交叉列联分析
交叉分析法怎么分析

交叉分析法怎么分析交叉分析法是一种常用的数据分析方法,通过对不同因素之间的关系进行交叉比较和分析,帮助研究者发现变量之间的联系和差异。
本文将介绍交叉分析法的基本概念和步骤,并以具体案例进行说明。
一、交叉分析法概述交叉分析法(Cross-Tabulation Analysis)也被称为列联表分析(Contingency Table Analysis),是一种定量分析方法,用来研究两个或更多变量之间的关系。
通过构建列联表,对不同变量之间的交叉频数进行统计和比较,可以揭示变量之间的关联性和差异性。
二、交叉分析法步骤1. 确定研究问题:明确研究问题并选择需要分析的变量。
例如,假设我们想研究消费者对不同手机品牌的偏好与性别之间的关系。
2. 构建列联表:根据所研究的变量,构建列联表(也称为交叉表)。
横列为一个变量的不同水平(例如手机品牌),纵列为另一个变量的不同水平(例如性别)。
在交叉点上填写交叉频数。
3. 计算频数和比例:根据列联表,计算每个交叉点上的频数和比例。
频数表示各组别的数量,比例表示各组别所占比例。
4. 绘制图表:通过绘制图表,直观地展示不同变量之间的关系。
常用的图表包括堆叠柱状图、簇状柱状图、饼图等。
5. 进行统计检验:为了验证变量之间的关系是否显著,可以进行统计检验,如卡方检验。
卡方检验可以检验各组别之间的差异是否由随机因素引起。
6. 分析结果和讨论:根据交叉分析的结果,进行结果分析和讨论。
解释变量之间的关系和差异,并提出合理的解释和解决方案。
三、交叉分析方法案例以消费者对不同手机品牌的偏好与性别之间的关系为例,进行交叉分析。
我们调查了300名消费者,结果如下表所示:--------------------------------------------------| Apple | Samsung | Huawei | Others--------------------------------------------------男性 | 50 | 30 | 20 | 10--------------------------------------------------女性 | 20 | 40 | 50 | 20--------------------------------------------------根据上表,我们可以计算出各组别的频数和比例,如下所示:--------------------------------------------------| Apple | Samsung | Huawei | Others--------------------------------------------------男性 | 50 | 30 | 20 | 10--------------------------------------------------女性 | 20 | 40 | 50 | 20--------------------------------------------------| 70(23%) | 70(23%) | 70(23%) | 30(10%)--------------------------------------------------通过绘制堆叠柱状图,我们可以直观地看到不同手机品牌在不同性别中的偏好程度。
第十四章--交叉表分析法(课件)

多变量描述统计分析交叉表分析法一、交叉表分析法的概念交叉表(交叉列联表) 分析法是一种以表格的形式同时描述两个或多个变量的联合分布及其结果的统计分析方法,此表格反映了这些只有有限分类或取值的离散变量的联合分布。
当交叉表只涉及两个定类变量时,交叉表又叫做相依表。
交叉列联表分析易于理解,便于解释,操作简单却可以解释比较复杂的现象,因而在市场调查中应用非常广泛。
频数分布一次描述一个变量,交叉表可同时描述两个或更多变量。
交叉表法的起点是单变量数据,然后依研究目的将这些数据分成两个或多个细目。
下面是一个描述交叉表法应用的例子。
某保险公司对影响保户开车事故率的因素进行调研,并对各种因素进行了交叉表分析。
表1 驾驶员的事故率从初始表1中可以看出,有61%的保险户在开车过程中从未出现过事故。
然后,在性别基础上分解这个信息,判断是否在男女驾车者之间有差别。
这样就出现了二维交叉表2。
表2 男女驾驶员的事故率这个表的结果令男士懊恼,因为他们的事故率较女士驾车时涉及的事故率要高。
但人们会提出这样的疑问而否定上述判断的正确性,即男士的事故多,是因为他们驾驶的路程较长。
这样就引出第三个因素"驾驶距离",于是出现了三维交叉表3。
表3 不同驾驶距离下的事故率结果表明,男士驾驶者的高事故率是由于他们的驾驶距离较女士长,但并没有证明男士和女士哪个驾驶得更好或更谨慎,仅证明了驾车事故率只与驾驶距离成正比,而与驾驶者的性别无关。
二、两变量交叉列联表分析例如,研究城镇居民在某地的居住时间与其对当地百货商场的熟悉程度之间的关系,对“居住时间”和“熟悉程度”这两个变量进行交叉列联分析。
如表4所示。
间低于30年的居民比居住时间在30年以上的居民似乎更熟悉百货商场。
进一步计算出百分比,则可以看得更直观一些。
见表5。
表5 居住时间与对百货商场的熟悉程度的交叉列联分析(%)行百分比与列百分比的选择取决于哪个变量是因变量哪个变量是自变量。
列联分析2篇

列联分析2篇第一篇:列联分析的基本概念与应用一、列联分析的基本概念1.列联表列联表是将两个或两个以上变量交叉分组的数据表。
其中每个变量的取值范围都被列为一列,而每个数据组合都在表格中占用一行。
列联表的用途在于,它提供了一种可视化和简化结果的方法,使研究者可以更轻松地发现和解释变量之间的关系。
2.卡方检验卡方检验是用来比较两个或多个不同类别之间差异的统计方法。
通过比较每个类别观察值和期望值之间的差异,卡方检验可以确定各类别是否存在显著性差异。
其中观察值是指实际的数据,而期望值是指在无差异假设下,每个类别的期望理论值。
3.独立性检验独立性检验是指检验两个变量之间是否存在关系的过程。
如果两个变量之间没有关系,则称它们是独立的。
而如果存在关系,则称它们是相关的。
在列联表中,独立性检验主要通过卡方检验实现。
二、列联分析的应用1.探究变量之间的相关性列联分析可以用来探究两个或多个变量之间的相关性。
通过观察列联表中的数据分布情况,可以发现变量之间的联系以及它们之间的差异。
例如,对于一份由性别和职业两个变量构成的列联表,可以通过分析数据发现不同性别的人在不同职业领域中的比例差异,从而判断性别和职业之间是否存在相关性。
2.研究变量之间的因果关系除了探究变量之间的相关性外,列联分析还可以用来研究变量之间的因果关系。
例如,对于一份由吸烟和患肺癌两个变量构成的列联表,可以通过分析数据得出吸烟与患肺癌之间的关系。
如果两个变量之间存在因果关系,那么研究者可以采取相应的措施降低因果关系的风险。
3.预测未来趋势列联分析可以用来预测未来的趋势。
通过分析历史数据,研究者可以发现不同变量之间的变化趋势,从而预测未来的发展方向。
例如,对于一份由年龄和购买力两个变量构成的列联表,可以通过分析历史数据预测不同年龄段的人的购买力变化趋势。
4.优化营销策略列联分析可以用来优化营销策略。
通过分析客户的属性和购买行为,可以发现客户的偏好和需求,从而制定相应的营销方案和产品推广策略。
定量分析 实验四 交叉列表Crosstabs

实验四交叉列表与等级相关分析(Crosstabs)主要知识点与功能交叉列表分析是对两个变量之间关系的分析方法。
被分析的变量可以是定类变量也可以是定序变量。
系统对两个变量进行交叉列表分析后生产交叉表和输出χ2检验结果。
调用此过程可进行计数资料和某些等级资料的列联表分析,在分析中,可对二维至n 维列联表(RC表)资料进行统计描述和χ2检验,并计算相应的百分数指标。
此外,还可计算四格表确切概率(Fisher’s Exact Test)且有单双侧( One-Tail、 Two-Tail),对数似然比检验(Likelihood Ratio)以及线性关系的Mantel-Haenszelχ2检验。
一、交叉列表分析(Crosstabs)(一)、执行命令:Analyze——Descriptive Statistics——Crosstabs,打开如下对话框(二)、确定交叉列表分析的变量从左侧窗口选择两个名义变量或顺序变量分别进入Row(s)(行)框和Column(s)(列)框。
Display clustered bar charts是在输出结果中显示聚类条形图。
Suppress tables是隐藏表格,如果选择此项,将不输出R*C交叉表。
(三)、选择统计分析内容单击Statistics按钮,打开如下对话框:(1)Chi-square是卡方(χ 2 )值选项,用以检验行变量和列变量之间是否独立。
适用于两个定类变量或一个定类变量一个定序变量之间的相关性分析。
(2)Correlations是相关系数的选项,用以测量变量之间的线性相关。
适用于两个定序变量或定距变量之间关系的分析。
(3)Nominal是定类变量选项栏,当分析的两个变量都是定类变量时可以选择的参数。
1、Contingency coefficient:列联相关的c系数,其值 =χχ22+N,界于0~1之间,其中N为总例数;2、Phi and Cramer's V:列联相关的V系数,V系数 = χ2N ,用于描述相关程度,在四格表χ 2 检验中界于-1~1之间,在RC表χ 2 检验中界于0~1之间;Cramer's V =χ2N(k-1),界于0~1之间,其中k为行数和列数较小的实际数;3、Lambda:λ值,在自变量预测中用于反映比例缩减误差,其值为1时表明自变量预测应变量好,为0时表明自变量预测应变量差;4、Uncertainty coefficient:不确定系数,以Z为标准的比例缩减误差,其值接近1时表明后一变量的信息很大程度来自前一变量,其值接近0时表明后一变量的信息与前一变量无关。
交叉表分析

data05-02为某公司工资数据(n=15)。
使用变量性别sex、收入高低earnings分析男女经理间薪金是否平等。
可以利用data05-01中的数据,使用变量occcat80为工作性质分类,region为地区,childs 为每个家庭的孩子数。
将childs为行变量,occcat80为列变量,region为控制变量选入Layer of框中,进行交叉表分析。
列联表(交叉表)分析1、项目名称Crosstabs过程4、实训原理Crosstabs过程用于定类数据和定序数据进行统计描述和简单的统计推断。
在分析时可以产生二维至n维列联表,并计算相应的百分数指标。
4-1 列联表分析的含义与任务在实际分析中,当问题涉及到多个变量时,我们不仅要了解单个变量的分布特征,还要分析多个变量不同取值下的分布,掌握多变量的联合分布特征,进而分析变量之间的相互影响和关系。
很明显,如果还采用单纯的频数分析方法显然不能满足要求。
因此,我们需要借助交叉分组下的频数分析,即列联表分析。
列联表分析的主要任务有两个:(1)根据样本数据产生二维或多维交叉列联表。
交叉列联表是两个或两个以上变量交叉分组后形成的频数分布表。
(2)在交叉列联表的基础上,分析两变量之间是否具有独立性或一定的相关性。
4-2 卡方检验的原理为了理解列联表中行变量(Row)和列变量(Column)之间的关系,我们需要借助非参数检验方法。
通常采用的方法是卡方检验。
和一般假设检验一样,卡方检验主要包括三个步骤:(1)建立零假设:行变量和列变量相互独立。
(2)选择和计算检验统计量。
列联表分析中的检验统计量是Pearson卡方统计量。
其公式为:()∑∑==-=r i cj eij e ij o ijf f f1122χ(4-9-1)其中,r 为列联表的行数,c 为列联表的列数,0f 为实际观测频数,e f 期望观测频数。
期望频数的计算公式为:nCTRT f e ⨯=(4-9-2) 其中,RT 是指定单元格所在行的观测频数合计,CT 是指定单元格所在列的观测频数合计,n 是观测频数的合计。
交叉列联分析

3.5 交叉列联表分析在实际分析中,除了需要对单个变量的数据分布情况进行分析外,还需要掌握多个变量在不同取值情况下的数据分布情况,从而进一步深入分析变量之间的相互影响和关系,这种分析就称为交叉列联表分析。
当所观察的现象同时与两个因素有关时,如某种服装的销量受价格和居民收入的影响,某种产品的生产成本受原材料价格和产量的影响等,通过交叉列联表分析,可以较好地反映出这两个因素之间有无关联性及两个因素与所观察现象之间的相关关系。
因此,数据交叉列联表分析主要包括两个基本任务:一是根据收集的样本数据,产生二维或多维交叉列联表;二是在交叉列联表的基础上,对两个变量间是否存在相关性进行检验。
要获得变量之间的相关性,仅仅靠描述性统计的数据是不够的,还需要借助一些表示变量间相关程度的统计量和一些非参数检验的方法。
常用的衡量变量间相关程度的统计量是简单相关系数,但在交叉列联表分析中,由于行列变量往往不是连续变量,不符合计算简单相关系数的前提条件。
因此,需要根据变量的性质选择其他的相关系数,如Kendall等级相关系数、Eta值等。
SPSS提供了多种适用于不同类型数据的相关系数表达,这些相关性检验的零假设都是:行和列变量之间相互独立,不存在显著的相关关系。
根据SPSS检验后得出的相伴概率(Concomitant Significance)判断是否存在相关关系。
如果相伴概率小于显著性水平0.05,那么拒绝零假设,行列变量之间彼此相关;如果相伴概率大于显著性水平0.05,那么接受原假设,行列变量之间彼此独立。
在交叉列联表分析中,SPSS所提供的相关关系的检验方法主要有以下3种:(1)卡方(χ2)统计检验:常用于检验行列变量之间是否相关。
计算公式为:(3.11)其中,f0表示实际观察频数,f e表示期望频数。
卡方统计量服从(行数-1)´(列数-1)个自由度的卡方统计。
SPSS在计算卡方统计量时,同时给出相应的相伴概率,由此判断行列变量之间是否相关。
列联分析

列联分析列联分析是一种常用的统计方法,用于探究两个或多个分类变量之间的关系。
它可以帮助我们揭示变量之间的相关性,追溯原因,并为决策制定提供依据。
本文将介绍列联分析的基本概念、流程和应用,并结合实际案例进行分析。
首先,我们来了解一下列联分析的基本概念。
列联分析又称为交叉表分析,适用于两个或多个分类变量且变量之间具有关联的情况。
在列联表中,将两个或多个分类变量进行交叉,统计各个交叉点的频数,并分析各个交叉点的差异是否显著。
通过列联分析,我们可以判断变量之间是否存在相关性,以及相关程度的大小。
进行列联分析的流程如下。
首先,确定需要分析的变量。
这些变量可以是定性或定量的,但需要是分类变量。
其次,准备数据并制作列联表。
将数据按照变量交叉进行统计,并记录交叉点的频数。
接下来,计算列联表的各种统计量,如卡方值、自由度等。
通过计算这些统计量,我们可以得出变量之间的关系是否显著。
最后,进行结果解释和后续分析。
根据分析结果,我们可以得出结论,并对进一步的决策制定提供支持。
列联分析可以应用于各个领域。
举个例子,我们可以使用列联分析来研究不同性别学生在不同科目考试成绩上的差异。
首先,我们可以将性别和科目作为两个分类变量进行交叉制表。
然后,我们可以计算各个交叉点的频数,并进行统计分析。
通过分析结果,我们可以得出不同性别学生在不同科目上的差异是否显著,并进一步研究造成这些差异的原因。
另一个例子是运用列联分析研究消费者购买决策与广告类型之间的关系。
我们可以将消费者购买决策和广告类型作为两个分类变量进行交叉制表。
然后,我们可以计算各个交叉点的频数,并进行统计分析。
通过分析结果,我们可以得出不同广告类型对消费者购买决策的影响程度,并为广告策划提供参考。
总结来说,列联分析是一种常用的统计方法,用于探究分类变量之间的关系。
它可以帮助我们理解变量之间的相关性,并为决策制定提供依据。
在实际应用中,列联分析可以用于研究不同性别学生的学科差异、消费者购买决策与广告类型之间的关系等。
列联表分析

列联表分析列联表分析是统计学中一种常用的方法,用于研究两个或更多个变量之间的关系。
它通过对数据进行分类和统计,能够揭示变量之间的相关性和相互影响。
列联表分析是一种二维表格形式的统计分析方法,也被称为交叉表或表格分析。
在一张列联表中,变量被分成若干行和列,交叉点处给出的是两个变量的交集部分的频数或频率。
通过对这些频数或频率进行分析,我们可以观察和推断两个变量之间的关系。
列联表可以应用于各种领域,例如市场调研、社会学、医学研究等。
在市场调研中,列联表可以用来分析不同产品类型的销售数据和顾客的购买偏好。
在社会学领域,列联表可以用来研究不同人群的特征和行为差异。
在医学研究中,列联表可以用来分析不同治疗方法的有效性和副作用。
列联表分析的基本原理是比较预期频数和观察频数之间的差异。
预期频数是基于各个变量的边际总数和整体频数的比例来计算的。
观察频数是实际观察到的频数。
通过比较预期频数和观察频数的差异,我们可以判断两个变量之间是否存在相关性。
进行列联表分析时,常用的统计指标包括卡方检验和列联比率。
卡方检验用于检验观察频数和预期频数之间的差异是否显著。
如果差异显著,即意味着两个变量之间存在相关性。
而列联比率则用于衡量两个变量之间的相关性强度,它是各个交叉点处的观察频数与预期频数的比值。
除了卡方检验和列联比率,还可以使用列联表的可视化方法来展示两个变量之间的关系。
常见的可视化方法有堆叠柱状图和热力图。
堆叠柱状图可以将两个变量的分布情况进行可视化比较,而热力图则可以直观地展示不同交叉点处的频数或频率大小。
在进行列联表分析时,需要注意的是样本的选取和数据的收集。
样本的选取应该具有一定的代表性,以确保统计结果的可靠性和推广性。
数据的收集应该严格按照统一的标准和方法进行,以减小误差和偏差的影响。
总之,列联表分析是一种重要的统计方法,可以用来揭示两个或更多个变量之间的关系。
通过对数据进行分类和统计,可以得出变量之间的相关性和相互影响。
叉生分析统计方法

叉生分析统计方法叉生分析统计方法是一种用来研究两个或多个变量之间关系的统计方法,也被称为交叉表分析或列联分析。
这种方法通过对变量之间的关系进行交叉分析,能够揭示出隐藏在数据背后的规律和趋势,提供了深入理解变量之间关系的洞见。
本文将详细介绍叉生分析统计方法的原理、应用场景和实施步骤。
叉生分析统计方法是基于列联表进行的,列联表是一种用来汇总两个或多个离散变量之间关系的统计表。
在列联表中,行表示一个自变量的水平,列表示另一个自变量的水平,交叉点处的数值表示两个变量同时出现的频次或百分比。
叉生分析则是对列联表进行进一步的分析。
1.市场调研:通过对顾客的性别和年龄进行叉生分析,可以了解特定产品或服务的受众特征,从而为市场定位和推广活动提供依据。
2.医学研究:在医学研究中,可以通过对病人的性别和病症进行叉生分析,来研究疾病的发病机制、风险因素和治疗效果。
3.教育评估:通过对教育项目的实施地区和参与学生的年级进行叉生分析,可以评估项目对学生学业成绩和学习动机的影响。
4.品牌研究:对消费者的品牌偏好和年收入水平进行叉生分析,可以了解品牌在不同收入阶层中的认知和接受度。
实施叉生分析统计方法的步骤下面将介绍进行叉生分析的具体步骤:1.收集数据:首先需要收集变量之间关系的数据,可以通过问卷调查、实地观察、实验设计等方式获取。
2.构建列联表:将收集到的数据整理成列联表的形式,行表示一个自变量,列表示另一个自变量,交叉点处的数值表示两个变量同步出现的频次或百分比。
3.描述性分析:对列联表中的数据进行描述性分析,可以计算出频次、百分比、平均值等统计指标,以了解两个变量间的总体关系。
4.统计推断:使用统计方法对列联表进行推断分析,用以确定代表显著性的P值,从而判断两个变量之间的关系是否具有统计学意义。
5.可视化呈现:使用图表或图形将叉生分析的结果可视化呈现,以便更直观地理解和传达研究结果。
总结叉生分析统计方法是一种揭示变量之间关系的重要工具。
5.交叉汇总分析

实用性表格2 实用性表格
a6房房房房 * b16 现现现现现现现现 Crosstabulation % within b16 现现现现现现现现 b16 现现现现现现现现
原 始 输 出 表 格
•
其中, 房屋结构”为行变量, 其中,“房屋结构”为行变量, “现 使用人从业状况”为列变量。在每一格中, 使用人从业状况”为列变量。在每一格中, 第一行数据为分组后的频次, 第一行数据为分组后的频次,第二行数据 称为行百分比,第三行数据称为列百分比 称为行百分比, (一般是比较列百分比,横向比较),第 一般是比较列百分比,横向比较),第 ), 四行称为总百分比。 四行称为总百分比。
•
•
百分比的计算方向—— 百分比的计算方向 计算百分比通常按照自变量的方 即列的方向, 向(即列的方向,应该使得每列的百 分比之和是100% 100%)。 分比之和是100%)。
因为研究的目的是要了解自变量对因变量的影响, 因为研究的目的是要了解自变量对因变量的影响, 应此应该计算在自变量的不同取值情况下因变量 的变化情况如何。 的变化情况如何。但当因变量在样本内的分布不能代
表其在总体内的分布时, 表其在总体内的分布时,百分比就要按照因变量的方向进 行计算。 行计算。
行百分比
列联表的格式
高高五高
因变量
自变量
列百分比 性性 * 文文文文 Crosstabulation
文文文文 高初初高高 初初 初中 大高五五
163 25.9% 53.1% 13.0% 144 23.2% 46.9% 11.5% 307 24.5% 100.0% 24.5%
16现使用人从业情况 a 6 房屋结构 * b 16现使用人从业情况 Crosstabulation 在岗 113 14.5% 17.7% 3.9% 191 21.8% 29.9% 6.6% 210 28.1% 32.9% 7.2% 96 26.7% 15.0% 3.3% 28 20.6% 4.4% 1.0% 638 22.0% 100.0% 22.0% b16现使用人从业情况 不在岗 离退休 309 245 39.5% 31.3% 38.8% 10.6% 233 26.5% 29.3% 8.0% 155 20.7% 19.5% 5.3% 59 16.4% 7.4% 2.0% 40 29.4% 5.0% 1.4% 796 27.4% 100.0% 27.4% 21.1% 8.4% 347 39.5% 29.9% 12.0% 333 44.6% 28.7% 11.5% 186 51.7% 16.0% 6.4% 51 37.5% 4.4% 1.8% 1162 40.0% 100.0% 40.0% 其它 115 14.7% 37.5% 4.0% 107 12.2% 34.9% 3.7% 49 6.6% 16.0% 1.7% 19 5.3% 6.2% .7% 17 12.5% 5.5% .6% 307 10.6% 100.0% 10.6% Total 782 100.0% 26.9% 26.9% 878 100.0% 30.2% 30.2% 747 100.0% 25.7% 25.7% 360 100.0% 12.4% 12.4% 136 100.0% 4.7% 4.7% 2903 100.0% 100.0% 100.0%
交叉列联表分析
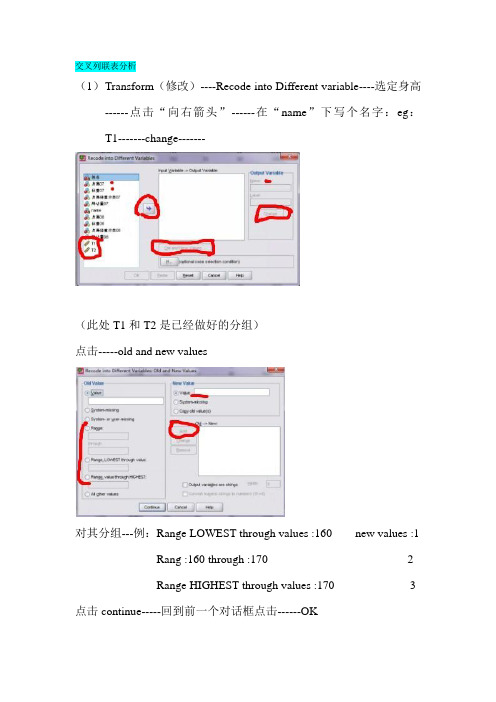
交叉列联表分析(1)T ransform(修改)----Recode into Different variable----选定身高------点击“向右箭头”------在“name”下写个名字:eg:T1-------change-------(此处T1和T2是已经做好的分组)点击-----old and new values对其分组---例:Range LOWEST through values :160 new values :1 Rang :160 through :170 2Range HIGHEST through values :170 3 点击continue-----回到前一个对话框点击------OK同样的方法做好T2---------点击“analyze(分析)”-----“Descriptive Statistics(描述性统计)”------“Crosstabs(交叉列联表)”选中行列------点击“Exat….“则弹出“exct tests(精确检测)对话框”点“Statistics…”则弹出“Crosstabs:statistics(交叉表统计)对话框”-------点击“Chi—square(卡方检验)”----“continue”点“Cells…”则弹出“Crosstabs:Cells display(交叉表统计)对话框”-------选择“Counts”中的“Observed”和“Expected”为期望频数,-------选择“Percentages”中的“Row”“Column”“Total”选项,分别计算“频数”“列频数”“总频数”-------选择“Residuals”中的“Standardized”分别计算单元格的非标准化残差、标准化残差、调整后的残差----“continue”回到前一页点----“OK”作业:1-10,11-25,26-30。
交叉列联表分析

交叉列联表分析 ---------用于分析属性数据1. 属性变量与属性数据分析从变量的测量水平来看分为两类:连续变量和属性(Categorical)变量,属性变量又可分为有序的(Ordinal)和无序的变量。
对属性数据进行分析,将达到以下几方面的目的:1) 产生汇总分类数据——列联表;2) 检验属性变量间的独立性(无关联性); 3) 计算属性变量间的关联性统计量;4) 对高维数据进行分层分析和建模。
在实际中,我们经常遇到判断两个或多个属性变量之间是否独立的问题,如:吸烟与患肺癌是否有关?色盲与性别是否有关?上网时间与学习成绩是否有关等等.解决这类问题常用到建立列联表,利用χ2统计量作显著性检验来完成.2.列联表(Contingency Table )列联表是由两个以上的属性变量进行交叉分类的频数分布表。
设二维随机变量(X ,Y ),X可能取得值为x x x r ,,,21 ,Y可能取得值为y y y s ,,,21 .现从总体中抽取容量为n 的样本,其中事件(X =x i Y =y j )发生的频率为n j i (i = 1,2, …,r ,j=1,2, …,s ,)记n i ∙=∑=s j j i n 1,n j ∙=∑=ri j i n 1,则有n =∑∑==r i s j j i n 11=∑=∙r i i n 1= ∑=∙sj j n 1,将这些数据排列成如下的表:这是一张r ×s 列联表.3.属性变量的关联性分析对于不同的属性变量,从列联表中可以得到它们联合分布的信息。
但有时还想知道形成列联表的行和列变量间是否有某种关联性,即一个变量取不同数值时,另一个变量的分布是否有显著的不同,这就是属性变量关联性分析的内容。
属性变量关联性检验的假设为 H0:变量之间无关联性;H1:变量之间有关联性由于变量之间无关联性说明变量互相独立,所以原假设和备择假设可以写为:H0:变量之间独立; H1:变量之间不独立χ2检验H 0:X 与Y 独立.记P (X =x i ,η=y j ) = p ji ,i =1,2,…,r ,,j = 1,2,…,s ,P (X =x i ) =pi ., i =1,2,…,r ,P (Y =y j ) =p j . ,j = 1,2,…,s .由离散性随机变量相互独立的定义,则原假设等价于 H 0:pji =p i .p j . ,i =1,2,…,r ,,j = 1,2,…,s .若pji已知,我们可以建立皮尔逊χ2统计量 χ2=∑==∑-ri sij ji j i j i p n p n n 112)(.由皮尔逊定理知,χ2的极限分布为)1(2-rs χ.但这里p j i 未知,因此用它的极大似然估计p ij ∧代替,这时检验统计量为χ2=∑==∧∧∑-ri sij ji ji j i pn p n n 112)(.在H 0成立的条件下,pji =p i .p j .,即等价于用p i ∙和p j ∙.的极大似然估计p i ∙∧和p j ∙∧的积去代替.可以求得p i ∙∧=nn i ∙, i =1,2,…,r , p j ∙∧=nn j∙ , j = 1,2,…,s ,则p ij ∧= n n i ∙nn j ∙ . i =1,2,…,r ,,j = 1,2,…,s ,从而得到统计量χ2=∑==∧∙∧∙∧∙∧∙∑-ri sij ji ji j i p p n p p n n 112)(=⎪⎪⎭⎫ ⎝⎛-∑∑==∙∙1112r i s ij j i j i n n n n . 在H 0成立的条件下,当n →∞时,χ2的极限分布为)12(2--+-)(s r rs χ= ))1)(1((2--s r χ. 对给定的显著性水平α,当 χ2>))1)(1((21---s r χα,则拒绝H 0,否则接受H 0.特别,当r = s = 2 时,得到2×2列联表,常被称为四格表,是应用最广的一种列联表.这时检验统计量为χ2=n n n n n n n n n2121211222112)(∙∙∙∙-它的极限分布为χ2(1).对于二维随机变量(X ,Y )是连续取值的情况,我们可采用如下方法将其离散化.① 将X 的取值范围(-∞,+∞)分成r 个互不相交的区间,将Y 的取值范围(-∞,+∞)分成s 个互不相交的区间,于是整个平面分成了rs 个互不相交的小矩形;② 求出样本落入小矩形中的频数n j i i =1,2,…,r ,,j = 1,2,…,s ; ③ 建立统计量χ2=⎪⎪⎭⎫⎝⎛-∑∑==∙∙1112r i s ij j i j i n n n n , 在H 0成立时且n 充分大时,χ2的极限分布为))1)(1((2--s r χ,拒绝域的确定同离散型的情况. 3.属性变量的关联度计算2χ检验的结果只能说明变量之间是否独立,如果不独立,并不能由2χ的值说明它们之间关系的强弱,这可以由ϕ系数来说明ϕ系数=⎪⎪⎩⎪⎪⎨⎧==++-∙∙∙∙其它,2,2212121122211n s r n n n n n n n n χ其中 当r=s=2即2×2列联表时-1<ϕ<1,其它0<ϕ<1,|ϕ|越接近1,它们之间关联性越强,反之越弱。
第十四章 交叉表分析法(课件)
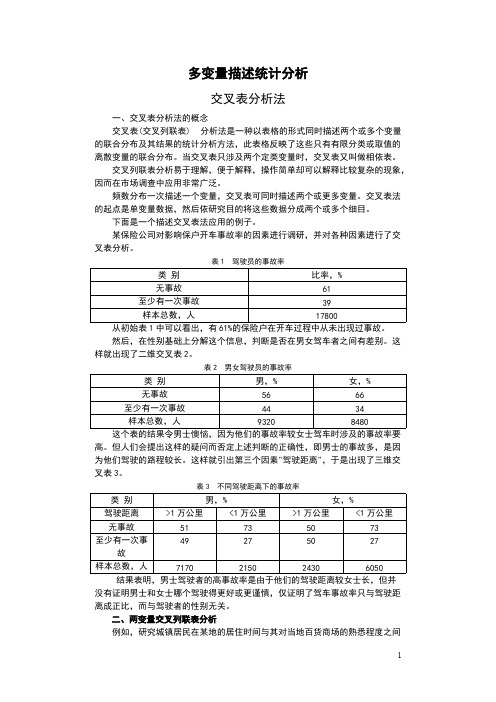
多变量描述统计分析交叉表分析法一、交叉表分析法的概念交叉表(交叉列联表) 分析法是一种以表格的形式同时描述两个或多个变量的联合分布及其结果的统计分析方法,此表格反映了这些只有有限分类或取值的离散变量的联合分布。
当交叉表只涉及两个定类变量时,交叉表又叫做相依表。
交叉列联表分析易于理解,便于解释,操作简单却可以解释比较复杂的现象,因而在市场调查中应用非常广泛。
频数分布一次描述一个变量,交叉表可同时描述两个或更多变量。
交叉表法的起点是单变量数据,然后依研究目的将这些数据分成两个或多个细目。
下面是一个描述交叉表法应用的例子。
某保险公司对影响保户开车事故率的因素进行调研,并对各种因素进行了交叉表分析。
表1 驾驶员的事故率类别比率,%无事故61至少有一次事故39样本总数,人17800从初始表1中可以看出,有61%的保险户在开车过程中从未出现过事故。
然后,在性别基础上分解这个信息,判断是否在男女驾车者之间有差别。
这样就出现了二维交叉表2。
表2 男女驾驶员的事故率类别男,%女,%无事故5666至少有一次事故4434样本总数,人93208480这个表的结果令男士懊恼,因为他们的事故率较女士驾车时涉及的事故率要高。
但人们会提出这样的疑问而否定上述判断的正确性,即男士的事故多,是因为他们驾驶的路程较长。
这样就引出第三个因素"驾驶距离",于是出现了三维交叉表3。
表3 不同驾驶距离下的事故率类别男,%女,%驾驶距离>1万公里<1万公里>1万公里<1万公里无事故51735073至少有一次事49275027故样本总数,人7170215024306050结果表明,男士驾驶者的高事故率是由于他们的驾驶距离较女士长,但并没有证明男士和女士哪个驾驶得更好或更谨慎,仅证明了驾车事故率只与驾驶距离成正比,而与驾驶者的性别无关。
二、两变量交叉列联表分析例如,研究城镇居民在某地的居住时间与其对当地百货商场的熟悉程度之间的关系,对“居住时间”和“熟悉程度”这两个变量进行交叉列联分析。
交叉列联表分析步骤

交叉列联表分析步骤1【分析】—【描述统计】—【交叉表】【精确】一般情况下,"精确检验"(Exact Tests)对话框的选项都默认为系统默认值,不作调整。
【统计量】【单元格】【格式】2 结果分析:职称* 学历交叉制表学历合计本科专科高中初中职称高级工程师计数 1 1 1 0 3 职称中的% 33.3% 33.3% 33.3% .0% 100.0%学历中的% 25.0% 25.0% 20.0% .0% 18.8%总数的% 6.3% 6.3% 6.3% .0% 18.8% 工程师计数 1 3 0 0 4 职称中的% 25.0% 75.0% .0% .0% 100.0%学历中的% 25.0% 75.0% .0% .0% 25.0%总数的% 6.3% 18.8% .0% .0% 25.0% 助理工程师计数 2 0 1 3 6 职称中的% 33.3% .0% 16.7% 50.0% 100.0%学历中的% 50.0% .0% 20.0% 100.0% 37.5%总数的% 12.5% .0% 6.3% 18.8% 37.5% 无技术职称计数0 0 3 0 3 职称中的% .0% .0% 100.0% .0% 100.0%学历中的% .0% .0% 60.0% .0% 18.8%总数的% .0% .0% 18.8% .0% 18.8% 合计计数 4 4 5 3 16 职称中的% 25.0% 25.0% 31.3% 18.8% 100.0%学历中的% 100.0% 100.0% 100.0% 100.0% 100.0%总数的% 25.0% 25.0% 31.3% 18.8% 100.0%卡方检验值df 渐进Sig. (双侧)Pearson 卡方18.533a9 .029似然比20.629 9 .014线性和线性组合 2.617 1 .106有效案例中的N 16职称* 学历交叉制表学历本科专科高中初中合计职称高级工程师计数 1 1 1 0 3职称中的% 33.3% 33.3% 33.3% .0% 100.0%学历中的% 25.0% 25.0% 20.0% .0% 18.8%总数的% 6.3% 6.3% 6.3% .0% 18.8% 工程师计数 1 3 0 0 4职称中的% 25.0% 75.0% .0% .0% 100.0%学历中的% 25.0% 75.0% .0% .0% 25.0%总数的% 6.3% 18.8% .0% .0% 25.0% 助理工程师计数 2 0 1 3 6职称中的% 33.3% .0% 16.7% 50.0% 100.0%学历中的% 50.0% .0% 20.0% 100.0% 37.5%总数的% 12.5% .0% 6.3% 18.8% 37.5% 无技术职称计数0 0 3 0 3职称中的% .0% .0% 100.0% .0% 100.0%学历中的% .0% .0% 60.0% .0% 18.8%总数的% .0% .0% 18.8% .0% 18.8% 合计计数 4 4 5 3 16职称中的% 25.0% 25.0% 31.3% 18.8% 100.0%学历中的% 100.0% 100.0% 100.0% 100.0% 100.0% a. 16 单元格(100.0%) 的期望计数少于5。
交叉分析法怎么分析

交叉分析法怎么分析交叉分析法是一种常用的数据分析方法,主要用于对多个变量之间的关系进行分析。
采用交叉分析法可以发现不同变量之间的相互影响和作用方式,从而更好地理解数据背后的规律和特征。
在下面的文章中,我们将介绍交叉分析法的具体分析流程和注意事项,帮助读者更好地了解和应用这种方法。
一、交叉分析法的定义交叉分析法,也称为交叉表法或列联表法,是一种通过将不同变量交叉排列建立交叉表的方法来研究变量之间相关性的一种统计方法。
交叉分析法根据样本数据构造一个列联表,以便比较各个不同维度之间的差异,从而进一步发现其内在联系和潜在规律。
二、交叉分析法的分析流程1. 选取研究对象和指标首先需要确定研究对象和研究指标。
在选择研究对象时,要确保大样本数量和充分代表性,以免数据偏误。
在选择指标时,应该着重考虑研究目的,避免指标内部关联性太强而导致冗余信息。
2. 建立交叉表将所选变量进行顺序或随机排列,形成一个行×列的交叉表。
在表格中,每一行代表一种分类变量的不同组别,每一列代表另一种分类变量的不同组别。
然后根据实际情况,填入相应的数据或统计概率。
3. 描述表格特征通过观察交叉表格中的特征,了解各个指标之间的关系和变化趋势。
这可以从几个方面来分析,例如行、列、总体、对角线等方面考虑。
归纳总结这些特征,可以为后续分析提供有力支撑。
4. 进行自由度统计自由度(df)指代两种分类变量所构成的列联表中具有独立划分的单元格个数。
在使用交叉分析法时,通常需要根据列联表的大小和分类变量的个数计算可用的自由度。
一般来说,自由度等于“列数-1×行数-1”。
5. 计算卡方值和P值卡方值是用来衡量观察值与理论值之间差异的一个指标。
在进行交叉分析时,一般会使用χ^2检验计算卡方值。
当卡方值越大时,表明所观察到的差异也越大。
在计算卡方值之后,还需要计算对应的P值。
P值是一个统计学上的重要指标,用于表示样本与总体误差概率大小。
如果P 值小于等于0.05,可以认为差异显著,反之则不显著。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
由于观察频数的总数为n ,所以f11 的期望频数 e11 应为
期望频数的分布
一分公司
二分公司 三分公司 四分公司
实际频数
68
赞成该 方案
期望频数
66
75
57
79
80
60
73
实际频数
32
反对该
方案
期望频数
34
45
33
31
40
30
37
检验统计量
在零假设成立时,该统计量近似服从自由度为(r1)×(s-1)的c2分布。当该统计量的值很大(或p值 很小)时,就可以拒绝零假设,认为这两个变量 不相互独立。
– 列观察值的合计数的分布 – 四个公司接受调查的人数分别为100人
列边缘分布
描述统计-百分比分布
• 在相同的基数上进行比较,可以计算相应的百
分比,称为百分比分布
– 行百分比:行的每一个观察频数除以相应的行合计 数(fij / ri)
– 列百分比:列的每一个观察频数除以相应的列合计 数( fij / cj )
期望频数的分布
一分公司 二分公司 三分公司 四分公司 合计
赞成该方案
68
75
57
79
279
反对该方案
32
45
33
31
141
合计
100
120
90
110
420
例如,第1行和第1列的实际频数为 f11 ,它落在第1行 的概率估计值为r1/n;它落在第1列的概率的估计值为 c1/n 。根据概率的乘法公式,该频数落在第1行和第1列 的概率应为
复式柱状图
61 70
49 60
50
40
30
20
10
2
10
0
酒店管理
旅游管理
图1 频数分布图
列联表分析
• 交叉分组下的频数分析称为列联表分析 • 两大基本任务
– 根据收集到的样本数据编制交叉列联表 – 在交叉列联表的基础上,对两两变量间是否存
在一定的相关性进行分析 – 拟合优度检验
一、编制交叉列联表(EXCEL)
团公司欲进行一项改革,此项改革可能涉及到各分公司的利 益,故采用抽样调查方式,从四个分公司共抽取420个样本 单位(人),了解职工对此项改革的看法,调查结果如下表
一分公司 二分公司 三分公司 四分公司 合计
赞成该方案
68
75
57
79
279
反对该方案
32
45
33
31
141
合计
100
120
90
110
420
每个分公司的看法是否相同
描述统计-观察值的分布
• 行边缘分布
– 行观察值的合计数的分布 – 赞成改革方案和反对改革方案的分别为279人,141人
行边缘分布
一分公司 二分公司 三分公司 四分公司 合计
赞成该方案
68
75
57
79
279
反对该方案
32
45
33
31
141
合计
100
120
90
110
420
• 列边缘分布
10%
0% 一分公司 二分公司 三分公司 四分公司
赞成 反对
推断统计-进行卡方检验
• 检验行变量与列变量是否独立 • 拟合优度检验(检验(基本原理)
• 原假设:行变量和列变量是相互独立的 • 前提成立的情况下,每个单元格的频数期望值称
之为期望频数eij,
• 如果期望频数和实际频数相差不大,不拒绝原假 设,如果二者相差很大,拒绝原假设
10.7%
28.6%
7.9%
21.4%
总百分比
四分公司 合计
28.3% 66.4%
71.8%
—
18.8%
—
22.0% 33.6%
28.2%
—
7.4%
—
26.2% 100%
80% 68.0%
70%
60%
62.5%
63.3%
71.8%
50% 40% 30%
32.0%
37.5% 36.7%
28.2%
20%
列联表举例(美国的General Social Survey )
幸福状况
婚姻状况 合计
已婚 丧偶 离异 分居 未婚
非常幸福 574 70 83 14 136 877
比较幸福 726 149 292 73 419 1659
不太幸福 82 59 79 30 99 349
合计 1382 278 454 117 654 2885
• 比如分析性别与受教育程度之间的关系 • 性别变量中’1’=‘男’,‘2’=‘女’ • 文化程度变量中 • 编制交叉列联表
男 女 合计
初中及 高中 以下
大学 研究生 合计 及以上
编制交叉列联表(SPSS)
三维交叉列联表举例
二、交叉列联表行列变量间关系 【例】一的个分集析团公司在四个不同的地区设有分公司,现该集
检验步骤
• 提出原假设
– H0:婚姻状况和幸福状况这两个变量相互独立 ;
– H1:婚姻状况和幸福状况不相互独立。
• 两个变量都是分类型,采用交叉列联分析 • 采用SPSS操作
结果分析
婚姻 已婚 状况
丧偶
离异
分居
未婚
合计
计数 期望的计数 计数 期望的计数 计数 期望的计数 计数 期望的计数 计数 期望的计数 计数 期望的计数
– 总百分比:每一个观察值除以观察值的总个数( fij / n)
行百分比
一分公司
赞成该方案 24.4%
68.0%
16.2%
反对该方案 22.7%
32.0%
合计
7.6%
23.8%
列百分比 二分公司 三分公司
26.9%
20.4%
62.5%
63.35
17.8%
13.6%
31.9%
23.4%
37.5%
36.7%
价格
品牌
款式
• 以列联表为基础可以对两个变量之间的关系进行多种统 计检验
列联表举例
条件频数—酒店管理专业的男生2人
列变量
行变量 酒店管理专业
男生
2
女生
49
合计
51
旅游管理专业
合计
行边缘分布
10
12
61
110
71
122
列边缘分布
男生
行百分比
列百分比
总百分比
性别
女生
Total
Count %within性别 %within专业 %of Total Count %within性别 %within专业 %of Total Count %of Total
专业
酒店管理 旅游管理
2
10
16.7%
83.3%
3.9%
14.1%
1.6%
8.2%
49
61
44.5%
55.5%
96.1%
85.9%
40.2%
50.0%
51
71
41.8%
58.2%
条件频数反映了数据的分布,但不适合对比 采取百分比分布更加直观
Total 12
9.8% 110
90.2% 122
100.0%
第8章 列联表分析 (Crosstabs )
●列联表是什么,可以用来做什么 ●采用卡方检验统计量
8.1 解释列联表
• 对分类数据的描述和分析通常使用列联表
• 根据两个变量分组,汇总得到的结果称为列联表,可以 用来分析两个变量之间的关系
列联表中的数字为交叉单元格中的频数或频率
大城市 中小城市 乡镇
农村
幸福状况
非常幸福 比较幸福 不太幸福