《编译原理》勘误表
《编译原理》(第2版)勘误表

《编译原理》(第2版)勘误表2008-8-311、第2页倒数第2行改成:分隔单词的空格通常在词法分析时被删去。
2、第3页图1.2改成:3、第16页倒数第9行开始的那段改成:上一节提到,字符串集合由叫做模式的规则来描述。
正规式是表示这些规则的一种重要方法,因此本节围绕正规式来介绍记号的描述与识别。
在介绍正规式前,先给“语言”一个形式定义。
4、第18页表2.3的第4行第4列改成:ε肯定出现在一个闭包中5、第26页图2.10上面的那段改成:ε-closure(T)的计算是从给定的结点集合出发,在图上搜索可达结点的典型过程。
该图只包含NFA的含ε标记的边,T是给定的结点集合。
计算ε-closure(T)的简单算法是用栈来保存那些边还没有完成ε转换检查的状态。
图2.11描述了这样的过程。
6、第43页倒数第5行第一句改成:正规式可以描述的语言都能用上下文无关文法来描述。
7、第61页5行开始的那段改成:(2)仅使用FOLLOW(A)作为A的同步集合是不够的。
例如,分号在C语言中作为语句的结束符,那么作为语句开始符号的关键字没有出现在表达式非终结符的FOLLOW集合中。
这样,仅按上面(1)来设定同步记号集合的话,作为赋值结束的分号的遗漏会引起下一语句的开始关键字被跳过。
8、第74页图3.15第2行改成:C = {closure ({[S'→ · S ]})};9、第80页图3.19倒数第7行改成:置C 的初值为{closure ({[S ' → · S , $]})};10、第111页倒数第4行开始的那段改成: 语法树作为一种中间表示,允许把翻译从分析中分离出来,形成先分析后翻译的方式,即先分析生成语法树,然后再基于语法树进行翻译。
即使是边分析边翻译,语法树作为一种概念上的中间表示,也是有用的。
C 和Java 的编译器通常显式构造语法树。
11、第119页图4.9下第1行第1句改成: 图4.10给出了图4.9的动作是怎样为a *5*b 构造语法树的。
《C语言程序设计习题解析与实验指导》教材勘误表

错误页及行
原内容
修改后的内容
修改说明
第39页选择第1题解析的第2行最后
…答案B是关键字,而…
…答案C是关键字,而…
将“B”改为“C”
第39页倒数第13行最后
;;
;
删除多余的“;”
第39页倒数第9行-倒数第5行
【参考答案】C
【解析】此题考查的是实型常量的表示方法:实型常量只采用十进制表示,其表示方式分为小数形式和指数形式两种。答案A采用指数形式,但指数部分3.1不是整数,故不合法;答案B同样采用指数形式,但尾数部分被省略了,也不合法;答案C采用小数形式,其小数部分可以省略;;答案D表示的是整型常量。因此本题选择答案C。
此题参考答案原“5处”改为“7处”;在16行最后再增加红色字体描述的两处修改
第104页第24行
char str[20]="programming";
char str[20]=" ห้องสมุดไป่ตู้rogramming";
字符数组初始化的时候最前面,即字符p前增加一个空格
第105页第2行与第3行之间
i do not love
原答案和解析是错的!
第39页倒数第3行
A. 01
A. 012
增加数字“2”
第46页倒数第14行
B. int(x*100+0.5)/100.0
B.(int)(x*100+0.5)/100.0
在int两边增加“( )”
第102页第26-28行(程序修改第1题的参考答案)
【参考答案】程序需要在5处作修改:行1改为:……,改为:s++;
蒋立源_《编译原理》_西北工业大学出版社_第3版课后答案

《编译原理》课后习题答案第一章1.解:源程序是指以某种程序设计语言所编写的程序。
目标程序是指编译程序(或解释程序)将源程序处理加工而得的另一种语言(目标语言)的程序。
翻译程序是将某种语言翻译成另一种语言的程序的统称。
编译程序与解释程序均为翻译程序,但二者工作方法不同。
解释程序的特点是并不先将高级语言程序全部翻译成机器代码,而是每读入一条高级语言程序语句,就用解释程序将其翻译成一段机器指令并执行之,然后再读入下一条语句继续进行解释、执行,如此反复。
即边解释边执行,翻译所得的指令序列并不保存。
编译程序的特点是先将高级语言程序翻译成机器语言程序,将其保存到指定的空间中,在用户需要时再执行之。
即先翻译、后执行。
2.解:一般说来,编译程序主要由词法分析程序、语法分析程序、语义分析程序、中间代码生成程序、代码优化程序、目标代码生成程序、信息表管理程序、错误检查处理程序组成。
3.解:C语言的关键字有:auto break case char const continuedefault do double else enum extern float for goto if int longregister return short signed sizeof static struct switch typedef union unsigned void volatile while。
上述关键字在C语言中均为保留字。
4.解:C语言中括号有三种:{},[],()。
其中,{}用于语句括号;[]用于数组;()用于函数(定义与调用)及表达式运算(改变运算顺序)。
C语言中无END关键字。
逗号在C语言中被视为分隔符和运算符,作为优先级最低的运算符,运算结果为逗号表达式最右侧子表达式的值(如:(a,b,c,d)的值为d)。
5.略第二章1.(1)答:26*26=676(2)答:26*10=260(3)答:{a,b,c,...,z,a0,a1,...,a9,aa,...,az,...,zz,a00,a01,...,zzz},共26+26*36+26*36*36=34658个2.构造产生下列语言的文法(1){anbn|n≥0}解:对应文法为G(S) = ({S},{a,b},{ S→ε| aSb },S)(2){anbmcp|n,m,p≥0}解:对应文法为G(S) = ({S,X,Y},{a,b,c},{S→aS|X,X→bX|Y,Y→cY|ε},S)(3){an # bn|n≥0}∪{cn # dn|n≥0}解:对应文法为G(S) = ({S,X,Y},{a,b,c,d,#}, {S→X, S→Y,X→aXb|#,Y →cYd|# },S)(4){w#wr# | w?{0,1}*,wr是w的逆序排列}解:G(S) = ({S,W,R},{0,1,#}, {S→W#, W→0W0|1W1|# },S)(5)任何不是以0打头的所有奇整数所组成的集合解:G(S) = ({S,A,B,I,J},{-,0,1,2,3,4,5,6,7,8,9},{S→J|IBJ,B→0B|IB|e, I→J|2|4|6|8, Jà1|3|5|7|9},S)(6)所有偶数个0和偶数个1所组成的符号串集合解:对应文法为 S→0A|1B|e,A→0S|1C B→0C|1S C→1A|0B3.描述语言特点(1)S→10S0S→aAA→bAA→a解:本文法构成的语言集为:L(G)={(10)nabma0n|n, m≥0}。
数据结构教材勘误表
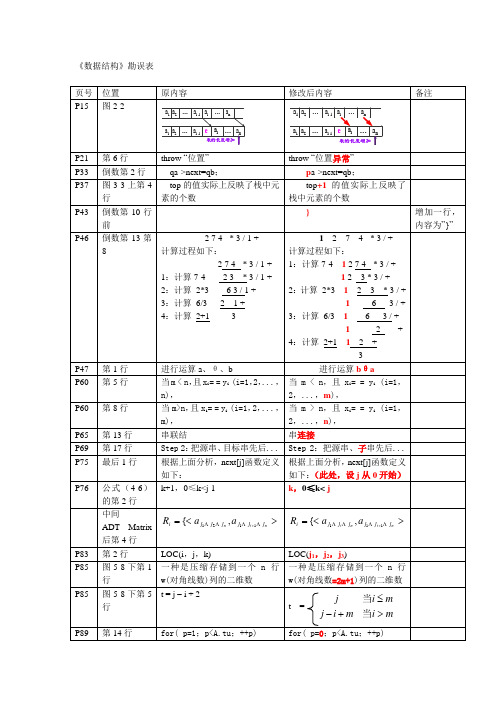
a1 a2 … ai-1 ai … an a1 a2 … ai-1 e ai … an
表的长度增加
修改后内容
a1 a2 … ai-1 ai … an a1 a2 … ai-1 e ai
备注
… an
表的长度增加
P21 P33 P37 P43 P46
for(col=0;col<A.nu ;++col) 0≤i<n,0≤j<m
p 1
A[i][k ] B[k ][ j ]
k 1
p
A[i][k ] B[k ][ j ]
k 0
108 108 108 117 119 123 132
15 18 倒数第 5 行 第一句 文字倒数第 4 行 图 6-13(c) 算法 6.6, 算法 6.13
……仍为 m 阶 B-树 //在 m 阶 B-树*t 上结点…… ……信息,以及指向…… ……解决以下两个问题: ……不同的符号在各位上…… ……位作为哈希地址。 ……稳定性:对任意…… ……进行排序,若相同…… ……将第 i 个记录后移: r[i+1]=r[i] 插入排序……的算法是简 单…… for(int j=i-1;j>=high+1;--j) 记录后移 L.key[j+1]=L.key[j]; L.key[high+1]=L.key[0]; 选择排序的思想是每一…… ……因此,它的空间复杂度为 O(1)。 Step1:……中的元素建大顶堆 不超过式(9-10) : ……,即 //
(ki1,ki2,……,kid)<……
P243 P243 P244 P246 P247 P248 P257 P257 P258 P258 P261
《C语言程序设计》-第1版-勘误表

倒 19 1 14 8 11 19,22 源程 序中 源程 序中
回车符 由于 m 不可能 if(i>m/2) 回送主函数 9.42690e+157 : child men*3+women*2 +child*0.5==45
换行符 当 m>2 时,由于 m 不可能 if(i>m/2 && m>1) 回送主调函数 9.426900e+157 (伪代码) ;
倒 5-6 偏移 倒 13 /* 指针 p 向 倒 11 :","%s 1 而不是将字符串放到
165
12
167
倒9
数组名是地址常量,不能对它 赋 值 。 数组名是常量,不能对 strcpy(sp, ”Hello”); 也 教材无错。仅补充 它赋值。 是不能执行的, 因为 sp 所指之 说明另一种情形 处为字符串常量,其存储空间 在据台存储区的常量池中。 char *s2) char *s2); 函数原型缺少分号
删除该两行 数组名是常量
130 133 134 135
4-5
或者定义„„ if(i<=j) 回车 回车 回车 回车 if(i<j) 换行 换行 换行 换行 short int 函数的参数;在函数 if(n<=0||n>8) n = 8; short int 元素的地址 /* 指针 p 指向 : %s 而不是将字符串的内容放到
1 倒1 2-3 倒 138 15,17 10,11 140 13 倒 2
删除该两行。应该 引导读者习惯从 0 开始计数。 不含主对角线元素
143 6,11,12 int 152 20 函数的参数,在函数 9 行后 156 添加 157 157 158 163 165 7 int
《C语言与程序设计方法(第二版)》勘误表_20120604

《C语言与程序设计方法(第二版)》勘误表请大家将发现的错误补充进来(请用不同颜色表示你的增加),谢谢!P19例2.1整型常量的表示。
#include <stdio.h>void main() {int a, b, c;a=50; // a为十进制整数50b=-032; // b为八进制整数-32c=0x5b; // c为十六进制整数5bprintf("a=%d, b=%d, c=%d\n", a, b, c); //以十进制整数形式输出a,b,c的值}运行结果如下:a=50, b=-26, c=91P31例2.7整型数据的格式输出。
# include <stdio.h>void main() {int a=-2, b=25;unsigned u=65534, v=28;short c=45;char d='A';printf("a:%d, %u, %o, %x\n", a, a, a, a);printf("u:%d, %u, %o, %x\n", u, u, u, u);printf("b:%d, %u v:%d, %u\n", b, b, v, v);printf("c=%d, d=%d\n", c, d);}运行结果如下:a:-2, 65534, 177776, fffeu:-2, 65534, 177776, fffeb:25, 25 v:28, 28c=45, d=65P33(4) 指定输出宽度。
指定输出宽度和对齐方式需用到附加格式字符m、.n和-。
其中m 为一正整数,用来指定输出宽度(对于f格式符,输出宽度包括整数位、小数点和小数位;对于e 格式符,输出宽度包括尾数部分和指数部分),如果数据的实际宽度比指定输出宽度大,则按实际宽度输出;附加格式符“.n ”的作用是指定输出n 位小数,对于e 格式小数点后仅输出n -1位;附加格式符“-”是用来说明采用左对齐方式,没有“-”时默认是右对齐方式。
《编译原理与技术》勘误表
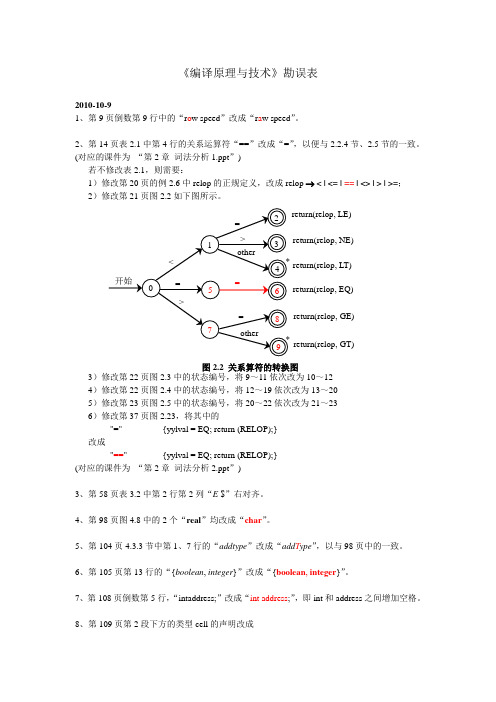
《编译原理与技术》勘误表2010-10-91、第9页倒数第9行中的“r o w speed ”改成“r a w speed ”。
2、第14页表2.1中第4行的关系运算符“==”改成“=”,以便与2.2.4节、2.5节的一致。
(对应的课件为 “第2章 词法分析1.ppt ”) 若不修改表2.1,则需要:1)修改第20页的例2.6中relop 的正规定义,改成relop → < | <= | == | <> | > | >=; 2)修改第21页图2.2如下图所示。
3)修改第22页图2.3中的状态编号,将9~11依次改为10~12 4)修改第22页图2.4中的状态编号,将12~19依次改为13~20 5)修改第23页图2.5中的状态编号,将20~22依次改为21~23 6)修改第37页图2.23,将其中的 "=" {yylval = EQ; return (RELOP);} 改成 "==" {yylval = EQ; return (RELOP);} (对应的课件为 “第2章 词法分析2.ppt ”)3、第58页表3.2中第2行第2列“E $”右对齐。
4、第98页图4.8中的2个“real ”均改成“char ”。
5、第104页4.3.3节中第1、7行的“addtype ”改成“add T ype ”,以与98页中的一致。
6、第105页第13行的“{boolean , integer }”改成“{boolean , integer }”。
7、第108页倒数第5行,“intaddress;”改成“int address ;”,即int 和address 之间增加空格。
8、第109页第2段下方的类型cell 的声明改成图2.2 关系算符的转换图return(relop, LE)return(relop, NE) return(relop, LT) return(relop, GE) return(relop, GT)return(relop, EQ)typedef struct cell {int info;struct cell*next;}cell;即在typedef和struct之间增加空格,将“struct_cell”中的下划线改成空格。
《编译原理勘误表

《编译原理》勘误表2004-1-31.第8页图1.4的语法树中inttoreal 和60之间少了一条竖线,即2.第17页的第12行r * = r + | ε 和r + = rr *改成:r * = r + | ε 和r + = rr *3.第216页的倒数第8行有向无环图(directed acyclic gra hp改成:有向无环图(directed acyclic gra ph4.第229页的第1行emit (t , ‘:=’, Elist 1.place , ‘(’, limit (Elist 1.array , m ) );改成:emit (t , ‘:=’, Elist 1.place , ‘*’, limit (Elist 1.array , m ) );5.第237页的第1行if id 1 > id 2 goto E .false改成:if id 1 ≥id 2 goto E .false6.第238页的倒数第11行的“next:”不应缩进L n -1: S n 的代码next:改成:L n -1: S n 的代码next:7.第239页的第10行的“next:”不应缩进test: if t = V 1 goto L 1if t = V 2 goto L 2. . .if t = V n -1 goto L n -1goto L nnext: inttoreal position + * 60initial rate inttoreal position + * 60 initial rate 改成改成:test: if t = V1 goto L1if t = V2 goto L2. . .if t = V n-1 goto L n-1goto L nnext:8.第239页的第21行的“next:”不应缩进test: case V1 L1case V2L2. . .case V n-1L n-1case t L nnext:改成:test: case V1 L1case V2L2. . .case V n-1L n-1case t L nnext:9.第9.10中顶点4到顶点3的回边少了箭头改成:2003-12-131.第318页图10.9的最下面的文字在内存中的已完全连接的可执行程序改成:完全连接的可执行代码已在内存中2003-12-61.第270页图9.1的第11行do j = j (1; while (a[j]> v);改成:do j = j 1; while (a[j]> v);2.第270页图9.2的第(8)条语句(8 ) if t3> v goto (5 )改成:(8 ) if t3< v goto (5 )3.第271页图9.3的第2个方框if t3> v goto B2改成:if t3< v goto B24.第273页图9.5的第2个方框if t3> v goto B2改成:if t3< v goto B25.第277页图9.9的第2个方框if t3> v goto B2改成:if t3< v goto B22003-12-11.第142页第5行E→E1 + T E. nptr := mknode ('+', E1. nptr, T. nptr ) 改成:E→E1 + T E. nptr := mknode ('+', E1. nptr, T. nptr )2. 第182页图6.1算法的倒数第2行qui C ksort(1,9)改成:qui c ksort(1,9)2003-10-121.目录第3页第8章代秒生成改成第8章代码生成2.第49页第2行对某个串α,存在推导A⇒*Aα改成对某个串α,存在推导A⇒+Aα3.第80页第1行如果S'⇒*rm αAw ⇒*rmαβ1β2w 改成:如果S'⇒*rm αAw ⇒rmαβ1β2w。
《C语言程序设计教程》勘误表(终)
87
2行D选项
原文:!(x%2)==0改正:!(x%2-1)==0
91
13
原文:main()改正:voidmain()
103
2
在“{”后插入:void func( );
104
第6题第(1)题第6行尾
第6题第(2)题第5行尾
原文:string;改正:string( );
原文:string;改正:string( );
105
1
原文: 改正:
108
第4题第4行
原文:{ int n,a[]改正:{ intj,a[]
111
第3题第2行
原文:intb[4][4]改正:inta[4][4]
174
第1行前插入
scanf(”%d”,&n);
改正:if ….‘Z’))
47
13
原文:(x≥1)
改正:(x=1)
47
16-19
将“提示:….之分。”全部删除。
52
倒数第2行
原文: 改正:
52
倒数第1行
原文: 改正: 、 、
55
13
原文: 改正:
55
15
插入一行:
#include <math.h>
57
8
原文:f(n-2)-3f(n-1)+f(n-1)
附录I
23(17)
对应字符:原文↕,改正:↕即原符号下加一短横。
附录I
最后一空
原文为空白,改正:127(7F)⌂
C语言程序设计实验指导与习题解析
页码
行数
42
倒数第3行
原文:printf(”\n b>a && b<c”,
《编译原理》考试试题及答案(汇总)

《编译原理》考试试题及答案(汇总)一、是非题(请在括号内,正确的划√,错误的划×)(每个2分,共20分)1.编译程序是对高级语言程序的解释执行.(× )2.一个有限状态自动机中,有且仅有一个唯一的终态。
(×)3.一个算符优先文法可能不存在算符优先函数与之对应. (√ )4.语法分析时必须先消除文法中的左递归。
(×)5.LR分析法在自左至右扫描输入串时就能发现错误,但不能准确地指出出错地点。
(√)6.逆波兰表示法表示表达式时无须使用括号。
(√ )7.静态数组的存储空间可以在编译时确定。
(×)8.进行代码优化时应着重考虑循环的代码优化,这对提高目标代码的效率将起更大作用。
(×) 9.两个正规集相等的必要条件是他们对应的正规式等价. (× )10.一个语义子程序描述了一个文法所对应的翻译工作。
(×)二、选择题(请在前括号内选择最确切的一项作为答案划一个勾,多划按错论)(每个4分,共40分)1.词法分析器的输出结果是_____。
A.( ) 单词的种别编码B.( ) 单词在符号表中的位置C.() 单词的种别编码和自身值D.() 单词自身值2.正规式M 1 和M 2 等价是指_____。
A.( ) M1和M2的状态数相等B.() M1和M2的有向边条数相等C.()M1和M2所识别的语言集相等D.()M1和M2状态数和有向边条数相等3.文法G:S→xSx|y所识别的语言是_____。
A.() xyx B.()(xyx)* C.() xnyxn(n≥0) D.() x*yx*4.如果文法G是无二义的,则它的任何句子α_____。
A.( )最左推导和最右推导对应的语法树必定相同B.() 最左推导和最右推导对应的语法树可能不同C.( ) 最左推导和最右推导必定相同D.()可能存在两个不同的最左推导,但它们对应的语法树相同5.构造编译程序应掌握______。
编译原理勘误表格

《编译原理》勘误表2004-1-31.第8页图的语法树中inttoreal 和60之间少了一条竖线,即2.第17页的第12行r * = r + | 和r + = rr *改成:r * = r + | 和r + = rr *3.第216页的倒数第8行有向无环图(directed acyclic gra hp改成:有向无环图(directed acyclic gra ph4.第229页的第1行emit (t , ‘:=’, , ‘(’, limit , m ) );改成:emit (t , ‘:=’, , ‘’, limit , m ) );5.第237页的第1行if id 1 > id 2 goto改成:if id 1 id 2 goto6.第238页的倒数第11行的“next:”不该缩进intto + * 6initi ra intto + * 6initi ra改L n-1: S n的代码next:改成:L n-1: S n的代码next:7.第239页的第10行的“next:”不该缩进test: if t = V1 goto L1if t = V2 goto L2. . .if t = V n-1 goto L n-1g oto L nnext:改成:test: if t = V1 goto L1if t = V2 goto L2. . .if t = V n-1 goto L n-1g oto L nnext:8.第239页的第21行的“next:”不该缩进test: case V1 L1case V2L2. . .case V n-1 L n-1case t L nnext:改成:test: case V1 L1case V2L2. . .case V n-1 L n-1case t L nnext:9.第278页的图中极点4到极点3的回边少了箭头310.改成:11.12.2003-12-131.第318页图的最下面的文字在内存中的已完全连接的可执行程序改成:完全连接的可执行代码已在内存中2003-12-61.第270页图的第11行d o j = j (1; while (a[j]> v);改成:do j = j 1; while (a[j]> v);2.第270页图的第(8)条语句(8 ) if t3> v goto (5 )改成:(8 ) if t3< v goto (5 )3.第271页图的第2个方框i f t3> v goto B2改成:if t3< v goto B24.第273页图的第2个方框i f t3> v goto B2改成:if t3< v goto B25.第277页图的第2个方框i f t3> v goto B2改成:if t3< v goto B22003-12-11.第142页第5行E E1 + T E. nptr := mknode ('+', E1. nptr, T. nptr )改成:E E1 + T E. nptr := mknode ('+', E1. nptr, T. nptr )2. 第182页图算法的倒数第2行qui C ksort(1,9)改成:qui c ksort(1,9)2003-10-121.目录第3页第8章代秒生成改成第8章代码生成2.第49页第2行对某个串,存在推导A*A 改成对某个串,存在推导A+A3.第80页第1行若是S*rm Aw *rm12w 改成:若是S*rm Aw rm12w。
《编译原理》勘误表

《编译原理》勘误表2007-3-291、第61页第5行例3.14把算法3.2用于文法(3.8)。
因为FIRST(TE ') = FIRST(T ) = {(, id},因此产生式E →TE '使得M[E, ( )和M[E, id]含产生式E →TE '。
产生式E '→ +TE '使M[E ', +]含产生式E '→ +TE '。
因为FOLLOW(E ') = { ), $},产生式E '→ε使M[E ', ] ]和M[E ', $]含产生式E '→ε。
改成例3.14把算法3.2用于文法(3.8)。
因为FIRST(TE ') = FIRST(T ) = {(, id},因此产生式E →TE '使得M[E, ( ]和M[E, id]含产生式E →TE '。
产生式E '→ +TE '使M[E ', +]含产生式E '→ +TE '。
因为FOLLOW(E ') = { ), $},产生式E '→ε使M[E ', ) ]和M[E ', $]含产生式E '→ε。
2、第85页图3.19项目集I0改成S'→·S, $ S'→·S, $S →·BB, $ S →·BB, $B →·bB, b/a B →·bB, b/aB →·A,B/a B →·a, b/aI0 I03、第90页倒数第4行例3.36语言L = {ww R| w ∈ (a | b)*}的文法改成例3.36语言L = {ww R| w ∈ (a | b)*}的文法2007-3-171、第108页中间3.22 证明下面文法S →Aa| bAc | B c | bdaA →d是LALR(1)文法,但不是SLR(1)文法。
编译原理实用教程 第10章 符号表和错误处理

(4)数组变量的表示。前面我们已经分析过,数 组的详细信息都登记在内情向量表中。数组符号在 符号表中可以设立一个指向内情向量的指针,而在 内情向量表中登记关于数组维数个数和每一维的元 素个数。 例如,设有两个数组: A1(sub1,sub2) A2(sub1,sub2,sub3,sub4,sub5,sub6) A1为一个二维数组,A2为一个四维数组。 它在符号表中的表示为图10-7所示:
符号表可以在词法分析时创建,也可以在语义分析时创建。 在编译程序中,符号表在词法分析时创建,此时符号表中只 含有标识符的名字,其他属性要在语义分析阶段填入。而变 量在符号表中的位置信息将作为标识符符号的属性出现,构 成词法分析器所产生的单词符号的一部分;语法分析阶段只 检查源程序语法的正确性,一般不使用符号表;语义分析程 序对该编码形式进行语义正确性分析,遇到声明语句时会填 入有关标识符的属性。在 符号表中的标识符的属性信息会在 代码生成阶段用于产生目标代码。因此,直到语义分析和代 码生成阶段,许多与变量有关的属性才能相继填入符号表。
第10章 符号表和错误处理
本章学习目标
为了检查语义的正确性和生成代码,需要知
道源程序中所使用的各种标识符的属性。这 些属性常常由编译程序集中起来并存放在一 个标识符表或符号表中。本章的主要内容有: 符号表的组织和内容 符号表的构造和查找 分程序的结构
10.1符号表的组织和内容
在编译的各个阶段经常要收集和使用出现在源程序 中的各种信息,为了方便,通常把这些信息用一些 表格进行记录、存储和管理,如常量表、数组信息 表、保留字表和标识符表等,这些表统称为符号表。 符号表主要保存各类标识符的属性,它在翻译过程 中有两个方面的重要作用,一是检查语义的正确性, 二是辅助生成代码。也就是说在实现语义检查和代 码生成时,需要不断插入和检索符号表中标识符的 属性来实现。
《C++语言程序设计教程》杨进才 勘误表
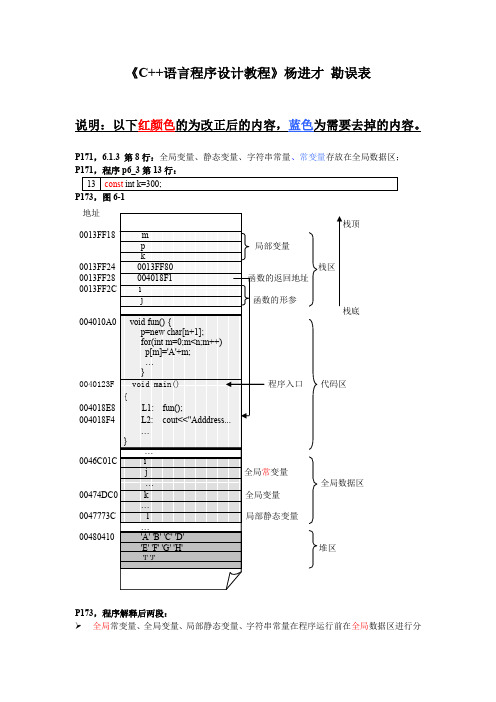
《C++语言程序设计教程》杨进才勘误表说明:以下红颜色的为改正后的内容,蓝色为需要去掉的内容。
P171,6.1.3 第8行:全局变量、静态变量、字符串常量、常变量存放在全局数据区;P173,图6-1地址栈顶0013FF180013FF24 栈区0013FF28 函数的返回地址栈底程序入口代码区004018E8004018F4变量全局数据区0047773C00480410堆区P173,程序解释后两段:全局常变量、全局变量、局部静态变量、字符串常量在程序运行前在全局数据区进行分配。
并且依次按照全局常变量、全局变量、局部静态变量的顺序从低地址向高地址分配。
其中各类变量按定义的先后次序分配,全局变量、局部变量也一样。
当程序运行结束后,各全局数据区各类变量的空间被系统收回,收回的顺序与分配的顺序相同,即:先分配先收回。
P174,程序解释倒数第1段:变量的生存期为从产生到消失的时期。
全局变量(包括全局常变量)、静态变量、局常变量、字符串常量生存周期为整个程序的生存周期,因此称为静态生存期;局部变量的生存周期起于函数调用,结束于函数调用结束,其生存期是动态的,因此称为动态生存期。
P186 6.5本章小结中第7行:◇全局变量(包括全局常变量)、静态变量、字符串常量、常变量存放在全局数据区; 所有的函数和代码存放在代码区; 为运行函数而分配的函数参数、局部auto变量、返回地址存放在栈区。
堆区用于动态内存分配。
◇全局变量(包括全局常变量)、静态变量、字符串常量、常变量生存周期为整个程序的生存周期,因此称为静态生存期;局部auto变量的生存周期起于函数调用,结束于函数调用结束,其生存期是动态的,因此称为动态生存期。
P187 习题6:(3) C++程序的内存分为四个区:________, ________, ________, ________。
全局变量(包括全局常变量)、静态变量、字符串常量、常变量存放在_______区,所有的函数和代码存放在________区,为运行函数而分配的函数参数、局部变量、返回地址存放在_______区。
C语言引论》勘误表(裘宗...

一元三次方程 CLOCKS_PER_SEC return n-1; 定义点和使用点 double f(double, int); int g(double); (sizeof(a)/sizeof(double)) (sizeof a/sizeof(double)) cs[10]={0,0,0,0,0,0,0,0,0,0}; double b1[3] = ... m = n / 2; "After reversion:\n"); int n, ... int n, ... for (j = 0; j < N; j++) { x = 0.0; /* 语句改到这里 */ j = 0; j < N q = &a[0]; void strCopy (...) char *days[] = { 第 1 个 argv 改为 argc while (y >= 1E-6 ... return res; getident(s, ...) mkpoint1(2.05, 3.7) icp->... POINT *mkpoint0 (...) union uu1 u1={3}, u2={5}; u1.c = '\n'; if (fp == NULL) { idcTable[IDCTABLE_SIZE] ...位置... printf /* 继续循环读入 */ () [] -> . ?:
《从问题到程序——程序设计与 C 语言引论》勘误表(裘宗燕,1999/12/10)
页 19 32 38 55 60 行 8 10 -1 -18 15 误 第四个数 #Finclude ... c_area(3,24) while(t <= 1E-6 ...) 正 第五个数 #include ... c_area(3.24) while(t >= 1E-6 ...)
南邮《编译原理》课后习题解答

b 短语 bB, AB, ABb,bBABb
简单短语 bB, AB, 句柄 bB
P40 18.分别对 i+i*i 和 i+i+i 中每一个句子构造两棵语法树, 是二义的。
从而证明下述文法 G[<表达式>]
<表达式>::=i|(v 表达式>)|<表达式 ><运算符 ><表达式> <运算符>::=+卜|*|/
编译程序是将高级语言写的源程序翻译成目标语言的程序。 关系:汇编程序、解释程序和编译程 序都是翻译程序,具体见 P4 图 1.3。
P14 3、编译程序是由哪些部分组成?试述各部分的功能? 答:编译程序主要由 8 个部分组成: ( 1)词法分析程序; ( 2)语法分析程序; ( 3)语义分 析程序;( 4)中间代码生成; ( 5)代码优化程序; ( 6)目标代码生成程序; ( 7)错误检查 和处理程序; ( 8)信息表管理程序。具体功能见 P7-9。
补充: 2、赋值语句: A:= 5 * C 的语法和语义指的是什么? 答:语法分析将检查该语句是否符合赋 值语句规则,语义是指将 5 * C 的结果赋值为 A 。
第二次作业:
P38 1、设 Ti= {11, 010}, T2= {0, 01, 1001},计算:T2T1, TI* , T2+。
T2T1 = {011, 0010, 0111, 01010, 100111, 1001010}
7
解: 0127 的最左推导 N=>ND=>NDD=>NDDD=>DDDD=>0DDD=>01DD=>012D=>0127 0127 的最 右推导 N=>ND=>N7=>ND7=>N27=>ND27=>N127=>D127=>0127 34 的最左推导 N=>ND=>DD=>3D=>34 34 的最右推导 N=>ND=>N4=>D4=>34 568 的最左推导 N=>ND=>NDD=>DDD=>5DD=>56D=>568 568 的最右推导 N=>ND=>N8=>ND8=>N68=>D68=>568
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
《编译原理》勘误表2007-3-291、第61页第5行例3.14把算法3.2用于文法(3.8)。
因为FIRST(TE ') = FIRST(T ) = {(, id},因此产生式E →TE '使得M[E, ( )和M[E, id]含产生式E →TE '。
产生式E '→ +TE '使M[E ', +]含产生式E '→ +TE '。
因为FOLLOW(E ') = { ), $},产生式E '→ε使M[E ', ] ]和M[E ', $]含产生式E '→ε。
改成例3.14把算法3.2用于文法(3.8)。
因为FIRST(TE ') = FIRST(T ) = {(, id},因此产生式E →TE '使得M[E, ( ]和M[E, id]含产生式E →TE '。
产生式E '→ +TE '使M[E ', +]含产生式E '→ +TE '。
因为FOLLOW(E ') = { ), $},产生式E '→ε使M[E ', ) ]和M[E ', $]含产生式E '→ε。
2、第85页图3.19项目集I0改成S'→·S, $ S'→·S, $S →·BB, $ S →·BB, $B →·bB, b/a B →·bB, b/aB →·A,B/a B →·a, b/aI0 I03、第90页倒数第4行例3.36语言L = {ww R| w ∈ (a | b)*}的文法改成例3.36语言L = {ww R| w ∈ (a | b)*}的文法2007-3-171、第108页中间3.22 证明下面文法S →Aa| bAc | B c | bdaA →d是LALR(1)文法,但不是SLR(1)文法。
3.23 证明下面文法S →XX →Ma | bMc | dc | bdaM→ d是LALR(1)文法,但不是SLR(1)文法。
改成3.22 证明下面文法S →Aa| bAc | d c | bdaA →d是LALR(1)文法,但不是SLR(1)文法。
2、第27页第1行表2.7 NFA的转换表Dtran改成表2.7 DFA的转换表Dtran3、第132页倒数第8行在使用M →ε时,M.i的值可以在val[top-2]找到。
改成在使用M →ε时,M.i的值可以在val[top-1]找到。
4、第132页倒数第4行表达式E的后缀表示可以如下递归定义改成表达式E的后缀表示可以如下归纳定义5、第228页倒数第12行(5) L →Elist ] {L.place := newtemp;emit (L.place, ‘:=’, base(Elist.array), ‘(’, invariant(Elist.array) );L.offset := newtemp;emit (L.offset, ‘:=’, Elist.place, ‘(’, w) }改成(5) L →Elist ] {L.place := newtemp;emit (L.place, ‘:=’, base(Elist.array), ‘-’, invariant(Elist.array) );L.offset := newtemp;emit (L.offset, ‘:=’, Elist.place, ‘*’, w) }6、第351页图11.9下第3行则新创建的C对象的地址在赋给pb2时必须调整,以指向其B2子对象,即提供C对象的B2视图。
遍译时将会产生以下代码:改成则新创建的C对象的地址在赋给pb2时必须调整,以指向其B2子对象,即提供C对象的B2视图。
编译时将会产生以下代码:7.第346页第5行obj.translate (-center.x, -center.y); // 将中心点移至原点(0, 0)改成obj.translate (-center.x, -center.y); // 将“中心点”移至“点(0, 0)”2005-5-71.第149页倒数第8行ΓNat表示在静态定型环境Γ下,Nat是一个类型表达式。
改成Γnat表示在静态定型环境Γ下,nat是一个类型表达式。
2.第150页第1行φtrue : Bool true具有类型Boolx : Nat x + 1 : Nat x + 1的类型是Nat,只要x具有类型Nat任何一个断言可以看成是有效的(valid)(例如Γtrue : Bool)或无效的(invalid)(例如Γtrue : Nat)。
有效性可用来使良类型化程序的概念形式化。
改成φtrue : boolean true具有类型booleanx : nat x + 1 : nat x + 1的类型是nat,只要x具有类型nat任何一个断言可以看成是有效的(valid)(例如Γtrue : boolean)或无效的(invalid)(例如Γtrue : nat)。
有效性可用来使良类型化程序的概念形式化。
3.第150页倒数第12行下面的语法规则本质上是说,在任何合适环境Γ下,Bool是一个类型。
(Type Bool) Γ◊⇒ΓBool推理规则的结论是定型断言的话,称之为定型规则。
例如,下面的第一条规则是说,在任何合式环境下,任何一个自然数都是类型为Nat的表达式。
第二条规则是说,两个自然数表达式M和N相加的结果是一个自然数表达式M+N,而且M和N的环境Γ继续作为M+N 的环境。
(Val n) (n= 0, 1, …)Γ◊⇒Γn : Nat(Val +) ΓM : Nat,ΓN : Nat⇒ΓM + N : Nat改成下面的语法规则本质上是说,在任何合适环境Γ下,boolean是一个类型。
(Type Bool) Γ◊⇒Γboolean推理规则的结论是定型断言的话,称之为定型规则。
例如,下面的第一条规则是说,在任何合式环境下,任何一个自然数都是类型为nat的表达式。
第二条规则是说,两个自然数表达式M和N相加的结果是一个自然数表达式M+N,而且M和N的环境Γ继续作为M+N 的环境。
(Val n) (n= 0, 1, …)Γ◊⇒Γn : nat(Val +) ΓM : nat,ΓN : nat⇒ΓM + N : nat4.第154页第一段在我们的文法中,语句这样的语言构造没有类型。
在类型系统设计中,可以给它们以特殊的基本类型void,这样便于我们从程序P的属性判断它是否有类型错误。
下面的规则用来确定语句和程序的类型。
(State Assign) Γid : T, ΓE : T⇒Γid := E :void(State If) ΓE : boolean, ΓS : void⇒Γif E then S : void(State While) ΓE : boolean, ΓS : void⇒Γwhile E do S: void(State Seq) ΓS1: void, ΓS2: void⇒ΓS1; S2 : void(Prog ) ΓS : void⇒Γ D ; S :void改成在我们的文法中,语句这样的语言构造没有类型。
在类型系统设计中,可以给它们以特殊的基本类型void,这样便于我们从语句S的属性判断程序是否有类型错误。
下面的规则用来确定语句的类型。
(State Assign) Γid : T, ΓE : T⇒Γid := E :void(State If) ΓE : boolean, ΓS : void⇒Γif E then S : void(State While) ΓE : boolean, ΓS : void⇒Γwhile E do S: void(State Seq) ΓS1: void, ΓS2: void⇒ΓS1; S2 : void5.第170页倒数第8行(Type Record) (l i是有区别的)ΓT1, …, ΓT n⇒Γrecord(l1:T1, …, l n:T n) (Val Record) (l i是有区别的)ΓM1: T1, …, ΓM n: T n⇒Γrecord(l1= M1, …, l n= M n) : record(l1:T1, …, l n:T n) (Val Record Select)ΓM : record(l1:T1, …, l n:T n) ⇒ΓM.l j : T j(j∈ 1..n)改成(Type Record) (l i是有区别的)ΓT1, …, ΓT n⇒Γrecord(l1:T1, …, l n:T n) (Val Record) (l i是有区别的)ΓM1: T1, …, ΓM n: T n⇒Γrecord(l1= M1, …, l n= M n) : record(l1:T1, …, l n:T n) (Val Record Select)ΓM : record(l1:T1, …, l n:T n) ⇒ΓM.l j : T j(j∈ 1..n)2005-3-271.第79页图3.16中改成I4 I5I4 I52.第351页图11.9下面第2行 B2 pb2 = new C; 改成 B2 *pb2 = new C;3.第355页倒数第4行 的每个值都只需占用抽象机的一个存储单元,以简化的讨论。
改成 的每个值都只需占用抽象机的一个存储单元,以简化讨论。
4.第356页图12.1中v n = = e n ;改成v n = = e n5.第359页倒数第10行= (ni 0=bdvar (e i ) ) ⋃ ( {v 1, …, v n } ⋂ freevar (e 0, …, e n ) )改成= (ni 0=bdvar (e i ) ) ⋃ ( {v 1, …, v n } ⋂ni 0=freevar (e i ) )6.第381页第1行 (b) letrec F = = λx . xy ; 改成(b) letrec F = = λx y . xy ;2005-3-61.第253页的倒数第4行如果基本块有两个相邻的语句: 改成如果基本块有两个相邻的语句(t 1和t 2是不同的临时变量):2.第31页最后一行 (a |b )*ab 改成 (a |b )*ab3.第351页图11.9下面第4行 视图。
遍译时将会产生以下代码: 改成 视图。
编译时将会产生以下代码:4.第352页第6行(*pb2->vptr[i].faddr)(pb2 + pb2->vptr[1].offset);改成(*pb2->vptr[i].faddr)(pb2 + pb2->vptr[i].offset);5.第353页中间Ellipse (Point ¢er, double x_radius, double y_radius, double angle = 0) {_center = center;_x_radius = x_radius;_y_radius = y_radius;_angle = angle;}// Ellipse area -- 'ClosedGraphics ::: area'double area (void) {return PI * _x_radius * _y_radius;}改成Ellipse (Point ¢er, double x_radius, double y_radius, double angle = 0) {_center = center;_x_radius = x_radius;_y_radius = y_radius;_angle = angle;}// Ellipse area --overwrites 'ClosedGraphics :: area'double area (void) {return PI * _x_radius * _y_radius;}2004-6-211.第7页的第18行词法分析器发现源程序的标识符时,把该标识符填入符号表。