)是基于Apache Flink的一种数据同步技术,用于在源数据库中捕获数据的变化,并将这些变化传输到目标数据源。
CDC的原理是通过读取数据库的事务日志来监视数据库的变化。
在数据库中,每个被更新的行都会生成一条日志,记录了操作类型(insert、update、delete)、修改前后的数据以及修改所属的事务信息。
CDC利用这些日志来捕获数据的变化并传输到目标数据源。
Flink CDC的实践流程通常包括以下几个步骤:1.配置源数据库的连接信息:包括数据库类型、连接地址、用户名、密码等。
2.配置目标数据源的连接信息:可以是另一个数据库、消息队列、文件系统等。
3. 配置CDC任务的规则:指定需要捕获的表,以及每个表的操作类型(insert、update、delete)。
4. 启动CDC任务:Flink会根据配置的规则连接到源数据库的事务日志,并定期读取和解析日志,将变化传输到目标数据源中。
5. 监控CDC任务:可以通过Flink的监控界面或者命令行查看CDC 任务的状态、数据同步的进度等。
在实际应用中,可以根据具体的需求对CDC进行优化。
以下是一些常见的优化方法:1.增量同步:每次读取事务日志时,只捕获发生变化的数据,而不是全量读取所有数据。
这样可以减少对源数据库的影响,并提高同步的效率。
2.批量写入:将捕获到的变化以批次的方式写入目标数据源,而不是每次都写入一条变化。
这样可以减少网络开销,并提高写入的吞吐量。
3. 并行同步:可以通过增加Flink的并行度来提高CDC任务的处理能力。
可以根据源数据库和目标数据源的性能情况来设置适当的并行度。
4.数据过滤:可以根据条件对捕获到的变化进行过滤,只同步满足特定条件的数据,而忽略其他数据,从而减少传输的数据量和目标数据源的写入负载。
5.目标数据源优化:根据目标数据源的特性,选择合适的数据写入方式和分区策略,以提高写入效率和查询性能。
mysql cdc原理

mysql cdc原理MySQLCDC(ChangeDataCapture)是一种用于追踪和记录数据库表中发生的变化的技术。
MySQLCDC的主要功能是通过捕获数据库表中的变化,以及使用增量技术复制变化到其他数据库表或应用程序中去。
MySQL CDC是一种数据同步技术,可以在多个数据库和应用程序之间同步数据。
MySQL CDC技术主要解决的是数据一致性问题,可以把本地数据库中发生的变化及时地复制到远程数据库中,从而保持数据的一致性。
MySQL CDC原理MySQL CDC是一种基于MySQL binlog的实现原理。
在MySQL中,数据变化会被记录在MySQL的binlog文件中。
binlog文件中会记录所有的数据库变化,包括数据的插入、更新、删除等操作。
MySQL CDC 就是根据binlog文件中记录的数据变化,来把这些变化记录,并同步到其他数据库或应用程序中去,以保持数据的一致性。
MySQL CDC主要包括以下三个组件:binlog reader、data logger data dispatcher。
binlog reader:binlog reader负责读取MySQL binlog文件,并解析出binlog的事件及相关的变化,然后解析出变动的具体内容,并把这些变动发送给data logger。
data logger:data logger负责接收来自binlog reader的变动,并把变动记录在日志中,以便之后把变动同步到其他数据库或应用程序中去。
data dispatcher:data dispatcher负责接收data logger发送过来的变化,并把这些变化同步到其他数据库或应用程序中去,保持数据的一致性。
MySQL CDC的应用MySQL CDC技术主要用于数据同步,可以把本地数据库中发生的变化及时地复制到远程数据库中,从而保持数据的一致性。
MySQL CDC 技术可以用于多个数据库之间的数据同步,也可以应用在数据仓库、高可用性数据库、实时数据分析、数据多活等场景中。
SQL SERVER CDC 增量数据抽取

SQL SERVER CDC 增量数据抽取.目录1、概述 (4)1.1、需求概述 (4)1.2、场景分析 (4)2、依赖关系 (5)3、服务方案 (5)3.1 设计的目标 (5)3.2 相关关键技术说明 (5)3.3、报表服务方案 (11)3.4 报表服务表结构 (13)3.5 报表服务过程及其描述 (14)3.6 报表服务使用 (14)1、概述1.1、需求概述本文档的主要目的是提出和测试报表服务实现,来提高Q3系统的报表统计性能。
该服务方案主要参考ERP报表服务方案,并结合Q3系统与SQLServer2008数据库的特点来实现,并尽量统一规划以提高该方案的兼容性。
1.2、场景分析报表服务需要将要进行统计、分析的数据库某一业务相关数据在一段时间内的变化(增量数据),同步到报表服务中间库,并将统计结果报表同步更新,这就需要:1.报表中间库转储和引用业务库对象。
2.同一数据库实例上不同数据库或分布式数据库的变更数据捕捉3.获得数据增量、并根据增量形成增量报表数据同步报表中间库。
4.或直接同步报表中间库。
5.业务执行的唯一性。
6.抽取日志的记录的记录。
7.增量数据日志记录清除。
8.同步异常记录。
2、依赖关系Q3系统采用SQLServer2008数据库,并且该版本数据库提供了CDC (change data capture)捕获变更数据的方法,并且提供了同义词和数据库级应用锁功能,结合排序函数,为在数据库级别上实现与ERP类似的报表服务提供了可能。
3、服务方案3.1 设计的目标Q3的报表服务方案,要满足如下功能性和非功能性要求。
⏹业务数据增量抽取。
⏹增量数据合并(算法最优)。
⏹增量抽取数据的准确性和有效性。
⏹数据抽取执行线程并发控制唯一性和入口统一性(采用数据库级应用锁并需要进行封装,提供与ERP一致的入口)。
⏹跨数据库或分布式数据库的抽取实现(链接服务器)。
⏹数据同步路径最短、同步效率最高(根据业务数据量和业务的复杂性分别采用不同的数据同步方式)。
四种CDC方案比较优劣
四种CDC⽅案⽐较优劣
抽取处理需要重点考虑增量抽取,也被称为变化数据捕获,简称CDC。
假设⼀个数据仓库系统,在每天夜⾥的业务低峰时间从操作型源系统抽取数据,那么增量抽取只需要过去24⼩时内发⽣变化的数据。
变化数据捕获也是建⽴准实时数据仓库的关键技术。
当你能够识别并获得最近发⽣变化的数据时,抽取及其后⾯的转换、装载操作显然都会变得更⾼效,因为要处理的数据量会⼩很多。
遗憾的是,很多源系统很难识别出最近变化的数据,或者必须侵⼊源系统才能做到。
变化数据捕获是数据抽取中典型的技术挑战。
常⽤的变化数据捕获⽅法有时间戳、快照、触发器和⽇志四种。
相信熟悉数据库的读者对这些⽅法都不会陌⽣。
时间戳⽅法需要源系统有相应的数据列表⽰最后的数据变化。
快照⽅法可以使⽤数据库系统⾃带的机制实现,如Oracle的物化视图技术,也可以⾃⼰实现相关逻辑,但会⽐较复杂。
触发器是关系数据库系统具有的特性,源表上建⽴的触发器会在对该表执⾏insert、update、delete等语句时被触发,触发器中的逻辑⽤于捕获数据的变化。
⽇志可以使⽤应⽤⽇志或系统⽇志,这种⽅式对源系统不具有侵⼊性,但需要额外的⽇志解析⼯作。
CDC⼤体可以分为两种,⼀种是侵⼊式的,另⼀种是⾮侵⼊式的。
所谓侵⼊式的是指CDC操作会给源系统带来性能的影响。
只要CDC 操作以任何⼀种⽅式对源库执⾏了SQL语句,就可以认为是侵⼊式的CDC。
基于时间戳的CDC、基于触发器的CDC、基于快照的CDC是侵⼊性的,基于⽇志的CDC是⾮侵⼊性的。
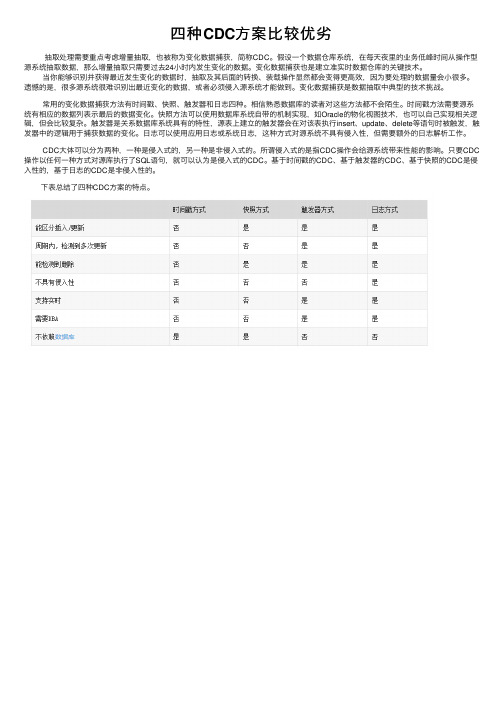
下表总结了四种CDC⽅案的特点。
flinkcdc断点续传案例

flinkcdc断点续传案例摘要:1.Flink CDC 概述2.Flink CDC 的断点续传功能3.Flink CDC 断点续传的实现原理4.Flink CDC 断点续传的案例分析5.Flink CDC 断点续传的优点和局限性正文:一、Flink CDC 概述Flink 是一款开源的流处理框架,可以实现高吞吐量、低延迟、状态管理等功能。
Flink CDC(Change Data Capture,变更数据捕获)是Flink 的一个重要组件,用于捕获数据流中的变更操作,从而实现增量式数据处理。
二、Flink CDC 的断点续传功能在实际应用中,由于计算资源或者网络问题的原因,Flink 任务可能会出现失败或者中断的情况。
为了解决这个问题,Flink CDC 提供了断点续传功能,允许用户在任务失败后,从上次断点的位置继续执行任务,避免重新处理已经处理过的数据,提高了任务的恢复效率。
三、Flink CDC 断点续传的实现原理Flink CDC 断点续传的实现原理主要依赖于Flink 的状态管理功能。
在任务执行过程中,Flink 会将任务的状态信息存储在内存或者文件中。
当任务出现失败时,Flink 会尝试从上次的断点位置恢复任务,加载相应的状态信息,继续执行任务。
四、Flink CDC 断点续传的案例分析假设有一个实时数据处理任务,需要对一批订单数据进行处理,每条订单数据包含订单号、商品名称、价格等信息。
在处理过程中,由于计算资源不足,任务出现了失败。
此时,通过Flink CDC 的断点续传功能,可以从上次的断点位置恢复任务,继续处理剩余的订单数据,避免了重新处理已经处理过的数据。
五、Flink CDC 断点续传的优点和局限性Flink CDC 的断点续传功能可以提高任务的恢复效率,减少重复计算的时间,提高系统的可用性。
然而,该功能也有一定的局限性,例如:断点续传功能依赖于Flink 的状态管理,如果状态信息过大,可能会占用较多的存储空间;同时,如果任务的初始状态信息丢失,断点续传功能将无法生效。
cdc应用场景

cdc应用场景CDC(Change Data Capture)是一种用于捕获数据变更的技术,可以应用于多个场景中,提供了数据同步、数据备份、数据分析等功能。
下面将以CDC应用场景为标题,介绍几个常见的应用场景。
一、数据同步在分布式系统中,数据的同步是一个常见的需求。
CDC可以通过捕获数据源的变更,将变更的数据同步到其他系统中,实现不同系统之间的数据一致性。
例如,在电商平台中,订单系统和库存系统需要保持数据的一致性,当订单系统产生一个新的订单时,CDC可以捕获到这个变更,并将变更的数据同步到库存系统中,以保持系统数据的一致性。
二、数据备份与恢复数据备份是系统运维中非常重要的一环,可以保证系统在出现故障时能够及时恢复。
CDC可以实时地捕获数据变更,并将变更的数据备份到其他存储介质中,以提供数据恢复的能力。
例如,在数据库系统中,CDC可以捕获到数据库的变更,并将变更的数据备份到其他存储设备中,当数据库发生故障时,可以通过CDC提供的备份数据进行恢复,减少系统停机时间。
三、数据分析与报表数据分析对于企业决策非常重要,而CDC可以提供实时的数据变更,为数据分析和报表提供了基础。
例如,在销售系统中,CDC可以捕获到销售数据的变更,并将变更的数据同步到数据分析系统中,分析师可以基于这些实时数据进行销售趋势分析和报表生成,以帮助企业做出更准确的决策。
四、实时数据传输在某些场景下,需要将实时产生的数据传输到其他系统中进行处理。
CDC可以捕获到数据源的实时变更,并将变更的数据传输到目标系统中。
例如,在物联网领域,传感器产生的数据需要实时传输到云平台中进行处理和分析,CDC可以捕获到传感器数据的变更,并将变更的数据传输到云平台中,以实现实时的数据处理和分析。
五、数据集成与扩展在企业中,往往存在多个独立的系统,而这些系统之间需要进行数据的交换和共享。
CDC可以捕获到系统的数据变更,并将变更的数据集成到其他系统中,实现系统之间的数据交换和共享。
cdc应用场景

CDC应用场景的实际应用情况1. 应用背景CDC(Change Data Capture)是一种数据同步技术,用于捕获数据库中的数据变化,并将变化应用到其他数据存储或数据处理系统中。
CDC技术的应用背景主要包括以下几个方面:1.数据库复制:在分布式系统中,将一个数据库的变化同步到其他数据库,以实现数据的备份、负载均衡或数据分析等目的。
2.数据仓库更新:将事务型数据库中的数据变化同步到数据仓库中,以保持数据的一致性和实时性。
3.数据集成:将不同系统或不同数据库中的数据变化进行集成,以实现数据的统一管理和共享。
4.数据缓存更新:将数据库中数据的变化同步到缓存系统中,以提高系统性能和响应速度。
2. 应用过程CDC技术的应用过程可以分为以下几个步骤:1.数据捕获:CDC技术通过监控数据库的日志或使用触发器等方式,实时捕获数据库中的数据变化。
捕获的数据变化包括插入、更新和删除操作。
2.数据解析:捕获到的数据变化需要进行解析,将变化前后的数据进行提取和转换,以便后续处理和应用。
3.数据传输:解析后的数据变化通过网络或其他方式传输到目标系统或存储中。
传输方式可以是同步的或异步的,根据具体应用场景选择合适的方式。
4.数据应用:目标系统或存储接收到数据变化后,根据具体需求进行处理和应用。
可能的应用包括数据复制、数据仓库更新、数据集成、数据缓存更新等。
5.数据一致性检查:在数据应用过程中,需要对数据的一致性进行检查和验证,确保数据的正确性和完整性。
3. 应用效果CDC技术在实际应用中可以带来以下几个方面的效果:1.数据实时性:CDC技术可以实现数据库中数据变化的实时捕获和同步,保证数据的实时性。
例如,在分布式系统中,将一个数据库中的数据变化实时同步到其他数据库,可以保证多个数据库之间的数据一致性和实时性。
2.数据一致性:CDC技术可以捕获到数据库中的所有数据变化,包括插入、更新和删除操作,保证数据的一致性。
在数据集成和数据仓库更新等场景中,CDC技术可以确保数据的完整性和一致性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
CDC增量集成示例一、项目中导入JKM
知识模块中右键“日记(JKM)”,点击“导入知识模块”。
选择“JKM Oracle Simple”,点击确定。
二、配置模型中的日记记录
双击接口源表所在的模型,点击“日记记录”,日记记录模式选择“简单”,知识模块选择刚才导入到项目中的JKM,保存。
三、启用CDC
右键源表,选择“已更改数据捕获”,点击“添加到CDC”
添加后,图标左上角会有橙色时钟,选择“已更改数据捕获”,点击“启动日记”,此时会弹出会话,点击确定后,ODI会在源表数据库自动创建一个源表相关的视图及触发器,
成功后,图标左上角时钟变为绿色
四、修改接口
接口映射中点击源表,勾选下方源属性中的“仅已进行日记记录的数据”,成功后,源表会多出一个沙漏图标。
五、重新生成场景,更新调度
至此,CDC增量集成修改已完成,此后该接口只会针对增删改的数据进行操作,而不是每次都全量集成。
可以右键源表,选择“已更改数据捕获”,点击“日记数据”,来查看数据的变化,日记数据里的内容,就是下次接口执行的时候所要处理的数据。