SIMCA-P使用说明——第二例
SIMCA-P_11.5_指南(中文)要点

SIMCA-P,SIMCA-P+指南11.0版本Umetrics AB1992-2005 Umetrics AB本篇文章诣在告诉本软件使用者一些该软件的注意事项,并且该文件并不能作为Umetrics AB 公司承担义务的一部分。
该软件中的信息(包括所包含的所有数据库)均需要得到已公布或未公布的许可协议方可使用,并且必须在获得许可协议的前提下方可以使用或拷贝,在未得到已公布或未公布的许可协议下擅自的进行软件的拷贝是一种违法行为,在未得到Umetrics AB公司书面许可的前提下,该产品的任何部分不可以再次安装或以任何形式、任何传播方式(包括电子传播方式、机械传播方式)进行软件的传播。
SIMCA是Umetrics 公司的注册商标,Windows是Microsoft 公司的注册商标。
包括以下商品:SIMCA-P,SIMCA-P+编辑日期:2005年5月16日目录SIMCA软件的启动基本操作规程基础信息SIMCA-P软件是以工程(projects)的形式来进行数据的建模处理。
一个工程就是一个包含着主要的数据集(dataset)分析结果(没有模型数量的限制)的集合。
你可以通过输入数据(主要是数据集)来进行一个新的工程的建立。
当你选择活动模型类型(Active Model Type)并列举一个新的工作集或一个已经存在的工作集时,SIMCA-P软件将自主建立不合适的模型。
在一个工程建立的最初,系统默认的工作集包含所有的数据,包含所有的居中变量及方差的变化范围,并将其视作变量X,并且模型是变量X的重要组成部分。
一个工程窗口可以显示每一个模型的分析结果,每一行数据及时对一个模型的分析结果进行总结。
活动模型(即所需要进行建模处理的模型),也可以在灰色区域(status bar)左边的显示框中显示,即在命令菜单的下方。
如果你想打开一个模型,在工程窗口中双击该模型,将打开一个包含模型结果所有信息(一行一个分类)的模型窗口。
SIMCA-P软件使用指南剖析

•
Geometrically
– The swarm of points in a K dimensional space (K = number of variables) is approximated by a (hyper)plane and the points are projected on that plane.
What is Multivariate Analysis
• Multivariate analysis is the best way to summarize a data tables with many variables by creating a few new variables containing most of the information. These new variables are then used for problem solving and display, i.e., classification, relationships, control charts, and more. The new variables, the scores, denoted by t, are created as weighted linear combinations of the original variables. Each observations has t-values. PCA, the basic MV method, summarizes one data table. Plotting the scores (t’s) gives an overview of the observations (objects) PLS summarizes simultaneously 2 data tables (X the predictor variables) and (Y the response variables) in order to develop a relationship between them PCA and PLS are called Projection methods
SIMCA-P详细操作说明书

SIMCA-P操作说明一装机软件一定要装在在C盘里不能装在其他盘里,不然会装不上。
如果还是装不上则重启。
多次尝试就可以二操作1 导入数据将excel中的数据预先处理好之后打开软件,菜单栏file 单击选择“open”或者“new”以下以选择“new”为例。
单击“new”后出现下图选择数据所在文档若为如图所示文件类型,会出现找不到文件,如图无法找到文件则修改格式,将excel.xlsx改为excel.xls,该软件的导入数据格式名称不能含有中文字符,且excel只能适用于97-03版本,故此需要改格式,且有时直接改变后缀在导入数据时会出现如下图所示情况,则选择另存为,并且在保存时将文件类型改为97-03版本并且将文件窗口中的文件类型改为“all files”如图则会出现需要选择的数据文档,初学者不妨多试几次当改好格式与文件类型后导入数据,若数据中有少量数据没有出现,如下图所示状况,可忽略,直接导入数据即可。
成功导入数据,如下图所示但是从图上可以看出与excel中的有差别。
则需要我们手动修改复制粘贴2 PCA主成分图将表中数据进行标定选定第一行物质的名称,然后选择左边菜单栏的深绿色方框primary命令栏选定第三到七行的第一二列,选择左边菜单栏的灰色方框exclude命令栏,在选定第一列,选择左边的深黄色方框primary命令栏,选定第二列,选择左边菜单栏的黄色方框secondary 命令栏,得到下图然后点击“下一步”若出现下图,则选择:“yes to all”则出现下图选择“完成”之后再选择窗口上方菜单栏的“analysis”选择“autofit”出现下图由于软件的原因会有水印,接下来,需要去掉水印并且将纵坐标字体变大,使之便于阅读则双击窗口空白处,出现下图选择左边菜单栏的:“background”如图将窗口右边所有的“background”项选为“white”再选择“OK”双击纵坐标的任意一个数值,出现窗口后选择“front”将“size”改为12.得到下图则此图做好,建议放大后截屏保存,便于之后对于表头的和图示的修饰3 PCA分析散点图依旧选择窗口上方的菜单栏的“analysis”选择“scores”选择“scatter plot”出现窗口后点击“OK”则出现下图去水印和修改坐标之前已经介绍过在此就不在赘述,需要者可以参考上一张图表的制作接下来,需要修改图例,使之更加便于说明问题单击右键选择“properties”在选择“color”出现下图将“coloring”改选为“by categories”出现下图将上图的“variable”改为“GLE”点击“add categoru”点击最下面的红色方框点击“确定”如下图则出现下图然而不同的实验要求的分析不一样,可根据自身不同的需求选择不同的“variable”则此图做好,建议放大后截屏保存,便于之后对于表头的和图示的修饰4 PCA分析载荷图仍然选择窗口上方的菜单栏的“analysis”选择“loadings”选择“scatter plot”出现窗口后选择“确定”出现下图去掉水印,修改坐标轴得则此图做好,建议放大后截屏保存,便于之后对于表头的和图示的修饰。
simcap简易图解教程

Simca-p简易图解教程1.simca-p软件下载,下载地址如下:选第一个SIMCA-P+ 12.0.1 Demo (37 MB),然后把下面的表格填好,就可以下载了,安装时选择试用版的注册码,就可以使用了;好像是有时间限制,不过现在本人已经用了有3天了,还没过期,也不清楚具体试用时间多长。
2.数据导入安装过程不再赘述。
Simca-p不支持直接键盘输入数据,需从已有文件导入,但是支持的文件类型很广。
我是直接用excel2007编辑数据,然后导入,可行。
但如步骤:,选择文件类型为all files ,然后选中你要导入的文件。
接下来还有一些设置,英文比较简单,不再赘述,一般按照默认的即可选择数据所在表(以导入excel文件为例),然后“下一步”导入效果如下图,默认第一列为标识列,第一行为标题行,不过simca-p对中文支持不是很好,导入之后标题中的中文全变成了乱码,可以双击直接在表上改,也可以在建立导入文件时全部使用英文。
下一步,默认设置即可。
如果提示有乱码,必须改正后才能进行此步骤。
导入效果,已经建立project,接下来软件还会提示进行操作,即设定X与y选项值。
默认情况下各列都为X值(自变量),可将因变量设为Y,点中改列名再点右边的“Y”选项即可。
设置完成,如下图,即可开始分析了。
3.分析偏最小二乘法分析最重要的是获得回归参数。
回归参数获取步骤:analysis→coefficients→list(输出为表)或者plot(输出为图)输出为表的结果如下,注意,此输出系数为自变量和因变量数据标准化后的回归参数,本人尚不知标准化前的数据是否可以自动输出。
回归模型检验参数获取方式尚未弄清。
4.模型检验由t[1]/u[1]图可以获得模型整体模型结果,如下图,如线性较好,则说明整体模型效果较好。
模型模拟值和实际值比较:predictions→Y predicted→line plot效果如下图。
如选用list,即可得到模拟值和实际值的比较表格。
SIMCA-P_11.5_指南(中文)要点
SIMCA-P,SIMCA-P+指南11.0版本Umetrics AB1992-2005 Umetrics AB本篇文章诣在告诉本软件使用者一些该软件的注意事项,并且该文件并不能作为Umetrics AB 公司承担义务的一部分。
该软件中的信息(包括所包含的所有数据库)均需要得到已公布或未公布的许可协议方可使用,并且必须在获得许可协议的前提下方可以使用或拷贝,在未得到已公布或未公布的许可协议下擅自的进行软件的拷贝是一种违法行为,在未得到Umetrics AB公司书面许可的前提下,该产品的任何部分不可以再次安装或以任何形式、任何传播方式(包括电子传播方式、机械传播方式)进行软件的传播。
SIMCA是Umetrics 公司的注册商标,Windows是Microsoft 公司的注册商标。
包括以下商品:SIMCA-P,SIMCA-P+编辑日期:2005年5月16日目录SIMCA软件的启动基本操作规程基础信息SIMCA-P软件是以工程(projects)的形式来进行数据的建模处理。
一个工程就是一个包含着主要的数据集(dataset)分析结果(没有模型数量的限制)的集合。
你可以通过输入数据(主要是数据集)来进行一个新的工程的建立。
当你选择活动模型类型(Active Model Type)并列举一个新的工作集或一个已经存在的工作集时,SIMCA-P软件将自主建立不合适的模型。
在一个工程建立的最初,系统默认的工作集包含所有的数据,包含所有的居中变量及方差的变化范围,并将其视作变量X,并且模型是变量X的重要组成部分。
一个工程窗口可以显示每一个模型的分析结果,每一行数据及时对一个模型的分析结果进行总结。
活动模型(即所需要进行建模处理的模型),也可以在灰色区域(status bar)左边的显示框中显示,即在命令菜单的下方。
如果你想打开一个模型,在工程窗口中双击该模型,将打开一个包含模型结果所有信息(一行一个分类)的模型窗口。
SIMCA-P软件使用指南

3/1/2020
SIMCA-P Getting started.ppt
8 (29)
Workset wizard on
ON
3/1/2020
SIMCA-P Getting started.ppt
9 (29)
Workset wizard
variables, observations Preprocessing, Class spec.
Work main menus from left to right
and pop-up menus from up to down
4. Fit the model Analysis Autofit
or fast button
Read Data File Specify Label Cols & Rows
2. Look at the data Data set
Quick Info; Variables or Obs. Preprocessing, Trim, etc.
3. Prepare a work copy Workset
(Y the response variables) in order to develop a relationship between them • PCA and PLS are called Projection methods
3/1/2020
SIMCA-P Getting started.ppt
3/1/2020
SIMCA-P Getting started.ppt
7 (29)
Steps in using SIMCA-P using the wizard
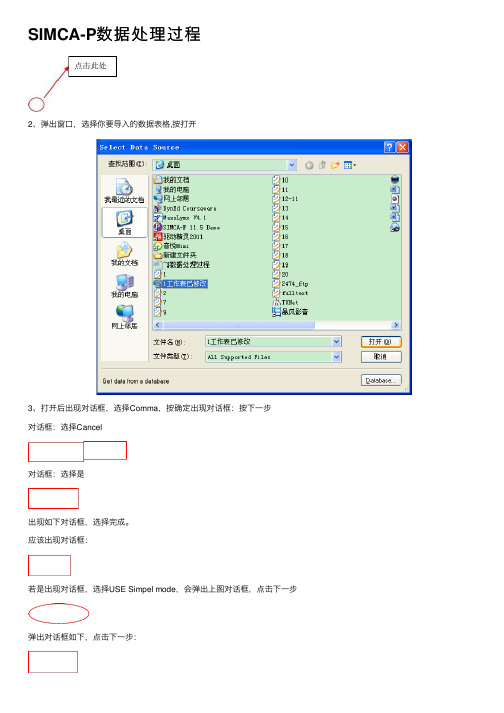
SIMCA-P数据处理过程

2、弹出窗口,选择你要导入的数据表格,按打开3、打开后出现对话框,选择Comma,按确定出现对话框:按下一步对话框:选择Cancel对话框:选择是出现如下对话框,选择完成。
应该出现对话框:若是出现对话框,选择USE Simpel mode,会弹出上图对话框,点击下一步弹出对话框如下,点击下一步:左单击鼠标一直向下拉,从K-1拉到K-6后点击Set Class后的Set此值变为2依次类推直至分完四组后会出现对话框:(同一对话框上下拉的两幅图),按下一步出现对话框如下图,有个Model下拉菜单点击后选择第二个进行PCA分组,然后点击完成。
出现如下对话框:单击后面的1工作表已修改,PCA处理完成。
下面进行PLS-DA处理:如下图所示,选择New,出现对话框如下。
点击下一步,其他操作同前面所示:直至出现对话框如下,在Model下拉菜单点击后选择第三个进行PLS-DA分组,然后点击完成。
会弹出对话框,选择里面的1工作表已修改,有红线里面的选项就说明PCA和PLS-DA分组完成。
后面是处理后的图形和数据查找方式:1、图形查找方式:首先注意选择PCA项,(也可以用PLS-DA项,但是每次只能选择一项)然后如图操作,点击Scatter Plot,然后是确定,观察PCA二维图形变化弹出对话框:具体对应值可以从下图操作方式查找到:VIP值大于1的为潜在标志物。
此处为M/Z与保留时间的对应的代码,可以通过代码找到对应的M/Z与保留时间,用来确定M/Z通过这两行找到对应的M/Z和保留时间。
举个例子:找第一个VIP最大的,如下图操作,我没说错的话你们这行前是保留时间,后面是M/Z,以后可以根据M/Z找到相应的化合物数据处理完毕。
没有出现椭圆,先点这里矫正,再看得分图。
改名字:series,class上面右击,rename。
simca-p简易图解教程

Simca-p简易图解教程1.simca-p软件下载,下载地址如下:/default.asp/pagename/downloads_software/c/1选第一个SIMCA-P+ 12.0.1 Demo (37 MB),然后把下面的表格填好,就可以下载了,安装时选择试用版的注册码,就可以使用了;好像是有时间限制,不过现在本人已经用了有3天了,还没过期,也不清楚具体试用时间多长。
2.数据导入安装过程不再赘述。
Simca-p不支持直接键盘输入数据,需从已有文件导入,但是支持的文件类型很广。
我是直接用excel2007编辑数据,然后导入,可行。
但如步骤:file→new,选择文件类型为all files ,然后选中你要导入的文件。
接下来还有一些设置,英文比较简单,不再赘述,一般按照默认的即可选择数据所在表(以导入excel文件为例),然后“下一步”导入效果如下图,默认第一列为标识列,第一行为标题行,不过simca-p对中文支持不是很好,导入之后标题中的中文全变成了乱码,可以双击直接在表上改,也可以在建立导入文件时全部使用英文。
下一步,默认设置即可。
如果提示有乱码,必须改正后才能进行此步骤。
导入效果,已经建立project,接下来软件还会提示进行操作,即设定X与y选项值。
默认情况下各列都为X值(自变量),可将因变量设为Y,点中改列名再点右边的“Y”选项即可。
设置完成,如下图,即可开始分析了。
3.分析偏最小二乘法分析最重要的是获得回归参数。
回归参数获取步骤:analysis→coefficients→list(输出为表)或者plot(输出为图)输出为表的结果如下,注意,此输出系数为自变量和因变量数据标准化后的回归参数,本人尚不知标准化前的数据是否可以自动输出。
回归模型检验参数获取方式尚未弄清。
4.模型检验由t[1]/u[1]图可以获得模型整体模型结果,如下图,如线性较好,则说明整体模型效果较好。
模型模拟值和实际值比较:predictions→Y predicted→line plot效果如下图。
SIMCA-P使用说明——第二例

矿物质的分类第25页下面这个例子,是从瑞典的的LKAB的一个矿物质分类设备中获得的数据。
LKAB的研究员Kent Tano负责这项调查在这个工艺过程中,粗铁矿石被磨光称为较好的材料(<100 mm, 50% Fe)。
经过磨光,材料被分类和浓缩。
分离包含几条平行的操作线,并且包括一些反馈系统来得到尽可能高纯度的铁。
浓缩的材料被分为两部分,一个是PAR,悬浮式的,另一个是FAR,较好的,是焊接式的。
这两部分的较高的铁含量是非常重要的。
12项操作因素被鉴定出来。
在这些当中,三个重要的因素被用来建立一个数据统计(RSM)。
每一次实验的结果都用6个因变量来表示。
一些个观察点被采集作为对应的设计关键。
这个项目装备了一个ABB Master系统和一个superview 900连接到数据处理系统。
数据从ABB系统,转移到带有SIMCA-P软件的个人电脑设计模型,这些模型在转回superview 900系统进行在线监测。
这项调查是在1992年进行的。
多元在线监控仍在产品质量方面产生非常良好的结果。
第26页总共18个变量,12个X,6个Y231次平行实验也被应用在模型上,每一次实验都有对应的日期和时间。
Table 1中显示的是231次平行观察实验的结果第27页为表1第28页目的本次调查的目的是研究12个自变量和6个因变量之间的关系在SIMCA—P中的操作步骤输入原始数据确定那些是X,那些是Y配置一个合适的模型,首先是PCA,然后是PLS优化模型,如果必要的话移除异常值用PLS模型做预测第29页打开SIMCA-P,输入数据通过NEW/FILE此页的后半部分与我们的软件不同,可不看第30页依次点击commands,create index,variable来产生自变量的标记序号,并且要通过second ID 来准确定位这些变量。
纵列变量用PAR标记,用箭头表示其中一个变量,按顺序将他们以此设定为Y点击NEXT第31页Import wizard界面打开,你可以设定项目的名称和存储的路径,确保use workset wizard方框是选中的,点击Finish,然后workset wizard界面打开这个界面包含了所有平行观察实验的所有变量X与Y,确定X与Y第32页扩展X矩阵采用squares或者cross 功能,这一操作是在advanced mode界面上,点击Expand 三个变量分别是TON_IN, HS_1 and HS_2是变化的根据数据统计系统,我们选择这三个变量扩展X矩阵。
SIMCA-P_11.5_指南(中文)要点
SIMCA-P,SIMCA-P+指南11.0版本Umetrics AB1992-2005 Umetrics AB本篇文章诣在告诉本软件使用者一些该软件的注意事项,并且该文件并不能作为Umetrics AB 公司承担义务的一部分。
该软件中的信息(包括所包含的所有数据库)均需要得到已公布或未公布的许可协议方可使用,并且必须在获得许可协议的前提下方可以使用或拷贝,在未得到已公布或未公布的许可协议下擅自的进行软件的拷贝是一种违法行为,在未得到Umetrics AB公司书面许可的前提下,该产品的任何部分不可以再次安装或以任何形式、任何传播方式(包括电子传播方式、机械传播方式)进行软件的传播。
SIMCA是Umetrics 公司的注册商标,Windows是Microsoft 公司的注册商标。
包括以下商品:SIMCA-P,SIMCA-P+编辑日期:2005年5月16日目录SIMCA软件的启动基本操作规程基础信息SIMCA-P软件是以工程(projects)的形式来进行数据的建模处理。
一个工程就是一个包含着主要的数据集(dataset)分析结果(没有模型数量的限制)的集合。
你可以通过输入数据(主要是数据集)来进行一个新的工程的建立。
当你选择活动模型类型(Active Model Type)并列举一个新的工作集或一个已经存在的工作集时,SIMCA-P软件将自主建立不合适的模型。
在一个工程建立的最初,系统默认的工作集包含所有的数据,包含所有的居中变量及方差的变化范围,并将其视作变量X,并且模型是变量X的重要组成部分。
一个工程窗口可以显示每一个模型的分析结果,每一行数据及时对一个模型的分析结果进行总结。
活动模型(即所需要进行建模处理的模型),也可以在灰色区域(status bar)左边的显示框中显示,即在命令菜单的下方。
如果你想打开一个模型,在工程窗口中双击该模型,将打开一个包含模型结果所有信息(一行一个分类)的模型窗口。
SIMCA-P数据处理过程

2、弹出窗口,选择你要导入的数据表格,按打开点击此处3、打开后出现对话框,选择Comma,按确定出现对话框:按下一步对话框:选择Cancel对话框:选择是出现如下对话框,选择完成。
应该出现对话框:若是出现对话框,选择USE Simpel mode,会弹出上图对话框,点击下一步弹出对话框如下,点击下一步:左单击鼠标一直向下拉,从K-1拉到K-6后点击Set Class后的Set依次类推直至分完四组后会出现对话框:(同一对话框上下拉的两幅图),按下一步此值变为2出现对话框如下图,有个Model下拉菜单点击后选择第二个进行PCA分组,然后点击完成。
出现如下对话框:单击后面的1工作表已修改,PCA处理完成。
下面进行PLS-DA处理:如下图所示,选择New,出现对话框如下。
点击下一步,其他操作同前面所示:直至出现对话框如下,在Model下拉菜单点击后选择第三个进行PLS-DA分组,然后点击完成。
会弹出对话框,选择里面的1工作表已修改,有红线里面的选项就说明PCA和PLS-DA分组完成。
后面是处理后的图形和数据查找方式:1、图形查找方式:首先注意选择PCA项,(也可以用PLS-DA项,但是每次只能选择一项)然后如图操作,点击Scatter Plot,然后是确定,观察PCA二维图形变化弹出对话框:调节这两个下来菜单可以改变分组情况,找出想要得到的分组情况即可此为所要的PCA二维图如下图操作,点击Scatter 3D Plot,然后是确定,观察PCA三维图形变化调节这两个下来菜单可以改变分组情况,找出想要得到的分组情况即可此为所要的PCA三维图2、数据查找方式:首先注意选择PLS-DA项(必须只能选择此项),具体操作如下图所示:具体对应值可以从下图操作方式查找到:VIP 值大于1的为潜在标志物。
此处为M/Z 与保留时间的对应的代码,可以通过代码找到对应的M/Z 与保留时间,用来确定M/Z通过这两行找到对应的M/Z 和保留时间。
SIMCA-P数据处理过程
2、弹出窗口,选择你要导入的数据表格,按打开点击此处3、打开后出现对话框,选择Comma,按确定出现对话框:按下一步对话框:选择Cancel对话框:选择是出现如下对话框,选择完成。
应该出现对话框:若是出现对话框,选择USE Simpel mode,会弹出上图对话框,点击下一步弹出对话框如下,点击下一步:左单击鼠标一直向下拉,从K-1拉到K-6后点击Set Class后的Set依次类推直至分完四组后会出现对话框:(同一对话框上下拉的两幅图),按下一步此值变为2出现对话框如下图,有个Model下拉菜单点击后选择第二个进行PCA分组,然后点击完成。
出现如下对话框:单击后面的1工作表已修改,PCA处理完成。
下面进行PLS-DA处理:如下图所示,选择New,出现对话框如下。
点击下一步,其他操作同前面所示:直至出现对话框如下,在Model下拉菜单点击后选择第三个进行PLS-DA分组,然后点击完成。
会弹出对话框,选择里面的1工作表已修改,有红线里面的选项就说明PCA和PLS-DA分组完成。
后面是处理后的图形和数据查找方式:1、图形查找方式:首先注意选择PCA项,(也可以用PLS-DA项,但是每次只能选择一项)然后如图操作,点击Scatter Plot,然后是确定,观察PCA二维图形变化弹出对话框:调节这两个下来菜单可以改变分组情况,找出想要得到的分组情况即可此为所要的PCA二维图如下图操作,点击Scatter 3D Plot,然后是确定,观察PCA三维图形变化调节这两个下来菜单可以改变分组情况,找出想要得到的分组情况即可此为所要的PCA三维图2、数据查找方式:首先注意选择PLS-DA项(必须只能选择此项),具体操作如下图所示:具体对应值可以从下图操作方式查找到:VIP 值大于1的为潜在标志物。
此处为M/Z 与保留时间的对应的代码,可以通过代码找到对应的M/Z 与保留时间,用来确定M/Z通过这两行找到对应的M/Z 和保留时间。
SIMCA-P数据处理过程
SIMCA-P数据处理过程
2、弹出窗⼝,选择你要导⼊的数据表格,按打开
3、打开后出现对话框,选择Comma,按确定出现对话框:按下⼀步
对话框:选择Cancel
对话框:选择是
出现如下对话框,选择完成。
应该出现对话框:
若是出现对话框,选择USE Simpel mode,会弹出上图对话框,点击下⼀步
弹出对话框如下,点击下⼀步:
左单击⿏标⼀直向下拉,从K-1拉到K-6后点击Set Class后的Set
此值变为
2
依次类推直⾄分完四组后会出现对话框:(同⼀对话框上下拉的两幅图),按下⼀步
出现对话框如下图,有个Model下拉菜单点击后选择第⼆个进⾏PCA分组,然后点击完成。
出现如下对话框:单击后⾯的1⼯作表已修改,PCA 处理完成。
下⾯进⾏PLS-DA 处理:如下图所⽰,选择New,出现对话框如下。
完成。
会弹出对话框,
选择⾥⾯的1⼯作表已修改,有红线⾥⾯的选项就说明PCA和PLS-DA分组完成。
后⾯是处理后的图形和数据查找⽅式:
1、图形查找⽅式:⾸先注意选择PCA项,(也可以⽤PLS-DA项,但是每次只能选择⼀项)然后如图操作,点击Scatter Plot,然后是确定,观察PCA⼆维图形变化
弹出对话框:。
SIMCA-P软件使用指南剖析
Work main menus from left to right and pop-up menus from up to down
4. Fit the model Analysis Autofit or fast button
5. Plot results Analysis Scores, Loadings Distance to Model
Generate the report writer to walk through the model results and interpretation
•
When displaying Simca-P plots always use the Analysis adviser to guide you.
10/27/2018
SIMCA-P Getting started.ppt
10 (29)
Autotransform variables
To transform all variables if any needed, mark the check box
10/27/2018
SIMCA-P Getting started.ppt
7 (29)
Steps in using SIMCA-P using the wizard
• Start a new project and import the data set
•
•
Use the workset wizard to guide through building the workset and fitting the model
– Summarizes the information in the observations as a few new (latent) variables
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
矿物质的分类第25页下面这个例子,是从瑞典的的LKAB的一个矿物质分类设备中获得的数据。
LKAB的研究员Kent Tano负责这项调查在这个工艺过程中,粗铁矿石被磨光称为较好的材料(<100 mm, 50% Fe)。
经过磨光,材料被分类和浓缩。
分离包含几条平行的操作线,并且包括一些反馈系统来得到尽可能高纯度的铁。
浓缩的材料被分为两部分,一个是PAR,悬浮式的,另一个是FAR,较好的,是焊接式的。
这两部分的较高的铁含量是非常重要的。
12项操作因素被鉴定出来。
在这些当中,三个重要的因素被用来建立一个数据统计(RSM)。
每一次实验的结果都用6个因变量来表示。
一些个观察点被采集作为对应的设计关键。
这个项目装备了一个ABB Master系统和一个superview 900连接到数据处理系统。
数据从ABB系统,转移到带有SIMCA-P软件的个人电脑设计模型,这些模型在转回superview 900系统进行在线监测。
这项调查是在1992年进行的。
多元在线监控仍在产品质量方面产生非常良好的结果。
第26页总共18个变量,12个X,6个Y231次平行实验也被应用在模型上,每一次实验都有对应的日期和时间。
Table 1中显示的是231次平行观察实验的结果第27页为表1第28页目的本次调查的目的是研究12个自变量和6个因变量之间的关系在SIMCA—P中的操作步骤输入原始数据确定那些是X,那些是Y配置一个合适的模型,首先是PCA,然后是PLS优化模型,如果必要的话移除异常值用PLS模型做预测第29页打开SIMCA-P,输入数据通过NEW/FILE此页的后半部分与我们的软件不同,可不看第30页依次点击commands,create index,variable来产生自变量的标记序号,并且要通过second ID 来准确定位这些变量。
纵列变量用PAR标记,用箭头表示其中一个变量,按顺序将他们以此设定为Y点击NEXT第31页Import wizard界面打开,你可以设定项目的名称和存储的路径,确保use workset wizard方框是选中的,点击Finish,然后workset wizard界面打开这个界面包含了所有平行观察实验的所有变量X与Y,确定X与Y第32页扩展X矩阵采用squares或者cross 功能,这一操作是在advanced mode界面上,点击Expand 三个变量分别是TON_IN, HS_1 and HS_2是变化的根据数据统计系统,我们选择这三个变量扩展X矩阵。
选中这三个变量TON_IN, HS_1, HS_2,点击button Sq & Cross,点击OK退出这一界面第33页首先为了整体上了解一下因变量,我们选择了一个PC模型来分析Y变量(PCY)当你离开上一届面时,一个不合适的(M1)模型被用PLS的形式创建起来,点击Analysis | Active Model Type并选择PCY。
模型转为PCY。
点击Analysis | 2 First Components来分析Y的两个主成份点击model summary line打开一个数据表,这一数据表包含R2X,R2X(cum),eigen values,Q2,Q2(cum),如上一食品例子所述。
得分t1和t2解释了70.9%第34页得分图和载荷图得分图依次点击Analysis | Scores | Line Plot,来显示t1和t2,在Label Types选择Obs ID (primary).按钮。
第35页得分点显示了不同的观察群组,每一组代表了一个实验设计方向。
测量是每分钟依次记录的。
没有异常值出现。
载荷图依次点击Analysis | Loadings | Scatter Plot来表示p1 vs p2.在Label Types界面选择Use Identifier Var ID (Primary)并点击Save AS Default Options以永久显示变量名称。
第36页在这个图里这三个变量PAR, FAR, %P_FAR是正相关的;负相关的%Fe_FAR. r_Far控制着第二主成份,和PAR是负相关的,而且与2组分中的其它变量只有很小的联系。
%Fe-Malm和这两个主成份中的其它变量基本不相关。
依次点击Analysis | Next Component,计算一个第三组份,显示出p1 vs. p3。
第三组分(解释22%)被%Fe-Malm控制。
第三组份的这个变量与%Fe-FAR, r_FAR and FAR正相关,但与其它变量不相关。
第37页没有异常点出现,除了%Fe-Malm以外,所有因变量都和彼此相关PLS模型New Model Type新模型依次点击Analysis | Active Model type,并选择PLS,出现不合适的模型M2Autofit自动配置依次点击Analysis | Autofit,形成一个带有交叉验证的PLS模型模型显示了R2Y(cum)变量Y所占的分数(根据模型中每一组份解释的),Q2(cum)变量Y所占的分数(根据交叉验证的模型预测的)这几个参数。
R2Y(cum),Q2Y(cum)越接近于1,模型的吻合度越高。
第38页双击model summary line行,显示模型中每一个组分的信息这一模型非常良好的解释了80%的Y变量,实现预测能力Q2到达76%。
Summary: X/Y Overview总结依次点击Analysis | Summary | X/Y Overview | Plot显示出R2Y(cum)and Q2Y(cum),除了%Fe-FAR 和%P-FAR,所有的因变量都有非常好的R2 和Q2Scores t1 vs. t2 得分图依次点击Scores | Scatter plot 和t1 vs. t2,采用标记,标记无关的实验,208个实验与第一主成份偏离较远第39页t1 vs. u1得分图点击右键,选择t1 vs u1,在Label Types选择ObsID (Primary)。
我们得到了非常好的t1 和u1的相关性。
第40页贡献图为了理解208次实验的为什么和其它实验不同,在t1 vs u1图中双击observation 208.这个贡献图表示出了不同之处,用w1*表示粗铁矿(TON_IN)等等远远在平均值以下优化模型我们移除208次实验,重组PLS模型Excluding observation 208 using the interactive tool box移除操作采用interactive tool box在t1 vs u1图中,选中208次实验,点击红色箭头。
移除后如果想产生一个新的不合适的模型M3,点击yes第41页M3模型的Workset bar界面打开了在这一界面按住Ctrl键,选中实验140-146, 173-179,350-379,551-555,点击右键,选择exclude Autofit自动配置依次点击Analysis | Autofit,来完善PLS模型Summary | Model Overview也在自动更新,伴随着模型的装配,可以看到R2Y(cum) 和Q2(cum)的提高第42页Summary: X/Y Overview总结依次点击Analysis | Summary |X/Y Overview | Plot来显示每一个因变量的R2Y 和Q2Y的累计值PAR, FAR and %FE_malm很好的解释了90%,其它的只解释了很少的一部分Scores t1 vs. t2得分图依次点击Analysis | Scores | Scatter t1 vs. t2。
我们可以看到实验是分组的,每一组表示一种设计方法第43页Scores t1 vs. u1得分图我们得到非常好的t1和u1关系图,并且没有任何的异常点Loadings w*c1 vs. w*c2载荷图在前两个主成份中,PAR 和FAR与其他所有载荷变量正相关,而与r_PAR,,%Fe-FaR ,%Fe_Malm三个变量负相关。
除了变量HS_2,模型几乎是直线的,主要解释第二主成份第44页Normal Probability plot of residuals依次点击Analysis | Residuals | Normal Probability Plot,观察这个图,发现残差近乎分散式的并且没有异常点,点击右键,进行调整。
Coefficients系数依次点击Analysis | Coefficients | Plot来显示PAR的PLS的回归系数,置信区间达到95%,主要因素是TON_IN, KR30_in KR40_in and Ton_S3产生一个积极的影响。
第45页Variable Importance变量重要性依次点击Analysis | Variable Importance,显示出与X和Y相关的重要性分析Distance to the Model与模型的距离依次点击Analysis | Distance to the Model | XBlock,来显示与模型的距离在X方向上。
这些距离是正常的单位,并且与行的剩余标准差一致第46页Observation Risk观察风险依次点击Analysis | Observation Risk这个图里显示出每一个Y的Observation Risk,并且表示出较差的情况。
放大349次实验附近的情况,我们可以看到349次实验存在较大的风险。
349次实验存在一个较大的Y的残差,因此它的预测是不确定的,有风险的第47页Predictions预测我们可以用这个模型去预测实验的结果依次点击Prediction | Specify Prediction set | Specify,移除所有的实验,在左侧的窗口中选择Workset Complement,点击Select All,用箭头把所有的变量全部移到左边,选中208次试验,并移除,点击apply,退出这个界面。
第48页依次点击Predictions |Y Predicted | Scatter plot.对于PAR 和FAR,我们都实现了非常良好的预测效果,但是对于其它因变量不如这两个好。