模型箱和加载方法40
工程结构实验简答题答案

1.直接作用和间接作用包括哪些内容?直接作用主要是荷载作用,包括结构的自重,建筑物楼层面的活荷载,重荷载,施工荷载,作用于工业厂房上的旧吊车荷载,机械设备的振动荷载,作用于桥梁上车辆的振动荷载,作用于海洋平台上的海浪冲击荷载等,在特殊情况下,还有地震,爆炸等荷载。
间接作用主要有温度变化,地基不均匀沉降和结构内部物理或化学作用等。
2.常用的加载方法和加载设备有哪些?目前采用的加载方法和加载设备有很多种类,在静力试验中有利用重物直接加载或通过杠杆作用间接加载的重力加载方法,有利用液压加载器千斤顶和液压加载试验机等液压加载方法,有利用绞车差动滑轮组,弹簧和螺旋千斤顶等机械设备的机械加载方法,以及利用压缩空气或真空作用的特殊加载方法等。
在动力实验中可以利用惯性力或电磁系统激振,比较先进的设备是由自动控制,液压和计算机系统相结合而组成的电液伺服加载系统和由此作为振源的地震模拟振动台加载等设备,此外,也可以采用人工爆炸和利用环境随机激振脉动法的方法。
3.重力加载技术包括哪几种方法?不同方法有何优缺点?直接重力加载法,优点是设备简单,取材方便,荷载恒定,缺点是荷载量不能很大,操作笨重。
间接重力加载法(杠杆加载方法),优点是荷载恒定,对持久荷载试验及进行刚度与裂缝的研究尤为适合,缺点是能产生的荷载值小,即使用了杠杆放大,最大荷载也在200kN以下。
4.液压加载系统主要由哪些设备组成?工作原理是什么?常用的液压加载设备有哪些?液压加载系统主要由液压加载器(千斤顶),油泵,阀门等通过油管连接起来,配以测力计和荷载架等组成一个加载系统。
工作的原理是利用高压油泵将具有一定压力的液压油压入液压加载器的工作油缸,使之推动活塞,对结构施加荷载。
常用的液压加载设备有:手动油压千斤顶,同步液压加载系统,双向液压加载千斤顶和结构试验机加载设备。
5.电液伺服加载系统由哪几部分组成?其自控系统的工作原理是怎样的?电液伺服加载系统主要由液压源,控制系统和执行系统三大部分组成,其自控系统的工作原理为将一个工作指令(电信号)加给比较器,通过比较器后进行伺服放大,输出电流信号振动伺服阀工作,从而使液压执行机构的作动器(双饲作用千斤顶)的活塞杆动作,作用在杆件上,连在作动器上的荷载传感器或连在试件上的位移传感器都有信号输出,给放大器放大后,由反馈选择器选择其中一种,通过比较器与原指令输入信号进行比较,若有差值信号,则进行伺服放大,使执行作动器继续工作,直到差值信号为零时,伺服放大的输出信号也为零,从而使伺服阀停止工作,即位移或荷载达到了所要给定之值,达到了进行位移或荷载控制的目的。
three.js加载obj模型

three.js加载obj模型Three.js 是一种轻量级的 JavaScript 图形库,用于在网页上创建和显示 3D 图形。
它支持多种渲染器和几何体,并提供了一个易于使用的 API,使开发人员能够轻松地创建和操纵 3D 模型。
在 Three.js 中,加载和显示 3D 模型是非常常见的需求之一。
本文将介绍如何使用 Three.js 加载和显示 OBJ 格式的模型。
OBJ 是一种常见的3D 模型文件格式,可以用于存储3D 模型的顶点、法线、纹理坐标等信息。
要使用 Three.js 加载 OBJ 模型,首先需要准备一个含有 OBJ 文件的服务器。
OBJ 文件可以用各种 3D 建模软件进行创建和编辑,如Blender、3ds Max 等。
在准备好 OBJ 文件后,将其上传到服务器上的某个目录中。
加载 OBJ 模型的第一步是创建 Three.js 的场景和相机。
场景是所有图形对象的容器,相机决定了视图的位置和方向。
下面的代码片段演示了如何创建场景和相机:```javascriptvar scene = new THREE.Scene();var camera = new THREE.PerspectiveCamera(75,window.innerWidth / window.innerHeight, 0.1, 1000);```接下来,需要创建一个渲染器,用于将场景渲染到浏览器的画布上。
以下代码片段展示了如何创建一个基于 WebGL 的渲染器:```javascriptvar renderer = new THREE.WebGLRenderer();renderer.setSize(window.innerWidth, window.innerHeight); document.body.appendChild(renderer.domElement);```现在,需要从服务器加载 OBJ 文件。
iOS App中数据加载的6种方式

iOS App中数据加载的6种方式我们看到的APP,往往有着华丽的启动界面,然后就是漫长的数据加载等待,甚至在无网络的时候,整个处于不可用状态。
那么我们怎么处理好界面交互中的加载设计,保证体验无缝衔接,保证用户没有漫长的等待感,而可以轻松自在的享受等待,对加载后的内容有明确的预期呢?今天这篇文章,会介绍6种常见的加载模式设计,和3种减少等待感的具体手法,希望对追求极致体验的产品人有帮助。
一、6种常见的数据加载模式目前APP设计中,合理的数据加载方式,主要分如下六种:这六种方式,适用于不同的需求场景,也适用于不同类型的APP,让我们来一一解读。
全屏加载就是整个屏幕白屏进行数据加载,一般会有菊花转配合,常用于手机网页的加载中。
优点是能保证内容的整体性,全部加载完才能够系统化的阅读。
缺点比较明显,就是有非常强烈的等待感,3s以上会产生焦躁情绪,所以在地铁等信号不好的地方,使用手机网页获取内容实在是比较灾难的一件事情。
一般这种情况会配合有明确进度标识的进度条。
如果一个页面有图片有文字,加载图片比较慢的情况下,可以先把文字都加载出来,保证用户可以顺畅阅读,然后再加载比较费流量的图片。
如果是用这一种加载方式,活动页什么的,千万不能重要信息全部放在头图上,导致加载不出来。
重要操作也不能用图片按钮,否则也会有操作显示不出来的风险。
优点是可以帮助用户快速阅读内容,了解信息。
缺点是也许会丢失掉重要的关键信息,无法建立信息获取的闭环。
这种加载形式更加适用于内容阅读型的APP。
当当前页与下一页是整页切换的时候,可以考虑采用整页加载的形式,但是要保证每个页面的数据量不是特别的大。
优点是能保证每个页面的完整性,体验比较整体。
缺点是不好保证整页的加载效率,且有可能影响浏览的流畅度。
一般适用于宫格图片模式、全屏图片模式、网状详情页模式。
自动加载适用于长列表的情况,可以设定规则,默认加载20条,滚动第20条的时候,自动再加载20条。
AI训练中的深度学习模型保存与加载 实用技巧

AI训练中的深度学习模型保存与加载实用技巧引言:在现代人工智能(Artificial Intelligence, AI)领域中,深度学习模型扮演着重要的角色。
深度学习模型的训练是一项耗时耗力的任务,在训练完成后,保存和加载模型成为了关键且实用的技巧。
本文将探讨AI训练中深度学习模型保存与加载的相关技巧。
一、深度学习模型保存在深度学习领域中,模型的保存是非常重要的。
一个保存完整的模型包括了模型的参数、权重、偏置以及网络结构。
以下是几种常见的深度学习模型保存方法:1. 保存整个模型通过保存整个模型,可以方便地加载该模型并在新数据上进行预测。
现代深度学习库(如TensorFlow、PyTorch)通常提供了保存整个模型的功能。
这种保存方式不仅包括了模型的结构,还有训练过程中的所有参数和状态。
在加载整个模型时,可以直接恢复到训练结束时的状态。
2. 仅保存模型参数如果只保存模型的参数,可以节省大量存储空间。
保存模型参数的方式通常包括将参数保存为Numpy数组或其他二进制文件,并在加载时重新构建模型结构。
这种方式的缺点是需要手动定义和构建模型架构,对于复杂的网络结构来说较为繁琐。
3. 冻结模型部分层在一些情况下,为了保持模型的某些层固定不变(如预训练模型的特征提取器),可以选择冻结模型的部分层并在保存时只保存这些层的参数。
冻结模型的写入可以通过设置层的`trainable`属性来实现,在保存模型时仅保存被设置为非冻结状态的层参数。
二、深度学习模型加载成功加载深度学习模型是使用训练好的模型进行推理、迁移学习或模型继续训练的前提。
以下是几种常见的深度学习模型加载方法:1. 加载整个模型当使用保存整个模型的方式保存时,加载整个模型非常简单。
TensorFlow和PyTorch等深度学习库提供了直接加载整个模型的API,只需调用相应的函数即可完成加载过程。
加载后,模型包含了之前训练过的所有参数和状态,可以直接用于推理或继续训练。
模型导入的操作方法

模型导入的操作方法模型导入的操作方法通常可以分为以下几个步骤:1. 安装相关库:首先需要安装机器学习或深度学习框架,如TensorFlow、PyTorch、Keras等。
具体安装方法可以根据框架官方文档进行操作。
2. 导入模型文件:在程序中导入已经训练好的模型文件。
通常来说,模型文件会以文件扩展名(例如.h5、.pt等)的形式存储。
3. 加载模型:使用相关库的API或函数加载模型文件。
具体的加载方法取决于所使用的深度学习框架。
4. 使用模型:根据具体需求,使用已加载的模型进行预测、推理或其他相关操作。
下面以TensorFlow为例,介绍模型导入的操作方法:1. 安装TensorFlow:可以使用pip命令进行安装,例如:pip install tensorflow。
2. 导入模型文件:将已经训练好的模型文件(例如model.h5)放置在程序所在目录或指定的目录下。
3. 加载模型:使用tf.keras.models.load_model函数加载模型文件。
例如:pythonimport tensorflow as tfmodel = tf.keras.models.load_model('model.h5')4. 使用模型:使用加载好的模型进行预测、推理或其他相关操作。
例如:pythonimport numpy as npinput_data = np.random.random((1, 10)) # 模拟输入数据output_data = model.predict(input_data) # 使用模型进行预测print(output_data)需要注意的是,具体的模型导入操作方法可能因框架和模型类型的不同而有所差异。
因此,在实际应用中,可以根据所使用的框架和模型类型查阅相关文档或资源,以获得更准确的操作指导。
神经网络中的模型存储与加载技巧

神经网络中的模型存储与加载技巧随着深度学习技术的快速发展,神经网络模型的存储和加载成为了一个重要的问题。
在实际应用中,我们通常需要将训练好的模型保存下来,以便后续使用或分享给他人。
同时,加载模型时也需要考虑到效率和灵活性的问题。
本文将介绍一些神经网络中的模型存储与加载技巧。
一、模型的存储方式在神经网络中,模型的存储方式通常有两种:二进制存储和文本存储。
1. 二进制存储二进制存储是将模型以二进制的形式保存到文件中。
这种方式存储的文件通常比文本存储的文件更小,加载速度也更快。
常用的二进制存储格式有HDF5和Protocol Buffers。
HDF5是一种用于存储科学数据的文件格式,支持多种数据类型和数据结构。
Protocol Buffers是Google开发的一种轻量级的数据交换格式,可以高效地序列化结构化数据。
2. 文本存储文本存储是将模型以文本的形式保存到文件中。
这种方式存储的文件可以直接查看和编辑,更加人性化。
常用的文本存储格式有JSON和YAML。
JSON是一种轻量级的数据交换格式,易于理解和使用。
YAML是一种人类可读的数据序列化格式,语法简洁明了。
二、模型的加载方式在神经网络中,模型的加载方式通常有两种:完整加载和逐层加载。
1. 完整加载完整加载是将整个模型一次性加载到内存中。
这种方式适用于模型较小且内存资源充足的情况下。
完整加载的优点是加载速度快,可以直接进行预测和推理。
缺点是占用内存较大,不适用于模型较大或内存资源有限的情况。
2. 逐层加载逐层加载是将模型按层次逐一加载到内存中。
这种方式适用于模型较大或内存资源有限的情况。
逐层加载的优点是节省内存资源,可以根据需要选择加载部分模型。
缺点是加载速度较慢,需要逐一加载每一层。
三、模型存储与加载的技巧在实际应用中,为了提高存储和加载的效率,我们可以采用一些技巧。
1. 压缩模型模型存储时可以采用压缩算法,减小存储空间。
常用的压缩算法有Gzip和Bzip2。
pytorch模型加载与保存函数

pytorch模型加载与保存函数【原创版】目录1.PyTorch 模型加载与保存的重要性2.加载模型的方法3.保存模型的方法4.模型加载与保存的注意事项正文一、PyTorch 模型加载与保存的重要性在深度学习领域,PyTorch 作为当前最受欢迎的框架之一,被广泛应用于各种神经网络模型的设计与训练。
在模型训练过程中,加载与保存模型是非常关键的操作。
合理的加载与保存模型可以节省训练时间,提高工作效率,同时有助于模型的可持续发展。
二、加载模型的方法1.使用 torch.load() 函数PyTorch 提供了一个方便的函数 torch.load(),可以用于加载预训练模型。
该函数可以加载.pth 文件,这是 PyTorch 专用的模型文件格式。
使用示例如下:```pythonimport torchmodel = torch.load("model.pth")```2.从磁盘加载模型除了使用 torch.load() 函数,还可以通过以下方式从磁盘加载模型:```pythonmodel_path = "path/to/your/model"model = torch.load(model_path)```三、保存模型的方法1.使用 torch.save() 函数当训练完成一个模型后,我们需要将其保存以便后续使用。
PyTorch 提供了 torch.save() 函数,用于将模型保存到磁盘。
使用示例如下:```pythonimport torchmodel.save("model.pth")```2.将模型保存到文件除了使用 torch.save() 函数,还可以通过以下方式将模型保存到文件:```pythonmodel.to("cpu")torch.save(model, "path/to/your/model.pth")```四、模型加载与保存的注意事项1.确保模型文件的路径正确,避免出现 FileNotFoundError。
AI训练中的深度学习模型保存与加载 实用技巧

AI训练中的深度学习模型保存与加载实用技巧Deep learning models are widely used in AI training, as they have proven to be effective in solving complex problems. However, managing and preserving these models can be challenging. In this article, we will explore practical techniques for saving and loading deep learning models in AI training. These techniques ensure that the models can be efficiently utilized and maintained.1. IntroductionDeep learning models are commonly used in AI training for various tasks, such as image classification, natural language processing, and recommendation systems. To make the most of these models, it is essential to understand how to save and load them effectively. This article aims to provide useful techniques for managing deep learning models in AI training.2. Saving Deep Learning ModelsOne crucial step in AI training is saving the trained deep learning models. By saving the models, we can preserve them for future use, sharing with others, or deploying them in production environments. Here are some techniques for saving deep learning models:2.1. Model WeightsSaving only the model weights is a common approach in deep learning. By saving just the weights, we can reduce the storage space required. Themodel architecture and configuration are then recreated when loading the model weights.2.2. Entire ModelAlternatively, we can save the entire model, including the architecture, configuration, and weights. This approach provides a more comprehensive representation of the model and ensures its reproducibility. However, it requires more disk space.2.3. Serialization FormatsDeep learning frameworks often support various serialization formats for saving models, such as HDF5, JSON, or Pickle. Each format has its advantages and limitations. It is essential to choose a format that balances file size, compatibility with different frameworks, and ease of use.3. Loading Deep Learning ModelsOnce the deep learning models are saved, we need to know how to load them for further training, evaluation, or deployment. Here are practical techniques for loading deep learning models:3.1. Model ReconstructionIf we saved only the model weights, we need to reconstruct the model architecture and configuration when loading the weights. This process ensures that the loaded model has the same structure as the trained model.3.2. Compatibility and VersioningWhen loading deep learning models, it is crucial to consider compatibility and versioning. Different versions of deep learningframeworks may have variations in model behavior or support. Therefore, it is advisable to save the framework version used during training with the model. This practice ensures proper compatibility and reproducibility.4. Fine-tuning and Transfer LearningFine-tuning and transfer learning are common techniques used to adapt pre-trained deep learning models to new tasks or datasets. When applying these techniques, it is essential to save and load the models correctly. Here are some tips:4.1. Freeze and Unfreeze LayersIn fine-tuning, we often freeze certain layers and only update the weights of specific layers during training. It is crucial to save and load the model in a way that preserves the freezing status of the layers. This approach allows us to continue training from the last checkpoint effectively.4.2. Replace Top LayersTransfer learning typically involves replacing the top layers of a pre-trained model and adding new layers for the target task. When loading the pre-trained model, we need to ensure that the replaced layers are excluded and the new layers are included correctly.5. Model Versioning and TrackingIn AI training, managing different versions of deep learning models is necessary for model comparisons, experimentation, and reproducibility. Here are some techniques for model versioning and tracking:5.1. Version Control SystemsUtilizing version control systems, such as Git, is a common practice for tracking and managing model versions. By committing changes at each step, we can easily track the model's evolution and revert to previous versions if necessary.5.2. Metadata and DocumentationIncluding metadata and documentation when saving the deep learning models can be beneficial for understanding their purpose, training settings, and performance metrics. This information assists in accurately selecting and loading the desired models for specific tasks.6. ConclusionSaving and loading deep learning models properly is crucial for efficient AI training. By applying the discussed techniques, practitioners can manage, preserve, and utilize deep learning models effectively. From saving model weights to implementing fine-tuning and version control systems, these practical tips enhance productivity and reproducibility in AI training.。
支持向量机的模型存储与加载方法

支持向量机的模型存储与加载方法支持向量机(Support Vector Machine,SVM)是一种常用的机器学习算法,广泛应用于分类和回归问题。
在实际应用中,我们通常需要将训练好的SVM模型进行存储和加载,以便在需要时快速调用。
本文将介绍支持向量机的模型存储与加载方法,帮助读者更好地应用SVM算法。
一、模型存储在将SVM模型存储到硬盘上之前,我们需要先将模型训练好。
SVM模型的训练过程是一个迭代优化的过程,通过调整模型的参数使得分类结果最优。
一旦训练完成,我们就可以将模型存储起来,以便后续使用。
常用的模型存储格式有两种:文本格式和二进制格式。
文本格式是一种人类可读的格式,可以用文本编辑器打开查看。
而二进制格式则是一种机器可读的格式,通常比文本格式更加紧凑,存储空间更小。
对于文本格式的存储,我们可以将模型的参数和支持向量等信息保存到一个文本文件中。
这样的存储方式便于人类阅读和理解,但是在加载模型时需要进行解析,相对较慢。
而对于二进制格式的存储,我们可以使用Python中的pickle库进行序列化操作。
pickle库可以将对象转化为字节流,然后存储到硬盘上。
这种方式存储的模型加载速度较快,但是不可读。
二、模型加载在需要使用SVM模型时,我们可以通过加载已存储的模型文件来快速获取模型参数,从而进行分类或回归预测。
如果我们选择了文本格式的存储方式,那么加载模型时需要进行解析操作。
我们可以使用Python中的文件读取函数,逐行读取模型文件,将参数和支持向量等信息提取出来,然后构建SVM模型对象。
如果我们选择了二进制格式的存储方式,那么加载模型时可以直接使用pickle 库的反序列化函数。
我们只需要读取模型文件,然后使用pickle库的load函数将模型对象从字节流中恢复出来即可。
需要注意的是,在加载模型时,我们需要确保模型文件的路径和文件名正确无误。
否则,加载过程可能会失败。
三、模型存储与加载的注意事项在进行模型存储与加载时,我们需要注意以下几个方面。
ChatGPT中的模型保存和加载方法

ChatGPT中的模型保存和加载方法ChatGPT是一个基于Transformer模型的自然语言生成模型,它可以用于生成对话、回答问题等任务。
在使用ChatGPT进行训练和生成对话时,模型的保存和加载方法是非常重要的。
本文将介绍ChatGPT中的模型保存和加载方法,以帮助读者更好地理解和使用该模型。
一、模型保存方法在ChatGPT中,保存模型可以帮助我们在需要时重新加载已经训练好的模型,而无需重新训练。
ChatGPT使用了Hugging Face的Transformers库,该库提供了方便的模型保存和加载功能。
首先,我们需要将ChatGPT模型保存为文件。
保存模型的方法如下:```pythonfrom transformers import ChatGPT# 创建ChatGPT模型model = ChatGPT()# 训练模型...# 保存模型model.save_pretrained("path/to/save/model")```在上述代码中,我们首先创建了一个ChatGPT模型,并进行了训练。
然后,我们使用`save_pretrained`方法将模型保存到指定的路径中。
保存模型后,我们可以将其用于生成对话或其他任务。
下面是一个使用保存的ChatGPT模型进行对话生成的示例:```pythonfrom transformers import ChatGPT# 加载保存的模型model = ChatGPT.from_pretrained("path/to/saved/model")# 使用模型生成对话response = model.generate_response("Hello!", max_length=50)print(response)```在上述代码中,我们使用`from_pretrained`方法加载保存的模型。
然后,我们使用加载的模型生成对话,`generate_response`方法用于生成回复。
模板和加载项使用方法

模板和加载项使用方法全文共四篇示例,供读者参考第一篇示例:模板和加载项是在软件开发中经常使用到的工具,它们可以帮助开发者更高效地创建和管理代码。
在本文中,我们将介绍模板和加载项的基本概念,并且详细讨论它们在不同开发环境中的使用方法。
一、模板的概念和使用方法1. 模板是一种可以重复使用的代码片段,它可以包含文本、代码和标记等元素。
在软件开发中,我们经常会遇到一些重复性高的工作,比如创建类、方法、页面等。
使用模板可以帮助我们快速地生成这些重复性的代码片段,从而提高工作效率。
2. 不同的开发工具和环境提供了不同类型的模板功能。
比如在IDE中,我们可以通过模板快捷键或者菜单来快速生成代码。
在一些代码生成工具中,我们可以通过配置模板文件来自定义生成的代码。
3. 使用模板的方法通常包括三个步骤:选择模板、填写参数、生成代码。
通过这三个步骤,我们就可以快速地生成我们需要的代码片段。
1. 加载项(Add-Ins)是一种可以扩展软件功能的插件,它可以在软件中添加新的功能或者工具。
加载项通常包括一些代码和配置文件,它们可以与软件进行交互,并且可以与软件内部的api进行通信。
2. 在不同的开发环境中,加载项的实现方式也会有所不同。
比如在微软的Visual Studio中,我们可以通过C#或者来编写加载项。
在一些网页开发工具中,我们可以通过Javascript或者其他脚本语言来实现加载项的功能。
3. 加载项的使用方法通常包括四个步骤:安装加载项、启用加载项、使用加载项、禁用加载项。
通过这四个步骤,我们就可以扩展软件的功能,实现更多的定制化需求。
三、模板和加载项的实际应用1. 模板和加载项在软件开发中有着广泛的应用。
比如在前端开发中,我们可以使用模板来生成页面的结构和样式。
在后端开发中,我们可以使用模板来生成数据库操作代码。
2. 加载项也是一个很有用的工具,它可以帮助我们扩展软件的功能,实现更多的定制化需求。
比如在一个网页编辑器中,我们可以使用加载项来添加新的插件,增强编辑器的功能。
AI训练中的深度学习模型保存与加载 实用技巧

AI训练中的深度学习模型保存与加载实用技巧深度学习模型的保存与加载是人工智能(AI)训练中至关重要的一环。
通过保存与加载模型,我们可以在不重新训练的情况下复用已经训练好的模型,从而提高训练效率。
本文将介绍几种实用技巧来保存和加载深度学习模型。
一、保存与加载整个模型深度学习模型通常由模型的结构和模型的参数两部分组成。
我们可以使用以下代码将整个模型保存为一个文件:'''import torch# 定义模型class MyModel(torch.nn.Module):def __init__(self):super(MyModel, self).__init__()# 模型结构定义def forward(self, x):# 模型前向传播定义# 实例化模型model = MyModel()# 保存模型torch.save(model, 'model.pt')'''要加载保存的整个模型,可以使用以下代码:'''import torch# 加载模型model = torch.load('model.pt')'''二、仅保存与加载模型参数有时候,我们只需要保存和加载模型的参数,而不保存和加载整个模型的结构。
这在模型结构发生变化的情况下非常实用。
以下代码展示了如何仅保存和加载模型参数:'''import torch# 定义模型class MyModel(torch.nn.Module):def __init__(self):super(MyModel, self).__init__()# 模型结构定义def forward(self, x):# 模型前向传播定义# 实例化模型model = MyModel()# 保存模型参数torch.save(model.state_dict(), 'model_params.pt')# 加载模型参数model.load_state_dict(torch.load('model_params.pt'))'''三、在训练和测试之间切换模型状态在实际应用中,我们通常会在训练和测试过程中切换模型的状态,以便在测试时获得更准确的结果。
stablediffusion加载大模型写法

随着大型神经网络模型的日益普及,stablediffusion加载大模型成为了一种常见的实践方法。
其通过逐步加载模型的各个部分,以减少对内存的特殊需求,从而实现了在资源受限的环境下也能够有效地加载大型模型的目的。
stablediffusion加载大模型的写法主要包括以下几个步骤:1. 理解模型结构:在进行stablediffusion加载大模型之前,首先需要对目标模型的结构有所了解。
这包括模型的各个组成部分,如卷积层、全连接层等,以及它们之间的连接关系。
只有对模型结构有清晰的认识,才能够有针对性地进行加载操作。
2. 划分加载阶段:将模型的加载过程划分为多个阶段,每个阶段只加载模型的一部分。
通常可以按照层级进行划分,先加载模型的基础部分,再逐步添加更深层次的组件。
这样可以有效地控制内存的占用,避免因为一次性加载整个模型而导致内存不足的情况。
3. 实现逐步加载:在代码实现上,可以通过各种方式实现逐步加载的操作。
可以使用Python中的`h5py`库来操作HDF5文件,逐层读取模型的权重和结构信息,并逐步构建完整的模型。
这样一来,即使模型非常庞大,也能够在资源受限的环境下进行有效加载。
4. 考虑模型压缩:除了逐步加载外,还可以考虑对模型进行压缩。
通过剪枝、量化等方法,可以减少模型的参数数量,从而降低模型的大小。
这样不仅可以减少加载时所需的内存,还可以提升模型的推理速度,是一个值得尝试的优化方向。
stablediffusion加载大模型是一种相对成熟的解决方案,通过合理的分阶段加载和模型压缩等手段,可以在资源受限的环境下依然能够高效地加载大型神经网络模型。
这对于一些嵌入式设备、移动端应用等场景而言具有重要意义,也是当前神经网络模型部署和优化中的一个关键技术。
随着人工智能技术的不断发展,神经网络模型的规模和复杂度也在不断增加。
大型神经网络模型通常具有数百万甚至数十亿的参数,需要大量的计算资源和内存来进行训练和推理。
PyTorch深度学习模型的保存和加载流程详解

PyTorch深度学习模型的保存和加载流程详解⼀、模型参数的保存和加载torch.save(module.state_dict(), path):使⽤module.state_dict()函数获取各层已经训练好的参数和缓冲区,然后将参数和缓冲区保存到path所指定的⽂件存放路径(常⽤⽂件格式为.pt、.pth或.pkl)。
torch.nn.Module.load_state_dict(state_dict):从state_dict中加载参数和缓冲区到Module及其⼦类中。
torch.nn.Module.state_dict()函数返回python中的⼀个OrderedDict类型字典对象,该对象将每⼀层与它的对应参数和缓冲区建⽴映射关系,字典的键值是参数或缓冲区的名称。
只有那些参数可以训练的层才会被保存到OrderedDict中,例如:卷积层、线性层等。
Python中的字典类以“键:值”⽅式存取数据,OrderedDict是它的⼀个⼦类,实现了对字典对象中元素的排序(OrderedDict根据放⼊元素的先后顺序进⾏排序)。
由于进⾏了排序,所以顺序不同的两个OrderedDict字典对象会被当做是两个不同的对象。
⽰例:import torchimport torch.nn as nnclass Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(1, 2, 3)self.pool1 = nn.MaxPool2d(2, 2)def forward(self, x):x = self.conv1(x)x = self.pool1(x)return x# 初始化⽹络net = Net()net.conv1.weight[0].detach().fill_(1)net.conv1.weight[1].detach().fill_(2)net.conv1.bias.data.detach().zero_()# 获取state_dictstate_dict = net.state_dict()# 字典的遍历默认是遍历key,所以param_tensor实际上是键值for param_tensor in state_dict:print(param_tensor,':\n',state_dict[param_tensor])# 保存模型参数torch.save(state_dict,"net_params.pth")# 通过加载state_dict获取模型参数net.load_state_dict(state_dict)输出:⼆、完整模型的保存和加载torch.save(module, path):将训练完的整个⽹络模型module保存到path所指定的⽂件存放路径(常⽤⽂件格式为.pt或.pth)。
pytorch-模型保存与加载自己训练的模型详解

pytorch-模型保存与加载⾃⼰训练的模型详解filename = 'cvae_' + str(epoch+1) + '.pkl'save_path = save_dir / Path(filename)states = {}states['model'] = cvae.state_dict() # 模型参数states['z_dim'] = args.z_dimstates['x_dim'] = args.x_dimstates['s_dim'] = args.s_dimstates['optim'] = cvae.state_dict()torch.save(states, str(save_path)) #检查点:将states字典存放在save_path⽂件下保存和加载模型的时候,配对的函数:对于仅保存state_dict()的⽅式,那保存和加载模型的⽅式为:保存:torch.save(model.state_dict(), PATH)加载:od_state_dict(torch.load(PATH))⼀般加载模型是在训练完成后⽤模型做测试,这时候加载模型记得要加上model.eval(),把模型切换到evaluation模式,这时候会调整dropout和bactch的模式。
对于保存和加载整个模型的情况:torch.save(model, PATH)model = torch.load(PATH)可以看到,前⾯的model.load_state_dict()和这⾥的不同,前⾯的情况需要你先定义⼀个模型,然后再load_state_dict()但是这⾥load整个模型,会把模型的定义⼀起load进来。
完成了模型的定义和加载参数的两个过程。
详细代码1def save(self):2 save_dir = os.path.join(self.save_dir, self.dataset, self.model_name)34if not os.path.exists(save_dir):5 os.makedirs(save_dir)67 torch.save(self.G.state_dict(), os.path.join(save_dir, self.model_name + '_G.pkl'))8 torch.save(self.D.state_dict(), os.path.join(save_dir, self.model_name + '_D.pkl'))910 with open(os.path.join(save_dir, self.model_name + '_history.pkl'), 'wb') as f:11 pickle.dump(self.train_hist, f)12 # 使⽤⽅法:对模型初始化以后,使⽤以下⽅法,加载模型的参数,以⾄于不⽤再对数据集进⾏训练13def load(self):14 save_dir = os.path.join(self.save_dir, self.dataset, self.model_name)1516 self.G.load_state_dict(torch.load(os.path.join(save_dir, self.model_name + '_G.pkl')))17 self.D.load_state_dict(torch.load(os.path.join(save_dir, self.model_name + '_D.pkl'))note:pickle.dump(obj, file, [,protocol]) 序列化对象,将对象obj保存到⽂件file中去。
一种城市级bim模型加载方法

一种城市级bim模型加载方法
一种城市级BIM模型加载方法包括以下步骤:
1. 数据获取:收集城市相关的BIM模型数据,包括建筑物、道路、公园、水体等各种要素。
2. 数据预处理:对收集到的BIM模型数据进行预处理,包括数据清洗、数据格式转换等,以便于后续加载和展示。
3. 数据存储:将预处理后的BIM模型数据存储到数据库中,通常使用空间数据库或图数据库。
4. 模型加载:根据用户需求,从数据库中加载特定的BIM模型数据,并进行渲染和展示。
可以根据需要进行模型的旋转、缩放、移动等操作,以便用户更好地浏览城市模型。
5. 数据更新:对城市BIM模型进行实时更新,可以通过传感器获取实时数据,或者与其他系统进行数据交换,保持模型与实际的一致性。
6. 可视化交互:提供用户友好的界面,让用户可以自由地与BIM模型进行交互,如选择、标注、查询等操作,以便用户能够更好地理解和分析城市模型。
7. 模型分析:对加载的BIM模型进行分析,可以进行可视化分析、空间分析、结构分析等,以便用户能够从模型中获取更多的信息。
需要注意的是,城市级BIM模型加载方法涉及到大规模数据的处理和展示,需要考虑数据的存储和访问的效率,以及系统的并发性能等方面的问题。
skyline三维模型加载流程
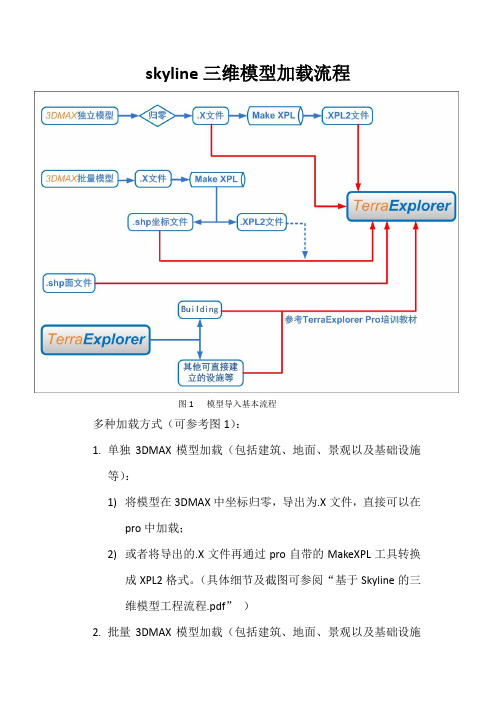
skyline三维模型加载流程
图1 模型导入基本流程
多种加载方式(可参考图1):
1.单独3DMAX模型加载(包括建筑、地面、景观以及基础设施
等):
1)将模型在3DMAX中坐标归零,导出为.X文件,直接可以在
pro中加载;
2)或者将导出的.X文件再通过pro自带的MakeXPL工具转换
成XPL2格式。
(具体细节及截图可参阅“基于Skyline的三维模型工程流程.pdf”)
2.批量3DMAX模型加载(包括建筑、地面、景观以及基础设施
等):
1)将模型逐个直接导出为.X文件,然后通过pro自带的
MakeXPL工具批量转换成XPL2格式,同时将坐标值记录在
其自动生成的shp文件中;
2)在pro中加载shp文件,文件类型选择“3D Model”,file
name项选择shp文件属性字段中的文件名字段(如
“name”),即可。
3.边缘辅助房屋模型加载:
1)首先确定包含房屋轮廓线以及房屋高度属性的shp面文件
已准备好;
2)在pro中导入该shp文件,文件类型选择“building”,房
顶高度与shp文件中的房屋高度字段相关联,即可。
结构检验~学习指南

结构检验一、单选题1•下列实验属于按试验对象分类的是()A. 静力试验B.真型试验C.生产性试验D.现场试验2•在试验中,局部性的试件尺寸可取为真型的()A. 1/4 〜1B.1/4 〜1/2C.1/8 〜1/4D.1/10 〜1/23•下列变形属于整体变形的是()A. 转角B.应变C裂缝D.钢筋滑移4•测定尺寸为20 cmX20 cm X20 cm的混凝土试块强度时,对结果采用的换算系数是()A. 0.95B.1.00C.1.05D.1.105. 下列不属于结构实验准备环节的是()A. 试件制作B.试件安装C.仪器设备的检测D.试验误差的控制6. 当滚轴受力为2〜4kN/mm 时,宜选用的滚轴直径为()A.20 〜40mmB.40 〜60mmC.60 〜80mmD.80 〜100mm7. 仪器最大被测值宜在满量程的()范围内A.1/7 〜2/5B.1/5 〜2/3C.2/5 〜1/2D.1/2 〜2/38. 对于混凝土结构试验,在达到使用状态短期试验荷载值以前,每级加载值不宜大于其荷载值的()A.50%B.40%C.30%D.20%9. 下列因素不影响结构动力特性的是()A.结构形式B.结构刚度C.构造连接D.外部荷载10. 回弹法测定混凝土强度时,对于每一试件的测区数目应不少于()个A.10B.15C.20D.2511. 回弹法测定混凝土强度时,每一测区的大小宜为()cm 2A.100B.200C.300D.40012. 回弹法测定混凝土强度时,每一测区的测点个数宜为()个A.25B.16C.9D.413. 回弹法最终按余下的()个回弹值取平均值A.5B.10C.15D.2014. 回弹法中相邻测点的净距一般不小于()伽A.10B.20C.30D.4015. 以下不属于系统误差来源的是()A.随机误差B.工具误差C.环境误差D.主观误差16. 下列不属于重力加载设备的是()A.加载重物B.活塞杆C.支座D.分配梁17. 以下不属于液压加载设备的是()A.油缸B.单向阀C.滑轮组D.球铰18. 以下不属于惯性力加载设备的是()A.绞车B.保护索C.摆锤D.桩头19. 以下不属于机械力加载装置的是()A.绞车B.激振头C.拉力测力计D.滑轮组20. 以下不属于电磁加载设备的是()A.磁屏蔽B.传感器C.驱动线圈D.气压计21. 以下不能用来测应变的是()A.读数显微镜B.电阻应变计C.位移传感器D.光测法22. 试件支撑装置中各支座支墩的高差不宜大于试件跨度的()A.1/100B.1/200C.1/300D.1/40023. 超声法检测钢管混凝土强度,圆钢管的外径不宜小于()伽A.300B.400C.500D.60024. 当混凝土强度低于(),不宜对结构采用钻芯法检测A.C10B.C20C.C30D.C4025. 当荷载接近抗裂荷载检验值时,每级荷载不宜大于标准荷载的()A.5%B.10%C.15%D.20%26. 以下属于按试验目的分类的是()A.静力试验B.科学研究性试验C.模型试验D.实验室试验27. 以下属于按荷载性质分类的是()A.现场试验B.长期荷载试验C.动力实验D.生产性试验28. 以下属于结构试验设计阶段的是()A.试验人员组织分工B.材料力学性能的测定C.试验加载D.试验安全措施29. 砌体试件尺寸一般取为真型的()A.1/4 〜3/4B.1/4 〜1/2C.1/2 〜3/4D.1/3 〜1/230. 框架节点一般取为真型比例的()A.1/2 〜1B.1/2 〜2/3C.1/4 〜2/3D.1/2 〜3/431. 在试验中,整体性的结构试件可取为真型的()A.1/10 〜1/2B.1/8 〜1/2C.1/6 〜1/2D.1/4 〜1/232. 对于一些比较重要的结构与工程,在实际建成后,要通过(),综合性鉴定其质量的可靠程度A.验算B.试验C.研究D.观察33. 在结构试验中,科学研究性试验解决的问题是()A.判断具体结构的实际承载力B.为工程质量事故提供技术依据C.验证结构计算理论的假定D.检验结构构件产品质量34. 对于研究性试验,确定试件数目的主要因数是()A.试件尺寸B.试件形状C.分析因子和试验状态数D.荷载类型35. 结构试验中常用生产性试验解决的问题是()A. 验证结构计算理论的假定B. 综合鉴定建筑物的设计与施工质量C. 为制定设计规范提供依据D. 为发展和推广新结构、新材料与新工艺提供实践经验36. 将物体本身的重力施加于结构上作为荷载的方法称为()A.液压加载B.气压加载C.重力加载D.电磁加载37. 在现场试验油库等特种结构时,()是最为理想的试验荷载A.土B.水C.砖D.石38. 气压加载法主要是利用空气压力对试件施加()A.静力荷载B.集中荷载C.分布荷载D.均布荷载39. 进行混凝土板承载力试验时,可利用砖作为试验荷载,砖在板面上要分堆堆放,砖堆之间应有5 cm的间隔,其目的是()A. 为了便于分级计量荷载值B. 增加重力加载的安全性C. 预防荷载材料因起拱而对结构产生卸载作用D. 为了真实模拟板面的均布荷载40. 下列()属于重力加载法的设备A.弹簧B.杠杆C.卷扬机D.气囊41. 弹簧加载法常用于构件的()试验A.持久荷载B.交变荷载C.短期荷载D.循环荷载42. 杠杆加载法与其他重力加载法相比较其独特的优点是()A.能产生较大的荷载值B.能产生持久的荷载值C.当荷载有变时,荷载可以保持恒定D.试验加载更安全,荷载计量更方便43. 在电液伺服加载系统中,利用()控制液压油的流量和流速A.液压加载器B.高压油泵C.电液伺服阀D.分油器44. 将加载设备产生的荷载按试验荷载图式的要求正确地传递到试验结构上,同时满足荷载量放大、分配和荷载作用形式转换要求的设备是()A.试件支承装置B.荷载传递装置C.荷载支承装置D.试验辅助装置45. 在选择试验荷载和加载方法时,()项要求不全面A. 试验加载设备和装置应满足结构设计荷载图式的要求B. 荷载的传递方式和作用点要明确,荷载的数值要稳定C. 荷载分级的分度值要满足试验量测的精度要求D. 加载装置安全可靠,满足强度要求46. 对铰支座基本要求的论述中,不准确的是()A.保证结构在支座处的自由转动B.保证结构在支座处力的传递C.保证结构在支座处能水平移动D.支座处的垫板要有足够的强度和刚度47. 预制板和梁等受弯构件一般是简支的,在试验安装时采用()A.正位试验B.反位试验C.卧位试验D.异位试验48. ()项要求非破损检测技术不能完成A. 评定结构构件的施工质量B. 处理工程事故,进行结构加固C. 检测已建结构的可靠性和剩余寿命D. 确定结构构件的承载能力49. 以下检测值()项不需要修正A.回弹法非水平方向的回弹值B.回弹法混凝土浇筑侧面的回弹值C.超声法非混凝土侧面测试的声速值D.钻芯法高径比大于1.0的强度换算值50. 下列对滚动铰支座的基本要求不正确的是()A.保证结构在支座处力的传递B.保证结构在支座处能自由转动C.结构在支座处有钢垫板D.滚轴的直径需进行的强度验算51. 试验荷载装置在满足强度要求的同时还必须有足够的刚度,这主要是试验装置的刚度将直接影响试件的()A.初始形态B.记载图式C.实验结果D.测试数据52. 沿台座纵向全长布置有槽道,用于锚固加荷支架,加载点的位置可沿台座的纵向任意变动的台座称为()A.地锚式试验台座B.槽式试验台座C.箱式试验台座D.抗侧力试验台座53. 以下对测点的阐述不正确的是()A.测点布置宜少不宜多B.测点位置要有代表性C.应布置一定数量的校核性测点D.测点布置要便于测读和安全54. 在确定结构试验的观测项目时,应首先考虑()A.局部变形B.整体位移C.应变观测D.裂缝观测55. 薄壳结构都有侧边构件,为了测量垂直和水平位移,须在侧边构件上布置()A.应变计B.速度计C.挠度计D.温度计56. 手持应变仪常用于现场测量,适用于测量实际结构的应变,且适用于()A.持久试验B.冲击试验C.动力试验D.破坏试验57. 结构在等幅稳定、多次重复荷载作用下的试验是属于()A.拟动力试验B.疲劳试验C.拟静力试验D.冲击试验58. 当用于测量非匀质材料的应变,或当应变测点较多时,为避免各测点相互影响,应尽量采用()A.全桥B.半桥C.1/4桥D.半电桥59. 在结构试验中,可以用两点之间的相对位移来近似地表示两点间的()A.最小应变B.最大应变C.平均应变D.局部应变60. 实验中测量试件混凝土应变时,由于混凝土材料的非均匀性,应变计的标距至少应是混凝土骨料粒径的()倍A.1 〜2B.2 〜3C.3 〜4D.4 〜561. 为得到梁上某截面的最大主应力及剪应力的分布规律,每个测点上要测量()个方向应变值A.1B.2C.3D.462. 基本构件结构性能研究试验,其试件大部分是采用()A.足尺模型B.缩尺模型C.结构模型D.相似模型63. 对象是实际结构的试验称为()A.模型试验B.缩尺试验C.原型试验D.足尺试验64. 现行规范采用的钢筋混凝土结构构件和砖石结构的计算理论,其基础是()A.理论分析B.试验研究的直接结果C.数值计算D.工程经验65. 为了测到试件相对于试验台座或地面位移,通常把传感器支架固定在()A.试件上B.任何表面上C.绝对不动点上D.试验台或地面的不动点上66. 结构试验时要求模型与原型的各相应点的应力和应变、刚度和变形间的关系相似,称作()A.几何相似B.质量相似C.荷载相似D.物理相似67. 采用正交试验法确定试件数目时,正交表L9(34)的含义是()A. 试件数目为4,因子数为3,水平数为9B. 试件数目为9,因子数为4,水平数为3C. 试件数目为3,因子数为9,水平数为4D. 试件数目为9,因子数为3,水平数为468. 结构动力特性主要包括的结构基本参数是()A.自振频率、阻尼系数、结构刚度B.自振频率、阻尼系数、振型C.结构形式、结构刚度、阻尼系数D.结构形式、结构刚度、振型69. 结构在对应某一固有频率的一个不变的振动形式,称为对应该频率时的()A.振型B.振幅C.振源D.振频70. 对构件进行低周反复加载时,为减少竖向荷载对试件水平位移的约束,在加载器顶部装有()A.固定支座B.滚动支座C.铰支座D.支墩71. 低周反复加载试验中,容易产生失控现象的是()A.控制位移等幅、变幅混合加载B.控制力加载法C.控制位移等幅加载法D.控制位移变幅加载法72. 目前在实际工程中应用的非破损检测混凝土强度的方法主要是()A.钻芯法B.预埋拔出法C.回弹法D.后装拔出法73. 回弹仪测定混凝土构件强度时,测区应尽量选择在构件的()A.靠近钢筋的位置B.侧面C.清洁、平整、湿润的部位D.边缘区域74. 屋架试验一般采用()试验A.卧位B.侧位C.正位D.反位75. 轴心受压钢筋混凝土柱试件在安装时()A.先进行几何对中B.先进行物理对中C.只进行物理对中D.只进行几何对中二、判断题1•结构静力试验时加载分级是为了控制加载等级。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
甘肃省地震局兰州地震研究所的 大型电伺服式振动台,由日本 kokusai生产,振动台台面尺寸为 4 m×6 m,总共由28台伺服电机 驱动,其中,垂直向由16台22 kW的AC伺服电机驱动,水平向 由12台37 kW水冷式伺服电机驱 动。
振动台横向AC伺服电机驱动
振动台竖向水冷式伺服电机驱动
利用运动物体质量的惯性施加动力荷载 1冲击力加载法
试验加载测量装置示意图
砝 码
DH3816静态应变仪 试验用土压力计
模型槽尺寸为 1.50x0.31x0.75m, 由厚度为5mm的钢 板焊接而成。
河海大学
(a) 前面
(b)后面
土槽模型试验设备概貌 ①模型槽;②气压活塞加力装置;③氮气瓶、压力表加压装置; ④砝码;⑤桩位移量测装置
采用升降装置抬升模型槽一端,达到倾斜模型槽的 目的,倾斜角度一般为10-30°。在模型槽中制作边坡模 型。
杠杆加载
利用杠杆加载比单纯 重物加载省工省时, 但杠杆应有足够刚度 ,杠杆比一般不宜大 于5。三个支点应在 同一直线上,避免杠 杆放大比例失真,保 证荷载稳定、准确。
(二)面力加载 单位面力强度为常数,如均布堆载、为线性变化, 如水、土压力。 面力加载方法有:重物堆载、挂载,液压加载、气 压加载、千斤顶加载等。 液压多用水和水银,用液压加载可利用液压作用力 沿高度呈三角形分布的特点来模拟水压力。
库水泄水管道
地面
典型的振动台模型土箱分为刚性模型箱、圆筒形柔性模型 土箱、层状剪切模型土箱 3 类。
(1)刚性模型土箱
土箱的整体刚度很大,振动时箱壁的侧向变形非常小。箱壁 常见采用钢板、木板或有机玻璃等材料并辅之以固定刚架。 在国内外早期的振动台试验中应用较多。由于箱壁侧向变 形刚度很大,导致边界上地震波的反射强烈。因此,箱壁上都 需要粘置一些柔性材料以放松土体边界的变形,从而减弱土箱 的边界效应。柔性材料主要有聚苯乙烯泡沫塑料以及海绵等。 柔性材料的性质和厚度对试验中的边界效应有较大的影响。材 料厚且柔,边界土体可能不符合剪切变形特征;材料薄且刚则 吸波能力不够,边界反射依然强烈。另外,还需要考虑箱壁和 箱底的摩擦效应。对于箱壁,通常采用一些薄膜材料以减小箱 壁对土体运动的摩擦作用;对于箱底,通常铺设一定厚度的碎 石等材料以增大摩擦,减小箱底和土体的相对位移。
c、 选择高容重、低强度模型材料的方法 由相似原理 C 1 ,当 c 1 时,即模
C C L
型与原型材料容重相同,不需另加模型自重荷载。但
C CL
, C CE C ,即弹模小,∴强度低。
d、预应力加载 对于预应力钢筋砼或其它预应力结构,预应力产 生的载荷在模型在施加的方法一般有两种。一是采用 锚头和张拉设备;另一种方法是施加外载,但应在弹 性范围内。
(1)激振法 小尺寸模型的激振可采用声波(扬声器)或压电 晶体激振模型,强迫模型振动的激振。 大尺寸模型可采用冲撞形式施加。 (2)电磁振动法 电磁振动台是模型试验中常用的加载方法。 (3)电液伺服法 这是目前最先进的动力加载方法。精度高。
电磁式激振器 磁系统(励磁线圈、铁心、磁极板)、动圈(工作 线圈)、弹簧、顶杆。
刚性密封模型箱
其内箱尺寸2.8 m× 1.4 m× 1.0 m,长度方向两侧为有 机玻璃板,板厚30 mm,宽度方向两侧普通碳钢板,板厚 20 mm。四角固定M20吊环以便吊装。底部采用50个六角 螺钉组M16×60固定在振动台台面上
0.6m
1.8m
Meymand最早研制了圆筒形柔性模型土箱,并进行了桩– 土相互作用的三向振动台试验。 该土箱侧壁为一块围成圆筒形的橡胶膜,其上端固定于上 部钢圆环,下端固定在下部基底钢板上。土箱的径向刚度由若 干根围成圆形的外包纤维带或钢丝提供。外包纤维带或钢丝的 间距要适中,间距太小,则箱壁刚度可能过大;间距太大,则 橡皮膜的柔性可使土体在振动过程中向外膨胀,土体可产生弯 曲变形。1Biblioteka 初位移加载法第二章荷载与加载
1冲击力加载法 2)初速度加载法
利用摆锤或落重的方法使结构瞬时受到水平或垂直冲 击,产生一个初速度,同时使结构获的一个冲击荷载。
3)反冲激振法 反冲激振法就是爆炸加载。利用火药或炸药使之 燃烧或引起爆炸,产生冲击荷载作用于试验结构或建 筑物。炸药爆炸后以应力波或冲击波的形式作用于试 验结构或建筑物,而火药燃烧是通过火箭激振加载器 以激振力的形式作用于结构或建筑物。 火箭激振加载也称为反冲激振器加载,是利用火 箭发动机的原理对试验结构施加荷载的。
2离心力加载法 离心加载使根据旋转质量产生离心力对结构 施加简谐荷载,特点具有周期性,作用力和频率 按一定规律变化,使结构产生强迫振动。 ♦ 优点:结构简单,容易产生较大振幅和激振力; ♦ 缺点:频率低,振幅调节难,只能产生简谐荷载 。
常用机具包括:吊链(葫芦)、卷扬机、花篮螺丝、螺 旋千斤顶、弹簧等; 适用于施加水平荷载; ������ 优点:设备简单,集中力的方向便于控制;方便 对结构施加拉力,与滑轮组合改变力的方向和大小, 拉力一般有测力计测得。 ������ 缺点:荷载较小,加卸载速度慢,荷载作用点的 变形会引起荷载值的较大改变。
(一)液压源 液压源是加载过程中的动力源,由油泵输出高压油,通过伺服阀控 制,进出加载器的两个油腔产生推拉荷载。为保证油压的稳定性,系统 中一般带有蓄能器。 (二)控制系统 电液伺服程控系统是由电液伺服阀和 计算机联机组成。 电液伺服阀是电液伺服系统的核心部 件,构造原理如图。当电信号输入伺 服线圈时,衔铁偏转,带动一挡板偏 移,使两边喷嘴油的流量失去平衡, 两个喷腔产生压力差,推动滑阀滑 移,高压油进入加载器的油腔使活塞 工作。滑阀的移动,又带动反馈杆偏 转,使另一挡板开始上述动作。如此 反复运动,使加载器产生动或静荷载。 由于高压油流量与方向随输入电信号而改变,再加上闭环回路的控制便 形成了电-液伺服工作系统。
拉力测力装置布置图
被认为是目前较为理想的能提供土体剪切变形条件的模 型土箱,通常由若干各自独立的刚制或铝制的矩形或圆形的 层状框架拼装而成。层状框架间放置一定数量的滚动轴承, 一方面限制竖向和侧向运动,另一方面使得框架间可以在振 动方向上相对滑动以模拟土的剪切变形。 Whitman 等提出了一种叠环式模型箱。该土箱由一组相 互之间无摩擦的叠环组成,允许土样沿水平方向发生剪切变 形,最大限度地限制了边壁处的反射波。 模型土箱应该尽可能轻,箱壁与土体之间有适当的摩擦 并且在振动过程中不消耗能量。理想情况下,变形完全由土 体控制,不受边界影响。此后,层状剪切土箱的研制和应用 得到了很大发展。
南京工业大学 模型土箱净 尺寸设计为 3.5 m(纵向) ×2.0 m(横向)×1.7 m( 竖向) 。 采用 15 层叠层方钢管框架 并辅之以双侧面钢板约束的 方案。
除最上一层框架外,其余框架间两侧分别焊接两片200 mm×80 mm×10 mm 不 锈钢垫板。在钢垫板上沿水平振动方向设置V形凹槽,凹槽内放置钢滚珠若干 ,形成可以自由滑动的支承点。模型土箱内壁贴厚度为2 mm的橡胶膜,以防止 土箱内土和水的漏出,模型土箱与振动台面之间用螺栓固定。
漳河渡槽模型加载装置
千斤顶加载
在模型试验中,体力是一项重要的荷载,它是指结 构、基础结构及其地基岩土的自重。 通常施加体力的方法有: ①、用分散集中载荷代替自重 ②、用面力代替体力的方法 ③、选高容重、低强度模型材料。 a 、用分散集中力代替体力方法 将模型划分成许多部分,找出每一部分重心,然后施 加等于该部分模型自重的集中载荷。 b、 用面力代替体力的方法。 对于常体力弹性模型,可采用以面力代替体力。
(一) 集中力加荷
通常采用挂重法、杠杆加载和千斤顶加载等。 挂重法:数值稳定、载荷值不自动下降,其缺点是 能产生的载荷值较小,一般≯200KN,加、卸载不方 便。 千斤顶加载方便、数值大小可调,缺点是设备 较贵。
重物加载
用重物加载的优点是设备简单,取材方便,荷载恒定。 缺点是荷载量不能很大,操作笨重。当进行破坏试验时,因 不能自动卸载,应特别注意安全,一般在试件底部或荷载盘 底下,加可调节的托架或垫块,并随时与试件或盘底保持5cm 左右间隙,以备破坏时托住,防止倒塌造成事故。
利用压缩空气加载,利用抽真空产生负压加载; 适用于平面结构施加均布荷载; 优点:加、卸载方便,荷载稳定、安全,结构破坏 时能够自动卸载; 缺点:加载面无法观测。
第二章荷载与加载
气压加载
漳河涵洞式渡槽为南水北调中线工程中主要跨河建筑物。 试验加荷必须确保槽身底板面上所施加的水荷载均匀分布,竖 向和横向水荷载由气压加载,压力气囊与底板受力变形后保持 协调一致,压力气囊选用弹性大、柔性和抗拉性能好的厚1 mm 的橡胶皮材料制作。
河海大学 槽钢焊接而成的模型槽 中进行,模型槽的长为1.6m,宽 为0.9m,高为1.2m。
试验模型槽
加载及量测装置
水平荷载主要通过钢丝绳、滑轮由砝码施加;桩泥面处的水 平位移由百分表测得,桩前后土压力由竖向埋设的土压力计 量测。桩身测点应变由静态应变仪测得。 滑 模 百 轮 砂 分 型 土 表 桩 模 型 槽
合肥工业大学:尺寸为 1 m×2 m×4 m(高×宽× 长),通过双联升降螺杆组 成的升降装置抬升模型槽的 一端。 在模型槽的正面和顶面 安装了2台高清数码摄像机 组成的影像采集系统。
ARTIFICIAL RAINING SYSTEM
考虑降雨的倾斜模型槽
三峡大学 3.5m ×0.8 m × 8.0 m (高×宽×长)
(三)执行机构 执行机构是由刚度很大的支承机构 和加载器(液压激振器或作动器)组 成。激振器一般为单缸双油腔结 构,刚度很大,内摩擦很小,适应 快速反应要求,尾座内腔和活塞前 端分别装有位移和荷载传感器,能 自动计量和发出反馈信号,分别实 行按位移、应变或荷载自动控制加 载,两端头均做成铰连接形式。 电液伺服工作系统的工作原理是,将一个工作指令(电信号)加给比较器, 通过比较器后进行伺服放大,输出电流信号推动伺服阀工作,从而使液压 执行机构的作动器的活塞杆动作,作用在试件上,连在作动器上的荷载传 感器或连在试件上的位移传感器都有信号输出,经放大器放大后,由反馈 选择器选择其中一种,通过比较器与原指令输入信号进行比较,若有差值 信号,则进行伺服放大,使执行机构作动器继续工作,直到差值信号为零 时,伺服放大的输出信号也为零,从而使伺服阀停止工作,即位移或荷载 达到了所要给定之值,达到了位移或荷载控制的目的。