Comprehensive Table of Contents of Vol. 16
基于主成分分析法评价酱香型白酒的不同轮次基酒

Modern Food Science and Technology
2021, Vol.37, No.7
基于主成分分析法评价酱香型白酒的不同轮次基酒
唐维川 1,孔祥凯 2,王婷 2,邱声强 2,赵金松 1,3,钱宇 1,4,5,云岭 2
(1.四川轻化工大学生物工程学院,四川自贡 643000)(2.四川省川酒集团酱酒有限公司,四川泸州 646500)
气相色谱(Gas Chromatography)、高效液相色 谱仪(High Performance Liquid Chromatography)等仪 器已广泛应用于白酒风味物质分析[2,10]。气相色谱质 谱联用(Gas Chromatograph Mass Spectrometer)不仅 用于简单的检测风味物质成分,同时可有效应用于白 酒品牌鉴定、白酒中塑化剂测定。随着越来越多的风 味 物 质 得 到 定 性 定 量 , 主 成 分 分 析 (Principal Component Analysis) 、 判 别 分 析 ( Distinguish Analysis)、偏最小二乘法判别分析(Partial Least Squares-Discriiminate Analysis)、聚类分析(Cluster Analysis )、人工神经网络分析(Artificial Neural Networks)等方法也应用到了酒类风味物质的分析研 究中[11]。
located below X axis and near Y axis, and the sixth and seventh rounds were concentrated near the positive axis of X axis. The comprehensive
Research_on_the_Construction_of_Intelligent_Innova

Research on the Construction of Intelligent Innovation and Entrepreneurship Teaching Platform in Universities Based on Neural Network TechnologyTao ZhangSchool of Foreign Languages, Zhengzhou University of Science and Technology, Zhengzhou City, Henan Province, 450064ABSTRACTWith the rapid development of artificial intelligence technology, neuralnetwork technology has become an important branch in the field ofAI. In higher education, neural network technology has also begun tobe applied in the construction of teaching platforms, providing newideas and methods for the development of intelligent innovation andentrepreneurship teaching platforms in universities. This paper aims toexplore the construction path of a university's intelligent innovation andentrepreneurship teaching platform based on neural network technology,providing references for the construction of intelligent innovation andentrepreneurship teaching platforms in universities.KEYWORDSNeural network technology; University; Intelligence; Innovation andentrepreneurship teaching platform; Construction pathDOI: 10.47297/taposatWSP2633-456913.202304011 IntroductionWith the continuous progress and widespread application of information technology, artificial intelligence has become an essential component of today’s society. Neural network technology, as an important branch of artificial intelligence, possesses powerful learning and prediction capabilities and has been widely applied in image recognition, natural language processing, speech recognition, and other fields. In higher education, neural network technology has also begun to be applied in the construction of teaching platforms, offering new ideas and methods for the development of intelligent innovation and entrepreneurship teaching platforms in universities.2 Research Background and Significance(1) The Role of Intelligent Teaching Platforms in Enhancing Innovation and Entrepreneurship EducationIntelligent teaching platforms play a crucial role in enhancing innovation and entrepreneurship education. They enable personalized learning and intelligent guidance, helping students better understand and master the study material, thereby improving learning outcomes and self-confidence. Additionally, these platforms also provide intelligent analysis and management tools for teachers, enabling them to gain insights into students’ learning progress and needs, leading to more preciseTheory and Practice of Science and Technologyteaching and personalized guidance, ultimately enhancing the overall teaching effectiveness and quality.(2) Analyzing the advantages of neural network technology application in the education sectorThe application of neural network technology in education offers various advantages. Firstly, it facilitates personalized learning, tailoring individualized learning plans for each student based on their learning characteristics and progress, thereby meeting their specific learning needs. Secondly, neural network technology enables intelligent guidance, analyzing students’ learning performance and difficulties, and providing them with corresponding learning advice and solutions. Thirdly, it facilitates intelligent assessment, conducting comprehensive and accurate evaluations of students’ learning performance and mastery, offering targeted feedback and improvement measures for both teachers and students. Furthermore, neural network technology can achieve intelligent recommendation, suggesting relevant learning resources and content based on students’ interests and abilities, thereby stimulating students’ learning motivation and engagement. Lastly, the intelligent analysis capabilities of neural network technology help teachers gain a better understanding of students’ learning situations and processes, providing scientific evidence for instructional design and management, and ultimately improving teaching effectiveness and quality.3 Application of Neural Network Technology in the Construction of Intelligent Innovation and Entrepreneurship Teaching Platforms in Universities(1) Personalized teachingUsing neural network technology, personalized learning models can be constructed based on students’ learning habits, abilities, interests, and other factors, providing tailored teaching services to students. For example, by analyzing students’ answer data, students can be categorized, and suitable learning resources can be recommended to them. For hands-on learners, more practical exercises and case analyses can be provided, while for theory-oriented learners, more theoretical knowledge can be offered. This approach better meets students' individual needs and enhances their learning motivation.(2) Intelligent assessmentThrough neural network technology, students' learning outcomes can be intelligently assessed, enabling a better understanding of their learning situation and timely adjustment of teaching strategies. For instance, during exams, neural networks can automatically grade students’ papers, providing quick and accurate scores and error analysis. This not only lightens the workload of teachers but also improves the accuracy and objectivity of assessments. Furthermore, through data analysis of students’ exam scores, trends in their academic performance can be predicted, leading to targeted learning recommendations.(3) Intelligent recommendationUsing neural network technology, students can receive recommendations for suitable courses, majors, and careers based on their learning progress and interests. For example, for students who enjoy programming, relevant learning resources and projects can be recommended to help themVol.4 No.1 2023 further develop their skills. Additionally, by analyzing students’ course selection data, the neural network can suggest courses that are beneficial for their career development.(4) Intelligent interactionLeveraging neural network technology enables intelligent interaction features. Students can interact with the system in real-time through voice, text, images, and other means, facilitating immediate communication and feedback, thus enhancing their learning experience and efficiency. Teachers can also provide real-time learning support and guidance through intelligent interaction. For instance, in programming education, the neural network can analyze students’ code in real-time, offering targeted suggestions and guidance to help students better understand and master the knowledge.4 Construction of Neural Network-based Intelligent Innovation and Entrepreneurship Teaching Platform in Universities(1) Establish data collection systemThe construction of a neural network-based intelligent innovation and entrepreneurship teaching platform in universities requires a substantial amount of data for training and optimization. Therefore, it is essential to establish a comprehensive data collection system. This system can utilize technological means to gather relevant student data, such as learning behavior, academic performance, and social interactions, while ensuring data accuracy and security.(2) Build model training platformThe development of an intelligent innovation and entrepreneurship teaching platform using neural network technology necessitates the construction of a model training platform. Cloud computing technology can be employed to establish a high-performance computing cluster, providing powerful computational support for model training. Additionally, a distributed training framework can be adopted to enable parallel processing of large-scale data. Students can access learning resources, participate in activities, and receive study reminders anytime, anywhere through mobile devices like smartphones and tablets. Moreover, mobile application platforms can facilitate interaction and communication between students and teachers or other students.(3) Formulate intelligent teaching strategiesThe formulation of intelligent teaching strategies is the foundation of constructing an intelligent innovation and entrepreneurship teaching platform in universities. By analyzing students’ learning situations and needs, personalized learning plans and resources that cater to individual students' characteristics can be devised to achieve personalized teaching. Additionally, intelligent assessment and recommendation functionalities can be utilized to provide intelligent teaching services.(4) Establish intelligent teaching environmentThe establishment of an intelligent teaching environment is crucial in the construction of an intelligent innovation and entrepreneurship teaching platform in universities. The creation of facilities such as intelligent classrooms and laboratories can facilitate the development of an intelligent teaching environment. Meanwhile, leveraging intelligent interaction capabilities enables real-timeTheory and Practice of Science and Technologycommunication and feedback between students and the system, enhancing their learning experience and efficiency.(5) Develop intelligent teaching resourcesThe development of intelligent teaching resources is the core of constructing an intelligent innovation and entrepreneurship teaching platform in universities. By developing intelligent textbooks, experimental materials, and other teaching resources, the creation of intelligent teaching resources can be achieved. Additionally, through intelligent recommendation features, students can access learning resources and services that align with their interests and needs.5 Empirical Study(1) Research methods and procedures1) Data CollectionCollect data from the experimental group and the control group. The experimental data comes from students enrolled in an innovation and entrepreneurship course at a certain university, including students’ personal information, learning data, grades, learning behaviors, and teachers’ assessments of students' learning.2) Data preprocessingConduct data cleaning, handle missing values, and perform feature extraction to ensure the accuracy and effectiveness of the data.3) Model trainingSelect suitable neural network models, such as convolutional neural networks, recurrent neural networks, etc., to analyze and model the data, establishing models for personalized teaching, intelligent assessment, intelligent recommendation, and intelligent interaction.4) Model evaluationDivide the processed data into training, validation, and testing sets, and use methods like cross-validation to evaluate the performance and accuracy of the models. Model parameters are adjusted based on student and course characteristics to improve model performance.(2) Analyzing experimental data and resultsBy comparing the performance of different neural network models, the experimental data and results are analyzed to evaluate the effectiveness and contribution of neural network technology in the construction of the innovation and entrepreneurship teaching platform. The advantages of the intelligent teaching platform are found in the following aspects:1) Personalized teachingThe intelligent teaching platform can provide personalized learning content and teaching strategies based on each student's learning data and interests, thereby increasing students’ learning motivation.Vol.4 No.1 20232) Intelligent assessmentThe intelligent teaching platform can provide accurate assessments and feedback by analyzing students’ learning outcomes and practice data, helping students understand their learning progress and areas for improvement, and making timely adjustments and improvements.3) Intelligent recommendationThe intelligent teaching platform can provide intelligent recommendation services to students based on their learning situation and interests, recommending suitable learning resources and activities to expand students’ knowledge and perspectives, thereby enhancing their learning effectiveness and satisfaction.4) Intelligent interactionBy deploying the trained models to practical application scenarios such as the intelligent teaching platform, intelligent interaction is achieved. The system analyzes users’ questions and historical data, uses the trained models for prediction, and returns the most likely answers. Through continuous interaction and learning, the system can gradually improve the accuracy and efficiency of responses, enhancing users’ overall experience.6 ConclusionThrough measures such as establishing a data collection system and constructing model training platforms, the level of construction and the quality of services of the intelligent innovation and entrepreneurship teaching platform in universities can be effectively improved. Neural network technology also provides new ideas and methods for the construction of intelligent innovation and entrepreneurship teaching platforms in universities: by formulating personalized teaching strategies, building intelligent teaching environments, and developing intelligent teaching resources, the construction and application of intelligent innovation and entrepreneurship teaching platforms in universities can be achieved. In the future, with the continuous development and application of neural network technology, the construction of intelligent innovation and entrepreneurship teaching platforms in universities will become more refined and widespread, providing better intelligent teaching services for more students.About the AuthorTao Zhang (1989-), male, Han nationality, native place: Queshan County, Henan Province, professional title: lecturer, postgraduate degree, research direction: employment and entrepreneurship guidance.References[1] Yingshuai Dong. Jiaxuan Qu. Innovative strategies for talent cultivation in universities under the background ofartificial intelligence [J] Industrial Innovation Research, 2022, (18): 193-95.[2] Gengjun Han. Research on the Dual Transformation of the Innovation and Entrepreneurship Education Ecosystem inUniversities under the Empowerment of Artificial Intelligence [J] Technology and Innovation, 2022, (18): 136-38.[3] Jixin He. Huanjun Yao. Gengjun Han. Innovation in the management path of innovation and entrepreneurship servicesin universities in the context of intelligence: from empowerment to empowerment [J] Innovation, 2022, 16 (03): 95-107.[4] Weinan Zheng. Platform-based teaching system construction and teaching model reform for Innovation and EntrepreTheory and Practice of Science and Technologyneurship education [J]. Cultural and Educational Materials, 2021 (23) : 191-94.[5] Qiang Wang.Discussion on the construction of “Innovation and Entrepreneurship” platform based on Co-construction of school and enterprise [J]. Qinghai Transportation Science and Technology,2021,33(04):46-48.。
Comprehensive Table of Contents of Vol. 15

y
S h o rt a g e
34
Ma
jo
v e
r
Te
c
hn
o lo
g ic
a
l B
re a
kt h r o
u
g hs
o
f
o IL
30
a n
d GAS
e
R ES OUR C ES
D is
c o v e r ie s
’
C N P C in 2 0 0 7 3 9
De lo p m
e s e n
o
P P B
E x p lo
ra
t io
n
T re
n
d
o
f L a rg
’
e
G
a s
F ie l d s i n
C h in
a n
a
n
d Cut Co
e
g ib l e S t e p s t o S m p t io n
y Re
s e rv e s
a v e
E
n e rg
y
C h in 2 7
a
v e m e n ts
o
s
S t ro
n
g G
ro w
th Mo
m e n tu m
5
ro
f it s
Of
C h in
a
s
0 II G ia
F a lI i n F i r s t
th
a
t Ho
m e
a n o s
d W o r ld w id e
t It s 0
常用溶剂的沸点、溶解性和毒性
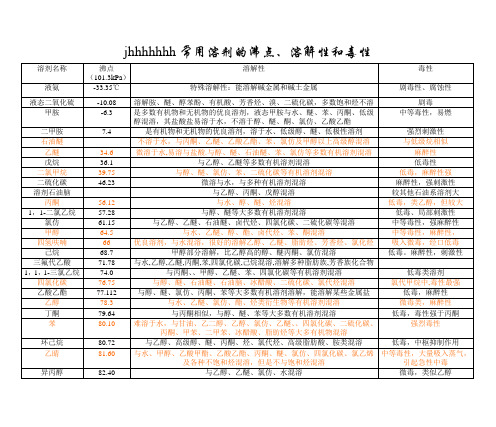
jhhhhhhh常用溶剂的沸点、溶解性和毒性有机合成的16本教科书中国化学化工论坛Advanced Organic Chemistry, Part B, 4th ed. (Carey/Sundberg; Plenum, 2001) - readable summary, great leading refs.Advanced Organic Chemistry, 5th ed. (Smith/March; Wiley, 2001) - summary/encyclopedia of reactions, >2000 refs. Art in Organic Synthesis, 2nd ed. (Anand/Bitra/Randanathan; Wiley, 1988) - discussions of classic synthesesClassic in Total Synthesis (Nicolaou/Sorenson; VCH, 1996) - insightful, expert discussion of great total syntheses Compendium of Organic Synthetic Methods(var. Eds.; Wiley) - 10 vol. set with easy tabular indices. Comprehensive Organic Transformations(Larock) - index is an acquired skill, but leading refereces are very numerousConcepts of Organic Synthesis - Carbocyclic Chemistry (Mundy; Dekker, 1979) - dated, but a very nice overview Evolution of Synthetic Pathways - Parallax and Calibration(Ho; World Sci., 1996) - analysis of total syntheses; chapters are Chemoselectivity Problems, Stereochemical Problems, and Regiochemical Problems. Assumes much synthesis knowledge.The Logic of Chemical Synthesis (Corey/Cheng) - great discussion of strategy by one of the true mastersName Reactions and Reagents in Organic Synthesis (Mundy/Ellerd; Wiley, 1988) - nice discussions with examples The Organic Chemistry of Drug Synthesis (var. Eds.; Wiley) - six vol. set; some very useful transformationsOrganic Synthesis - The Disconnection Approach(Warren; Wiley, 1982) - a little old, but excellent for learning retrosynthetic analysisProtective Groups in Organic Synthesis, 3rd Ed. (Greene/Wuts; Wiley, 1999) - the best compilation around Strategies for Organic Drug Synthesis and Design (Lednicer; Wiley, 1998) - arranged by compound typeTactics of Organic Synthesis(Ho; Wiley, 1994) - excellent discussion of reaction types and their utility; upper level The Total Synthesis of Natural Products (J. ApSimon, Ed.) - 11vol. set; each vol. has 1-4 chapters on N.P. families [Tables of Contents]-。
Online recognition of chinese characters the state-of-the-art

Online Recognition of Chinese Characters:The State-of-the-ArtCheng-Lin Liu,Member,IEEE,Stefan Jaeger,and Masaki Nakagawa,Member,IEEE Computer Society Abstract—Online handwriting recognition is gaining renewed interest owing to the increase of pen computing applications and new pen input devices.The recognition of Chinese characters is different from western handwriting recognition and poses a specialchallenge.To provide an overview of the technical status and inspire future research,this paper reviews the advances in onlineChinese character recognition(OLCCR),with emphasis on the research works from pared to the research in the1980s,the research efforts in the1990s aimed to further relax the constraints of handwriting,namely,the adherence to standard stroke orders and stroke numbers and the restriction of recognition to isolated characters only.The target of recognition has shifted fromregular script to fluent script in order to better meet the requirements of practical applications.The research works are reviewed interms of pattern representation,character classification,learning/adaptation,and contextual processing.We compare importantresults and discuss possible directions of future research.Index Terms—Online Chinese character recognition,state-of-the-art,pattern representation,character classification,model learning, contextual processing,performance evaluation.æ1I NTRODUCTIONI N online character recognition,the trajectories of pen tip movements are recorded and analyzed to identify the linguistic information expressed.Owing to the availability of both temporal stroke information and spatial shape information,online character recognition is able to yield higher accuracy than offline recognition.Online recognition also provides good interaction and adaptation capability because the writer can respond to the recognition result to correct the error or change the writing style.In recent years,new types of pen input devices and interfaces have been developed to improve the precision of trajectory capturing and the comfort of writing.Devices are available for writing on ordinary paper and wireless transmission of handwriting,for example.Powerful soft-ware is available now for analyzing and retrieving hand-written documents.This development stimulates new applications of handwriting recognition and has resulted in a renewed interest in research[114].The applications of online recognition include text entry for form filling and message composition,personal digital assistants(PDA), computer-aided education[90],handwritten document retrieval[77],[107],etc.For handheld devices,pen input is competitive to speech input because it is insensitive to environmental noise,which is an important advantage for many applications.For desktop applications,online recog-nition is well-suited to text entry for large alphabets(like Oriental languages).A common feature of these applica-tions is that they require high recognition accuracy.The research of online character recognition started in the1960s and has been receiving intensive interest from the 1980s.The comprehensive survey of Tappert et al.reviewed the status of research and applications before1990[120]and early works of online Japanese character recognition have been reviewed in[85],[132].A recent comprehensive survey of handwriting recognition,by Plamondon and Srihari,mainly concerns western handwriting[102].Our paper contributes a survey to online Chinese character recognition(OLCCR)since this recognition problem is very different from western handwriting recognition and it posesa special challenge.1.1Related ProblemsPen computing applications closely related to handwriting recognition are mathematical formula recognition[5],[148] and diagram recognition[3],where both the character classes(mostly Latin characters)and the layout are recognized.Another application is signature verification that checks whether a handwritten signature is generated by a specific writer or not.It does not necessarily identify the symbolic classes of a signature’s constituent characters though.Signature verification has been reviewed in[61], [102]and recent works are reported in[44],[57].A form of handwritten document retrieval,the so-called ink matching, does not identify the character classes either[78].Hand-written sketch recognition is based mostly on noncharacter data and typically ignores linguistic information[82],[109]. We do not cover these problems further because they are not relevant to the methodology of OLCCR.1.2Characteristics of Chinese CharactersChinese characters are used in daily communications by over one quarter of world’s population,mainly in Asia. There are mainly three character sets:traditional Chinese characters,simplified Chinese characters,and Japanese. C.-L.Liu is with the Central Research Laboratory,Hitachi,Ltd.,1-280Higashi-koigakubo,Kokubunji-shi,Tokyo185-8601,Japan.E-mail:liucl@crl.hitachi.co.jp..S.Jaeger and M.Nakagawa are with the Department of Computer Science,Tokyo University of Agriculture and Technology,2-24-16Naka-cho,Koganei-shi,Tokyo184-8588,Japan.E-mail:stefan@hands.ei.tuat.ac.jp,nakagawa@cc.tuat.ac.jp.Manuscript received27Sept.2002;revised19May2003;accepted11Aug.2003.Recommended for acceptance by K.Yamamoto.For information on obtaining reprints of this article,please send e-mail to:tpami@,and reference IEEECS Log Number117468.0162-8828/04/$20.00ß2004IEEE Published by the IEEE Computer SocietyKanji.Japanese Kanji characters have mostly identical shape to the corresponding traditional Chinese or simplified Chinese.For some Kanji characters,nevertheless,the shape is slightly different from both the traditional and simplified Chinese.Fig.1shows some examples of the three character sets.We can see that,among the14characters,four havedifferent shapes(the last character only varies slightly, while the fourth one is treated identically in three sets).In the mainland of China,two character sets,containing 3,755characters and6,763characters,respectively,were announced as the National Standard GB2312-80(the first set is a subset of the second one)[116].In Taiwan,5,401traditional characters are included in a standard set.In both traditional and simplified Chinese,about5,000characters are frequently used.In Japan,2,965Kanji characters are included in the JIS level-1standard and3,390Kanji characters are in the level-2standard(the two sets are disjoint).A Chinese character is an ideograph and is composed of mostly straight lines or“poly-line”strokes.Many characters contain relatively independent substructures,called radi-cals,and some common radicals are shared by different characters.This property can be utilized in recognition to largely reduce the size of reference model database and speed up recognition.Chinese handwritten scripts are classified into three typical styles:regular script,fluent script,and cursive script. The intermediate styles are called fluent-regular script and fluent-cursive script,respectively.Some examples of the three typical styles are shown in Fig.2.We can see that,in regular script,strokes are mostly straight-line segments.The fluent script has many curved strokes and,frequently, successive strokes are connected.In cursive script,some character shapes totally differ from the standard shape,so it is difficult to recognize them,even for humans.1.3The State-of-the-ArtSince the1990s,the research efforts of OLCCR have been aiming at the relaxation of constraints imposed on writers to ensure successful recognition,namely,the isolation of characters and the compliance with standard shapes.For Chinese characters,the main problem in online recognition is to overcome the stroke-order and stroke-number varia-bility.The target of OLCCR in the1990s has shifted from regular script to fluent script,which features greater variability of stroke-order and stroke-number and occurs frequently in practical writing.In the literature of character recognition,the regular style is also referred to as block style or hand-printed style,while the fluent style is often called“cursive”style.The current systems can recognize regular script with high accuracy,whereas the recognition of fluent style still remains unsolved and requires more intensive research efforts.The fluent script or fluent-regular script is the target of most recognition systems because people naturally write this way.The methods of OLCCR can be roughly divided into two categories:structural methods and statistical methods. Structuralmethodsarebasedonstrokeanalysis.Thecharacter models of structural methods can be further divided into stroke-order dependent models and stroke-order free ones. Statistical methods mainly utilize the holistic shape informa-tion,so it is easier to achieve stroke-order independence.From an application’s point of view,a recognition method can be writer-dependent or writer-independent.Writer-indepen-dent recognition is more challenging due to the diversity of writing styles.On the other hand,writer-dependent recogni-tion allows stable recognition of cursive script due to the relative stability of personal writing styles.1.4Contents of the PaperThis survey will emphasize the research efforts from the 1990s.On comparing the performance of state-of-the-art methods,discussing their insufficiencies,we will suggest future research directions.The rest of this paper is organized as follows:Section2gives the overview of a typical OLCCR system and Section3briefly reviews preprocessing. Sections4,5,and6address the main tasks of character recognition,namely,pattern representation,classification (including coarse classification and fine classification),and reference model learning/adaptation,respectively.Though in an OLCCR system,the schemes of classification and learning largely depend on that of representation,a scheme in a task can still connect with multiple schemes in another task. Hence,we address the three tasks in separate sections and try to thread the connected schemes in different tasks.Section7 addresses the contextual processing of character segmenta-tion and recognition.Section8compares the performance of representative methods and Section9discusses the future research directions.2O VERVIEW OF A T YPICAL OLCCR S YSTEMA practical OLCCR system is depicted diagrammatically in Fig.3.The input to the system is a sequence of handwritten character patterns.First,the handwriting sequence is segmented into character patterns according to the temporal and shape information.Often,the boundary between characters cannot be determined unambiguously before character recognition,so candidate character patterns are generated and recognized and the correct patterns are selected in contextual processing at the end of the process chain.The recognition of segmented(candidate)patterns involves the following steps:preprocessing,description,andFig. 1.Examples of traditional Chinese,simplified Chinese,andJapanese Kanji.Fig.2.Chinese writing styles:regular,fluent,and cursive.classification.Classification is often decomposed into coarse classification and fine classification.Pattern description is also referred to as feature extraction,which represents the input pattern either statistically by feature vectors or structurally by various levels of primitives.The model database(also called reference database or recognition dictionary)contains the reference models or classification parameters for coarse classification and fine classification.To speed up the recognition of the large category set,a fast coarse classification procedure is commonly used to first select a small subset of candidate classes to which the input pattern is expected to belong to.Then,the input pattern is classified into one of these candidate classes in the fine classification stage.This two-stage recognition strategy has been widely adopted by now,though tree classification and multistage classification can further speed up the recognition.In contextual processing,linguistic knowledge and geometric features are used to verify the segmentation and classification results.The performance of character recognition relies largely on the quality of the model database.This database is built from heuristic knowledge, manually selected character prototypes,or from multiple sample patterns.For writer-dependent recognition,the models or parameters can adapt to the writer’s style to improve the recognition performance.3P REPROCESSINGThe preprocessing of the trajectory of input pattern directly facilitates pattern description and affects the quality of description.The preprocessing tasks of online character patterns include noise elimination,data reduction,and shape normalization.The noise in character trajectories is due to erratic hand motions and the inaccuracy of digitization.The noise reduction techniques used in most systems are basically those explained in[120]:smoothing,filtering,wild point correction,stroke connection,etc.As the quality of input devices steadily advances,trajectory noise becomes less influential and simple smoothing operations will suffice.Data reduction can be accomplished by two approaches: equidistance sampling and line approximation(feature point detection).With equidistance sampling,the trajectory points are resampled such that the distance between adjacent points is approximately equal.The data amount of equidistance point representation is still appreciable.A higher data reduction rate can be achieved by detecting the corner points of trajectories.The corner points and the ends of a stroke trajectory are often called feature points.Corner detection from digitized curves has been widely addressed in the shape recognition literature.The basic idea is to estimate the curvature at each point on the curve and retain the points of high curvature[105].An alternative is polygonal approximation,which recursively finds the vertex of maximum point-to-chord distance[104].Corner detection and polygonal approximation are complementary and can be combined to achieve better performance[138]. Line approximation of strokes has been used in many online recognition systems(e.g.,[38],[55],[63],[145],[146]).Normalization of character trajectories to a standard size is adopted in almost every character recognition system. Conventionally,the coordinates of stroke points are shifted and scaled such that all points are enclosed in a standard box(this is called linear normalization).Alternatively,by moment normalization[4],the centroid of input pattern is shifted to the center of standard box and the second-order moments are scaled to a standard value.To alleviate the shape deformation of handwritten Chinese characters,nonlinear normalization was proposed in the 1980s and was proven efficient to improve the accuracy of offline character recognition.It was later successfully applied to online character recognition as well[28],[45],[88],[99], [100].Nonlinear normalization reassigns the coordinates of stroke points according to the line density distribution with the aim of equalizing the stroke spacing[62],[127],[141].For comparing the effects of normalization,Fig.4shows two character patterns and the results of linear,moment,and nonlinear normalization.It was shown that moment normal-ization can yield comparable recognition accuracy to non-linear normalization[70].For online patterns,the line density can be computed directly from the online trajectory[45],[88], instead of the2D image.4P ATTERN R EPRESENTATIONThe representation schemes of input pattern and model database are of particular importance since the classification method depends largely on them.We divide the schemes into three groups:statistical,structural,and hybrid statistical-structural.In statistical representation,the input pattern is described by a feature vector,while the model database(also called parameter database in this case)contains the classifica-tion parameters.The structural representation scheme hasFig.3.Diagram of a practical OLCCRsystem.Fig.4.Examples of linear normalization,moment normalization,andnonlinear normalization.long been dominating the OLCCR technology,whereas the statistical scheme and the hybrid scheme are receiving increasing attention in recent years.The statistical-structural scheme is only used for describing the reference models.It takes the same structure as the traditional structural representation,yet the structure elements(primitives)and/ or relationships are measured probabilistically.Hidden Markov Models(HMMs)can be regarded as instances of the statistical-structural representation.The structural representation schemes can be further partitioned into five levels:sampling points,feature points or line segments,stroke codes or HMMs,relational,and hierarchical.Fig.5shows the hierarchy of five levels.For describing the input pattern or the model database,the primitives of higher-level structure are composed of the lower-level primitives, e.g.,a stroke is recorded by the constituent line segments or sampling points,while the relational structure takes strokes as primitives.We treat HMMs on the same level as stroke code representation because HMMs are frequently used to model strokes or substrokes,while a sequence of HMMs represent a radical or a character.The feature point representation is equivalent to the line segment representation because every pair of succeeding feature points gives a line segment.In stroke code representa-tion,the types of strokes in input pattern or reference models are specified and the reference model is represented as a sequence of strokes.The relational structure represents a character model or a radical model wherein the relationship between strokes is specified.In the hierarchical representa-tion of model database(also called structured representa-tion),a number of radical models are shared to construct the character models of all categories.On the other hand,the hierarchical structure of input pattern is a relational structure with radicals as primitives.The structured representation of model database is very storage efficient,while the sampling points representation is data intensive.An OLCCR system can use different representation schemes for the input pattern and the model database, respectively.In the case of structural or statistical-structural representation,the model database is usually described at higher level than the input pattern.In recognition,for example,the input pattern is represented in point sequence or line segments,then strokes and relational structure are extracted by matching the point sequence or line segments with the higher-level primitives of reference models.In the following,we review the detailed schemes of structural representation,statistical-structural representa-tion,and statistical representation,respectively.4.1Structural RepresentationWe review the structural representation schemes in the order of the levels as shown in Fig.5.4.1.1Point and Line Segment RepresentationA representation with resampled points can cope well with curved strokes,though it results in large size of model database.If both the input pattern and the character prototype in the model database are represented as point sequences,they can be matched based on stroke correspon-dence in which the between-stroke distance is computed by aligning the points[132],[133],[134].The feature point or line segment representation is widely adopted nowadays.It is especially suited to regular-style characters,which are composed of mostly straight-line segments.Input patterns represented as feature point sequences can be matched with character models represented as feature point sequences[13],[55], [86],higher-level primitives(such as stroke codes)[20],or hierarchical structures[60].Analogously,input patterns represented as line segments can be matched with character models represented as line segments[18],[35],[124]or higher-level structures[16],[139].4.1.2Stroke Code RepresentationStroke code representation schemes have been adopted from the early stages of OLCCR research(e.g.,[145],[146]). The strokes in regular script can be categorized into classes according to the constituent line segment sequence and each class is assigned a code or index number[63],[65]. Each stroke code has a corresponding reference model/ prototype or a set of rules.A character model is then represented as a sequence of stroke codes or a relational structure with stroke codes as primitives[14],[65].When using stroke code-based models in recognition,the stroke codes of input pattern are determined in matching with character/stroke models.In[74],[106],the input pattern is initially represented as line segments and strokes are detected using finite state automaton.The stroke code representation of[47]is unique in that a connected stroke(a piece of trajectory containing one or multiple normal strokes)is represented as a single feature vector and stroke prototypes are designed by clustering sample patterns.However,because it does not rely on stroke decomposition,this scheme does not generalize to novel stroke shapes not contained in the learning samples.4.1.3Relational RepresentationFor stroke-order-free recognition,the primitives(strokes or line segments)of a character and the relationship between them are often represented by means of a relational structure, such as an Attributed Relational Graph(ARG).In an ARG,the nodes denote primitives and the arcs denote the relationships between nodes.If the attributes of nodes and/or arcs are represented with fuzzy sets,the graph is called fuzzy ARG (FARG)[6].Fig.6shows an example of ARG.Two problems arise in ARG matching of characters.First, the primitives and relation codes of the reference models must be carefully designed to tolerate the shape variation ofFig.5.Hierarchy of structural representation schemes.input ing fuzzy attributes or multiattribute relation codes can alleviate this problem[7],[10],[71]. Second,the description of input patterns in ARGs is not straightforward because it is often difficult to reliably extractthe primitives and their relationships prior to ARG matching. To solve this problem,the input pattern is represented in lower-level primitives(usually line segments),which are grouped into higher-level primitives by matching them with reference ARGs[149].Because a stroke may contain multiple line segments,using line segments instead of strokes as the primitives of ARGs can facilitate the extraction of primitives from input pattern[72],[73].4.1.4Structured RepresentationDue to the hierarchical nature of Chinese characters,a character pattern can be described in a tree structure,with the character itself at the top level and the radicals and strokes as low-level primitives.In a structured representation of reference models,the radical models or stroke models are shared by different characters such that a character model is constructed dynamically using the constituent radicals and strokes.This strategy can largely save the storage space of model database,considering the fact that hundreds of distinct radicals are shared by thousands of characters[87].The character models with shared radical models can be organized in a lookup table[8],[9],[38],[146],a tree structure[11],[75],[76],or a network[47].Fig.7shows an example of network representation of model database.Via stroke and radical extraction from the input pattern,the character model fitting the input pattern can be retrieved by traversing the tree or network.The structured representa-tion approach can vary in the representation scheme of radicals:line segments[75],[76],connected stroke codes [47],and hierarchies of substroke HMMs[91].4.2Statistical-Structural ModelsIn a statistical-structural representation scheme,a character model is described in a string,tree,or graph structure,with the primitives and/or relationships measured probabilisti-cally to better model the shape variations of input patterns. In principle,any structural model can be described probabilistically by replacing the attributes of primitives and/or relationships with probability density functions (PDFs).The mean and variance of stroke and relationship attributes in[76]are connected to PDF representations. Gaussian PDFs have been used for describing the distribu-tions of feature points[20]and stroke attributes[150].This direction has not been explored adequately yet.The Hidden Markov Model(HMM)is a directed graph with nodes and between-node transitions measured probabilistically.HMMs have been used in speech recognition since the1970s[103]and have been applied to western character recognition since the1980s.Only in recent years have HMMs been applied to Chinese characters.Generally,left-right HMMs are used to model the sequences of points or line segments for substrokes [91],[92],[121],strokes,radicals[48],or whole characters [117],[143].Since the character-based HMM is stroke-order dependent,multiple models are often generated for the characters with stroke-order variations or large shape variations[117],[143].Using stroke-based or substroke-based HMMs,the character models can be constructed hierarchically and the stroke-order variations can be represented in a variation network[93].A constrained ergodic HMM,named path controlled HMM(PCHMM),was proposed to overcome the stroke-order variation of online characters[150].The successor attribute matrix(SAM)of[58]is similar to ergodic HMMs since it estimates the transition probabilities between strokes.4.3Statistical RepresentationIn the statistical recognition approach,we are mainly concerned with the representation of input patterns (basically in feature vectors).The model database contains the classification parameters,which can be estimated by standard statistical techniques[22],[25].We will review the statistical classification techniques in Section5.The feature vector representation of character patterns enables stroke-order and stroke-number free recognition by, for example,mapping the pattern trajectory into a2D image and extracting so-called offline features[28].In this context, various feature extraction techniques in offline character recognition[32],[128]can be applied to online recognition as well.The so-called direction feature[144],which is widely used in offline character recognition[50],[51],is being used in online recognition[28],[45],[88].In offline recognition,the skeleton or contour pixels of the character image are classified into either four(horizontal,vertical,diagonal,and antidia-gonal)or eight directions and stored in respective directional planes.Each directional plane is compressed by grid partitioning or blurring(spatial filtering and sampling)[67]. In[41],we named the resulting features“histogram features,”which is motivated by the fact that they describe the number of occurrences for each direction.For online recognition, directional features can be extracted directly from the onlineFig.6.An example of ARG representation(left:character,right:ARG). The relation codes“X,”“T,”“L,”and“P”stand for intersection,end-to-line adjacency,end-to-end adjacency,and positional relation,respectively.work representation of characters with shared radical models.Every path corresponds to a character as shown in the rightmost column.trajectory[45].A“direction-change”feature characterizing the temporal information was proposed to enhance the recognition performance of direction feature[99],[100].5C HARACTER C LASSIFICATIONIn this section,we first review the coarse classification techniques.For fine classification,we categorize the techniques into three groups:structural matching,prob-abilistic matching,and statistical classification.5.1Coarse ClassificationCoarse classification can be accomplished by class set partitioning or dynamic candidate selection.In class set partitioning,the character classes are divided into disjoint or overlapping groups.The input pattern is first assigned to a group or multiple groups and then,in fine classification,the input pattern is compared in detail with the classes in the group(s).In dynamic candidate selection,a matching score (similarity)is computed between the input pattern and each class and a subset of classes with high scores is selected for detailed classification.The average number of candidates can be significantly reduced without loss of precision via selecting avariablenumberofcandidatesbyconfidenceevaluation[68].For coarse classification based on class set partitioning,the groups of classes are determined in the classifier design stage using clustering or prior knowledge.Class grouping can be based on overall character structure[66],basic stroke substructure[12],stroke sequence[14],and statistical or neural classification[79].Partitioning into overlapping groups can reduce the risk of excluding the true class of input pattern.Dynamic candidate selection avoids the training process of class set partitioning.The character classes are ordered according to a matching score based on simple structural features or statistical features.For instance,the number of strokes or line segments of the input pattern can be used to filter out the unlikely classes[7],[65],[132],[133].For efficient filtering,the bounds of stroke number depend on the character class and writing quality[29].As to other features,the matching score is computed by string match-ing[124],peripheral feature matching[19],voting of structural features[126],or feature vector matching[28], [81],[88],[94],[99],[139].The matching score of coarse classification can also be combined with that of fine classification to improve the final accuracy[119],[139].In coarse classification by feature vector matching,the distance measure,such as city block distance and Euclidean distance,can be computed very efficiently and the efficiency can be further improved by dimensionality reduction and combining class-specific features[81].In structural matching, candidate classes can also be selected via radical detection [16],[60],[76].A detected radical excludes all the classes not containing the radical from fine classification.The radical detection approach is tightly connected to structural match-ing and will be addressed later.5.2Structural MatchingIn fine classification by structural matching,the input pattern is matched with the structural model of each(candidate)class and the class with the minimum matching distance is taken as the recognition result.We divide the structural matching methods into four categories:DP(dynamic programming)matching,stroke correspondence,relational matching,and knowledge-based matching.DP matching works on ordered sequences and,hence,is stroke-order dependent.Stroke correspondence is different from relational matching in that it does not consider the interstroke relationship.Connected to these approaches,some general strategies are:hierarchical matching and deformation methods.Hierarchical matching can improve the speed of structur-al recognition.When stroke codes or radical models are shared by different characters,the classification can be performed by a decision tree[11]or a network[47].When the strokes or radicals of input pattern have been identified,the character recognition is reduced to traversing a path in the tree/network.However,the accuracy of classification is limited by the identification of strokes or radicals in the input pattern,which is not a trivial task.Therefore,instead of deterministic traversals,measuring the likelihood of paths and search with backtrack is helpful to improve the recognition performance.Deformation techniques are useful to improve the matching similarity by deforming the character prototype or the input pattern.Based on the stroke correspondence, the deformation vector field(DVF)between the input pattern and the prototype can be computed and the prototype is iteratively deformed by local affine transforma-tion(LAT)to fit the input pattern[131].A noniterative stroke-based affine transformation(SAT)decomposes the DVF of each stroke incorporating the relationship between successive strokes[134].In another work,a so-called parabola transformation was proposed to deform the character prototype based on attributed string matching of feature point sequences[13].5.2.1DP MatchingDP matching finds the ordered correspondence between the symbols(primitives)of two strings with the aim of minimizing the edit(Levinstein)distance.The DP matching of point sequences is also referred to as dynamic time warping(DTW).Attributed string matching refers to the matching of sequences of attributed primitives.In online character recognition,feature points or line segments are often taken as the primitives of sequence representation [55],[88],[124].The search space of DP matching is represented in a rectangular grid with two diagonal corners denoting empty matching(start)and complete matching(goal),respectively. In a path from start to goal,the transition between neighbor-ing grid points corresponds to symbol deletion,insertion,or substitution.A generalization of attributed string matching can merge multiple primitives in one string to match with one primitive in another string[123].By imposing constraints onto potential grid transitions,the search speed can be largely improved with little loss of accuracy(e.g.,[86],[88]).DP matching is a mature technique,but the performance of recognition depends strongly on the selection of primitives and the definition of the between-primitive distance measure.For dealing with stroke-order variations,a character class needs multiple prototypes.5.2.2Stroke CorrespondenceBased on the stroke correspondence between the input pattern and a character prototype,the character matching distance is computed as the sum of between-stroke。
Table of Contents

Enter Coff-e-mail. The Coff-e-mail project sets out to bring internet notification and web-based monitoring of the coffee machine in the lounge of the Computer Science Department. Coff-e-mail is an embedded system which will be non-intrusively retro-fitted to work with the current coffee machine in the Computer Science Department lounge (it will be designed to interface with any coffee machine). It includes sensors to detect when coffee brewing starts and the amount of coffee left in the machine (coffee level), along with a camera to take pictures when people fill their coffee mugs with fresh coffee. Coff-e-mail delivers a full-blown web server which can be accessed off the local intranet, which displays coffee statistics (pots of coffee brewed per day, last brew time, cups of coffee per brew, etc.) and pictures of people filling their coffee mugs. Client software will be available to poll Coff-e-mail and notify the user that a fresh pot of coffee is brewing or that coffee is running out and a fresh pot should be brewed.
《沈阳化工大学学报》2020年总目次

沈阳化工大学学报JOURNAL OF SHENYANG UNIVERSITY OF CHEMICAL TECHNOLOGY第34卷第4期2020.12Vol. 34 No. 4Dec. 20202020年总目次-化学与化学工程-CUO-WO 3纳米立方块的合成及气体传感特性研究司建朋,王明月,孟高耐碱表面活性剂的开发及在工业清洗中的应用张冬喜,李新钰,石磊,王Co/g - C 3N 4- CHIT/GCE 修饰电极的制备及其对H 2PO 4-的测定陈异构十三醇聚氧乙烯醚磷酸酯的合成及性能研究十六烷值改进剂的制备与性能研究离子液体分离乙酸甲酯-甲醇共沸物系的模拟研究离子液体-环己烷(乙醇)二元体系气液相平衡研究萃取精馏分离苯-甲醇共沸体系的模拟碳纳米管对 C u O - ZnO - Ga 2 O 3/HZSM - 5催化剂性能的影响低品位菱镁矿浮选剂实验研究均三乙苯的合成研究甲基丙烯酸混合醇酯-苯乙烯-醋酸乙烯酯三元聚合物的合成与降凝性能研究车用水蜡的研究新型银制品洗涤剂的研制间氨基乙酰苯胺的合成及分离研究岩,思,李文秀,王英文,丹,刘冬雨,赵 嘉,李玉娇,江寒峰1 (1)张志刚,郭禹含,李晓茜,许光文2 (97)刘坤,于丹舟,杨旺,姚慧2 (107)-魏田,张芮,王瑞灵,陈永杰 2 (115)宋明龙,龙小柱 2 (120)李继鹏,张羽,张志刚,张弢3 (193)-李宏辉,李文秀,张志刚,张弢3(198)-尹海鹰,李文秀,张志刚,张弢3 (205)王 开,于欣瑞,刘 楠,张雅静3 (210)康坤红,龙小柱3 (216)-马婉莹,张风雨,丁茯,王东平 4 (289)-徐妍,龙小柱,靳璐璐,于海洋4 (295)-高鹏飞,龙小柱,靳璐璐,高碌4 (301)-卢羲亚,于媛,韩英男,龙小柱 4 (306)-王瑞灵,陈永杰,曹爽,张芮4 (310)高效液相色谱法同时测定邻位香兰素、香兰素、甲基香兰素和乙基香兰素贾璇,王国胜4 (314)Pd/N 3 - SiO 2催化剂制备及其催化乙烘气相加氢性能研究王梦娇,王康军,李东楠4(319)2沈阳化工大学学报2020年-生物与环境工程-积雪草酸A环衍生物的合成及其抗肿瘤活性研究.........................李孝孝,佟贺,熊果酸衍生物的合成及体外抗肿瘤活性研究.......................................徐川东,N-金刚烷基-N,-芳杂基二酰肼类化合物的合成..............刘丹,关月月,张淑曼,齐墩果酸A环衍生物的合成与体外抗肿瘤活性研究...............................王强,模板剂对MnO”催化剂微观形貌的调控及其催化氧化甲苯性能.......................................项文杰,刘威,赵恒,齐墩果酸衍生物的合成及其与MEK靶点分子对接研究.............................张蓬勃,齐墩果酸硫脲类衍生物的合成及以VEGFR-2为靶点的分子对接研究........................................................李杰,2-(漠甲基)-3-取代丙烯酸酯的合成及生物活性研究.............................廖桥,WBS-RBS和AHP的方法在化工园区安全容量评价的应用.........................孟宇强,-材料科学与工程-以三(二乙胺基)环硼氮烷为前驱体制备六方氮化硼李宗鹏,王长松,石墨烯/二氧化锰复合材料的制备及其电化学性能的研究李静梅,不同分散剂对天然橡胶性能的影响孟唯,刘浩,武文斌,张舒雅,肉豆蔻酸/棕榈醇共晶物作为相变材料的热性能研究李蛟龙,任子真,Ni2P/Cu3P复合纳米材料的制备、表征及电催化性能研究鲍彤,祁佳音,赵国庆,g-C3N4/CeVO4/Ag纳米复合材料的制备及光催化性能的研究钱坤,邱永堃,高雨,丁茯,孙亚光,两相闭式热虹吸管的强化传热新能源集成厨用加热系统结构形式对挡板岀口截面流体力学性能的影响多孔板旋流静态混合器强化传热性能分析基于声发射技术的减速顶故障诊断三聚磷酸钠对镁合金阳极氧化膜性能的影响•机械工程•蔡长庸,'战洪仁,史胜,张倩倩,惠尧,惠尧,陈彤,翟雪发,战洪仁,张海春,周圆圆,龚斌,吴剑华,龚斌,刘海良,王巍,周圆圆,金志浩,迟展,孟艳秋1(9)孟艳秋1(18)王然1(22)孟艳秋2(125)张学军3(222)宋艳玲3(230)宋艳玲4(324)杨桂秋4(330)宫博4(334)梁兵1(25)张辉1(31)王重2(130)李贵强3(236)郭卓4(338)徐振和4(345)王立鹏1(41)曾祥福1(47)张静2(135)张静2(142)于宝刚2(147)付广艳,姜天琪,钱神华2(153)第4期《沈阳化工大学学报》2020年总目次3稳流器结构对消防直流水枪水力学性能的影响风载荷作用下倾斜塔板压降的数值模拟...... Mg-xZn合金的制备及腐蚀性能研究..........带有内螺纹的重力热管仿真模拟研究........带有开槽中性捏合块和反向螺纹双螺杆挤岀机的三维流场分析.........................张静,陈生国,张平,张丽,张平,王豪,付广艳,钱神华,许文兰,战洪仁,张倩倩,史胜,王立鹏,郭树国,于淼,王丽艳,汤霖森,陈科昊,网格类型对管内旋流特性数值计算的影响•信息与计算机工程-BP神经网络算法在“摇头”避障小车中的应用.....................................任帅男,基于GPRS DTU远程通讯技术在油气集输管线上的应用..................赵思渊,何戡,基于通信节点的WSN自主聚类非均匀分簇路由协议......................刘一珏,王军,基于冗余节点间歇性的WSN路由协议的设计..................马德朋,王军,田鹍,基于Python爬虫的电影数据可视化分析.................................高巍,孙盼盼,基于STM32的CAN总线数据采集卡设计..........................................李蛟龙,基于物联网的雾化降尘效果优化研究...................................安然然,路晨贺,基于SPA-SVDD方法对间歇过程的故障检测...........................谢彦红,薛志强,基于Labview的三容水箱液位控制系统设计.............................李凌,曹纪中,基于数据分片的WSN安全数据融合方案优化..................王军,陈羽,田鹍,基于加权优化树的WSN分簇路由算法............................................刘一珏,筛分车间矿料仓除尘优化策略.................................安然然,路晨贺,高文文,多路光功率监测系统的设计......................................................高淑芝,餐饮业液化气罐物联网智能管理系统...................................汪滢,于洋,布袋除尘器耗损件生命周期监控策略...........................路晨贺,安然然,孙晓鑫,仿海底洋流实验中水流动状况智能监控系统..........王金亮,安然然,路晨贺,孙晓鑫,基于潜隐变量自相关性子空间划分的故障检测策略......................张成,郭青秀,无混载校车路线分析模型优化实现方法.................................高巍,陈泽颖,-数理科学•非定常对流占优扩散方程的龙格库塔伽辽金有限元方法.............................冯立伟,龚斌3(239)秦然3(245)姜天琪3(250)惠尧4(352)韩彦林4(358)王宗勇4(363)王庆辉1(51)宗学军1(56)田鹍1(60)徐万一1(67)李大舟1(73)任子真1(79)张蔓蔓1(85)李元2(158)王璐2(165)赵子君2(171)王军2(178)张蔓蔓2(187)徐林涛3(255)张延华3(261)张语仙3(268)张语仙3(275)李元4(369)李大舟4(377)席伟1(91)外磁场下的双层类石墨烯系统的元激发能谱赵宇星,成泰民3(282)4沈阳化工大学学报2020年Comprehensive Table of Contents2020・Chemistry and Chemical Engineering・Synthesis and Gas Sensing Properties of CuO-WO3Nanocubes SI Jian-peng,et al1(i) Development of High Alkali-Resistant Surfactant and ItsApplication in Industrial Cleaning ZHANG Dong-xi,et al2(97) Preparation of Co/g-C;N4-CHIT/GCE Modified Electrode andDetermination of Dihydrogen Phosphate CHEN Si,et al2(i07) Study on the Synthesis and Properties of the Phosphate Ester ofIso-Tridecanol Polyoxyethylene WEI Tian,et al2(115) Preparation and Properties of Cetane Number Improver SONG Ming-long,et al2(120) Simulation Study on Separation of Methyl Acetate-MethanolAzeotrope System by Ionic Liquid LI Wen-xiu,et al3(193) Vapor-Liquid Equilibrium of Ionic Liquids with Cyclohexane orEthanol Binary System LI Hong-hui,et al3(198) Simulation of Azeotrope Separation of Benzene-Methanol byExtractive Distillation YIN Hai-ying,et al3(205) Effect of Carbon Nanotubes on the Performance ofCuO-ZnO-Ga2O3/HZSM-5Catalysts WANG Ying-wen,et al3(210) Experimental Study on Flotation Agentfor the Low Grade Magnesite KANG Kun-hong,et al3(216) The Synthesis of1,3,5-Triethylbenzene MA Wan-ying,et al4(289) Study on Synthesis and Pour Point Depressing Performance of Methyl AcrylicAcid Mixed Alcohol Ester-Styrene-Vinyl Acetate Terpolymer XU Yan,et al4(295) Study on Vehicle Water Wax GAO Peng-fei,et al4(301) Development of New Detergent for Silver Products LU Xi-ya,et al4(306) Synthesis and Separation of m-Acetamidoaniline WANG Rui-ling,et al4(310) Simultaneous Determination of o-Vanillin,Methyl Vanillin,Ethyl Vanillin andVanillin by High Performance Liquid Chromatography JIA Xuan,et al4(314) Synthesis of Pd/N s-SiO?Catalyst and its Catalytic Performance forAcetylene Hydrogenation to Ethylene WANG Meng-jiao,et al4(319)・Biological and Environmental Engineering・Synthesis and Antitumor Activity of A-Ring Derivatives of Asiatic Acid LI Xiao-xiao,et al1(9) Synthesis and Antitumor Activity in Vitro of Ursolic Acid Derivatives XU Chuan-dong,et al1(18) Synthesis of N-adamantyl-N'-arylheterodihydrazides LIU Dan,et al1(22) Synthesis and Anti-Tumor Activity of Oleanolic AcidA Ring Derivatives in Vitro WANG Qiang,et al2(125) Tunable Synthesis of Morphologies of MnO^Catalyst by Template andIts Catalytic Oxidation Performance for Toluene XIANG Wen-jie,et al3(222)第4期《沈阳化工大学学报》2020年总目次5Synthesis of Oleanolic Acid Derivatives and MolecularDocking Studies with MEK.............................................................................................ZHANG Peng-bo,et al3(230) Synthesis of Oleanolic Acid Thiourea Derivatives and MolecularDocking Study with VEGFR-2Kinase.............................................................................................LI Jie,et al4(324) Synthesis and Biological Activities of2-(bromomethyl)-3-substituted Acrylate.......................................................................................................................LIAO Qiao,et al4(330) Application of WBS-RBS and AHP in Safety Capacity Analysis ofChemical Industrial Park.................................................................................................MENG Y u-qiang,et al4(334)・Material Science and Engineering・Synthesis of the Hexagonal Boron Nitride Using Tris(diethylamino)borazine as Precursor...................................................................................................................LI Zong-peng,et al1(25) Preparation and Electrochemical Properties of Graphene/ManganeseDioxide Composites.......................................................................................................................LI Jing-mei,et al1(31) Effect of Different Dispersants on the Properties of Natural Rubber..............................................MENG Wei,et al2(130) Thermal Properties of Myristic Acid/1-hexadecanol EutecticMixture as Phase Change Material.........................................................................................LI Jiao-long,et al3(236) Hydrothermal Synthesis,Characterization and Electrocatalytic HydrogenEvolution of Nif/Cuf Nanomaterials.........................................................................................BAO Tong,et al4(338) Preparation of Photocatalytic Properties g-C3N4/CeVO q/Ag Nanocomposites........................QIAN Kun,et al4(345)・Mechanical Engineering・The Enhancement of Heat Transfer in Two-Phase Closed Thermosyphon....................ZHAN Hong-ren,et al1(41) New Energy Integrated Kitchen Heating System...................................................................CAI Chang-yong,et al1(47) Effect of the Baffle Structure on Hydrodynamic Performanceat the Outlet Section ZHANG Hai-chun,et al2(135) Analysis on Enhanced Heat Transfer Performance of Cyclone StaticMixer with the Porous PlateFault Diagnosis of Retarder in Railway Stations Based on Acoustic Emission TechnologyInfluence of Sodium Tripolyphosphate on the Properties of Anodizing Films of Magnesium AlloyEffect of the Stabilizer Structure on the Hydraulic Characteristics in the Fire Water GunGONG Bin,et al2(142) JIN Zhi-hao,et al2(147) FU Guang-yan,et al2(153) ZHANG Jing,et al3(239)Numerical Simulation of Pressure Drop of ObliqueTray under Wind Load ZHANG Ping,et al3(245)Preparation and Corrosion Properties of Mg-xZn Alloys.......... Numerical Simulation of Gravity Heat Pipe with Internal Threads Three Dimensional Flow Field Analysis of Twin Screw Extruder with Slotted Neutral Kneading Block and Reverse Thread.................■-FU Guang-yan,et al3(250) ZHAN Hong-ren,et al4(352)GUO Shu-guo,et al4(358)6沈阳化工大学学报2020年Influence of Grid Type on Numerical Calculation of SwirlCharacteristics in Tubes......................................................................................................CHEN Ke-hao,et al4(363)・I information and Computer Engineering・Application of BP Neural Network Algorithm in“Shaking Head”Vehicle forObstacle Avoidance..................................................................................................................REN Shuai-nan,et al1(51) The Application of GPRS DTU Remote Communication Technology inOil and Gas Gathering Pipeline.............................................................................................ZHAO Si-yuan,et al1(56) WSN Autonomous Cluster Heterogeneous Clustering Routing ProtocolBased on Communication Nodes.................................................................................................LIU Yi-jue,et al1(60) Design of WSN Routing Protocol Based on Redundancy Node Intermittent.............................MA De-peng,et al1(67) Visual Analysis of Film Data Based on Python Crawler...................................................................GAO Wei,et al1(73) Design of CAN Bus Data Acquisition Card Based on STM32..................................................LI Jiao-long,et al1(79) Study on Optimization of Atomization and Dust Reduction EffectBased on Internet of Things..........................................................................................................AN Ran-ran,et al1(85) Fault Detection Based on SPA-SVDD in Batch Process......................................................XIE Yan-hong,et al2(158) Design of Three Tank Level Control System Based on Labview...........................................................LI Ling,et al2(165) Optimization of WSN Secure Data Aggregation SchemeBased on Data Slice...................................................................................................................WANG Jun,et al2(171) A WSN Cluster Routing Algorithm Based on theOptimized-Weighting Tree......................................................................................................LIU Yi-jue,et al2(178) Optimization Strategy for Dust Removal of Mine MaterialWarehouse in Sieve Workshop.................................................................................................AN Ran-ran,et al2(187) Design of Multi-Channel Optical Power Monitoring System..................................................GAO Shu-zhi,et al3(255) The Internet of Things Intelligent Management System ofCatering Industry Liquefied Gas Tank.....................................................................................WANG Ying,et al3(261) Life Cycle Monitoring Strategy for Bag Filter Wearer...............................................................LU Chen-he,et al3(268) Intelligent Monitoring Scheme for Water Flow inImitation Ocean Current Experiment................................................................................WANG Jin-liang,et al3(275) Fault Detection Strategy Based on Dividing Autocorrelation ofLatent Variables.......................................................................................................................ZHANG Cheng,et al4(369) Optimization Implementation Method of No-Mixed SchoolBus Route Analysis Model..............................................................................................................GAO Wei,et al4(377)・Science of Mathematics and Physics・Rung-Kutta Galerkin FEM Method for Unsteady ConvectionDominated Diffusion Equation.................................................................................................FENG Li-wei,et al1(91) Elementary Excitation Energy Spectra of Double-Layer Graphene-LikeSystem Under External Magnetic Field ZHAO Yu-xing,et al3(282)。
滇红玫瑰精油超临界CO2萃取工艺、挥发性成分及抗氧化活性研究

基金项目:云南中烟工业有限责任公司科技项目(编号:JB2022XY03);中国烟草总公司重大科技项目(编号:110202101068〔XX 13〕)作者简介:刘劲芸,女,云南中烟新材料科技有限公司助理研究员,硕士。
通信作者:吴恒(1987—),男,云南中烟新材料科技有限公司助理研究员,硕士。
E mail:yunnan200 2@163.com收稿日期:2022 09 09 改回日期:2022 11 30犇犗犐:10.13652/犼.狊狆犼狓.1003.5788.2022.80792[文章编号]1003 5788(2023)03 0175 08滇红玫瑰精油超临界CO2萃取工艺、挥发性成分及抗氧化活性研究StudyonsupercriticalCO2extractionprocess,volatilecomponentsandantioxidantactivityofroseoilfromDianhongrose刘劲芸犔犐犝犑犻狀 狔狌狀 常 健犆犎犃犖犌犑犻犪狀 蒋卓芳犑犐犃犖犌犣犺狌狅 犳犪狀犵徐重军犡犝犆犺狅狀犵 犼狌狀 陈 婉犆犎犈犖犌犠犪狀 吴 恒犠犝犎犲狀犵(云南中烟新材料科技有限公司,云南昆明 650106)(犢狌狀狀犪狀犜狅犫犪犮犮狅犐狀犱狌狊狋狉犻犪犾犎犻 犜犲犮犺犕犪狋犲狉犻犪犾犆狅.,犔狋犱.,犓狌狀犿犻狀犵,犢狌狀狀犪狀650106,犆犺犻狀犪)摘要:目的:综合利用云产滇红玫瑰花资源,提高产品附加值。
方法:以玫瑰花精油得率为判别指标,通过单因素试验和响应面试验优化超临界CO2萃取玫瑰花精油的提取工艺;通过气相色谱—质谱技术分析不同精油的成分及相对含量,并评价不同玫瑰精油的抗氧化活性。
结果:超临界CO2萃取玫瑰花精油的最佳工艺参数为:玫瑰花粉末颗粒40目,萃取压力25.5MPa、萃取温度45.5℃、萃取时间123min,CO2流量20L/h,该工艺条件下玫瑰花精油得率为1.185%;不同产地滇红玫瑰精油中共鉴定出74种挥发性成分,安宁产的滇红玫瑰花精油挥发性物质总量最高;不同产地滇红玫瑰花精油均具有较好的自由基清除能力,但不同产地的抗氧化能力存在明显差异。