应用Profiler优化SQL Server数据库系统
SQLServerProfiler(SQl跟踪器)的简单使用

SQLServerProfiler(SQl跟踪器)的简单使⽤⼀、⼯具介绍在实际开发中,我们的数据库应⽤系统因为不可避免会存在有⼤量表,视图,索引,触发器,函数,存储过程,sql语句等,所以会出现⼀系列问题,有问题不可怕,找对⼯具很重要。
接下来我就介绍⼀款性能检测⼯具--SQL Server Profiler,它可以对sql运⾏情况进⾏跟踪,从⽽找出问题所在。
⼆、使⽤⽅法1、打开⼯具可以从开始菜单打开也可以从数据库界⾯打开:2、新建跟踪a、点击:⽂件->新建跟踪b、连接服务器,输⼊地址、账户名、密码c、设置跟踪名称(常规选项)名称可以随意取,如果使⽤多个跟踪时,需要唯⼀名字。
d、选择要跟踪的事件(事件跟踪选项)设置完成后,单击“运⾏”按钮就可以了。
这⾥需要介绍⼀下列选择器的含义:ApplicationName: 创建 SQL Server 连接的客户端应⽤程序的名称。
此列由该应⽤程序传递的值填充,⽽不是由所显⽰的程序名填充的;BinaryData: 依赖于跟踪中捕获的事件类的⼆进制值。
ClientProcessID: 调⽤ SQL Server 的应⽤程序的进程 ID。
CPU: 事件使⽤的 CPU 时间(毫秒)。
Duration: 事件占⽤的时间。
尽管服务器以微秒计算持续时间,SQL Server Profiler 却能够以毫秒为单位显⽰该值,具体情况取决于“⼯具”>“选项”对话框中的设置EndTime: 事件结束的时间。
对指⽰事件开始的事件类(例如 SQL:BatchStarting 或 SP:Starting)将不填充此列。
LoginName: ⽤户的登录名(SQL Server 安全登录或 Windows 登录凭据,格式为“域\⽤户名”)NTusername: Windows⽤户名。
Reads: 由服务器代表事件读取逻辑磁盘的次数。
TextDate: 依赖于跟踪中捕获的事件类的⽂本值;SPID: SQL Server 为客户端的相关进程分配的服务器进程 ID。
sqlserver profiler使用

sqlserver profiler使用摘要:1.简介2.SQL Server Profiler 的用途3.SQL Server Profiler 的安装与配置4.SQL Server Profiler 的使用步骤5.SQL Server Profiler 的示例与实践6.SQL Server Profiler 的高级功能7.总结正文:SQL Server Profiler 是SQL Server 的一个性能分析工具,用于捕获、跟踪和分析数据库中的所有事件。
它能够帮助用户诊断和解决SQL Server 性能问题,优化SQL 查询,提高数据库的运行效率。
1.简介SQL Server Profiler 是一个强大的性能分析工具,它允许用户捕获、跟踪和分析数据库中的所有事件。
通过使用SQL Server Profiler,用户可以深入了解SQL Server 的运行情况,发现性能瓶颈,并对SQL 查询进行优化。
2.SQL Server Profiler 的用途SQL Server Profiler 主要用于以下场景:- 诊断和解决SQL Server 性能问题- 优化SQL 查询- 提高数据库的运行效率- 分析数据库的访问模式- 监控数据库活动3.SQL Server Profiler 的安装与配置SQL Server Profiler 作为SQL Server 的一个组件,无需额外安装。
只需在SQL Server Management Studio 中,通过“工具”菜单打开SQL Server Profiler 即可。
在使用SQL Server Profiler 之前,需要对跟踪事件和数据进行配置,以便收集到所需的信息。
4.SQL Server Profiler 的使用步骤SQL Server Profiler 的使用步骤如下:- 打开SQL Server Profiler:在SQL Server Management Studio 中,通过“工具”菜单打开SQL Server Profiler。
快速应用SQL_Server事件探查器(SQLServer2008)

模板 每次启动事件探查器监视时都会让您选择一个模板来进行跟踪,默 认是一个标准模板(SQLProfilerStandard)。里面有事先定义好的 的事件和数据列,没有筛选。 我们可以创建一个模板以指定使用哪些事件、数据列和筛选。然后 可以保存该模板,并用当前的模板设置启动跟踪。捕获的跟踪数据 基于模板中指定的选项。模板不执行且必须用 .tdf 扩展名保存到 文件。
警告:使用相同的名称保存跟踪文件将重写原来的跟踪文件,这将导致任何当 初捕获的事件或已删除或筛选的数据列丢失
SQL 事件探查器术语
事 件 事件是在 Microsoft SQL Server 引擎中生成的操作。 例如: 登录连接、失败和断开。 Transact-SQL SELECT、INSERT、UPDATE 和 DELETE 语句。 远程过程调用 (RPC) 批处理状态。 存储过程的开始或结束。 SQL 批处理的开始或结束。 存储过程内的语句的开始或结束。 写入 SQL Server 错误日志的错误。 在数据库对象上获取或释放的锁。 打开的游标。 安全权限检查。 由事件生成的所有数据显示在单个行中的跟踪内 。该行包含详细描述 事件的数据列,称为事件类。
SQL Server事件探查器使用说明
用友医疗 PUB-HRPS开发部 2014年 3月
整体概念
SQL Server事件探查器(Profiler)可以帮助数据库 管理员及其他人员跟踪SQL Server数据库所执行的 特定事件,监视数据库的行为;并将这些有价值的信 息保存到文件或表,以便以后用来分析解决数据库 出现的问题,对数据库引擎性能进行优化。 例如:对于HRP实施及开发人员可以达到以下目的: 1.追踪功能操作在数据库后台所影响的物理表, 视图或存储过程等。 2.当发生系统异常或报错时,追踪是发生在操作 哪个数据库对象。 3.追踪影响操作性能的数据库后台执行记录。
sqlserverprofiler使用教程

sqlserverprofiler使⽤教程
1.进⼊SSMS后,点击Tools找到Profiler点击打开。
2.进⼊profiler后点击New Trace
3.连接你想要监控的服务器。
4.进⼊后在General后选择合适的监控模板(下图中选择的是TSQL_Sps即存储过程监控模板),然后转到Events Selection 页⾯。
5.在Events Selection页⾯中选择 Show all Colums,然后你可以选择你需要column,然后点击Column filter可以进⼊筛选。
注意在Column下⽅有⼀个Organize Columns,点击它后可编辑要显⽰列的前后顺序。
6.筛选页⾯如下,选中你要筛选的列后填写相应的筛选条件。
下图为筛选ObjectName(即procedure的名称),最好选中下⽅的Exclude row that do not contain values(排除不包含的值。
)
下图为筛选后显⽰截图……
由于才开始使⽤此⼯具,对其操作不太了解,特记之以备忘。
sqlserver profiler使用

sqlserver profiler使用摘要:1.SQL Server Profiler 简介2.SQL Server Profiler 的主要功能3.SQL Server Profiler 的操作步骤4.SQL Server Profiler 的实战应用5.SQL Server Profiler 的优缺点6.总结与建议正文:本文将详细介绍SQL Server Profiler的使用,包括其简介、主要功能、操作步骤、实战应用、优缺点以及总结与建议。
通过阅读本文,读者可以更好地了解和运用SQL Server Profiler,从而提高数据库管理和维护效率。
1.SQL Server Profiler 简介SQL Server Profiler是一款由微软推出的数据库性能分析工具,它可以捕获和分析SQL Server中的数据库引擎、查询处理器和存储引擎的事件。
通过SQL Server Profiler,数据库管理员(DBA)可以识别性能瓶颈、排查问题并优化数据库性能。
2.SQL Server Profiler 的主要功能SQL Server Profiler具备以下主要功能:- 实时监控:实时捕获数据库中的事件,便于DBA及时发现性能问题。
- 事件过滤:根据需求自定义事件过滤器,仅捕获关心的数据。
- 数据可视化:以图表和报表形式展示捕获到的数据,便于分析。
- 存储事件:将捕获到的events saved to a file 或SQL Server database,方便后续分析。
- 整合性:与SQL Server Management Studio(SSMS)集成,方便操作。
3.SQL Server Profiler 的操作步骤以下是使用SQL Server Profiler的基本操作步骤:- 打开SQL Server Management Studio,点击工具菜单,选择“SQL Server Profiler”。
SQL优化工具及使用技巧介绍

SQL优化工具及使用技巧介绍SQL(Structured Query Language)是一种用于管理和操作关系型数据库的编程语言。
它可以让我们通过向数据库服务器发送命令来实现数据的增删改查等操作。
然而,随着业务的发展和数据量的增长,SQL查询的性能可能会受到影响。
为了提高SQL查询的效率,出现了许多SQL优化工具。
本文将介绍一些常见的SQL优化工具及其使用技巧。
一、数据库性能优化工具1. Explain PlanExplain Plan是Oracle数据库提供的一种SQL优化工具,它可以帮助分析和优化SQL语句的执行计划。
通过使用Explain Plan命令,我们可以查看SQL查询的执行计划,了解SQL语句是如何被执行的,从而找到性能瓶颈并进行优化。
2. SQL Server ProfilerSQL Server Profiler是微软SQL Server数据库管理系统的一种性能监视工具。
它可以捕获和分析SQL Server数据库中的各种事件和耗时操作,如查询语句和存储过程的执行情况等。
通过使用SQL Server Profiler,我们可以找到数据库的性能瓶颈,并进行相应的优化。
3. MySQL Performance SchemaMySQL Performance Schema是MySQL数据库提供的一种性能监视工具。
它可以捕获和分析MySQL数据库中的各种事件和操作,如查询语句的执行情况、锁的状态等。
通过使用MySQL Performance Schema,我们可以深入了解数据库的性能问题,并对其进行优化。
二、SQL优化技巧1. 使用索引索引是提高SQL查询性能的重要手段之一。
在数据库中创建合适的索引可以加快查询操作的速度。
通常,我们可以根据查询条件中经常使用的字段来创建索引。
同时,还应注意索引的维护和更新,避免过多或过少的索引对性能产生负面影响。
2. 避免全表扫描全表扫描是指对整个表进行扫描,如果表中数据量较大,查询性能会受到较大影响。
SQLServer中事件探测器Profiler的使用

SQLServer中事件探测器Profiler的使⽤简单的新建⼀个跟踪就不在这⾥多说了。
⽂件 --> 新建 --> 跟踪。
(也可以直接使⽤功能按钮)我们这⾥主要是讲⼀个精确的跟踪。
注:如果事件探测器在处理过程中检测到了Password,则事件探查器中根本看不到⼀句数据库SQL语句,所有的操作全部都⽤语句句柄来做了,看到最多的就是 exec sp_execute 11,1,即便在事件探查器中添加参数SP:StmtStaring,SP:StmtCompleted,也没有结果,探查器给替换了⽂本。
真是万恶,这样就起到了隐藏代码的⽬的。
1、跟踪指定的数据库有时我们机器上跑了⼏个服务,连了不⽌⼀个数据库,⽽我们⼜只想探测其中的⼀个或⼏个数据库。
这时我们可以设置事件探测器的筛选条件。
①⽂件 --> 属性 --> “筛选”选项卡。
(注意:此时需要将运⾏的跟踪提前停⽌,这样才能在这⾥设置筛选条件,否则只能查看)②找到“DatabaseID”,然后将你需要探测的数据库的id填⼊即可。
查找数据库id的⽅法:(假设数据库名为scm02)SELECT dbid FROM master.dbo.sysdatabases WHERE (name = 'scm02')这⾥也有⼀个DatabaseName的筛选条件,我试了,但是没有效果,暂时不知道这个筛选条件是怎么⽤的。
2、设置筛选的数据列我们新建跟踪时,默认选择的“跟踪模板”是SQLProfilerStander标准模板,⾥⾯筛选的数据列有些是不必要的。
我们如果想把多余的筛选数据去掉的话,可以按如下操作:⽂件 --> 属性 --> “数据列”选项卡。
(注意:需要暂停当前跟踪)数据列名称数据类型说明列ID可筛选ApplicationName nvarchar客户端应⽤程序的名称,该客户端应⽤程序创建了指向 SQL Server 实例的连接。
SQL.Server性能优化工具Profiler

SQL.Server性能优化工具Profiler概述这个实验演示了一些重要的性能优化工具,例如Profiler,动态管理视图和数据库调节顾问。
准备步骤:配置SQL Profiler场景本实验使用SidebySide虚拟机为了后续的练习,你将使用SQL Profiler进行性能分析。
额外准备步骤:配置Database Tuning Advisor场景在后续的项目中将使用Database Tuning Advisor做性能分析。
在整个实验中将多次重复这个步骤。
注意这个实验将配置Database Tuning Advisor来生成调节建议。
练习1:创建表和视图场景练习2:死锁场景练习3:性能分析和调节场景在这个练习中你将使用SQL Profiler,自定义视图和Database Tuning Advisor来进行性能分析。
练习4:分析性能数据场景附录1:创建自定义管理视图USE [AdventureWorks]GOIF OBJECT_ID ( 'dbo.vw_process_waiting_for_resources' ) IS NOT NULL BEGINDROP VIEW dbo.vw_process_waiting_for_resources ENDGOCREATE VIEW dbo.vw_process_waiting_for_resourcesASSELECT wt.session_id,wt.wait_duration_ms,wt.wait_type,e.blocked blocked_by,t.kernel_time,ermode_time,w.state,wt.blocking_task_address,wt.resource_description,w.affinity,e.cpu,e.physical_io,e.memusage,w.context_switch_count,w.pending_io_count,d.Total_Reads,d.Total_Writes,w.is_fiberFROMsys.dm_os_waiting_tasks wtINNER JOINsys.dm_os_workers wON ( wt.waiting_task_address = w.task_address )INNER JOINsys.dm_os_threads tON ( t.worker_address = w.worker_addressAND t.scheduler_address = w.scheduler_addressAND t.thread_address = w.thread_address )INNER JOIN( SELECT session_id, SUM( num_reads ) total_reads, SUM( num_writes ) total_writes FROM sys.dm_exec_connectionsGROUP BY session_id ) dON ( wt.session_id = d.session_id )INNER JOIN( SELECT spid, blocked, cpu, physical_io, memusage FROM sys.sysprocesses ) e ON ( e.spid = wt.session_id )GO附录2:创建数据表1USE [AdventureWorks]GOIF OBJECT_ID ( 'b_table1' ) IS NOT NULLBEGINDROP TABLE lab_table1ENDGOCREATE TABLE b_table1(col1 INT IDENTITY(1,1) PRIMARY KEY CLUSTERED WITH FILLFACTOR = 90,col2 VARCHAR (10) NOT NULL DEFAULT 'Harry',col3 VARCHAR (10) NOT NULL DEFAULT 'Brenda',col4 VARCHAR (10) NOT NULL DEFAULT 'Larry')GOSET NOCOUNT ONDECLARE @l_count BIGINTSELECT @l_count = 1WHILE (@l_count <= 10000)BEGININSERT INTO lab_table1DEFAULT VALUESSELECT @l_count = @l_count + 1ENDSET NOCOUNT OFFGO附录3:创建数据表2USE [AdventureWorks]GOIF OBJECT_ID ( 'b_table2' ) IS NOT NULLBEGINDROP TABLE b_table2ENDGOCREATE TABLE b_table2(col1 INT IDENTITY(1,1) PRIMARY KEY CLUSTERED WITH FILLFACTOR = 90,col2 VARCHAR (10) NOT NULL DEFAULT 'Harry',col3 VARCHAR (10) NOT NULL DEFAULT 'Brenda',col4 VARCHAR (10) NOT NULL DEFAULT 'Larry')GOCREATE NONCLUSTERED INDEX INC_col2 ON b_table2 (col2) WITH ( FILLFACTOR = 90) GOCREATE NONCLUSTERED INDEX INC_col3 ON b_table2 (col3) WITH ( FILLFACTOR = 90) GOCREATE NONCLUSTERED INDEX INC_col4 ON b_table2 (col4) WITH ( FILLFACTOR = 90) GOSET NOCOUNT ONDECLARE @l_count BIGINTSELECT @l_count = 1WHILE (@l_count <= 10000)BEGININSERT INTO b_table2DEFAULT VALUESSELECT @l_count = @l_count + 1 ENDSET NOCOUNT OFFGO附录3:Deadlock附录4:性能分析附录5:分析性能数据。
SQLServer数据库优化实用技巧

SQLServer数据库优化实用技巧SQL Server数据库优化实用技巧随着互联网的飞速发展,海量数据的存储和处理变得越来越重要。
而SQL Server数据库就是其中之一。
随着数据库的规模增大,数据量也会随之增加,导致查询速度变得很慢。
所以,我们需要对SQL Server数据库进行优化来提高其处理速度和稳定性,本文将从以下几个方面来讲解SQL Server数据库的优化实用技巧。
一、数据库优化前的准备工作在进行SQL Server数据库优化之前,我们需要做好以下准备工作:1.备份数据库:在数据库优化之前需要备份数据库,以防因操作失误导致数据丢失。
2.生成关键字:根据数据库的运行情况,生成关键字来优化查询。
例如,数据倾斜、常用的表连接等。
3.性能监控:使用SQL Server Profiler来监控数据库运行的临时数据、活动情况等。
4.目录重建:重建索引,以提高查询速度。
5.删除不必要的表和视图:删除对整个数据库只起到负面影响的表和视图对象。
二、SQL Server数据库性能优化SQL Server数据库性能优化需要注意以下几点:1.数据类型:选择合适的数据类型可以提高数据库的性能。
数据类型包括大小、数据格式等。
尽量使用较小的数据类型,以减少I/O的负担。
2.索引:索引可以大大提高查询速度,但是索引也会占用大量的存储空间,因此需要根据实际情况来选择和创建索引。
为频繁查询的列或组合列创建索引是比较合适的。
3.使用视图:使用视图可以减少数据访问的复杂度,提高查询速度。
但过多的视图也会影响数据库的性能,因此需要注意选择使用视图的频率。
4.分区表:分区表将一个大表分成多个小表,可以提高查询速度,减少对整个表的访问开销。
5.使用存储过程:存储过程可以提高数据库的效率和稳定性。
通过存储过程,可以将多个SQL语句封装到一起,减少客户端和服务器之间的通信,大大提高数据库的性能。
6.升级硬件:在处理大量数据时,硬件性能的升级也是提高数据库性能的有效方法。
使用SQLProfiler优化SQL

使用SQL Profiler优化SQL性能我们在开发基于J2EE架构的应用时,经常会遇到各种各样性能问题,特别是在企业级应用的开发过程中,性能问题时有发生。
而这些性能问题中,有很大一部分是是和数据库相关的,通常执行数据库操作的时间会占到整个响应时间的80%左右。
常见的一些和数据库相关的问题如SQL性能不够优化、索引建的不合理等,都会对程序的性能代理很大影响。
当我们碰到数据库性能问题时,一个比较有效的方法就是直接跟踪每一个 SQL 语句的执行情况,对其进行分析和优化,一般来说优化SQL 语句、创建合适的索引往往会取得很明显直接的效果。
现在有很多工具可以做到监控分析应用程序执行的SQL语句,我们选择开源工具SQL Profiler来执行这一操作,SQL Profiler 是一个由 提供的基于 P6Spy 引擎的图形化快速分析工具,用来统计 SQL 查询语句以便分析在哪些地方可能存在性能瓶颈,在哪里创建索引或者采取相应的办法可能会提高SQL的执行效率,并且能根据 SQL 查询语句的实际执行情况生成一个相对合适的索引脚本。
这个小工具可以实时地显示数据库查询的情况,通过集成的 SQL 解析器,在访问大多数表与列上面建立统计分析,并生成索引脚本。
同时也可以收集和现实其他的信息,比如:单个数据库请求的时间、一类请求的时间以及所有请求的时间。
因此,可以有效地通过对视图的排序来检测可能存在性能问题的点。
这个工具对于大量需要进行分析的请求非常有用,减少了人工逐条语句分析的工作负担和纰漏。
当需要知道比如对相同的表和列进行访问但是采用不同的查询值时,这种分组的查询可以用建立在 ANTLR 上的 SQL 解析器进行辅助分析。
SQL Profiler是基于P6Spy引擎开发的,下面我们结合经常使用的Spring框架开发的应用程序的情况对如何使用SQL Profiler和P6Spy监控SQL语句进行概要的介绍。
P6SpyP6Spy是提供的一个可以用来在应用程序中拦截和修改数据库操作语句的开源框架。
sql profiler用法

SQL Server Profiler是一个功能丰富的界面,用于创建和管理跟踪,并分析和重播跟踪结果。
以下是SQL Server Profiler的基本使用方法:
1. 打开Sql server Profiler,点击开始--程序--Microsoft SQL Server 2005--性能工具--SQL Server Profiler。
2. 在弹出的Sql server Profiler窗口中,鼠标单击“文件---【新建跟踪(N)...】”,弹出数据库连接对话窗口,在对话窗口内输入跟踪的数据库服务器名称、用户名和密码等信息。
3. 输入完成后,单击连接按钮,弹出跟踪属性窗口。
在窗口中左边的“常规”选项卡是一个基本设置,一般使用默认的就OK了。
右边的“事件选择”选项卡,用来设置要跟踪的事件有哪些,列表的事件可以一一选择,基本上Sql上有的事件都有,包括使用SQL Server Management Studio操作数据库的过程都可以跟踪的到,只要单击显示所有事件就可以进行全部事件的选择了。
在使用SQL Server Profiler时,你可以根据不同的需求来选择跟踪的事件类型,比如查询语句的执行情况、登录尝试、权限获取等。
同时,还可以通过重播跟踪来执行负载测试和质量保证,以及分析性能问题等。
以上信息仅供参考,如果在使用过程中遇到问题,建议咨询专业
人士或查阅相关书籍。
sqlserver profiler使用

sqlserver profiler使用SQL Server Profiler 使用指南1. 引言SQL Server Profiler 是一款强大的工具,用于监视和分析SQL Server 数据库中的各种事件和操作。
它可以帮助开发人员和数据库管理员了解数据库的性能、优化查询、调试问题并进行安全审计。
本篇文章将一步一步地介绍如何使用SQL Server Profiler。
2. 安装与启动SQL Server Profiler 是SQL Server Management Studio (SSMS) 的一部分,所以在使用之前,必须先安装并启动SSMS。
可以从Microsoft 官网下载对应版本的SSMS,并按照安装向导进行安装。
安装完成后,在Windows 菜单中找到并启动SQL Server Management Studio。
3. 连接到数据库服务器在SQL Server Management Studio 中,点击“连接到服务器”按钮,在弹出的对话框中输入服务器名和身份验证方式。
如果是本地数据库,可以直接使用“电脑名\实例名”的格式作为服务器名。
如果是远程数据库,需要输入完整的服务器地址。
根据数据库服务器的设置,选择适当的身份验证方式并输入凭据,点击“连接”按钮建立连接。
4. 打开SQL Server Profiler在SQL Server Management Studio 中,依次选择“工具”-> “SQL Server Profiler”打开SQL Server Profiler。
5. 创建一个新的跟踪在SQL Server Profiler 窗口中,点击“文件”-> “新建”-> “跟踪”来创建一个新的跟踪。
在出现的对话框中,输入跟踪的名称和描述,选择要监视的事件和数据列,并可以设置过滤条件和事件列队的大小。
点击“运行”按钮启动跟踪。
6. 监视跟踪结果一旦跟踪开始,SQL Server Profiler 将显示数据列队的实时结果。
sqlserver profiler使用

sqlserver profiler使用摘要:1.SQL Server Profiler 简介2.SQL Server Profiler 的安装与配置3.SQL Server Profiler 的使用方法4.SQL Server Profiler 的功能与特点5.SQL Server Profiler 的实用案例正文:【1.SQL Server Profiler 简介】SQL Server Profiler 是微软SQL Server 数据库管理系统的一款性能分析工具,用于监视和分析SQL Server 的性能,帮助数据库管理员发现潜在的性能问题,提高数据库运行效率。
【2.SQL Server Profiler 的安装与配置】SQL Server Profiler 是SQL Server 的组件之一,因此在安装SQL Server 时,只需确保选中“SQL Server Profiler”组件,即可在安装过程中自动安装。
安装完成后,无需进行额外配置,即可直接使用。
【3.SQL Server Profiler 的使用方法】SQL Server Profiler 的使用方法分为以下几个步骤:(1)打开SQL Server Profiler:在SQL Server Management Studio 中,选择“工具”菜单下的“SQL Server Profiler”命令,即可打开SQL Server Profiler 窗口。
(2)创建跟踪事件:在SQL Server Profiler 窗口中,点击“创建跟踪事件”按钮,选择需要跟踪的事件类型,如“数据库操作”、“对象操作”等,填写相关信息并保存。
(3)启动跟踪事件:在SQL Server Profiler 窗口中,选择需要启动跟踪的事件,点击“启动”按钮,即可开始收集相关数据。
(4)停止跟踪事件:在SQL Server Profiler 窗口中,选择需要停止跟踪的事件,点击“停止”按钮,即可结束数据收集。
sql server profiler 用法

sql server profiler 用法SQL Server Profiler是一种用于监视和分析SQL Server数据库活动的工具。
本文将分步骤阐述SQL Server Profiler的使用方法。
第一步是启动SQL Server Profiler。
在SQL Server Management Studio(SSMS)中,选择“工具”菜单,然后选择“SQL Server Profiler”。
也可以使用Windows命令提示符通过键入“profiler”来启动。
第二步是创建一个新跟踪。
在SQL Server Profiler中,单击“新跟踪”按钮。
接下来,输入跟踪的名称,选择跟踪时长以及其他选项。
第三步是配置跟踪属性,以确定要监视哪些事件。
使用“事件选择器”窗格选择要监视的事件。
可以选择SQL语句、过程、连接等事件。
第四步是选择要监视的服务器和数据库。
在SQL ServerProfiler中,选择“文件”菜单,然后选择“属性”。
在“属性”窗格中,选择要监视的服务器和数据库。
第五步是开始跟踪。
在SQL Server Profiler中,选择“跟踪”菜单,然后选择“启动跟踪”。
或者,使用快捷键CTRL + E。
第六步是分析跟踪数据。
跟踪数据可以随时保存到文件中,然后可以在任何时间进行分析。
在分析跟踪数据时,可以使用多种筛选器来聚焦于指定的事件。
第七步是停止跟踪。
在SQL Server Profiler中,选择“跟踪”菜单,然后选择“停止跟踪”。
或者,使用快捷键CTRL + ALT + F。
SQL Server Profiler是一个非常强大的工具,可以帮助开发人员监视SQL Server数据库的性能和运行情况。
虽然它可以提供大量有用的数据,但也可以对服务器性能造成一定的影响。
因此,在使用SQL Server Profiler时,应尽量避免过多地监视服务器。
应用Profiler优化SQLServer数据库系统-ReadTrace

应⽤Profiler优化SQLServer数据库系统-ReadTrace本页内容1.2.3.4.5.6.概述当你的SQL Server数据库系统运⾏缓慢的时候,你或许多多少少知道可以使⽤SQL Server Profiler(中⽂叫SQL事件探查器)⼯具来进⾏跟踪和分析。
是的,Profiler可以⽤来捕获发送到SQL Server的所有语句以及语句的执⾏性能相关数据(如语句的read/writes页⾯数⽬,CPU 的使⽤量,以及语句的duration等)以供以后分析。
但本⽂并不介绍如何使⽤Profiler ⼯具,⽽是将介绍如何使⽤read80trace(有关该⼯具见后⾯介绍)⼯具结合⾃定义的存储过程来提纲挈领地分析Profiler捕获的Trace⽂件,最终得出令⼈兴奋的数据分析报表,从⽽使你可以⾼屋建瓴地优化SQL Server数据库系统。
本⽂对那些需要分析SQL Server⼤型数据库系统性能的读者如DBA等特别有⽤。
在规模较⼤、应⽤逻辑复杂的数据库系统中Profiler产⽣的⽂件往往⾮常巨⼤,⽐如说在Profiler中仅仅配置捕获基本的语句事件,运⾏⼆⼩时后捕获的Trace⽂件就可能有GB级的⼤⼩。
应⽤本⽂介绍的⽅法不但可以⼤⼤节省分析Trace的时间和⾦钱,把你从Trace⽂件的海量数据中解放出来,更是让你对数据库系统的访问模式了如指掌,从⽽知道哪⼀类语句对性能影响最⼤,哪类语句需要优化等等。
Profiler trace⽂件性能分析的传统⽅法以及局限先说⼀下什么是数据库系统的访问模式。
除了可以使⽤Trace⽂件解决如死锁,阻塞,超时等问题外,最常⽤也是最主要的功能是可以从Trace⽂件中得到如下三个⾮常重要的信息:1. 运⾏最频繁的语句2. 最影响系统性能的关键语句3. 各类语句群占⽤的⽐例以及相关性能统计信息本⽂提到的访问模式就是上⾯三个信息。
我们知道,数据库系统的模块是基本固定的,每个模块访问SQL Server的⽅式也是差不多固定的,具体到某个菜单,某个按钮,都是基本不变的,所以,在⾜够长的时间内,访问SQL Server的各类语句及其占⽤的⽐例也基本上是固定的。
SQLServerProfiler使用教程,通俗易懂才是王道

SQLServerProfiler使⽤教程,通俗易懂才是王道 做开发,平时难免和数据库打交道,特别是写存储过程,对于我们这些不常写SQL的⼈来说是⼀件极其痛苦的事,每次写完运⾏总是有错,如果⽤的是本地数据库的话还好,可以在本机调试SQL,那如果在数据库在服务器上⾯,调试被禁⽤,那就悲剧了~ 最近,由于⼯作需求,写⼀个存储过程,有⼏⼗个参数,数据库在服务器上⾯,写完了,测试完查询语句没有问题,但是到了项⽬⾥⾯查询时就出错,很是⽓⼈!想到了⽤SQL Profiler这个⼯具,打开选择默认设置,开始跟踪,晕,海量数据涌来,看的头晕,根本找不到要跟踪的语句。
后来,经过百度搜索和仔细研究,算是学会使⽤SQL Profiler了。
下⾯和⼤家分享⼀下。
⼀、SQL Server Profiler简介SQL Profiler是⼀个图形界⾯和⼀组系统存储过程,其作⽤如下:图形化监视SQL Server查询;在后台收集查询信息;分析性能;诊断像死锁之类的问题;调试T-SQL语句;模拟重放SQL Server活动;也可以使⽤SQL Profiler捕捉在SQL Server实例上执⾏的活动。
这样的活动被称为Profiler跟踪。
⼆、SQL Profiler的简单配置和使⽤ 不多说废话了,关于SQL Profiler的介绍⽹上多的是,⼤家⾃⼰找吧。
下⾯说到实⽤的,开始动⼿操作吧!(注:本地数据库的就不⽤说了,可以调试运⾏,主要说数据库在服务器上⾯的情况。
) ⾸先说明⼀下SQL Server Express版本是没有SQL Profiler⼯具的,企业版有这个⼯具,其他版本没有⽤过。
下⾯来看下SQL Profiler在什么地⽅,⾸先打开SQL Server Management Sutdio,点击菜单,Tools > SQL Server Profiler,如图:点击后,⾸先会出现登录界⾯,输⼊⽤户名密码后,会看到如下界⾯:第四⾏有⼀项Use the template,选择Standard,如果是本地数据库的话,访问数据库的只有你⼀个⼈,点击Run就可以了。
SQL Server Profiler使用方法
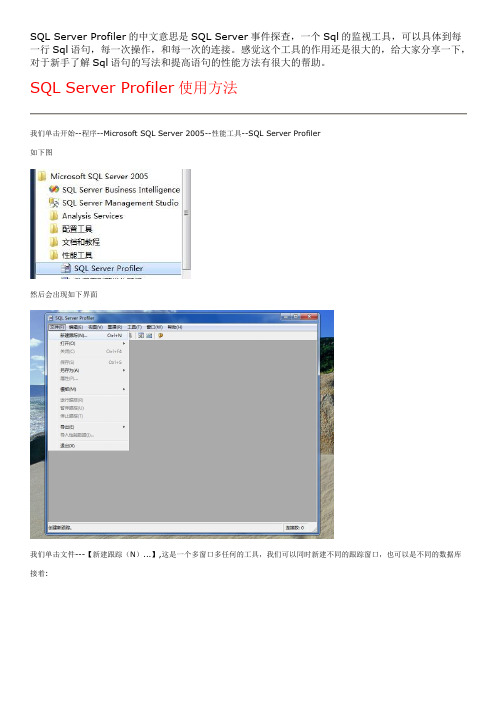
SQL Server Profiler的中文意思是SQL Server事件探查,一个Sql的监视工具,可以具体到每一行Sql语句,每一次操作,和每一次的连接。
感觉这个工具的作用还是很大的,给大家分享一下,对于新手了解Sql语句的写法和提高语句的性能方法有很大的帮助。
SQL Server Profiler使用方法我们单击开始--程序--Microsoft SQL Server 2005--性能工具--SQL Server Profiler如下图然后会出现如下界面我们单击文件---【新建跟踪(N)...】,这是一个多窗口多任何的工具,我们可以同时新建不同的跟踪窗口,也可以是不同的数据库接着:在这里我们输入我们的跟踪的数据库的服务器名称,用户名和密码等信息。
单击连接进入下一个界面上图中左面的可以进行一个基本设置,使用的模板选择,和文件的保存选择等。
我们一般使用默认的就OK了,不用动上面的东西,右面的图是事件选择,也就是说我们要跟踪的事件有那个,在这里可以一一的选择,基本上Sql上有的事件都有,包括你用SQL Server Management Studio操作数据库的过程都可以跟踪的到。
具体的事件和说明大家可以自己看一下。
只要单击显示所有事件就可以进行全部事件的选择了。
我们还可以对统计的字段进行筛选,单击任意一个列标题可以查看列的说明如下图需要过滤具体的列名值,则选择对应的列,在右边树形框录入具体的值,并必须选择排除不包含值的行哈。
我们从上图上依次说明为:TextDate依赖于跟踪中捕获的事件类的文本值;ApplicationName创建SQL Server 连接的客户端应用程序的名称。
此列由该应用程序传递的值填充,而不是由所显示的程序名填充的;NTusername Windows 用户名。
LoginName用户的登录名(SQL Server 安全登录或Windows 登录凭据,格式为“域\用户名”)CPU 事件使用的CPU 时间(毫秒)。
sqlserver profiler使用

sqlserver profiler使用摘要:一、SQL Server Profiler简介1.SQL Server Profiler的作用2.适用场景二、SQL Server Profiler的使用1.开启SQL Server Profiler2.配置SQL Server Profiler3.选择需要跟踪的事件4.保存跟踪结果5.查看和分析跟踪结果三、SQL Server Profiler的高级功能1.过滤器2.快照3.事件属性四、SQL Server Profiler的优缺点1.优点a.帮助诊断性能问题b.提供详细的SQL查询执行信息c.方便数据库优化2.缺点a.可能影响数据库性能b.结果难以解读五、SQL Server Profiler与其他性能分析工具的比较1.SQL Server Profiler与SQL Server Performance Monitor2.SQL Server Profiler与SQL Server Extended Events六、结论1.总结SQL Server Profiler的特点2.强调SQL Server Profiler在数据库管理中的重要性正文:SQL Server Profiler是SQL Server的一个性能分析工具,它可以帮助数据库管理员(DBA)和开发人员诊断性能问题,优化SQL查询,提高数据库的运行效率。
在本文中,我们将介绍SQL Server Profiler的使用方法、高级功能以及与其他性能分析工具的比较。
首先,让我们了解一下SQL Server Profiler的基本概念。
SQL Server Profiler主要用于跟踪和捕获SQL Server实例中的事件,包括数据库访问、查询执行、存储过程调用等。
通过分析这些事件,我们可以找到性能瓶颈,对数据库进行优化。
要使用SQL Server Profiler,首先需要开启它。
在SQL Server Management Studio中,右键单击所连接的服务器,选择“属性”,然后在“性能”选项卡中勾选“启用SQL Server Profiler”。
sqlserverprofiler 列说明 -回复

sqlserverprofiler 列说明-回复SQL Server Profiler 列说明在SQL Server数据库管理系统中,SQL Server Profiler是一款强大的性能分析工具,用于跟踪、监视和分析数据库活动。
它提供了详细的信息,帮助开发人员和管理员优化数据库查询和操作,以获得更好的性能。
本文将详细介绍SQL Server Profiler列说明,解释每个列的含义和用途。
1. TextDataTextData列包含执行的SQL语句或存储过程的名称。
它是Profiler最常用的列之一,可以通过分析这些语句来识别潜在的性能瓶颈和优化机会。
2. DurationDuration列显示每个事件的持续时间,单位是毫秒。
通过观察持续时间,可以确定哪些查询或操作需要进一步优化。
3. SPIDSPID (Server Process ID) 列显示执行操作的进程标识符。
每个连接到SQL Server的会话都有一个唯一的SPID。
通过分析SPID,可以跟踪特定会话的活动。
4. StartTimeStartTime列显示每个事件的开始时间。
这是一个非常有用的列,可以用于分析活动的时间分布情况,以及检测和解决可能的并发性问题。
5. EndTimeEndTime列显示每个事件的结束时间。
与StartTime列一起使用,可以计算事件的持续时间,并检测执行效率问题。
6. DatabaseNameDatabaseName列显示与事件相关联的数据库的名称。
通过分析DatabaseName列,可以确定哪个数据库的活动对整个系统性能产生了影响。
7. LoginNameLoginName列显示执行操作的登录名。
通过分析LoginName,可以追踪具体的用户活动,并进行安全审计。
8. HostNameHostName列显示执行操作的计算机名称。
通过HostName,可以识别哪些主机上的活动可能导致性能问题。
9. ApplicationNameApplicationName列显示执行操作的应用程序名称。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
应用Profiler优化SQL Server数据库系统发布日期:6/28/2005 | 更新日期:6/28/2005作者:苏有全本页内容概述Profiler trace文件性能分析的传统方法以及局限Read80trace工具介绍以及它的Normalization 功能使用存储过程分析Normalize后的数据使用usp_GetAccessPattern的一些技巧蛇足:哪个是HOT 数据库?概述当你的SQL Server数据库系统运行缓慢的时候,你或许多多少少知道可以使用SQL Server Profiler(中文叫SQL事件探查器)工具来进行跟踪和分析。
是的,Profiler可以用来捕获发送到SQL Server的所有语句以及语句的执行性能相关数据(如语句的read/writes页面数目,CPU的使用量,以及语句的duration等)以供以后分析。
但本文并不介绍如何使用Profiler 工具,而是将介绍如何使用read80trace(有关该工具见后面介绍)工具结合自定义的存储过程来提纲挈领地分析Profiler捕获的Trace文件,最终得出令人兴奋的数据分析报表,从而使你可以高屋建瓴地优化SQL Server数据库系统。
本文对那些需要分析SQL Server大型数据库系统性能的读者如DBA等特别有用。
在规模较大、应用逻辑复杂的数据库系统中Profiler产生的文件往往非常巨大,比如说在Profiler 中仅仅配置捕获基本的语句事件,运行二小时后捕获的Trace文件就可能有GB级的大小。
应用本文介绍的方法不但可以大大节省分析Trace的时间和金钱,把你从Trace文件的海量数据中解放出来,更是让你对数据库系统的访问模式了如指掌,从而知道哪一类语句对性能影响最大,哪类语句需要优化等等。
返回页首Profiler trace文件性能分析的传统方法以及局限先说一下什么是数据库系统的访问模式。
除了可以使用Trace文件解决如死锁,阻塞,超时等问题外,最常用也是最主要的功能是可以从Trace文件中得到如下三个非常重要的信息:1. 运行最频繁的语句2. 最影响系统性能的关键语句3. 各类语句群占用的比例以及相关性能统计信息本文提到的访问模式就是上面三个信息。
我们知道,数据库系统的模块是基本固定的,每个模块访问SQL Server的方式也是差不多固定的,具体到某个菜单,某个按钮,都是基本不变的,所以,在足够长的时间内,访问SQL Server的各类语句及其占用的比例也基本上是固定的。
换句话说,只要Profiler采样的时间足够长(我一般运行2小时以上),那么从Trace文件中就肯定可以统计出数据库系统的访问模式。
每一个数据库系统都有它自己独一无二的访问模式。
分析Profiler Trace文件的一个重要目标就是找出数据库系统的访问模式。
一旦得到访问模式,你就可以在优化系统的时候做到胸有成竹,心中了然。
可惜直到目前为止还没有任何工具可以方便地得到这些信息。
传统的Trace分析方法有两种。
一种是使用Profiler工具本身。
比如说可以使用Profiler 的Filter功能过滤出那些运行时间超过10秒以上的语句,或按照CPU排序找出最耗费CPU 的语句等。
另一种是把Trace文件导入到数据库中,然后使用T-SQL语句来进行统计分析。
这两种方法对较小的Trace文件是有效的。
但是,如果Trace文件数目比较多比较大(如4个500MB以上的trace文件),那么这两种方法就有很大的局限性。
其局限性之一是因为文件巨大的原因,分析和统计都非常不易,常常使你无法从全局的高度提纲挈领地掌握所有语句的执行性能。
你很容易被一些语句迷惑而把精力耗费在上面,而实际上它却不是真正需要关注的关键语句。
局限性之二是你发现尽管很多语句模式都非常类似(仅仅是执行时参数不同),却没有一个简单的方法把他们归类到一起进行统计。
简而言之,你无法轻而易举地得到数据库系统的访问模式,无法在优化的时候做到高屋建瓴,纲举目张。
这就是传统分析方法的局限性。
使用下面介绍的Read80trace工具以及自定义的存储过程可以克服这样的局限性。
返回页首Read80trace工具介绍以及它的Normalization 功能Read80Trace工具是一个命令行工具。
使用Read80Trace工具可以大大节省分析Trace 文件的时间,有事半功倍的效果。
Read80Trace的主要工作原理是读取Trace文件,然后对语句进行Normalize (标准化),导入到数据库,生成性能统计分析的HTML页面。
另外,Read80trace可以生成RML文件,然后OSTRESS工具使用RML文件多线程地重放Trace文件中的所有事件。
这对于那些想把Profiler捕获的语句在另外一台服务器上重放成为可能。
本文不详细介绍Read80trace或OStress工具,有兴趣的读者请自行参阅相关资料,相关软件可以从微软网站下载(注:软件名称为RML,/downloads/)。
我要利用的是Read80Trace的标准化功能。
什么是标准化?就是把那些语句模式类似,但参数不一样的语句全部归类到一起。
举例说Trace中有几条语句如下:select * from authors where au_lname = 'white'select * from authors where au_lname = 'green'select * from authors where au_lname = 'carson'经过标准化后,上面的语句就变成如下的样子:select * from authors where au_lname = {str}select * from authors where au_lname = {str}select * from authors where au_lname = {str}有了标准化后的语句,统计出数据库系统的访问模式就不再是难事。
运行Read80trace 的时候我一般使用如下的命令行:Read80trace –f –dmydb –Imytrace.trc其中-f开关是不生成RML文件,因为我不需要重放的功能。
生成的RML文件比较大,建议读者如果不需要重放的话,也使用-f开关。
-d开关告诉read80trace把trace文件的处理结果存到mydb数据库中。
我们后面创建的存储过程正是访问read80trace在mydb中生成的表来进行统计的。
-I开关是指定要分析的的trace文件名。
Read80trace工具很聪明,如果该目录下有Profiler产生的一系列Trace文件,如mytrace.trc,mytrace1.trc,mytrace2.trc等,那么它会一一顺序读取进行处理。
除了上面介绍的外,Read80trace还有很多其它有趣的开关。
比如说使用-i开关使得Read80trace可以从zip或CAB文件中读取trace文件,不用自己解压。
所有开关在Read80trace.chm中有详细介绍。
我最欣赏的地方是read80trace的性能。
分析几个GB大小的trace文件不足一小时就搞定了。
我的计算机是一台内存仅为512MB的老机器,有这样的性能我很满意。
你也许会使用read80trace分析压力测试产生的trace文件。
我建议还是分析从生产环境中捕获的Trace文件为好。
因为很多压力测试工具都不能够真正模拟现实的环境,其得到的trace文件也就不能真实反映实际的情况。
甚至有些压力测试工具是循环执行自己写的语句,更不能反映准确的访问模式。
建议仅仅把压力测试产生的trace作为参考使用。
返回页首使用存储过程分析Normalize后的数据有了标准化后的语句就可以使用存储过程进行统计分析了。
分析的基本思想是把所有模式一样的语句的Reads,CPU和Duration做group by统计,得出访问模式信息:1. 某类语句的总共执行次数,平均读页面数(reads)/平均CPU时间/平均执行时间等。
2. 该类语句在所有语句的比例,如执行次数比例,reads比例,CPU比例等。
存储过程的定义以及说明如下:/*************************************************************/ Create procedure usp_GetAccessPattern 8000@duration_filter int=-1 --传入的参数,可以按照语句执行的时间过滤统计as begin/*首先得到全部语句的性能数据的总和*/declare @sum_total float,@sum_cpu float,@sum_readsfloat,@sum_duration float,@sum_writes floatselect @sum_total=count(*)*0.01,--这是所有语句的总数。
@sum_cpu=sum(cpu)*0.01, --这是所有语句耗费的CPU时间@sum_reads=sum(reads)*0.01, --这是所有语句耗费的Reads数目,8K为单位。
@sum_writes=sum(writes)*0.01,--这是所有语句耗费的Writes数目,8K为单位。
@sum_duration=sum(duration)*0.01--这是所有语句的执行时间总和。
from tblBatches --这是Read80Trace产生的表,包括了Trace文件中所有的语句。
where duration>=@duration_filter --是否按照执行时间过滤/*然后进行Group by,得到某类语句占用的比例*/Select ltrim(str(count(*))) exec_stats,''+str(count(*)/@sum_total,4,1)+'%' ExecRatio,ltrim(str(sum(cpu)))+' : '++ltrim(str(avg(cpu)))cpu_stats,''+str(sum(cpu)/@sum_cpu,4,1)+'%' CpuRatio,ltrim(str(sum(reads) ))+' : '+ltrim(str(avg(reads) ))reads_stats,''+str(sum(reads)/@sum_reads,4,1) +'%' ReadsRatio ,--ltrim(str(sum(writes) ))+' : '+ltrim(str(avg(writes) ))--writes_stats,''+str(sum(writes)/@sum_writes,4,1) +'%)',ltrim(str(sum(duration) ))+' : '+ltrim(str(avg(duration))) duration_stats,''+str(sum(duration)/@sum_duration,4,1)+'%' DurRatio ,textdata,count(*)/@sum_total tp,sum(cpu)/@sum_cpucp,sum(reads)/@sum_reads rp,sum(duration)/@sum_duration dpinto #queries_staticstics from/* tblUniqueBatches表中存放了所有标准化的语句。