PostgresQL与oracle区别
postgresql和oracle表分区对比
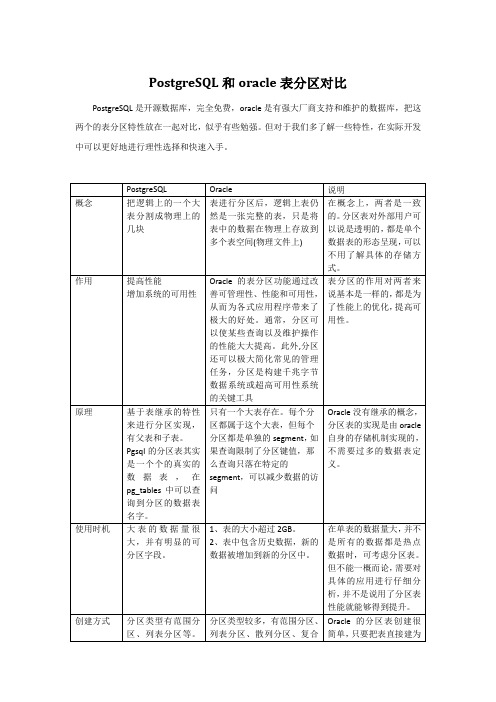
PostgreSQL和oracle表分区对比PostgreSQL是开源数据库,完全免费,oracle是有强大厂商支持和维护的数据库,把这两个的表分区特性放在一起对比,似乎有些勉强。
但对于我们多了解一些特性,在实际开发中可以更好地进行理性选择和快速入手。
总结,数据库的表分区特性优点很多,比如:1、改善查询性能:对分区对象的查询可以仅搜索自己关心的分区,提高检索速度。
2、增强可用性:如果表的某个分区出现故障,表在其他分区的数据仍然可用;3、维护方便:如果表的某个分区出现故障,需要修复数据,只修复该分区即可;4、均衡I/O:可以把不同的分区映射到磁盘以平衡I/O,改善整个系统性能。
5、将很少用的数据可以移动到便宜的、慢一些地存储介质上。
这两种数据库的分区表都具有这些优点。
对比来说,Oracle的分区创建和管理更加方便,很多工作是由oracle的内部机制来实现的。
postgreSQL的分区表其实是一个个实际存在的数据表,分区的创建和管理都需要我们用语言来控制,增加了应用人员的工作量。
但,由于oracle自身的“侵占式”硬盘存储,对过期数据进行清除时,即便是drop分区表,也不能直接释放硬盘空间,属于“占了就占了”,这个管理起来就比较麻烦,除非对每个分区表都建立各个独立的tablespace,放在独立的物理文件上,删除过期分区表时,可以同时drop tablespace including contents。
而postgreSQL在truncate 分区表时,可以直接释放硬盘,会看到硬盘使用率下降了,这一点对硬盘资源紧张时,就非常好了。
两种数据库的分区表使用,各有利弊,但总的来说,比较偏向postgreSQL,毕竟硬盘有限。
而且,oracle收费。
Ps,在数据量很大时,任何关系型数据库都有性能上的瓶颈,不属于我们这两种数据库分区表对比的范围了。
以上,是一些使用中的总结,还请达人们指教:)。
PostgreSQL,mysql,MS SQL,Oracle性能对比

PostgreSQL
MySQL
MsSQL
Oracle
支持系统
Windows下不太稳定
很多
Windows
很多
可编写环境
较多
较多
用户普遍性
普遍
流行
较普遍
查询速度
比较慢
较慢
较快
应用灵活性
较灵活
可单独应用,也可进行嵌套
灵活
查询包含性
较差
较强
负载程度
很低
很高
价格
免费开源
收费
管理简易程度
较容易
非常容易
中文支持
MySQL是一个开放源码的小型关联式数据库管理系统
MS SQL是指微软的SQL Server数据库服务器,它是一个数据库平台,提供数据库的从服务器到终端的完整的解决方案,其中数据库服务器部分,是一个数据库管理系统,用于建立、使用和维护数据库。
Oracle SQL Developer是一个免费非开源的用以开发数据库应用程序的图形化工具,使用SQL Developer可以浏览数据库对象、运行SQL语句和脚本、编辑和调试PL/SQL语句。另外还可以创建执行和保存报表。
PostgreSQL
PostgreSQL支持大部分SQL标准并且提供了许多其他现代特性:复杂查询、外键、触发器、视图、事务完整性、多版本并发控制。同样,PostgreSQL可以用许多方法扩展,比如,通过增加新的数据类型、函数、操作符、聚集函数、索引方法、过程语言。并且,因为许可证的灵活,任何人都可以以任何目的免费使用,修改,和分发PostgreSQL,不管是私用,商用,还是学术研究使用。
支持
支持,但开发和转移数据时容易出现中文字符问题
postgresql同oracle语法差异

很多内容是网上查的资料,我只是整理下,有遗漏的地方,欢迎补充首先用工具(Ora2pg)自动转换由于这个项目后台程序量很大,存储过程+触发器大约有15万行代码。
用这个工具可以将一些oracle与pgsql的语法差异自动处理下,但不是全部,剩下的需要手工修改。
ORACLE语法→ PostgreSQL语法1、VARCHAR2 → varchar2、DATE → timestamp3、SYSDATE → localtimestamp4、Oracle中''和NULL是相同的,但pgsql是不同的,所以需要将''修改成NULL5、字符串连接符||Oracle:'a'||null 结果是'a'pgsql: 'a'||null 结果是null所以用concat()函数替代6、trunc(时间) → date_trunc()7、to_char, to_number, to_date pgsql都需要指定格式8、DECODE → case9、NVL → coalesce()10、外连接(+) → left(right) join11、GOTO语句→ pgsql不支持12、pgsql不支持procedure和package,都需要改写成function当package有全局变量的情况修改起来比较麻烦,我们是用临时表传递的。
13、cursor的属性%FOUND → found%NOTFOUND → not found%ISOPEN → pgsql不支持%ROWCOUNT → pgsql不支持另外关于cursor的其他差异,参照这个帖子/client/post_show.php?zt_auto_bh=5675114、COMMIT,ROLLBACK;SAVEPOINT → pgsql不支持15、Oracle的系统包,例如DBMS_OUTPUT,DBMS_SQL,UTIL_FILE,UTIL_MAIL → pgsql不支持16、异常处理方法不同17、trigger的语法不同18、日期的加减计算语法不同。
Oracle、MySQL和PostgreSQL的功能比较

复杂SQL(优化引擎)SQL是你与你的数据库交互的基础和最关键的方法,无论你选择哪个。
这三个平台也恰恰是从它开始真正分离。
Oracle支持非常复杂的查询、几乎不限制表的个数、所有的类型的连接和合并。
虽然Oracle有很多功能,但是它真正宝贵的却是它基于成本的优化器,它可以分析SQL、如果可能的话进行重写和简化、基于成本选择索引、决定对表的操作和它之中的所有其它的各种功能。
阅读MySQL的文档,你会发现对偏向于性能的描述和供应商定义的细节使优化器和性能调整在任何平台上都很复杂。
MySQL规定的最大规模是在任何连接或在一个视图中表的最大数目为61个。
再一次的,我个人觉得无论如何在任何一个应用中这么多表的一个查询将是难以使用的,所以正如上面提到的,目前更适用的是优化器而不是查询最大表规格,等等。
8.x版本的Postgresql支持所有SQL92规范,几乎没有任何限制。
再一次的,我认为你会看到的一个数据库优于其它的数据库的方面就是在优化方面。
复杂的查询会变得凌乱,并且查询计划是你在诊断性能瓶颈时的最好的朋友。
索引类型索引技术对于数据库性能是至关重要的,而Oracle有大量的选项可供选择。
有非常多的不同的索引类型,包括标准的二进制树、转换键的、基于功能的、常被错误使用的位图索引,甚至还有索引表。
随着附加项技术的发展,数据库管理员有了可用的提供索引的Oracle文本,它允许你搜索CLOB(字符大对象),并且Oracle Spatial 提供用于基于位置的数据的索引。
在MySQL中,我们发现有二进制树、哈希、纯文本和GIS索引(对于基于位置的数据)。
还有集群索引,但是如果说我在Oracle方面的经验给我任何指导的话,那么就是大多数应用通常是不相关的。
因此,大多数情况下我在Oracle、MySQL或Postgres应用中看到的只有二进制树索引。
另外,尽管像在MySQL中基于功能的索引是不可用的,但是他们可以通过创建另一个保存使用这个函数的数据的列来进行模拟,然后添加一个触发器来将安装它。
Oracle与Postgresql数据库对比.ppt

Oracle RAC体系架构
2020年4月7日星期二
Oracle RAC体系架构
2020年4月7日星期二
Oracle Partitioning管理
2020年4月7日星期二
Oracle DataGuard体系架构
2020年4月7日星期二
2020年4月7日星期二
ቤተ መጻሕፍቲ ባይዱ QLCS系统数据库选型
QLCS系统为生产线系统,需要达到较高可用性及稳定性,充分考虑的性能及 服务支持,建议采用目前主流的关系型数据库Oracle 11g R2,并且购买 Oracle RAC套件,以达到系统安全稳定运行。
2020年4月7日星期二
Click to edit Master title style, the title can be up to three lineOsrlaocnlge(与if Preoqsutgirreeds)ql对比方案
Click to edit Master subtitle style
Oracle 数据库产品
2020年4月7日星期二
Oracle 数据库产品系列
2020年4月7日星期二
Oracle 数据库发展史
04 自动管理
97 表分区 89 并行服务器
84 读一致性 82 跨平台
01 RAC与DG 闪回查询
2020年4月7日星期二
Postgresql简介
PostgreSQL is a powerful, open source object-relational database system. It has more than 15 years of active development and a proven architecture that has earned it a strong reputation for reliability, data integrity, and correctness. It runs on all major operating systems, including Linux, UNIX (AIX, BSD, HP-UX, SGI IRIX, Mac OS X, Solaris, Tru64), and Windows. It is fully ACID compliant, has full support for foreign keys, joins, views, triggers, and stored procedures (in multiple languages). It includes most SQL:2008 data types, including INTEGER, NUMERIC, BOOLEAN, CHAR, VARCHAR, DATE, INTERVAL, and TIMESTAMP. It also supports storage of binary large objects, including pictures, sounds, or video. It has native programming interfaces for C/C++, Java, .Net, Perl, Python, Ruby, Tcl, ODBC, among others, and exceptional documentation.
sql与oracle的区别

001、SQL与ORACLE的内存分配ORACLE的内存分配大部分是由INIT.ORA来决定的,一个数据库实例可以有N种分配方案,不同的应用(OLTP、OLAP)它的配置是有侧重的。
SQL概括起来说,只有两种内存分配方式:动态内存分配与静态内存分配,动态内存分配充许SQL自己调整需要的内存,静态内存分配限制了SQL对内存的使用。
002、SQL与ORACLE的物理结构总得讲,它们的物理结构很相似,SQL的数据库相当于ORACLE的模式(方案),SQL的文件组相当于ORACLE的表空间,作用都是均衡DISK I/O,SQL创建表时,可以指定表在不同的文件组,ORACLE则可以指定不同的表空间。
CREATE TABLE A001(ID DECIMAL(8,0)) ON [文件组]--------------------------------------------------------------------------------------------CREATE TABLE A001(ID NUMBER(8,0)) TABLESPACE 表空间注:以后所有示例,先SQL,后ORACLE003、SQL与ORACLE的日志模式SQL对日志的控制有三种恢复模型:SIMPLE、FULL、BULK-LOGGED;ORACLE对日志的控制有二种模式: NOARCHIVELOG、ARCHIVELOG。
SQL的SIMPLE相当于ORACLE 的NOARCHIVELOG,FULL相当于 ARCHIVELOG,BULK-LOGGED相当于ORACLE大批量数据装载时的NOLOGGING。
经常有网友抱怨SQL的日志庞大无比且没法处理,最简单的办法就是先切换到SIMPLE模式,收缩数据库后再切换到FULL,记住切换到FULL 之后要马上做完全备份。
004、SQL与ORACLE的备份类型SQL的备份类型分的极杂:完全备份、增量备份、日志备份、文件或文件组备份;ORACLE 的备份类型就清淅多啦:物理备份、逻辑备份;ORACLE的逻辑备份(EXP)相当于SQL 的完全备份与增量备份,ORACLE的物理备份相当于SQL的文件与文件组备份。
Postgres 与Oracle对比

Postgres 与Oracle对比(进程结构与并发控制)Postgres 与Oracle对比(进程结构与并发控制)一.进程结构Postgres中主要有以下几种进程:postmaster, postgres, vacuum, bgwriter, pgarch, walwriter, pgstat(1)postmaster负责在启动数据库的时候创建共享内存并初始化各种内部数据结构,如锁表,数据库缓冲区等,该进程在数据库中只有一个。
在数据库启动以后负责监听用户请求,创建postgres进程来为用户服务。
这一点与Oracle 的TNS listener进程类似。
(2)postgres负责执行用户发出的所有SQL语句,该进程在数据库中可能有多个, Oracle中叫shadow process。
(3)vacuum负责清除数据库中无用的历史数据(已经被删除或更新的记录)。
更新优化器的统计信息,确保产生可以接受的查询计划,该进程在数据库可能有多个, Oracle无此种类型进程。
(4)bgwriter负责将数据缓冲区中已被更新的数据库写入数据库物理数据文件中, Oracle中对应的进程叫DBWR, 该进程在数据库中只有一个。
(5)pgarch负责将系统产生的redo log复制到其他外部存储介质中, Oracle中对应的进程叫Archiver,该进程在数据库中只有一个。
(6)walwriter负责将系统产生的redo log 写到redo log 文件中(在pg_xlog目录下), Oracle中对应的进程叫LGWR,该进程在数据库中只有一个。
(7)pgstat负责收集数据库运行中的统计信息,如一个表上面进行了多少次插入与更新操作,该进程在数据库中只有一个, Oracle无此种类型进程。
二.并发控制Postgres用的是多版本并发控制机制(Multiversion concurrency control, Concurrency Control in Distributed Database Systems by Philip Bernstein and Nathan Goodman,1981),如果有兴趣,可以区看原始论文,Oracle使用的也是多版本并发控制机制。
PostgreSQL VS MySQL&Oracle

记录少量回滚信息,redo日志就记录操作信息;对于PostgreSQL只需要在数据 文件和WAL日志中记录操作。 对于delete操作,oracle和innodb,需要在数据文件删除数据,在回滚段
中记录旧数据,redo日志就记录操作信息;对于PostgreSQL只需要更新数据文 件和在WAL日志中记录操作。 对于update操作,PostgreSQL需要新生成一行,会导致原表膨胀,而对于
事务,会带来很多严重的问题。同时回滚的过程也会再次产生大量的redo日志。 4. WAL日志要比oracle和Innodb简单,对于oracle不仅需要记录数据文
件的变化,还要记录回滚段的变化。
PostgreSQL多版本实现
PostgreSQL的主要劣势在于:
最新版本和历史版本不分离存储,导致清理老旧版本需要作更多的扫描,代 价比较大,但这个问题一般并不是突出,因为VACUUM中也有很多的优化。如 PostgreSQL 8.3中加入了HOT技术。使用HOT后,若所有索引属性都没被修改 (索引键是否修改是在执行时逐行判断的,因此若一条UPDATE语句修改了某属 性,但前后值相同则认为没有修改),且新版本与原版本存储在一个页面上则不 会产生新的索引记录 由于索引中完全没有版本信息,不能实现Coverage index scan,即查询只
扫描索引,直接从索引中返回所需的属性,还需要访问表。而oracle是完全实现 了Covera index scan,Innodb是部分实现了(在某种情况下也是可以的,但不 是所有情况下都可以了)。
PostgreSQL多版本实现
在业务上产生的差异:
对于insert操作,oracle和innodb,需要在数据文件插入数据,在回滚段中
oracle转PostgreSQL

oracle转PostgreSQL从2019年开始,就有一个很火热的话题:“去O化”。
O就是oracle,也就是将oracle替换成别的数据库。
为什么要去O?大致有以下原因:•oracle是收费的,为了进一步降低成本;•以美国为首的西方国家对华科技种种遏制行为,最近越闹越厉害,最近docker的付费服务就禁止中国企业使用;•甲骨文公司中国区大幅度裁员,或将放弃中国市场也说不定;•2020年12月31起,甲骨文公司将不再对oracle11.2版本提供技术支持,即出现bug也不会维护了。
鉴于以上种种原因,很多企业都在更换数据库,但是如果新的数据库语法和oracle差别很大,那工作量会特别大,权衡之下,postgreSQL是个不错的选择。
本人前两周就在做这个“去O化”,将遇到的改造点记录下来,供大家参考。
1、jar包/maven依赖的更换:驱动包要换成postgresql-xxx.jrex.jar,x表示版本。
如果是maven项目,则添加如下依赖:<dependency><groupId>org.postgresql</groupId><artifactId>postgresql</artifactId><version>版本</version></dependency>2、driverClassName等信息的更换:datasource.driverClassName=org.postgresql.Driverhibernate.dialect=org.hibernate.dialect.PostgreSQLDialect3、字段类型问题:•主外键字段类型问题:A表的主键在B表做外键时,这个字段在两张表的类型一定要一致,否则连接查询会报错。
•实体类与数据表字段类型问题:实体类字段类型一定要与数据表字段类型对应,否则映射的时候就报错了。
oracle增强型时间类型以及postgresql时间类型

oracle增强型时间类型以及postgresql时间类型oracledate 包含时间和日期类型,包括年月日,小时,分钟,秒。
这个经常用,相信大家都熟悉timestamp 这个类型很精确,是精确到微妙的时间单位。
指定精度的小数位,最多为9位,默认6位timestamp with time zone 这个除了包含了timestamp的外,又有了时区。
timstamp with local time zone 这个类型不包含时区偏移量,由用户当地会话时区确定。
interval year to monthinterval day to secondtimestamp可以通过to_timestamp_t转换到timestamp with time zone tz_offset可以查看时区的差位移查看数据库时区:SELECT dbtimezone FROM dual;select sessiontimezone from dual;SQL> select extract(year from sysdate) from dual;--获取年份EXTRACT(YEARFROMSYSDATE)------------------------2012SQL> select extract(month from sysdate) from dual;--获取月份EXTRACT(MONTHFROMSYSDATE)-------------------------9SQL> select extract(day from sysdate) from dual;--获取日EXTRACT(DAYFROMSYSDATE)-----------------------6SQL> select from_tz(timestamp '2012-09-06 09:00:00','8:00') from dual; --timestamp转timestamp with time zoneFROM_TZ(TIMESTAMP'2012-09-0609:00:00','8:00')---------------------------------------------------------------------------06-SEP-12 09.00.00.000000000 AM +08:00SQL> create table test_zone2 (timestamp_dt TIMESTAMP,3 zone_dt TIMESTAMP WITH TIME ZONE,4 local_zone_dt TIMESTAMP WITH LOCAL TIME ZONE);Table created.SQL> insert into test_zone values (sysdate,sysdate,sysdate);1 row created.SQL> col TIMESTAMP_DT for a35SQL> col ZONE_DT for a35SQL> col LOCAL_ZONE_DT for a35SQL> select * from test_zone;TIMESTAMP_DT ZONE_DT LOCAL_ZONE_DT---------------------------------------------------------------------------------------------------------06-SEP-12 01.50.10.000000 PM 06-SEP-12 01.50.10.000000 PM +08:00 06-SEP-12 01.50.10.000000 PMSQL> insert into test_zone values(to_date('20090101','yyyymmdd'),to_timestamp('20090101','yyyymmdd'),to_timestamp_tz('20090101 010101 -8:00','yyyymmdd hh24miss TZH:TZM'));1 row created.SQL> select * from test_zone;TIMESTAMP_DT ZONE_DT LOCAL_ZONE_DT----------------------------------- ----------------------------------- -----------------------------------06-SEP-12 01.50.10.000000 PM 06-SEP-12 01.50.10.000000 PM +08:00 06-SEP-12 01.50.10.000000 PM01-JAN-09 12.00.00.000000 AM 01-JAN-09 12.00.00.000000 AM +08:00 01-JAN-09 05.01.01.000000 PMSQL> alter session set time_zone='+05:00';Session altered.SQL> select * from test_zone;TIMESTAMP_DT ZONE_DT LOCAL_ZONE_DT (提前了三个小时)----------------------------------- ----------------------------------- -----------------------------------06-SEP-12 01.50.10.000000 PM 06-SEP-12 01.50.10.000000 PM +08:00 06-SEP-12 10.50.10.000000 AM01-JAN-09 12.00.00.000000 AM 01-JAN-09 12.00.00.000000 AM +08:00 01-JAN-09 02.01.01.000000 PMSQL> select * from v$timezone_names where rownum<10; --查看时区名称TZNAME TZABBREV---------------------------------------------------------------- ----------------------------------------------------------------Africa/Abidjan LMTAfrica/Abidjan GMTAfrica/Accra LMTAfrica/Accra GMTAfrica/Accra GHSTAfrica/Addis_Ababa LMTAfrica/Addis_Ababa ADMTAfrica/Addis_Ababa EATAfrica/Algiers LMTSQL> select tz_offset('Africa/Accra')from dual;TZ_OFFS-------+00:00alter session set nls_date_format='yyyy-mm-dd hh24:mi:ss';--设置会话日期显示格式SQL> select to_timestamp('20120909 00:01:02.123456789','yyyymmdd hh24:mi:ss.ff')from dual; --to_timestamp函数使用TO_TIMESTAMP('2012090900:01:02.123456789','YYYYMMDDHH24:MI:SS.FF')---------------------------------------------------------------------------09-SEP-12 12.01.02.123456789 AMSQL> select to_timestamp_tz('20120909 00:01:02.123456789 0:0','yyyymmdd hh24:mi:ss.ff tzh:tzm')from dual; --to_timestamp_tz使用TO_TIMESTAMP_TZ('2012090900:01:02.1234567890:0','YYYYMMDDHH24:MI:SS.FFTZH:T ---------------------------------------------------------------------------09-SEP-12 12.01.02.123456789 AM +00:00postgresql时间类型:9.1.2版本名字存储空间描述最低值最高值分辨率timestamp[无时区] 8字节包括日期和时间4713 BC 5874897AD 1毫秒/14位timestamp[含时区] with time zone 8字节日期和时间,带时区4713 BC 5874897AD 1毫秒/14位interval 12字节时间间隔-178000000年178000000年1毫秒/14位date 4字节只用于日期4713 BC 32767AD 1天time[无时区] 8字节只用于一日内时间00:00:00 24:00:00 1毫秒/14位postgres=# select current_timestamp; --可以看到精度6位,显示时区+8,和oracle的timestamp with time zone类型是一致的now-------------------------------2012-09-06 14:04:51.363932+08postgres=# create table test_t (time_col time,date_col date,timestamp_col timestamp);类型区别CREATE TABLEpostgres=# insert into test_t values(now(),now(),now());INSERT 0 1postgres=# select * from test_t;time_col | date_col | timestamp_col-----------------+------------+----------------------------14:19:24.277477 | 2012-09-06 | 2012-09-06 14:19:24.277477(1 row)精度和时区的控制:postgres=# create table test_t1 (time_col time,date_col date,timestamp_coltimestamp,timestamp_col0 timestamp(0)without time zone);CREATE TABLEpostgres=# insert into test_t1 values(now(),now(),now(),now());INSERT 0 1postgres=# select * from test_t1;time_col | date_col | timestamp_col | timestamp_col0-----------------+------------+----------------------------+---------------------14:34:59.840947 | 2012-09-06 | 2012-09-06 14:34:59.840947 | 2012-09-06 14:35:00postgres=# alter table test_t1 add column timestamp_col1 timestamp(0)with time zone;ALTER TABLEpostgres=# insert into test_t1 values(now(),now(),now(),now(),now());INSERT 0 1postgres=# select * from test_t1;time_col | date_col | timestamp_col | timestamp_col0 | timestamp_col1 -----------------+------------+----------------------------+---------------------+------------------------14:34:59.840947 | 2012-09-06 | 2012-09-06 14:34:59.840947 | 2012-09-06 14:35:00 |14:36:31.265579 | 2012-09-06 | 2012-09-06 14:36:31.265579 | 2012-09-06 14:36:31 | 2012-09-06 14:36:31+08由此可见,timestamp本身不带时区,但是带精度,如果需要带时区,那么加上with time zone即可postgres=# select now()::timestamp(0)without time zone;now---------------------2012-09-06 14:42:12。
Postgre与Oracle编写SQL的区别与转换方法

Postgre与Oracle编写SQL的区别与转换⽅法1.instr函数可以⽤like替换也可以⽤ POSITION ('试油' in T1.WELL TEST METHOD)>0替换2.decode可以⽤case when 2 then 2 when 1 then -1替换SELECTM.DESIGN_ID,MAX( DECODE( M.AUDIT_CODE, 2, 2, 1,- 1, 0, 0 ) ) AUDIT_CODEFROMPC_BUILD_DAILY_REPORT_DAY MWHEREto_date ( m.control_date, 'yyyy-mm-dd' ) = to_date ( '2019-05-21', 'yyyy-mm-dd' )GROUP BYM.DESIGN_IDSELECTA.design_id,MAX(CASE A.AUDIT_CODEWHEN '2' THEN '2'WHEN '1' THEN '-1'WHEN '0' THEN '0'END) AS AUDIT_CODEFROM PC_BUILD_DAILY_REPORT_DAY AWHEREto_date ( A.control_date, 'yyyy-mm-dd' ) = to_date ( '2019-05-21', 'yyyy-mm-dd' )GROUP BYA.DESIGN_ID3.SUBSTR 截取字符串的开始位置必须为1 例如截取aaaaa的四位 SUBSTR ('aaaaa',1,4) 若为SUBSTR ('aaaaa',0,4) 则⽆效4.PostgreSQL中不需要dual虚拟表 select语句可以没有from5.类似于select *from(select...) from⾥⾯的⼦查询必须要起别名,多层嵌套⼀样都要起别名如select *from(select *from(select...) as A)as B6.postgre中没有trunc、add months、last day函数可以⽤date_trunc、interval替代(已经编写了f_add_months f_last_day函数可⽤)例⼦:求⽇期该年第⼀天trunc(TO_DATE('20190714', 'yyyymmdd'),'yyyy')date_trunc('year',TO_DATE('20190714', 'yyyymmdd'))求⽇期该年最后⼀天两种⽅式替换(第⼆种⽐较好)last_day(add_months(trunc(TO_DATE('20190714', 'yyyymmdd'),'y'),11))date_trunc('day',(date_trunc('year',TO_DATE('20190714', 'yyyymmdd'))+ interval '11 month')+interval '30 day')(date_trunc('MONTH',date_trunc('year',TO_DATE('2019-07-14', 'yyyy-mm-dd'))+ interval '11 month') + INTERVAL '1 MONTH - 1 day')求⽇期该⽉第⼀天TRUNC(TO_DATE('20190414', 'yyyymmdd'),'mm')TRUNC(ADD_MONTHS(LAST_DAY(TO_DATE('20190414', 'yyyymmdd')),-1)) + 1date_trunc('MONTH',(date_trunc('MONTH',to_date('2019-07-09','yyyy-mm-dd')) - INTERVAL '1 MONTH')+ INTERVAL '1 MONTH') 7.postgre中没有nvl函数,可以⽤coalesce函数替代nvl(collect_result,0) as collect_resultcoalesce(collect_result,0) as collect_result8.字符串去掉空格oracleSelect LTRIM(' sql_in_a_nutshell'),Select RTRIM('sql_in_a_nutshell '),TRIM(' sql_in_a_nutshell ')FROM dual;PostgreSQLSelect TRIM(LEADING FROM ' sql_in_a_nutshell'),TRIM(TRAILING FROM 'sql_in_a_nutshell '),TRIM(BOTH FROM ' sql_in_a_nutshell ');9.上⾯清除空格相反的操作,添加空格oracleSelect LPAD(('sql', 5, ' '),RPAD(('sql', 5, ' ')FROM dual;PostgreSQLSelect LPAD('sql', 5, ' '),LPAD('sql', 2, ' '),RPAD('sql', 5, ' '),RPAD('sql', 2, ' '),;//结果为 ' sql' 'sq' 'sql ' 'ql'10.字符串替换oracleSelectREPLACE('wabbit_season','it_','it_hunting_')FROM dual;PostgreSQLSelect TRANSLATE('wabbit_season','it_','it_hunting_');Select replace('wabbit_season','it_','it_hunting_');11.NULLIF(expression1, expression2) 如果 expression1 等于 expression2则返回 NULL,如果expression1的值为null,也返回NULLoracleSelect DECODE(foo,'Wabbits!',NULL)FROM dual;PostgreSQLSelect NULLIF(foo, 'Wabbits!');12.postgre中没有nvl2函数,可以⽤case when is not null then 2 else 1替换nvl2(name, '有⼈', '⽆⼈')when name is not null then '有⼈' else '⽆⼈' end13 REGEXP_SUBSTR可以替换为substring (匹配正则表达式)REGEXP_SUBSTR(ST.STRAT_UNIT_NAME,'[^'|| UNISTR('\4e00') ||'-'||UNISTR('\9fa5') || ']',1,1)SELECT substring(ST.STRAT_UNIT_NAME from '[^\u4e00-\u9fa5]')14 postgre函数学习⼿册15 FN SPLIT 可以⽤regexp split to table替换(列转⾏)SELECT split_part('哈-哈哈哈', '哈', 2) //结果 -SELECT substring('你好-哈哈' from '([\u3007\u3400-\u4DB5\u4E00-\u9FCB\uF900-\uFA2D]+-)')//结果你好-SELECT a.string_to_array[2] from (SELECT string_to_array ('a,b,b',',')) as a //结果bSELECT split_part('accb','c',2) //⽆结果SELECT regexp_split_to_table('a,b,b',',')//结果a b b集合16(⾏转列)PIVOT(MAX(BTM_DEPTH) BTM_DEPTH,(MAX(BTM_DEPTH - TOP_DEPTH)) THICKNESS, MAX(OIL_GAS_POSITION)OIL_GAS_POSITION, MAX(DIP_ANGLE) DIP_ANGLEFOR PHASE IN('设计' DESIGN, '实际' ACTUAL))max( CASE WHEN PHASE = '设计' THEN BTM_DEPTH ELSE 0 END ) AS DESIGN_BTM_DEPTH,max( CASE WHEN PHASE = '实际' THEN BTM_DEPTH ELSE 0 END ) AS ACTUAL_BTM_DEPTH,max( CASE WHEN PHASE = '设计' THEN BTM_DEPTH - TOP_DEPTH ELSE 0 END ) AS DESIGN_THICKNESS,max( CASE WHEN PHASE = '实际' THEN BTM_DEPTH - TOP_DEPTH ELSE 0 END ) AS ACTUAL_THICKNESS,max( CASE WHEN PHASE = '设计' THEN OIL_GAS_POSITION ELSE '' END ) AS DESIGN_OIL_GAS_POSITION,max( CASE WHEN PHASE = '实际' THEN OIL_GAS_POSITION ELSE '' END ) AS ACTUAL_OIL_GAS_POSITION,max( CASE WHEN PHASE = '设计' THEN DIP_ANGLE ELSE 0 END ) AS DESIGN_DIP_ANGLE,max( CASE WHEN PHASE = '实际' THEN DIP_ANGLE ELSE 0 END ) AS ACTUAL_DIP_ANGLE17 postgre对于数据类型的要求⼗分严格,并且没有⾃动转换格式,⽽oracle对于数据类型要求不是⼗分严格例如⽤||拼接字符串的时候 'aaa'||123||'bbb' 这种就会报错(oracle不会报错,正常运⾏) 需要改为 'aaa'||to_char(123,'99999999999')||'bbb' 才能拼接 ,需要编写者⾃⾏匹配正确的数据格式,如果格式不相符,则需要⽤to_char(字段,'999999999999')或to_number(字段,'9999999999999999')或cast(字段 as varchar) cast(字段 as integer)PS:对于to_char 9的数量没有限制,尽量多些,不然会丢失结果,如to_char(123,'9') 结果为 ' #';to_char(123,'99') 结果为 ' ##';to_char(123,'999') 结果为 ' 123'to_char(123,'9999') 结果为 ' 123'随着9的增加 123前⾯的空格增多,但并不影响计算对于to_number 9的数量没有限制,尽量多些,不然会丢失位数,如to_number('123','9') 结果为 1;to_number('123','99') 结果为 12;to_number(123,'999') 结果为 123to_char(123,'9999') 结果为 123 随着9的增加结果始终是12318 贼实⽤的generate_series函数函数参数类型返回类型描述generate_series(start, stop)int 或 bigintsetof int 或 setofbigint(与参数类型相同)⽣成⼀个数值序列,从start 到 stop,步进为⼀generate_series(start, stop, step)int 或 bigintsetof int 或 setofbigint(与参数类型相同)⽣成⼀个数值序列,从start 到 stop,步进为step timestamp ortimestamp 或⽣成⼀个数值序列,generate_series(start, stop, step_interval)timestamp 或timestamp with timezone(same asargument type)⽣成⼀个数值序列,从start 到 stop,步进为stepSELECT generate_series(1,5,2)结果135select date(zz) as t from generate_series(date_trunc('month',to_date('201505','yyyymm')), date_trunc('month',to_date('201507','yyyymm')),'1 month') as zz;结果2015-05-012015-06-012015-07-0119 新增fn_get_month_days函数,获取当⽉天数例⼦:select fn_get_month_days('201912')结果 3120 替代Oracle中ALL_TAB_COLUMNS与ALL_TABLESALL_TAB_COLUMNS:SELECTcol_description ( A.attrelid, A.attnum ) AS COMMENT,format_type ( A.atttypid, A.atttypmod ) AS TYPE,A.attname AS NAME,A.attnotnull AS NOTNULLFROMpg_class AS C,pg_attribute AS AWHEREC.relname = 'cd_well'AND A.attrelid = C.oidAND A.attnum > 0ALL_TABLES:SELECTrelname AS tabname,CAST ( obj_description ( relfilenode, 'pg_class' ) AS VARCHAR ) AS COMMENTFROMpg_class CWHERErelkind = 'r'AND relname NOT LIKE'pg_%'AND relname NOT LIKE'sql_%'ORDER BYrelname21 ‘a’ || null=?Oracle中 ‘a’ || null = ‘a’Postgre中 ‘a’ || null = null。
postgresql和oracle数据库对比

postgresql和oracle数据库对⽐SQL执⾏计划⼲预从使⽤postgresql来看,想要改变执⾏计划只能通过対表进⾏分析,不能通过添加hint的⽅式来改变执⾏计划;oracle不仅可以通过对表进⾏收集统计来改变执⾏计划,⽽且很重要的⼀点⽀持通过添加hint的⽅式以达到⾃⼰想要的执⾏计划。
查询效率从整体上⽐,不管是在离散数据的获取,还是在⼤数据量的统计分析,oracle的查询效率要好于postgresql,尤其在⼤数据量的统计分析(⽐较、排序、去重、表关联。
);有⼀个⽐较奇怪的地⽅是⼤表数据的加载,⽐⽅说link7的数据量有2G多,执⾏总数查询:select count(*) from link7; -----------------------------第⼀次执⾏时间⽐⽅说120s;在第⼆次执⾏时,执⾏时间可能是20s,但link7并没有全部加载到缓存中,只是有10%-20%的数据加载到缓存中,但执⾏时间缩短到了⾸次的1/10-1/9--------我猜想的是应该是⾸次执⾏完后,加载了表link7的位置信息到缓存中,再次查询时,可以快速定位数据。
语法功能在单条数据的功能上postgresql要强,尤其空间查询、转换,⽀持很多的⽅法函数在统计分析上oracle要强,如分析函数、sql model等数据加载在使⽤门槛上,postgresql要简单,如数据导⼊导出,copy 表 to '' with csv; copy 表 from '' with csv;在效率、多样性上oracle要强要多,如imp/exp、数据泵、sqlload等事务postgresql基本上⾃动提交事务,如果要控制⾃动提交,需要使⽤begin end;oracle默认是需要commit才会进⾏数据持久化,或者执⾏DDL总结体会postgresql开源免费、单数据处理转换、查询⽐较适⽤。
PostgreSQL、MsSQL、Oracle简单性能比较

PostgreSQL、MsSQL、Oracle简单性能⽐较由于版权关系,最近对PostgreSQL⽐较感兴趣,但⽹上有说PostgreSQL性能不⾼,所以⾃⼰做了个简单的⽐较。
公共环境:1. CPU双核1.5,2G内存。
2. WindowsXP软件版本:MsSQLServer2000,PostgresSQL8.3.3 for Windows,Oracle817 for Windows都是默认配置。
测试表:建⽴⼀个简单的表,只有⼀个可变长度字符串字段,并设置为主键。
访问接⼝:1.Vs2008开发的Windows程序。
2.SqlServer使⽤System.Data.SqlClient访问。
3.PostgreSQL使⽤Npgsql2.0.1访问,⼀个开源的实现。
4.Oracle使⽤System.Data.OracleClient。
Insert测试:1.插⼊2万条随机Guid字符串,隐式事务,每插⼊⼀条后⾃动提交:结果: SqlServer: 15sPostgreSQL:30sOracle: 44s2.插⼊2万条随机Guid字符串,显⽰事务,在所有插⼊完成后⼀次Commit:结果: SqlServer: 4sPostgreSQL:6sOracle: 16sCPU占⽤率都不⾼,差不多都10%左右。
Select测试:上述表在10万⾏时,查找⼀条记录执⾏100次(每次sql语句不⼀样):结果:SqlServer: 22msPostgreSQL:50msOracle: 60ms结论:1. 根据上⾯的插⼊测试,性能顺序从⾼到低:SQLServer2000、PostgreSQL833、Oracle817。
听说PostgreSQL在Linux上有更佳表现,以前PostgreSQL是没有原⽣Win版本的,只是8x开始才在Win上编译。
2. ⼀个没想到的问题是Oracle817为何表现这么差(最近项⽬⽤到,本机正好安装了这个版本),不会是需要调优?也许是Oracle817发⾏较早吧(1998年),但MsSQL2000也是2000年发布的呀,只有PostgreSQL8.33是2008年新版本。
从Oracle到PostgreSQL:动态性能视图vs标准统计视图

从Oracle到PostgreSQL:动态性能视图vs标准统计视图Oracle数据库的性能视图几乎可以说是最引以为骄傲的功能,在那样细粒度的采样统计强度下,依然保持卓越的性能,基于这些性能数据采样之后形成的AWR,更是Oracle DBA分析数据库性能问题的最重要手段之一。
那么在誉为最接近Oracle的开源数据库PostgreSQL中,如果要诊断性能问题,又有哪些视图可以使用呢?作为Oracle DBA,在学习PostgreSQL的时候,不可避免地会将PostgreSQL和Oracle进行比较。
以下SQL命令,在mydb=#提示符下的均为在PostgreSQL中执行的,在SQL>提示符下的均为在Oracle中执行的。
先看一下在PostgreSQL中存在那些统计信息视图。
PostgreSQL 中数据字典的命名还是很规范的,所有统计信息基本上都以pg_stat_开头。
••••••••••••••••••••••••••••••••••mydb=# select relname from pg_class where relname like 'pg_stat_%'; relname ---------------------------------- pg_statistic pg_stats pg_stat_all_tables pg_stat_xact_all_tables pg_stat_sys_tables pg_stat_xact_sys_tables pg_stat_user_tables pg_stat_xact_user_tables pg_statio_all_tables pg_statio_sys_tables pg_statio_user_tables pg_statio_all_indexes pg_statio_sys_indexes pg_statio_user_indexes pg_statio_all_sequences pg_statio_sys_sequences pg_statio_user_sequences pg_stat_activity pg_stat_replication pg_stat_database pg_stat_database_conflicts pg_stat_user_functions pg_stat_xact_user_functionspg_stat_archiver pg_stat_bgwriter pg_stat_all_indexes pg_stat_sys_indexes pg_stat_user_indexes pg_statistic_relid_att_inh_index(29 rows)pg_stat_activity 该视图显示了连接入一个Cluster下所有数据库的会话的统计信息,每个会话一行记录,类似于Oracle中的V$SESSION视图。
postgres oracle 编码

PostgreSQL 和 Oracle 是两种流行的关系型数据库管理系统,它们在编码方面有一些重要的差异。
在 PostgreSQL 中,默认的字符集是 UTF-8,这是一个非常全面的字符集,支持全球范围内的各种语言和符号。
这意味着你可以在 PostgreSQL 中存储任何 Unicode 字符,无需进行额外的配置或转换。
相比之下,Oracle 数据库的默认字符集是 AL32UTF8,也支持全球范围的字符。
但是,如果你想更改字符集,在 Oracle 中可能会更复杂一些。
此外,Oracle 也支持一些特定的 national character sets,这些字符集是为特定语言或地区设计的。
总的来说,对于大多数用途,PostgreSQL 和 Oracle 的默认字符集应该都能满足需求。
但是,如果你需要处理特定的语言或符号,或者需要进行复杂的字符集转换,你可能需要对数据库进行更深入的配置。
PostgreSQL的递归查询(withrecursive),替代oracle的级联查询c。。。

PostgreSQL的递归查询(withrecursive),替代oracle的级联查询c。
开发有需求,说需要对⼀张地区表进⾏递归查询,Postgres中有个 with recursive的查询⽅式,可以满⾜递归查询(⼀般>=2层)。
测试如下:create table tb(id varchar(3) , pid varchar(3) , name varchar(10));insert into tb values('002' , 0 , '浙江省');insert into tb values('001' , 0 , '⼴东省');insert into tb values('003' , '002' , '衢州市');insert into tb values('004' , '002' , '杭州市') ;insert into tb values('005' , '002' , '湖州市');insert into tb values('006' , '002' , '嘉兴市') ;insert into tb values('007' , '002' , '宁波市');insert into tb values('008' , '002' , '绍兴市') ;insert into tb values('009' , '002' , '台州市');insert into tb values('010' , '002' , '温州市') ;insert into tb values('011' , '002' , '丽⽔市');insert into tb values('012' , '002' , '⾦华市') ;insert into tb values('013' , '002' , '⾈⼭市');insert into tb values('014' , '004' , '上城区') ;insert into tb values('015' , '004' , '下城区');insert into tb values('016' , '004' , '拱墅区') ;insert into tb values('017' , '004' , '余杭区') ;insert into tb values('018' , '011' , '⾦东区') ;insert into tb values('019' , '001' , '⼴州市') ;insert into tb values('020' , '001' , '深圳市') ;测试语句,查询浙江省及以下县市:test=# with RECURSIVE cte astest-# (test(# select a.id,,a.pid from tb a where id='002'test(# union alltest(# select k.id,,k.pid from tb k inner join cte c on c.id = k.pidtest(# )select id,name from cte;id | name-----+--------002 | 浙江省003 | 衢州市004 | 杭州市005 | 湖州市006 | 嘉兴市007 | 宁波市008 | 绍兴市009 | 台州市010 | 温州市011 | 丽⽔市012 | ⾦华市013 | ⾈⼭市014 | 上城区015 | 下城区016 | 拱墅区017 | 余杭区018 | ⾦东区(17 rows)如果查询有报错如死循环跳出,则需要检查下⽗字段与⼦字段的数据是否有相同。
PostgreSQL“平替”Oracle应用和基础架构改造技巧经验分享

PostgreSQL“平替”Oracle应用和基础架构改造技巧经验分享数据库替换已经是很多企业必须面对或者正在面对的问题,在数据库迁移替代工作中,能够“平替”肯定会大大节约迁移的成本,但是我们不能因为两者业务代码和迁移的高兼容性,忽视和轻视应用和基础架构、运维改造工作,否则就会为今后的长期应用与运维埋下不稳定的因素。
本文作者总结了PostgreSQL替换Oracle过程中,一些常用的应用的改造技巧和PostgreSQL索引的选择场景,以及二者运维中的差异,希望能为大家提供参考。
一、引言Oracle数据库是商业专用多模型数据库管理系统,也是世界上最大的关系数据库管理系统(RDBMS)。
尽管Oracle依旧是市场上排名第一的数据库,但是2013年以来,开源数据库势不可挡的崛起。
尤其是PostgreSQL开源数据库,导致了Oracle市场份额的大幅度下降。
和Oracle比较,在应用和基础架构的运维方面,PostgreSQL有很多的不同之处。
很多企业在系统改造的时候,越来越多的采用PostgreSQL数据库替换Oracle数据库。
在数据库迁移替代工作中,能够“平替”肯定会大大节约迁移的成本,但是我们不能因为“平替”能力的不足而放弃优化工作,否则就会为今后的长期应用与运维埋下隐患。
特别是平替过程中,应用和架构的改造必须与实际的企业场景和生态相结合。
二、应用和基础架构的平滑替换数据库平滑替换的时候不仅仅要考虑数据库本身的兼容性,还要考虑二者之间的一些技术差异,要想办法弥补PostgreSQL数据库的缺陷。
例如Oracle应用开发时候,很少考虑技术细节,全部交给数据库做都是可以的。
但是在PostgreSQL使用中,就需要有所考虑了,不能完全把PostgreSQL 当作Oracle的性能使用。
比如对于PostgreSQL数据库来说,一些WHERE 条件带or的SQL,如果以前Oracle上的执行计划使用HASH JOIN效果很好,到了PostgreSQL数据库上,就只能走NESTED LOOP了。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
POSTGRESQL:
SELECT * FROM (
SELECT * FROM (
SELECT * FROM SCHEMA.PREFIX_TABLE ORDER BY COL1 ALIAS1
) WHERE X=1 ORDER BY COL2 ALIAS2
analysis,这个只是把以前标记为不可用的空间设为空闲,那么在有新数据插入时可以复写这些
空间,但是analysis后表的存储大小不变,表内可能只有10M数据,但是原来有10M垃圾被标记
为空闲,这是表大小还是20M。如果要降表空间大小,就要用另一种回收方式做VACUUM full
这时相当于把表进行重建了,这时也会锁表哦,而且是表级锁哦。我感觉就像是Oracle要降水位
) WHERE Y=2 ORDER BY COL3
(7) PostgresQL中没有rownum,无法使用where rownum < = X的方法进行分页,取而代
之的是limit X,offset Y方法,而ORACLE中不允许使用LIMIT X的方法
ORACLE:
SELECT * FROM ( SELECT * FROM (SELECT * FROM SCHEMA.PREFIX_TABLE1 ORDER BY
CREATE OR REPLACE VIEW dual AS
SELECT NULL::"unknown"
WHERE 1 = 1;
ALTER TABLE dual OWNER TO postgres;
GRANT ALL ON TABLE dual TO postgres;
GRANT SELECT ON TABLE dual TO public;
DESC,COL2 ASC) selb order by col3 asc,col4 desc limit 50 ) sela
order by col5 desc,col6 asc limit 20;
--注意!!limit必须用于order by之后
--例:取1到50条数据
select * from VOIP_FEE_RATE temp offset 0 limit 50
线一样的。这样操作后,表的空间就会显示只有10M了呢。
(1)注意增加约束时的写法,和ORACLE略有不同
Oracle:
ALTER TABLE SCHEMA.PREFIX_INFO ADD (
CONSTRAINT PK_PREFIX_INFO PRIMARY KEY (INFO_ID));
select (case check_type when '01' then '1' when '02' then '4' when '03' then '3' else '' end) check_type from tb_msc_intr_loana_check;
数为COL1字段的长度]
(12)DECODE用法
Oracle -- SELECT DECODE(ENDFLAG,'1','A','B') ENDFLAGFROM TEST
Postgresql- SELECT (CASE ENDFLAG WHEN '1' THEN 'A'ELSE 'B' END) AS ENDFLAG FROM TEST
INCREMENT BY 1
START WITH 582
MINVALUE 1
MAXVALUE 9999999999999999999999999999
NOCYCLE
CACHE 20
NOORDER;
PostgresQL:
CREATE SEQUENCE schema.prefix_info_sequence
个session的,但在pg中connection和session应该是一个级别的了(这点望大牛们指教)。
大家都熟悉Oracle的process结:
pg的存储结构简单多了只有文件和block的概念了,我理解这里文件应该还是一个逻辑概念,一
般一个表对应一个到多个segment文件,一个segment文件包含多个block,一般一个segment
language 'sql' volatile;
alter function concat(text, text) owner to postgres;
--无需特殊授权即可在其他schema中使用
(4)PostgresQL中没有dual虚拟表,为保证程序兼容性,可创建伪视图(view)替代:
C,SCHEMA.PREFIX_TABLE4 D
WHERE 1 = 1
AND A.COL2 = B.COL2
AND A.COL3 = C.COL3(+)
AND A.COL4 = D.COL4(+)
AND A.COL5 > 0
AND A.COL6 = '1'
POSTGRESQL:
PostgresQL:
alter table schema.prefix_info add constraint prefix_info_pkey primary key(info_id);
(2)系统默认的最大值与ORACLE不同
Oracle:
CREATE SEQUENCE PREFIX_INFO_SEQUENCE
and a.col6 = '1'
(6)PostgresQL中子查询较为规范,子查询结果集必须拥有alias
ORACLE:
SELECT * FROM (
SELECT * FROM (
SELECT * FROM SCHEMA.PREFIX_TABLE ORDER BY COL1
) WHERE X=1 ORDER BY COL2
increment 1
minvalue 1
maxvalue 9223372036854775807
start 582
cache 20;
(3)PostgresQL中的 || 用法与其他数据库不同:
select a||b from table1;
当a或b其中一个为null时,该查询返回null,
(4)PostgresQL中没有concat函数,且由于||用法的问题,无法使用||替换,解决方法为在
public schema中创建函数concat
create or replace function concat(text, text)
returns text as
$body$select coalesce($1,'') || coalesce($2,'')$body$
简单外连接:
select count(distinct(a.col1)) as rcount from
schema.prefix_table1 a left outer join schema.prefix_table2 b on (a.col2 = b.col2)
where 1 = 1
--注意,此方法前提是dual视图已建立,如没有,可省略FROM DUAL
PostgresQL 学习记录之与oracle区别2
(9)字段取别名必须用as
Oracle -- SELECT A.COL1 A_COL1,A.COL2 A_COL2 FROM A_TABLE A
Postgresql---- SELECT A.COL1 AS A_COL1,A.COL2 AS A_COL2 FROM A_TABLE A
FS_VALUE1,COALESCE(SUM(VALUE21),0) AS FS_VALUE2
FROM FIELD_SUM
(11)TO_NUMBER用法
Oracle -- SELECT COL1 FROM A_TABLE ORDER BY TO_NUMBER(COL1)
Postgresql- select TO_NUMBER(COL1,'99G999D9S') from A_TABLE [注:'999999' ---- 6位
COL1 DESC,COL2 ASC) where ROWNUM <= 50 ORDER BY COL3 ASC,COL4 DESC)
WHERE ROWNUM <= 20 ORDER BY COL5 DESC,COL6 ASC;
POSTGRES:
select * from ( select * from (SELECT * FROM SCHEMA.PREFIX_TABLE1 ORDER BY COL1
(8)序列使用的区别
ORACLE:
SELECT SCHEMA.PREFIX_TABLE1_SEQUENCE.NEXTVAL AS nCode FROM DUAL
POSTGRES:
SELECT NEXTVAL('SCHEMA.PREFIX_TABLE1_SEQUENCE') AS nCode FROM DUAL
(10)NVL用法
Oracle --SELECT NVL(SUM(VALUE11),0) FS_VALUE1, NVL(SUM(VALUE21),0) FS_VALUE2
FROM FIELD_SUM