基于Eclipse的Hadoop开发环境配置方法
基于Eclipse的Hadoop应用开发环境的配置

基于Eclipse的Hadoop应用开发环境的配置/s/blog_537770820100byho.html基于Eclipse的Hadoop应用开发环境的配置配置好了Hadoop运行环境,下一步就要配置,开发环境了。
实际上开发环境很好配置,网上很多的帖子,都指向了IBM提供的Hadoop开发工具,这个工具很好用。
大家打开这个网址,很容易就能Step by step搞定,/tech/mapreducetools。
但是细心的读者不难发现,这个工具似乎是个绝版,到现在似乎还是停留在2007年3月23日呢,而且其支持的Eclipse也是3.3的,Hadoop更是0.17的。
很多人在forum上还抱怨,安装上这个工具后,报出错误:Refresh DFS Children has encountered a problem:Refreshing DFS node failed: 1。
呵呵,这个问题我也遇到了,我也很郁闷。
我心里也在骂IBM这帮官僚如此不思进取。
这两天我在装载Hadoop Core的Examples测试,由于想要多了解些Hadoop,于是就打开了Hadoop的每个子目录,在打开/hadoop-0.19.0 /contrib/意外发现了eclipse-plugin,心里不禁窃喜,不知道是不是IBM的这个工具的升级版移到这里还是其他什么原因,工具不是在这里吗?只不过与以前不同,是个jar包!我把hadoop-0.19.0-eclipse-plugin.jar,拷贝到eclipse-SDK- 3.4-win32\eclipse\plugins下面,启动eclipse,居然真的安装成功了,真的是该工具的升级版,也没有了那个错误!真的是很意外!界面是这样滴,选择Window->Open Perspective,可见到一个窗口,里面有一个小象图标:Map/Reduce,点击它,会打开一个新的Perspective。
Hadoop搭建与Eclipse开发环境设置

hadoop搭建与eclipse开发环境设置――邵岩飞1.Ubuntu 安装安装ubuntu11.04 desktop系统。
如果是虚拟机的话,这个无所谓了,一般只需要配置两个分区就可以。
一个是\另一个是\HOME 文件格式就用ext4就行了。
如果是实机的话建议在分配出一个\SWAP分区。
如果嫌麻烦建议用wubi安装方式安装。
这个比较傻瓜一点。
2.Hadoop 安装hadoop下载到阿帕奇的官方网站下载就行,版本随意,不需要安装,只要解压到适当位置就行,我这里建议解压到$HOME\yourname里。
3.1 下载安装jdk1.6如果是Ubuntu10.10或以上版本是不需要装jdk的,因为这个系统内置openjdk63.2 下载解压hadoop不管是kubuntu还是ubuntu或者其他linux版本都可以通过图形化界面进行解压。
建议放到$HOME/youraccountname下并命名为hadoop.如果是刚从windows系统或者其它系统拷贝过来可能会遇到权限问题(不能写入)那么这就需要用以下命令来赋予权限。
sudo chown –R yourname:yourname [hadoop]例如我的就是:sudo chown –R dreamy:dreamy hadoop之后就要给它赋予修改权限,这就需要用到:sudo chmod +X hadoop3.3 修改系统环境配置文件切换为根用户。
●修改环境配置文件/etc/profile,加入:你的JAVA路径的说明:这里需要你找到JAVA的安装路径,如果是Ubuntu10.10或10.10以上版本,则应该在/usr/bin/java这个路径里,这个路径可能需要sudo加权限。
3.4 修改hadoop的配置文件●修改hadoop目录下的conf/hadoop-env.sh文件加入java的安装根路径:●把hadoop目录下的conf/core-site.xml文件修改成如下:<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Put site-specific property overrides in this file. --><configuration><property><name>hadoop.tmp.dir</name><value>/hadoop</value></property><property><name></name><value>hdfs://ubuntu:9000</value></property><property><name>dfs.hosts.exclude</name><value>excludes</value></property><property>●把hadoop目录下的conf/ hdfs-site.xml文件修改成如下:<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Put site-specific property overrides in this file. --><configuration><property><name>dfs.data.dir</name><value>/hadoop/data</value></property><property><name>dfs.replication</name><value>3</value></property></configuration>●把hadoop目录下的conf/ mapred-site.xml文件修改成如下:注意:别忘了hadoop.tmp.dir,.dir,dfs.data.dir参数,hadoop存放数据文件,名字空间等的目录,格式化分布式文件系统时会格式化这个目录。
Hadoop的配置方法

Hadoop的配置方法本文主要讲述了Linux环境下(这里以Ubuntu操作系统为例)Hadoop的安装与配置。
在Linux下Hadoop的配置主要有四个步骤:安装JDK、安装SSH、Hadoop环境配置和配置基于Eclipse的Hadoop开发环境。
一、安装JDK可参考文章:/view/84c36a8e84868762caaed5c4.html?st=1(Ubuntu环境下JDK的安装)二、安装SSH确认已经连上互联网,并在Terminal输入以下命令:sudo apt-get install ssh(完成SSH的安装)三、Hadoop环境配置1)Hadoop的下载首先,进入Hadoop官方网站的下载页面:/dyn/closer.cgi/hadoop/common/在此页面选择一个合适版本的Hadoop。
可以选择如下版本的Hadoop并下载:/hadoop/common/hadoop-0.20.2/(这里下载的是hadoop-0.20.2.tar.gz)2)Hadoop的配置conf/hadoop-env.shexport JA V A_HOME=/home/wenqisun/Documents/JDK/jdk1.6.0_31(要把export前面的注释符号#去掉)conf/core-site.xml<configuration><property><name></name><value>hdfs://localhost:9000</value></property></configuration>conf/hdfs-site.xml<configuration><property><name>dfs.replication</name><value>1</value></property></configuration>conf/mapred-site.xml<configuration><property><name>mapred.job.tracker</name><value>localhost:9001</value></property></configuration>四、配置基于Eclipse的Hadoop开发环境可参考文章:/view/0a3c4cc2aa00b52acfc7cafc.html?st=1(基于Eclipse的Hadoop开发环境配置方法)。
eclipse hadoop开发环境配置

eclipse hadoop开发环境配置win7下安装hadoop完成后,接下来就是eclipse hadoop开发环境配置了。
具体的操作如下:一、在eclipse下安装开发hadoop程序的插件安装这个插件很简单,haoop-0.20.2自带一个eclipse的插件,在hadoop目录下的contrib\eclipse-plugin\hadoop-0.20.2-eclipse-plugin.jar,把这个文件copy到eclipse的eclipse\plugins目录下,然后启动eclipse就算完成安装了。
这里说明一下,haoop-0.20.2自带的eclipse的插件只能安装在eclipse 3.3上才有反应,而在eclipse 3.7上运行hadoop程序是没有反应的,所以要针对eclipse 3.7重新编译插件。
另外简单的解决办法是下载第三方编译的eclipse插件,下载地址为:/p/hadoop-eclipse-plugin/downloads/list由于我用的是Hadoop-0.20.2,所以下载hadoop-0.20.3-dev-eclipse-plugin.jar.然后将hadoop-0.20.3-dev-eclipse-plugin.jar重命名为hadoop-0.20.2-eclipse-plugin.jar,把它copy到eclipse的eclipse\plugins目录下,然后启动eclipse完成安装。
安装成功之后的标志如图:1、在左边的project explorer 上头会有一个DFS locations的标志2、在windows -> preferences里面会多一个hadoop map/reduce的选项,选中这个选项,然后右边,把下载的hadoop根目录选中如果能看到以上两点说明安装成功了。
二、插件安装后,配置连接参数插件装完了,启动hadoop,然后就可以建一个hadoop连接了,就相当于eclipse里配置一个weblogic的连接。
Eclipse配置hadoop开发环境
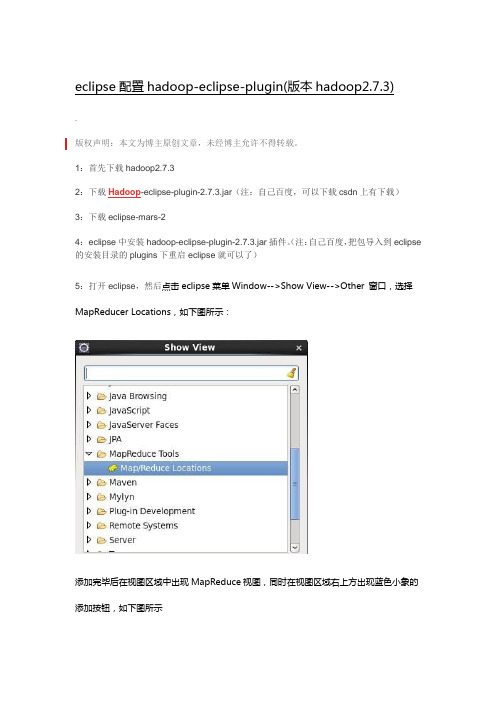
eclipse配置hadoop-eclipse-plugin(版本hadoop2.7.3)
.
版权声明:本文为博主原创文章,未经博主允许不得转载。
1:首先下载hadoop2.7.3
2:下载Hadoop-eclipse-plugin-2.7.3.jar(注:自己百度,可以下载csdn上有下载)
3:下载eclipse-mars-2
4:eclipse中安装hadoop-eclipse-plugin-2.7.3.jar插件。
(注:自己百度,把包导入到eclipse 的安装目录的plugins下重启eclipse就可以了)
5:打开eclipse,然后点击eclipse菜单Window-->Show View-->Other 窗口,选择MapReducer Locations,如下图所示:
添加完毕后在视图区域中出现MapReduce视图,同时在视图区域右上方出现蓝色小象的添加按钮,如下图所示
6:新建Hadoop Location
点击蓝色小象新增按钮,提示输入MapReduce和HDFS Master相关信息,其中:Lacation Name:为该位置命名,能够识别该,可以随意些;
MapReduce Master:与$HADOOP_DIRCONF/mapred-site.xml配置保持一致;
HDFS Master:与$HADOOP_DIRCONF/core-site.xml配置保持一致
User Name:登录hadoop用户名,可以随意填写
7:配置完毕后,在eclipse的左侧DFS Locations出现CentOS HDFS的目录树,该目录为HDFS文件系统中的目录信息:。
Hadoop安装及基于Eclipse的开发环境部署(限IT组内部使用)20150427

Had oop安装及基于Eclipse的开发环境部署1、Had oop-1.2.1安装1.1 Hadoop安装工具1、操作系统:Win7系统2、虚拟机软件:VMware Workstation 103、Linux系统安装包:ubuntukylin-14.04-desktop-i386.iso(32位)4、JDK包:jdk-8u45-linux-i586.gz5、Hadoop-1.2.1程序安装包(非源码):/apache/hadoop/common/hadoop-1.2.1/hadoop-1.2.1.tar.gz 1.2Hadoop安装步骤(部分详细内容可参见《Hadoop安装指南》)1、Ubuntu虚拟机安装(建议安装32位Ubuntu操作系统)2、Windows与linux之间的共享文件夹设置,实现windows与linux之间的文件共享;具体设置如下图:设置完成后,可以看到一个共享文件夹,通过该文件夹可以实现windows与linux之间的文件共享;该共享文件夹默认在linux系统的/mnt/hgfs目录下。
3、ssh安装(ubuntu默认没有安装ssh,需要通过apt-get install 进行安装,这里建议暂时不要生成公钥)4、网络连接配置;网络连接配置的主要目的是保证能够使用Xshell等工具链接虚拟机进行操作。
由于采用NAT模式没有连接成功,本文建议使用自定义的虚拟网络进行连接,具体步骤及设置如下:1)本地虚拟网络IP设置;具体设置如图(可以根据自己的情况设置IP(如192.168.160.1),该IP将作为虚拟机的网关):2)虚拟机网络适配器设置;建议采用自定义虚拟网络连接,设置如下:3)虚拟机网络IP设置;主要目的是设置自定义的IP、网关等;具体设置流程如下:4)当网络连接设置完成后,使用Ubuntu:service networking restart(centOS:service network restart)命令重启虚拟机网络服务;注意,重启网络服务后,建议在本机的DOS环境下ping一下刚刚在虚拟机中设置的IP地址,如果ping不通,可能是网卡启动失败,可以使用ifconfig eth0 up命令启动网卡(eh0是网卡名称,可以在网路连接设置中查看网卡名称)。
Cygwin+Eclipse搭建Hadoop开发环境

Cygwin的安装1.先在/install.html上下载安装文件打开后双击setup.exe安装。
如下图:2. 直接点击下一步后如下图:图中有三个选项,意思一看就懂啊。
这里直选择下一步3.直接点击下一步后如下图:这里是要选择安装路径,设置在哪里都可以。
没有特殊要求。
4. 设置好路径后下一步进入下图:这是设置Cygwin安装文件的目录。
先安装的exe只是个引导它需要自己下载安装文件。
设置这个目录就是存储这些文件的。
5.设置好后下一步进入下图:这里是你网络的链接方式,第一个是直接链接,第二个是使用IE代理,第三个使用你指定的HTTP/FTP代理。
你要根据你自己的情况选择。
通常选第一个如不好使则查看你的联网是否使用了代理用了就选下面两个中的一个。
6.设置好后下一步进入下图:选择其中一个url用作下载的站点。
我选第一就行挺快的。
你的不行可以试试别的。
也可以在下面的User URL中添加url写完地址一点Add就加入到上面的url列表中了。
然后选择你自己加入的url即可。
如果自己加入可以尝试一下这个url:/pub/。
然后点击下一步进行安装文件的下载,需要点时间。
如果点击下一步后出现这个错误Internal Error: gcrypt library error 60 illegal tag。
就是上一步网络选择的问题或者选择的url不能下载。
自己可以尝试改动一下。
正常下载的话也可能出现一个警告窗口如下图:点击确定即可。
随即会进入下图。
7. 来到此图就要开始进行一些配置了。
选择一下要安装的包。
如下图:首先:选择其中的Base Default,通常这里的包都已经选择上了。
你要确保sed已选择上,这样你可以在eclipse中使用hadoop了。
如下图这样即可:其次:选择Devel Default,将其中的subversion选中第一个即可。
如下图:最后:选择Net default包,将其中的openssh及openssl选上。
2.3.3 在Eclipse 中配置Hadoop[共2页]
![2.3.3 在Eclipse 中配置Hadoop[共2页]](https://img.taocdn.com/s3/m/f32952c56edb6f1aff001ff7.png)
Categories=Development;StartupNotify=true接下来,将此文件复制到桌面并添加可执行权限。
$ cp /usr/share/applications/eclipse.desktop ~/桌面$ chmod +x ~/桌面/eclipse.desktop之后,双击Ubuntu的桌面上的eclipse图标,即可自由地启动Eclipse。
2.3.2 下载hadoop-eclipse-plugin插件由于Hadoop和Eclipse的发行版本较多,不同版本之间往往存在兼容性问题,因此必须注意hadoop-eclipse-plugin的版本问题。
(1)访问以下链接,可下载hadoop-eclipse-plugin-2.7.2.jar包。
/detail/tondayong1981/9432425根据上传者“tondayong1981”介绍,该插件通过了Eclipse Java EE IDE for Web Developers. Version: Mars.1 Release (4.5.1)的测试。
在此,作者请求本书的读者首先对上传者的分享精神点赞,因为他们的努力方便了大家的学习。
【注意】当我们确实找不到一个合适的插件时,可通过以下操作方法来获得想要的插件。
①首先,下载一个包含插件源码的zip文件,例如通过https:///winghc/hadoop2x- eclipse-plugin下载hadoop2x.eclipse-plugin-master.zip。
解压之后,release文件夹中的hadoop. eclipse-kepler-plugin-2.2.0.jar就是编译好的插件,只是这个文件不是我们想要的插件。
$ unzip hadoop2x.eclipse-plugin-master.zip②进入hadoop2x-eclipse-plugin/src/contrib/eclipse-plugin目录。
Win7+Eclipse+Hadoop2.6.4开发环境搭建

Win7+Eclipse+Hadoop2.6.4开发环境搭建Hadoop开发环境搭建⼀、软件准备JDK:jdk-7u80-windows-x64.exeEclipse:eclipse-jee-mars-2-win32-x86_64.zipHadoop:hadoop-2.6.4.tar.gzHadoop-Src:hadoop-2.6.4-src.tar.gzAnt:apache-ant-1.9.6-bin.zipHadoop-Common:hadoop2.6(x64)V0.2.zip (2.4以后)、(hadoop-common-2.2.0-bin-master.zip)Hadoop-eclipse-plugin:hadoop-eclipse-plugin-2.6.0.jar⼆、搭建环境1. 安装JDK执⾏“jdk-7u80-windows-x64.exe”,步骤选择默认下⼀步即可。
2. 配置JDK、Ant、Hadoop环境变量解压hadoop-2.6.4.tar.gz、apache-ant-1.9.6-bin.zip、hadoop2.6(x64)V0.2.zip、hadoop-2.6.4-src.tar.gz到本地磁盘,位置任意。
配置系统环境变量JAVA_HOME、ANT_HOME、HADOOP_HOME,并将这些环境变量的bin⼦⽬录配置到path变量中。
将hadoop2.6(x64)V0.2下的hadoop.dll和winutils.exe复制到HADOOP_HOME/bin⽬录下。
3. 配置Eclipse将hadoop-eclipse-plugin-2.6.0.jar复制到eclilpse的plugins⽬录下。
启动eclipse,并设置好workspace。
插件安装成功的话,启动之后可以看到如下内容:4. 配置hadoop打开“window”-“Preferenes”-“Hadoop Mep/Reduce”,配置到Hadoop_Home⽬录。
hadoop搭建与eclipse开发环境设置--已验证通过
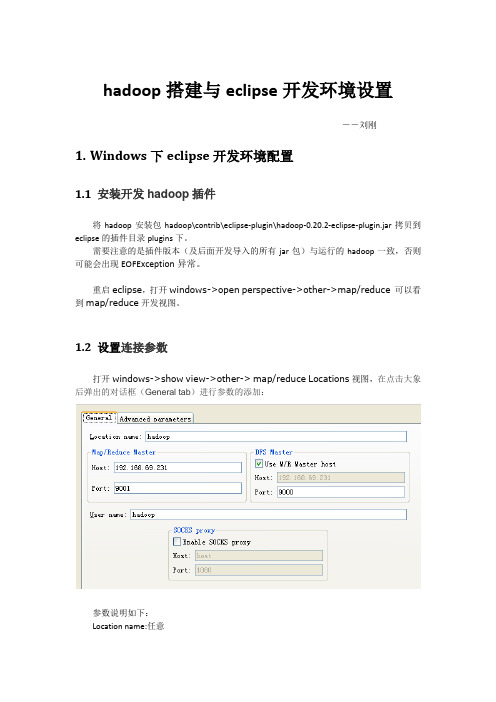
hadoop搭建与eclipse开发环境设置――刘刚1.Windows下eclipse开发环境配置1.1 安装开发hadoop插件将hadoop安装包hadoop\contrib\eclipse-plugin\hadoop-0.20.2-eclipse-plugin.jar拷贝到eclipse的插件目录plugins下。
需要注意的是插件版本(及后面开发导入的所有jar包)与运行的hadoop一致,否则可能会出现EOFException异常。
重启eclipse,打开windows->open perspective->other->map/reduce 可以看到map/reduce开发视图。
1.2 设置连接参数打开windows->show view->other-> map/reduce Locations视图,在点击大象后弹出的对话框(General tab)进行参数的添加:参数说明如下:Location name:任意map/reduce master:与mapred-site.xml里面mapred.job.tracker设置一致。
DFS master:与core-site.xml里设置一致。
User name: 服务器上运行hadoop服务的用户名。
然后是打开“Advanced parameters”设置面板,修改相应参数。
上面的参数填写以后,也会反映到这里相应的参数:主要关注下面几个参数::与core-site.xml里设置一致。
mapred.job.tracker:与mapred-site.xml里面mapred.job.tracker设置一致。
dfs.replication:与hdfs-site.xml里面的dfs.replication一致。
hadoop.tmp.dir:与core-site.xml里hadoop.tmp.dir设置一致。
hadoop.job.ugi:并不是设置用户名与密码。
HadoopEclipse开发环境搭建

HadoopEclipse开发环境搭建This document is from my evernote, when I was still at baidu, I have a complete hadoop development/Debug environment. But at that time, I was tired of writing blogs. It costsme two day’s spare time to recovery from where I was stoped. Hope the blogs will keep on. Still cherish the time speed there, cause when doing the same thing at both differenttime and different place(company), the things are still there, but mens are no more than the same one. Talk too much, Let’s go on.在,已经搭建好了⼀个⽤于开发/测试的haoop集群,在这篇⽂章中,将介绍如何使⽤eclipse作为开发环境来进⾏程序的开发和测试。
2.) 在Eclipse的Windows->Preferences中,选择Hadoop Map/Reduce,设置好Hadoop的安装⽬录,这⾥,我直接从linux的/home/hadoop/hadoop-1.0.3拷贝过来的,点击OK按钮:3.) 新建⼀个Map/Reduce Project4.) 新建Map/Reduce Project后,会⽣成如下的两个⽬录, DFS Locations和suse的Java⼯程,在java⼯程中,⾃动加⼊对hadoop包的依赖:5.)是⽤该插件建⽴的⼯程,有专门的视图想对应:6.)在Map/Reduce Locations中,选择Edit Hadoop Location…选项,Map/Recuce Master和 DFS Master的设置:7.)在Advanced parameters中,设置Hadoop的配置选项,将dfs.data.dir设置成和linx环境中的⼀样,在Advanced parameters中,将所有与路径相关的都设置成对应的Linux路径即可:8.)将Hadoop集群相关的配置设置好后,可以在DFS location中看到Hadoop集群上的⽂件,可以进⾏添加和删除操作:9.)在⽣成的Java⼯程中,添加Map/Reduce程序,这⾥我添加了⼀个WordCount程序作为测试:10.)在Java⼯程的Run Configurations中设置WordCount的Arguments,第⼀个参数为输⼊⽂件在hdfs的路径,第⼆个参数为hdfs的输出路径:11.)设置好Word Count的RunConfiguration后,选择Run As-> Run on Hadoop:12.) 在Console中可以看到Word Count运⾏的输出⽇志信息:13.)在DFS Location中可以看到,Word Count在result⽬录下⽣成的结果:14.)进⾏Word Count程序的调试,在WordCount.java中设置好断点,点击debug按钮,就可以进⾏程序的调试了:⾄此, Hadoop+Eclipse的开发环境搭建完成。
Eclipse搭建hadoop开发环境
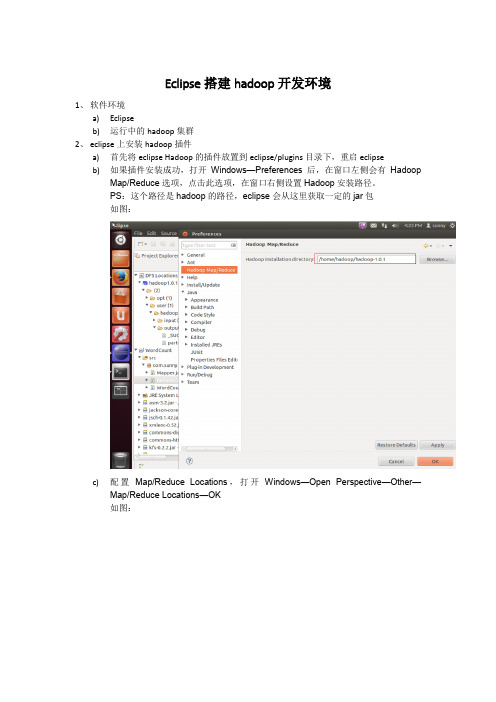
Eclipse搭建hadoop开发环境1、软件环境a)Eclipseb)运行中的hadoop集群2、eclipse上安装hadoop插件a)首先将eclipse Hadoop的插件放置到eclipse/plugins目录下,重启eclipseb)如果插件安装成功,打开Windows—Preferences后,在窗口左侧会有HadoopMap/Reduce选项,点击此选项,在窗口右侧设置Hadoop安装路径。
PS:这个路径是hadoop的路径,eclipse会从这里获取一定的jar包如图:c)配置Map/Reduce Locations,打开Windows—OpenPerspective—Other—Map/Reduce Locations—OK如图:d)点击新增hadoop如图:3、新建WordCount项目a)上传两个文件到hadoop集群里面b)分别写Mapper、Reducer、Main,如图所示:c)运行WordCountMain.java,Run As-----Run Configurations,然后配置如图:d)结果如图:4、碰到的错误a)Windows eclipse配置插件时候,碰到权限不够(org.apache.hadoop.security.AccessControlException),导致不能连接到hadoop,解决方案:1、将windows的账户名和用户组都设置成hadoop启动的账号一样的名字2、如果是自己的测试机器,可以关闭dfs的权限检测,在conf/hdfs-site.xml 将dfs.permissions修改成falseb)Exception in thread "main" java.io.IOException: Failed to set permissions of path:\tmp\hadoop-Administrator\mapred\staging\Administrator-519341271\.staging to0700这个是Windows下文件权限问题,在Linux下可以正常运行,不存在这样的问题。
基于Eclipse的Hadoop应用开发环境配置

基于Eclipse的Hadoop应用开发环境配置我的开发环境:操作系统fedora 14 一个namenode 两个datanodeHadoop版本:hadoop-0.20.205.0Eclipse版本:eclipse-SDK-3.7.1-linux-gtk.tar.gz第一步:先启动hadoop守护进程第二步:在eclipse上安装hadoop插件1.复制 hadoop安装目录/contrib/eclipse-plugin/hadoop-eclipse-plugin-0.20.205.0.jar 到eclipse安装目录/plugins/ 下。
2.重启eclipse,配置hadoop installation directory。
如果安装插件成功,打开Window-->Preferens,你会发现Hadoop Map/Reduce 选项,在这个选项里你需要配置Hadoop installation directory。
配置完成后退出。
3.配置Map/Reduce Locations。
在Window-->Show View中打开Map/Reduce Locations。
在Map/Reduce Locations中新建一个Hadoop Location。
在这个View中,右键-->New Hadoop Location。
在弹出的对话框中你需要配置Location name,如Hadoop,还有Map/Reduce Master和DFS Master。
这里面的Host、Port分别为你在mapred-site.xml、core-site.xml中配置的地址及端口。
如:Map/Reduce Master192.168.1.1019001DFS Master192.168.1.1019000配置完后退出。
点击DFS Locations-->Hadoop如果能显示文件夹(2)说明配置正确,如果显示"拒绝连接",请检查你的配置。
hadoop搭建与eclipse开发环境设置

hadoop搭建与eclipse开发环境设置――罗利辉1.前言1.1 目标目的很简单,为进行研究与学习,部署一个hadoop运行环境,并搭建一个hadoop开发与测试环境。
具体目标是:✓在ubuntu系统上部署hadoop✓在windows 上能够使用eclipse连接ubuntu系统上部署的hadoop进行开发与测试1.2 软硬件要求注意:Hadoop版本和Eclipse版本请严格按照要求。
现在的hadoop最新版本是hadoop-0.20.203,我在windows上使用eclipse(包括3.6版本和3.3.2版本)连接ubuntu上的hadoop-0.20.203环境一直没有成功。
但是开发测试程序是没有问题的,不过需要注意权限问题。
如果要减少权限问题的发生,可以这样做:ubuntu上运行hadoop的用户与windows 上的用户一样。
1.3 环境拓扑图ubuntu 192.168.69.231ubuntu2192.168.69.233 ubuntu1192.168.69.2322.Ubuntu 安装安装ubuntu11.04 server系统,具体略。
我是先在虚拟机上安装一个操作系统,然后把hadoop也安装配置好了,再克隆二份,然后把主机名与IP修改,再进行主机之间的SSH配置。
如果仅作为hadoop的运行与开发环境,不需要安装太多的系统与网络服务,或者在需要的时候通过apt-get install进行安装。
不过SSH服务是必须的。
3.Hadoop 安装以下的hadoop安装以主机ubuntu下进行安装为例。
3.1 下载安装jdk1.6安装版本是:jdk-6u26-linux-i586.bin,我把它安装拷贝到:/opt/jdk1.6.0_263.2 下载解压hadoop安装包是:hadoop-0.20.2.tar.gz。
3.3 修改系统环境配置文件切换为根用户。
●修改地址解析文件/etc/hosts,加入3.4 修改hadoop的配置文件切换为hadoop用户。
伪分布式hadoop的安装方法和eclipse开发环境的安装与使用方法。

伪分布式hadoop的安装方法和eclipse开发环境的安装与使用方法。
一、引言在当今大数据时代,Hadoop和Eclipse作为开源技术和开发工具,受到了越来越多开发者的关注。
本文将详细介绍如何安装和使用伪分布式Hadoop 以及Eclipse开发环境。
二、伪分布式Hadoop的安装方法1.准备环境在开始安装伪分布式Hadoop之前,请确保您的计算机满足以下要求:- 操作系统:Windows、Linux或Mac OS- 64位处理器- 至少4GB内存2.下载并安装JDK访问Oracle官网下载最新版本的JDK,然后按照官方文档安装并配置JDK环境变量。
3.下载Hadoop访问Hadoop官网下载适用于您操作系统的Hadoop版本。
下载完成后,将Hadoop解压缩到一个合适的位置。
4.配置Hadoop环境变量在Windows系统上,设置系统环境变量,将Hadoop的bin目录添加到Path中;在Linux或Mac OS系统上,编辑~/.bashrc或~/.bash_profile文件,添加以下内容:```export HADOOP_HOME=/path/to/your/hadoopexport PATH=$HADOOP_HOME/bin:$PATH```5.配置Hadoop的核心配置文件在Hadoop的conf目录下,找到core-site.xml、hdfs-site.xml和mapred-site.xml三个配置文件,根据官方文档进行相应的配置。
6.启动Hadoop在命令行中执行以下命令启动Hadoop:```hdfs namenode -formathdfs dfs -mkdir /tmpmapreduce job -submit -jobclass com.example.MyJob -arguments "arg1 arg2"```三、Eclipse开发环境的安装与使用方法1.下载并安装Eclipse访问Eclipse官网,根据您的操作系统下载相应版本的Eclipse。
基于Eclipse的Hadoop开发环境配置方法

基于Eclipse的Hadoop开发环境配置方法(1)启动hadoop守护进程在Terminal中输入如下命令:$ bin/hadoop namenode -format$ bin/start-all.sh(2)在Eclipse上安装Hadoop插件找到hadoop的安装路径,我的是hadoop-0.20.2,将/home/wenqisun/hadoop-0.20.2/contrib/eclipse-plugin/下的hadoop-0.20.2-eclipse-plugin.jar拷贝到eclipse安装目录下的plugins里,我的是在/home/wenqisun/eclipse /plugins/下。
然后重启eclipse,点击主菜单上的window-->preferences,在左边栏中找到Hadoop Map/Reduce,点击后在右边对话框里设置hadoop的安装路径即主目录,我的是/home/wenqisun/hadoop-0.20.2。
(3)配置Map/Reduce Locations在Window-->Show View中打开Map/Reduce Locations。
在Map/Reduce Locations中New一个Hadoop Location。
在打开的对话框中配置Location name(为任意的名字)。
配置Map/Reduce Master和DFS Master,这里的Host和Port要和已经配置的mapred-site.xml 和core-site.xml相一致。
一般情况下为Map/Reduce MasterHost:localhostPort:9001DFS MasterHost:localhostPort:9000配置完成后,点击Finish。
如配置成功,在DFS Locations中将显示出新配置的文件夹。
(4)新建项目创建一个MapReduce Project,点击eclipse主菜单上的File-->New-->Project,在弹出的对话框中选择Map/Reduce Project,之后输入Project的名,例如Q1,确定即可。
Hadoop在Windows7操作系统下使用Eclipse来搭建hadoop开发环境-电脑资料

Hadoop在Windows7操作系统下使用Eclipse来搭建hadoop开发环境-电脑资料网上有一些都是在Linux下使用安装Eclipse来进行hadoop应用开发,但是大部分Java程序员对linux系统不是那么熟悉,所以需要在windows下开发hadoop程序,所以经过试验,总结了下如何在windows下使用Eclipse来开发hadoop程序代码,。
1、需要下载hadoop的专门插件jar包2、把插件包放到eclipse/plugins目录下为了以后方便,我这里把尽可能多的jar包都放进来了,如下图所示:3、重启eclipse,配置Hadoop installation directory如果插件安装成功,打开Windows—Preferences后,在窗口左侧会有Hadoop Map/Reduce选项,点击此选项,在窗口右侧设置Hadoop安装路径。
4、配置Map/Reduce Locations打开Windows-->Open Perspective-->Other选择Map/Reduce,点击OK,在右下方看到有个Map/Reduce Locations的图标,如下图所示:点击Map/Reduce Location选项卡,点击右边小象图标,打开Hadoop Location配置窗口:输入Location Name,任意名称即可.配置Map/Reduce Master 和DFS Mastrer,Host和Port配置成与core-site.xml的设置一致即可。
去找core-site.xml配置: hdfs://name01:9000在界面配置如下:点击"Finish"按钮,关闭窗口。
点击左侧的DFSLocations—>myhadoop(上一步配置的location name),如能看到user,表示安装成功,但是进去看到报错信息:Error: Permission denied: user=root,access=READ_EXECUTE,inode="/tmp";hadoop:superg roup:drwx---------,如下图所示:应该是权限问题:把/tmp/目录下面所有的关于hadoop的文件夹设置成hadoop用户所有然后分配授予777权限。
搭建eclipse的hadoop开发环境知识点

搭建eclipse的hadoop开发环境知识点一、概述在大数据领域,Hadoop是一个非常重要的框架,它提供了分布式存储和处理海量数据的能力。
而Eclipse作为一款强大的集成开发环境,为我们提供了便利的开发工具和调试环境。
搭建Eclipse的Hadoop 开发环境对于开发人员来说是必不可少的。
本文将从安装Hadoop插件、配置Hadoop环境、创建Hadoop项目等方面来详细介绍搭建Eclipse的Hadoop开发环境的知识点。
二、安装Hadoop插件1. 下载并安装Eclipse我们需要在全球信息湾上下载最新版本的Eclipse,并按照提示进行安装。
2. 下载Hadoop插件在Eclipse安装完成后,我们需要下载Hadoop插件。
可以在Eclipse 的Marketplace中搜索Hadoop,并进行安装。
3. 配置Hadoop插件安装完成后,在Eclipse的偏好设置中找到Hadoop插件,并按照提示进行配置。
在配置过程中,需要指定Hadoop的安装目录,并设置一些基本的环境变量。
三、配置Hadoop环境1. 配置Hadoop安装目录在Eclipse中配置Hadoop的安装目录非常重要,因为Eclipse需要通过这个路径来找到Hadoop的相关文件和库。
2. 配置Hadoop环境变量除了配置安装目录,还需要在Eclipse中配置Hadoop的环境变量。
这些环境变量包括HADOOP_HOME、HADOOP_COMMON_HOME、HADOOP_HDFS_HOME等,它们指向了Hadoop的各个组件所在的目录。
3. 配置Hadoop项目在Eclipse中创建一个新的Java项目,然后在项目的属性中配置Hadoop库,以及其它一些必要的依赖。
四、创建Hadoop项目1. 导入Hadoop库在新建的Java项目中,我们需要导入Hadoop的相关库,比如hadoopmon、hadoop-hdfs、hadoop-mapreduce等。
Windows 下配置 Eclipse 连接 Hadoop 开发环境
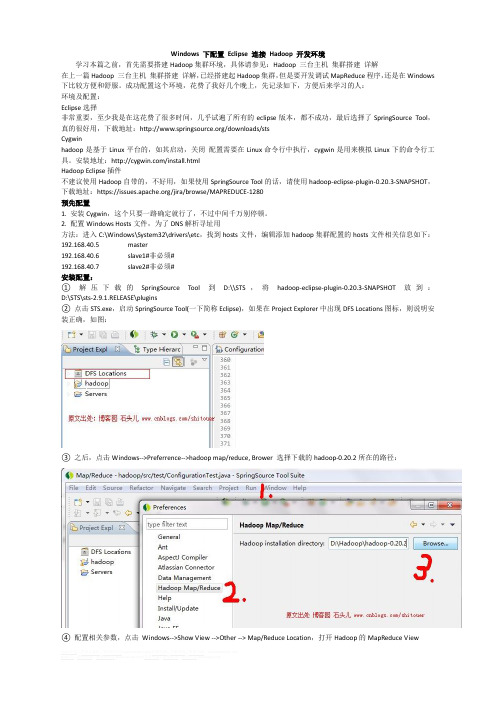
Windows 下配置Eclipse 连接Hadoop 开发环境学习本篇之前,首先需要搭建Hadoop集群环境,具体请参见:Hadoop 三台主机集群搭建详解在上一篇Hadoop 三台主机集群搭建详解,已经搭建起Hadoop集群,但是要开发调试MapReduce程序,还是在Windows 下比较方便和舒服。
成功配置这个环境,花费了我好几个晚上,先记录如下,方便后来学习的人:环境及配置:Eclipse选择非常重要,至少我是在这花费了很多时间,几乎试遍了所有的eclipse版本,都不成功,最后选择了SpringSource Tool,真的很好用,下载地址:/downloads/stsCygwinhadoop是基于Linux平台的,如其启动,关闭配置需要在Linux命令行中执行,cygwin是用来模拟Linux下的命令行工具。
安装地址:/install.htmlHadoop Eclipse插件不建议使用Hadoop自带的,不好用,如果使用SpringSource Tool的话,请使用hadoop-eclipse-plugin-0.20.3-SNAPSHOT,下载地址:https:///jira/browse/MAPREDUCE-1280预先配置1. 安装Cygwin,这个只要一路确定就行了,不过中间千万别停顿。
2. 配置Windows Hosts文件,为了DNS解析寻址用方法:进入C:\Windows\System32\drivers\etc,找到hosts文件,编辑添加hadoop集群配置的hosts文件相关信息如下:192.168.40.5master192.168.40.6slave1#非必须#192.168.40.7slave2#非必须#安装配置:①解压下载的SpringSource Tool到D:\\STS,将hadoop-eclipse-plugin-0.20.3-SNAPSHOT放到:D:\STS\sts-2.9.1.RELEASE\plugins②点击STS.exe,启动SpringSource Tool(一下简称Eclipse),如果在Project Explorer中出现DFS Locations图标,则说明安装正确,如图:③之后,点击Windows-->Preferrence-->hadoop map/reduce, Brower 选择下载的hadoop-0.20.2所在的路径:④配置相关参数,点击Windows-->Show View -->Other --> Map/Reduce Location,打开Hadoop的MapReduce View点击Ok之后,出现如下图⑤上一步你不应该看到hadoopLoc, 应该什么都没有,右键点击空白处-->New Hadoop Location, 你会看到一个填写MapReduce Location参数的一个界面:其中:Location Name:这个不用在意,就是对这个MapReduce的标示,只要能帮你记忆即可Map/Reduce Master 部分相关定义:Host:上一节搭建的集群中JobTracker所在的机器的IP地址port:JobTracker的端口两个参数就是mapred-site.xml中mapred.job.tracker的ip和端口DFS Master部分:Host:就是上一节集群搭建中Namenode所在机器IPPort:就是namenode的端口这两个参数是在core-site.xml里里面的ip和端口User Name:就是搭建Hadoop集群是所用的用户名,我这里用的是root⑥填写完以上信息以后,关闭Eclipse,然后重新启动。
windows下搭建hadoop开发环境(Eclipse)

public class WordCount { public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context ) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one);
} } } public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context ) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); if (otherArgs.length != 2) { System.err.println("Usage: wordcount <in> <out>"); System.exit(2); } Job job = new Job(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } } 5.2 配置运行参数 Run As -> Open Run Dialog... 选择 WordCount 程序,在 Arguments 中配置运行参数:
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
基于Eclipse的Hadoop开发环境配置方法(1)启动hadoop守护进程在Terminal中输入如下命令:$bin/hadoop namenode-format$bin/start-all.sh(2)在Eclipse上安装Hadoop插件找到hadoop的安装路径,我的是hadoop-0.20.2,将/home/wenqisun/hadoop-0.20.2/contrib/eclipse-plugin/下的hadoop-0.20.2-eclipse-plugin.jar拷贝到eclipse安装目录下的plugins里,我的是在/home/wenqisun/eclipse/plugins/下。
然后重启eclipse,点击主菜单上的window-->preferences,在左边栏中找到Hadoop Map/Reduce,点击后在右边对话框里设置hadoop的安装路径即主目录,我的是/home/wenqisun/hadoop-0.20.2。
(3)配置Map/Reduce Locations在Window-->Show View中打开Map/Reduce Locations。
在Map/Reduce Locations中New一个Hadoop Location。
在打开的对话框中配置Location name(为任意的名字)。
配置Map/Reduce Master和DFS Master,这里的Host和Port要和已经配置的mapred-site.xml和core-site.xml相一致。
一般情况下为Map/Reduce MasterHost:localhostPort:9001DFS MasterHost:localhostPort:9000配置完成后,点击Finish。
如配置成功,在DFS Locations中将显示出新配置的文件夹。
(4)新建项目创建一个MapReduce Project,点击eclipse主菜单上的File-->New-->Project,在弹出的对话框中选择Map/Reduce Project,之后输入Project的名,例如Q1,确定即可。
然后就可以新建Java类,比如你可以创建一个WordCount类,然后将你安装的hadoop程序里的WordCount源程序代码(版本不同会有区别),我的是在/home/wenqisun/hadoop-0.20.2/src/examples/org/apache/hadoop/examples/WordCount.java,写到此类中。
以下是WordCount的源代码:1import java.io.IOException;2import java.util.StringTokenizer;34import org.apache.hadoop.conf.Configuration;5import org.apache.hadoop.fs.Path;6import org.apache.hadoop.io.IntWritable;7import org.apache.hadoop.io.Text;8import org.apache.hadoop.mapreduce.Job;9import org.apache.hadoop.mapreduce.Mapper;10import org.apache.hadoop.mapreduce.Reducer;11import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;12import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;13import org.apache.hadoop.util.GenericOptionsParser;1415public class WordCount{1617public static class TokenizerMapper18extends Mapper<Object,Text,Text,IntWritable>{1920private final static IntWritable one=new IntWritable(1);21private Text word=new Text();2223public void map(Object key,Text value,Context context24)throws IOException,InterruptedException{25StringTokenizer itr=new StringTokenizer(value.toString());26while(itr.hasMoreTokens()){27word.set(itr.nextToken());28context.write(word,one);29}30}31}3233public static class IntSumReducer34extends Reducer<Text,IntWritable,Text,IntWritable>{35private IntWritable result=new IntWritable();3637public void reduce(Text key,Iterable<IntWritable>values,38Context context39)throws IOException,InterruptedException{40int sum=0;41for(IntWritable val:values){42sum+=val.get();43}44result.set(sum);45context.write(key,result);46}47}4849public static void main(String[]args)throws Exception{50Configuration conf=new Configuration();51String[]otherArgs=new GenericOptionsParser(conf, args).getRemainingArgs();52if(otherArgs.length!=2){53System.err.println("Usage:wordcount<in><out>");54System.exit(2);55}56Job job=new Job(conf,"word count");57job.setJarByClass(WordCount.class);58job.setMapperClass(TokenizerMapper.class);59job.setCombinerClass(IntSumReducer.class);60job.setReducerClass(IntSumReducer.class);61job.setOutputKeyClass(Text.class);62job.setOutputValueClass(IntWritable.class);63FileInputFormat.addInputPath(job,new Path(otherArgs[0]));64FileOutputFormat.setOutputPath(job,new Path(otherArgs[1]));65System.exit(job.waitForCompletion(true)?0:1);66}67}(5)配置参数点击Run-->Run Configurations,在弹出的对话框中左边栏选择Java Application,点击右键New,在右边栏中对Arguments进行配置。
在Program arguments中配置输入输出目录参数/home/wenqisun/in/home/wenqisun/out这里的路径是文件存储的路径。
在VM arguments中配置VM arguments的参数-Xms512m-Xmx1024m-XX:MaxPermSize=256m注意:in文件夹是需要在程序运行前创建的,out文件夹是不能提前创建的,要由系统自动生成,否则运行时会出现错误。
(6)点击Run运行程序程序的运行结果可在out目录下进行查看。
在Console中可以查看到的运行过程为:12/04/0706:21:00INFO jvm.JvmMetrics:Initializing JVM Metrics withprocessName=JobTracker,sessionId=12/04/0706:21:00WARN mapred.JobClient:No job jar file er classes may not be found.See JobConf(Class)or JobConf#setJar(String).12/04/0706:21:00INFO input.FileInputFormat:Total input paths to process:212/04/0706:21:01INFO mapred.JobClient:Running job:job_local_000112/04/0706:21:01INFO input.FileInputFormat:Total input paths to process:212/04/0706:21:02INFO mapred.MapTask:io.sort.mb=10012/04/0706:21:30INFO mapred.MapTask:data buffer=79691776/9961472012/04/0706:21:30INFO mapred.MapTask:record buffer=262144/32768012/04/0706:21:32INFO mapred.JobClient:map0%reduce0%12/04/0706:21:34INFO mapred.MapTask:Starting flush of map output12/04/0706:21:40INFO mapred.LocalJobRunner:12/04/0706:21:40INFO mapred.MapTask:Finished spill012/04/0706:21:40INFO mapred.JobClient:map100%reduce0%12/04/0706:21:40INFO mapred.TaskRunner:Task:attempt_local_0001_m_000000_0is done.And is in the process of commiting12/04/0706:21:40INFO mapred.LocalJobRunner:12/04/0706:21:40INFO mapred.TaskRunner:Task'attempt_local_0001_m_000000_0' done.12/04/0706:21:44INFO mapred.MapTask:io.sort.mb=10012/04/0706:22:00INFO mapred.MapTask:data buffer=79691776/9961472012/04/0706:22:00INFO mapred.MapTask:record buffer=262144/32768012/04/0706:22:03INFO mapred.MapTask:Starting flush of map output12/04/0706:22:03INFO mapred.MapTask:Finished spill012/04/0706:22:03INFO mapred.TaskRunner:Task:attempt_local_0001_m_000001_0is done.And is in the process of commiting12/04/0706:22:03INFO mapred.LocalJobRunner:12/04/0706:22:03INFO mapred.TaskRunner:Task'attempt_local_0001_m_000001_0' done.12/04/0706:22:04INFO mapred.LocalJobRunner:12/04/0706:22:04INFO mapred.Merger:Merging2sorted segments12/04/0706:22:05INFO mapred.Merger:Down to the last merge-pass,with2segments left of total size:86bytes12/04/0706:22:05INFO mapred.LocalJobRunner:12/04/0706:22:08INFO mapred.TaskRunner:Task:attempt_local_0001_r_000000_0is done.And is in the process of commiting12/04/0706:22:08INFO mapred.LocalJobRunner:12/04/0706:22:08INFO mapred.TaskRunner:Task attempt_local_0001_r_000000_0is allowed to commit now12/04/0706:22:08INFO output.FileOutputCommitter:Saved output of task'attempt_local_0001_r_000000_0'to/home/wenqisun/out12/04/0706:22:08INFO mapred.LocalJobRunner:reduce>reduce12/04/0706:22:08INFO mapred.TaskRunner:Task'attempt_local_0001_r_000000_0' done.12/04/0706:22:08INFO mapred.JobClient:map100%reduce100%12/04/0706:22:09INFO mapred.JobClient:Job complete:job_local_000112/04/0706:22:09INFO mapred.JobClient:Counters:1212/04/0706:22:09INFO mapred.JobClient:FileSystemCounters12/04/0706:22:09INFO mapred.JobClient:FILE_BYTES_READ=3984012/04/0706:22:09INFO mapred.JobClient:FILE_BYTES_WRITTEN=80973 12/04/0706:22:09INFO mapred.JobClient:Map-Reduce Framework12/04/0706:22:09INFO mapred.JobClient:Reduce input groups=512/04/0706:22:09INFO mapred.JobClient:Combine output records=712/04/0706:22:09INFO mapred.JobClient:Map input records=412/04/0706:22:09INFO mapred.JobClient:Reduce shuffle bytes=012/04/0706:22:09INFO mapred.JobClient:Reduce output records=512/04/0706:22:09INFO mapred.JobClient:Spilled Records=1412/04/0706:22:09INFO mapred.JobClient:Map output bytes=7812/04/0706:22:10INFO mapred.JobClient:Combine input records=812/04/0706:22:10INFO mapred.JobClient:Map output records=812/04/0706:22:10INFO mapred.JobClient:Reduce input records=7。